Part IV: Validating the User Experience
14. User Evaluation
Life is a full circle, widening until it joins the circle motions of the infinite
– Anais Nin
Evaluation methodologies are the principal means by which the UX specialist answers the questions ‘What needs to be done?’, and after an interface manipulation has occurred, ‘What is the effect of this manipulation?’
There are many ways to categorise different evaluation methodologies within UX. Here I equate naturalistic field evaluation with the qualitative methods of anthropologists, I see quantitative methods, characterised by sociological surveys, as being between fieldwork and laboratory experimentation (we’re already looked at these). Finally, I see laboratory-based evaluation, mainly in non-naturalistic settings, as being the main way of enacting true experimental methods most often used within experimental psychology and the cognitive sciences.
Each of these key categories has a unique way of viewing the world and a particular set of strengths arising from the kind of evaluation and answers needed. There are many debates within each particular discipline as to the kind of methods that give the best outcomes. However, in UX we can take a more pragmatic approach and select the appropriate evaluation method from each category, combining them all together in our final experimental design, so that we can build an end-to-end story.
If you notice, I’m using the term ‘evaluation’ quite frequently. This is because these methods all evolved from scientific evaluation methods within a particular academic discipline. But do not be confused, their applicability to real-world scenarios and their use within practical settings, of the kind we often face in application and interface development, is what has made them popular and particularly suited to the kinds of questions the UX specialist is required to answer.
Evaluation methods are slightly different from the kind of requirements analysis and requirements elicitation scenarios that we have seen. As we state there, requirements analysis and elicitation, along with the models that are created from them, are often engineering – or craft based – as opposed to having their roots within empirical scientific methodologies; certainly this is the case informally. In this case, they are more akin to the qualitative evaluation methods of participant observation, interviewing, or focus group discussion. However, these three methods are not bound with the same kind of system architecture design metaphors and methods as are those of requirements analysis. It is my opinion that this makes requirements analysis far weaker than the evaluation methods we will discuss here. I would only hazard a guess, which this is the case because the final testing of the software system will validate or invalidate the requirements model, whereas, there is no such concept of a final implementation validating an evaluation method in the domain of anthology or sociology. This means that, if the model is wrong, a large amount of time is needed to fix it at the end of the project. In some cases, this means that the interface is left unfixed because time and cost constraints dictate a speedy completion.
Understanding the requirements – and having the tools to create experimental methods to test the interface is correctly created from those requirements – are key to the user experience. As such, this chapter should be one of your primary references when creating testing and evaluation plans involving the user.
14.1 Expert Evaluation via the Audit
Walk-throughs and heuristic evaluations are closely linked and listed here because they are slightly different from the other techniques introduced. They differ because they mainly occur before formal evaluation with participants and are often conducted by the evaluator, or the UX specialist responsible for creating the interface, themselves.
14.1.1 Walk-throughs
There are many flavours of walk-throughs including the cognitive walk-through and the barrier walk-through, along with the code walk-through. However, in all cases, the evaluator formally addresses each step of the system based on the interaction that is required and the system components that are required to enact that interaction. At each stage, the outputs, inputs, and performance will be evaluated, and this presupposes that the walk-through is far more about an evaluation of the system performing correctly than it is about the aesthetic or design nature of the interface itself. In this case, walk-throughs can also be used to understand how easy the system is to learn and whether aspects of usability, such as progressive disclosure, or accessibility are present. However, to create a reasonably accurate walk-through the evaluator needs to have a good understanding or description of the prototype system; a description or understanding of the task the users are to perform; the action that is required to complete the task; and an indicator of who the users will be. This last indicator is particularly difficult in that it presupposes the evaluator understands all aspects of a user’s behaviour and character that, as we have seen, can be particularly difficult to assess.
14.1.2 Heuristic Evaluation
Related to the walk-through is the heuristic evaluation. This approach differs from the walk-through only in that there are specific aspects that need to be assessed as the evaluation proceeds. These aspects are based upon the general principles that have already been covered. However in this case, as opposed to the developer walking through the different scenarios of user interaction, a set of evaluators are asked to independently answer questions regarding the usability of the interface, rating different aspects as they go. Once complete, average ratings can be generated for all aspects of the interface based on the consensus opinion of the evaluators. This is a reasonably effective method and is often used as an initial test before the main evaluation begins.
In both cases an expert user, or key participant (informer), is required to perform these evaluations and the results of the evaluation are very much based on the skills, ability, and knowledge of the evaluator. In reality, this means that the principles that you have learnt should be reapplied back into development, but this time as questions. These questions may take the form of ‘Is the need to Facilitate Progressive Disclosure met?’, ‘How is Progressive Disclosure met?’, or the questions to think about when designing your prototype to Facilitate Progressive Disclosure) – such as ‘Is there a tight logical hierarchy of actions?’ – could be used as metrics for understanding the success of failure.
14.2 Qualitative (Fieldwork) Methods
Anthropologists and sociologists describe field evaluation variously as fieldwork, ethnography, case study, qualitative evaluation, interpretative procedures, and field evaluation. However, among anthropologists fieldwork is synonymous with the collection of data using observational methods. For the sociologist, the term often describes the collection of data using a social survey. While it was often thought that these two competing methods of qualitative and quantitative evaluation are disjoint, many sociologists also utilise participant observation, structured interviews, and documentary evidence as interpretive methods. These methods owe much to social anthropologists following the theoretical tradition of ‘interactionism’; interactionists place emphasis on understanding the actions of participants by their active experience of the world and the ways in which their actions arise and are reflected back on the experience. This is useful for the UX specialist as the interactionists component of the method makes it quite suitable investigating subjective aspects.
To support these methods and strategies, many suggest the simultaneous collection and analysis of data. This implies the keeping of substantive field notes consisting of a continuous record of the situations events and conversations in which the practitioner participates [Van Maanen, 2011]; along with methodological notes consisting of personal reflections on the activities of the observer as opposed to the observed. The field notes should be preliminary analysed within the field and be indexed and categorised using the standard method of ‘coding’ different sections of the notes to preliminary categories that can be further refined once the fieldwork has concluded.
The most used methods on qualitative evaluation are participant observation, interviewing, archival and unobtrusive methods. I suggest that these methods are mainly used for building a body of evidence that is deep but narrow in extent and scope. The evidence can then be used to help generate hypotheses, and understanding, to be confirmed in later tests. In this case, aspects of Mills Method of Agreement can be used to build evidence before the computational artefact, the application, utility, software, or system is created. Indeed, these methods will give you an idea of what to build or what is wrong with whatever already exists.
14.2.1 Unobtrusive Methods
Imagine you have been employed by the local library to review the number and placement of cataloguing terminals that can be used for book searches by the general public. If these terminals are all placed together large queues form, and besides, members of the public must return from the area of the library, they are in, to the area that houses the centralised terminals if they wish to evaluation the catalogue. To determine how many terminals are required, and in what locations, you may wish to conduct an analysis of floor tile wear, by visual inspection and also by consulting the maintenance records of the library. In this case, you will be able to understand the amount of traffic to each of the different library sections and optimise the placement of terminals along these routes and in these areas. If you decided to use this approach then, you would be using a methodology that is unobtrusive to the participants (in this case library users).
‘Unobtrusive methods’ is a phrase first coined in 1965/66 and the book in which it was first proposed has since become a classic [Webb, 1966]. Simply, unobtrusive methods propose that evaluations should look for traces of current activity in a similar way to the way archival material is used as a past by-product of normal human activities. This unobtrusive way of investigation is important because in direct experimentation unintended changes can occur, as part of the investigator intervention, which skew the findings (think ‘Bias’).
These sources of invalidity can be roughly categorise as ‘reactive measurement effect’ or ‘errors from the respondent’ such as:
- The guinea pig effect, whereby people feel like guinea pigs being tested in experiments and so, therefore, change their behaviour patterns;
- Role selection, whereby participants see the experimenter as taking a certain role, having an elevated status above the participant, who therefore follows that experimenters lead;
- Measurement as change agent, in which aspects of the initial measurement activity introduces real changes in what’s being measured; and finally,
- Response sets, whereby respondents will more frequently endorse a statement than disagree with its opposite.
Also, errors from the investigator can also be introduced. These range from the interviewer effect, whereby characteristics of the interviewer contributes to the variance in findings because interviewees respond differently to different kinds of interviewer based on the visible and audio cues which that interviewer gives. And changes in the evaluation instrument, whereby the measuring instrument is frequently an interviewer, whose characteristics we have just shown may alter responses, yet that interviewer changes over the course of the investigation. To overcome these possible errors, all contact with participants is removed, and the practitioner bases their findings on observation – Simple Observation – of both the participants and the environment.
Simple observation is the practice of observing exterior physical signs of people as they are going around their normal business along with the expressivity of their movement and their physical location in conjunction. This kind of observation can be extended to include conversation sampling, and time duration sampling for certain observable tasks. Of course, enhanced observational techniques known as contrived observation may also be undertaken. Here techniques such as hardware instrumentation can be particularly useful for different kinds of computer-based activity as long as ethical considerations are taken into account. In general, unobtrusive methods take a holistic approach of the participant, the task or activity, and the environment. By observing, but not intervening or questioning, the UX specialist can understand the interaction activities and interface issues of individuals enacting a real system in a natural setting without disturbing or affecting that system. We can see how unobtrusive methods can be applied to understanding the user experience from a social perspective in.
14.3 Quantitative & Hybrid Methods
As we have seen, qualitative methods are mainly used for building a body of evidence that is deep but narrow in extent and scope. The evidence can be used to help generate hypotheses, and extend understanding, to be confirmed in later experiments. Simply, hybrid and quantitative methods give the UX specialist the tools and techniques to enact these confirmatory experiments [Tullis and Albert, 2008]. Questionnaires, also know as survey methods, are probably the most flexible and useful tools we have for gathering this kind of confirmatory information. They are widely used in the social sciences, as the main form of a systematic method for empirical investigation and critical analysis, to develop and refine a body of knowledge about human social structure and activity.
However, questionnaires have some facets that need careful consideration if the quantitative results produced by their application are to be valid. For instance, questionnaires already make many assumptions regarding the domain under investigation, obviously, the mere activity of asking a specific question has some very implicit assertions associated with it. Therefore, even questionnaires that look to be appropriate may in-fact, be biassed. Indeed, practitioners have criticised the tradition that has allowed questionnaires to become the methodological sanctuary to which many UX specialists retreat. In this context, the most fertile search for validity comes from a combined series of different measures each with its idiosyncratic weaknesses each pointing to a single hypothesis. In this case, when a hypothesis can survive the confrontation of a series of complementary methods of testing it contains a degree of validity unattainable by one tested within the more constricted framework of the single method. Therefore, practitioners have proposed the hybrid method; also known as mixed methods or triangulation. Here, many complimentary methods are used and indeed this approach is the one I would espouse for most UX work.
Methods that I classify as between field and laboratory are meant to signify quantitative methods used to retest knowledge derived from qualitative investigations and confirm the initial hypothesis selection process. While, quantitative methods are often used as the only method applied to many social science questions, in UX they do not stand up as verifiable when evaluating or testing an interface or human facing system. A more rigorous approach is required in this case in which experimental metrics can be directly applied in a controlled environment.
14.3.1 Card Sorting
There are several well-understood experimental methodologies used for knowledge elicitation. One such methodology is card sorting techniques used along with triadic elicitation techniques to capture the way people compare and order different interfaces based on different criteria. This framework allows the UXer to investigate both qualitative and quantitative aspects of the user experience while recognising that participants are difficult to recruit. By using card sorting methods, you can produce a quantitative analysis with a definite error rate and statistical significance, and by using triadic elicitation, you can also accommodate the most illusive aspects of the user experience and add depth to the quantitative data.
Card sorting is the simplest form of sorting. During this procedure, the participant is given many cards each displaying the name of a concept (or images / wireframes / screenshots, etc.). The participant has the task of repeatedly sorting the cards into piles such that the cards in each pile have something in common. By voicing what each pile has in common, or the difference between each pile, or description of the characteristics of each pile, the participant is vocalising implicit knowledge they have about the things on the cards.
Suppose we wish to find the attributes of a Web page, by which it is judged as simple or complex. Here, the cards are a screen-print of each Web page that was used for testing. With the continuous sorting, the participant is unintentionally giving information on the attributes and values to describe the characteristics of each Web page, describing the reasons for the perceived complexity.
Triadic elicitation is often used along with card sorting techniques. During this technique, the user is asked about what they think is similar and different about three randomly chosen concepts and in what way two of them similar and different. This technique is used to elicit attributes that are not immediately and easily articulated by the user and helps to determine the characteristics of the card sorted concepts. Further, picking three cards forces us into identifying differences between them – there will always be two that are closer together, although which two cards that are may differ depending on your perspective. The application is very simple. Basically, you select three cards at random, you then identify which two cards are the most similar. Now analyse what makes them similar and what makes them different.
14.3.2 Socio / Unobtrusive Methods
There are many ways to conduct unobtrusive observations within the user experience domain, these might range from remote observations in the real world – of peoples mobile phone usage, say – to collecting data via proxy methods and based on website usage, etc. UX can be unobtrusively measured, directly or indirectly; individually or collectively. And by having the proper metrics, UxD can be leveraged towards the constant improvement of products and services. And this can, I argue, be replicated and generalised across products and services. Let’s have a look at kinds of metrics that can be used.
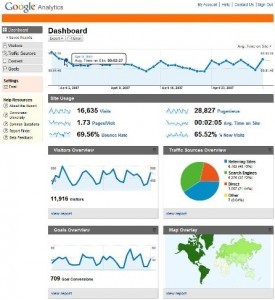
Analytics (PULSE + HEART) [Rodden et al., 2010], Social Sensing or Net Promoter Score Are unobtrusive observational methods that collected and – better still – combined enable us to understand how people feel about a website or desktop application. PULSE – Page views, Uptime, Latency, Seven-day active users (i.e. the number of unique users who used the product at least once in the last week), and Earnings (for instance see Google Analytics PULSE Example – can be derived from standard quantitative data, however HEART – Happiness, Engagement, Adoption, Retention, and Task success – requires a little more social networking and user monitoring. In both cases, by understanding the quantity, types, and return rates of users we can infer favourable experiences once we have some social sensing data. My rational here is that analytics provides us with information that is all inferential – people may return to the site not just because they like it but because they have no choice because they want to complain because they found it difficult last time. But if people are also tweeting, Facebook ‘liking’ then you can expect that if this figure is say 20% then over 60% will like the site but can’t be bothered to ‘Like’ it – this is the same with Net Promoter Score1.
