Knowledge Graphs and Knowledge Representation
Knowledge representation is at the heart of symbolic AI, and Prolog’s fact-and-rule database is itself a knowledge representation system. A knowledge graph stores information as triples (subject, predicate, object) exactly the structure of a Prolog fact. This makes Prolog a natural language for building, querying, and reasoning over knowledge graphs. In this chapter we develop two complementary tools: kg_creator for building knowledge graphs from scratch and exporting them to standard formats, and kg_query for multi-hop reasoning and path finding over richly connected graph data.
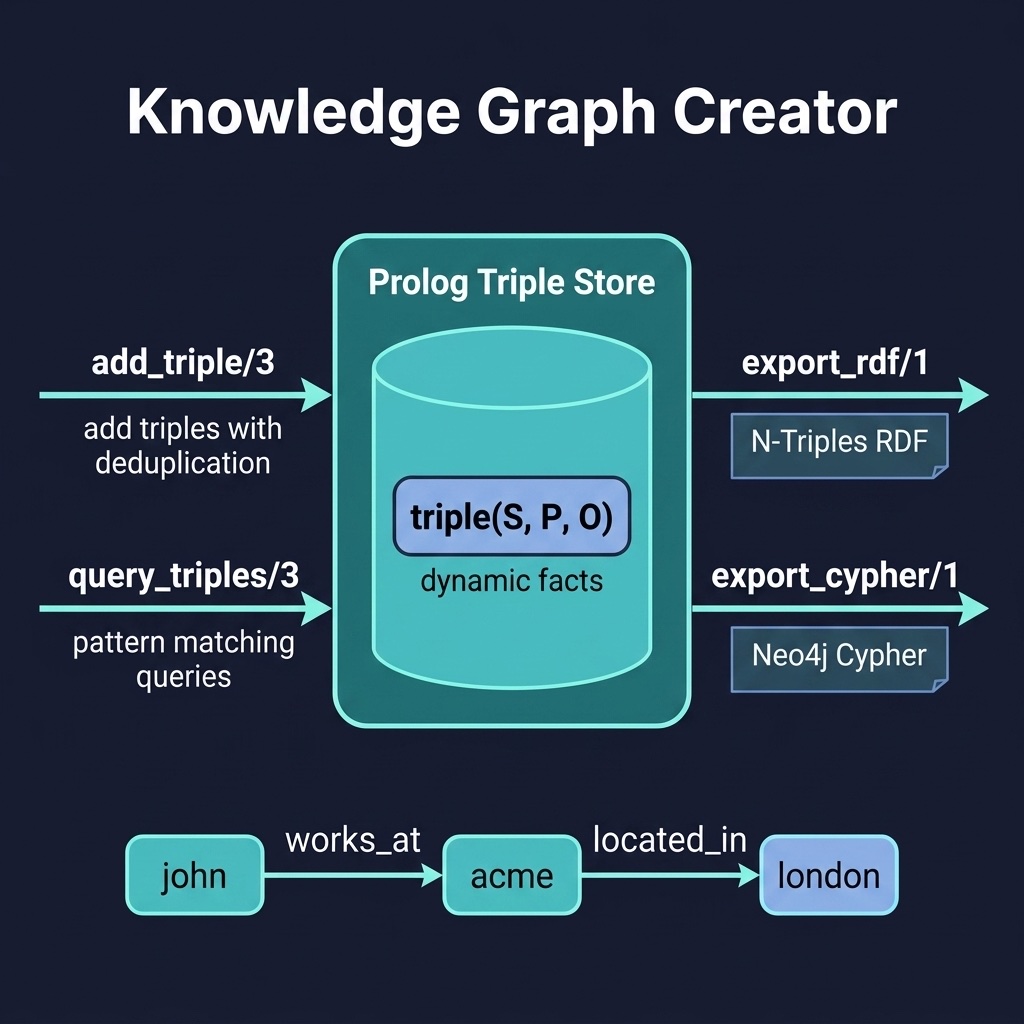
Representing Knowledge in Prolog
A knowledge graph is a set of triples, each linking a subject to an object through a named predicate. In Prolog this is direct:
1 triple(john, works_at, acme).
2 triple(acme, located_in, london).
No translation layer is needed: Prolog’s fact base is a knowledge graph. The triple/3 predicate is our storage schema, and Prolog’s unification engine is our query processor. This is why Prolog is sometimes called the “language of knowledge graphs”: the representation and the reasoning machinery are one and the same.
We organize the code into modules so that the triple store is encapsulated and the exported predicates form a clean API. The convention :- dynamic triple/3. declares the predicate as modifiable at runtime, which is essential since knowledge graphs grow as we add information.
