Total vernetzt
Bei allem, was ich Ihnen bisher in diesem Buch erzählt habe, habe ich ein riesiges Themenfeld sträflich ausgelassen. Dass Computer miteinander vernetzt sein können, war allenfalls bei den Smartphones ein Thema. Dabei wäre vieles, was wir heute mit Computern machen, ohne Vernetzung und vor allem ohne das “Netz der Netze” gar nicht mehr denkbar. Das Internet ist allgegenwärtig: Viele von uns sind ständig online - oft sogar mit mehreren Geräten gleichzeitig. Diese Allgegenwärtigkeit wird oft als Revolution empfunden, denn das Internet verändert viele Medien, die es seit Jahrzehnten oder gar Jahrhunderten gibt. Tageszeitungen und Zeitschriften haben seit Jahren zu kämpfen und auch das klassische lineare Fernsehen und das Radio bekommen es immer stärker zu spüren.
Je nach Alter erinnern Sie sich vielleicht noch an eine Zeit “vor dem Internet” oder Sie kennen Menschen, die Ihnen davon erzählen. Um welche Zeit handelt es sich dabei eigentlich? Seit wann gibt es das Internet? Die Beantwortung dieser Frage ist letztlich eine Frage der Definition. Im Jahr 1969 nahm das von der Advanced Research Projects Agency (ARPA), einer Abteilung des US-Verteidigungsministeriums, finanzierte und betriebene ARPAnet seinen Betrieb auf. Dieses Netz gilt als Keimzelle des späteren Internet. Die Verbindung zum Verteidigungsministerium erklärt sicherlich den Mythos, das Internet sei als atomkriegssicheres Computernetz für das Militär geplant worden. Zwar gab es durchaus Überlegungen zu einer ausfallsicheren Netzwerktechnik für das Militär, aber mit dem Internet und seinen Vorläufern hat das wenig zu tun. Auf der Karte sieht man das Layout des Netzes im Jahr 1973. Wenn man sich anschaut, was in den mit IMP oder TIP beschrifteten Rechtecken steht, sieht man, dass es sich nicht um militärische Einrichtungen handelt, sondern um Universitäten und andere Forschungseinrichtungen. Die ARPA hat sie über ihr Netzwerk miteinander verbunden. Sicherlich erhoffte man sich davon auch einen Innovationsschub in Forschungsbereichen, die eigentlich dem Militär vorbehalten waren, aber das Netzwerk beschränkte sich nicht darauf.
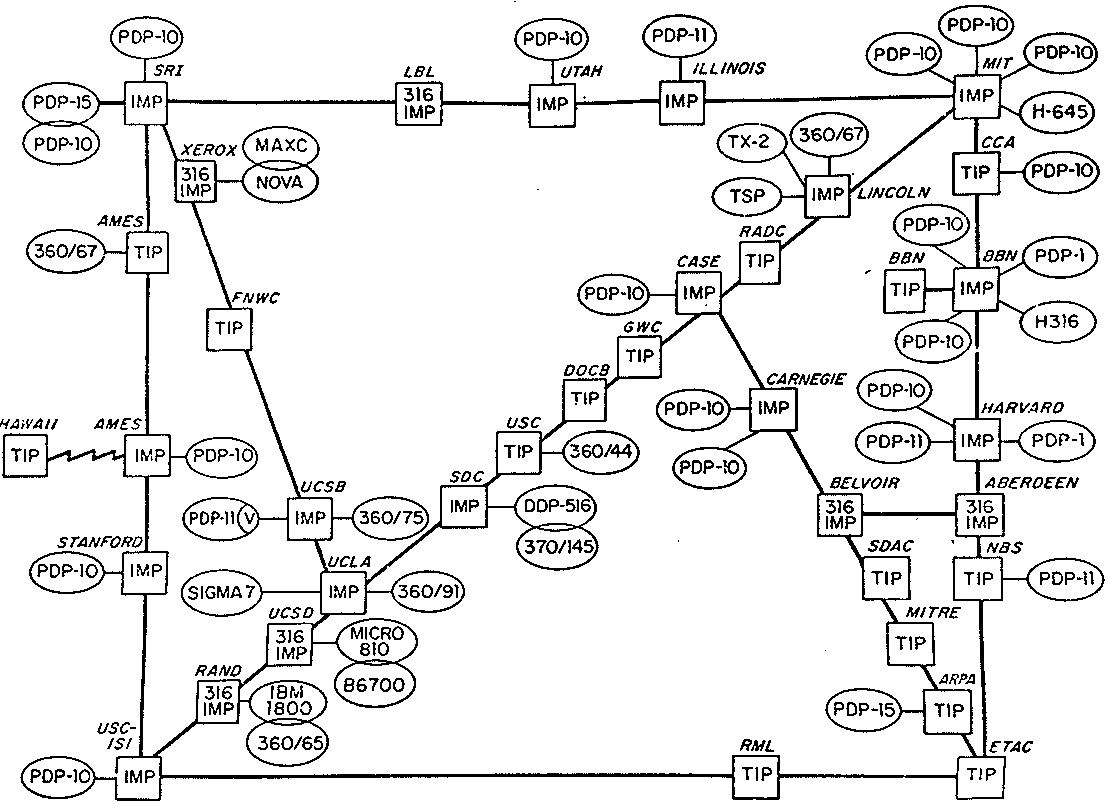
Der Zweck des ARPnet war es, den Zugriff auf die Großrechenanlagen der Forschungseinrichtungen zu ermöglichen und somit Ressourcen gemeinsam zu nutzen. Sich aus der Ferne mit einer Rechenanlage zu verbinden, war im Prinzip nichts Neues. Im Kapitel über Timesharing haben Sie bereits davon gelesen. Beim Timesharing wurden Fernschreiber und andere Terminals mit einem Zentralrechner verbunden. Dies konnte über ein direktes Kabel oder über eine Telefonleitung und ein Modem erfolgen. Beim Timesharing befindet sich auf der einen Seite der Verbindung ein Computer, auf der anderen Seite ein Terminal oder ein Fernschreiber. Mit der gleichen Technik können natürlich auch zwei Computer untereinander Daten austauschen.

Datenübertragung per Modem
Der Begriff Modem wird Ihnen in diesem Kapitel noch öfter begegnen. Lassen Sie mich also kurz vorab erklären, was das eigentlich ist. Modems werden gebraucht, wenn man zwischen Computern Daten austauschen möchte, dafür aber eine Leitung verwenden muss, die sich für binäre Datenübertragung – Strom an oder Strom aus – nicht eignet. Modems wandeln die digitalen Daten des Computers in hörbare Töne um1, die per Telefonleitung übertragen werden. Auf der anderen Seite der Verbindung befindet sich ebenfalls ein an einen Computer angeschlossenes Modem. Dort werden die Töne, die für den Menschen nur ein unangenehmes Kreischen darstellen, wieder in digitale Daten umgewandelt, die der Computer verarbeiten kann. Oben sehen Sie einen Akustik-Koppler, ein einfaches Modem für die Übertragung von Computerdaten über eine Telefonleitung. Auch bei so einem Akustik-Koppler werden die digitalen Daten des Computers in hörbare Töne umgewandelt. Ein Computernutzer, der Daten übertragen will, hebt den Hörer ab und wählt die Nummer einer Gegenstelle, die mit einem Computer verbunden ist. Kommt die Verbindung zustande, legt er den Hörer in den Akustik-Koppler. Der Vorteil von Akustik-Kopplern ist, dass man nichts an der Verkabelung des Telefonanschlusses ändern muss, sondern sein normales Telefon verwenden kann. Es gibt aber zwei Nachteile: Zum einen ist das Ganze etwas umständlich, weil man händisch wählen muss. Vor allem aber stören Geräusche aus der Umgebung die Übertragung. Professionellere Modems wurden unter Umgehung des häuslichen Telefons direkt an die Telefonleitung angeschlossen, was sowohl praktischer ist als auch schnellere Verbindungen ermöglicht.
Pakete im Netz
Ruft man einen entfernten Computer mittels Modem an, besteht eine dauerhafte Verbindung. Ein großflächiges Computernetz kann man auf diese Art und Weise aber nicht gut aufbauen, denn so viel Kapazität, um alle Rechner mit allen anderen dauerhaft zu verbinden, hat auch das beste Telefonnetz nicht. Es wäre auch absolute Verschwendung, denn mit den allermeisten Netzwerkteilnehmern möchte man ja nicht dauerhaft Daten austauschen. Eine andere Lösung muss her.
Die Idee hinter dem Internet beruht darauf, dass einzelne Computer nicht mit allen anderen, sondern immer nur mit einigen wenigen verbunden sind, die dann wiederum mit anderen verbunden sind und so weiter. Hinzu kommt die sogenannte Paketvermittlung. Sie können sich beides mit einer Analogie erklären, denn das Internet funktioniert weniger so wie das klassische Telefonnetz, sondern ist eher mit der Paketpost vergleichbar. Stellen Sie sich vor, Sie besitzen einen Oldtimer. Diesen wollen Sie mit der Post an einen Freund verschicken. Das ganze Auto verschickt die Post aber nicht. Es ist viel zu groß. Sie nehmen das Auto also kurzerhand auseinander, packen die Einzelteile in Pakete, legen jeweils einen Zettel mit dazu, wie die Teile wieder zusammenzusetzen sind, und bringen die einzelnen Pakete zur Post. Die Pakete werden nun von der Post nicht direkt zum Zielpostamt gebracht. Dann müssten ja zwischen allen Postämtern ständig Transporter hin und her fahren. Das wäre nicht effizient. Das lokale Postamt schickt ein Paket stattdessen an ein Verteilzentrum. Dieses schickt das Paket entsprechend der Zieladresse an ein anderes Verteilzentrum weiter. Je nach Entfernung wiederholt sich der Vorgang einige Male. Da Sie ja mehrere Pakete verschicken, könnte es durchaus sein, dass das eine Paket eine bestimmte Route nimmt, ein anderes Paket aber auf einem anderen Weg ankommt. Letztlich ist der Weg, den die Pakete genommen haben, aber ganz egal. Wichtig ist, dass alle Pakete am Ziel ankommen und das Auto am Zielort wieder zusammengesetzt werden kann.
Ganz vergleichbar funktioniert auch das Internet. Wenn Sie eine Datei auf einen Server hochladen, dann wird sie in viele kleine Teile zerlegt. Diese werden dann über ein Geflecht von Verteilerrechnern, den sogenannten Switches, bis zum Ziel geschickt und dort wieder zusammengesetzt.
Natürlich konnte nicht nur die ARPA Netze betreiben, die auf diese Art und Weise funktionierten. 1981 nahm die National Science Foundation (NSF) das Computer Science Network in Betrieb. 1986 kam dann das allgemeinere NSFNet dazu. Durch die Verbindung der Netze der NSF mit dem ARPAnet und dem Anschluss internationaler Netze an das NSFNet entstand ein Netz, das die Netze verband, ein Zwischen-Netz, ein Inter-Net. Dieser Begriff wurde Mitte bis Ende der 1980er Jahre immer gebräuchlicher. Das Internet ist also fast 40 Jahre alt oder, je nach Sichtweise, auch schon über 50 wenn man das ARPAnet als Anfang nimmt. Es kommt ganz darauf an, was man als den Anfang ansehen möchte.
Sprechen die Leute, die von der Zeit vor dem Internet sprechen, also von den 1960er oder 1970er Jahren? Möglich ist das natürlich, aber auch viel spätere Zeitpunkte können durchaus gemeint sein, denn das Internet und die Netze, aus denen es hervorgegangen ist, waren bis in die 1990er Jahre hinein der breiten Öffentlichkeit und auch in der Privatwirtschaft gar nicht bekannt. In einem Bericht des ARD-Magazins Panorama von 1987 über die Tätigkeiten deutscher Hacker des Chaos Computer Club[s] ist nur allgemein von einem “Internationalen Netzwerk” die Rede. Der Begriff “Internet” hätte wohl keinem etwas gesagt. Ein Bericht des ZDF Morgenmagazins aus dem Jahr 1996 behandelt die Frage “Was ist denn Internet überhaupt?”. Von NBCs Today Show aus Amerika gab es 1995 aus heutiger Sicht Kurioses zu sehen: Der Moderator der Sendung weiß nicht, wie man das a mit dem Kringel drumherum nennt und lässt sich zur verzweifelten Frage “What is Internet anyway?” hinreißen. Seine Kolleginnen und Kollegen können ihm auch nicht so recht weiterhelfen. Erst ein Assistent aus dem Off meint zu wissen, dass es sich um ein “Computer Billboard” handelt, also um ein computerisiertes Schwarzes Brett. Wenn Leute also von “vor dem Internet” sprechen, dann kann das durchaus auch die 1980er und die erste Hälfte der 1990er Jahre einschließen. Kaum jemand, der nicht an einer Universität oder Forschungseinrichtung damit zu tun hatte, kannte damals das Internet und auch für diese Leute hatte es keine so dominante Rolle wie heute.
Die spannende Geschichte des Internet umfangreich und vollständig zu erzählen, schaffe ich hier natürlich nicht. Ich empfehle Ihnen sehr, wenn es Sie interessiert, sich das Buch “ARPA Kadabra”2 zu besorgen. Darin erfahren Sie alle technischen und nicht technischen Hintergründe und lernen die Protagonisten hinter der Entwicklung kennen. In diesem Buch fokussiere ich mich, was das Internet angeht, auf eine eher späte, aber sehr dominante Entwicklung, mit der das Netz öffentliche Wahrnehmung bekam – dem World Wide Web. Doch bevor wir dort hinkommen, gilt es, andere Vernetzungsprojekte zu betrachten, denn auch “vor dem Internet”, in den späten 1970er Jahren und in den 1980ern, konnte man bereits online gehen und einige dieser frühen Online-Dienste hatten sogar eine Nutzerschaft, deren Zahl in die Millionen ging.
Bildschirmtexte und Online-Dienste
Lassen Sie uns eine Zeitreise ins Jahr 1985 machen! Nicht politisch, nicht modisch, sondern in Sachen Computern und Kommunikationstechnik. Grundsätzlich hat sich natürlich technisch in allen Bereichen seit 1985 viel getan. Dennoch hätten wir bei unserer Zeitreise wahrscheinlich keine Probleme. Lassen wir mal die Computer beiseite, war das meiste nicht so sehr anders als heute. Genau wie heute gab es Autos und die hatten auch schon ein Lenkrad, ein Zündschloss und drei Pedale. Auch Züge und Flugzeuge gab es natürlich schon. Die Flugzeuge und Züge von 1985 funktionierten im Prinzip genauso wie heute und könnten durchaus auch heute noch betrieben werden. Das gleiche gilt auch für ein Radio oder einen Kugelschreiber. Mit all diesen Dingen hätten wir bei unserer Zeitreise kaum Probleme. Selbst mit einem Fernseher der damaligen Zeit kämen wir wahrscheinlich zurecht, obwohl es sich damals um recht wuchtige Geräte mit erstaunlich kleinem Bild handelte, die meisten Leute nur drei Programme empfangen konnten und viele Fernseher noch keine Fernbedienung hatten. Wo wir durchaus umdenken müssten, wäre der Bereich Telekommunikation. Dass man nicht whatsappen konnte, haben Sie sich wahrscheinlich schon gedacht. Smartphones gab es natürlich noch nicht. Darüber haben wir ja schon gesprochen. Das erste Mobiltelefonnetz für die größere Allgemeinheit, das analoge C-Netz, gab es erst ab 1986. Wenn wir also jemanden von unterwegs erreichen wollten, dann mussten wir uns eine Telefonzelle suchen. Die waren damals postgelb und standen an jeder Ecke. Das C-Netz wurde, genauso wie das “öffentliche Fernsprechnetz” – heute sagt man Festnetz dazu – und die Telefonzellen, von der Post betrieben.
Als jüngerer Leser mögen Sie jetzt stutzen. Was hat denn die Post mit Telefon und Mobilfunk zu tun? Heute nichts mehr, im Jahr 1985 jedoch sehr viel. Die Post hieß damals noch Bundespost. Das klingt nicht nur sehr offiziell, das war es auch. Es handelte sich um eine Bundesbehörde. Alles was mit der Post zu tun hatte, war also eine hoheitliche Angelegenheit. Die Briefträger und Paketzusteller der Bundespost waren Postbeamte und wollte man ein Paket aufgeben, tat man das nicht in irgendeiner Geschäftsstelle, sondern in einem Postamt. Den Paket-, Päckchen- und Briefdienst der Bundespost kennen Sie heute unter dem Namen Deutsche Post und zum Teil unter dem Namen DHL. Die Bundespost hatte aber viele weitere Aufgaben als das Verschicken von Briefen, Päckchen und Paketen. Zur bereits vorgestellten, sogenannten “gelben Post” kamen die sogenannte “blaue Post” – die Postbank – und die “graue Post”, die die Dienste für die elektronische Kommunikation vereinigte. Hierzu gehörte das genannte “öffentliche Fernsprechnetz”, ein Netz für Fernschreiber, Telex genannt, aber auch alle nennenswerten Rundfunk- und Fernsehsender. Sicher kennen Sie auch bei sich in der Gegend einen Rundfunk- und Fernsehturm3 oder eine große Antenne auf einer Anhöhe. Wenn Sie in Westdeutschland wohnen, wurde dieser Turm wahrscheinlich von der Bundespost errichtet und betrieben.
1995 wurde die Deutsche Bundespost privatisiert und in drei Aktiengesellschaften (Deutsche Post AG, Postbank AG und Deutsche Telekom AG) aufgespalten. Daran hat man 1985 aber noch nicht gedacht. Noch war Kommunikation in allen Bereichen eine staatliche Angelegenheit, denn die Bundespost hatte ein staatliches Monopol. Im Bereich der Briefe mag das nicht so einen großen Unterschied gemacht haben, aber in der Welt der Telekommunikation hatte dieses Monopol für die heutige Zeit eigenartige Konsequenzen. Das Telefon in meiner Familie, zum Beispiel, war im Jahr 1985 eines mit Wählscheibe4. Es stand im Flur auf einem kleinen Tischchen. Das Kabel des Telefons ging direkt in eine Dose an der Wand. Es gab keinen Stecker und auch keine Buchse. Man konnte das Telefon also nicht einfach austauschen oder außer Betrieb nehmen. Das war nicht nur schwer möglich, es war sogar verboten. Die Fernmeldeordnung bestimmte klar: “Der Teilnehmer darf die Teilnehmereinrichtungen nicht eigenmächtig ändern; unzulässig ist auch das eigenmächtige Einschalten selbstbeschaffter Apparate.” Unser Telefon war also natürlich kein selbstbeschaffter Apparat. Wie fast alle hatten wir es bei der Post gemietet und eigenmächtig haben wir es auch nicht angeschlossen. Ein Techniker der Bundespost hat dies getan.
