Große Computeranlagen, wie sie sich in Universitäten, Forschungseinrichtungen und manchen Firmen seit den 1960er Jahren fanden, waren im Vergleich zu den frühen Rechnern wie einem ENIAC oder einer Z4 sehr leistungsfähig, aber auch sehr teuer, sowohl in der Anschaffung als auch im Unterhalt. Die Bedienung der Rechner selbst erforderte Fachwissen, eine umfangreiche Einweisung und eine Menge Erfahrung. Den wenigen Menschen, die über dieses Wissen verfügten, meist Operator genannt, standen viele Nutzer gegenüber, die ein Interesse daran hatten, den Computer für ihre Berechnungen und für andere Formen der Datenverarbeitung zu verwenden. Der hohe Bedarf an Rechnernutzung und die Notwendigkeit, den teuren, leistungsstarken Rechner möglichst ideal auszunutzen, führte zur bereits im vorherigen Kapitel erläuterten Arbeitsweise, bei der die Computernutzer gar keinen Kontakt zur rechnenden Maschine hatten.
Die Nutzer erstellten das Programm und hatten alle notwendigen Daten in Form von Lochstreifen oder Lochkarten zur Verfügung. Programm und Daten bildeten zusammen einen Rechenauftrag, einen sogenannten „Job“.
Die Lochkarten oder Lochstreifen wurden im Rechenzentrum abgegeben. Dort wurden sie in eine Art Warteschlange einsortiert, während der Computer noch die Jobs anderer Nutzer verarbeitete.
Wenn der entsprechende Job an der Reihe war, wurde zunächst das Programm von den Lochkarten oder vom Lochstreifen eingelesen und Befehl für Befehl in den Speicher kopiert. Es lag dann als Stored Program vor und konnte nun gestartet werden.
Das Programm las im Laufe seiner Verarbeitung die Eingabe von den Lochkarten oder Lochstreifen ein. Dass das Programm die Daten zunächst vollständig las und in den Speicher übertrug, war möglich, beschränkte aber die mögliche Datenmenge aufgrund des limitierten Arbeitsspeichers.
Während der Verarbeitung erzeugte das Programm Ausgaben in Form von Ausdrucken mittels Schnelldrucker oder elektrischer Schreibmaschine oder in Form neuer Lochkarten oder Lochstreifen.
Nach Durchlauf des Programms wurden die Lochstreifen oder Lochkarten, die man eingereicht hatte, zusammen mit den erzeugten Ausgaben in ein Rückgabefach gelegt, aus dem sie vom Nutzer bei Gelegenheit abgeholt werden konnten.
Diese Arbeitsweise, die man job-basiert nennt, blieb aus Nutzersicht bei großen Rechnern in Universitäten, Forschungsinstituten und den meisten Firmen über viele Jahre hinweg gleich. Hinter den Kulissen wurden allerdings Optimierungen durchgeführt, denn die oben beschriebene Arbeitsweise verschwendete wertvolle Ressourcen des Computers, insbesondere dann, wenn es sich um einen Computer handelte, der über ein schnelles Rechenwerk verfügte. Idealerweise sollte die Recheneinheit des Computers nämlich während der kompletten Betriebszeit des Rechners ohne Unterbrechung rechnen. Betrieb man den Computer indes wie oben beschrieben, musste der Rechner sehr oft ziemlich lange warten und konnte nicht weitermachen. Der Hauptgrund hierfür war das Einlesen von Lochstreifen oder Lochkarten. Selbst wenn hierfür sogenannte „Schnellleser“ eingesetzt wurden, waren diese im Vergleich zur Recheneinheit eines großen Universitätsrechners langsam wie eine Schnecke. Wertvolle Prozessorzeit wurde also mit Warten auf das Einlesen des Programms verschwendet. Das gleiche Problem ergab sich beim Einlesen der Daten während der Laufzeit des Programms und auch bei der Erzeugung der Ausgaben. Hier wurden zwar in großen Organisationen Schnelldrucker eingesetzt, aber natürlich war auch so ein Schnelldrucker um ein Vielfaches langsamer als die Recheneinheit eines Großrechners.
Die UNIVAC I, vorne die Bedienkonsole, im Hintergrund Bandlaufwerke – Bild: United States Census Bureau (Public Domain)
Eine Abmilderung dieses Problems erreichte man dadurch, dass Eingaben nicht von langsamen Eingabegeräten wie Lochkartenlesern oder Lochstreifenlesern und Ausgaben entsprechend nicht auf Druckern und Stanzern gemacht wurden, sondern indem ein erheblich schnelleres Medium genutzt wurde. Das Medium der Wahl waren hier zunächst Magnetbänder, die bedeutend rascher gelesen und auch beschrieben werden konnten. Computer, die nur von Magnetbändern lasen und nur auf Magnetbänder schrieben, mussten viel weniger auf die Lese- und Schreiboperationen warten. Die Recheneinheit wurde also bedeutend besser ausgenutzt. Die oben abgebildete UNIVAC I von 1951 war ein Rechner, der ausschließlich auf Magnetbänder als Ein- und Ausgabeformat setzte. Nun ergab sich aber ein neues Problem. Wie kommen Programm und Daten auf das Band? Und wie kommen die Ergebnisdaten vom Band wieder herunter? Da die Nutzer eines solchen Computers die Bänder weder selbst beschreiben noch die auf den Bändern gespeicherten Ausgaben lesen konnten, musste eine Reihe von externen Zusatzgeräten genutzt werden. Es gab dementsprechende Einheiten zum Kopieren von Lochkartenstapeln auf Magnetband und entsprechend solche zum Ausstanzen von auf Magnetband gespeicherten Daten auf Lochkarten oder zur Ausgabe auf einen Drucker.
