Persönliche Computer
Mit den Minicomputern wie der PDP-8 sind wir den Personal Computern schon ziemlich nahegekommen. Manch später Minicomputer mutet wie ein Personal Computer an. Unten abgebildet sehen Sie ein VT78 von DEC. Dieses Gerät kam 1977 auf den Markt. Es ist technisch eine inzwischen auf Chip-Größe geschrumpfte PDP-8, die in ein VT52-Terminal eingebaut wurde. Auf diesem kompakten Gerät lief eine angepasste Version von OS/8 und das Textverarbeitungsprogramm WPS-8 von DEC. Der Rechner basierte auf der Architektur eines bewährten Minicomputers und eines ebenso bewährten VT52-Terminals. Handelt es sich also um einen kompakten Minicomputer? Um ein intelligentes Terminal? Oder ist das schon ein Personal Computer?

Sie sehen, dass es wieder einmal gar nicht einfach ist, zu sagen, was einen Personal Computer ausmacht. Der Begriff „Personal Computer“, vor allem in seiner Abkürzung PC, steht heute meist für den IBM 5150, also den IBM Personal Computer von 1981, und seine direkten Nachfolger und Kompatiblen. Die damals von IBM auf den Markt gebrachte Architektur ist wohl eine der beständigsten Computer-Architekturen überhaupt. Nahezu alle Desktop-PCs und Laptops, die heute, im Jahre 2021, genutzt werden, sind Nachfolger dieses Rechners und sind noch heute mit damaligen Rechnern und mit ihrer Software grundsätzlich kompatibel1. Tatsächlich ist die IBM-PC-Architektur mit ihrem zum Intel 8086 kompatiblen Prozessor allerdings bei Weitem nicht mehr die verbreitetste Computer-Architektur. Es gibt inzwischen weit mehr Smartphones und Tablets als PCs und Laptops, und diese Geräte basieren auf einer anderen technischen Grundlage – doch zu den Smart-Geräten kommen wir erst im nächsten Abschnitt des Buches.
Hier soll es zunächst um den Personal Computer gehen, aber natürlich nicht nur um den IBM PC, denn den Begriff „Personal Computer“ so einzuschränken, würde uns nicht erlauben, die Entwicklungslinien zu verfolgen. Es gab erheblich mehr, was seinerzeit „Personal Computer“, „Heimcomputer“ oder auch „Tischcomputer“ genannt wurde. Dass die Firma IBM auf den Gedanken kam, einen PC herauszubringen und dass dann später Microsoft darauf kam, eine Arbeitsumgebung mit dem Namen „Windows“ zu kreieren, hat eine Vorgeschichte, die es zu erkunden gilt.
Es bleibt nun aber immer noch die Frage, was denn nun ein Personal Computer ist. Wie verhält sich der Personal Computer zum Minicomputer? Zunächst gibt es eine große Gemeinsamkeit: Ein Personal Computer ist wie ein Minicomputer eine lokale Ressource, verfügt also über einen lokalen Speicher und lokale Ein- und Ausgabegeräte. Auch wenn man zur Bedienung eines Minicomputers oder eines frühen Personal Computers vielleicht einen Fernschreiber oder ein Terminal benutzte, stand der Computer in der Regel nur wenige Meter neben dem Terminal und nicht etwa weit entfernt in einem Rechenzentrum. Eine Konsequenz dieser lokalen Ressourcen und der lokalen Nutzung war, dass der Computer nicht mehrere Nutzer im Time-Sharing bediente, sondern zu jedem Zeitpunkt von nur einem Nutzer bedient wurde2.
Aufgrund der genannten ähnlichen Charakteristika von Personal Computer und Minicomputer, werden Rechner wie die PDP-8 und der LINC von manchen Enthusiasten als „frühe Personal Computer“ bezeichnet. Vergleicht man Minicomputer zu ihrer Hochzeit Anfang der 1970er mit Personal Computern ab 1975, kann man aber durchaus Unterschiede ausmachen. Minicomputer entstanden zur Zeit transistorbasierter Rechner, aber noch vor dem Aufkommen integrierter Schaltkreise und vor allem vor dem Aufkommen des Mikroprozessors. Viele spätere Minicomputer waren zwar mehr und mehr miniaturisiert und verwendeten auch Mikrochips, verblieben aber noch längere Zeit bei Recheneinheiten, die aus mehreren Komponenten bestanden. Personal Computer hingegen entstanden zeitgleich mit dem Aufkommen der ersten Mikroprozessoren. Mit der Miniaturisierung, der Massenherstellung von Komponenten und der Bastel-Anstrengungen früher PC-Pioniere gelang es, Computer zu erheblich niedrigeren Preisen herzustellen. Ein weiterer, wichtiger Unterschied zwischen einem Minicomputer und einem Personal Computer liegt im Namen. Natürlich sind Namen Schall und Rauch, doch ist das „Personal“ in Personal Computer nicht unberechtigt. Ein Personal Computer ist in den meisten Fällen einem Nutzer oder einer Familie zugeordnet. Man besitzt seinen eigenen Personal Computer oder teilt sich einen in der Familie, und selbst im Büro steht einem ein Personal Computer individuell zur Verfügung, auch wenn er einem nicht direkt gehören mag. Minicomputer hingegen waren meist nicht einer Person zugeordnet, sondern gehörten eher zur Einrichtung einer Werkstatt oder eines Labors.
Verwandt mit den Personal Computern sind auch die Rechner, die „Workstations“ genannt werden. Hier ist eine Abgrenzung noch schwieriger zu treffen. Sie liegt vor allem in den Kosten und damit in der Leistungsfähigkeit. Während Personal Computer im Heimbereich, in der Schule und im Büroumfeld anzutreffen sind, werden die leistungsfähigeren Workstations eher im technisch-wissenschaftlichen Umfeld eingesetzt. Typische Workstations wie die Rechner von Sun Microsystems schauen wir uns im Rahmen dieser Geschichtserzählung nicht an. Im Kapitel „Schreibtische und Fenster“ werfen wir aber einen Blick auf die Rechner Alto und Star von Xerox, die man wohl dieser Geräteklasse zuordnen könnte.
In der folgenden Tabelle sehen Sie typische Charakteristiken jeder Geräteklasse inklusive eines typischen Vertreters aufgeführt. Den Personal Computer habe ich hier in Hobby-Computer, Heim-Computer und Büro-Computer aufgeteilt. Sie werden im Verlaufe des Kapitels sehen, dass es hier durchaus Unterschiede gab, was Leistungsfähigkeit, Ausstattung und auch die Nutzungsschnittstelle anging.
| Großrechner | Mini-Computer | Hobby-Computer | Heim-Computer | Büro-Computer | Workstation | |
|---|---|---|---|---|---|---|
| Beispiel | DEC PDP-10 (1966) | DEC PDP-8 (1965) | Altair 8800 (1975) | C64 (1982) | IBM PC (1981) | Sun-1 (1982) |
| Größe | Raum | Schrank, Truhe | Koffer | Schuhkarton | Koffer | Koffer |
| CPU | Transistor | Transistor | Micro | Micro | Micro | Micro |
| Preis | sehr hoch | hoch | niedrig | niedrig | gemäßigt | hoch |
| Leistung | hoch | niedrig | niedrig | niedrig | mittel | hoch |
| Ressourcen | remote | lokal | lokal | lokal | lokal | vernetzt |
| Nutzer | viele | wenige | 1 | 1 | wenige | wenige |
| Persönlich | nein | nein | ja | ja | ja | teilweise |
| Einsatz-bereich | Verwaltung, Wissenschaft | Wissenschaft, Technik | Heim | Heim | Büro | Wissenschaft, Technik |
Auf die Frage, was einen Personal Computer in der Geschichte der Nutzungsschnittstelle ausmacht, kommen wir im Kapitel „Kleine Computer im Büro“ nochmals zurück. Sie werden dann sehen, dass, vielleicht wichtiger als die oben besprochenen Unterschiede, die Software und ihre Ausnutzung der Potenziale interaktiver Nutzungsschnittstellen den kleinen, aber feinen Unterschied ausmacht, der die Personal Computer von den Minicomputern qualitativ abhebt.
Auf zum Altair!
Ebenso wie es ein Bedürfnis vieler zu sein scheint, den ersten Computer überhaupt benennen zu können, wird auch der erste Personal Computer vielfach gesucht und benannt. Hier einen Ersten zu finden, ist aber fast noch müßiger und noch aussichtsloser, als beim Computer an sich, denn natürlich war es auch hier nicht so, dass der Blitz in jemanden fuhr, der dann mit einem Personal Computer etwas völlig Neues, noch nie Dagewesenes ersonnen hätte, ohne Anleihen bei bisherigen Computern zu nehmen. Ich stelle Ihnen in diesem Kapitel mit dem Altair 8800 den Computer vor, dem die Ehre, der erste Personal Computer gewesen zu sein, vielleicht am häufigsten zugeschrieben wird. Sie werden sehen, dass Funktions- und Arbeitsweisen bestehender Computer, vor allem der populären Minicomputer, bei der Konzeption des Altair eindeutig Pate standen.
Mit Minicomputern wie der PDP-8 aus dem vorhergehenden Kapitel wurden Computer relativ klein und günstig und waren so erstmals auch für kleine Organisationen erschwinglich. Für eine Firma mit einem Elektrolabor etwa war eine PDP-8/E von 1970 mit ihren 6.800 Dollar (2021: 47.000 Dollar) durchaus preisgünstig. Für Privatleute sah das aber anders aus, zudem ja auch noch Kosten für Terminals und Speichergeräte, etwa ein DECTape-Gerät, hinzukamen. Computer waren bis etwa Mitte der 1970er Jahre daher etwas, das es in Firmen, im Militär, in Universitäten und Hochschulen gab und von dem Privatleute vielleicht etwas gehört hatten, was ihnen aber nicht direkt zugänglich war. Computer umgab dadurch durchaus eine etwas mystische Aura. Gerade für eher Linksdenkende gehörten sie zum militärisch-industriellen Komplex. Das Bedürfnis vieler Hobbybastler, sich ihren eigenen Computer für zu Hause zu bauen, hat so neben dem reinen Interesse an der Technik durchaus auch einen politischen Aspekt. Sich seinen eigenen Computer zu bauen statt der Computertechnik nur ausgeliefert zu sein, kann man regelrecht als einen Akt der Befreiung und Selbstbestimmung interpretieren. Aus dieser Stimmungslage entstanden viele der amerikanischen Computerpioniere des Silicon Valley. Ein entsprechender Duktus findet sich noch heute oft in ihrer Außendarstellung, was eine gewisse Ironie innehat, denn die Rolle von Firmen wie Apple hat sich natürlich im Laufe der Jahrzehnte stark gewandelt. Werden wir aber nicht politisch und greifen wir der Geschichte nicht vor, sondern kommen wieder zur Situation in den 1970er Jahren, in der die ersten Personal Computer aufkamen.
Anfang der 1970er Jahre brachte die Firma Intel den ersten vollintegrierten Mikroprozessor auf den Markt. Der Prozessor mit der Bezeichnung 4004 und der ein Jahr später erschienene 8008 kamen zum Beispiel in Taschenrechnern, Tisch-Rechenmaschinen und teils auch in frühen Videospielen zum Einsatz. Auch Hobbybastler fanden Interesse an den Prozessoren und konstruierten sich eigene kleine, experimentelle Computersysteme auf Basis dieser Prozessoren. Für wirklich ernsthafte Rechenanlagen waren sie aber nicht geeignet. Das änderte sich im Jahr 1974 mit der Vorstellung des Intel 8080, einem 8-Bit-Mikroprozessor mit einem 16-Bit-Datenbus, der 64 KB Arbeitsspeicher adressieren konnte.
Angaben in Bit, hier 8-Bit, haben Sie in Bezug auf einen Prozessor sicher schon einmal gehört. Aber was bedeutet das eigentlich? Ich sollte an dieser Stelle vielleicht einige Begriffe und Sprechweisen erklären.
8-Bit Prozessor?
Dass ein Prozessor ein 8-Bit-Prozessor ist, bedeutet, dass er darauf ausgelegt ist, mit Folgen von je 8 Bit zu operieren. So ein Prozessor kann zum Beispiel zwei Zahlen, die je in 8 Bit binär codiert sind, in einem Schritt addieren, weil er über einen eingebauten 8-Bit-Addierer verfügt. Mit 8 Bit lassen sich nur 256 verschiedene Werte darstellen, etwa die von 0 bis 255. Die Konsequenz daraus ist aber nicht, dass man mit einem solchen Prozessor nur kleine Zahlen verarbeiten könnte. Es ist ohne weiteres möglich, viel größere Zahlen, die mehr Bits benötigen, zu verarbeiten. Das macht es aber komplizierter. Sie können sich das klarmachen, indem Sie einen Prozessor annehmen, der im normalen Zehnersystem rechnet. Das kann man es sich etwas leichter vorstellen, als die für den Menschen unhandlichen Einsen und Nullen im Binärsystem. Unser imaginärer Prozessor hat die Fähigkeit, zwei Zahlen zu addieren, kann allerdings immer nur drei Stellen einer Zahl gleichzeitig verarbeiten. 54 + 92 können sie ohne Probleme ausrechnen, doch was machen Sie bei 12742 + 7524? Ganz einfach, Sie rechnen zunächst mal nur mit den hinteren drei Stellen. 742 + 524 = 1266. Dieses Ergebnis ist mit 4 Stellen zu lang! Sie können nur die 266 „abspeichern“ und haben einen Überlauf von 1. Also „Eins im Sinn“, wie man in der Schule so schön sagte. Diese 1 müssen Sie mitverarbeiten, wenn Sie die vorderen Teile der Zahl verrechnen. Wir haben nun für den vorderen Teil also 1 + 12 + 7 zu berechnen. Diese Berechnung müssen Sie in zwei Schritten durchführen, denn der Prozessor kann immer nur zwei Zahlen addieren. Also: 1 + 12 = 13 und 13 + 7 = 20. Das Ergebnis des vorderen Ergebnisteils ist also 20, das des hinteren 266. Das Gesamtergebnis unserer Addition ist also 20266. Wie Sie sehen, konnten wir die Berechnung durchführen, doch statt einmal zu addieren, mussten wir gleich dreimal ran. Hinzu kam noch Aufwand für die Koordination des Prozesses.
Adress-Bus?
Auch der Adressraum des Arbeitsspeichers eines Systems wird in Bit angegeben. Was bedeutet die Bit-Zahl hier? Stellen Sie sich den Arbeitsspeicher eines Computers der Einfachheit halber wie einen Schrank mit ganz vielen Schubladen vor. In jede Schublade können Sie eine bestimmte Zahl von Bits hineinlegen. Diese Bitfolge nennt man ein „Wort“. Wie lang ein solches Wort ist, wie viel Bits es also enthält, hat sich im Laufe der Computergeschichte oft geändert. Nehmen wir hier der Ära entsprechend wieder einmal 8 Bit. 8 Bit werden üblicherweise auch ein Byte genannt. Die Größe des Arbeitsspeichers in Bytes ist nun die Anzahl der Schubladen des Schranks. Ein Prozessor muss dem Arbeitsspeicher im Computer mitteilen können, welche Schublade er braucht. Stellen Sie sich das so vor, dass an jeder Schublade eine Zahl steht. Ein Programm kann also das Byte aus Schublade Nummer 245 anfordern oder einen neuen Byte-Wert dort hineinschreiben. Die Auswahl der Schubladen geschieht über den sogenannten Adress-Bus, der einfach nur aus einer Reihe von Stromleitungen besteht. Die Frage ist nun, wie viele Stromleitungen benötigt werden. Würde der Adress-Bus aus nur einer einzigen Leitung bestehen, könnte nur die eine Speicherzelle – wenn keine Spannung auf der Leitung ist – oder die andere – wenn Spannung auf der Leitung ist – angesprochen werden. Es gäbe also nur zwei verschiedene Speicherstellen (0 und 1), die angesprochen werden könnten. Das Resultat wäre ein Arbeitsspeicher von 2 Byte. Bei zwei Leitungen wären es schon 22=4 Speicherstellen (00, 01, 10, 11), bei drei Leitungen 23=8 Byte und so weiter. Bestünde der Adress-Bus aus 8 Leitungen, man spricht dann von einer Busbreite von 8 Bit, könnten 28=256 verschiedene Speicherstellen direkt angesprochen werden. Damit ließe sich ein Taschenrechner bauen, aber für einen ernsthaften Computer reicht das natürlich nicht. Verwendet man nun wie beim Intel 8080 16-Bit-lange Adressen, sind es 216 Bytes, also 65.536 Bytes oder auch 64 KB3. Ein Prozessor mit einem 16-Bit Adressraum kann also 64 KB Speicher direkt adressieren. Mit Techniken wie Bank Switching kann man aber durchaus auch mehr Speicher ansprechen.
Bank Switching?
Die Beschränkung auf eine Adress-Bus-Breite von 16 Bit bedeutet nicht, dass man mit einem solchen Prozessor auch wirklich zwangsweise nur 64 KB nutzen könnte, denn es gibt Techniken, mit denen man die Speichergröße prinzipiell beliebig erweitern kann. Kommen wir nochmal zum Schrank mit den Schubladen zurück und erweitern das Bild ein wenig. Stellen Sie sich eine Wand vor. An diese Wand stellen Sie direkt nebeneinander Schränke mit Schubladen, bis die Wand voll ist. Die Schubladen bilden nach wie vor die direkt adressierbaren Speicherzellen des Systems. Sie können immer auf die Schubladen in den Schränken an der Wand zugreifen. Wenn Sie nun mehr Daten speichern müssen, können Sie sich behelfen, indem Sie ganze Teilschränke austauschen. Sie haben nebenan eine große Lagerhalle mit ganz vielen Schränken und können bei Bedarf einen oder mehrere der Teilschränke von der Wand ins Lager bringen und dafür andere Schränke aus dem Lager holen und an die Zugriffswand stellen. Diese Technik nennt man „Bank-Switching“. Commodores C128 von 1985 ist ein Beispiel für einen Rechner, der diese Technik verwendete, um trotz eines 16-Bit-Adress-Busses 128 KB Speicher zu verwalten. Der Nachteil des Bank-Switchings ist natürlich der Zusatzaufwand. Sie haben zwar viel Speicher, aber können Teile davon nicht direkt adressieren, sondern müssen erst immer dafür sorgen, dass der richtige Schrank an der Wand steht. Dadurch kann die Programmierung komplex werden, je nachdem wie maschinennah Sie programmieren. In jedem Fall benötigt es immer Zeit, die Speicherbänke auszutauschen.
Intels frühe Prozessoren 8008 und 8080 waren 8-Bit-Prozessoren. Der 8008 hatte einen 14-Bit-Adress-Bus, konnte also 16 KB Speicher direkt adressieren. Beim 8080 waren es, wie oben schon erwähnt, 16 Bit Busbreite und somit 64 KB direkt adressierbarer Arbeitsspeicher. Das war im Vergleich zu Großrechnern wenig, im Vergleich zu Minicomputern aber gar nicht mal schlecht. Eine PDP-8 konnte selbst in ihrer größten Ausbaustufe keine 64 KB adressieren. Das Maximum waren hier 32-K-Worte à 12 Bit, was rein rechnerisch 48 KB Speicher entspricht. Diese Umrechnung hinkt allerdings in der Praxis, denn wenn Sie 32.768 Speicherstellen mit je 12 Bits haben, sind das zwar genau so viele Bits wie 49.152 Speicherstellen à 8 Bit, also 48 KB, aber natürlich können Sie sie nicht so nutzen, denn die Bits sind ja nicht byte-weise ansprechbar und stehen nicht in dieser „Stückelung“ zur Verfügung.
Der Altair 8800 – Die Wunderkiste
„Bastel’ dir deinen eigenen Computer“ war ein beliebtes Thema von (US-amerikanischen) Elektronik-Hobbyzeitschriften in der Mitte der 1970er Jahre. Bemerkenswert war etwa der 1974 in der Zeitschrift „Radio-Electronics“ vorgestellte Bastelcomputer Mark-8. Die Zeitschrift erläuterte die Funktionsweise und stellte Bauanleitungen für den auf einem Intel 8008-Prozessor basierenden Computer zur Verfügung. Man konnte den Rechner nicht komplett zusammengebaut bestellen oder gar im Laden kaufen, sondern musste selbst zum Lötkolben greifen. Das war natürlich bei Weitem nicht jedermanns Sache. Der größte Einfluss des Mark-8 war dann auch nicht der Rechner selbst, sondern dass er die Redakteure der Zeitschrift „Popular Electronics“ dazu veranlasste, im Jahr 1975 selbst einen Computer, den Altair 8800, vorzustellen.

Dieser Computer basierte auf der oben genannten, modernen 8080-CPU. Computerinteressierte konnten den Rechner bei der Firma MITS als Bausatz bestellen und selbst zusammenbauen, aber auch diejenigen, die das nicht konnten oder wollten, hatten die Möglichkeit, an den Rechner zu kommen, denn für „nur“ 621 Dollar, was nach heutiger Kaufkraft (2021) etwa 3.100 Dollar entspricht, ließ sich der Rechner komplett zusammengebaut mit Gehäuse beziehen. Für die 621 Dollar bekam man die Grundausstattung des Rechners, die ziemlich spärlich war. Der Rechner verfügte dann über keinerlei externe Speichermöglichkeit und nur über sage und schreibe 256 Byte Arbeitsspeicher. Diese sparsame Grundausstattung hinderte die Autoren bei Popular Electronics nicht daran, den Computer euphorisch zu beschreiben:
The era of the computer in every home–a favorite topic among science-fiction writers–has arrived! It’s made possible by the POPULAR ELECTRONICS/MITS Altair 8800, a full-blown computer that can hold its own against sophisticated minicomputers now on the market. And it doesn’t cost several thousand dollars.
Hier wurde also überschwänglich der Anfang einer neuen Ära beschrieben, einer Ära, die man aus Science-Fiction-Literatur kenne. Nüchterner ist dann der Vergleich des Rechners mit schon bekannten Geräten. Der Altair könne es mit den Minicomputern aufnehmen. Auf dem Titelblatt der Zeitschrift ist der Altair dann auch mit „World’s First Minicomputer Kit to Rival Commercial Models…“ angekündigt. Popular Electronics propagierten hier zwar also einen Computer für zu Hause, aber der Computer, den man dann daheim hatte, entsprach den Computern der damaligen Zeit, den Minicomputern – eben ein Minicomputer für zu Hause. Mit diesem Hintergrund erklärt sich auch das Aussehen des Computers. Aus der heutigen Erwartung, wie PCs aussehen, ist das Design des Altair sehr außergewöhnlich, nimmt man aber einen Minicomputer wie DECs PDP-8 als Maßstab, ist das Design des Altair 8800 ganz folgerichtig: Es handelt sich um eine Kiste mit einem Front-Panel, an dem sich eine Reihe von Leuchtdioden und eine ganze Menge Kippschalter befinden. Jemand, der Minicomputer und ihre Bedienung kannte, fühlte sich hier sofort zu Hause.
Der Vergleich mit der zehn Jahre älteren Architektur der PDP-8 offenbart weitere Parallelen. Auch die PDP-8 musste in ihrem Grundzustand ohne weitere angeschlossene Ein- und Ausgabegeräte über das Front-Panel bedient werden. War ein kleines Loader-Programm in den Speicher eingegeben, konnte die PDP-8 Programme von einem externen Medium, etwa von einem Lochstreifen einlesen. Der Anschluss eines Fernschreibers oder eines anderen Terminals an eine PDP-8 ermöglichte die interaktive Nutzung des Systems. DEC stellte für die PDP-8 die im vorherigen Kapitel beschriebene einfache Interpreter-Programmiersprache FOCAL bereit. Später folgte dann mit OS/8 und einigen Parallelentwicklungen der Übergang zu kommandozeilenorientierten Betriebssystemen, die von der Bedienweise an verbreitete Time-Sharing-Systeme angelehnt waren, allerdings nicht deren Komplexität aufwiesen. Nahezu die gleichen Entwicklungsschritte konnte man nun, zehn Jahre später, beim Altair 8800 nochmals nachvollziehen. Auch hier verwirklichten sich mit der Entwicklung der Nutzungsschnittstellen die Potenziale digitaler Systeme. Es lohnt sich, diese Entwicklung etwas genauer zu betrachten, denn die Produkte, die hier entstanden, waren nicht auf den Altair beschränkt, sondern waren maßgeblich für die weitere Entwicklung der Personal Computer noch bis zum heutigen Tag.
Front-Panel-Programmierung – Bits zum Anfassen
Einen taufrischen Altair 8800 dazu zu bringen, etwas Sinnvolles zu tun, war gar nicht so einfach, denn es bedeutete, den Rechner über das Front-Panel zu programmieren, Werte einzugeben und Ergebnisse abzulesen. Mit dem charakteristischen Front-Panel aus Leuchtdioden und Kippschaltern ließen sich Speicherstellen mit Werten befüllen, entsprechend auslesen, der Programmzähler setzen, das Programm starten und unterbrechen oder, zwecks Fehlersuche, in Einzelschritten ausführen. Wollte man den Altair 8800 programmieren, musste man den Maschinencode des Intel 8080 kennen und die Befehle nacheinander, Byte für Byte, über Kippschalter in den Speicher eingeben. Wenn das geschehen war, empfahl es sich, die Werte im Speicher nochmals genau zu überprüfen, denn schnell konnten sich Fehler eingeschlichen haben. War das Programm in Ordnung, setzte man den Programmzähler auf den ersten Befehl des Programms und betätigte den mit RUN beschrifteten Schalter, um das Programm ablaufen zu lassen. Wenn das Programm zu einem Ende gekommen war, oder wenn der Programmablauf unterbrochen wurde, konnte, wieder über das Front-Panel, der Inhalt des Speichers und somit auch ein eventuelles Rechenergebnis abgelesen werden.
Das folgende Programm ist eine abgewandelte Form eines Programms aus dem Operator’s Manual des Altair. Es handelt sich um ein sehr einfaches Programm, das zwei Zahlen, die in den Speicherstellen 128 und 129 gespeichert wurden, addiert und das Ergebnis in Speicherstelle 130 speichert.
00 111 010 Lade in den Akkumulator Inhalt
10 000 000 von Speicherstelle 128
00 000 000 (2. Byte der Speicherstelle, da 16 Bit pro Adresse)
01 000 111 Speichere Akkumulator in Register B
00 111 010 Lade in den Akkumulator Inhalte
10 000 001 von Speicherstelle 129
00 000 000
10 000 000 Addiere Register B zum Akkumulator
00 110 010 Speichere den Akkumulator-Inhalt
10 000 010 in Speicherzelle 130
00 000 000
01 110 110 Halt
Das eigentliche Programm besteht hier nur aus den vorne in den Zeilen angegebenen Bitfolgen. Die dahinterstehenden Texte sind nur Kommentar und dienen Ihnen als Leser des Programms dem Verständnis. Um das Programm eingeben zu können, musste man natürlich zunächst einmal den Computer einschalten. Er befand sich dann in einem zufälligen Startzustand. Alle Speicherstellen und Register des Rechners hatten einen zufälligen Wert. Das Betätigen von RESET beseitigte diesen misslichen Zustand und setzte alle Werte auf 0. Nun wurden die Befehle nacheinander binär über die Kippschalter eingegeben und mittels der DEPOSIT-Taste oder der DEPOSIT-NEXT-Taste bestätigt. DEPOSIT NEXT war eine Bequemlichkeitsfunktion. Statt jede einzelne Adresse erst anwählen zu müssen, bevor man einen Wert speicherte, sprang DEPOSIT NEXT jeweils automatisch zur nächsten Speicheradresse, sodass die Befehle hintereinander eingegeben werden konnten. Als nächstes mussten die beiden zu addierenden Zahlen eingegeben werden. Dies ging durch Setzen der Kippschalter auf 128 (binär 10 000 000) und einem Druck auf EXAMINE. Der aktuelle Speicherinhalt, also 0, wurde jetzt dadurch angezeigt, dass keine Leuchtdiode aufleuchtete. Ein Wert konnte nun eingegeben und mit DEPOSIT NEXT gespeichert werden. Angezeigt wurde dann automatisch Speicherstelle 129. Auf die gleiche Art und Weise konnte nun hier ein Wert gespeichert werden. Da nun Programm und Daten vollständig eingegeben wurden, konnte das Programm gestartet werden. Dafür wurde der Programmzähler auf den Beginn des Programms gesetzt. Da das Programm ab der Speicheradresse 0 eingegeben wurde, musste also der Programmzähler wieder auf 0 gestellt werden, um das Programm ab dieser Adresse loslaufen lassen zu können. Dazu wurden alle Kippschalter nach unten gestellt und dann EXAMINE betätigt. Nun konnte das Programm durch Betätigen von RUN gestartet werden. Das extrem kurze Programm hatte natürlich keinerlei nennenswerte Laufzeit. Direkt nach dem Auslösen von RUN war das Programm auch schon beendet, was durch das Aufleuchten der WAIT-Leuchtdiode angezeigt wurde. Man konnte nun das Ergebnis aus der Speicherzelle 130 ablesen. Dies geschah durch Eingeben von 130 (binär 10 000 010) und einer Auslösung von EXAMINE.
Die Front-Panel-Schnittstelle des Altair 8800 war eine reine Maschinenschnittstelle. Das, was man in dieser Schnittstelle sah und eingab, war ganz direkt der Zustand der Maschine, explizit vor allem der Zustand des Speichers. Die Ausgabe entsprach den Bits in Speicherzellen, die Eingaben entsprachen genau den Bits, die in die Speicherzellen geschrieben werden sollten und die einzelnen Befehle entsprachen eins zu eins den Operationen des Prozessors. Auf diese Art und Weise, durch das Eingeben von Programmen und Daten vom Front-Panel, mag es grundsätzlich möglich gewesen sein, alle möglichen komplexen Programme in den Computer einzugeben, wirklich praktikabel war das aber natürlich nicht. Die Betriebsart eignete sich eher dafür, die Funktionsweise des Computers zu erlernen und zu verstehen, aber nicht wirklich für ernsthafte Programmierung. Hinzu kam noch, dass das Programm ja nur im Arbeitsspeicher vorlag und dieser, ganz im Gegensatz zur PDP-8 mit ihrem Magnetkernspeicher, flüchtig war. Schaltete man das Gerät aus, waren sowohl Programm als auch Daten verschwunden.
Lochstreifen – Programme von der Rolle
Natürlich war die Front-Panel-Programmierung nicht die einzige Betriebsart des Altair. Über nachrüstbare Schnittstellen ließ sich zum Beispiel ein Fernschreiber an den Computer anschließen. Wie schon Jahre zuvor bei den Minicomputern und den Time-Sharing-Systemen war auch hier wieder der Teletype ASR Model 33 ein gern verwendetes Gerät. Dieser Fernschreiber verfügte über eine Tastatur, über die Buchstaben, Zahlen und Steuerzeichen eingegeben werden konnten. Außerdem hatte er einen Druckkopf, der Buchstaben auf „endloses“ Papier druckte. Der Fernschreiber war mit einem Lochstreifenleser und einem Lochstreifenstanzer ausgestattet. Zeichen konnten damit im 8-Bit-Code auf die Lochstreifen gestanzt und auch von ihnen gelesen werden. Der Lochstreifenstanzer konnte dafür genutzt werden, die von der Gegenstelle kommenden Zeichen nicht nur auszudrucken, sondern sie auch auf einem Lochstreifen zu speichern. Der Lochstreifenleser konnte umgekehrt anstelle der direkten Tastatureingabe genutzt werden. Dieses System hatte sich für die Weiterleitung von Nachrichten bewährt und konnte nun auch für das Laden von Programmen in den Altair genutzt werden. Dass der Fernschreiber einen 8-Bit-Code nutzte, war natürlich praktisch, denn der Rechner hatte ja eine Architektur, bei der jedes Datenwort 8 Bit lang war, also jede ansprechbare Speicherstelle 8 Bit an Daten speicherte.
Mit dem Fernschreiber war es möglich, Programme vom Lochstreifen einzulesen. Dabei stellte sich allerdings ein grundlegendes Problem: Ein Altair „wusste“ schlichtweg nichts von Fernschreibern oder Lochstreifen. Er konnte nur das im Arbeitsspeicher gespeicherte Programm ausführen, aber direkt nach dem Einschalten gab es dort ja gar kein Programm. Wollte man ein Programm vom Lochstreifen lesen, musste man daher zunächst ein kleines Programm per Front-Panel in den Computer eingeben und dieses starten. Die Aufgabe dieses Programms, „Loader“ genannt, war es, Daten vom Lochstreifenleser zu lesen, in den Arbeitsspeicher des Computers zu kopieren und dann auszuführen. Dieses Programm konnte sich dann seinerseits der Fähigkeiten des Fernschreibers bedienen, also etwa Ergebnisse ausdrucken oder Nutzereingaben verarbeiten. Eine wichtige Software, die auf diese Art und Weise ausgeliefert wurde, war ihrerseits eine Programmierumgebung.
BASIC – Programmierung interaktiv
Der Anschluss eines Fernschreibers erlaubte es, am Altair eine interaktive Programmierumgebung zu nutzen, also ein Programm in dem man programmieren und das Programm ausführen und testen kann. Auch hier kann man Parallelen zur PDP-8 ausmachen. Bei dieser stand seinerzeit mit dem FOCAL-Interpreter eine solche Umgebung zur Verfügung. FOCAL-Programme wurden zwar langsam ausgeführt, doch ihre Programmierung war recht komfortabel. Für den 8080-Prozessor von Intel gab es zunächst keine vergleichbare Programmierumgebung. Es gab zwar einige Compiler für höhere Programmiersprachen, jedoch keine interaktive Programmierumgebung. Eine solche Umgebung, und damit faktisch das erste Betriebssystem für den Altair 8800, wurde von Bill Gates und Paul Allen entwickelt. Die beiden gründeten mit ein paar Mitstreitern kurze Zeit darauf die Firma Microsoft. Die von Allan und Gates hier implementierte Programmiersprache BASIC war natürlich keine Erfindung der beiden. Von den Ursprüngen von BASIC war ja bereits im Kapitel über Time-Sharing die Rede. Als die Programmiersprache in den 1960er Jahren am Dartmouth College eingeführt wurde, wurde sie von Studierenden und Angestellten des College genutzt. Diese Nutzer saßen seinerzeit vor einem Fernschreiber, genau wie beim BASIC von Microsoft am Altair. Allerdings hatten die Dartmouth-Nutzer natürlich keinen kleinen Computer neben sich stehen, sondern verbanden sich mit dem zentralen Time-Sharing-System DTSS. Der Altair war natürlich kein Time-Sharing-System4 und im Gegensatz zum DTSS wurde nun kein BASIC-Compiler, sondern ein Interpreter5 eingesetzt, aber aus der Nutzungsperspektive waren die BASIC-Programmierungen am DTSS und am Altair ziemlich vergleichbar und in beiden Fällen profitierte die Programmierbarkeit des Computers durch die interaktiven Möglichkeiten der Programmiersprache und durch den auf Fernschreibernutzung optimierten interaktiven Editor.
Mit den 256 Byte Grundausstattung des Altair konnte natürlich kein BASIC verwendet werden. Der Speicher musste entsprechend aufgestockt werden. Gates und Allen schafften es, sehr speichereffizient zu programmieren, sodass schon 4 KB Arbeitsspeicher ausreichten, um BASIC zu betreiben.
Da es sich beim BASIC am Altair um einen Interpreter handelte, konnten BASIC-Befehle ausgeführt werden, ohne ein ganzes Programm schreiben zu müssen. Die Eingabe PRINT 5+5 wurde umgehend ausgeführt und das Ergebnis direkt ausgegeben. Das Erstellen eines Programms konnte ebenfalls sofort beginnen, indem die Zeilen mit vorangestellter Zeilennummer eingegeben wurden. In vielen Fällen würden Sie aber wahrscheinlich kein neues Programm erstellen, sondern ein vorhandenes wiederverwenden wollen. Es mag Sie nun verblüffen, dass der erste BASIC-Interpreter von Microsoft über keinerlei Einrichtung verfügte, Programme einzulesen. Es gab weder ein LOAD noch einen SAVE-Befehl. Microsoft hatte diese beiden Befehle aber nicht etwa einfach vergessen. Eine Laderoutine war vielmehr gar nicht nötig, denn Microsoft konnte sich eine Eigenart der Fernschreiber zunutze machen. Um ein neues Programm zu laden, musste ein Nutzer einfach NEW eintippen, um das vorherige Programm aus dem Speicher zu löschen, musste dann den Lochstreifen mit dem Programm in den Lochstreifenleser einfädeln und den Fernschreiber so einstellen, dass er den Lochstreifen einlas. Der Fernschreiber „tippte“ dann das BASIC-Programm anstelle des Nutzers ein. Für den Interpreter verhielt es sich genau so, als würde der Nutzer es selbst gerade händisch eingeben. Ähnlich funktionierte das Speichern. Der Nutzer tippte LIST, also den Befehl, der das komplette Programm ausdruckte, startete den Lochstreifenstanzer und drückte dann auf die Zeilenvorschubtaste. Der BASIC-Interpreter führte dann den LIST-Befehl aus, gab also das komplette Programm aus und der Fernschreiber schrieb es dabei auf dem Lochstreifen mit.
Stattete man seinen Computer mit BASIC von Microsoft aus, verfügte man über eine Schnittstelle, die es ermöglichte, das Gerät zu verwenden, ohne wissen zu müssen, wie der Arbeitsspeicher des Rechners strukturiert war. Man musste nun nicht mehr ein Programm in der Maschinensprache des Prozessors eingeben, vom Loader einmal abgesehen. Auf der Ebene der Programmierumgebung stand der Quelltext des Programms zeilenweise in Form virtueller Objekte zur Verfügung, die interaktiv manipuliert werden konnten. Ein BASIC-Programm konnte natürlich selbst virtuelle Objekte erzeugen, also so geschrieben worden sein, dass es Daten auf eine Art und Weise abfragte und anzeigte, die es der Nutzungswelt entsprechend zu Objekten machte. An vielen Stellen hatte ein Nutzer von BASIC am Altair aber noch sehr direkt mit der Technik des Computers und des Fernschreibers zu tun. Zwar war das geladene Programm am Rechner manipulierbar, die Programme selbst waren aber keine Objekte im Computer, sondern realweltliche Objekte, nämlich die Lochstreifenrollen, auf denen sie gespeichert waren. Wollte der Nutzer ein Programm laden oder speichern, konnte er nicht auf ein Objekt im Computer referenzieren, sondern musste sich mit dem auf dem Lochstreifen gespeicherten Datenstrom und seiner Verarbeitung im Lochstreifenleser und -stanzer beschäftigen. Auch Eingabedaten waren nicht als eigene Objekte verfügbar, denn es gab im Microsoft BASIC dieser Generation kein Konzept von Dateien, die man hätte laden oder speichern können. Eingabedaten, so nicht von der Tastatur eingegeben, standen vielmehr in DATA-Zeilen direkt im Programm oder kamen, wie die Programme selbst, von Lochstreifenrollen als Ersatz einer Eingabe per Tastatur.
Auftritt: Terminal und Kassette

Der frühe BASIC-Interpreter für den Altair war ganz und gar auf den Fernschreiber ausgelegt. Er diente nicht nur der Eingabe per Tastatur und der Ausgabe auf Papier, sondern auch als Lese- und Speichergerät für Massenspeicher (Lochstreifen) und als externalisierte Lade- und Speicherroutine. Fernschreiber waren aber Mitte der 1970er Jahre nicht mehr der neuste Schrei in Sachen Nutzungsschnittstelle und wurden daher auch am Altair schnell ersetzt. Natürlich konnte man das BASIC von Microsoft auch mit einem Terminal einsetzen, allerdings war dieses BASIC nicht im Geringsten auf Terminals ausgelegt und konnte seine Vorteile nicht nutzen.
- BASIC hatte keine Möglichkeit, den Cursor auf dem Bildschirm zu positionieren oder den Bildschirminhalt zu löschen. So wie es der BASIC-Befehl
PRINTnahelegt, konnte BASIC immer nur etwas Neues dazuschreiben. - Es gab keine Backspace-Funktionalität im heutigen Sinne, denn Fernschreiber hatten natürlich keine Möglichkeit, ein Zeichen wieder vom Papier zu entfernen. Wollte man etwas löschen, musste man dies durch Eingeben eines Unterstrichs tun. Wollte man
PRINTtippen, hat aber versehentlichPRReingegeben, konnte man das zweiteRdurch die Eingabe eines Unterstrichs „löschen“, das R und der Unterstrich blieben aber am Bildschirm stehen. Eine Eingabe vonPRR_INT 5_6+_*6wurde genau so angezeigt, wurde aber intern zuPRINT 6*6verarbeitet und gab dementsprechend36aus. - Ein Terminal verfügte natürlich nicht über einen Lochstreifenleser und -stanzer. Es konnten aber ohne diese Vorrichtungen keine Programme geladen und gespeichert werden, was die Nutzbarkeit des BASIC-Interpreters am Terminal natürlich stark einschränkte.
Angepasste BASIC-Versionen gingen diese Probleme an. Sie erlaubten nun das Laden und Speichern von Programmen mittels der Befehle CLOAD und CSAVE. Das Medium für die Programme war dann eine Musikkassette, die sich in einem an den Altair angeschlossenen Kassetten-Recorder befand. Das Programm wurde auf den Kassetten als schrille Tonfolgen gespeichert. Außer dem anderen Medium änderte sich aber nicht viel, denn es gab keinerlei Dateisystem und damit auch keine Programme als Objekte. Im Gegensatz zu Bandlaufwerken von Großrechnern und Minicomputern, etwa dem DECTape, gab es hier keinen vom Computer verwalteten Index und keine Möglichkeit, das Band computergesteuert an bestimmte Stellen zu spulen. Diese lästige Aufgabe oblag ganz allein dem Nutzer. Spätere BASIC-Versionen ergänzten die Unterstützung der Backspace-Taste, sodass fälschlich eingegebene Zeichen wieder gelöscht werden konnten. Das BASIC des Altair unterstützte allerdings nie die programmierte Positionierung des Cursors auf dem Bildschirm. Es gab also keine Programme, die Objekte räumlich stabil und manipulierbar am Bildschirm darstellen konnten.
Disketten – mehr als nur schnell und wahlfrei
Während der pure Altair in seiner Grundausstattung relativ günstig war, kam schnell eine gehörige Summe zusammen, wenn der Rechner mit mehr Speicher, einer seriellen Schnittstelle und mit einem Terminal oder einem Fernschreiber versehen wurde. Derart ausgestattete Rechner standen eher nicht mehr bei Privatleuten, sondern in Firmen, Schulen oder Universitäten. Noch häufiger war dies so, wenn der Rechner mit einem Diskettenlaufwerk bestückt wurde, denn dieses kostete im Jahr 1975 allein schon 2.000 Dollar, was umgerechnet auf 2021 etwa 10.000 Dollar entspricht.

Oben sehen Sie unter dem eigentlichen Altair 8800 ein fast ebenso großes Gehäuse, in das ein 8-Zoll-Diskettenlaufwerk eingebaut ist. Disketten sind Ihnen vielleicht noch bekannt. Sie waren in verschiedenen Ausführungen bis in die 2000er Jahre als günstige, beschreibbare Wechseldatenträger verbreitet, bevor sie durch die USB-Sticks endgültig verdrängt wurden. Disketten waren im Prinzip billige, kleine Wechselfestplatten. Normale Festplatten bestehen aus mehreren magnetisierten Metallscheiben, die mittels Schreib-Leseköpfen gelesen und beschrieben werden können, indem die Magnetisierung der Oberfläche abgetastet oder verändert wird. Eine Diskette war nur eine einzige solche Scheibe und speicherte somit verhältnismäßig wenige Daten (einige 100 Kilobyte). Bei der Scheibe handelte es sich überdies nicht um eine Metallscheibe, sondern lediglich um eine magnetisierte Folie. Ähnlich wie bei der Festplatte bewegte sich ein Schreib-Lesekopf über die rotierende Scheibe und las und schrieb Daten. Die Rotationsgeschwindigkeit und damit die Schreib- und Lesegeschwindigkeit war aber natürlich erheblich niedriger. Im Vergleich zu Musikkassetten war die Diskette aber dennoch weit überlegen. Die höhere Datenrate und damit das schnellere Laden von Programmen wurde hier vielfach als der große Vorteil von Disketten beschrieben. Dieser Geschwindigkeitszuwachs ist natürlich nicht zu verachten, ist für uns hier aber nicht das Spannendste. Viel interessanter ist, dass mit der Diskette die Nutzungsschnittstelle nun um weitere Objekte bereichert wurde.