Ähnlich wie in Deutschland war es überall in Westeuropa. In Österreich gab es die Österreichische Post- und Telegraphenverwaltung, in den Niederlanden die PTT (Staatsbedrijf der Posterijen, Telegrafie en Telefonie). In Frankreich hieß das staatliche Unternehmen DGT (Direction Générale des Télécommunications). Die Telekommunikation in Europa Mitte der 1980er Jahre war also geprägt durch ihre zentralisierte Struktur, betrieben durch meist staatliche Post- und Telekommunikationsunternehmen, die in ihrem Markt ein Monopol hatten. Das konnte ein Vorteil sein, konnte aber auch zum Nachteil werden. Beides werden wir sehen, wenn wir uns die europäischen “Vorgänger des Internets” ansehen. Der Beginn zu dieser Technik - der Videotext – lag in England und hatte erstmal gar nichts mit der Post oder mit Telefonleitungen zu tun.
Begriffsverwirrungen: Was in Deutschland vor allem von ARD und ZDF Videotext genannt wird, wird im internationalen Rahmen meist Teletext genannt. Videotex (ohne t) hingegen ist die internationale Bezeichnung für Dienste wie der deutsche Bildschirmtext, den ich Ihnen weiter hinten vorstelle. Um die Verwirrung komplett zu machen, gab es in Deutschland auch noch Teletex (ohne t) als modernere Variante des Fernschreibdienstes, der seinerseits Telex genannt wurde. Um es mir und Ihnen ein bisschen einfacher zu machen, verwende ich durchgehend die deutschen Begriffe Videotext und Bildschirmtext auch für die anderen europäischen Informationsdienste.
Eine Lücke geschickt ausgenutzt: Der Videotext
Techniker der BBC ersannen in den 70er Jahren eine Technik, um gleichzeitig mit dem Fernsehprogramm, quasi Huckepack im gleichen Sendesignal, textuelle Informationen auszuliefern. Der Dienst Ceefax (für “see facts”) ging dort bereits 1974 in den Regelbetrieb. Die private Konkurrenz ging wenig später an den Start und hieß Oracle. In Deutschland dauerte es etwas länger. Hier war man 1980 soweit.
Um es zu bewerkstelligen, neben dem normalen Fernsehbild und dem Ton auch noch ein textuelles Informationsprogramm auszuliefern, nutzte man eine Eigenschaft des Bildsignals aus, das seinerseits aufgrund einer technischen Notwendigkeit bestand. Um das Prinzip zu verstehen, muss man sich klarmachen, wie ein altes analoges Fernsehsignal an einem alten Röhrenfernseher dargestellt wird.

So ein Fernseher verwendet eine Kathodenstrahlröhre, um ein Bild anzuzeigen. Meist wird sie der Einfachheit halber Bildröhre genannt. Im hinteren Teil der Bildröhre, da wo sie ganz dünn wird, wird ein Elektronenstrahl erzeugt, der vorne auf dem eigentlichen Bildschirm auf eine Substanz trifft, die er zum Leuchten anregt. Mittels durch Spulen erzeugte Magnetfelder kann der Strahl umgelenkt werden, sodass verschiedene Bereiche des Bildschirms erreicht werden können. Damit man mit einer solchen Röhre ein flächiges Bild sieht, müssen alle Bereiche des Bildschirms von einem sehr kräftigen Elektronenstrahl regelmäßig getroffen werden. Dies geschieht beim Fernseher (und auch bei Computermonitoren) Zeile für Zeile von oben nach unten und von links nach rechts.
Stellen wir uns den Vorgang zur Verdeutlichung in einem Gedankenexperiment vor. Wir simulieren die Bilddarstellung eines Schwarz-Weiß-Fernsehers. Sie sind der Fernsehempfänger und ein Bekannter von Ihnen spielt den Fernsehsender. Er sendet Ihnen ein Bild, indem er eine Ihrer Hände ergreift und unterschiedlich stark zudrückt. In Ihrer anderen Hand halten Sie einen Stift mit einer breiten Spitze. Diesen Stift ziehen sie nun zeilenweise über ein Blatt Papier. Sie fangen in der ersten Zeile oben links an. Je stärker Sie den Stift auf das Papier drücken, desto dunkler wird es. Sie drücken immer genauso stark mit dem Stift auf das Papier, wie Ihr Bekannter Ihre Hand drückt. Dabei bewegen Sie den Stift gleichmäßig weiter. Wenn Sie am Ende einer Zeile angekommen sind, geht es in der nächsten Zeile weiter. Wenn das Blatt voll ist, haben Sie auf diese Weise ein komplettes Bild gezeichnet. Sie reißen das Blatt ab und fangen direkt oben wieder mit dem nächsten Bild an. Auf diese Art und Weise kann Ihnen ihr Bekannter eine Reihe von Bildern übertragen. Wenn das ganze schnell genug vonstatten ginge, entstünde dabei der Eindruck eines bewegten Bildes. Beim klassischen Fernsehen wurden so seinerzeit 25 Bilder in der Sekunde übertragen5.
Bilder können Sie auf diese Weise nun übertragen. Das Bild interessiert uns aber eigentlich gar nicht so sehr, denn es geht uns ja um den Text. Für den ist viel interessanter, was passiert, wenn gerade kein Bild übertragen wird. Das passiert bei unserem Gedankenexperiment, ohne dass ich es erwähnt hätte, ziemlich oft. Immer wenn eine Zeile voll ist, zum Beispiel, brauchen Sie ein klein bisschen Zeit, um den Stift an den Anfang der Folgezeile zu bewegen. Diese Zeitspanne ist nicht besonders lang. Länger dauert es dann schon, wenn ein ganzes Bild fertig ist. Sie müssen dann das fertige Bild abreißen und dann mit Ihrer Hand wieder nach oben links gehen. Während dieser Zeit können Sie kein Bild zeichnen. Man spricht beim Fernsehen hier von der vertikalen Austastlücke6. Ihr Bekannter hat in dieser Zeit aber ja immer noch Ihre Hand fest im Griff, kann Ihnen also etwas senden, Sie können damit aber nichts anfangen, denn Sie können es ja nicht zu Papier bringen. Diese Lücke, während derer kein Bild gezeichnet werden kann, macht man sich beim Videotext zu Nutze, indem man im Bildsignal digitale Daten unterbringt. Im Bild oben rechts wurde das Fernsehbild vertikal verschoben, sodass man die Austastlücke sieht. Die weiße, etwas unruhige Linie vor dem Beginn des Bildes ist das Ceefax-Signal der BBC.
Die Inhalte des Videotexts der BBC wurden von einer Redaktion beim Rundfunksender bereitgestellt. Typische Inhalte waren Nachrichten, Wetterberichte oder Sportergebnisse. Die Möglichkeiten der Darstellung waren der Technik der späten 1970er Jahre und Röhrenfernsehtechnik mit einer für heutige Verhältnisse niedrigen Auflösung entsprechend. Eine Seite bestand aus 24 Zeilen à 40 Zeichen. Ursprünglich standen nur acht Farben jeweils für Vordergrund und Hintergrund zur Verfügung. Bei diesen acht Farben handelt es sich um die Grundfarben und ihren Kombinationen, also Rot, Grün, Blau, Gelb, Cyan, Magenta, Schwarz und Weiß. Jede Seite verfügte über eine Nummer. Die nummerierten Seiten wurden vom Fernsehsender nach und nach ausgestrahlt. Man konnte an einem Fernseher mit Videotext-Decoder eine dreistellige Nummer eingeben und musste dann warten, bis die entsprechende Seite wieder gesendet wurde. Sie wurde dann dekodiert und angezeigt. Besonders wichtige Seiten, wie etwa die Übersichtsseite 100 oder Untertitel für das aktuell laufende Programm, wurden häufiger übertragen als andere, damit sie schneller aufgerufen werden konnten und häufiger aktualisiert wurden. Im Laufe der Jahre verbesserte sich die Videotext-Technik ein wenig. Mehr Farben wurden verfügbar und auch die Grafikfähigkeiten wurden etwas besser. Videotext behielt aber bis heute den Charme der 1970er und 1980er Jahre.
Trotz all seiner Einschränkungen kann man den Videotext in manchen Bereichen als altmodischen Vorgänger von Websites ansehen, denn man kann ihn ganz ähnlich nutzen. Statt im Web-Angebot der Tagesschau nach den aktuellen Nachrichten zu schauen, konnte man die entsprechende Videotextseite aufrufen und die Nachrichten lesen. Was beim Videotext aber natürlich gar nicht funktionieren kann, ist alles, was über die Seitenauswahl hinaus auf Eingaben des Nutzers basiert, denn einen Rückkanal gibt es ja nicht. Man könnte im Videotext also nie eine individuelle Fahrplanauskunft von Start- und Zielbahnhof realisieren. Es kann lediglich innerhalb der begrenzten Menge an Seiten, die übertragen wird, etwas ausgewählt werden. Diesen Nachteil kann man dadurch abschaffen, dass man das Übertragungsmedium ändert, also die Seiten nicht per Fernsehantenne, sondern z. B. per Telefonkabel ins Haus kommen lässt.
Prestel in Großbritannien
Genau das hat das UK Post Office Telecommunication, seit 1981 unter dem Namen “British Telecom”, getan und unter dem Namen “Prestel” ab 1979 angeboten. Prestel stand als Abkürzung für “press telephone”. In Sachen Darstellung hatte Prestel genau die gleichen Eigenschaften wie der Videotext. Seiten mit 24 Zeilen à 40 Zeichen konnten in acht Farben dargestellt werden. Über die Telefonleitung gab es nun aber einen Rückkanal, sodass ein Computer der British Telecom auf der anderen Seite Eingaben verarbeiten und entsprechend antworten konnte. Diese Antwort musste nicht immer eine komplette neue Seite sein. Viewdata, wie der Videotext- und Prestel-Standard betitelt wurde, verfügte über Cursor-Control-Character. Dadurch konnte durch Signale vom Postcomputer die angezeigte Seite in Teilen aktualisiert werden, ohne sie komplett neu laden zu müssen. Hiermit wurden sogar simple Animationen möglich. Was spannend klingt, war in der Praxis wohl ziemlich langweilig. Wirklich interaktive Dienste blieben die Ausnahme. Größtenteils bestand der Prestel-Dienst aus Seiten, die ganz ähnlich wie der Videotext mit einer Nummer aufgerufen wurden. Auf den Seiten gab es dann Verweise auf Unterseiten, die über ein Nummernpad aufgerufen werden konnten. Im Prinzip bot Prestel damit nicht viel mehr als das, was es schon im Videotext gab – allerdings mit einer größeren Ausrichtung auf geschäftliche Daten, wie etwa Aktienkursen. Ab 1983 kam das Feature hinzu, anderen Teilnehmern Nachrichten schicken zu können.
Wenn man der Darstellung von History Today glauben kann, kostete der günstigste Prestel-taugliche Fernseher im Jahr 1985 650 Britische Pfund. Umgerechnet auf das Jahr 2020 sind das 2320 Euro. Hinzu kamen Kosten von etwa 6 Euro pro Monat, tagsüber zusätzlich 6 Cent pro Minute zusätzlich zu den Telefonkosten und ggf. Sonderkosten für einzelne Seiten. Im Vergleich zum Btx in Deutschland, das ich Ihnen etwas später vorstellen will, war das gar nicht so viel, aber im Vergleich zum Videotext, der zwar einen etwas teureren Fernseher brauchte, aber ansonsten kostenfrei war, war Prestel ziemlich teuer. Ein Erfolg war der Dienst nicht. Über 90.000 Teilnehmer kam er nie hinaus.
Minitel/Télétel in Frankreich
Der Prestel-Dienst bot einer allgemeinen Öffentlichkeit im Prinzip die Möglichkeit, Computerdienste ohne größere Hürden zu nutzen. Besonders populär wurde der Dienst aber auf Grund des langweiligen Angebots nicht. Ganz anders sah das in Frankreich aus, und dass das so war, lag an Entscheidungen des französischen Staats in Form des staatlichen Kommunikationsunternehmens DGT (Direction Générale des Télécommunications).

Zu Beginn der 1980er Jahre befand der französische Staat die Kommunikationsinfrastruktur des Landes für veraltet. Dies galt es zu ändern. Ein modernes Telefonnetz sollte aufgebaut werden. Teil dieses Netzes sollte ein Bildschirmtextdienst mit dem Namen Télétel werden. Technisch orientierte sich die DGT am englischen Viewdata-Standard, den sie leicht verbesserte. Maßgeblich für den späteren großen Erfolg des Dienstes waren aber nicht diese technischen Verbesserungen, sondern die Entscheidung, jedem Teilnehmer ein kleines Zugangsgerät kostenfrei zur Verfügung zu stellen. Wenn man in Frankreich einen Telefonanschluss hatte, konnte man sich fortan entscheiden, ob man ein normales Telefonbuch oder ein solches Minitel haben wollte, mit dem sich Telefonnummern natürlich viel praktischer herausfinden ließen. Und das beste: Das Ganze war sogar kostenfrei! Durch diesen Trick brachte die DGT ihr Télétel in viele Haushalte. Da der Dienst so sehr mit den Zugangsgeräten, den Minitels, verbunden wurde, wurde der Begriff Minitel im Volksmund und auch in der Werbung zum Namen für den Dienst als Ganzes. “Faites-le en Minitel!” war die Devise! 1985 hatte der Dienst bereits 2 Millionen Nutzer. Anfang der 1990er waren es 6,5 Millionen und im Jahr 2000 erreichte der Dienst mit 25 Millionen Nutzern sein Maximum. Bei 55 Millionen Einwohnern sind dies mehr als beeindruckende Zahlen.
Auch wenn die Technik für die Datenübertragung und Darstellung dem britischen Prestel sehr ähnlich war, gab es in der praktischen Anwendung doch starke Unterschiede. Das britische System war in seinen Grundzügen zentralistisch. Der große Teil der Inhalte war auf Rechnern der British Telecom abgelegt. Mittels eines sogenannten Suchbaums navigierte man durch diese Seiten. Vereinzelt gab es Computer externer Dienstleister, die über das System erreichbar waren, etwa für Fahrkartenbuchungen und Online-Banking, aber das war eher die Ausnahme. In Frankreich hingegen waren externe Dienstleister der Normalfall. Die DGT bot zwar auch ein paar eigene Dienste an, war aber ansonsten größtenteils lediglich Vermittler.
Télétel konnte über verschiedene Einwahlnummern erreicht werden, die für den Nutzer mit verschiedenen Kosten verbunden waren. Die Preise in der folgenden Aufstellung entstammen dem Gebührenkatalog von 1994.
- Unter 3611 erreichte man das Telefonbuch. Drei Minuten konnte man diesen Dienst kostenfrei nutzen, was für die allermeisten Nummernrecherchen sicher ausgereicht hat. Wenn nicht, konnte man einfach auflegen, sich neu einwählen und bekam wieder drei freie Minuten.
- Für die Services auf 3613 mussten von Kundenseite nur die normalen Telefonkosten aufgebracht werden. Diese beliefen sich auf 7,80 Francs pro Stunde (heute etwa 2,10 Euro). Die Kosten für den Télétel-Dienst selbst trug hier der Anbieter.
- Bei 3614 war es umgekehrt. Hier zahlte der Anbieter nichts, aber der Kunde musste 21,90 Francs pro Stunde aufbringen (entsprechend 6,40 Euro).
Ab 1984 wurden diese Zugangsnummern um die “Kiosque”-Dienste erweitert. Dieser Name kam nicht ganz von ungefähr. Unter der zunächst eingeführten 3615 sollten zunächst nur Presseangebote zu finden sein. Schnell kamen auch andere Anbieter dazu – teils auf 3615, andere dann auf 3616 oder 3617. Wählte man sich hier ein, wurde man nach einer Kennung für den Dienst, den “code du service” gefragt. Dieser Code war bei Télétel in der Regel ein Wort. Mit den Diensten, die so erreichbar waren, waren dann Kosten von 50 Francs pro Stunde bis zu mehreren Hundert Francs pro Stunde verbunden. Das Geld haben sich France Telecom und der Anbieter geteilt. Bei einem klassischen 3615-Angebot mit 60 Francs pro Stunde gingen 20 Francs an die Telecom und 40 Francs an den Anbieter. Der Kiosque machte den Dienst für Presse- und Diensteanbieter sehr attraktiv, erlaubte er doch, Artikel und Informationen bereitzustellen und für diese bezahlt zu werden, ohne dass zwischen jedem Kunden und dem Anbieter ein Vertrag abgeschlossen werden musste und ohne dass man jeweils Kunden-Logins brauchte, so wie es heute im Web nötig ist, wenn man die Bezahlangebote von Zeitungen und Zeitschriften im Netz nutzen möchte. Im Télétel-Kiosque brauchte es das nicht. Das Geld für die Nutzung kam automatisch von der France Télécom und die holte es sich vom Kunden über die Telefonrechnung mit Aufschlag zurück.
Durch den niedrigschwelligen Einstieg mit den “verschenkten” Geräten und dem im Prinzip kostenlosen Telefonbuch-Dienst wurden die Minitels sehr erfolgreich. Auch die angebotenen Dienste wurden teils sehr beliebt. Wer als Firma, als Bank oder Versicherung etwas auf sich hielt, musste im Kiosque verfügbar sein. Schaut man sich französische Werbung der 1980er und 1990er an, sah man daher an allen Ecken Angaben wie “3615TOYOTA”. Doch nicht nur die klassische Wirtschaft und Presse hatten Interesse an Minitel. Viele Angebote für Horoskope, Telespiele, Jobvermittlungen und nicht zuletzt Erotikangebote und die sogenannte “Messagerie”, also das Chatten, machten das Minitel beliebt und zogen manchem Franzosen und mancher Französin das Geld aus der Tasche.
Frankreich war stolz auf sein Minitel und hielt lange daran fest. Selbst als das Web schon durchaus verbreitet war, verwendeten viele Franzosen gerne weiter die kleinen Terminals, eben weil sie so gut funktionierten, man keinen Computer und keine damit auch keine Computerkenntnisse brauchte und weil viele Dienste dort schnell und einfach verfügbar waren. 2012 war es dann aber doch soweit. Télétel samt dem Telefonbuchdienst und dem Kiosque wurden eingestellt.
Bildschirmtext (Btx) in Deutschland
Télétel in Frankreich mit seinen günstigen Minitel-Geräten war ein großer Erfolg – ein so großer sogar, dass die Minitel-Popularität die Verbreitung des Web in Frankreich zunächst hemmte. Gerade aus Sicht der Anbieter ist das verständlich, denn die Möglichkeit, sehr einfach Dienste gegen Geld anzubieten, bot das Web so damals nicht und tut es an sich auch heute noch nicht.
In Westdeutschland entwickelte die Bundespost einen grundsätzlich vergleichbaren Dienst. Hier sah die Sache aber ganz anders aus. Sprichwörtlicher deutscher Perfektionismus und Bürokratie verhinderten einen Erfolg wie in Frankreich. Doch fangen wir von vorne an.
