Probabilistic Logic Programming
Probabilistic logic programming combines the expressiveness of Prolog with the ability to reason under uncertainty. SWI-Prolog supports several probabilistic programming frameworks that are highly relevant for modern AI applications. We look at a simple example in this chapter and then take a more general look at probability in the next chapter.
Why Probabilistic Reasoning?
In classical logic, a statement is either true or false. This binary worldview works well for pure mathematics but fails in real-world AI applications where information is almost always incomplete, noisy, or uncertain.
Classical Prolog relies on the Closed World Assumption: if a fact cannot be proven true from the knowledge base, it is assumed to be false. However, in the real world, a lack of evidence does not equal evidence of absence. Furthermore, classical logic is monotonic: once a fact is proven, it remains true regardless of any new information added to the system.
In contrast, real-world reasoning is non-monotonic and probabilistic. For instance, we might believe a patient has a specific illness with 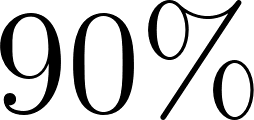 certainty, but when a new test result comes back negative, our belief should adapt. Probabilistic logic programming solves this by representing truth values as real numbers in the range
certainty, but when a new test result comes back negative, our belief should adapt. Probabilistic logic programming solves this by representing truth values as real numbers in the range 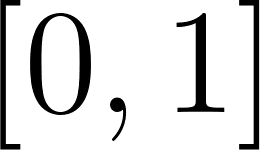 , representing the probability or degree of belief that a statement holds. This allows us to build logic models that handle exceptions, noisy measurements, and uncertain outcomes.
, representing the probability or degree of belief that a statement holds. This allows us to build logic models that handle exceptions, noisy measurements, and uncertain outcomes.
ProbLog and Probabilistic Facts
One of the most popular frameworks for combining logic with probability is ProbLog. In ProbLog, facts can be annotated with their probability of being true:
1 0.3::windy.
2 0.5::cloudy.
This notation declares that windy has a 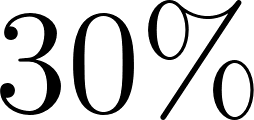 chance of being true, and
chance of being true, and cloudy has a 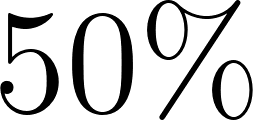 chance. Under the distribution semantics introduced by Taisuke Sato, a ProbLog program defines a probability distribution over a set of possible worlds. In each possible world, every probabilistic fact is independently chosen to be either true (with probability
chance. Under the distribution semantics introduced by Taisuke Sato, a ProbLog program defines a probability distribution over a set of possible worlds. In each possible world, every probabilistic fact is independently chosen to be either true (with probability 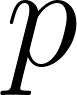 ) or false (with probability
