Préoccupations et risques entourant l’IA
 |
Les préoccupations concernant l’IA sont sérieuses. Les risques sont réels. Parfois, ils sont exprimés de manière hystérique, mais, quand on creuse, l’impact de l’IA a le potentiel d’être énormément destructeur. |
Il y a tellement de problèmes et de préoccupations entourant l’IA qu’ils remplissent des volumes entiers. Voici un nuage de mots des sujets que je surveille. Je suis sûr qu’il m’en manque quelques-uns.

Il y a beaucoup d’informations disponibles sur chacun de ces sujets, et je vous encourage à lire autant que possible. Il est possible que vous concluiez que les risques l’emportent sur les avantages, et que vous ne vouliez pas poursuivre l’utilisation de l’IA, que ce soit personnellement ou au sein de votre organisation. Cette décision apporte ses propres risques ; l’habituel, d’être laissé pour compte. Mais c’est un choix personnel.
Si vous faites une recherche Google avec “livres concernant les risques de l’IA”, vous trouverez une sélection de volumes intéressants. Un podcast récent que j’ai trouvé particulièrement effrayant est la conversation d’Ezra Klein avec Dario Amodei, co-fondateur et PDG d’Anthropic (la société qui développe Claude.ai). Vous apprenez que ces entreprises sont conscientes des risques. Amodei fait référence à un système de classification des risques internes appelé A.S.L., pour “Niveaux de sécurité de l’IA” (et non American Sign Language). Nous sommes actuellement à ASL 2, “des systèmes qui montrent des signes précoces de capacités dangereuses - par exemple, la capacité de donner des instructions sur la façon de fabriquer des armes biologiques.” Il décrit ASL 4 comme “permettant aux acteurs étatiques d’augmenter considérablement leur capacité… où nous craindrions que la Corée du Nord, la Chine ou la Russie puissent grandement améliorer leurs capacités offensives dans divers domaines militaires grâce à l’IA d’une manière qui leur donnerait un avantage substantiel au niveau géopolitique.” Des choses effrayantes.
Dans ce contexte sombre, je vais mettre en avant les questions les plus pertinentes pour les écrivains et les éditeurs.
Droit d’auteur enfreint ?
|
Les questions de droit d’auteur sont un miasme de complexité et d’ambiguïté. Il semble certain que certains livres encore sous droit d’auteur ont été inclus dans l’entraînement de certains LLM. Mais il n’est certainement pas vrai, comme certains auteurs le craignent, que tout leur travail a été aspiré dans chacun des grands modèles de langage. |
Les questions de droit d’auteur sont à la fois spécifiques et larges. Il est bien connu que tous les LLM sont entraînés sur le web ouvert - tout ce qui peut être extrait des 1,5 milliard de sites web aujourd’hui, que ce soit des articles de journaux, des publications sur les réseaux sociaux, des blogs web et, apparemment, des transcriptions de vidéos YouTube.
Il est prouvable qu’au moins l’un des LLM a ingéré le texte réel de milliers de livres non tombés dans le domaine public.
Était-il légal d’ingérer tout ce texte pour aider à construire des entreprises d’IA valant des milliards de dollars, sans aucune compensation pour les auteurs ? Les entreprises d’IA fondent leur argumentation sur l’usage équitable ; les tribunaux finiront par décider. Même si c’était légal, était-ce éthique ou moral ? L’éthique semble moins complexe que les considérations juridiques. À vous de décider.
Les lois sur le droit d’auteur n’ont évidemment pas anticipé les défis uniques que l’IA pose à cette question, et la recherche de solutions juridiques prendra du temps, peut-être des années. (Si vous souhaitez approfondir la question de savoir pourquoi les lois sont inadaptées au problème particulier en question, lisez l’excellent article de A. Feder Cooper et James Grimmelmann intitulé “Les fichiers sont dans l’ordinateur : Droit d’auteur, mémorisation et IA générative.”)
Voici une liste de treize des poursuites les plus en vue, qui ne concernent pas toutes les livres ; également des images et de la musique. Et voici une autre liste qui met à jour le statut de toutes les poursuites.