Stapelverarbeitung
Ein wirklicher Vorteil für die Auslastung des Rechners ergab sich durch den Einsatz der Magnetbandtechnik natürlich nur dann, wenn möglichst wenig Zeit dadurch verschwendet wurde, Bänder zu wechseln. Jeden einzelnen Job erst auf ein Magnetband zu kopieren, dieses dann in den Computer einzulegen, die Ausgaben abzuwarten, das Ausgabe-Magnetband zu entnehmen und die Ergebnisse auszudrucken oder auszustanzen, ergab keinen wirklichen Sinn, denn es entstanden dann ja nach wie vor lange Wartezeiten durch das Wechseln der Bänder. Ihren wirklichen Vorteil spielte die Magnetbandtechnik erst dann aus, wenn der Computer ohne Bandwechsel einen Job nach dem anderen abarbeiten konnte. Genau in diese Richtung wurden dann auch Optimierungen vorgenommen. Jobs wurden nicht mehr einer nach dem anderen, sondern in sogenannten „Batches“ dem Computer zugeführt.
Bei der „Batch-Verarbeitung“ oder auf deutsch auch „Stapelverarbeitung“ wurden die Job-Daten, also die Programme und Daten der Computernutzer, von Lochkarten und Lochstreifen auf ein Magnetband kopiert. Auf ein Band kam nicht nur ein einzelner Job, sondern eine Vielzahl. Eine solche Jobsammlung wurde als „Stapel“ (englisch: batch) bezeichnet. Ein Stapel wurde als Ganzes dem Computer zugeführt. Wenn der Computer etwa zwei Magnetbandlaufwerke für das Einlesen der Jobs hatte, konnten so, vorausgesetzt es gab genügend Jobs, Wartezeiten durch Bandwechsel fast vollständig vermieden werden. Der Computer im Batch-Betriebsmodus arbeitete die Programme eines nach dem anderen ab. Die Ausgaben wurden in gleicher Art und Weise wie die Job-Daten nacheinander auf ein Ausgabe-Magnetband geschrieben. Dieses wurde, wenn es voll war, dem Computer entnommen und in eine Zusatzmaschine gegeben, mit der die erzeugten Ausgaben entsprechend den Wünschen des Nutzers ausgedruckt oder ausgestanzt wurden. Alle langsamen Ein- und Ausgabeoperationen wurden so vom Hauptcomputer abgekoppelt und beanspruchten ihn nicht mehr.
Mit der Einführung der Batch-Verarbeitung dieser Art ging eine der letzten Eingriffsmöglichkeiten verloren, die es vorher durch die menschlichen Operateure noch gab. Ein menschlicher Operator konnte die Reihenfolge der Rechenaufträge leicht abändern, sie somit priorisieren und konnte sogar die Verarbeitung eines Jobs abbrechen, wenn ein wichtigerer Job hereinkam, der eine umgehende Bearbeitung verlangte. Das klappte in dieser Form nun nicht mehr, da die Programme nacheinander vom Magnetband kamen und gar kein Mensch mehr da war, der eine Entscheidung hätte treffen können. Dieser Missstand wurde natürlich erkannt und im Laufe der Zeit beseitigt. Die Rechenanlagen wurden so weiterentwickelt, dass sie die Rechenzeiten der Rechnernutzer verwalten und nach Prioritätenlisten entscheiden konnten, welches Programm wann ausgeführt werden sollte. Das Verwaltungssystem beendete automatisch die Programme, die zu lange rechneten oder andere Ressourcen über Maß in Anspruch nahmen. Es war nun sogar möglich, bei Eintreffen eines Jobs mit hoher Priorität ein gerade laufendes Programm zu unterbrechen, das wichtige Programm vorzuziehen und das unterbrochene Programm an der Stelle fortzusetzen, an der es unterbrochen wurde. Damit all dies so funktionieren konnte, brauchte es aber ein paar technische und organisatorische Voraussetzungen.
Für jedes Programm musste fortan im Voraus angegeben werden, welche Priorität es hat und wie viele Ressourcen es für sich beansprucht. Diese Informationen mussten dem Computersystem für alle anstehenden Jobs eines Batches zur Verfügung stehen, damit es einen der Jobs zur Ausführung auswählen konnte. Das klappte natürlich nicht, wenn diese Daten immer am Anfang eines Jobs auf einem Magnetband standen, das nach und nach eingelesen wurde. Entweder mussten diese Job-Informationen am Beginn des Bandes zusätzlich bereitgestellt werden oder die kompletten Job-Daten mussten vom Computer in einen Speicher kopiert werden, auf den ohne große Zeitverzögerung und ohne größeres Spulen zugegriffen werden konnte. Solche Speichersysteme mit sogenanntem wahlfreien Zugriff (meist Festplatten) kamen Mitte der 1950er Jahre auf den Markt.