Das Diskettenlaufwerk des Altair las und beschrieb Disketten mit 8 Zoll Größe, hier links abgebildet. Diese Disketten sowie die später bei vielen Büro- und Heimcomputern üblichen 5,25 Zoll großen Disketten (Mitte) wurden „Floppy Disks“ oder kurz „Floppy“ genannt. Der Name rührt wohl schlicht daher, dass die Datenträger aufgrund ihrer biegsamen datentragenden Folie und der ebenfalls biegsamen Plastikummantelung ziemlich labbrig, oder englisch eben „floppy“ waren. Die später üblichen kleineren 3,5-Zoll-Disketten (rechts), die bis in die 2000er Jahre hinein verwendet wurden, verfügten über eine dickere Plastikummantelung und über eine metallische Schutzlasche, die den eigentlichen Datenträger vor Berührungen schützte. 3,5-Zoll-Disketten sind feste Gebilde. Der Begriff „Floppy“ passt hier, obwohl manchmal noch verwendet, nicht mehr wirklich.
Microsoft passte das BASIC so an, dass es mit Disketten umgehen konnte. Statt mit CLOAD und CSAVE konnte nun mit LOAD und SAVE geladen und gespeichert werden. Der Unterschied wirkt klein, ist aber doch gewaltig, denn bei der Diskette musste und konnte nicht mehr von Hand gespult werden. Ein Programm wurde nun geladen, indem ein vorher vergebener Name angegeben wurde. Mit der Unterstützung von Disketten wurden die Programme also selbst zu Objekten. Mittels CAT konnte eine Liste der gespeicherten Programme ausgegeben werden. Die Programme selbst konnten per Name referenziert und somit geladen, gespeichert oder auch gelöscht werden. Programme wurden zu Objekten der Nutzungsschnittstelle. Wie das Laden und Speichern technisch ablief, brauchte den Nutzer nun nicht mehr zu kümmern. Es war kein Spulen, kein Einfädeln und auch kein manuelles Ein- und Ausschalten von Lese- und Speichergeräten mehr nötig. Nicht nur die Programme wurden mit dem Disketten-BASIC zu Objekten. Auch Ein- und Ausgaben konnten Objekte werden, denn BASIC erlaubte nun das Einlesen von Daten aus Dateien, genauso wie die Ausgabe in Dateien. Mit dieser Funktionalität übertraf das Microsoft-BASIC die Fähigkeiten des originalen BASIC des Dartmouth-College, denn dort war es zwar möglich, Programme zu laden und zu speichern, ein Konzept von Daten-Dateien gab es aber nicht.
CP/M – Das Betriebssystem
Microsoft lieferte zwar ein BASIC mit Disketten-Funktionalitäten und rudimentärer Unterstützung von Terminals, schöpfte aber das volle Potenzial beider Techniken auf dem Altair nicht aus. Anders sah es aus, wenn man das Betriebssystem CP/M nutzte. CP/M steht für Control Program/Monitor (später geändert zu Control Program for Microcomputers). Das Betriebssystem wurde bereits 1974, also vor der Präsentation des Altair von Gary Kildall für den Prozessor Intel 8080 entwickelt. Kildall bot den Erzählungen nach Intel das Betriebssystem an. Der Prozessorhersteller war aber offenbar nicht daran interessiert. CP/M war das erste weit verbreitete Betriebssystem für Home- und Personal-Computer. Der Wikipedia-Eintrag zu CP/M listet sage und schreibe 200 verschiedene Rechnertypen, auf denen das System lief. Es ist leider heute selbst bei vielen Retro-Computing-Anhängern in Vergessenheit geraten, was wohl daran liegen mag, dass das System rein textbasiert war und nicht auf den beliebten, spieletauglichen Geräten der 1980er zu finden war oder dort zumindest nicht genutzt wurde. Obwohl den meisten nicht mehr bekannt, finden sich Spuren der Nutzungsschnittstelle von CP/M aber selbst in aktuellen Versionen von Microsoft Windows wieder. CP/M gehörte allerdings nie der Firma Microsoft. Kildall gründete 1976 seine eigene Software-Firma mit dem wohlklingenden Namen Digital Research. Wie die Nutzungsschnittstelle von CP/M in Windows landete, dazu später mehr.
Kildall traf in CP/M viele interessante technische Entscheidungen. Das System war im Prinzip auf allen Rechnern mit Intel 8080 und kompatiblen Prozessoren lauffähig. Abgesehen vom kompatiblen Prozessor waren die Rechner, auf denen CP/M lief, aber sehr verschieden. Um dennoch das gleiche System und die gleiche Software einsetzen zu können, ersann Kildall das Basic Input/Output System, kurz BIOS. Dieses BIOS musste für jede Systemarchitektur angepasst werden. Der Rest des Betriebssystems konnte wiederverwendet werden und, vielleicht noch wichtiger, die Software konnte rechnerunabhängig programmiert werden. Anstatt die Hardware direkt anzusprechen, galt es nun, die Funktionen des BIOS zu nutzen. In der Praxis ging diese Rechnerunabhängigkeit allerdings nicht so weit, wie es wünschenswert gewesen wäre. Das BIOS abstrahierte etwa nicht vom eingesetzten Terminal. Da verschiedene Terminals ganz unterschiedliche Fähigkeiten hatten und verschiedene Steuersignale verwendeten, um etwa den Bildschirm zu löschen und den Cursor zu positionieren, war man daher immer darauf angewiesen, eine passende Kombination aus Software und Terminal zu nutzen.
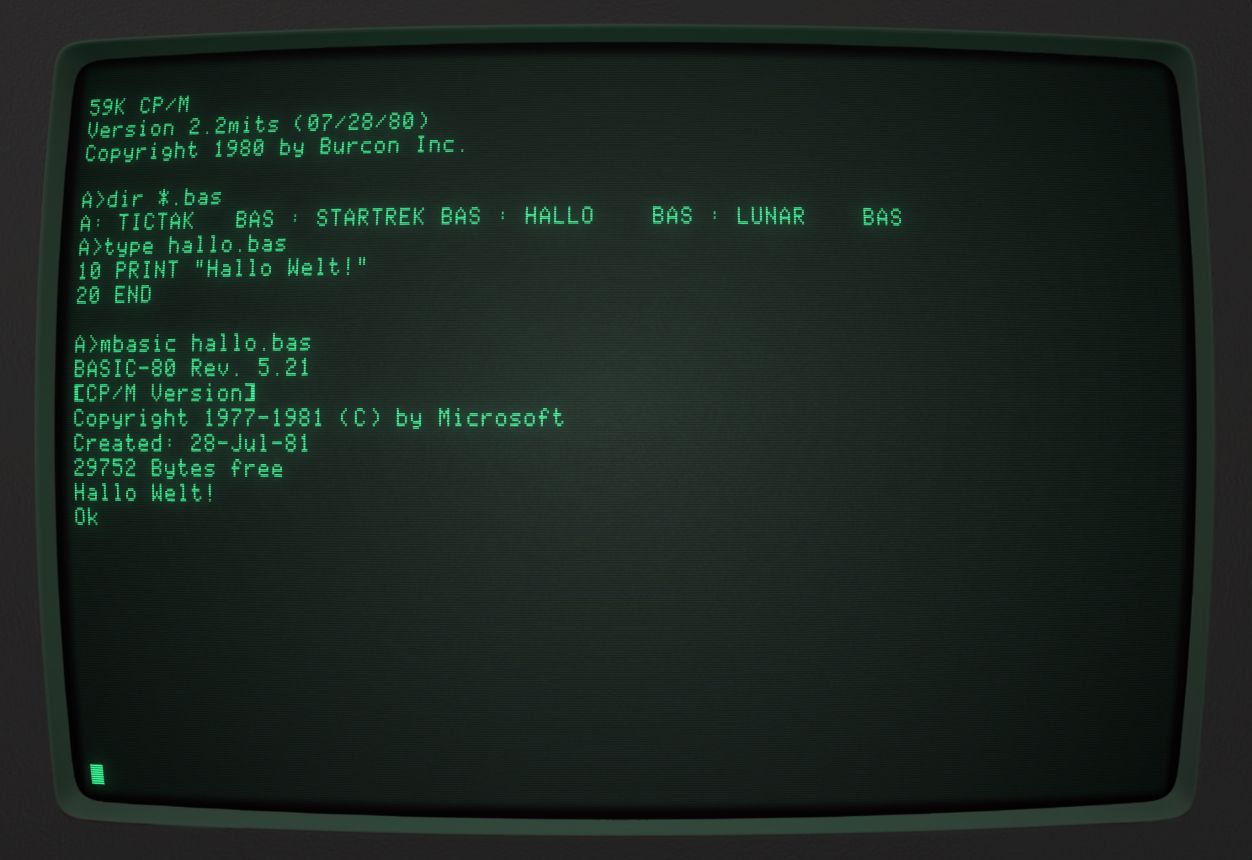
Die Eigenarten verschiedener Terminals wurden sicher deshalb nicht für das BIOS berücksichtigt, da CP/M selbst die Vorteile eines Terminals kaum ausnutzte. Die Haupt-Interaktion mit dem Betriebssystem erfolgte über einen Command Processor namens CCP (Console Command Processor). Da Kildall selbst Rechner von DEC nutzte und auf diesen auch CP/M entwickelte, war die Funktionsweise bis hin zu den Befehlen angelehnt an TOPS-10 und war damit dem OS/8 der PDP-8 ziemlich ähnlich. CP/M war im Vergleich zu OS/8 allerdings noch einfacher. Wie OS/8 hatte CP/M keinerlei Nutzerverwaltung und keine Vorrichtungen für Time-Sharing oder Multitasking. Während OS/8 allerdings sehr flexibel in Sachen Speichermedien war und vom DEC-Tape bis zu Festplatten so ziemlich alles unterstützte oder durch Programmieren eines Treibers zugänglich machen konnte, unterstützte CP/M ausschließlich Disketten, auf denen Dateien gespeichert werden konnten. Diese Dateien hatten einen Namen von maximal acht Zeichen Länge, gefolgt von einem Punkt gefolgt von drei weiteren Zeichen, dem sogenannten „Suffix“, auch „Dateiendung“ genannt. Das Suffix wurde genutzt, um klarzumachen, um welche Art von Datei es sich handelte. COM etwa stand für direkt ausführbare Programme, BAS für BASIC-Programme und TXT für Textdateien. CP/M unterstützte mehrere Diskettenlaufwerke, die mit Buchstaben angesprochen wurden. A stand für das erste Laufwerk, B für das zweite und so weiter. Mit dem Befehl dir konnten die Dateien auf der Diskette aufgelistet werden. Eine Ordnerstruktur unterstützte CP/M noch nicht, was aufgrund des beschränkten Speicherplatzes der Disketten aber kein Problem darstellte.
Auf der Abbildung oben sehen Sie, wie es aussah, wenn CP/M auf einem Altair mit angeschlossenem Terminal verwendet wurde. CP/M meldete dem Nutzer seine Eingabebereitschaft in Form einer Kommandozeile. A> bedeutete, dass sich die eingegebenen Kommandos auf die Diskette im ersten Diskettenlaufwerk beziehen. Der Befehl dir *.bas auf der Kommandozeile bewirkte, dass alle Dateien mit der Dateiendung .bas, also alle BASIC-Programme, angezeigt wurden. Der Befehl type diente dazu, eine Datei auf den Bildschirm auszugeben und der Aufruf von mbasic hallo.bas startete den BASIC-Interpreter von Microsoft, der mit jedem CP/M mitgeliefert wurde, und führte in ihm das Programm „hallo.bas“ aus. Dieses tat hier nichts mehr, als Hallo Welt auf den Bildschirm auszugeben. Die Ideenherkunft von CP/M in den Time-Sharing-Systemen der 1970er Jahre merkte man dem System stark an. Es bediente sich letztlich wie ein Time-Sharing-System, an das ein Fernschreiber angeschlossen wurde. Der Nutzer konnte Befehle eintippen, das Computersystem schrieb dann die Ausgabe der Ausführung des Befehls auf den Bildschirm, darunter konnte wieder ein Befehl eingegeben werden und so weiter.
Der Kommandozeilen-Interpreter von CP/M war einige Jahre später die Vorlage für das Betriebssystem 86-DOS von Seattle Computer Products. Im Gegensatz zu CP/M lief 86-DOS, ganz dem Namen entsprechend, nicht mit dem 8-Bit-Prozessor 8080, sondern mit Intels neuem 16-Bit-Prozessor 8086 und dessen günstiger Variante 8088, der im ersten IBM PC verbaut wurde. 86-DOS wurde mitsamt Entwickler von Microsoft gekauft und dann unter den Namen PC-DOS für IBM und MS-DOS für kompatible Rechner vertrieben. Sowohl CP/M als auch DOS fordern mit A> zu einer Eingabe auf. Das Konzept der Laufwerkszuordnung per Buchstabe wurde übernommen, das Wechseln zwischen den Laufwerken funktionierte auf die gleiche Art und Weise und auch die grundlegenden Befehle wie dir und type waren die gleichen. Da diese Grundkonzepte auch in die Eingabeaufforderung von Windows übernommen wurden, können Sie diese Grund-Arbeitsweisen des CP/M von 1974 auch heute, 46 Jahre später, noch erleben. Zu Microsofts DOS und der Entwicklung von Windows kommen wir aber später im Kapitel Windows und MacOS. Bleiben wir zunächst einmal in den 1970ern und werfen einen Blick auf die Killer-App von CP/M. Bei einer Killer-App handelt es sich nicht etwa um ein Ballerspiel. Es ist auch sonst nichts Gefährliches. Als Killer-App bezeichnet man Anwendungsprogramme, die einen so großen Nutzen bringen, dass sie allein die Anschaffung eines bestimmten Systems rechtfertigen.
WordStar – Die Killer-App
Die Interaktionsmethode von CP/Ms Kommandozeilen-Interpreter CCP war in keinster Weise herausragend. Sie glich der Methode von Time-Sharing-Systemen der 1960er und 1970er Jahre, blieb in Sachen Komfort aber sogar hinter diesen zurück. Viel interessanter in Bezug auf die Nutzungsschnittstelle waren viele Anwendungsprogramme, die unter CP/M liefen, denn durch CP/M wurde dem Computer nicht nur eine komfortable Umgebung zur Programmierung in verschiedensten Programmiersprachen bereitgestellt, sondern vor allem auch die Grundlage für Standard-Software geschaffen. Ein gutes und sehr wichtiges Beispiel ist hier das Programm „WordStar“, das erste nennenswerte Textverarbeitungsprogramm für Mikrocomputer. Es verfügte bereits über viele Funktionen, die man auch heute noch von Textverarbeitungssystemen kennt, von der Textformatierung bis hin zur Rechtschreibprüfung. Es war damit eine der frühen Killer-Apps für Mikrocomputer-Systeme. Neben seinen funktionalen Aspekten hatte WordStar auch eine sehr fortschrittliche Nutzungsschnittstelle, die auch heute noch in manchen Aspekten herausragend ist.
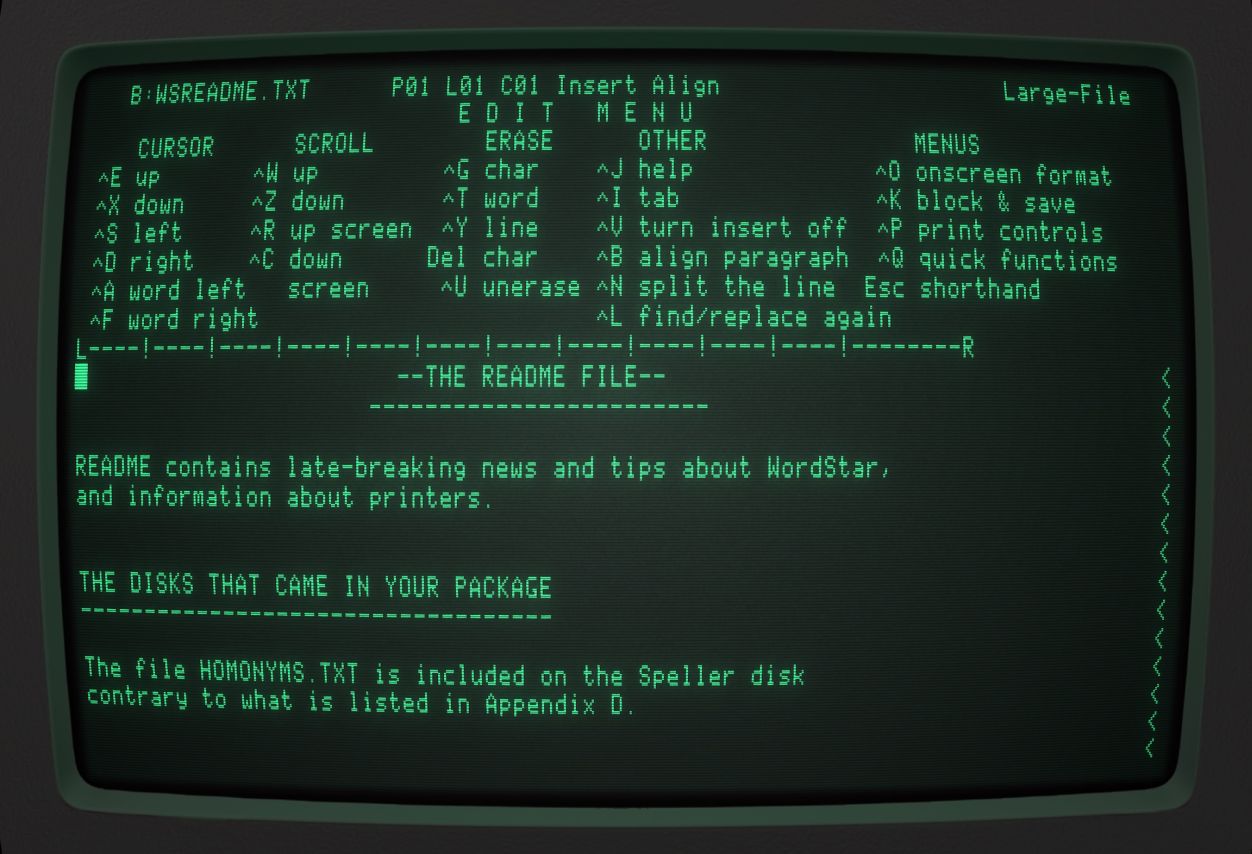
Diese Abbildung zeigt die Nutzungsoberfläche von WordStar mit einem schon geladenen Text. Der Bildschirm ist in zwei Bereiche eingeteilt. Der Bereich unterhalb der Zeile mit den vielen Minus-Zeichen ermöglicht die Textbearbeitung. Hier kann ein Eingabe-Cursor frei positioniert werden. Es ist möglich, Text zu löschen und neue Zeichen zwischen die bereits vorhandenen Textteile einzufügen. Statt einer damals noch verbreiteten Kommandozeile wurde bei WordStar also die direkte Manipulation verwendet. WordStar ist daher zwingend auf ein Terminal mit Bildschirm angewiesen, denn die Software nutzte den Vorteil von Terminals gegenüber Fernschreibern aus. Während ein Fernschreiber immer nur unten auf dem Papier etwas Neues ausdrucken konnte und sich das vorher Gedruckte nach oben verschob, konnte auf einem Terminal die Schreibmarke an beliebige Stellen gesetzt und dort konnte geschrieben werden. Dadurch bekamen die Zeichen am Bildschirm eine räumliche Position, an der sie stabil stehenblieben bzw. von der sie an beliebige andere Stellen verschoben werden konnten. Eine Manipulation der Zeichen bedeutete nicht ein komplettes Neu-Drucken, sondern wurde zu einer räumlichen Änderung an Ort und Stelle des Zeichens.
Der Bereich oberhalb der Trennlinie zeigte Status-Informationen und ermöglichte den Zugriff auf die Funktionalität der Software. Vor allem dieser Bereich war seinerzeit außergewöhnlich, denn mit den dort angezeigten Informationen war es möglich, sich das Programm zu erschließen und Auskunft darüber zu erhalten, welche Eingaben und Manipulationen möglich waren. In den seinerzeit üblichen Programmen mit Kommandozeile oder auch einem Editor wie „vi“ war das nicht so. Hier musste man wissen, welche Eingaben möglich waren oder musste es im Handbuch nachlesen. Die Programme selbst gaben keinerlei Hinweise darauf. Natürlich konnten nicht alle Funktionen des Programms vollständig in diesem Steuerungsbereich aufgeführt werden, denn schon zu diesem Zeitpunkt hatte die Textverarbeitungs-Software weit mehr Funktionen und Formatierungsmöglichkeiten als darstellbar waren. Genutzt wurde daher ein System von Menüs und Untermenüs. CTRL+k zum Beispiel öffnete das Untermenü für Block- und Speicher-Kommandos.
Die Erschließbarkeit von WordStar war in der damaligen Zeit herausragend. Bei Weitem nicht jede Software, die die Möglichkeit der räumlichen Einteilung auf dem Bildschirm ausnutzte, erläuterte ihre Bedienung auf diese Art und Weise selbst. Trotz der für heutige Verhältnisse arg eingeschränkten grafischen Möglichkeiten erlaubte es WordStar gut, sich die angebotenen Handlungsoptionen zu erschließen. In einigen Aspekten war die Erschließbarkeit sogar besser als bei heutigen Textverarbeitungen. Man kann das am Beispiel der Block-Operationen, die ich Ihnen zuvor für „vim“ beschrieben habe, ganz gut nachvollziehen. Die auszuführende Aktion war es, einen Textauszug zu markieren und an eine andere Stelle im Text zu verschieben. Grundvoraussetzung hierfür ist natürlich die Möglichkeit, Textbereiche markieren zu können. Zu Zeiten von WordStar war die Computermaus zwar schon erfunden, war jedoch auch in der Fachwelt noch im großen Stile unbekannt. Recht komfortabel konnte jedoch durch Positionieren des Schreibcursors und der Eingabe von Tastaturkürzeln beispielsweise ein Block Text räumlich selektiert und verschoben werden. Die Tastaturkürzel wurden jeweils auf dem Bildschirm angezeigt. Ein Druck auf CTRL und k wechselte das im oberen Bereich angezeigte Menü und gab die möglichen „Blockbefehle“ an. Ein Nutzer erfuhr dort unter anderem, dass B für Blockbeginn, K für Blockende und C für Kopieren steht. WordStar erlaubte es also, sich über die angezeigten Menüs herzuleiten, wie diese Markierung erreicht werden kann. Moderne Textverarbeitungen gehen hingegen davon aus, dass man schon wissen wird, wie man per Maus oder per Tastatur eine Selektion vornehmen kann. Am Bildschirm gibt es keine erkennbaren Hinweise darauf, wie das zu bewerkstelligen ist.
Die Rolle des Altair
Ob der Altair 8800 tatsächlich als erster Personal Computer bezeichnet werden sollte, ist, wie zu Beginn erläutert, fraglich. Durchaus sinnvoll ist es aber, im Altair den Rechner zu sehen, mit dem die Computer im Privatbesitz den Schritt von experimentellen Bastelrechnern zu voll ausgereiften Produkten schafften, die man im Laden kaufen konnte. Mit dem Altair und seinen vielen sehr ähnlichen Nachbauten wie dem IMSAI 8080 oder dem Cromemco-Z1 erhielt der PC seine eigene Charakteristik. Während das System zu Beginn mit seiner Programmierung über das Front-Panel und einem angeschlossenen Fernschreiber noch eher als ein erschwinglicher, leicht eingeschränkter Minicomputer für Hobbyisten anzusehen war, hatte er sich mit der Verbesserung der Ein- und Ausgabemöglichkeiten weiterentwickelt und trat mit dem Betriebssystem CP/M und Software wie WordStar aus dem Schatten seiner großen Brüder. Nutzer verfügten nun über ein System mit einer leistungsstarken Nutzungsschnittstelle. Statt mit den technischen Details der Maschine beschäftigten sie sich nun ausschließlich mit vom Computer für sie erzeugten virtuellen und räumlichen Objekten. Auch die Charakteristik von Software änderte sich von selbst geschriebenen, sehr spezifischen Programmen hin zu Anwendungsprogrammen als (kommerzielle) Produkte. Es war der Beginn der Standard-Software.
Der Altair war der Startschuss für viele Entwicklungen. Seine schiere Existenz hat Computerbastler und Unternehmer inspiriert. Von Microsoft war hier bereits die Rede, aber auch Steve Jobs und Steve Wozniak, die Gründer der Firma Apple, geben den Altair als ihre Inspiration an. Über die entstandenen Produkte erfahren Sie mehr in den folgenden Kapiteln.
Die Dreifaltigkeit von 1977
Auch wenn der Altair 8800 von 1975 als erster Personal Computer bezeichnet werden kann, ist doch viel eher 1977 das Jahr, in dem die Ära der Personal Computer wirklich begann. Denn in diesem Jahr kamen drei Computermodelle auf den Markt, die schon rein äußerlich viel mehr dem glichen, was wir heute einen PC nennen würden, und die die Entwicklung über viele Jahre prägten. Der Commodore Personal Electronic Transactor 2001 (kurz PET), der Apple II und der TRS-80 der amerikanischen Elektronik-Kette Tandy/Radio-Shack wurden einige Jahre später von der Computerzeitschrift „Byte“ als die sogenannte „1977 Trinity“ bezeichnet.

Oben abgebildet sehen Sie die drei Computer. Sie sehen im Gegensatz zum Altair 8800 nicht mehr aus wie ein eingelaufener Minicomputer mit Kippschaltern und Leuchtdioden, sondern haben die heutige Anmutung eines PCs mit Bildschirm, einer Zentraleinheit, Speichergeräten und einer Tastatur. Die Komponenten waren bei den drei Rechnern mehr oder weniger stark integriert. Der TRS-80 war der am stärksten modular aufgebaute Rechner mit separater Basiseinheit, Bildschirm und Tastatur, beim Apple II waren Zentraleinheit und Tastatur kombiniert – eine bis in die 1990er Jahre beliebte Bauweise – und beim links abgebildeten Commodore PET gab es alles aus einem Guss. Nicht nur Tastatur, Zentraleinheit und Bildschirm, sondern sogar ein Kassettenrekorder als Datenspeicher wurden hier integriert. Von den drei im Jahr 1977 vorgestellten Geräten begann die Entwicklung des Apple II relativ früh, nämlich bereits früh im Jahre 1976. Commodore PET und TRS-80 waren hingegen ziemlich schnelle Entwicklungen. Der PET wurde im Januar 1977 als erster von den drei Rechnern der Öffentlichkeit vorgestellt, kam jedoch erst im Oktober des gleichen Jahres auf den Markt und war erst Ende des Jahres wirklich verfügbar. Zu diesem Zeitpunkt konnte der TRS-80 bereits ab August und der Apple II ab Juni gekauft werden. Wieder einmal ist es also schwierig, den ersten zu küren.
Die drei Rechner sind sich von der Bedienung her recht ähnlich. Sie bedienen sich im Prinzip wie ein voll ausgestatteter Altair 8800 mit integriertem Terminal und direkt eingebautem BASIC-Interpreter. Der Apple II war insofern eine Ausnahme, als dass er als einziger der drei Computer grafikfähig war, also nicht nur Textzeichen auf dem Bildschirm ausgeben konnte, sondern auch Linien, Kreise und andere grafische Objekte. Der TRS-80 und der PET hatten eine reine Textausgabe. Da der PET aber über viele grafische Sonderzeichen, inklusive allerlei Linien und Muster-Zeichen, verfügte – die sogenannten PETSCII-Zeichen – konnten Anwendungen und Spiele erzeugt werden, die fast die Anmutung einer echten Grafikausgabe hatten. TRS-80 und Apple II verfügten über eine leicht abgewandelte Schreibmaschinen-Tastatur. Der erste PET hatte hingegen eine gänzlich unmögliche Tastatur mit winzigen Tasten in einer eigenartigen Anordnung. Das Tastenfeld glich optisch mehr einer Tafel Schokolade als einer ernstzunehmenden Tastatur. Natürlich war dieser Missstand auch bei Commodore bekannt. Alle nachfolgenden Modelle des Rechners verfügten daher über eine sehr solide Schreibmaschinentastatur, die als einzige sogar einen Ziffernblock besaß. Dafür musste aber der eingebaute Kassettenrecorder weichen und fortan bei Bedarf extern angeschlossen werden.
Die drei Rechner richteten sich grundsätzlich an Privatleute, Schulen und kleine Firmen, wurden aber aufgrund unterschiedlicher Marktpositionierungen und Ausstattungsmerkmale unterschiedlich angenommen. Der TRS-80 war von den drei Rechnern zunächst der erfolgreichste. Sein Vorteil war, dass er vergleichsweise günstig war und durch das US-weite Netz von „Radio Shack“ überall verfügbar war. Durch die Verbreitung in diesen Elektronikläden fand er natürlich bei Elektronikbastlern Anklang. Den Commodore PET gab es in verschiedenen Ausführungen, die sich vor allem in der Speicherausstattung und in der Grafikausgabe unterschieden. Vor allem auf den Büroeinsatz war die Variante mit achtzig Zeichen pro Zeile ausgerichtet. Die günstigere Vierzig-Zeichen-Variante mit größeren Buchstaben war vor allem in Schulen beliebt. Der Apple II war erheblich teurer als TRS-80 und PET, verfügte allerdings, wie gesagt, auch als einziger über die Möglichkeit, Grafik darzustellen. In frühen Versionen des Apple II musste man sich allerdings aufgrund der Art und Weise, wie die Farbe erzeugt wurde, zwischen einer scharfen Darstellung von Text auf einem monochromen Monitor und einer bunten, aber nicht gut lesbaren Darstellung auf einem Farbmonitor entscheiden. Apples Werbung zielte vor allem auf den Heimmarkt ab. Eltern wurde nahegelegt, dass die Kinder nur dann fit für die Welt von morgen seien, wenn sie einen Apple II besäßen. Seine Verbreitung in Schulen war dementsprechend auch ziemlich hoch – und das nicht nur in den USA, sondern auch in Europa. Der Apple II blieb lange Zeit ein erfolgreiches Produkt. Er wurde als vollständig kompatibler Apple IIe bis 1993 gebaut6.
| Commodore PET | Apple II | TRS-80 | |
|---|---|---|---|
| Vorgestellt | Januar 1977 | April 1977 | August 1977 |
| Verfügbar | Dezember 1977 | Juni 1977 | August 1977 |
| Preis | 795 $ (2021: 3.520 $) | 1.298 $ (2021: 5.750 $) | 600 $ (2021: 2.660 $) |
| Zeichen | 40/80 | 40 (80 mit Zusatzkarte) | 64 |
| CPU | MOS 6502, 1 MHz | MOS 6502, 1 MHz | Zilog Z80, 1,774 MHz |
| Modul | Ja | Nein | Nein |
| Kassette | Ja | Ja | Ja |
| Diskette | Ja | Ja | Ja |
| BASIC | Microsoft | Apple, ab 1979 Microsoft | Tiny BASIC, später Microsoft |
| Betriebssystem | Keines | DOS, ProDOS, CP/M (mit Zusatzkarte) | TRSDOS, NewDOS80 |
| RAM (typisch) | 4 KB, 8 KB | 4 KB | 4 KB |
| RAM (maximal) | 32 KB | 64 KB | 16 KB |
| Grafik | Keine | 40 x 48 bei 16 Farben, 280 x 192 bei 2 Farben | Keine |
Alle drei Rechner verfügten aber über einen eingebauten BASIC-Interpreter im ROM (Read Only Memory). Man musste also kein BASIC laden, wie noch beim Altair, sondern den Rechner nur einschalten. Die Programmierumgebung stand sofort zur Verfügung. Das BASIC des Commodore PET stammte von Microsoft. Apple und Tandy hatten zunächst andere, eingeschränktere BASIC-Dialekte, schwenkten dann aber um, sodass am Ende alle drei Rechner ein von Microsoft hergestelltes BASIC verwendeten. Leider bedeutete das aber nicht, dass die BASIC-Programme zwischen den Rechnern austauschbar gewesen wären, denn nur die Grundsprache war identisch. Funktionen, die spezifischer waren, etwa zur Grafikdarstellung oder zum Zugriff auf die externen Schnittstellen waren bei den drei Rechnern unterschiedlich. Die BASIC-Programme des einen Computers waren daher inkompatibel mit den BASIC-Interpretern der anderen. Auch jenseits des BASIC-Dialekts waren die Computer nicht softwarekompatibel. Programme, die für einen Rechnertyp entwickelt wurden, liefen nur auf diesem. Nicht einmal die Codierung auf den Disketten und Kassetten an sich war identisch, sodass auch die Dateien des einen Rechners auf dem anderen nicht gelesen oder gar bearbeitet werden konnten.
Bei Markteinführung war bei den drei Rechnern die Musikkassette das Medium, auf dem Programme ausgeliefert wurden, von dem eigene Programme geladen und auf dem sie gespeichert werden konnten. Das war natürlich nicht besonders praktisch. Für alle drei Computer kamen daher zügig Diskettenlaufwerke auf den Markt. Vor allem beim PET und Apple II verdrängte die Diskettennutzung die kassettenbasierte Nutzung nahezu vollständig. Mit der Verfügbarkeit der Diskettenlaufwerke kam natürlich die Notwendigkeit für ein entsprechendes Betriebssystem. Ein solches auf Diskettennutzung optimiertes Betriebssystem wurde Disk Operating System, kurz DOS, genannt.
Sowohl Apple als auch Tandy nannten diese Software DOS (DOS und ProDOS bei Apple, TRSDOS und NewDOS/80 bei Tandy). Heute wird mit DOS meistens das Betriebssystem MS-DOS von Microsoft gemeint. Dafür ist es hier aber noch vier Jahre zu früh.
Man darf sich unter Betriebssystem hier allerdings nicht das vorstellen, was wir heute von unseren PCs und Laptops kennen oder was im Time-Sharing-Betrieb üblich war. Die Betriebssysteme von Apple II und TRS-80 erweiterten lediglich das eingebaute BASIC um Routinen zum Diskettenzugriff. Commodore verzichtete sogar gänzlich auf ein softwarebasiertes Betriebssystem im eigentlichen Sinne, sondern baute die entsprechende Funktionalität direkt in die Diskettenlaufwerke ein.
Fazit
So wichtig die Geräte für die frühe Geschichte persönlicher Computer waren, so vergleichsweise unwichtig waren sie aus Nutzungsschnittstellen-Sicht. Zwar machen die Rechner die Computertechnik der Bevölkerung jenseits der Selbstbastler und Computerbegeisterten zugänglich, in Sachen Nutzungsschnittstelle bieten sie jedoch keinen Vorteil zu einem voll ausgestatteten Altair 8800 mit laufendem Altair-BASIC von Microsoft. Die Nutzer bedienen in allen Fällen eine für Time-Sharing-Systeme auf Fernschreiber-Basis entwickelte Programmiersprache, die um das Handling lokaler Datenträger erweitert wurde.
Kleine Computer im Büro
Ende der 1970er und Anfang der 1980er Jahre spielte die elektronische Datenverarbeitung in vielen Firmen zwar bereits eine immer größer werdende Rolle, die Schreibtische in den Büros waren aber noch meist computerfrei. Die Ergebnisse von Computer-Auswertungen wurden meist in Papierform weiterverarbeitet. Wenn es eine interaktive Computernutzung gab, fand diese an Terminals statt, die mit einem firmeneigenen Großrechner oder einem leistungsstarken Minicomputer wie einer PDP-10 verbunden waren. Allenfalls eine Entwicklungsabteilung oder ein Labor hatte einen eigenen Minicomputer. Als Ende der 1970er Jahre mit dem Altair und der 1977-Dreifaltigkeit Computer für Bastler und Privatleute verfügbar wurden, entdeckte auch manch kleiner Betrieb die Technik für sich und optimierte seine Verwaltung durch den Einsatz eines kleinen Computers. Zuvor war für diesen Anwenderkreis ein Computer weit jenseits alles Finanzierbaren. Große Unternehmen, die seit langem große Rechenanlagen betrieben, sahen in den neuen, kleinen Computern indes keinen Sinn. Sie galten eher als Spielzeug denn als ernsthaftes Arbeitsgerät. Diese Einschätzung sollte sich bald ändern. Der Meinungswandel kam interessanterweise nicht durch bessere oder schnellere Hardware oder gar dadurch, dass die Firmenbosse Teil einer vorgeblichen Revolution sein wollten. Verantwortlich waren vielmehr einige wenige Software-Anwendungen, die für die kleinen Rechner verfügbar waren. Diese Programme allein rechtfertigten die Anschaffung der kleinen Computer für den Büroeinsatz.
Apple II und VisiCalc
Das vielleicht wichtigste dieser neuen Programme, die es nur auf den neuen kleinen Computern gab, war das 1979 von Dan Bricklin und Bob Frankston entwickelte Programm „VisiCalc“. Bricklin bezeichnete das Programm seinerzeit als „a magic sheet of paper that can perform calculations and recalculations“. Es handelte sich um die erste Tabellenkalkulations-Software nach heutigem Maßstab. Schaut man sich die Software heute an, ist die Ähnlichkeit mit Excel von Microsoft bestechend. Nach dem Starten der Anwendung wird der Großteil des Bildschirms durch ein Tabellenblatt in Anspruch genommen. In die Zellen der Tabelle können Texte, Zahlenwerte oder auch Formeln eingetragen werden. Jede Zelle ist durch Angabe der Zeile (als Nummer) und der Spalte (als Buchstabe) identifizierbar und auch innerhalb von Berechnungen referenzierbar. Die Werte in einer Zelle können somit in Formeln genutzt werden. Werden die referenzierten Werte geändert, aktualisieren sich auch automatisch alle aus diesen Werten berechneten Zellinhalte. All das kennen Sie heute genau so aus Programmen wie Excel, LibreCalc oder Google Spreadsheets.
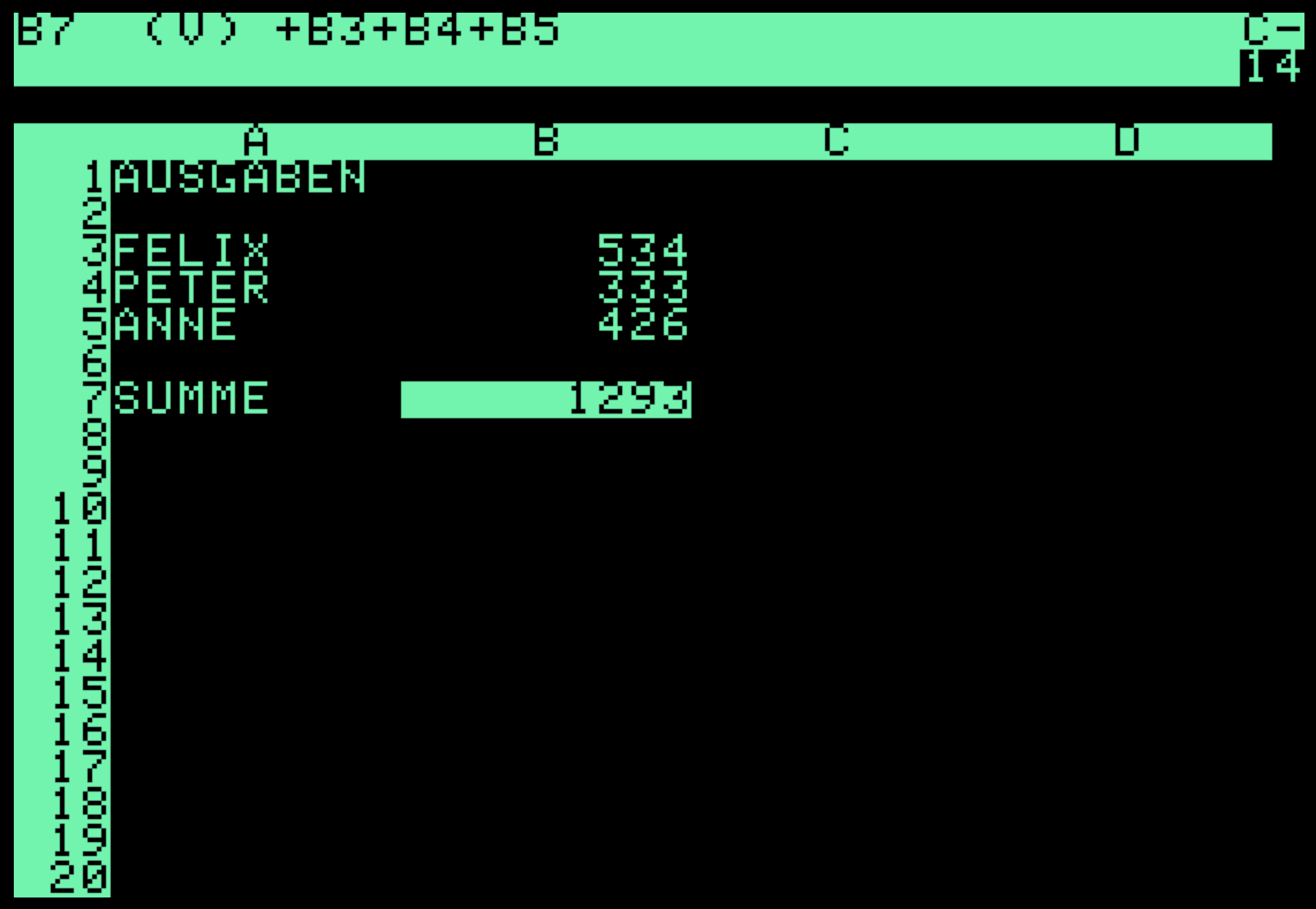
Das Herausragende an VisiCalc war nicht, dass Berechnungen angestellt werden konnten oder dass die Rechenergebnisse in Tabellenform präsentiert wurden. Auch andere Software-Produkte ermöglichten das. Das Überzeugende für die Nutzer war vielmehr die Interaktivität der Software. Am besten kann man sich das klarmachen, wenn man sich überlegt, wie eine einfache Berechnung mit und ohne VisiCalc durchgeführt werden konnte.
Sollte eine Berechnung wie die oben zu sehende mit einer klassischen Software auf einem Time-Sharing-System durchgeführt werden, mussten zunächst die Eingabedaten erzeugt werden. Dafür erstellte man eine Datei, in der die von den einzelnen Personen getätigten Ausgaben entsprechend einer festgelegten Notationsweise abgelegt wurden. In einer anderen Datei wurde nun definiert, wie die Daten zu verrechnen sind, hier also, dass eine Summe zu bilden ist. Auf der Kommandozeile startete man dann die Auswertungs-Software und erhielt, der Konfiguration entsprechend, etwa eine tabellarische Aufbereitung der Berechnung und des Ergebnisses. Sollte nun ein Wert geändert werden, musste die Datei mit den Eingabewerten bearbeitet und die Auswertung neu durchgeführt werden. Bei VisiCalc war es nun ganz anders: Sowohl Eingabewerte als auch Berechnungsvorschriften waren als Objekte am Bildschirm sichtbar. Sie konnten vom Nutzer selbst ohne Programmiereingriffe oder komplexe Editor-Operationen erstellt und angepasst werden, indem der Eingabefokus einfach auf die entsprechende Zelle gesetzt wurde. Sollten Änderungen gemacht werden, musste nur der Wert oder die Formel geändert werden. Alle abhängigen Werte aktualisierten sich sofort. Es mussten keine Programme geändert werden, es gab keine komplexen Codierungen und auch die „unfreundliche“ Kommandozeile musste nicht genutzt werden. Die einfache Änderbarkeit, die permanente Sichtbarkeit von Eingabe, Ausgabe und Verarbeitungsvorschriften und die schnelle Aktualisierung konnten gar nicht hoch genug eingeschätzt werden, ermöglichten sie doch Nutzungsszenarien, die vorher gar nicht denkbar waren. Bei Kreditberechnungen etwa konnte einfach mit Zinssatz und Rückzahlung gespielt werden. Die Änderungen wurden sofort sichtbar und erlaubten so ein exploratives Vorgehen, das bei der alten Lösung so mühselig gewesen wäre, dass es faktisch unmöglich war.
VisiCalc lief auf dem Apple II und zunächst auch nur auf diesem. Dass die Software gerade für diesen Computer entwickelt wurde, hatte offenbar wenig damit zu tun, dass er so besonders gut geeignet gewesen wäre. Mit einem Commodore PET oder einem TRS-80 wäre es sicher genau so gut gegangen. Bob Frankston entwickelte das Programm nur deshalb für den Apple II, weil auf dem Time-Sharing-System des MIT, das er für die Entwicklung nutzte, ein entsprechender Cross-Assembler zur Verfügung stand, der Maschinencode für den Apple II erzeugen konnte. Er konnte also komfortabel den leistungsfähigen Rechner zur Programmierung nutzen und dann das Programm auf dem günstigen Personal Computer ausführen.
Die Nutzungsschnittstelle von VisiCalc
Wenn man sich VisiCalc heute auf einem echten Apple II oder in einem Emulator ansieht, hat man sofort eine Vorstellung davon, wie es sich bedient. Die Art der Zellennummerierung und die Art und Weise, wie berechnet wird, ist in einem aktuellen Excel nahezu identisch. Probleme hat man allerdings wahrscheinlich erst einmal mit dem Bewegen des Cursors, was dem Umstand geschuldet ist, dass frühe Apple II nur zwei Tasten zur Cursor-Steuerung hatten. Man konnte mit ihnen folglich entweder nur horizontal nach rechts und links oder vertikal nach oben und unten steuern. Mit der Leertaste schaltete man in VisiCalc daher zwischen horizontal und vertikal um. Auf dem obigen Screenshot ist in der rechten oberen Ecke an dem Minus-Zeichen zu sehen, dass gerade der horizontale Modus aktiv ist. Die Eigenarten der Cursorbewegung in VisiCalc waren zwar seltsam, stellen einen Nutzer aber nicht vor allzu große Probleme. Größere Probleme bekam man aber, wenn man versuchte, eine Datei zu laden oder zu speichern, denn ganz im Gegensatz zum im Altair-Kapitel besprochenen WordStar zeigte VisiCalc dem Nutzer nur sehr unzureichend an, welche Optionen verfügbar waren. So spannend und innovativ die Software von der Funktionalität her war, so sehr war sie, was die Erschließbarkeit der Funktionen anging, ein Kind ihrer Zeit. Man musste die notwendigen Eingaben und Kommandos entweder kennen oder das Handbuch nutzen, um das Programm zu bedienen. Das Beispiel des Ladens einer Datei zeigt das gut:
Um eine Datei zu laden, musste man das Programm zunächst in den Kommando-Modus versetzen. Wie das ging, stand allerdings nirgendwo. Man musste wissen oder nachschlagen, dass man dazu / eintippen muss. Wenn man das getan hat, zeigte VisiCalc in der ersten Bildschirmzeile an, welche Kommandos eingegeben werden konnten. Man erfuhr, dass man B, C, D, F, G, I, M, P, R, S, T, V, W oder - wählen konnte – mehr nicht. Mit dieser Information war man aber natürlich nicht viel schlauer als vorher und musste wieder ausprobieren oder nachlesen. Tat man das, erfuhr man, dass man nun S für storing und dann L für load eingeben konnte, um eine Datei zu laden. Auch das Beenden hatten Bricklin und Frankston dem „Storing“ zuordnet. Der Befehl dafür lautete im Ganzen /SQ.
Dass Bricklin und Frankston ein so komplexes Programm wie eine Tabellenkalkulation auf einem doch relativ schwachbrüstigen Rechner wie dem Apple II realisieren konnten, ist nicht zu gering einzuschätzen. Tabellenkalkulationen sind heute so selbstverständlich, dass das Innovative an dem Konzept nicht mehr offensichtlich ist: Bei VisiCalc wurden Zahlen, Texte und Formeln in Zellen geschrieben. Die Daten waren damit nicht nur Werte in Variablen, die auf Anforderung ausgegeben werden konnten, sondern standen stabil am Bildschirm als räumlich manipulierbare und referenzierbare Objekte zur Verfügung. Änderungen an Zellen und Werten wurden nicht nur sofort angezeigt, anstatt erneut per Befehl zur Anzeige gebracht werden zu müssen, sondern auch alle anhängigen Zellen wurden automatisch aktualisiert. Das ganze angezeigte Blatt wurde komplett neu durchgerechnet und war folglich immer aktuell. Sie mussten nie eine Neuberechnung manuell anstoßen. VisiCalc bot also nicht nur räumliche Objekte, sondern erfüllte vor allem auch das Potenzial der Responsivität. Der Clou der Software lag in der Kombination dieser beiden Potenziale. Dass die Informationen in den Arbeitsblättern in räumlich eindeutige, per Koordinaten ansprechbare und referenzierbare Zellen abgelegt wurden, erlaubte auch Nicht-Computerkundigen, Berechnungen zu „programmieren“, ohne eine komplexe Programmiersprache zu kennen oder gar wissen zu müssen, wie der Computer im Inneren funktioniert. Damit eine solche responsive Aktualisierung möglich war, mussten Bricklin und Frankston austüfteln, wie sie die Daten der Arbeitsblätter geschickt im Speicher ablegen konnten, um eine schnelle Neuberechnung und Aktualisierung zu erreichen, ohne dass die Neuberechnung für eine merkliche Verzögerung bei der Bedienung sorgen würde.
Dieses kleine Wunder in Sachen Interaktivität brauchte keinen leistungsstarken experimentellen Rechner in einem Labor, sondern lief auf einem „billigen“ Apple II mit 32 KB Arbeitsspeicher und auch nur auf diesem Gerät. Die teuren Time-Sharing-Systeme im Rechenzentrum hatten nichts Vergleichbares. VisiCalc allein war daher für manche Firma Grund genug, Apple IIs für den Büroeinsatz zu erwerben.
CP/M auf den Apple II – Der Computer im Computer
Im Kapitel über den Altair 8800 haben Sie WordStar kennengelernt. Auch diese Textverarbeitung war eine Anwendung, die die Anschaffung eines Computers für den Büroeinsatz rechtfertigen könnte, denn WordStar ermöglichte es einem Büroangestellten mit Personal Computer, einen Text selbst zu tippen und zu formatieren, ohne selbst eine Schreibmaschine nutzen zu müssen oder auf eine Sekretärin zuzugreifen, die ein aufgenommenes Diktat abtippt. WordStar wurde allerdings nicht für den Apple II, sondern für das Betriebssystem CP/M entwickelt. Dieses Betriebssystem lief aber nicht auf dem Apple II, denn dieser verfügte nicht über einen Prozessor, der zum Intel 8080 kompatibel war. Firmen, die Personal Computer für den Büroeinsatz anschaffen wollten, standen damit vor einem Dilemma. Für den Apple II gab es VisiCalc, aber die anderen attraktiven Programme – neben WordStar auch das Datenbanksystem dBase und viele Programmierumgebungen und Compiler – liefen unter CP/M.
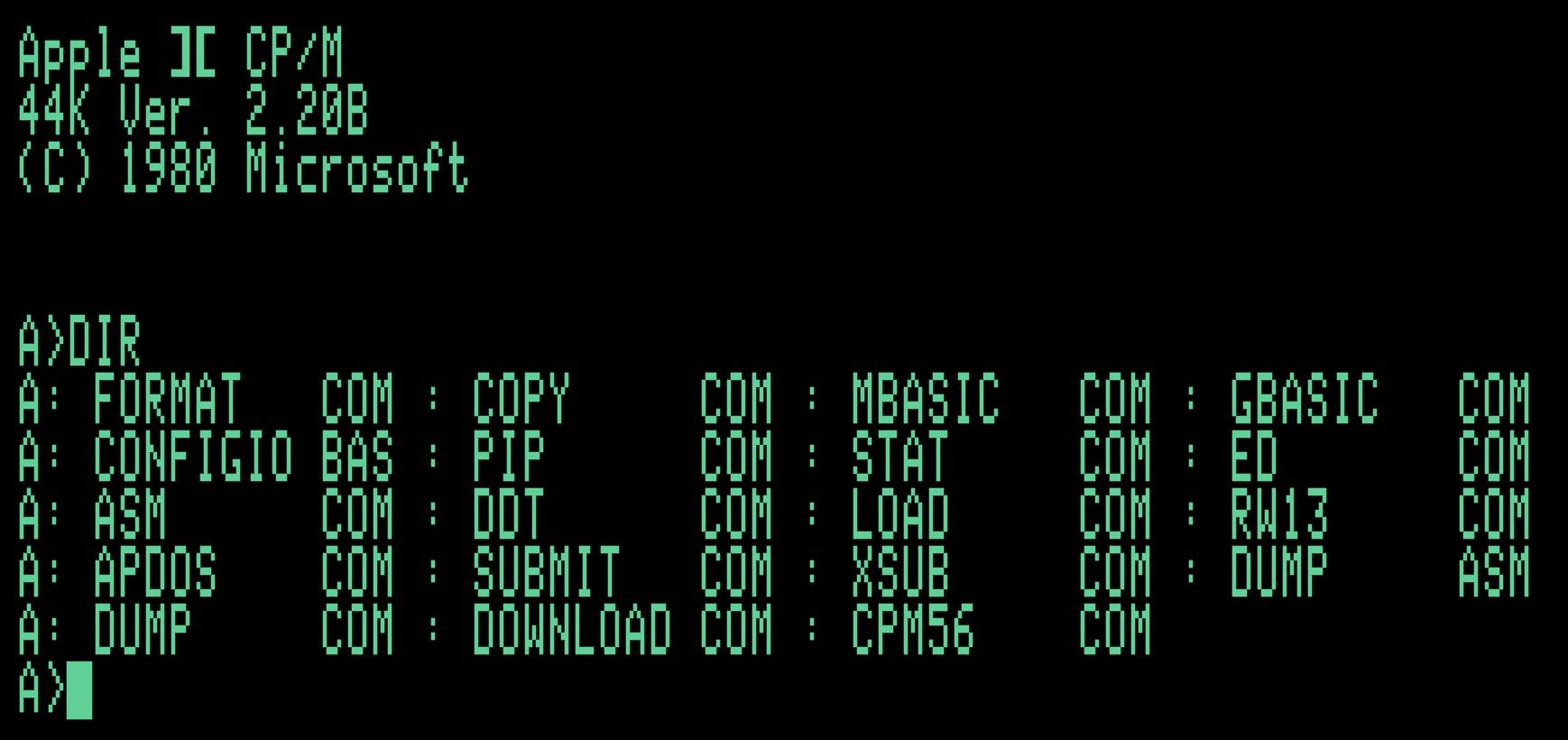
Die Lösung dieses Problems kam von einer anderen Seite, als man es vielleicht vermuten würde. Techniker von Microsoft entwickelten eine als „SoftCard“ bezeichnete Einsteckkarte für den Apple II. Die Karte verfügte über einen eigenen zum Intel 8080 kompatiblen Zilog-Z80-Prozessor. Die restliche Schaltung auf der Einsteckkarte diente dazu, die Hardware des Apple II so „umzubiegen“, dass sie für den Prozessor der Karte wie ein typischer CP/M-Rechner wirkte. Es handelte sich gewissermaßen um einen Computer im Computer. Eingesteckt in einen Apple II ermöglichte die Karte also das Ausführen von CP/M auf einem Apple-Gerät. Ein entsprechend angepasstes CP/M und Microsofts BASIC-Interpreter wurden mitgeliefert (MBASIC.COM und GBASIC.COM auf dem Screenshot oben), sodass auch für den Altair oder andere CP/M-Rechner entwickelte BASIC-Software sofort auf dem Apple II lauffähig war. Zusätzlich ausgestattet mit einer Einsteckkarte, die auf dem Bildschirm achtzig Zeichen pro Zeile verfügbar machte und zusätzlichen Arbeitsspeicher bereitstellte, liefen nun auch WordStar und dBase auf dem Apple II. Die Erweiterungsoption blieb kein Nischenprodukt, sondern wurde massenhaft erworben. Die SoftCard war damit ein großer Erfolg. Im Jahr 1980 war sie Microsofts größte Einnahmequelle und durch die Karte und spätere Nachbauten wurde der Apple II der CP/M-Rechner mit der größten Verbreitung.
IBMs Weg zum Personal Computer
Mit dem Apple II und CP/M zogen die ersten Personal Computer in Büros und Unternehmen ein. Apple, Commodore, MITS (der Hersteller des Altair) und die anderen Hersteller von Personal Computern waren für die Firmenwelt genauso neu wie für Privatleute. Natürlich gab es auch vorher schon Computer in Wirtschaftsunternehmen, doch waren ganz andere Firmen in diesem Markt aktiv. Neben der Firma Digital Equipment (DEC) mit ihren beliebten Großrechnern und Minicomputern gab es etwa Computer von Bull, Nixdorf und vor allem vom Branchen-Primus IBM. Die Firma stand regelrecht synonym für große Rechenanlagen in Militär, Verwaltung und Universitäten. Unzählige Entwicklungen in der Computertechnik, wie Festplatten, Multitasking und Paralleles Rechnen gehen auf IBM-Erfindungen zurück oder wurden, wenn von IBM schon nicht erfunden, dann zumindest dort zur Marktreife gebracht. IBMs Computer waren vor allem große Rechenanlagen, aber auch Minicomputer waren im Angebot. Verbreitet war in den 1970er Jahren zum Beispiel der Minicomputer System/3 Model 6.
Ende der 1970er und Anfang der 1980er Jahre drangen nun die neuen Firmen mit kleinen, flexiblen Produkten in den angestammten Bereich von IBM vor. Es dauerte einige Jahre, bis IBM antwortete und seinen eigenen Personal Computer herausbrachte. Die populäre Computergeschichte stellt diesen Fakt, dass IBM erst vier Jahre nach Apple, Commodore und Tandy und sechs Jahre nach dem Altair 8800 einen Personal Computer im Angebot hatte, so dar, dass IBM kleinen Computern nichts abgewinnen konnte und nur große Rechner für beachtenswert hielt. Diese Darstellung wurde sicherlich noch vom Marketing der Firma Apple unterstützt. Im Rahmen der Einführung des Apple Macintosh im Jahre 1984 etwa behauptete Steve Jobs:
In 1977, Apple, a young fledgling company on the west coast invents the Apple II, the first personal computer as we know it today. IBM dismisses the personal computer as too small to do serious computing and unimportant to their business.
Hier ist wohl Steve Jobs’ typisches „Reality Distortion Field“ am Werke gewesen7. IBMs vermeintliche Geringschätzung kleiner Computer fand ihren Eingang in manches Buch und manche Dokumentation. Ganz so einfach war es aber nicht. In der Tat hatte IBM mit seinen Computern nicht die Privatperson im Blick. IBM baute Computer für Firmen, keine Heimcomputer. Das hieß aber nicht, dass man keinen Sinn in einem kleinen Computer sah. Das konnte schon deswegen nicht der Wahrheit entsprechen, weil IBM schon seit 1973 einen mobilen Computer entwickelte und diesen ab 1975 verkaufte. Dieser Computer, der IBM 5100, ist heute nahezu vergessen. Es handelte sich um einen tragbaren Computer mit einer ausklappbaren Tastatur, einem eingebauten Bildschirm und einem Bandlaufwerk für Daten und Programme. Warum IBM mit diesem Computer nicht der Marktführer bei den Personal Computern wurde, ist natürlich letztendlich teilweise Spekulation, doch liegen einige Gründe nahe.
Unter anderem war der Rechner mit 16.000 Dollar (in 2021er Kaufkraft entsprechend 79.800 Dollar) extrem teuer. Eine wichtige Rolle spielt meiner Ansicht nach aber auch die Software, bzw. das Fehlen derselben. Als um die Jahre 1979 und 1980 herum die ersten Personal Computer Einzug in die Firmenwelt hielten, hatte sich diese neue Rechnergattung weniger in der Hardware, sondern vor allem durch Software wie VisiCalc, WordStar und Co. von früheren Rechnergenerationen emanzipiert. Rechner wie ein ausgebauter Altair 8800 mit Diskettenlaufwerk, Terminal und CP/M, ein Commodore PET, ein Apple II oder TRS-80 waren keine reinen Fortführungen der Geräte der 1960er und 1970er. Es handelte sich nicht um abgespeckte, verkleinerte Großrechner und auch nicht um billigere Minicomputer, sondern um ein neues Konzept kleiner, autarker Rechner auf der technischen Grundlage von Mikroprozessoren, mit eigener Software und eigenen Nutzungsweisen.