Droit d’auteur et IA pour les auteurs
|
Les auteurs font face à des problèmes supplémentaires concernant la possibilité de droit d’auteur pour le contenu généré par IA. |
La position de l’Office américain du droit d’auteur sur la possibilité de droit d’auteur pour le contenu généré par IA stipule que l’IA seule ne peut pas détenir de droit d’auteur car elle ne possède pas le statut juridique d’un auteur. Cela a du sens. Mais cela suppose que 100 % du travail soit généré par IA. Comme discuté ailleurs, peu d’auteurs laisseront l’IA générer un livre entier. Il est plus probable que ce sera 5 %, ou 10 %, ou… Et c’est là que l’Office du droit d’auteur trébuche (comme moi).
Dans une décision plus récente, l’Office a conclu qu’un roman graphique composé de texte écrit par des humains combiné à des images générées par le service IA Midjourney constituait une œuvre protégée par le droit d’auteur, mais que les images individuelles elles-mêmes ne pouvaient pas être protégées par le droit d’auteur. Eh bien !
|
Il suffit de dire que les auteurs et les éditeurs doivent être attentifs à l’évolution des questions de droit d’auteur, sur plusieurs fronts. |
Quelles sont les implications à long terme ?
Certains comparent les litiges actuels à la poursuite Google Books, qui a mis 10 ans à se résoudre légalement. Qui sait combien de temps le processus d’appel traînera pour ces dossiers. En attendant, les éditeurs sont prudents d’agir comme si les entreprises d’IA allaient perdre, ce qui, au moins théoriquement, expose toute personne qui accorde une licence, ou peut-être même utilise Chat AI, à une sorte de responsabilité contingente.
Mais ce n’est pas le problème le plus sérieux pour un éditeur. C’est la perception. Pour de nombreux auteurs, certains éminents, d’autres obscurs, le puits a été empoisonné. L’IA est radioactive au sein de la communauté des écrivains et des éditeurs. Tout ce qui a même une odeur d’IA attire des critiques intenses.
Il y a de nombreux exemples. Dans un incident récent, Angry Robot, un éditeur britannique “dédié au meilleur de la science-fiction moderne pour adultes, de la fantasy et du WTF,” a annoncé qu’il utiliserait un logiciel d’IA, appelé Storywise, pour trier un grand lot de soumissions de manuscrits prévu. Il a fallu juste cinq heures pour que l’entreprise abandonne le plan et revienne à l’ancienne boîte de réception.
Le dilemme insupportable pour les éditeurs commerciaux utilisant des outils d’IA en interne : si vos auteurs le découvrent, vous aurez du mal à affronter la tempête qui en résultera. Je crois que les éditeurs n’ont pas d’autre choix que d’être courageux, d’adopter (au moins certains de) ces outils, d’expliquer clairement comment ces outils sont entraînés et comment ils sont utilisés, et de continuer.
Au Royaume-Uni, The Society of Authors adopte une approche stricte : « Demandez à votre éditeur de confirmer qu’il n’utilisera pas de manière substantielle l’IA à quelque fin que ce soit en rapport avec votre travail - comme la relecture, l’édition (y compris la vérification d’authenticité et la vérification des faits), l’indexation, la vérification juridique, la conception et la mise en page, ou quoi que ce soit d’autre sans votre consentement. Vous pouvez souhaiter interdire la narration d’audiobooks, la traduction et la conception de couverture rendues par l’IA. »
La Authors Guild semble accepter que « les éditeurs commencent à explorer l’utilisation de l’IA comme outil dans le cours habituel de leurs opérations, y compris les usages éditoriaux et marketing. » Je ne pense pas que beaucoup de membres de la Guild soient aussi compréhensifs.
Licence de contenu aux entreprises d’IA
La plupart des éditeurs, et de nombreux auteurs, cherchent des moyens de licencier du contenu aux entreprises d’IA. Chacun a une idée différente de ce que devraient être les termes de la licence et de la valeur de leur contenu, mais au moins les discussions sont en cours.
Il existe plusieurs startups cherchant à collaborer avec les éditeurs (et, dans certains cas, les auteurs individuels). Calliope Networks et Created by Humans sont toutes deux intéressantes à cet égard.