Neben dieser Hardware-Voraussetzung gab es aber natürlich eine sehr wichtige Software-Voraussetzung: Statt eines Operators mussten viele Aufgaben nun von der Maschine durchgeführt werden können. Das erledigte eine Software, ein sogenanntes Monitoring System oder Operating System, zu Deutsch also ein Betriebssystem. Dieses System sorgte von nun an statt eines menschlichen Operators unter anderem für das Laden von Job-Daten und das Bereitstellen und Zuordnen von Ausgabedaten. Eine weitere wichtige Aufgabe der Betriebssysteme war (und ist immer noch) das Behandeln von Fehlern in den Programmen. Wenn ein Programm bei seiner Ausführung in eine Fehlersituation kam, durfte das den Computer nicht etwa, wie vorher noch üblich, in einen Alarmzustand versetzen und alle weiteren Operationen anhalten, denn schließlich gab es noch eine lange Warteschlange anderer Jobs, die auch abgearbeitet werden sollten. Stattdessen mussten entsprechende Ausgaben generiert und die Abarbeitung des Batches mit einem anderen Job fortgesetzt werden. Eine weitere wichtige Aufgabe der Betriebssysteme war das Verwalten von Prioritäten und Laufzeitkonten. Studentische Jobs an Universitäten bekamen zum Beispiel geringere Priorität und nur wenig Rechenzeit zugewiesen. Wurde diese Rechenzeit erreicht, wurde die Verarbeitung automatisch abgebrochen. Kam während der Verarbeitung von Jobs mit niedriger Priorität einer mit höchstem Stellenwert herein, wurde die aktuelle Verarbeitung gegebenenfalls unterbrochen und der wichtigere Job vorgezogen.
Selbst beim Einlesen von Daten von Bandlaufwerken und Festplatten gab es noch immer verschenkte Rechenzeit. Zwar ging es natürlich viel schneller als das Einlesen von einem Lochstreifen oder von Lochkarten, doch der Geschwindigkeitsunterschied zu einer schnellen Recheneinheit war immer noch vorhanden. Mehr und mehr technische Kniffe erreichten aber eine immer bessere Auslastung des Rechners. Rechenanlagen von IBM konnten zum Beispiel mehrere Programme gleichzeitig im Arbeitsspeicher halten. Dadurch konnte, während der Computer mit vergleichsweise langsamen Ein-/Ausgabe-Operationen beschäftigt war, das Betriebssystem zu einem anderen Programm wechseln und dieses weiterlaufen lassen. Diese frühe Form des Multitaskings nannte sich „Multi Programming“. Der Preis für den erhöhten Durchsatz durch diese Technik war natürlich ein System, das über viel Arbeitsspeicher verfügen musste und dementsprechend sehr teuer war.
