LLM Integration
Large Language Models are transforming AI, and Prolog can serve as a powerful orchestration layer — combining LLM-generated text with symbolic reasoning, structured knowledge, and explainable inference.
Calling LLM APIs from Prolog
SWI-Prolog’s HTTP client libraries (covered in the Web Clients chapter) make it straightforward to call any REST API, including LLM endpoints. The workflow is:
- Read the API key from an environment variable using
getenv/2. - Build the JSON request payload as a Prolog term.
- Send an HTTP POST request with
http_post/4, which automatically serialises the payload and deserialises the JSON response into a SWI-Prolog dict. - Extract the generated text from the response dict using dot notation.
Because http_post/4 is synchronous, the call blocks until the model returns its full response. For streaming responses (where tokens arrive incrementally), you would use http_open/3 with a read loop — but for most Prolog applications, the simpler synchronous approach is sufficient.
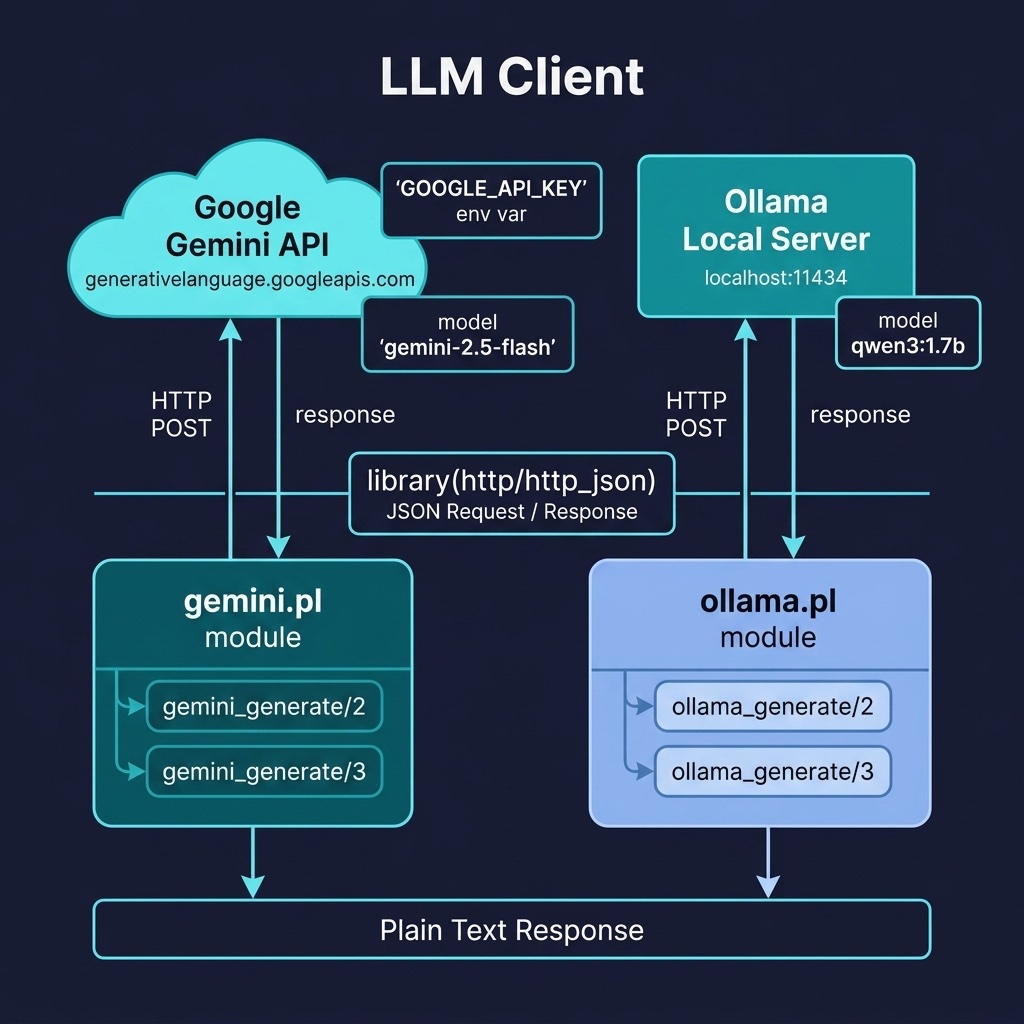
The llm_client project provides clients for Google Gemini and Ollama. Here is the file llm_client/prolog/gemini.pl:
1 %% gemini.pl - Google Gemini API client
2 :- module(gemini, [
3 gemini_generate/2,
4 gemini_generate/3
5 ]).