How to capture the user experience in a single session, this is difficult with any degree of accuracy. This could be thought of as the kind of user evaluation method you will become used to. In reality, one session does not make a good evaluation, you should think about the possibility of introducing proxies2 to collect longitudinal usage data.
Mindshare goals – qualitative measures such as awareness, branding effectiveness. In general how much chatter is there in the media, around the coffee machine, water cooler, about your application or site. Lots either means love or hate, silence means mediocre. This is mainly a marketing metric, applied with few changes into the UX domain – indeed, there are some obvious similarities between Mindshare and Social Sensing as discussed in ‘Analytics…’.
Customer support responsiveness and Customer satisfaction evaluation. Quantitative and qualitative loyalty. This is a general purpose quantitative and qualitative interview or questionnaire in which consumer satisfaction can be elicited on a wide scale with deployed resources. You normally find this kind of thing in Social Science, and these techniques haven’t changed much in the move to UX. One interesting development is their combination with social metrics such that peer review is provided by giving star ratings to various resources, or as part of ‘Net Promoter’.
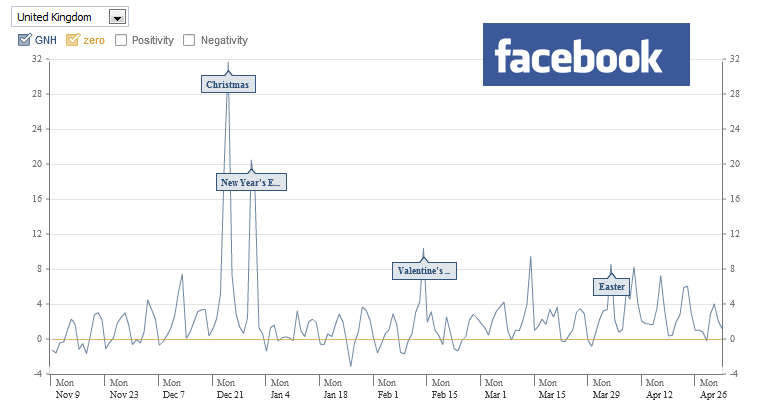
Now these methods should interest you (for example see Facebook ‘Gross National Happiness Index’) – not least because their creation, application, and the inferences made from the resultant data tie into user feedback without participant bias. As we’ve previously seen, UX pays more attention to the individual and subjective realm in which ‘intangibles’ are required to become tangible for testing purposes – so that user feedback can be factored into the new design.
So how do we form these methods into a cohesive framework, well the jury is still out, but Google think it is via Goals, Signals, and Metrics.
Goals: “The first step is identifying the goals of the product or feature, especially regarding user experience. What tasks do users need to accomplish? What is the redesign trying to achieve?” Signals: “Next, think about how success or failure in the goals might manifest itself in user behaviour or attitudes. What actions would indicate the goal had been met? What feelings or perceptions would correlate with success or failure? At this stage, you should consider what your data sources for these signals will be, e.g. for logs-based behavioural signals.” Metrics: Finally, “think about how these signals can be translated into specific metrics, suitable for tracking over time on a dashboard” again playing into longitudinal observation —Google.
14.3.3 A Short Note on Longitudinal Observation
Observation of user behaviour when interacting with applications and the Web – especially for the skill gaining process – is better observed at a longitudinal fashion. This statement is founded on the fact that increased intervals enable the consolidation of declarative knowledge in long-term memory, where consolidation does not happen automatically, and it is not determined at the time it has been learned. To gain insights into the user experience in the context of your development, we should conduct a longitudinal analysis of those users if at all possible.
14.3.4 Think-Aloud
It is sometimes difficult to understand exactly what the user is thinking or, in some cases, doing when they are navigating a complex interface. This is especially the case when the user is familiar with the interface and interaction, and may even be undertaking different, but related, tasks at the same time as the primary task. In this case, to understand explicitly the activities and thoughts of the user, as they are performing the interaction, the think aloud methodology can be used [Lazar et al., 2010].
The think aloud methodology is a classic of the UX evaluation process evolving mainly from design-based approaches (created by Clayton Lewis while at IBM). It produces qualitative data and often occurs as part of an observational process, as opposed to a direct measurement of participant performance, as would be normal in laboratory settings. While it is true that think aloud requires tasks to be completed, the object is not the direct measurement of those tasks. Instead, it is the associated verbalisations of the participants as they progress through the task describing how they are feeling and what they think they need to do.
Think aloud is intended to produce data which is deeper than standard performance measures in that some understanding of the thoughts, feelings, and ideas that are running through the mind of the participant can be captured. The main problem with think aloud is, also its strength in that, it is very easy to set up and run, and therefore, the design aspect of the tasks can be ill conceived. In this way, it is often easy to implicitly influence the participant into providing outcomes that are positive regardless of the true nature of the interface or interaction. Indeed, the very act of verbalising their thoughts and feelings means that participants often change the way they interact with the system. It is for this reason that think aloud should not be used as a methodology on its own but should provide the qualitative aspects lacking in other quantitative or performance-based measures.
14.3.5 Co-Operative Evaluation & Participatory Design
As we have seen3 Co-operative evaluation and participatory design are closely related techniques that enable participants to take some form of ownership within the evaluation and design process. It is often thought that these participants will be in some way key informants, as we have seen in participant observation, and will therefore have an insight into the systems and interfaces that are required by the whole. Both methods are closely linked to the think aloud protocol, but instead of entirely focusing on evaluation the users are encouraged to expand their views with suggestions of improvements based on their knowledge of the system or interfaces that are required. Indeed, the participants are encouraged to criticise the system in an attempt to get to the real requirements. This means that in some cases a system design is created before the participatory or co-operative aspects have begun so that the participants have a starting point.
UCD and cooperative evaluation are related approaches that emphasize the involvement of users in the design and evaluation of interactive systems. While user-centred design focuses on incorporating user feedback throughout the design process, cooperative evaluation specifically addresses the collaborative and iterative evaluation of a system with users. User-centred design involves understanding user needs, preferences, and behaviours through methods such as user research, interviews, and observations. This user understanding is used to inform the design of interfaces, products, or systems. Throughout the design process, user feedback is collected and integrated, ensuring that the final product meets user expectations and requirements.
Cooperative evaluation, on the other hand, is a specific technique within the user-centred design process. It involves actively involving users as partners in the evaluation and improvement of a system. Rather than solely relying on expert evaluations or usability testing, cooperative evaluation emphasizes the collaboration between designers, developers, and users to identify usability issues, gather feedback, and suggest improvements. In a cooperative evaluation, users are invited to provide input and insights on the system’s usability, user experience, and functionality. They may participate in various evaluation activities, such as walk-throughs, user testing, think-aloud protocols, or focus groups. Through this cooperative process, users can contribute their first-hand experiences, identify potential issues or challenges, and provide suggestions for enhancements or refinements.
The relationship between user-centred design and cooperative evaluation lies in their shared commitment to involving users throughout the design and evaluation process. Both approaches recognize the value of user input, perspective, and feedback in creating usable and effective systems. By combining user-centred design with cooperative evaluation, designers can engage users as active collaborators, fostering a user-centric approach that leads to more user-friendly and satisfying experiences.
Cooperative evaluation and participatory design are likewise related approaches that share several similarities in their focus on user involvement and collaboration; including:
- User Participation: Both cooperative evaluation and participatory design emphasize the active involvement of users in the design and evaluation process. Users are seen as valuable contributors who provide insights, perspectives, and expertise that shape the final product or system.
- Collaborative Approach: Both approaches foster collaboration and cooperation between designers, developers, and end-users. They encourage open communication, dialogue, and knowledge sharing among all stakeholders involved in the design process.
- User Empowerment: Cooperative evaluation and participatory design seek to empower users by giving them a voice in decision-making and allowing them to influence the design outcomes. Users are seen as experts in their own experiences and are encouraged to actively participate in shaping the design process.
- Iterative and Agile Process: Both approaches embrace an iterative and agile design process. They involve multiple rounds of feedback, testing, and refinement to ensure that user needs and expectations are addressed. The design is continuously adapted and improved based on the insights and feedback gathered from user participation.
- Contextual Understanding: Both cooperative evaluation and participatory design emphasize the importance of understanding the users’ context, needs, and goals. They aim to design solutions that are relevant and meaningful within the specific user context, promoting user satisfaction and usability.
- User-Centric Design: Both approaches prioritize designing for users’ needs and preferences, focusing on creating user-centric solutions. The insights gained through cooperative evaluation and participatory design help ensure that the final product or system aligns with user expectations and requirements.
While there are similarities, it’s worth noting that cooperative evaluation is primarily focused on evaluating and refining an existing system, while participatory design is concerned with involving users in the entire design process from ideation to implementation. Nonetheless, both approaches share a user-centred philosophy and highlight the importance of user involvement in the design and evaluation of systems.
The UX specialist must understand that co-operative evaluation, and participatory design are not fast solutions. Indeed, they should only be used when a firm understanding of the boundaries of the system is possessed. Also, participatory design often runs as a focus group based activity and, therefore, active management of this scenario is also required. Enabling each to fully interact within the discussion process while the UX specialist remains outside of the discussion just acting as a facilitator for the participants views and thoughts is a key factor in the process design.
14.3.6 Survey Questionnaires – Reprise
How do you find out if the system or interface that you have designed and deployed is useful and has useful features? What kinds of improvements could be made and in what order should these improvements be prioritised? To answer these kinds of questions, it is useful to talk to a large number of people, far more than you could expect to recruit for a laboratory experiment. In this case, you may decide to use a questionnaire-based survey, recruiting as many users as you possibly can.
Question-based surveys are usually designed to provide statistical descriptions of people and their activities by asking questions of a specific sample and then generalising the results of that survey to a larger population [Bryman, 2008] (for example Figure: Online Survey Example). This means that the purpose of the survey is to produce statistics and that the main way of collecting information is by asking people questions. In this case, there are three different properties of a good survey, being probability sampling, standardised measurement, and the special-purpose design. Components of a survey sample are based around the question design, the interview method (the questionnaire in this case), and the mode of data collection (verbal or written); all being taken together as total survey design. Critical issues are the choice of how the sample is selected, randomly or non-randomly, creating a probability or non-probability sample; and the sample frame, the size of the sample, the sample design, and the rate of response. One fundamental premise of the survey process is that by describing the sample of people who respond, one can describe the target population. The second fundamental premise of survey evaluation processes is that the answers people give can be used to accurately describe characteristics of the respondent. The sample frame describes the part of the population who have a chance to be selected. Also, if the sample is not random, then the respondents who answer are likely to be different from the target population as a whole. Surveys normally capture two different aspects: objective facts and subjective states. Objective facts include things like the person’s height, whereas subjective facts include, how much of the time the persons felt tired, say.

Designing questions to be good measures, which are reliable and provide valuable and valid answers, is an important step in maintaining the validity of a survey. Always avoid inadequate, incomplete, or optional wording while ensuring consistent, meaningful responses. Remove poorly defined terms and avoiding multiple questions conflated to be a single question. However, it is acceptable to include specialised wording for specialist groups. Remember, participants may be tempted to give incorrect responses if they have a lack of knowledge, or change their answers if they find it socially desirable. This should be pre-empted in the designing of the questions, in which questions should be created as reliably as possible. In addition, there are four different ways in which measurement can be carried out: nominal, people or events are sorted into unordered categories; ordinal, people or events are ordered or placed in all categories along a single dimension; interval, numbers are attached that provide meaningful information regarding the distance between ordered stimuli or classes; and ratio, in which numbers are assigned such that ratios between values are meaningful.
Survey questions should be evaluated before the survey is given using techniques such as focus groups, question drafting sessions, critical reviews, and more formal laboratory interviews. The questions should also be field tested before the main survey becomes available. Remember that survey interviewing can be a difficult job and the type of participant selection is critical in this case. For instance, the commonly used non-probabilistic quota based technique can be particularly troublesome as interviewers are left to survey a certain demographic profile to a certain quota size. This means that many aspects of the validity of a survey are left to the interviewer, who make non-random choices such as choosing houses that are of a higher value, in good areas, without pets or dogs; male interviewers will choose younger female respondents, and female interviewers will choose older male respondents. These biases should be accounted for within the questions and the design of the survey.
Survey methods can be very useful to the UX specialist for confirming qualitative work or evaluating systems that do not immediately lend themselves to the more rigorous laboratory-based methods that will be described in subsequent sections. In the real world, the UX specialist is often unlikely to be able to solicit enough respondents for completely accurate probabilistic methods, and it is more likely that non-probabilistic quota-based methods will be used. However, simple random sampling can be used if the sample frame is tightly defined, and in this case readily available ordinal identification, such as employee number, could lend itself to the selection process. While surveys should not be the only method used, they are useful for understanding general points regarding systems and interactions, over a large set of users who could not normally be evaluated in a formal laboratory setting.
14.3.7 Hybrid Methods
The hybrid method; also known as mixed methods or triangulation are terms used to denote the use of many complimentary methods because the UX specialist recognises the inadequacies of a single method standing alone. Indeed, the hallmark of being a field practitioner is flexibility concerning theoretical and substantive problems on hand. Therefore, the use of ‘triangulation’ (a term borrowed from psychology reports) is used to refer to situations where the hypotheses can survive the confrontation of a series of complementary methods of testing. Triangulation can occur as ‘data triangulation’ via time, space, or person; ‘investigator triangulation’ in which more than one person exams the same situation; ‘theory triangulation’ in which alternative or competing theories are used in any one situation; and ‘methodological triangulation’ which involves within method triangulation using the same method used on different occasions, and between-method triangulation when different methods are used in relation to the same object of study. Indeed, mixed methods contrast quantitative and qualitative work, characterising them by behaviour versus meaning; theory and concepts tested in evaluation versus theory and concepts emergent from data; numbers versus words; and artificial versus natural. In reality, for the UX specialist, the confrontational aspects can be thought of as being purely complimentary.