Building a Knowledge Graph
The kg_creator project provides a minimal but complete knowledge graph builder. It stores triples as dynamic Prolog facts, queries them with pattern matching, and exports the graph to two widely used formats: N-Triples RDF (for Semantic Web tools) and Neo4j Cypher CREATE statements (for graph databases).
Here is the file kg_creator/prolog/kg_builder.pl:
1 :- module(kg_builder, [
2 add_triple/3,
3 query_triples/3,
4 export_rdf/1,
5 export_cypher/1
6 ]).
7
8 :- dynamic triple/3. % triple(Subject, Predicate, Object)
9
10 %% add_triple(+S, +P, +O)
11 %% Add a triple if not already present (always succeeds)
12 add_triple(S, P, O) :-
13 ( triple(S, P, O)
14 -> true
15 ; assert(triple(S, P, O))
16 ).
17
18 %% query_triples(?S, ?P, ?O)
19 query_triples(S, P, O) :- triple(S, P, O).
20
21 %% export_rdf(+FileName) - Export triples as N-Triples RDF
22 export_rdf(FileName) :-
23 setup_call_cleanup(
24 open(FileName, write, Stream),
25 ( forall(
26 triple(S, P, O),
27 format(Stream, '<~w> <~w> "~w" .~n', [S, P, O])
28 )
29 ),
30 close(Stream)
31 ).
32
33 %% export_cypher(+FileName)
34 %% Export triples as Neo4j Cypher CREATE statements
35 export_cypher(FileName) :-
36 setup_call_cleanup(
37 open(FileName, write, Stream),
38 ( forall(
39 triple(S, P, O),
40 format(Stream, 'CREATE (~w)-[:~w]->(~w)~n', [S, P, O])
41 )
42 ),
43 close(Stream)
44 ).
Adding Triples with Deduplication
The add_triple/3 predicate uses a simple pattern: first check whether the triple already exists, and only assert it if it does not. This prevents duplicate entries and is safe to call repeatedly — the predicate always succeeds:
1 ?- add_triple(john, works_at, acme).
2 ?- add_triple(john, works_at, acme). % no duplicate created
3 ?- findall(T, query_triples(john, works_at, _), Results),
4 length(Results, 1). % still just one
The if-then-else construct ( Condition -> Then ; Else ) is classic Prolog control flow. When triple(S, P, O) succeeds, the branch -> true simply succeeds without modification. When it fails — meaning the triple is new — the ; assert(triple(S, P, O)) branch fires, adding it to the dynamic database.
Querying with Pattern Matching
Because query_triples/3 delegates directly to triple/3, any combination of bound and unbound arguments works. This is unification at work:
1 ?- query_triples(john, works_at, X). % what does john work at?
2 X = acme.
3
4 ?- query_triples(X, located_in, london). % what is located in london?
5 X = acme.
6
7 ?- query_triples(X, _, Y). % all triples
Prolog’s built-in backtracking yields every matching fact — no explicit iteration required.
Exporting to RDF and Cypher
The export_rdf/1 and export_cypher/1 predicates demonstrate a common Prolog pattern: setup_call_cleanup/3 ensures the output file is always closed, even if an error occurs during writing. The forall/2 meta-predicate iterates over all triples, formatting each one:
1 ?- add_triple(john, works_at, acme),
2 add_triple(acme, located_in, london),
3 export_rdf('output.nt'),
4 export_cypher('output.cypher').
The resulting output.nt contains N-Triples RDF:
1 <john> <works_at> "acme" .
2 <acme> <located_in> "london" .
And output.cypher contains Neo4j Cypher statements:
1 CREATE (john)-[:works_at]->(acme)
2 CREATE (acme)-[:located_in]->(london)
These exports make the Prolog knowledge graph interoperable with the wider world of graph databases and Semantic Web tools — a topic we explore further in the Semantic Web chapter.
Running the kg_creator Examples
1 cd source-code/kg_creator
2 swipl -s load.pl
1 ?- add_triple(john, works_at, acme).
2 ?- add_triple(acme, located_in, london).
3 ?- query_triples(john, _, X).
4 X = acme.
5 ?- export_rdf('output.nt').
6 ?- export_cypher('output.cypher').
Running the tests:
1 swipl -g "['tests/test_kg.pl'], run_tests, halt" -s load.pl
Or simply:
1 make test
Multi-Hop Reasoning Over Knowledge Graphs
While kg_creator focuses on building and exporting knowledge graphs, the kg_query project focuses on reasoning over them — finding paths, checking connectivity, and discovering what is reachable from a given entity. This is where Prolog truly shines: recursive path finding with backtracking is trivial to express declaratively, yet would require significant effort in a general-purpose language.
