Im Vergleich mit anderen technischen Einrichtungen, die wir im Alltag nutzen, etwa Aufzügen, Autos, Taschenlampen oder Kugelschreibern, sind Computer eine sehr neue Erscheinung. Die ersten elektrischen und elektronischen Computer wurden Ende der 1930er und in den 1940er Jahren gebaut. Bis Computer in jedem Büro und in vielen Haushalten zu finden waren, dauerte es noch weitere vierzig Jahre. Dieser erste Abschnitt des Buches betrachtet die Entwicklung des Computers und seiner Nutzungsschnittstelle von den Anfängen bis zum Aufkommen der Personal Computer Ende der 1970er Jahre. Sie werden sehen, dass der Personal Computer nicht etwa eine völlig aus dem Nichts entstandene Revolution war, wie es so manche Computergeschichte suggeriert, sondern dass PCs und deren Nutzungsschnittstellen in der Tradition einer zunehmenden Miniaturisierung der Rechen- und Speichertechnik und einer zunehmend direkten Interaktion des Nutzers mit von der Nutzungsschnittstelle erzeugten virtuellen Objekten stehen.
Die frühen Computer
Wenn Technikgeschichten erzählt werden, gibt es, wie ich in der Einleitung schon angedeutet habe, offenbar ein Bedürfnis, das erste Exemplar eines bestimmten Gerätes herauszufinden. Auch in der Welt der Computer und Rechenmaschinen ist dieser Wunsch nicht unbekannt. In einer Gesellschaft, die vom Wettbewerb gekennzeichnet ist, scheint es wichtig, herauszufinden, welcher Computer von allen der erste war. Leider ist diese Frage gar nicht ohne Weiteres zu beantworten, denn man müsste zunächst einmal wissen, was überhaupt ein Computer ist. Darauf, dass ein Computer etwas ist, mit dem man rechnen kann, kann man sich vielleicht noch recht schnell einigen. Diese Beschreibung gilt aber auch für einen Abakus, einen Rechenschieber oder eine alte mechanische Registrierkasse aus dem Museum. Diese Gegenstände und Geräte werden aber üblicherweise nicht Computer genannt. Welche Eigenschaften muss ein Gerät also haben, damit man es einen Computer nennen kann und mit ins Rennen um den ersten Computer schickt? Je nachdem, wie man diese Frage beantwortet, kann man ein anderes Gerät als den ersten Computer identifizieren. Es ist zum Beispiel durchaus verständlich, den amerikanischen ENIAC (Electronic Numerical Integrator and Computer) aus dem Jahr 1945 als ersten Computer anzusehen. Der deutsche Ingenieur Konrad Zuse hat allerdings schon Jahre vorher automatische Rechengeräte konzipiert und gebaut. Wenn wir seine mechanischen Rechner außen vor lassen, die noch nicht wirklich einsatzfähig waren, kann man Zuses Computer Z3 von 1941 genauso gut als ersten Computer betrachten. Die Z3 war allerdings im Gegensatz zum ENIAC nicht elektronisch, sondern elektrisch bzw. elektromechanisch1, denn sie arbeitete mit Telefonrelais. Auch war die Z3 nicht als turingmächtige Maschine konzipiert. „Turingmächtig“ ist ein Begriff aus der theoretischen Informatik. Er bedeutet, vereinfacht gesagt, dass Sie mit dem Computer, wenn er denn nur über genug Speicher verfügt und Sie hinreichend Zeit haben, all das zu berechnen imstande sind, was Sie auch mit einem heutigen PC berechnen können. Mit Computern, die nicht turingmächtig sind, können Sie einige Berechnungen nicht durchführen. Die Zuse Z3 hatte etwa keine bedingte Befehlsausführung. Sie konnten mit ihr also nichts automatisch berechnen, was einer Fallunterscheidung bedürfte.
Die Z3 war in gewisser Weise wirklich der erste, aber eben (nur) der erste elektromechanische, programmierbare, vollautomatische Computer, während der ENIAC auch der erste, aber eben der erste elektronische, universell programmierbare Computer war. Auch andere Rechengeräte kommen für das Rennen um den ersten Computer infrage, so etwa der britische Colossus von 1943, der wie der ENIAC mit Röhren arbeitete und somit elektronisch war. Es handelte sich bei dieser Maschine aber nicht um einen universellen Rechner, sondern um einen Spezialrechner zum Knacken verschlüsselter Textnachrichten. Er wurde im Zweiten Weltkrieg genutzt, um Nachrichten der deutschen Admiralität zu entschlüsseln. Seine Programmiermöglichkeiten waren sehr beschränkt. Dennoch war der Colossus der erste Computer, nämlich der erste elektronische, teilprogrammierbare, digitale Spezialrechner.
Welcher Computer nun, mit den jeweiligen Attributen versehen, als erster Computer beschrieben wird, hängt – absurderweise – oft davon ab, aus welchem Land derjenige kommt, der die Zuschreibung macht. In den USA wurde lange Zeit nur der ENIAC als erster Computer betrachtet, in Deutschland wurde eher die Zuse Z3 als erster Computer angesehen und in England feierte man seit dem Ende der Geheimhaltung über das Knacken der deutschen Codes während des Zweiten Weltkriegs den Colossus als den ersten Computer. Ich möchte in dieser Frage nicht den Schiedsrichter spielen und einen ersten Computer küren, denn letztlich ist es ziemlich belanglos, welchem Gerät Sie den Titel geben, und die offenbare Verbindung der Suche nach dem Ersten mit Nationalstolz macht mir die Frage gänzlich unsympathisch. Aus dem Wettstreit darum, wer nun der Erste war, können wir eine vielleicht versöhnliche Konsequenz ziehen: Ende der 1930er bis Anfang der 1940er Jahre wurden an mehreren Orten auf der Erde unabhängig voneinander Anstrengungen unternommen, vollautomatische, elektronische Rechenanlagen zu bauen. Der Zweite Weltkrieg spielte bei der Entwicklung zwar eine zentrale Rolle, doch offenbar war auch – unabhängig davon – die Zeit einfach reif für die Erfindung des Computers.
Programmierung durch Verkabelung
Wenn Sie einmal etwas über die Bedienung früher Computer gesehen oder gelesen haben, haben Sie vielleicht ein Bild des amerikanischen ENIAC gesehen. Der Rechner wurde von 1943 bis 1945 für das amerikanische Militär gebaut und unter anderem dafür eingesetzt, komplexe Berechnungen für ballistische Flugbahnen durchzuführen. Der Rechner war dreißig Tonnen schwer, füllte eine ganze Halle und hatte eine Leistungsaufnahme von sage und schreibe 150 kW. Seine auffälligste Eigenheit war aber wohl, dass er per Verkabelung programmiert wurde und dass Eingabewerte für die Berechnungen unter anderem durch das Stellen von Drehschaltern eingegeben wurden.
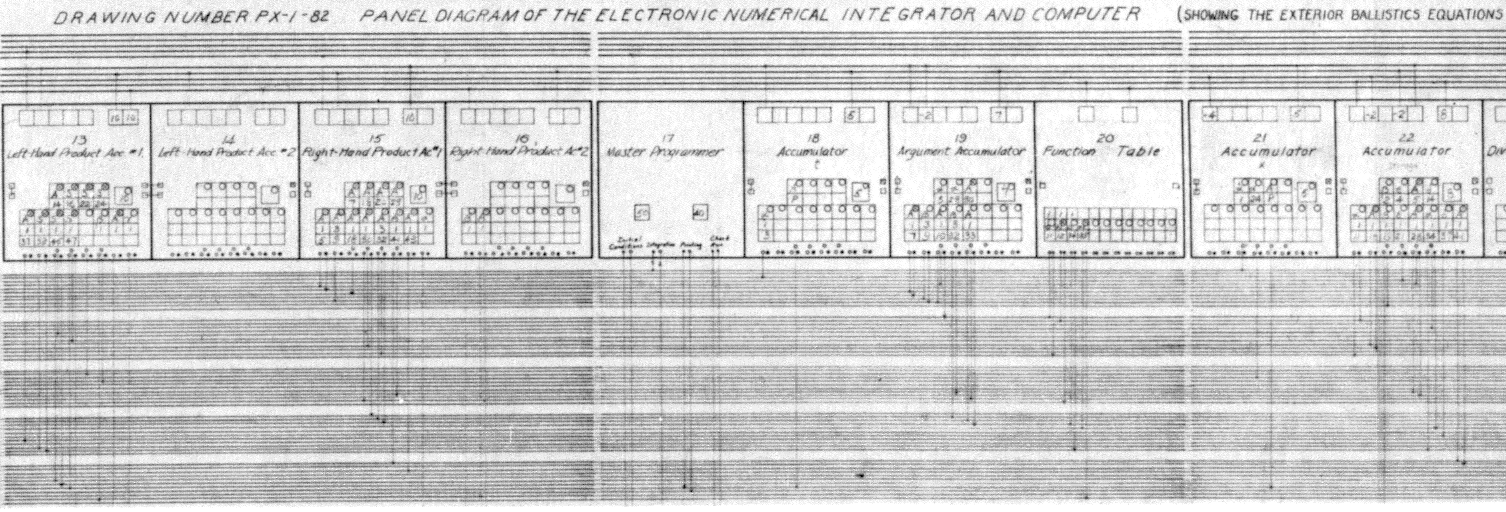
ENIAC – Bild: Public Domain (US Army Photo)
Oben sehen Sie eine typische Ansicht des ENIAC. Auf der linken Seite sehen Sie das Programm in Form der Verkabelung der Module des Rechners. Auf der rechten Seite sind auf fahrbaren Gestellen angebrachte Anordnungen von Drehschaltern zu sehen, mit denen Zahlenwerte eingestellt werden konnten. Programmieren bedeutete beim ENIAC in seiner ursprünglichen, hier abgebildeten Konfiguration, etwas ganz anderes, als das, was man sich heute darunter vorstellt. Selbst das „Programm“ war beim ENIAC überhaupt nicht mit dem zu vergleichen, was später als Programm bezeichnet wurde und auch heute noch so bezeichnet wird. Der ENIAC war nur Hardware und auch das Programm war Teil dieser Hardware. Ohne die gesteckten Kabel war der ENIAC einfach nur eine Sammlung von Modulen wie etwa Akkumulatoren (Addierern), Multiplikatoren, Dividierern, Einstellfeldern sowie Druckern, Lochkartenlesern und entsprechenden Stanzern für die Ein- und Ausgabe. Die Verbindungen zwischen den Modulen bildeten das Programm. Den ENIAC zu programmieren, bedeutete, die Module entsprechend dem, was man berechnen wollte, miteinander zu verbinden. Heutzutage wird unter einem Programm im Allgemeinen eine Folge von Anweisungen verstanden, die dazu dienen, den Computer zu steuern. Dabei wird das Programm vom Computer Anweisung für Anweisung verarbeitet. Beim ENIAC konnte man das so nicht sagen. Der Rechner verarbeitete das Programm nicht und das Programm steuerte den Rechner auch nicht, sondern war ein Teil des Computers. Es handelte sich beim ENIAC um eine Art raumfüllenden Bausatz, aus dem sich der Programmierer für jedes zu lösende Problem einen neuen Computer zusammensetzte. Der ENIAC, der das Problem A lösen konnte, war, genau genommen, nicht der gleiche Computer, wie der, der das Problem B zu lösen imstande war.
Ein Ausschnitt aus einem ENIAC-Programm – Bild: Public Domain (US Army Photo)
Ein Programm für den ENIAC, also seine Verkabelung zum Lösen einer speziellen, meist komplexen, Rechenaufgabe, wurde auf Papier geplant. Oben ist ein Ausschnitt aus einem solchen „Panel Diagram“ abgebildet. Das Erstellen solcher Pläne dauerte oft Wochen und das anschließende Programmieren des Rechners durch das Stecken von Kabeln dann nochmals mehrere Tage. Die eigentliche Berechnung war dann, insofern der Rechner richtig funktionierte und bei der Planung und Verkabelung keine Fehler gemacht wurden, innerhalb weniger Minuten oder allenfalls Stunden erledigt.
Bilder des ENIAC werden gerne gezeigt, um darzustellen, wie weit die Computertechnik inzwischen fortgeschritten ist, schließlich sieht der ENIAC so schön primitiv und ungewöhnlich aus. Diese etwas verächtliche Sicht wird aber weder dem ENIAC noch den Computern danach wirklich gerecht. Die Art, wie der ENIAC programmiert wurde, hatte nämlich durchaus einen Vorteil, nämlich den der vergleichsweise hohen Rechengeschwindigkeit. Große Teile des Rechenprozesses liefen beim ENIAC parallel ab. Zudem konnte der Rechner sofort nach dem Start mit der Berechnung beginnen, denn das Programm lag ja in Form der Verkabelung und der Stellungen der Einstellglieder komplett vor. Es musste nicht erst langwierig eingelesen werden, wie es bei vielen Rechnern danach nötig war. Beides machte den ENIAC für die damalige Zeit extrem schnell. Diesem Vorteil stand allerdings die sehr schwierige Programmierung gegenüber. Es zeigte sich schnell, dass eine serialisierte und dadurch langsamere Arbeitsweise zugunsten einer besseren Programmierbarkeit gut in Kauf genommen werden konnte.
Programme als eigenständige Artefakte
Ein Programm des ENIAC war nicht im heutigen Sinne eine Abfolge von Anweisungen an den Computer, sondern der aktuelle Hardware-Zustand des Rechners, also die aktuellen Verkabelungen und Einstellungen. Es war kein eigenständiges physikalisches Artefakt, das dem Computer von außen zugeführt werden konnte. Den ENIAC neu zu programmieren, bedeutete, ihn komplett neu zu konfigurieren und zu verkabeln. Meines Wissens nach steht der ENIAC mit dieser Art und Weise der Programmierung ziemlich allein auf weiter Flur. Alle mir bekannten späteren, aber auch früheren Computer, wie die von Konrad Zuse, mussten zum Programmieren nicht komplett neu verkabelt werden. Programme lagen stattdessen als ein eigenes Artefakt vor, das dem Computer von außen als Eingabe zugeführt wurde. Die eigentliche Hardware des Computers blieb beim Programmwechsel unverändert. Als Grenzfall kann man hier einige IBM-Geräte ansehen, die durchaus über Programme auf Stecktafeln und damit als Verkabelung verfügten. IBM knüpfte hier an die Tradition seiner Maschinen an, mit denen Daten von Lochkarten tabelliert und verarbeitet werden konnten. Diese Geräte wurden durch Stecken von Kabeln konfiguriert. Kabelverbindungen legten etwa fest, welche Spalte eines Datensatzes addiert und was mit dem Ergebnis am Ende geschehen sollte. Frühe IBM-Rechner übernahmen diese Konfigurationsmöglichkeit zum Teil, waren aber nicht darauf festgelegt, dass Programme zwangsläufig auf diese Art und Weise spezifiziert werden mussten.
Betrachten wir einen Computer, der fast gleichzeitig mit dem ENIAC entwickelt wurde: Unten abgebildet ist der Rechner Z4 von Konrad Zuse. Die Entwicklung an diesem Rechner begann 1942 und war 1945 abgeschlossen. Vorher hatte Zuse den bereits kurz erwähnten Rechner Z3 gebaut, der 1941 fertiggestellt wurde. Die Z3 war aber für heutige Maßstäbe ziemlich eingeschränkt. Sie war, obwohl sie natürlich ziemlich groß war, eher vergleichbar mit einer Art automatisierbarem Taschenrechner als ein Computer im modernen Sinne, denn dem Rechner fehlte etwas ganz Grundlegendes, ohne das wir uns heute Computer und Programmierung gar nicht mehr vorstellen können. Der Befehlssatz der Z3 enthielt, wie oben schon angedeutet, keine bedingten Befehlsausführungen. Die Konsequenz: Die Programme der Z3, von Zuse „Rechenpläne“ genannt, konnten zwar die gleichen Rechenschritte für verschiedene Eingaben durchführen, aber nicht anhand von Zwischenergebnissen verschiedene Rechenwege wählen. Die Z4 war der Z3 von der grundsätzlichen Arbeitsweise her zwar sehr ähnlich, verfügte aber im Gegensatz zu ihrer Vorgängerin über ebendiese bedingten Befehlsausführungen.
Zuse Z4 im Deutschen Museum – Bild: floheinstein (CC BY-SA 2.0) auf flickr
Lochstreifen – Bild: TedColes (CC0)
Programme lagen bei Zuses Rechnern Z3 bis Z11 als Lochstreifen2 vor. Auf der Abbildung rechts ist ein kurzer Lochstreifen zu sehen. Lochstreifen dieser Art wurden bei Computern bis in die 1970er Jahre hinein als Eingabemedium genutzt. Es handelt sich um einen einfachen Papierstreifen. Auf diese Streifen wurden Reihen von Löchern gestanzt. Eine solche Reihe war jeweils eine binäre Codierung eines Zeichens oder einer Zahl. Binär bedeutet, dass es sich um eine Codierung mit zwei Zuständen handelt. Jede Zahl entspricht also einer Folge aus Ja und Nein, 1 und 0 oder hier Loch und Nicht-Loch. Typische Lochstreifen enthielten pro Zeile meist entweder 5 oder 8 Löcher, der Code entsprechend 5 oder 8 Bit.
Diese Lochstreifen wurden nicht für den Computer erfunden, sondern fanden schon lange vorher in der Nachrichtentechnik für Fernschreiber Verwendung. Ein Fernschreiber war im Prinzip nichts anderes als eine Schreibmaschine, die mit einer anderen Schreibmaschine – einem anderen Fernschreiber – verbunden werden konnte. Diese Verbindung konnte über explizite Telegrafenleitungen oder auch über eine Telefonleitung per Modem erfolgen. Sobald zwei Fernschreiber miteinander verbunden waren, erschien alles, was auf einem der Fernschreiber geschrieben wurde, auch auf dem anderen Gerät. Fernschreiber erlaubten also das simultane Übermitteln von Textnachrichten über große Entfernungen – also etwa das, was wir heute „Chatten“ nennen. Viele Fernschreibgeräte verfügten über Lochstreifenleser und Lochstreifenstanzer. War ein Stanzer beim Empfang einer Nachricht eingeschaltet, wurden die empfangenen und eingegebenen Zeichen nicht nur auf Papier gedruckt, sondern zusätzlich entsprechend codiert auf den Streifen gestanzt. Über einen Leser konnte ein Fernschreiber einen Lochstreifen elektronisch einlesen und verhielt sich dann so, als würden die codierten Zeichen gerade in diesem Moment eingetippt. Lochstreifen dienten also dazu, Texte zwischenzuspeichern, um sie mehrfach senden oder um einen von einer Gegenstelle empfangenen Text an eine andere Stelle weitergeben zu können. Fernschreiber werden uns im Kapitel Time-Sharing wieder begegnen. Im Moment reicht uns ihr Speichermedium, der Lochstreifen.
Zuse verwendete die Lochstreifen nicht zur Speicherung von natürlichsprachlichen Texten, sondern zur Speicherung eines „Rechenplans“, also dessen, was wir heute „Programm“ nennen würden. Ein Rechenplan bestand aus einer Reihe von recht simplen Befehlen, die dann, eventuell um Zahlenwerte angereichert, in Bit-Folgen umgewandelt auf dem Lochstreifen abgelegt waren. Ich möchte hier, was diese Befehle angeht, nicht zu sehr ins Detail gehen. Es reicht an dieser Stelle, wenn Sie wissen, dass die Befehle größtenteils aus einfachen Rechenoperationen, also Addieren, Subtrahieren, Multiplizieren, Dividieren, Wurzelziehen etc. bestanden. Hinzu kamen Befehle, um Zahlen im Speicher des Computers abzulegen oder aus dem Speicher zu laden. Der Computer verfügte über zwei sogenannte „Register“. Diese Register waren spezielle Speicher, die die Recheneinheit in direktem Zugriff hatte. Es standen also stets nur zwei Zahlen direkt für Berechnungen zur Verfügung. Brauchte man im Programmverlauf eine berechnete Zahl später erneut, musste man sie im Arbeitsspeicher ablegen und danach wieder in ein Register laden. Einer der wichtigsten Befehle im Befehlssatz des Z4 und seiner Nachfolger war die bedingte Befehlsausführung. Sie prüfte zum Beispiel, ob das aktuelle Zwischenergebnis in einem der Register größer als Null war. War dies der Fall, wurde der darauffolgende Befehl auf dem Lochstreifen ausgeführt, andernfalls wurde er ignoriert.
Zuses Rechner lasen das Programm von einem Lochstreifenleser Befehl für Befehl ein und führten es direkt aus. Die Z3 hatte nur einen derartigen Programmleser. Die Rechner ab der Z4 besaßen zwei Lochstreifenleser. Mittels eines speziellen Programmbefehls konnte ein Programm den Rechner dazu veranlassen, zwischen beiden Lochstreifenlesern umzuschalten. Das Hinzufügen des zweiten Lochstreifenlesers erlaubte es den Programmierern, sogenannte Schleifen zu programmieren. Schleifen sind eine sehr grundlegende Technik in der Programmierung. Man braucht sie immer dann, wenn man es mit einer großen Menge an Informationen, etwa einer Liste, zu tun hat, die abgearbeitet werden muss, oder allgemeiner, wenn man etwas so lange wiederholen muss, bis eine bestimmte Bedingung erfüllt ist. Das Programm muss in solchen Fällen einen ganzen Satz von Befehlen immer wieder durchführen, bis alle Daten verarbeitet sind oder die gewünschte Bedingung eingetreten ist. Den Ausdruck „Schleife“ konnte man bei der Z4 ziemlich wörtlich nehmen. Es wurde zum Erzeugen einer Schleife nämlich schlicht und ergreifend der in den zweiten Leser eingelegte Lochstreifen zu einer Schleife (bzw. eigentlich zu einem Ring) gebunden, sodass die gleichen Programmbefehle immer wieder von vorne gelesen wurden. Im vom ersten Lochstreifenleser gelesenen Programm konnte auf den zweiten Lochstreifenleser umgeschaltet werden. Auf diesem lief die Schleife ab. Damit der Rechner nun nicht bis in alle Ewigkeit diese Schleife abarbeitete, musste der in Schleife gebundene Programmteil einen bedingten Befehl enthalten, der irgendwann wieder auf den ersten Lochstreifen zurückschaltete oder den Programmablauf ganz beendete.
In der Architektur von Zuses Rechnern kann man die Charakteristik der Probleme erkennen, die Zuse lösen wollte. Zuse musste in seiner früheren Arbeit als Ingenieur im Bereich der Luftfahrt feststellen, dass immer gleiche Berechnungen immer wieder mit verschiedenen Werten durchgeführt werden mussten. Um diese mühselige und sich stets wiederholende Arbeit zu vereinfachen, wollte er eine Maschine entwickeln. Diese Grundcharakteristik – gleiche Rechenschritte, verschiedene Werte – spiegelte sich in der Nutzungsschnittstelle seiner Maschinen wider. An einem Zuse-Rechner, und hier unterscheiden sich die Rechner von Z3 bis Z11 überhaupt nicht, wurde stets grundsätzlich folgendermaßen gearbeitet:
Die Lochstreifen, auf denen „der Rechenplan“ gespeichert war, wurden in die Lochstreifenleser eingefädelt.
In den ersten Schritten des Rechenplanes wurden die initialen Werte per Tastatur „eingetastet“ und im Speicher abgelegt. Obwohl Zuses Rechner intern im Binärsystem arbeiteten, also mit 0 und 1, erfolgte die Eingabe im ingenieurfreundlichen Dezimalsystem. Die Konvertierung fand direkt nach der Eingabe statt.
Waren alle Werte eingegeben, startete die eigentliche Berechnung. Der Rechner arbeitete nun die auf dem Lochstreifen gespeicherten Befehle einen nach dem anderen ab. Ausgaben des Programms erfolgten auf einer elektrischen Schreibmaschine.
Die Bedienung der Zuse Z4
Zuses Z4 war ein Rechner für Ingenieure. Diese Ingenieure saßen in der Regel selbst am Rechner und führten ihre Berechnungen durch. Wichtig ist dabei – wir werden gleich sehen, dass es auch ganz anders sein kann – dass Eingaben direkt am Rechner und direkt vor der Programmausführung gemacht wurden. Der Nutzer war bei der Rechnung anwesend und konnte den Programmablauf an der Steuerkonsole des Rechners kontrollieren, im Fehlerfall unterbrechen und Befehle manuell, vom Programm unabhängig, ausführen. Zahlen konnte die Z4 sowohl von einer Tastatur als auch von einem speziellen Lochstreifen – Zahlenstreifen genannt – einlesen, wobei gerade der Eingabe per Tastatur in Sachen Nutzungsschnittstelle viele Überlegungen zukamen. Eine Bedienungsanleitung des Rechners von 19533 etwa beschreibt:
Die eingetastete Zahl erscheint zur Kontrolle im Lampenfeld. Wenn
diese Kontrolle nicht stimmt: Taste "Irrtum" drücken und korrigieren.
Stimmt die Kontrolle: Taste "Fertig" drücken; dies bewirkt Überfüh-
rung der Zahl ins Rechenwerk und verunmöglicht jede Korrektur.