To a large extent, the UX specialist does not need to concern themselves with the methodological debates that are often prevalent within the human sciences such as anthropology, sociology, social science, and psychology. This is mainly because these methodologies and the instruments which are used within them are not directly created as part of the human factors domain but are used and adapted in combination to enable a verifiable, refutable, and replicable evaluation of the technical resource. In UX, a single methodology would not normally ever be enough to support an evaluation or to understand the interaction of technology and user. However, the view I take of the evaluation domain is far more holistic than may be found in most UX or user experience books. By reliance on only the evaluation aspects of a specific technical interface we miss the possibility of understanding how to make that interface better, not just by metrics as shallow as time to task, but by a combined qualitative and quantitative understanding of the factors surrounding user interaction, both cognition and perception, for a particular software artefact or system architecture.
14.4 Tools of the Trade
As a UXer, there are many tools that you can use both in a laboratory-based setting or in the field. Most tools are portable and so, therefore, can be moved around to different sites and venues such that you are more reactive to the locational needs of your participants; as opposed to expecting them to come to you4.
UX tools range from the very simple, such as the notebook, through audio recording devices, portable cameras and video cameras, screen capture and screen recorders, to the more complex (and costly) static and portable eye trackers, bio–feedback system such as galvanic skin response and heart rate monitors, through to neuro–feedback such as functional magnetic resonance imaging (fMRI), electro-encephalo-graphy (EEG — for example, see Figure: EEG Data Plot Example) , event-related potentials (ERPs), and transcranial magnetic stimulation (TMS) systems. All these tools may be mobile, but now often some of the more expensive tools can only be applied in a laboratory setting, and certainly a laboratory-based setting is useful when you wish to control an evaluation; and the possible confounding factors that may apply to that evaluation.

These laboratories, known in the industry as ‘user labs’ or ‘usability labs’, often comprised of three rooms. The first room a user would enter is the reception room where there may be coffee tea and comfy sofas to place the user at ease. There would be a user testing room in which the user and, often, a UXer will sit and conduct the evaluations (this is where the ‘tools’ will be). Finally, there is normally an observation room in which other members of the UX team will observe the evaluations in progress. In some cases, only the user will be present in the user testing room, and only the UX specialists will be present in the observation room5 (see Figure: User Observation).
As we have seen, there are many techniques in the UX specialists arsenal for investigating user behaviour, however, four of the most common listed below:
Performance Measures. Measuring performance is one of the most used techniques for assessing and evaluating interaction. The rationale is that if the task is completed faster than it was before the interactive component was either altered or created when the Interface design must be better as an enhancement has occurred. Common performance measures include: the time required by the user to complete a task; the time spent navigating the interface; the number of incorrect choices or errors created; the number of jobs completed, either correctly or incorrectly; the number of observations of user frustration (see facial expressions below); and finally the frequency of interface components or behaviour that is never used. While performance measures are the most used and most easy to describe to non-specialist audiences, there are some problems that can be introduced at the time the study is created. Indeed, it is often very easy to introduce bias into a set of tasks such that the desired outcome will always be the outcome that performs best. As a UX specialist, you must be especially careful when designing your studies to make sure that this is not the case.

Eye Tracking. Eye tracking technologies are now increasingly used in studies that analyse the user behaviour in a Web search or to reveal possible usability and accessibility problems. Simply, while reading, looking at a scene or searching for a component, the eye does not move smoothly over the visual field, but it makes continuous movements called saccades and between the saccades, our eyes remain relatively still during fixations for about 200-300 ms. A sequence of saccades provides the scanpath (for example see Figure: Eye-Tracking Gaze Plot Example) that the eye follows while looking. Fixations follow the saccades and are the periods that the eye is relatively immobile indicating where it pays more attention, hence, the component that is viewed. Mostly used for usability evaluations we can see their application in determining specific scanpaths about each interface component is highly useful. If each design is associated with a scanpath and fixation points, feedback can be provided for enhancing the design. However, as technology has continued to evolve, applications where an understanding of human perception, attention, search, tracking and decision making are becoming increasingly important. This is because eye movements are driven both by properties of the visual world and processes in a person’s mind. Indeed, tracking eye movements has now become a valuable way of understanding how people allocate their visual attention.
Facial Expression. There are many implicit cues in user behaviour which are difficult to measure by conventional means such as eye tracking or user performance. One way of capturing some of these implicit aspects is by understanding that most users will show these implicit behaviours, such as happiness or frustration, by their facial expressions. Techniques, therefore, exist in which the expression of the user is recorded via a standard computer camera, where each task is timed, and the time of the facial expression is then matched to the task being undertaken at that time. In this way, the specialist can collect a wealth of implicit information concerning the quality of the user experience, if not the participants performance. Again, the UX specialist should be careful to make sure their study is designed correctly and that the analysis of the facial expressions captured in the evaluation is as accurate as possible. Indeed, as we have said before it may be useful to present these expressions, for categorisation, to a disinterested party as a confirmatory step; remember, this is the best way of enhancing the validity of the evaluation when interpretation by the evaluator is required.
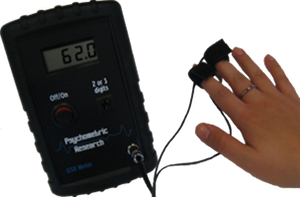
Biofeedback and Affective Measures [Picard, 1997]. As with facial expressions, biofeedback is as implicit evaluation process that involves measuring a participants quantifiable bodily functions such as blood pressure, heart rate, skin temperature, sweat gland activity, and muscle tension, recording the information for later analysis. Within the UX domain the most often used biofeedback measurement is Galvanic Skin Response (see Figure: Galvanic Skin Response) which is a measure of the electrical resistance of the skin; this being a good indicator of the participants stress levels. Also, more simplistic by a feedback mechanism such as heart rate and skin temperature can be used in a non-invasive manner to also ascertain the levels of comfort, excitement, or the stress of a participant. Most biofeedback measurements must be analysed in the context of the individual user in a relative format, so, therefore, increases from the baseline recorded when the user is relaxed and under normal conditions are more important than absolute measurements. One final thing to note for the UX specialist is that undisputed scientific evaluation into the possible application of biofeedback is lacking. This is not such a problem for evaluation and analysis but does indicate the immaturity of this kind of technique.
As a UX specialist you are being asked to perform these kinds of experiments and evaluations for some perceived gain. By conforming as closely as possible to the scientific principles of impartiality the evaluation methodologies and preterite tools, you will be able to maximise these gains, and exhibit a high degree of professionalism in what is often a practical engineering setting. Indeed, as we shall see, pushing a bad interaction design to market will only necessitate a more costly redesign at a later date.
Caveat – Experimental Methods
You may have noticed that I’ve not mentioned any tightly controlled task based trials that measure performance directly - and mostly in laboratory-based settings. These kinds of tests are normally used in research and validation of human performance for critical systems or in ‘hard-core’ usability / HCI trials. I’ve steered away from these because in everyday UX you won’t need to use them, and because we only have a limited time in which to cover UX, and these are not – in my opinion – primary to this domain; but rather human factors, ergonomics, cognitive science, and experimental psychology.
Laboratory-based evaluation using experimental methods has been mainly adopted within the human sciences by experimental or cognitive psychologists requiring similar empirical confirmations as their natural science counterparts. In this case, it is seen that the rigorous and formalised testing of participants can only occur in a controlled laboratory setting. While this is the major strength of laboratory-based evaluation, it is also acknowledged to be a possible problem in that the laboratory is not a naturalistic setting. In turn, the negative aspects are accentuated even beyond that of the survey questionnaire. However, in some cases, the UX specialist has little choice in performing laboratory experimentation because the quantifiable richness and rigour of the data produced is not available from any other source. The power of the arguments created from experimental work is often too strong to ignore, and this is why you will find that when only one opportunity for evaluation exists, the UX specialist will most naturally choose a laboratory-based experimental method; in some ways returning to their computer science / engineering roots.
There are some increasingly understood aspects of laboratory-based work that may be problematic:
- Experimenter Bias: The experimenter my bias the laboratory work via aspects such as the guinea pig effect or role bias;
- Obtrusive Observation: The act of observation changes the observed in some way.;
- Not Longitudinal: And so do not represent users changing states over time and experience; and therefore,
- Not Ecologically Valid: In that the results are only valid in the laboratory and not in the real world.
Further definitive aspects of laboratory-based work are the emphasis placed upon control and validity. Aspects of both can be seen at various points throughout both quantitative and qualitative methods however the focus is far more acute in laboratory-based experimental evaluation. This means that various methods for designing and controlling laboratory-based experimental work have evolved both in psychology and in medicine concerning clinical trials, and we have already covered this to some extent. The key aspect of laboratory-based evaluation is the concept of internal and external validity. External validity refers to the degree to which we can generalise the results of the study to other subjects, conditions, times, and places. While internal validity, is specifically focused on the validity of the experiment as it is carried out and the results that derive from the sample. Remember these terms as we’ll be looking at them in more detail), but for now, if you’d like more information on more experimental methods take an initial look at Graziano and Raulin [Graziano and Raulin, 2010].
14.5 Summary
In summary then, we can see that evaluation methodologies range from the very deep qualitative work undertaken by anthropologists, often resulting in an ethnography, through the broad quantitative work undertaken by social scientists, to the observational empirical work of the experimental or cognitive psychologist. Into this mix comes the interdisciplinary aspects of user experience based in software evaluation and design, and in the form of walk-throughs and think aloud protocols. In all cases, there is a need for a combinatorial approach to evaluation design if an accurate view of the user, and their interaction requirements and experiences, are to be formulated. The value of these aspects of the entire software design cannot be underestimated, without them the user experience cannot be assessed, and a bad user experience will directly affect the approval, and, therefore, sales, of the product under investigation. It’s also not all about participants and numbers, remember, Facebook did UX testing For Facebook Home (With Fewer Than 60 People), 6. However, UX is not solely focused on the interface. Indeed, aspects of the interaction enable us to formulate a scientific perspective and enables us to understand more about the behaviour, cognition, and perception of the user, as opposed to purely focusing on changes to the interface; in this way, UX evaluation methodologies have both practical and scientific outcomes. While I would not suggest that the evaluation methodologies discussed here can be applied in every setting, the UX specialist should attempt to create evaluations that can be undertaken in as near perfect conditions as possible.
So what does all this mean, well ‘methods maketh the discipline’, and I’d say that UX has some nice native methods in use with some others pulled in from other more traditional product marketing domains spliced up with advertising metrics. Importantly, the most interesting for me are HEART+PULSE, which together represent some very innovative thinking that – with minor mods – can be directly applied from UX back to the wider Human Factors CS domain.
14.5.1 Optional Further Reading
- [M. Agar.] The professional stranger: an informal introduction to ethnography. Academic Press, San Diego, 2nd ed edition, 1996.
- [A. Bryman.] Social research methods. Oxford University Press, Oxford, 3rd ed edition, 2008.
- [A. M. Graziano] and M. L. Raulin. Research methods: a process of inquiry. Allyn and Bacon, Boston, 7th ed edition, 2010.
- [J. Lazar,] J. H. Feng, and H. Hochheiser. Research methods in human-computer interaction. Wiley, Chichester, West Sussex, U.K., 2010.
- [J. Van Maanen.] Tales of the field: on writing ethnography. Chicago guides to writing, editing, and publishing. University of Chicago Press, Chicago, 2nd ed edition, 2011.
- [R. W. Picard.] Affective computing. MIT Press, Cambridge, Mass., 1997.
- [T. Tullis] and B. Albert. Measuring the user experience: collecting, analyzing, and presenting usability metrics. The Morgan Kaufmann interactive technologies series. Elsevier/Morgan Kaufmann, Amsterdam, 2008.
15. Human-in-the-Loop Systems and Digital Phenotyping
Systems simulations were a mix of hardware and digital simulations of every—and all aspects of—an Apollo mission which included man-in-the-loop simulations, making sure that a complete mission from start to finish would behave exactly as expected.
– - Margaret H. Hamilton (1965) NASA.
In the bad old days, computer systems were highly inefficient took huge amounts of resources and were not user friendly. Indeed, the head of IBM through the 50s said that he could only see the need for two computers in the world. Obviously, that was incorrect and as time has progressed, users became more important and we became more aware of the fact that humans were an integral part of the system. And so human computer interaction and therefore user experience were created. As part of this, the idea that humans in the loop would be a necessary part of a computer system was not considered until the various Apollo missions whereby human interaction with the system, indeed control of the system became important. Indeed, we may think of it as human middleware became more important, especially with computer systems flying or at least controlling complex mechanical ones.
There is an accessibility saying: ‘nothing about us without us’ and we consider that this should be extended to the human and to the user such that users are integrated into most aspects of the build lifecycle. After all, the human will be controlling the system and even in terms of intelligence systems, artificial/hybrid intelligence and machine learning, have shown to benefit from human input.
Indeed, humanistic artificial intelligence are becoming increasingly more important with most large scale computational organisations. Acknowledging this fact and having large departments which are tailored to this kind of development so for all software engineering and development the human should be considered from the outset and the humans, control actions should also be factors when designing systems which wrap around the user.
15.1 Human-in-the-Loop (HITL) Systems
Human-in-the-Loop (HITL) systems are a collaborative approach that combines the capabilities of both humans and machines in a loop or iterative process. It involves the interaction and collaboration between human experts or operators and automated systems or algorithms to achieve a desired outcome. In a HITL system, humans are actively involved in various stages of the decision-making process, providing input, feedback, and guidance to the automated systems. The automated systems, on the other hand, assist humans by performing tasks that can be automated, analyzing large amounts of data, or making predictions based on complex algorithms.