À la mi-juillet, le Copyright Clearance Center, depuis longtemps le principal acteur de l’industrie dans la licence collective des droits d’auteur, a annoncé la disponibilité de « droits de réutilisation de l’intelligence artificielle (IA) dans le cadre de ses licences annuelles de droits d’auteur (ACL), une solution de licence de contenu à l’échelle de l’entreprise offrant des droits sur des millions d’œuvres aux entreprises abonnées. »
Publishers Weekly a couvert l’annonce, citant Tracey Armstrong, présidente et PDG du CCC, déclarant « Il est possible d’être pro-IA et pro-droit d’auteur, et de coupler l’IA avec le respect des créateurs. »
Bien que cela ne soit pas exhaustif, c’est probablement une avancée dans le rapprochement de l’édition vers un degré de coopération avec les développeurs de grands modèles de langage.
Il est trop tard pour éviter l’IA
|
Pour les auteurs et les éditeurs qui préfèrent ne pas être souillés par l’IA, les nouvelles sont mauvaises : vous utilisez l’IA aujourd’hui, et vous l’utilisez depuis des années. |
L’intelligence artificielle, sous différentes formes, a déjà été intégrée dans la plupart des outils logiciels et services que nous utilisons chaque jour. Les gens comptent sur la correction orthographique et grammaticale alimentée par l’IA dans des programmes comme Microsoft Word ou Gmail. Microsoft Word et PowerPoint appliquent l’IA pour fournir des suggestions d’écriture, offrir des recommandations de conception et de mise en page, et plus encore. Les assistants virtuels comme Siri et Alexa utilisent le traitement du langage naturel pour comprendre les commandes vocales et répondre aux questions. Les services de messagerie utilisent l’IA pour filtrer les messages, détecter les spams et envoyer des alertes. L’IA alimente les chatbots de service client et génère des recommandations de produits basées sur votre historique d’achats.
Et une grande partie de cela est basée sur les grands modèles de langage, comme c’est le cas avec ChatGPT.
Pour qu’un auteur ou un éditeur dise : « Je ne veux pas que l’IA soit utilisée sur mon manuscrit, » est, en termes généraux, presque impossible, à moins qu’ils ne travaillent tous les deux avec des machines à écrire et des crayons.
Ils pourraient essayer de dire : « Je ne veux pas que l’IA générative » soit utilisée sur leur livre. Mais c’est difficile à découper. Les logiciels de vérification grammaticale n’ont pas été initialement construits sur l’IA générative. Grammarly l’a ajoutée comme ingrédient à son produit, comme le feront tous les autres correcteurs orthographiques et grammaticaux. L’IA générative est également au cœur des logiciels de marketing proposés.
Quand les auteurs utilisent l’IA
Un autre aspect des auteurs et de l’utilisation de l’IA présente des similitudes avec la question du droit d’auteur discutée ci-dessus. Dans les cas extrêmes, nous voyons du contenu généré à 100 % par l’IA être publié sur Amazon. La plupart (tout ?) de ce contenu est de mauvaise qualité, mais cela n’empêche pas sa publication. (Voir aussi la section Amazon.) Ce qui est plus préoccupant pour les éditeurs, ce sont les soumissions générées par l’IA. Oui, l’IA augmente la quantité, mais les grands éditeurs ont déjà un filtre pour la quantité. Ces filtres sont appelés agents. Ce sont eux qui vont devoir trouver comment gérer le problème de la quantité, et apparemment, ils vont devoir trouver une solution qui n’emploie pas l’IA.
C’est un problème existentiel - est-ce que je veux publier un livre écrit par ‘une machine’ ? Pour la plupart des éditeurs, c’est un ‘non’ sans équivoque. Simple comme bonjour. Eh bien, qu’en est-il d’un livre dont 50% du contenu a été généré par un LLM, sous la supervision d’un auteur compétent ? Hmm, essayons aussi un ‘non’ là-dessus. D’accord : alors qu’en est-il de 25%, ou 10%, ou 5% ? Où tracez-vous la ligne ?
