Anomaly Detection
Anomaly detection is a machine learning technique for finding data points that differ significantly from the majority of observations. Unlike classification — where we train on balanced examples of each class — anomaly detection works well when we have many normal examples and only a few (or zero) anomalous ones. The algorithm learns what “normal” looks like, then flags anything that deviates from that profile.
This chapter implements a Gaussian anomaly detector in SWI-Prolog, ported from a Java implementation. We apply it to the Wisconsin Diagnostic Breast Cancer dataset, where benign samples define the normal distribution and malignant samples appear as statistical outliers.
The Gaussian Approach
The core idea is straightforward. For each feature in the training data, we fit a Gaussian (bell curve) distribution by computing its mean 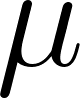 and variance
and variance 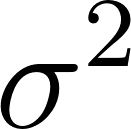 . At prediction time, we evaluate the Gaussian probability density function (PDF) for each feature of an unseen data point:
. At prediction time, we evaluate the Gaussian probability density function (PDF) for each feature of an unseen data point:
p(x_i) = \frac{1}{\sqrt{2\pi}\sigma_i} \exp\left(-\frac{(x_i - \mu_i)2}{2\sigma_i2}\right)
If the average per-feature probability falls below a learned threshold 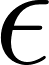 (epsilon), the data point is flagged as anomalous — it lies too far from the centre of the normal distribution.
(epsilon), the data point is flagged as anomalous — it lies too far from the centre of the normal distribution.
This approach has two appealing properties:
- One-class training. We only need normal examples to build the model. Anomalies are defined implicitly as “not normal.”
- Interpretability. Each feature contributes an independent probability, so we can see which features drove the anomaly classification.
The Training Pipeline
The complete pipeline has six stages. Here is an overview before we walk through each one:
- Load and subsample the Wisconsin cancer CSV
- Preprocess: scale, log-transform, normalise, remap target
- Split into training, cross-validation, and test sets
- Compute per-feature mean and variance from training data
- Search for the best epsilon threshold via cross-validation
- Evaluate precision, recall, and F1 on held-out test data
Module Structure
The module exports the full API:
1 :- module(anomaly_detection, [
2 load_wisconsin_data/1, % -Rows
3 preprocess/2, % +RawRows, -Processed
4 split_data/4, % +Rows, -Train, -CV, -Test
5 compute_mu/3, % +Train, +NF, -Mu
6 compute_sigma_sq/4, % +Train, +NF, +Mu, -SigmaSq
7 train_model/2, % +Rows, -Model
8 is_anomaly/2, % +Model, +Row
9 evaluate_model/2, % +Model, +TestRows
10 print_histogram/4, % +Title, +Rows, +Index, +NumBins
11 subsample_rows/3 % +Rows, +MaxN, -Sampled
12 ]).
13
14 :- use_module(library(csv)).
15 :- use_module(library(lists)).
16 :- use_module(library(apply)).
17 :- use_module(library(random)).
We rely on four standard SWI-Prolog libraries: csv for reading the dataset, lists and apply for list operations and higher-order predicates like maplist/3 and foldl/4, and random for data splitting.
Loading and Subsampling
The Wisconsin cancer dataset has 648 rows with 10 columns: 9 integer features (cell measurements) and 1 target class (2 = benign, 4 = malignant). The data file ships as a headerless CSV.
1 load_wisconsin_data(Rows) :-
2 once(source_file(anomaly_detection:_, ThisFile)),
3 file_directory_name(ThisFile, Dir),
4 atomic_list_concat([Dir,
5 '/../data/cleaned_wisconsin_cancer_data.csv'], Path),
6 csv_read_file(Path, CsvRows,
7 [separator(0',), convert(true), arity(10)]),
8 maplist(row_to_list, CsvRows, AllRows),
9 once(subsample_rows(AllRows, 200, Rows)).
The source_file/2 call locates the module’s own source directory, making the data path relative and portable. We wrap it in once/1 because source_file/2 returns one solution per exported predicate — without the cut, Prolog would backtrack through all of them.
We subsample to approximately 200 rows to keep runtime fast in an interpreted language. The subsample_rows/3 predicate uses reservoir-style random sampling:
1 subsample_rows(Rows, MaxN, Sampled) :-
2 length(Rows, Len),
3 ( Len =< MaxN
4 -> Sampled = Rows
5 ; Frac is MaxN / Len,
6 include(keep_row(Frac), Rows, Sampled)
7 ).
8
9 keep_row(Frac, _) :- random(P), P < Frac.