Der 5100 war kein solcher Rechner. Er war ein kompakter, mobiler Computer, der Programme für IBM-Minicomputer und IBM-Mainframes ausführen konnte. Damit das möglich war, baute IBM Interpreter für die Programmiersprachen APL und BASIC ein. Mittels Schalter konnte zwischen den beiden Programmiersprachen umgeschaltet werden. Der APL-Compiler entsprach dem der System/370-Großrechner und der implementierte BASIC-Dialekt wurde auch auf den System/3-Minicomputern verwendet.

IBM hatte 1975 beim 5100 also eher einen Einzelnutzer-Mini-Großrechner im Angebot als einen Personal Computer. Dabei blieb es aber nicht, denn auf den 5100 folgten eine ganze Reihe weiterer Rechner. Betrachtenswert war der System/23 Datamaster. Dieser ab dem Juli 1981 verkaufte Computer war ein Schreibtischrechner mit zwei integrierten Diskettenlaufwerken. Das Gerät konnte mit vielen bürotypischen Anwendungen wie Buchhaltungssoftware und Textverarbeitung ausgestattet werden. Der Datamaster war IBM-typisch teuer und zielte auf die typische IBM-Kundschaft, also auf Firmenkunden ab. Im Fokus standen allerdings nicht die Unternehmen mit einem großen Rechenzentrum, sondern vor allem kleine Firmen ohne Erfahrung mit elektronischer Datenverarbeitung. Der Rechner wurde mit einer sehr gut verständlichen Anleitung ausgeliefert und Software wurde so gestaltet, dass sie ohne komplizierte IT-Begrifflichkeiten auskam. Diesen Computer könnte man durchaus Personal Computer nennen. Mit einem Preis von 9.000 Dollar, was inflationsbereinigt auf das Jahr 2021 über 26.500 Dollar entspricht, war das System allerdings weit teurer als typische Personal Computer, und mit der Möglichkeit, zwei Nutzer an zwei Konsolen gleichzeitig zu bedienen, gingen die Möglichkeiten des Systems über das hinaus, was man üblicherweise einem Personal Computer zuschrieb. Der Datamaster blieb einige Jahre im Angebot von IBM, wurde aber bereits einen Monat später vom IBM 5150, dem „IBM Personal Computer“ in den Schatten gestellt.
Der IBM PC und ein Betriebssystem von Microsoft
Im August 1981 war es soweit: IBM brachte den Rechner „IBM 5150 Personal Computer“ auf den Markt, der den Begriff „Personal Computer“ prägte und dessen direkte Nachfolger heute noch genutzt werden. Fast jeder PC, den Sie heute kaufen können ist ein Rechner, der zu diesem Ur-PC kompatibel ist. Sie könnten den Rechner im Prinzip also mit dem ursprünglichen DOS starten und die Software von 1981 laufen lassen. Von 2006 bis 2020 verwendeten auch alle Apple Macintoshs diese Architektur.

Vergleicht man die technischen Daten des 5150 mit denen typischer Computer der damaligen Zeit, erscheint er nicht besonders herausragend. Als Prozessor kam ein Intel 8088 zum Einsatz. Dieser arbeitete intern mit 16-Bit-Daten, hatte aber einen 8-Bit-Daten-Bus. Um 16 Bit aus dem Speicher zu lesen, musste der Prozessor also zwei Ladevorgänge durchführen. Intel hätte auch einen 8086 mit 16-Bit-Daten-Bus nehmen können. Dann wäre der Speicherzugriff schneller, der Speicher allerdings auch teurer gewesen. Der 8088-Prozessor verwendete eine Adresslänge von 20 Bit. Da jede Adresse 8 Bit Daten bezeichnete, was einem Byte entspricht, hätte der IBM PC also theoretisch 220 Bytes, also 1 MB Arbeitsspeicher adressieren können. Kaufte man 1981 allerdings einen PC, war dieser bei Weitem nicht so gut ausgebaut. Man konnte den Rechner mit 16 KB oder mit 64 KB bestellen. Eine Erweiterung war zwar bis 640 KB möglich, aber natürlich auch sehr teuer.
Man konnte einen IBM PC seinerzeit gänzlich ohne Diskettenlaufwerk und ohne Betriebssystem erwerben und betreiben, denn in jeden IBM PC und dem Nachfolgerechner PC XT war ein Microsoft-BASIC direkt in die Hardware eingebaut. Schaltete man den Rechner ohne Diskettenlaufwerk oder ohne eingelegte Betriebssystemdiskette ein, startete automatisch das Cassette BASIC von Microsoft. Es konnte also wie beim Apple II oder einem Commodore PET sofort mit dem Programmieren begonnen werden. Programme konnten mit dem eingebauten BASIC von Kassette gelesen und darauf gespeichert werden. Der PC verfügte dazu über eine Buchse auf der Rückseite, an die ein handelsüblicher Kassetten-Recorder angeschlossen werden konnte. Kaum jemand benutzte den Rechner jedoch so, denn für diese eingeschränkte Arbeitsweise war er viel zu teuer. Software für den Rechner wurde nahezu zu 100 % nicht auf Kassette, sondern auf Diskette angeboten. Die allermeisten ausgelieferten PCs verfügten daher über mindestens ein Diskettenlaufwerk. Zwei Laufwerke waren sehr verbreitet und vereinfachten die Bedienung des Rechners im Alltag. Auch die Diskettenlaufwerke des IBM 5150 waren im Vergleich zur Konkurrenz übrigens nicht sehr besonders. Das ursprüngliche Laufwerk, das die Disketten nur einseitig beschreiben konnte, brachte 160 KB auf einer Diskette unter. Zum Vergleich: Der Apple II konnte zu dieser Zeit schon seit einigen Jahren 140 KB auf einer Diskettenseite speichern. Man lag also etwa im gleichen Leistungsbereich.
Ein IBM PC war im Vergleich zu anderen Personal Computern vergleichsweise teuer. Die günstigste Variante mit 16 KB Arbeitsspeicher, CGA-Grafik (siehe unten) und ohne Diskettenlaufwerk kostete 1.565 Dollar (entsprechend 2021: 4.620 Dollar). Mit dieser Variante des Rechners konnte man allerdings fast nichts anfangen, außer eigene BASIC-Programme zu programmieren, zu speichern und zu laden. Das hätte man an anderer Stelle günstiger bekommen können. Ein voll ausgestatteter Rechner mit Betriebssystem, Diskettenlaufwerk und 64 KB Arbeitsspeicher kostete locker das Doppelte. Für Privatleute war dieser Rechner dann aber unerschwinglich und letztendlich wohl auch nicht gedacht, denn der Zielmarkt von IBM waren seit jeher Wirtschaftsunternehmen, die die Firma seit Langem kannten und auch vor allem für IBMs Wartungsverträge schätzten.
Zur Business-Ausrichtung des IBM PCs passten auch die weiteren technischen Eigenschaften. Der Rechner hatte zum Beispiel keine nennenswerte Klangausgabe. Es gab zwar einen Lautsprecher, doch dessen Aufgabe war es eher, bei einer fehlerhaften Eingabe zu piepsen. Im Grafikbereich gab es zwei Ausstattungsmöglichkeiten. Bei der Verwendung eines „Monochrome Display Adapters“, kurz MDA, konnte der Rechner nur Text in zwei Helligkeitsstufen darstellen. Auf dem verwendeten Monitor entstand dabei ein scharfes, nicht flackerndes Bild mit einer guten Zeichendarstellung in grüner oder bernsteinfarbener Schrift auf schwarzem Grund. Die MDA-Karte bot auch eine Schnittstelle zum Anschluss eines Druckers, der natürlich auch im Firmenumfeld wichtiger war als zu Hause. Die Alternative zum MDA-Adapter war die Verwendung eines Color Graphics Adapters, kurz CGA. Auch der CGA-Adapter erlaubte die Darstellung von 80 Zeichen pro Textzeile. Die Zeichendarstellung war hier allerdings ein wenig gröber. Dafür verfügte der Textmodus über sechzehn Farben, die, ganz im Gegensatz zum Apple II, auf entsprechenden Monitoren gut lesbar dargestellt werden konnten. CGA-Grafik verfügte natürlich auch über echte Grafikmodi: 640 x 200 Pixel konnten monochrom und 320 x 200 Pixel bei vier Farben8 dargestellt werden. Leider hatte sich IBM hier für sehr ungeschickte Farbpaletten entschieden. Wirklich schöne Grafik war in CGA daher nicht möglich und für Spiele war ein IBM PC mit CGA-Ausgabe sicher nicht ideal. Natürlich gab es Spiele für den IBM PC mit CGA-Grafik. Eine wirkliche Plattform für Spiele im Heimbereich wurde der PC allerdings erst Jahre später.
Ein Betriebssystem muss her!
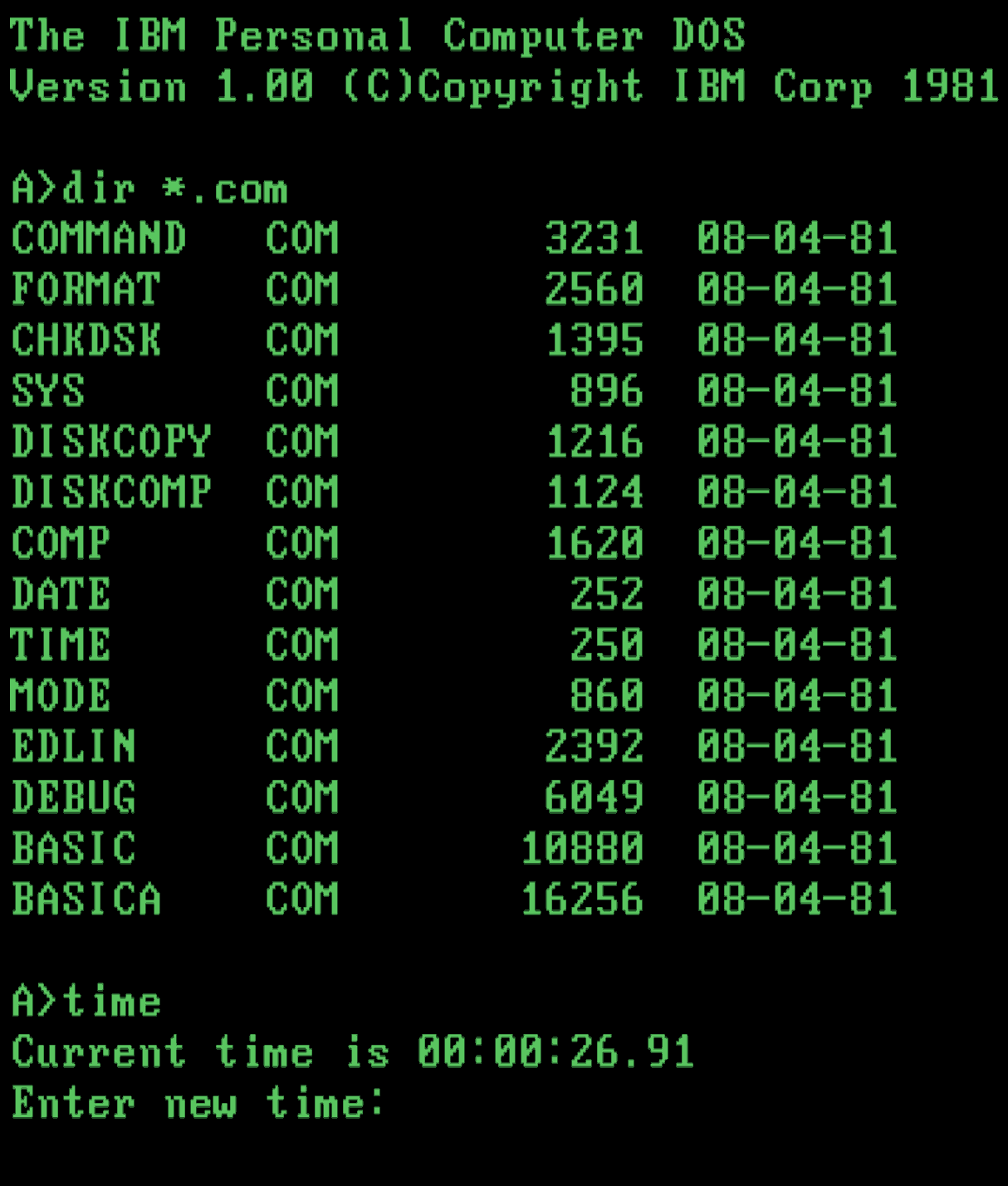
Für einen gut ausgestatteten IBM PC mit einem oder zwei Diskettenlaufwerken brauchte es ein Betriebssystem. Beim Datamaster im gleichen Jahr war noch ein BASIC-Interpreter mit integrierten Befehlen für das Diskettenhandling die Hauptinteraktionskomponente. Beim PC entschied man sich für ein von einer Programmierumgebung unabhängiges Betriebssystem. IBM hatte kein Betriebssystem für den Rechner, entwickelte es aber auch nicht selbst, sondern lizenzierte ein System von Microsoft, das Microsoft eigentlich selbst auch noch gar nicht hatte. Der Programmierer Tim Patterson hatte ein Betriebssystem für die 8086er-Linie von Intel-Prozessoren entwickelt und sich dafür die Bedienweise und einige der zentralen Konzepte bei CP/M von Digital Research abgeschaut. Sein Betriebssystem 86-DOS sah CP/M zum Verwechseln ähnlich. Viele der von CP/M bekannten Befehle funktionierten auch unter dem neuen Betriebssystem. Die Ähnlichkeit der Systeme bestand auch auf der Architekturebene, was bedeutete, dass CP/M-Programme relativ leicht auf 86-DOS übertragen werden konnten. Microsoft kaufte das Betriebssystem und lizenzierte es unter dem Namen PC-DOS an IBM. Viele, teils in sich widersprüchliche, Geschichten ranken sich darum, wieso IBM ein Betriebssystem von Microsoft orderte und nicht auf das etablierte CP/M von Digital Research zurückgriff. Je nach Einstellung erschien dann Bill Gates von Microsoft als der gerissene Geschäftsmann, der seine Konkurrenz mit einem schlechten Produkt aus dem Markt drängte, oder aber es wird behauptet, dass Gary Kildall von Digital Research die IBM-Verantwortlichen habe sitzen lassen und daher selbst schuld gewesen sei, nicht zum Zuge gekommen zu sein. Lesen Sie diese Geschichten gerne an anderer Stelle nach, aber glauben Sie nichts von dem, was Sie da lesen, denn fünf verschiedene Erzählungen geben sieben verschiedene Versionen der gleichen Geschichte wieder. Die Wahrheit ist kaum noch festzustellen, wahrscheinlich aber ohnehin viel langweiliger als die spannenden Geschichten.
Microsofts DOS wurde fortan mit jedem neuen IBM PC, der über ein Diskettenlaufwerk verfügte, vertrieben. Es gilt allgemein als Geniestreich von Microsoft, dass IBM seinerzeit nicht die exklusiven Rechte an dem Betriebssystem erhielt. Microsoft durfte es auch anderen Unternehmen lizenzieren und tat dies auch. Da der IBM-Rechner großteils aus Standardkomponenten bestand, kamen bald viele Klone (die sogenannten IBM-Kompatiblen) auf den Markt, auf denen DOS, dann unter dem Namen MS-DOS, lauffähig war.
Die Software macht den Unterschied!
Es ist bemerkenswert, dass die frühen Personal Computer zwar über Betriebssysteme verfügten, die stark der alten Fernschreiber-Bedienweise von Time-Sharing-Systemen entsprachen, der Siegeszug von Personal Computern in Büros aber auf einer Reihe von Anwendungen beruhte, die über diesen Kommandozeilen-Stil weit hinausgingen. Das war schon beim Apple II und bei den CP/M-Geräten so. Sowohl VisiCalc, Wordstar als auch dBase zeichneten sich dadurch aus, dass sie die Potenziale interaktiver Computersysteme zu einem weit höheren Grad erfüllten als das Betriebssystem, auf dem sie liefen. Alle drei Anwendungen boten ihren Nutzern eine räumliche Nutzungsoberfläche mit Objekten, die am Bildschirm dauerhaft dargestellt und an ihrem Anzeigeort bearbeitet werden konnten. Im Vergleich zu den Nutzungsoberflächen von heute wirken sie zwar altmodisch und kompliziert, doch war vieles von dem, was es heute gibt, hier schon angelegt. Sie stellten die alten Time-Sharing-Oberflächen mit Fernschreibern oder Glass-Terminals weit in den Schatten. Der IBM PC und sein Betriebssystem MS-DOS bzw. PC-DOS brachten in Sachen Nutzungsschnittstelle nichts Neues. Das Betriebssystem war sehr stark an CP/M angelehnt, was ja seinerzeit seine Eigenschaften vom Großrechner-Time-Sharing-System TOPS-10 geerbt hatte. Arbeiten mit dem Kommandozeilen-Interpreter von DOS fühlte sich daher an, wie die Nutzung eines Großrechners mittels Fernschreiber. Die Möglichkeiten der räumlichen Anordnung von Objekten am Bildschirm wurden nicht genutzt. Zwar konnte der Computer mit einer CGA-Grafikkarte im Grafikmodus betrieben werden und das im monochromen Modus sogar in für damalige Verhältnisse ganz ordentlicher Auflösung, das Betriebssystem und die meisten Anwendungen machten davon aber kaum Gebrauch. Grafikausgabe wurde in Spielen und in Anwendungen für die Darstellung von Inhalten verwendet, etwa für die Anzeige eines Diagramms in der Tabellenkalkulation „Lotus 1-2-3“.
IBM-Computer und die vielen günstigen Kompatiblen wurden in der Geschäftswelt ein großer Erfolg. Die populäre Business-Software aus der Apple-II- und CP/M-Welt wurde übertragen. VisiCalc, WordStar und Co. waren also auch unter DOS verfügbar. Im Laufe der Jahre wurden sie durch Konkurrenzprogramme verdrängt, die vor allem von der Grafikfähigkeit und von der Möglichkeit, den Rechner mit mehr Speicher zu bestücken, profitierten. WordStar blieb recht lange am Markt, bekam aber schon 1982 mit WordPerfect und 1983 mit Microsoft Word Konkurrenz. VisiCalc verlor schnell an Bedeutung. Microsofts erster Versuch einer Tabellenkalkulation namens „Multiplan“ konnte 1982 zwar noch nicht viele Anhänger finden, aber das 1983 erschienene Lotus 1-2-3 lief VisiCalc schnell den Rang ab. Es stand innerhalb kürzester Zeit genauso synonym für Tabellenkalkulation wie vorher VisiCalc und heute Excel. Das große neue Feature von Lotus 1-2-3 im Vergleich zu VisiCalc war vor allem, dass sich nun Diagramme und Business-Grafiken darstellen ließen.
Die Menge, der für den IBM PC verfügbaren Software wuchs in kurzer Zeit extrem an. Neben vielen Programmen aus dem Büro- und Firmenbereich standen natürlich schnell auch allerlei Entwicklungsumgebungen zur Verfügung. Eine Übersicht über alle nennenswerten Software-Produkte der frühen IBM PC-Zeit zu geben, führt an dieser Stelle natürlich viel zu weit. Es kann aber durchaus spannend sein, sich alte Software aus dieser Zeit exemplarisch anzuschauen. Natürlich wirkt ihre Nutzungsschnittstelle heute altmodisch, aber mitunter verfügte die alte Software über interessante Eigenschaften, die man sich heute wieder wünschen würde.
Als ein Beispiel für eine interessante Nutzungsschnittstelle schauen wir uns hier einmal die frühen Versionen von Microsoft Word an. Die erste Version von Word erschien 1983. Die Abbildung zeigt diese erste Version mit seiner sehr typischen Nutzungsschnittstelle. Von Version 1 bis 5 verwendete Microsoft für Word einen Design-Stil, den Microsoft als Standard-Schnittstelle für viele seiner Programme verwendete. Oben befand sich der Inhaltsbereich der Software. Hier sah man etwa den gerade zur Bearbeitung geöffneten Text. Am unteren Bildschirmrand befand sich stets ein Kommandobereich. Durch Drücken von ESC gelangte man in diesen Bereich. Alle hinter dem Wort „COMMAND:“ stehenden Worte entsprachen einer Funktion oder einem Untermenü. Aufgerufen werden konnte die Funktion oder das Untermenü durch das Eingeben des Anfangsbuchstabens. Um einen markierten Textblock zu kopieren, tippte man also ESC und dann C. Alternativ konnten die Kommandos auch ohne vorheriges Drücken der ESC-Taste mit einer Maus ausgewählt werden. Kaum jemand verfügte 1983 jedoch über eine Maus, die als Standard-Eingabegerät erst ein Jahr später mit der Vorstellung des Apple Macintosh überhaupt Verbreitung fand. Bis sie auch bei IBM PCs und Kompatiblen zum Standard gehörte, dauerte es noch bis in die 1990er Jahre.
Das Beachtenswerteste an den frühen Word-Versionen war nicht der Kommandobereich. Die Bedienung damit funktionierte und ermöglichte, sich die Funktionalität des Programms zu erschließen, war allerdings nichts wirklich Besonderes. Spannend waren aber einige Funktionalitäten der Software. Eine sehr interessante Funktion versteckte sich beispielsweise hinter „Window“. Hatte Microsoft zu diesem frühen Zeitpunkt schon Nutzungsschnittstellen mit Fenstern? Wie man auf der Abbildung sieht, erlaubte es Word in der Tat, den Bildschirm in mehrere Bereiche, die Microsoft „Fenster“ nannte, aufzuteilen und darin zum Beispiel verschiedene Dateien anzuzeigen. Das ist für sich genommen nichts Besonderes. Jede moderne Textverarbeitung bietet Ihnen diese Möglichkeit. Spannend ist aber, dass zwei Fenster dieser Art auch das gleiche Dokument anzeigen konnten. Die Abbildung oben zeigt in beiden Fenstern die gleiche Datei „PB.TXT“ an. Diese zwei Fenster im gleichen Dokument machen es möglich, in einem Bereich etwa den Anfang des Textes anzuzeigen, in dem man vielleicht ankündigt, was man alles schreiben möchte, während man im anderen Bereich weiter unten im Dokument schreibt und die gegebenen Versprechen erfüllt. Als ich bei einer Erkundung der alten Word-Version in einem Emulator diese Funktion fand, war ich begeistert. So eine Funktion hätte ich gerne in aktuellen Textverarbeitungen. Umso erstaunter war ich, denn ich fand diese Funktion auch in späteren Word-Versionen – und zwar in allen Versionen von Word bis zum heutigen Tage. Die Funktion ist aber bei Weitem nicht mehr so prominent und mir deshalb nie aufgefallen. Man findet sie in aktuellen Word-Versionen im Ribbon „Ansicht“ unter „Neues Fenster“ bzw. „Teilen“ und in älteren im entsprechenden Menü.
Ebenfalls sehr interessant waren die Funktionen zum Ausschneiden und Einfügen. Die entsprechenden Befehle hießen Copy, Delete und Insert, wobei Delete dem heutigen „Ausschneiden“ entsprach. Bemerkenswert war, was passierte, wenn man einen Block markiert hatte und dann Copy oder Delete aufrief. Man wurde nämlich aufgefordert, diesem Schnipsel einen Namen für das „Glossary“ (auf deutsch etwa „Textbausteine“) zu geben. Es gab also nicht wie heute eine einzige Zwischenablage, in der immer nur ein Inhalt vorhanden ist und bei der ein neuer Inhalt den vorherigen überschreibt, sondern eine richtige Sammlung von Text-Schnipseln, die verfügbar bleiben. Diese Schnipselsammlung konnte man in der Software einsehen und beim Einfügen konnten beliebige Schnipsel eingesetzt werden. Dafür musste man den vergebenen Namen kennen oder aus der Liste auswählen. Das Glossar, also die Schnipselsammlung, war im Gegensatz zur modernen Zwischenablage überdies auch nicht flüchtig. Es konnte unabhängig vom Dokument abgespeichert und dann bei der nächsten Nutzung der Textverarbeitung wiederverwendet werden. So eine Schnipselsammlung mit ihrer komplexen Logik des Kopierens und Einfügens, die viel mehr dem typischen Umgang mit Texten entspricht als der heutige von Apples „Lisa“ übernommene Umgang mit der Zwischenablage, würde ich mir in modernen Textverarbeitungen wünschen – und, oh Wunder, es gibt auch auch diese Funktionalität noch in modernen Word-Versionen (unter dem Namen „Schnellbausteine“). Sie hat allerdings inzwischen ihre Verbindung mit der Zwischenablage und ihren Operationen verloren.
Der PC als Heimcomputer?
Heute sind die allermeisten Computer, die man zu Hause hat und die nicht Smartphones oder Tablets sind, direkte Nachfahren des IBM PC. Zum damaligen Zeitpunkt am Anfang der 1980er Jahre war der IBM PC für den Heimanwender hingegen noch ziemlich uninteressant. Ein heimtauglicher Rechner musste günstig sein, vielleicht das Programmieren ermöglichen, er musste aber vor allem für Spiele geeignet sein. Mit guter Ausstattung war der IBM PC sehr teuer, aber trotzdem nicht sehr spieletauglich und mit schlechter Ausstattung war er immer noch teuer, dann aber in jeder Hinsicht völlig unattraktiv. Wer es auf Spiele abgesehen hatte, war mit einer der damals aufkommenden Spielekonsolen besser bedient, und wer einen Computer zum gelegentlichen Spielen, für eigene Programmierexperimente und für die gelegentliche Textverarbeitung nutzen wollte, konnte mit einem Apple II mehr anfangen. Interessant waren auch ein VIC 20 (in Deutschland unter dem Namen VC 20 verkauft) oder ein Atari 800. Diese beiden gehörten zur neuen Rechnerklasse der Heimcomputer, deren bekanntester Vertreter der Commodore 64, kurz C64, werden sollte, und die wir uns im kommenden Kapitel genauer anschauen wollen.
Die Heimcomputer der 8-Bit-Ära
Mit den Heimcomputern dringen wir in den Bereich der Computergeschichte vor, der heute unter dem Schlagwort „Retro Computing“ viele begeisterte Anhänger hat. Die Retro-Fans basteln an den alten Rechnern herum, schreiben neue Software und Spiele für dreißig Jahre alte Computer und schwelgen in Erinnerungen an ihre Kindheit und Jugend, als sie mit diesen Rechnern ihre ersten Schritte in der Computerwelt machten, ihre ersten eigenen Programme schrieben und als sie auf dem Schulhof die neusten Spiele mit ihren Kumpels tauschten. Viele Bücher über Computergeschichte legen ihren Fokus genau auf diese Epoche der Rechnergeschichte, beschreiben alle Geräte ganz genau und erzählen Geschichten und Anekdoten über die Herstellerfirmen, die Entstehung der Geräte und über die damalige Nutzerszene. In diesem Buch wird dieses Kapitel allerdings wohl eines der kürzesten werden. Dafür gibt es einen persönlichen und einen fachlichen Grund: Der persönliche Grund ist, dass ich kein Spieler bin. Der fachliche und wohl auch der wichtigere Grund ist, dass diese Geräte zwar für viele der Einstieg in die Computerwelt waren, sie in Bezug auf die Nutzungsschnittstellen aber nur wenig Neues brachten.
1981, als der IBM PC begann, in die Bürowelt vorzudringen, gab es in den meisten heimischen Wohnungen noch keine Computer. Die am Markt angebotenen Computer waren nicht gerade günstig (Apple II), nicht gut für Spiele geeignet (Commodore PET) oder sogar keines von beidem (IBM PC). Seit einigen Jahren waren aber die ersten Spielekonsolen von Atari und Activision auf dem Markt. Sie boten gute Grafik- und Soundfähigkeiten und wurden einfach an den heimischen Fernseher angeschlossen. Spiele wurden als Steckmodule, sogenannte „Cartridges“, ausgeliefert. Die Bedienung war dadurch sehr einfach. Um ein Spiel laufen zu lassen, musste man nur die Konsole an den Fernseher und die Controller an die Konsole anschließen, ein Modul einstecken und das Ganze einschalten. Umfangreiches Wissen über Computertechnik war nicht nötig. Die Spielekonsolen wurden im Laufe der Jahrzehnte natürlich weiterentwickelt. Es gibt sie auch heute noch und nach wie vor zeichnen sie sich dadurch aus, dass sie vergleichsweise einfach zu bedienen sind und keine besonderen Computerkenntnisse erfordern. Die frühen Spielekonsolen waren ein Grundstein der nun aufkommenden Heimcomputer, die sich dann unabhängig von ihnen weiterentwickelten.
Im Jahr 1979 bereits brachte Atari die Computer Atari 400 und Atari 800 auf den Markt. Die beiden Rechner waren im Prinzip Atari-Spielekonsolen mit eingebauter Tastatur, wobei gerade die Tastatur des Atari 400 für effektives Tippen nicht geeignet war, denn es handelte sich um eine Folientastatur wie man sie heute allenfalls noch von älteren und billigen Fernbedienungen kennt. Programme und Spiele für die Atari-Computer erschienen in Form von Einsteckmodulen. Wenn man so ein Einsteckmodul hatte, öffnete man die Klappe oberhalb der Tastatur, setzte das Modul ein und startete den Rechner. Wie bei den Spielekonsolen wurde das Programm sofort gestartet und konnte direkt verwendet werden. Die meisten Module waren natürlich Spiele, es gab aber auch ein Textverarbeitungsmodul und einen BASIC-Interpreter. Steckte man dieses Modul ein und startete das Gerät, startete das Atari BASIC und man konnte, wie auf einem Commodore PET oder Apple II, eigene Programme erstellen.

Wenn man mit dem Computer in BASIC programmierte, musste man die Programme natürlich abspeichern und laden können. Hierfür musste man einen Programmrekorder erwerben. Dabei handelte es sich um einen Kassettenrecorder für handelsübliche Musikkassetten, allerdings mit zusätzlicher Elektronik, sodass die Codierung der Daten in Töne und die Decodierung der Töne in Daten schon im Gerät vorgenommen wurde. Auf eine Musikkassette mit dreißig Minuten Länge (also einer Seite einer 60er-Kassette) passten 50 KB Daten. Da die Kassette in ihrer normalen Geschwindigkeit abgespielt wurde, hieß das natürlich, dass das Laden von 50 KB Programm ganze dreißig Minuten gedauert hätte. So lange musste man aber nie warten, denn die Rechner verfügten nur über 8 KB Arbeitsspeicher, was die mögliche Programmgröße selbstredend beschränkte. Auch ein Diskettenlaufwerk war verfügbar, das natürlich einen schnelleren Zugriff bot und pro Diskette insgesamt 180 KB, also 90 KB pro Diskettenseite, speichern konnte.
Die Atari-Computer blieben nicht die einzigen Computer dieser Art. Atari selbst baute ab 1983 die Computer 600XL und 800XL, die mit 16 bzw. 64 KB Arbeitsspeicher ausgerüstet waren und das Atari BASIC bereits integriert hatten. Bereits 1980 erschien der VIC 20 der Firma Commodore (in Deutschland VC 20 genannt). Gegenüber den Atari-Rechnern war er ziemlich eingeschränkt. Er konnte nur etwa 22 Zeilen à 23 Zeichen Text auf den Bildschirm bringen und hatte keinen richtigen Grafikmodus. Aufgrund seines günstigen Preises fand er aber durchaus Verbreitung. 1982 folgte auf den VIC 20 der Heimcomputer der 1980er schlechthin9, der Commodore 64, kurz C64. Er wurde bis 1994 gebaut.
Der Commodore 64 (C64)
Commodore hatte 1977 den Commodore PET auf den Markt gebracht. Dieser wuchtige Rechner mit integrierter Tastatur und integriertem Bildschirm war vor allem für Schulen und Unternehmen interessant. Mit dem VIC 20 verfügte Commodore 1980 dann über einen Computer, der für Arbeit und Programmierung eher weniger geeignet, dafür aber günstig und dank einfacher Grafik- und Soundoptionen spieletauglich war. Ganz in dieser Linie stand auch der Commodore 64, kurz C64, der 1982 erschien. Der Rechner wurde unter der Maßgabe entwickelt, günstiger als ein Apple II zu sein, eine komfortable Programmierung zu ermöglichen und vor allem auch durch die Unterstützung von Grafik und Sound gut für Spiele geeignet zu sein und damit auch Atari den Rang ablaufen zu können.

Wie konnte man beim C64 etwa gegenüber einem teuren Apple II etwas einsparen, um günstiger zu sein? Sparen konnte man sich zum Beispiel den Monitor, denn jeder Nutzer hatte bereits einen Monitor zu Hause, nämlich den heimischen Fernseher. Der C64 wurde also wie zuvor schon der VIC 20 an das Fernsehgerät daheim angeschlossen. Dieser erledigte auch gleich die Klangwiedergabe, es brauchte also keinen eingebauten Lautsprecher. Dass durch die Fernsehausgabe die Auflösung eingeschränkt war, war für den Einsatzzweck im Heimbetrieb weniger problematisch. Der C64 war nicht der Rechner zum Verfassen von Serienbriefen oder für umfangreiche Tabellenkalkulation. Diesen Bereich überließ man gerne anderen oder bot mit den Nachfolgern des PET selbst entsprechende Geräte an.
| RAM | Zeichen | Textfarben | 2 | 4 | 16 | Sound | |
|---|---|---|---|---|---|---|---|
| C64 | 64 KB | 40 | 16 | 320 x 200 | 320 x 200 | 320 x 200 | 3 Stimmen, moduliert |
| IBM PC | 16/64 KB | 80 | 16 | 640 x 200 | 320 x 200 | 160 x 120 | 1 Stimmen-Beeper |
Der C64 war ein sehr attraktives Gerät. Obige Tabelle zeigt einige technische Eigenschaften des Commodore 64 und des IBM PC 5150 im Vergleich. Wie Sie sehen, war der PC tatsächlich nur in den eher für Büroeinsatz wichtigen Eigenschaften im Vorteil: Es konnten im Textmodus achtzig Zeichen pro Textzeile und im Grafikmodus bei zwei Farben eine Auflösung von 640 x 200 Pixeln erreicht werden. Der Commodore 64 hingegen erlaubte die Darstellung von sechzehn Farben im Text- und im Grafikmodus bei einer Auflösung von 320 x 200 Pixeln. Der PC konnte bei dieser Auflösung nur vier Farben anzeigen. Aus ganz verschiedenen Welten waren die Klanggeneratoren der Systeme. Der PC hatte nur einen einstimmigen Piepser, der C64 hingegen einen dreistimmigen Synthesizer, der für ein durchaus hörenswertes Klangerlebnis sorgen konnte.