Et, maintenant que vous êtes entré dans le domaine du traçage de lignes, comment résolvez-vous le dilemme que des outils de correction orthographique et grammaticale reposent désormais, au moins en partie, sur l’IA générative ? Qu’en est-il des outils de transcription pilotés par IA, comme Otter.ai, ou la fonction de transcription intégrée à Microsoft Word ?
Je ne trouve aucun éditeur commercial qui ait déclaré qu’il ne publierait pas une œuvre avec une quantité pré-spécifiée de texte généré par IA. Voici ce que dit la Authors Guild sur le sujet :
“Si une quantité appréciable de texte, de personnages ou d’intrigue générés par IA sont incorporés dans votre manuscrit, vous devez le divulguer à votre éditeur et devriez également le divulguer au lecteur. Nous ne pensons pas qu’il soit nécessaire pour les auteurs de divulguer l’utilisation d’IA générative lorsqu’elle est utilisée uniquement comme un outil de brainstorming, de génération d’idées ou de correction de texte.”
Inutile de dire que ‘appréciable’ n’est pas défini (Oxford le définit comme “suffisamment grand pour être remarqué ou jugé important”), mais le post continue en expliquant que l’inclusion de plus de “de minimis texte généré par IA” violerait la plupart des contrats d’édition. De minimis, en termes juridiques, n’est pas précisément spécifié, mais, en général, signifie plus ou moins la même chose qu’appréciable.
L’IA peut-elle être détectée dans l’écriture ?
J’ai animé un webinaire sur la détection de l’IA, sponsorisé par le BISG, en mai 2024. La rediffusion est en ligne sur YouTube. Jane Friedman a offert un compte rendu complet du webinaire dans sa newsletter Hot Sheet.
Pour de nombreux auteurs, la toxicité de l’IA signifie la garder loin de leurs mots. Les éditeurs portent un fardeau particulier - ils ne créent pas le texte, mais, une fois publié, ils assument une obligation substantielle envers le texte. Nous avons vu beaucoup de dynamite exploser près de livres incendiaires, que ce soit autour des implications sociales du contenu, ou du plagiat et de la piraterie des mots et idées d’autres écrivains. Maintenant, avec l’IA, nous faisons face à tout un nouvel ensemble de questions éthiques et juridiques, dont aucune n’était décrite dans les écoles d’édition.
En partie, cela semble similaire à ce que les gens craignent pour les étudiants, que l’utilisation de l’IA soit en quelque sorte de la triche, similaire à copier un article de Wikipédia, ou peut-être simplement demander à un ami d’écrire votre essai.
L’un de nos intervenants au webinaire, un éducateur, José Bowen, a partagé sa divulgation pour les étudiants. Ce n’est pas exactement ce que vous utilisez pour un auteur, mais cela démontre une sorte de “niveaux de risque” de l’utilisation de l’IA.
Accord de Divulgation Modèle pour les Étudiants
J’ai fait tout ce travail moi-même sans l’aide d’amis, d’outils, de technologie ou d’IA.
-
J’ai fait le premier brouillon, puis j’ai demandé à des amis/famille, à des logiciels de paraphrase/grammaire/plagiat IA de le lire et de faire des suggestions. J’ai apporté les modifications suivantes après cette aide :
Correction de l’orthographe et de la grammaire
Changement de la structure ou de l’ordre
Réécriture des phrases/paragraphes entiers
J’étais bloqué sur des problèmes et j’ai utilisé un thésaurus, un dictionnaire, j’ai appelé un ami, je suis allé au centre d’aide, j’ai utilisé Chegg ou un autre fournisseur de solutions.
J’ai utilisé l’IA/amis/tuteur pour m’aider à générer des idées.
J’ai utilisé des outils/assistance/IA pour faire un plan/premier brouillon, que j’ai ensuite édité. (Décrivez la nature de votre contribution.)
Et donc un éditeur pourrait rédiger quelque chose comme cela pour ses auteurs. Disons que l’auteur divulgue le niveau supérieur : j’ai utilisé l’IA de manière extensive, puis j’ai édité les résultats. Que se passe-t-il alors ? Rejetez-vous automatiquement le manuscrit ? Si oui, pourquoi ?