[...]
Die Aufforderung an die Bedienungsperson zum Eintasten (beim Rechnen
mit eingelegtem Rechnenplan) ist ein rotes Blinksignal, oder das
Aufleuchten einer Protokoll-Lampe.
Die besagte Protokoll-Lampe unterstützte den Ingenieur am Rechner bei der Eingabe vieler Werte für seine Berechnung. Sie war Teil des sogenannten Protokollfeldes, das darauf hinwies, welcher Wert zur Eingabe erwartetet wurde. Die Bedienungsanleitung beschreibt:
Das Prokollfeld dient zur Erleichterung des Eingebens vieler
Zahlen in bestimmter Anordnung (Matrix). Es ist jeweils die Zahl
des Protokolls einzugeben, unter der das Licht aufleuchtet. Dazu
müssen die Zahlen auf einem Protokollformular notiert werden, das
auf die Mattscheibe aufgelegt wird. Ein Protokollformular kann
natürlich nur zusammen mit einem bestimmten Rechenplan verwendet werden.
Für einen Rechenplan, bei dem eine ganze Reihe von Eingabewerten gemacht wurden, wurde also in gewisser Weise eine Art Eingabeformular mitgeliefert. Der Rechner konnte so jeweils anzeigen, welcher Wert nun eingegeben werden sollte.
Da die Eingabebefehle der Z4 die Recheneinheit anhielten und der Rechner außerdem über eine bedingte Befehlsausführung verfügte, wäre mit der Z4 grundsätzlich eine interaktive Arbeitsweise möglich gewesen, bei der die Nutzer während des Programmablaufs dazu aufgefordert worden wären, weitere Werte einzugeben, auf die das Programm dann hätte reagieren können. Diese Arbeitsweise war allerdings nicht üblich. Alle Erklärungen und Programmbeispiele für die Z4, die sich finden lassen, sehen vor, zu Beginn alle Daten eingeben zu lassen und diese danach ohne weitere Eingabenotwendigkeiten zu verarbeiten. Eine Programmieranleitung von Zuse aus dem Jahr 19454 empfiehlt etwa explizit:
Bei längeren Rechenplänen speichert man nicht nur diejenigen
Werte, deren Speicherung unbedingt nötig ist, um das Rechenwerk
frei zu machen, sondern es werden zunächst einmal sämtliche
Ausgangswerte ins Speicherwerk eingegeben und daraufhin die
eigentlich Rechnung durchgeführt. Dies hat folgende Vorteile:
1.) Der Aufbau des Rechenplanes ist einfacher.
2.) Bei der praktischen Durchrechnung erfolgt die Eintastung
der Ausgangswerte zügig am Anfang hintereinander. Darauf-
hin kann man die Maschine sich selbst überlassen.
3.) Die Werte können in der logischen Reihenfolge eingetastet
werden.
4.) Es kann nachträglich kontrolliert werden, ob die Maschine
mit den richtigen Werten gerechnet hat.
Dass eine interaktive Nutzung nicht das war, was Zuse für seinen Rechner im Sinne hatte, wurde im Übrigen schon durch die Aufteilung der Ein- und Ausgabgeräte (in der Anleitung Eingang und Ausgang genannt) klar. Protokollfelder, Tastatur und Zahlenfeld, also die Elemente für die komfortable Dateneingabe, befanden sich in unmittelbarer Nähe zueinander, die Schreibmaschine zur Ausgabe in einiger Entfernung davon. Zwar hatte diese Schreibmaschine auch eine Tastatur. Diese diente aber nicht der Eingabe für den Rechner.
Die angenehme Möglichkeit der Eingabe von Daten kann durchaus als ein Vorteil der Z4 angesehen werden. Ihr größter Nachteil, den sie mit allen frühen Rechnern von Zuse bis einschließlich Z11 teilte, war ihre geringe Verarbeitungsgeschwindigkeit. Die Computer arbeiteten mit Telefonrelais, die in ihrer Geschwindigkeit aufgrund der elektromechanischen Arbeitsweise natürlich eingeschränkt waren. Vor allem aber begrenzte die Art und Weise der Programmausführung, bei der das Programm während seiner Verarbeitung Befehl für Befehl vom Computer eingelesen wurde, die Geschwindigkeit. Zwar konnte man das Einlesen von Lochstreifen in gewissem Rahmen beschleunigen, doch hier gab es eine Obergrenze dessen, was möglich war, denn schließlich musste ja ein Papierstreifen von einer Rolle abgerollt werden. Das Papier durfte dabei nicht reißen oder zerknittern. Selbst wenn man hiervon einmal absah, gab es ein grundlegendes Problem: Ein Programm, das sequenziell eingelesen wurde, konnte natürlich auch nur sequenziell abgearbeitet werden. Es gab keine Möglichkeit, in einem Schritt an eine andere Stelle auf dem Lochstreifen zu springen und das Programm dort fortzusetzen. Ein Sprung an Stellen im Programm ist aber für komplexere Programme unbedingt notwendig. Zuses Rechner hatten, im Gegensatz zu den Computern, die ich Ihnen im weiteren Verlauf des Buches vorstellen werde, keinen Sprungbefehl, sondern einen Übersprungbefehl, der während des Einlesens des Programms alle Befehle überging, bis ein bestimmter Code eingelesen wurde. Durch die trickreiche Kombination dieses Übersprungbefehls mit der zuvor erläuterten Technik der Schleife war es so möglich, Programme mit mehreren Unterprogrammen zu erzeugen.
Ein Unterprogramm verwendet man in der Programmierung, wenn bestimmte Befehlsfolgen in einem Programm an verschiedenen Stellen immer wieder genutzt werden. Statt sie jedes mal zu wiederholen, lässt man den Computer an die Stelle im Programm springen, an der diese Befehle notiert sind, und springt hinterher wieder zurück ins eigentliche „Hauptprogramm“. Die Verwendung von Unterprogrammen macht die Programme nicht nur kürzer, sondern auch besser wartbar, denn Verbesserungen müssen nun nicht mehrfach sondern nur noch an einer Stelle vorgenommen werden. Da die Zuse-Rechner keinen Sprungbefehl hatten, war das Anspringen eines solchen Unterprogramms stets mit dem Überspringen vieler Programmbefehle verbunden, die dennoch eingelesen werden mussten5. Die Recheneinheit musste in dieser Zeit warten, bis es weitergehen konnte. Diese Arbeitsweise war weder schnell noch in der Programmierung besonders praktisch.
Stored Program – Das Programm im Computer
Nachbau von Lochkartengeräten von Hollerith, oben die Zähluhren, auf dem Tisch links ein Lochungsgerät, rechts die Vorrichtung zum Abtasten der Lochkarten – Bild: Adam Schuster (CC BY 2.0), Ausschnitt, freigestellt
Eine viel schnellere Programmausführung und ein einfacheres Springen innerhalb eines Programms wurde dadurch möglich, dass das Programm während der Ausführung nicht Befehl für Befehl eingelesen wird, sondern bereits vollständig im Speicher vorliegt. Ein Rechner, der dies ermöglicht, wird „Stored Program Computer“ genannt. Im Deutschen wird hierfür oft der Begriff „speicherprogrammierbar“ verwendet, der aber, genau genommen, nicht ganz das Gleiche bezeichnet, legt er doch nicht nur nahe, dass sich das Programm im Speicher befindet, sondern auch, dass es im Speicher erstellt und bearbeitet werden kann. Auf diese Möglichkeit will ich an dieser Stelle aber (noch) nicht hinaus.
Einen Stored Program Computer zu betreiben, bedeutete natürlich, das Programm zunächst vollständig einlesen zu müssen. Wie lag so ein Programm vor? Was war das Speichermedium? Lochstreifen als Eingabemedium haben Sie schon kennengelernt. Auch ein Stored Program Computer konnte grundsätzlich mit Lochstreifen gefüttert werden. Der britische EDSAC von 1949, einer der ersten nennenswerten Computer, die nach dem Stored-Program-Konzept arbeiteten, verwendete zum Beispiel dieses einfache Eingabemedium – sowohl für das Programm als auch für die Daten.
Ein weiteres verbreitetes Speichermedium für Computer der damaligen Zeit waren Lochkarten. Die Geschichte der Lochkarten ist, wie auch schon die der Lochstreifen, weit älter als die Geschichte digitaler Computer. Die ersten Lochkarten wurden schon 1890 für die teilautomatische Auswertung der US-amerikanischen Volkszählung verwendet. Die Daten der einzelnen Bürger wurden dazu mit einem speziellen Gerät auf Karten gelocht. Ein Loch an einer bestimmten Stelle stand für das Geschlecht des Bürgers, ein anderes für die Religionszugehörigkeit, ein drittes gab den Beruf an. Die so erzeugten gelochten Karten konnten in Zählgeräte eingegeben werden. Je nach Lochung wurden dann Zähluhren einen Schritt weiter geschaltet. Herman Hollerith, der die Lochkartentechnik für die Volkszählung erfand, gründete Firmen auf Grundlage dieser Technologie. Seine Firmen bauten sowohl Eingabegeräte, um Lochkarten mit Daten zu füllen, als auch Verarbeitungsgeräte, die etwa die Daten eines Lochkartensatzes aggregieren und tabellarisch darstellen konnten. Holleriths Firmen gingen 1911 in der Computing Tabulating Recording Company auf, die in den 1920er Jahren in International Business Machines umbenannt wurde. Von dieser Firma IBM sollte in den folgenden Jahren der Computergeschichte noch häufig die Rede sein.
Lochkartenstanzer – Bild: Mwaelder (CC BY-SA 3.0)
Eine Standard-Lochkarte – Bild: Mutatis mutandis (CC-SA 3.0)
Die Standard-Lochkarten von IBM wurden nun auch für Computerprogramme und zur Dateneingabe in einen Computer verwendet. Das Prinzip einer Lochkarte war dem eines Lochstreifens dabei grundsätzlich sehr ähnlich. Ein Lochkartenleser las einen Lochkartenstapel Karte für Karte ein. Beschrieben werden konnten Lochkarten auf Lochkartenstanzern wie dem oben abgebildeten. Eine einzelne Karte entsprach in der Regel einem Datensatz oder, im Falle der Programmierung, einem Programmbefehl.
Nahezu alle Computer, die nach dem ENIAC gebaut und entwickelt wurden, waren Stored Program Computer. Auch der ENIAC wurde so umgebaut, dass man ihn als Stored Program Computer bezeichnen konnte6. Er lief dann zwar, je nach Berechnung, nur noch mit einem Sechstel der vorherigen Geschwindigkeit, da die Parallelität nicht mehr so gut ausgenutzt werden konnte, doch wurde dieser Performance-Verlust während der Berechnungen durch die erheblich einfachere Programmierbarkeit mehr als ausgeglichen. Als dritte Möglichkeit konnte der ENIAC nach dem Umbau auch das Programm direkt von Lochkarten einlesen. Das war natürlich noch langsamer und schränkte die Programmierbarkeit ein, da das Programm nicht im Speicher abgelegt, sondern Schritt für Schritt abgearbeitet wurde. Es hatte aber den Vorteil, dass keine Hardware-Änderungen mehr vorgenommen werden mussten und Programme leicht austauschbar und damit auch verbesserbar wurden.
Wie nutzt man einen Stored Program Computer wie den EDSAC?
Um einen typischen Stored Program Computer nutzen zu können, mussten sowohl das Programm als auch alle Eingabedaten vor dem Programmablauf vorliegen. Es mussten also zumindest alle Daten auf Lochkarten oder Lochstreifen vorbereitet werden. Wenn ein neues Programm geschrieben und ausgeführt werden musste, geschah dies in einem langwierigen Prozess:
Das Programm wurde auf Papier in einem Code aufgeschrieben, der dem Befehlssatz des Computers entsprach. Diese Art des Programmcodes wird Assembler-Sprache7 genannt. In Assembler-Sprache entsprechen die Befehle direkt denen der Computerarchitektur. Befehle müssen aber nicht als Bitmuster oder Zahlen eingegeben werden, sondern werden durch leichter verstehbare Kürzel, sogenannte „Mnemonics“, notiert. Statt 01001011 notiert man in Assembler-Sprache zum Beispiel ADD für den Addierbefehl. Auch höhere Programmiersprachen waren möglich, kamen aber erst Anfang der 1960er Jahre auf. Mehr dazu daher im folgenden Kapitel.
Aus dem Assembler-Code musste das Programm in die Maschinensprache umcodiert werden. Aus Befehlen, die aus kurzen Buchstabenfolgen bestehen, etwa JMP für den Sprungbefehl, wurden so wieder Zahlenwerte, die der Computer direkt verarbeiten konnte.
Dieses Maschinensprachenprogramm musste nun auf Lochkarten oder Lochstreifen gestanzt werden.
Die Lochkarten oder Lochstreifen mit dem Programm und allen Eingabedaten wurden einem Operator übergeben. Der Operator verwaltete eine Warteschlange von Programmen, die noch vor dem abgegebenen abzuarbeiten waren.
Wenn das Programm an der Reihe war, ließ der Operator das Programm einlesen, legte die Eingabedaten in den Lochstreifen- oder Lochkartenleser und startete das Programm.
Ausgaben des Programms wurden auf einem Drucker ausgeführt.
Der Operator legte das Programm, die Eingabedaten und die ausgedruckten Ausgaben des Programms in einem Ausgabefach bereit, wo sie vom Nutzer abgeholt werden konnten.
Ganz schön kompliziert, etwas mit einem solchen Computer zu programmieren und das Programm dann auszuführen! Charakteristisch für die skizzierte Arbeitsweise war, dass Nutzer oder Programmierer – in den meisten Fällen wohl ein und dieselbe Person – mit dem Computer selbst gar nicht in Berührung kamen. Wie hoch, meinen Sie, war wohl die Wahrscheinlichkeit, dass ein so erstelltes Programm beim ersten Versuch komplett korrekt war? Es musste korrekt in Assembler-Sprache auf Papier programmiert, fehlerfrei in Maschinencode übertragen und dann ebenso richtig abgelocht worden sein. Ich möchte nicht für alle sprechen, aber ich zumindest würde sicher stets etliche Durchläufe brauchen, bis mein Programm korrekt wäre. Dieses Programmierproblem war nicht die einzige Konsequenz der Abgekoppeltheit zwischen der Bereitstellung von Programm und Daten und der Verarbeitung des Programms durch den Computer. Problematisch war auch die fehlende Interaktivität. Es war bei dieser Nutzungsweise gar nicht möglich, ein Programm zu schreiben, das dem Nutzer während des Programmablaufs eine Entscheidung abverlangte. Auch konnte der Nutzer nicht eingreifen, wenn das Programm „Amok lief“, also sinnlos lange rechnete, in eine Dauerschleife geriet oder massenweise unsinnige Ausgaben produzierte. Der Nutzer war ja überhaupt nicht anwesend. Alle Eventualitäten mussten vorher bedacht werden. Explizit formuliert wird dies in einem unter Informatikern recht berühmten Paper, das unter dem Namen John von Neumanns veröffentlicht wurde. In diesem „First Draft Report on the EDVAC“8 von 1945 wird ausgeführt:
An automatic computing system is a (usually highly composite) device, which can carry out
instructions to perform calculations of a considerable order of complexity—e.g. to solve a non-linear partial differential equation in 2 or 3 independent variables numerically.
The instructions which govern this operation must be given to the device in absolutely exhaustive detail. They include all numerical information which is required to solve the problem under consideration: Initial and boundary values of the dependent variables, values of fixed parameters (constants), tables of fixed functions which occur in the statement of the problem. These instructions must be given in some form which the device can sense: Punched into a system of punchcards or on teletype tape, magnetically impressed on steel tape or wire, photographically impressed on motion picture film, wired into one or more fixed or exchangeable plugboards—this list being by no means necessarily complete. All these procedures require the use of some code to express the logical and the algebraical definition of the problem under consideration, as well as the necessary numerical material.
Once these instructions are given to the device, it must be able to carry them out completely and without any need for further intelligent human intervention. At the end of the required operations the device must record the results again in one of the forms referred to above. The results are numerical data; they are a specified part of the numerical material produced by the device in the process of carrying out the instructions referred to above. (Hervorhebung nicht im Original)
Von Neumann beschreibt hier also einen Computer, bei dem Programme „without any need for further intelligent human intervention“ ablaufen. Nimmt man diese Definition so hin, kann man daraus ableiten, dass Computer für Nutzer und Programmierer überhaupt keine Nutzungsschnittstelle brauchen. Natürlich war auch von Neumann klar, dass tatsächliche Computer durchaus einige Bedienelemente brauchten, denn schließlich handelte es sich um Maschinen und Maschinen mussten gesteuert werden. Es brauchte zum Beispiel mindestens Knöpfe zum Ein- und Ausschalten, zum Starten und Unterbrechen der Operation und zum Einlesen des Programms und der Daten vom Lochkarten- oder Lochstreifenleser. Außerdem mussten sie natürlich auch über irgendeine Art Ausgabegerät, wie zum Beispiel einen Fernschreiber oder eine elektrische Schreibmaschine, verfügen. Diese Schnittstelle wäre das absolute Minimum. Die Kontrollpulte der Computer der damaligen Zeit hatten meist deutlich mehr Anzeigen und Knöpfe. Das reichte von der Anzeige der Aktivität einzelner Komponenten über die umfangreichen Darstellungen des Speicherinhalts bis hin zu Lampen zur Anzeige von Alarmzuständen. In der Tat gab es aber für das Programm selbst keinerlei Nutzungsschnittstelle. Das Programm lief, ganz von Neumann entsprechend, völlig ohne menschliche Intervention ab.
Diese Arbeitsweise mag Ihnen unpraktisch und unhaltbar vorkommen. Tatsächlich aber war diese Operationsart in vielen Bereichen bis weit in die 1970er Jahre der Standard. Die Trennung von Nutzer und Maschine wurde sogar, wie Sie im nächsten Kapitel sehen werden, noch weiter verstärkt.
Jobs und Batches
Große Computeranlagen, wie sie sich in Universitäten, Forschungseinrichtungen und manchen Firmen seit den 1960er Jahren fanden, waren im Vergleich zu den frühen Rechnern wie einem ENIAC oder einer Z4 sehr leistungsfähig, aber auch sehr teuer, sowohl in der Anschaffung als auch im Unterhalt. Die Bedienung der Rechner selbst erforderte Fachwissen, eine umfangreiche Einweisung und eine Menge Erfahrung. Den wenigen Menschen, die über dieses Wissen verfügten, meist Operator genannt, standen viele Nutzer gegenüber, die ein Interesse daran hatten, den Computer für ihre Berechnungen und für andere Formen der Datenverarbeitung zu verwenden. Der hohe Bedarf an Rechnernutzung und die Notwendigkeit, den teuren, leistungsstarken Rechner möglichst ideal auszunutzen, führte zur bereits im vorherigen Kapitel erläuterten Arbeitsweise, bei der die Computernutzer gar keinen Kontakt zur rechnenden Maschine hatten.
Die Nutzer erstellten das Programm und hatten alle notwendigen Daten in Form von Lochstreifen oder Lochkarten zur Verfügung. Programm und Daten bildeten zusammen einen Rechenauftrag, einen sogenannten „Job“.
Die Lochkarten oder Lochstreifen wurden im Rechenzentrum abgegeben. Dort wurden sie in eine Art Warteschlange einsortiert, während der Computer noch die Jobs anderer Nutzer verarbeitete.
Wenn der entsprechende Job an der Reihe war, wurde zunächst das Programm von den Lochkarten oder vom Lochstreifen eingelesen und Befehl für Befehl in den Speicher kopiert. Es lag dann als Stored Program vor und konnte nun gestartet werden.
Das Programm las im Laufe seiner Verarbeitung die Eingabe von den Lochkarten oder Lochstreifen ein. Dass das Programm die Daten zunächst vollständig las und in den Speicher übertrug, war möglich, beschränkte aber die mögliche Datenmenge aufgrund des limitierten Arbeitsspeichers.
Während der Verarbeitung erzeugte das Programm Ausgaben in Form von Ausdrucken mittels Schnelldrucker oder elektrischer Schreibmaschine oder in Form neuer Lochkarten oder Lochstreifen.
Nach Durchlauf des Programms wurden die Lochstreifen oder Lochkarten, die man eingereicht hatte, zusammen mit den erzeugten Ausgaben in ein Rückgabefach gelegt, aus dem sie vom Nutzer bei Gelegenheit abgeholt werden konnten.
Diese Arbeitsweise, die man job-basiert nennt, blieb aus Nutzersicht bei großen Rechnern in Universitäten, Forschungsinstituten und den meisten Firmen über viele Jahre hinweg gleich. Hinter den Kulissen wurden allerdings Optimierungen durchgeführt, denn die oben beschriebene Arbeitsweise verschwendete wertvolle Ressourcen des Computers, insbesondere dann, wenn es sich um einen Computer handelte, der über ein schnelles Rechenwerk verfügte. Idealerweise sollte die Recheneinheit des Computers nämlich während der kompletten Betriebszeit des Rechners ohne Unterbrechung rechnen. Betrieb man den Computer indes wie oben beschrieben, musste der Rechner sehr oft ziemlich lange warten und konnte nicht weitermachen. Der Hauptgrund hierfür war das Einlesen von Lochstreifen oder Lochkarten. Selbst wenn hierfür sogenannte „Schnellleser“ eingesetzt wurden, waren diese im Vergleich zur Recheneinheit eines großen Universitätsrechners langsam wie eine Schnecke. Wertvolle Prozessorzeit wurde also mit Warten auf das Einlesen des Programms verschwendet. Das gleiche Problem ergab sich beim Einlesen der Daten während der Laufzeit des Programms und auch bei der Erzeugung der Ausgaben. Hier wurden zwar in großen Organisationen Schnelldrucker eingesetzt, aber natürlich war auch so ein Schnelldrucker um ein Vielfaches langsamer als die Recheneinheit eines Großrechners.
Die UNIVAC I, vorne die Bedienkonsole, im Hintergrund Bandlaufwerke – Bild: United States Census Bureau (Public Domain)
Eine Abmilderung dieses Problems erreichte man dadurch, dass Eingaben nicht von langsamen Eingabegeräten wie Lochkartenlesern oder Lochstreifenlesern und Ausgaben entsprechend nicht auf Druckern und Stanzern gemacht wurden, sondern indem ein erheblich schnelleres Medium genutzt wurde. Das Medium der Wahl waren hier zunächst Magnetbänder, die bedeutend rascher gelesen und auch beschrieben werden konnten. Computer, die nur von Magnetbändern lasen und nur auf Magnetbänder schrieben, mussten viel weniger auf die Lese- und Schreiboperationen warten. Die Recheneinheit wurde also bedeutend besser ausgenutzt. Die oben abgebildete UNIVAC I von 1951 war ein Rechner, der ausschließlich auf Magnetbänder als Ein- und Ausgabeformat setzte. Nun ergab sich aber ein neues Problem. Wie kommen Programm und Daten auf das Band? Und wie kommen die Ergebnisdaten vom Band wieder herunter? Da die Nutzer eines solchen Computers die Bänder weder selbst beschreiben noch die auf den Bändern gespeicherten Ausgaben lesen konnten, musste eine Reihe von externen Zusatzgeräten genutzt werden. Es gab dementsprechende Einheiten zum Kopieren von Lochkartenstapeln auf Magnetband und entsprechend solche zum Ausstanzen von auf Magnetband gespeicherten Daten auf Lochkarten oder zur Ausgabe auf einen Drucker.
Stapelverarbeitung
Ein wirklicher Vorteil für die Auslastung des Rechners ergab sich durch den Einsatz der Magnetbandtechnik natürlich nur dann, wenn möglichst wenig Zeit dadurch verschwendet wurde, Bänder zu wechseln. Jeden einzelnen Job erst auf ein Magnetband zu kopieren, dieses dann in den Computer einzulegen, die Ausgaben abzuwarten, das Ausgabe-Magnetband zu entnehmen und die Ergebnisse auszudrucken oder auszustanzen, ergab keinen wirklichen Sinn, denn es entstanden dann ja nach wie vor lange Wartezeiten durch das Wechseln der Bänder. Ihren wirklichen Vorteil spielte die Magnetbandtechnik erst dann aus, wenn der Computer ohne Bandwechsel einen Job nach dem anderen abarbeiten konnte. Genau in diese Richtung wurden dann auch Optimierungen vorgenommen. Jobs wurden nicht mehr einer nach dem anderen, sondern in sogenannten „Batches“ dem Computer zugeführt.