The purpose of HITL systems is to leverage the strengths of both humans and machines. Humans bring their domain expertise, intuition, and contextual understanding, while machines offer computational power, speed, and the ability to process vast amounts of data. By combining these capabilities, HITL systems aim to improve accuracy, efficiency, and decision-making in various domains, such as healthcare, customer service, autonomous vehicles, and cybersecurity.
HITL systems often involve an iterative process, where humans provide initial input or guidance, machines generate outputs or suggestions, and humans review, validate, or modify those outputs. This iterative feedback loop allows for continuous improvement and adaptation, with humans refining the system’s performance and the system enhancing human capabilities. Overall, HITL systems enable the development of more robust, reliable, and trustworthy solutions by harnessing the power of human intelligence and machine capabilities in a symbiotic relationship.
HITL systems have been utilized for a long time, although the term itself may have gained prominence in recent years. The concept of involving humans in decision-making processes alongside automated systems has been present in various fields and industries for decades. One early example of HITL systems is found in aviation. Pilots have been working in collaboration with autopilot systems for many years, where they oversee and intervene when necessary, ensuring the safety and efficiency of flight operations. This demonstrates the integration of human expertise with automated systems.
NASA has embraced the concept of HITL systems across various aspects of its operations, including space exploration, mission control, and scientific research. Here are a few examples of how NASA has adopted HITL approaches. Human space exploration missions, such as those to the International Space Station (ISS) and beyond, heavily rely on HITL systems. Astronauts play a critical role in decision-making, performing experiments, and conducting repairs or maintenance tasks during their missions. While automation is present, human presence and decision-making capabilities are essential for handling unforeseen situations and ensuring mission success.
NASA’s mission control centres, such as the Johnson Space Center’s Mission Control Center in Houston, Texas, employ HITL systems to monitor and manage space missions. Teams of experts, including flight directors, engineers, and scientists, collaborate with astronauts to provide real-time support, make critical decisions, and troubleshoot issues during missions. NASA utilizes robotic systems in space exploration, such as the Mars rovers (e.g., Spirit, Opportunity, Curiosity, and Perseverance). While these robots operate autonomously to some extent, human operators on Earth are actively involved in planning, commanding, and interpreting the data collected by the rovers. Humans in mission control provide guidance, analyse results, and adjust mission objectives based on discoveries made by the robotic systems.
HITL systems are prevalent in data analysis and scientific research conducted by NASA. Scientists and researchers work alongside machine learning algorithms and data processing systems to analyse large volumes of space-related data, such as satellite imagery, telescope observations, and planetary data. Human expertise is crucial for interpreting results, identifying patterns, and making scientific discoveries.
Overall, HITL approaches are integrated into various aspects of NASA’s operations, where human expertise is combined with automated systems to achieve mission objectives, ensure astronaut safety, and advance scientific knowledge in space exploration.
In the field of computer science and artificial intelligence, the idea of HITL systems has been explored since the early days of AI research. In the 1950’s and 1960’s, researchers were already investigating human-computer interaction and the combination of human intelligence with machine processing power. More recently, with advancements in machine learning, data analytics, and robotics, HITL systems have gained increased attention. They have been applied in various domains such as healthcare, where clinicians work alongside diagnostic algorithms to improve disease detection, treatment planning, and patient care. Additionally, HITL systems have become essential in the development and training of AI models. Human involvement is crucial for labelling and annotating training data, evaluating model performance, and ensuring ethical considerations are taken into account. While the exact introduction of HITL systems cannot be pinpointed to a specific date or event, their evolution and adoption have been shaped by the continuous advancements in technology and the recognition of the value of human expertise in conjunction with automated systems.
15.2 Digital Phenotyping
Digital Phenotyping (DP) can be seen as an extension (or at least has a very strong relationship to) HITL systems, in that the human in DP systems is carrying around a mobile device / wearable / or the like and their behaviour in both the real-world and in digital services. This behaviour is monitored and the collected data is used to make inferences about their behaviour.
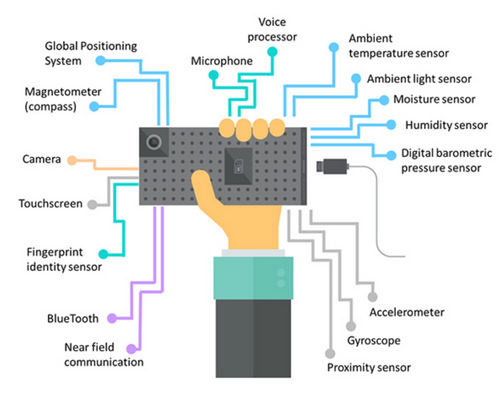
Defined by Jukka-Pekka Onnela in 2015, but undertaken for over a decade before it was named, DP utilises digital technologies such as smartphones, wearable devices, and social media platforms to collect and analyse data on human behaviour and psychological states. This approach is used to monitor, measure, and analyse various aspects of human behaviour, including sleep patterns, physical activity, social interaction, and emotional states. And uses sensors embedded in smartphones and wearables to track various physiological and environmental parameters, such as heart rate, breathing rate, and temperature, as well as factors like location, movement, and interaction with the device. The data collected is then analysed using machine learning algorithms to generate insights into an individual’s behaviour, including patterns of activity, stress levels, mental health, and well-being, and sleep quality. Roughly DP proceeds by:
- Data Collection: Digital phenotyping relies on the collection of data from individuals using their smartphones, wearables, or other digital devices. This data can include GPS location, accelerometer and gyroscope readings, screen interaction patterns, call and text logs, app usage statistics, social media posts, and more. Sensors within the devices capture data related to movement, activity, and contextual information.
- Data Processing and Feature Extraction: Once the data is collected, it undergoes processing and feature extraction. This involves converting the raw data into meaningful features or variables that represent specific behavioural or physiological aspects. For example, data from accelerometer readings can be transformed into activity levels or sleep quality indicators.
- Machine Learning and Pattern Recognition: Digital phenotyping employs machine learning and pattern recognition techniques to analyse the extracted features and identify patterns, trends, or anomalies. Algorithms are trained on labelled data to recognize specific behavioural patterns or indicators related to mental health, cognitive function, or physical well-being.
- Behaviour Modelling and Prediction: By analysing the collected data and applying machine learning models, digital phenotyping can develop behavioural models and predictive algorithms. These models can identify patterns and correlations between digital data and specific outcomes, such as predicting depressive episodes, detecting stress levels, or assessing cognitive performance.
- Continuous Monitoring and Feedback: Digital phenotyping allows for continuous monitoring and tracking of individuals’ behaviours and mental states over time. The data collected can provide real-time insights into changes in behaviour or well-being, enabling early intervention or personalized feedback.
- Integration with Clinical and Research Applications: The insights generated through digital phenotyping can be integrated into clinical settings or research studies. Mental health professionals can use the data to inform treatment decisions, monitor patient progress, or identify potential relapses. Researchers can leverage the data for population-level studies, understanding disease patterns, or evaluating the efficacy of interventions.
It’s important to note that digital phenotyping raises ethical concerns regarding privacy, data security, and informed consent. Safeguards must be in place to protect individuals’ privacy and ensure transparent and responsible use of the collected data.
DP as a term is evolved from the term ‘genotype’ which is the part of the genetic makeup of a cell, and therefore of any individual, which determines one of its characteristics (phenotype). While phenotype is the term used in genetics for the composite observable characteristics or traits of an organism. Behavioural phenotypes include cognitive, personality, and behavioural patterns. And the interaction or interactions with the environment. Therefore digital phenotyping implies monitoring; a moment-by-moment quantification of the individual-level human phenotype in situ using data from personal digital devices in particular smartphones.
The data can be divided into two subgroups, called active data and passive data, where the former refers to data that requires active input from the users to be generated, whereas passive data, such as sensor data and phone usage patterns, are collected without requiring any active participation from the user. We might also equate Passive Monitoring / Sensing to Unobtrusive Monitoring and Active Monitoring / Sensing to Obtrusive Monitoring.
DP conventionally has small participant numbers however the data collected is the key and when you’re collecting ~750,000 records/person/day adaption and personalisation to a user is critical! We can think of Data as the ‘Population’ where small N becomes big N, in this case, DP supports personalised data analysis. Generalized Estimating Equations and Generalized Linear Mixed Models create a population-based model instead of a personalised one however, personal models are however needed in many complex applications. Machine and Deep Learning algorithms don’t prioritise clinical knowledge but rather structure of the data and assume the distribution of the training set is static, but human behaviour is not and often requires tuning, this requires expertise which in practice would not be available for each patient.
Digital phenotyping has many potential applications in healthcare and mental health research. For example, it could be used to monitor and manage chronic conditions such as diabetes or to identify early signs of mental health issues such as depression or anxiety. It could also be used to provide personalized interventions and support for individuals based on their unique patterns of behaviour and psychological state. However, DP has diverse application domains across mental health, and behaviour monitoring among others:
- Mental Health Monitoring: Digital phenotyping enables the continuous monitoring of individuals’ mental health by analysing digital data such as smartphone usage, social media activity, and communication patterns. It can help detect early signs of mental health disorders, track symptoms, and monitor treatment progress.
- Mood and Stress Management: Digital phenotyping can assess and track individuals’ mood states and stress levels by analysing behavioural patterns, including activity levels, sleep quality, communication patterns, and social media content. It can provide insights into triggers and patterns related to mood changes and help individuals manage stress more effectively.
- Cognitive Function Assessment: By analysing smartphone usage patterns, digital phenotyping can provide insights into individuals’ cognitive function, attention, and memory. It can help assess cognitive impairments, monitor cognitive changes over time, and provide personalized interventions or reminders.
- Physical Health Monitoring: Digital phenotyping can be used to monitor individuals’ physical health by analysing data from wearable devices, such as heart rate, sleep patterns, and activity levels. It can track physical activity, sleep quality, and identify deviations that may indicate health issues or support healthy behaviour change.
- Personalized Interventions and Treatment: Digital phenotyping insights can be used to deliver personalized interventions, recommendations, or treatment plans. By understanding individuals’ behaviours, triggers, and context, interventions can be tailored to their specific needs and preferences, enhancing treatment outcomes.
- Population Health Studies: Digital phenotyping can be applied in large-scale population health studies to understand disease patterns, identify risk factors, and evaluate the effectiveness of interventions. By analysing aggregated and anonymized digital data, researchers can gain insights into population-level health trends and inform public health strategies.
- Behaviour Change and Wellness Promotion: Digital phenotyping can support behaviour change interventions by providing real-time feedback, personalized recommendations, and tracking progress towards health and wellness goals. It can motivate individuals to adopt healthier behaviours and sustain positive changes.
As technology advances and our understanding of human behaviour and health improves, digital phenotyping is likely to find further applications in various fields related to well-being, healthcare, and personalized interventions.
15.2.1 Can you build a Digital Twin using Digital Phenotyping?
While Digital twins and digital phenotyping are related concepts in the realm of technology and data-driven analysis, but they focus on different aspects and applications.
Digital twins are virtual replicas of physical objects, systems, or processes. They are used to monitor, analyse, and simulate the behaviour of their real-world counterparts. Digital twins are often associated with industrial applications, such as manufacturing, energy, and healthcare, where they help optimize operations, predict maintenance needs, and improve efficiency. They involve real-time data integration, simulation, and visualization to provide insights and predictions about the physical entity they represent. Digital twins are more about replicating the entire behaviour of a physical entity in a digital environment. On the other-hand, Digital phenotyping focuses on the collection and analysis of data related to an individual’s behaviour, activities, and physiological responses using digital devices. It is often used in healthcare and psychology to monitor mental and physical health, track disease progression, and understand behavioural patterns. Digital phenotyping involves the use of smartphones, wearables, and other digital sensors to gather data like movement, sleep patterns, communication style, and more. The goal of digital phenotyping is to gain insights into an individual’s health and well-being by analysing patterns and changes in their digital behaviour.
This said, it is possible to incorporate digital phenotyping techniques into the development and enhancement of a digital twin, which are in many ways complimentary. By integrating data collected through digital phenotyping methods, you can create a more accurate and comprehensive representation of the physical entity within the digital twin environment.
Using digital devices such as smartphones, wearables, and other sensors to collect behavioural and physiological data from the physical entity you want to model in your digital twin. This could include data on movement, activity levels, sleep patterns, heart rate, communication patterns, and more. Then integrate the digital phenotyping data with the data streams from other sources that contribute to your digital twin’s functionality. For instance, if you’re creating a digital twin of a human body for healthcare purposes, you might combine phenotypic data with medical records, genetic information, and environmental data. Incorporate the collected data into the digital twin’s model. Depending on the complexity of your digital twin, this could involve refining the simulation algorithms to better mimic the behaviour of the physical entity based on the behavioural and physiological data you’ve collected. Analyse the digital phenotyping data to identify patterns, trends, and anomalies in the behaviour of the physical entity. This analysis can inform the simulation algorithms and contribute to a more accurate representation within the digital twin. Use the integrated data to make predictions and gain insights. For example, if your digital twin represents a person’s health, you could predict potential health issues based on changes in behavioural patterns and physiological data. Continuously update the digital twin with new data from digital phenotyping to ensure that the virtual representation stays aligned with the real-world counterpart. This real-time monitoring can help detect changes and provide early warnings for potential issues. Implement a feedback loop where insights and predictions generated by the digital twin can influence how data is collected through digital phenotyping. This can help optimize the data collection process and improve the accuracy of both the digital twin and the phenotyping analysis.
By combining digital phenotyping with the concept of a digital twin, you can create a more dynamic and accurate representation of a physical entity, enabling better insights, predictions, and decision-making in various fields such as healthcare, sports science, and more. You can skip backwards to understand how digital twins relate to requirements elicitation if you missed this.