Alle hier genannten Optimierungen durch Magnetbänder, Festplatten und Betriebssysteme spielten sich für den Nutzer eines Computers im Verborgenen ab, denn die Nutzer hatten nach wie vor mit den Vorgängen im Rechenzentrum nichts direkt zu tun und bekamen den Computer selbst überhaupt nicht zu sehen.
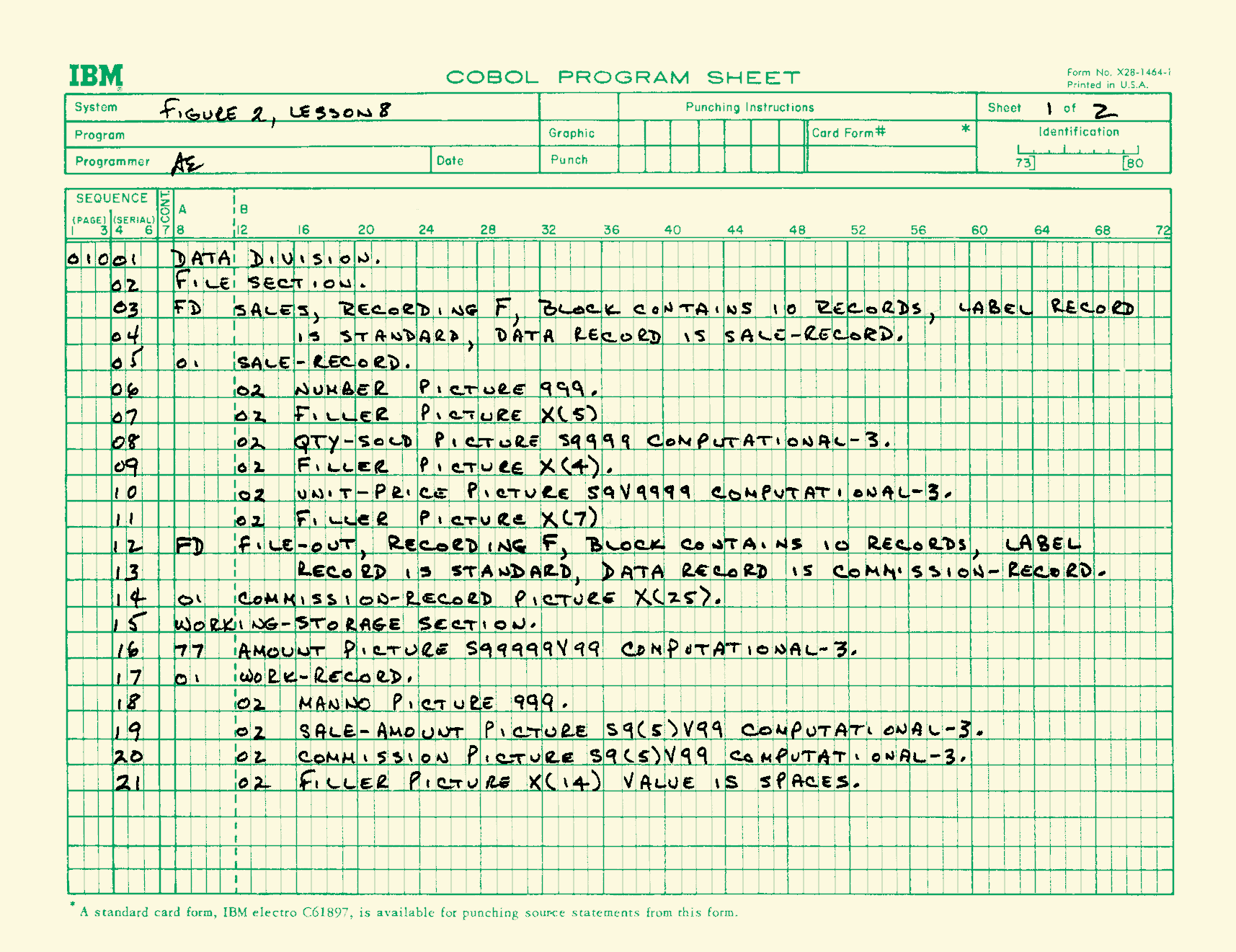
Codierbogen mit einem Teil eines COBOL-Programms
Der komplette Programmierprozess war nach wie vor vorgelagert und fand nur mit analogen, sprich mit mechanischen Mitteln statt. Programmiert wurde zunächst mit einem Stift auf Papier, auf sogenannten „Codierbögen“. Oben ist ein Codierbogen für eine IBM-Computeranlage abgebildet. Wenn diese Phase des Programmierens beendet war, musste der Code auf Lochkarten übertragen werden. Bei der Programmierung mit Lochkarten entsprach eine Karte in der Regel einer Programmzeile. Dazu kamen noch Datenkarten, die man entweder auf die gleiche Art und Weise erstellte oder von einem vorherigen Programm als Ausgabe erhalten hatte. Als Anweisung für das Betriebssystem gehörte zu jedem Job noch eine Job-Steuerkarte, die all dem vorangestellt wurde. Sie diente zum einen der Job-Separierung, aber auch der Spezifikation der Programmiersprache – dazu gleich mehr – sowie weiteren Ablaufdetails wie etwa der Priorität und der erlaubten maximalen Laufzeit. Diesen Satz an Lochkarten versuchte der Programmierer – tunlichst ohne ihn vorher fallen zu lassen – im Rechenzentrum abzugeben. Alles, was nun passierte, entzog sich dem Benutzer. Die Zeit von der Abgabe des Programms bis zum Erhalten des Ergebnisses, die sogenannte „Turnaround-Time“ oder „Jobverweilzeit“, konnte unter Umständen sehr lang sein. Die Universität Münster beschrieb dies eindrucksvoll im Newsletter „inforum“ des Hochschulrechenzentrums 9:
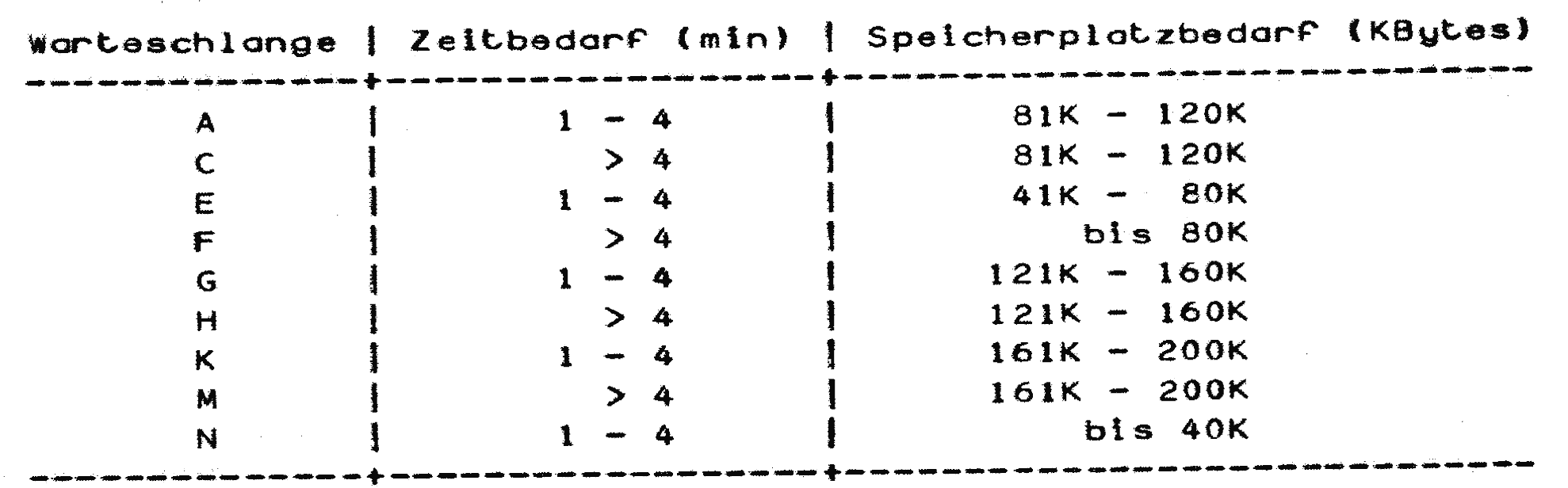
Jeder Auftrag zur Ausführung von Programmen (kurz: Job), der dem Rechner übergeben wird, muß vom Betriebssystem verwaltet werden. Diese Aufgabe übernimmt bei uns die Betriebssystemkomponente HASP (Houston Automatic Spooling Priority System). HASP liest die Jobs von den Kartenlesern im Rechenzentrum und an den Terminals. […] Jeder Job wird in eine der folgenden Warteschlangen nach CPU-Zeit und Speicherplatz-Bedarf einsortiert:
Warteschlange – Quelle: „inforum“ des Hochschulrechenzentrums der Universität Münster, April und Juli 1977.