Bei der „Batch-Verarbeitung“ oder auf deutsch auch „Stapelverarbeitung“ wurden die Job-Daten, also die Programme und Daten der Computernutzer, von Lochkarten und Lochstreifen auf ein Magnetband kopiert. Auf ein Band kam nicht nur ein einzelner Job, sondern eine Vielzahl. Eine solche Jobsammlung wurde als „Stapel“ (englisch: batch) bezeichnet. Ein Stapel wurde als Ganzes dem Computer zugeführt. Wenn der Computer etwa zwei Magnetbandlaufwerke für das Einlesen der Jobs hatte, konnten so, vorausgesetzt es gab genügend Jobs, Wartezeiten durch Bandwechsel fast vollständig vermieden werden. Der Computer im Batch-Betriebsmodus arbeitete die Programme eines nach dem anderen ab. Die Ausgaben wurden in gleicher Art und Weise wie die Job-Daten nacheinander auf ein Ausgabe-Magnetband geschrieben. Dieses wurde, wenn es voll war, dem Computer entnommen und in eine Zusatzmaschine gegeben, mit der die erzeugten Ausgaben entsprechend den Wünschen des Nutzers ausgedruckt oder ausgestanzt wurden. Alle langsamen Ein- und Ausgabeoperationen wurden so vom Hauptcomputer abgekoppelt und beanspruchten ihn nicht mehr.
Mit der Einführung der Batch-Verarbeitung dieser Art ging eine der letzten Eingriffsmöglichkeiten verloren, die es vorher durch die menschlichen Operateure noch gab. Ein menschlicher Operator konnte die Reihenfolge der Rechenaufträge leicht abändern, sie somit priorisieren und konnte sogar die Verarbeitung eines Jobs abbrechen, wenn ein wichtigerer Job hereinkam, der eine umgehende Bearbeitung verlangte. Das klappte in dieser Form nun nicht mehr, da die Programme nacheinander vom Magnetband kamen und gar kein Mensch mehr da war, der eine Entscheidung hätte treffen können. Dieser Missstand wurde natürlich erkannt und im Laufe der Zeit beseitigt. Die Rechenanlagen wurden so weiterentwickelt, dass sie die Rechenzeiten der Rechnernutzer verwalten und nach Prioritätenlisten entscheiden konnten, welches Programm wann ausgeführt werden sollte. Das Verwaltungssystem beendete automatisch die Programme, die zu lange rechneten oder andere Ressourcen über Maß in Anspruch nahmen. Es war nun sogar möglich, bei Eintreffen eines Jobs mit hoher Priorität ein gerade laufendes Programm zu unterbrechen, das wichtige Programm vorzuziehen und das unterbrochene Programm an der Stelle fortzusetzen, an der es unterbrochen wurde. Damit all dies so funktionieren konnte, brauchte es aber ein paar technische und organisatorische Voraussetzungen.
Für jedes Programm musste fortan im Voraus angegeben werden, welche Priorität es hat und wie viele Ressourcen es für sich beansprucht. Diese Informationen mussten dem Computersystem für alle anstehenden Jobs eines Batches zur Verfügung stehen, damit es einen der Jobs zur Ausführung auswählen konnte. Das klappte natürlich nicht, wenn diese Daten immer am Anfang eines Jobs auf einem Magnetband standen, das nach und nach eingelesen wurde. Entweder mussten diese Job-Informationen am Beginn des Bandes zusätzlich bereitgestellt werden oder die kompletten Job-Daten mussten vom Computer in einen Speicher kopiert werden, auf den ohne große Zeitverzögerung und ohne größeres Spulen zugegriffen werden konnte. Solche Speichersysteme mit sogenanntem wahlfreien Zugriff (meist Festplatten) kamen Mitte der 1950er Jahre auf den Markt.
Neben dieser Hardware-Voraussetzung gab es aber natürlich eine sehr wichtige Software-Voraussetzung: Statt eines Operators mussten viele Aufgaben nun von der Maschine durchgeführt werden können. Das erledigte eine Software, ein sogenanntes Monitoring System oder Operating System, zu Deutsch also ein Betriebssystem. Dieses System sorgte von nun an statt eines menschlichen Operators unter anderem für das Laden von Job-Daten und das Bereitstellen und Zuordnen von Ausgabedaten. Eine weitere wichtige Aufgabe der Betriebssysteme war (und ist immer noch) das Behandeln von Fehlern in den Programmen. Wenn ein Programm bei seiner Ausführung in eine Fehlersituation kam, durfte das den Computer nicht etwa, wie vorher noch üblich, in einen Alarmzustand versetzen und alle weiteren Operationen anhalten, denn schließlich gab es noch eine lange Warteschlange anderer Jobs, die auch abgearbeitet werden sollten. Stattdessen mussten entsprechende Ausgaben generiert und die Abarbeitung des Batches mit einem anderen Job fortgesetzt werden. Eine weitere wichtige Aufgabe der Betriebssysteme war das Verwalten von Prioritäten und Laufzeitkonten. Studentische Jobs an Universitäten bekamen zum Beispiel geringere Priorität und nur wenig Rechenzeit zugewiesen. Wurde diese Rechenzeit erreicht, wurde die Verarbeitung automatisch abgebrochen. Kam während der Verarbeitung von Jobs mit niedriger Priorität einer mit höchstem Stellenwert herein, wurde die aktuelle Verarbeitung gegebenenfalls unterbrochen und der wichtigere Job vorgezogen.
Selbst beim Einlesen von Daten von Bandlaufwerken und Festplatten gab es noch immer verschenkte Rechenzeit. Zwar ging es natürlich viel schneller als das Einlesen von einem Lochstreifen oder von Lochkarten, doch der Geschwindigkeitsunterschied zu einer schnellen Recheneinheit war immer noch vorhanden. Mehr und mehr technische Kniffe erreichten aber eine immer bessere Auslastung des Rechners. Rechenanlagen von IBM konnten zum Beispiel mehrere Programme gleichzeitig im Arbeitsspeicher halten. Dadurch konnte, während der Computer mit vergleichsweise langsamen Ein-/Ausgabe-Operationen beschäftigt war, das Betriebssystem zu einem anderen Programm wechseln und dieses weiterlaufen lassen. Diese frühe Form des Multitaskings nannte sich „Multi Programming“. Der Preis für den erhöhten Durchsatz durch diese Technik war natürlich ein System, das über viel Arbeitsspeicher verfügen musste und dementsprechend sehr teuer war.
Alle hier genannten Optimierungen durch Magnetbänder, Festplatten und Betriebssysteme spielten sich für den Nutzer eines Computers im Verborgenen ab, denn die Nutzer hatten nach wie vor mit den Vorgängen im Rechenzentrum nichts direkt zu tun und bekamen den Computer selbst überhaupt nicht zu sehen.
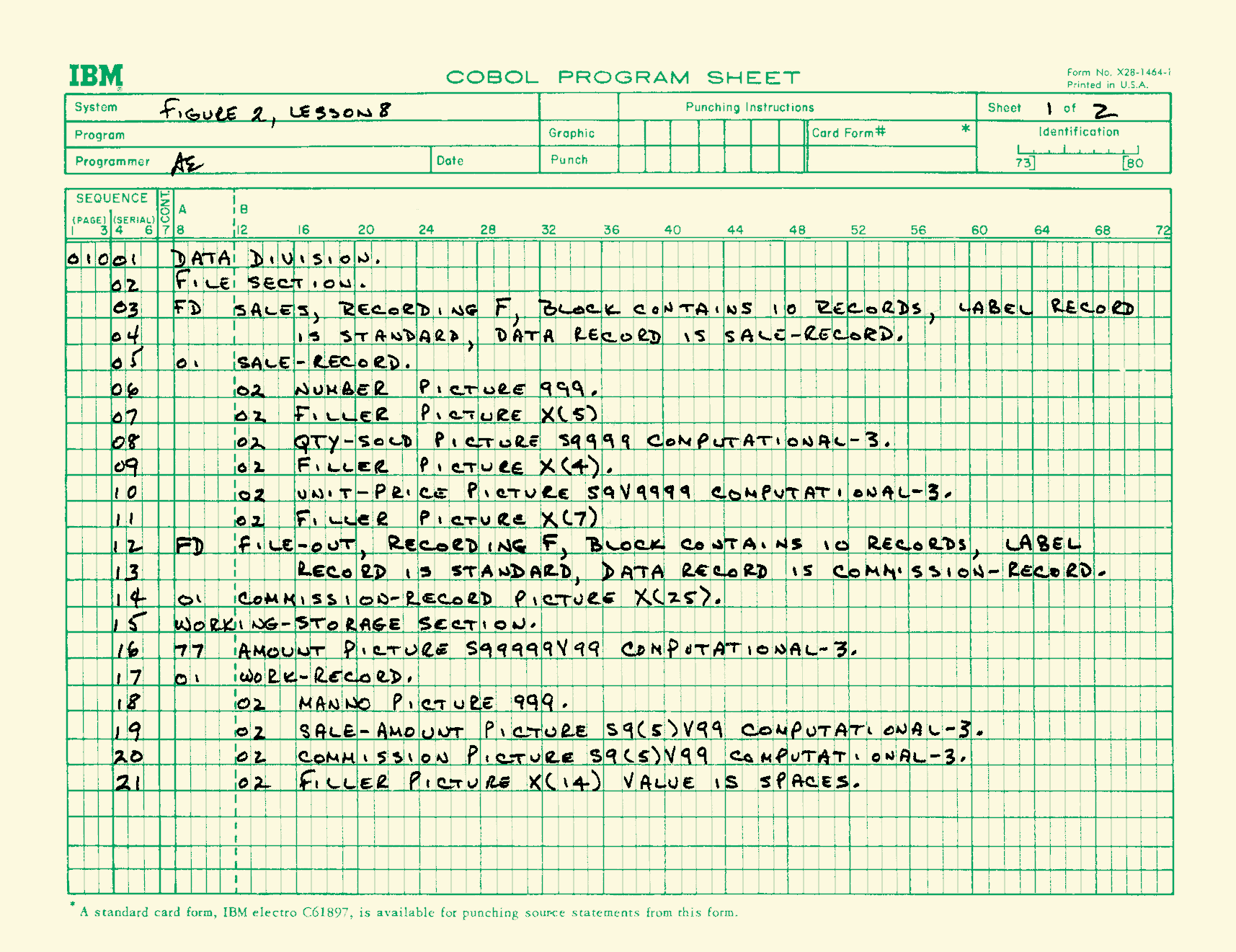
Codierbogen mit einem Teil eines COBOL-Programms
Der komplette Programmierprozess war nach wie vor vorgelagert und fand nur mit analogen, sprich mit mechanischen Mitteln statt. Programmiert wurde zunächst mit einem Stift auf Papier, auf sogenannten „Codierbögen“. Oben ist ein Codierbogen für eine IBM-Computeranlage abgebildet. Wenn diese Phase des Programmierens beendet war, musste der Code auf Lochkarten übertragen werden. Bei der Programmierung mit Lochkarten entsprach eine Karte in der Regel einer Programmzeile. Dazu kamen noch Datenkarten, die man entweder auf die gleiche Art und Weise erstellte oder von einem vorherigen Programm als Ausgabe erhalten hatte. Als Anweisung für das Betriebssystem gehörte zu jedem Job noch eine Job-Steuerkarte, die all dem vorangestellt wurde. Sie diente zum einen der Job-Separierung, aber auch der Spezifikation der Programmiersprache – dazu gleich mehr – sowie weiteren Ablaufdetails wie etwa der Priorität und der erlaubten maximalen Laufzeit. Diesen Satz an Lochkarten versuchte der Programmierer – tunlichst ohne ihn vorher fallen zu lassen – im Rechenzentrum abzugeben. Alles, was nun passierte, entzog sich dem Benutzer. Die Zeit von der Abgabe des Programms bis zum Erhalten des Ergebnisses, die sogenannte „Turnaround-Time“ oder „Jobverweilzeit“, konnte unter Umständen sehr lang sein. Die Universität Münster beschrieb dies eindrucksvoll im Newsletter „inforum“ des Hochschulrechenzentrums 9:
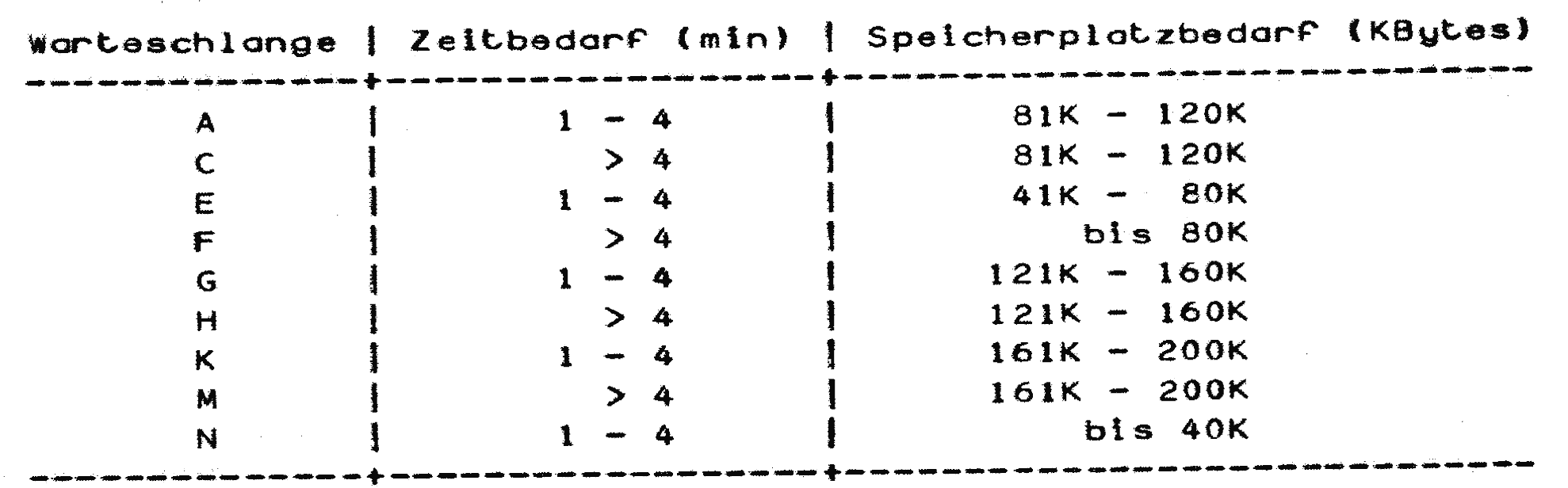
Jeder Auftrag zur Ausführung von Programmen (kurz: Job), der dem Rechner übergeben wird, muß vom Betriebssystem verwaltet werden. Diese Aufgabe übernimmt bei uns die Betriebssystemkomponente HASP (Houston Automatic Spooling Priority System). HASP liest die Jobs von den Kartenlesern im Rechenzentrum und an den Terminals. […] Jeder Job wird in eine der folgenden Warteschlangen nach CPU-Zeit und Speicherplatz-Bedarf einsortiert:
Warteschlange – Quelle: „inforum“ des Hochschulrechenzentrums der Universität Münster, April und Juli 1977.
[…]
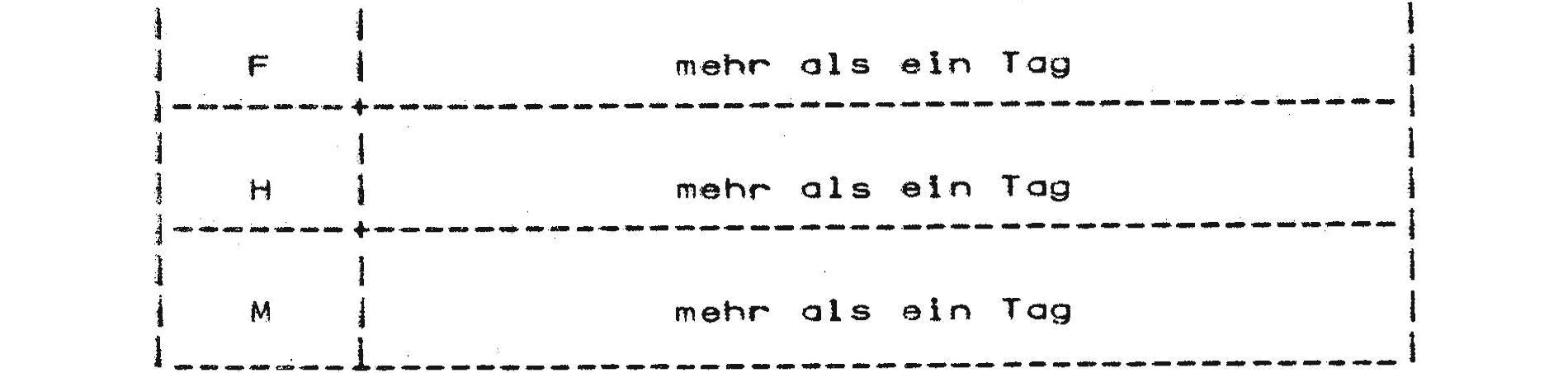
Der Benutzer kann Zeit- und Speicherplatzbedarf seines Jobs auf der JOB-Karte angeben. Die Job-Karte //ABC99XY JOB (ABC99,0020,Z23),A,USER,REGION=155K z.B. fordert 20 Minuten CPU-Zeit in 155 KBytes Hauptspeicher an. HASP sortiert den Job demnach in Warteschlange H ein. Die gleiche Wirkung hat CLASS=H anstatt REGION=155K.
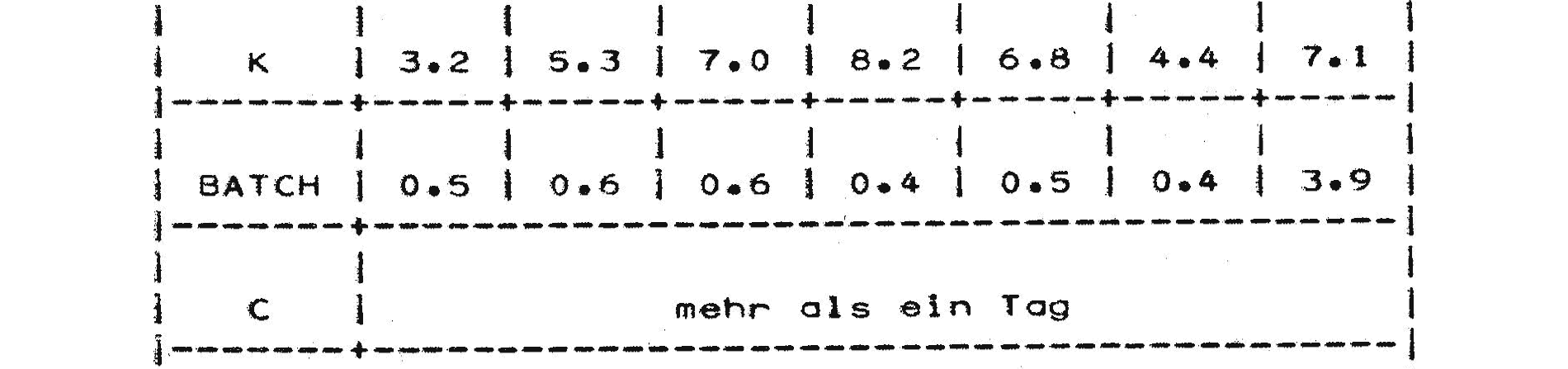
Die durchschnittliche Zeit, die ein Job vom Einlesen bis zum Drucken entsprechend seiner Klasse und Einlesezeit in der Maschine ist (Jobverweilzeit), kann für den derzeitigen Rechnerbetrieb der nachfolgenden Tabelle entnommen werden.10
Die Ausführung des im Beispiel der Uni Münster angegebenen Jobs mit zwanzig Minuten Rechenzeit und 155 KB benötigtem Hauptspeicher dauerte im März 1977 also im Durchschnitt mehr als einen Tag. Diese lange Zeit konnte natürlich mehr oder weniger kritisch sein. Wenn man ein bereits ausgefeiltes Programm hatte, das man immer wieder verwendete und bei dem man nur die Daten anpasste, konnte man sich mit der langen Zeit bis zum Erhalten des Ergebnisses eventuell arrangieren. Gerade im Wissenschaftsbetrieb war es jedoch so, dass oft neue, recht spezielle Berechnungen anzufertigen waren. Man musste für die meisten Aufgaben also stets neue Programme schreiben. Diese Programme wurden nicht oft wiederverwendet, sondern dienten eben der Lösung genau eines Problems. Wenn es gelöst war, standen andere Aufgaben an, die andere Programme verlangten, die dann wieder explizit programmiert werden mussten.
Gerade während der Entwicklungszeit eines solchen Programms stellte die lange Turnaround-Zeit ein großes Problem dar. Das kann sich jeder leicht klarmachen, der schon mal programmiert hat. Allen anderen sei versichert: Ein Programm ist so gut wie nie auf Anhieb korrekt. Fast immer gibt es bei den ersten Versuchen der Ausführung eine Reihe von Fehlermeldungen oder man stellt fest, dass das Programm zwar syntaktisch korrekt ist, also korrekt in der Programmiersprache verfasst wurde, aber leider nicht das tut, was man sich vorgestellt hat. Es braucht also nahezu immer mehrere Korrekturschritte, bis ein Programm korrekt arbeitet. Stellen Sie sich das nun bei einer Programmierung auf Papier, bei manueller Übertragung auf Lochkarten und vor allem bei einer Antwort, die es erst Stunden später oder am nächsten Tag gibt, vor. Eine Fehlerkorrektur oder Programmieren durch schrittweises Optimieren, wie heute üblich, dauerte so Stunden bis Tage. Die einzige Abhilfe, die das Programmieren von Rechnern im Batch-Betrieb zumindest etwas komfortabler machte, war das Aufkommen sogenannter „höherer Programmiersprachen“.
Höhere Programmiersprachen
Das Nutzen eines Computers bedeutete in den 1950er, 1960er und 1970er Jahren in der Regel, dass die Nutzer zum Lösen eines Problems, also etwa zur Durchführung einer Berechnung, ein eigenes Programm schreiben mussten. Da der Computer selbst seinen Nutzern nicht zugänglich war, war die Programmiersprache, mit der ein Computer programmiert werden konnte, daher das einzige, was einer Nutzungsschnittstelle irgendwie nahekam. Bis Ende der der 1950er Jahre konnten Computer nur in Maschinencode bzw. im sehr maschinennahen Assembler-Code programmiert werden. Programmierer, die eine Aufgabe mit einem Computer lösen wollten, mussten die Architektur der Maschine dabei ziemlich genau kennen. Sie mussten zum Beispiel wissen, wie viele Register eine Maschine hatte, wie der Speicher organisiert und mit welchem Befehlssatz die Maschine zu programmieren war. Programmieren auf diese Art ist auch heute noch möglich und wird dann und wann auch durchgeführt, wenn es auf höchste Performance ankommt. Der größte Teil der Programmierung wird jedoch schon lange nicht mehr so maschinennah, sondern in sogenannten „höheren Programmiersprachen“ erledigt. Die ersten dieser Sprachen kamen Ende der 1950er Jahre auf.
Betrachten wir an einem einfachen Beispiel zunächst die maschinennahe Programmierung eines Computers: Der Prozess des Programmierens in einer maschinennahen Programmiersprache geht immer mit einer Dekontextualisierung des Problems einher. Alle Hinweise auf die Bedeutung dessen, was dort programmiert wird, gehen in diesem Prozess verloren. Eine Lösung eines Problems als Computerprogramm ist dadurch stets sehr schwer zu verstehen. Das Beispiel, das ich Ihnen hier erläutern möchte, ist ein kleines Programmfragment, das bestimmt, ob jemand „pleite ist“. In natürlicher Sprache wollen wir, leicht vereinfachend, „pleite sein“ definieren als: „Wenn jemand mehr ausgibt, als er einnimmt, dann ist er pleite“. Mathematisch formuliert könnte man das als "pleite: a > e" aufschreiben. Diese Definition sieht sehr formal aus und ist es auch. Es haben sich aber einige Hinweise auf menschenverstehbare Semantik erhalten. Die Wahl des Wortes pleite und die Wahl der Variablennamen a für Ausgaben und e für Einnahmen sind nicht Teil des mathematischen Formalismus, sondern verweisen auf die Problemdomäne. Man könnte auch ganz andere Bezeichner wählen, ohne an der formalen Spezifikation etwas zu ändern. Die Verstehbarkeit durch den Menschen würde aber leiden, wenn wir diese Hinweise auf die Bedeutung wegließen. Leider müssen wir genau das tun, wenn wir das Problem als Maschinenprogramm aufschreiben. Es entsteht dann ein Programm wie das folgende11:
0: LOAD 2
1: SUB 1
2: JGTZ 5
3: LOAD=1
4: JUMP 6
5: LOAD=0
6: STORE 3
7: HALT
Das zu lösende „Problem“ wurde bei der Übertragung in das Computerprogramm in eine Reihe von Anweisungen heruntergebrochen, die Zeile für Zeile aufgeschrieben wurden. Die Werte für Einnahmen und Ausgaben werden in zwei Registern der Maschine erwartet. Ein Register kann man sich als Speicherstelle für genau einen Wert vorstellen. Der Wert für die Ausgaben ist in Register 1, der für die Einnahmen in Register 2 als Zahl gespeichert. Register 3 enthält am Ende dieses Mini-Programms eine 1 im Falle einer Pleite. Andernfalls wird dort eine 0 gespeichert. Unsere Maschine, für die hier programmiert wird, verfügt eine besondere Speicherstelle, die „Akkumulator“ genannt wird. Alle Rechenoperationen der Maschine werden auf diesen Akkumulator angewandt. Das Programm startet in Zeile 0 und läuft dann folgendermaßen ab:
In Zeile 0 wird der Wert des Registers 2 in den Akkumulator geladen. „Laden“ bedeutet dabei nichts anderes, als dass der Wert dorthin kopiert wird. Der Wert im Akkumulator ist nun der gleiche wie der in Register 2, also der Wert der Einnahmen.