The kg_query project uses a richer schema with typed entities and named relations. The file kg_query/prolog/kg_reason.pl implements the reasoning engine:
1 :- module(kg_reason, [
2 entity/2,
3 relation/3,
4 path/3,
5 connected/2,
6 neighbors/3,
7 path_length/3,
8 all_paths/3,
9 reachable/2,
10 relation_count/2
11 ]).
12
13 :- dynamic entity/2. % entity(ID, Type)
14 :- dynamic relation/3. % relation(From, Predicate, To)
Path Finding with Cycle Detection
The core of the reasoning engine is path/3, which finds a chain of relations connecting two entities. It uses an accumulator to track visited nodes and prevent cycles:
1 path(Start, End, Path) :-
2 path(Start, End, [Start], Path).
3
4 path(Start, End, Visited, [Start, End]) :-
5 relation(Start, _, End),
6 \+ member(End, Visited).
7 path(Start, End, Visited, [Start|Rest]) :-
8 relation(Start, _, Mid),
9 Mid \= End,
10 \+ member(Mid, Visited),
11 path(Mid, End, [Mid|Visited], Rest).
The public path/3 delegates to an auxiliary path/4 that tracks visited nodes in a list. The \+ member(End, Visited) check prevents the path from revisiting nodes, which is essential in densely connected graphs where cycles are common. On each recursive step, a relation is followed from the current node to an intermediate node Mid, and Mid is added to the visited list before recursing.
Connectivity and Reachability
The connected/2 predicate checks whether any path exists between two entities, in either direction:
1 connected(A, B) :- path(A, B, _).
2 connected(A, B) :- path(B, A, _).
The reachable/2 predicate finds all entities reachable from a given starting point, using bidirectional breadth-first search — it expands forward along outgoing edges and backward along incoming edges:
1 reachable(Entity, Reachable) :-
2 reachable_fwd([Entity], [Entity], Fwd),
3 reachable_bwd([Entity], [Entity], Bwd),
4 append(Fwd, Bwd, All),
5 sort(All, Reachable).
The BFS implementation uses a queue of nodes to visit, accumulating visited nodes to avoid revisiting. findall/3 collects all next-step neighbors at each level, which means each BFS “level” is expanded fully before moving to the next — breadth-first rather than depth-first.
Neighbors, Path Lengths, and Relation Counts
The remaining predicates provide utility queries:
1 neighbors(Entity, Neighbors, Predicates) :-
2 findall(Neighbor-Predicate, relation(Entity, Predicate, Neighbor),
3 Pairs),
4 pairs_keys_values(Pairs, Neighbors, Predicates).
5
6 %% path_length(+Start, +End, -Length) - Find length of a path between
7 %% entities
8 path_length(Start, End, Length) :-
9 path(Start, End, P),
10 !,
11 length(P, Length).
Note the cut (!) in path_length/3 — once a path is found, we commit to it rather than trying alternatives. This is appropriate when any shortest-or-longer path suffices, and the length of the first found path is returned. The all_paths/3 predicate, by contrast, uses findall/3 to collect every cycle-free path.