[…]
Der Benutzer kann Zeit- und Speicherplatzbedarf seines Jobs auf der JOB-Karte angeben. Die Job-Karte //ABC99XY JOB (ABC99,0020,Z23),A,USER,REGION=155K z.B. fordert 20 Minuten CPU-Zeit in 155 KBytes Hauptspeicher an. HASP sortiert den Job demnach in Warteschlange H ein. Die gleiche Wirkung hat CLASS=H anstatt REGION=155K.
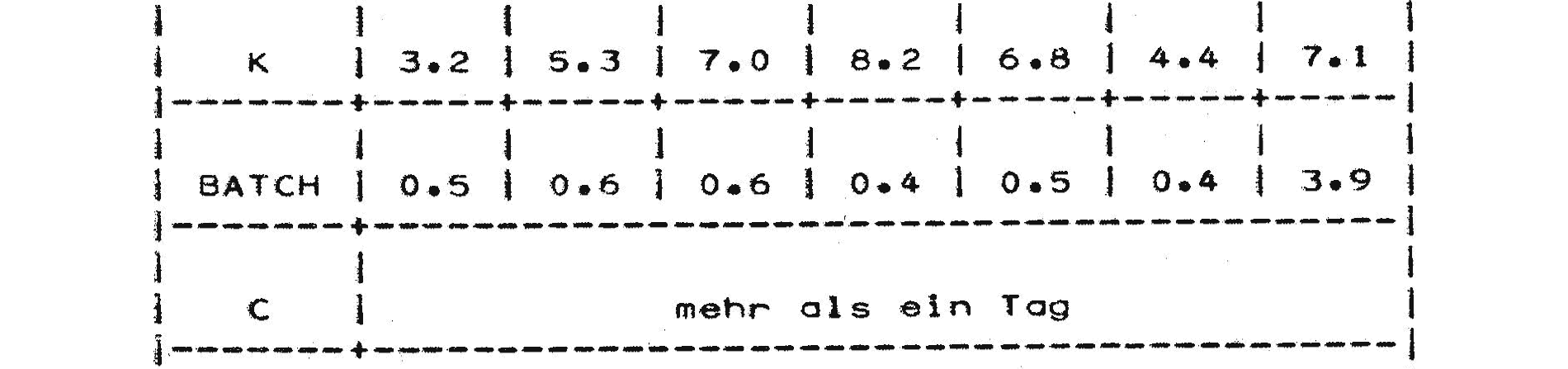
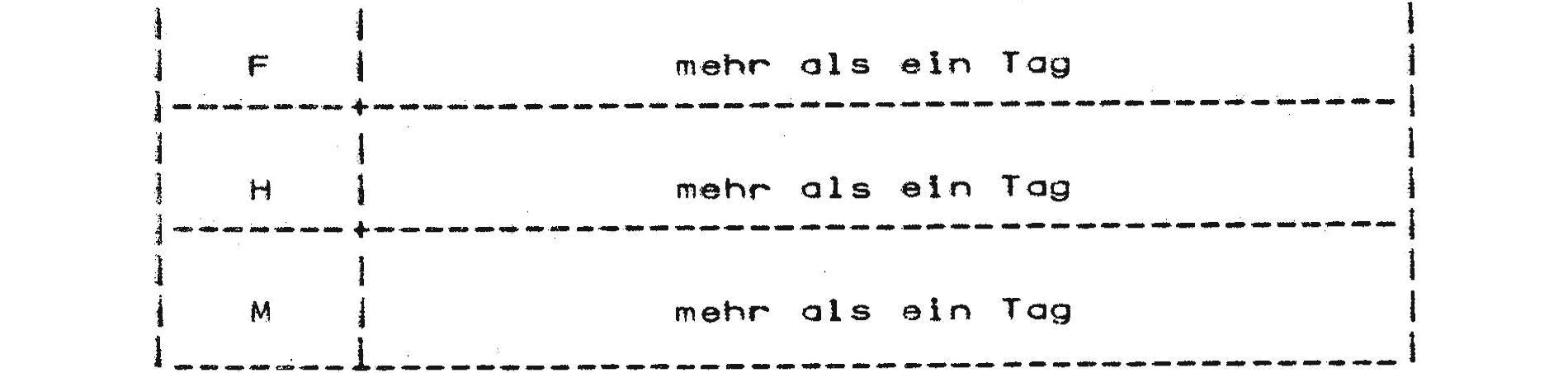
Die durchschnittliche Zeit, die ein Job vom Einlesen bis zum Drucken entsprechend seiner Klasse und Einlesezeit in der Maschine ist (Jobverweilzeit), kann für den derzeitigen Rechnerbetrieb der nachfolgenden Tabelle entnommen werden.10
Die Ausführung des im Beispiel der Uni Münster angegebenen Jobs mit zwanzig Minuten Rechenzeit und 155 KB benötigtem Hauptspeicher dauerte im März 1977 also im Durchschnitt mehr als einen Tag. Diese lange Zeit konnte natürlich mehr oder weniger kritisch sein. Wenn man ein bereits ausgefeiltes Programm hatte, das man immer wieder verwendete und bei dem man nur die Daten anpasste, konnte man sich mit der langen Zeit bis zum Erhalten des Ergebnisses eventuell arrangieren. Gerade im Wissenschaftsbetrieb war es jedoch so, dass oft neue, recht spezielle Berechnungen anzufertigen waren. Man musste für die meisten Aufgaben also stets neue Programme schreiben. Diese Programme wurden nicht oft wiederverwendet, sondern dienten eben der Lösung genau eines Problems. Wenn es gelöst war, standen andere Aufgaben an, die andere Programme verlangten, die dann wieder explizit programmiert werden mussten.
Gerade während der Entwicklungszeit eines solchen Programms stellte die lange Turnaround-Zeit ein großes Problem dar. Das kann sich jeder leicht klarmachen, der schon mal programmiert hat. Allen anderen sei versichert: Ein Programm ist so gut wie nie auf Anhieb korrekt. Fast immer gibt es bei den ersten Versuchen der Ausführung eine Reihe von Fehlermeldungen oder man stellt fest, dass das Programm