) or false (with probability 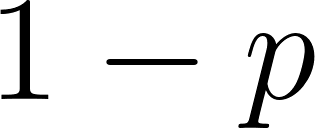 ). The probability of a query is the sum of the probabilities of all possible worlds in which the query can be logically proven.
). The probability of a query is the sum of the probabilities of all possible worlds in which the query can be logically proven.
While a full ProbLog solver requires compiling queries into Binary Decision Diagrams (BDDs) to handle dependencies and logical cycles, we can implement a lightweight reasoner using certainty factors in pure Prolog. This approach propagates probabilities recursively through backtracking search.
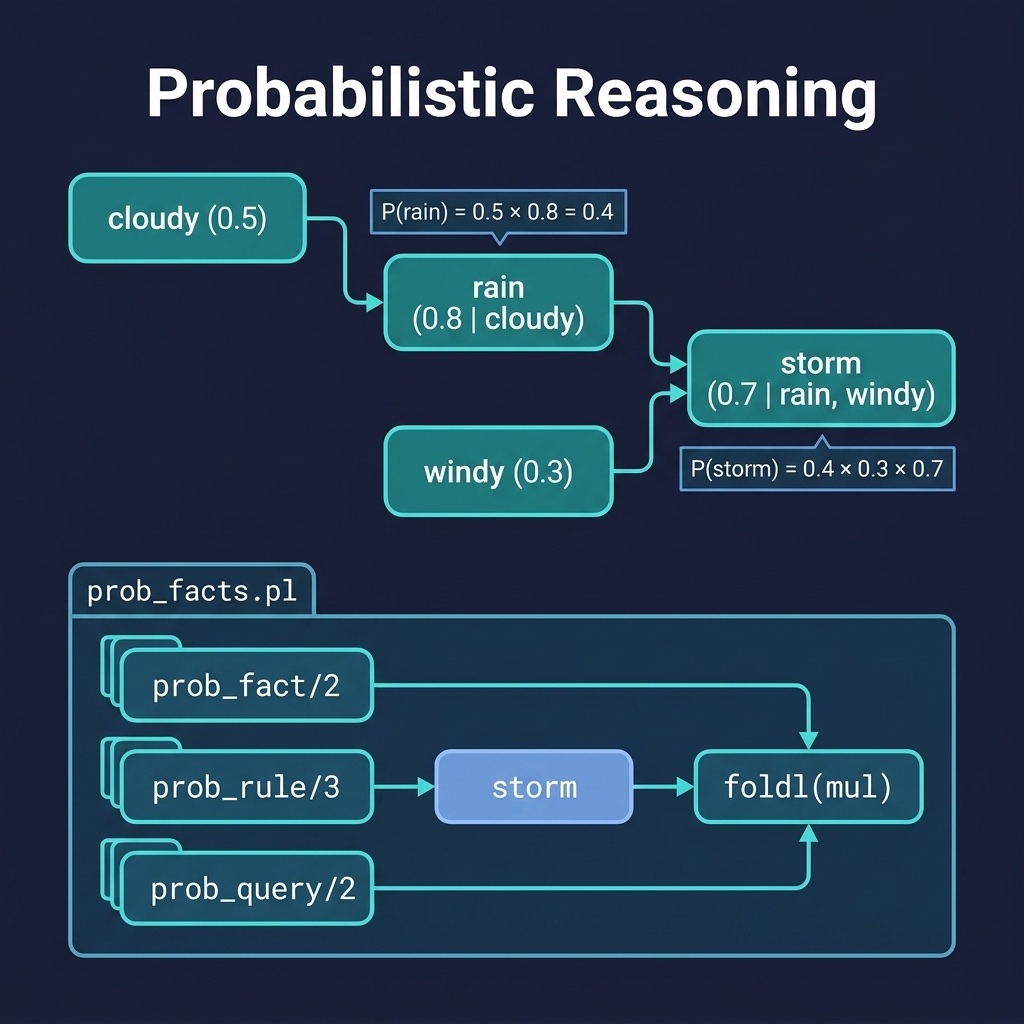
The prob_reasoning project implements a lightweight probabilistic reasoner. Here is the file prob_reasoning/prolog/prob_facts.pl:
1 %% prob_facts.pl - Probabilistic reasoning with certainty factors
2 %% A lightweight implementation without external pack dependencies
3 :- module(prob_facts, [
4 prob_fact/2,
5 prob_rule/3,
6 prob_query/2
7 ]).
8
9 :- dynamic prob_fact/2. % prob_fact(Fact, Probability)
10
11 %% prob_rule(+Conditions, +Conclusion, +CondProb)
12 %% If all Conditions hold, conclude Conclusion with conditional
13 %% probability
14 :- dynamic prob_rule/3.
15
16 %% prob_query(+Goal, -Probability)
17 %% Query the probability of a goal given known facts and rules
18 prob_query(Goal, Prob) :-
19 prob_fact(Goal, Prob), !.
20 prob_query(Goal, Prob) :-
21 prob_rule(Conditions, Goal, CondProb),
22 maplist(prob_query, Conditions, CondProbs),
23 foldl(mul, CondProbs, 1.0, JointProb),
24 Prob is JointProb * CondProb.
25
26 mul(X, Acc, Result) :- Result is Acc * X.
27
28 %% Example knowledge base (simple)
29 :- assert(prob_fact(cloudy, 0.5)).
30 :- assert(prob_fact(windy, 0.3)).
31 :- assert(prob_rule([cloudy], rain, 0.8)).
32 :- assert(prob_rule([rain, windy], storm, 0.7)).
33
34 %% Complex weather knowledge base
35 %% 5 base facts, 7 rules, 4 levels of reasoning depth
36 %% Chain: low_pressure -> unstable_air -> thick_clouds -> severe_storm
37 %% -> tornado_risk
38 %% cold_front + warm_front -> frontal_zone -> storm_system ->
39 %% severe_storm -> flash_flood_risk
40 %% Probabilities:
41 %% P(unstable_air) = 0.5*0.8 = 0.4
42 %% P(thick_clouds) = 0.5*0.4*0.5 = 0.1
43 %% P(frontal_zone) = 0.5*0.5*0.6 = 0.15
44 %% P(storm_system) = 0.15*0.5*0.8 = 0.06
45 %% P(severe_storm) = 0.1*0.06*0.5 = 0.003
46 %% P(tornado_risk) = 0.003*0.6 = 0.0018
47 %% P(flash_flood_risk) = 0.003*0.8 = 0.0024
48 :- assert(prob_fact(low_pressure, 0.5)).
49 :- assert(prob_fact(high_humidity, 0.5)).
50 :- assert(prob_fact(cold_front, 0.5)).
51 :- assert(prob_fact(warm_front, 0.5)).
52 :- assert(prob_fact(jet_stream_dip, 0.5)).
