Natural Language Processing with Definite Clause Grammars
Definite Clause Grammars (DCGs) are one of Prolog’s most powerful features for AI applications. DCGs allow us to write grammars directly as Prolog rules, making natural language processing and text parsing a natural fit for Prolog.
DCG Fundamentals
Definite Clause Grammars (DCGs) are a formal way of describing languages (both natural languages and programming languages) in Prolog. Under the hood, they compile directly into standard Prolog clauses, eliminating the need to write complex list manipulation code manually.
The --> Notation
In standard Prolog rules, the neck operator is :-. In DCGs, rules are defined using the grammar rule pointer -->.
- Non-terminal symbols: Represent syntactic categories (e.g.,
sentence,noun_phrase). - Terminal symbols: Represent the actual words or tokens in the language, written as list literals (e.g.,
[the],[dog]).
For example, a simple grammar rule:
1 sentence --> noun_phrase, verb_phrase.
This states: “A sentence consists of a noun phrase followed by a verb phrase.”
Desugaring to Difference Lists
When Prolog compiles a DCG rule, it appends two hidden variables representing a difference list to each non-terminal. A difference list is a pair of lists representing a prefix: the input list and what remains after the predicate has consumed its part.
For example, the rule sentence --> noun_phrase, verb_phrase. compiles into:
1 sentence(InputList, RemainingList) :-
2 noun_phrase(InputList, IntermediateList),
3 verb_phrase(IntermediateList, RemainingList).
Terminal rules like noun --> [dog]. compile into simple unifications:
1 noun([dog | Rest], Rest).
Parsing and Generating
To call a DCG predicate, use the built-in phrase/2 or phrase/3 helper.
-
Parsing (validating input):
1 ?- phrase(sentence, [the, dog, runs]). 2 true.
-
Generating (producing sentences from the grammar):
1 ?- phrase(sentence, Words). 2 Words = [the, dog, chases, the, dog] ; 3 Words = [the, dog, chases, the, cat] ; 4 ...
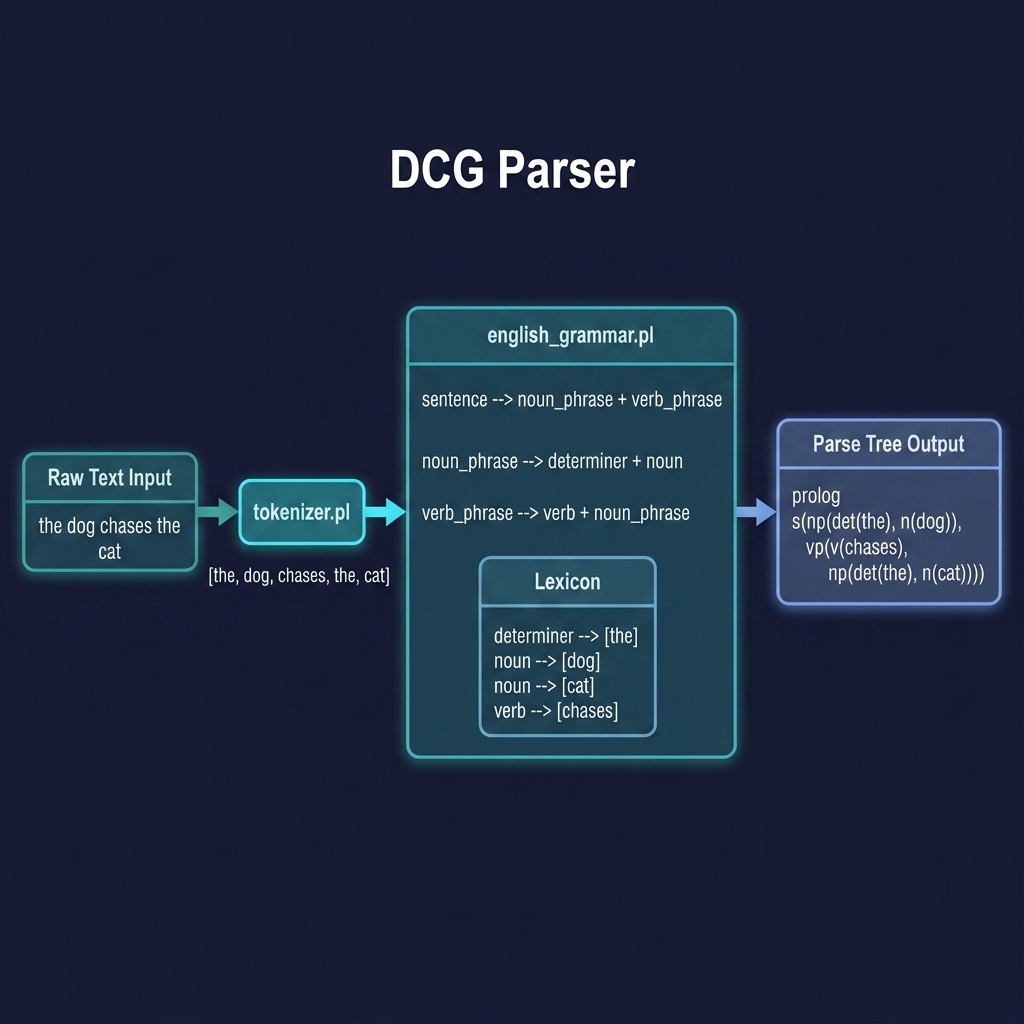
Tokenizing and Preprocessing Text
Before a grammar can parse a natural language sentence, the raw input string must be converted into a list of clean tokens. This process, called tokenization, involves:
- Normalizing the character casing (converting everything to lowercase).