In Zeile 1 wird der Wert aus Register 1 – die Ausgaben – vom Wert im Akkumulator abgezogen. Im Akkumulator befindet sich dann das Resultat dieser Rechnung, der Wert der Einnahmen abzüglich des Wertes der Ausgaben.
Zeile 2 ist ein bedingter Sprung. Der Wert im Akkumulator wird darauf überprüft, ob er größer als 0 ist (JGTZ für Jump if Greater Than Zero). Wenn dies der Fall ist, wird in Zeile 5 fortgefahren.
Nehmen wir an, dass der Wert im Akkumulator kleiner ist als 0, die Person also pleite ist. In diesem Fall trifft die Bedingung nicht zu. Der Sprung wird also nicht ausgeführt, sondern es wird in Zeile 3 fortgefahren. In dieser Zeile wird der Wert 1 in den Akkumulator geschrieben.
Zeile 4 ist wieder ein Sprungbefehl, in diesem Fall jedoch ein Sprung ohne Bedingung. Es geht also in Zeile 6 weiter.
Wenn die Überprüfung in Zeile 2 anders abgelaufen wäre, wäre das Programm nicht in Zeile 3, sondern in Zeile 5 weitergegangen. Auch hier wäre ein Wert in den Akkumulator geladen worden, allerdings wäre es hier eine 0 gewesen.
In Zeile 6 wird der Wert aus dem Akkumulator, also eine 1 oder eine 0, im Register 3 gespeichert.
In Zeile 7 endet das Programm.
Sicher haben Sie es gemerkt: Um dieses Programm überhaupt schreiben zu können, muss man sehr viel über die Architektur des Rechners wissen. Man muss etwa wissen, was Register sind und dass der Rechner über einen Akkumulator verfügt. Auch die Befehle müssen bekannt sein. Man muss sich darüber hinaus vieles merken, etwa, welcher Wert in welchem Register gespeichert ist. Vor allem muss man es hinbekommen, zu programmieren, ohne dass es Hinweise auf eine menschenverstehbare Semantik gibt. In der Praxis konnte man sich mit Kommentaren behelfen, die man zusätzlich zu den Programmbefehlen notierte. Dies änderte aber nichts daran, dass das Programm selbst komplett ohne Hinweise auf die Bedeutung auskommen musste.
Bei der Programmierung stehen sich unterschiedliche Arbeitsweisen scheinbar unversöhnlich gegenüber. In der Sphäre des Nutzers spielt die Bedeutung dessen, was gelöst werden soll, eine große Rolle. Es ist wichtig, wofür die Zahlen stehen, mit denen gerechnet wird, und was das Ergebnis bedeutet. Die Arbeitsweise des Computers hingegen ist völlig frei von Bedeutungen und basiert rein auf der Form und der Anordnung von Zeichen. Diese Zeichen steuern den Computer, der dann entsprechend addiert, vergleicht, lädt oder im Programm an eine andere Stelle springt. Der Computer tut dies völlig unabhängig davon, was das Programm für den Menschen bedeutet, der es verwendet. Höhere Programmiersprachen versuchen, genau diesen Gegensatz zu überbrücken. Zum einen abstrahieren sie von der internen Struktur der Maschine, was den Programmierer schon mal von der Notwendigkeit der Kenntnis allzu spezifischer technischer Details entbindet, die ja nichts mit dem von ihm zu lösenden Problem, sondern ausschließlich mit dem Gerät zu tun haben. Das ist bereits eine große Hilfe. Es sind aber vielleicht die sprachlichen Aspekte der Programmiersprachen, die noch wichtiger für eine gute Programmierbarkeit sind.
Höhere Programmiersprachen erfüllen nämlich zwei Rollen gleichzeitig: Es handelt sich zum einen um Sprachen, die im Gegensatz zu natürlichen Sprachen vollständig formal spezifiziert sind. Nur deshalb können sie zur Steuerung der Operationen eines Computers verwendet werden. Trotzdem bieten sie aber Grundstrukturen natürlicher Sprache, sodass ein „Text“ entsteht, der auch für den Menschen einigermaßen verständlich ist. Diese Natürlichsprachlichkeit fängt bei den Schlüsselworten und Konstrukten der Sprache selbst an. Statt wirre Sprünge an Programmzeilen gibt es etwa Konstrukte wie if, then, else und eine an die Mathematik angelegte Funktionssemantik mit Übergabeparametern und Rückgabewerten. Eine extreme Erleichterung bei der Programmierung bringt darüber hinaus vor allem die Möglichkeit, Programmkonstrukte mit eigenen Namen versehen zu können. Für die automatische Verarbeitung eines Programms durch einen Computer ist der Name einer Variablen (eines gespeicherten Wertes) oder eines Unterprogramms irrelevant. Dem Programmierer hilft sie jedoch, die inhaltliche Bedeutung dessen, was ein Programmkonstrukt tut, verstehen zu können. Es macht für das Verständnis einen beträchtlichen Unterschied, ob man sich auf so etwas abstraktes wie „Register 2“ oder „x“ beziehen muss, oder ob im Programm das verstehbare Wort ausgaben auftaucht.
Die ersten höheren Programmiersprachen mit diesen Eigenschaften kamen Ende der 1950er Jahre auf und fanden in den 1960ern zunehmend Einsatz. Die neuen Sprachen verfügten über unterschiedliche Charakteristika je nach ihrem intendierten Einsatzgebiet; von Fortran (Formula Translation) und Algol (Algorithmic Language) für wissenschaftliche Berechnungen bis hin zu COBOL (Common Business Oriented Language) für Business-Datenverarbeitung. Das oben maschinennah erläuterte Programm stellte sich in COBOL und Fortran wie folgt dar:
Programme in einer höheren Programmiersprache können von einem Computer nicht direkt ausgeführt werden. Spezielle Programme, „Compiler“ genannt, übersetzen zunächst den Programmcode in den systemeigenen Maschinencode, der dann ausführbar ist. Aus diesem Grund mussten Programmierer bei der Benutzung eines Computers im Batch-Betrieb die genutzte Programmiersprache auf der Job-Control-Karte ihrer Jobs angeben. Das Betriebssystem führte dann automatisch erst den entsprechenden Compiler und dann das von diesem erzeugte Programm in Maschinensprache aus.
Programmiersprachen werden üblicherweise nicht in den Zusammenhang mit Nutzungsschnittstellen gebracht. Gerade im Kontext heutiger Systeme ist das sicher auch richtig so, denn kaum ein Nutzer muss seinen Computer heute selbst programmieren, und wenn es doch passieren sollte, sieht man das als etwas anderes als die Nutzung des Geräts an. Es wird relativ klar zwischen Nutzung und Programmierung unterschieden. Zur damaligen Zeit jedoch, in der ein Computernutzer stets gleichzeitig ein Computerprogrammierer war, war die Beschaffenheit einer Programmiersprache von essenzieller Bedeutung dafür, wie effizient der Computer genutzt werden konnte. Die Charakteristiken der höheren Programmiersprachen nahmen dabei etwas vorweg, was wir im weiteren Verlauf der Nutzungsschnittstellen-Entwicklung weiter beobachten werden. Sie ermöglichten dem Nutzer des Computers eine Denkweise, die sich von der technischen Realität der Maschine stark unterscheidet. Nutzer haben es in der höheren Programmiersprache mit namentlich ansprechbaren Variablen und Funktionen statt mit Registern und Sprungbefehlen zu tun. Die Strukturen im Rechner bleiben ihnen verborgen. Dieses Schaffen einer Nutzungswelt durch das Computersystem, die ganz andere Eigenschaften als die technische Struktur hat, ist eine Grundeigenschaft interaktiver Nutzungsschnittstellen, auf die ich später intensiv zu sprechen komme. Zunächst will ich Ihnen aber erläutern, dass die hier beschriebene Batch-Nutzung mit ihrer großen Distanz zwischen Mensch und Maschine keineswegs alternativlos war.
Frühe Echtzeitsysteme
Im vorherigen Kapitel haben Sie erfahren, wie Computer im Batch-Betrieb funktionieren. Dabei wurden Probleme offenbar, die durch die sehr langen Wartezeiten zwischen Programmabgabe und Aushändigung des Ergebnisses und durch die Notwendigkeit entstanden, ohne Computerkontakt auf Papier mit Lochkarten und Lochstreifen programmieren zu müssen. Wenn eine Geschichte des Computers erzählt wird, wird es oft so dargestellt, als sei der Batch-Betrieb regelrecht alternativlos gewesen und eine direktere Computernutzung erst relativ spät, irgendwann in den 1970ern, erfunden worden. Das ist in dieser Absolutheit so allerdings nicht wahr. Zwar war der Batch-Betrieb sicher dominant, doch hat man schon damals Computer im sogenannten „Echtzeitbetrieb“ betreiben können. Verbreitet war seinerzeit auch der Begriff „On-Line-Betrieb“ oder „Dialogbetrieb“.
Gerade in Universitäten und Forschungsinstituten dominierten ziemlich lange Rechenanlagen, die im Batch-Betrieb arbeiteten. Diese Art der Computernutzung war hier vor allem deshalb so verbreitet, weil es eine sehr große Zahl an Nutzern gab, die Computerdienste nutzen wollten. Aufgrund der Anforderungen an wissenschaftliche Berechnungen kam zudem nur ein gut ausgestatteter Computer infrage, der über viel Speicher verfügte und der schnell rechnen konnte. Da solche Computer Großanschaffungen und damit teuer waren, musste ein einzelner Rechner ausreichen, um eine große Menge Aufträge von einer Vielzahl von Nutzern abzuarbeiten. Der Batch-Betrieb war hier, trotz der beschriebenen Nachteile, am besten geeignet. Es gab allerdings auch damals bereits Nutzungsszenarien, in denen hohe Rechenleistung nicht das Wichtigste war, in denen es nur wenige Nutzer gab, die einen Computer nutzen wollten, oder in denen eine nur kleine Anzahl von selten geänderten Programmen genutzt wurden. Für diese Einsatzbereiche standen schon früh, man könnte fast sagen von Anfang an, Rechner zur Verfügung, die im Echtzeitbetrieb verwendet wurden. Schauen wir uns im Folgenden einige solcher Systeme mit ganz verschiedenen Charakteristiken an.
Flurbereinigung: Zuse Z11
Schon im ersten Kapitel haben Sie etwas über die Rechner von Konrad Zuse erfahren. Der Fokus lag dabei auf der Z4. Wir schauen uns nun einen etwas späteren Rechner, die Z11, an. Diese Z11 war der erste Computer der Zuse KG, der in Serie gefertigt wurde. Die Idee hinter der Computerentwicklung von Konrad Zuse war, wie bereits erläutert, seine Erfahrung, dass Ingenieure immer wieder gleiche Berechnungen mit verschiedenen Werten durchführen müssen. Aus diesem Gedanken folgt ziemlich direkt, dass Zuse keine Maschinen im Sinn hatte, die laufend mit neuen Programmen bestückt wurden. Er ging eher davon aus, dass es einige wenige „Rechenpläne“ gab, die immer wieder für neue Berechnungen mit anderen Startwerten genutzt, selbst aber eher selten geändert werden.
Bedienpult der Zuse Z11 – Bild: Dr. Bernd Gross (CC BY-SA 4.0)
Hier abgebildet sehen Sie einen Teil der Bedienkonsole der Z11. Zentral ist eine Tastatur für Dezimalzahlen. Diese Tastatur wurde vom Ingenieur genutzt, um die Werte seiner Berechnung einzugeben. Danach wurde mittels eines Knopfes an der Konsole die Berechnung gestartet. Auf einer angeschlossenen elektrischen Schreibmaschine wurden die Ergebnisse der Berechnung ausgegeben. Ein typisches Einsatzszenario für die Z11 war die Flurbereinigung13. Um diese durchzuführen, bedurfte es einer Reihe von Berechnungen, die immer wieder für verschiedene Fälle durchgeführt werden mussten. Für die Aufgaben der Flurbereinigung wurde also nur eine kleine Zahl von Programmen gebraucht, die sehr häufig verwendet wurden. Da die Programme für den Einsatzzweck so typisch waren und es so wenig Variation bedurfte, waren die wichtigsten von ihnen sogar fest eingebaut, mussten also gar nicht mehr von Lochstreifen eingelesen werden. Der Lochstreifen erlaubte aber natürlich weitergehende Berechnungen und den Einsatz des Rechners in anderen Einsatzfeldern.
Die Z11 war gerade für die Angestellten in den Vermessungsämtern ein sehr angenehmer Rechner, da er den Nutzern wenig Wissen über Computertechnik abverlangte und zudem schnell Ergebnisse lieferte. Die Programme konnten an der Bedienkonsole per Knopfdruck gestartet werden. Dann mussten nur noch die Zahlen auf festgelegte Art und Weise „eingetastet“ werden und schon startete die Berechnung. Direkt nach dem Erhalt der Ergebnisse stand die Maschine für die nächste Berechnung wieder zur Verfügung. Es gab bei dieser Nutzungsweise keine Notwendigkeit, sich mit Computerinterna wie Zahlencodierung, Registern oder Sprungbefehlen zu belasten.
Die Zuse Z11 war, auch schon für die damalige Zeit Mitte der 1950er Jahre, ein ziemlich langsamer Rechner. Sie arbeitete, genau wie die Z3 und die Z4, mit Telefonrelais und verfügte ebenso wie diese nicht über ein Stored Program im Sinne eines Programms, in dem beliebige Stellen im Programm angesprungen werden können. In Szenarien wie der Flurbereinigung war das allerdings nicht schlimm. Die Geschwindigkeit war bei diesem Rechner nicht das entscheidende Kriterium. Es war weder das Ziel, den Rechner dauerhaft laufen zu lassen noch die Rechengeschwindigkeit und den Durchsatz zu optimieren. Der Vorteil des Rechners bestand vielmehr darin, für die Anwender jederzeit zur Verfügung zu stehen. Obwohl der Rechner als solcher langsam war, lieferte er den Nutzern doch viel schneller Ergebnisse, als wenn diese einen schnellen Computer im Batch-Betrieb hätten nutzen und dann auf die Ergebnisse immer lange warten müssen.
Buchhaltung: IBM 305 RAMAC und IBM 1401
Weitere typische Bereiche, bei denen die Anforderung an schnelles Einlesen vieler verschiedener Programme und das Befriedigen vielseitiger Bedürfnisse unterschiedlicher Nutzer nicht im Vordergrund standen, waren Buchhaltung, Lagerhaltung und vergleichbare Verwaltungsvorgänge. Solche Vorgänge sind dadurch gekennzeichnet, dass es große Datenmengen gibt, die verarbeitet werden müssen. Jedes Ein- und Auslagern in einem Hochregal etwa ist ein eigenes Datum und entsprach damals daher im Prinzip einer eigenen Lochkarte, die verarbeitet werden musste. In diesem Einsatzkontext ist es auch heute noch so, dass sich die Anzahl verschiedener Programme in Grenzen hält, und die bestehenden Programme sehr stabil sind, was heißt, dass sie nur sehr selten geändert werden müssen. Schon vor dem Beginn des Computerzeitalters im engeren Sinne wurden für Verwaltungszwecke dieser Art Maschinen benutzt, die Lochkarten verarbeiteten. Die Firma IBM bot zum Beispiel Geräte an, die auf Lochkarten gespeicherte Daten verrechnen oder als Tabelle ausgeben konnten. In der Tradition dieser Lochkarten-Verarbeitungs-Systeme standen dann auch die auf diesen Bereich der Datenverarbeitung optimierten Computer von IBM, von denen wir uns hier zwei anschauen wollen:
IBM 305 RAMAC
1956 brachte IBM das System IBM 305 RAMAC auf den Markt. Die Abkürzung RAMAC steht für Random Access Method of Accounting and Control. „Random Access“ bedeutet, dass auf die gespeicherten Daten wahlfrei zugegriffen werden kann, ohne dass Lochkartenstapel durchlaufen werden müssten oder auf Bändern sequenziell nach den Daten gesucht werden müsste. Für diesen wahlfreien Zugriff wurde von der Firma IBM eigens ein neuer Datenspeicher, die Festplatte, entwickelt. Sie sehen diese Festplatte auf dem Bild als Stapel von Magnetscheiben hinter der Dame schräg links unter dem Schriftzug „RAMAC“. Die Zielgruppe der 305 RAMAC waren nicht Wissenschaftler oder andere Nutzer mit komplexem Rechenbedarf, sondern die Unternehmen, die bisher Lochkartenverarbeitungsmaschinen und Drucker von IBM zum Sortieren, Tabellieren und Akkumulieren von Daten genutzt hatten.
IBM 305 RAMAC – Bild mit freundlicher Genehmigung von IBM
Nutzer der IBM 305 RAMAC konnten, ganz ähnlich wie bei der Zuse Z11, über ein Programmwahlrad ein Programm auswählen und laufen lassen. Das Programm war entweder per Kabelverbindungen fest im Rechner verdrahtet oder befand sich auf dem Trommelspeicher der Maschine. So ein Trommelspeicher war vom Prinzip her einer Festplatte nicht unähnlich. Es handelte sich um eine schnell rotierende Walze, die mit einer magnetisierbaren Schicht versehen wurde. Mehrere fest eingebaute Schreib-Lese-Köpfe waren über die Länge der Trommel verteilt. Sie befinden sich auf der Abbildung hinter den gut sichtbaren Anschlusskabeln, die nach vorne herausgeführt sind. Die gespeicherten Daten rotierten unter den Schreib-Lese-Köpfen hinweg. Der Speicherplatz auf einer solchen Trommel war relativ beschränkt. Der Trommelspeicher der RAMAC konnte auf 32 Spuren insgesamt 3200 Zeichen abspeichern. Die Magnettrommel bildete den Programm- und Arbeitsspeicher des Rechners. Ein großer Vorteil dieser Technologie verglichen mit heutigen Speicher-Modulen war ihre Persistenz. Moderne RAM-Module verlieren ihren Speicherinhalt, sobald sie nicht mehr mit Strom versorgt werden. Wurde ein Rechner mit Magnettrommelspeicher ausgeschaltet, blieben die Speicherinhalte hingegen erhalten. Bei der nächsten Verwendung des Geräts konnten die vorher geladenen Programme also direkt wieder gestartet und mussten nicht neu eingelesen werden. Auch alle auf der Trommel gespeicherten Variablen und Konfigurationen blieben erhalten.
Magnettrommelspeicher – Bild: Robert Freiberger from Union City, CA, USA (CC BY 2.0)
Die Programme der RAMAC verarbeiteten Eingabedaten in Form von Lochkarten, hatten aber auch Zugriff auf die Daten der Festplatte und die des Magnettrommelspeichers. Ausgaben konnten auf einem Drucker, mittels eines Lochkartenstanzers oder auf einer Konsolen-Schreibmaschine getätigt werden, die eigentlich nichts anderes war als eine elektrische Schreibmaschine mit Computeranschluss. Im Gegensatz zu den Großcomputern von Universitäten verarbeitete ein RAMAC-System nicht dauerhaft Daten. Der Clou des Systems war vielmehr, Daten in Form von Lochkarten direkt dann zu verarbeiten, wenn sie eintrafen, statt dies in einem großen Programmlauf nur einmal am Tag zu erledigen. Der aktuelle Gesamtstand der Daten befand sich persistent, also dauerhaft zugreifbar, auf dem Plattenstapel. Sollten beispielsweise aktuelle Informationen über den Lagerbestand bezogen werden, konnte das entsprechende Programm ausgewählt oder gegebenenfalls per Lochkarte eingelesen werden. Das Programm erzeugte dann den Bericht anhand der Daten auf dem Plattenstapel, ohne dass es nötig war, hierfür nochmals große Mengen Eingabedaten per Lochkarte bereitstellen zu müssen. Daten-Lochkarten waren somit nicht mehr die Grundlage aller Datenverarbeitung, sondern dienten nur noch der Erfassung von Änderungen am Datenstand, der auf der Festplatte gespeichert und damit dauerhaft im Zugriff war.
Die Verbesserungen in der Datenhaltung sind durchaus interessant und sicher auch ein Fortschritt in der Computertechnik, aber für sich genommen nicht der Grund, aus dem ich mich an dieser Stelle damit beschäftige. Das Spannende an diesem Computersystem ist, zumindest aus meiner Perspektive, die Konsole (im deutschen IBM-Sprech „das Konsol“ genannt) bestehend aus einer Tastatur und gegebenenfalls zusätzlich einer angeschlossenen Schreibmaschine. Auf dem Bild oben sitzt die Dame an dieser Konsole. Die Konsole erlaubte eine gewisse Form von Interaktivität. Zwar gab es keine interaktiven Programme, bei denen Nutzer Eingaben machen und so den Programmablauf steuern konnten – Programme liefen ganz klassisch ohne menschliche Interventionen ab. Was aber möglich war, war das Auslesen und Manipulieren von auf dem Trommelspeicher gespeicherten Daten. Diese Funktionalität war vor allem zur Fehlersuche und für Korrekturen von Interesse. Noch interessanter war die Funktion, sich auch Datensätze von der Festplatte abrufen und direkt ausgeben lassen zu können. Diese Ausgabe war allerdings noch unabhängig von einer programmierten Nutzungsschnittstelle und musste daher sehr maschinennah erfolgen. Dem Nutzer musste der physikalische Ort der gespeicherten Daten auf der Platte bekannt sein. Durch Angabe dieses Ortes konnten die Daten dann auf die Konsolenschreibmaschine ausgegeben werden.
Die 305 RAMAC war kein besonders rechenstarker Computer. Komplexe Berechnungen wären mit dem Rechner sicher möglich gewesen, wären aber recht langsam abgelaufen. Auch die Nutzung einer Magnettrommel als Arbeitsspeicher war ziemlich langsam. Das machte aber nichts, denn Geschwindigkeit und Rechenleistung standen auch bei dieser Maschine nicht im Fokus. Typische Buchhaltungs- und Verwaltungsprogramme führten keine komplexen Berechnungen durch, und da der Rechner nicht unter Vollauslastung betrieben wurde, war die Arbeitsgeschwindigkeit kein limitierender Faktor.
IBM 1401
Der IBM-Rechner 1401 erschien nur drei Jahre nach der 305 RAMAC. Die 1959 eingeführte 1400er-Serie von IBM konnte in einer Vielzahl von Konfigurationen bestellt und verwendet werden. Sie konnte zum Beispiel, ganz klassisch, im Batch-Betrieb genutzt werden. In vielen Universitäten wurden 1401-Rechner dafür verwendet, die Magnetbänder größerer Rechenanlagen vorzubereiten und auszulesen, also Daten von Lochkarten auf die Bänder zu kopieren und vorhandene Daten von den Bändern auszustanzen und auszudrucken. Neben diesen Betriebsmöglichkeiten ließen die Rechner aber auch eine Arbeitsweise ähnlich der 305 RAMAC zu, gingen aber an entscheidender Stelle noch darüber hinaus. Über eine spezielle Konsole erlaubten die Rechner der 1400er Serie nämlich die Eingabe von Daten, die dann vom laufenden Programm verarbeitet werden. Die Bedienungsanleitung der IBM 140114 beschreibt das Arbeiten mit der Konsole (mit der internen Bezeichnung 1407) wie folgt:
When an inquiry is to be made, the operator presses the request enter key-light. As soon as the system is free to act on the request, the enter light comes ON and the operator can type the message and enter it into 1401 core storage.
When the system completes the processing of the inquiry, it is transferred to the inquiry station by the stored program. The message is typed, and the operator may act on the reply.
Auch der Vorteil dieser Arbeitsweise wird herausgestellt:
An account record or stock-status record needed by management can be requested by the operator and made available in a short time. Thus, management can, at a moment’s notice, request information from the 1401 system and have an answer almost instantaneously.
IBM 1407 Control Inquiry Station – Bild: Reference Manual IBM 1401 Data Processing System. IBM. 1962.
Um bei der 1401 Daten abzurufen, bedurfte es nicht mehr der Angabe von physikalischen Speicheradressen. Der Rechner erlaubte es vielmehr in einem speziellen Modus, „messages“, also Nachrichten, einzugeben. Bei den Nachrichten, wir würden heute vielleicht eher „Befehl“ oder „Kommando“ sagen, konnte es sich um alles Mögliche handeln. Gehen wir von einer Lagerhaltung aus, lagen zum Beispiel Nachrichten zum Anfragen von Lagerbeständen oder Änderungen der Bestandsdaten nahe. Die IBM 1401 ermöglichte also eine Art Kommandomodus und damit eine ziemlich interaktive Arbeitsweise. Es handelte sich allerdings noch nicht um einen interaktiven Programmablauf, wie wir ihn uns heute vorstellen. Ein Programm forderte nicht etwa den Nutzer zu einer Eingabe auf. Stattdessen hatte der Nutzer die Möglichkeit, das laufende Programm zu unterbrechen, um einen „request“ zu stellen. Diese Eingabe wurde in einen festen Bereich des Speichers des Rechners geschrieben, von wo aus das Programm sie auslesen und verarbeiten konnte. Das mag uns heute von der Nutzung und Programmierung her etwas umständlich erscheinen, doch erfüllte das System so bereits das wichtigste Potenzial interaktiver Schnittstellen, nämlich die Responsivität, ermöglichte also eine umgehende Reaktion auf eine Nutzeranfrage. In der Anleitung wird das deutlich. Eine Anfrage kann „at a moment’s notice“ getätigt werden, die Antwort kommt „almost instantaneously“.