zwar syntaktisch korrekt ist, also korrekt in der Programmiersprache verfasst wurde, aber leider nicht das tut, was man sich vorgestellt hat. Es braucht also nahezu immer mehrere Korrekturschritte, bis ein Programm korrekt arbeitet. Stellen Sie sich das nun bei einer Programmierung auf Papier, bei manueller Übertragung auf Lochkarten und vor allem bei einer Antwort, die es erst Stunden später oder am nächsten Tag gibt, vor. Eine Fehlerkorrektur oder Programmieren durch schrittweises Optimieren, wie heute üblich, dauerte so Stunden bis Tage. Die einzige Abhilfe, die das Programmieren von Rechnern im Batch-Betrieb zumindest etwas komfortabler machte, war das Aufkommen sogenannter „höherer Programmiersprachen“.
Höhere Programmiersprachen
Das Nutzen eines Computers bedeutete in den 1950er, 1960er und 1970er Jahren in der Regel, dass die Nutzer zum Lösen eines Problems, also etwa zur Durchführung einer Berechnung, ein eigenes Programm schreiben mussten. Da der Computer selbst seinen Nutzern nicht zugänglich war, war die Programmiersprache, mit der ein Computer programmiert werden konnte, daher das einzige, was einer Nutzungsschnittstelle irgendwie nahekam. Bis Ende der der 1950er Jahre konnten Computer nur in Maschinencode bzw. im sehr maschinennahen Assembler-Code programmiert werden. Programmierer, die eine Aufgabe mit einem Computer lösen wollten, mussten die Architektur der Maschine dabei ziemlich genau kennen. Sie mussten zum Beispiel wissen, wie viele Register eine Maschine hatte, wie der Speicher organisiert und mit welchem Befehlssatz die Maschine zu programmieren war. Programmieren auf diese Art ist auch heute noch möglich und wird dann und wann auch durchgeführt, wenn es auf höchste Performance ankommt. Der größte Teil der Programmierung wird jedoch schon lange nicht mehr so maschinennah, sondern in sogenannten „höheren Programmiersprachen“ erledigt. Die ersten dieser Sprachen kamen Ende der 1950er Jahre auf.