- Handling and stripping punctuation.
- Splitting the stream of characters on spaces to form separate atoms.
In SWI-Prolog, this can be done using built-in predicates like downcase_atom/2 (which normalizes case) and atom_chars/2 (which decomposes an atom into a list of characters).
The dcg_parser project includes a simple tokenizer that converts strings to word lists. Here is the file dcg_parser/prolog/tokenizer.pl:
1 :- module(tokenizer, [
2 tokenize/2
3 ]).
4
5 %% tokenize(+String, -Words)
6 %% Splits a string into a list of lowercase atoms
7 tokenize(String, Words) :-
8 downcase_atom(String, Lower),
9 atom_chars(Lower, Chars),
10 split_words(Chars, Words).
11
12 split_words([], []).
13 split_words(Chars, [Word|Rest]) :-
14 skip_spaces(Chars, Chars1),
15 Chars1 \= [],
16 take_word(Chars1, WordChars, Remaining),
17 atom_chars(Word, WordChars),
18 split_words(Remaining, Rest).
19 split_words(Chars, []) :-
20 skip_spaces(Chars, []).
21
22 skip_spaces([' '|T], Rest) :- !, skip_spaces(T, Rest).
23 skip_spaces(L, L).
24
25 take_word([], [], []).
26 take_word([' '|T], [], T) :- !.
27 take_word([H|T], [H|W], Rest) :-
28 H \= ' ',
29 take_word(T, W, Rest).
Parsing Natural Language Sentences
To analyze a sentence beyond simple validation, we can augment DCG rules to construct a parse tree. This is done by adding arguments to our non-terminals. During the parsing process, these arguments unify to construct a nested Prolog compound term representing the syntactic structure of the sentence.
For example, we can define the non-terminals with arguments:
1 sentence(s(NP, VP)) --> noun_phrase(NP), verb_phrase(VP).
If noun_phrase unifies with np(det(the), n(dog)) and verb_phrase unifies with vp(v(runs)), the resulting tree will be s(np(det(the), n(dog)), vp(v(runs))).
The dcg_parser project uses DCG notation to define an English grammar with parse tree construction. Here is the file dcg_parser/prolog/english_grammar.pl:
1 %% english_grammar.pl - English grammar with parse tree construction
2 :- module(english_grammar, [parse_sentence/2]).
3
4 %% parse_sentence(+WordList, -ParseTree)
5 parse_sentence(Words, Tree) :-
6 phrase(sentence(Tree), Words).
7
8 sentence(s(NP, VP)) --> noun_phrase(NP), verb_phrase(VP).
9
10 noun_phrase(np(det(D), n(N))) --> det(D), noun(N).
11 noun_phrase(np(name(N))) --> proper_noun(N).
12
13 verb_phrase(vp(v(V))) --> verb(V).
14 verb_phrase(vp(v(V), NP)) --> verb(V), noun_phrase(NP).
15 verb_phrase(vp(v(V), PP)) --> verb(V), prep_phrase(PP).
16 verb_phrase(vp(v(V), NP, PP)) --> verb(V), noun_phrase(NP),
17 prep_phrase(PP).
18
19 prep_phrase(pp(p(P), NP)) --> prep(P), noun_phrase(NP).
20
21 %% Lexicon
22 det(the) --> [the]. det(a) --> [a].
23 noun(dog) --> [dog]. noun(cat) --> [cat].
24 noun(man) --> [man]. noun(park) --> [park].
25 verb(chases) --> [chases]. verb(runs) --> [runs].
26 verb(walks) --> [walks]. verb(sees) --> [sees].
27 prep(in) --> [in]. prep(on) --> [on].
28 proper_noun(john) --> [john]. proper_noun(mary) --> [mary].
Semantic Analysis with DCGs
Beyond syntactic parsing, we can use DCGs to extract the semantic meaning of sentences. By inserting arbitrary Prolog goals inside curly braces { ... }, we can execute code during the parse. These are called semantic actions.