Schaltete man einen Commodore 64 ein, startete sofort ein BASIC-Interpreter. Verwendet wurde das gleiche BASIC, das Commodore auch schon beim PET verwendet hatte, also ein BASIC-Dialekt von Microsoft. Ein Besitzer eines C64 konnte sofort nach dem Einschalten BASIC-Befehle eingeben und etwa wie auf der Abbildung oben die einfache Berechnung 5+3*7 durchführen. Auch mit der Programmierung eines richtigen BASIC-Programms konnte sofort begonnen werden. Der C64 verfügte, wie auch schon der PET, über einen komfortablen Editor für die BASIC-Programmierung. Der Cursor ließ sich frei auf dem Bildschirm bewegen. Da die Ausgabe einer Zeile im BASIC-Listing der Definition ebendieser Zeile entspricht, ließ sich das Programm komfortabel bearbeiten, indem im Listing in die entsprechende Zeile navigiert, die Ausgabe dort verändert und die geänderte Zeile durch das Drücken von „Return“ zur Neueingabe gemacht wurde. Andere Rechner wie der Apple II unterstützten dies grundsätzlich zwar auch, doch war die Bewegung des Cursors dort nur sehr umständlich durch die Eingabe von Tastenkombinationen zu erreichen.
Auch die in BASIC erstellten Programme konnten die Vorteile eines Text-Bildschirms ausnutzen. Der Bildschirm ließ sich löschen, Farben konnten verwendet werden und der Cursor ließ sich durch das Programm frei positionieren. Eigenartigerweise gab es trotz der herausragenden Grafik-Soundchips des C64 keine BASIC-Befehle zur Grafik- und Klangausgabe. Programmierer mussten sich behelfen, indem sie mit dem Befehl POKE direkt Werte in Speicherbereiche des Computers schrieben. Dies funktionierte zwar, brachte den Programmierer aber eigentlich unnötig nah an die Hardware-Ebene.
Wie beim Atari 800, beim Apple II, dem PET und dem TRS-80 gab es auch beim C64 die zwei Varianten des Massenspeichers, die in den 1980er Jahren üblich waren. Die günstigere, aber langsame Variante war die Nutzung von handelsüblichen Musikkassetten. Das zugehörige Abspielgerät wurde von Commodore „Datassette“ genannt. Auf ein dreißigminütiges Band konnten mit Bordmitteln 100 KB Daten gespeichert werden. Vielen Nutzern, Entwicklern und Bastlern war das allerdings zu wenig und zu langsam. Mit Hilfe von sogenannten „Turbo-Loadern“, die es sowohl in Hardware- als auch in Software-Form gab, gelang es ihnen, bis zu 1 MB auf die Kassettenseite zu quetschen. Auch für den C64 gab es natürlich Diskettenlaufwerke. Erstaunlicherweise war die Verbreitung dieser Laufwerke national unterschiedlich. In Großbritannien etwa war die Kassette das Medium der Wahl, gerade, was Spiele für den C64 anging, in Deutschland waren beide Speichermedien anzutreffen und in den USA wurde ein C64 eigentlich nur mit Diskettenlaufwerken verwendet. Auf eine Seite einer Diskette passten 163 KB Daten. Auch die andere Diskettenseite konnte beschrieben werden. Dafür musste man die Diskette allerdings händisch umdrehen. Die Diskette konnte mit 400 Bytes pro Sekunde sagenhaft langsam gelesen werden. Eine ganze Diskette einzulesen, dauerte sage und schreibe sieben Minuten. Auch bei der Disketten-Nutzung gab es Schnell-Lader, die den Datendurchsatz auf 10 KB pro Sekunde steigern konnten.
Die meisten Computer der damaligen Zeit mussten mit einem eigenen Disk Operating System ausgestattet werden, um mit Disketten arbeiten zu können (Apple II, TRS-80, IBM PC) oder hatten ein solches integriert (etwa Atari 600XL/800XL). Bei den Commodore-Rechnern war das nicht so. Deren Betriebssystem unterstützte, genau schon wie das des PET und des VIC 20, Diskettenlaufwerke eigentlich überhaupt nicht. Wollte man Daten von der Diskette laden, musste man die Gerätenummer des angeschlossenen Geräts angeben. Bei Diskettenlaufwerken war das üblicherweise die Nummer 8. Dass es sich dabei dann um ein Diskettenlaufwerk handelte, war für den Rechner irrelevant. Man konnte ein Programm auf genau die gleiche Art und Weise – unter Angabe einer anderen Gerätenummer – auch von einer Schnittstelle lesen, an der zum Beispiel ein anderer Computer per Kabel angeschlossen war, der die Daten sendete. Für das System war es unerheblich, welche Art von Gerät auf der anderen Seite hing. Wie die Daten also von einer Diskette zu lesen waren, wie eine Diskette strukturiert war oder wie sie formatiert wurde, war keine Sache des Betriebssystems des C64. All diese Funktionen brachte Commodore direkt im Diskettenlaufwerk unter, das dadurch letztlich zu einem kleinen Computer für sich wurde. Diese von Commodore gewählte Architektur für den Diskettenzugriff klingt sehr sinnvoll, denn die konkrete Implementierung des Datenträgerzugriffs wurden so vom Computer und vom Betriebssystem abgekoppelt. Dies erlaubte grundsätzlich, verschiedenste Disketten- oder sogar Festplattenlaufwerke anzuschließen, die alle auf die gleiche Art und Weise hätten angesprochen werden können, solange sie nur über die gleiche Schnittstelle verfügten. Leider war diese Entkopplung in der Praxis aber gar nicht so toll, denn der C64 hatte nicht etwa eine abstrahierte Unterstützung von Diskettenlaufwerken als allgemeine Datenträger, sondern schlichtweg gar keine Unterstützung für sie.
Im Bild oben sehen Sie, wie am Commodore 64 ein Programm, hier das Programm „RATEN“ von Diskette geladen wurde. Dies gelang über den Befehl LOAD "RATEN",8. Wichtig ist der Zusatz ,8, die Angabe der Gerätenummer 8. Vergaß man diese zwei Zeichen, versuchte der C64 das Programm von Kassette zu laden. Auf die gleiche Art und Weise wie das Laden funktionierte das Speichern, also etwa mit SAVE "NEU",8. Diese beiden Operationen waren noch recht einfach und einleuchtend. Kompliziert wurde es aber, wenn man zum Beispiel ein Programm auf der Diskette löschen wollte. Der C64 kannte keinen Befehl dafür. Man musste also eine Verbindung zum Diskettenlaufwerk aufbauen, eine speziell formatierte Nachricht dort hinschicken und die Verbindung wieder schließen. Wollte man zum Beispiel das Programm „UNSINN“ löschen, ging das durch die Eingabe von OPEN 1,8,15,"S:UNSINN.PRG":CLOSE 1. Aus Nutzungsschnittstellen-Sicht war das natürlich ziemlich schrecklich. Statt mit virtuellen Objekten umzugehen, diese zu erstellen, zu löschen oder zu manipulieren, öffnete man Kanäle zu angeschlossenen Geräten und schickte diesen kryptische Nachrichten. Man begab sich also für so alltägliche Operationen wie das Löschen, Kopieren oder Umbenennen von Dateien ganz tief hinab in die Technik des Computers bzw. des Diskettenlaufwerks. Diesen Missstand dürften viele der Besitzer des Rechners aber wohl gar nicht bemerkt haben, sie steckten nur eine Diskette ein und gaben LOAD "*",8,1 ein, um das erste Programm auf der Diskette direkt zu laden und zu starten und schon konnten sie ihr Lieblingsspiel spielen.
Die Rolle der 8-Bit-Heimcomputer
Mit den Heimcomputern der 8-Bit-Ära drangen Computer in die Wohn- und Kinderzimmer vor, was natürlich zu einem nicht geringen Anteil daran lag, dass sie mit ihren Grafik- und Soundfähigkeiten gut für Spiele geeignet waren und dass sich diese Spiele, wenn sie auf Kassette oder Diskette verbreitet wurden, gut kopieren ließen. Dadurch, dass die Geräte beim Einschalten mit einem BASIC-Interpreter starteten und damit einen schnellen Zugang zur Programmierung boten, hat aber auch so mancher, der den Computer zum Spielen angeschafft hatte, auch das Programmieren erlernt und kleine Programme für die Probleme des Alltags oder der Hobbys gebaut. Betrachtet man die Rechner aus der Nutzungsschnittstellen-Perspektive, brachten sie nichts wirklich Neues. Im Gegenteil: Sie hinkten Betriebssystemen wie CP/M oder auch dem DOS des Apple II sogar hinterher.
Die Heimcomputer entwickelten sich natürlich weiter. Die Nachfolgegeneration der 8-Bit-Computer von Commodore und Atari war nicht nur eine aufgemotzte Variante dieser Geräte, sondern auch stark beeinflusst vom Apple Macintosh. Der Commodore Amiga und der Atari ST waren somit gleichermaßen Nachfolger der auf Spiele fokussierten 8-Bit-Computer und Konkurrenten für die Bürocomputer Macintosh und IBM PC. Gleichzeitig wurden die IBM PCs mit besserer Grafik und besserem Sound stetig spieletauglicher und fanden mit sinkenden Preisen auch ihren Platz auf manch heimischem Schreibtisch. Die Zeit der an den Fernseher angeschlossenen Computer ging zu Ende und die Unterscheidung zwischen typischen Heim- und Bürocomputern schwand zusehends.
Schreibtisch mit Fenster
Machen wir uns klar, wo wir in der Geschichte des Personal Computers inzwischen angekommen sind. Aus den bescheidenen Anfängen Mitte der 1970er hat sich eine beeindruckende Industrie entwickelt. Versetzen wir uns zum Beispiel ins Jahr 1983: Heimprogrammierer und Spieleliebhaber bekamen für ein überschaubares Budget einen Commodore 64 oder einen Atari 800XL. Wer mehr Geld ausgeben konnte, besorgte sich einen Apple II. Auch manche Schule und kleinere Firma rüstete sich mit den Apple-Rechnern aus. Für Firmen attraktiv war natürlich auch der IBM PC, inzwischen in seiner zweiten Ausführung PC XT. Viele andere Hersteller wie Compaq boten Nachbauten des IBM PCs für kleines Geld an. Nahezu alle genannten Rechner waren grafikfähig. Die Grafikfähigkeiten wurden genutzt, um etwa Diagramme auszugeben, Grafiken anzuzeigen und natürlich, um Spiele möglich zu machen. Teil der Nutzungsschnittstelle der Betriebssysteme und der Software wurde die Grafik noch nicht. Die Betriebssysteme blieben textterminal-basiert. Populäre Software nutzte allerdings die Möglichkeit, mit Textzeichen den Bildschirm räumlich zu strukturieren. Wie das geschah, war nicht standardisiert. Jeder Software-Hersteller kochte im Prinzip sein eigenes Süppchen, sodass sich jede Anwendung anders bediente. 1984 wurde ein Computer auf den Markt gebracht, der dies änderte. Seine Nutzungsschnittstelle setzte auf Grafik und die Firma, die den Rechner herstellte, stellte Ressourcen und Vorgaben bereit, die dafür sorgten, dass alle Software-Programme eine einheitliche Nutzungsschnittstelle erhielten. Dieser Rechner war der Apple Macintosh. Seine Nachfahren, heute nur noch „Mac“ genannt, kennen wir noch immer als größte Konkurrenz zu Rechnern mit Microsoft Windows. Der Macintosh war der erste wirtschaftlich (mehr oder weniger) erfolgreiche Rechner, dessen Nutzungsschnittstelle das WIMP-Paradigma (Windows, Icons, Menus und Pointer) verwendete und dessen zentrales Konzept der sogenannte Desktop war. Um die Geschichte dieser Art der Nutzungsschnittstellen geht es in diesem Kapitel, denn die Wurzeln des Macintosh und seiner Nutzungsschnittstelle reichen weit in die Computergeschichte zurück. Sie liegen in experimentellen Rechnern der 1960er und 1970er Jahre. Auch die Computermaus fand in diesen Jahrzehnten ihren Anfang.
Das Zeigegerät – Die Geschichte der Maus
Eine Nutzungsschnittstelle mit verschiebbaren Fenstern, auswählbaren Icons und aufklappbaren Menüs kann nicht effektiv mit einer reinen Text-Tastatur verwendet werden. Sie verlangt vielmehr nach einem Eingabegerät, das eine räumliche Auswahl ermöglicht. Nun wird das Aufkommen von Computern mit Nutzungsschnittstellen genannter Art meist, und das auch zu Recht, mit der Maus als Eingabegerät verbunden. Sie wissen aber aus dem Kapitel über experimentelle grafische Systeme, dass es räumliche Eingabemethoden schon sehr lange gab und dass die Maus nicht den Anfang machte. An SAGE und Sketchpad haben Sie nämlich Lichtgriffel (Lightpens) als Eingabegeräte kennengelernt. Ebenfalls früh in Betracht gezogen, hier allerdings nicht betrachtet, wurden Joysticks als Eingabegeräte, um die Auswahl eines Bildschirmobjektes zu ermöglichen. Die Computermaus brachte gegenüber Lichtgriffel und Joystick Vorteile durch ihre Eigenschaft, sehr genaue und präzise Selektionen und Manipulationen zu ermöglichen, dabei aber nicht sehr ermüdend zu sein.
Beim Versuch, die Anfänge der Computermaus herauszubekommen, geraten wir wieder in eine Situation, in der man sich streiten kann, wer die erste Maus erdacht, erfunden und auf den Markt gebracht hat und wieder, wie schon bei der Frage nach dem ersten Computer, wird die Frage meist je nach nationaler Brille auf dem Kopf des Fragestellers unterschiedlich beantwortet.
Wir kennen Computermäuse als kleine, kästchenartige Gebilde, die über eine Tischoberfläche geschoben werden können und deren Bewegungen eine korrespondierende Bewegung eines Zeigers am Bildschirm auslösen. Heutige Mäuse funktionieren meist rein optisch. In den 1980er und 1990er Jahren waren hingegen Mäuse verbreitet, in denen sich eine Kugel mechanisch drehte. Diese Kugel war in der Maus so gelagert, dass ihre Bewegung mit der Bewegung des Gerätes über die Tischoberfläche korrelierte. Die Idee, die Rotation einer Kugel mechanisch abzutasten und als Eingabe zu nutzen, ist allerdings älter als interaktive Computer und damit auch älter als die Maus. Bereits in den 1950er Jahren wurden sogenannte „Trackballs“ in der Radartechnik eingesetzt. Ein solcher Trackball war, wie der Name sagt, eine Kugel (ball), deren Bewegung nachvollzogen (tracked) wird. Trackballs wurden in die Oberfläche der Radarstation eingelassen. Radar-Operatoren konnten die Kugel dann mit der Hand bewegen, um etwa die Bewegung eines Auswahlkreuzes auf dem Radarschirm zu steuern.
Unter den Firmen, die derartige Bedienkonsolen für die Luftraumüberwachung mit Trackball herstellten, war auch die deutsche Firma Telefunken. Telefunken deutschte den Begriff „Trackball“ ein und nutzte den wunderschönen Begriff „Rollkugelsteuerung“. Im Angebot der Firma war Ende der 1960er und Anfang der 1970er Jahre eine Großrechnerserie namens TR-440. Sie fand Einsatz in vielen Universitäten, was unter anderem daran lag, dass ihre Anschaffung durch öffentliche Gelder unterstützt wurde. In den allermeisten Einrichtungen dürfte der Rechner seinerzeit im typischen Batch-Betrieb genutzt worden sein, um eine Massennutzung zu ermöglichen. Allerdings war auch eine interaktive und sogar eine grafische Nutzung des Rechners möglich. Telefunken bot dazu einen sogenannten „Satellitenrechner“ namens TR-86 an. Die Aufgabe dieses Rechners war die Abwicklung der Ein- und Ausgabe, die damit vom eigentlichen Großrechner abgetrennt wurde, denn schließlich konnte man es nicht rechtfertigen, dass ein ganzer Großrechner seine Rechenzeit dafür „verschwendete“, dass ein Nutzer etwas eintippte. An den Satellitenrechner konnten Terminals angeschlossen werden. In der Produktpalette von Telefunken fand sich neben Text-Terminals auch ein grafisches Terminal mit der Bezeichnung SIG 100 (SIG für Sichtgerät). Das SIG 100 bestand aus einem Schwarz-Weiß-Fernseher und einer angebauten Tastatur. An dieses Sichtgerät wiederum konnte eine eigene Version der Rollkugelsteuerung mit der Bezeichnung RKS 100-86 angeschlossen werden.
Die Rollkugelsteuerung RKS 100-86 – ich nenne sie im Folgenden kurz „Rollkugel“ – funktionierte im Prinzip genauso wie die Rollkugelsteuerung der Radargeräte, allerdings mit einem wichtigen Unterschied: Die Rollkugel an den Radargeräten war fest in die Bedienkonsolen integriert. Für den Einsatz am SIG 100 war das nicht geeignet, denn dieses war ein Gerät, dass man auf vorhandene Tische stellen sollte. Einen Trackball in diese Tische einzulassen, passte nicht ins Konzept. Man drehte die Rollkugel also kurzerhand um und baute sie in ein Gehäuse, das über den Tisch geschoben werden konnte.


Oben sehen Sie die Abbildung einer dieser Rollkugelsteuerungen. Das Gerät ist größer als das, was man von heute kennt und als einen das Foto erahnen lässt. Die Halbkugel, die über den Tisch geschoben wird, hat einen Durchmesser von zwölf Zentimetern. Man bediente sie also, indem man die ganze Hand darauflegte. Dabei musste man darauf achten, nicht versehentlich den Knopf auf der Oberseite zu drücken. Wenn man die Rollkugel über den Tisch schob, bewegte sich im inneren des Geräts eine Kugel. Wie Sie auf der unteren Abbildung sehen, wird die Rotation der Kugel an zwei Bauteile übertragen, die ein bisschen an Fahrrad-Dynamos erinnern. Diese Bauteile sind sogenannte „Encoder“, die die Bewegung der Kugel in einen 8-Bit-Code übertragen, der dann über ein Kabel nach außen geführt wird.
Der Telefunken-Ingenieur Rainer Mallebrein entwickelte die Rollkugel ab 1965. Ab 1968 konnte man sie als Zubehör für das Sichtgerät erwerben. Oft verkauft wurde sie allerdings nicht. Keine fünfzig Exemplare wurden hergestellt. Die Zeit für diese Art von Eingabegeräten war noch nicht gekommen, denn nur wenige verwendeten einen zwanzig Millionen Mark teuren Großrechner interaktiv und noch weniger hatten Verwendung für eine grafische Ein- und Ausgabe. Entsprechend gering war natürlich die Menge der Software, die überhaupt mittels Rollkugel bedienbar war. Spätere Rechner von Telefunken unterstützten die Rollkugel daher nicht mehr – das innovative Eingabegerät geriet in Vergessenheit. Hiermit endete die deutsche Geschichte der Computermaus, die nicht einmal so hieß.
Am Stanford Research Institute (SRI) entwickelten etwa ab 1963 der Informatiker Douglas Engelbart und seine Kollegen des Augmentation Research Centers, dessen Leiter Engelbart war, ein experimentelles Computersystem namens oNLine-System, kurz NLS. In einer Selbstdarstellung10 beschreiben Engelbart und Co. das Projekt folgendermaßen:
Viewed as a whole, the program is an experiment in cooperation of man and machine. The comprehensible part of man’s intellectual work involves manipulation of concepts, often in a disorderly cut-and-try manner, to arrive at solutions to problems. Man has many intellectual aids (e.g., notes, files, volumes of reference material, etc.) in which concepts are represented by symbols that can be communicated and manipulated externally. We are seeking to assist man in the manipulation of concepts–i.e., in his thinking, by providing a computer to aid in manipulation of these symbols. A computer can store and display essentially any structure of symbols that a man can write on paper; further, it can manipulate these symbols in a variety of ways. We argue that this service can be made available to help the on-going intellectual process of a problem-solving man; the service can be instantly available to perform tasks ranging from the very smallest to the very largest.
Dieser Text wurde 1965 geschrieben. Für diese Zeit war das, was beschrieben wurde, absolut außergewöhnlich, denn es wurde ein Computersystem beschrieben, das interaktiv genutzt werden konnte. 1965 wurden, wie Sie inzwischen wissen, die wenigsten Rechner so betrieben, und ein interaktiver Betrieb von leistungsstarken Rechnern kam schon mal gar nicht infrage. Nur militärische und einige experimentelle Systeme wurden so genutzt. Es war die Rede von einem System, das den Menschen beim Denken unterstützen sollte, indem es einen dynamischen Umgang mit Symbolen am Bildschirm erlaubte. Im weiteren Textverlauf erfährt man, dass dies nicht nur für einzelne Nutzer, sondern auch kollaborativ möglich sein sollte. Engelbart und seine Kollegen beschrieben viele faszinierende Techniken, wie das Verknüpfen von Texten miteinander, die Einteilung eines Bildschirms in verschiedene Bereiche und die räumliche Auswahl von Operationen am Bildschirm. Damit das alles möglich war, brauchte es natürlich einen leistungsfähigen Computer, aber eigentlich gab es solche Computer in vertretbarer Größe und mit vertretbarem Budget noch gar nicht. Engelbart und seine Kollegen nutzten daher letztlich einen universitären Großrechner einfach so wie einen modernen PC.

Eines der Konzepte von NLS war es, die Nutzer keine Funktionsnamen eingeben zu lassen, sondern die Funktionen am Bildschirm zur Auswahl anzubieten. Damit das möglich war, brauchte es etwas, was Engelbart und Kollegen „Operand Selecting Device“ nannten. Die Gruppe testete eine Reihe von Geräten, die zu diesem Zweck verwendet werden konnten, darunter auch Joysticks und die von SAGE und Sketchpad bekannten Lichtgriffel. Als das vielversprechendste Eingabegerät stellte sich ein Konstrukt namens „Mouse“ heraus11, deren ersten Prototypen sie 1964 selbst entwickelt hatten. Gegenüber dem Lichtgriffel hatte die Maus vor allem den Vorteil, dass nicht direkt auf den vertikalen Bildschirm gezeigt werden musste, was sehr ermüdend sein konnte und auch den Nachteil hatte, dass man stets den Inhalt mit den eigenen Fingern verdeckte. Bei der Maus wird stattdessen ein „bug“, wir würden heute „Mauszeiger“ sagen, auf dem Bildschirm positioniert.
Auf dem Bild sehen Sie einen Nachbau des frühen Maus-Prototypen. Wie Sie sehen, handelte es sich um ein erheblich einfacheres Gerät als die deutsche Rollkugel. Auf der Unterseite der Maus befanden sich zwei Rollen. Diese Rollen waren so gestaltet, dass sie sich drehten, wenn die Maus längs der Rolle bewegt wurde, und einfach rutschten, wenn die Bewegung quer zur Rolle erfolgte. Die Bewegung der Maus wurde in NLS in eine Bewegung des „bug“ auf dem Bildschirm umgesetzt. Vorgestellt wurde die Maus 1968 in der „Mother of All Demos“, bei dem auch die anderen innovativen Features des Systems präsentiert wurden.
Wir haben nun eine deutsche und eine amerikanische Maus. Beide wurden unabhängig voneinander entwickelt. Die deutsche Rollkugel wurde zur Marktreife gebracht und war erheblich solider gebaut – sie war allerdings kein Erfolg und geriet in Vergessenheit. Unter anderem mag das daran gelegen haben, dass die Rollkugel für ein System entwickelt wurde, für das eine grafisch-räumliche Bedienung allenfalls eine Ausnahme war. Engelbarts Maus war seinerzeit eher ein „Proof of Concept“. Das System, an dem sie eingesetzt wurde, war allerdings eines, das stark auf die grafisch-räumliche Bedienung ausgerichtet war. Auch wenn Engelbarts Maus noch kein fertiges Produkt war und auch seine direkten Weiterentwicklungen keine Verbreitung außerhalb des SRI hatten, haben seine Entwicklungen am NLS mehr Einfluss auf die weitere Nutzungsschnittstellen-Entwicklung gehabt, als die Rollkugel von Telefunken, denn viele, die an der Maus des NLS mitentwickelten, landeten später am Xerox PARC, wo die Maus zum zentralen Eingabegerät innovativer Computer wurde. Dieser größere Einfluss schmälert die Entwicklungsleistung von Herrn Mallebrein und seinen Kollegen nicht im Geringsten, es zeigt vielmehr, wie sehr es manchmal eine Frage der Begleitumstände oder letztlich sogar ein wenig des Zufalls ist, welche technischen Entwicklungen sich durchsetzen und welche nicht.
Das Experiment – Der Xerox Alto

Die ersten grafischen Nutzungsschnittstellen der Art, wie wir sie auch heute noch verwenden, wurden am Xerox PARC entwickelt. Anders als in Deutschland ist Xerox (gesprochen etwa „Sie-Rocks“) in den USA ein Name, den absolut jeder kennt. Die Firma hat ihren Namen von der Trockenkopie, die im Englischen „Xerography“ genannt wird. Xerox hielt das Patent an dieser Kopiertechnik, auf der alle modernen Fotokopierer und Laserdrucker basieren. Der Firmenname „Xerox“ wird in den USA so sehr mit Fotokopien verbunden, wie Google mit Websuche und bei uns in Deutschland Zewa mit Küchenrollen. „A Xerox“ ist dort ein Ausdruck für eine Fotokopie und „to xerox“ steht für das Fotokopieren. Innovationen in der Computer- und Nutzungsschnittstellen-Technik erwartet man nun nicht unbedingt bei einer Firma, die Kopierer herstellt, doch gerade diese Firma gründete eines der wichtigsten Forschungsinstitute für innovative Nutzungskonzepte und Computer. Xerox wollte auch in der Zukunft der Büro- und Informationstechnik mit von der Partie sein und gründete daher 1970 das Xerox Palo Alto Research Center (Xerox PARC). Bemerkenswert an der Philosophie von Xerox war, dass die Forscher, die am PARC beschäftigt waren, in dem, was sie taten und woran sie forschten, im Prinzip völlig frei waren. Das Resultat war eine unglaubliche Kreativität und Innovationskraft. Wenn man sich die Liste dessen anguckt, was alles am PARC entwickelt und konzipiert wurde, kann man manchmal den Eindruck gewinnen, dass nahezu alle moderne Computertechnik, die wir heute noch nutzen, dort ihren Anfang nahm. Zentrale Konzepte der Objektorientierung, einer Programmiertechnik, wurden am PARC entwickelt, der Ethernet-Standard stammt vom PARC, der Laserdrucker und vieles, vieles mehr.
Eines der frühen zentralen Projekte am Xerox PARC war die Entwicklung des Alto. Die ersten Konzepte zu diesem Rechner wurden schon 1972 entwickelt und im März 1973 wurde der erste Alto fertiggestellt. Der Alto war wohl der erste Computer, sieht man mal von NLS ab, der für seine Bedienung im großen Stile auf die Maus setzte. Er nimmt damit und vor allem mit der für ihn entwickelten Software eine sehr wichtige Rolle in der Entwicklung der grafischen Nutzungsschnittstelle ein. Erstaunlicherweise wird er in vielen Computergeschichten entweder vergessen oder mit dem Xerox Star von Anfang der 1980er Jahre in einen Topf geworfen. Für diesen und quasi für alle grafischen Nutzungsschnittstellen, die in den 1980er-Jahren folgten, war der Alto ein Grundstein, aber er war eben doch etwas eigenes, das es sich zu betrachten lohnt.
Eine Dokumentation des PARC aus dem Jahr 1974 beschreibt den Xerox Alto als „personal computer system“12. Eine interessante Wortwahl, denn üblicherweise lässt die Computergeschichte die Personal Computer ja mit dem Altair im Jahr 1975 beginnen. Die Entwickler bei Xerox verraten uns in der Dokumentation, was sie unter einem personal computer verstehen:
By ‘personal computer’ we mean a non-shared system containing sufficient power, storage and input-output capability to satisfy the computational need of a single user.
Diese Definition hätte später auch ziemlich gut auf IBMs Personal Computer von 1981 gepasst, denn Xerox zielte hier darauf ab, dass der Computer von einer einzelnen Person genutzt wird und quasi komplett für diese zur Verfügung steht. Dass der Computer dieser Person auch gehört im Sinne der Personal-Computer-Idee beim Altair, wurde hier nicht erwähnt und war wohl auch nicht das, was Xerox sich vorstellte, denn am PARC sollten ja die Bürocomputer der Zukunft entwickelt werden. Günstige Heimcomputer hatte man nicht im Blick13.
Technisch gesehen handelte es sich beim Xerox Alto um einen Minicomputer. Üblicherweise standen auf einem Tisch Bildschirm, Tastatur und die vom NLS-Projekt übernommenen Eingabegeräte Maus und „Chord Keyset“, einer Fünf-Finger-Tastatur. Diese Zusatztastatur war für die Bedienung der Alto-Programme sehr wichtig, da sie mit wichtigen Programmfunktionen belegt wurde. In der Regel unter dem Tisch stand die Prozessoreinheit in der Größe eines durchschnittlichen Kühlschranks. Ein Alto war für die damalige Zeit mit einem Minimum von 128 KB und einem Maximum von 512 KB mit sehr viel Speicher ausgestattet. In den Rechner waren zwei Wechselplattenlaufwerke eingebaut. Jede der Wechselplatten fasste 2,5 MB Daten. Der Bildschirm des Alto wurde hochkant verwendet, was auf die intendierte Nutzung als Bürorechner zurückzuführen ist, denn der Hochkant-Bildschirm kann den kompletten Inhalt eines Papierblattes anzeigen. Der Alto zeigte auf dem Bildschirm Inhalte im Grafikmodus an. Die Anzeige war rein schwarz-weiß (ohne Grautöne) mit einer für die damalige Zeit extrem hohen Auflösung von 606 x 808 Bildpunkten.
Wo Sie nun von den technischen Gegebenheiten dieses Rechners erfahren haben, erwarten Sie wahrscheinlich, dass er mit einem innovativen Betriebssystem mit einer spannenden Nutzungsschnittstelle ausgeliefert wurde. Wenn Sie sich nun das Grundsystem des Alto ansehen würden, wären Sie wahrscheinlich enttäuscht, denn der Computer verfügte über eine Kommandozeile mit der typischen Charakteristik dieser Interaktionsform. Interessant für uns sind nicht die Eigenschaften dieser Kommandozeile, sondern die Anwendungsprogramme, die am PARC für den Alto entwickelt wurden. Eigentlich all diese Programme hatten großen Einfluss auf das, was in den Jahrzehnten darauf kommen sollte. Hier eine nicht vollständige Aufstellung interessanter Programme:
Neptune: Ein Dateimanager mit zweispaltiger Darstellung und Datei- und Operationsauswahl per Mausbedienung. Neptune ist ein entfernter Vorgänger von heutigen Dateimanagern wie Explorer oder Finder.
Bravo (1974): Eine Textverarbeitung, die die Formatierung des Textes nicht nur grundsätzlich ermöglichte, sondern diesen auch direkt am Bildschirm anzeigen konnte. Bravo erlaubte die Verwendung verschiedener Schriftarten in einem Dokument und sogar die Einbindung von Bildern, die gleichzeitig mit dem Text am Bildschirm zu sehen waren. Bravo gilt allgemein als das erste Textverarbeitungssystem, das nach dem WYSIWYG-Prinzip arbeitete (What you see is what you get).

Gypsy (1975): Der Nachfolger von Bravo. Das Programm zeichnet sich durch eine „moduslose“ Oberfläche aus. Was das bedeutet, kann man sich am Verschieben eines Textblocks klarmachen. In einem modusbasierten System verschiebt man einen Textblock, indem man einen Verschiebemodus aktiviert. Das System bittet den Nutzer dann nacheinander, zunächst den zu verschiebenden Block zu markieren und dann die Stelle mit dem Zeiger anzufahren, an die man den Block verschieben möchte. Während der Modus aktiv ist, kann man mit dem Programm nur Text verschieben. Alle anderen Programmfunktionen stehen nicht zur Verfügung. Auch Bravo funktionierte noch so. In Gypsy wurde es nun anders gelöst. Eine spannende Erfindung in diesem Zusammenhang war etwas, was etwa dem nahekommt, was wir heute „Zwischenablage“ nennen. Gypsy verwendete den Begriff „Wastebasket“, was auf eine leicht andere Funktionsweise hindeutet. Der Wastebasket war dauerhaft am Bildschirm sichtbar. Die Bedienungsanleitung14 erläutert:
The Wastebasket has two lines but can be expanded at the expense of the document window. Whenever material is cut (deleted) it is put in the Wastebasket so that the operator can see what has been cut and have access to it for reinsertion.
Im Wastebasket landeten nur Inhalte, die aus dem Dokument gelöscht wurden. Für ein normales Kopieren oder Verschieben im Text war diese Ablage nicht notwendig. Man markierte bei gedrückter, rechter Maustaste den Ursprungstext und mit gedrückter, mittlerer Maustaste den Zielbereich. Drückte man nun die Taste PASTE auf der Fünf-Finger-Tastatur, wurde der Text von der Quelle in den Zielbereich kopiert – ganz ohne Wastebasket. Dieser konnte beim Einfügen aber durchaus ins Spiel kommen, denn da der vorher am Zielort vorhandene Text überschrieben wurde, landete dieser im Wastebasket und blieb damit verfügbar, um ihn gegebenenfalls an anderer Stelle wieder benutzen zu können.
Markup: Ein pixel-basiertes Grafikprogramm, ganz ähnlich dem späteren Apple Paint oder Microsoft Paint.
Draw: Ein Vektor-Grafikprogramm, das es ermöglichte, Texte, Figuren und Linien zu zeichnen. Alles Gezeichnete stand als Objekt zur Verfügung, konnte also auch als solches weiterverarbeitet und manipuliert werden.
Laurel und Hardy: Diese zwei E-Mail-Programme erlaubten nicht nur das Versenden von Nachrichten innerhalb des bürointernen Netzwerks (der Alto nutzte intensiv das ebenfalls am PARC entwickelte Ethernet), sondern sogar schon die Übertragung von Dokumenten und Zeichnungen.
Die Software des Alto war überaus innovativ. Mit dem Computer wurden frühe Erfahrungen damit gemacht, wie man die Grafikfähigkeit des Systems in der Nutzungsschnittstelle ausnutzte, indem man sowohl Elemente der Nutzungsschnittstelle als auch des zu bearbeitenden Inhalts am Bildschirm als räumliche Objekte darstellte und auch an Ort und Stelle bedienbar machte. Man kann die Leistung der Entwickler des Alto nur dann richtig würdigen, wenn man betrachtet, zu welchem Zeitpunkt die Geräte hergestellt und die Software programmiert wurde – nämlich in den frühen 1970er Jahren. Computernutzung bedeutete zu dieser Zeit in aller Regel Programmierung mit Lochkarten im Batch-Betrieb oder Terminal-Betrieb mittels Fernschreiber und Kommandozeile. Die räumlich-grafische Software des Alto war hier der Einstieg in eine ganz andere Welt.
Die Welt in Fenstern – Die Smalltalk-Umgebung
Von der einen Nutzungsschnittstelle des Xerox-Alto zu sprechen, ist eigentlich gar nicht sinnvoll möglich. Jedes der oben angesprochenen Anwendungsprogramme hatte seine ganz eigenen Arten der Steuerung und der Objekt-Interaktion. Verwendet man die Programme heute, kommt einem die Bedienung durchaus kompliziert und ungewohnt vor. Es gab noch nicht das heute quasi universelle Konzept von Buttons, Menüs, Icons, Fenstern oder Scrollbars, doch auch diese Spielart der Nutzungsschnittstellen hat ihren Anfang am Xerox PARC und am Alto in der Smalltalk-Programmierumgebung.

Smalltalk ist zunächst einmal eine am Xerox PARC entwickelte Programmiersprache, die in der Geschichte der objektorientierten Programmierung eine wichtige Rolle gespielt hat. Auch das heute in der Programmierung viel verwendete Model-View-Controller-Konzept15 hat seine Ursprünge in Smalltalk. Smalltalk war aber weit mehr als nur eine Programmiersprache. Ab der Version Smalltalk 76 war die Sprache eng verbandelt mit der Umgebung, in der entwickelt wurde. Wie Sie auf der Abbildung sehen, bestand die Nutzungsschnittstelle der Smalltalk-Umgebung aus einem grauen Hintergrund, auf dem Fenster angeordnet werden konnten. Diese Fenster waren Sichten von Smalltalk-Objekten oder laufenden Smalltalk-Programmen. Sie ließen sich auf dem Hintergrund verschieben, in der Größe ändern und soweit zusammenfalten, dass nur noch ihr Label zurückblieb. Die Fenster verfügten, wenn nötig, auf der linken Seite über eine Scrollbar, mit der ein Ausschnitt aus dem Inhalt gewählt werden konnte. Ein Klick mit der mittleren Maustaste auf ein Smalltalk-Objekt – und in Smalltalk war im Prinzip alles ein selektierbares Objekt – öffnete ein Menü. Dieses Menü enthielt unter anderem stets den Eintrag „examine“. Wenn Sie diese Funktion aufriefen, erhielten Sie Zugriff auf die Definitionen des Objekts. Vereinfacht kann man sagen, Sie erhielten Zugriff auf die hinter dem Objekt stehende Programmierung und konnten diese auch verändern – und das im laufenden System.
Programmieren in Smalltalk war etwas ganz anderes als der Umgang mit Programmierumgebungen, wie Sie sie vielleicht heute kennen, etwa wenn Sie mit XCode oder mit Microsoft Visual Studio programmieren. Lassen Sie mich das an einem kleinen Beispiel klarmachen, das erläutert, wie Sie mit ihrem Computer umgehen könnten, wenn die Nutzungsschnittstelle Ihres Windows- oder Macintosh-Rechners so funktionieren würde wie die Smalltalk-Umgebung. Programmierer mögen mir meine Sprachwahl verzeihen; ich versuche, die Eigenschaften von Smalltalk zu verdeutlichen, ohne zu viel Programmier-Fachvokabular zu verwenden. Wenn Ihr Windows oder Ihr MacOS so funktionieren würde wie die Smalltalk-Umgebung, dann stünde alles, was Sie am Bildschirm als Objekt sehen, Ihnen auch in seiner dahinterstehenden Programmierung zur Verfügung und es wäre Ihnen möglich, diese Programmierung im laufenden Betrieb zu ändern. Nehmen wir an, Sie hätten immer ein Problem damit, dass Sie Buttons versehentlich auslösen. Sie könnten dem nun abhelfen, indem Sie sich in einem Programm, das einen Button hat, mit Hilfe der Programmierumgebung durchhangeln, bis Sie bei der Grundspezifikation eines Buttons angekommen sind. Diese ändern Sie nun so ab, dass ein Button zum Beispiel nur dann auslöst, wenn Sie auch die SHIFT-Taste auf der Tastatur drücken. Ab dem Zeitpunkt, an dem Sie diese Neudefinition durchgeführt hätten, würde sie gelten und zwar für alle Buttons im kompletten System. Das Besondere wäre hier nicht, dass Sie das Verhalten einer Standardkomponente ändern können – das können Sie grundsätzlich bei jeder Programmierung, wenn es zugegebenermaßen auch nicht sehr einfach ist – sondern, dass Sie das zur Laufzeit des Systems und für das ganze System machen könnten, dass Sie also keine Programme neu in Maschinencode übersetzen und neu starten müssten.
Sehr bemerkenswert war auch die Verbindung von Programmcode und formatierbarem Text im gleichen Dokument. Nehmen wir ein Fenster, das den Inhalt eines Dokuments am Bildschirm anzeigt. Der Text dieses Dokuments konnte im Fenster direkt formatiert werden, also etwa in verschiedene Schriftarten, Schriftgrößen, fett, kursiv und unterstrichen gesetzt werden. Das für sich ist zwar nicht trivial, aber auch nicht übermäßig interessant. Spannend ist aber, dass die Dokumente auch Smalltalk-Code enthalten konnten und dieser an Ort und Stelle ausgeführt werden konnte. Dazu musste der Text nur markiert, das Menü aufgerufen und der Programmcode mit „Do it“ direkt an Ort und Stelle ausgeführt werden.
Der Desktop – Xerox Star und Apple Lisa
Der Alto ist ein in der Computergeschichte gerne übersehener Meilenstein, dem ich hier natürlich auch nur in Streiflichtern gerecht werden konnte. Zentrale Konzepte aktueller grafischer Nutzungsschnittstellen inklusive der Vorgänger heutiger Standardsoftware wurden auf und mit diesem Computer entwickelt. Vieles war seiner Zeit voraus. Die Textverarbeitung Bravo und die Smalltalk-Umgebung (beide von 1976) sind hier besonders zu erwähnen. Aber: Der Rechner war sehr experimentell angelegt. Es wurden im Laufe der 1970er Jahre etwa 2.000 Geräte gebaut und größtenteils innerhalb von Xerox und dem PARC eingesetzt. Erst Ende der 1970er wurde der Rechner für 32.000 Dollar (2021: 118.000 Dollar) verkauft.
Es gehört zur populären Computergeschichte, dass dem Apple-Mitgründer Steve Jobs bei einem Besuch im Xerox PARC Anfang der 1980er Jahre Smalltalk gezeigt wurde und er so begeistert war, dass er das Design der sich in der Entwicklung befindenden Apple Lisa, die er verantwortete, komplett umkrempeln ließ. Die „Lisa“ wurde damit zu einem der ersten beiden kommerziell hergestellten Computersysteme mit der Desktop-Metapher. Bereits zwei Jahre bevor Apple seinen ersten Rechner mit der Desktop-Metapher vorstellte, brachte Xerox selbst allerdings das Xerox 8010 Information System auf den Markt. Die auf diesem Computer laufende Software hatte die Bezeichnung „Star“. Es hat sich jedoch eingebürgert, dass auch der Computer als solches als „Xerox Star“ bezeichnet wird.