6
7 :- use_module(library(http/http_client)).
8 :- use_module(library(http/http_json)).
9 :- use_module(library(json)).
10
11 %% gemini_generate(+Prompt, -Response)
12 %% Uses GOOGLE_API_KEY environment variable
13 gemini_generate(Prompt, Response) :-
14 gemini_generate(Prompt, Response, []).
15
16 %% gemini_generate(+Prompt, -Response, +Options)
17 gemini_generate(Prompt, Response, _Options) :-
18 getenv('GOOGLE_API_KEY', ApiKey),
19 format(atom(URL),
20 'https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=~w',
21 [ApiKey]),
22 Payload = json([
23 contents=[json([
24 parts=[json([text=Prompt])]
25 ])]
26 ]),
27 http_post(URL, json(Payload), Result, [json_object(dict)]),
28 extract_text_response(Result, Response).
29
30 extract_text_response(Result, Text) :-
31 Candidates = Result.candidates,
32 [First|_] = Candidates,
33 Content = First.content,
34 Parts = Content.parts,
35 [Part|_] = Parts,
36 Text = Part.text.
The gemini_generate/2 predicate reads the GOOGLE_API_KEY environment variable, constructs the Gemini API URL, builds the nested JSON payload, and posts it. The extract_text_response/2 helper navigates the response dict’s candidates[0].content.parts[0].text path using SWI-Prolog’s dot notation for dicts.
And a client for local Ollama models. Here is the file llm_client/prolog/ollama.pl:
1 %% ollama.pl - Ollama local LLM API client
2 :- module(ollama, [
3 ollama_generate/2,
4 ollama_generate/3
5 ]).
6
7 :- use_module(library(http/http_client)).
8 :- use_module(library(http/http_json)).
9 :- use_module(library(json)).
10
11 %% ollama_generate(+Prompt, -Response)
12 %% Uses default model and localhost:11434
13 ollama_generate(Prompt, Response) :-
14 ollama_generate(Prompt, Response, [model('qwen3:1.7b')]).
15
16 %% ollama_generate(+Prompt, -Response, +Options)
17 ollama_generate(Prompt, Response, Options) :-
18 (member(model(Model), Options) -> true ; Model = 'qwen3:1.7b'),
19 URL = 'http://localhost:11434/api/generate',
20 Payload = json([
21 model=Model,
22 prompt=Prompt,
23 stream= @(false)
24 ]),
25 http_post(URL, json(Payload), Result, [json_object(dict)]),
26 Response = Result.response.
The Ollama client follows the same pattern but targets the local Ollama REST API on port 11434. The stream= @(false) option tells Ollama to return the complete response in a single JSON object rather than streaming tokens. The model name defaults to qwen3:1.7b but can be overridden via the options list.
Both clients can be tested in the REPL:
1 ?- gemini_generate("What is Prolog?", Response).
2 Response = "Prolog is a logic programming language...".
3
4 ?- ollama_generate("Explain backtracking", Response).
5 Response = "Backtracking is a systematic method...".
Structured Output from LLMs
Raw LLM text is useful for human consumption, but for integration with Prolog’s reasoning engine we need structured data. The key technique is to craft prompts that instruct the LLM to return its output as JSON with a specific schema. For example:
1 Extract all people and organizations from the following text.
2 Return your answer as JSON with this schema:
3 {"entities": [{"name": "...", "type": "person|org"}],
4 "relations": [{"subject": "...", "predicate": "...", "object": "..."}]}
Once the LLM returns JSON, we parse it into a SWI-Prolog dict and assert the extracted entities and relations as dynamic Prolog facts. This bridges the gap between statistical language understanding (the LLM) and symbolic reasoning (Prolog).