Der Dienst Bildschirmtext der Deutschen Bundespost, kurz Btx, ging nach einer Testphase in Berlin und Düsseldorf 1983 bundesweit an den Start. Das Angebot war ähnlich wie das britische Prestel hierarchisch organisiert mit vielen Informationsseiten und Unterseiten, die auf Rechnern der Bundespost gespeichert wurden. Auch externe Diensteanbieter wie Banken, Dienste der Bundespost selbst sowie Fahrplan- und Fahrkartendienste der Bundesbahn waren erreichbar. Auch einen Mitteilungsdienst gab es. Grundsätzlich sind dies gute Voraussetzungen für einen erfolgreichen Dienst. Dass es nicht so kam, lag auf der Kundenseite sicherlich an den Kosten. Das zeigt ein direkter Vergleich: Der einmalige Anschluss an Btx kostete zunächst einmal schon 55 DM (DM-Preise von Mitte der 1980er Jahre entsprechen in etwa Euro-Preisen von 2021). Für Btx brauchte man natürlich noch ein Modem. Dieses musste man bei der Post für 8 DM im Monat mieten. Ein eigenes Modem durfte man nicht betreiben. Zur Eingabe und als Anzeigegerät brauchte man dann noch einen Btx-Decoder. Das konnte zum Beispiel ein Btx-fähiges Fernsehgerät sein. Solche Fernseher waren aber mit 2500 bis 3500 DM sehr teuer und waren nie wirklich verbreitet. Ein eigenständiger Decoder, den man an einen vorhandenen Fernseher anschließen konnte, schlug immerhin noch mit 1300 DM zu Buche. Minitel-ähnliche Geräte, sogenannte BITELs oder Multitels, konnte man von der Post für sage und schreibe 48 Euro im Monat mieten. Rechnen wir zusammen, kommen wir, von den Fixkosten abgesehen, schon auf 56 DM Grundkosten pro Monat, ohne auch nur eine einzige Minute den Dienst genutzt zu haben. Diese Kosten waren in Frankreich 0 Francs. Wollten wir den Dienst nun nutzen, schlug das mit 23 Pfennig alle 8 oder 12 Minuten zu Buche, je nach Tageszeit. Rechnen wir mit einem Durchschnitt und gehen von 1 Stunde Nutzung am Tag aus, sind das nochmals 41 DM, vorausgesetzt dass wir nur kostenfreie Angebote aus dem bundesweiten Angebot oder unserem eigenen Regionalangebot7 nutzen und keine “Mitteilungen” (also E-Mails) versendeten. Das Versenden einer solchen Mitteilung kostete nämlich 40 Pfennig, das Speichern beim Empfänger, wenn man die Nachricht also nicht nur einmal lesen, sondern auch behalten wollte, 1,5 Pfennig. Briefe kosten nun einmal Porto. Auch einzelne Angebote konnten Geld kosten; von 1 Pfennig bis 9,99 DM pro Aufruf konnten anfallen. Somit war es auch in Deutschland möglich, dass Anbieter, wie etwa die Frankfurter Allgemeine Zeitung, für ihre Inhalte bezahlt werden konnten.
Btx war für Privatleute sicher zu teuer. Lohnend war es hingegen für Unternehmen, denn die Post ermöglichte geschlossene Benutzergruppen. Reisebüros etwa konnten per BTX Flüge und Hotels über spezielle Seiten buchen, die für die Allgemeinheit nicht verfügbar waren, und Handelsreisende konnten sich über BTX mit ihrem Unternehmen synchronisieren.
Technisch war das deutsche Btx komplexer sowohl als Prestel als auch als der französische Télétel-Dienst. Die Bundespost trieb mit anderen europäischen Post- und Telekommunikationsbehörden den sogenannten CEPT-Standard8 voran. Dieser Standard sorgte dafür, dass Btx erheblich schöner aussehen konnte als Prestel und Télétel. Er war aber gleichzeitig auch ein Hemmschuh, denn der Dienst wurde dadurch fehleranfälliger und in Bezug auf die möglichen Endgeräte eingeschränkter. Letzteres mag, entsprechend der Geisteshaltung einer staatlichen Behörde, die gerne alles unter Kontrolle haben möchte, sogar durchaus gewünscht gewesen sein. Im Gegensatz zum Prestel-System, das auch mit Heim- und Personal-Computern genutzt werden konnte, mussten es in Deutschland teure Spezialdecoder sein, denn die Computer der damaligen Zeit konnten CEPT nicht darstellen und waren damit auch nicht für den BTX-Dienst zugelassen.
Das Besondere am CEPT-Standard im Vergleich mit den anderen Diensten war die für damalige Verhältnisse hohe Bildqualität. Neben Textdarstellung, die sicherlich dominierte, konnten auch echte Grafiken eingebunden werden. Andere Dienste konnten Grafik allenfalls mit speziellen Grafik-Buchstaben simulieren. Ein CEPT-Bild einer Btx-Seite hatte eine Auflösung von 480x250 Pixeln und konnte auf einer Bildschirmseite 32 Farben aus einer Gesamtpalette von 4096 Farben verwenden. Mit dieser Anforderung schieden nahezu alle verbreiteten Computer Mitte der 1980er Jahre als Endgeräte aus. Im PC-Bereich herrschte noch der CGA-Standard vor. Dieser erlaubte maximal vier fest zugeordnete Farben und hatte dann nur eine Auflösung von 320x200 Pixeln; das reichte auf keinen Fall. Die seit 1984 verfügbare, aber sehr teure EGA-Grafik hätte mit 640x350 Pixeln zwar eine hinreichend große Auflösung gehabt, konnte aber nur 16 Farben aus einer Palette von 64 nutzen. Selbst das ab 1987 verfügbare VGA zeigte bei einer ausreichenden Auflösung von 640x480 nur 16 Farben (immerhin aus einer Palette von 262.144). Abseits der IBM-PC-Kompatiblen sah es nicht wirklich besser aus. Der Commodore 64 stand mit 16 festen Farben und einer Auflösung von 320x200 Pixeln auf verlorenem Posten. Die gleiche Farbzahl und Auflösung hatte auch der Atari ST, wenn er mit einem Farbmonitor betrieben wurde. Lediglich der brandneue Commodore Amiga erfüllte die Voraussetzungen zur korrekten Anzeige von Btx-Seiten im CEPT-Standard.
Durch die Kombination aus hohen Kosten, übermäßig hohen technischen Anforderungen und viel Bürokratie wurde Btx in Deutschland nicht der Erfolg, den das Minitel in Frankreich der DGT brachte. Mit dem Aufkommen des World Wide Web ging der Dienst zunächst in T-Online auf und wurde dort T-Online Classic genannt. 2001 wurde er dann größtenteils eingestellt. Lediglich für den Bereich des Online-Banking blieb die alte Technik noch bis 2007 in Betrieb, denn Banken schätzten die technischen Eigenschaften des geschlossenen Dienstes. Wer die Btx-Seite einer Bank anwählte, war durch seine Zugangskennung bei der Telekom bekannt. Die Bank musste nur eine Zuordnung von Zugangskennungen zu Konten machen und brauchte sich ansonsten nicht um die Absicherung der Kommunikation oder ähnliches kümmern. Der wilde Westen des World Wide Web bot diese so wohltuende Geschlossenheit nicht.
Btx in Österreich
Mit Prestel, Télétel und Bildschirmtext habe ich Ihnen, glaube ich, die wichtigsten Vertreter dieser frühen Variante von Online-Diensten nahegebracht. Es lohnt sich aber, einen kleinen Abstecher zu machen in Deutschlands südliches Nachbarland Österreich, denn hier ging man einen anderen Weg als in Frankreich und in Deutschland.
Die Österreichische Post und Telegraphenverwaltung (PTV) betrieb einen auf dem gleichen CEPT-Standard wie in Deutschland basierenden Dienst, der auch ebenfalls Bildschirmtext hieß. Der Dienst war allerdings etwas günstiger als in Deutschland. Das macht ihn für sich genommen noch nicht interessant. Besonders und damit herausragend war aber die österreichische Einschätzung zum Endgerät. Während man in Frankreich ja auf ein sehr einfaches, kleines Gerät setzte und dieses kostenfrei abgab und während man in Deutschland sehr restriktiv in Sachen Endgeräten vorging und diese teuer verkaufte oder vermietete, entwickelte die PTV zusammen mit der Universität Graz unter Leitung des Informatik-Professors Hermann Maurer einen eigenen Btx-Decoder namens Mupid (Mehrzweck Universell Programmierbarer Intelligenter Decoder). Ein Mupid konnte von der PTV gemietet werden. Dafür musste man einmalig 1000 Schilling aufbringen und dann 130 Schilling pro Monat bezahlen (18,17 Euro in 2021).

Hier abgebildet sehen Sie die zweite Version des Mupid. Die erste Version wurde noch für die Testphase des Btx-Dienstes hergestellt, als man noch den englischen Prestel-Standard nutzte. Das abgebildete Gerät erschien 1984 nach der Umstellung auf CEPT. Es sieht aus wie ein typischer Heimcomputer der Zeit und, wie ich finde, sogar wie ein ziemlich modern designter. Der Mupid sah aber nicht nur wie ein Heimcomputer aus, er war auch einer oder er konnte zumindest einer werden, wenn man ihn mit Zusatzgeräten versah.
Ein Mupid wurde über ein Kabel an einen Fernseher angeschlossen. Ebenfalls angeschlossen werden musste, zumindest wenn man Btx-Seiten ansehen wollte, das von der PTV gemietete Modem. Der Mupid selbst verfügte über einen Z80-Prozessor. Den kennen Sie schon aus einer ganzen Reihe von Heimcomputern. Er ist kompatibel zum Intel 8080, also dem Computer, der nicht zuletzt mit dem Altair 8800 den Anfang des Personal-Computer-Zeitalters mit einläutete. Mit 128 KB Arbeitsspeicher war das Gerät ganz ordentlich ausgestattet. Schloss man ein separat erhältliches Diskettenlaufwerk an, konnte man auf dem Mupid tatsächlich CP/M und die zugehörige Software laufen lassen und hatte dann einen Heimcomputer. Unter den CP/M-Computern war der Mupid allerdings ein ganz besonderer, denn eigentlich sind CP/M-Systeme ja stets reine Textsysteme. Der Mupid hingegen verfügte über für die damalige Zeit durchaus beeindruckende Grafikfähigkeiten in Bezug auf Farbanzahl und Auflösung. Um Btx-Seiten im CEPT-Standard darstellen zu können, durfte das ja auch nicht anders sein.
Der Mupid konnte also sowohl Btx-Decoder als auch Heimcomputer sein. Der Clou bestand nun aber darin, diese beiden Eigenschaften miteinander zu verbinden. Im Btx-Modus konnte ein Mupid nämlich mehr als es ein “dummer” Decoder konnte. Er vermochte es beispielsweise, vektorbasierte Zeichnungen anzuzeigen oder Eingaben auf dem Decoder zu überprüfen, ohne sie übertragen zu müssen. Verfügte man über ein Diskettenlaufwerk, ließen sich mit dem Mupid Btx-Seiten auf Diskette speichern. Diese konnten dann ohne Telefonkosten zu verursachen gelesen werden. Mit der passenden Software ließen sich Btx-Seiten sogar auf dem Mupid erstellen und auf die Postcomputer übertragen.
Auch ohne Diskettenlaufwerk konnte auf einem Mupid Software ausgeführt werden. Diese kam dann direkt aus dem Btx auf den Rechner. Der Screenshot oben zeigt, wie das aussah. Sogenannte Telesoftware, wie die oben angekündigte einfache Textverarbeitung konnten aus dem Btx geladen und dann auf dem Mupid ausgeführt werden. Auch ein BASIC-Interpreter zum Programmieren kam so auf das Gerät. Software konnte, egal ob von Diskette oder aus dem Btx geladen, den Dienst als Datenverbindung und als Speicherort nutzen, also Daten aus dem Btx empfangen oder dorthin senden. Mit diesen Eigenschaften ließen sich spannende Szenarien umsetzen, wie diese Pressemitteilung aus dem Jahr 1986 zeigt:
EDV-Ausbildungsinitiative aus Graz als Weltpremiere.
Die Arbeitsgemeinschaft für Datenverarbeitung (ADV), die größte österreichische Vereinigung von Computeranwendern, stellt anlässlich der Grazer Btx-Tage (19.02. - 22.02.86 im Kongreßsaal Messegelände) ein von der steirischen Landesgruppe der ADV (Präsident Dr.J.Koren) initiiertes neuartiges Ausbildungsprogramm für jedermann vor.
Angelehnt an das weitverbreitete Taschenbuch “EDV für jedermann” von J. Koren und W. Thaller wurde unter der wissenschaftlichen Betreuung von o. Univ. Prof. Dr. H. Maurer (TU Graz) ein 20-teiliger Kurs zur Einführung in die wichtigsten Aspekte der EDV erarbeitet: die 20 Lektionen sind im Bildschirmtextsystem (Btx) der österreichischen Post gespeichert und sind daher österreichweit über die Telefonleitung (zum Telefonortstarif) abrufbar. Jede Lektion wird zunächst in den von der Post mietbaren Btx-Computer MUPID geladen und dort (ohne weitere Telefonverbindung) durchgearbeitet.
Im Gegensatz zu einem gedruckten Fernkurs bietet diese Art der Wissensvermittlung die anschauliche Darstellung von Abläufen durch bewegte Grafik (deren Geschwindigkeit vom Benutzer gesteuert wird, die wiederholbar ist, und vieles mehr) und die direkte Kontrolle des erarbeiteten Wissens durch Fragen, die der Btx-Computer MUPID stellt und die vom Benutzer beantwortet werden sollen. (MUPID kontrolliert, ob die Antworten stimmen!) Durch die Verwendung von Btx als “Lektionenbibliothek” ist es dem Lernenden möglich, Kommentare und Verbesserungsvorschläge an den Kursersteller elektronisch zu vermitteln, die auf gleichem Wege gegebenenfalls beantwortet werden: das Institut für Informationsverarbeitung wird diese Art der Betreuung probeweise durchführen. Übrigens, die ADV denkt auch daran, Prüfungen (mit entsprechenden Zeugnissen) für diesen Kurs anzubieten.
Sicherlich war diese Form des Lernens mit dem Computer nicht die Speerspitze der Forschung. Mit experimentellen, universitären Systemen waren ähnliche Szenarien auch schon vorher und auch ausgefeilter möglich. Spannend und innovativ an dem Ansatz in Verbindung mit Btx und Mupid ist aber, dass sowas nun alltagstauglich in einem öffentlichen Dienst und damit potenziell für jeden verfügbar wurde, ohne dass komplexeste Technik angeschafft werden musste. Mit dem französischen Minitel wäre das so nicht gegangen, denn die einfachen Geräte konnten ja keine Software ausführen und im deutschen Btx wäre es auch nicht gegangen, denn hier gab es kein flächendeckend verbreitetes, “intelligentes” Gerät wie den Mupid.
Der Mupid hatte ein faszinierendes Konzept. Die Entwickler um Hermann Maurer dachten sowohl in Sachen Technik als auch in Sachen Einsatzszenarien erheblich weiter, als dies in vielen anderen Ländern der Fall war. Sie brachten die Idee der Kommunikationsinfrastuktur und die des Heimcomputers zusammen und kreierten damit einen niedrigschwelligen Zugang mit Potenzialen, die eine größere Öffentlichkeit erst Jahrzehnte später für sich entdeckten. Dies erreichten sie mit einem freundlichen, einfachen Gerät, also ohne dass man zwangsläufig zum Computerspezialisten werden musste.
Fazit
Man kann durchaus von den Bildschirmtexten einiges lernen. Dazu gehört zum Beispiel, dass “das Internet”, und hier meine ich jetzt das WWW, zwar sicherlich vieles veränderte, aber nun auch nicht aus heiterem Himmel über uns kam. Die Zeit war offensichtlich reif für digitale Mediendienste wie den Bildschirmtext. Eine Betrachtung der Dienste zeigt auch, dass es möglich ist, Technologie dieser Art in einer Art und Weise bereitzustellen, die die technischen Hürden beim Kunden niedrig halten, denn für die Nutzer von Prestel, Btx oder Télétel war es ein einfaches Leben ohne ständige Sicherheitsupdates und ohne dass man von ihnen verlangt hätte, ein Betriebssystem zu beherrschen. Man erfährt auch, und das ja nicht zum ersten Mal, dass sich nicht immer das technisch Bessere durchsetzt, sondern oft auch das Verfügbarere, Einfachere und Niedrigschwelligere. Man lernt, dass zentralisierte Systeme großartig sein können und Kreativität fördern, wenn sie die Infrastruktur für individuelle, kreative Anbieter und Kunden bieten, aber dass solche Systeme zum Hemmschuh werden, wenn sie bürokratisch und unflexibel gestaltet sind. Letztendlich lehrt einen das Beispiel des österreichischen Btx, dass man durch Blicke über den Tellerrand, durch intelligente Kombinationen das Bekannte neu denken kann und sich dann neue Nutzungsmöglichkeiten ergeben.
Online-Dienste und Bulletin Board Systems
So attraktiv die Bildschirmtext-Dienste auch scheinen mögen, blieben sie doch eine ziemlich europäische Angelegenheit. Es gab einige Ableger in Asien und auch in den USA gab es vereinzelte Projekte, die aber lokal blieben und meist auch nicht lange überlebten. Dort gab es jedoch Online-Dienste und sogenannte Bulletin Board Systeme, die einen anderen Ursprung haben als die Bildschirmtexte in Europa.
Die Grundidee hinter Online-Diensten ist fast so alt wie die der interaktiven Computer selbst. Erinnern wir uns: Beim Time Sharing teilten sich viele Teilnehmer die Rechenzeit des Computers, der sie reihum bediente. Dazu bedienten sie sich Terminals – zu Beginn meist Fernschreiber, später dann eigene Geräte mit Tastatur und Bildschirm. Man konnte den Computer aus der Ferne nutzen, ohne die eigentliche Anlage je sehen zu müssen. Innerhalb eines Firmensitzes oder eines Universitätscampus war dies durch das Legen eines direkten Kabels zur Rechenanlage möglich, doch lag es ja nun auch nahe, die Dienste auch aus größerer Entfernung anzubieten. Schließlich gab es bereits ein landesweites Kommunikationsnetz in Form des Telefonnetzes. Mittels Modems konnten über dieses Telefonnetz sowohl Computer miteinander als auch, und darum geht es ja hier, Terminals mit entfernten Computern verbunden werden. Man konnte sich so von entfernten Orten mit Firmen- oder Universitätscomputern verbinden. Die Terminals selbst konnten nichts weiter als Textzeichen anzeigen und Tastatureingaben verschicken. Wenn das gut klappte, wirkte es so, als säße man direkt vor Ort am Terminal.