Die Zielgruppe von Xerox Star und Apple Lisa waren nicht Techniker und schon gar nicht Computer-Bastler – für diese waren beide Computer viel zu teuer – sondern Menschen, die in ihrer Arbeit mit Dokumenten zu tun hatten, Texte schrieben, Illustrationen anfertigten oder Listen verwalteten. Diese Nutzer kannten sich in diesen Bereichen gut aus. Computertechnik war in den meisten Fällen nicht ihr Interesse. Star und Lisa waren daher die ersten beiden nennenswerten Computersysteme, die darauf ausgelegt wurden, von Nutzern bedient zu werden, die explizit nichts von Computern verstanden. Es dauerte ziemlich lange, bis es wieder Systeme gab, die den Nutzern so wenig technische Kenntnis abverlangten wie diese Rechner. Erst die PDAs der 1990er Jahre konnten das wieder für sich beanspruchen.
| Preis | RAM | Festplatte | Diskette | Bildschirm | Maus | Netzwerk | |
|---|---|---|---|---|---|---|---|
| Xerox Star | 16.500 $ (2017: 44.415 $) | 0,5 - 1,5 MB | 10 MB - 40 MB | - | 1 Bit16 17” 1024 x 800 | 2 Tasten | Ethernet |
| Apple Lisa | 13.500 $ (2017: 37.515 $) | 1 MB | 5 MB - 10 MB | Ja | 1 Bit 12” 720 x 360 | 1 Taste | AppleNet |
Abgesehen vom Umstand, dass der Star und die Lisa beide über ein Desktop-Konzept verfügten und ihre Bedienung zu einem großen Teil auf der Maus basierte, waren die Rechner schon im äußeren Erscheinungsbild ziemlich unterschiedlich. Der Xerox Star war ein sehr wuchtiges Gerät, das aussah wie ein zu breit geratener PC-Tower oder ein schmaler Kühlschrank. Er fand unter dem Tisch Platz. Auf dem Tisch standen nur Bildschirm, Tastatur und Maus, die oben abgebildet sind. Ein Xerox Star verfügte über bis zu 1,5 MB RAM, eine lokale Festplatte von 10 bis 40 MB und einen für die damalige Zeit riesigen hochauflösenden 17-Zoll-Monitor mit 1024 x 800 monochromen Bildpunkten. Das System konnte zwar isoliert genutzt werden, war aber vom Konzept her auf die Nutzung in einem Firmennetzwerk ausgerichtet. Ein typischer Xerox Star wurde per Ethernet mit Dateiservern und anderen Computern verbunden, was unter anderem auch das Verschicken von E-Mails im Firmenkontext erlaubte. Zwar bedeutete die Verwendung des Stars eine intensive Nutzung der Maus, die über zwei Tasten verfügte, doch spielte auch die Tastatur eine große Rolle. Neben der Möglichkeit, Zahlen und Buchstaben einzugeben, verfügte diese Tastatur nämlich über eine Reihe von Tasten für allgemeine Funktionen wie Löschen, Kopieren, Verschieben oder das Anzeigen von Eigenschaften.
Die Apple Lisa hatte ein ganz anderes Erscheinungsbild: Sie war ein sehr kompaktes All-In-One-Gerät. Das komplette Gerät stand auf dem Schreibtisch. Bildschirm und Zentraleinheit waren integriert. Die erste Version der Lisa verfügte über zwei 5,25-Zoll-Laufwerke für 871-KB-Disketten. Eine spätere Revision, die ebenfalls oben abgebildet ist, verfügte über ein einziges 3,5-Zoll-Laufwerk für 400-KB-Disketten. Ausgestattet war die Apple Lisa mit üppigem 1 MB RAM. Sie wurde in der Regel mit einer 5-MB-Festplatte verwendet, die extern angeschlossen werden musste (auf der Abbildung oben auf das Gerät gestellt). Der Bildschirm war mit 12 Zoll Größe und einer Auflösung von 720 x 360 Pixeln im Vergleich zum Star ziemlich klein. Die Maus der Lisa verfügte nur über eine einzige Taste und auch die Tastatur war einfacher gestaltet als die des Star. Spezielle Sondertasten wie am Star gab es nicht. Die Tastatur spielte damit bei der Bedienung der Lisa eine erheblich geringere Rolle. Alle Operationen und Funktionsaufrufe wurden per Maus durchgeführt. Die Tastatur musste und konnte nur zum Eingeben von Texten genutzt werden.
Der Desktop des Xerox Star
Sowohl die Apple Lisa als auch der Xerox Star hatten ein komplexes Desktop-Konzept, das sich von aktuellen Nutzungsschnittstellen, die über ein gleichnamiges Konzept verfügen, also Windows, MacOS und die üblichen Linux-Oberflächen, durchaus in wichtigen Punkten unterschied.
Das Grundkonzept der Nutzungsschnittstelle des Star war eine „Desktop“ genannte Hintergrundfläche, auf der die Objekte der aktuellen Arbeit, also Textdokumente, Grafiken, Datenbankobjekte und Tabellen abgelegt wurden. Ich nenne diese Art von Objekten im Folgenden der Einfachheit halber zusammenfassend „Dokumente“. Die Dokumente wurden auf dem Desktop üblicherweise in einer verkleinerten Form, als sogenanntes „Icon“, dargestellt. Ein Dokument konnte durch Öffnen genauer betrachtet werden. Dazu wurde zunächst das Objekt mit der Maus selektiert und dann auf der Tastatur die Open-Taste gedrückt. Das Dokument wurde dann zu einem Fenster vergrößert. Das Icon selbst verblieb als weißer Schatten auf dem Desktop. Auf der Abbildung oben sehen Sie das Dokument „Star picture“ geöffnet als Fenster und daneben als komplett weißes Icon auf dem Desktop.
Finden Sie die Formulierung „Das Dokument wurde dann zu einem Fenster vergrößert.“ eigenartig? Heute würde man das wohl nicht so formulieren. Man würde eher sagen: „Ein Doppelklick öffnet die Datei im entsprechenden Anwendungsprogramm.“ Beim Star konnte man das so aber nicht sagen, denn in der Nutzungsschnittstellen-Welt des Star gab es gar keine Anwendungsprogramme17. Sie kamen in der Nutzungswelt nicht vor. Es war nicht möglich, eine Textverarbeitung oder ein Grafikprogramm per Icon oder per Name anzusprechen und zu starten. Die Interaktionswelt funktionierte anders. Es gab nur Dokumente und Ordner, die als Icons oder in Fenster-Form sichtbar waren. Neue Dokumente wurden dadurch erzeugt, dass auf dem Desktop liegende Dokumente kopiert wurden. Dazu wurde ein Icon ausgewählt, auf der Tastatur „Copy“ gedrückt und mit der Maus eine Zielposition ausgewählt. Die Grundoperation der Arbeit mit dem Star war folglich – sehr passend für einen Kopierer-Hersteller – das Duplizieren von Vorlagen. Ein Initial-Set von leeren Dokumenten aller Art (inklusive Ordnern) lag für diesen Zweck in einem „Directory“ auf dem Schreibtisch bereit. Eine Vorlage musste aber keinesfalls ein leeres Dokument aus dem Directory, sondern konnte sehr gut auch ein vorher verfasstes Dokument sein. Der Star-Bedienungsphilosophie entsprach zum Beispiel, dass sich ein Nutzer eine Briefvorlage mit einem Blindtext erstellte, diese auf dem Desktop ablegte und später bei Bedarf duplizierte, wenn ein Brief geschrieben werden sollte.
Man konnte am Star mit mehreren Dokumenten gleichzeitig arbeiten, indem mehrere Icons in einem Fenster geöffnet wurden. Mehrere Programme liefen also gleichzeitig. Den Fachbegriff für diese Betriebsart haben Sie sicher schon einmal gehört: Multitasking. Die ursprüngliche Betriebssystemversion des Star ordnete die Fenster automatisch an. Spätere Versionen erlaubten überlappende Fenster. Wenige Computer boten 1981 Multitasking und keines davon, von rein experimentellen Systemen mal abgesehen, machte die verschiedenen Programme bzw. Dokumente in grafisch-räumlicher Darstellung gleichzeitig sichtbar.
Das Desktop-Konzept des Star war konsequenter als das heutiger Computersysteme. Der Desktop war der zentrale Ort für die Objekte der aktuellen Arbeit. Umgesetzt wurde hier eine klare Unterscheidung zwischen diesem Arbeitsbereich und der Ablage von Dokumenten. Die Ablage bestand innerhalb der Oberfläche aus Icons, die wie Aktenschränke aussahen. Hinter ihnen standen Datei-Ablage-Server, die per Netzwerk mit dem Star verbunden wurden. Dokumente konnten in diese Aktenschränke, „Drawer“ genannt, verschoben oder kopiert werden. Wenn ein Dokument dann aus einem Drawer wiederverwendet werden sollte, musste es erst auf den Desktop verschoben oder kopiert werden, denn Dokumente konnten immer nur vom Desktop aus bearbeitet werden. Das mag kompliziert erscheinen, ist aber letztlich in der Nutzungsschnittstellen-Welt folgerichtig, wenn man das Konzept des Desktops als dem Ort für die aktuellen Arbeitsobjekte ernst nimmt. Die Dokumente der aktuellen Arbeit wurden auf den Schreibtisch gelegt. Wollte man mit etwas arbeiten, musste man es erst dort hinlegen. Man fing nicht etwa an, direkt im Aktenschrank an Dokumenten herumzuwerkeln. Ob diese Notwendigkeit, Dokumente erst auf den Schreibtisch zu legen, übrigens wirklich darauf zurückzuführen ist, dass man es bei Xerox für nötig hielt, die Arbeitsweise im Büro so genau nachzuahmen, kann durchaus bezweifelt werden, denn es gibt einen sehr plausiblen technischen Grund dafür, dass Dokumente nicht aus einer Dateiablage heraus geöffnet werden können. Die Dateiablagen sind Dateiserver im Netzwerk, der Desktop hingegen ist auf der lokalen Festplatte gespeichert. Dateien direkt in der Dateiablage zu bearbeiten, hätte eine hohe Netzlast verursacht und zudem Probleme provoziert, wenn verschiedene Nutzer an verschiedenen Geräten auf das gleiche Dokument zugegriffen hätten. Durch die Einschränkung, dass nur Dokumente auf dem Desktop bearbeitet werden konnten, wurden derartige Probleme vermieden.
Der Desktop der Apple Lisa
Die Nutzungsoberfläche der Apple Lisa ähnelte auf den ersten Blick viel mehr heutigen Nutzungsschnittstellen als die des Xerox Star. Es handelte sich um eine typische Apple-Oberfläche mit einer Menüleiste am oberen Bildschirmrand, wie sie auch heute noch üblich ist. Auf dem Desktop befand sich ein Icon für die Festplatte und eines für den Papierkorb. Diese optische Ähnlichkeit mit heutigen Systemen kann einen leicht in die Irre führen, denn schaut man sich die Funktionsweise des Lisa-Desktops genauer an, gab es doch große Unterschiede zu heutigen Systemen, denn der Desktop spielte bei der Lisa als der Ort, an dem sich die Dokumente der aktuellen Arbeit befinden, eine viel größere Rolle als heute.
Im Gegensatz zum Xerox Star standen bei der Lisa Anwendungsprogramme durchaus als Objekte zur Verfügung. Programme wurden auf Diskette ausgeliefert. Man konnte sie entweder direkt von dort verwenden oder aber, was natürlich sinnvoller war, auf die eigene Festplatte kopieren, indem man die Icons von der Diskette auf die Festplatte zog. Apple implementierte einen ziemlich heftigen Kopierschutz. Jede Lisa verfügte über eine eigene Seriennummer, die nicht etwa nur aufgedruckt war, sondern im Rechner selbst in einem Chip gespeichert war. Beim ersten Zugriff auf die Programme, also beim Starten oder beim Kopieren, wurden die Programmdisketten „serialisiert“. Das Programm lief fortan nur noch auf genau dieser einen Lisa.
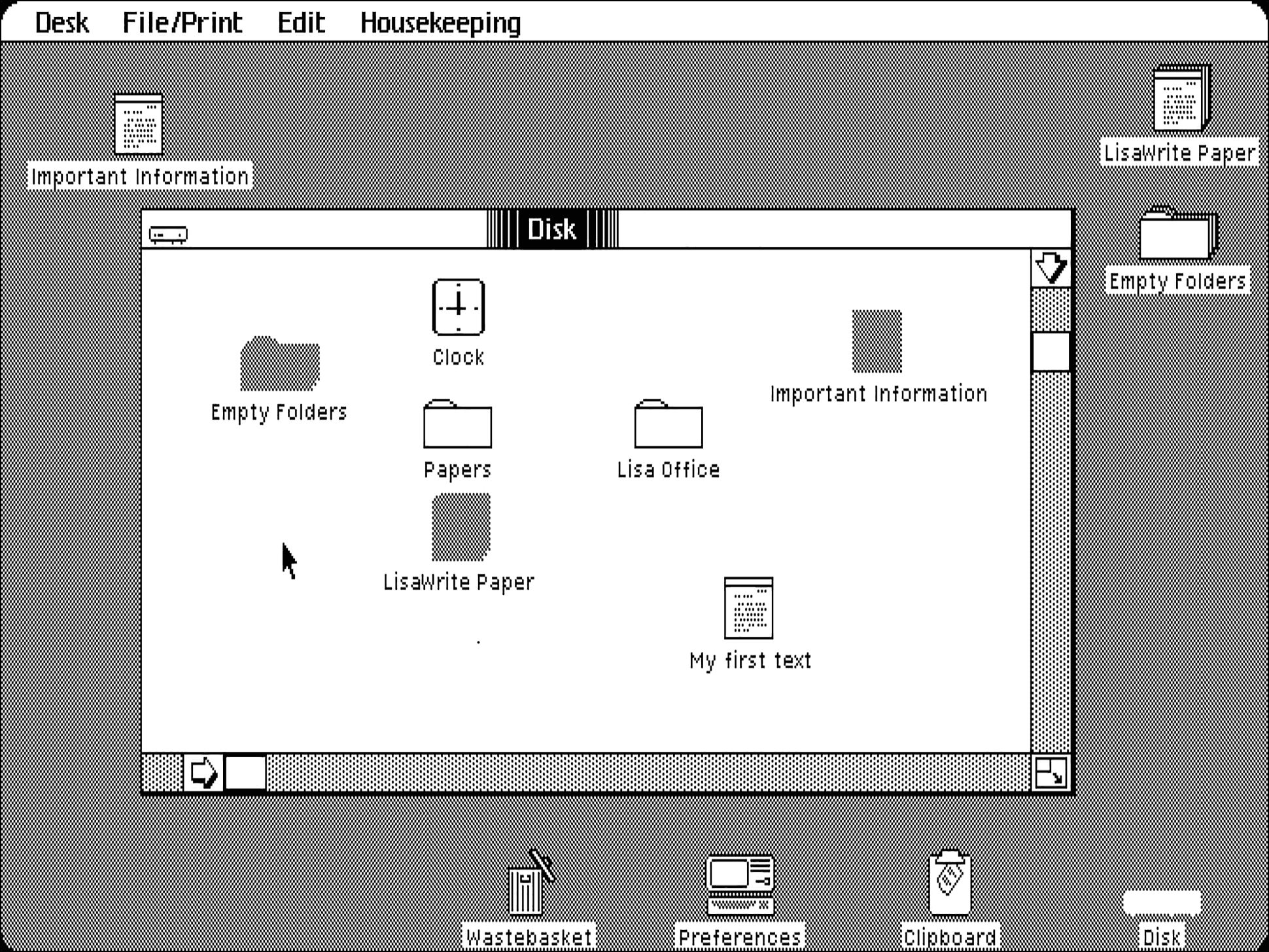
Nur einige werkzeugartige Programme, wie etwa ein Taschenrechner oder die Uhr, wurden bei der Lisa direkt per Doppelklick gestartet. Die anderen Programme lagen zwar als Objekte auf der Festplatte, startete man sie jedoch direkt, erhielt man nur eine Meldung, die einen darüber informierte, dass man es falsch gemacht hat. Die eigentliche Nutzung der Programme erfolgte ähnlich wie beim Xerox Star über den Zugriff auf Dokumente, die, in der gleichen Logik wie beim Star, in ein Fenster vergrößert wurden. Neue Dokumente wurden, ähnlich wie beim Star, dadurch erzeugt, dass bestehende Dokumente dupliziert wurden. In der Arbeitsweise des Star lag es bereits nahe, einige Dokumente zu Vorlagen zu erklären, also etwa eine Briefvorlage zu erzeugen. Was eine Vorlage war, wurde beim Star allerdings nicht technisch explizit gemacht. Die entsprechenden Dokumente waren Dokumente wie alle anderen auch. Apple dachte sich für die Lisa das erheblich ausgefeiltere Schnittstellenkonzept der Abreißblöcke (englisch: „stationery pad“) aus, das in der Bedienungsanleitung des Systems wie folgt beschrieben ist:
Each stationery pad represents an infinite supply of either blank or customized paper, which you use for creating new documents. The design on the pad matches the design on the tool and documents associated with the pad. […] Each tool comes with a pad of blank stationery, and you can make your own custom stationery pads.
Mit jeder Software-Anwendung, die mit Dokumenten arbeitete, wurde also ein entsprechender Abreißblock mitgeliefert. Wenn man diesen Abreißblock zu öffnen versuchte oder einen Doppelklick machte, wurde ein Blatt abgerissen, was technisch bedeutete, dass das leere Dokument kopiert wurde, die Kopie neben dem Abreißblock abgelegt und mit einem automatischen Titel versehen wurde. Auch eigene Dokumente mit Inhalt oder sogar ganze Ordner inklusive ihres Inhalts konnten bei der Lisa zum Abreißblock gemacht werden. Die Funktionsweise im Umgang war damit immer gleich. Ein Doppelklick auf so eine selbst erzeugte Vorlage erstellte eine Kopie am gleichen Ort, die dann in der Folge bearbeitet werden konnte.
Bei der Lisa spielte der Desktop als Ort für die aktuellen Arbeitsdokumente eine große Rolle. Apple hat sich hier ein ausgefeilteres System überlegt als Xerox bei seinem Star, was teils auch daran liegen dürfte, dass es sich bei der Lisa um ein System handelte, das auf eine lokale Festplatte und weniger auf Dateiserver ausgerichtet war. Im Gegensatz zum Star musste man bei der Lisa die Dokumente, die man bearbeiten wollte, nicht erst auf den Desktop bringen – das System erledigte diesen Schritt vielmehr quasi nebenbei für den Nutzer. Grundsätzlich hatte jedes Dokument und jeder Ordner bei der Apple Lisa einen Ort in der Dateiablage der Festplatte18. Diese Dokumente und Ordner lagen, wenn gerade mit ihnen gearbeitet wurde, auf dem Desktop, ihr Ort innerhalb der Dateiablage blieb aber bestehen. Sie können das auf obiger Abbildung gut am Dokument „Important Information“ sehen, das sich auf dem Desktop befindet, aber auch an seinem eigentlichen Speicherort auf der Festplatte als ausgegrautes Icon zu sehen ist. Diese zweite Position in der Dateiablage spielte bei der Verwaltung der Arbeitsobjekte an der Lisa eine wichtige Rolle.
Es gab eine Reihe von Möglichkeiten, wie ein Dokument auf den Schreibtisch kommen konnte. Die vielleicht naheliegendste Möglichkeit war, ein Dokument per Drag and Drop auf den Schreibtisch zu ziehen. Wenn man das tat, wurde das Dokument faktisch weder verschoben noch kopiert, sondern nur auf dem Desktop zugreifbar gemacht und am ursprünglichen Speicherort „ausgegraut“. Eine andere Methode, ein Dokument auf den Desktop zu legen, erfolgte aus einem Anwendungsfenster heraus. Sie konnten bei der Lisa im Gegensatz zum Star ein Dokument direkt am Speicherort auf der Festplatte öffnen und bearbeiten. Wenn Sie mit der Bearbeitung fertig waren, hatten Sie nun aber, im Gegensatz zu anderen Systemen, zwei Möglichkeiten: Sie konnten zwischen „Save & Put Away“ und „Set Aside“ wählen. Ersteres wählten Sie, wenn Sie das Dokument nicht mehr brauchten. Letzteres, also „Set Aside“, schloss das Anwendungsfenster und stellte das Dokument auf dem Desktop zur späteren Verwendung bereit – und zwar ganz unabhängig davon, ob es vorher vom Desktop aus geöffnet wurde oder nicht19. Dieses System sorgte dafür, dass quasi automatisch all das, was man noch weiter verwenden wollte, auf den Desktop gelangte. Brauchte man Dokumente oder Ordner, die auf dem Desktop lagen, nun nicht mehr, konnte man sie in den Papierkorb legen – dann wurden sie endgültig gelöscht. Wenn man sie für die spätere Bearbeitung behalten wollte, musste man sie wieder ablegen. Dafür reichte es, sie einfach zu markieren und im Menü „Put Away“ auszuwählen. Die Dokumente wurden dann gespeichert und an ihren eigentlichen Ort auf der Festplatte zurückgelegt.
Genau wie beim Star war bei der Lisa der Desktop der Ort für die aktuellen Arbeitsmaterialien. Alles, was gerade bearbeitet wurde, lag auf dem Desktop als Icon bereit oder war als Fenster geöffnet. Dass ein solcher Arbeitsprozess natürlich länger sein konnte als ein Arbeitstag, hat Apple bei der Gestaltung der Nutzungsschnittstelle durchaus vorgesehen. Es war nicht nötig, bei Arbeitsende alles abzuspeichern, dann in die Dateiablage einzusortieren und beim nächsten Mal wieder zusammenzusuchen. Das System nahm dem Nutzer diese Aufgabe ab. Drückte man auf den Ausschalter der Lisa, wurden alle Änderungen automatisch gespeichert. Beim nächsten Start des Systems wurden die Dokumente, die vorher auf dem Desktop lagen, automatisch wieder an ihren Platz gelegt und, sofern sie vorher geöffnet waren, auch automatisch erneut geöffnet. Die Arbeitsvorgänge wurden dadurch unabhängig von den technisch-organisatorisch bedingten Rechnersitzungen.
Fazit
Die Apple Lisa und der Xerox Star schafften eine Nutzungsschnittstellen-Welt, die von technischen Aspekten der Maschine sehr unabhängig war. Zwar brauchten alle interaktiven Computer virtuelle Objekte und boten natürlich Anwendungsobjekte als solche an, doch bedurfte es bei den meisten Nutzungsschnittstellen auch Kenntnisse über die Objekte der technischen Computerwelt und ihrer Operationen. Allen voran waren das Programme als Objekte und Operationen wie das Laden und Speichern von Dateien. Lisa und Star funktionierten da anders: Es gab kein Konzept eines Programms, das man verwendete, um eine Datei in den Arbeitsspeicher einzulesen. Angeboten wurde vielmehr eine Darstellung eines Objektes in einem Fenster, also in seiner detailreichen und bearbeitbaren Form. Das Dokument wurde in beiden Systemen zum zentralen Objekt der Interaktion und der Desktop zum zentralen Ort der aktuellen Arbeitsmaterialien. Es gab übrigens in beiden Systemen keine „Speichern unter“-Funktion. Diese hätte in die angebotene Objektwelt auch nicht gut hineingepasst, denn durch diese Funktion würde ja eine Anwendung eine Aufgabe ausführen, die ein neues Dokument erzeugt. Eine solche Funktion ergibt aber keinen Sinn, wenn das Fenster nicht ein Programm, sondern ein Dokument ist. Die Laden- und Speichern-Funktionen an sich, also im Sinne einer Anwendung, die eine Datei in den Arbeitsspeicher einliest oder den Arbeitsspeicherinhalt in einer Datei ausgibt, ergab in den Dokumenten-Welten von Star und Lisa schlichtweg keinen Sinn. Zwar gab es bei der Lisa ein „Save & Continue“ und auch dem „Put Away“ war stets ein „Save“ an die Seite gestellt – dies hatte aber eher Sicherheitsgründe, um beispielsweise einen Bearbeitungsstand nicht zu verlieren, wenn etwa der Strom ausfiel oder der Rechner eine Funktionsstörung hatte. Funktionierte alles richtig, musste man eigentlich nie explizit speichern, denn das passierte automatisch, wenn die Dokumentfenster geschlossen oder, im Falle der Lisa, die Dokumente zurückgelegt wurden.
Spätere Nutzungsschnittstellen mit Desktop-Konzept, wie wir sie noch heute großteils nutzen, sind nicht mehr so ausgefeilt wie Star und Lisa. Das kann man bedauern – dass es so gekommen ist, hat aber durchaus Gründe, auf die ich im folgenden Kapitel genauer eingehe. Um es kurz zu sagen: Die Arbeitsweise von Star und Lisa erforderte einen erheblichen Hardware-Einsatz, der die Rechner so teuer machte, dass beide Computer als wirtschaftliche Misserfolge angesehen werden müssen. Günstige Rechner wie der Apple Macintosh folgten, doch ihre erheblich sparsamere Hardware-Ausrüstung machten derart ausgeklügelte Nutzungskonzepte wie die der Lisa unmöglich.
Fenster jetzt auch für zu Hause
Die im Kapitel „Schreibtisch mit Fensterblick“ vorgestellten Systeme Xerox Alto, Xerox Star und Apple Lisa haben die Nutzungsschnittstellen von Computern mit Konzepten wie dem Desktop, Fenstern, Menüs und mit ihrer Optimierung für die Mausbedienung und damit auf grafisch-räumliche Eingaben neu definiert. Wirklich große Verbreitung hatten die Rechner aber nicht. Dies lag nicht zuletzt daran, dass sie aufgrund ihrer hohen technischen Anforderungen extrem kostspielig waren. Obwohl für sich genommen kein Erfolg, wurden Alto, Star und Lisa die Grundlage für die 16-Bit-Personal-Computer der Mitte der 1980er Jahre. Bis zur Vorstellung des Apple Macintosh im Jahr 1984 bedienten sich alle populären Heim- und Bürorechner (also Apple II, Commodore PET, C64, IBM PC, usw.) des Kommandozeilen-Paradigmas. Einzelne Anwendungen wie WordStar, VisiCalc, später Lotus 1-2-3 und Word nutzten die Räumlichkeit des Bildschirms, basierten aber grundsätzlich auf Textdarstellungen und verfügten nicht über eine einheitliche Nutzungsschnittstelle. Die Grafikfähigkeiten der Computer, soweit vorhanden, wurden für Spiele und zur Wiedergabe von Inhalten genutzt, etwa für Business-Grafiken, nicht aber für die Nutzungsschnittstelle.
Apple Macintosh – Der Kleine

Ein Jahr nach der Apple Lisa, also im Jahr 1984, präsentierte Apple mit großem medialen Aufwand einen kleinen Computer mit dem Namen „Macintosh“. Mitunter wird behauptet, dass der Rechner entwickelt worden sei, weil die Lisa nicht erfolgreich war. So kann es aber nicht gewesen sein, denn es war schlichtweg gar nicht möglich, in nur einem Jahr einen komplett neuen Computer samt so komplexer Nutzungsschnittstelle zu entwickeln. Die Entwicklung beider Computer verlief größtenteils parallel. Nachdem der Macintosh zunächst als günstiger, textbasierter Computer geplant war, wurde die Entwicklung schon etwa ab 1981 in Richtung eines Computers mit grafischer Nutzungsschnittstelle geändert. Diese Schnittstelle war auf den ersten Blick der Nutzungsschnittstelle der Lisa sehr ähnlich. Der Rechner wurde hauptsächlich per Maus bedient, es gab Fenster, die am Bildschirm verschoben werden konnten, es gab eine ständig sichtbare Menüleiste am oberen Bildschirmrand und das Betriebssystem präsentierte sich dem Nutzer als graue Fläche, auf der Dokumente abgelegt werden und auf der Fenster verschoben werden konnten, die die Inhalte von Datenträgern als Datei-Icons anzeigten. Diese Fläche wurde, genau wie bei der Lisa, „Desktop“ genannt.
| Prozessor | RAM | Diskette | Festplatte | Bildschirm | Klang | |
|---|---|---|---|---|---|---|
| Lisa | 5 MHz | 1 MB | 2x 871 KB | 5-10 MB | 12” 720 x 360 | Beep |
| Macintosh | 7,8 MHz | 128 KB | 400 KB | - | 9” 521 x 342 | 8 Bit Samples |
Der Computer wurde in den ersten Jahren mit „Lisa Technology“ beworben. Eine typische Lisa kostete 10.000 Dollar (entsprechend 26.950 Dollar im Jahr 2021). Mit 2.500 Dollar war der Macintosh viel günstiger, allerdings war er ihr gegenüber technisch stark eingeschränkt. Zwei dieser Einschränkungen hatten zur Folge, dass die Nutzungsschnittstellen-Welt des Macintosh bei genauer Betrachtung doch bedeutend anders funktionierte als die der Lisa. Die erste Einschränkung betraf den Arbeitsspeicher. Die Lisa hatte einen für damalige Zeit sehr groß bemessenen Speicher von 1 MB. Beim ersten Macintosh wurde hier extrem gespart. Er verfügte nur über 128 KB Arbeitsspeicher. Das war zwar doppelt so viel wie bei Heimcomputern der damaligen Zeit mit ihren üblichen 64 KB, doch für ein grafisches System, das auch für komplexere Aufgaben wie Textverarbeitung samt grafischer Anzeige des Texts genutzt werden sollte, war das sehr knapp bemessen. Die zweite gewichtige Einschränkung betraf den Massenspeicher. Eine Lisa wurde in aller Regel mit einer Festplatte betrieben. Die hatte zwar für heutige Verhältnisse eine geradezu winzige Größe von 5 oder 10 MB, erlaubte zur damaligen Zeit aber, alle Anwendungsprogramme und viele Dokumente komfortabel gleichzeitig in schnellem Zugriff zu haben. Der Macintosh konnte zwar später auch Festplatten ansprechen, das Betriebssystem war aber auf reinen Disketten-Betrieb ausgelegt. Das Diskettenlaufwerk war natürlich nicht nur viel langsamer als eine Festplatte, mit nur 400 KB war die Menge der auf einer Diskette speicherbaren Daten und Programme ebenso bescheiden.
Die Einschränkungen auf der Ausstattungsseite hatten Auswirkungen auf die Funktionsweise der Nutzungsschnittstelle. Im Gegensatz zur Lisa war der Macintosh eine Single-Tasking-Maschine, konnte also nur ein Programm zur gleichen Zeit ausführen. Mehrere Programme passten schlichtweg nicht in den knapp bemessenen Speicher. Eine Auslagerung von Speicherinhalten auf den Massenspeicher – die heute typische Technik, wenn der Arbeitsspeicher nicht ausreicht – war ohne eine schnelle Festplatte nicht möglich, und über diese verfügte der Macintosh zunächst ja nicht. Der Single-Tasking-Betrieb änderte natürlich die Art und Weise, wie mit dem System gearbeitet werden konnte. Hatte man ein Dokument in einer Anwendung geöffnet, hatte man keinen Zugriff mehr auf die Dateiverwaltung und den Desktop. Wollte man nun Dateiverwaltungsoperationen durchführen, musste man die gerade geöffnete Anwendung erst wieder verlassen. Ein Desktop als zentraler Ort, der ständig zur Verfügung stand, quasi hinter allem liegt, war beim Macintosh schlichtweg nicht realisierbar.
Da der erste Macintosh keine Festplatte hatte, standen die Programme logischerweise nicht permanent zur Verfügung, sondern mussten von ihrer jeweiligen Diskette geladen werden. Das System erlaubte es zwar, sich ein Dokument auf den Desktop zu legen oder an seinem Speicherort in der Dateiablage zu öffnen, doch dann kam es in aller Regel zu einer Unterbrechung, denn man musste meist die Datendiskette herausnehmen, die Diskette mit dem Anwendungsprogramm einlegen, das Anwendungsprogramm starten, dann die Diskette mit dem Dokument wieder einlegen und erst dann konnte man mit der Bearbeitung des Dokuments beginnen. Gerade da in der Standardausstattung des Geräts nur ein einziges Disketten-Laufwerk zur Verfügung stand, wurde man zum regelrechten Discjockey. Hier beispielhaft die notwendigen Schritte zum Einfügen eines auf einer Diskette gespeicherten Bildes in einen auf einer anderen Diskette gespeicherten Text:
- Textverarbeitungs-Programmdiskette einlegen
- Programm-Icon suchen und Programm starten
- Textverarbeitungs-Programmdiskette auswerfen
- Dokumentdiskette einlegen
- Dokument laden
- Dokumentdiskette auswerfen
- Bilderdiskette einlegen
- Bild laden und in den Text einfügen
- Bilderdiskette auswerfen
- Dokumentdiskette wieder einlegen
- Datei speichern und warten, bis das Programm wieder reagiert
Das Arbeiten mit den Disketten und das ständige Ein- und Auswerfen schlug sich auch in den Funktionen der Nutzungsschnittstellen der Anwendungsprogramme selbst nieder. Im Gegensatz zu den Anwendungen von Lisa und Star etwa konnte ein Abspeichern beim Macintosh nicht implizit erfolgen. Was heißt das? Als Nutzer einer Lisa musste man über das Laden von Dateien und das Abspeichern eigentlich nicht nachdenken. Das Laden geschah durch das Öffnen aus der Dateiablage heraus und das Speichern passierte bei sich anbietender Gelegenheit von selbst, spätestens dann, wenn man den Computer ausschaltete. Die Einschränkungen des Macintosh machten diese Arbeitsweise unmöglich, denn der kleine Arbeitsspeicher erlaubte nicht, die Inhalte mehrerer Dokumente gleichzeitig zu halten. Man kam also nicht umhin, Dokumente zwischenzeitlich zu speichern und zu schließen, um den Arbeitsspeicher wieder frei zu machen. Das Speichern konnte leider auch nicht, wie bei der Lisa, quasi nebenher, bei Bedarf oder automatisch bei Programmende ohne explizite Nutzerinteraktion durchgeführt werden, da das Schreiben auf Diskette zum einen laut und langsam war, und vor allem aber, weil der Rechner während des Schreibvorgangs blockierte und ein Weiterarbeiten nicht möglich war. Ein implizites Speichern, also ohne Nutzerinteraktion, war auch beim Beenden der Anwendungen oder dem Schließen des Fensters eines Dokumentes nicht möglich, denn es war durchaus unwahrscheinlich, dass sich die Diskette, auf der ein Dokument gespeichert werden sollte, zum Zeitpunkt des Speicherns überhaupt im Laufwerk befand.
Die technischen Einschränkungen von Arbeitsspeicher- und Massenspeichergröße führten, wie Sie sehen, notwendigerweise dazu, dass das implizite Speichern der früheren, sehr teuren Systeme, auf dem Macintosh nicht umsetzbar war. Die Anwendungsprogramme mussten daher zwangsläufig Mechanismen erhalten, um Dateien laden, speichern, unter einem anderen Namen oder auf einer anderen Diskette zusätzlich speichern zu können.
Atari ST – Der Vielseitige

An dieser Stelle ist die Gelegenheit günstig, Ihnen ein Konkurrenzprodukt zum Apple Macintosh vorzustellen, dessen Nutzungsschnittstelle an vielen Stellen noch mehr auf die Einschränkungen eines Single-Tasking-Betriebssystems mit Diskettenbedienung optimiert war, als die des Macintosh. Obige Abbildung zeigt einen Atari 520ST+, der im Jahre 1986 erschien. Der einzige Unterschied zum ursprünglichen ST war der auf 1 MB verdoppelte Arbeitsspeicher. Abgesehen davon waren die beiden Rechner identisch. Der ST erschien 1985 und kostete in der Ausstattungsvariante mit monochromem Monitor mit knapp 800 Dollar (entsprechend 2.000 Dollar im Jahr 2021) zwar nur ein Drittel des Macintosh, war aber technisch erheblich besser ausgestattet.
| Preis ca. | Prozessor | RAM 1985 | RAM 1986 | Diskette | Bildschirm | Klang | |
|---|---|---|---|---|---|---|---|
| Apple Macintosh | 2.500 $ | Motorola 6800 5 MHz | 512 KB | 1 MB | 400 KB | 9” 521 x 342 | 8 Bit Samples |
| Atari ST | 800 $ | Motorola 6800 8 MHz | 512 KB | 1 MB | 700 KB | 12” 640 x 400 | 3-Stimmen-Synthesizer |
Ataris Computer spielte, wenn man so will, zwei Rollen. Man konnte ihn mit einem Farbmonitor erwerben oder über ein Zusatzgerät an den eigenen Fernseher anschließen. In dieser Nutzungsform konnte der Rechner je nach gewählter Auflösung vier bzw. sechzehn Farben darstellen und war mit seinem Soundchip und seiner schnellen Motorola-CPU der moderne Nachfolger von Ataris 8-Bit-Heimcomputern der frühen 1980er. Entschied man sich jedoch für den monochromen Monitor, war der ST vor allem eine Konkurrenz zum Macintosh, und vermochte als Rechner in Büros und Verwaltung durchaus zu überzeugen. Der ST war nicht nur viel günstiger als der Macintosh, sondern verfügte auch über eine bessere Tastatur mit Pfeiltasten und Nummernblock und über einen erheblich größeren Monitor, der eine sehr hohe, flimmerfreie Bildqualität lieferte.
Das Betriebssystem des Atari ST trug den Namen TOS (The Operating System). Technisch stand hinter diesem System eine 16-Bit-Umsetzung des Betriebssystems CP/M von Digital Research, das Sie im Kapitel über den Altair 8800 kennengelernt haben. Frühe Bücher über den Atari ST, die noch vor seinem Erscheinen geschrieben wurden, enthielten zum Teil noch Beschreibungen des Kommandozeilen-Interpreters von CP/M und beschreiben die Grundcharakteristika dieses Betriebssystems. Sie erläutern auch eine grafische Nutzungsoberfläche mit dem Namen GEM (Graphics Environment Manager), die wie CP/M von Digital Research entwickelt wurde. Als der Computer 1985 erschien, war von der Kommandozeile von CP/M dann nichts mehr zu sehen. Atari hatte sich entschlossen, das Betriebssystem so zu gestalten, dass es wie der Apple Macintosh direkt in die grafische Nutzungsoberfläche GEM startete und auch nur auf diese Art und Weise zu bedienen war. An mancher Eigenart konnte man die CP/M-Basis aber durchaus erkennen, etwa beim Ansprechen von Diskettenlaufwerken über Laufwerksbuchstaben oder auch dem Benennungsschema von Dateien mit acht Zeichen für den Namen, gefolgt von einem Punkt und drei Zeichen zur Definition des Dateityps. In dieser Hinsicht glich das System des Atari ST mehr dem DOS der IBM PCs als dem Betriebssystem des Apple Macintosh, bei dem dem Nutzer viel mehr Flexibilität bei den Dateinamen gegeben wurde.
Im Vergleich zum Macintosh war der Desktop des Atari stark abgespeckt. Startete man den Rechner, bekam man zwar wie beim Macintosh eine graue Oberfläche zu sehen, auf der in Fenstern die Inhalte von Disketten und Ordnern angezeigt werden konnten und auch Desktop-Icons sowie ein Papierkorb waren vorhanden, doch so grundsätzliche Möglichkeiten wie das Ablegen einer Datei direkt auf der Desktop-Oberfläche war nicht möglich. Diese Funktionsbeschneidung war in Bezug auf die Ausstattung des Rechners durchaus folgerichtig, denn die Sinnhaftigkeit, Dateien auf den Desktop zu legen, waren in einem Single-Tasking-System und der Ausrichtung auf Disketten, wie oben erläutert, ja ohnehin arg eingeschränkt.
Da beim Single-Tasking-System des Atari ST der Desktop als Ort der Dateiverwaltung nicht zur Verfügung stand, wurden in vielen Anwendungsprogrammen Funktionen zur Dateiverwaltung bereitgestellt. Obige Abbildung zeigt die Textverarbeitung 1st Word Plus, die neben dem Angebot, Dateien laden, speichern und drucken zu können, auch das direkte Löschen von Dateien auf der Diskette anbot. Versetzt man sich in die Lage eines Diskettennutzers, war diese Funktion sehr sinnvoll. Stellen Sie sich die Situation vor: Sie haben an einem wichtigen Text geschrieben, wollen ihn nun abspeichern, stellen dann aber fest, dass nicht mehr genug Platz auf der Diskette vorhanden ist. Wenn Sie Glück haben, haben Sie eine andere Diskette zur Hand, doch was, wenn nicht? Sie können nicht auf den Desktop wechseln und ein paar Dateien löschen, denn es handelt sich ja um ein Single-Tasking-System. Zum Desktop zu wechseln, hieße, das laufende Programm zu beenden, aber das würde bedeuten, den geschriebenen Text zu verwerfen, weil Sie ihn ja nicht abspeichern können. Die Funktion, direkt aus der Textverarbeitung nicht mehr benötigte Dateien auf der Diskette löschen zu können, kann da Ihre letzte Rettung sein.
Commodore Amiga – Der Multimediale