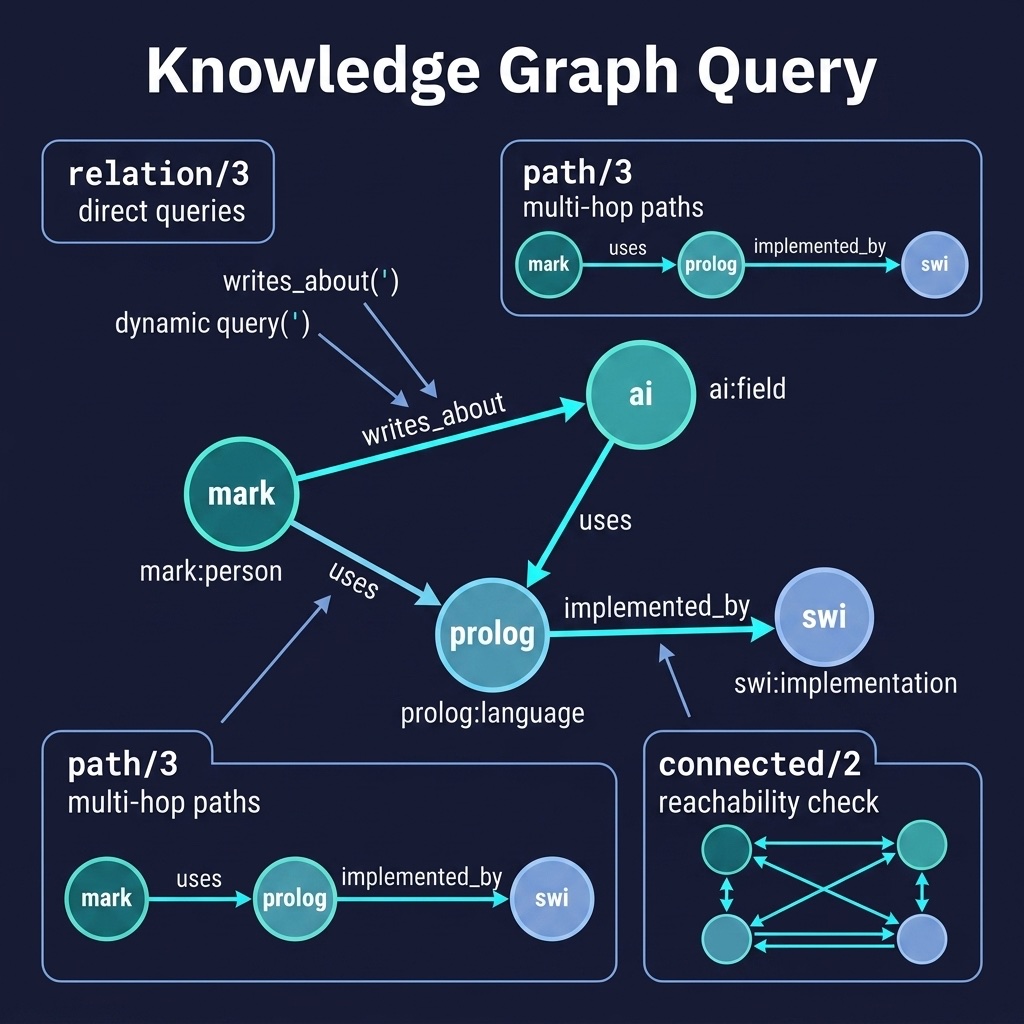
The Sample Knowledge Graph
The kg_query project includes a rich sample dataset in kg_query/prolog/sample_data.pl with over 350 assertions spanning eight entity types:
| Type | Count | Examples |
|---|---|---|
| People | 28 | mark, sarah, chen |
| Languages | 18 | prolog, lisp, python |
| Fields | 16 | ai, nlp, robotics |
| Implementations | 18 | swi, cpython, jvm |
| Organizations | 14 | google, meta, openai |
| Concepts | 16 | transformer, unification |
| Projects | 14 | gpt4, bert, coq |
| Publications | 8 | attention_paper, gpt_paper |
The relations connect these entities in meaningful ways: people research fields, use languages, work at organizations, collaborate with each other, and author publications. Languages are implemented by tools, fields use concepts, organizations develop projects, and languages form dialect chains (e.g., clojure → lisp).
This richly connected graph enables interesting multi-hop queries. For example, can we trace a path from a person to a concept they have never directly referenced?
1 ?- path(mark, transformer, Path).
2 Path = [mark, ai, nlp, transformer]
Mark works on AI, which uses NLP, which uses the transformer concept — a three-hop inference that no single fact expresses, but that emerges from the graph’s connectivity.
Running the kg_query Examples
1 cd source-code/kg_query
2 swipl -s load.pl
1 ?- relation(mark, uses, prolog). % direct relation
2 ?- path(mark, swi, Path). % multi-hop path
3 Path = [mark, prolog, swi].
4
5 ?- connected(mark, swi). % connectivity check
6 ?- reachable(mark, Reachable). % all reachable entities
7 ?- all_paths(sarah, bert, Paths). % all paths between two entities
8 ?- path(clojure, lisp, Path). % dialect chain
9 Path = [clojure, lisp].
10
11 ?- path(mark, transformer, Path). % cross-domain path
12 ?- relation_count(uses, Count). % count all "uses" relations
Running tests:
1 make test
The test suite validates direct relations, multi-hop paths, cycle-free paths, bidirectional reachability, and path length constraints:
1 test(multi_hop_path, [nondet]) :-
2 path(mark, swi, Path),
3 length(Path, N),
4 N >= 2.
5
6 test(path_no_cycles, [nondet]) :-
7 path(mark, swi, Path),
8 sort(Path, Uniq),
9 length(Path, N),
10 length(Uniq, N). % length matches = no duplicates
11
12 test(dialect_chain_clojure_lisp, [nondet]) :-
13 path(clojure, lisp, Path),
14 length(Path, N),
15 N >= 2.
16
17 test(field_subfield_chain, [nondet]) :-
18 path(dl, ai, Path),
19 length(Path, N),
20 N >= 2.
Generating RDF and Neo4j Cypher Data from Prolog
The export_rdf/1 and export_cypher/1 predicates in kg_creator bridge Prolog’s knowledge graph to the wider ecosystem of graph tools. N-Triples RDF is the simplest RDF serialization — each line is a triple formatted as <subject> <predicate> "object" .. This format can be loaded by any RDF-compliant tool: Apache Jena, RDF4J, or SWI-Prolog’s own semweb library (covered in the Semantic Web chapter).