Diese Technik, um aus Entfernung auf Timesharing-Computersysteme zugreifen zu können, wurde zu einer Geschäftsidee, denn nicht jeder, der vielleicht davon profitieren könnte, hatte Zugang zu einem Timesharing-System. Vor allem viele kleinere Firmen konnten sich weder eigene Computer leisten noch hatten sie Zugang zu universitären Rechnern. Sehr zupass kam ihnen da das Angebot von Timesharing-Anbietern. Das waren Firmen, die es zu ihrem Geschäftsmodell machten, Computersysteme zu betreiben, auf die man sich gegen Gebühr aus Entfernung verbinden und auf denen man dann seine Programme laufen lassen konnte. Solche Firme gab es in kleiner Größe oder auch als große Player, wie etwa das schon 1969 gegründete CompuServe. Über das Telefonnetz konnte man sich von vielen großen Städten der USA auf die zentralen Timesharing-Computer von CompuServe verbinden und seine Programme laufen lassen. Diese Programme konnten ganz individuell sein. Viele Firmen brauchten aber natürlich ganz ähnliche Dienste und viele Dienste konnten gerade auch vom zentralen Charakter des Anbieters profitieren.
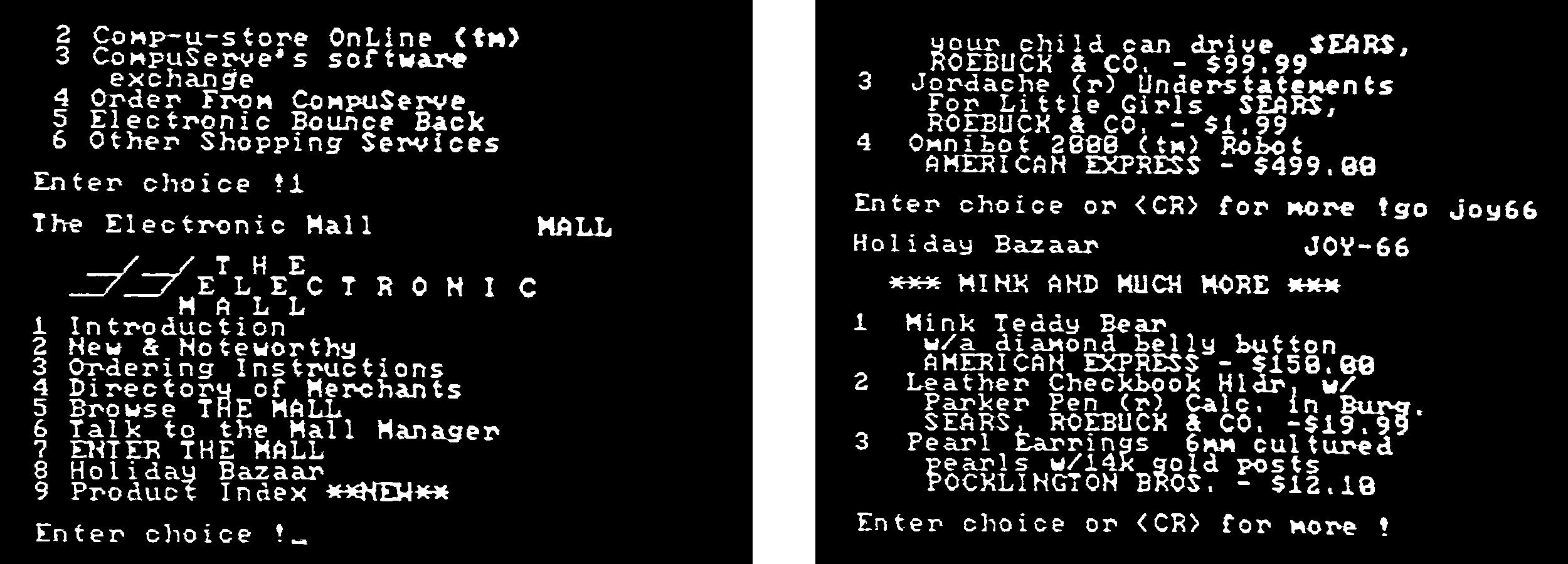
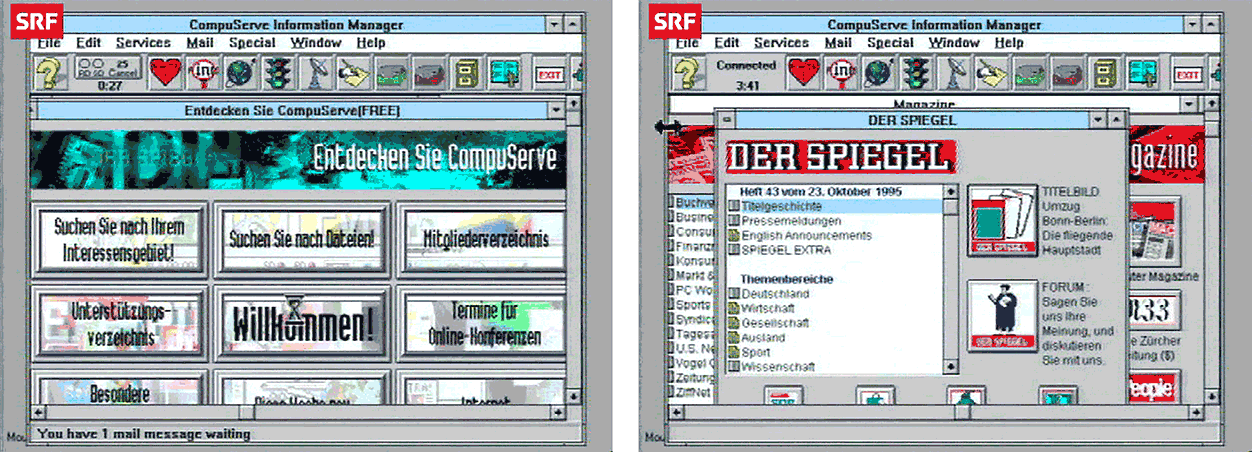
Ende der 1970er Jahre wurde CompuServe so von einem Timesharing-Anbieter zu einem Onlinedienst mit Zugriff auf Finanzinformationen, auf Banking, auf Lexika und Nachschlagewerke, auf Nachrichtenangebote und mit der Möglichkeit, zwischen den Teilnehmern Nachrichten zu verschicken. Zugang erlangte man nun nicht mehr mit Fernschreibern und Terminals, sondern mit aufkommenden Personal- und Heimcomputern. Das Ergebnis war bis in die 1990er Jahre, ganz wie der Großteil der Nutzungsschnittstellen der damaligen Computer, textbasiert. Mit dem Aufkommen grafischer Nutzungsschnittstellen änderte sich dies natürlich. CompuServe-Inhalte wurden nun in Fenstern und mit einer grafischen Nutzungsschnittstelle angezeigt. Andere Anbieter kamen hinzu. Bekannt sind America Online (AOL) und das Microsoft Network (MSN).
Einen regelrechten Gegenentwurf zu den großen Online-Diensten, die von großen Anbietern gepflegt wurden und stark kommerzielle Zwecke erfüllten, bildeten die BBS, die Bulletin Board Systems. Im deutschen Sprachraum wurde dieser Begriff erstaunlicherweise weder im englischen Original noch in der Übersetzung “Nachrichtenbrett-Systeme” verwendet. Stattdessen verwendete man mit “Mailbox” einen anderen englischen Ausdruck, der gar nicht besonders gut passt, denn private Briefe standen nie im Mittelpunkt der Systeme.
Hinter BBS-Systemen standen keine großen, kommerziellen Anbieter, sondern oft Privatleute oder allenfalls kleinere Firmen. Als das erste System dieser Art wird das Computerized Bulletin Board System (CBBS) angesehen. Ab 1978 konnte es im Raum Chicago per Modem angewählt werden. Man erreichte dann einen Altair-artigen Computer, um die digitale Version eines schwarzen Bretts einzusehen und dort Nachrichten zu hinterlassen. Diese namensgebende Funktionalität wurde im Laufe der Jahre ergänzt um private Nachrichten von einem Teilnehmer an einen anderen, die Möglichkeit, Software für den eigenen Heimcomputer herunterzuladen und oft sogar um einfache Online-Spiele und Chats. Ein solcher Chat war natürlich nur dann möglich, wenn das BBS-System über mehr als eine Leitung verfügte, denn nur dann konnten ja mehrere Teilnehmer gleichzeitig verbunden sein. Das war bei Weitem nicht bei allen BBS-Systemen der Fall. Typische BBS-Systeme waren häufig Heimcomputer von Technikbegeisterten. In den 1980er Jahren waren es oft IBM-kompatible PCs, die mit Microsofts DOS betrieben wurden. Auch C64-Systeme wurden gerne als BBS-Server eingesetzt. Diese Computer waren mit einem oder vielleicht auch mal mit zwei Modems ausgestattet. Nutzer des Systems brauchten ebenfalls ein Modem und konnten dann von ihrem Heimcomputer aus den BBS-Rechner anrufen und Daten austauschen. Oft war dieses Modem nur ein einfacher Akustikkoppler. Gerade in Deutschland hatte man, wenn man nichts Illegales machen wollte, auch kaum eine andere Wahl, denn Privatleute durften ja keine eigenen Modems an das Telefonnetz anschließen.
Ein BBS-System war eine Insel mit einem eigenen Angebot. Viele BBS-Systeme boten aber den sogenannten NetMail-Dienst an. Man konnte mit diesem Dienst Nachrichten an die Teilnehmer anderer BBS-Systeme schicken. Dies geschah natürlich noch nicht über das Internet, das zum damaligen Zeitpunkt ja noch nahezu rein auf Forschungseinrichtungen beschränkt war und damit weit weg war von dem, was man mit Heimcomputern machte. Vielmehr schlossen sich die BBS-Systeme selbst in Netzwerken zusammen. Verfasste man eine Nachricht an einen Teilnehmer in einem anderen BBS-System, wurde diese nicht sofort zugestellt, sondern erstmal zwischengespeichert. Irgendwann in der Nacht dann riefen sich die BBS-Computer untereinander an und tauschten die Nachrichten aus.
BBS-Systeme waren natürlich weit weniger professionell als die amerikanischen Online-Dienste oder die europäischen Bildschirmtext-Dienste. Das konnte aufgrund der Struktur ja auch nur so sein. BBS-Systeme stehen in einer ähnlichen Tradition wie die Personal Computer. Im Kapitel über den Altair 8800 habe ich Ihnen die Situation Ende der 1970er Jahre erläutert, als sich in den USA Bastler in Clubs zusammentaten, um ihre eigenen Rechner zu bauen und damit dafür zu sorgen, dass Computer nicht mehr nur eine Sache von Militär, Industrie und Verwaltung waren, mit der die normale Bevölkerung nichts zu tun haben sollte. Man kann das Ziel dieser Clubs regelrecht als Versuch eines Befreiungsschlags ansehen. BBS-Systeme haben einen ganz ähnlichen Charakter. Es waren nun nicht professionelle Firmen oder Postorganisationen, die die Welt der computerisierten Kommunikation eröffneten, sondern Technikbegeisterte und Hobbyisten, die mit ganz einfachen Mitteln die Welt verändern wollten.
Auf der Höhe ihrer Popularität ging die Anzahl der BBS-Systeme in den USA in die Zehntausende, mit Millionen regelmäßiger Nutzer. Zusammengenommen hatten die BBS-Systeme mehr Nutzer als Online-Dienste wie CompuServe. So mag es einen auch nicht wundern, dass das neue Betriebssystem Windows 95 im Jahr 1995 zwar noch keinen Webbrowser enthielt, aber sowohl einen Zugang zu Microsofts Online-Dienst MSN als auch ein Terminalprogramm, mit dem man ein angeschlossenes Modem ansteuern und mit einem BBS-System verbinden konnte. All dies sollte sich bald ändern, denn BBS-Systeme und Onlinedienste bekamen Konkurrenz durch lokale ISPs, Internet Service Provider. Das World Wide Web lief den etablierten Angeboten in nur wenigen Jahren den Rang ab.
Das World Wide Web
Mit der steigenden Popularität des Internets durch das World Wide Web ging die Zeit der Bildschirmtextsysteme, der Online-Dienste und der BBS-Systeme zu Ende. Das Internet hat seine Anfänge im Bereich von Universitäten und Wissenschaftsorganisationen. Es hat an sich keine Nutzungsschnittstelle, sondern ist eine reine Infrastruktur, die die Nutzung verschiedenster Dienste ermöglicht. Der wohl ursprünglichste Internetdienst hat den Namen telnet und erlaubt es Nutzern, sich über das Netz auf entfernten Computern anzumelden und diese fernzusteuern, den eigenen Computer also als Terminal für entfernte Großrechner zu verwenden. Der Dienst trat an die Stelle der Einwahl auf entfernte Computer über eine Telefonleitung. Über die Jahre kamen viele weitere Dienste hinzu. Einer der bekanntesten ist der E-Mail-Dienst, den wir ja auch heute noch nutzen. Vom FTP, dem Dienst zum entfernten Zugriff auf Dateien, wird im Kapitel Verteilte Persistenz noch die Rede sein. In diesem Kapitel soll es hauptsächlich um den Dienst gehen, der heute so dominant ist, dass er in der Öffentlichkeit allgemein für das Internet steht. Wir beginnen unsere Betrachtung des Internets aber – so kennen Sie das von mir schon – nicht direkt mit dem Web, sondern mit einer Parallelentwicklung und werden wieder sehen, dass die Zeit für bestimmte Entwicklungen offensichtlich reif war.
Ein Gopher wühlt sich durch Dokumente
Anfang der 1990er Jahre entstand an der Universität von Minnesota in den USA ein Dienst zur Verfügbarmachung von Text-Dokumenten. Dem Dienst wurde der Name Gopher (gesprochen Goffer) gegeben. Der Name ist etwas eigenartig. Schlägt man im Wörterbuch nach, findet man die “Taschenratte”. Der Hintergrund hinter der kuriosen Namensgebung ist vielschichtig. Das Maskottchen der Universität und des Staats Minnesota spielt mit hinein, aber auch umgangssprachliche Definitionen des Wortes und die Eigenart von Gophern, sich “durchzuwühlen”, spielt eine Rolle. Die offizielle Beschreibung von Gopher9 führt aus:
gopher n. 1. Any of various short tailed, burrowing mammals of the family Geomyidae, of North America. 2. (Amer. colloq.) Native or inhabitant of Minnesota: the Gopher State. 3. (Amer. colloq.) One who runs errands, does odd-jobs, fetches or delivers documents for office staff. 4. (computer tech.) software following a simple protocol for burrowing through a TCP/IP internet.
Der Zweck und die Charakteristik von Gopher erklären sich durch seine Herkunft als universitäres Informationssystem gut. Hier gilt es natürlich, viele Dokumente verfügbar und diese auf eine ordentliche, gut verständliche Art und Weise erschließbar zu machen. Man entschied sich dazu, die Dokumente in einer hierarchischen Struktur darzustellen, einer Organisationsform, die aus Bibliotheken und Verwaltung schon bekannt war. Auch dies erläutert die Beschreibung von Gopher sehr schön:
A hierarchical arrangement of information is familiar to many users. Hierarchical directories containing items (such as documents, servers, and subdirectories) are widely used in electronic bulletin boards and other campus-wide information systems. People who access a campus-wide information server will expect some sort of hierarchical organization to the information presented.
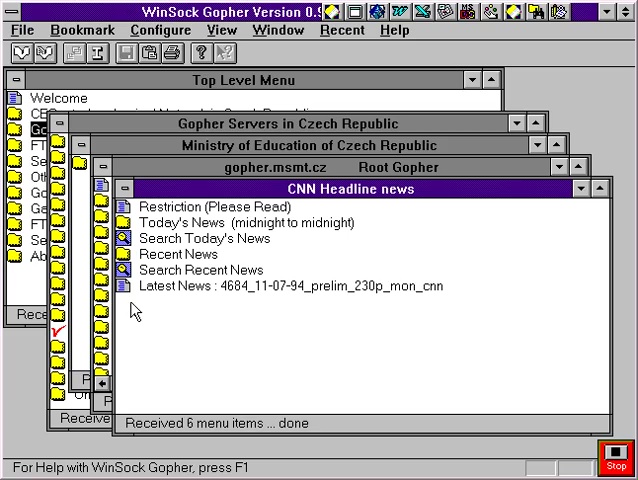
Das Gopher-System der Universität von Minnesota war technisch sehr simpel gestaltet. Im Vordergrund standen Textdateien, die in einer einfachen, hierarchischen Struktur organisiert waren und mit Volltextindizes leicht durchsucht werden konnten. Das System sollte zum einen leicht verständlich sein und zum anderen wenig Ressourcen benötigen. Wie das aussah, sehen Sie zum Beispiel auf obiger Abbildung. Hier werden die Indizes von Gopher-Seiten unter Windows 3.1 gezeigt. Aufgrund der Einfachheit der Struktur ließ sich der sogenannte Gopher-Space aber auch sehr einfach auf reinen Textterminals erobern. Gerade an Universitäten mit ihren Unix-Terminals war dies nicht zu vernachlässigen.
Gopher ist heute weitgehend unbekannt. Der Dienst wurde vom World Wide Web regelrecht überrollt. Als ein Grund dafür gilt auch, dass die Universität von Minnesota sich anschickte, mit der Technologie Geld verdienen zu wollen und sie nicht mehr frei zur Verfügung zu stellen. Dieser wirtschaftliche Faktor mag sicher eine Rolle gespielt haben, obgleich es nie wirklich dazu kam, dass Geld für die Gopher-Technologie verlangt wurde. Im Zusammenhang betrachtet scheinen mir andere Faktoren viel wichtiger gewesen zu sein. Die reine hierarchische Struktur und der starke Fokus auf Textdateien, die noch nicht einmal in Sachen Farbe und Schriftart angepasst werden konnten, passten nicht so recht zum aufkommenden Multimedia-Zeitalter. Firmenpräsenzen, aber auch Vereins- und Privat-Gopher-Seiten wären schon einigermaßen öde gewesen.
Das frühe World Wide Web
Die Grundidee hinter der Entwicklung des World Wide Web ist der von Gopher an der Universität von Minnesota gar nicht unähnlich, denn in beiden Fällen ging es letztlich um das Zugänglich-Machen von Informationsinhalten. Der britische Informatiker Tim Berners-Lee und sein belgischer Kollege Robert Calliau konzipierten und entwickelten das WWW am CERN in Genf. CERN steht für Conseil Européen pour la Recherche Nucléaire und ist das größte europäische Kernforschungszentrum. Bekannt ist es vor allem für seine großen Teilchenbeschleuniger. Die vielleicht einflussreichste Entwicklung des CERN ist aber bei Weitem nicht so kompliziert wie Teilchenphysik.
Man kann sich gut vorstellen, dass am CERN schon seit jeher viele Computer genutzt, viele Informationen abgelegt und viele Dokumente geschrieben wurden. So beschreibt es auch das Proposal für das WWW aus dem Jahr 199010:
At CERN, a variety of data is already available: reports, experiment data, personnel data, electronic mail address lists, computer documentation, experiment documentation, and many other sets of data are spinning around on computer discs continuously.
Das Problem war aber die Verbindung der Informationen.