Each row is independently kept with probability MaxN/Len, giving us roughly MaxN rows while preserving the original class balance.
Preprocessing
The raw integer features (ranging 1–10) need to be transformed before Gaussian modelling. The preprocessing pipeline matches the Java original:
1 preprocess_row([F1, F2, F3, F4, F5, F6, F7, F8, F9, Target], Out) :-
2 Features = [F1, F2, F3, F4, F5, F6, F7, F8, F9],
3 maplist(scale01, Features, Scaled),
4 maplist(log_transform, Scaled, Logged),
5 min_list(Logged, Min), max_list(Logged, Max),
6 Span is Max - Min,
7 ( Span =:= 0
8 -> maplist(=( 0.0), Normed)
9 ; maplist(normalise(Min, Span), Logged, Normed)
10 ),
11 TargetOut is (Target - 2) * 0.5,
12 Normed = [N1, N2, N3, N4, N5, N6, N7, N8, N9],
13 Out = [N1, N2, N3, N4, N5, N6, N7, N8, N9, TargetOut].
14
15 scale01(X, Y) :- Y is X * 0.1.
16 log_transform(X, Y) :- Y is log(X + 1.2).
17 normalise(Min, Span, X, Y) :- Y is (X - Min) / Span.
Four transformations happen in sequence:
- Scale by 0.1 — Maps integer features from [1, 10] to [0.1, 1.0].
- Log-transform —
log(x + 1.2)compresses the right tail, making the distribution more bell-shaped. The offset 1.2 preventslog(0). - Min-max normalise — Rescales each row’s features to [0, 1]. This per-row normalisation removes scale differences between samples.
- Target remapping — The original target encodes benign as 2 and malignant as 4. The formula
(x - 2) * 0.5maps these to 0.0 (normal) and 1.0 (anomaly).
Notice how maplist/3 applies each transform in a declarative, functional style. The normalise/4 predicate takes Min and Span as its first two arguments — a partial application pattern that works naturally with maplist.
Data Splitting
The split assigns each row to one of four buckets: train, cv (cross-validation), test, or skip. We use a tag-then-filter strategy for full determinism:
1 split_data(Rows, Train, CV, Test) :-
2 maplist(assign_row, Rows, Tagged),
3 include(is_train, Tagged, TrainTagged),
4 include(is_cv, Tagged, CVTagged),
5 include(is_test, Tagged, TestTagged),
6 maplist(untag, TrainTagged, Train),
7 maplist(untag, CVTagged, CV),
8 maplist(untag, TestTagged, Test).
9
10 assign_row(Row, Tag-Row) :-
11 random(P1),
12 last(Row, Target),
13 ( P1 < 0.6
14 -> ( Target < 0.5
15 -> Tag = train
16 ; random(P2),
17 ( P2 < 0.1
18 -> Tag = train % leak ~10% anomalies into training
19 ; Tag = skip % discard anomaly from training
20 )
21 )
22 ; random(P3),
23 ( P3 < 0.7
24 -> Tag = cv
25 ; Tag = test
26 )
27 ).
28
29 is_train(train-_).
30 is_cv(cv-_).
31 is_test(test-_).
32 untag(_-Row, Row).
The assignment logic mirrors the Java original:
- 60% chance of going to training — but only if the row is normal (target < 0.5). Anomalous rows are mostly skipped, with ~10% leaking through. This ensures the training set is dominated by normal examples, which is the key requirement for anomaly detection.
- 28% to cross-validation, 12% to test.
- Skipped anomalies are simply dropped.
The tag-then-filter pattern deserves comment. An earlier version used direct recursive splitting with Prolog disjunctions (;), but this left choicepoints that caused backtracking across the entire pipeline. The maplist/assign_row approach is fully deterministic — each row gets exactly one tag, and include/3 partitions without any choicepoints.
Computing Statistics
With the training set isolated, we compute per-feature mean () and variance ():
1 compute_mu(Rows, NF, Mu) :-
2 length(Rows, N),
3 ( N =:= 0
4 -> length(Mu, NF), maplist(=(0.0), Mu)
5 ; numlist(1, NF, Indices),
6 maplist(feature_mean(Rows, N), Indices, Mu)
7 ).