Betrachten wir an einem einfachen Beispiel zunächst die maschinennahe Programmierung eines Computers: Der Prozess des Programmierens in einer maschinennahen Programmiersprache geht immer mit einer Dekontextualisierung des Problems einher. Alle Hinweise auf die Bedeutung dessen, was dort programmiert wird, gehen in diesem Prozess verloren. Eine Lösung eines Problems als Computerprogramm ist dadurch stets sehr schwer zu verstehen. Das Beispiel, das ich Ihnen hier erläutern möchte, ist ein kleines Programmfragment, das bestimmt, ob jemand „pleite ist“. In natürlicher Sprache wollen wir, leicht vereinfachend, „pleite sein“ definieren als: „Wenn jemand mehr ausgibt, als er einnimmt, dann ist er pleite“. Mathematisch formuliert könnte man das als "pleite: a > e" aufschreiben. Diese Definition sieht sehr formal aus und ist es auch. Es haben sich aber einige Hinweise auf menschenverstehbare Semantik erhalten. Die Wahl des Wortes pleite und die Wahl der Variablennamen a für Ausgaben und e für Einnahmen sind nicht Teil des mathematischen Formalismus, sondern verweisen auf die Problemdomäne. Man könnte auch ganz andere Bezeichner wählen, ohne an der formalen Spezifikation etwas zu ändern. Die Verstehbarkeit durch den Menschen würde aber leiden, wenn wir diese Hinweise auf die Bedeutung wegließen. Leider müssen wir genau das tun, wenn wir das Problem als Maschinenprogramm aufschreiben. Es entsteht dann ein Programm wie das folgende11:
0: LOAD 2
1: SUB 1
2: JGTZ 5
3: LOAD=1
4: JUMP 6
5: LOAD=0
6: STORE 3
7: HALT
Das zu lösende „Problem“ wurde bei der Übertragung in das Computerprogramm in eine Reihe von Anweisungen heruntergebrochen, die Zeile für Zeile aufgeschrieben wurden. Die Werte für Einnahmen und Ausgaben werden in zwei Registern der Maschine erwartet. Ein Register kann man sich als Speicherstelle für genau einen Wert vorstellen. Der Wert für die Ausgaben ist in Register 1, der für die Einnahmen in Register 2 als Zahl gespeichert. Register 3 enthält am Ende dieses Mini-Programms eine 1 im Falle einer Pleite. Andernfalls wird dort eine 0 gespeichert. Unsere Maschine, für die hier programmiert wird, verfügt eine besondere Speicherstelle, die „Akkumulator“ genannt wird. Alle Rechenoperationen der Maschine werden auf diesen Akkumulator angewandt. Das Programm startet in Zeile 0 und läuft dann folgendermaßen ab:
In Zeile 0 wird der Wert des Registers 2 in den Akkumulator geladen. „Laden“ bedeutet dabei nichts anderes, als dass der Wert dorthin kopiert wird. Der Wert im Akkumulator ist nun der gleiche wie der in Register 2, also der Wert der Einnahmen.
In Zeile 1 wird der Wert aus Register 1 – die Ausgaben – vom Wert im Akkumulator abgezogen. Im Akkumulator befindet sich dann das Resultat dieser Rechnung, der Wert der Einnahmen abzüglich des Wertes der Ausgaben.
Zeile 2 ist ein bedingter Sprung. Der Wert im Akkumulator wird darauf überprüft, ob er größer als 0 ist (JGTZ für Jump if Greater Than Zero). Wenn dies der Fall ist, wird in Zeile 5 fortgefahren.
Nehmen wir an, dass der Wert im Akkumulator kleiner ist als 0, die Person also pleite ist. In diesem Fall trifft die Bedingung nicht zu. Der Sprung wird also nicht ausgeführt, sondern es wird in Zeile 3 fortgefahren. In dieser Zeile wird der Wert 1 in den Akkumulator geschrieben.
Zeile 4 ist wieder ein Sprungbefehl, in diesem Fall jedoch ein Sprung ohne Bedingung. Es geht also in Zeile 6 weiter.
Wenn die Überprüfung in Zeile 2 anders abgelaufen wäre, wäre das Programm nicht in Zeile 3, sondern in Zeile 5 weitergegangen. Auch hier wäre ein Wert in den Akkumulator geladen worden, allerdings wäre es hier eine 0 gewesen.
In Zeile 6 wird der Wert aus dem Akkumulator, also eine 1 oder eine 0, im Register 3 gespeichert.
In Zeile 7 endet das Programm.
Sicher haben Sie es gemerkt: Um dieses Programm überhaupt schreiben zu können, muss man sehr viel über die Architektur des Rechners wissen. Man muss etwa wissen, was Register sind und dass der Rechner über einen Akkumulator verfügt. Auch die Befehle müssen bekannt sein. Man muss sich darüber hinaus vieles merken, etwa, welcher Wert in welchem Register gespeichert ist. Vor allem muss man es hinbekommen, zu programmieren, ohne dass es Hinweise auf eine menschenverstehbare Semantik gibt. In der Praxis konnte man sich mit Kommentaren behelfen, die man zusätzlich zu den Programmbefehlen notierte. Dies änderte aber nichts daran, dass das Programm selbst komplett ohne Hinweise auf die Bedeutung auskommen musste.