It is however impossible to “jump” from one set to another in an automatic way: once you found out that the name of Joe Bloggs is listed in an incomplete description of some on-line software, it is not straightforward to find his current electronic mail address. Usually, you will have to use a different lookup-method on a different computer with a different user interface. Once you have located information, it is hard to keep a link to it or to make a private note about it that you will later be able to find quickly.
Berners-Lee und Calliau wollten mit ihrem System also ein sehr konkretes Problem am CERN lösen. In der heutigen Geschichtserzählung, auch betrieben von Tim Berners Lee selbst, erscheint das mitunter anders. Die Wikipedia spricht zum Beispiel von seiner “vision of a global hyperlinked information system”. Ob es die gegeben hat, wann es sie gegeben hat und ob nicht aus dem späteren Erfolg dann ex post die Gedanken der Vergangenheit zu einer Vision verklärt wurden, wird hier nicht zu klären sein. Interessanter jedenfalls wird die Geschichtsbetrachtung, wenn man nicht von geniegleichen Visionären ausgeht, sondern wenn man, wie auch beim Rest der Computergeschichte, Beweggründe, Kontexte und Einflüsse betrachtet.
Betrachtet man das WWW rein von der technischen Seite her, war es nicht besonders innovativ und visionär, sondern im Gegenteil ziemlich einfach. Web-Technologie bestand nur aus zwei Spezifikationen, einer für Server, die das Übertragungsprotokoll HTTP beherrschen mussten, und einer weiteren für Terminalprogramme, Browser genannt, die die Auszeichnungssprache HTML interpretieren können mussten.

Die Hauptfunktionalität von HTTP-Servern ist das Ausliefern von Dokumenten. Dieser Prozess läuft sehr simpel ab. Stellen Sie sich einen HTTP-Server vor wie jemanden, der vor einem Telefon sitzt. Sie können diese Person anrufen. Nach dem Abnehmen sagen Sie ihr, welches Dokument Sie vorgelesen haben möchten. Die Person am anderen Ende liest das Dokument vor und legt direkt wieder auf. Diesen Vorgang sehen Sie in der Abbildung oben. Dort wurde ein Webserver ohne Browser angefragt, sodass man mitlesen kann, welche Daten gesendet und empfangen werden. In den ersten Zeilen sehen Sie in grün, dass hier eine Verbindung zum Port 80 des Rechners, der unter checkip.dyndns.org erreichbar ist, aufgebaut wird. Der Computer “nimmt ab” und erwartet, dass man ihm sagt, was man will. “GET /” bedeutet nicht weniger als “Gib mir die Hauptseite!”11. Hätte der Server auch ein Impressum zu haben, könnte man zum Beispiel “GET /impressum.html” anfragen und würde entsprechend bedient. Unter der Anfrage sehen Sie die Antwort in Form eines sehr einfachen HTML-Dokuments. Danach beendet der Server direkt die Verbindung.
Wenn ein Browser eine Anfrage über HTTP an einen Server schickt, kriegt er eine Antwort. Das haben Sie gerade gesehen. Meist war und ist das wie oben reiner Text. Auch der Text, den Sie hier gerade lesen, könnte so übertragen werden. Es ergäben sich aber Einschränkungen, wenn man auf einfache Zeichen beschränkt bliebe. Grundsätzlich besteht ein reiner Text zwar aus einer Aneinanderreihung von Buchstaben, Zahlen, Leerzeichen und einigen Sonderzeichen. Dokumente wie das, das Sie gerade lesen, bestehen aber aus mehr als nur einer solchen Aneinanderreihung. Sie haben auch eine Struktur, die sich in sichtbaren Eigenschaften offenbart. Der Satz, den Sie gerade lesen, ist Teil eines Absatzes, etwas weiter oben und auch weiter unten finden Sie Überschriften verschiedener Hierarchieebenen. Sie erkennen sie an der Formatierung mit großer oder fetter Schrift. An mancher Stelle wird durch Änderung des Schriftstils etwas besonders herausgestellt. Die Textzeichen, die von einem HTTP-Server kommen, können selbst aber nicht groß, klein, kursiv oder fett sein. Bei reinem Text ist in Sachen Formatierung nicht mehr möglich als bei einer alten Schreibmaschine oder einem Fernschreiber. Es gibt nur Buchstaben, Zahlen, Sonderzeichen, Leerzeichen und Zeilenumbrüche. Damit ein Browser daraus einen formatierten, strukturierten Text machen kann, muss man in den Text etwas hineinschreiben, was nicht direkt angezeigt wird, was aber die Struktur beschreibt. Genau das macht HTML, die Hypertext Markup Language. Wir schauen uns zunächst einmal ein paar Beispiele an. Keine Angst, Sie müssen dafür nicht zum Programmierer werden.
Die Originalfassung von HTML von Tim Berners-Lee definierte 22 sogenannte Tags, die genutzt werden konnten, dem Text Struktur zu geben. Das englische Wort “Tag” übersetzt sich als “Etikett”. Man klebt also quasi Etiketten an den Text, um seine Struktur zu beschreiben. Das sah dann zum Beispiel so aus:
<TITLE>Ein einfaches Dokument</TITLE>
2: <H1>Dies ist
3: HTML
4: <P>Dies ist ein sehr einfaches HTML-Dokument.
5: <P>Zu HTML gibt es viel zu sagen. <HP1>Das Wichtigste sind die Tags</HP1>.
6: <H2>Tags!
7: <P>Die erste Version hat 22 Tags: TITLE, NEXTID, A, ISINDEX, PLAINTEXT,
8: LISTING, P, H1, H2, H3, H4, H5, H6, ADDRESS, DL, DT, UL, LI, MENU
9: und DIR. 14 davon sind auch heute noch aktuell.
In Zeile 1 wird der Dokument-Titel bestimmt. Alles, was zwischen <TITLE> und </TITLE> steht, ist der Titel des Dokuments. Bei aktuellen Browsern ist das der Text, der in der Titelzeile des Fensters bzw. als Beschriftung des Tabs angezeigt wird. Zeile 2 beginnt mit <H1>. Das sagt dem Browser, dass alles, was danach kommt, eine Überschrift der ersten Ordnung ist, also der obersten Ebene. Browser zeigen Überschriften in der Regel in großer, fetter Schrift an. Zeilenumbrüche werden in HTML übrigens ignoriert. Dass das Wort “HTML” in einer eigenen Zeile steht, hat also keine Konsequenz in der Darstellung. Eine Überschrift würde da wieder aufhören, wo </H1> steht. Das hat man sich hier aber gespart. Also endet die Überschrift da, wo eine andere Textart beginnt. Das ist in Zeile 4 der Fall, denn da beginnt mit <P> ein Absatz (auf Englisch paragraph). Ähnlich sieht es in Zeile 5 aus. Hier beginnt ein neuer Absatz; der davor endet also automatisch. Interessant ist, was im zweiten Teil der Zeile passiert, denn hier steht Text zwischen <HP1> und </HP1>. HP steht für “highlighted phrase”. Es handelt sich also um Text, der besonders herausgestellt wird. Er könnte zum Beispiel fett dargestellt werden12. Zeile 6 definiert wieder eine Überschrift, dieses Mal eine der zweiten Ordnung, also etwas kleiner in der Darstellung. In Zeile 7 folgt dann wieder ein Absatz.
Das ist alles keine Hexerei, oder? Man kann sich das Ganze eigentlich so vorstellen, als würde einem jemand den Text durchgeben, den man in einer Textverarbeitung wie Word eingeben soll. Die Tags sind dann immer Hinweise, welche Formatierungsknöpfe man drücken soll. Bei H1, H2 und P wählt man jeweils die Formatvorlagen für Überschriften und Absätze aus und bei HP1 klickt man auf fett. Mehr ist es zunächst einmal gar nicht. Das eigentlich Interessante an HTML, weswegen das Ganze für das CERN interessant war und was auch den Namen Hypertext Markup Language erklärt, zeigt dieses Beispiel:
<H2>Links
<P>Das Wichtigste an HTML sind die <A HREF=links.htm>Links zu anderen
Ressourcen</A>. Mehr erfahren Sie, wenn Sie auf den Link klicken.
Die erste Zeile definiert wieder eine Überschrift. Das kennen wir schon. Dann folgt ein Absatz – auch schon bekannt. Interessant ist dann <A HREF=links.htm> bis </A>. Hier handelt es sich um einen Link, also eine Verknüpfung zu einem anderen Dokument. Der Text dazwischen, also “Links zu anderen Ressourcen”, kann angeklickt werden. A steht für “anchor”. Danach folgt ein Attribut HREF für “hypertext reference” und dahinter steht dann, wohin dieser Link führt, nämlich zum Dokument mit dem Namen links.htm. Wählt ein Nutzer den Link aus, kontaktiert der Browser per HTTP den Server und sendet den Befehl GET /links.htm. Die Antwort wird wieder ein HTML-Dokument sein, das der Browser anzeigen kann. Ein Anker konnte nicht nur Ausgangspunkt eines Links, sondern auch dessen Ziel sein. In dem Dokument links.htm könnte zum Beispiel <A NAME=wichtig><H1>Wichtige Links</H1></A> stehen. Man könnte den Link oben dann zu <A HREF="links.htm#wichtig"> ändern. Er würde dann direkt zum Anker im Zieldokument springen.
Die ganzen komischen Abkürzungen, die Sie hier kennengelernt haben, HREF für “hypertext reference”, HTML für “hypertext markup language”, HTTP für “hypertext transport protocol” haben das merkwürdige Wort Hypertext gemeinsam. Über Hypertext wurde in den 1980ern und 1990ern sehr viel geforscht. Viele Hypertext-Systeme wurden entwickelt, von denen heute selbst unter Informatikern kaum noch jemand etwas weiß. Weiter unten erzähle ich Ihnen mehr darüber, welche Potenziale hinter Hypertext stecken. Beim World Wide Web bedeutet Hypertext nicht mehr als das, was ich Ihnen gerade bereits erläutert habe, nämlich die Möglichkeit, in ein Textdokument sogenannte Anker einzubauen, die Start- und Endpunkte von Verknüpfungen sein können.
Mit dem, was ich bis hierher erläutert habe, habe ich das frühe Web technisch fast vollständig beschrieben. Charakteristisch für das WWW war nicht seine technische Finesse, sondern gerade seine extrem technische Einfachheit und Offenheit. Nicht nur war es recht einfach, eigene Webserver und Browser zu programmieren, durch die Dezentralität war es auch möglich, einen eigenen Server einzurichten. Insofern man über einen dauerhaften Internetzugang verfügte, was am Anfang natürlich vor allem an Universitäten, später dann bei vielen Unternehmen und dann nach und nach bei mehr und mehr sogenannten “Hostern” der Fall war, konnte man einen Server ans Netz anschließen und war damit Teil des World Wide Web, ohne dass es irgendeiner zentralen Koordination bedurft hätte und dieser Server mit irgendwelchen anderen Webservern etwas zu tun haben müsste.
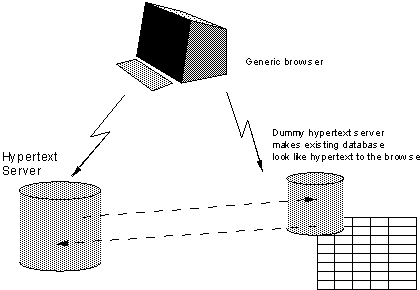
Typisch gerade für das frühe WWW war, dass ein Server in der Regel nicht mehr tat, als Dateien, die auf einer großen Festplatte gespeichert waren, so auszuliefern, wie sie waren. Von vornherein war allerdings auch vorgesehen, dass über Webserver und Browser auch Zugriff auf bereits vorhandene Systeme realisiert werden konnte. Damit das funktionierte, musste ein Server so programmiert werden, dass er mehr konnte als einfach nur Dateien versenden. Er musste vorhandene Systeme im Hintergrund aufrufen, die erhaltenen Informationen aufarbeiten und HTML-garnierten Text an den Browser schicken. Dadurch wurde es möglich, über das Web auch auf die Inhalte von existierenden CERN-internen Hilfesystemen, auf eine Informationssuchmaschine und sogar auf das Telefonbuch zuzugreifen. Die Proposals für das WWW weisen darauf hin, dass das Telefonbuch dann z. B. Links zwischen Personen, Abteilungen und Arbeitsgruppen beinhalten könnte. Natürlich sind diese Beispiele recht simpel, aber, wenn man es nüchtern betrachtet, liegt hier die Grundlage für das, was man später Web-Anwendung nennen sollte, also eine webbasierte Nutzungsschnittstelle für eine komplexe Anwendungslogik im Hintergrund.
Da das WWW zunächst vor allem für das CERN entwickelt wurde, fehlten ihm Eigenschaften, die für eine allgemeine Nutzung durchaus vieler Features nötig gewesen wären. Der erste Browser für das WWW, der von Tim Berners-Lee selbst geschriebene Browser, der verwirrenderweise auch selbst den Namen “World Wide Web” trug, konnte nicht nur Webseiten anzeigen, sondern diese auch ändern. Das klappte sowohl bei HTML-Dateien auf der lokalen Festplatte als auch über HTTP. Was fehlte, war jegliche Art von Zugriffsbeschränkungen. Im Proposal heißt es dazu:
[The project will not aim] to use sophisticated network authorisation systems. Data will be either readable by the world (literally), or will be readable only on one file system, in which case the file system’s protection system will be used for privacy. All network traffic will be public.
[…]
Discussions on Hypertext have sometimes tackled the problem of copyright enforcement and data security. These are of secondary importance at CERN, where information exchange is still more important than secrecy. Authorisation and accounting systems for hypertext could conceivably be designed which are very sophisticated, but they are not proposed here.
Diese Lösung mochte CERN-intern funktionieren; sobald das World Wide Web allerdings wirklich “worldwide” wurde, wurde dieser Mangel kritisch. Stellen Sie sich einmal vor, Sie könnten die Website der Tagesschau aufrufen und den Text einer Nachricht einfach ändern und er wäre dann für jeden geändert, ohne dass an irgendeiner Stelle überprüft würde, wer Sie sind und ob Sie überhaupt berechtigt sind, diese Änderung vorzunehmen. Die praxisuntaugliche Funktionalität zum Ändern des Inhalts von Websites, wie Berners-Lee sie umsetzte, fehlte dann logischerweise bei nahezu allen öffentlichen Servern und Browsern.
Die Geschichte der Browser
Den Browsern und ihrer Entwicklung kam in der Geschichte des World Wide Web eine große Rolle zu. Das Web wurde nicht zentral kontrolliert. Daher konnte keiner wirklich bestimmen, was Webtechnologie ist und was nicht. Verschiedenste Nutzergruppen und Anbieter hatten natürlich ganz unterschiedliche Vorstellungen darüber, was die Technik leisten sollte. Der Wettstreit unter verschiedenen Browser-Entwicklern wurde gleichermaßen zu einem Innovationstreiber als auch zu einem Spaltpilz.
Die ersten Browser wurden am CERN entwickelt. Neben einem Browser für reine Textterminals war das vor allem der Browser “World Wide Web” von Tim Berners-Lee, von dem oben schon die Rede war. Er entwickelte die Software für NeXT-Computer, die ich Ihnen in meiner Geschichtserzählung bisher vorenthalten habe. Die Firma NeXT gehörte dem Apple-Mitgründer Steve Jobs, der bei Apple zwischenzeitlich in Ungnade gefallen war. Ende der 1990er Jahre kaufte Apple die Firma inklusive Jobs selbst und dem NeXT-Betriebssystem, das die Grundlage für Mac OS 10 darstellte.

Hier sehen Sie den Browser “World Wide Web”. Zu sehen sind zwei Fenster mit Webinhalten, von denen eines ein Bild zeigt. Das Bild befindet sich in einem Extrafenster. Bilder als Teil des Textes konnte der Browser nicht anzeigen und HTML sah dies zunächst einmal auch gar nicht vor, was natürlich selbst für nüchterne wissenschaftliche oder wirtschaftliche Dokumente eine gehörige Einschränkung war. Sollten Bilder verfügbar gemacht werden, wurden sie einfach verlinkt und konnten dann durch Anklicken in einem neuen Fenster geöffnet werden.
Nach einigen frühen Browserentwicklungen an Universitäten und Hochschulen, von denen die meisten für verschiedene Unix-Betriebssysteme entwickelt wurden, war der Browser NCSA Mosaic von 1993 derjenige, der für die frühe Popularität des WWW sorgte. Auch Mosaic war ein Universitätsprodukt, denn das National Center for Supercomputing Applications (NCSA) ist eine Organisation, die an der University of Illinois Urbana-Champaign angesiedelt ist. Die Software war allerdings nicht nur für Universitäten interessant, denn sie war einfach zu bedienen, einfach zu installieren und stand nicht nur für Unix, sondern auch für den Apple Macintosh und für Microsoft Windows zur Verfügung. Das herausragende Feature des Browsers war sicherlich die Anzeige von Bildern innerhalb des HTML-Dokuments. Persönlich sehr spannend finde ich aber eine Funktionalität, die in späteren Browsern gänzlich verloren gegangen ist und an der man die Herkunft von Mosaic im Wissenschaftsumfeld noch gut erkennen kann. Mosaic erlaubte es nämlich, Webdokumente mit Kommentaren zu versehen und das, wie im Folgenden beschrieben13, nicht nur persönlich, sondern auch in Arbeitsgruppen und sogar öffentlich.
Mosaic provides a mechanism whereby any piece of information on the Internet – in other words, any document that can be named by a URL – can be annotated with voice or textual comments. Such annotations are persistent across sessions and can themselves be annotated. There are several possible levels, or domains, of annotations: personal, workgroup, public, and global. Personal annotations are stored in the local file space of the user who makes the annotations and are visible only to that user. This is the default annotation domain.
Persönliche Anmerkungen wurden also lokal auf der Festplatte abgespeichert. Wollte man in einer Arbeitsgruppe Anmerkungen teilen, musste man sich einen entsprechenden Annotation-Server installieren.
Workgroup annotations are shared among a fairly small, fairly local group of people working together on a common problem. This is the type of asynchronous collaboration originally envisioned as a core capability of Mosaic. NCSA has developed a prototype workgroup annotation server that enables this type of collaboration. New annotations, if they are placed in the “workgroup domain” by the user making the annotation, are registered with the annotation server. Each time any member of the group accesses the annotated document, the annotation will then appear as a hyperlink virtually inlined – transparently merged, on the fly – into the bottom of the document.
Auch für allgemein-öffentliche Anmerkungen hatten die Programmierer von Mosaic Lösungen vorgesehen. Leider sind die entsprechenden Funktionalitäten nie wirklich zu Ende entwickelt worden. Die große Zeit des Browsers Mosaic war in der schnelllebigen Zeit des frühen Web wohl auch nicht lang genug, als dass sich ein solches Feature im größeren Sinne hätte durchsetzen können. Mehr auf Privatleute und die allgemeine Wirtschaft ausgelegte Browser setzten andere Prioritäten.