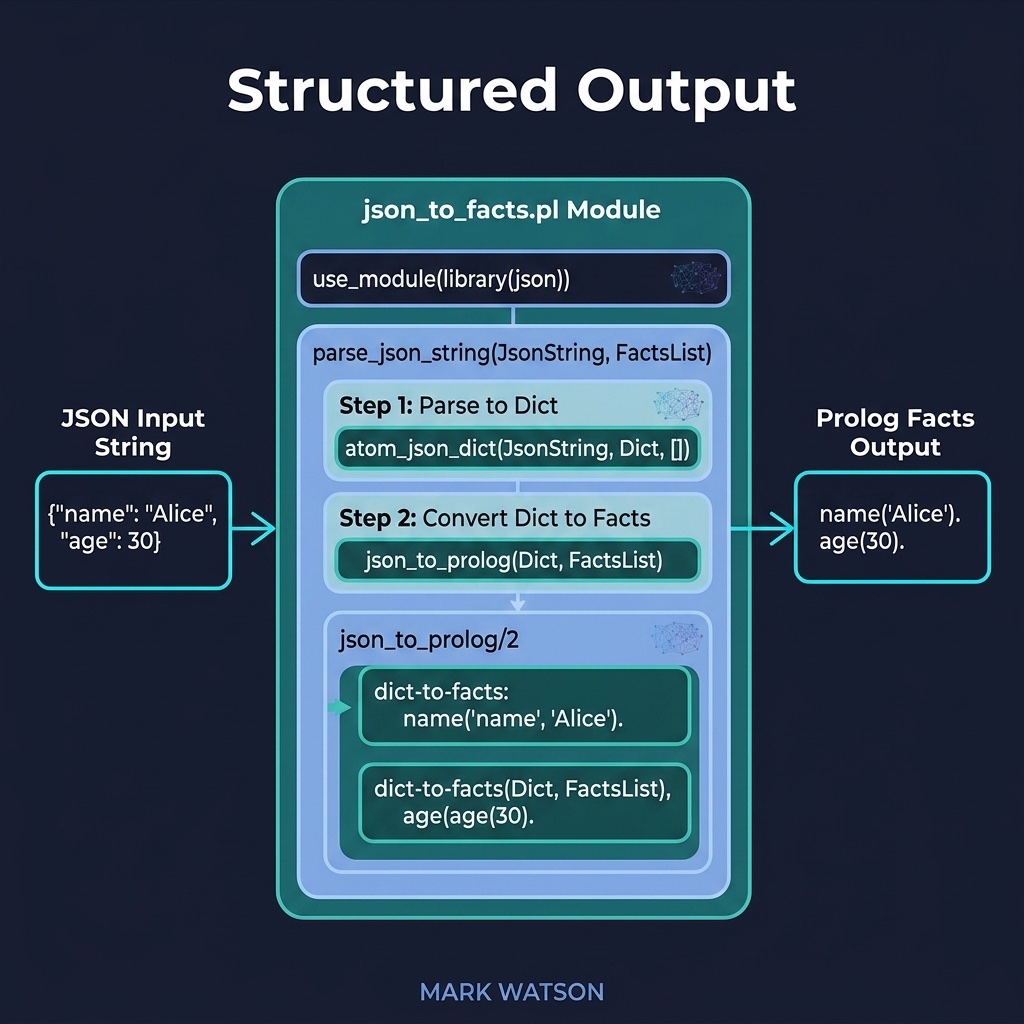
The structured_output project converts JSON LLM output into assertable Prolog facts. Here is the file structured_output/prolog/json_to_facts.pl:
1 %% json_to_facts.pl - Convert structured LLM JSON output into Prolog
2 %% facts
3 :- module(json_to_facts, [
4 json_string_to_facts/1,
5 extracted_entity/2,
6 extracted_relation/3
7 ]).
8
9 :- use_module(library(json)).