In Konkurrenz sowohl zum Atari ST als auch in gewisser Weise zum Macintosh stand der Commodore Amiga, dessen erstes Modell ebenfalls 1985 erschien. Oben abgebildet sehen sie das verbreitetste Modell des Rechners, den Amiga 500 aus dem Jahr 1987. Auf den ersten Blick sieht dieser Rechner dem Atari ST sehr ähnlich. Auch beim Amiga 500 sind Recheneinheit und Tastatur integriert, beide verfügen über eine Maus und verwenden als Speichermedium 3,5-Zoll-Disketten. Wie Sie auf dem Bildschirm sehen, verfügte auch der Amiga über eine Nutzungsschnittstelle mit Icons und Fenstern und war insofern auch dem Macintosh ähnlich. Statt von einem Desktop wurde beim Amiga aber von „Workbench“, also einer Werkbank, gesprochen. Disketten enthielten dementsprechend auch keine Ordner, sondern Schubladen. Werkbank und Schubladen für die zentralen Konzepte sind zunächst einmal nur andere Namen, doch zeigte sich in diesem Namen letztlich eine ganz andere Ausrichtung, die sich entgegen der vom Xerox Star übernommenen Denkweise des Macintosh und des Atari ST nicht an der Büroarbeit orientierte.
Die große Stärke des Rechners waren seine Grafik- und Sound-Fähigkeiten. Er verfügte über unzählige Grafikmodi, von hohen Auflösungen von 640 x 512 Pixeln mit sechzehn Farben bis hin zu 580 × 368 Pixeln20 bei sage und schreibe 4.096 gleichzeitig darstellbaren Farben. Keine andere Heim- oder Personal-Computer-Plattform war zu diesem Zeitpunkt so grafikmächtig. Das Videosignal und die Bildschirmtechnologie waren bekannte, solide Fernsehtechnik. Der mitgelieferte Monitor war im Prinzip ein kleiner Farbfernseher ohne Empfangsteil. Die Verwendung dieser Technik hatte ihre Vorteile was die multimedialen Fähigkeiten des Rechners anging. Verbunden mit dieser Design-Entscheidung waren allerdings auch erhebliche Nachteile, die einen Einsatz gerade im Büro erschwerten, denn zwar bot der Monitor eine hohe Auflösung, die grundsätzlich auch feine Textausgaben oder Grafiken erlaubt hätte, doch stand die hohe Auflösung nur im sogenannten „Interlaced-Modus“ zur Verfügung. Der Nachteil dieser Technik, auf die ich hier im Detail nicht genauer eingehen möchte, war, dass es zu einem sichtbaren und unangenehmen Flimmern kam, wenn in der Vertikalen Bildelemente mit einem hohen Kontrast aufeinandertrafen. Das Flimmern ließ sich zwar durch eine geschickte Farbwahl minimieren, doch dann litt der Kontrast. Für die klassische Büroanwendung Textverarbeitung mit der Darstellung von feinem, schwarzem Text auf weißem Grund war der Amiga daher eher schlecht geeignet. Durch seine herausragende Grafikeinheit zusammen mit einem ebenfalls hervorragenden Soundchip war der Amiga jedoch eine ideale Plattform für Spiele. Darüber hinaus wurden die Grafik- und Sound-Funktionalitäten auch für Bildbearbeitung und Animation genutzt. Hier wurde die technische Entscheidung, bei der Grafikausgabe auf Fernsehtechnik zu setzen, zu einem großen Vorteil, denn die Videosignale des Amiga ließen sich direkt mit vorhandener Video- und Fernsehtechnik koppeln. So manche Animation, die seinerzeit im Fernsehen zu sehen war, wurde von einem Amiga-Rechner erzeugt.
Der Amiga und sein Betriebssystem waren in einer weiteren Hinsicht den Pendants von Atari, Apple und auch IBM überlegen, denn im Gegensatz zu diesen war der Amiga multitaskingfähig. Öffnete man eine Textdatei oder ein Bild aus einem Fenster in der Workbench, öffnete sich ein weiteres Fenster, das den Text oder das Bild darstellte. Auch die Workbench mit ihren Fenstern blieb aber weiterhin verfügbar. Weder der Atari ST, der Apple Macintosh oder der IBM PC konnten das damals bieten. Selbst dann wenn die Fenstertechnik nicht eingesetzt werden konnte, weil das verwendete Programm einen anderen Grafikmodus verwendete als die Workbench, konnte zwischen den Programmen gewechselt werden, unter anderem – hier zeigen sich wieder die herausragenden Grafikfähigkeiten des Systems – durch eine Einteilung des Bildschirms in mehrere „Viewports“. Dann lief etwa in der oberen Bildschirmhälfte eine Animation in niedriger Auflösung mit vielen Farben und in der unteren Hälfte ein anderes Programm mit hoher Auflösung und nur wenigen Farben.
Multitasking und Fenster auf dem IBM PC
Mitte der 1980er Jahre waren mit Macintosh, Atari ST und Amiga drei Computersysteme auf dem Markt, die die grafische Nutzungsschnittstelle und im Falle des Amiga auch das Multitasking im Personal-Computer-Bereich etablierten. Verglich man die drei Systeme mit dem DOS des IBM PC, schien dieses eher noch der vorherigen Computergeneration anzugehören, während Macintosh, ST und Amiga frisch und modern wirkten. Auch die Nutzungsschnittstelle des IBM PC blieb aber natürlich nicht auf dem Stand von 1981 stehen, sondern schloss mehr und mehr zu den drei fensterbasierten Systemen auf. Die Grundlage hierfür war neben schnelleren Prozessoren und mehr Arbeitsspeicher vor allem die zunehmende Verbreitung von Festplatten.
War zu Beginn der 8-Bit-Heimcomputer-Ära noch die Kassette das Speichermedium der Wahl, war die 16-Bit-Generation von vorn herein auf Diskettennutzung ausgelegt. Die Zeit der Diskette als Haupt-Massenspeicher war jedoch nur eine Zwischenperiode. Sowohl der Atari ST, Commodore Amiga, Apple Macintosh als auch der IBM PC konnten um eine Festplatte ergänzt werden. In der ersten Gerätegeneration war eine solche Platte oft noch ein externes Gerät, das zusätzlich auf dem Tisch stand. Später war eine Platte oft schon ab Werk eingebaut. Der IBM PC XT (für Extended Technology) von 1983 konnte etwa schon mit einer eingebauten 10-MB-Platte erworben werden. Doch Vorsicht! Dass die 16-Bit-Computergeneration im Prinzip schon von Anfang an Schnittstellen für den Anschluss einer Festplatte vorsah und dass heutige Exemplare dieser Rechner in den Sammlungen der Retro-Computing-Fans auch meist über eine Festplatte verfügen, sollte Sie nicht dazu verleiten, zu glauben, dass Festplatten schon damals im Heimbereich verbreitet waren. Retro-Computing-Anhänger haben oft viel Spaß daran, die alten Rechner auf ihre maximale Ausbaustufe zu erweitern. Teils schaffen sie es mit modernen Tricks sogar, die alten Computer weiter aufzurüsten, als es damals überhaupt möglich war. Zum damaligen Zeitpunkt waren die meisten Systeme natürlich nicht derartig üppig ausgestattet. Es waren viel bescheidenere Konfigurationen verbreitet, denn Festplatten und Arbeitsspeicher waren sündhaft teuer. Bestellte man den IBM PC XT mit der 10-MB-Festplatte, einem Monitor und einer Arbeitsspeicherausstattung von 640 KB, musste man 8.000 Dollar auf den Tisch legen. Berechnet man die Inflation mit ein wären das im Jahr 2021 über 21.500 Dollar gewesen und damit selbst für viele kleine Betriebe zu teuer – von Heimanwendern ganz zu schweigen.
Als Microsoft 1981 die erste Version seines DOS an IBM lizenzierte, standen Festplatten noch nicht im Fokus. DOS war, wie das CP/M, an das es angelehnt war, klar ein Betriebssystem für Disketten. Das merkte man vor allem daran, dass es ein zentrales Element heutiger Betriebssysteme, das hierarchische Dateisystem, bei DOS noch nicht gab. DOS und CP/M erlaubten es, Dateien auf Disketten zu schreiben und diese über ihren Dateinamen ansprechbar zu machen. Eine Diskette war aber in sich nicht weiter strukturiert. Es gab also keine Unterverzeichnisse oder Ordner. Alle Dateien lagen auf einer Ebene. Bei einer Diskette, auf die 180 KB oder 320 KB Daten geschrieben werden konnten, war eine solche Strukturierung im Prinzip auch nicht nötig. Die Diskette selbst war quasi die Ordnungseinheit für die Dateien. Schloss man nun aber eine Festplatte an und hatte 5 oder gar 10 MB zur Verfügung, wurde es unpraktisch, alle Dateien in einer großen Liste zu führen. Eine Unterstrukturierung wurde notwendig.
1983 erschien die zweite Version des DOS von Microsoft. Das Betriebssystem hatte zwar den gleichen Namen und mutete von der grundsätzlichen Bedienung auch recht ähnlich an, es handelte sich aber im Grunde um eine nahezu komplette Neuentwicklung. Microsoft erweiterte das DOS um eine ganze Reihe von Funktionen und Konzepten aus dem Betriebssystem Unix. Dazu gehörten die Technik des Piping, bei dem Ein- und Ausgabe von Programmen umgeleitet werden, sowie eine einfache Programmiermöglichkeit durch sogenannte Batch-Dateien. Mehr zu diesen Unix-Konzepten erfahren Sie im Kapitel über Linux und Unix. Die für die meisten Nutzer wahrscheinlich wichtigste Neuerung war die Einführung des hierarchischen Dateisystems mit Ordnern und Unterordnern. Mit ihnen kamen zentrale neue Befehle, die ins Standardrepertoire aller DOS-Nutzer aufgenommen wurden: Zum schon bekannten dir zum Auflisten des Inhalts eines Verzeichnisses kamen nun etwa cd für change directory zum Wechseln in ein anderes Verzeichnis und md für make directory zum Erstellen eines Unterverzeichnisses.
Während die frühen Personal-Computer mit ihrer Diskettenzentrierung und wenig Speicher zwangsläufig Geräte sein mussten, bei denen sich zu jedem Zeitpunkt nur ein einziges Programm im Speicher befand und abgearbeitet wurde, erfüllten gut ausgestattete IBM-kompatible PCs mit einer Festplatte und mit viel Arbeitsspeicher grundsätzlich die Voraussetzung, auch mehrere Programme gleichzeitig verfügbar zu machen. Tatsächlich konnte man bei IBM den PC in einer Konfiguration erwerben, die das ermöglichte. Als Betriebssystem wurde dann nicht Microsofts DOS, sondern Unix ausgeliefert, zunächst in der Variante PC/ix der Firma ISC und ab 1985 mit Xenix von Microsoft. Unix auf dem IBM PC setzte sich zum damaligen Zeitpunkt aber nicht durch, denn die Hardware-Anforderungen waren hoch und die Software-Auswahl aufgrund der geringen Verbreitung bescheiden. Die große Menge an Software, die den IBM PC so attraktiv machte, von Tabellenkalkulationen über Textverarbeitungsprogramme bis hin zu Datenbanken oder gar Spielen, wurden für DOS entwickelt. DOS ermöglichte zwar kein richtiges Multitasking, eine sehr einfache, eingeschränkte Möglichkeit, ein Programm zu starten, ohne das andere dafür beenden zu müssen, gab es ab der Version 2 aber doch, denn ein Programm konnte nun ein anderes Programm starten. Die verwendete Software musste diese Möglichkeit aber explizit vorsehen. Um zu verstehen, wie die Verwendung mehrerer Programme möglich war, braucht es einen kleinen Ausflug in die Mechanismen, wie ein Programm geladen wird. Keine Angst, ich versuche, es nicht zu kompliziert zu machen:
Wenn Sie ein CP/M oder ein MS-DOS starteten, begrüßte Sie nach einiger Zeit der Kommandozeilen-Interpreter, der es Ihnen ermöglichte, Befehle einzugeben, um Dateien zu kopieren, sie zu löschen oder aber auch, um ein Programm zu starten. Der Kommandozeilen-Interpreter selbst war aber auch nur ein Programm. Seine einzige Besonderheit war, dass es vom Betriebssystem automatisch gestartet wurde. Nutzte man den Kommandozeilen-Interpreter, um ein anderes Programm zu starten, wurde das Programm in den Arbeitsspeicher kopiert und dann gestartet. Wurde das Programm beendet, ging die Kontrolle zurück an das Betriebssystem, das dann automatisch wieder den Kommandozeilen-Interpreter in den Speicher lud und startete. Zu jedem Zeitpunkt war also nur ein Programm im Speicher – und folglich lief auch zu jedem Zeitpunkt nur ein einziges Programm. Auf die gleiche Art funktionierten auch die anderen Betriebssysteme. Bei einem Macintosh war es das Programm Finder, das automatisch gestartet wurde. Es stellte die Ordnerfenster und den Desktop bereit. Startete man aus dem Finder heraus ein anderes Programm, wurde dieses an des Finders Stelle in den Speicher kopiert und gestartet. Nach dem Beenden des Programms lud und startete das Betriebssystem automatisch wieder den Finder. Mit der Version 2 von Microsofts DOS wurde die Möglichkeit des Programm-Startens ein wenig verändert. Es war nun nicht mehr so, dass das Laden eines Programms unbedingt das bisherige Programm im Speicher verdrängte. Ein laufendes Programm, ich nenne es einmal „A“, konnte nun ein anderes Programm „B“ in den Speicher laden und starten. Dabei blieben aber alle Daten von Programm A im Speicher erhalten. War der Nutzer mit dem, was er in Programm B erledigen wollte, fertig und beendete das Programm, wurde das Programm A dort fortgesetzt, wo es unterbrochen wurde. Diese technische Änderung, wie Programme geladen werden konnten, ermöglichte es noch nicht, mehrere Programme gleichzeitig laufen zu lassen und zwischen ihnen hin und her zu wechseln, denn dafür hätte es eine Art von übergeordneter Steuerung gebraucht, die die verschiedenen im Speicher befindlichen Programme unter ihrer Kontrolle gehabt und dem Benutzer das Wechseln ermöglicht hätte. So etwas gab es unter MS-DOS aber noch nicht. Was aber möglich war, war das Ausführen von Programmen in einer Art Kette. Stellen Sie sich die folgende Situation einmal vor: Sie wollen einen Brief schreiben, haben dafür die Textverarbeitung geöffnet und bereits einen längeren Textabschnitt verfasst. Nun bemerken Sie aber, dass Sie für den Brief eine Information brauchen, die in einem Tabellenblatt der Tabellenkalkulation steht. Wenn Ihre Textverarbeitung es nun ermöglicht, können Sie direkt aus ihr heraus die Tabellenkalkulation starten und dort die Information in Erfahrung bringen. Nach dem Beenden des Tabellenkalkulationsprogramms landen Sie – als wäre nichts gewesen – automatisch wieder in Ihrem Text in der Textverarbeitung, in dem Sie die neuen Erkenntnisse direkt unterbringen können. Wirklich komfortabel war das nicht, doch es verringerte zumindest die Notwendigkeit, im Programm A alles speichern zu müssen und das Programm zu beenden, nur um ein Programm B nutzen zu können.
Die Voraussetzung dafür, dass das so klappte, war natürlich das Vorhandensein von hinreichend Arbeitsspeicher und das war durchaus ein Problem, denn Speicher war nicht nur teuer, sein Handling unter DOS war auch ein sehr komplexes Unterfangen. Wenn Sie einen Computer-Freak in Ihrem Bekanntenkreis haben, der alt genug ist, dass er oder sie noch mit DOS gearbeitet haben könnte, sprechen Sie ihn oder sie mal darauf an. Ein stundenlanger Vortrag (zum Beispiel über die Unterschiede zwischen oberem und hohem Speicher oder gar zwischen Extended Memory und Expanded Memory) oder ein plötzliches Erbleichen verbunden mit Schnappatmung sind Ihnen sicher!
VisiOn, TopView, DESQView
Weiter oben habe ich Ihnen erzählt, dass das erste Computersystem nach Xerox Star und Apple Lisa, das auf Mausbedienung und Fenster gesetzt hat, der Apple Macintosh von 1984 gewesen sei. In einer groben Betrachtung stimmt das auch. Schaut man aber genau hin, findet man VisiOn, eine grafische Arbeitsumgebung für IBM PCs, die bereits 1982 präsentiert wurde und ab Ende 1983 in den Verkauf kam. Der Hersteller der VisiON-Bedienoberfläche war die Firma VisiCorp, die auch hinter VisiCalc stand, der Urversion der Tabellenkalkulation, die ich Ihnen im Kapitel über den Apple II vorgestellt habe. In mancher Hinsicht war VisiOn der Nutzungsschnittstelle des Macintosh überlegen, denn im Gegensatz zum Apple-Rechner bot das System die Möglichkeit, mehrere Dokumente in verschiedenen Anwendungen gleichzeitig geöffnet zu haben und zwischen diesen hin und her zu wechseln. Diese Fähigkeit ging natürlich mit entsprechenden Hardware-Anforderungen einher. Der PC brauchte 512 KB Arbeitsspeicher, eine Festplatte von mindestens 5 MB Größe, eine CGA-Grafikkarte und eine Maus. IBMs PC XT aus dem gleichen Jahr verfügten zwar, wenn man die teuere Ausstattungsvariante wählte, über eine Festplatte, aber üblicherweise nur über 128 KB Arbeitsspeicher. Eine Maus gehörte nicht zum Lieferumfang des Rechners. Zu den 5.000 Dollar für dieses Spitzengerät kamen also noch die Kosten für die Speicheraufrüstung und für eine Maus hinzu.
VisiOn war kein komplettes Betriebssystem. Um es zu nutzen, startete man den Computer zunächst mit Microsofts DOS und lud dann VisiOn wie jede andere DOS-Anwendung. VisiOn präsentierte sich dann zunächst mit dem „Application-Manager“, mit dem Anwendungen aufgerufen werden konnten. Die Anwendungen wurden, wie oben zu sehen, jeweils in einem eigenen Fenster dargestellt. Bei besagten Anwendungen handelte es sich nicht um die normalen Anwendungen für IBM PCs, sondern um eigens für VisiON erstellte Programme. Neben dem Application Manager stand eine Textverarbeitung (VisiOn Word), eine Tabellenkalkulation (VisiOn Calc) und eine Software zum Erzeugen von Business-Grafiken (VisiOn Graph) zur Verfügung. Das System wäre grundsätzlich um weitere Anwendungen erweiterbar gewesen, zusätzliche Software erschien jedoch nie.
Wenn man moderne fensterbasierte Nutzungsoberflächen kennt, erscheint einem die Bedienung von VisiOn in mancherlei Hinsicht eigenartig. Schon beim ersten Blick auf die Abbildung wirkt die Nutzungsschnittstelle fast ein bisschen auf den Kopf gestellt. Statt eines Menüs oben im Fenster, wie bei Windows, oder am oberen Bildschirmrand, wie beim Macintosh, werden systemweite Funktionen ganz unten auf dem Bildschirm und Anwendungsfunktionen in der Fußzeile des jeweiligen Fensters angezeigt. Den Fenstern fehlen überdies all die kleinen Bedienelemente zum Schließen, Verschieben, Vergrößern und Verkleinern. Diese findet man stattdessen im Menü in der Fußzeile. Nicht nur die Position ist aber aus heutiger Sicht außergewöhnlich; die komplette Arbeitsweise wirkt regelrecht verdreht. Alle heutigen grafischen Nutzungsschnittstellen verwenden das Objekt-Verb-Paradigma. Man markiert zunächst ein Objekt, etwa eine Datei oder ein Fenster, und wählt dann die Handlung aus, die man ausführen will, etwa Öffnen, Schließen oder Löschen ebenjener Datei oder des Fensters. VisiOn verwendete hingegen eine Verb-Objekt-Arbeitsweise. Wollte man ein Fenster schließen, klickte man unten zunächst auf „CLOSE“. In der Zeile darüber meldete das System dann „Close. Which Window?“. Nun musste man das Objekt anklicken, das geschlossen werden sollte, hier also eines der Fenster. Diese Arbeitsweise erscheint uns heute total ungewöhnlich. Dass die Software-Ingenieure bei VisiCorp trotzdem darauf kamen, ist aber aus der damaligen Sicht gar nicht so unverständlich, denn nach dem Verb-Objekt-Prinzip funktionierten auch die damals ja noch dominierenden Kommandozeilen-Schnittstellen. Wollte man unter DOS die Datei „unsinn.txt“ löschen, schrieb man den Befehl an den Anfang und das Objekt, auf das er sich bezog, als Zweites: del unsinn.txt.
Dass VisiOn kein Erfolg war, können Sie sich vermutlich denken. Das lag jedoch nicht an der eigenartigen Bedienweise. An diese hätte man sich durchaus gewöhnen können und auch ein Umstellen auf Objekt-Verb-Betrieb wäre in späteren Versionen sicher umsetzbar gewesen. Das Problem war eher, dass VisiOn aufgrund seiner hohen Anforderungen an die Hardware wohl ein paar Jahre zu früh kam. Nur für die Nutzung der Maus und der Fenstertechnik einen derart hochgezüchteten, teuren Computer anzuschaffen, war letztlich nicht zu rechtfertigen. Problematisch war auch die Software-Situation. Zwar lieferte VisiOn typische Büro-Software mit, doch liefen eben nicht die etablierten Software-Produkte, wegen derer die IBM-Rechner und ihre Kompatiblen in der Wirtschaftswelt so verbreitet waren. Die Textverarbeitung war kein WordPerfect und kein WordStar und die Tabellenkalkulation war kein Lotus 1-2-3, noch nicht einmal ein vollwertiges VisiCalc.
Wenn Sie meine Erläuterungen zum Xerox Alto gelesen haben, dann haben Sie dort erfahren, dass das System, wenn auch kein kommerzieller Erfolg, großen Einfluss auf die Entwicklung der Nutzungsschnittstellen hatte, was auch damit zusammenhing, dass Steve Jobs einen Besuch beim Xerox PARC machte, wo ihn die Präsentation der Smalltalk-Umgebung zu weitreichenden Änderungen der in der Entwicklung befindlichen Schnittstellen der Apple Lisa und letztlich des Macintosh bewog. Auch VisiOn fand seine Inspiration in der Smalltalk-Umgebung, war aber auch wiederum Inspiration für spätere Entwicklungen. Der Erzählung nach sah Bill Gates die Präsentation der Umgebung auf der COMDEX 1982, was ihn darin bestärkte, sein eigenes Projekt voranzutreiben, das unter dem Namen „Windows“ bekannt werden sollte. Noch war es aber nicht soweit und die Nutzer des IBM PCs mussten sich mit MS-DOS und seiner eingeschränkten Nutzungsschnittstelle zufrieden geben.
Wenn Sie sich Mitte der 1980er Jahre einen IBM PC oder einen seiner günstigeren Kompatiblen leisteten und diesen mit hinreichend Arbeitsspeicher und einer Festplatte ausstatteten, stand Ihnen eine große Software-Vielfalt offen. Der PC war nicht gerade eine Spiele- oder Grafik-Plattform, aber gerade im Bereich der Business-Software blieben am PC kaum Wünsche offen. Die ärgerlichste Einschränkung des Systems bei der täglichen Arbeit war, dass es sich immer noch um ein Single-Tasking-System handelte. Die Nutzer waren gezwungen, ständig Dateien zu speichern, Programme zu schließen, andere Programme zu starten, sie wieder zu schließen und so weiter. Die Programme, die eigentlich gleichzeitig gebraucht wurden, konnten nur abwechselnd verwendet werden. Nutzer des Amiga oder auch die wenigen Nutzer von VisiOn waren hier klar im Vorteil. Sie konnten einfach zwischen den Programmen hin und her wechseln. Wenn ich von Multitasking rede, ist mir an dieser Stelle übrigens egal, ob es sich um echte Gleichzeitigkeit handelt, bei dem die Programme im Hintergrund weiterlaufen, oder ob nur der Wechsel zwischen Programmen ermöglicht wird, bei dem das aktive Programm ausgeführt wird, während die anderen Programme einfrieren. Es gibt Situationen, in denen echtes Multitasking wichtig ist, etwa, wenn Sie in einem Programm Musik spielen lassen und währenddessen in einem anderen Programm arbeiten wollen. In sehr vielen Fällen gibt es in der Praxis aber keinen Unterschied, ob ein Hintergrundprogramm weiterläuft oder nicht. Wenn Sie etwa von der Textverarbeitung in die Tabellenkalkulation wechseln, ist es völlig egal, ob die Textverarbeitung dabei angehalten wird.
Eine Reihe von Software-Herstellern brachte 1985 Systemerweiterungen heraus, die es ermöglichen sollten, mehrere DOS-Programme gleichzeitig laufen zu lassen und zwischen ihnen nach Belieben zu wechseln. Verbreitung fanden IBMs TopView und die Software DESQView von QuarterDeck. Beide Produkte erlaubten es, MS-DOS-Programme jeweils in ihrem eigenen Fenster laufen zu lassen. Dieser Fensterbetrieb funktionierte allerdings nicht mit jedem Programm. Programme, die den kompletten Bildschirm verwendeten, um zum Beispiel Grafiken anzuzeigen, konnten zwar oft mit den Systemerweiterungen verwendet, allerdings nicht in einem Fenster dargestellt werden. Im November 1985 erschien die erste Version von Microsoft Windows. Auch diese neue Betriebssystem-Umgebung erlaubte es, mehrere Programme gleichzeitig in Fenstern ausführen zu lassen. Neben Anwendungen, die extra für Windows geschrieben wurden, funktionierte das auch mit DOS-Programmen, sofern das Programm mitspielte und der Arbeitsspeicher ausreichte. Beides war nicht oft der Fall.
In der Praxis blieb Multitasking auf IBM-kompatiblen Systemen noch recht lange eingeschränkt. Das hängt damit zusammen, dass Beschränkungen von IBMs ursprünglichem PC und die Notwendigkeit, zu diesem kompatibel zu bleiben, die Speicherverwaltung unter MS-DOS extrem komplex machten. Alle gleichzeitig laufenden Programme mussten im Prinzip in einem Speicherbereich von nur 640 KB Platz finden. Hinzu kam das Problem, dass in DOS-Programmen oft hardwarenahe Tricks angewendet wurden, um die Software schneller zu machen. In Multitasking-Umgebungen machten diese Tricks immer Probleme, da jeder der Software-Entwickler davon ausging, den Rechner komplett unter Kontrolle zu haben. Fingen nun zwei Programme an, gleichzeitig direkt auf die Hardware zuzugreifen, zum Beispiel um etwas auf den Bildschirm zu zeichnen, gab es bestenfalls eine chaotische Darstellung, schlimmstenfalls stürzte der Rechner einfach ab. DOS-Programme waren schlicht und ergreifend nicht für Multitasking-Betrieb ausgelegt. Und Windows? Windows-Anwendungen waren natürlich von vornherein fenster- und multitaskingtauglich, doch bis Windows wirklich eine nennenswerte Verbreitung bekommen sollte, gingen noch gut fünf Jahre ins Land.
Windows und MacOS
Ein Blick ins Jahr 1985 offenbart im Markt der Heim- und Personal-Computer eine bunte Vielfalt. Gerade im amerikanischen Business-Bereich sehr beliebt waren der IBM PC und seine unzähligen Nachbauten. Viel verkauft wurden natürlich die 8-Bit-Heimcomputer wie der Commodore 64 oder der Atari 800XL. Dazu kam der teurere, aber auch besser ausgestattete Apple II. Die Geräte der Nachfolgegeneration dieser Rechner, der Commodore Amiga, der Atari ST und der Apple Macintosh waren bereits verfügbar, fanden ihre Abnehmer und sprengten allmählich die Trennung zwischen Heim- und Bürocomputer. C64 und Co blieben aber noch lange Zeit erfolgreich, da sie viel günstiger waren, als die neuen Geräte, und da es ein riesiges Software- und Spieleangebot für die Geräte gab, die man zudem noch leicht kopieren konnte. In Amerika waren verschiedenste Computer unter der Marke Tandy verfügbar und der britische Computermarkt bereicherte die Auswahl um Rechner von Sinclair, Amstrad und Acorn. Diese Aufstellung ist natürlich bei Weitem nicht komplett. Was nahezu all diese Computertypen gemein hatten, war nicht nur, dass sie klein und – im Vergleich zu Minicomputern von nur zehn Jahren vorher – auch günstig waren und auf Mikroprozessortechnologie basierten, sondern dass sie zueinander nicht kompatibel waren: Sie hatten jeweils ein eigenes Betriebssystem mit einer eigenen Nutzungsschnittstelle, sodass sie sich unterschiedlich bedienten. Auch die Programme des einen Rechners waren auf dem anderen nicht lauffähig. Meist waren noch nicht einmal die Datenträger lesbar. Die Inkompatibilität galt sogar für die Computer des gleichen Herstellers. Ein Apple Macintosh konnte die Programme des Apple II nicht laufen lassen und auch ein Spiel, das für den C64 entwickelt wurde, lief nicht auf einem Amiga.
Computer-Nostalgiker trauern dieser Zeit mit den vielen verschiedenen Systemen oft nach, denn jedes System hatte seine eigenen Macken, seine eigenen Stärken und seine typischen Charakteristika. In der damaligen Zeit jedoch haben sich viele darüber geärgert, denn die Inkompatibilitäten auf allen Ebenen kosteten viel Zeit und Nerven. Schrieb etwa ein stolzer Besitzer eines Macintosh einen Text im mitgelieferten MacWrite, speicherte ihn auf einer 3,5-Zoll großen Diskette ab und gab sie einem Bekannten mit einem IBM PC, dann hatte der schon mal das Problem, dass er wahrscheinlich gar kein Laufwerk hatte, in das er diese Disketten stecken konnte, denn beim IBM PC waren damals 5,25-Zoll große Disketten und die entsprechenden Laufwerke üblich. Gab er sie seinem Kollegen mit einem Amiga, konnte der die Diskette zwar physikalisch ins Laufwerk stecken, doch lesen konnte er sie nicht, denn die Art und Weise, wie die Daten auf der Diskette gespeichert wurden, unterschied sich zwischen den Systemen. Selbst dann, wenn es jemand hinbekam, die Dateien des einen Rechners auf dem anderen zugreifbar zu machen – der Atari ST konnte zum Beispiel mit einem PC formatierte 720-KB-Disketten lesen – war damit auch noch nicht viel erreicht, denn auf den verschiedenen Systemen gab es jeweils eigene Software, die meist mit der der anderen Systeme nicht kompatibel war. Man konnte die Dateien des fremden Systems dann zwar auf dem Desktop sehen, aber leider weder betrachten noch bearbeiten. Natürlich gab es damals Möglichkeiten, die Inkompatibilitäten zu umschiffen. Dateien wurden zum Beispiel oft nicht per Diskette, sondern mittels eines Kabels übertragen, das zum Beispiel die standardisierten Schnittstellen der Rechner an der Stelle miteinander verband, an der man normalerweise einen Drucker anschloss. Jeweils eine kompatible Übertragungs-Software auf beiden Systemen, die man sich zur Not sogar noch selbst programmieren konnte, ermöglichte es, die Dateien zu übertragen. Einigte man sich dann noch auf Standard-Dateiformate oder war im Besitz von praktischen Konvertierungsprogrammen, konnte man durchaus Dateien zwischen den Rechnern austauschen. Praktisch war das alles aber nun wirklich nicht.
Die Vielfalt auf dem Personal-Computer-Markt hielt sich bis etwa Mitte der 1990er Jahre. Ataris Falcon 030 war 1993 der letzte Computer der ST-Reihe. Im gleichen Jahr beendete Apple die Produktion des Apple IIe. Der Commodore 64 wurde bis 1994 gebaut und die letzten Amiga-Modelle wurden 1996 auf den Markt gebracht. Die bisherige Vielfalt ging verloren – der Personal-Computer-Markt wurde mehr und mehr eine zweiseitige Angelegenheit mit Apple und seinem MacOS21 auf der einen Seite und Microsoft mit Windows auf der anderen. Betrachtet man die beiden Systeme heute, findet man weit mehr Ähnlichkeiten als Unterschiede. Es handelt sich bei beiden Systemen um ausgereifte Betriebssysteme mit komplexen Nutzungsschnittstellen. Ihre Unterschiede fallen größtenteils in den Bereich persönlicher Präferenzen. Inkompatibilitäten sind heute auch nicht mehr das Problem. Große Teile der Software sind auf beiden Systemen verfügbar, Datenträger des einen Systems sind auf dem jeweils anderen meist zumindest lesbar und standardisierte Dateiformate erleichtern die Zusammenarbeit über die Systemgrenzen hinweg.
Ich will Ihnen nachfolgend in aller Kürze erläutern, wie sich die beiden Betriebssysteme dahin entwickelt haben, wo sie heute sind, denn die Voraussetzungen für die Entwicklung waren alles andere als gleich. Apple musste, mit einer kurzen Ausnahme Ende der 1990er Jahre, stets nur seine eigenen Geräte mit seiner eigenen Hardware im Blick haben. Microsoft sah sich hingegen der Situation gegenüber, eine Systemsoftware entwickeln zu müssen, die auf einer Vielzahl von Geräten einsetzbar war. In dieser Hinsicht ist Apple noch heute im Vorteil, was manchmal ein Grund dafür sein dürfte, dass das MacOS etwas glatter läuft und etwas weniger komplex ist als Microsofts Windows. Mein Fokus im folgenden geschichtlichen Abriss liegt nicht auf derartigen produktpolitischen Aspekten, sondern auf der Nutzungsschnittstellen-Welt der Systeme. Mich interessiert nur am Rande, was sich bei den Systemen „unter der Haube“ tat. Dass es zum Beispiel bei Apple dreimal einen Wechsel der Hardware-Architektur gab, ignoriere ich hier einfach, genauso wie die Multimedia- und Internetfähigkeiten der Systeme, die sich bis auf Kleinigkeiten nicht unterschieden.
MacOS – Der Desktop und der Finder
Die erste Version von MacOS erschien mit dem Ur-Macintosh im Jahre 1984. Dieser Macintosh war, wie im vorherigen Kapitel beschrieben, ein sehr einfacher Rechner mit nur 128 KB RAM, einem einzigen Diskettenlaufwerk und ohne Festplatte. Folge dieser Einschränkung war, dass der Rechner im Single-Tasking-Betrieb laufen musste, also stets nur ein Programm zur gleichen Zeit genutzt werden konnte. Die Hauptoberfläche des Betriebssystems war eine Software namens Finder. Der Finder erlaubte den Zugriff auf das Dateisystem, bot einen Desktop an, auf dem sich ein Papierkorb befand, eingelegte Disketten als Icons angezeigt wurden und Dateien abgelegt werden konnten. Ein Doppelklick auf ein Disketten-Icon öffnete ein Fenster, das die auf der Diskette gespeicherten Dateien als Icons anzeigte. Befand sich auf der Diskette ein Ordner, konnte auch dieser mit dem Finder geöffnet werden. Ein Doppelklick auf ein Datei-Icon startete das mit dem Dokument verbundene Programm. Oft musste dazu allerdings eine andere Diskette eingelegt werden, auf der das Programm gespeichert war. War der Nutzer mit der Bearbeitung fertig, musste er das Programm beenden und die Betriebssystemdiskette wieder einlegen. Es wurde dann wieder der Finder mit dem Desktop geladen.
Typisch für MacOS war, dass Dateien und Ordner per Drag and Drop verschoben werden konnten, so zum Beispiel auch zwischen geöffneten Ordnerfenstern oder von einer Diskette auf eine andere. Das ging sogar mit nur einem Diskettenlaufwerk. Der Finder ermöglichte es dafür, eine Diskette zwar auszuwerfen, allerdings auf dem Desktop noch zugreifbar zu halten. Sobald auf diese Diskette zugegriffen werden sollte, verlangte das System den Wechsel der Diskette. Das Kopieren einer Datei von einer Diskette auf die andere wurde dadurch möglich, war aber natürlich durch den kleinen Arbeitsspeicher begrenzt und war bei großen Dateien mit vielfachem Hin- und Herwechseln der Disketten verbunden. Komfortabler funktionierte es, wenn man sich ein zusätzliches, externes Diskettenlaufwerk kaufte und an den Rechner anschloss. Auf der Diskette gespeicherte Dokumente und Ordner konnten nicht nur zwischen Fenstern verschoben, sondern überdies auch aus den Fenstern herausgezogen und direkt auf der Desktop-Oberfläche abgelegt werden. Dass das bei einem rein auf Diskettenbetrieb ausgelegten Betriebssystem funktionierte, kann einen durchaus erstaunen. Wo befand sich eine Datei, wenn sie auf den Desktop gelegt wurde? Die Antwort auf diese Frage kennen Sie schon, wenn Sie im vorherigen Kapitel gelesen haben, was es mit dem Desktop der Apple Lisa auf sich hatte. Wurden am Macintosh Dateien auf den Desktop verschoben, wurden sie, wie bei der Lisa, zwar auf dem Desktop-Hintergrund angezeigt, ihr eigentlicher Speicherort blieb aber die Diskette. Bei der Lisa sah man die Datei dann weiterhin auch als ausgegrautes Icon am ursprünglichen Speicherort, beim Macintosh hat man auf diese Darstellung des eigentlichen Speicherorts verzichtet. Eine auf dem Desktop abgelegte Datei erschien nur dort und nicht mehr im Disketten- oder Ordnerfenster, so dass der Eindruck entstehen konnte, die Datei wäre von der Diskette auf den Desktop verschoben worden. Von diesem visuellen Unterschied abgesehen, funktionierte der Mechanismus aber genau so wie bei der Lisa. Wählte man eine auf dem Desktop abgelegte Datei aus und klickte dann im Menü auf „Put Away“ (in frühen Versionen des Betriebssystems mit „Put Back“ betitelt) wurde die Datei vom Desktop entfernt und erschien fortan wieder an ihrem ursprünglichen Speicherort, sie wurde der Metapher entsprechend „zurückgelegt“.
Der Desktop des Macintosh zeigte stets die Dateien an, die auf der gerade eingelegten Diskette als auf dem Desktop liegend verzeichnet, waren. Auf jeder Diskette gab es dafür einen eigenen Bereich. Hier wurde gespeichert, welche Ordner einer Diskette gerade in einem wie gearteten Fenster geöffnet und welche Dateien einer Diskette auf dem Desktop an welcher Position abgelegt waren. Nur durch das Speichern dieser Informationen auf der Diskette war es möglich, dass nach der Beendigung eines Programms der Finder wieder die gleichen Dateien auf dem Desktop und die gleichen Fenster geöffnet darstellen konnte. Legte man bei laufendem Finder eine Diskette ein, erschienen die von dieser Diskette früher auf dem Desktop abgelegten Dateien wieder an ihrer gespeicherten Stelle und auch die Ordnerfenster, die zuvor geöffnet waren, erschienen wieder. Jede Diskette speicherte also in gewisser Weise ihren eigenen Desktop. Diese Art der Desktop-Verwaltung eröffnete ganz interessante Einsatzszenarien für die Arbeit in verschiedenen Arbeitskontexten, etwa in verschiedenen Projekten: Setzte man voraus, dass eine Diskette immer die Dokumente eines einzelnen Projekts speicherte, konnte man sich für jedes seiner Projekte einen Desktop einrichten und diesen dann bei Bedarf laden, indem man die passende Diskette erneut einlegte. Spannend war diese Technik auch, wenn man in einem Büro arbeitete, in dem es mehrere Macintoshs gab, denn man konnte nun seine Projektdiskette mitnehmen, in den Macintosh an einem anderen Arbeitsplatz einlegen und hatte trotzdem alle Arbeitsmaterialien auf dem Desktop parat und auch alle Ordnerfenster wieder so geöffnet, wie man sie am eigenen Rechner hinterlassen hatte.
Microsoft Windows – Ein Fehlschlag?
1983, bereits vor der Veröffentlichung des Macintosh, kündigte Microsoft eine grafische Nutzungsoberfläche namens Windows an. Microsoft war an der Software-Entwicklung des Macintosh beteiligt. Die ersten Versionen von Excel und PowerPoint und die erste Word-Version mit grafischer Nutzungsschnittstelle erschienen nicht für den IBM PC, sondern für den Macintosh. Diese Entwicklungseinblicke erlaubten Microsoft natürlich, sich für das eigene System „inspirieren“ zu lassen. Der Vorwurf des Ideendiebstahls stand fortan immer im Raum und war Gegenstand von Gerichtsurteilen und nicht zuletzt Stoff für die religionsartig geführten Debatten über das bessere System. Wenn Sie in dieser Hinsicht eine Meinung haben, möchte ich Sie bitten, sich zumindest für den Moment davon zu lösen und MacOS und Windows zunächst einmal als das zu betrachten, was sie sind bzw. was sie waren, denn die Unterschiede der Systeme sind eigentlich viel interessanter, als die Inspirationen, von denen es im Laufe der kommenden Jahrzehnte ohnehin in beiderlei Richtung viele geben sollte.
Die erste veröffentliche Version von Windows erschien im November 1985. Dieses Windows 1.0 hatte einen schlechten Ruf. Der war sicherlich teilweise berechtigt – dazu später mehr. Auf der anderen Seite gilt es jedoch durchaus anzuerkennen, was Microsoft hier hinbekommen hat. Die Hardware-Voraussetzungen von Windows waren auf dem Papier recht bescheiden. Ein Nutzer brauchte nur 256 KB RAM, einen Rechner mit zwei Diskettenlaufwerken, eine Maus und eine Bildwiedergabe, die nicht nur Text, sondern auch Grafik anzeigen konnte. Mit Ausnahme der Maus, die damals noch kein Standard war, war diese Ausstattung für Rechner des Jahres 1985 nichts Besonderes mehr. So wie es auch bei vielen Windows-Versionen in den folgenden Jahren der Fall sein sollte, war diese von Microsoft angegebene Minimalausstattung für das System aber nicht wirklich nutzbar. Eine Festplatte und vor allem mehr Arbeitsspeicher waren sehr anzuraten. Festplatten wurden zwar im Firmenkontext bereits üblich, doch Arbeitsspeicher über die 1-MB-Grenze hinaus war noch extrem kostenintensiv. Besaß man aber eine damit verbundene teure Speicher-Erweiterungskarte, konnte Windows den zusätzlichen Speicher verwenden und stellte seinen Anwendungen somit mehr Speicher als die unter MS-DOS direkt verwendbaren 640 KB zur Verfügung.
Windows 1.0 war noch kein eigenständiges Betriebssystem. Ein Windows-Nutzer startete seinen Rechner mit MS-DOS und lud dann Windows so wie jedes andere DOS-Programm. Je nach eingebauter Grafikkarte erschien das System nun in verschiedener Optik. War nur eine CGA-Grafikkarte eingebaut, wurde Windows monochrom dargestellt. Die Auflösung war mit 640 x 200 Punkten etwas eingeschränkt, aber durchaus nutzbar. Verfügte der stolze Windows-Nutzer hingegen über eine extrem moderne EGA-Grafikkarte, stieg die Auflösung auf 640 x 350 Pixel bei sechzehn Farben. Die beste Auflösung von 720 x 348 Pixeln konnte mit einer sogenannten Hercules-Grafikkarte erreicht werden. Da Hercules-Grafikkarten von Haus aus keine Farbe unterstützten, war natürlich auch hier die Darstellung monochrom. In der Abbildung oben sehen Sie Windows in der EGA-Darstellung. Die Farbwahl von Microsoft lässt aus ergonomischer Sicht stark zu wünschen übrig. Über die Gründe hierfür kann ich nur spekulieren. Zum einen war die Fähigkeit des EGA-Grafikstandards, gedeckte Farben anzuzeigen, eingeschränkt. Die sechzehn möglichen Farben waren allesamt recht grell und gesättigt. Zum anderen kann ich mir gut vorstellen, dass Microsoft durchaus ein wenig herausstellen wollte, dass das eigene System im Gegensatz zu damaligen Macintosh-Rechnern, Farben unterstützt. Es mag sein, dass deswegen so auffällige Farben gewählt wurden.
Windows erlaubte die Ausführung von DOS-Anwendungen im Fenster, aber vor allem natürlich die Ausführung von expliziten Windows-Anwendungen. Es gab bei Windows keinen Desktop und auch kein mit dem Finder wirklich vergleichbares Tool. Zentrale Schnittstelle war die sogenannte „MS-DOS Executive“, ein sehr simpler Dateimanager und Programmstarter. Er bestand aus nur einem Fenster, in dem ein Datei-Listing angezeigt wurde. Es gab keine Icons, keine räumliche Positionierung und kein Drag and Drop. Da Windows auf DOS aufsetzte, wurde auch dessen Dateinamenbeschränkung von acht plus drei Zeichen in Großbuchstaben und ohne Sonderzeichen geerbt. Man konnte also eine Datei nicht „Der 5. Versuch eines Buches über Computergeschichte.doc“ nennen, sondern musste sich mit so etwas wie „CGESCH_5.DOC“ begnügen. Windows 1.0 sah verglichen mit Apples Betriebssystem eher grobschlächtig aus. Die Farben waren extrem bunt, das System verwendete in seiner Nutzungsschnittstelle durchgehend Schriftarten aus der Terminal-Ära statt für die grafische Schnittstelle neu entwickelten Fonts wie bei Apple, und selbst die kleinen Icons an den Fenstern, etwa die an den Scrollbars, sahen im Vergleich zu denen bei Apple sehr altbacken aus. Hinzu kam, dass das System auf den meisten damaligen Computern unwahrscheinlich langsam lief. Vielfach konnte man regelrecht zuschauen, wie die Bildschirminhalte neu gezeichnet wurden.
Windows war MacOS aber auch in manchem durchaus voraus. Allem voran muss hier das Multitasking genannt werden. Mehrere Anwendungen konnten bei Windows in Fenstern gleichzeitig laufen. Die Fenster konnten dabei so angeordnet werden, dass man die Anwendungen gleichzeitig im Blick hatte. Oben sehen Sie die Anwendungen Paint und Write nebeneinander. Eine systemweite gemeinsame Zwischenablage erlaubte es, Daten zwischen den Programmen auszutauschen. Es konnte zum Beispiel die in Paint gezeichnete Grafik kopiert und im Text in Write eingefügt werden. Das ging so zwar sehr vergleichbar auch beim Macintosh, etwa mit den Programmen MacPaint und MacWrite, allerdings musste bei Windows keines der Programme erst beendet werden, um die Operation im anderen durchzuführen – ausreichend Arbeitsspeicher natürlich vorausgesetzt.
Das Fensterhandling bei Windows 1.0 unterschied sich von dem späterer Windows-Versionen und auch von dem von MacOS. Verwenden wir das System heute, ist ein bisschen Eingewöhnung erforderlich. Noch recht normal ist die Möglichkeit, ein Fenster zu minimieren, bei Windows 1.0 durchaus korrekt „Iconize“ genannt, denn eine minimierte Anwendung erschien nun als Icon am unteren Bildschirmrand. Auch eine Darstellung, bei der ein Fenster den ganzen Bildschirm füllte, „Zoomed“ genannt, war bereits vorhanden. Auffällig im Vergleich zu heutigen Systemen ist aber, dass es bei Windows 1.0 mit der Ausnahme von Meldungsfenstern und eingeblendeten Fenstern zum Laden und Speichern von Dateien keine überlappenden Fenster gab. Diese Eigenschaft wird aus heutiger Sicht gerne als Nachteil des Systems beschrieben. Probiert man es aber einmal selbst aus, wird klar, dass die Art und Weise, wie bei Windows 1.0 Fenster angeordnet wurden, durchaus sehr praktisch war. Im Gegensatz zu einem heutigen Windows oder MacOS, bei dem der Nutzer die volle Kontrolle über die Fensterpositionierungen hat, übernahm bei Windows 1.0 das System selbst einen Großteil der Aufteilungsarbeit. Lief nur ein einziges Programm, etwa nach dem Start die MS-DOS-Executive, wurde diesem der maximale Platz eingeräumt. Startete der Nutzer dann ein weiteres Programm, wurde der Bildschirm automatisch aufgeteilt, sodass beide Anwendungen ihren Platz fanden. Ganz der Automatik hingeben musste man sich aber nicht. Der Nutzer hatte durchaus Einfluss auf die Anordnung. Nahm er etwa ein Icon einer minimierten Anwendung auf und zog es an den oberen Bildschirmrand, wies Windows dem dazugehörigen Fenster die obere Bildschirmhälfte zu. Gleiches funktionierte auch mit den anderen Bildschirmrändern und mit nicht-minimierten Fenstern durch die Auswahl des Menüeintrags „Move“ oder durch Ziehen der Titelleiste an den entsprechenden Rand. Hatte man diesen Mechanismus erst einmal heraus, war es in Windows 1.0 sehr einfach, mehrere Anwendungen bzw. mehrere Dokumente gleichzeitig in den Blick zu bringen, um mit ihnen im Zusammenhang zu arbeiten. Eine Anordnung wie die obige von Write und Paint in späteren Windows-Versionen oder auch in MacOS zu erzeugen, bedeutete viel Aufwand, unter Windows 1.0 dauerte es nur wenige Sekunden. Erst in Windows 7, also 24 Jahre später, führte Microsoft wieder eine Funktion ein, mit der eine automatische Aufteilung der Fenster auf diese Art und Weise möglich war und verband damit die Vorteile der automatischen Fensteraufteilung mit den Vorteilen frei positionierbarer Fenster.
Die erste Windows-Version war kein Erfolg, obwohl die grafische Nutzungsschnittstelle von Microsoft der von Apple in einigen Punkten durchaus überlegen war. Sie ermöglichte Multitasking, das Fensterhandling war gerade bei der Ausführung mehrerer Anwendungen zur gleichen Zeit sehr praktisch, und im Gegensatz zum Macintosh konnte Windows auch in Farbdarstellung verwendet werden. In vielen anderen und vielleicht auch wichtigeren Bereichen hinkte Microsoft aber hinterher. Das optische Design von MacOS war viel ausgetüftelter. Mit dem Finder stand ein effektives Werkzeug zur Dateiverwaltung zur Verfügung, der Desktop konnte im Rahmen der Einschränkung des Systems als Ort für die aktuellen Arbeitsdokumente dienen und das System war durch seine Einschränkung auf Single-Tasking und seine Optimierung auf die verwendete Hardware recht flott. Windows hingegen war auf den meisten damaligen PCs zwar lauffähig, verfügte dann aber nicht über genug Leistung für ein wirklich flüssiges Arbeiten. Mit dazu beigetragen, dass kaum jemand Windows 1.0 kaufte, hat sicher auch, dass es außer den einfachen, mitgelieferten Programmen quasi gar keine Software gab. Selbst Microsofts eigene Anwendungen Word und Excel wurden erst für die zweite Version von Windows verfügbar.
Die Möglichkeit, mehrere Programme gleichzeitig im Zugriff zu haben, war natürlich auch beim Macintosh gefragt. Nach einigen speziellen Lösungen wurde im Jahr 1987 der Multifinder eingeführt. Verwendete man ihn statt des klassischen Finders, konnte man in der Menüleiste des Macintosh zwischen den laufenden Anwendungen wechseln. Für Macs mit wenig Speicher oder ohne Festplatte, also Systemen bei denen Multitasking wenig Sinn ergab, blieb der alte Finder mit dem Single-Tasking-Betrieb erhalten.
Ebenfalls im Jahr 1987 stellte Microsoft die zweite Version von Windows vor. Das System lief nun glatter und schneller. Ebenso wie beim Macintosh gab es nun überlappende Fenster. Die praktische Funktion des automatischen Fenster-Handlings fiel dem leider zum Opfer. Für Windows 2 gab es nun auch Software zu kaufen. Zu nennen sind hier vor allem Adobe Pagemaker, MS Word und MS Excel. Alle drei Programme sind von der jeweiligen Macintosh-Software portiert worden.
Windows 3 – Windows wird erwachsen
Die ersten wirklich erfolgreichen Windows-Versionen erschienen mit der 3er-Serie ab 1990. Windows 3.0 wurde optisch komplett neu gestaltet. Die klobigen Terminal-Schriften, die auch in Windows 2 noch verwendet wurden, wurden zum Teil durch modernere Bildschirmschriften ersetzt. Auch die MS-DOS-Executive wurde abgeschafft und durch zwei Programme ersetzt, die die grundsätzliche Arbeitsweise mit Windows von nun an prägten. Der Programm-Manager diente der Übersicht der auf dem Rechner installierten Anwendungsprogramme. Diese wurden als Icons dargestellt, die in sogenannte „Programmgruppen“ eingeordnet wurden. Das Konzept des Programm-Managers war ähnlich dem der Programm-Launcher und Homescreens bei iOS und Android. Auch hier steht das Anwendungsprogramm im Vordergrund, wird durch ein Icon repräsentiert und von einer zentralen Stelle aus gestartet. Dem Programm-Manager wurde ein neu entwickelter Datei-Manager an die Seite gestellt. Dieses Dateiverwaltungsprogramm ermöglichte einen erheblich komfortableren Umgang mit den Dateien im Dateisystem als die vorherige MS-DOS-Executive. Innerhalb des Datei-Managers konnten mehrere Fenster geöffnet werden. Dateioperationen ließen sich somit bequem per Drag and Drop erledigen.
Das sehr populäre Windows 3.1 aus dem Jahr 1992 brachte vor allem Änderungen unter der Haube. Aus Nutzungsschnittstellen-Sicht erwähnenswert war die OLE-Technik (Object Linking and Embedding), die es erlaubte, Objekte aus einem Programm in ein anderes Programm einzubetten und dabei die Bearbeitbarkeit des Objektes weiterhin zu gewährleisten. So ließen sich zum Beispiel Ausschnitte aus Excel-Tabellen in Word einbinden, ohne die Möglichkeit der weiteren Bearbeitbarkeit zu verlieren.
Die 3er-Versionen von Windows waren durch die starke Präsenz des Programm-Managers als Haupt-Nutzungsoberfläche stark programmbasiert. Man öffnete in der Regel nicht ein Dokument, sondern startete ein Programm und lud dann darin das Dokument. Der Dateimanager ermöglichte zwar eine komfortable Dateiverwaltung innerhalb von Windows, hatte aber einen ganz anderen Charakter als der Finder. Das lag schon mal daran, dass der Datei-Manager erheblich weniger zentral war. Er stellte nicht, wie der Finder, die Hauptoberfläche des Betriebssystems, sondern war nur eines der vielen Anwendungsprogramme. Auch seine Darstellung war viel technischer als Apples Finder. Man arbeitete nicht mit als Icons dargestellten Dokumenten, die frei innerhalb eines Fensters oder auf dem Desktop positionierbar waren, sondern organisierte Dateien in Listenform.
MacOS 7 – Der Zenit des klassischen Betriebssystems
Bei Apple endete 1991 mit MacOS 7 die Ära der Betriebssysteme, die auf Rechnern liefen, die nur über ein Diskettenlaufwerk verfügten. Das System verlangte nun eine Festplatte und mindestens 2 MB RAM. Da viele alte Macintosh-Computer noch gerne genutzt wurden, blieb MacOS 6 noch lange in Gebrauch und wurde auch von neuerer Software noch unterstützt. Die Version 7 führte einige Änderungen in der Arbeitsweise des Systems ein. Eher eine Kleinigkeit war hier vielleicht die Einführung von Labels. Dateien konnten nun mit einer Markierung wie etwa „fertig“ oder „kritisch“ versehen werden. Besonders praktisch war dieses Feature auf Systemen mit Farbmonitoren, denn Labels wurden mit Farben verbunden. Wurde eine Datei etwa mit „hot“ beschriftet, wurde das Icon rötlich eingefärbt und hob sich somit direkt optisch von den anderen ab. Da MacOS nun sicher davon ausgehen konnte, dass eine Festplatte zur Verfügung steht, wurden einige Änderungen an der Arbeitsweise des Systems vorgenommen. Eine dieser Änderungen betraf das Löschen von Dateien. Bis hierhin funktionierte der Papierkorb von MacOS so, dass eine Datei, die gelöscht wurde, zunächst nur zur Löschung vorgemerkt und fortan an ihrem Ort im Dateisystem nicht mehr angezeigt wurde. Das eigentliche Löschen passierte erst dann, wenn die Diskette ausgeworfen oder wenn der Desktop-Prozess selbst beendet wurde, im Single-Tasking-Betrieb also beim Laden eines anderen Programms, im Multi-Tasking-Betrieb spätestens beim Herunterfahren des Rechners. Ab MacOS 7 hatte der Papierkorb nun einen festen Ort auf der Systemfestplatte. Sein Inhalt blieb also fortan so lange erhalten, bis er explizit geleert wurde.
Eine durchaus tiefgreifende Änderung, die aber den meisten Nutzern wahrscheinlich gar nicht direkt auffiel, betraf die Funktionsweise des Desktops an sich. Bis einschließlich MacOS 6 funktionierte der Desktop in der zu Beginn beschriebenen Funktionsweise. Auf dem Desktop abgelegte Dateien wurden zwar dort angezeigt, ihr eigentlicher Speicherort war aber ein Ort auf einer eingelegten Diskette oder auch einer angeschlossenen oder eingebauten Festplatte. Dateien konnten im Finder auf den Desktop gezogen werden und von dort aus per „Put Away“ wieder zurückgelegt werden. Speicherte man eine Datei aus einer Anwendung heraus ab, konnte man sie auf die Platte oder auf eine Diskette speichern, nicht aber direkt auf den Desktop legen. Diesen Schritt musste man später im Finder unternehmen. Ab MacOS 7 war es nun möglich, Dateien und Ordner auch direkt auf dem Desktop zu erzeugen und unmittelbar dorthin zu speichern. Für diese Dateien und Ordner funktionierte „Put Away“ nun nicht mehr, die Funktion blieb grundsätzlich aber erhalten.
Zehn Jahre nach der Lisa wurde auch das Konzept der „Stationery Pads“ wieder eingeführt. Zur Erinnerung: Bei der Apple Lisa waren Stationery Pads das zentrale Konzept zum Erzeugen neuer Dateien. Statt in einer Anwendung eine Datei unter einem neuen Dateinamen abzuspeichern, erzeugte man bei der Lisa die Kopie einer Vorlagendatei, indem man einen Doppelklick auf einem Stationery Pad, was im übertragenen Sinn „Abreißblock“ bedeutet, machte. Daraufhin wurde automatisch eine Kopie erzeugt, die nun zur Bearbeitung geöffnet werden konnte. Nun gab es die Abreißblöcke auch beim Macintosh. Die Implementierung der Stationery Pads unter MacOS 7 war allerdings erheblich einfacher. Bei der Lisa erzeugte ein Klick auf einen Abreißblock eine Kopie am gleichen Speicherort und in räumlicher Nähe. Bei MacOS 7 wurde lediglich die Originaldatei im verknüpften Programm geladen. Hier stand dann die Option „Speichern“ nicht zur Verfügung, was den Nutzer zwang, „Speichern unter“ zu wählen. Die Funktion der Stationery Pads gibt es übrigens heute noch. Sie kann über die Eigenschaft „Formularblock“ in den Datei-Informationen aktiviert werden. Die Umsetzung entspricht heute aber eher wieder der der Lisa. Es wird eine Kopie am gleichen Speicherort erzeugt.
Betrachten wir die beiden wichtigsten Betriebssysteme im Jahr 1994, finden wir zwei unterschiedliche Paradigmen: Auf dem Macintosh hatte sich eine dokumentbasierte Arbeitsweise etabliert. Es gab kein Äquivalent zu einem Programm-Manager. Die zentrale Komponente des Betriebssystems war der Finder mit seiner grafisch-räumlichen Darstellung des Dateisystems. Bei Windows hingegen standen die Anwendungen im Vordergrund, was sich vor allem durch die Dominanz des Programm-Managers ausdrückte. Die Dateiverwaltung fand in einem Zusatz-Tool als eine der vielen möglichen Funktionen des Computersystems statt. Im Jahre 1995 sollte sich dieser Unterschied in den Arbeitsweisen drastisch verringern, denn mit Windows 95 gelang Microsoft die Verbindung der beiden Welten. Zudem war Windows 95 technisch in vielerlei Hinsicht dem Apple-Betriebssystem überlegen. Apple geriet in Sachen Betriebssystem zunehmend ins Hintertreffen. Noch stärker als bei Windows 95 zeigte sich Microsofts technischer Vorsprung bei Windows NT. NT stand für New Technology. NT-Systeme wurden in der Regel bei Servern und auf Firmenrechnern eingesetzt. Das Betriebssystem ging aus der zunächst gemeinsamen Entwicklung eines Betriebssystems namens OS/2 zusammen mit IBM hervor. Windows NT war im Gegensatz zu anderen Windows-Versionen inklusive Windows 95, 98 und ME kein Aufsatz auf MS-DOS, sondern ein eigenständiges System. Die erste Version von Windows NT hatte im Jahre 1993 die Versionsnummer 3.1. Sie war das erste Windows, das Nutzerkonten und lange Dateinamen unterstützte, hatte ansonsten aber die gleiche Nutzungsschnittstelle wie Windows 3.1. Das im Jahr 1996 veröffentlichte Windows NT 4 war von der Bedienweise identisch mit Windows 95. Die technischen Neuheiten von Windows NT waren mannigfaltig. Ihre Erörterung würde an dieser Stelle aber viel zu weit führen, denn sie betreffen nicht die Nutzungsschnittstelle des Systems und hatten keinerlei Einfluss darauf, welche Nutzungsschnittstellen-Welten am PC zur Verfügung standen.
Windows 95 – Die Verbindung der zwei Welten
Für Windows 95 konzipierte Microsoft eine komplett neue Desktop-Oberfläche. Vieles, was Sie heute als Nutzungsschnittstelle von Windows kennen, wurde in dieser Windows-Version eingeführt. Alle Windows-Versionen ab 1995 unterstützten lange Dateinamen mit Leerzeichen und Umlauten. Windows verfügte nun über einen Desktop, auf dem sich ein Papierkorb und ein Icon namens „Arbeitsplatz“ (im Englischen: „My Computer“) befanden. Die Papierkorb-Funktionalität war bei Windows gänzlich neu. Dateien wurden nun wie beim Macintosh nicht mehr direkt gelöscht, sondern zunächst im Papierkorb abgelegt, aus dem sie wieder zurückgeholt werden konnten. Der „Arbeitsplatz“ bot Zugriff auf die Festplatten und Diskettenlaufwerke des Computers. Der bisherige Dateimanager wurde durch den Windows Explorer ersetzt. Seine Standard-Darstellung ähnelte der von MacOS. Ein Ordner öffnete sich in ein Fenster mit Icon-Ansicht, die räumlich anpassbar war. Wurde ein Ordner-Icon innerhalb dieses Fensters per Doppelklick geöffnet, öffnete sich ein neues Fenster, das die Inhalte dieses Ordners anzeigte. Dieses Verhalten konnte stärker als bei Apple angepasst werden. Viele stellten sich den Explorer zum Beispiel so ein, dass das Öffnen eines Unterordners kein neues Fenster öffnete, sondern dieser einfach im gleichen Fenster angezeigt wurde. Diese Variante wurde in späteren Windows-Versionen zum Standard. Waren viele Dateien zu organisieren, bot der Explorer eine zweigeteilte Ansicht. In einer Leiste auf der linken Seite wurde dann der Verzeichnisbaum angezeigt, während im Hauptinhaltsbereich die Dateien des ausgewählten Ordners in Listenform angezeigt wurden. Diese durchaus praktische Ansichtsvariante des Explorers ist leider im Laufe der Jahre abhandengekommen und durch eine Anzeige wichtiger Ordner an dieser Stelle ersetzt worden.
Der Explorer von Windows 95 war nicht nur viel anpassbarer als Apples Finder, er ermöglichte im Gegensatz zu diesem auch Nebenläufigkeit. Der Fachbegriff hierfür lautet „Multi-Threading“. Im Grunde ist Multi-Threading fast das Gleiche wie das bekanntere Multitasking. Während man unter Multitasking heute allerdings meist das gleichzeitige Ausführen mehrerer Programme versteht, meint Multi-Threading die gleichzeitige Ausführung mehrerer Aktionen innerhalb einer Anwendung. Das Multi-Threading machte sich vor allem bei langlaufenden Operationen bemerkbar. Kopierte man zum Beispiel viele Dateien, zeigten sowohl Windows 95 als auch MacOS Fenster an, die den Fortschritt des Kopiervorgangs anzeigten und dessen Abbruch ermöglichten. Bei MacOS musste man nun entweder das Kopieren abwarten oder aber abbrechen, bevor man mit dem Finder weiterarbeiten konnte. Unter Windows 95 hingegen blieben Explorer und Desktop auch während der Kopieroperation arbeitsbereit. Das Kopieren wurde im Hintergrund zu Ende geführt, während der Nutzer andere Aufgaben erledigten konnte.
Mit dem Explorer holte Microsoft in Sachen Desktop und Datei-Handling zu Apples Betriebssystem auf und war diesem in manchen Bereichen voraus. Windows konnte von nun an wie MacOS dokumentzentriert betrieben werden. Während man unter Windows 3.1 noch Microsoft Word öffnete, dann im Datei-Menü „Öffnen“ wählte, um eine Datei auszuwählen, wurde es unter Windows 95 üblich, den Ordner mit der gewünschten Datei im Explorer anzunavigieren und durch Doppelklick die Datei im passenden Programm zu öffnen. Die bisherige Möglichkeit, eine Anwendung direkt zu starten, blieb in Windows 95 erhalten. Die Auswahl der Anwendung geschah allerdings nicht mehr aus einem Bildschirm füllenden Programm-Manager heraus, sondern aus dem neu erfundenen Startmenü, das neben dem Zugriff auf die Systemeinstellungen und die neu eingeführte Dateisuche Zugriff auf die installierten Anwendungen in einem hierarchisch organisierten Menü ermöglichte. Die Abbildung oben zeigt das geöffnete Startmenü mit der ausgewählten einfachen Textverarbeitung WordPad. Das Startmenü war Teil der ebenfalls neu eingeführten Taskleiste am unteren Bildschirmrand. Mit dieser bekam Windows eine neue Nutzungsschnittstelle für das Wechseln zwischen den laufenden Programmen und Fenstern. In vorherigen Windows-Versionen war dies nur mittels der Tastenkombination „ALT-Tab“ möglich, die auch heute noch bei Windows (und inzwischen auch als „CMD-Tab“ unter MacOS) funktioniert. Der Nachteil dieser Methode ist, dass die Liste der laufenden Anwendungen nicht dauerhaft sichtbar ist und nur derjenige, der die Tastenkombination kennt, überhaupt die Chance hat, Anwendungen zu wechseln ohne laufend Fenster verkleinern oder verschieben zu müssen. Mit der Taskleiste gab es nun ein Stück Nutzungsschnittstelle, das den Windows-Nutzern durchgehend anzeigte, welche Programme liefen und den Wechsel zwischen den Anwendungen mit einem einzigen Klick erlaubte.
Mit Windows 95 hat sich die Nutzungswelt für Windows-Nutzer komplett geändert. Man mochte sich über manche Implementierungsdetails streiten und den von MS-DOS geerbten Konfigurations-Wahnsinn beklagen, aus Nutzungsschnittstellen-Sicht jedoch war Microsoft hier ein großer Wurf gelungen. Die dokumentzentrierte Desktop-Welt, wie es sie am Macintosh gab, wurde mit der programmbasierten Arbeitsweise, wie sie bei Windows üblich war, erstaunlich bruchlos verwoben. Windows verfügte nun im Vergleich zu MacOS mit dem Explorer über einen potenteren Datei-Manager und mit der Taskleiste über einen viel besseren Task-Switcher. Apple geriet durch Windows 95 unter Druck, denn das System war nicht nur von der Nutzungsschnittstelle her mindestens auf gleichem Niveau, auch die Systemstruktur an sich war solider als die von MacOS, bei dem Apple an das ursprüngliche Single-Tasking-System immer neue Funktionalitäten „drangebastelt“ hatte und das daher viele Altlasten mitschleppte. MacOS hatte zum Beispiel keinen Speicherschutz. Wenn mehrere Programme gleichzeitig laufen, belegt jedes dieser Programme einen eigenen Bereich im Arbeitsspeicher. Unter MacOS waren diese Bereiche nicht gegeneinander geschützt. Ein laufendes Programm konnte die Speicherinhalte der anderen Programme lesen und auch verändern. Das war nicht nur sehr unsicher, sondern auch absturzgefährdend. Ein fehlerhaftes Programm konnte leicht andere Programme oder sogar das ganze Betriebssystem mit sich reißen. Eine Neuentwicklung tat not! Die Entwicklung eines Nachfolgers für das klassische MacOS verzögerte sich jedoch immer wieder. Für Microsoft war die Anpassung der Nutzungsschnittstelle, die sie mit Windows 95 vornahmen, hingegen die Vorgabe für das nächste Jahrzehnt. Die folgenden Windows-Versionen NT 4, 98, ME, 2000 und XP wurden zwar optisch jeweils an den Zeitgeist angepasst, die Grundelemente der Nutzungsschnittstelle Desktop, Explorer, Taskleiste und Startmenü blieben aber nahezu unverändert bestehen.
Apple versuchte sich in den folgenden Jahren an einer Betriebssystem-Neuentwicklung namens „Copland“, geriet damit aber in große interne Schwierigkeiten. Gezwungen, mit dem alten Betriebssystem weiterzumachen, erschienen die Versionen 8, 8.5 und 9 von MacOS. Apple nahm hier vor allem viele optische Veränderungen vor und integrierte einige Komponenten der gescheiterten Neuentwicklung in das alte Betriebssystem. Ab 1997 unterstützte auch der Finder Nebenläufigkeit, sodass nun auch hier Dateioperationen das Weiterarbeiten im Finder nicht mehr blockierten. Mit MacOS 8.5 integrierte Apple die Suchsoftware „Sherlock“ in das Betriebssystem. Diese Software erlaubte nicht nur die lokale Suche, sondern suchte über Schnittstellen auch in Internet-Datenbanken. MacOS 9 brachte eine Unterstützung für mehrere Nutzer am gleichen Macintosh. Microsoft sah dies bereits in NT 3.1 aus dem Jahr 1993 vor. Auch Windows 95 unterstützte, wenn auch eingeschränkt, mehrere Benutzerkonten am gleichen Computer. Von diesen Änderungen abgesehen blieb das alte MacOS viel länger, als Apple es plante. Zusammen mit einer unübersichtlichen Produktpolitik brachte es Apple 1997 an den Rand der Pleite. Die Firma rettete sich durch den Kauf der Firma Next Computer, einer Gründung von Apple-Mitgründer Steve Jobs. Teil dieses Kaufs war das Betriebssystem NextStep, eine innovatives, grafisches Betriebssystem auf Unix-Basis. NextStep wurde auf die Macintosh-Architektur portiert. Einige Elemente der NextStep-Nutzungsoberfläche, etwa ein zentrales Dock, wurden in die neu konzipierte Oberfläche namens Aqua übernommen, das sich ansonsten stark an der Funktionsweise des bisherigen MacOS orientierte. Das neue Betriebssystem, das rein technisch kaum etwas mit der vorherigen Version zu tun hatte, bekam die Versionsnummer 10, die fortan immer als X geschrieben wurde. Über 10 ist Apple bis zum Jahr 2020 nicht hinausgekommen, denn seit der Version 10.0 wurde nur noch hinter dem Komma hochgezählt. Erst mit der Version mit dem Codenamen “Big Sur” erhöhte Apple die Versionsnummer auf 11.
MacOS X (10) – MacOS neu erfunden