Im Jahr 1994 bereits erschien die erste Version des Netscape-Browsers14. Unter der Leitung von Marc Andreessen, einem der Hauptentwickler von Mosaic, wurde ein komplett neuer Browser entwickelt, der nun gar nichts mehr mit Universitäten zu tun hatte. Die Gestaltung der Nutzungsschnittstelle hatte höhere Priorität. Verwendet man mit den heutigen Nutzungsgewohnheiten Mosaic und Netscape15, kommt einem der Wechsel zu Netscape wie eine Offenbarung vor. Auf der Abbildung von Mosaic oben sehen Sie über dem Mauszeiger die Web-Adresse, die sogenannte URL. Was aussieht, wie eine auch heute noch bekannte Eingabezeile, ist gar keine. Es handelt sich um eine reine Ausgabe. Wenn sie eine Website öffnen wollen, müssen sie dies über das Öffnen-Menü tun und die Adresse dann ganz genau angeben, mit http:// vorweg. Ohne funktioniert es nicht. Beim Netscape dann hat die Adresszeile ihre heutige Funktionalität und auch andere heute selbstverständliche Features findet man, etwa die Möglichkeit, Lesezeichen anzulegen. Sehr prominent direkt als Button verfügbar (der 5. in der Buttonleiste) ist eine Funktion, die heute fast unverständlich wird: das Nachladen von Bildern.
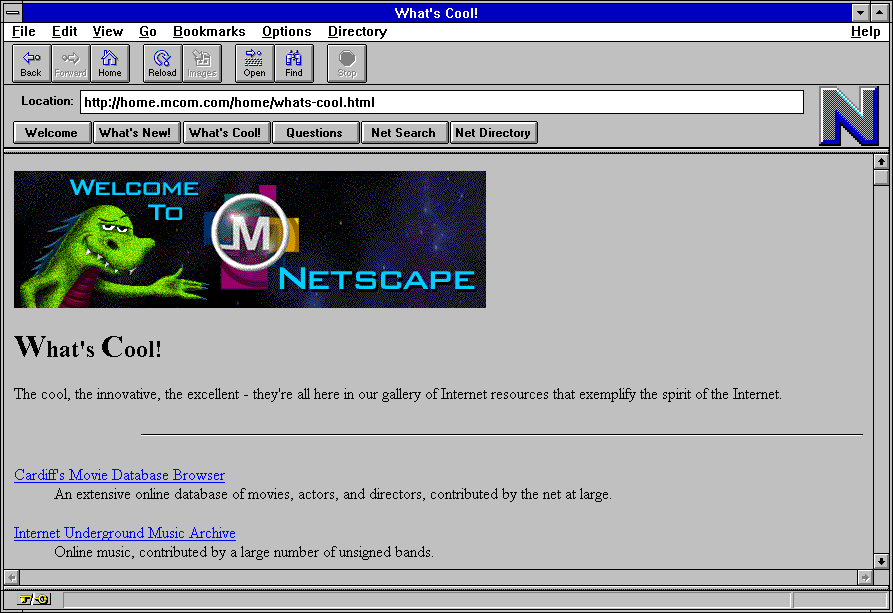
Heute, in Zeiten schneller Netze und dauerhaft verfügbarer Netzwerkverbindungen, erscheint das Ausschalten von Bildern nicht mehr sinnvoll. Allenfalls Werbebilder möchte man manchmal gerne loswerden. Mitte der 1990er sah die Sache noch anders aus. Modems aus der Zeit hatten oft eine Geschwindigkeit von 9600 Bit/Sekunde. Bei 8 Bit für einen Buchstaben konnten also 1200 Buchstaben in einer Sekunde über eine Telefonleitung gehen. Das klingt nach viel, doch machen wir mal einen Vergleich: Im Oktober 2020 war die durchschnittliche Zugangsgeschwindigkeit in Deutschland 65 Mbit/s. Das ist über 6000-mal schneller. Ein Bild von 100 KiByte entspricht 100 x 1024 x 8 Bit = 819.200 Bit. Mitte der 1990er Jahre hätte die Übertragung dieser Datei bei idealen Bedingungen ganze 85 Sekunden gedauert, heute sind es noch 12,6 Millisekunden. Wollte man sich also nur schnell informieren, tat man gut daran, die Bilder auszuschalten, denn Bilddaten waren und sind naturgemäß viel größer als die reinen HTML-Inhalte. Hatte man die Bilder eingeschaltet, dauerte es ggf. nicht nur lange, sondern wurde dadurch auch teuer16. Außerdem war man dann stundenlang telefonisch nicht erreichbar, denn ein Modem verwendete ja die ganz normale Telefonleitung, um sich mit einem Provider zu verbinden. Bilder ausschalten konnte man sowohl in Netscape als auch in Mosaic. Kam man nun aber auf eine Website, auf der man die Bilder dann sehen wollte, konnte man beim Netscape diese mit nur einem Klick nachladen. Bei Mosaic musste man das Laden von Bildern einschalten, die Seite dann händisch neu laden und das Laden von Bildern dann für die nächste Seite ebenso händisch wieder abschalten. Der Knopf war keine große Sache, aber doch ungemein praktisch.
Abgesehen von genannten Verbesserungen in der Nutzungsschnittstelle bestanden die neuen Funktionen des Netscape für Anbieter vor allem in mehr Einfluss auf das Aussehen, wodurch sich attraktivere Websites erstellen ließen. Bereits in Version 1.1 konnten HTML-Autoren den normalerweise grauen Texthintergrund durch ein Bild ersetzen lassen:
<BODY BACKGROUND="tisch.gif">
<P>Diese Seite hat einen Holztisch-Hintergrund</P>
In Version 2 erfand Netscape einige weitere Tags und Attribute, um das Aussehen des Textes zu beeinflussen.
<P>Hier kommt <FONT SIZE=+2 FACE="arial,helvetica" COLOR="red">
ganz besonderer</FONT> Text.</P>
<CENTER>Dieser Text ist zentriert.</CENTER>
Verwendeten Anbieter von Websites diese Tags, konnte das ein Problem werden, denn zunächst konnte nur Netscape etwas damit anfangen. Ein älterer Browser wie Mosaic ignorierte diese neuen Tags einfach. Oft war das egal, aber wenn der <FONT>-Tag dafür benutzt wurde, um, zum Beispiel unter einer Menge von Möglichkeiten, durch grüne Farbe die korrekte herauszustellen, dann fehlte diese Information schlimmstenfalls völlig. Probleme dieser Art sollten noch schlimmer werden, denn Netscape sollte nicht der einzige erfolgreiche Browser-Hersteller bleiben und andere Entwickler erfanden andere Tags und unterstützten ihrerseits die von Netscape erfundenen nicht unbedingt oder nur teilweise.
Der erste Netscape-Browser war ab Dezember 1994 verfügbar. Zu diesem Zeitpunkt war die Firma Microsoft schwer beschäftigt mit dem Abschluss der Entwicklung ihres neuen Betriebssystems Windows 95, das im August 1995 auf den Markt kam und das Arbeiten im PC-Bereich mit der neuen Nutzungsoberfläche und den multimedialen Fähigkeiten stark veränderte. So wie es auch heute noch üblich ist, waren bei Windows 95 manche Programme vorinstalliert, darunter zum Beispiel die simple Textverarbeitung WordPad, das Grafikprogramm Paint und das Programm HyperTerminal zur Verbindung mit entfernten Rechnern. Ein Webbrowser jedoch war nicht mit dabei. Es wird gerne behauptet, dass Bill Gates, der Mitgründer und damalige Chef von Microsoft, noch 1993 das Web als Hype bezeichnet habe und dass man sich bei Microsoft um Wichtigeres kümmern solle. Wie so oft ist nicht belegt, und wahrscheinlich auch gar nicht belegbar, dass es diese Aussage so überhaupt gegeben hat. Selbst wenn es so gewesen sein sollte, gäbe es eigentlich keinen wirklichen Grund, sich über die Aussage lustig zu machen. 1993 war das WWW ja noch überhaupt nicht verbreitet, die allermeisten Inhalte kamen von Forschungsinstituten. Die Websites waren reine Textwüsten und Zugang zum Web war für Privatleute kaum zu bekommen. Onlinedienste wie CompuServe und AOL erfreuten sich hingegen größer werdender Beliebtheit. Im Web nicht die Revolution zu sehen wäre zu diesem Zeitpunkt keine absurde Einschätzung gewesen. Im Nachhinein mit Schadenfreude darüber herzuziehen ist wohlfeil. Die Aussage wird im Übrigen, unabhängig davon, ob es sie gegeben hat oder nicht, gerne noch unzulässig ausgedehnt. In der deutschen Wikipedia findet sich zum Beispiel die Aussage, dass “Bill Gates und somit auch Microsoft zu Zeiten von Windows 95 nicht an den Erfolg des Internets glaubten”17. Das ist ganz nachweislich und belegbar falsch, denn schon im Mai 1995, also noch vor dem Erscheinen von Windows 95, schrieb Gates in einem Memo von einer “Internet Tidal Wave”, der man sich nun ganz hingeben solle, und die man sogar dominieren wolle. Auch in öffentlichen Fernsehauftritten im Jahr 1995 wurde Gates nach dem Internet befragt. Er schwärmte dort davon in den höchsten Tönen und bezeichnete es als “Next Big Thing”.
Hatte man die erste Version von Windows 95 ohne mitgelieferten Browser installiert, konnte man sich natürlich Netscape nachinstallieren. Der Browser war auf vielen der damals verbreiteten Zeitschriften-CDs enthalten. Auch einen Browser von Microsoft, den Internet Explorer, konnte man sich bald besorgen, denn Microsoft bot für etwa 50 Dollar ein sogenanntes Plus-Paket für Windows 95 an und das beinhaltete neben Hintergrundbildern, Bildschirmschonern, Mauszeigern und Systemsounds auch den eigenen Browser. Die Softwarefirma hatte kurz entschlossen einen Browser der Firma Spyglass18 lizensiert. Der erste Internet Explorer wurde nur von sehr wenigen Leuten genutzt. Erst Version 3 im Jahr 1996, die in aktualisierten Windows-95-Versionen dann vorinstalliert war und die auch vielfach bei Softwareinstallationen mitgeliefert wurde, wurde populär. Version 4 aus dem Jahr 1997 überholte bereits Netscape. 1998 hatte Microsoft dann den sogenannten “Browserkrieg” praktisch gewonnen. Die Gründe dafür waren vielfältig. Zum einen war Microsoft in Sachen Features zum damaligen Zeitpunkt durchaus innovativ und setzte mit dem Internet Explorer Maßstäbe. Andererseits ließ Microsoft der Konkurrenz von Netscape kaum eine Chance. Im oben bereits erwähnten Dokument, dem mit der “Tidal Wave”, verkündete Bill Gates das Ziel, das Internet dominieren zu wollen, und diesem Ziel ging man mit allen Mitteln nach. Nicht nur, dass der Internet Explorer ab Version 3 vorinstalliert und mit Windows 98 fest ins Betriebssystem integriert wurde, Microsoft setzte sogar die Computerhersteller unter Druck. Wollten diese ihre Computer mit Windows ausliefern – was natürlich fast jeder Hersteller wollte –, dann durfte dies nur ohne vorinstallierten Alternativbrowser geschehen. Wollte der Hersteller einen anderen Browser mitliefern, bekam er keine Windows-Lizenz. Dieses Verhalten wurde später Gegenstand von Gerichtsverhandlungen, die für Microsoft nicht erfreulich waren. Der Firma Netscape brachte das allerdings nichts mehr.
In den 4er-Versionen der Browser war der Browserkrieg zwischen Netscape und Internet Explorer noch auf seinem Höhepunkt – und auch die Inkompatibilitäten zwischen den Browsern erreichten ihr Maximum. Beide Browser ermöglichten inzwischen dynamische Inhalte, bei denen sich Elemente auf der geladenen Seite je nach Eingabe änderten. Einfache Beispiele hierfür, die damals auch sehr populär waren, waren Navigationsmenüs, bei denen man die Oberpunkte aufklappen konnte, sodass die Unterpunkte sichtbar wurden. Die Technik ermöglichte aber weitaus mehr bis hin zu komplett in Webtechnologie programmierten Anwendungen und Spielen. Das Problem war nun aber, dass Microsoft und Netscape ganz verschiedene HTML-Tags, ganz verschiedene Techniken zur Programmierung und Formatierung anboten. Websites, die für den Internet Explorer gestaltet wurden, konnten im Netscape nicht gescheit angesehen werden und umgekehrt. Man stand als Anbieter also vor einem Problem. Manche entschieden sich für einen der Browser und präsentierten den Nutzern des anderen einen unfreundlichen Hinweis, dass sie das falsche Programm verwendeten. Andere machten sich entweder die Mühe und erstellten zwei Versionen ihrer Websites oder bissen in den sauren Apfel und verzichteten ganz auf die modernen Features.
Die Spaltung des Web war aufgrund der offenen Gestaltung natürlich von vornherein ein mögliches Problem. Es gab daher schnell Bestrebungen, die Webtechnologie zumindest ein bisschen beisammenzuhalten und für Kompatibilität zu sorgen. Zunächst kümmerte sich eine Gruppe am CERN selbst darum und zwischenzeitlich gab es eine entsprechende Gruppe der IEEE19. Recht zügig bildete sich dann das W3C, das World Wide Web Consortium. Hier arbeiten alle großen Softwarehersteller zusammen und legen Spezifikationen für Webtechnologie fest. Die erste definierte Version von HTML hatte die Nummer 2.0 und wurde im November 1995 publiziert. 1997 folgte die Version 3.2. Die einleitenden Worte dazu weisen darauf hin, wie der Standard erstellt wurde:
HTML 3.2 is W3C’s specification for HTML, developed in early `96 together with vendors including IBM, Microsoft, Netscape Communications Corporation, Novell, SoftQuad, Spyglass, and Sun Microsystems. HTML 3.2 adds widely deployed features such as tables, applets and text flow around images, while providing full backwards compatibility with the existing standard HTML 2.0.
Die Browserhersteller setzten sich also zusammen und schrieben eine Definition, die aus dem bestand, was sich in ihren Browsern als erfolgreich erwiesen hat und worauf sie sich untereinander einigen konnten. Dieser Ansatz hatte dann seine Probleme, ab dem es nur noch einen einzigen nennenswerten Browseranbieter gab. Was der implementierte, war faktisch Standard, und was in der W3C-Vorgabe stand, aber vom Internet Explorer nicht umgesetzt wurde, konnte faktisch auch nicht angewandt werden.
1998 hatte Microsoft den Browserkrieg gewonnen. Netscape stellte den Programmcode seines Browsers frei zur Verfügung und gründete die Mozilla-Organisation. Diese machte sich an eine Neuentwicklung, aus der 2002 der erste Firefox-Browser hervorging. Firefox hatte es allerdings sehr schwer gegen den Internet Explorer. Der erschien 2001 in Version 6 und war ein für die damalige Zeit ordentlicher Browser. Er war stark in die Betriebssysteme von Microsoft eingebunden, namentlich in das brandneue Windows XP. Da ihn so viele Nutzer verwendeten, gestalteten fast alle Anbieter von Websites diese so, dass sie mit dem Internet Explorer problemlos funktionierten. Das Problem der Marktführerschaft ohne nennenswerte Konkurrenz war, dass Microsoft sich mit der Weiterentwicklung sehr viel Zeit lassen konnte. Erst 2006 erschien die Nachfolgeversion 7. Leider, und hier spreche ich aus eigener Erfahrung, blieb der “IE6”, wie er meist abgekürzt wurde, als Untoter noch länger das Maß aller Dinge, denn viele verwendeten ihn auch weiterhin. Microsoft hatte sich nämlich entschlossen, etwas gegen illegale Kopien seines Windows zu tun. Das bedeutete unter anderem, dass die Aktualisierung des Internet Explorers auf Version 7 auf Windows-Versionen, die nicht bei Microsoft legal erworben und registriert wurden, verhindert wurde - und das waren nicht ganz wenige20. Eine andere Gruppe, die den alten Internet Explorer länger verwendete, fand sich erstaunlicherweise in vielen Firmen, denn da der IE6 so lange aktuell war, wurden viele interne Webanwendungen genau auf diesen Browser abgestimmt. Der Internet Explorer 7 hatte viele der Fehler der Version 6 nicht mehr und entsprach viel mehr den Vorgaben des W3C, und genau damit konnte er die Unternehmens-Webanwendungen nicht mehr korrekt anzeigen.
Mit der Vorherrschaft des Internet Explorers stagnierte die browserseitige Weiterentwicklung des WWW faktisch für fast ein Jahrzehnt. Eine Besserung dieser Situation ergab sich erst Ende der Nuller-Jahre, zum einen mit der Vorstellung des iPhone und der darauffolgenden Smartphone-Welle und zum anderen damit, dass Google seinen eigenen Browser Chrome auf den Markt warf. Dieser konnte schnell Marktanteile gewinnen und ist inzwischen selbst recht unangefochten Marktführer – zumindest im Bereich der klassischen Personal Computer.
Das Web als Plattform
Das World Wide Web hat sich weit fortentwickelt vom ursprünglichen Zweck der Zugänglichmachung von Dokumenten am CERN. Dafür, dass das so kam, gab es viele Einflussfaktoren, wobei Ursache und Wirkung oft gar nicht zu trennen sind. Die frühe Webtechnologie an sich war offenbar attraktiv sowohl für Anwender als auch für Anbieter, waren dies Universitäten, öffentliche Stellen oder auch Firmen. Die Seiten wurden immer aufwändiger, da die Browser für die Seitenanbieter immer mehr Gestaltungsfeatures anboten. Neue Features im Browser führten zu neuen Ideen bei den Anbietern und Nutzern und diese führten ihrerseits wieder zu Weiterentwicklungen im Browserbereich. Komplexere und reichhaltigere Websites benötigten immer mehr Bandbreite. Die allgemeine Verfügbarkeit höherer Bandbreiten und die dauerhafte Verfügbarkeit des Netzes ermöglichten im Gegenzug wieder Nutzungsszenarien, die vorher gar nicht denkbar waren. Die Konkurrenz unter Anbietern, sowohl was die Browser, die Zugangsprovider als auch die Diensteanbieter anging, sorgte in einer komplexen Wechselwirkung für eine Weiterentwicklung von Technik und Nutzungsformen.
Das Web heute ist eine Plattform, eine Ansammlung von Technologien in Browsern und auf Servern, mit denen nicht nur Web-Seiten, sondern auch Web-Anwendungen erzeugt werden können. Wie oben beschrieben, waren die Grundzüge dafür ja bereits im Ur-Web am CERN vorgesehen, wenn man die Anbindung des Telefonbuchs und anderer Auskunftssysteme des CERN an das Web als sowas ansehen möchte. Damals handelte es sich natürlich noch um relativ simple Anfragen. Komplexere Anwendungen waren aus vielerlei technischen Gründen zunächst nur schwer möglich.