15.3 Summary
Digital phenotyping and HITL systems are related concepts that can complement each other in various ways. Digital phenotyping relies on the collection and analysis of digital data from various sources such as smartphones, wearables, and sensors. HITL systems can play a role in ensuring the accuracy and reliability of the collected data. Humans can validate and verify the collected data, identify errors or inconsistencies, and provide feedback to improve the quality of the data used in digital phenotyping algorithms. HITL systems can contribute to the development and validation of digital phenotyping algorithms. Human experts, such as clinicians or researchers, can provide their expertise and domain knowledge to guide the development of algorithms that capture meaningful behavioural or health-related patterns. Humans can also participate in the evaluation and validation of the algorithms, providing insights and judgments to assess their performance and effectiveness.
Digital phenotyping algorithms generate insights and predictions based on the analysis of collected data. HITL systems can assist in the interpretation and contextualization of these results. Human experts can provide a deeper understanding of the implications of the findings, identify potential confounders or biases, and help translate the results into actionable information for healthcare providers, researchers, or individuals. HITL systems enable continuous feedback loops for digital phenotyping. Users or individuals can provide feedback on the insights or predictions generated by digital phenotyping algorithms. This feedback can help refine and improve the algorithms over time, ensuring that the system becomes more accurate, sensitive, and tailored to individual needs. Further, HITL systems play a crucial role in addressing ethical considerations related to digital phenotyping. Humans can ensure that privacy concerns, data security, informed consent, and fairness are appropriately addressed. Human judgment and decision-making can guide the responsible and ethical use of digital phenotyping technologies.
Overall, HITL systems can enhance the reliability, interpretability, and ethical considerations of digital phenotyping. By involving humans in the data collection, algorithm development, interpretation of results, and feedback loops, we can create more robust and responsible digital phenotyping systems that align with user needs, expert knowledge, and ethical standards.
15.3.1 Optional Further Reading
- [Mackay, R. S. (1968).] — Biomedical telemetry. Sensing and transmitting biological information from animals and man.
- [Webb, E. J., Campbell, D. T., Schwartz, R. D., & Sechrest, L. (1966)] — Unobtrusive measures: Nonreactive research in the social sciences (Vol. 111). Chicago: Rand McNally.
- [Licklider, J. C. R. (1960)] Man-Computer Symbiosis, IRE Transactions on Human Factors in Electronics, volume HFE-1, pages 4-11, March 1960.
- [Onnela, Jukka-Pekka; Rauch, Scott L. (June 2016)] — Harnessing Smartphone-Based Digital Phenotyping to Enhance Behavioral and Mental Health. Neuropsychopharmacology. 41 (7): 1691–1696. doi:10.1038/npp.2016.7. ISSN 0893-133X. PMC 4869063. PMID 26818126.
- [Harald Baumeister (Editor), Christian Montag (Editor) (2019)] — Digital Phenotyping and Mobile Sensing: New Developments in Psychoinformatics (Studies in Neuroscience, Psychology and Behavioral Economics) 1st Edition
- [David Nunes, Jorge Sa Silva, Fernando Boavida (2017)] — A Practical Introduction to Human-in-the-Loop Cyber-Physical Systems (IEEE Press) 1st Edition
16. Evaluation Analysis
You can design and create, and build the most wonderful place in the world. But it takes people to make the dream a reality.
– Walt Disney
Designing your evaluations is one of the most important aspects of any user experience process. If these evaluations are designed badly you will not be able to apply the correct analysis, and if you cannot apply the correct analysis you will not be able to make any conclusions as to the applicability or success of your interventions at the interface or interactive level [Baggini and Fosl, 2010]. In reality, this means that if this is not done correctly the previous ≈200 pages of this book have been, to a large extent, pointless.
As we shall see, good design is based upon an understanding of how data should be collected, how that data should be analysed, and how the ethical aspects of both the collection and analysis should proceed. However, the two most important aspects of any evaluation are an understanding of science, and more specifically the scientific method; and an understanding of the importance of how you select your participants (called ‘subjects’ in the old–days and still referred to as such in some current texts).
You probably think you already know what science is, how it is conducted, and how science progresses; but you are probably wrong. We will not be going very deep into the philosophy of science, but cover it as an overview as to how you should think about your evaluations and how the scientific method will help you in understanding how to collect and analyse your data; to enable you to progress your understanding of how your interventions assist users; key to this is the selection of a representative sample of participants.
Science works by the concept of generalisation – as do statistics, in which we expect to test our hypothesis by observing, recording and measuring user behaviour in certain conditions. The results of this analysis enabling us to disprove our hypothesis, or support it, thereby applying our results – collected from a small subset of the population (called a sample) – to the entirety of that population. You might find a video demonstrating this concept more helpful [Veritasium, 2013].
The way this works can be via two methods:
- Inductive reasoning, which evaluates and then applies to the general ‘population’ abstractions of observations of individual instances of members of the same population, for example; and,
- Deductive reasoning, which evaluates a set of premises which then necessitate a conclusion7 – for example: {(1) Herbivores only eat plant matter; (2) All vegetables contain only plant matter; (3) All cows are herbivores} → Therefore, vegetables are a suitable food source for Cows8.
Now, let’s have a look at the scientific method in a little more detail.
16.1 Scientific Bedrock
Testing and evaluation are the key enablers behind all user experience interaction work, both from a scientific and practical perspective. These twin concepts are based within a key aspect of HCI, the scientific method, and its application as a means of discovering information contained within the twin domains of human behaviour and use of the computer. It is then appropriate that you understand this key point before I move on to talking in more detail about the actual implementation of the scientific method in the form of validating your interface design.
As you may have noticed, UX takes many of its core principles from disjoint disciplines such as sociology and psychology as well as interface design and ergonomics, however, laying at its heart is empiricism9. The scientific landscape, certainly within the domain of the human sciences, is contingent on the concept of logical positivism. Positivism attempts to develop a principled way of approaching enquiry through a combination of empiricism, methods employed within the natural sciences, and rationalism10. The combination of empiricism (observation) and rationalism (deduction) make a powerful union that combines the best points of both to form the scientific method.
The scientific method is a body of techniques for investigation and knowledge acquisition [Rosenberg, 2012]. To be scientific, a method of inquiry must be based on the gathering of observable, empirical and measurable evidence, and be subject to specific principles of reasoning. It consists of the collection of data through observation and experimentation, and one of the first to outline the specifics of the scientific method was John Stuart Mill. Mill’s method of agreement argues that if two or more instances of a phenomenon under investigation have only one of several possible causal circumstances in common, then the circumstance in which all the instances agree is the cause of the phenomenon of interest. However, a more strict method called the indirect method of difference can also be applied. Firstly, the method of agreement is applied to a specific case of interest, and then the same principle of the agreement is applied to the inverse case of interest.
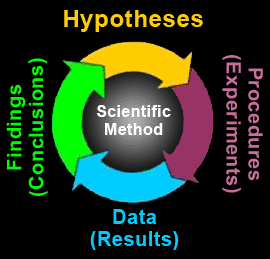
Philosophical debate has found aspects of the method to be weak and has generated additional layers of reasoning which augment the method. For instance, the concept of ‘refutability’ was first proposed by the philosopher Karl Popper. This concept suggests that any assertion made must have the possibility of being falsified (or refuted). This does not mean that the assertion is false, but just that it is possible to refute the statement. This refutability is an important concept in science. Indeed, the term ‘testability’ is related and means that an assertion can be falsified through experimentation alone.
So we can see that put simply (see Figure: The Scientific Method), the scientific method enables us to test if the things we believe to be true, are in fact true. At it’s most basic the method progresses along the following lines:
- Firstly, we create a hypothesis that, in the best case, cannot be otherwise interpreted and is ‘refutable’; for example we might make the statement ‘all swans are white’. In this case, we may have travelled widely and tried to observe swans in every country and continent in an attempt to support our hypothesis.
- While, we may be able to amass many observations of white swans we must also realise that a statement must be refutable. If the hypothesis remains intact it must be correct; in our example, we may try to observe every swan that exists in, say, the UK, or Europe, or the Americas, which is not white.
- However, one instance of an observation of a non-white swan will disapprove our hypothesis; in this case, when we arrive in Australia we discover a black swan, in this case, we can see all swans are not white and our hypothesis is found to be incorrect.
There have been many debates regarding the question of whether inductive reasoning leads to truth. In general, we can make some inductive leaps if they are based on good science, and these leaps may not be accurate, but may well assist us in our understanding. In the UX domain, we use mathematical (statistical) methods to help us understand these points. For example, if we collect a set of data which compares the time it takes to select a point of the screen with the mouse then we can make sure that data is valid within just the set of people who participated; this is called internal validity. However, we then want to generalise these results to enable us to say something about the wider population, here we can use well formed and tested statistical tests that enable us to mathematically generalise to a population; this is called external validity. In the human sciences, there is often no 100% certainty, all we have is a level of confidence in how a particular test relates to the population, and, therefore, how useful the knowledge generated from it is.
16.1.1 Variables
Many variable types have arisen in the human sciences methodology to enable better discussion and more accurate planning of these more controlled experiments. In general, evaluations can be characterised by the presence of a subject variable, a behavioural variable (the behavioural variables are really the user demographics, and these are really only used as part of the analysis or in participant selection to create a representative sample of the population.), a stimulus variable, and an observable response. For, the UX specialist this means that the behavioural variable can be equated to the user, the stimulus variables can be equated to the interface or the computer system, and the observable response is a thing that we often measure to understand if there is a benefit after we have manipulated the stimulus. In more detail, the subject variable discusses aspects such as the participant and the characteristics of that participant that can be used to classify them; so this would mean factors such as age, weight, gender, etc. The experimental evaluation also relies on independent and dependent variables. The confusing aspect of all of this is the same variable is sometimes named differently in different subjects; so:
- Behavioural = demographics, or subject variables, or conditions;
- stimulus = independent variable, or input, or cause; and
- response = dependent variable, or output, or effect;
The independent variable is the thing that we manipulate, in UX, this is normally an aspect of the interface that is under investigation; for instance the level of a menu item, or the position of a click button. The dependent variable is the thing that we measure, the response, in UX, this is often the response of a user interacting with the interface or system. Further, a constant is any variable that is prevented from varying and an extraneous variable is any variable other than the independent variable that might affect the dependent measure and might confound the result. Therefore, we can see that the definition of the variables along with an understanding of their presence and the means by which to control them are key to creating a well-found experimental study.
There are many different factors that may affect the internal or external validity of an experiment; called confounding variables. The effects of confounding variables can be decreased by adequate preparation of the laboratory setting for the experimental work such that participants feel comfortable; single or double blind procedures in which the UX specialist is applying the evaluation does not know the desired outcome. Or, in the case of triple blind procedures, where the practitioner applying the evaluation and the practitioner analysing the results does not know the desired outcome. Multiple observers may also be used in trying to reduce the confounding variables as well as specifically objective measures and in some cases automation of the process. Finally, one of the key pillars of evaluation is that the work can be replicated by a third party, and this may be one of the most useful approaches when tried to minimise the introduction of confounding variables, because all aspects of the experimentation, except the methodology and hypotheses, are different.
16.1.2 Measuring Variables
Measurement is another factor that needs accurate control. There are three main types of scales to facilitate measurement, these being the nominal scale, which denotes identity; the ordinal scale, which denotes identity and magnitude; and the interval scale, which denotes identity, magnitude and has the benefit of equal intervals. There is also a fourth scale called the ratio scale that has the positive properties of the three we have already seen as well as a true zero point. Thus, ratio scales provide the best match to the real number system, and we can carry out all of the possible mathematical operations using such scales. These scales are seen to be hierarchical in rigour such that the nominal scale is the least rigorous and be ratio scale is the most rigorous. These are often misunderstood so let me clarify in a different way:
- Nominal Variable (plural nominal variables). A variable with values that have no numerical value, such as gender or occupation. For example: opposite, alternate, whorled. Also known as Categorical Variable (plural categorical variables).
- Ordinal Variable (plural ordinal variables). A variable with values whose order is significant, but on which no meaningful arithmetic-like operations can be performed. For example: fast < very fast < very, very fast
- Cardinal Variable (not very used - here for completeness) (plural cardinal variables). A variable whose values are ordered that can be multiplied by a scalar, and for which the magnitude of differences in values is meaningful. The difference between the values j and the value j+1 is the same as the difference between the values k and k +1. For example: wages, population.
- Interval Variable (plural interval variables). An ordinal variable with the additional property that the magnitudes of the differences between two values are meaningful. For example: 10PM (today) > 8PM (today) — 10PM (today) - 8PM (today) = 2 hours.
- Ratio Variable (plural ratio variables). A variable with the features of interval variable and, additionally, whose any two values have a meaningful ratio, making the operations of multiplication and division meaningful. For example: 10 meters per second > 8 meters per second — 10 mps - 8 mps = 2 mps.
Also, the scale can be distorted so the observation is no longer accurately reflecting reality, this is called measurement error and is part of the operational definition of the variable; i.e. the definition of the variable regarding the procedures used to measure or manipulate that variable. Further, measurement has an aspect of reliability that must also be understood and refers to the measure’s reproducibility. This reliability can be subdivided into interrater reliability, test–retest reliability, and internal consistency reliability. The interrater reliability requires that when a judgement by a UX specialist is required, then more than one practitioner should judge the same aspect, and these judgements should be matching. Test–retest reliability requires that if a set of variables should be stable over time, then if tested at period one and then retested at period two, the answer from those measures should be consistent. Finally internal consistency reliability is the aspect of reliability which means that when participants are tested, or observed, under several different conditions the outcomes of those observations are consistent.
16.1.3 Hypothesis Testing
Variables and their measurement are important because they inform the experimental design process and the kind of analysis that will be possible once the data has been collected. In general, the lower the number of independent variables, the more confident we can be about the data collected and the results of the analysis. Collecting many different types of variable data at the same time may be a pragmatic choice, in that the participant has already been recruited and is already in the laboratory environment. However, it will make data analysis much more difficult. Indeed, variable measurement is key to the dominant principle of the scientific method, namely, hypothesis testing. The hypothesis is a statement that has the additional aspect of being refutable and in this case, it has a ‘null hypothesis’11 which dictates that there is no difference between two conditions beyond chance differences. In addition to this null hypothesis, we have the confounding variable hypothesis that states that a statistically significant difference in the predicted direction can be found at the surety of the observed differences being due to an independent variable as opposed to some extent this variable cannot be supported. Finally, the causal hypothesis states that the independent variable has the predicted effect on the dependent variable.