8
9 feature_mean(Rows, N, FIdx, Mean) :-
10 maplist(nth1(FIdx), Rows, Vals),
11 sumlist(Vals, Sum),
12 Mean is Sum / N.
For each feature index, feature_mean/4 extracts all values via maplist(nth1(FIdx), Rows, Vals), sums them, and divides by the number of training examples. The variance computation follows the same pattern, using squared differences from the mean:
1 feature_var(Rows, N, Mu, FIdx, Var) :-
2 nth1(FIdx, Mu, M),
3 maplist(sq_diff(FIdx, M), Rows, Diffs),
4 sumlist(Diffs, SumSq),
5 Var is SumSq / N.
6
7 sq_diff(FIdx, M, Row, D) :-
8 nth1(FIdx, Row, X),
9 D is (X - M) * (X - M).
The Gaussian PDF
The Gaussian Probability Density Function (PDF) is the heart of the algorithm. For each feature in a data point, we compute how likely that value is under the learned normal distribution. The implementation walks three lists in parallel — the row’s features, the means, and the variances — accumulating the sum of per-feature PDF values:
1 gaussian_prob(Row, Mu, SigmaSq, _NF, P) :-
2 sqrt_2_pi(S2P),
3 num_columns(NC),
4 gaussian_sum(Row, Mu, SigmaSq, S2P, 0, 0.0, Sum),
5 P is Sum / NC.
6
7 %% gaussian_sum(+Row, +Mu, +SigmaSq, +S2P, +Idx, +Acc, -Sum)
8 % Walk the first 9 elements (skip target at position 10).
9 gaussian_sum(_, _, _, _, 9, Acc, Acc) :- !.
10 gaussian_sum([X|Xs], [M|Ms], [S2|Ss], S2P, I, Acc, Sum) :-
11 ( S2 =:= 0
12 -> PDF = 0.0
13 ; Sigma is sqrt(S2),
14 Exp is -((X - M) * (X - M)) / (2.0 * S2),
15 PDF is (1.0 / (S2P * Sigma)) * exp(Exp)
16 ),
17 Acc1 is Acc + PDF,
18 I1 is I + 1,
19 gaussian_sum(Xs, Ms, Ss, S2P, I1, Acc1, Sum).
The parallel list walk ([X|Xs], [M|Ms], [S2|Ss]) is a deliberate performance choice. An earlier version used nth1/3 to extract each feature by index — but nth1 is O(n) on linked lists, and calling it 3 times per feature × 9 features × every row added up badly. Walking the lists in parallel is O(1) per element.
The base case gaussian_sum(_, _, _, _, 9, Acc, Acc) stops after 9 features, skipping the target column at position 10. The cut prevents backtracking into the recursive clause.
Epsilon Search
Epsilon is the threshold that separates normal from anomalous. We find the best value by grid search over the cross-validation set. The key optimisation is to precompute the Gaussian probability for each CV row once, then sweep epsilon across the precomputed values:
1 precompute_probs([], _, _, _, []).
2 precompute_probs([Row|Rows], Mu, SigmaSq, NF, [P-T|Rest]) :-
3 gaussian_prob(Row, Mu, SigmaSq, NF, P),
4 last(Row, T),
5 precompute_probs(Rows, Mu, SigmaSq, NF, Rest).
This creates a list of Probability-Target pairs. The epsilon sweep then counts errors without recomputing any PDFs:
1 search_epsilon(PTPs, BestEps) :-
2 numlist(0, 19, Steps),
3 maplist(step_to_epsilon, Steps, Epsilons),
4 maplist(count_errors(PTPs), Epsilons, ErrorCounts),
5 min_list(ErrorCounts, MinErr),
6 nth0(BestIdx, ErrorCounts, MinErr), !,
7 nth0(BestIdx, Epsilons, BestEps).
8
9 step_to_epsilon(Step, Eps) :-
10 Eps is 0.001 + 0.05 * Step.
We test 20 epsilon values from 0.001 to 0.951, spaced at 0.05 intervals. For each epsilon, an error occurs when:
- An anomaly (target > 0.5) has probability above epsilon — a false negative (missed anomaly)
- A normal point (target <= 0.5) has probability below epsilon — a false positive (false alarm)
The epsilon with the fewest total cross-validation errors wins.
Putting It Together
The train_model/2 predicate orchestrates the full pipeline:
1 train_model(Rows, Model) :-
2 preprocess(Rows, Processed),
3 once(split_data(Processed, Train, CV, Test)),
4 length(Train, NTrain), length(CV, NCV), length(Test, NTest),
5 format('Split: ~w train, ~w cv, ~w test~n', [NTrain, NCV, NTest]),
6 num_input_features(NF),
7 compute_mu(Train, NF, Mu),
8 compute_sigma_sq(Train, NF, Mu, SigmaSq),
9 precompute_probs(CV, Mu, SigmaSq, NF, CVProbs),
10 once(search_epsilon(CVProbs, BestEps)),
11 format('~n**** Best epsilon value = ~6f~n', [BestEps]),
12 Model = model(Mu, SigmaSq, NF, BestEps),
13 evaluate_model(Model, Test), !.