Das Hauptproblem war die Gedächtnislosigkeit des HTTP-Protokolls. Denken Sie nochmal an meinen Vergleich des HTTP-Servers mit jemandem, der ein Telefon abnimmt, dem dann gesagt wird, was man vorgelesen haben will, der das dann vorliest und der dann direkt wieder auflegt. In diesem ganzen Prozess hat man sich nie mit Namen oder irgendeinem Erkennungszeichen gemeldet. Wenn Sie den gleichen Server nochmal “anrufen”, dann kennt er Sie nicht mehr. Jeder Anruf ist unabhängig vom anderen. Dem kann man mit einem Trick abhelfen. Der Server kann Ihnen bei der ersten Antwort eine Kennung mitgeben. Bei jedem weiteren Kontakt geben Sie diese Kennung wieder an. Wofür braucht man das? Zum Beispiel, wenn Sie einen Bestellvorgang auf einer Website haben, dann machen Sie ja nicht alle Angaben auf einer Seite, sondern durchlaufen mehrere Seiten hintereinander. Damit das vernünftig funktionieren kann, müssen diese Angaben natürlich miteinander in Verbindung gesetzt werden können. Sonst wüsste die Website dann, wenn Sie die Kreditkarteninformationen eingeben, schon nicht mehr, wer Sie eigentlich sind und was Sie kaufen wollen.
Die einzelnen HTML-Seiten waren in der Browser-Anzeige zunächst statisch. Die frühen Browser konnten eine HTML-Seite vom Server abrufen und anzeigen. Das einzig Dynamische dann war das Scrollen im Browser, falls das Dokument länger als eine Bildschirmseite war. Sollte etwas Neues, etwa etwas Aktualisiertes auf der Seite erscheinen, musste man sie manuell neu laden oder auf einen Link zu einem anderen Dokument klicken. Wirklich interaktive Anwendungen waren so kaum möglich, denn das Neuladen war langsam und erfolgte immer nur auf explizite Anforderung des Nutzers. Im Laufe der Jahre wurden verschiedenste Techniken ersonnen, um dieses Problem zu umgehen oder abzuschaffen.
Die Versionen 3 der Browser von Microsoft und Netscape ermöglichten die Einbindung von Java-Applets. Java war und ist eine recht verbreitete Programmiersprache, die auch heute noch vielfach eingesetzt wird und an Schulen und Universitäten gelehrt wird. Einer der großen Vorteile der Sprache war, dass die damit erzeugten Programme plattformunabhängig waren, es also egal war, ob man sie unter Windows, unter Linux oder auf einem Macintosh laufen ließ. Sie liefen überall gleichermaßen. Das machte Java für das Web interessant. Viele Java-Programme haben gar keine Nutzungsschnittstelle, sondern laufen auf den Servern im Internet, also auf den Computern, die Dienste anbieten, auf die man aus der Ferne zugreifen kann. Java-Programme mit Nutzungsschnittstelle sehen in den jeweiligen Betriebssystemen meist nicht anders aus als die übrige Software, die dort sonst so läuft – sie wird also in der Regel in einem Fenster angezeigt. Ein Java-Applet hingegen hatte kein Fenster, sondern wurde in eine HTML-Seite eingebunden, genauso wie ein Bild. In einem Bereich der geladenen HTML-Seite lief dann ein Programm mit all dem, was in Java so möglich war, von der Office-Anwendung bis zum Spiel. Die Applets konnten sogar ihrerseits Verbindungen ins Netz aufnehmen und Daten von dort beziehen.
Bereits in Version 2 des Netscape-Browsers war es möglich, kleine Programme in der Programmiersprache JavaScript in die Website einzubinden. Obwohl der Name JavaScript es nahelegt, hat diese zum damaligen Zeitpunkt noch sehr einfache Programmiersprache nur wenig mit Java zu tun. JavaScript wurde für sehr simple Aufgaben benutzt. Man konnte mit ihr zum Beispiel prüfen, ob eine eingegebene E-Mail-Adresse das richtige Format hatte, also etwa, ob ein @-Zeichen in ihr vorkam. JavaScript konnte auch eine Brücke zu einem Java-Applet sein, also zum Beispiel auf der Website eingegebene Daten an das Applet weitergeben und vom Applet erzeugte Daten auf die Website schreiben. Merken Sie, was durch diese Kombination aus JavaScript mit Zugriff auf den HTML-Inhalt und Java-Applet mit der Möglichkeit des Netzwerkzugriffs möglich wird? Zum Beispiel könnte ein Applet alle paar Sekunden aus dem Netz die aktuelle Temperatur in Palma de Mallorca abrufen und diese an das JavaScript weitergeben, das sie dann an einer bestimmten Stelle im Dokument anzeigt. Es konnten also Inhalte nachgeladen werden. Wirklich im großen Stil durchgesetzt hat sich eine solche Teilaktualisierung der Seite aber erst erheblich später.
Java-Applets hielten sich nicht lange, was unter anderem daran gelegen haben dürfte, dass gut aussehende Nutzungsschnittstellen und multimediale Inhalte nicht gerade die Stärke von Java waren. Ab 1997 liefen Flash-Inhalte den Applets den Rang ab. Unter dem Namen Flash bot die Firma Macromedia seinerzeit ein Produkt an, mit dem sich grafische Szenen und Animationen programmieren ließen. Für Webbrowser entwickelte Macromedia ein “Plugin”, also ein kleines Zusatzprogramm, das ein Einbinden der Flash-Inhalte in die HTML-Dokumente erlaubte, ganz so, wie es auch bei den Java-Applets möglich war. Auch hier konnte JavaScript als Brücke verwendet werden. Flash-Inhalte waren aufgrund der guten Grafik-, Sound- und Videofeatures vor allem bei vielen Werbeagenturen beliebt, was dazu führte, dass manche Website gar keine klassischen HTML-Inhalte mehr bereitstellte, sondern dass nur bildschirmfüllend ein Flash-Inhalt eingebunden wurde. Kein Wunder, denn so konnte man bunte, animierte Buttons realisieren, die Geräusche machten, wenn man darauf klickte und die Inhalte, die dann aufgerufen wurden, konnten animiert hinein- oder hinausgeschoben werden. Das Ganze konnte also sehr interaktiv sein und, ebenso wie die Java-Applets, sich selbst aus dem Netz mit Daten versorgen. Der Einsatz von Flash hatte allerdings auch seine Nachteile. So ließen sich Flash-Inhalte kaum ausdrucken, waren für Suchmaschinen schlecht zu finden, einzelne Seiten waren nicht mehr über eine eigene Webadresse verfügbar und das Ganze verlangte den damaligen Computern einiges ab. Bei vielen Nutzern der Websites waren Flash-Inhalte daher überhaupt nicht beliebt.
Die Flash-Technik blieb den Websurfern recht lange erhalten. Zu Ende ging es mit ihr erst mit dem Aufkommen von Smartphones ab dem ersten iPhone im Jahr 2007, denn auf dem iPhone und auch auf den meisten Android-Geräten liefen Flash-Inhalte nie. Um diese Zeit herum gab es aber ohnehin viele Umbrüche. Google beglückte die Welt mit seinem eigenen Browser namens Chrome, der sehr schnell große Beliebtheit bekam. Apple schaffte es, dem iPhone einen Browser zu spendieren, der Websites, mit Ausnahme von Flash und Applets, sehr gut auf dem kleinen Bildschirm darstellen konnte. Microsoft brachte im Jahr 2009 nicht nur das neue Betriebssystem Windows 7 heraus, sondern spendierte diesem nach langer Zeit auch eine neue Version des Internet Explorers. Bei den wichtigen Playern in Sachen Browsern war also viel los. Dies äußerte sich auch darin, dass eben diese Player, Apple, Google, Mozilla (der Organisation hinter Firefox) und Microsoft sich zusammensetzten und eine neue HTML-Definition entwickelten. Diese HTML-Version, die dann als HTML5 bekannt wurde, hob den Browser nun in ganz neue Höhen. 2015 wurde sie fertig. Seitdem wird HTML ohne Versionsnummer weiterentwickelt. Der sogenannte “lebende Standard” enthält stets das, was sich bewährt hat und worauf sich die Browserhersteller geeinigt haben.
Die Techniken, die seit Mitte der 2000er hinzugekommen sind, machten Browser quasi zu kleinen Computern in sich, zu einer Sammlung von technischen Einrichtungen, mit denen netzbasierte, komplexe und multimediale Anwendungen umgesetzt werden können:
- Die Fähigkeiten der Formatierung von Text und Bild sowie die Positionierung und Animation von Elementen im Browser sind inzwischen so umfangreich, dass webbasierte Nutzungsschnittstellen den nativen Anwendungen in fast nichts mehr nachstehen. Ganz im Gegenteil ist es inzwischen oft so, dass sich auch “normale” Programme den Webtechnologien als Nutzungsschnittstelle bedienen.
- Die Programmiersprache JavaScript wurde standardisiert und verbessert. Die sogenannten JavaScript-Engines in den Browsern wurden immer weiter optimiert, was dazu führt, dass in modernen Browsern die JavaScript-Programme sehr performant ausgeführt werden können. Mit aktuellem JavaScript lassen sich komplexe Programme umsetzen, die zügig laufen.
- Um 2005 kam die AJAX21-Technik auf. Dahinter steht die Möglichkeit, dass ein JavaScript-Programm im Hintergrund Kontakt zum Webserver aufnehmen kann, um Daten dort abzurufen oder dort hinzuschicken, ohne dass eine komplett neue Seite geladen werden müsste. Dies verringerte nachhaltig die Notwendigkeit für Java-Applets oder Flash-Inhalte.
- Die AJAX-Technik wurde ergänzt um WebSockets, bei denen ein Webserver eine länger andauernde Verbindung zu einem Server herstellt. Hierdurch wurde es möglich, dass Server und Browser zügig Daten austauschen und dass ein Server einem Browser Nachrichten schicken kann, ohne dass diese explizit angefragt werden müssten. Wofür das gut ist, kann man sich an einem Chat gut klarmachen. Mit klassischer Web-Technologie müsste man eine Chatseite regelmäßig neu laden, um zu schauen, ob neue Nachrichten eingetroffen sind. Mit der AJAX-Technik würde dies im Hintergrund automatisch erledigt. Eine Webanwendung mit AJAX könnte zum Beispiel alle fünf Sekunden neue Daten anfragen und die Anzeige aktualisieren. Besteht hingegen eine WebSocket-Verbindung, braucht es diese Nachfrage nicht mehr. Vielmehr schickt der Server die Nachrichten über die aktive Verbindung selbst an den Browser ohne Verzögerungen.
- Das
<canvas>-Element von HTML5 schafft eine Grafikfläche, auf die ein JavaScript-Programm pixelbasiert zeichnen kann. Es dient Webanwendungen zur Abspielfläche für grafiklastige Anwendungen von der webbasierten Bildbearbeitung bis zum komplexen Spiel. - Für Algorithmen und Programmmodule, die trotz optimierter JavaScript-Engines nicht performant genug laufen, besteht die Möglichkeit, diese in einer typischen höheren Programmiersprache zu programmieren und dann in eine Webassembly-Datei übersetzen zu lassen22. Der Browser kann diese dann ausführen. Programme, die auf diese Art geschrieben werden, laufen zwar nicht so schnell wie normale, ausführbare Programme, sind aber doch erheblich schneller als in JavaScript geschriebene Software.
Übrigens: Auch auf der Server-Seite blieb die Entwicklung der Webtechnologie natürlich nicht stehen. Da die Nutzungsschnittstellen, um deren Betrachtung es in diesem Buch ja in erster Linie gehen sollte, aber natürlich nicht beim Server, sondern im Browser liegen, erspare ich Ihnen die Geschichte der serverseitigen Webprogrammierung an dieser Stelle.
Betrachtet man das WWW heute, erscheint es einem überhaupt nicht mehr wie ein einfaches Hypertext-System für wissenschaftliche Texte, als das es geplant wurde. Ein moderner Browser ermöglicht die Text- und Grafikanzeige in diversesten Formaten inklusive Vektorgrafik. Vor allem aber ermöglicht der Browser die Umsetzung von komplexer Software, von in Web-Seiten selbst eingebetteten Logik-Inhalten und kleineren interaktiven Elementen bis hin zu vollständigen Anwendungen. Die moderne Browser-Technik ermöglicht Software, die teils auf dem Server läuft, teils beim Anwender selbst, also im Browser. Selbst eine dauerhafte Internetverbindung ist dafür heute nicht mehr vonnöten. Einmal geladene Webanwendungen können, wenn die entsprechenden Vorkehrungen getroffen wurden, auch offline arbeiten. Selbst Bearbeitungen von Inhalten sind bei geschickter Programmierung offline möglich. Wenn wieder eine Internetverbindung zur Verfügung steht, werden die zwischengespeicherten Bearbeitungen dann automatisch mit dem Server synchronisiert. Das heutige Web ist eine technische Plattform. Alles kann heute im Browser laufen, von Spielen über Textverarbeitungen, Grafikbearbeitung bis zu Lerntools. Wenn Sie das Kapitel zu den Bildschirmtextdiensten nochmal anschauen, fällt Ihnen vielleicht auf, dass ein heutiger Browser ziemlich ähnlich zu dem ist, was man sich in Graz für das Mupid ausgedacht hat. Ein Browser kann vorbereitete Inhalte aus dem Netz zeigen, kann aber auch mit lokal gespeicherten Seiten arbeiten. Ein Browser kann in eine Seite eingebettete Software ausführen und eignet sich sogar auch selbst als Plattform für Software. Diese Software kann das Netz ihrerseits als Kommunikationskanal und als Speichermedium nutzen. All das hatten wir schon beim Mupid in den 1980er Jahren.
Die Potenziale des Hypertext
Ob Hermann Maurer aus Graz meine Charakterisierung aktueller Browser als moderne Mupids wohl gefallen würde? Einerseits wahrscheinlich schon, schließlich war der Mupid ja sein Kind. Er und seine Kollegen hatten eine Idee, die, was mit heutigen Browsern möglich ist, schon sehr früh umsetzte. Andererseits könnte Maurer vom Web auch ziemlich enttäuscht sein, denn er und seine Kollegen sahen großes Potenzial im Konzept des Hypertext und in der Beziehung war und ist das WWW ein ziemlicher Reinfall. Maurer und Kollegen hatten eine Alternative zu bieten, die sich allerdings gegen das WWW nicht durchsetzte.
Die Hypertextidee wird häufig auf ein Konzept aus dem Jahr 1945 zurückgeführt. Damals beschrieb der Ingenieur Vannevar Bush ein hypothetisches Gerät namens Memex. Oben ist es abgebildet. Was Sie dort sehen, ist kein Computer in dem Sinne, wie ich ihn in diesem Buch vorgestellt habe. Digitale Computer waren 1945 noch an einer Hand abzuzählen und das, was Bush mit dem Memex vorhatte, gehörte damals sicher nicht zu dem, wofür man die Rechenknechte nutzen wollte. Bush ging es bei seinem Gerät nicht ums Rechnen, sondern um die Unterstützung der Wissensarbeit durch moderne Technologie. Zentral war hier eine komplexe Mechanik und die Mikrofilmtechnik, eine Archivierungstechnologie, bei der Buchseiten und Dokumente abfotografiert und dann extrem verkleinert auf einem Filmstreifen abgelegt wurden. Mittels entsprechender Sichtgeräte konnten die Dokumente wieder sichtbar gemacht werden. Wirklich umgesetzt wurde die Memex-Idee damals nicht, auch wenn die technischen Komponenten grundsätzlich existierten. Das Ganze war nicht als Bauanleitung, sondern als Denkanregung gedacht. Lassen wir die innere Architektur des Memex daher beiseite und betrachten die intendierte Nutzungsschnittstelle des Geräts, also das, was oben auf der Tischplatte zu sehen ist.
Zentral sehen Sie zwei Bereiche, in denen Dokumente dargestellt werden können. Verwenden wir der Einfachheit halber den Begriff “Bildschirm” dafür. Mittels der Knöpfe rechts können für beide Bildschirme Dokumente aus dem Dokumentarchiv abgerufen werden. Dieses Archiv war groß angedacht – quasi eine ganze Bibliothek. Zwei Dokumente gleichzeitig im Blick zu haben ist sicher nicht unpraktisch, aber nun auch nicht revolutionär. Spannend war die von Bush beschriebene Technik, Dokumente miteinander in Verbindung setzen zu können. Bush sprach hier von einem Trail, also einem Pfad durch Dokumente zu einem bestimmten Thema. Diese Trails hätten einen Namen bekommen und wären in einer Memex unabhängig von den Dokumenten selbst abgespeichert worden. Durch Angabe des Namens über eine Tastatur hätte man einen Trail wieder hervorbringen können. Sogar die Möglichkeit, den Dokumenten Informationen hinzuzufügen oder neue, eigene Dokumente einzufügen, hatte Bush im Blick, denn seine Idee eines Memex enthielt auch Vorrichtungen zur Fotografie und zur Erstellung neuer Mikrofilme. Diese Vorrichtung war auch für ein weiteres wichtiges Feature notwendig, denn da Bush natürlich klar war, dass Wissensarbeit keine Ein-Personen-Show ist, sah er vor, dass ein kompletter Trail von der Maschine auf einen Mikrofilm hätte ausbelichtet werden können, um ihn an andere Wissensarbeiter weiterzugeben. Diese hätten ihn dann in ihre eigene Memex eingelegt, um die Dokumente in ihrem Zusammenhang zur Verfügung zu haben und nun selbst weiterverarbeiten zu können.
Die Ideen der Memex nahmen zentrale Elemente von dem vorweg, was später unter dem Begriff Hypertext diskutiert wurde. Der Begriff selbst und viele der zentralen Konzepte gehen auf Ted Nelsons Projekt Xanadu zurück. Xanadu ist bekannt dafür, seit 1960 in Entwicklung zu sein, wohl aber nie komplett fertig zu werden. Das gesamte Konzept dahinter hätte, wenn es denn umgesetzt worden wäre, sogar Lösungen für Urheberrechtsprobleme und die Bezahlung für referenzierte und zitierte Inhalte gehabt. Auf all das kann und will ich hier nicht eingehen. An einem tatsächlich existiert habenden System namens Intermedia will ich Ihnen aber ein von Memex schon bekanntes Potenzial verdeutlichen, das auch bei Xanadu eine ganz zentrale Rolle spielte.
Intermedia wurde ab Mitte der 1980er Jahre an der Brown University in den USA entwickelt. Es lief auf dem Betriebssystem A/UX, einem Unix-Derivat von Apple, das auf den leistungsfähigeren Macintosh-Geräten ausgeführt werden konnte. Das System ist ein interessanter Hybrid, denn es verfügte einerseits über die Nutzungsschnittstelle von MacOS mit seinen Menüs, Fenstern und Icons, hatte aber andererseits auch den kompletten Unix-Unterbau mit seinen Multitasking-Funktionalitäten und der Netzwerkfähigkeit. Das System war in dieser Hinsicht dem NextStep, auf dem Tim Berners-Lee das World Wide Web entwickelte, nicht ganz unähnlich. Vor allem war es aber genau wie dieses ein absolutes Nischenprodukt.