Flugbuchung: SABRE
Ein weiteres wichtiges Beispiel für frühe Echtzeit-Anwendungen ist das SABRE-System (Semi-automated Business Research Environment) von American Airlines. Besonders interessant ist an diesem System die US-weite Vernetzung von Eingabeterminals mit einem zentralen Computer. Prototypisch ab 1961 und im vollen Einsatz ab 1964 verwaltete dieses System alle Buchungen der Fluggesellschaft American Airlines. Wenn ein Kunde der Airline telefonisch einen Flug buchte oder in eine der Service-Stellen der Fluglinie kam, konnten Kundendienstmitarbeiter über spezielle Terminals Kontakt mit einem Zentralcomputer aufnehmen, der die Anfragen in Echtzeit annahm und verarbeitete. Es gab über tausend dieser im ganzen Land verteilten Terminal-Stationen. Die Terminals waren mit dem zentralen Computer per Telefonleitung verbunden. Sie konnten genutzt werden, um direkt einen Flug zu buchen. Das System gab dem Service-Mitarbeiter der Airline ohne nennenswerte Verzögerungen Informationen über verfügbare Plätze und verarbeitete die Fluggastdaten des Kunden. Noch fehlende Informationen zu einer Buchung wurden vom System umgehend moniert. Die Terminals konnten auch genutzt werden, um vorhandene Buchungen zu ändern oder zu stornieren. Über den Namen des Kunden und die Angabe des gebuchten Fluges konnte eine frühere Buchung wiedergefunden und dann abgeändert werden. Da es sich um ein vernetztes System handelte, wo alle Terminals Zugriff auf den gleichen Datenbestand hatten, musste eine Änderung nicht am gleichen Terminal erfolgen, sondern konnte zum Beispiel auch in einer ganz anderen Stadt durchgeführt werden, etwa wenn ein Reisender am Zielort den Rückflug umbuchen wollte.
SABRE-Terminal – Einzelbild aus „An Introduction to SABRE“, American Airlines, 1961.
Die Abbildung oben zeigt ein Terminal, mittels dessen Servicemitarbeiter die Flugbuchungen durchführen konnten. Zentrales Element war eine elektrische Schreibmaschine. Links neben der Maschine befand sich eine Einlassung im Tisch für sogenannte „Air Information Cards“. Diese Karten enthielten sowohl lesbare Informationen für den Service-Mitarbeiter, als auch maschinenlesbare Lochungen, sodass das Terminal eine Karte identifizieren konnte. Die Karten wurden in einen Halter oberhalb der Schreibmaschine eingelegt. Mit Knöpfen links und oben konnten Felder (Zeilen und Spalten) auf der Karte ausgewählt werden. Rechts neben der Schreibmaschine befand sich neben einer Wählscheibe für Telefonanrufe der sogenannte „Director“. Hiermit konnten Befehle für Buchung, Stornierung und für die Angabe von Sitzwünschen etc. direkt ausgeführt werden. Die Schreibmaschine selbst diente zur Ausgabe von Nachrichten des Zentralrechners und zur Eingabe von textuellen Daten wie Namen, Adressen und Telefonnummern.
Auch das SABRE-Szenario hat eine ganz andere Charakteristik als der universitäre und wissenschaftliche Computereinsatz, ist aber auch anders als das Buchhaltungsszenario. Bei SABRE arbeiten alle Nutzer mit dem gleichen Programm, dem Flugbuchungsprogramm. Das Programm ist ihnen fest vorgegeben. Sie müssen es nicht erst programmieren oder laden und können es auch nicht verändern. Das Programm wird eher selten, und wenn, dann von anderen Personen als den Kundendienstmitarbeitern, verändert. Ganz anders war es im wissenschaftlichen Bereich: Jeder Nutzer kam hier mit einem eigenen Programm daher, das ganz verschieden geartete Daten verarbeiten sollte. Auch handelte es sich bei SABRE um kein System, das hohe Rechenleistung brauchte, denn bei einer Flugbuchung wurde kaum nennenswert etwas berechnet, was über das Zählen freier Plätze hinausgegangen wäre.
Wissenschaft und Technik: LGP-30
Auch in den Bereichen Wissenschaft und Technik konnte es natürlich sehr von Vorteil sein, einen Computer vor Ort zu haben und ihn ohne Wartezeiten und ohne den administrativen Aufwand eines Großrechners mit Batch-Verarbeitung betreiben zu können. Die Vorteile konnten Abstriche in der Rechengeschwindigkeit durchaus aufwiegen.
LGP-30 – Bild mit freundlicher Genehmigung des Computermuseums der Informatik der Universität Stuttgart
Rechner, die dieser Charakteristik entsprachen, waren der LGP-30 der Firma Librascope von 1956 und sein Nachfolger LGP-21 von Mitte der 1960er Jahre. In Deutschland wurden die Maschinen in Lizenz von der Firma Schoppe & Faeser gebaut. Der oben abgebildete, funktionstüchtige Rechner steht im Computermuseum der Informatik der Universität Stuttgart. Der eigentliche Rechner ist der rechte der beiden Kästen. Er ist für die damaligen Verhältnisse relativ kompakt, hat etwa das Volumen einer kleineren Kühltruhe.
Wie bei der IBM 305 RAMAC handelte es sich beim LGP-30 um einen Rechner mit Trommelspeicher, der bei diesem Rechner das zentrale Element war, da es keine anderen Massenspeicher gab. Da die Trommel magnetisch war, blieb der Speicherinhalt nach dem Ausschalten erhalten. Wenn man also ein Programm einmal auf die Trommel geladen hatte, musste man es nach dem Ausschalten nicht neu laden. Es konnte nach dem Wiedereinschalten des Rechners gleich wieder ausgeführt werden. Die Trommel konnte 4.096 Wörter à 31 Bit speichern. Wenn Ihnen der Begriff „Wort“ in diesem Zusammenhang nichts sagt, macht das nichts. Ich möchte an dieser Stelle nicht allzu sehr in die technischen Details einsteigen, gebe Ihnen hier daher einen groben Überschlag, der Ihnen einen Eindruck vermitteln soll: Würden Sie die Trommel komplett mit Textzeichen vollschreiben wollen und pro Textzeichen sechs Bit veranschlagen, würden etwa 20.500 bis 21.000 Zeichen Platz finden. Das sind etwa zwölf DIN-A4-Seiten. Sie können es sich also ungefähr so vorstellen, als hätten Sie einen Computer mit einem Arbeitsspeicher von zwanzig Kilobyte – nicht Gigabyte, nicht Megabyte, sondern Kilobyte – und diese zwanzig Kilobyte Arbeitsspeicher sind gleichzeitig auch die Festplatte Ihres Rechners.
Umgebaute Schreibmaschine als Konsole der LGP-30 – Bild: Marcin Wichary from San Francisco, U.S.A. (CC BY 2.0)
Zentrales Ein- und Ausgabegerät des LGP-30 war eine umgebaute Schreibmaschine vom Typ Friden Flexowriter, ihrerseits eine umgebaute IBM-Schreibmaschine, die um einen Lochstreifenleser und -stanzer erweitert wurde. Die wichtigste Erweiterung dieser Maschine war eine Schnittstelle, die eingegebene oder vom Lochstreifenleser gelesene Zeichen an den Computer weitergab und von dort kommende Zeichen so ausgab, als wären sie an der Maschine direkt eingegeben worden. Hinzu kamen Kontrolltasten, mittels derer der Computer in Gang gesetzt und mit denen zwischen manueller Eingabe und Eingabe vom Lochstreifen umgeschaltet werden konnte. Eine Lampe in der Mitte der Maschine oberhalb der Tastatur diente der Anzeige, dass der Computer eine Eingabe vom Nutzer erwartete. Schlussendlich wurden einige Tasten der Maschine durch helle Tasten ausgetauscht. Diese hellen Tasten entsprechen den Befehlen des Maschinencodes und sind hier optisch abgesetzt worden.
Mittels Eingaben von der Schreibmaschine konnten Werte direkt in den Speicher des Computers geschrieben werden. Auf diese Weise war es möglich, den Rechner direkt zu programmieren oder zumindest ein bereits auf der Magnettrommel vorhandenes Programm zu starten. Hierzu musste ein Sprungbefehl zur Startadresse des entsprechenden Programms eingegeben, dieser Befehl ausgeführt und der Rechner dann auf automatischen Betrieb umgeschaltet werden. Neue Programme konnten per Handeingabe oder per Lochstreifen auf die Trommel gebracht werden. Ein einfaches Betriebssystem verfügte über Routinen, mit denen das Laden von Programmen auf die Trommel und auch das Ausführen von Programmen ab einer angegebenen Speicheradresse relativ einfach möglich war. Mittels eines Compilers für die einfache Hochsprache ACT-III ließen sich komplexere Programme entwickeln, ohne auf die Maschinensprache des Rechners zurückgreifen zu müssen.
Interessant in Bezug auf die Nutzungsschnittstelle war die Einstellung „Eingabe von Hand“ an der Konsolen-Schreibmaschine. War diese Taste gedrückt, las der Computer Eingaben nicht vom Lochstreifenleser, sondern direkt von der Tastatur der Schreibmaschine. Der Computer ermöglichte hierdurch Programme, die während ihrer Ausführung die Eingabe von Werten über die Tastatur verlangten und damit auch die Steuerung des Fortgangs des Programms durch Nutzereingaben ermöglichten. Der Computer ließ sich also in einem ganz modernen Sinne interaktiv nutzen. Selbst einfache Spiele waren so möglich. Noch nicht umgesetzt war der Betrieb eines interaktiven Editors, also eines Programms, das es ermöglicht hätte, den Quellcode eines Hochsprachenprogramms im Speicher zu halten und direkt am Computer zu bearbeiten. Obwohl dies grundsätzlich mit dem Rechner hätte gehen müssen, hat wohl vor allem der geringe Speicher des Rechners einen praktischen Einsatz unmöglich gemacht, denn es hätte auf der Trommel dann ja Platz für den Editor, den zu bearbeiteten Programmcode, den Compiler und das Kompilat in Maschinensprache geben müssen, von eventuellen Daten des Programms ganz zu schweigen. Programmiert wurde also auch bei diesem Computer daher in der schon etliche Male beschriebenen Art und Weise, also zunächst mit dem Stift auf einem Codierbogen und dann durch Ablochen auf Lochstreifen. Da es sich um einen Rechner handelte, der lokal genutzt wurde und nicht im Batch-Betrieb arbeitete, war es aber immerhin möglich, die Programme oft abzuändern und dann immer wieder auszuprobieren. Im Batch-Betrieb hätte das mehrere Tage gedauert.
Der LGP-30 war ein Rechner mit relativ geringer Rechen- und Speichergeschwindigkeit und nur geringer Speichergröße. Er war dafür relativ günstig. 1956 kostete er 47.000 Dollar, was inflationsbereinigt heute fast einer halben Million Dollar entspricht. Natürlich ist das viel Geld. Ein typischer Computer der Zeit, wie etwa die UNIVAC I, die von 1951 bis 1954 gebaut wurde, kostete jedoch mit 1,25 bis 1,5 Millionen Dollar fast dreißig mal so viel.
Interaktivität an großen Computern – UNIVAC I
Sie haben die UNIVAC im vorherigen Kapitel kurz im Zusammenhang mit Bandlaufwerken kennengelernt. Dort ging es um eine Verbesserung der Auslastung von teuren Rechnern durch das Lesen und Speichern von Programmen und Daten auf Magnetbändern. Die Dateneingabe mittels Tastatur läuft dieser Art der Optimierung natürlich total entgegen. Interessant ist aber, dass sich eine UNIVAC grundsätzlich auf ähnliche Art bedienen ließ wie eine LGP-30, denn die Bedienkonsole des Rechners ermöglichte die Eingabe von Werten in das Programm und der Befehlssatz des Rechners gab es her, Werte von der Konsole abzufragen oder auf ihr auszugeben. Die Bedienungsanleitung des Rechners beschreibt15:
The programmer may arrange to use the Supervisory Control as an input-output device. When this is done certain options are available depending on the switch settings. These options are explained in “Supervisory Control Operations”. The two programmed instructions which may be used for input or output in connection with the Supervisory Control are listed.
INSTRUCTIONS
10m: Stop UNIVAC operations and produce a visual signal. Call for one word to be typed from the Supervisory Control keyboard into memory location m. UNIVAC operations are resumed after the “word release button” on the Supervisory Control has been actuated.
50m: Print one word from memory location, m, onto the printer associated with the Supervisory Control. UNIVAC operations are resumed automatically after m has been transferred to an intermediate output storage location prior to printing.
Diese Art der Bedienung der UNIVAC war zwar möglich, allerdings wurde damit der Computer in seiner Verarbeitung oft angehalten und somit wertvolle Rechenzeit verschenkt. Im Gegensatz zur Bedienungsanleitung von IBMs 1401 wird daher für eine solche Nutzungsform auch nicht geworben, sondern explizit auf die Nachteile hingewiesen:
The ability to type into or print out of any desired memory location during the processing of a problem permits a very flexible control of that problem. However, it is well for the programmer to remember that the time required to execute these instructions is relatively great especially for a type-in instruction which is a human operation and an added source of error.
Beachtenswert ist, dass hier nicht nur darauf hingewiesen wird, dass der Mensch bei der Ausführung der Eingaben sehr langsam ist; problematisiert wird vielmehr auch, dass es sich bei Eingaben durch Menschen um eine zusätzliche Fehlerquelle handelt. Bei der UNIVAC mag dieser Hinweis dahingehend gedeutet werden, diese Betriebsart doch lieber zu meiden. In der Tat ergibt sich durch interaktive Nutzung eines Computers eine wichtige Änderung in der Programmierung. Konnte vorher davon ausgegangen werden, dass Eingabedaten im Großen und Ganzen korrekt und wohlformatiert waren, musste nun ein gehöriges Maß an Programmieraufwand in die Eingabebehandlung und die Verarbeitung von Eingabefehlern gelegt werden. Der Hauptaufwand bei der Programmierung verschob sich. Auf einmal entstand ein großer Programmieraufwand nicht für die eigentliche Programmlogik, sondern für seine Nutzungsschnittstelle.
Geteilte Zeit: Time-Sharing
In den im vorhergehenden Kapitel vorgestellten Einsatzszenarien etwa des RAMAC-Computers und des LGP-30 überwogen die Vorteile der Echtzeitverarbeitung die Nachteile eines nicht vollständig ausgelasteten und zudem recht langsamen Computers. Die Echtzeitnutzung kam hier deswegen infrage, weil wenige Nutzer den Rechner gebrauchten und die mit dem Rechner zu lösenden Probleme übersichtlich waren. Es gab somit keinen Bedarf an besonders gut ausgestatteten, schnellen Rechnern. Wollten jedoch viele Nutzer Rechendienste beanspruchen und brachten diese Nutzer eine Vielzahl verschiedener Programme mit, deren Erledigung eine gut ausgebaute Rechenanlage voraussetzte, kamen die genannten Geräte und eine Bedienung des Computers durch den Nutzer selbst nicht mehr infrage. Ärgerlicherweise war aber gerade für diese Nutzer, die ja häufig neue, umfangreiche Programme für komplexe Berechnungen erstellen mussten, die Batch-Betriebsart besonders lästig, denn sie machte das Programmieren sehr umständlich, zeitaufwändig und fehlerträchtig. Programme mussten handcodiert und abgelocht werden und die Rückmeldung zu nahezu unausweichlichen Programmierfehlern kamen erst nach Stunden oder gar Tagen. Den Ausweg aus der Batch-Nutzung für große, leistungsfähige Rechner brachte die Erfindung des „Time-Sharing“. Erste konzeptuelle und theoretische Vorarbeiten hierzu begannen bereits in den 1950er Jahren, die ersten nicht-rein-experimentellen Systeme wurden jedoch erst Mitte der 1960er in Betrieb genommen.
Beim Batch-Computing wurde eine hohe Auslastung des Computers dadurch erreicht, dass ein Computer sich nahezu nie im Wartezustand befand, sondern immer ein Programm vorlag, an dem gerechnet wurde. Auch beim Time-Sharing war es das Ziel, den Computer möglichst gut auszulasten. Das wurde allerdings nicht mehr dadurch gewährleistet, dass dem Computer in hoher Taktung Jobs zugeführt wurden, die dann nacheinander abgearbeitet werden konnten. Beim Time-Sharing teilten sich vielmehr die Programme vieler Nutzer die Rechenzeit des Computers. Sie liefen quasi gleichzeitig, bzw. so schnell abwechselnd, dass es so erschien, als sei dies der Fall. Mit dem Time-Sharing kam der Nutzer nun auch mit dem Rechner selbst in Kontakt. Dies geschah allerdings nicht direkt im Rechnerraum, der nach wie vor tabu war, sondern mittels sogenannter „Terminals“, die mit dem Rechner verbunden waren. Typische Terminals für frühe Time-Sharing-Systeme waren einfache Fernschreiber wie der rechts abgebildete. Nutzer konnten an Fernschreibern Eingaben machen und bekamen Ausgaben ihres Programms während des Programmablaufs direkt ausgedruckt. Ein Nutzer eines Time-Sharing-Systems musste an seinem Fernschreiber nicht warten, bis ein Programm eines anderen Nutzers zum Ende gekommen war, denn Time-Sharing-Systeme arbeiteten die Programme der Nutzer ja im Rundumverfahren ab. Es wurde in so schneller Folge zwischen den Programmen hin- und hergewechselt, dass für jeden einzelnen Nutzer die Illusion entstand, den Computer ganz für sich zu haben.
Das Nutzererlebnis eines Time-Sharing-Systems mit Fernschreiber war fundamental anders als das der Nutzung eines Computers im Batch-Betrieb. Statt Lochkartenstapel abzugeben und Stunden später Lochkarten und Ausdrucke zurückzuerhalten, wurden nun Befehle per Texteingabe über den Fernschreiber an den Computer gegeben. Dieser reagierte wiederum durch die Ausgabe von Texten, die vom Fernschreiber auf Endlospapier gedruckt wurden. Statt wie bisher stundenlang auf Ergebnisse zu warten, erschienen die Ergebnisse innerhalb von Minuten oder gar wenigen Sekunden. Die Arbeitsweise ist der des SABRE-Systems ganz ähnlich, bei der ja auch Terminals mit einem Computer verbunden wurden und Eingaben gemacht werden konnten, auf die der Zentralrechner umgehend antwortete. Beim SABRE-System gab es jedoch nur ein einziges laufendes Programm, das alle Terminals mit der gleichen Funktionalität bediente. Time-Sharing-Systeme hingegen waren so ausgelegt, dass sie die volle Flexibilität der individuellen Programmierung verfügbar machten. Jeder Computernutzer konnte seine eigenen Programme erstellen, auf dem Time-Sharing-System laufen lassen und zeitnah ein Ergebnis erhalten.
Für die Performance und Auslastung einer Rechenanlage hatte Time-Sharing natürlich seinen Preis:
Arbeitsspeicherbedarf: Da sich viele Programme gleichzeitig im Speicher befanden und zusätzliche Daten für die Verwaltung der angemeldeten Nutzer und der laufenden Programme notwendig waren, mussten Time-Sharing-Systeme mit mehr Arbeitsspeicher ausgestattet werden als für die Durchführung der gleichen Berechnungen im Batch-Betrieb notwendig gewesen wäre.
Performance: Die Organisation des Time-Sharing-Betriebs selbst verursachte einen sogenannten „Overhead“. Wenn zwanzig Nutzer gleichzeitig angemeldet waren und ein Programm laufen ließen, dann dauerte es insgesamt länger, als wenn man die zwanzig Programme hintereinander ablaufen lassen hätte, denn für das Wechseln zwischen den Programmen ging stetig Rechenzeit verloren. Diese verschenkte Zeit wurde umso größer, je mehr Nutzer das System benutzten. Die Verzögerung in der Bearbeitung war aber in der Regel zu verschmerzen, denn da das für den Nutzer ja so besonders unpraktische Job-Handling, das Ablochen und das lange Warten auf ein Ergebnis entfielen, wurde es für jeden einzelnen Nutzer trotz insgesamt langsamerer Verarbeitung doch signifikant schneller.
Auslastung: Der Batch-Betrieb sorgte für eine gleichmäßige Auslastung des Rechners auch in Zeiten, in denen wenige neue Jobs eingingen. Während der Stoßzeiten häuften sich die Jobs und landeten in einer Warteschlange. Diese Warteschlange konnte in Zeiten mit wenig Andrang abgearbeitet werden. Beim Time-Sharing hingegen wurde die Bearbeitung sehr langsam, wenn viele Nutzer das System nutzen, während Rechenzeit im großen Stile verschwendet wurde, wenn nur wenige Nutzer Programme laufen ließen. Um dennoch für eine gute Auslastung zu sorgen, wurden Time-Sharing- und Batch-Betrieb häufig kombiniert. Das Betriebssystem des Rechners bediente Nutzer an ihren Fernschreibern im interaktiven Betrieb, arbeitete aber gleichzeitig auch klassische Jobs ab. In Zeiten, in denen wenig interaktive Nutzung zu verzeichnen war, konnte dem Batch-Betrieb entsprechend mehr Priorität eingeräumt werden. Manche Time-Sharing-Systeme verbanden die beiden Betriebsarten sogar noch geschickter. Sie erlaubten etwa den Nutzern das Bearbeiten und Testen ihres Programms im Echtzeitbetrieb und ermöglichten es dann, die Ausführung des Programms, eventuell mit einer großen Datenmenge, in eine Batch-Warteschlange einreihen zu lassen, die dann bei Gelegenheit abgearbeitet wurde. M. V. Wilkes beschreibt dies16 für das Cambridge Time-Sharing System. Dort konnten Programmdateien per Editor vorbereitet werden und dann durch die Eingabe von RUNJOB und dem Dateinamen in eine klassische Job-Queue eingereiht werden. Die Ausgaben dieser Programme wurden entweder klassisch ausgedruckt oder aber wiederum als Datei zur Verfügung gestellt.
Mit dem Time-Sharing änderte sich die Art und Weise, wie Programme erzeugt und bearbeitet wurden. Es war nun nicht mehr nötig, diese Aufgabe auf Papier zu erledigen und das Programm dann manuell abzulochen. Der Computer konnte nun endlich selbst zum Programmieren genutzt werden. Damit das ging, brauchte es aber ein spezielles Programm zum Bearbeiten des Programmcodes, also einen Editor. Diesem Editor werden wir uns gleich widmen. Vorher sollten Sie sich jedoch einige Konsequenzen des Time-Sharings für die Nutzungsschnittstelle bewusst machen.
Virtuelle Objekte
Mit dem Aufkommen von Time-Sharing ging auch der Übergang von Konsolen zur Steuerung und Überwachung der Maschine zu für den Nutzer geschaffenen Nutzungsschnittstellen einher. Bisherige Computer brauchten keine Schnittstelle für den Nutzer des Rechners, denn Rechner und Nutzer kamen schon physisch gar nicht miteinander in Kontakt. Das wurde nun anders: Ein Nutzer, der am Fernschreiber saß, stand direkt mit dem Computer in Verbindung, auf dem seine Programme liefen. Er musste also eine Möglichkeit haben, die Programme auszuwählen und zu starten, sie zu erstellen oder sie gegebenenfalls zu löschen. Hierfür reichte es nicht, einfach eine textuelle Umsetzung dessen bereitzustellen, was bisher mit den Operator-Konsolen möglich war. Diese Konsolen waren sehr komplex und boten direkten Zugriff auf die Hardware des Rechners, auf interne Zustände und Speicherregister. Ein Nutzer an einem Fernschreiber war aber an Maschinenzuständen und Speicheradressierungen nicht interessiert, sondern benötigte eine Schnittstelle, die sich auf die von ihm verarbeiteten Daten und Programme bezog. Die vom Computer bereitgestellte Schnittstelle musste dem Nutzer die Programme und die Daten als etwas anbieten, auf das er sich beziehen konnte. Das begann schon bei dem Grundsystem des Time-Sharing-Systems, dem Kommando-Interpreter, mit dem etwa Programme gestartet werden konnten.
Eines der ersten Time-Sharing-Systeme, das nicht nur rein experimentell war, war das Dartmouth Time Sharing System (DTSS) am Dartmouth College in den USA. Es wurde 1964 in Betrieb genommen. Meldete man sich beim System an, musste man sich zunächst mit einer Nutzernummer identifizieren. War dies geschehen, konnte man entweder direkt mit der Programmierung eines Programms beginnen – dazu später mehr – oder aber auch bereits existierende Programme verwalten. Dazu stand eine Reihe von Befehlen zur Verfügung:
LIST gab das Listing des aktuell geladenen Programms aus.