16.2 Evaluation Design and Analysis
The design of experiments (DOE, DOX, or experimental design) is the design of any task that aims to describe and explain the variation of information under conditions that are hypothesized to reflect the variation. UX works with observational experiments for which you must know what you are trying to understand, gather the correct data, use the correct analysis tool to uncover knowledge, and make sure you can test your results. An experiment is supposed to be dispassionate …but it rarely is. Typically you are collecting data to discover. You are actively looking for something, looking for relationships in collected data, so you can model some interaction, behaviour, or process, so you are able to better build a system.
Now, the scientific method is not applied in-and-of itself, but is captured as part of evaluation methods that you will need to build into an evaluation design such that the questions you want to be answered, are answered; let’s look at that now.
Before getting started just consider that you need to include ethics in your design here too.
Evaluation design and analysis are two of the most important aspects of preparing to validate the user experience. Indeed for any scientific discipline, designing the validation methodology and analysis techniques from the very beginning enables you to understand and allay any possible problems about missing data or the general conduct of the evaluation process [Floridi, 2004]. Also, a full evaluation plan, including analytic techniques, is often one of the key aspects of UX work required for ethical purposes – and also demonstrates due diligence.
16.2.1 Design
Evaluation Design is so important that attempts to formalise it exist through the human sciences; the methodological debates of anthropology and sociology stem in some regard from the problems and inadequacies of single method research. In general, there are some stages that the UX’er must undertake to try to understand the domain of investigation. Indeed, research must begin with ideas and so the idea generating stage is of key importance; for the UX specialist, this may be a moot point as these ideas may already have been developed as part of the complete system design. The UX’er will also need to understand and define the various problems that may be encountered within both the system, and the study, and design a set of inter-related procedures which will enable data to be collected and any gaps in that data, identified. Once these procedures have been completed, you may move into the observation stage whereby the evaluations will be conducted. Once the data has been collected the analysis stage can begin, in which additional collection may be required if after analysis there are perceived but unforeseen weaknesses within the research design. Next, the UX’er can interpret the data based on their experience, knowledge of other work within the field, and based on the results of the data analysis stage. Finally, complete information is to be communicated to the stakeholders. It is often advisable at this stage to create a technical report whereby all the data, findings, and analysis are listed in minute detail. The UX specialist can then create executive summaries or extended abstracts for faster consumption while still ensuring that the basis of those shortened reports is available if required.
Often, different subject domains will espouse, or, at least, be heavily based upon, a single favourite research methodology. In anthropology this is often participant observation, in the social sciences this is often the questionnaire, in psychology this is mainly non-naturalistic experimentation, in history this is the firsthand account, and in UX, this is very often the qualitative summative evaluation. While it is correct that hybrid approaches are often espoused by communities within each of these domains the general predisposition for single methodology research designs are still prevalent. In an interdisciplinary subject area such as UX, this is not acceptable. Indeed, this is especially the case when the number of participants for a particular evaluation is in the order of 10’s as opposed to the 100’s or even 1000’s often found in social science quantitative survey work. By using single methodology designs with small numbers of participants, the UX specialist cannot be assured of the validity of the outcomes. Indeed, over-reliance on summative evaluation suggests that assessing the impact of the interface, or the system design, in general, has not been taken seriously by the developers, or maybe seen as a convenient post-hoc add-on.
Quantitative methods often provide a broad overview but the richness of the data is thin; qualitative methods are often very specific but provide a very rich and deep set of data; finally, laboratory-based methods usually provide exact experimental validation with the key aspect of refutation, but again are often limited in the number of participants tested, and are mostly ecologically unsound (as they are not naturalistic). In this case, the UX specialist should design their research methodology to include aspects of qualitative, quantitative, and laboratory-based evaluation. Building a qualitative body of evidence using combinations of participant observation, unobtrusive methods, and interview technique will enable well-found hypotheses to be formed (we’ll look at these in more detail). These hypotheses can be initially tested by the use of quantitative survey based approaches such as questionnaires or walk-through style approaches. A combination of this work can then be used to design laboratory-based experimental work using scenarios that are as natural as possible. Again, quantitative approaches can be revisited as confirmation of the laboratory-based testing, and to gain more insight into the interaction situation after the introduction of the interface components. Using all these techniques in combination means that the development can be supported with statistical information in a quantitative fashion, but with the added advantage of a deeper understanding which can only be found through qualitative work. Finally, the hypotheses and assertions that underpinned the project can be evaluated in the laboratory, under true experimental conditions, which enable the possibility of refutation.
16.2.2 Analysis
Once you’ve designed your evaluation, are are sure you are getting back the data that will enable you to answer your UX questions, you’ll need to analyse that data.
Now, data analysis enables you to do three things: firstly, it enables you to describe the results of your work in an objective way. Secondly, it enables you to generalise these results into the wider population. And finally, it enables you to support your evaluation hypotheses that were defined at the start of the validation process. Only by fulfilling these aspects of the evaluation design can your evaluation be considered valid, and useful for understanding if your interface alterations have been successful in the context of the user experience. You will need to be able to plan your data analysis from the outset of the work, and this analysis will inform the way that you design aspects of the data collection. Indeed to some extent, the analysis will dictate the different kinds of methodologies employed so that a spread of research methodologies are used.
Even when it comes to qualitative data analysis, you will find that there is a predisposition to try and quantify aspects of the work. In general, this quantification is known as coding and involves categorising phrases, sentences, and aspects of the quantitative work such that patterns within an individual observation, and within a sample of observations, may become apparent. Coding is a very familiar technique within anthropology and sociology. However, it can also be used when analysing archival material; in some contexts, this is known as narrative analysis.
Luckily there are a number of tools – called Computer Assisted/Aided Qualitative Data AnalysiS (CAQDAS) – to aid qualitative research such as transcription analysis, coding and text interpretation, recursive abstraction, content analysis, discourse analysis, grounded theory methodology, etc. (see Figure: NVivo Tool); and include both open source and closed systems.
These include:
- A.nnotate;
- Aquad;
- Atlas.ti;
- Coding Analysis Toolkit (CAT);
- Compendium;
- HyperRESEARCH;
- MAXQDA;
- NVivo;
- Widget Research & Design;
- Qiqqa;
- RQDA;
- Transana;
- Weft QDA; and
- XSight.
However, ‘NVivo’ is probably the best known and most used.
When analysing qualitative work, and when coding is not readily applicable, the UX specialist often resorts to inference and deduction. However, in this case, additional methods of confirmation must then be employed so that the validity of the analysis is maintained; this is often referred to as ‘in situ’ analysis. Remember, most qualitative work spans, at the very minimum, a number of months and therefore keeping running field notes, observations, inferences and deductions, and applying ad-hoc retests, for confirmation purposes, in the field is both normal and advisable; data collection is often not possible once the practitioner has left the field work setting.
This said, the vast majority of UX analysis work uses statistical tests to support the internal and external validity of the research being undertaken. Statistical tests can be applied in both a quantitative and laboratory-based setting. As we have already discussed, internal validity is the correctness of the data contained within the sample itself. While external validity is the generalisability of the results of the analysis of the sample; i.e. whether the sample can be accurately generalised to the population from which the sample has been drawn (we’ll discuss this a little later). Remember, the value of sampling is that it is an abbreviated technique for assessing an entire population, which will often be too large for every member to be sampled individually. In this case, the sample is intended to be generalizable and applicable across an entire sample so that it is representative of the population; an analysis of every individual within the population is known as a census.
Statistics then are the cornerstone of much analysis work within the UX domain. As a UX specialist, you’ll be expected to understand how statistics relates to your work and how to use them to describe the data you have collected, and support your general assertions about that data. I do not intend to go into full treaties of statistical analysis at this point (there is more coming), there are many texts that cover this in far more detail than I can. In general, you will be using statistical packages such as SPSS (or PSPP in Linux) to perform certain kinds of tests. It is, therefore, important that you understand the types of tests you wish to apply based on the data that has been collected. In general, there are two main types of statistical tests: descriptive, to support internal validity; and inferential, to support external validity.
Descriptive statistics, are mainly concerned with analysing your data concerning the standard normal distribution; that you could expect an entire population to exhibit. Most of these descriptive tests are to enable you to understand how much your data differs from a perfect standard distribution and in this way enable you to describe and understand its characteristics. These tests are often known as measures of central tendency and are coupled with variance and standard deviation. It is often useful to graph your data so that you can understand its characteristics concerning aspects such as skew and kurtosis. By understanding the nature and characteristics of the data you’ve collected, you will be able to decide which kinds of inferential testing you require. This is because most statistical tests assume a standard normal distribution. If your data does not exhibit this distribution, within certain bounds, then you will need to choose different tests so that you can make accurate analyses.
Inferential statistics, are used to support the generalisability, of your samples’ characteristics, about that of the general population from which the sample is drawn. The key aspect of inferential testing is the t–test, where ‘t’ is a distribution, just like a normal distribution and is simply an adjusted version of the normal distribution that works better for small sample sizes. Inferential testing is divided into two types: parametric, and non-parametric. Parametric tests are the set of statistical tests that are applied to data that exhibit a standard normal distribution. Whereas, non-parametric tests are those which are applied to data that are not normally distributed. Modern parametric methods, General Linear Model (GLM), do exist which work on normally distributed data and incorporate many different statistical models such as the ANOVA and ANCOVA. However, as a UX specialist, you will normally be collecting data from a small number of users (often between 15 and 40), which means that because your sample size is relatively small, its distribution will often not be normally distributed, in this case, you will mainly be concerned with non-parametric testing.
16.2.3 Participants
Participants – users – are the most important aspect of your methodological plan because without choosing a representative sample you cannot hope to validate your work accurately. Originally the sampling procedures for participants came from human facing disciplines such as anthropology and sociology; and so quite naturally, much of the terminology is still specific to these disciplines. Do not let this worry you, once you get the hang of it, the terminology is very easy to understand and apply.
The most important thing to remember is that the participants you select, regardless of the way in which you select them, need to be a representative sample of the wider population of your users; i.e. the people who will use your application, interfaces, and their interactive components. This means that if you expect your user base to be, say, above the age of 50, then, testing your application with a mixture of users including those below the age of 50 is not appropriate. The sample is not representative and therefore, any results that you obtain will be (possibly) invalid.
Making sure that you only get the correct participants for your work is also very difficult. This is because you will be tempted – participants normally being in such short supply – to include as many people as possible, with many different demographics, to make up your participant numbers12, you’ll be tempted to increase your participants because the alpha (α - also know as the probability ‘p’) value in any statistical test is very responsive to participant numbers – often the more, the better. This is known as having a heterogeneous set, but in most cases you want a homogeneous set.
Good sampling procedures must be used when selecting individuals for inclusion in the sample. The details of the sample design its size and the specific procedures used for selecting individuals will influence the tests precision. There are three characteristics of a ‘Sample Frame’, these being comprehensiveness, whether the probability of selection can be calculated; efficiency, how easily can the sample be selected and recruited, and method:
- Simple Random Sampling ‘Probabilistic’ — Simple random sampling equates to drawing balls at a tombola. The selection of the first has no bearing and is fully independent of, the second or the third, and so forth. This is often accomplished in the real world by the use of random number tables or, with the advent of computer technology, by random number generators;
- Systematic Sampling Probabilistic — Systematic samples are a variation of random sampling whereby each possible participant is allocated a number, with participants being selected based on some systematic algorithm. In the real world we may list participants numbering them from, say, one to three hundred and picking every seventh participant, for instance;
- Stratified Sampling Probabilistic — Stratified samples are used to reduce the normal sampling variation that is often introduced in random sampling methods. This means that certain aspects of the sample may become apparent as that sample is selected. In this case, subsequent samples are selected based on these characteristics, this means that a sample can be produced that is more likely to look like the total population than a simple random sample;
- Multistage Sampling Probabilistic — Multistage sampling is a strategy for linking populations to some grouping. If a sample was drawn from, say, the University of Manchester then this may not be representative of all universities within the United Kingdom. In this case, multistage sampling could be used whereby a random sample is drawn from multiple different universities independently and then integrated. In this way we can ensure the generalisability of the findings; and
- Quota Sampling ‘Non-Probabilistic’ — Almost all non-governmental polling groups or market research companies rely heavily on non-probability sampling methods; the most accurate of these is seen to be quota based sampling. Here, a certain demographic profile is used to drive the selection process, with participants often approached on the street. In this case, a certain number of participants are selected, based on each point in the demographic profile, to ensure that an accurate cross-section of the population is selected;
- Snowball Sampling Non-Probabilistic — The process of snowball sampling is much like asking your participants to nominate another person with the same trait as them.
- Convenience Sampling Non-Probabilistic — The participants are selected just because they are easiest to recruit for the study and the UX’er did not consider selecting participants that are representative of the entire population.
- Judgmental Sampling Non-Probabilistic — This type of sampling technique is also known as purposive sampling and authoritative sampling. Purposive sampling is used in cases where the speciality of an authority can select a more representative sample that can bring more accurate results than by using other probability sampling techniques.
For the normal UX evaluation ‘Quota’ or ‘Judgmental’ sampling are used, however ‘Snowball’ and ‘Convenience’ sampling are also popular choices if you subscribe to the premise that your users are in proximity to you, or that most users know each other. The relative size of the sample is not important, however, the absolute size is, a sample size of between 50 and 200 is optimal as anything greater than 200 starts to give highly diminished returns for the effort required to select the sample.
Finally, you should understand Bias – or sampling error – which is a critical component of total survey design, in which the sampling process can affect the quality of the survey estimates. If the frame excludes some people who should be included, there will be a bias, and if the sampling processes are not probabilistic, there can also be a bias. Finally, the failure to collect answers from everybody is a third potential source of bias. Indeed, non-response rates are important because there is often a reason respondents do not return their surveys, and it may be this reason that is important to the survey investigators. There are multiple ways of reducing non-response. However, non-response should be taken into account when it comes to probability samples.