Hier sehen Sie Intermedia im Stand von etwa 1988. Grundobjekte des Systems sind Dokumente verschiedenster Art. Zunächst einmal hatte das System daher die grundsätzlichen Funktionalitäten damaliger Desktop-Systeme. Es gab, neben einigen spezielleren Anwendungen, vor allem eine einfache Textverarbeitung und ein Tool zur Erstellung und Bearbeitung von Grafiken. Da es auf einem Unix-System basierte, verfügte Intermedia über eine komplexe Rechteverwaltung und war netzwerktauglich. Dokumente konnten also lokal oder auch auf einer Netzwerk-Festplatte gespeichert sein. Wie es sich für ein Hypertext-System gehört, waren natürlich Verknüpfungen ein zentrales Konzept. Diese waren aber nun nicht, wie beim Web, in das Dokument selbst eingebaut (in HTML schreibt man ja <A>-Tags in die Dokumente), sondern waren, wie die Trails bei der Memex, als zusätzliche Objekte gespeichert. Dokumente in Intermedia enthielten selbst also keine Links. Ein Nutzer konnte trotzdem Links anlegen, die dann im Dokument dargestellt wurden. Oben in der Abbildung ist dieser Vorgang dargestellt. Zunächst wurde in einem Dokument ein Stück Text markiert und im Menü “Start Link” ausgewählt. Dann wurde in einem anderen Dokument Text markiert und der Link mit “Complete Link” vervollständigt. So wurden zwei Textstellen miteinander verbunden. Diese Verbindung war bidirektional. Man kam also, wie beim Memex, nicht nur vom ersten Dokument zum zweiten, sondern auch vom zweiten zum ersten. Die Links wurden zwar im Dokument angezeigt, nicht aber im Dokument abgespeichert. Das Dokument existierte nach wie vor als unabhängiges Objekt. Die Links wurden in einem sogenannten Web (das nichts mit dem World Wide Web zu tun hat) abgespeichert. Ein Web verband die Dokumente. Wollte man die Dokumente als verlinkt im Zusammenhang sehen, musste man immer auch ein Web laden. Schloss man das Web wieder, waren alle Links verschwunden und die Dokumente erschienen wieder jungfräulich. Öffnete man das Web, erschienen auch die Links erneut. Diese Trennung öffnete Potenziale, die das Web nicht erfüllen konnte.
- Link setzen ist bei Intermedia nicht die Aufgabe der Autoren. Das Konzept von Intermedia war es, dass die Nutzer Links setzten. Diese Funktionalität wurde an der Brown University in der Lehre genutzt. Studierenden wurden Dokumente zur Verfügung gestellt, die sie zum Teil erweitern, vor allem aber selbst verknüpfen sollten.
- Das heißt, dass man auch in Dokumente, für die man keine Schreibrechte hatte, die man also nicht bearbeiten durfte, dennoch Links einfügen konnte.
- Verschiedene Nutzer konnten unabhängig voneinander die gleichen Ressourcen auf verschiedene Arten und Weisen verlinken, indem sie jeweils ein eigenes Web erstellten.
- Links konnten durch Weitergabe von Webs also geteilt werden oder aber auch privat bleiben.
Intermedia war als auf Unix basierendes System natürlich netzbasiert. Es war aber nicht als öffentliche Ressource à la World Wide Web gedacht, sondern bezog sich auf lokale Arbeitsgruppen im Universitätskontext. Hier kommen Herman Maurer und seine Kollegen wieder ins Spiel. Seine Gruppe in Graz entwickelte, stark von Intermedia inspiriert, ein internetbasiertes Hypertextsystem namens Hyper-G, das später in Hyperwave umbenannt wurde. Oben sehen Sie, dass es über ein vergleichbares Feature verfügte, denn auch hier ließen sich Dokumente miteinander verknüpfen, ohne dass es einer Änderung der Dokumente selbst bedurft hätte. Links wurden auf unabhängigen Servern in von den Dokumenten unabhängigen Datenbanken gespeichert. Interessanterweise waren solche Features wohl durchaus auch einmal für das World Wide Web zumindest angedacht. Das Proposal von 1989 besagte nämlich: “One must be able to add one’s own private links to and from public information. One must also be able to annotate links, as well as nodes, privately.” Die Aussage ist einigermaßen erstaunlich, denn Konzept und Technologie des WWW gaben ein solches Feature überhaupt nicht her und tun es in ihrer Kerntechnologie auch heute noch nicht.
Fassen wir zusammen, muss man dem WWW natürlich einen großen Erfolg bescheinigen und muss zum anderen auch anerkennen, dass das heutige Web eine potente technische Plattform für netzbasierte Anwendungen aller Art ist. Betrachtet man jedoch die Potenziale des Hypertexts, ist das Web keine Offenbarung. Die tatsächlich existiert habenden Hypertextsysteme wie Intermedia oder Hyper-G wirken in dieser Hinsicht auch heute noch regelrecht futuristisch.
Verteilte Persistenz
Bis hierher habe ich Ihnen in der Geschichte der Vernetzung von Computern Technik vorgestellt, die im Großen und Ganzen Informationen im Netz abruft und zur Anzeige bringt oder teilweise auch als Programm ausführt. Dies ging von einfachen Darstellungen wie bei den BBS-Systemen über netzbasierte Hypertextsysteme bis hin zu modernen Browser-Infrastrukturen für netzbasierte Software im World Wide Web. Vernetzung hat aber natürlich weitere Potenziale. Ein wichtiges dieser Potenziale, das ich “verteilte Persistenz” nenne, möchte ich Ihnen abschließend vorstellen.
Wenn Sie heute einen PC, einen Laptop oder ein Tablet nutzen, ist es gar nicht mehr so einfach festzustellen, was eigentlich lokal auf dem Gerät gespeichert ist und was im Netz abgelegt wurde. Häufig wird dann der Begriff “Cloud” verwendet. Was das eigentlich genau bedeuten soll, ist selbst wolkig oder gar nebulös. Der Begriff ist wohl eher den Werbe- als den Technikabteilungen entsprungen. Er kann alles und nichts bedeuten. Wenn von “Dateien in der Cloud” die Rede ist, dann meint es in der Regel, dass Dateien irgendwo im Netz gespeichert sind und bei Bedarf lokal auf ein Gerät synchronisiert werden, ohne dass man sich genau darum kümmern müsste, wo und wie die Daten gespeichert sind und auf welche Art und Weise sie synchronisiert werden. Die bekanntesten Vertreter solcher Clouds sind Dropbox und OneDrive.
FTP, der Urahn der netzbasierten Dateiablage
Zugriff auf im Netz gespeicherte Daten ist prinzipiell nicht neu. Im Internet-Vorgänger ARPAnet gab es bereits seit 1971 den FTP-Dienst. Mit FTP (File Transport Protocol) konnte man sich bereits damals auf einem entfernten Computer anmelden, durch die dort freigegebenen Verzeichnisse stöbern und dann Daten auf den eigenen Rechner herunterladen oder von dort aus hochladen. Der Dienst wird auch heute noch bei manchem Webhoster verwendet, um Dateien auf den Server zu laden, die dann über einen Webserver abgerufen werden können. Im Gegensatz zu den 1970ern und 1980ern geschieht dies heute in der Regel mittels einer Software mit grafischer Nutzungsschnittstelle, die oft ziemlich ähnlich aussieht, wie die Dateimanager der Betriebssysteme. FTP erfüllt sicherlich seinen Zweck, ist aber nicht besonders praktisch, denn das Prinzip ist recht umständlich: Ist auf einem FTP-Server ein Dokument einer Textverarbeitung gespeichert, das man gerne bearbeiten will, kann man das nicht einfach so öffnen und bearbeiten, sondern muss das Dokument erst auf den eigenen Rechner herunterladen, kann es dort öffnen und bearbeiten, um es dann explizit wieder hochzuladen. Moderne FTP-Programme haben häufig das Feature, dies zu automatisieren. Ein Doppelklick auf eine Datei lädt diese herunter, öffnet sie mit dem verknüpften Programm und lädt das ganze nach Speichern auch automatisch wieder hoch. Das ist besser als nichts, aber doch behalten die per FTP zugreifbaren Dateien eine andere Charakteristik als die lokal gespeicherten. Sie erscheinen nicht im Explorer oder Finder und auch über die Funktionen zum Öffnen und Speichern in Programmen lässt sich meist auf keine Dateien per FTP zugreifen.
Dateifreigaben im lokalen Netz
In den 1980er Jahren kamen im Bereich kleinerer Netzwerke in Unternehmen Techniken zur Dateifreigabe auf: 1984 etwa das Network File System (NFS) in den Unix-Systemen von Sun Microsystems und bereits 1983 das SMB-Protokoll von IBM sowie Netware von Novell für IBM-kompatible PCs. Gerade letzteres erfreute sich im Bereich von Firmennetzwerken großer Beliebtheit. In allen genannten Fällen mussten Dateien nicht, wie bei FTP, händisch hoch- oder heruntergeladen werden. Vielmehr wurden Verzeichnisse, die auf einem Server gespeichert wurden, im lokalen System so eingebunden, als ob sie lokal vorlägen. Eine Freigabe von Novell Netware erschien unter MS-DOS als Laufwerk mit eigenem Laufwerksbuchstaben, also wie eine Festplatte oder ein Diskettenlaufwerk. Netzwerke dieser Art konnten klein sein, bestanden beispielsweise aus zwei oder drei PCs, oder wurden allen Rechnern einer Firma verfügbar gemacht. Privat betrieb man 1983 hingegen noch keine Netzwerke. Die meisten privaten Nutzer von Computern hatten zu diesem Zeitpunkt noch nicht einmal eine Festplatte.
Techniken wie Novell Netware, SMB oder NFS sind grundsätzlich auch in größeren Netzwerkverbünden wie dem Internet anwendbar. Rein technisch ist das kein Problem. Die Nützlichkeit ist jedoch eingeschränkt. Greift nämlich ein Programm auf eine Datei auf einem Netzlaufwerk zu, ist dies für das Programm genau so, als handele es sich um eine lokal auf dem Rechner gespeicherte Datei. Der Zugriff auf eine Datei im Netz ist natürlich langsamer, als wenn die Datei auf der Festplatte liegt. Im lokalen Netzwerk ist er aber immerhin schnell genug, damit eine sinnvolle Nutzung noch möglich ist. Ist man mit dem Server allerdings über eine sehr langsame Leitung per Internet verbunden, funktioniert das meist nicht mehr vernünftig. Das Laden und Speichern einer Datei dauert dann sehr lange – und wenn ein Programm die Datei zwischenzeitlich speichert, was ja zu empfehlen ist, muss man als Nutzer warten, bis man weiterarbeiten kann.
Synchronisation mit lokalen Kopien.
Noch schlimmer wird das Problem mit den Netzlaufwerken dann, wenn die Netzwerkverbindung gar nicht dauerhaft besteht. Das ist selbst in Firmennetzwerken mitunter der Fall, etwa wenn man ein Laptop verwendet und damit die Firma verlässt. Unter Windows kann man daher etwa einstellen, dass die Dateien eines Netzlaufwerks offline vorgehalten werden. Das Praktische daran ist, dass es für die Arbeit auf dem Rechner gar keinen Unterschied macht, ob man gerade eine Netzwerkverbindung hat oder nicht. Bearbeitet man ein Dokument, ohne dass es eine Verbindung gibt, bearbeitet man lediglich eine lokale Kopie. Sobald die Netzwerkverbindung wieder vorliegt, wird die Kopie ins Netzwerk übertragen. Um all dies braucht man sich als Nutzer nicht selbst zu kümmern. Laden, Bearbeiten und Speichern laufen genauso ab wie immer. Dieses Prinzip lässt sich auch auf im Internet gespeicherte Dateien anwenden, denn dann spielt das langsame Netz keine so große Rolle mehr. Populär wurde das mit dem Dienst Dropbox, den es seit 2007 gibt. Ganz so wie in Dateifreigaben bei Windows werden bei Dropbox und vergleichbaren Diensten die Dateien lokal auf den eigenen Computer synchronisiert. Man kann sie dort ganz normal verwenden, was auch daran liegt, dass es sich ja in der Tat um lokal auf der Festplatte gespeicherte Dateien handelt. Im Hintergrund werden die Dateien bei Änderungen mit den Kopien im Netz synchronisiert – eine vorhandene Netzwerkverbindung natürlich vorausgesetzt.
Probleme entstehen in beiden Fällen, wenn mehrere Personen gleichzeitig an den Dateien arbeiten. Bei im Netzwerk gespeicherten Dateien, die man oft ja gerade aus dem Grund dort ablegt, um sie gemeinsam verwenden zu können, kann genau eine solche gleichzeitige Bearbeitung natürlich schnell vorkommen. Es gibt dann zwei Versionen der gleichen Datei, die nicht automatisch synchronisiert werden können. Man muss sich als Nutzer explizit für eine der beiden Dateien entscheiden oder diese händisch zusammenführen.
Gemeinsame Objekte
Nehmen wir einmal an, Sie besitzen eine Datei mit einer Folienpräsentation. Sie sind dafür zuständig, die Folien 6 bis 10 zu überarbeiten, ihr Kollege kümmert sich um die Folien 1 bis 5. Wenn Sie versuchen, die Überarbeitung mit den genannten Dateiablagediensten zusammenzuführen, kommt es zu einem Synchronisationskonflikt, den Sie natürlich nicht sinnvoll dadurch lösen können, dass Sie sich entweder für Ihre Datei oder die Ihres Kollegen entscheiden. Sie würden dann immer entweder Ihre eigene Arbeit oder die Ihres Kollegen in den Müll werfen. Das Problem ist hier die zu grobe Granularität. Dateifreigaben und auch cloudbasierte Dateiablagen wie Dropbox arbeiten auf Dateiebene. Von den einzelnen Folien oder gar die einzelnen Elemente auf den Folien wissen diese Dienste nichts. Sie können die Präsentation also nicht auf dieser feinen Granularitätsstufe synchronisieren.
Anders sieht das aus, wenn man Software nutzt, die über das Netzwerk synchronisiert Zugriff auf gemeinsame Objekte bietet. Google Docs ist ein modernes Beispiel für eine solche Software. Sie können damit Texte gleichzeitig mit mehreren Mitstreitern online bearbeiten. Alle arbeiten gleichzeitig am gleichen Text. Es ist kein Hin-und-her-Schicken und keine explizite Synchronisierung notwendig. Natürlich müssen solche Dienste nicht zwangsweise internetbasiert sein. Wenn Sie Apple-Nutzer sind, können Sie sich zum Beispiel das Programm SubEthaEdit herunterladen und haben damit einen Texteditor, mit dem Sie im lokalen Netzwerk gemeinsam an Dateien arbeiten können.
In dieser Abbildung sehen Sie zwei frühe Repräsentanten solcher Programme. Links zu sehen23 ist der Unix-Editor EMacs, der es in dieser Version erlaubt, jemandem über das Netz beim Bearbeiten eines Textes zuzusehen. Das Fenster oben zeigt den Master (in der letzten Zeile zu lesen), das untere den Observer, der zusehen, nicht aber selbst bearbeiten kann. Der Editor ShrEdit von 1994 auf der rechten Seite24 erlaubt bereits das gemeinsame, gleichzeitige Bearbeiten des Textes.
Dass man auf diese Weise potenziell von unterschiedlichen Enden der Welt gemeinsam und gleichzeitig an einem Dokument arbeiten kann, wirkt heute fast selbstverständlich. Wenn man sich mal überlegt, was eigentlich dahintersteckt, kann man aber schon ins Staunen kommen, denn dieses gemeinsame Objekt, das Dokument, mit seinen Teilobjekten gibt es ja eigentlich gar nicht. Jeder sieht und bearbeitet eine eigene Kopie. Diese wird im Hintergrund so schnell mit den Kopien der anderen synchronisiert, dass der Eindruck eines gemeinsamen, geteilten Objekts entsteht. Dass das klappt, ist kein Pappenstiel, denn ein einfaches Synchronisieren des ganzen Dokuments würde ja nicht ausreichen. Zum einen würde das viel zu lange dauern. Ein komplexes großes Dokument könnte man wohl kaum mehrmals pro Sekunde per Netz durch die ganze Welt schicken. Das geht selbst bei den heutigen hohen Netzwerkgeschwindigkeiten nicht. Die Entwickler entsprechender Tools standen also vor der Aufgabe sich zu überlegen, wie man die Datenmenge stark reduzieren kann, etwa, indem man nur die Stellen des Dokuments versendet, die sich verändert haben, oder indem man die Änderungsoperationen als solche überträgt. Das allein reicht aber nicht, denn dann würden zwar die Änderungen der Mitarbeiter stets zügig sichtbar werden, der Überblick darüber, wer gerade wo arbeitet, könnte sich aber schwieriger gestalten. Es braucht also zusätzliche Informationen, die mit übertragen werden müssen. Dazu gehört etwa der Mauszeiger oder der Schreib-Cursor der Mitarbeiter zusammen mit der Anzeige ihrer Namen. Mit solchen Awareness- oder zu Deutsch Gewärtigkeitsinformationen gelingt die gemeinsame Arbeit erheblich einfacher. Trickreich bleibt es dennoch, denn bekannte Funktionalitäten wie Undo und Redo werden nun ziemlich kompliziert. Stellen Sie sich vor, wir würden gemeinsam an diesem Absatz arbeiten. Ich schriebe am Ende des Absatzes einen neuen Satz. Kurz danach korrigieren Sie einen Fehler am Beginn des Absatzes. Wenn ich dann auf “Undo” klicke, was passiert dann eigentlich? Wird meine Änderung zurückgenommen oder Ihre? Was würde man erwarten?
Halten wir an dieser Stelle mal inne. Wo sind wir jetzt angekommen? Wir arbeiten weltweit verteilt, gleichzeitig und gemeinsam an virtuellen Objekten. Eine Vielzahl von Entwicklern hat sich intelligente Dinge ausgedacht, damit das so funktioniert und wenn es funktioniert, dann ist alles super. Eigentlich ist es fast schon Zauberei, wenn es nicht so selbstverständlich geworden wäre. Dadurch, dass sich die technischen Hintergründe auf geschickte Art und Weise immer mehr der Wahrnehmung der Nutzer entziehen, sind Nutzungsformen möglich, die vorher undenkbar waren. Dieses Verstecken der Technik ist die Grundlage der Potenziale, die die digitale Technik bietet. Damit verbunden ist dann aber, dass man fast zwangsläufig als Nutzer und als Interessierter das technische System gar nicht mehr durchblicken kann und immer auf die bereits vorgefertigten Lösungen angewiesen ist. Bei einem Commodore 64 konnte man noch jeden einzelnen Chip ergründen, konnte das komplette auf einem Chip untergebrachte ROM analysieren und an Software und gegebenenfalls sogar an Hardware selbst Hand anlegen. Ein moderner Laptop ist mehrere tausend Mal potenter in jeder Hinsicht und bietet durch die Geschwindigkeit, die Vernetzung und durch geschickte Programmierung die geschilderten verteilten Wunderwelten mit gemeinsamen, persistenten Objekten, aber wirklich durchdringen kann man das alles nicht mehr.