53 :- assert(prob_rule([low_pressure], unstable_air, 0.8)).
54 :- assert(prob_rule([high_humidity, unstable_air], thick_clouds, 0.5)).
55 :- assert(prob_rule([cold_front, warm_front], frontal_zone, 0.6)).
56 :- assert(prob_rule([frontal_zone, jet_stream_dip], storm_system, 0.8)).
57 :- assert(prob_rule([thick_clouds, storm_system], severe_storm, 0.5)).
58 :- assert(prob_rule([severe_storm], tornado_risk, 0.6)).
59 :- assert(prob_rule([severe_storm], flash_flood_risk, 0.8)).
How the Reasoner Works
- Facts and Rules: The reasoner defines probabilistic facts using
prob_fact(Fact, Probability)and conditional rules usingprob_rule(Conditions, Goal, CondProb). -
Query Propagation: The
prob_query/2predicate calculates the probability of a goal:- If the goal matches a base fact directly, it returns that probability.
- If the goal is derived via a rule, it recursively calls
prob_query/2on all conditions in the rule’s body usingmaplist/3. - It then multiplies all the condition probabilities together using
foldl/4and themul/3helper to compute theJointProbof the preconditions. - Finally, the joint probability is multiplied by the rule’s conditional probability (
CondProb) to get the final goal probability.
Deep Probability Attenuation
The weather knowledge base demonstrates how probabilities attenuate (rapidly decrease) across deep inference chains. Consider the path from low_pressure to tornado_risk:
low_pressureis a base fact with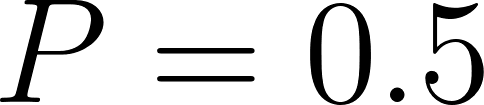 .
.
unstable_airis derived fromlow_pressurewith conditional probability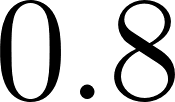 , yielding
, yielding  .
.
thick_cloudsis derived fromhigh_humidity() and unstable_air(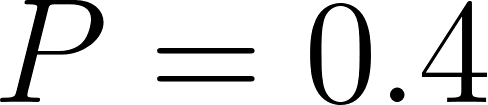 ) with conditional probability
) with conditional probability 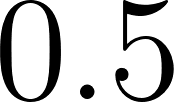 , yielding
, yielding 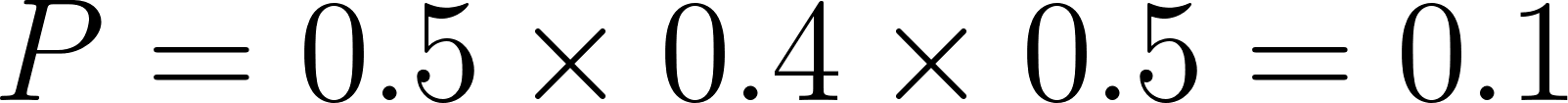 .
.
- Parallel reasoning yields
frontal_zone(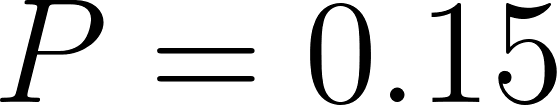 ) and
) and storm_system(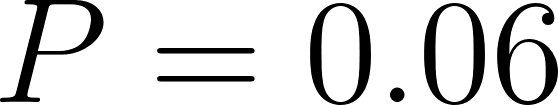 ).
).
severe_stormconverges fromthick_cloudsandstorm_systemwith conditional probability, yielding  .
.
tornado_riskis derived fromsevere_stormwith conditional probability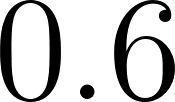 , yielding
, yielding 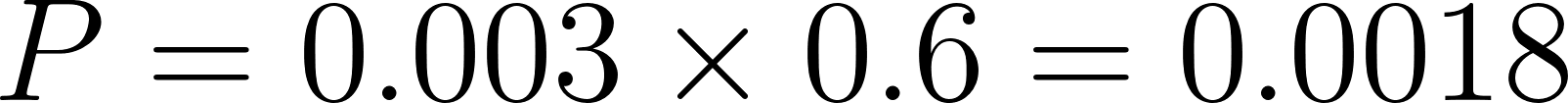 .
.
This rapid attenuation shows that naive multiplication across deep chains can quickly shrink probabilities. In real-world applications, to prevent underflow and model complex dependencies correctly, we use more sophisticated models like Bayesian networks or full ProbLog.
Learning Probabilities from Data
Writing down exact probability values for every fact and rule is difficult. In practice, we often have the logical structure of the model but need to learn the probability values from experimental data or observations.
This process is called parameter learning (implemented in ProbLog as LFI, or Learning from Interpretations). The learning system is given:
- A logic program containing facts and rules with unknown probability parameters.