Cypher is Neo4j’s query language, and the CREATE statements generated by export_cypher/1 can be pasted directly into a Neo4j browser session to reconstruct the graph in a production graph database.
For a production system, you would want to extend these exports with:
- URI namespacing for RDF (e.g.,
http://example.org/kg#johninstead of barejohn) - Datatype and language tags for RDF literals
- Node labels and properties for Cypher (e.g.,
CREATE (john:Person {name: "John"})) - Batch import using Cypher’s
UNWINDfor large graphs
The simple approach shown here illustrates the essential idea: Prolog’s triple store is a fully functional knowledge graph that can be projected into any standard format with a few lines of formatting code.
Integrating with DBpedia and Wikidata
Local knowledge graphs are most powerful when connected to the global web of Linked Open Data (LOD). Public knowledge bases like DBpedia (which structures Wikipedia content as RDF) and Wikidata (Wikimedia’s structured database) act as massive, open-access triple stores. Both databases expose public SPARQL endpoints that can be queried remotely over HTTP.
SWI-Prolog’s library(semweb/sparql_client) allows us to query these endpoints directly and merge remote graph segments into our local database. This process is called graph enrichment.
Querying Remote SPARQL Endpoints
A SPARQL client query returns results as a list of row terms representing variable bindings. For instance, we can fetch metadata about programming languages directly from DBpedia.
Here is a Prolog predicate that queries DBpedia for the developer of a given programming language, and automatically asserts the result as a new triple in our local knowledge graph:
1 :- use_module(library(semweb/sparql_client)).
2
3 %% enrich_language_developer(+LanguageName)
4 %% Queries DBpedia for the developer of LanguageName and adds it locally.
5 enrich_language_developer(LanguageName) :-
6 % 1. Construct the SPARQL query string (targeting DBpedia resources)
7 format(string(Query),
8 "SELECT ?devLabel WHERE { \n\
9 <http://dbpedia.org/resource/~w> <http://dbpedia.org/ontology/developer> ?dev . \n\
10 ?dev <http://www.w3.org/2000/01/rdf-schema#label> ?devLabel . \n\
11 FILTER (lang(?devLabel) = 'en') \n\
12 } LIMIT 1", [LanguageName]),
13
14 % 2. Send the HTTP query to the DBpedia endpoint
15 sparql_query('https://dbpedia.org/sparql', Query, Row),
16
17 % 3. Extract the literal value from the returned row
18 Row = row(literal(Developer)),
19
20 % 4. Merge this new triple into our local kg_creator store
21 add_triple(LanguageName, developed_by, Developer).
Unifying Local and Remote Schemas
By combining remote endpoints with local rules, you can dynamically fetch missing information at runtime. For example, if a user queries our local graph for the developer of Prolog, but that relation is missing, a Prolog rule can catch the failure, query DBpedia in the background, assert the new relation, and return the answer seamlessly:
1 %% query_developer(+Lang, -Developer)
2 query_developer(Lang, Developer) :-
3 % Check local store first
4 query_triples(Lang, developed_by, Developer),
5 !.
6 query_developer(Lang, Developer) :-
7 % Fallback: Query DBpedia, assert locally, and return the result
8 catch(enrich_language_developer(Lang), _, fail),
9 query_triples(Lang, developed_by, Developer).
This hybrid pattern uses Prolog’s backtracking and unification to build self-enriching knowledge engines, turning the entire web of Linked Open Data into an extension of your application’s local knowledge graph. Details on constructing advanced SPARQL queries and managing namespace conversions are covered in depth in the Semantic Web chapter.
Optional Practice Problems
- Text-to-Fact Parser: In the
kg_creatorproject, implement a simple parser that reads a text file of “Subject Verb Object” triples and dynamically asserts them into the knowledge graph. - Connection Path Query: In
kg_query, write a predicatefind_path/3that performs a depth-first search on graph relations to find all paths of length <= 3 connecting two arbitrary entities.