MacOS 10.0 von 2001 sah dem vorherigen Betriebssystem durchaus ähnlich. Es gab aber gewichtige Unterschiede in der Nutzungsschnittstelle. Da der Unterbau des Betriebssystems nun Unix war, gab es erstmals eine Kommandozeile, die in einem Terminal-Programm aufgerufen werden konnte. Das auffälligste neue Element des Betriebssystems war aber nicht die Kommandozeile, sondern das von NextStep geerbte Dock am unteren Bildschirmrand. Im Dock werden bis zum heutigen Tage bei MacOS häufig genutzte Programme dauerhaft vorgehalten. Außerdem zeigt es an, welche Programme gerade aktiv sind und enthält einen Bereich, in dem minimierte Fenster abgelegt werden können. Die Menüleiste des Finders konnte Verknüpfungen zu Ordnern und Dateien aufnehmen und stand dem Nutzer damit als Schnellzugriff zur Verfügung. In der Abbildung oben sind hier die Ordner Computer, Home, Favorites und Applications untergebracht. Ab MacOS 10.3 wurde diese Funktion in eine Leiste auf die linke Seite eines Finder-Fensters verschoben, wo man sie auch bei aktuellen MacOS-Versionen noch findet. Der Desktop war nun, wie bei Windows, ein dedizierter Ordner im Nutzerverzeichnis, der lediglich vollflächig angezeigt wurde. Dateien wurden auf den Desktop verschoben oder kopiert. Das praktische „Put Away“ gab es fortan leider nicht mehr.
Mit MacOS 10 war Apple mit Microsoft grundsätzlich wieder gleichauf. Ehrlicherweise musste man sich aber eingestehen, dass die Versionen 10.0 und 10.1 noch mit vielen „Kinderkrankheiten“ zu kämpfen hatten und auf vielen der damals verbreiteten Macs nicht performant liefen. Auch bei neuen Geräten lieferte Apple zunächst beide Systeme aus, was viele Nutzer dazu veranlasste, weiter auf das altbekannte MacOS 9 und seine umfangreiche Software-Bibliothek zu setzen. Schlussendlich setzten sich die neuen Versionen aber durch, denn nicht nur waren die Systeme nach Beseitigung der anfänglichen Probleme stabiler, der Finder wurde ebenso erheblich verbessert und auch das Dock erwies sich als große Stärke des Systems. Gleichzeitig wurde die Einfachheit der Bedienung früherer Systeme beibehalten. Apple schloss aber nicht nur auf, sondern ging in einigen Bereichen auch weiter als Microsoft, etwa mit der neuen zentralen Anwendung namens „Vorschau“. Die Vorschau konnte eine Vielzahl von Dateien anzeigen, ohne das Anwendungsprogramm überhaupt starten zu müssen. Diese Funktion war sehr praktisch und sinnvoll, denn in der Tat sollen Dateien in vielen Fällen ja nur betrachtet und nicht etwa bearbeitet werden. Diese Vorschaufunktion in MacOS wurde daher im Laufe der Jahre stets weiter verbessert.
Ebenfalls im Jahr 2001 erschien Microsofts beliebtes Windows XP. Aufgrund von Problemen bei der Entwicklung eines Nachfolgers und des schlechten Rufs des 2007 erschienenen Windows Vista blieb Windows XP faktisch bis 2009 die aktuelle Windows-Version. Mit Windows XP führte Microsoft die professionelle NT-Linie und die klassische, auf MS-DOS basierende Windows-Linie zusammen. Windows XP war keine DOS-Erweiterung mehr, sondern ein vollständiges Betriebssystem. In Sachen Nutzungsschnittstelle stand Windows XP weiterhin in der Tradition von Windows 95, verfügte aber über ein Standard-Aussehen, das die Oberfläche sehr bunt darstellte. Zusammen mit dem Standard-Hintergrundbild einer hügeligen Wiesenlandschaft brachte dies dem System den Spitznamen „Teletubby-Windows“ ein.
In den folgenden Jahren glichen sich MacOS und Windows nach und nach immer mehr aneinander an. Ab 2003 bot MacOS 10.3 eine komfortable Funktion, alle geöffneten Fenster in einer Übersicht namens „Exposé“ auf die Schnelle zu überblicken. Im 2005 erschienenen MacOS 10.4 machte Apple die Suche bzw. ihre Ergebnisse zu einem zentralen Element des Betriebssystems. Ein Index-System namens „Spotlight“ wurde eingeführt, die Suche wurde in die Finder-Fenster und in die System-Menüleiste eingefügt. Auch bei Windows wurde die Suche zentraler. Ab Windows Vista (2007) befand sich ein Suchfeld prominent im Startmenü. In Windows 10 ist es dann dauerhaft sichtbar in die Taskleiste gewandert. Ebenfalls 2007 verminderte MacOS 10.5 nochmals die Notwendigkeit, Anwendungen zu öffnen. Eine Quickview-Funktion wurde eingeführt, die eine markierte Datei durch Druck auf die Leertaste direkt anzeigte und durch abermaliges Betätigen der Leertaste wieder verschwinden ließ. Nach der gefloppten Windows-Version Vista erschien 2009 mit Windows 7 wieder eine Windows-Version, die sehr populär wurde. Die wohl auffälligste Neuerung dieses Systems betraf die Taskleiste, die nun wie das Dock von MacOS eine Kombination aus Task-Switcher und Schnellstartleiste wurde. Als Antwort auf Apples Exposé konnte in der Taskleiste mit der Funktion Aero-Peek eine Schnellübersicht der Fenster einer geöffneten Anwendung angezeigt werden. Hilfreich waren auch die Verbesserungen im Fenster-Handling. Mit der Funktion Aero-Snap gab es 24 Jahre nach Windows 1.0 wieder eine Funktion, Fenster automatisch anordnen zu lassen. Zog man ein Fenster an den rechten oder linken Bildschirmrand, nahm es automatisch die Hälfte des Bildschirms ein. Unter Windows 10 wurde diese Funktion nochmals optimiert, sodass nun auch Drei-Fenster-Anordnungen möglich wurden.
MacOS 10.7 – Implizites Speichern sorgt für Verwirrung
2011 führte Apple in MacOS 10.7 eine Änderung ein, die nicht nur Freunde fand, in Bezug auf die Sichtweise, wie ich hier die Idee von Nutzungsschnittstellen eingeführt habe, aber sehr sinnvoll und bei Weitem überfällig war. Die Art und Weise, wie Dateien gespeichert werden, wurde so geändert, dass ein explizites Speichern nicht mehr nötig war. Eigentlich ist es verwunderlich, dass das Laden und Speichern bei MacOS im Jahre 2011 noch genau so funktionierte, wie im Jahr 1984, denn die Gründe dafür, es damals so zu gestalten, bestanden schon lange nicht mehr. Zu Beginn des Kapitels habe ich Ihnen erläutert, dass die Hardware-Einschränkungen des Macintosh dafür sorgten, dass Nutzer bearbeitete Dateien explizit speichern mussten. Dieses explizite Speichern war nach wie vor üblich, obwohl es mit auf Festplatten basierenden Systemen und üppiger Speicherausstattung eigentlich keine Notwendigkeit mehr dafür gab bzw. gibt. Es wäre, sagen wir einmal im Jahr 1993, durchaus performant möglich gewesen, regelmäßig automatisch zu speichern, statt diese Bürde dem Nutzer aufzuerlegen.
Ein implizites, dauerhaftes Speichern hätte für die Nutzer der Computer große Vorteile gehabt, denn explizit speichern zu müssen, ist immer eine große Fehlerquelle. Auch Sie haben es sicher schon erlebt, dass sie längere Zeit an etwas gearbeitet haben, ohne zu speichern, und dann kam es zum Unglück, sei es, dass das Programm abstürzte, der Strom ausfiel, oder Sie die Frage, ob Sie die Änderungen verwerfen oder speichern wollen, versehentlich falsch beantwortet haben. Explizit speichern zu müssen, ist aber nicht nur ein Problem für fahrlässige oder schusselige Computernutzer. Es widerspricht vielmehr auch der Grundidee, die von den Nutzungsschnittstellen vermittelt wird. Die Desktop-Metapher, die es ja bei MacOS seit jeher und bei Windows seit 1995 gab, vermittelt die Illusion, dass ein Dokument, das als Icon vorliegt, in ein Fenster vergrößert und darin bearbeitet werden kann. Die vom System erzeugte Welt sorgt eigentlich dafür, dass der Computernutzer die technischen Operationen wie das Laden von Festplatteninhalten in den Arbeitsspeicher nicht mehr wahrnehmen sollte. Man manipuliert in der Welt der Nutzungsschnittstelle nicht irgendwelche Speicherinhalte, sondern bearbeitet die Elemente eines Dokuments am Bildschirm. Verwendet man aber, wie beim Macintosh des Jahres 1984 Operationen wie „Laden“, „Speichern“ und „Speichern unter“, bricht die Illusion. Nutzer müssen nun den Unterschied zwischen Festplattenspeicher und Arbeitsspeicher kennen, verstehen, dass die Dokumentinhalte vom Festplattenspeicher in den Arbeitsspeicher kopiert werden und von dort wieder auf den Festplattenspeicher zurückgespeichert werden. Dieses Wissen und diese Aktionen haben aber überhaupt nichts mit der dargebotenen Objektwelt zu tun, sondern mit der technischen Funktionsweise dahinter und sollten dem Nutzer eigentlich verborgen bleiben. Leider wurde das explizite Speichern von Betriebssystemgeneration zu Betriebssystemgeneration sowohl am Mac als auch in Microsofts Windows fortkopiert.
Nach 27 Jahren änderte Apple bei seinem Betriebssystem nun diese grundlegende Arbeitsweise. Ein geöffnetes Dokument wurde nun fortlaufend gespeichert. Ein explizites Speichern war nicht mehr nötig. Man öffnete eine Datei, bearbeitete sie und schloss sie wieder. Es wurde stets automatisch und ohne Nutzerinteraktion gespeichert. Das neue Paradigma war eigentlich eine viel konsequentere Umsetzung der Objektwelt einer dokumentbasierten Nutzungsschnittstelle. Die Änderung dieser doch sehr grundlegenden Funktion brachte aber ihre Probleme mit sich. Zum einen arbeiteten nicht alle Programme nach dem neuen Paradigma. Die Mac-Versionen von Microsoft Office und LibreOffice funktionieren zum Beispiel bis zum heutigen Tage (2021) auf die alte Art und Weise. Ein noch größeres Problem entstand aber vor allem durch die über Jahrzehnte erlernten Abläufe, die nun zu einem Datenverlust führen konnten. Ein Beispiel macht das klar: Sie haben vor, einen Brief zu schreiben. Um sich ein bisschen Arbeit zu erleichtern, tun Sie dies, indem Sie einen vorhandenen Brief überarbeiten und unter einem neuen Namen ablegen. Fast dreißig Jahre lang ging das, indem Sie den alten Brief in der Textverarbeitung öffneten, die notwendigen Anpassungen vornahmen und den Text dann per „Speichern unter“ als neue Datei abspeicherten. Wenn Sie das nun bei einem Programm machen, das Apples neues Speicher-Paradigma verwendet, ändern Sie fortwährend den ursprünglichen Brief, dessen Inhalt dann verloren geht und ein „Speichern unter“ finden Sie gar nicht mehr22. Die fortan richtige Abfolge der Handlungen ist nun wieder die Gleiche wie schon beim Xerox Star. Der ursprüngliche Brief wird zunächst dupliziert, das Duplikat umbenannt und dann zwecks Anpassung geöffnet. Apple ist die Problematik der versehentlichen Überarbeitungen durchaus aufgefallen. Glücklicherweise führte Apple zur gleichen Zeit eine Dateiversionierung ein, mit der die versehentlich geänderte Version des ursprünglichen Briefes wieder hervorgebracht werden kann. Viele versehentliche Überschreibungen wurden zudem dadurch verhindert, dass das System Dateien, die seit Längerem nicht geändert wurden, automatisch mit einem speziellen Schreibschutz versieht. Öffnet man sie und versucht, die Dateiinhalte zu ändern, wird man vor die Auswahl gestellt, die Datei zu entsperren oder zu duplizieren und das Duplikat zu bearbeiten.
Mit der Überarbeitung der Speichern-Funktion sorgte Apple für einige Probleme bei den Nutzern seiner Betriebssysteme, obwohl die Entwickler mit der Umstellung auf implizites Speichern die Macintosh-Anwendungen eigentlich nur der Arbeitsweise anpassten, mit der Anwendungen auf iPhones und iPads schon seit jeher arbeiteten. In Apples iOS, in Googles Android und auch vorher schon bei den PDAs gab es das explizite Speichern und mit ihm die Notwendigkeit, sich mit dessen technischen Hintergründen auseinander zu setzen, noch nie, und kaum jemand vermisst sie hier auch, denn bei iOS und Android war immer klar, dass man in einer App ein Objekt bearbeitet. Die Denkweise, dass man mit einem Programm eine Datei in einen unsichtbaren Arbeitsspeicher lädt, war nie Teil dieser Nutzungsschnittstellen-Welt.
Windows 8 – Das gescheiterte Experiment
Die Umstellung der Dateispeicherung bei MacOS war sicherlich eine Änderung, die die Art und Weise, wie über die Nutzungsschnittstelle und ihre Objekte nachgedacht werden musste, änderte. Das war jedoch nichts gegen die Änderungen, die Microsoft 2012 wagte. Der Umbau vom vorherigen Windows 7 zu Windows 8 wirkte noch drastischer als der von Windows 3 zu Windows 95, und im Gegensatz zu diesem war er ein ziemlicher Reinfall.
Windows 8 schaffte das zentrale Element der Nutzungsschnittstelle, das dem ganzen System den Namen gibt, nämlich die Fenster, großteils ab. Auch Desktop und Taskleiste waren nun nicht mehr so zentral wie in den letzten siebzehn Jahren. Das Startmenü wurde sogar ganz abgeschafft. An der Stelle all dieser Konzepte übernahm Microsoft die Nutzungsschnittstelle, die für das Telefon-Betriebssystem Windows Phone und für die Spielekonsole Xbox entwickelt wurde. Statt mit Fenstern, Desktop und Startmenü präsentierte sich das System nun mit großen farbigen Kacheln, die allerlei Informationen anzeigen konnten. Die Nachrichten-App konnte etwa die neusten Schlagzeilen, die Mail-App die Betreffs der neusten Nachrichten und die Kalender-App die anstehenden Termine direkt anzeigen. Tippte man auf eine Kachel oder klickte sie an, öffnete sich die entsprechende Anwendung. Eines der Ziele von Windows 8 war es, alle Systeme des Herstellers mit der gleichen Nutzungsschnittstelle auszurüsten, vom Telefon über Tablets, Laptops, Spielekonsolen bis zum klassischen PC auf dem Schreibtisch. Das Resultat war, dass faktisch eine an Touch-Bedienung auf kleinen Geräten angepasste Nutzungsschnittstelle zum Standard für alle Zielsysteme erklärt wurde. Der Bruch war radikal.
Die Anwendungen von Windows 8, zumindest die, die für das System neu entwickelt wurden, sahen anders aus als bisherige Windows-Anwendungen und wurden auch anders bedient. Windows hatte, anders als es der Name nahelegt, keine Fenster mehr. Programme hatten von nun an auch keine Titelzeile und kein sichtbares, zentrales Menü mehr. Bisher zentrale Elemente der Nutzungsschnittstelle waren nicht mehr sichtbar. Die Standardmenüs einer Anwendung erschienen erst, wenn sie per Touch-Geste „hineingeslided“ wurden oder wenn innerhalb der Anwendung die rechte Maustaste geklickt wurde. Sie erschienen auch nicht mehr in Form einer Menüleiste, sondern als ein breiter Balken am rechten Bildschirmrand. Noch mehr als die Menüs war die Nutzungsschnittstelle zum Beenden von Programmen regelrecht versteckt. Es gab keinen sichtbaren Hinweis mehr darauf, wie man ein Programm beenden konnte. Der etablierte X-Button existierte nicht mehr. Stattdessen musste man das Programm im oberen Bildschirmbereich anklicken und dann nach unten ziehen. Ich spare mir an dieser Stelle die Erläuterung, auf welche Art und Weise fortan zwischen Programmen gewechselt, das Pendant zur Taskleiste eingeblendet oder das System heruntergefahren werden konnte. Sie können sich vorstellen, dass all dies ähnlich kompliziert wurde. Das Problem war weniger, dass es nicht mehr auf die gewohnten Arten und Weisen funktionierte. Der Übergang von Windows 3.11 zu Windows 95 zeigte, dass man sich hier durchaus zügig umgewöhnen kann. Wirklich problematisch war vielmehr, dass es keine am Bildschirm sichtbaren Hinweise mehr darauf gab, welche Operationen möglich waren, oder dass sie überhaupt angeboten wurden.
Ganz verschwunden war der Desktop unter Windows 8 nicht. Viele Nutzer, die die Windows-Version in der Praxis genutzt haben, werden ihn wahrscheinlich sogar nahezu ständig gesehen haben, denn immer wenn man eine klassische Windows-Anwendung verwendete, und dazu gehörten auch Microsoft Office und der beliebte Firefox-Browser, wechselte Windows 8 zum Desktop, der wie immer mit einem Arbeitsplatz-Icon und einer Taskleiste ausgestattet war, die auch die unter Windows 7 eingeführte Schnellstart-Funktion für Programme beinhaltete. Es gab allerdings keinen Start-Knopf und kein Startmenü mehr. Befand man sich auf dem Desktop, funktionierte Windows fast wie immer. Anwendungen erschienen in Fenstern und hatten die typischen Kontrollfelder zum Minimieren, Maximieren und Schließen. Allerdings funktionierten nur die klassischen Windows-Anwendungen so. Startete man eine moderne, neue Anwendung, was auch vom Desktop aus grundsätzlich möglich war, wechselte man wieder in den Vollbildmodus. Windows 8 fühlte sich daher an, als würde man zwei Betriebssysteme gleichzeitig verwenden. Auf der einen Seite eines mit Desktop, Fenstern und Taskleiste, auf der anderen Seite eines mit Kacheln, Anwendungen im Vollbildmodus und mit viel Gesten-Interaktion. Das System bediente sich in einem Moment so und im nächsten Moment ganz anders. Das Gefühl der „Zweigeteiltheit“ wurde noch dadurch verstärkt, dass die beiden Teile kaum miteinander verbunden wurden. Der neue Task-Switcher von Windows 8 zeigte zum Beispiel zwar auch die im Desktop laufenden Anwendungen an und erlaubte es, hierhin umzuschalten, die Taskleiste der Desktop-Oberfläche jedoch ignorierte die modernen Anwendungen vollständig und zeigte nur die klassischen Windows-Anwendungen an.
Windows 8 war ein Fiasko! Der Versuch, die Nutzungswelten des klassischen Windows mit denen von Smartphones und Tablets zusammenzuführen, resultierte mehr in einem absurden Spagat als in einer wirklichen Integration. Microsoft legte im Jahr 2013 Windows 8.1 nach, das einige der ärgerlichsten Änderungen von Windows 8 wieder ausglich. Man konnte nun zum Beispiel einstellen, dass das System gleich nach dem Start den Desktop anzeigte und das Wiedereinführen des Start-Buttons in der Taskleiste erlaubte den Nutzern von Desktop-Rechnern und Laptops nun wieder, mit der Maus oder dem Trackpad auf einfache Art und Weise zur Anwendungsübersicht zu gelangen. Die Änderungen nutzten Microsoft aber nichts mehr. Windows 8 und 8.1 wurden von Firmen nahezu komplett ignoriert und auch von Privatanwendern wenig verwendet. Windows 7 blieb de facto bis zur Einführung von Windows 10 das aktuellste genutzte Windows-Betriebssystem. Ein Windows mit der Versionsnummer 9 gab es nie. Wohl auch, um die Abkehr vom ungeliebten Windows 8 darzustellen, sprang Microsoft 2015 von Version 8 gleich zu Windows 10.
Auch Windows 10 sollte sowohl für klassische Desktop-Rechner und Laptops genauso gut funktionieren wie für Tablets und Telefone. Dieses Mal ging Microsoft es aber geschickter an. Statt wie bei Windows 8 eine einzige Nutzungsschnittstelle für beide Interaktionsarten vorzusehen, gab es nun zwei Modi: Im Desktop-Modus ist die Nutzungsschnittstelle sehr ähnlich wie die von Windows 7. Die Kacheln wurden ins Startmenü verbannt, das mit dieser Windows-Version wieder eingeführt wurde. Alle Anwendungen, ob modern oder klassisch, erschienen wieder in Fenstern und hatten normale Fenster-Controls zum Minimieren, Maximieren oder Schließen. Verwendet man Windows hingegen im Tablet-Modus, verhält es sich ganz anders: Das zentrale Nutzungsschnittstellen-Element ist dann der Kachel-Bildschirm, der allerdings weniger bunt ausfällt, als unter Windows 8. Alle Anwendungen, egal, ob modern oder klassisch, erscheinen im Tablet-Modus im Vollbild, allerdings blieben die Fenster-Controls erhalten. Programme lassen sich also per Klick auf das X in der rechten oberen Ecke schließen. Nicht nur das System als Ganzes passt sich dem Eingabe-Modus an, auch die für Windows 10 optimierten Anwendungen können den aktuellen Modus erkennen und im Tablet-Modus eine touch-optimierte Nutzungsschnittstelle verwenden. Im Explorer etwa wird im Tablet-Modus mehr Platz zwischen den Dateien in Listenform gelassen, um zu verhindern, dass man versehentlich auf die falsche Datei tippt.
Fazit
Die verbleibenden beiden großen grafischen Nutzungsschnittstellen von Apple und Microsoft haben sich, vom Ausreißer Windows 8 abgesehen, im Laufe der Jahre stark angeglichen. Es gibt Unterschiede in manchem Detail, aber im Großen und Ganzen sehen sich die Nutzer der Systeme sehr ähnlichen Objektwelten ausgesetzt, die auf sehr ähnliche Arten und Weisen manipuliert und verwaltet werden können. Betrachtet man den obigen Abriss nochmal im Rückblick, sieht man weniger Revolution als viele kleine Evolutionsschritte, die im Laufe der Jahre zu Nutzungsschnittstellen führten, die es immer weniger notwendig machten, sich mit den technischen Details der Computersysteme zu beschäftigen. Gestartet waren die beiden Betriebssysteme aber mit ganz unterschiedlichen Konzepten.
| Anwendungen starten | Anwendungen wechseln | Dokumente öffnen | |
|---|---|---|---|
| MS-DOS | Kommandozeile | - | - |
| Lisa/Star | - | - | direkt über Dokument-Icon |
| Windows 3 | Programm-Manager | - | - |
| MacOS <10 | - | - | Finder |
| Windows 95 | Startmenü | Taskleiste | Explorer |
| MacOS 10 | Dock | Dock | Finder |
| Windows 7 | Taskleiste | Startmenü + Taskleiste | Explorer |
Unter DOS musste man, wie in jedem mir bekannten kommandozeilenorientierten Betriebssystem, das Programm, mit dem man eine Datei bearbeiten wollte, explizit starten. In der Nutzungsschnittstellen-Welt von Lisa und Star hingegen stand das Dokument an zentraler Stelle. Das direkte Starten von Anwendungen war gar nicht möglich. Diese unterschiedlichen Fokussierungen in der Arbeitsweise findet man noch immer, wenn man sich die Windows- und MacOS-Versionen von Anfang der 1990er ansieht. Unter Windows 3 war der Programm-Manager die zentrale Schaltstelle des Betriebssystems. Folglich nutzte man das System eher, indem man ein Programm startete, als dass man ein Dokument direkt öffnete. Dies war im Dateimanager zwar grundsätzlich möglich, aber recht unüblich. Unter MacOS hingegen gab es keine zentrale Verwaltung von Programmen. Programme konnten aus dem Finder heraus explizit gestartet werden. Das war hier aber eher unüblich. Eher navigierte man mit dem Finder eine Datei an, die man bearbeiten wollte und öffnete sie direkt. Mit Windows 95 und Mac OS 10 schafften es beide Betriebssystemhersteller, die beiden Denk- und Arbeitsweisen zu vereinheitlichen. Startmenü, Taskleiste und Dock bieten Direktzugriff auf die Anwendungen, während Finder und Explorer so zentral im System sind, dass eine dokumentzentrierte Arbeitsweise nach wie vor möglich und üblich ist.
In den aktuellsten Versionen der Systeme kann man übrigens einen neuen Trend ausmachen, den man verkürzt als „Abschaffung der Dateien“ bezeichnen könnte und der sicherlich durch die Beliebtheit der Mobilbetriebssysteme iOS und Android befördert wird. Es gibt immer mehr Anwendungen, die Objekte darstellen und verwalten können, die nicht mehr direkt als Dateien in Erscheinung treten. Die Apple-Anwendungen iTunes und Fotos (früher iPhoto) und plattformübergreifend die Notizbuch-Software Evernote sind gute Beispiele für diese neue Art von Software. In den Anwendungen können Musikstücke, Videos, Fotos und Textnotizen verwaltet bzw. bearbeitet werden. Diese Objekte liegen zwar als Dateien auf der Festplatte des Rechners, sind aber im Regelfall nicht mehr direkt zugänglich, denn die Anwendungen selbst kümmern sich um alle Verwaltungsoperationen. Mit dieser Entwicklung ist, wie wohl mit jeder Entwicklung in der Nutzungsschnittstelle, nicht jeder einverstanden. Dem Nutzer wird ein Teil der Flexibilität, die die freie Dateiverwaltung bietet, genommen. Im Gegenzug dazu ist die Nutzung des Computers einfacher und weniger technisch, denn man betrachtet und bearbeitet nun Fotos, Videos, Textdokumente oder Notizen statt generischer Dateiobjekte. Die einen reden hier vom sogenannten „Goldenen Käfig“ und beklagen die Einschränkungen, manch anderer wird durch solche Vereinfachungen erst in die Lage versetzt, die Computer überhaupt zu nutzen. Ich habe meine Meinung dazu, verrate Sie Ihnen aber nicht, denn ein richtiges Wahr und Falsch gibt es an dieser Stelle sicher nicht.
Unix und Linux
In meinen bisherigen Darstellungen der Entwicklung von Nutzungsschnittstellen habe ich das Betriebssystem Unix zwar dann und wann erwähnt, aber im Großen und Ganzen ignoriert. Tatsächlich hatte ich ursprünglich vor, es auch dabei zu belassen, denn Unix kam zum einen als Vertreter der textbasierten Time-Sharing-Betriebssysteme relativ spät auf den Markt und ist zum anderen, was die grafischen Nutzungsschnittstellen angeht, zumindest im Bereich der PC-Betriebssysteme nicht verbreitet. Man findet es wohl sehr oft auf Rechnern, die nicht direkt von Endnutzern verwendet werden, sondern Dienste im Hintergrund bereitstellen. Solche Rechner nennt man im Allgemeinen „Server“. Nahezu alle Websites, die Sie heute aufrufen können, laufen unter einem unix-artigen Betriebssystem, doch kann das dem Nutzer des Computers, auf dem der Webbrowser läuft, letztlich egal sein. Im Laufe der Recherche für viele der anderen Kapitel dieses Buches habe ich dann entschieden, dass es doch ein eigenes Unix-Kapitel braucht, denn das Betriebssystem hatte zum einen starken Einfluss auf andere Betriebssysteme und zum anderen werden im Unix-Bereich Nutzungsschnittstellen entwickelt, die zwar wenig genutzt werden, die aber dennoch teils so interessante Eigenschaften haben, dass man sie nicht einfach unter den Tisch fallen lassen sollte.
Von Multics zu Unics – Die Frühgeschichte
Lassen Sie mich mit der Geschichte von Unix etwa fünf Jahre vor dem Zeitpunkt beginnen, an dem das System das erste Mal in Erscheinung getreten ist, denn die Vorgeschichte des Systems erklärt manche der typischen Unix-Eigenheiten. Nachdem wir im vorherigen Kapitel schon in der Gegenwart angekommen sind, machen wir also einen Sprung weit zurück ins Jahr 1964, etwa zehn Jahre vor dem Aufkommen der ersten Personal Computer, in die Zeit, in der im großen Stile an der Time-Sharing-Technik entwickelt und geforscht wurde. In diesem Jahr 1964 begannen das Massachusetts Institute of Technology (MIT), die Firma General Electric (GE), damals ein Hersteller von Computern, und die Bell Labs mit der Entwicklung eines komplexen Time-Sharing-Systems. Wichtig für die Geschichte von Unix ist hier vor allem die Beteiligung des Forschungslabors Bell Labs. Diese Einrichtung war Teil des damaligen amerikanischen Telefon-Monopolisten AT&T, ein Fakt, der für die weitere Geschichte noch wichtig werden sollte.
MIT, GE und Bell Labs begannen im Jahr 1964 mit der Entwicklung eines Time-Sharing-Betriebssystems namens Multiplexed Information and Computer Service, kurz Multics. Das Betriebssystem war für die damalige Zeit extrem modern und mit Eigenschaften ausgestattet, die gerade im Einsatz in einer großen Rechenanlage mit vielen zugreifenden Nutzern sehr sinnvoll waren. Hierzu gehörte zum Beispiel die Verwaltung von Massenspeichern wie Festplatten, Magnetbändern oder Wechselplatten. Das System hatte in Sachen Datenträgerverwaltung interessante Konzepte. Heutige PC-Betriebssysteme wie Windows oder MacOS verwalten Datenträger in den meisten Fällen als unabhängige Einheiten. Wenn Sie etwa eine externe Festplatte oder einen USB-Stick an den Rechner anschließen, erscheint ein neuer Datenträger im System. Sie können nun darauf zugreifen und etwa Dateien herauf- oder herunterkopieren. Die Organisation, was auf welchem Datenträger gespeichert ist, müssen Sie aber selbst durchführen. Ist Ihnen die Festplatte in Ihrem Rechner zu klein und Sie bauen eine weitere ein, müssen Sie sich selbst darum kümmern, welche Dateien Sie auf welcher Festplatte abspeichern. Bei Multics war das anders: Dort vergrößerte eine neue, angeschlossene Festplatte oder ein eingelegtes Band die Menge des zur Verfügung stehenden Massenspeichers. Das System schichtete die gespeicherten Dateien automatisch so um, dass sich die häufig genutzten Dateien auf einem schnelleren Speichermedium befanden, etwa einer schnellen Festplatte, während die weniger genutzten auf langsame Medien wie Wechselplatten oder Magnetbänder umgelagert wurden. Diese Platten und Bänder mussten nicht dauerhaft vorgehalten werden. Operatoren im Rechenzentrum konnten Platten und andere Medien nahezu beliebig hinzufügen und entfernen. Würden Sie das bei einem heutigen System machen, würden im Normalfall Dateien und Verzeichnisse verschwinden oder wie von Geisterhand erscheinen. Das Dateisystem von Multics machte diese technische Realität der Speichermedien jedoch für den Nutzer vollständig unsichtbar. Nehmen wir einmal an, ein Nutzer hatte Monate zuvor eine Datei angelegt, diese aber seitdem nicht wiederverwendet. Zwischenzeitlich wurde sie vom System auf ein Magnetband umkopiert und archiviert. Wollte unser Nutzer nun auf diese Datei erneut zugreifen, war das kein Problem. Sie wurde ihm nach wie vor als vorhanden angezeigt. Sollte sie nun geladen oder ausgegeben werden, ging das nicht sofort. Der Benutzer wurde zunächst mit einer Systemmeldung vertröstet, während dem Operator im Rechenzentrum angezeigt wurde, dass er ein bestimmtes Magnetband einlegen sollte. Sobald er das tat, stand die Datei wieder zur Verfügung und wurde gegebenenfalls automatisch wieder auf ein schnelleres Speichermedium verschoben. Niemand musste händisch die Datei vom Magnetband auf eine Arbeitsfestplatte kopieren oder ähnliches. Diese Aufgabe wurde vollständig vom System selbst übernommen.
Das Multics-System war groß und komplex und verfügte über viele Funktionen für große Time-Sharing-Rechenanlagen, von der gerade beschriebenen Datenträgerverwaltung bis hin zu einer ausgefeilten Nutzerverwaltung. Die Weiterentwicklung zog sich hin, was nicht allen am Projekt Beteiligten zusagte. Im Jahre 1969 zogen sich die Bell Labs daher aus dem Projekt zurück. Dies setzte einerseits Ressourcen frei, führte aber andererseits zum Problem, dass für die eigenen Computer nun andere Betriebssysteme gefunden oder entwickelt werden mussten. Ken Thompson und Dennis Ritchie, zwei Techniker bei Bell Labs begannen daher, einfach aus der Notwendigkeit heraus, mit der Entwicklung eines eigenen, kleineren Betriebssystems für die am Bell Labs eingesetzten Minicomputer PDP-7 und später PDP-11/20 von DEC. Im Jahre 197023 wurde das System als Verballhornung von Multics zunächst Unics (Uniplexed Information and Computer Service) getauft. Der Name wurde später in „Unix“ geändert, wobei heute nicht mehr genau zu klären ist, wann die Umbenennung stattfand und wer dafür verantwortlich war. Die frühen Unix-Versionen wurden in der maschinennahen Assembler-Programmiersprache für die PDP-7 und die PDP-11 geschrieben, liefen also auch nur auf diesen Computern. Ab 1973 änderte sich das, denn große Teile des Systems wurden in der von Dennis Ritchie entwickelten Programmiersprache C, die auch heute noch weithin genutzt wird, neu geschrieben. Dieser Schritt erhöhte nicht nur die Wartbarkeit des Betriebssystems von Seiten der Entwickler, sondern erlaubte später auch die Portierung des Systems auf andere Hardware-Architekturen.
Jedem sein Unix – Die Zersplitterung
Das neue Betriebssystem Unix wurde zunächst nur innerhalb von AT&T verwendet und entwickelt. Das System wuchs dabei in Funktionalität und Komplexität natürlich an, von einem einfachen Single-Tasking-Betriebssystem noch auf der PDP-7 zu einem Multi-User-Multi-Tasking-Betriebssystem, das es auch noch heute ist. Der Entwickler Bell Labs war, wie bereits angedeutet, Teil des damaligen Telefonmonopolisten AT&T. Eine der Bedingungen dafür, dass AT&T sein Monopol haben durfte, war, dass sich der Konzern auf Telefondienstleistungen und Kommunikation beschränkte und mit seinem Angebot nicht etwa auch in verwandte Wirtschaftsbereiche ausuferte. Der Verkauf von Computern und Betriebssystemen war damit für die Firma ein Tabu. Natürlich konnte niemand AT&T verbieten, für interne Zwecke ein Betriebssystem zu entwickeln. Lediglich verkaufen durfte AT&T ein solches System nicht. Was allerdings erlaubt war, und auch intensiv betrieben wurde, war die Lizensierung des Systems an Interessenten. Computerhersteller, die ein Betriebssystem suchten, konnten bei AT&T eine Lizenz erwerben und erhielten damit Zugriff auf den Programmcode des Systems, den sie relativ frei verwenden und für ihre Belange anpassen konnten. Besonders attraktiv war diese Lizenzierung für Bildungseinrichtungen und Universitäten, die für die Lizenz nur einmalig 200 Dollar bezahlen mussten. Einer dieser Lizenznehmer war die University of Berkeley. Informatiker und Studierende der Universität passten das System von AT&T für ihre Forschungszwecke an, erweiterten die Netzwerkfunktionalitäten und verbesserten die Performanz. Das daraus entstehende System wurde BSD (Berkeley Software Distribution) genannt. Nachfolger dieses Systems sind in der Form von FreeBSD und NetBSD noch heute verbreitet.
Dass Lizenznehmer von Unix das System ihren eigenen Bedürfnissen anpassen konnten, führte dazu, dass es kein einheitliches Unix mehr gab. Es gab das UNIX von AT&T, das in der Regel in Großbuchstaben geschrieben wurde. Daneben gab es viele andere Unixe, etwa das BSD der University of Berkeley, SunOS von Sun Microsystems, Xenix von Microsoft, AIX von IBM und viele andere mehr. All diese Systeme waren irgendwie jeweils Unix, aber sie waren doch verschieden. Das war natürlich einerseits der Charme des Projektes, denn jedes Unix war für seinen Einsatzzweck optimiert, andererseits brachte diese Zersplitterung die Gefahr, dass ein absolutes Chaos entsteht. Um ebendieses zu vermeiden, wurde ab 1985 eine Standardisierung angestrebt, die heute unter dem Begriff „POSIX-Standard“ bekannt ist. Der Standard beschreibt eine Art Mindestanforderung für Unix-Systeme, die bei allen Derivaten gleich sein soll.
Das Telefonmonopol von AT&T wurde in den 1980er Jahren zerschlagen. Ab dem Jahr 1984 durfte das an den Bell Labs entwickelte System daher auch als Produkt verkauft werden. AT&T verschärfte fortan die Lizenzpolitik. Neue Versionen des UNIX von AT&T konnten nicht mehr so günstig lizenziert und angepasst werden. Dieser Schritt sorgte natürlich für Gegenreaktionen. Unix war an Universitäten weit verbreitet und dort wegen seiner Flexibilität sehr geschätzt. Die University of Berkeley mit ihrem wichtigen Unix-Derivat BSD schrieb alle vorhandenen AT&T-Teile aus ihrem System heraus und ersetzte sie durch funktionsgleichen, also zum POSIX-Standard kompatiblen, eigenen Code. Ab 1991 stand BSD dann AT&T-frei unter einer Open-Source-Lizenz zur Verfügung. „Open Source“ bedeutet, sehr einfach formuliert, dass jeder sich den Quellcode beschaffen und nach Lust und Laune für eigene Projekte anpassen kann, ohne Lizenzgebühren bezahlen zu müssen. Nach diesem Prinzip funktioniert heute sehr viel Software, etwa der Browser Firefox, die Grundlage des Browsers Chrome und die Office-Programme LibreOffice und OpenOffice.