One common application is constructing logical formulas or query representations directly from the syntax tree. For example, we can map a sentence like “every person likes a cat” into a first-order logic representation:
1 sentence(every(X, Type => Likes)) --> noun_phrase(X, Type), verb_phrase(X, Likes).
2
3 noun_phrase(X, person) --> [everyone].
4 noun_phrase(X, person) --> [every, person].
5
6 verb_phrase(X, likes(X, Y)) --> [likes], noun_phrase(Y, _).
Running this grammar:
1 ?- phrase(sentence(Semantics), [every, person, likes, everyone]).
2 Semantics = every(_A, person=>likes(_A, _B)).
By passing semantic variables up the parse tree and executing constraints inside { ... }, DCGs can translate natural language questions directly into database queries or logical structures.
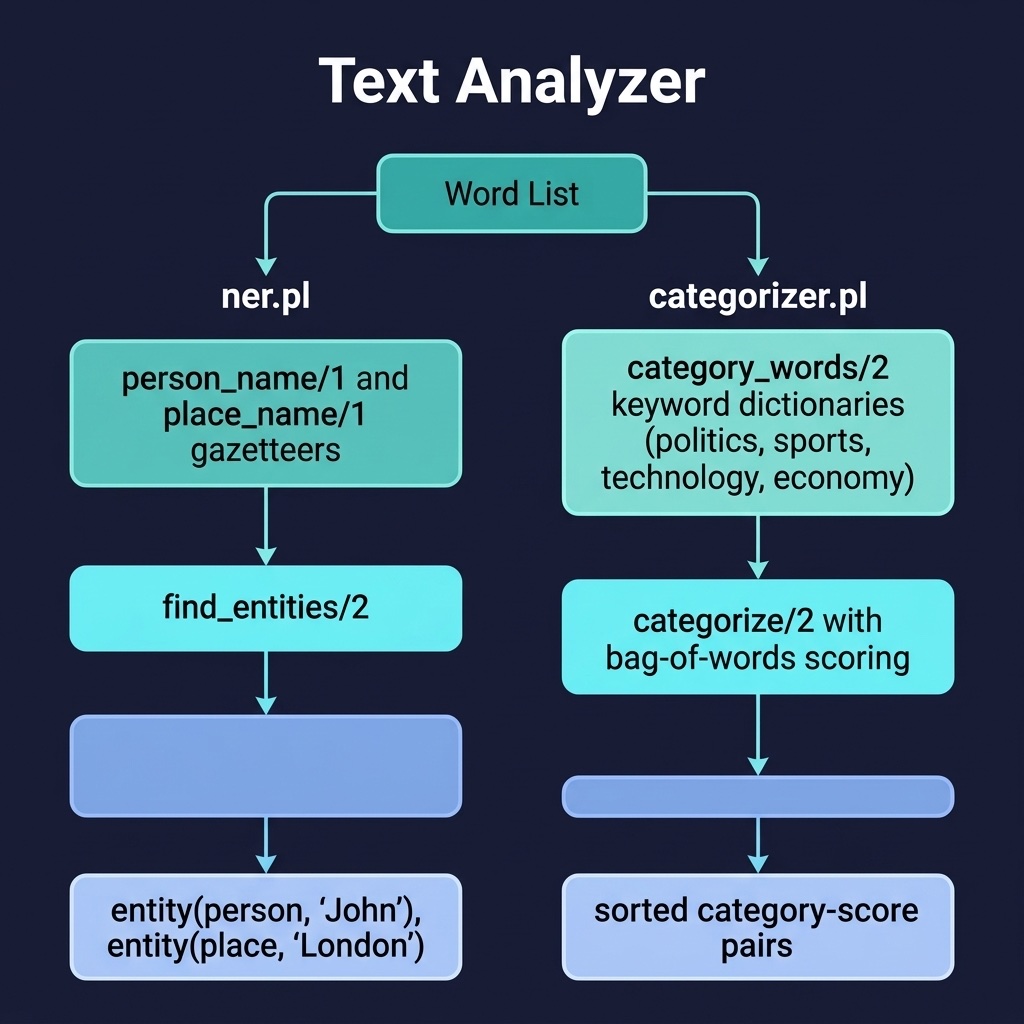
Named Entity Recognition
Named Entity Recognition (NER) is an information extraction task that identifies and classifies key entities in text into predefined categories such as person names, geographic locations, and organizations.
In Prolog, this can be efficiently implemented using a gazetteer—a lookup database of known names. By asserting these names as facts (e.g., person_name('Einstein').), we can use Prolog’s high-speed indexing and pattern matching to scan tokenized word lists and extract typed entity structures.