- A database of training interpretations (examples of observed states, which may be complete or incomplete).
Under the hood, the system uses the Expectation-Maximization (EM) algorithm:
- Expectation Step (E-step): Using the current probability estimates, the system computes the expected truth values of all unobserved (latent) variables in the training data.
- Maximization Step (M-step): The system updates the probability parameters to maximize the likelihood of both the observed and expected data.
This iterative process continues until the parameters converge, allowing us to train probabilistic logic systems directly from tabular data, sensor logs, or historical records.
Bayesian Networks in Prolog
A Bayesian Network is a directed acyclic graph (DAG) where nodes represent random variables and edges represent conditional dependencies. Each node is associated with a Conditional Probability Table (CPT) expressing the probability of the node given the states of its parent nodes.
Prolog is well-suited for representing Bayesian networks. We can represent the network structure and CPTs directly as facts:
1 % network_structure: parent(ParentNode, ChildNode)
2 parent(cloudy, rain).
3 parent(cloudy, sprinkler).
4 parent(rain, wet_grass).
5 parent(sprinkler, wet_grass).
6
7 % CPT entries: cpt(Node, State, ParentStates, Probability)
8 cpt(cloudy, true, [], 0.5).
9 cpt(sprinkler, true, [cloudy=true], 0.1).
10 cpt(sprinkler, true, [cloudy=false], 0.5).
11 cpt(rain, true, [cloudy=true], 0.8).
12 cpt(rain, true, [cloudy=false], 0.2).
13
14 % wet_grass depends on both rain and sprinkler
15 cpt(wet_grass, true, [sprinkler=true, rain=true], 0.99).
16 cpt(wet_grass, true, [sprinkler=true, rain=false], 0.90).
17 cpt(wet_grass, true, [sprinkler=false, rain=true], 0.90).
18 cpt(wet_grass, true, [sprinkler=false, rain=false], 0.01).
To perform inference (such as calculating 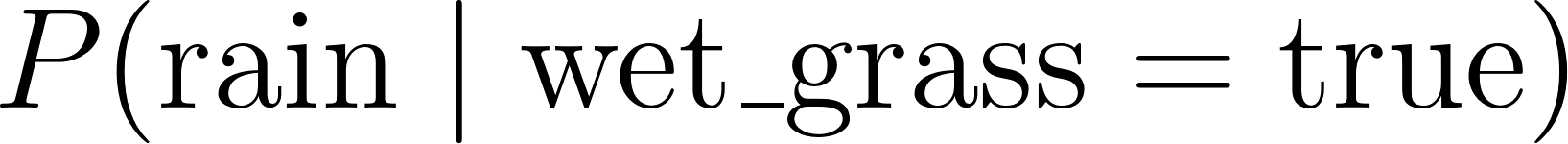 ), we can write a query solver that uses variable elimination or enumeration to sum out the latent variables over the joint distribution:
), we can write a query solver that uses variable elimination or enumeration to sum out the latent variables over the joint distribution:
P(A \mid B) = \frac{P(A, B)}{P(B)} = \frac{\sum_{Y} P(A, B, Y)}{\sum_{X, Y} P(X, B, Y)}
Prolog’s pattern matching and list processing make it easy to traverse parent-child relationships and lookup CPT probabilities during joint probability factorization.
Practical Applications
Probabilistic logic programming has several unique strengths for real-world AI systems:
Fault Diagnosis under Uncertainty: Industrial systems contain many interconnected components. When a sensor reports a failure, we must diagnose the root cause. Since sensors are noisy and can fail themselves, probabilistic logic allows us to model rules like “If component X fails, sensor Y shows error with 95% probability, but sensor Y has a 2% random failure rate.” The inference engine can then identify the most likely failed component.
Medical Reasoning: Diseases and symptoms do not have a simple one-to-one mapping. A symptom can be caused by multiple diseases, and a disease does not always produce all symptoms. By modeling symptoms as probabilistic facts and diseases as conditional hypotheses, we can calculate the posterior probability of each diagnosis given a patient’s clinical file.
Information Extraction Pipelines: Modern NLP systems (like NER taggers or relation extractors) output extracted facts with confidence scores. By feeding these confidence scores directly into a probabilistic Prolog reasoner as probabilistic facts (e.g.,
0.85::extracted_relation('ACME', 'acquired', 'BetaCorp')), we can run logical reasoning while correctly propagating the extraction uncertainty downstream to final conclusions.
Optional Practice Problems
- Weather Delay Probability: In the
prob_reasoningproject, add a probabilistic fact representing a flight delay caused by weather (e.g., 30% chance of snow, which leads to 80% chance of delay) and calculate the overall probability of arriving on time. - Coin Toss Network: Write a ProbLog-style program in
prob_facts.plto compute the probability of getting at least two heads out of three independent biased coin flips.