10
11 :- dynamic extracted_entity/2. % extracted_entity(Name, Type)
12 :- dynamic extracted_relation/3. % extracted_relation(Subject,
13 % Predicate, Object)
14
15 %% json_string_to_facts(+JsonString)
16 %% Parses JSON with entities/relations arrays into Prolog facts
17 json_string_to_facts(JsonString) :-
18 atom_json_dict(JsonString, Dict, []),
19 ( get_dict(entities, Dict, Entities)
20 -> maplist(assert_entity, Entities)
21 ; true
22 ),
23 ( get_dict(relations, Dict, Relations)
24 -> maplist(assert_relation, Relations)
25 ; true
26 ).
27
28 assert_entity(E) :-
29 Name = E.name,
30 Type = E.type,
31 ( \+ extracted_entity(Name, Type)
32 -> assert(extracted_entity(Name, Type))
33 ; true
34 ).
35
36 assert_relation(R) :-
37 S = R.subject,
38 P = R.predicate,
39 O = R.object,
40 ( \+ extracted_relation(S, P, O)
41 -> assert(extracted_relation(S, P, O))
42 ; true
43 ).
The json_string_to_facts/1 predicate parses the JSON string into a dict, then uses get_dict/3 to safely extract the entities and relations arrays (defaulting to no-op if either is missing). The maplist/2 calls iterate over each array element, asserting facts into the dynamic database. The duplicate check (\+ extracted_entity(Name, Type)) prevents the same fact from being asserted twice if the LLM returns redundant extractions.
After calling json_string_to_facts/1, the extracted knowledge is immediately available for Prolog queries:
1 ?- json_string_to_facts('{"entities":[{"name":"Paris","type":"city"}]}').
2 true.
3
4 ?- extracted_entity(Name, Type).
5 Name = "Paris",
6 Type = "city".
Combining LLMs with Prolog Reasoning
The most powerful pattern in this book is the hybrid AI pipeline: use an LLM for tasks it excels at (natural language understanding, summarisation, information extraction) and use Prolog for tasks where it excels (structured reasoning, constraint satisfaction, explainable inference). Each system handles what it does best.
A typical hybrid pipeline has four stages:
- LLM Extraction — The LLM processes unstructured text and returns structured JSON (entities, relations, classifications).
- Fact Assertion — The JSON is parsed and asserted into Prolog’s dynamic database as facts.
- Symbolic Reasoning — Prolog rules fire over the asserted facts, producing conclusions, classifications, or recommendations.
- Explanation — Prolog’s proof-tree facilities (covered in the Reasoning chapter) explain why each conclusion was reached — something LLMs cannot reliably do.