Et, en attendant, si vous faites attention, vous apprenez que le manuscrit que vous venez de lire et d’aimer, que l’auteur a juré n’a même pas été vérifié par Grammarly, pourrait en fait avoir été généré à 90% par IA, par un auteur expert à dissimuler son utilisation.
Vous êtes alors obligé de repenser la question. Cela devient, “Pourquoi suis-je si déterminé à détecter cette chose qui est indétectable ?”
En partie, c’est l’inquiétude alarmiste concernant la capacité de droit d’auteur du texte généré par IA. Le bureau des droits d’auteur n’offrira pas de protection de droit d’auteur à un texte généré à 100 % par IA (ou musique, ou images, etc.). Mais qu’en est-il d’un texte généré à 50 % par IA ? Eh bien, nous ne couvririons que les 50 % générés par l’auteur. Et comment sauriez-vous quelle moitié ? Nous reviendrons vers vous sur ce point.
Ne serait-il pas formidable de pouvoir simplement alimenter chaque manuscrit dans un logiciel qui vous dirait si l’IA avait été utilisée pour créer le texte ?
En laissant de côté le fait que la seule façon de le faire serait d’utiliser des outils IA, la question plus importante est : le logiciel serait-il (suffisamment) précis ? Pourrais-je compter sur lui pour me dire si l’IA avait été utilisée pour créer un manuscrit ? Et pourrais-je compter sur lui pour ne pas produire de “faux positifs” - indiquer que l’IA avait été utilisée, alors qu’en fait ce n’était pas le cas ?
Il existe maintenant beaucoup de logiciels sur le marché qui relèvent ces défis. Beaucoup d’études académiques évaluant ce logiciel pointent son manque de fiabilité. Le texte généré par IA passe à travers. Pire, un texte qui n’a pas été généré par une IA est faussement étiqueté comme ayant été contaminé.
Mais les éditeurs de livres vont vouloir avoir des mesures de sécurité en place. Il semble que, dans le meilleur des cas, ces outils pourraient vous alerter de préoccupations possibles, mais vous devrez toujours vérifier. Peut-être qu’ils pourraient vous alerter des textes qui doivent être examinés plus attentivement que d’autres ? Est-ce une efficacité ?
La véritable efficacité sera trouvée en allant au-delà des préoccupations concernant la genèse d’un texte, en maintenant plutôt nos critères existants quant à sa qualité.
Perte d’emploi
“Vous n’allez pas être remplacé par l’IA. Vous allez être remplacé par quelqu’un qui sait comment utiliser l’IA.” —Anonyme
La perte d’emploi due à l’adoption de l’IA pourrait être sévère. Les estimations varient, mais les chiffres sont sombres. Il y a des exemples évidents : les taxis sans conducteur de San Francisco éliminent… les chauffeurs de taxi et de covoiturage. Les diagnostics assistés par IA pourraient réduire le besoin de techniciens médicaux.
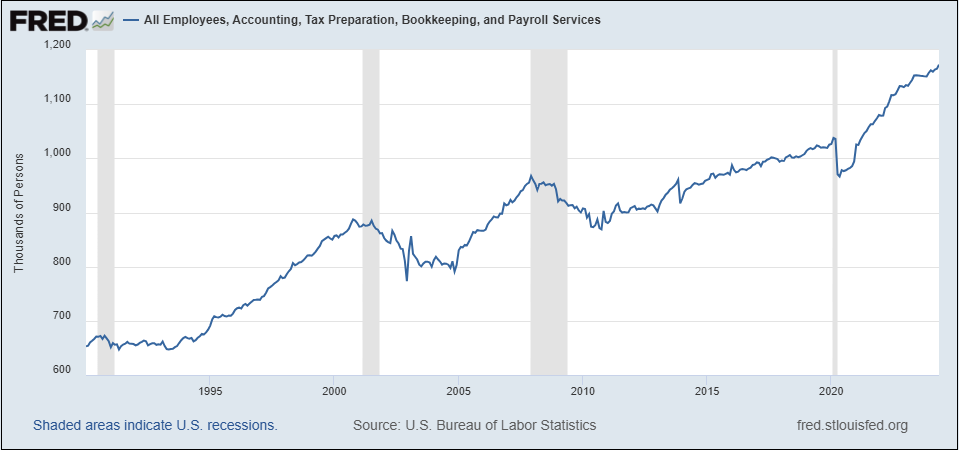
L’optimiste en moi pointe, par exemple, l’introduction du tableur et son impact sur l’emploi. Comme vous pouvez le voir dans le graphique ci-dessous, l’emploi dans les “Services de comptabilité, préparation des déclarations de revenus, tenue de livres et services de paie” a presque doublé depuis 1990 - difficile d’accuser les tableurs et autres technologies qui ont largement automatisé ces tâches.