The text_analyzer project implements NER with gazetteer lookup. Here is the file text_analyzer/prolog/ner.pl:
1 %% ner.pl - Named Entity Recognition using gazetteer lookup
2 :- module(ner, [find_entities/2, person_name/1, place_name/1]).
3
4 %% Gazetteer data (expandable)
5 person_name('John'). person_name('Mary').
6 person_name('Smith'). person_name('Clinton').
7
8 place_name('London'). place_name('Paris').
9 place_name('USA'). place_name('England').
10
11 %% find_entities(+WordList, -Entities)
12 find_entities(Words, Entities) :-
13 findall(entity(person, W),
14 (member(W, Words), person_name(W)), People),
15 findall(entity(place, W),
16 (member(W, Words), place_name(W)), Places),
17 append(People, Places, Entities).
Text Categorization
Text categorization involves assigning predefined labels to a document based on its textual content. A classic, lightweight approach is bag-of-words scoring. In this approach, we ignore grammar and word order, and instead match words against category-specific keyword lists.
In Prolog, we can define keywords for different categories (e.g., politics, technology, economy) and score an input document by counting the overlaps.
The text_analyzer project includes a bag-of-words categorizer. Here is the file text_analyzer/prolog/categorizer.pl:
1 %% categorizer.pl - Bag-of-words text categorization with expanded vocabulary
2 :- module(categorizer, [
3 categorize/2
4 ]).
5
6 %% categorize(+WordList, -Categories)
7 %% Returns list of category-score pairs, sorted by score descending
8 categorize(Words, Categories) :-
9 findall(
10 Score-Category,
11 ( category_words(Category, Keywords),
12 score_category(Words, Keywords, Score),
13 Score > 0
14 ),
15 Pairs
16 ),
17 sort(1, @>=, Pairs, Categories).
18
19 score_category(Words, Keywords, Score) :-
20 include(word_in_list(Keywords), Words, Matches),
21 length(Matches, Score).
22
23 word_in_list(Keywords, Word) :-
24 downcase_atom(Word, Lower),
25 member(Lower, Keywords).
Text Summarization
Extractive text summarization is the process of selecting a subset of sentences from a larger document that best represent its overall meaning or core categories. In a logic programming paradigm, this can be implemented by:
- Scoring each sentence based on the count or weights of category-specific keywords it contains.
- Ranking sentences by their score.
- Selecting the top-ranked sentences to form the summary.
Here is a simple, elegant implementation of an extractive summarizer that scores sentences using keywords from our categorization system:
1 :- module(summarizer, [summarize/3]).
2 :- use_module(categorizer, [category_words/2]).
3
4 %% summarize(+Sentences, +Category, -Summary)
5 %% Extracts the top 2 sentences representing the given Category
6 summarize(Sentences, Category, Summary) :-
7 category_words(Category, Keywords),
8 score_sentences(Sentences, Keywords, ScoredSentences),
9 % Sort by score descending (keysort sorts ascending, so we negate/reverse)
10 sort(1, @>=, ScoredSentences, Sorted),
11 % Take the top 2 sentences
12 take(2, Sorted, TopScored),
13 % Extract the sentences from the score-sentence pairs
14 pairs_values(TopScored, Summary).
15
16 score_sentences([], _, []).
17 score_sentences([S|Rest], Keywords, [Score-S | ScoredRest]) :-
18 score_sentence(S, Keywords, Score),
19 score_sentences(Rest, Keywords, ScoredRest).
20
21 score_sentence(Sentence, Keywords, Score) :-
22 include(word_in_keywords(Keywords), Sentence, Matches),
23 length(Matches, Score).
24
25 word_in_keywords(Keywords, Word) :-
26 downcase_atom(Word, Lower),
27 member(Lower, Keywords).
28
29 take(0, _, []) :- !.
30 take(_, [], []) :- !.
31 take(N, [X|Xs], [X|Ys]) :-
32 N > 0,
33 N1 is N - 1,
34 take(N1, Xs, Ys).
Running the Summarizer
To summarize a short text with three sentences about technology and healthcare:
1 ?- Sentences = [
2 [the, hospital, installed, a, new, software, database, system],
3 [technology, startups, are, building, quantum, encryption, algorithms],
4 [cats, and, dogs, run, in, the, local, park]
5 ],
6 summarize(Sentences, technology, Summary).
7 Summary = [
8 [technology, startups, are, building, quantum, encryption, algorithms],
9 [the, hospital, installed, a, new, software, database, system]
10 ].
Optional Practice Problems
- Adjective Support: Modify the DCG parser in the
dcg_parserproject to support adjectives modifying nouns (e.g., parsing sentences like “the quick brown fox jumps”). Update your grammar rules to handle arbitrary numbers of adjectives. - Question Answering Rule: In
text_analyzer, add categorizer rules to recognize question patterns (e.g., sentences starting with interrogatives like “who”, “what”, “where”) and extract the question target.