NEW erzeugte ein neues Programm. Ein Programmname wurde nach der Eingabe von NEW abgefragt.
OLD ermöglichte, ein früheres Programm wieder zu laden. Nach Eingabe von OLD wurde der Programmname des gespeicherten Programms abgefragt.
SAVE speicherte das Programm unter dem aktuellen Programmnamen ab.
UNSAVE löschte das Programm mit dem aktuellen Programmnamen.
SCRATCH löschte das Programm, behielt aber den Programmnamen bei. Der Nutzer konnte also von vorne beginnen.
CATALOG gab eine Liste aller für den angemeldeten Nutzer gespeicherten Programme aus.
Worauf bezogen sich diese Befehle? Es ging nun nicht mehr wie bei klassischer Programmierung um Register, Speicherstellen oder Sektoren auf Massenspeichern. Die Befehle bezogen sich zwar auf Programme, aber nicht im Sinne der einzelnen Anweisungen einer Programmiersprache, sondern auf Programme als Ganzes, auf etwas, das der Nutzer mit einem Namen ansprechen konnte. Ich nenne derartige Entitäten, auf die sich ein Nutzer in einer interaktiven Nutzungsschnittstelle beziehen kann und die von dieser Schnittstelle für den Nutzer erzeugt und zugreifbar gemacht werden, virtuelle Objekte.
Das Wort „virtuell“ wird in der deutschen Wikipedia meiner Meinung nach sehr bestechend definiert:
Virtualität ist die Eigenschaft einer Sache, nicht in der Form zu existieren, in der sie zu existieren scheint, aber in ihrem Wesen oder ihrer Wirkung einer in dieser Form existierenden Sache zu gleichen. Virtualität meint also eine gedachte Entität, die in ihrer Funktionalität oder Wirkung vorhanden ist.
Das, was ich hier „virtuelle Objekte“ nenne, existiert nicht realweltlich als Objekt im Sinne eines Gegenstandes. Für den Umgang mit dem Computer haben die virtuellen Objekte aber die Eigenschaften von tatsächlichen Objekten. Man kann sich also auf sie beziehen, sie erzeugen, vernichten und natürlich manipulieren.
In diesem Zusammenhang den Begriff „Objekt“ zu verwenden, ist übrigens meine Wortwahl entsprechend der Perspektive, die ich Ihnen in diesem Buch darlegen will. Auch in älteren Beschreibungen und Anleitungen von Computersystemen und Programmiersprachen findet man den Objekt-Begriff mitunter in dieser Verwendung. Mit dem Aufkommen der sogenannten „objektorientierten Programmierung“ wurde der Objektbegriff in der Informatik mit einem gewissen Programmierparadigma belegt. Der Begriff wurde regelrecht annektiert. Es geht mir hier aber nicht um die Programmierung, sondern auf die von der Nutzungsschnittstelle erzeugte Welt für den Nutzer. Das, was ich hier „Objekt“ nenne, ist für den Nutzer ein ansprechbares und manipulierbares Gebilde. Wie ein Programmierer hinter den Kulissen dieses Objekt realisiert, ob es auch da etwas gibt, was das Objekt als eine Einheit erscheinen lässt, oder ob es sich um eine Ansammlung von Variablen oder gar Datenströmen handelt, ist aus der Perspektive der Nutzungsschnittstelle nicht von Belang.
Die Time-Sharing-Applikation schlechthin: Der Editor
Die Möglichkeit, Programme unter direkter Nutzung des Computers zu bearbeiten und so die Misslichkeiten der Programmierung mit Lochkarten und Lochstreifen hinter sich zu lassen, war eine der Haupt-Triebkräfte hinter der Entwicklung von Time-Sharing-Systemen. Dass mit diesen Systemen dann auch Programme möglich waren, die interaktiv gesteuert werden können, wurde zwar gesehen, stand aber nicht unbedingt im Vordergrund und war, wie Sie gleich sehen werden, auch nicht in jedem Time-Sharing-System von Beginn an möglich. Haupt-Anwendung war in der Regel die Editor-Funktionalität.
Wenn Sie sich unter einem Editor ein Programm vorstellen, dass in etwa so aussieht wie ein Texteditor unter Windows oder MacOS oder gar wie eine moderne Programmierumgebung, dann haben Sie eine falsche Vorstellung. Die Bedienung eines Editors der damaligen Zeit war ganz anders als die Verwendung moderner Editoren. Begründet liegt dies in den Eigenschaften des Fernschreibers als Ein- und Ausgabegerät, die nicht recht zur Aufgabe eines Editors passten. Da Fernschreiber ganz analog etwas auf ein Blatt schrieben, kann man mit einem Fernschreiber wie mit einer Schreibmaschine immer nur etwas hinzufügen, also etwas Neues dazuschreiben. Die Aufgabe eines Editors ist es jedoch, einen im Computer befindlichen Text, etwa einen Programm-Quelltext, zu bearbeiten, also zu ändern. Was schon auf einem Blatt Papier steht, kann man aber nicht ändern. Es gab bei einem Fernschreiber kein Löschen und kein Backspace im heutigen Sinne. Fernschreiber wie der zuvor abgebildete ASR-33 verfügten zwar über eine „Rubout“-Taste, die gedrückt werden konnte, um durchzugeben, dass das vorher gesendete Zeichen „ausgewischt“ werden sollte. Natürlich wurde aber auch hier das vorherige Zeichen nicht vom Papier des Empfängers getilgt. Wurde einem Computer ein solches Zeichen geschickt, löschte er die Eingabe intern und schickte zur Bestätigung ein neues Zeichen zurück – häufig das Dollarzeichen – um darzustellen, dass die Eingabe akzeptiert wurde. Diese Art der Ein- und Ausgabe mag für das Löschen eines gerade eingegebenen falschen Zeichens noch hinreichend sein, stieß aber spätestens beim Versuch, Text zwischen vorhandene Worte einzufügen, an ihre Grenzen. Komplexere Aufgaben wie das Einfügen von Text konnten nur durchgeführt werden, indem dem Editor Befehle eingegeben wurden, die beschrieben, wie der Text angepasst werden konnte.
Wenn Sie Zugriff auf ein Linux- oder Unix-System (inklusive MacOS) haben, können Sie diese Funktionsweise früher Editoren noch heute nachvollziehen. Der in diesen Systemen verfügbare Zeileneditor „ed“ stammt aus der Anfangszeit des Betriebssystems Unix von Anfang der 1970er Jahre, aus einer Zeit also, als viele Computer noch per Fernschreiber bedient wurden.
Wird der Editor durch die Eingabe von ed in der Kommandozeile gestartet, passiert zunächst einmal gar nichts, außer dass ein Zeilenvorschub ausgelöst wird oder im modernen Bildschirm-Terminal der Cursor (die Schreibmarke) in die nächste Zeile wandert. Schreiben Sie nun nacheinander H und P jeweils gefolgt von Enter. Diese beiden Befehle sorgen dafür, dass Meldungen ausgegeben werden, wenn Fehler auftreten, und dass mit einem * angezeigt wird, wenn Sie eine Befehlseingabe machen können. Als ersten Schritt laden Sie eine Datei. Nehmen wir an, dass eine Datei „textfile.txt“ bereits existiert. Mit der Eingabe von r textfile.txt wird, nach der Bestätigung mit Enter, die Datei eingelesen. Der Editor antwortet mit der Anzahl der gelesenen Bytes, in unserem Beispiel 86. Da die Datei nicht groß ist, können Sie sie in ganzer Länge ausgeben. Dies geschieht durch eine Eingabe des Befehls ,l (hierbei handelt es sich um ein kleines L und nicht um die Zahl 1).
$ed
H
P
*r textfile.txt
86
*,l
This is the heading.$
The text starts hree. There may be many important things to say.$
Wie Sie sehen, handelt es sich hier um einen einfachen Text bestehend aus zwei Zeilen. Das Dollarzeichen steht jeweils für das Zeilenende. Sie können diesen Text nun bearbeiten, indem Sie Befehle eingeben. Im Beispiel werden wir zum einen unterhalb der Überschrift eine Zeile mit Plus-Zeichen einfügen, um sie besser abzusetzen, und zum anderen das Wort „hree“, wohl ein Tippfehler, durch das korrekte Wort „here“ ersetzen.
Um die Pluszeichen einzugeben, müssen Sie dem Editor mitteilen, dass Sie in Zeile 2 etwas einfügen wollen. Dies geschieht durch den Befehl 2i. Nun können Sie den neuen Text eingeben. Um die Eingabe abzuschließen, schreiben Sie einen einzelnen Punkt in eine Zeile und beenden Sie mit Enter:
*2i
+++++++++++++++++++++
.
Die ehemalige Zeile 2 müsste durch das Einfügen einer weiteren Zeile jetzt zur Zeile 3 geworden sein. Sie können das überprüfen, indem Sie die Zeile 3 mit dem Befehl ,3 ausgeben lassen.
*,3
The text starts hree. There may be many important things to say.$
Nun geben Sie einen Befehl ein, um in Zeile 3 das erste Vorkommen von „hree“ durch „here“ zu ersetzen und geben anschließend den kompletten berichtigten Text mit ,l nochmals aus.
*3s/hree/here/
*,l
This is the heading.$
+++++++++++++++++++++$
The text starts here. There may be many important things to say.$
Hiermit sind die beabsichtigten Änderungen abgeschlossen. Abschließend können Sie den verbesserten Text mit w besser.txt als „besser.txt“ abspeichern. Der Editor quittiert das wiederum durch die Angabe der geschriebenen Bytes. Die Eingabe des Befehls q beendet dann den Editor.
*w besser.txt
108
*q
Konnten Sie beim Nachvollziehen dieses Beispiels das Hin und Her an einem Fernschreiber nachempfinden? Das Bearbeiten eines Textes ist auf diese Art und Weise sehr umständlich, denn man bearbeitet den Text nur indirekt. Der Text liegt im Computer zwar als bearbeitbares Objekt vor, aber man kann ihn nicht als Text sehen und an Ort und Stelle bearbeiten. Man muss stattdessen Befehle zur Bearbeitung geben und den aktuellen Zustand des Textes immer wieder ganz oder in Ausschnitten anfragen. Man kann diese Arbeitsweise in etwa damit vergleichen, als würde man jemanden anrufen, der einen Text vor sich liegen hat und diesen immer in Teilen durchgibt. Dieser Person könnten sie nun die Änderungen, die Sie machen wollen, durchgeben und dann immer wieder erfragen, wie jetzt der aktuelle Zustand des Texts ist.
Virtuelle Objekte: Interaktive Objektmanipulation
Im Editor erscheint der Text nicht etwa als Bitstrom oder als lange Zeichenkette, die er ja faktisch ist. Würde „ed“ kein Konzept von Zeilen als ansprechbare Objekte haben, wäre es noch viel umständlicher, den Editor zu nutzen, denn dann könnte man sich nicht auf Zeilen beziehen, sondern müsste Bytes innerhalb eines Datenstroms adressieren, sich also noch viel stärker auf die Ebene der Rechnerarchitektur hinunterbegeben. „Ed“ erzeugt hingegen durch seine Nutzungsschnittstelle für den Nutzer verstehbare, adressierbare, wahrnehmbar-machbare und manipulierbare Objekte. Jede sinnvolle Schnittstelle für Echtzeitsysteme erzeugt derartige virtuelle Objekte, auf die sich der Nutzer beziehen kann. Bei „ed“ waren es hier Zeilen und Zeichen. Auf der Ebene des Kontrollprogramms, des Kommandozeilen-Interpreters, sind es Programme und Dateien. Verwenden Sie ein Programm zur Verwaltung von Terminen, sind es Kalendereinträge. In all diesen Fällen beziehen Sie sich auf ein Objekt der Welt der Nutzungsschnittstelle statt auf Adressbereiche und Maschinenoperationen. Es handelt sich in all diesen Fällen, so einfach die Umsetzung der Nutzungsschnittstellen noch sein mag, um Nutzungsschnittstellen, die durch den Computer erzeugt werden, anstatt nur die Schnittstelle für den Computer zu sein. Programme für den Echtzeitbetrieb erzeugen sowohl die Bedienelemente, mit Hilfe derer sie bedient werden können, als auch die Objekte, wegen derer die Software überhaupt existiert. Was auf der anderen Seite der Nutzungsschnittstelle steckt, also die technische Implementierung der Software, ist für den Nutzer – zumindest in dieser Sichtweise – nicht von Belang und bleibt für ihn unsichtbar.
Das folgende Bild zeigt Studenten des Dartmouth College samt dem Mathematikprofessor John G. Kemeny. Sie sitzen rund um eine Reihe von Fernschreibern, die mit einem zentralen Computer verbunden sind. Am Dartmouth College wurde eines der ersten Time-Sharing-Betriebssysteme in Betrieb genommen. Von diesem Dartmouth Time-Sharing System war oben bereits einmal die Rede. Das System ging am 1. Mai 1964 in Betrieb.
BASIC-Miterfinder John G. Kemeny mit einigen Studenten an mit dem DTSS verbundenen Fernschreibern – Bild mit freundlicher Genehmigung der Dartmouth College Library
Für das System wurde von besagtem John G. Kemeny zusammen mit Thomas E. Kurtz und Mary Kenneth Keller eine Programmiersprache namens BASIC (Beginner’s All-purpose Symbolic Instruction Code) entwickelt. BASIC zielte, wie der Name es sagt, auf den Einsatz als Anfängersprache, gerade in Bildungsinstitutionen, ab. Ziel war es, nicht nur angehenden Technikern und Ingenieuren, sondern allen Studierenden und Mitarbeitern des College und darüber hinaus das Programmieren zu ermöglichen. Die Sprache wurde etwa fünfzehn Jahre später zu einer der weitestverbreiteten Programmiersprachen. Quasi alle Heim- und Personal-Computer der 1980er Jahre waren mit einem BASIC-Interpreter ausgestattet. Betrachten Sie einmal das folgende kleine Programm, das die Zahlen von 1 bis 10 ausgibt.
10FORI=1TO1020PRINTI30NEXTI40END
Wie Sie sehen, beginnt jede Zeile mit einer Zeilennummer. Die Zeilennummern gehören fest zur Sprache BASIC. Sie dienen zwei ganz unterschiedlichen Funktionen. Rein funktional werden die Zeilennummern gebraucht, um im Programm springen zu können. Ein GO TO 100 (in späteren BASIC-Dialekten meist ohne Leerzeichen, also GOTO 100, geschrieben) etwa setzt den Programmablauf in Zeile 100 fort. Die Zeilennummern haben aber auch eine Funktion in der Nutzungsschnittstelle, erlauben sie es doch, Zeilen neu zu definieren und neue Zeilen zwischen den schon vorhandenen einzufügen. Wollen Sie das obige Programm etwa so abändern, dass es nicht die Zahlen von 1 bis 10, sondern von 2 bis 20 in Zweierschritten ausgibt, können Sie Zeile 20 einfach neu definieren:
20PRINT2*I
Wenn Sie geschickterweise zwischen den Zeilennummern größere Abstände gelassen haben, können Sie auch leicht Zeilen zwischenfügen, indem Sie einfach Zeilennummern zwischen den vorhandenen verwenden, also etwa:
15PRINT"EINE ZAHL",35PRINT"FERTIG!"
Die erste Version des Dartmouth BASIC verfügte zwar durch das DTSS über einen interaktiven Editor, man konnte mit der Sprache allerdings keine Programme schreiben, die selbst interaktiv waren, denn es gab keine Möglichkeit, den Nutzer zu Eingaben aufzufordern. Alle Eingabedaten mussten, wie bei der Batch-Verarbeitung, im Vorfeld bekannt sein. BASIC fehlte auch eine Möglichkeit, Daten aus Dateien zu lesen, denn DTSS unterstützte keinerlei Daten-Dateien. Alle Daten mussten also im Programm selbst angegeben werden. Im folgenden Beispiel sehen Sie, dass dabei die frühere Batch-Denkweise mit Programm-Lochkarten und Daten-Lochkarten durchaus noch durchscheint.
100 PRINT "RECHNUNG"
200 PRINT
300 PRINT "MENGE","PREIS"
400 PRINT "------------------------------------"
500 LET SUMME=0
600 READ MENGE
700 IF MENGE=0 THEN 1100
800 READ PREIS
850 PRINT MENGE, PREIS
900 LET SUMME = SUMME + MENGE * PREIS
1000 GO TO 600
1100 PRINT
1200 PRINT "SUMME:"; SUMME
1300 REM
1400 REM RECHNUNGSDATEN
1500 REM
1600 DATA 5,1.90
1700 DATA 1,2.70
1800 DATA 2,1.39
1900 DATA 7,0.99
2000 DATA 0
9000 END
Dieses Programm gibt eine Rechnung aus. Hierzu werden in Zeile 600 und 800 Daten eingelesen. Diese Daten sind im unteren Bereich des Programms ab Zeile 1600 angegeben. Der Ort dieser DATA-Zeilen ist ohne Belang. Sie könnten genauso gut auch am Anfang des Programms oder verteilt im Programm auftauchen. Die Daten wurden hier, dem Programm entsprechend, in Zweiergruppen aus einer Menge und einem Preis angegeben. Für BASIC ist diese Gruppierung allerdings unwichtig. Nur die Reihenfolge entscheidet. Es könnten etwa alle Daten mit Komma getrennt innerhalb einer Zeile definiert werden. In Zeile 2000 steht eine 0 als Datum. Diese Null wird in der Programmlogik als Indikator dafür genutzt, dass keine weiteren Daten folgen. Wird diese Null in Zeile 600 gelesen, springt das Programm von Zeile 700 in Zeile 1100 und setzt mit der Ausgabe der Gesamtsumme fort. Würde man die Null weglassen, würde das Programm versuchen, weiter Daten einzulesen und mit einer Fehlermeldung abbrechen. Startete man das Programm, erhielt man eine Ausgabe folgender Art:
BASIC wurde – unter anderem von Studenten des College – intensiv weiterentwickelt. In der dritten Iteration im Jahre 1966 wurde der INPUT-Befehl eingeführt, der nun interaktive Programme ermöglichte. Wurde der Befehl ausgeführt, gab das System ein Fragezeichen aus. Der Nutzer konnte nun eine Eingabe machen. Mit einem Zeilenvorschub wurde die Eingabe beendet. Mit diesem INPUT-Befehl wurden nun Programme wie das folgende möglich:
100PRINT"RATE EINE ZAHL ZWISCHEN 1 UND 100."110LETX=INT(100*RND(0)+1)120LETN=0150PRINT"DEIN TIPP";160INPUTG170LETN=N+1180IFG=XTHEN400190IFG<XTHEN250200PRINT"ZU GROSS!"210GOTO150250PRINT"ZU KLEIN!"260GOTO150400PRINT"RICHTIG GERATEN!"410PRINT"DU HAST";N;"ZUEGE GEBRAUCHT"420END
Bei diesem Programm handelt es sich um ein einfaches Spiel. Die Aufgabe des Spielers ist es, eine Zahl zwischen 1 und 100 zu erraten. Der Computer gibt nach jedem Raten an, ob die geratene Zahl zu groß oder zu klein ist, bis die Zahl schlussendlich geraten wird. An einigen Merkmalen dieses Listings sehen Sie, wie sehr BASIC ganz auf fernschreiberbasierte Time-Sharing-Systeme ausgelegt ist. Das beginnt bereits bei der Wahl der Worte für die Befehle. PRINT bedeutet nicht neutral „Schreiben“, sondern eben das, was ein Fernschreiber tut, nämlich Drucken. Der Befehl INPUT erzeugt eine für Fernschreiberbedienung typische Eingabemöglichkeit. Ein Hinweiszeichen wird ausgegeben, das dem Nutzer anzeigt, dass eine Eingabe erwartet wird. Der Computer verarbeitet vorhandene Eingaben auf Zeilenbasis. Der Zeilenvorschub wird also zur Freigabe der Eingabe. Ebenfalls gut optimiert ist die Funktionsweise des Editors. Programmteile können durch das Definieren neuer Zeilen und das Überschreiben bestehender Zeilen verändert werden. Einblick in das Programm kann ganz oder auch in Teilen durch den Befehl LIST genommen werden. Diese Art, das Programm zu verbessern und zu ergänzen, ist einer Bedienung per Fernschreiber und der mit ihm verbundenen Nachteile sehr angemessen. Das Problem bleibt, ähnlich wie bei „ed“ oben, dass man das Programm nur im Überblick sieht, wenn man es „auslistet“. Wenn man es dann bearbeitet, ist diese Änderung natürlich nicht im vorher gedruckten Listing zu sehen. Man muss als Programmierer den aktuellen Zustand des Programmcodes also im Kopf haben oder häufig neue Listings anfordern.
Was ist geblieben?
Das Time-Sharing-System DTSS ist von seinem Funktionsumfang her ziemlich eingeschränkt. Es stellt seinen Nutzern lediglich eine Programmierumgebung bereit. Neben BASIC konnte auch in den wissenschaftlichen Programmiersprachen ALGOL und FORTRAN mit dem System programmiert werden. Spätere Time-Sharing-Systeme, die im Laufe der Jahre entstanden, waren weit umfangreicher. Sie boten dem Nutzer Zugriff auf eine Vielzahl von Systemprogrammen, verfügten über ausgefeilte Editoren und Compiler für eine Vielzahl von Programmiersprachen. Hinzu kamen Verwaltungsfunktionen für die Nutzer des Systems. Für jeden Nutzer mussten eigene Bereiche für das Speichern von Programmen und Daten vorgesehen und vor dem Zugriff durch andere Nutzer geschützt werden. Time-Sharing-Systeme in großen Organisationen wie Universitäten verfügten zudem oft über Einrichtungen zu Rechenzeit- und Plattenplatzbeschränkung (sogenannte „Quotas“), um einen Betrieb mit vielen Nutzern gewährleisten zu können.
Was ist geblieben von den Time-Sharing-Systemen der frühen Zeit, die doch heute einigermaßen altertümlich wirken? Es mag Sie vielleicht wundern, aber tatsächlich können viele der Eigenheiten heutiger Betriebssysteme auf die frühen Time-Sharing-Systeme zurückgeführt werden. Es lassen sich hier sehr klare Entwicklungslinien erkennen. Großen Einfluss hatte zum Beispiel das ab 1963 entwickelte Multics (Multiplexed Information and Computing Service). Viele der Innovationen dieses Betriebssystems, etwa ein hierarchisches Dateisystem, fanden Eingang in das Betriebssystem UNIX, das beim amerikanischen Telefonmonopolisten AT&T ab 1969 entwickelt wurde. UNIX, ebenfalls ein Time-Sharing-System, hatte starken Einfluss auf das PC-Betriebssystem MS-DOS und damit auch auf Windows. Schlussendlich basiert das freie Betriebssystem Linux ebenfalls auf den Konzepten von UNIX.
Ein weiteres einflussreiches frühes Time-Sharing-System war das System TOPS-10 von 1967, das auf Großrechnern der Digital Equipment Corporation, kurz DEC, lief. Die für die damalige Zeit sehr benutzerfreundliche Arbeitsweise dieses Systems war Grundlage für das Betriebssystem OS/8 für die Minicomputer von DEC. Dieses OS/8 wiederum inspirierte Gary Kildall bei der Entwicklung des Betriebssystems CP/M, das auf frühen Microcomputern sehr große Verbreitung fand. CP/M wiederum war die Vorlage für Microsofts MS-DOS und MS-DOS blieb lange Zeit die technische Basis von Windows. Noch heute entspricht der Kommandozeilen-Interpreter von Windows, die „Eingabeaufforderung“, der Funktionsweise der MS-DOS-Kommandozeile. In dieser Eingabeaufforderung können Sie zum Auflisten von Dateien den Befehl dir eingeben. Diesen können Sie durch die ganze Kette über MS-DOS, CP/M, und OS/8 bis zu TOPS-10 zurückverfolgen.
Auch wenn Sie diese konkreten Befehle einmal außer Acht lassen, sind die Kommandozeilen heutiger Betriebssysteme Werkzeuge, die ihren Großvätern und Urgroßvätern aus der Time-Sharing-Ära sehr ähneln. Öffnen Sie doch einmal die Eingabeaufforderung von Windows oder ein Terminal unter MacOS oder Linux und probieren Sie einige Befehle aus. Bei dem ständigen Hin und Her zwischen der Eingabezeile und den Ausgaben des Systems können Sie mit etwas Fantasie noch regelrecht den Fernschreiber rattern hören…
Terminals statt Fernschreiber
Ich fasse noch einmal zusammen: Durch Fernschreiber, die mit Computern im Time-Sharing-Betrieb verbunden wurden, war die interaktive Nutzung von Computern bei gleichzeitiger Erfüllung der hohen Anforderungen an Durchsatz und Rechenleistung möglich. Turnaround-Zeiten sanken von Tagen und Stunden auf Minuten und Sekunden und mittels Editoren konnten die Computer als Werkzeug zum Schreiben der Programme verwendet werden, die dann später auf dem Computer auch gleich gestartet werden konnten. Der Fernschreiber oder die elektrische Schreibmaschine als Ein- und Ausgabegerät hatten aber ihre Nachteile, denn Fernschreiber und Schreibmaschinen erzeugten ein analoges Medium durch Einschreibung von Schriftzeichen auf ein Endlospapier. Innerhalb des Computers wurden durch die interaktive Software virtuelle Objekte erzeugt, die durch den Nutzer sehr dynamisch änderbar waren, doch nach außen hin ließen sich diese Objekte nicht mit den gleichen dynamischen, manipulierbaren Eigenschaften darstellen. Man konnte zum Beispiel einen im Computer gespeicherten Text ändern, aber man konnte mit dem Fernschreiber eben nicht den schon ausgegebenen Text auf dem Papier ändern. Die Konsequenz aus dieser Lücke zwischen der flexiblen Welt im Computer und der statisch eingeschriebenen Welt der Nutzungsschnittstelle war, dass Änderungen der virtuellen Objekte im Computer nur dadurch vorgenommen werden konnten, dass die Änderungen sprachlich beschrieben wurden. Sich dabei ergebende Änderungen konnten nicht direkt, sondern nur vermittelt über eine Anforderung des Nutzers und eine Antwort in Form eines Ausdrucks des Systems wahrgenommen werden.