Bei der Programmierung stehen sich unterschiedliche Arbeitsweisen scheinbar unversöhnlich gegenüber. In der Sphäre des Nutzers spielt die Bedeutung dessen, was gelöst werden soll, eine große Rolle. Es ist wichtig, wofür die Zahlen stehen, mit denen gerechnet wird, und was das Ergebnis bedeutet. Die Arbeitsweise des Computers hingegen ist völlig frei von Bedeutungen und basiert rein auf der Form und der Anordnung von Zeichen. Diese Zeichen steuern den Computer, der dann entsprechend addiert, vergleicht, lädt oder im Programm an eine andere Stelle springt. Der Computer tut dies völlig unabhängig davon, was das Programm für den Menschen bedeutet, der es verwendet. Höhere Programmiersprachen versuchen, genau diesen Gegensatz zu überbrücken. Zum einen abstrahieren sie von der internen Struktur der Maschine, was den Programmierer schon mal von der Notwendigkeit der Kenntnis allzu spezifischer technischer Details entbindet, die ja nichts mit dem von ihm zu lösenden Problem, sondern ausschließlich mit dem Gerät zu tun haben. Das ist bereits eine große Hilfe. Es sind aber vielleicht die sprachlichen Aspekte der Programmiersprachen, die noch wichtiger für eine gute Programmierbarkeit sind.
Höhere Programmiersprachen erfüllen nämlich zwei Rollen gleichzeitig: Es handelt sich zum einen um Sprachen, die im Gegensatz zu natürlichen Sprachen vollständig formal spezifiziert sind. Nur deshalb können sie zur Steuerung der Operationen eines Computers verwendet werden. Trotzdem bieten sie aber Grundstrukturen natürlicher Sprache, sodass ein „Text“ entsteht, der auch für den Menschen einigermaßen verständlich ist. Diese Natürlichsprachlichkeit fängt bei den Schlüsselworten und Konstrukten der Sprache selbst an. Statt wirre Sprünge an Programmzeilen gibt es etwa Konstrukte wie if, then, else und eine an die Mathematik angelegte Funktionssemantik mit Übergabeparametern und Rückgabewerten. Eine extreme Erleichterung bei der Programmierung bringt darüber hinaus vor allem die Möglichkeit, Programmkonstrukte mit eigenen Namen versehen zu können. Für die automatische Verarbeitung eines Programms durch einen Computer ist der Name einer Variablen (eines gespeicherten Wertes) oder eines Unterprogramms irrelevant. Dem Programmierer hilft sie jedoch, die inhaltliche Bedeutung dessen, was ein Programmkonstrukt tut, verstehen zu können. Es macht für das Verständnis einen beträchtlichen Unterschied, ob man sich auf so etwas abstraktes wie „Register 2“ oder „x“ beziehen muss, oder ob im Programm das verstehbare Wort ausgaben auftaucht.
Die ersten höheren Programmiersprachen mit diesen Eigenschaften kamen Ende der 1950er Jahre auf und fanden in den 1960ern zunehmend Einsatz. Die neuen Sprachen verfügten über unterschiedliche Charakteristika je nach ihrem intendierten Einsatzgebiet; von Fortran (Formula Translation) und Algol (Algorithmic Language) für wissenschaftliche Berechnungen bis hin zu COBOL (Common Business Oriented Language) für Business-Datenverarbeitung. Das oben maschinennah erläuterte Programm stellte sich in COBOL und Fortran wie folgt dar:
Programme in einer höheren Programmiersprache können von einem Computer nicht direkt ausgeführt werden. Spezielle Programme, „Compiler“ genannt, übersetzen zunächst den Programmcode in den systemeigenen Maschinencode, der dann ausführbar ist. Aus diesem Grund mussten Programmierer bei der Benutzung eines Computers im Batch-Betrieb die genutzte Programmiersprache auf der Job-Control-Karte ihrer Jobs angeben. Das Betriebssystem führte dann automatisch erst den entsprechenden Compiler und dann das von diesem erzeugte Programm in Maschinensprache aus.
Programmiersprachen werden üblicherweise nicht in den Zusammenhang mit Nutzungsschnittstellen gebracht. Gerade im Kontext heutiger Systeme ist das sicher auch richtig so, denn kaum ein Nutzer muss seinen Computer heute selbst programmieren, und wenn es doch passieren sollte, sieht man das als etwas anderes als die Nutzung des Geräts an. Es wird relativ klar zwischen Nutzung und Programmierung unterschieden. Zur damaligen Zeit jedoch, in der ein Computernutzer stets gleichzeitig ein Computerprogrammierer war, war die Beschaffenheit einer Programmiersprache von essenzieller Bedeutung dafür, wie effizient der Computer genutzt werden konnte. Die Charakteristiken der höheren Programmiersprachen nahmen dabei etwas vorweg, was wir im weiteren Verlauf der Nutzungsschnittstellen-Entwicklung weiter beobachten werden. Sie ermöglichten dem Nutzer des Computers eine Denkweise, die sich von der technischen Realität der Maschine stark unterscheidet. Nutzer haben es in der höheren Programmiersprache mit namentlich ansprechbaren Variablen und Funktionen statt mit Registern und Sprungbefehlen zu tun. Die Strukturen im Rechner bleiben ihnen verborgen. Dieses Schaffen einer Nutzungswelt durch das Computersystem, die ganz andere Eigenschaften als die technische Struktur hat, ist eine Grundeigenschaft interaktiver Nutzungsschnittstellen, auf die ich später intensiv zu sprechen komme. Zunächst will ich Ihnen aber erläutern, dass die hier beschriebene Batch-Nutzung mit ihrer großen Distanz zwischen Mensch und Maschine keineswegs alternativlos war.