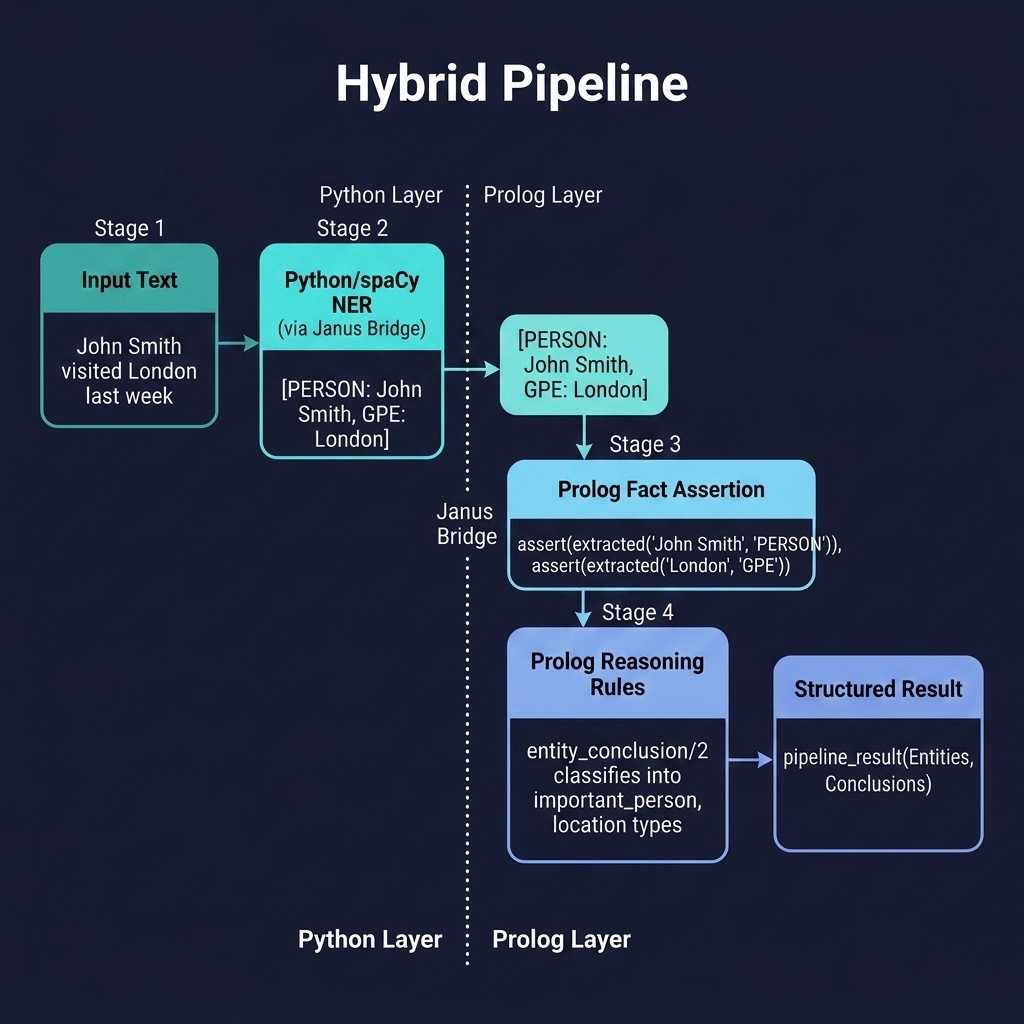
The hybrid_pipeline project demonstrates this architecture using Python/spaCy for NER and Prolog for reasoning, connected via the Janus bridge. Here is the file hybrid_pipeline/prolog/pipeline.pl:
1 %% pipeline.pl - Hybrid AI pipeline: Python preprocessing + Prolog
2 %% reasoning
3 :- module(pipeline, [
4 run_pipeline/2
5 ]).
6
7 :- use_module(library(janus)).
8
9 %% run_pipeline(+InputText, -Result)
10 %% 1. Use Python/spaCy for NER extraction
11 %% 2. Assert extracted entities as Prolog facts
12 %% 3. Apply Prolog reasoning rules
13 %% 4. Return structured conclusions
14 run_pipeline(InputText, Result) :-
15 %% Step 1: Python NER
16 py_call(nlp_bridge:extract_entities(InputText), Entities),
17 %% Step 2: Assert as Prolog facts
18 maplist(assert_entity, Entities),
19 %% Step 3: Prolog reasoning
20 findall(conclusion(E, Type), entity_conclusion(E, Type),
21 Conclusions),
22 Result = pipeline_result(Entities, Conclusions),
23 %% Cleanup
24 retractall(extracted(_,_)).
25
26 :- dynamic extracted/2.
27
28 assert_entity(Entity) :-
29 py_call(Entity:label_, Type),
30 py_call(Entity:text, Text),
31 assert(extracted(Text, Type)).
32
33 entity_conclusion(E, important_person) :-
34 extracted(E, 'PERSON').
35 entity_conclusion(E, location) :-
36 extracted(E, 'GPE').
The run_pipeline/2 predicate orchestrates the full workflow. The py_call/2 predicate (from library(janus)) calls Python’s spaCy NER model to extract entities from the input text. Each entity is then asserted as an extracted/2 fact, and Prolog’s entity_conclusion/2 rules classify them. The retractall/1 at the end cleans up the dynamic facts so the next pipeline run starts fresh.
This pattern generalises easily: replace spaCy with an LLM call (using our gemini_generate/2 or ollama_generate/2 clients), replace the simple classification rules with domain-specific expert system rules, and you have a production-grade hybrid AI system.
Optional Practice Problems
- Fact Extraction Prompt: Write a structured JSON prompt in the
structured_outputproject that asks the LLM to output details about historical events. Parse this JSON into Prolog facts of the formevent(Name, Year, Location). - System Instruction Support: Extend the wrapper in
llm_clientto support system instructions, allowing you to configure the persona of the LLM before running queries.