Die geschilderte kommandoorientierte Arbeitsweise lässt sich ein bisschen mit dem Bestellen von Pizza vergleichen. Stellen Sie sich vor, Sie rufen bei einer Pizzeria an, von der Sie keine dieser praktischen, faltbaren Papierkarten bei sich zu Hause haben. Sie wollen dort Pizza bestellen. Wir denken uns nun einen sehr fantasielosen Angestellten der Pizzeria, der immer nur genau das tut, was Sie ihm sagen. Vor seiner Nase hat dieser Angestellte der Pizzeria die komplette Speisekarte, einen Zettel und einen Stift, um aufzuschreiben, was Sie gerne haben möchten. Sie sehen von all dem natürlich nichts, denn Sie haben ihn ja am Telefon. Wie kommen Sie nun zu Ihrem Essen?
Zunächst einmal müssen Sie fragen, was Sie überhaupt bestellen können, also vielleicht erst einmal, welche grundsätzlichen Gruppen an Gerichten es gibt, also Nudeln, Pizza, Fischgerichte und so weiter. Letztlich können Sie durch mehrfaches Nachfragen so hinter die Inhalte der Speisekarte kommen und etwas auswählen.
Nun geben Sie einige Bestellungen auf. Natürlich wissen Sie für viele der Gerichte nicht genau, welche Zutaten sie haben, welche Pizza etwa welchen Belag hat. Sie müssen also wieder einmal – und wahrscheinlich öfter – nachfragen.
Die Antwort zu einem Gericht Ihrer Wahl gefällt Ihnen vielleicht nicht. Brokkoli? Kann man das nicht durch Paprika ersetzen? Wieder müssen Sie nachfragen und gegebenenfalls eine entsprechende Anweisung geben.
Was hatten Sie jetzt gleich alles bestellt? Haben Sie vielleicht etwas vergessen? Hat Ihr Gegenüber Sie immer richtig verstanden? Haben Sie sich vielleicht versprochen? Da Sie den Zettel Ihres Gegenübers auf der anderen Seite nicht sehen können, bleibt Ihnen nur, sich die Bestellung nochmal vorlesen zu lassen.
Wo Sie sich das jetzt nochmal so anhören, fällt Ihnen auf, dass die überbackenen Nudeln vielleicht doch etwas mächtig sein könnten. Sie bitten darum, diese zu streichen und bestellen lieber eine Pizza Margherita. Wurde das richtige Gericht entfernt? Sie ahnen es schon – Sie müssen wieder nachfragen.
So kompliziert ist es bei Ihnen nicht, wenn Sie etwas bestellen? Wahrscheinlich nicht, denn Sie haben eventuell eine App oder eine Speisekarte der Pizzeria zu Hause, auf der Sie sehen können, was zur Auswahl steht und auch, welche Anpassungen an den Gerichten Sie vornehmen können. Außerdem weiß Ihr Gegenüber natürlich um die Probleme der Bestellungen dieser Art und denkt mit, wiederholt etwa, was er verstanden hat und gibt gegen Ende der Bestellung von selbst eine Zusammenfassung. In dieser Situation sind Sie bei der Nutzung des Computers nicht. Sie haben keinen Einblick in die komplette Auswahl, die Ihnen das System bietet, und der Kommandozeilen-Interpreter ist leider – vielleicht auch Gott sei Dank – sehr schlecht darin, für Sie mitzudenken und zu erkennen, wenn Sie etwas versehentlich getan haben.
Terminals und räumliche Objekte
ADM-3A – Bild: FreeImages.com/Konrado Fedorczyko
Die Probleme dieser sprachlich-indirekten Interaktion mit dem Computer können mit der Einführung von Terminals mit Bildschirm und Tastatur überwunden werden, denn das Terminal erlaubt Ihnen eine dauerhafte, räumliche Darstellung und Manipulation von virtuellen Objekten der Nutzungsschnittstelle.
Die Entwicklung von Terminals ist ein in der Computergeschichte tendenziell zu wenig betrachteter Bereich. Man könnte ohne Weiteres ganze Bücher nur über die Entwicklung von Terminals und ihren Einfluss auf die Entwicklung von Nutzungsschnittstellen schreiben, denn spätere Terminals wurden mit eigenen Prozessoren, einem eigenen Betriebssystem und Speichermedien ausgestattet und wurden damit quasi zu Personal Computern. Wir wollen es vorerst aber nicht so weit treiben und uns auf die einfachen Geräte wie das rechts abgebildete ADM-3A von Lear Siegler beschränken. Dieses Gerät ist kein Computer, sondern nur ein Terminal. Ein solches Gerät konnte anstelle eines Fernschreibers an einen Computer angeschlossen werden und dann zunächst einmal genau so wie dieser verwendet werden. Anstelle eines Ausdrucks wurden die Zeichen auf dem Bildschirm ausgegeben. War der Bildschirm vollgeschrieben, rutschten die Zeichen automatisch nach oben. Terminals mit zusätzlichem Speicher erlaubten sogar das Scrollen nach oben, um wie beim Papierausdruck das vorher Ausgegebene ansehen zu können. Das hier gezeigte ADM-3A konnte 24 Zeilen zu je 80 Zeichen anzeigen und unterstützte im Gegensatz zur Version ohne das A am Ende nicht nur Großbuchstaben, sondern auch Kleinbuchstaben. 80 Zeichen pro Zeile bedeutet, dass die komplette Breite des US-Letter-Formats oder auch des DIN-A4-Formats dargestellt werden konnte.
Häufig wurden Terminals dieser Art zunächst als Ersatz für einen Fernschreiber, aber sonst genauso wie dieser, eingesetzt. Der Betrieb war leiser, es wurde nicht so viel Papier verbraucht und ein Terminal war auch erheblich kleiner als ein Fernschreiber. Wenn man es bei der fernschreiberartigen Betriebsart beließ, wurde das Potenzial des neuen Geräts aber gar nicht genutzt. Scherzhaft wurde dann der Begriff „Glass Teletype“ verwendet, denn das Terminal war dann funktionsidentisch mit einem Teletype, also einem Fernschreiber, nur dass das Papier eben aus Glas war. Der eigentliche innovative Vorteil von Terminals dieser Art lag aber nicht im Sparen von Papier, sondern in der Möglichkeit, Zeichen nicht nur ausgeben, sondern auch löschen und überschreiben zu können, und damit vor allem darin, den Cursor frei auf dem Bildschirm positionieren zu können. Diese Positionierungstechnik erlaubte es, die Buchstaben auf dem Bildschirm zu arrangieren und dieses Arrangement flexibel zu aktualisieren. Diese Art der Terminal-Nutzung, bei der mit Steuerzeichen der Bildschirm gelöscht werden und der Ein- und Ausgabecursor frei positioniert werden konnte, war damit die Grundlage von sich aktualisierenden Statusanzeigen, Formularmasken am Bildschirm, Menüs, Editoren, bei denen der bearbeitete Text am Bildschirm dauerhaft zu sehen und zu bearbeiten ist, und vielem Weiteren mehr, was für uns heute an den Nutzungsschnittstellen der Computer selbstverständlich erscheint.
Dumme und intelligente Terminals
Bei dem ADM-3A – ADM steht übrigens für American Dream Machine – handelte es sich um ein Gerät, das man als „Dumb Terminal“ bezeichnete. Der Hersteller Lear Siegler verwendete diesen Ausdruck sogar in der eigenen Werbung für das Gerät, allerdings mit dem Kniff, dass die Verwendung eines solchen dummen Terminals doch eine sehr intelligente Sache sei. Wenn es „dumb terminals“ gab, musste es natürlich andere Terminals gegeben haben, die weniger dumm waren. In der Tat gab es die und ganz folgerichtig wurden sie „intelligent terminals“ genannt.
Den Unterschied zwischen den beiden Terminal-Arten kann man sich an einem Beispiel gut klarmachen: Stellen Sie sich ein Programm vor, in dem Sie ein Formular ausfüllen können, sagen wir, für eine Lieferung. Beim Dumb Terminal füllte das Programm den Bildschirm des Terminals mit den Zeichen der Eingabemaske, positionierte dann den Cursor beispielsweise an die Position hinter „Nachname:“ und wartete auf Eingaben des Nutzers. Das Programm merkte sich dabei, dass nun das Eingabefeld „Nachname“ ausgefüllt wird. Tippte der Nutzer nun ein „F“ ein, verarbeitete der Computer diese Eingabe, aktualisierte die Eingabevariable und schrieb ein F auf den Bildschirm. Folgte nun ein Backspace, verarbeitete der Computer auch dies und löschte das F wieder aus dem Speicher und vom Bildschirm. So ging das für alle eingegebenen Zeichen weiter. Erst wenn irgendwann die Eingabe mit ENTER abgeschlossen wurde, speicherte das Programm die bisherige Eingabevariable in eine Programmvariable, positionierte dann den Cursor hinter „Vorname:“ und das Spiel begann von Neuem. Sie merken sicher, dass der Programmieraufwand und damit auch der Ausführungsaufwand während der Nutzung bei einem solchen Programm hoch war, denn das System musste jede einzelne Eingabe interpretieren, in Ausgaben umsetzen, den Cursor positionieren und so weiter.
Beim Einsatz eines „intelligent terminals“ war der Aufwand auf dieser Ebene viel geringer. Wurde zum Beispiel ein ADM-1 oder ein Datapoint 3300 verwendet, wurde vom Programm eine komplette Bildschirmmaske übertragen, die auch Informationen darüber enthielt, welche Bereiche für den Nutzer manipulierbar waren und welche nicht. Das Terminal selbst übernahm die Eingabekontrolle innerhalb der festgelegten Felder. Wenn ein Nutzer etwas in ein mehrzeiliges „Bemerkungen“-Feld tippte, konnte er darin beliebig Korrekturen vornehmen, Zeichen oder gar ganze Zeilen einfügen, ohne dass das Computerprogramm mit dieser Bearbeitung etwas zu tun hatte. Erst beim Betätigen einer Sende-Taste, oft auch „Datenfreigabe“ genannt, wurden die Daten an das Time-Sharing-System übertragen. Intelligente Terminals sparten dadurch erheblich Aufwand bei der Anwendungsprogrammierung und „Rechenzeit“ bei der Programmausführung, da viele der Standardverarbeitungen der Texteingabe an das Terminal selbst abgegeben wurden. Sie können das etwa mit dem Programmieren eines Eingabeformulars für eine Website vergleichen. Auch hier verwenden die Nutzer eine Art intelligentes Terminal, nämlich einen Webbrowser. Sie müssen sich als Programmierer einer Website nicht mit Details wie der Eingabe des Nutzers auf der Ebene der Eingabe von Buchstaben auf der Tastatur beschäftigen, sondern können darauf bauen, dass Browser und Betriebssystem die entsprechenden Funktionen zur Verfügung stellen. Sie behandeln erst wieder die fertige Eingabe des Nutzers.
Die Verwendung von Intelligent Terminals scheint sehr sinnvoll zu sein. Dumb Terminals waren dennoch viel verbreiteter und haben die Nutzungsschnittstellen stärker weitergebracht. Warum war das so? Zum einen waren diese Terminals natürlich erheblich günstiger, was gerade dann, wenn in einer Organisation viele Terminals genutzt werden sollten, natürlich ein nicht zu unterschätzender Vorteil war. Der zweite Vorteil betraf auf der anderen Seite die Einsatzbereiche der Terminals. Intelligent Terminals entfalteten ihren größten Vorteil bei klassischen Masken, also Eingabeformularen mit vielen Datenfeldern. Dumb Terminals waren darauf hingegen nicht festgelegt, denn sie konnten alles darstellen und verarbeiten, was mit einer dynamischen Text-Ein-und-Ausgabe denkbar war, und waren nicht auf die Eingabeformate beschränkt, die ihnen das Terminal vorgab. Einen Editor, wie den im Folgenden vorgestellten „vi“, können Sie zum Beispiel kaum mit den Funktionalitäten eines intelligenten Terminals umsetzen. Natürlich konnten Sie ein intelligentes Terminal auch wie ein Dumb Terminal betreiben, doch gingen dann alle Vorteile verloren. Andersherum können Sie die Funktionalität eines Intelligent Terminals, genug Rechenleistung vorausgesetzt, gut mit Software simulieren.
Direkte Manipulation: Visuelle Editoren
Wir haben uns ein paar Seiten zuvor angesehen, wie man einen Text mit dem Unix-Editor „ed“ bearbeiten kann. Sein Nutzungsparadigma ist noch heute auf einfache Terminals und Fernschreiber ausgelegt. Wir wagen nun, ausgestattet mit einem Terminal wie dem ADM-3A, den Schritt zu einem visuellen Editor.
Von „ed“ zu „vi“
Der Unix-Editor vi im Insert-Modus
Der oben abgebildete Unix-Editor „vi“ aus dem Jahr 1976 – „vi“ steht für „visual“ – ist dem Editor „ed“ im Grunde von der Funktionsweise her gar nicht unähnlich. Im Gegensatz zu „ed“ sieht man bei „vi“ jedoch einen Ausschnitt des Textes dauerhaft am Bildschirm. „vi“ erlaubt es auch, einen Cursor im Text zu positionieren, dann in einen Einfügemodus zu wechseln und neue Textinhalte an der Stelle des Eingabecursors einzufügen. In einem Befehlsmodus erlaubt „vi“ die Eingabe von Befehlen in eine Befehlszeile am unteren Bildschirmrand. Das Resultat dieser Befehle, zum Beispiel das Ersetzen eines Wortes durch ein anderes, wird in „vi“ sofort als Änderung des dargestellten Textes angezeigt. Die Bedienung des „vi“ ist für heutige Maßstäbe kryptisch und kompliziert, doch verwirklicht der Editor, ganz seinem Namen entsprechend, die Potenziale von am Bildschirm dauerhaft sichtbaren und auch dort bearbeitbaren Zeichen. Zwar erlaubt der Editor die Eingabe von Befehlen, doch müssen diese nicht mehr für das Einfügen genutzt werden und auch für die Ausgabe ist es nicht mehr nötig, die Zeilennummer im Text zu kennen. „vi“ unterstützt weiterhin die Manipulation von Texten per Befehl. Fans von „vi“ mögen den Editor oft gerade wegen dieser Möglichkeit, Textmanipulationen per Kommando durchführen können. In der Tat kann dies gerade bei komplexen Operationen und wenn man sich gut auskennt, sehr schnell von der Hand gehen, denn „vi“ erlaubt Textumformungen per regulärer Ausdrücke. Für Unkundige sehen diese Befehle allerdings oft so aus, als sei jemand auf die Tastatur gefallen.
Vergleicht man die Ur-Version von „vi“ mit der Funktionalität heutiger Text-Editoren, bemerkt man, dass eine heute ganz grundlegende Eigenschaft noch fehlt: Der große Vorteil der Textbearbeitung an Terminals war ja, dass der ausgegebene Text selbst direkt an Ort und Stelle bearbeitet werden konnte. Statt eines Befehls der Art „Füge in Zeile 20 nach dem 4. Wort ein Komma ein“, konnte mit dem Cursor an diese Stelle navigiert und das Komma eingefügt werden. Jeder moderne Editor unterstützt diese Arbeitsweise – auch „vi“. Was bei „vi“ aber nicht ging, war die räumliche Markierung eines Textausschnitts und das Anwenden eines Manipulationsbefehls auf diesen Bereich. Wenn Sie heute auf einem Linux- oder Unix-basierten System „vi“ eingeben, öffnet sich ein Editor, den Sie genau wie zuvor beschrieben verwenden können. Es handelt sich aber in der Regel nicht mehr um den „vi“ aus den 1970er Jahren, sondern um eine erweiterte Version mit Namen „vim“ (für „vi improved“). Ende der 1980er Jahre wurde der klassische Editor in vielerlei Hinsicht erweitert. Unter anderem gibt es nun einen Modus, der eine räumliche Selektion von Textteilen erlaubt. Die selektierten Textteile werden invertiert dargestellt. Dieses Selektieren unter „vim“ funktioniert folgendermaßen:
Sicherstellen, dass Sie sich im Befehlsmodus befinden. Den Einfügemodus gegebenenfalls durch ESC verlassen,
den Cursor am Beginn des Blocks positionieren,
durch Eingabe von SHIFT+v die komplette Zeile, durch STRG+v den kompletten Block markieren oder
v eingeben, um den Blockanfang festzulegen,
mit dem Cursor zum Blockende navigieren,
d (delete) eingeben, um den Block auszuschneiden oder y (yank), um ihn zu kopieren,
mit dem Cursor zur Zielposition navigieren,
p (paste) eingeben, um den Block hier einzufügen.
Die Möglichkeit der räumlichen Selektion der auf dem Bildschirm angezeigten Elemente ermöglicht hier die direkte Manipulation. Klassischerweise wird dieser Begriff „direkte Manipulation“ mit Maus-Interaktion und grafischen Darstellungen verbunden17. Im Prinzip reicht aber ein Text-Terminal aus, insofern Objekte räumlich dargestellt und auch räumlich selektiert und manipuliert werden können. Das ist bei „vi“ der Fall. „Direkte Manipulation“ bedeutet, dass der Handlungs- und der Wahrnehmungsraum gekoppelt sind. Objekte werden bei „vi“ an einem Ort am Bildschirm angezeigt, werden an ebendiesem Ort selektiert und an Ort und Stelle manipuliert. Wenn „vi“ allerdings im Befehlsmodus verwendet wird, ist das nicht so, denn dann werden die Manipulationen in einer Befehlszeile eingegeben, wirken sich aber auf Objekte an anderer Stelle aus.
Experimentelle grafische Systeme
Die bis hierhin beschriebenen interaktiven Computersysteme mit angeschlossenen Fernschreibern oder später mit Text-Terminals beschränkten sich in ihrer Schnittstelle auf rein textuelle Ein- und Ausgaben oder allenfalls auf Textzeichen, mit denen eine Art Pseudo-Grafik erzeugt werden konnte.
Im „vim“-Beispiel des vorherigen Kapitels wurde ein Cursor räumlich positioniert, um Objekte am Bildschirm zu selektieren. Eine solche Selektion per Cursor-Tasten ist innerhalb von Texten praktikabel, in vielen Fällen aber jedoch recht umständlich und indirekt. Von Smartphones kennen Sie heute alle eine erheblich direktere Methode, nämlich das Zeigen auf ein Objekt mit dem Finger. Es ist durchaus erstaunlich, dass etwas ganz Ähnliches bereits in den 1950er Jahren erdacht und genutzt wurde. Zwar brauchte das Zeigen damals noch ein Zusatzgerät, doch dieses Zusatzgerät konnte damals schon direkt auf den Bildschirm gerichtet werden. Die Anfänge dieser direkten räumlichen Selektion und der grafischen Darstellung von Informationen liegen, wie oft in der Computergeschichte, beim Militär.
Whirlwind und SAGE
Der erste Lightpen – Bild: Mitre Corporation
Mitte der 1940er bis Anfang der 1950er Jahre entwickelte das Massachusetts Institute of Technology (MIT) einen Echtzeitcomputer für die US Navy. Er war zunächst als Flugsimulator geplant, wurde dann später aber für die Anforderungen der Flugüberwachung neu konzipiert. Dieser „Whirlwind“-Computer war in vielerlei Hinsicht technisch beachtenswert, schon allein weil es sich um einen Echtzeit-Computer handelte, der laufend Daten verarbeitete, anzeigte und Eingaben erwartete. Whirlwind konnte unter anderem auch Speicherinhalte auf dem Bildschirm eines Oszilloskops zur Anzeige bringen. Das war für sich genommen nicht außergewöhnlich. Selbst der britische EDSAC von 1945 verfügte schon über eine solche Einrichtung, bei der Speicherinhalte des Computers als Punkte auf einem Bildschirm angezeigt werden konnten. Eine Innovation war jedoch die Entwicklung eines stiftartigen Geräts, „Lightpen“ oder zu Deutsch „Lichtgriffel“ genannt. Das einfache Instrument ist rechts abgebildet. Mit diesem Stift konnte auf Punkte auf dem Bildschirm gezeigt werden. Der Computer konnte die Position des Stiftes auf dem Bildschirm erkennen und somit das Speicherbit, auf das gezeigt wurde, identifizieren.
Der Lightpen war eine genial einfache Konstruktion, die sich die Funktionsweise von Monitoren mit Bildröhre zunutze machte. Stifte dieser Art bestanden im Prinzip nur aus einer einfachen Fotozelle, die an der Spitze des Stiftes angebracht war. Der Stift selbst kann also nur feststellen, ob es an der Spitze des Stiftes hell ist oder nicht. Bei einem Monitor mit Kathodenstrahlröhre, also etwa auch bei den alten, klobigen Fernsehern, wurde ein Bild dadurch erzeugt, dass ein Elektronenstrahl Punkte auf einer fluoreszierenden Schicht auf der Vorderseite der Röhre zum Leuchten bringt. Der Bildaufbau erfolgte dabei wie ein geschriebener Text Zeile für Zeile von links nach rechts und von oben nach unten. Dies geschah allerdings so schnell, dass man mit bloßem Auge den Bildaufbau nicht erkennen konnte. Zeigte man nun mit einem Lightpen auf eine Stelle auf einem erleuchteten Bildschirm, wurde die Fotozelle zu einem spezifischen Zeitpunkt hell beleuchtet. Durch präzise Messung dieses Zeitpunktes und den Abgleich mit dem Wissen, wann die Darstellung des Bildes in der oberen linken Ecke begann, konnte errechnet werden, auf welche Bildschirmposition der Lightpen gerade zeigte. Der Lightpen des Whirlwind-Computers war allerdings noch nicht als Eingabegerät für die eigentliche Funktionalität des Computers gedacht, sondern wurde zu Fehlerbehebungszwecken genutzt.
Eine Weapons Director Console – Bild mit freundlicher Genehmigung des Computer History Museums
Der Whirlwind-Computer war die Grundlage für das in den 1950er Jahren vom MIT und IBM aufgebaute SAGE-System. SAGE steht für Semi-Automatic Ground Environment. Das Herzstück von SAGE waren zwei riesige, von IBM hergestellte Computer. Die beiden Systeme arbeiteten parallel, um Computerfehler und Ausfälle möglichst auszuschließen. Die Aufgabe des SAGE-Systems war die Luftraumüberwachung. Feindliche sowjetische Flugzeuge sollten erkannt und gegebenenfalls Abwehrmaßnahmen eingeleitet werden können. Eine einfache Radarüberwachung des Luftraums konnte das nicht gut leisten, da mit einer üblichen Radaranlage immer nur recht kleine Bereiche überwacht werden konnten und es zum damaligen Zeitpunkt bereits viele völlig ungefährliche militärische und zivile Flugbewegungen gab.
Lightgun – Bild mit freundlicher Genehmigung des Computer History Museums
Ein verdächtiges Radar-Echo konnte so leicht in der Fülle der Informationen untergehen. Um die Luftraumüberwachung zu verbessern, wurden die Daten vieler verteilter Radarstationen im SAGE-Computer zusammengeführt. Diese Daten wurden mit den vorhandenen Informationen über gemeldete Flugbewegungen abgeglichen. Alles für ungefährlich Erachtete wurde herausgefiltert, sodass nur noch Informationen über abweichende, potenziell feindliche Flugzeuge übrigblieben. Der Luftraum wurde mit einer Vielzahl spezieller Konsolen überwacht. Oben abgebildet sehen Sie eine Weapons Director Console. Zentral war ein Bildschirm, ein sogenanntes „View Scope“, der der Radartechnik entliehen wurde. Er zeigte die vom Computer berechneten Daten, also etwa eine Karte vom Umriss des Geländes und die Positionen von eventuell feindlichen Flugzeugen an. Die Soldaten, die an diesen Konsolen saßen, konnten mittels eines Zeigegeräts Objekte auf dem Bildschirm auswählen. Sie nutzten dafür eine sogenannte „Lightgun“, die sie auf den Bildschirm hielten und „abdrückten“. Die vielen Knöpfe rund um den Bildschirm erlaubten es unter anderem, auf das markierte Objekt bezogene Funktionen aufzurufen, also etwa die bisherige Route des Flugobjektes anzuzeigen, oder die aktuelle Route virtuell in die Zukunft fortzusetzen. Schlussendlich konnten auf diese Weise Ziele zum Abfangen durch Raketen vorgemerkt werden.