The model is a compound term model(Mu, SigmaSq, NF, BestEps) that bundles everything needed for prediction. After training, you can classify new data points with:
1 is_anomaly(model(Mu, SigmaSq, NF, Eps), Row) :-
2 gaussian_prob(Row, Mu, SigmaSq, NF, P),
3 P < Eps.
This succeeds (returns true) if the row is an anomaly, and fails otherwise — a natural fit for Prolog’s success/failure semantics.
Evaluation
The evaluate_model/2 predicate computes standard binary classification metrics on the test set:
1 evaluate_model(Model, TestRows) :-
2 foldl(classify_row(Model), TestRows,
3 counts(0,0,0,0), counts(TP,FP,FN,TN)),
4 ...
The accumulator is a counts(TP, FP, FN, TN) term that threads through the fold, updating one counter per test row. The final counts yield:
- Precision = TP / (TP + FP) — of the points we called anomalies, how many actually were?
- Recall = TP / (TP + FN) — of the actual anomalies, how many did we catch?
- F1 = 2 * Precision * Recall / (Precision + Recall) — harmonic mean of precision and recall.
Running the Example
1 $ cd source-code/anomaly_detection
2 $ make run
3 === Running anomaly detection on Wisconsin cancer data ===
4 Split: 86 train, 45 cv, 22 test
5
6 **** Best epsilon value = 0.801000
7
8 -- number of test examples = 22
9 -- true positives = 6
10 -- false positives = 0
11 -- false negatives = 3
12 -- true negatives = 13
13 -- precision = 1.000000
14 -- recall = 0.666667
15 -- F1 = 0.800000
Because the data split is random, your exact numbers will vary across runs. Precision is typically high (the model rarely cries wolf), while recall varies depending on which anomalies end up in the test set.
Run the tests with:
1 $ make test
2 % All 7 tests passed in 0.043 seconds (0.036 cpu)
Prolog-Specific Design Decisions
Determinism. The most challenging aspect of this port was controlling Prolog’s backtracking. Several predicates naturally produce choicepoints:
source_file/2returns one solution per exported predicate- Disjunction (
;) inside recursive predicates leaves choicepoints at every branch nth0/3with an unbound index generates solutions lazily
We addressed these with once/1 wrappers and a tag-then-filter strategy for split_data. The final ! in train_model commits to the first successful training run.
Lists vs. arrays. Prolog lists are linked lists — nth1/3 is O(n) per access. The Gaussian PDF needs to access three parallel lists (row, means, variances) for each of 9 features. Using nth1 would mean 27 * O(n) lookups per row. Instead, we walk the three lists in parallel via pattern matching ([X|Xs], [M|Ms], [S2|Ss]), giving O(1) per element. This alone gave us a large speedup.
Precomputed probabilities. The Java version recomputes the Gaussian PDF for every epsilon candidate. In Prolog, where arithmetic is slower than in the JVM, we precompute all PDF values before the epsilon sweep. The 20-step grid search then just compares precomputed floats to the epsilon threshold — pure arithmetic with no list traversal.
Subsampling. The full 648-row dataset with 200 epsilon steps would be impractical in interpreted Prolog. We subsample to ~200 rows and use 20 epsilon steps, reducing the workload by roughly 65x. The model quality remains strong thanks to the class-balanced sampling and the dataset’s clear separation between benign and malignant clusters.
Wrap Up
This example demonstrates that statistical machine learning algorithms can be implemented naturally in Prolog. The Gaussian anomaly detector uses only standard SWI-Prolog libraries — no external packs — and fits comfortably into Prolog’s declarative style. The key techniques — maplist for transforms, foldl for accumulators, parallel list walking for performance, and tag-then-filter for deterministic splitting — are broadly useful patterns for any numerical computation in Prolog.
Optional Practice Problems
- Sensitivity Threshold: In the
anomaly_detectionproject, modify the thresholding logic to accept a dynamic sensitivity parameter that increases or decreases the strictness of the anomaly classification. - Out-of-Order Sequence Check: Write a predicate in
anomaly.plthat flags sequences of log events that violate a predefined transaction state transitions order.