16.2.4 Evaluation++
In the first part of this chapter, we have placed the scientific bedrock and discussed how to design and analyse evaluations, which in our case, will mostly be qualitative. However, evaluations do not a stop at the qualitative level but move on to quantitative work and work that is both laboratory-based and very well controlled. While I do not propose an in-depth treatise of experimental work, I expect that some aspects might be useful, especially for communications inside the organisation and as a basic primer if you are required to create these more tightly controlled evaluations. There is more discussion on controlled laboratory work and you can think of this as Evaluation++13. Evaluation++ is the gold standard for deeply rigorous scientific work and is mostly used in the scientific research domain.
To make things easier, let’s change our terminology from Evaluation++ to ‘experimental’, to signify the higher degree of rigour and the fundamental use of the scientific method (which mostly cannot be used for qualitative work, or work which used Grounded Theory14) found in these methods.
An experiment has five separate conditions that must be met. Firstly, there must be a hypothesis that predicts the causal effects of the independent variable (the computer interface, say) on the dependent variable (the user). Secondly, these should be two different sets of independent variables. Thirdly, participants are assigned in an unbiased manner. Fourthly, procedures for testing hypotheses are present. Fifthly, there must be some control concerning accentuate internal validity. There are several different kinds of evaluation design ranging from a single variable, independent group designs, through single variable, correlated groups designs, to factorial designs. However, in this text we will primarily focus on the first; single variable, independent group designs.
Single Group, Post-Test – In this case, the evaluation only occurs after the computer-based artefact has been created and also there is only one group of participants for user testing. This means that we cannot understand if there has been an increase or improvement in interaction due to purely to the computer-based artefact, and also, we cannot tell if the results are only due to the single sample group.
Single Group, Pre-Test and Post-Test –, In this case, the evaluation occurs both before and after the computer-based artefact has been introduced. Therefore, we can determine if the improvement in interaction is due purely to the computer-based artefact but we cannot tell if the results, indicating either an improvement or not, are due to the single sample group.
Natural Control Group, Pre-Test and Post-Test – This design is similar to the single group, pre-test and post-test however a control group is added but this control group is not randomly selected but is rather naturally occurring; you can think of this as a control group of convenience or opportunity. This means that we can determine if the interaction is due to the computer-based artefact and we can also tell if there is variance between the sample groups.
Randomised Control Group, Pre-Test and Post-Test – This design is the same as a natural control group, pre-test and post-test, however, it has the added validity of selecting participants for the control group from a randomised sample.
Within-Subjects – A within-subjects design means that all participants are exposed to all different conditions of the independent variable. In reality, this means that the participants will often see both the pre-test state of the interface and the post-test state of the interface, and from this exposure, a comparison, usually based on a statistical ANOVA test (see later), can be undertaken.
Others – These five designs are not the only ones available however they do represent basic set of experimental designs increasing validity from the first to see last. You may wish to investigate another experiment to design such as Solomon’s four group design or multilevel randomised between subject designs etc.
To an extent, the selection of the type of experimental design will be determined by more pragmatic factors than those associated purely with the ‘true experiment’. Remember, your objective is not to prove that a certain interface is either good or bad. By exhibiting a certain degree of agnosticism regarding the outcome of the interaction design, you will be better able to make improvements to that design that will enhance its marketability
16.2.5 Pre and Post Test and A/B Testing
A/B testing, also known as split testing, is a statistical method used to compare two versions of something (usually a webpage, advertisement, or application feature) to determine which one performs better in achieving a specific goal or objective. The goal could be anything from increasing click-through rates, conversion rates, or user engagement to improving revenue or user satisfaction.
You first need to clearly define what you want to improve or optimize. For example, you may want to increase the number of users signing up for your service or buying a product. Develop two (or more) different versions of the element you want to test. For instance, if you’re testing a website’s landing page, you could create two different designs with varying layouts, colours, or calls-to-action (CTAs). Randomly split your website visitors or users into two equal and mutually exclusive groups, A and B (hence the name A/B testing). Group A will see one version (often referred to as the “control”), and group B will see the other version (often called the “variant”). Allow the test to run for a predetermined period, during which both versions will collect data on the chosen metrics, such as click-through rates or conversion rates. A/B testing is a powerful technique because it provides objective data-driven insights, allowing businesses to make informed decisions about design, content, and user experience. By continuously testing and optimizing different elements, organizations can improve their overall performance and achieve their goals more effectively.
Pre and post-test and A/B testing are two different experimental designs used in research and analysis, but they share some similarities and can be used together in certain scenarios. In this design, Pre and Post-Test participants are assessed twice – once before they are exposed to an intervention (pre-test), and once after they have undergone the intervention (post-test). The change between the pre-test and post-test measurements helps evaluate the impact of the intervention. A/B Testing involves comparing two or more versions of something to see which one performs better. So while this may not be ‘Within-Subjects’ the idea of testing two different interventions is the same.
The main objective of Pre and Post-Test design is to evaluate the effect of an intervention or treatment. Researchers want to determine if there’s a significant change in the outcome variable between the pre-test and post-test measurements. While the primary objective of A/B Testing is to compare two or more versions to identify which one yields better results in achieving a specific goal, such as increased conversion rates or user engagement. Again the two are very similar. Pre and post-test and A/B testing are distinct experimental designs with different objectives. Pre and post-test evaluates the impact of an intervention over time, while A/B testing compares different versions simultaneously to determine which one is more effective in achieving a particular goal. However, they can complement each other when studying the effects of changes or interventions over time and simultaneously evaluating different versions for performance improvements.
16.3 A Note on Statistics & How To Use & Interpret
Most car drivers do not understand the workings of the internal combustion engine or – for that matter – any of the machinery which goes to make up the car. While some people may find it rewarding to understand how to make basic repairs and conduct routine maintenance, this knowledge is not required if all you wish to do is drive the vehicle. Most people do not know much beyond the basics of how to operate the car, choose the right fuel, and know where the wiper fluid goes. It is exactly the same with statistics. While it is true that the ‘engineers’ of statistical methods, the statistician, need to understand all aspects of statistical analysis from first principles; and while it is also true that ‘mechanics’ need to understand how to fix and adapt those methods to their own domains; most users of statistics see themselves purely as ‘drivers’ of these complex statistical machines and as such think that they don’t need to know anything more than the basics required to decide when and how to apply those methods.
Now, my view is not to be that cavalier on the subject, most statistical work is conducted by non-statisticians and in many cases these non-statisticians use a plug and play mentality. They choose the most popular statistical test as opposed to the correct one to fit their datasets, they are not sure why they are applying the data to a certain test, and they not absolutely sure why they are required to hit a 0.05 or 0.01 p-value (whatever ‘p’ is). As an example let’s consider a critique of the recently acclaimed book ‘Academically Adrift’ the principle finding of which claims that “45 percent of the more than 2,000 students tested in the study failed to show significant gains in reasoning and writing skills during their freshman and sophomoric years.” suggesting that “Many students aren’t learning very much at all in their first two years of college”.
As Alexander W. Astin15 discusses in his critique16 “The goal was to see how much they had improved, and to use certain statistical procedures to make a judgment about whether the degree of improvement shown by each student was ‘statistically significant’.”.
Austin goes on to say “the method used to determine whether a student’s sophomore score was ‘significantly’ better than his or her freshman score is ill suited to the researchers’ conclusion. The authors compared the difference between the two scores–how much improvement a student showed — with something called the ‘standard error of the difference’ between his or her two scores. If the improvement was at least roughly twice as large as the standard error (specifically, at least 1.96 times larger, which corresponds to the ‘. 05 level of confidence’, they concluded that the student ‘improved.’ By that standard, 55 percent of the students showed ‘significant’ improvement — which led, erroneously, to the assertion that 45 percent of the students showed no improvement.”
He continues, ‘The first thing to realise is that, for the purposes of determining how many students failed to learn, the yardstick of ‘significance’ used here–the .05 level of confidence–is utterly arbitrary. Such tests are supposed to control for what statisticians call “Type I errors,” the type you commit when you conclude that there is a real difference, when in fact there is not. But they cannot be used to prove that a student’s score did not improve.” Stating that, “the basic problem is that the authors used procedures that have been designed to control for Type I errors in order to reach a conclusion that is subject to Type II errors. In plainer English: Just because the amount of improvement in a student’s CLA score is not large enough to be declared ‘statistically significant’ does not prove that the student failed to improve his or her reasoning and writing skills. As a matter of fact, the more stringently we try to control Type I errors, the more Type II errors we commit.”
Finally, Austin tells us that “To show how arbitrary the ‘.05 level’ standard is when used to prove how many students failed to learn, we only have to realise that the authors could have created a far more sensational report if they had instead employed the .01 level, which would have raised the 45 percent figure substantially, perhaps to 60 or 70 percent! On the other hand, if they had used a less–stringent level, say, the .10 level of confidence, the ‘nonsignificant’ percent would have dropped way down, from 45 to perhaps as low as 20 percent. Such a figure would not have been very good grist for the mill of higher–education critics.”
Austin discusses many more problems in the instruments, collection, and analysis than those discussed above, but these should indicate just how open to mis-application, mis-analyses, and mis-interpretation statistics are. You don’t want to be like these kinds of uninformed statistical-tool users; but instead, a mechanic, adapting the tools to your domain can only be accurately done by understanding their application, the situations in which they should be applied, and what their meaning is. This takes a little more knowledge than simple application, but once you realise their simplicity – and power – using statistics becomes a lot less scary, and a lot more exciting!
16.3.1 Fisherian and Bayesian Inference
The relationship between Fisherian inference and Bayesian inference lies in their fundamental approaches to statistical inference, but they differ in their underlying principles and methodologies.
Fisherian inference, also known as classical or frequentist inference, was developed by Sir Ronald A. Fisher and is based on the concept of repeated sampling from a population. In Fisherian inference, probabilities are associated with the data and are used to make inferences about population parameters.
Fisherian inference heavily relies on Null Hypothesis Significance Testing (NHST), where a null hypothesis is formulated, and statistical tests are performed to determine whether the observed data provide sufficient evidence to reject the null hypothesis in favor of an alternative hypothesis. Fisherian inference considers the sampling distribution of a statistic under repeated sampling to make inferences about the population parameter of interest. The focus is on estimating and testing hypotheses about fixed but unknown parameters. Fisherian inference uses point estimation to estimate population parameters. The most common method is maximum likelihood estimation (MLE), which aims to find the parameter values that maximize the likelihood function given the observed data.
On the other hand, Bayesian inference, developed by Thomas Bayes, takes a different approach by incorporating prior knowledge and updating it with observed data to obtain posterior probabilities.
Bayesian inference assigns probabilities to both the observed data and the parameters. It starts with a prior probability distribution that reflects prior beliefs or knowledge about the parameters and updates it using Bayes’ theorem to obtain the posterior distribution. Bayesian inference uses the posterior distribution to estimate population parameters. Instead of providing a single point estimate, Bayesian estimation provides a full posterior distribution, which incorporates both prior knowledge and observed data. Bayesian inference allows for direct model comparison by comparing the posterior probabilities of different models. This enables the selection of the most plausible model given the data and prior beliefs.
While Fisherian inference and Bayesian inference have different philosophical foundations and computational approaches, they are not mutually exclusive. In fact, there are connections and overlaps between the two approaches. Bayesian inference can incorporate frequentist methods, such as maximum likelihood estimation, as special cases when certain assumptions are made. Bayesian inference can provide a coherent framework for incorporating prior information and updating it with new data, allowing for a more comprehensive and flexible analysis. Some Bayesian methods, such as empirical Bayes, borrow concepts from Fisherian inference to construct prior distributions or to estimate hyper-parameters.
In practice, the choice between Fisherian and Bayesian inference often depends on the specific problem, the available prior knowledge, computational resources, and the preference of the analyst. Both approaches have their strengths and weaknesses, and their use depends on the context and goals of the statistical analysis.
In UX we currently use Fisherian inference which we would call ‘Statistics’ while Bayesian inference would be know as a principle component of ‘Machine Learning’.
16.3.2 What Are Statistics?
Before I answer this question, let me make it clear that designing your evaluations is one of the most important aspects of the analysis process. If your evaluations are designed badly you will not be able to apply the correct analysis, and if you cannot apply the correct analysis you will not be able to make any conclusions as to the applicability or success of your interventions at the interface or interactive level. In reality this means that if this is not done correctly all of you previous work in the UX design and development phases will have been, to a large extent, pointless. Further, any statistical analysis you decide to do will give you incorrect results; these may look right, but they wont be.
Statistics then, are the cornerstone of much analysis work within the UX domain. As a UX specialist you’ll be expected to understand how statistics relate to your work and how to use them to describe the data you have collected, and support your general assertions with regard to that data (In general, you will be using statistical packages such as SPSS – or PSPP in Linux – to perform certain kinds of tests.). It is therefore, important that you understand the types of tests you wish to apply based on the data that has been collected; but before this, you need to understand the foundations of statistical analysis. Now there are many texts which cover this in far more detail than I can; but these are mainly written by statisticians. This discussion is different because it is my non-statistician’s view, and the topic is described in a slightly different (but I think easier way), based on years of grappling with the topic.
Let’s get back to the question in our title “What Are Statistics?”. Well, statistics are all about supporting the claims we want to make, but to make these claims we must first understand the populations from which our initial sampling data will be drawn. Don’t worry about these two new terms – population and sampling data – they’re very easy to understand and are the basis for all statistics; let’s talk about them further, now.