L’étude d’Ethan Mollick avec le Boston Consulting Group (BCG) était une expérience visant à mieux comprendre l’impact de l’IA sur le travail, en particulier sur les tâches complexes et intensives en connaissances. L’étude impliquait 758 consultants de BCG, assignés au hasard à utiliser ou non GPT-4 d’OpenAI pour deux tâches : l’innovation de produits créatifs et la résolution de problèmes commerciaux. L’étude mesurait la performance, le comportement et les attitudes des participants, ainsi que la qualité et les caractéristiques des résultats de l’IA.
Parmi les conclusions, il a été constaté que “l’IA agit comme un niveleur de compétences. Les consultants qui avaient obtenu les pires résultats lorsqu’on les évaluait au début de l’expérience ont eu la plus grande augmentation de performance, 43%, lorsqu’ils ont pu utiliser l’IA. Les meilleurs consultants ont également obtenu un coup de pouce, mais moins important.” L’article complet est révélateur et, comme tout le travail de Mollick, provocateur mais accessible.
Éducation
L’éducation a été au centre des débats pour et contre l’IA. L’introduction de l’IA dans les salles de classe est largement considérée comme une malédiction, ou du moins un défi. D’autres éducateurs, comme le conférencier principal de PW Ethan Mollick, embrassent l’IA comme un nouvel outil remarquable pour les éducateurs ; Mollick insiste pour que ses étudiants travaillent avec ChatGPT.
Le meilleur livre sur le sujet est Enseigner avec l’IA: Un guide pratique pour une nouvelle ère de l’apprentissage humain par José Antonio Bowen et C. Edward Watson.
Je ne vais pas me plonger dans l’édition éducative dans ce livre - c’est un sujet vaste, demandant un rapport séparé. On peut dire que l’édition devient d’un intérêt secondaire dans l’éducation : les outils IA sont des logiciels, pas du contenu, en soi.
L’avenir de la recherche
|
La recherche est un sujet délicat dans l’IA. Je vous encourage à visiter perplexity.ai et You.com pour avoir un aperçu de ce qui nous attend. La prochaine fois que vous pensez lancer une recherche sur Google, allez plutôt sur Perplexity. Cela ne semblera pas radicalement différent - c’est similaire aux graphes de connaissances que Google affiche souvent sur le côté droit d’un écran de recherche, ou parfois en haut des listes de résultats de recherche. Au lieu de devoir cliquer sur un lien, l’information est directement là pour vous. |
La perplexité va un peu plus loin, reformulant les informations qu’elle recueille de plusieurs sources afin que vous n’ayez vraiment pas besoin de cliquer sur un lien. Elle fournit des liens vers ses sources, mais les cliquer est généralement inutile—vous avez déjà la réponse à votre question.
Ce changement apparemment modeste a d’énormes implications pour chaque entreprise et chaque produit qui repose, au moins en partie, sur le fait d’être découvert à travers les moteurs de recherche. Si les chercheurs ne sont plus envoyés vers votre site, comment pouvez-vous les engager et les convertir en clients ? Réponse simple, vous ne pouvez pas.
Joanna Penn est à l’avant-garde de la réflexion sur l’impact des nouvelles technologies sur l’écriture et l’édition. Elle a abordé ce sujet complexe dans son podcast et sur son blog en décembre dernier.