TX-0 und TX-2
In Zeiten des Kalten Krieges beflügelten sich zivile und militärische Forschung oft gegenseitig. Das Lincoln Lab des MIT, an dem Whirlwind gebaut wurde und das am SAGE-System beteiligt war, entwickelte 1955 bis 1956 eine experimentelle, transistorbasierte Version des Whirlwind-Computers mit dem Namen TX-0 (Transistorized Experimental Computer Zero). Mit dem System wurden neue Ansätze zur Mensch-Maschine-Interaktion exploriert. Es verfügte wie der Whirlwind über eine grafische Ausgabe mittels eines an die Radartechnik angelehnten Bildschirms. Er diente nun aber nicht mehr nur der Fehlerbehebung, sondern wurde auch als reguläre Ausgabemöglichkeit genutzt. Wie beim SAGE-System konnte ein Gerät zur räumlichen Eingabe an diesem Bildschirm genutzt werden. Im nicht-militärischen Kontext wurde dafür nun wieder der Begriff „Lightpen“ verwendet.
Der TX-0 hatte zwei direkte Nachfolger. Zum einen wurde am Lincoln Lab mit dem TX-2 ein weiterer experimenteller Rechner entwickelt und 1958 in Betrieb genommen. Aus den Erkenntnissen des TX-0 und einigen Einflüssen des TX-2 entstand aber auch der erste kommerzielle Rechner mit grafischer Ein- und Ausgabe, die PDP-1 der Firma Digital Equipment (DEC), von der später noch einmal die Rede sein wird. An den drei Systemen, dem TX-0, dem TX-2 und der PDP-1, wurde am MIT in den 1950er und 1960er Jahren an so fortschrittlichen Ideen wie Handschrifterkennung, grafischen Texteditoren, interaktiven Debuggern (Programmen zum Finden und Entfernen von Programmfehlern), Schachprogrammen und anderen frühen Projekten der sogenannten „künstlichen Intelligenz“ gearbeitet.
Eines der Projekte, das wegweisend für die Entwicklung von Nutzungsschnittstellen mit räumlich-grafischer Anzeige und Objektmanipulation war, war das „Sketchpad“-System, das 1963 von Ivan Sutherland im Rahmen seiner Doktorarbeit konzipiert und umgesetzt wurde. Das Foto unten zeigt einen Wissenschaftler des MIT am auf dem TX-2 laufenden Sketchpad-System. In der Hand hat er einen Lightpen. Mit diesem Stift konnten grafische Objekte erzeugt und manipuliert werden. Dies geschah durch Zeigen auf einen Punkt und die Betätigung einer der Tasten auf der Tastatur auf der linken Seite. Auf diese Art und Weise konnten Strecken oder Kreise aufgezogen werden. Beschränken wir uns hier beispielhaft auf Strecken. Um eine Strecke zu zeichnen, wurde der Stift zum gewünschten Startpunkt bewegt und eine Taste auf der Tastatur gedrückt. Nun wurde der Stift zum Endpunkt der Strecke bewegt. Das System zeichnete während dieses Erzeugungsprozesses fortlaufend eine gerade Linie zwischen dem Startpunkt und der aktuellen Position des Stifts auf dem Bildschirm. Ein Tastendruck fixierte auch diesen Punkt, der dann wiederum zum Ausgangspunkt der nächsten Strecke wurde. Dieser Prozess konnte abgebrochen werden, indem der Stift vom Bildschirm genommen wurde.
Alle Punkte von Strecken und den anderen geometrischen Figuren konnten auch im Nachhinein noch bearbeitet werden. Dafür musste ein Punkt zunächst ausgewählt werden. Dies geschah durch Zeigen mit dem Lightpen. Der Punkt musste dabei nicht ganz genau getroffen werden, was sich hätte schwierig gestalten können. Das System unterstützte die Auswahl eines Punkts dadurch, dass auch die unmittelbare Umgebung des Punktes dem Punkt zugeordnet wurde. Ein Auswahlcursor, der unter der Stiftposition angezeigt wurde, sprang in diesem Fall auf den Punkt, um anzuzeigen, dass sich die folgenden Manipulationen auf diesen Punkt beziehen würden. Auch wenn mit dem Stift also leicht neben den Punkt gezeigt wurde oder wenn die Abtastung nicht genau war, konnte ein Punkt präzise selektiert werden. War ein Punkt selektiert, konnte dieser durch Betätigen einer Taste in einen Verschiebezustand gebracht werden, der wiederum per Tastendruck oder durch Wegnehmen des Stiftes beendet wurde. Auch bei dieser Operation wurde während des kompletten Manipulationsvorgangs die Zeichnung laufend aktualisiert, sodass der Sketchpad-Nutzer jederzeit fortlaufend über die Konsequenzen seiner Manipulation auf dem Laufenden war.
Timothy Johnson nutzt Sketchpad an einem TX-2 – Bild: Computer Sketchpad, National Education Television, MIT 1964
Diese direkte Manipulation setzt eine Reihe von technischen Gegebenheiten voraus, die zur Zeit von Sketchpad noch alles andere als selbstverständlich waren.
Objekte mussten dauerhaft und stabil sichtbar gemacht werden. Hierfür bedurfte es eines Bildschirms und einer Ansteuerung desselben, die es ermöglichen, die Zeichen oder Grafiken in so schneller Folge zur Anzeige zu bringen, dass sie für das menschliche Auge als stabile Objekte erschienen.
Die Objekte mussten räumlich selektiert werden können. Es bedurfte also eines räumlichen Eingabegeräts, das sich auf Koordinaten am Bildschirm beziehen konnte. Diese Rolle übernahm bei Sketchpad der Lightpen des TX-2. Darüber hinaus brauchte es eine Programmierung, die diese Koordinaten den am Bildschirmort vorhandenen Objekten zuordnen konnte.
Räumliche Manipulationen mussten umgehend in Manipulationskommandos übersetzt werden, die wiederum unverzüglich für eine Aktualisierung der Darstellung sorgten, denn nur durch die schnelle und unmittelbare Verarbeitung konnte der Eindruck einer direkten Manipulation erreicht werden. Wäre es in solchen Abläufen zu Verzögerungen gekommen, wäre ein präzises Arbeiten nicht mehr möglich gewesen. Um diesen extrem hohen Grad der Responsivität zu erreichen, entwickelte Sutherland eine performante Datenstruktur18, die in Kombination mit der hohen Rechenleistung der Maschine, die entsprechende Verarbeitungsgeschwindigkeit erlaubte.
Für Sketchpad entwickelte Sutherland neben den geschickten Datenstrukturen, die die direkte Manipulation ermöglichten, eine Vielzahl anderer spannender Konzepte, die sich auch noch in heutigen CAD-Systemen (Computer Aided Design) wiederfinden. All diese würden sicher eine umfangreiche Betrachtung verdienen, können hier aber nur exemplarisch und in aller Kürze aufgezählt werden. Beachtenswert ist etwa:
Beim Zeichnen geometrischer Strukturen konnten Zwangsbedingungen, sogenannte „Constraints“, definiert werden. Ein Zeichner konnte zum Beispiel festlegen, dass der Winkel zwischen zwei Strecken neunzig Grad betragen muss, dass zwei Strecken gleich lang sein sollen oder dass Linienführungen parallel zueinander verlaufen müssen.
Sketchpad bot seinen Nutzern nicht nur mehrere virtuelle Zeichenblätter, zwischen denen umgeschaltet werden konnten. Jedes dieser Zeichenblätter war zudem noch erheblich größer als die Darstellung auf dem Bildschirm. Sketchpad erlaubte es, den sichtbaren Ausschnitt zu verschieben und die Granularität der Anzeige zu verändern, also zu zoomen.
Bei Sketchpad konnten Objekte aus Teilobjekten zusammengesetzt werden. Ein auf einem der virtuellen Zeichenblätter erzeugtes Objekt konnte in ein anderes Blatt in beliebiger Größe und Rotation eingefügt werden. Die auf diese Art eingefügten Objekte waren keine Kopien, sondern Referenzen auf das Ursprungsobjekt. Änderungen an einem der Teilobjekte wurden somit automatisch in alle zusammengesetzten Objekte übernommen. Ein Sketchpad-Nutzer konnte zum Beispiel auf einem Zeichenblatt ein Fenster zeichnen, auf dem zweiten eine Tür und auf dem dritten ein Haus. Für das Haus verwendete er die vorher gestalteten Komponenten. Kehrte er nun zum Zeichenblatt der Tür zurück und verfeinerte die Darstellung durch Hinzufügen eines Schlosses und einer Klinke, hatte auch das Haus auf dem dritten Blatt ein Schloss und eine Klinke in seiner Tür.
Das Vermächtnis von SAGE, Sketchpad und Co.
Die technischen Gegebenheiten des TX-2, die eine Software wie Sketchpad ermöglichten, waren zum damaligen Zeitpunkt herausragend. Es handelte sich um ein experimentelles System, auf dem genau solche Versuche durchgeführt werden konnten. Der große Rest der Computerwelt war noch lange Zeit ganz anders als diese Rechner mit ihrer direkten Nutzerinteraktion.
DEC PDP-1 im Computer History Museum – Bild: Alexey Komarov (CC BY-SA 4.0)
Die Entwicklung vom Whirlwind über SAGE und TX-0 zum TX-2 und entsprechender innovativer Software führte 1959 zur Entwicklung der PDP-119, dem ersten Minicomputer, den man käuflich erwerben konnte. Das Foto oben zeigt eine voll ausgestattete PDP-1. Der eigentliche Computer ist das schrankartige Gebilde auf der linken Seite. Im unteren Bereich des Rechners sehen Sie das Bedienfeld zur Steuerung. Darüber befand sich ein Lochstreifenleser. DEC verwendete Lochstreifen mit einer speziellen Faltung. Sie sehen einige dieser Lochstreifen in der Halterung über dem Leser. Ebenso wie beim TX-0 und dem TX-2 stand bei der PDP-1 die Interaktion im Fokus. Ein- und Ausgaben erfolgten also nicht nur über das Bedien-Panel, sondern auch über eine angeschlossene elektrische Schreibmaschine oder über Bildschirm und Lightpen. Sie sehen beides rechts im Bild. Auch hier wurde wieder auf die bewährte Technik aus dem Radarbereich zurückgegriffen. Mit 53 Exemplaren war die PDP-1 noch kein wirklich viel verkaufter Rechner. Mit einem Preis von 120.000 Dollar (umgerechnet auf 2021 etwa 1,1 Million Dollar) war der Rechner auch nicht gerade erschwinglich. Das sollte sich durch die von der PDP-1 eröffnete neuen Geräteklasse der Minicomputer aber ändern. Die PDP-8, die Sie im nächsten Kapitel kennenlernen, war eine der erfolgreichsten Vertreterinnen dieser Geräteklasse, deren Eigenschaften ein wichtiger Schritt in Richtung Personal Computer waren.
Minicomputer
Minicomputer sind eine in der populären Computergeschichte mitunter übersehene Geräteklasse. In der vom ZDF produzierten deutschen Version der amerikanischen Dokumentation „Triumph of the Nerds“ mit dem Namen „Die kurze Geschichte des PCs“ wird im Zusammenhang mit dem „ersten PC“, dem Altair 8800, den Sie im nächsten Kapitel kennenlernen werden, behauptet: „Zuvor hatten Computer ganze Räume gefüllt, versteckt in Großkonzernen, Behörden oder Instituten.“ Natürlich stimmt es, dass die meisten Menschen vor dem Aufkommen der Personal Computer Ende der 1970er Jahre nicht direkt mit Computern in Kontakt kamen und schon gar keinen Computer ihr Eigen nennen konnten, aber dass Computer vor dem PC immer ganze Räume füllten, ist eben nicht wahr. Relativ kleine Computer gab es schon fünfzehn bis zwanzig Jahre vorher. Selbst der LGP-30 von 1956, den Sie im Kapitel „Frühe Echtzeitsysteme“ kennengelernt haben und die PDP-1 von 1960 aus dem vorangehenden Kapitel waren bereits recht kompakte Rechner.
Ein originalgetreuer, funktionsfähiger Nachbau einer LINC I – Bild: HNF
Ein anderer interessanter und sehr kompakter Rechner entstand Anfang der 1960er Jahre ebenfalls am Lincoln Lab des MIT. Der oben abgebildete Library Instrument Computer, kurz LINC, war ein schrankgroßer Computer, unter dem Rollen angebracht waren. Der Computer wurde dadurch mobil und konnte in einem Labor immer an die Stelle gebracht werden, an der er gerade gebraucht wurde. Auch sonst war der Computer sehr auf Laborbedürfnisse zugeschnitten. Das betraf schon die Recheneinheit selbst, die beim LINC über eine Fließkomma-Recheneinheit verfügte. In der Praxis bedeutete das, dass mit dem LINC gut mit Zahlen mit vielen Nachkommastellen gerechnet werden konnte. Nicht bei allen Computern war das der Fall und oft war es auch nicht von Nöten. In der Buchhaltung und bei der Flugbuchung beispielsweise kam man über die zwei Nachkommastellen für Pfennig- oder Centbeträge in der Regel nicht hinaus. Wenn es im Labor jedoch um genaue Messwerte ging, mussten diese natürlich auch im Computer gespeichert und verarbeitet werden können. Bemerkenswert war der Rechner durchaus auch was seine Nutzungsschnittstelle anging. Interessant war bereits das fest zum System gehörende Bandlaufwerk mit der sogenannten LINCTape-Technologie, die später von der Firma Digital Equipment Corporation (DEC) unter dem Namen DECTape auch in anderen Minicomputern verwendet wurde. Sie sehen zwei LINCTape-Laufwerke auf dem Foto rechts auf dem Tisch. Im Gegensatz zu Bändern von Großrechnern, bei denen es in erster Linie auf hohe Lese- und Schreibgeschwindigkeit ankam, die Daten auf den Bändern aber nicht wieder verändert wurden, wurde das DECTape als System mit wahlfreiem Zugriff gestaltet. Ein DECTape verfügte über ein Datei-Inhaltsverzeichnis und damit über Dateien, die per Namen angesprochen und manipuliert werden konnten. Eine ausgeklügelte Fehlerkorrektur sorgte dafür, dass die Bänder nicht nur einigermaßen schnell im Zugriff, sondern auch sehr ausfallsicher waren.
Die erste Version der PDP-8 – Bild mit freundlicher Genehmigung des Computer History Museums
Für einen Laborrechner besonders wichtig war die Möglichkeit, analoge Signale in Form von Spannungen direkt verarbeiten und auch analoge Ausgabesignale erzeugen zu können. Auch in der Hardware-Schnittstelle befanden sich analoge Komponenten. Eingabewerte konnten nicht nur per Tastatur eingegeben, sondern auch mit Drehknöpfen eingestellt werden. Neben der Bedienung per elektrischer Schreibmaschine konnte der LINC auch per Tastatur und Bildschirm genutzt werden. Tastatur und Bildschirm sehen Sie auf dem Foto links auf dem Tisch. Ein zentrales und sehr interessantes Programm war hier ein Screen Editor für Programme, die mit ihm auf dem Bildschirm als Text ausgegeben und mit Hilfe der Tastatur bearbeitet werden konnten.
Das LINC-Projekt wurde von der Firma Digital Equipment weitergeführt, die die Technik mit eigenen Rechnern kombinierte und einzelne Komponenten auch in Minicomputer mit weniger direkter Ausrichtung auf den Laborbetrieb integrierte. Der Inbegriff des Minicomputers schlechthin war DECs PDP-8. Die erste Version dieses Rechners sehen Sie rechts abgebildet. Es handelte sich um einen der ersten Computer, die auf einem Schreibtisch Platz fanden, wenn man von kleinen Rechnern für reine Schulungszwecke mal absieht. Der Computer kostete im Jahr 1965 18.500 Dollar, was in heutiger Kaufkraft (2021) etwa 157.500 Dollar entspricht. Im Vergleich zu Großrechnern der damaligen Zeit war das eine sehr günstige Anschaffung. Mit Verbesserungen in der Transistor- und später in der Mikrochip-Technologie wurden im Laufe der Jahre viele Versionen dieses Computers hergestellt. Bereits im Folgejahr folgte eine funktionsidentische, aber sehr langsame PDP-8/S, die der erste ernstzunehmende Computer mit Kosten unter 10.000 Dollar war. Die sehr verbreitete PDP-8/E aus dem Jahr 1970 kostete dann sogar nur noch 6.500 Dollar.
Die PDP-8-Versionen nach der Urversion waren erheblich kleiner, als das hier abgebildete Gerät. Die komplette Technik konnte in den unteren Kasten eingebaut werden. Der große Aufbau oben war nicht mehr notwendig. Markant für alle Versionen der PDP-8 war das Front-Panel mit seinen Lämpchen und Schaltern, mit denen Werte in den Speicher eingegeben und ausgelesen sowie die Operationen des Geräts gesteuert werden konnten. Über ebendiese Schalter konnte das Gerät programmiert werden. Programmieren über das Front-Panel bedeutete, dass ein Programm Bitfolge für Bitfolge in den Speicher eingegeben wurde. War dies geschehen, konnte der Programmzähler auf die Startadresse gesetzt und das Programm gestartet werden. Natürlich blieb diese Programmiermöglichkeit nicht die einzige. War etwa ein Lochstreifenleser oder ein Leser für DECTape angeschlossen, musste im Zweifelsfalle nur noch ein kleiner Loader von Hand eingegeben werden. Das eigentliche Programm wurde dann vom Medium nachgeladen. In der Praxis der PDP-8-Nutzung mussten relativ selten Programme per Schalter eingegeben werden, denn wenn sie erst einmal eingegeben waren, blieben sie auch nach dem Ausschalten des Computers erhalten. Dass dies so war, lag an der Speichertechnologie, die die PDP-8 verwendete. Wir haben im Zusammenhang mit der IBM 305 RAMAC im Kapitel Frühe Echtzeitsysteme bereits Magnettrommeln als persistenten Arbeitsspeicher kennengelernt. Diese Trommeln waren allerdings klobig und in Bezug auf die Speicherkapazität ziemlich beschränkt. Zudem war die Technologie sehr langsam. Bei der PDP-8 wurde daher eine andere Technologie gewählt.
Detailansicht eines Magnetkernspeicherelements – Bild: Original: Konstantin Lanzet, derivate work: Appaloosa (CC BY-SA 3.0)
Der Arbeitsspeicher der PDP-8 war ein Magnetkernspeicher. Ein solcher Speicher besteht aus Feldern mit kleinen Eisenringen, die auf Drähte aufgefädelt sind. Ein diagonal durchgezogener Draht dient dem Auslesen des Speichers. Jeder Eisenring kann individuell magnetisiert werden. Da es zwei verschiedene Möglichkeiten gibt, diese Magnetisierung vorzunehmen, zwei mögliche Polarisierungen, ergeben sich zwei mögliche Speicherwerte, entsprechend einer 1 oder einer 0, also einem Bit. Wenn beim Schreiben eines Bits dieses Bit „kippt“, wird im Lesedraht – dem diagonalen Draht – eine Spannung induziert. Ein Bit wird also dadurch gelesen, dass versucht wird, es zu setzen. Das Auslesen des Speichers zerstörte also die gespeicherten Daten. Um die Information zu erhalten, musste der Bitwert nach dem Lesen also neu gespeichert werden. Ein Magnetkernspeicher war schnell, aber vor allem teuer, denn die Ringe wurden per Hand aufgefädelt. Sein großer Vorteil war, dass er wie die Magnettrommel auf Magnetismus basierte und die Speicherhaltung daher nicht auf Strom angewiesen war. Der Speicher behielt seine Information ohne anliegende Spannung. Die Grundausstattung der PDP-8 verfügte über einen Speicher von 4.096 12-Bit-Worten. Bei einer Zeichencodierung von 6 Bit bedeutete das, dass 8.192 Zeichen im Speicher Platz fanden. Durch Hinzufügen eines Speichererweiterungscontrollers konnte der Speicher bis auf 32.768 Worte erweitert werden.
Ein Magnetkernspeicherelement – Bild: Original: Konstantin Lanzet, derivate work: Appaloosa (CC BY-SA 3.0)
Ab dem Jahr 1968 war für die PDP-8 eine einfache Programmiersprache namens FOCAL (Formulating On-Line Calculations in Algebraic Language) verfügbar. Die Sprache war in etwa mit BASIC vergleichbar, hatte gegenüber dieser aber einige Vorteile. Das folgende Beispiel eines FOCAL-Programms findet sich in einer Werbebroschüre von DEC aus dem Jahr 196920.
01.10ASK"HOW MUCH MONEY DO YOU WANT TO BORROW ?",PRINCIPAL01.20ASK"FOR HOW MANY YEARS ?",TERM01.30FORRATE=4.0,.5,10;DO2.001.40QUIT02.10SETINTEREST=PRINCIPAL*(RATE/100)*TERM02.20TYPE"RATE",RATE," ","INTEREST",INTEREST,!
Ein hier sichtbarer Unterschied zu BASIC ist, neben unterschiedlichen Schlüsselworten wie ASK statt INPUT und TYPE statt PRINT, die Unterstützung von Blöcken. Sie zeigen sich in der Zeilennummerierung. Dieses einfache Beispiel hat zwei Blöcke. Die Zeilen des ersten Blocks beginnen mit „01.“, die zweiten mit „02.“ Ein Block kann als Ganzes referenziert werden. Das geschieht hier in Zeile 01.30. Es handelt sich bei der Zeile um eine Schleife, die die Variable RATE von 4 bis 10 in Schritten von 0.5 hochzählt. Der eigentliche Schleifenrumpf, also die Befehle, die mehrfach ausgeführt werden sollen, folgt im Beispiel aber nicht direkt an Ort und Stelle, wie es bei BASIC notwendig wäre. Stattdessen wird für jede Iteration DO 2.0 aufgerufen, also der zweite Block ausgeführt. Wird das Programm gestartet, sieht das Ergebnis etwa folgendermaßen aus:
Interaktive Programmierung in FOCAL ist natürlich nicht die einzige Art, wie man die PDP-8 verwenden kann. Eine Reihe von Betriebssystemen wurden für den Rechner entwickelt. Am beliebtesten und verbreitetsten unter ihnen war das System OS/8. Es war stark inspiriert vom Betriebssystem TOPS-10 für DECs Großrechnerreihe PDP-10. TOPS-10 war ein Time-Sharing-Betriebssystem, das für seine recht einfache Bedienweise geschätzt wurde. Für die erheblich einfachere und schlechter ausgestattete PDP-8 konnte und musste das System aber natürlich abgespeckt werden. Es handelte sich bei der PDP-8 ja eben nicht um einen Rechner, der gut für Time-Sharing geeignet war. In OS/8 verwendete folglich nur ein Nutzer zu einer Zeit das System. Es brauchte dementsprechend keine time-sharing-typischen Verwaltungsoperationen, keine Nutzerverwaltung, keine Quotas und auch keine komplexe Verwaltung für externe Massenspeicher. Übrig blieb ein einfaches Betriebssystem, das über einen Kommandozeilen-Interpreter verfügte, ein integriertes Hilfesystem hatte und sich Kommandozeilen-Parameter früherer Aufrufe eines Programms merkte. Letzteres war und ist durchaus etwas Besonderes! Der Befehl DIR beispielsweise gab bei OS/8 das Inhaltsverzeichnis der Dateien auf einem DECTape aus. DIR /A /N zeigt die Dateien in alphabetischer Sortierung mit lesbarem Änderungsdatum an. Hatte man diese Parameter einmal eingegeben, wurde fortan auch bei einem einfachen DIR das Verzeichnis auf die beschriebene Art angegeben. Die Parameter wurden automatisch wieder angewandt. Diese Funktionalität war besonders praktisch, wenn man etwa zwischen einem Editor und einem Compiler hin- und herwechselte. Nur einmal mussten dann Dateinamen und Parameter angegeben werden. Danach reichte das Aufrufen des Editors und des Compilers ohne die Zusatzinformationen, denn die passenden Parameter und Dateinamen wurden automatisch ergänzt.
Das Betriebssystem OS/8 und sein großer Bruder TOPS-10 waren Inspiration für das Betriebssystem CP/M, dem ersten verbreiteten Betriebssystem für Personal Computer. Dessen Entwickler Gary Kildall arbeitete selbst mit den DEC-Betriebssystemen und nutzte sie zur Entwicklung seines CP/M. Die Nutzungsschnittstelle von CP/M war ihrerseits die Vorlage für Microsofts MS-DOS, dessen Kommandozeilen-Interpreter sich, kaum verändert, immer noch in Windows findet. Den Befehl dir, mit dem Sie heute noch in der Eingabeaufforderung von Windows ein Verzeichnis-Listing ausgeben können, können Sie über MS-DOS, CP/M und OS/8 bis zu TOPS-10 zurückverfolgen.