Die quelloffenen BSD-Versionen von 1989 und 1991 waren nicht der erste Versuch, ein Unix ohne AT&T-Abhängigkeit zu erzeugen. Bereits 1983 startete Richard Stallman eigens zu diesem Zweck das GNU-Projekt. Das Ziel Stallmans war freie Software24 – und hier im Speziellen ein UNIX-kompatibles Betriebssystem ohne eine einzige Zeile des Original UNIX-Codes von AT&T. Die Abkürzung GNU steht daher auch vielsagend für „GNU is Not UNIX!“. GNU als Komplett-Betriebssystem ist bis heute noch nicht fertig. Aus dem Projekt hervorgegangen sind aber eine ganze Menge wichtiger Tools und Programmpakete, darunter der Kommandozeilen-Interpreter „bash“, der weit verbreitet ist und in vielen Unixen und darüber hinaus genutzt wird. Die ganze Palette der GNU-Software-Werkzeuge bildete zusammen mit einem von Linus Torwalds Anfang der 1990er Jahre entwickelten Open-Source-Betriebssystemkern vor allem aber die Grundlage für das Betriebssystem Linux25.
Linux steht somit in der Unix-Tradition, aber ist Linux damit auch ein Unix? Man kann die Frage nur mit einer Gegenfrage beantworten: Ist BSD ein Unix, obwohl explizit alle Programmcodes von AT&T entfernt wurden? Woran will man das festmachen? Eine Möglichkeit wäre der oben genannte POSIX-Standard, denn der beschreibt unix-artige (oder auch „unixoide“) Betriebssysteme. Bezeichnet man alle Betriebssysteme, die diesen Standard vollständig oder zumindest großteils erfüllen, als Unix, müsste man, wenn man die aktuellen Varianten von BSD (FreeBSD, OpenBSD) als ein Unix bezeichnet, auch Linux als ein Unix ansehen. In der Praxis wird das jedoch oft nicht gemacht. Ganz im Gegenteil: Wenn Sie eine Linux-Distribution nutzen und diese als Unix bezeichnen, werden Sie viele Informatiker zurechtweisen. Wir haben hier einmal wieder so einen Streit, den ich an dieser Stelle nicht auflösen kann, nicht auflösen will und glücklicherweise auch nicht auflösen muss, denn ich habe mir ja die Nutzungsschnittstellen-Brille ausgesucht, um die Computergeschichte zu beschreiben und aus dieser Perspektive gibt es keinen nennenswerten Unterschied zwischen einem FreeBSD, also einem Unix, und einem Linux. Ein kommandozeilenorientiertes BSD und ein kommandozeilenorientiertes Linux können Sie kaum unterscheiden und das Gleiche gilt für Unixe oder Linuxe mit den grafischen Nutzungsschnittstellen wie KDE oder Gnome. Sie sehen sehr ähnlich aus, verhalten sich ähnlich und sind daher, zumindest aus meiner Sicht, auch ähnlich genug, um sie beide unter „Unix“ zusammenzufassen.
Die Macht der Kommandozeile – Die Unix-Shell
Ich habe Ihnen nun viel über die Geschichte des Systems erzählt, aber noch kein Wort darüber verloren, wie sich Unix in der Nutzung darstellt. Beginnen wir mit dem Grundkonzept, den wichtigsten Objektarten, mit denen ein Unix-Nutzer umgehen muss. Unix ist an dieser Stelle sehr einfach. Die wichtigsten Objekte sind Dateien und Verzeichnisse bzw. Unterverzeichnisse. Heute wird ein Unterverzeichnis gerne als „Ordner“ bezeichnet. Das ist für Unix aber eigentlich anachronistisch, denn dieser Ausdruck entstammt dem Begriffsrepertoire der grafischen Nutzungsschnittstellen der 1980er Jahre. Im Jahre 1970 stellten sich die meisten Computernutzer ihr Dateisystem noch nicht als Analogie zu Büros mit Dokumenten und Ordnern vor. Sie sahen viel eher Dateien, die in einem Index aufgelistet wurden. Dieser Index wurde „Verzeichnis“ oder, auf Englisch, „Directory“ genannt. Unix ist ein Betriebssystem, das um das Dateisystem herum entwickelt wurde. Das Grundkonzept der Unix-Dateiablage, eine hierarchische Verzeichnisstruktur, wurde von Multics übernommen. „Hierarchisch“ bedeutet, dass ein Verzeichnis nicht nur Dateien, sondern auch seinerseits Verzeichnisse beinhalten kann. In einem solchen Dateisystem kann jede Datei durch die Angabe eines Pfades identifiziert werden. Dieser beginnt an einer allgemeinen Wurzel und folgt dann den Unterverzeichnissen bis zur Datei. Ein / wird als Trennzeichen verwendet. Ein typischer Unix-Pfad ist etwa /home/User/texts/history.txt.
Die Interaktion mit dem Unix-Betriebssystem erfolgt klassischerweise mit einem Kommandozeilen-Interpreter. Im Unix-Bereich wird dieser meist „Shell“ genannt. Nutzer der Shell befinden sich zu einem Zeitpunkt immer in einem bestimmten Pfad der Dateisystem-Hierarchie und können diese Position mit Hilfe des Befehls cd ändern. cd dirname wechselt etwa ins Unterverzeichnis dirname. Die Zeichenfolge .. steht für das übergeordnete Verzeichnis, auch Elternverzeichnis genannt. cd .. wechselt also in das Verzeichnis, das das Verzeichnis enthält, in dem man sich gerade befindet. Dieses Konzept, inklusive des Befehls cd und des Parameters .. für das Elternverzeichnis wurde auch in andere Betriebssysteme übernommen. Microsoft portierte sie schon 1983 in die zweite Version seines DOS. Lediglich das Trennzeichen im Pfad drehte Microsoft um und verwendete den Rückschrägstrich, meist „Backslash“ genannt. In einer aktuellen Eingabeaufforderung von Windows können Sie sowohl \ als auch / als Trennzeichen verwenden.
In der Nutzungswelt von Unix erscheint eigentlich alles als Datei. Selbst an den Computer angeschlossene Geräte werden als Datei dargestellt und haben dementsprechend einen Pfad im Dateisystem. Das hat für den modernen Nutzer eigentümliche Konsequenzen. Man kann zum Beispiel eine Datei auf einem angeschlossenen Drucker ausdrucken lassen, indem man sie auf den Drucker kopiert. Der Befehl dafür lautete zum Beispiel cp ./test.txt /dev/lp0. Mit einem ähnlichen Befehl kann man die Datei aber auch an die Soundkarte schicken oder auf dem Bildschirm eines anderen angemeldeten Nutzers ausgeben, denn all diese Ressourcen stehen genauso als Dateien, also über einen Dateipfad, zur Verfügung.
Unix ist sehr modular aufgebaut. Nahezu jede Komponente kann durch eine andere ersetzt werden. Es gibt zum Beispiel nicht den einen Kommandozeilen-Interpreter, sondern mehrere Alternativen, die eingesetzt werden können. Sehr verbreitet ist heute zum Beispiel die bash aus dem GNU-Repertoire. Auch die zur Verfügung stehenden Befehle können ausgetauscht und erweitert werden, denn sie sind, von wenigen Ausnahmen abgesehen, nicht wie bei MS-DOS in den Kommandozeilen-Interpreter eingebaut, sondern liegen als kleine ausführbare Programme vor. Über alle Unix-Derivate hinweg, so unterschiedlich sie auch sein mögen, gibt es aber einen typischen Satz an kleinen Tools und Shell-Befehlen. Dazu gehören etwa:
-
lszur Ausgabe einer Liste der Einträge in einem Verzeichnis -
catzur Ausgabe eines Dateiinhalts -
cpzum Kopieren von Dateien -
mvzum Verschieben oder Umbenennen von Dateien -
rmzum Löschen von Dateien -
mkdirzum Erstellen von Verzeichnissen -
cdzum Wechseln in Verzeichnisse
Die meisten dieser Befehle ergeben für sich allein stehend keinen Sinn. cat etwa muss man zumindest noch mitgeben, welche Datei es ist, die man angezeigt haben will und wenn man cp eingibt, muss man zumindest sagen, welche Datei man wohin kopieren möchte. Diese zusätzlichen Angaben werden „Parameter“ genannt. Sehr typisch für Unix-Systeme ist die oft sehr große Zahl möglicher Parameter. Der Befehl ls etwa gibt, für sich allein stehend, alle nicht versteckten Dateien im aktuellen Verzeichnis als einfache Liste aus. Gibt man den Parameter a hinzu, also ls -a, werden auch versteckte Dateien angezeigt. Gibt man hingegen ls -l an, wird eine umfangreichere Liste ausgegeben, die auch Dateigröße, Erstellungsdatum usw. beinhaltet. Will man, dass in dieser Liste auch die versteckten Dateien enthalten sind, kann man beides durch ls -a -l oder auch ls -al kombinieren. Diese beiden Parameter sind bei Weitem nicht die einzig möglichen. Alle Parameter von ls lassen sich im in die meisten Unix-Systeme integrierten Hilfesystem, den sogenannten „man-pages“ nachlesen. Bei einem BSD-Unix steht dort dann zum Beispiel ls [-ABCFGHLOPRSTUW@abcdefghiklmnopqrstuwx1] [file ...]. Jeder Buchstabe steht für einen möglichen Parameter.
Software von verbreiteten Betriebssystemen wie Windows oder auch MS-DOS unterscheidet sich stark von typischer Unix-Software. Eine typische DOS- oder Windows-Anwendung ist interaktiv, verfügt über eine eigene Nutzungsschnittstelle und deckt in der Regel einen großen Funktionsbereich ab. Unter Unix hingegen sind Programme meist recht kleine Werkzeuge, die eine bestimmte Aufgabe ohne weitere Nutzerinteraktion besonders gut machen, jedoch nicht darüber hinaus gehen. Diese kleinen Programme kann man kombinieren, indem man die Ausgabe des einen Programms zur Eingabe des anderen Programms macht. Neben Dateien sind damit auch Datenströme ein Grundkonzept des Betriebssystems. Um diese zu verstehen, hilft es, sich wieder in die Urgeschichte des Computers zurückzuversetzen. Stellen Sie sich jedes kleine Unix-Tool als einen kleinen Computer vor, der mit einem Lochstreifenleser und einem Lochstreifenstanzer ausgestattet ist. Wenn Sie einen solchen Computer nun loslaufen lassen, wird ein Eingabe-Lochstreifen gelesen und dabei ein Ausgabe-Lochstreifen erzeugt. Diesen Ausgabe-Lochstreifen könnten Sie nun einem anderen kleinen Computer mit einem anderen Programm als Eingabe-Lochstreifen geben. Wenn Sie den dann laufen lassen, wird die vorherige Ausgabe als Eingabe aufgefasst und wiederum ein neuer Ausgabe-Lochstreifen erzeugt. Auf genau diese Art und Weise funktionieren im Prinzip die Unix-Tools. Nehmen wir den Befehl cat ./events.log. Dieser Befehl gibt die Datei „events.log“ aus dem aktuellen Verzeichnis aus – in unserem eben angestellten Gedankenspiel erzeugt sie einen Lochstreifen mit dem Inhalt der Datei. Diesen Lochstreifen geben wir nun einem anderen unserer kleinen Computer als Eingabe. Auch zu diesem gehört natürlich ein Befehl, nämlich grep ERROR. Wenn Sie diesen Befehl so für sich eingeben – versuchen Sie es ruhig einmal, wenn sie ein MacOS oder ein Linux zur Verfügung haben –, passiert erst einmal wenig. grep erwartet eine Eingabe, und da Sie keine Eingabe zur Verfügung gestellt haben, erwartet das Tool, dass Sie sie selbst machen. Tippen Sie zum Beispiel „Hallo Welt!“ und drücken Sie die Eingabetaste, passiert, außer dass dieser Text auf dem Bildschirm steht, nichts. Schreiben Sie aber „Dies ist ein ERROR!“ und drücken auf Enter, passiert etwas. Die Zeile steht nun zweimal am Bildschirm. Was grep ERROR nämlich tut, ist, die Zeilen der Eingabe, die das angegebene Wort, also ERROR enthalten, in die Ausgabe zu übernehmen. Alle anderen Zeilen werden verworfen.
Nun haben Sie schon zwei kleine Computer. Der eine erzeugt einen Lochstreifen mit dem Inhalt der Datei „events.log“ und der andere arbeitet als Filter, indem er alle eingegebenen Zeilen, die das Wort „ERROR“ enthalten auf den Ausgabe-Lochstreifen übernimmt und alles andere ignoriert. Nun müssen Sie dem System noch mitteilen, dass der Ausgabe-Lochstreifen des ersten Computers der Eingabe-Lochstreifen des zweiten werden soll. Hierzu dient bei Unix der senkrechte Strich, entsprechend dem Namen der Technik auch „Pipe-Zeichen“ genannt. Mit dem | erzeugen Sie eine Verbindung, eine Pipe, zwischen der Ausgabe eines Tools und der Eingabe des anderen. Das Resultat cat ./events.log|grep ERROR gibt also alle Zeilen aus der Datei „events.log“ aus, die das Wort „ERROR“ enthalten. Mit einer besonderen Art von Pipe können Sie dafür sorgen, dass diese Ausgabe nicht einfach auf dem Bildschirm steht, sondern wieder in eine Datei geschrieben wird. Dies geht mit dem „Größer“-Zeichen gefolgt vom Dateinamen. Der Befehl cat ./events.log|grep ERROR>errors.log erzeugt also eine Datei „errors.log“ mit den ausgefilterten Zeilen der Datei „events.log“.
Mit dem Piping kann man, wenn man es erst einmal verstanden hat, die vielen kleinen Tools von Unix auf geschickte Weise miteinander kombinieren. Manche Aufgaben sind aber komplexer, als dass man sie als einfaches Hintereinander-Ausführen mehrerer Programme bei gleichzeitiger Weitergabe der Ausgabe verstehen könnte. Als Beispiel soll hier einmal das Problem des Umbenennens von Dateien gelten. Erstaunlicherweise ist Unix an dieser Stelle nicht besonders gut ausgestattet. Stellen Sie sich einmal vor, Sie haben einen Ordner voll mit Bilddateien, die „bild001.jpg“, „bild002.jpg“ und so weiter heißen. Sie wollen diese Dateien nun so umbenennen, dass „image001.jpg“, „image002.jpg“ und so weiter herauskommt. Wenn Sie Windows-Nutzer sind und die Eingabeaufforderung verwenden, geht das ganz einfach mit einem einzigen Befehl ren bild*.* image*.*. Unter Unix geht es leider nicht so einfach. Warum das so ist, hängt damit zusammen, wie die Sternchen, die für beliebige weitere Zeichen stehen, aufgelöst werden. Ich spare mir an dieser Stelle eine genaue Erklärung, denn ich nutze das Umbenennen nur als Beispiel und nehme nicht an, dass Sie mein Buch verwenden wollen, um in die Geheimnisse der Unix-Shells tiefer einzusteigen.
Um das Umbenennen auch unter Unix hinzubekommen, kann man sich ein kleines Programm, ein Shell-Script, schreiben. Das könnte zum Beispiel26 wie folgt aussehen. Die hier abgedruckten Zeilennummern dienen nur der folgenden Beschreibung. Sie sind nicht Teil des Shell-Scripts.
Gehen wir das Programm kurz durch: Die ersten drei Zeilen sind im Grunde nur Kommentare, die dazu dienen, dass man auf die Schnelle erkennen kann, was dieses Shell-Script macht. Eine besondere Rolle kommt dabei der ersten Zeile zu, denn dort steht, welcher Kommandozeilen-Interpreter dieses Shell-Script ausführen soll. Es handelt sich hier um die schon angesprochene bash-Shell aus dem GNU-Projekt. Die Zeilen 5 bis 7 dienen vor allem der besseren Lesbarkeit des Programms. Hier werden die Parameter, die dem Script mitgegeben werden, in Variablen mit sinnvollen Namen gespeichert. Startet ein Nutzer das Script mit dem Aufruf rename.sh *.jpg bild image, wird an dieser Stelle *.jpg in criteria gespeichert, die Variable re_match erhält den Wert bild und entsprechend findet sich image in der Variablen replace. Das eigentliche Programm beginnt erst in Zeile 9. Betrachten Sie zunächst einmal, was dort innerhalb der Klammer steht. Dort wird der Befehl ls aufgerufen, der, wie Sie inzwischen wissen, für das Ausgeben eines Verzeichnisinhalts verantwortlich ist. Hier im Script wird das Ergebnis aber nicht ausgegeben, sondern in einer Variablen gespeichert. Vor der Klammer steht for i in. Hierbei handelt es sich um eine der typischsten Strukturen eines jeden Computerprogramms, nämlich um eine sogenannte „Schleife“. Alles zwischen do in Zeile 10 und done in Zeile 14 wird nicht nur einmal, sondern mehrfach ausgeführt, und zwar genau so oft, wie das Verzeichnislisting aus der Klammer lang ist. Das Listing wird also Zeile für Zeile durchgegangen. In einer Variablen namens i steht dann jeweils der aktuelle Dateiname. Was innerhalb der Schleife passiert, ist im Grundsatz ganz einfach. In Zeile 11 wird der ursprüngliche Dateiname, also der, der aus dem Listing gerade dran ist, in eine Variable src gespeichert. In Zeile 12 wird bestimmt, wie der neue Dateiname lauten soll. Das Ergebnis wird in der Variablen tgt gespeichert. In Zeile 13 wird nun die Datei unter Zuhilfenahme des Befehls mv umbenannt.
Trickreich ist die Zeile 12, denn hier greifen wieder die Unix-Tools ineinander. Schauen wir uns zunächst an, was innerhalb der Klammer passiert. Zunächst steht hier einmal der Befehl echo. Diesen Befehl kann man zum Beispiel dafür benutzen, um in einem Script etwas auf dem Bildschirm auszugeben, denn echo erzeugt genau das: ein Echo. Tippen Sie in einer Linux-Konsole echo Hallo, wird in der Zeile darunter Hallo ausgegeben. Im Script wird hier natürlich nicht Hallo ausgegeben, sondern der Inhalt der Variablen i, also des Dateinamens, der angepasst werden soll. echo schreibt in diesem Fall auch nicht auf den Bildschirm, denn dahinter steht das schon bekannte Pipe-Zeichen. Die Ausgabe wird also zur Eingabe für ein anderes Unix-Tool. Dieses Tool ist der Editor „sed“. „Sed“ steht für „stream editor“. Er funktioniert ähnlich wie der „ed“, den wir in einem früheren Kapitel besprochen haben, kennt im Gegensatz zu diesem aber kein Konzept von Zeilen. Eine Textdatei ist in „sed“ einfach eine lange Folge von Zeichen. Als praktischer Editor ist „sed“ damit ziemlich nutzlos, doch für den Zweck der automatisierten Verarbeitung ist er ideal. „Sed“ bekommt den soeben mit echo ausgegebenen Dateinamen als Eingabe. Nehmen wir einmal an, diese Eingabe sei einbildung.jpg. „Sed“ wurde mit dem Parameter -e gestartet. Hinter diesem befindet sich ein sogenannter „regulärer Ausdruck“. Diese Zeichenfolgen sind Befehle, um in einem Text etwas zu finden und gegebenenfalls auch darin etwas zu verändern. Der hier angegebene Ausdruck sucht nach dem, was in der Variablen re_match steht und ersetzt es durch das, was in replace steht. In unserem Beispiel wird also in einbildung.jpg nach bild gesucht und dieses Vorkommen in image geändert. Im Normalfall würde das Ergebnis einimageung.jpg wieder auf dem Bildschirm landen, aber hier im Shell-Script landet es stattdessen in der Variablen tgt.
Unix ist nicht das einzige Betriebssystem, das Shell-Scripte unterstützt, und auch die Technik des Piping ist nicht auf Unix beschränkt. Microsoft übernahm beide Techniken bereits 1983 für seine zweite Version des DOS. Scripte sind dort unter dem Namen „Batch-File“ oder auch „Batch-Datei“ bekannt. Der Begriff hat nicht besonders viel mit dem Batch-Processing aus der Lochkartenzeit zu tun. Der Name ist in vielen Fällen auch einigermaßen irreführend, denn natürlich kann ein solches Script dafür genutzt werden, um viele Dateien oder Datensätze in einem Rutsch, also als einen Stapel zu bearbeiten. Genau so ein Beispiel haben Sie gerade gesehen. Nicht jedes Shell-Script und schon gar nicht jede Batch-Datei von DOS oder Windows erfüllt aber diese Eigenschaft. Oft handelte es sich einfach nur um fünf Befehle, die hintereinander ausgeführt werden sollten, und deren ewige Wiederholung eingespart werden sollte oder es handelte sich, gerade bei DOS, um einfache Menüstrukturen, die sich viele Nutzer bastelten, um schnell die Programme ihrer Wahl starten zu können, ohne Befehle auf der Kommandozeile eingeben zu müssen.
Piping und Shell-Scripting ist unter Unix aufgrund der vielen kleinen Tools sehr mächtig. In Systemen wie DOS oder der Windows-Eingabeaufforderung sind ähnliche Techniken zwar möglich, aber bei Weitem nicht so verbreitet und so oft eingesetzt. Unix ist mit seiner Shell ein sehr leistungsfähiges Betriebssystem. Die Nutzungsschnittstellen-Welt von Unix ist aber ganz anders als die, die Nutzer aktueller Betriebssysteme meist gebrauchen. Es herrscht nach wie vor ein fernschreiberartiger Terminal-Stil. Die einzig wirklich interaktiven Programme, die man bei einem klassischen Unix braucht, sind die Shell selbst und ein Editor. Außer diesem Editor braucht es in der Unix-Welt im Prinzip keine Software, die die Räumlichkeit des Bildschirms ausnutzen würde. Zwar sind in der Unix-Welt Dateien die zentralen Objekte der Interaktion, es ist aber für das Piping auch eine datenstromorientierte Denkweise notwendig. Gerade diese Denkweise, die ich Ihnen oben durch die Metaphorik mit den vielen kleinen Computern und den Lochstreifen zu erklären versucht habe, ist für Nutzer heutiger Systeme, zumindest wenn sie nicht auch Programmierer sind, nur schwer verständlich, denn sie ist sehr technisch. Die Genialität der klassischen Unix-Schnittstelle liegt dann auch nicht in ihrer Einfachheit, sondern in der unerreichten Flexibilität, denn mit Shell, Dateisystem, Piping und Scripting kann man sich die vielen kleinen Unix-Tools stets so zusammensetzen, wie man es gerade braucht.
X-Window-System – Unix kann auch grafisch
Die klassische Unix-Schnittstelle, die ich Ihnen gerade beschrieben habe, finden Sie bei allen unixoiden Betriebssystemen. Egal, ob Sie ein Xenix aus den 1980ern nutzen oder unter einem Ubuntu-Linux oder unter MacOS ein Terminal starten: Sie befinden sich immer in der oben beschriebenen Nutzungsschnittstellen-Welt, die sich auch immer ganz ähnlich gibt. Natürlich ist die Entwicklung zu grafischen Nutzungsschnittstellen aber auch an der Unix-Welt nicht spurlos vorbeigezogen. Als Grundlage für die größere Verbreitung grafischer Nutzungsoberflächen unter Unix kann das X-Window-System des MIT angesehen werden, das seit 1987 in stabiler Version zur Verfügung steht. Ein Blick in die Computergeschichte offenbart durchaus auch frühere grafische Schnittstellen, doch blieben diese oft experimentell oder waren auf einzelne Unix-Derivate beschränkt. Die X-Window-Technik hingegen war ein allgemeiner Standard, der sich bis heute gehalten hat27. Wohl wegen der Namensähnlichkeit mit Microsofts Windows wird die X-Window-Technik mitunter selbst als grafische Nutzungsschnittstelle angesehen. Das ist jedoch eine Fehlcharakterisierung. X-Window stellt nur einen allgemeinen Mechanismus zur Verfügung, den laufende Programme dafür nutzen können, auf den Bildschirm zu zeichnen und Eingaben von Maus, Tastatur usw. zu erhalten. Wie das aussieht, wie die Nutzungsschnittstelle beschaffen ist, welche Objekte es gibt, und letztlich sogar, ob es überhaupt Fenster gibt, ist nicht der Gegenstand von X-Window.
Windows und MacOS sind mehr oder weniger monolithische Systeme. Sie bieten die Methoden zur Anzeige auf dem Bildschirm generell, bieten Bildschirmelemente wie Buttons, Eingabefelder etc. an und kümmern sich auch um die Verwaltung von Fenstern. Hinzu kommen noch Nutzungsschnittstellen zur Dateiverwaltung, zum Starten von Programmen und zum Wechseln zwischen diesen Programmen. Bei grafischen Nutzungsoberflächen unter Unix sind all diese Bereiche getrennt. Das sieht in etwa wie folgt aus:
- Die grundlegendste Ebene bildet der sogenannte X-Server. Er bietet Anwendungen Möglichkeiten, auf den Bildschirm zu zeichnen und die Maus- und Tastatur-Interaktionen des Nutzers zu empfangen. Die Begrifflichkeit „Server“ ist hier etwas verwirrend. Als Server bezeichnet man üblicherweise einen Computer im Netz oder ein Programm auf einem solchen Computer, das Dienste zur Verfügung stellt, die dann mittels Nutzungsschnittstellen-Programmen genutzt werden können. Diese nennt man üblicherweise „Clients“. Das Konzept des X-Servers stellt das ein bisschen auf den Kopf. Der X-Server ist es, der allgemeine Funktionalitäten zur räumlich-grafischen Ein- und Ausgabe zur Verfügung stellt. Die Software-Programme bedienen sich dieser Fähigkeiten und sind damit die Clients. Der Nutzer nutzt also die Clients mittels eines X-Servers.
- Nutzungsschnittstellen sind zusammengesetzt aus sehr grundlegenden Elementen wie Bildschirmbereichen, Buttons, Menüs und Eingabefeldern. Damit nicht jede Software-Anwendung hier das Rad neu erfinden muss, bedienen Entwickler sich Bibliotheken mit solchen Elementen. Diese werden Widget Toolkits genannt.
- Die grundlegende Funktionalität von Fenstern und ihrer Verwaltung obliegt den Window Managern. Der Umfang dieser Fenster-Manager ist unterschiedlich. Auf jeden Fall gehört zu ihnen die Möglichkeit des Fensterverschiebens sowie des Schließens von Fenstern. Die meisten Fenster-Manager setzen dafür die bekannten Methoden mit einem in der Größe veränderbaren Fensterrahmen und einer Reihe von Buttons zum Minimieren, Maximieren und Schließen um. Viele Fenster-Manager stellen auch einen Task Switcher zum Umschalten zwischen Fenstern und einen Application Launcher zum Starten von Programmen bereit.
- Die Kombination aus Window Manager, Widget Toolkits und so grundlegenden Programmen wie einem Datei-Manager und einem Application Launcher bildet ein sogenanntes Desktop Environment.
- Mit einem Betriebssystem wird üblicherweise auch ein Satz typischer Anwendungen ausgeliefert, der teilweise allgemein verfügbar, in anderen Fällen aber extra an das entsprechende System angepasst ist. Im Linux-Bereich werden diese Sammlungen installierter Software-Produkte und Verwaltungswerkzeuge Distribution genannt. Jede Distribution macht eine Vorauswahl bezüglich des Desktop Environments, der mitgelieferten Tools und Verwaltungswerkzeuge und passt diese entsprechend der Philosophie der Distribution an, fügt eigene Plug-Ins hinzu, tauscht Module aus und passt das Aussehen und die Einstellungen an.
Die populäre Linux-Distribution Ubuntu beispielsweise verwendet, Stand 2021, die Desktop-Umgebung GNOME. Der Window-Manager von GNOME heißt „Mutter“, als Datei-Manager kommt „Nautilus“ zum Einsatz. Zu GNOME gehört auch das GTK-Toolkit, das Nutzungsschnittstellen-Elemente bereitstellt. Die Distribution openSUSE hingegen setzt auf die Desktop-Umgebung KDE Plasma mit dem Window-Manager KWin und dem Widget Toolkit qt. Der Datei-Manager von KDE nennt sich „Dolphin“. Linux Mint nutzt den Window Manager Cinnamon mit dem Datei-Manager Nemo, der eine Abspaltung (ein sogenannter „Fork“) einer früheren Nautilus-Version ist. Sie haben hier also dreimal Linux, aber dreimal gibt es sich anders, mit anderen Werkzeugen und mit einer anderen Nutzungsschnittstelle. Damit ist die Verwirrung aber noch nicht am Ende, denn Sie können nicht nur das Desktop Environment austauschen, sondern die Werkzeuge auch kreuz und quer verwenden. Auch wenn man also eine KDE Plasma-Umgebung einsetzt, kann man GNOME-Programme nutzen, insofern man die passenden Toolkits mitinstalliert hat, worum sich die Verwaltungswerkzeuge des Betriebssystems in aller Regel von selbst kümmern. Man kann also auch ein Nautilus unter KDE laufen lassen oder die teils umfassenden KDE-Anwendungen unter Linux Mint installieren. Diese große Flexibilität und Kompatibilität ist es, weswegen es schlichtweg nicht möglich ist, über die grafische Nutzungsschnittstelle von Unix und Linux allgemein zu sprechen. Man braucht, um überhaupt etwas sagen zu können, die Angabe der Distribution, die Version und letztlich eigentlich auch immer die Angabe aller Anpassungen, die ein Nutzer gemacht hat.
KDE Plasma
Eine Betrachtung der grafischen Unix-Nutzungsschnittstellen kann also nur exemplarisch sein, aber diese Beispiele können es stark in sich haben, denn es ist mit ihnen teils viel mehr möglich, als Windows und MacOS im Angebot haben. Um das zu belegen, zeige ich Ihnen einmal die Linux-Distribution Kubuntu 19.03 mit dem Desktop Environment KDE Plasma 5.
Die Nutzungsschnittstelle von KDE Plasma ist grundsätzlich ziemlich stark an die Nutzungsschnittstelle aktueller Windows-Versionen angelehnt. Es gibt einen Startbutton und ein Startmenü, eine Taskleiste und einen Desktop. Der Datei-Manager Dolphin wirkt wie eine Mischung aus Apples Finder und dem Explorer von Microsoft, hat allerdings interessante Features wie eine Split View, die es weder unter Windows noch auf dem Mac von Haus aus gibt. Spannend an der Nutzungsschnittstelle ist das Desktop-Konzept. Bei Windows und auch bei aktuellem MacOS ist der Desktop ein Ordner auf der Festplatte, dessen einzige besondere Eigenschaft es ist, dass seine Inhalte, also die enthaltenen Dateien und Ordner, großflächig als Hintergrund hinter allen Fenstern angezeigt werden. Bei KDE Plasma ist dies auch möglich und in Kubuntu ist diese Einstellung der Standard. Das Layout kann jedoch von „Ordneransicht“ auf „Arbeitsfläche“ umgeschaltet werden.
In der Arbeitsflächen-Ansicht können auf dem Desktop in jeweils eigenen Bereichen kleine aktive Komponenten untergebracht werden. Diese als „Widget“ bezeichneten Miniprogramme können allerlei Aufgaben erfüllen, von der Anzeige des aktuellen Wetters bis zur direkten Einbindung von Websites auf dem Desktop. Wenn Sie ein Android-Telefon besitzen, kennen Sie dieses Konzept, denn auch Android ermöglicht es, auf den Übersichtsbildschirmen nicht nur Icons zum Starten der gewünschten Anwendungen unterzubringen, sondern auch direkt Objekte auf diesen Bildschirmen zu haben, die etwas anzeigen und mit denen interagiert werden kann. Auch in Windows Vista konnte man sich kleine Progrämmchen auf den Desktop legen. Widgets allein wären daher noch nicht etwas, was mich dazu bewegen würde, Ihnen etwas vom KDE-Desktop vorzuschwärmen. Spannend wird die Sache aber dann, wenn man sich über die Möglichkeiten eines sehr einfachen Widgets ein wenig Gedanken macht, nämlich dem Widget, das die Inhalte eines Ordners zur Anzeige bringt. Oben sehen Sie ein Beispiel dafür. Zwei Ordner-Anzeige-Widgets zeigen jeweils einen Ordner an. Der obere Bereich zeigt den Inhalt des Download-Ordners, während der untere den Inhalt eines Ordners mit dem Namen „Projekt 1“ zeigt.
Diese Ordner-Widgets ermöglichen es, viel mehr als Windows und MacOS, dass man sich den Desktop zum eigenen Arbeitsplatz machen kann. Nutzt man KDE Plasma, kann man sich die Projekte, an denen man gerade arbeitet, als eigene Bereiche auf dem Desktop einrichten, mit den Dateien arbeiten und sie sogar zwischen den Ordnern hin und herschieben. Braucht man zwischenzeitlich einen weiteren Bereich direkt im Zugriff, richtet man sich einfach ein weiteres Widget ein. Ist ein Projekt abgeschlossen und nicht mehr relevant, kann man einfach das Widget entfernen. Die Dateien liegen dann nicht mehr auf dem Desktop, sind aber natürlich in der Dateiablage weiterhin vorhanden.
Ebenfalls sehr praktisch bei der Arbeit mit einer Vielzahl von Projekten ist die Funktion „Activities“. Mit ihr lassen sich verschiedene Desktops für verschiedene Aufgaben einrichten. Jeder Desktop hat seine eigene Einrichtung, mit eigenen Widgets, eigenem Hintergrundbild und auch eigenen geöffneten Anwendungen. Die Funktionalität, mehr als einen Desktop anzubieten und so mehrere Arbeitskontexte zu ermöglichen, ist gerade im Bereich der Unix-GUIs schon sehr alt. Inzwischen sind ähnliche Funktionen auch in MacOS und in Windows verfügbar. Ihre Umsetzung ist allerdings im Verhältnis zu den „Activities“ von KDE sehr eingeschränkt, denn weder unter Windows noch unter MacOS werden einem wirklich verschiedene Desktops mit verschiedenen Elementen bereitgestellt. Man kann lediglich zwischen Sätzen geöffneter Fenster wechseln. Anders bei KDE Plasma: Dort kann sich so etwa einen Heim-Desktop und einen Arbeits-Desktop einrichten und sich beiden Kontexten entsprechend anpassen, ohne dass die Objekte des einen Kontextes mit denen des anderen in Konflikt geraten. Braucht man die gleichen Elemente auf mehr als einem dieser Desktops, ist das mit der Widget-Einrichtung gar kein Problem, denn niemand hindert einen daran, für den gleichen Ordner der Festplatte jeweils ein Anzeige-Widget auf den Desktop zu schieben.
Die Anzahl der Leute, die Unix- oder Linux-Systeme mit grafischer Nutzungsschnittstelle bei sich zu Hause oder auf der Arbeit einsetzen, ist verschwindend gering, im niedrigen einstelligen Prozentbereich. Um so erstaunlicher ist es, dass, wie hier zum Beispiel bei KDE Plasma, sehr interessante Nutzungsschnittstellen für die Systeme entwickelt werden, und um so bedauerlicher ist es natürlich, dass kaum jemand in den Genuss dieser Nutzungsschnittstellen kommt. Warum das letztlich so ist, hat sicherlich viele Gründe, über die ich hier nur spekulieren kann. Manches hat sicherlich mit der Marktmacht der großen Firmen Microsoft und Apple und der damit zusammenhängenden großen Verbreitung ihrer Software-Infrastrukturen zu tun. Ein anderer gewichtiger Grund ist meiner Meinung nach aber auch, dass Unix und Linux sich mit ihrer grundsätzlichen Philosophie ein wenig selbst die Möglichkeit des Erfolgs verbauen. Die oben skizzierte Offenheit der Konfiguration und die Möglichkeit, nahezu alles mit allem zu kombinieren, scheint Entwickler durchaus zu beflügeln, neue innovative Funktionen einzubauen. Sie sorgt aber auch dafür, dass man sich als Linux- oder Unix-Nutzer bei Problemen immer noch ein wenig mehr alleine fühlt als andere. Wenn Sie mit Ihrem Windows 10 ein Problem haben, finden Sie sicher jemanden im Bekanntenkreis, der das Problem nachvollziehen und Ihnen helfen kann. Wenn Sie Linux nutzen, wird das aufgrund der Verbreitung schwieriger, aber selbst wenn Sie jemanden finden, der auch Linux nutzt, dann nutzt der wahrscheinlich eine andere Distribution mit anderen Fenster-Managern, anderen Einstellungen und anderen Systemtools.
Unix auf Smartphones?
Dass Unix und Linux im Endanwenderbereich geringe Verbreitung haben, gilt nur, wenn man nur den Bereich der Desktop-Betriebssysteme betrachtet und wenn man MacOS nicht als Unix, sondern als eigenes System zählt. Generell ganz anders sieht die Sache aus, wenn Sie Smartphones und Tablets mit hinzuzählen, denn Apples iOS basiert wie MacOS auf BSD-Unix und Android von Google verwendet unter der Haube Linux als Betriebssystem. Sollte ich Ihnen MacOS, Android und iOS nun also hier als Unix-Systeme vorstellen? Es gibt wie immer mehrere Sichtweisen. Meine ist die der Nutzungsschnittstellen-Welten. Es ergibt zum Beispiel Sinn, wie im vorherigen Kapitel dargelegt, Windows als etwas anderes als MS-DOS zu beschreiben, denn es hat seine ganz eigene Nutzungsschnittstellen-Welt. Wenn Sie einem erfahrenen Informatiker etwas vom Betriebssystem Windows 3.11 erzählen, wird er Sie aufklären, dass es sich bei Windows 3.11, genauso wie bei Windows 95, 98 und ME, nicht um eigenständige Betriebssysteme handelte, sondern um Erweiterungen für MS-DOS. Aus Sicht der Betriebssystemtechnologie mag das stimmen, doch für mich ist es schlichtweg egal. Die Nutzungswelten von reinem DOS mit nur einem gleichzeitig laufenden Programm, einer Kommandozeile und Anwendungen im Text-Modus, und von Windows, mit mehreren gleichzeitig laufenden Anwendungen, einem Programm-Manager und grafischen Objekten, die räumlich manipuliert werden können, sind ganz verschieden. Ein Windows-Nutzer nutzt nicht eigentlich immer noch DOS – zumindest nicht, wenn man die Nutzungsschnittstellen-Brille aufhat. Das Gleiche gilt noch viel stärker für Unix, Android und iOS. Auf der technischen Ebene der Prozess- und Datenträgerverwaltung mag das eine ein Aufsatz auf das andere sein, aber aus Sicht des Nutzers handelt es sich jeweils um eigene Nutzungsschnittstellen-Welten. Android und iOS stehen in einer ganz anderen Tradition als Unix und Linux. Sie sind nicht die Urenkel eines alten Time-Sharing-Systems, sondern Nachfolger der mobilen Personal Digital Assistants der 1990er Jahre und in diesem Zusammenhang will ich sie Ihnen im folgenden Kapitel auch beschreiben.