C’est encore le début pour l’IA et la transformation de la recherche.
Livres de pacotille sur Amazon
|
Les livres de pacotille générés par IA sur Amazon sont un problème, bien que leur gravité soit peut-être plus viscérale que littérale. D’une part, ces livres encombrent la librairie en ligne avec du contenu de faible qualité et plagié, utilisant parfois les noms de vrais auteurs pour tromper les clients et profiter de leur réputation. Les livres ne sont pas seulement une nuisance pour les lecteurs mais aussi une menace pour les auteurs, les privant potentiellement de royalties durement gagnées. Les livres générés par IA affectent également le classement et la visibilité des vrais livres et auteurs sur le site d’Amazon, car ils rivalisent pour les mêmes mots-clés, catégories et avis. |

Amazon exige désormais des auteurs qu’ils divulguent les détails de leur utilisation de l’IA pour créer leurs livres. Sans aucun doute, cela peut être abusé.
Essayez de chercher sur Amazon des “livres générés par IA”. Il y en a beaucoup. Certains des résultats sont des livres didactiques sur l’utilisation de l’IA pour créer des livres. Mais d’autres sont, sans vergogne, générés par IA. “Images de chats drôles et mignons- Vous ne pouvez pas voir ce genre de photos dans le monde-PART-1” (stet) est crédité à Rajasekar Kasi. Il n’y a aucun détail de sa bio sur une page d’auteur, mais six autres titres sont crédités à ce nom. Le livre, publié le 26 août 2023, n’a pas d’avis et pas de classement de ventes. Le titre grammaticalement incorrect de l’ebook ne correspond pas au titre grammaticalement incorrect sur la couverture du livre imprimé.
Mais d’autres auteurs utilisent clairement l’IA de manière extensive dans la création de leurs livres, sans le divulguer. Comme je l’ai mentionné plus haut, détecter l’utilisation de l’IA est quasi-impossible avec des ‘faussaires’ qualifiés. Des livres de coloriage, des journaux, des livres de voyage et des livres de cuisine sont générés avec des outils d’IA en une fraction du temps et des efforts de l’édition traditionnelle.
Recherchez “livre de cuisine vegan coréen” et vous trouverez le titre numéro un, par Joanne Lee Molinaro, en première place. Mais juste derrière, il y a d’autres titres qui sont des copies évidentes. “Le livre de cuisine vegan coréen : Recettes simples et délicieuses traditionnelles et modernes pour les amateurs de cuisine coréenne” a deux avis, dont un qui note “Ce n’est pas un livre de cuisine vegan. Toutes les recettes contiennent des ingrédients de viande et d’œufs.” Mais le livre est classé #5,869,771 en termes de ventes, contre l’original, qui est classé #2,852 sur la liste.
Il est difficile de déterminer l’étendue des dégâts causés. Rien de bon ne peut en sortir, mais à quel point est-ce mauvais ?
Amazon a mis en place des politiques qui lui permettent de retirer tout livre qui ne “fournit pas une expérience client positive”. Les directives de contenu Kindle interdisent le “contenu descriptif destiné à tromper les clients ou qui ne représente pas fidèlement le contenu du livre.” Ils peuvent également bloquer “le contenu généralement décevant pour les clients.” Est-ce le volume qui défait les surveillants d’Amazon ? Ou y a-t-il une autre raison ?
Biais
Les LLM sont formés sur ce qui a déjà été publié en ligne. Ce qui a été publié en ligne est truffé de biais et les LLM reflètent donc ce biais. Et bien sûr, pas seulement le biais, mais aussi la haine, reflétée dans ses apprentissages, et maintenant un potentiel de sortie dans les mots et images générés par IA. La pornographie est un autre bénéficiaire naturel de la remarquable facilité de l’IA avec les images, et il y a des histoires récentes troublantes de jeunes femmes trouvant des images nues fabriquées, leurs camarades masculins étant les suspects les plus probables. The New York Times a rapporté séparément une augmentation des images en ligne d’abus sexuels sur enfants.
Les auteurs et éditeurs doivent être conscients de ces limitations intégrées lors de l’utilisation des outils d’IA.