First of all let’s define a population, the OED tells us it is the ‘totality of objects or individuals under consideration’. In this case when we talk about populations we do not necessarily mean the entire population of say the United Kingdom, but rather, the total objects or individuals under our consideration. This means that if we were talking about students taking the user experience course we would define them as the population. If we wanted to find something useful out about this population of UX students, such as the mean exam mark, we may work this out by taking all student marks from our population into account — In reality this is exactly what we would do because there are so few students that a census of this total population is easily accomplished; this is called a census, and the average mark we arrive at is not called a statistic, but rather a parameter. However, suppose that we had to work the mean out manually – because our computer systems are broken down and we had a deadline to meet – in this case arriving at a conclusion may be a long and tedious job. It would be much better if we could do less work and still arrive at an average score of the entire class which we can be reasonably certain of. This is where statistics come into their own; because statistics are related to a representative sample drawn from a larger population.
The vast majority of UX analysis work uses statistical tests to support the internal and external validity of the research being undertaken. As we have already discussed, internal validity is the correctness of the data contained within the sample itself, while external validity is the generalisability to the population of the results of the analysis of the sample; i.e. whether the sample can be accurately generalised to the population from which the sample has been drawn. Remember, the value of sampling is that it is an abbreviated technique for assessing an entire population, which will often be too large for every member to be sampled individually. In this case, the sample is intended to be generalisable and applicable across an entire sample so that it is representative of the population; an analysis of every individual within the population; the census.
16.3.3 Distributions
You may not realise it but statistics are all about distribution. In the statistical sense the OED defines distribution as ‘The way in which a particular measurement or characteristic is spread over the members of a class’. We can think of these distributions as represented by graphs such that the frequency of appearance is plotted along the x-axis, while the measurement or characteristic is ordered from lowest to highest and then plotted along the y-axis. In statistics we know this as the variable; and in most cases this variable can be represented by the subject variable (such as: age, height, gender, weight, etc) or the observable response / dependent variable.
Let’s think about distributions in a little more detail. We have a theoretical distributions created by statisticians and built upon stable mathematical principles. These theoretical distributions are meant to represent the properties of a generic population. But we also have distributions which are created based on our real-world empirical work representing the actual results of our sampling. To understand how well our sample fits the distribution expected in the general population, we must compare the two; statistical analysis is all about this comparison. Indeed, we can say that the population is related to the theoretical distribution, while the statistic is related to the sample distribution
16.3.3.1 Normal Distributions
Normal Distributions are at the heart of most statistical analysis. These are theoretical distributions and basis for probability calculations which we shall come to in the future. This distribution are also known as a bell shaped curve whereby the highest point in the centre represents the mean (Mean: The average of all the scores.), median (Median: the number which denotes the 50th percentile in a distribution.), or mode (Mode: The number which occurs most frequently in a distribution.); and where approximately 68% of the population fall within one standard deviation unit of this position. These three measures of mean, median, and mode are collectively know as measures of central tendency; and try to describe the central point of the distribution.
16.3.3.2 Standard Deviation
The standard deviation is a simple measure of how spread out the scores in a distribution are. While the range (Range: difference between the highest and lowest scores.) and IQR (Inter-Quartile Range: difference between the scores are the 25th and 75th percentiles.) are also measures of variability, the variance (Variance: the amount of dispersion in a distribution.) is more closely related to the standard deviation. While we won’t be touching formulas here it is useful to understand exactly what standard deviation really means. First, we measure the difference between a single score in a distribution and the mean score for the distribution; we then find the average of these differences, and we have the standard deviation.
16.3.4 A Quick Guide to Selecting a Statistical Test
There are four quadrants that we can place tests in. We have parametric and non-parametric test - this simply means those with an expected standard distribution (parametric) which would typically need to have a lot of participants over 100 say, and those not expected to follow a standard distribution (non-parametric) so less than 30 and this will normally be the range you are working in as UX’ers.
Next we have causation and correlation. This means that if something correlates it exhibits some kind of relationship but you can’t decide if one causes the other to occur - and so these are the most common types of test and are slightly less strong, but easier to see. Causation on the other-hand is a stronger test and requires more data - you will typically not use these tests much. So you are looking at non-parametric correlation.
16.3.5 Correlation Tests
Parametric statistical tests are used to analyse data when certain assumptions about the data distribution and underlying population parameters are met.
- Student’s t-test: The t-test is used to compare means between two independent groups. It assesses whether there is a significant difference between the means of the two groups.
- Paired t-test: The paired t-test is used to compare means within the same group or for related samples. It assesses whether there is a significant difference between the means of paired observations.
- Analysis of Variance (ANOVA): ANOVA is used to compare means between multiple independent groups. It determines whether there are significant differences in the means across different groups or levels of a categorical variable.
- Analysis of Covariance (ANCOVA): ANCOVA is an extension of ANOVA that incorporates one or more covariates (continuous variables) into the analysis. It examines whether there are significant differences in the means of the groups after controlling for the effects of the covariates.
- Pearson’s correlation coefficient (Pearson’s r): This is the most commonly used correlation test, which measures the linear relationship between two variables. It assesses both the strength and direction of the relationship. It assumes that the variables are normally distributed.
- Chi-square test: The chi-square test is used to determine if there is an association or dependence between two categorical variables. It assesses whether there is a significant difference between the observed and expected frequencies in the contingency table.
These are some of the main parametric statistical correlation tests used to assess the relationship between variables. The choice of which test to use depends on the nature of the variables and the specific research question or hypothesis being investigated.
Non-parametric statistical tests are used when the assumptions of parametric tests are violated or when the data is not normally distributed. Here are some of the main non-parametric correlation tests:
- Spearman’s rank correlation coefficient (Spearman’s rho): This non-parametric test is similar to the parametric Spearman’s rank correlation coefficient. It assesses the monotonic relationship between two variables using ranks instead of the actual values of the variables. It is suitable for non-linear relationships and is less sensitive to outliers.
- Kendall’s rank correlation coefficient (Kendall’s tau): Kendall’s tau is another non-parametric measure of the monotonic relationship between two variables. It uses ranks and determines the strength and direction of the association. It is robust to outliers and is suitable for non-linear relationships.
- Goodman and Kruskal’s gamma: This non-parametric correlation test is used to assess the association between two ordinal variables. It measures the strength and direction of the relationship, particularly in cases where the data is not normally distributed.
- Somers’ D: Somers’ D is a non-parametric measure of association that is commonly used when one variable is ordinal, and the other is binary. It evaluates the strength and direction of the relationship between the two variables.
- Kendall’s coefficient of concordance: This non-parametric test is used when there are multiple variables that are ranked by multiple observers or raters. It measures the agreement or concordance among the raters’ rankings.
- Mann-Whitney U test: The Mann-Whitney U test, also known as the Wilcoxon rank-sum test, is a non-parametric test used to compare the distributions of two independent samples. It assesses whether there is a significant difference between the medians of the two groups.
- Kruskal-Wallis test: The Kruskal-Wallis test is a non-parametric alternative to ANOVA. It compares the distributions of three or more independent groups and determines whether there are significant differences among the medians.
These non-parametric correlation tests are useful alternatives to parametric tests when the assumptions of parametric tests are not met or when dealing with non-normally distributed data. They provide a robust and distribution-free approach to assessing the relationship between variables. Again, the choice of which test to use depends on the type of variables involved and the research question at hand.
16.3.6 Causation Tests
Regression analysis is a statistical method used to examine the relationship between a dependent variable and one or more independent variables. And is one of the main ways in which causation is supported, and aims to model the relationship and understand how changes in the independent variables impact the dependent variable.
The dependent variable, also known as the outcome variable or response variable, is the variable that is being predicted or explained. It is typically a continuous variable. The independent variables, also called predictor variables or regressors, are the variables that are hypothesized to have an influence on the dependent variable. These can be continuous or categorical variables.
The regression analysis estimates the coefficients of the independent variables to create a regression equation. The equation represents a line or curve that best fits the data points and describes the relationship between the variables. The equation can be used to predict the value of the dependent variable based on the values of the independent variables. There are various types of regression analysis, depending on the nature of the data and the research question.
- Simple Linear Regression: This type of regression involves a single independent variable and a linear relationship between the independent and dependent variables. It estimates the slope and intercept of a straight line.
- Multiple Linear Regression: Multiple linear regression involves two or more independent variables. It estimates the coefficients for each independent variable, indicating the strength and direction of their relationship with the dependent variable while considering other variables.
- Polynomial Regression: Polynomial regression is used when the relationship between the variables is non-linear. It can model curves of different orders (e.g., quadratic or cubic) to capture more complex relationships.
- Logistic Regression: Logistic regression is used when the dependent variable is binary or categorical. It estimates the probabilities or odds of an event occurring based on the independent variables.
The regression analysis provides several statistical measures to assess the goodness of fit and the significance of the model. These include the coefficient of determination (R-squared), which indicates the proportion of the variance in the dependent variable explained by the independent variables, and p-values for the coefficients, indicating the significance of each variable’s contribution.
16.4 Caveat
I was pleased recently to receive this (partial) review for a paper a submitted to ‘Computers in Human Behaviour’. It seems like this reviewer understands the practicalities of UX work. Instead of clinging to old and tired statistical methods more suited to large epidemiology – or sociology – studies this reviewer simply understands:
“The question is whether the data and conclusions already warrant reporting, as clearly this study in many respects is a preliminary one (in spite of the fact that the tool is relatively mature). Numbers of participants are small (8 only), numbers of tasks given are small (4 or 6 depending on how you count), the group is very heterogeneous in their computer literacy, and results are still very sketchy (no firm conclusions, lots of considerations mentioned that could be relevant). This suggests that one had better wait for a more thorough and more extensive study, involving larger numbers of people and test tasks, with a more homogeneous group. I would suggest not to do so. It is hard to get access to test subjects, let alone to a homogeneous group of them. But more importantly, I am convinced that the present report holds numerous valuable lessons for those involved in assisting technologies, particularly those for the elderly. Even though few clear-cut, directly implementable conclusions have been drawn, the article contains a wealth of considerations that are useful to take into account. Doing so would not only result in better assistive technology designs, but also in more sophisticated follow-up experiments in the research community.”
Thanks, mystery reviewer! but this review opens up a wider discussion which you, as UX specialists should be aware of; yes, yet another cautionary note. Simply, there is no way that any UX work – Any UX Work – can maintain ‘External Validity’ with a single study, the participant numbers are just way too low and heterogeneous – even when we have 50 or 100 users. To suggest any different is both wrong and disingenuous; indeed, even for quota based samples – just answering a simple question – we need in the order of 1000 participants. I would rather, two laboratory-based evaluations using different methods, from different UX groups, using 10 participants, both come up with the same conclusions than a single study of 100 people. In UX, we just end up working with too few people for concrete generalisations to be made – do you think a sample of 100 people is representative of 60 million? I’m thinking not. And, what’s more, the type of study will also fox you… perform a lab evaluation which is tightly controlled for ‘Confounding Factors’ and you only get ‘Internal Validity’, do a more naturalistic study which is ‘ecologically’ valid, and you have the possibility of so many confounding variables that you cannot get generalisability.
‘But surely’, I hear you cry ‘Power Analysis (statistical power) will save us!’17. ‘We can use power analysis to work out the number of participants, and then work to this number, giving us the external validity we need!’ – Oh if it was only so easy. In reality, ‘Statistical power is the probability of detecting a change given that a change has truly occurred. For a reasonable test of a hypothesis, power should be >0.8 for a test. A value of 0.9 for power translates into a 10% chance that we will miss conclude that a change has occurred when indeed it has not’. But power analysis assumes an alpha of 0.05 (normally), the larger the sample, the more accurate, and the bigger the effect size, the easier it is to find. So again large samples looking for a very easily visible effect (large effect), and without co-variates, gives better results. But, these results are all about accepting or rejecting the null hypothesis – that always states that the sample is no different from the general population, or that there is no difference between the results captured from ‘n’ samples. This, presuming the base case is a good proxy of the population (randomly selected) – which it may not be.
So is there any point in empirical work? Yes, internal validity suggests an application into the general population (which is why we are mostly looking at measures of internal ‘Statistical Validity’). What’s more, one internally valid study is a piece of the puzzle, bolstered with ‘n’ more small but internally valid studies allows us to make more concrete generalisations.
16.5 Summary
So then, UX is used in areas of computer science spectrum that may not seem as though they obviously lend themselves to interaction. Even algorithmic strategies in algorithms and complexity have some aspects of user dependency, as do the modelling and simulation aspects of computational science. In this regard, UX is very much at the edge of discovery and the application of that discovery. Indeed, UX requires a firm grasp of the key principles of science, scientific reasoning, and the philosophy of science. This philosophy, principles, and reasoning are required if a thorough understanding of the way humans interact with computers is to be achieved. Further, Schmettow tells us that user numbers cannot be prescribed before knowing just what the study is to accomplish, and Robertson tells us that the interplay between Likert-Type Scales, Statistical Methods, and Effect Sizes are more complicated than we imagine when performing usability evaluations. In a more specific sense if you need to understand, and show, that the improvements made over user interfaces to which you have a responsibility in fact real and quantifiable, and conform to the highest ethical frameworks.
16.5.1 Optional Further Reading
- [J. Baggini] and P. S. Fosl. The philosopher’s toolkit: a compendium of philosophical concepts and methods. Wiley-Blackwell, Oxford, 2nd ed edition, 2010.
- [L. Floridi.] The Blackwell guide to the philosophy of computing and information. Blackwell Pub., Malden, MA, 2004.
- [A. Rosenberg.] Philosophy of Science: a contemporary introduction. Routledge contemporary introductions to philosophy. Routledge, New York, 3rd ed. edition, 2012.
- [J. Cohen] — Applied multiple regression/correlation analysis for the behavioral sciences. L. Erlbaum Associates, Mahwah, N.J., 3rd ed edition, 2003.
- [P. Dugard, P. File, J. B. Todman] — Single-case and small-n experimental designs: a practical guide to randomization tests, second edition. Routledge Academic, New York, NY, 2nd ed edition, 2012.
- [M. Forshaw] Easy statistics in psychology: a BPS guide. Blackwell Pub., Malden, MA, 2007.
- [J. J. Hox.] Multilevel analysis: techniques and applications. Quantitative methodology series. Routledge, New York, 2nd ed edition, 2010.
- [T. C. Urdan.] Statistics in plain English. Routledge, New York, 3rd ed edition, 2010.