Verteilte Persistenz
Bis hierher habe ich Ihnen in der Geschichte der Vernetzung von Computern Technik vorgestellt, die im Großen und Ganzen Informationen im Netz abruft und zur Anzeige bringt oder teilweise auch als Programm ausführt. Dies ging von einfachen Darstellungen wie bei den BBS-Systemen über netzbasierte Hypertextsysteme bis hin zu modernen Browser-Infrastrukturen für netzbasierte Software im World Wide Web. Vernetzung hat aber natürlich weitere Potenziale. Ein wichtiges dieser Potenziale, das ich “verteilte Persistenz” nenne, möchte ich Ihnen abschließend vorstellen.
Wenn Sie heute einen PC, einen Laptop oder ein Tablet nutzen, ist es gar nicht mehr so einfach festzustellen, was eigentlich lokal auf dem Gerät gespeichert ist und was im Netz abgelegt wurde. Häufig wird dann der Begriff “Cloud” verwendet. Was das eigentlich genau bedeuten soll, ist selbst wolkig oder gar nebulös. Der Begriff ist wohl eher den Werbe- als den Technikabteilungen entsprungen. Er kann alles und nichts bedeuten. Wenn von “Dateien in der Cloud” die Rede ist, dann meint es in der Regel, dass Dateien irgendwo im Netz gespeichert sind und bei Bedarf lokal auf ein Gerät synchronisiert werden, ohne dass man sich genau darum kümmern müsste, wo und wie die Daten gespeichert sind und auf welche Art und Weise sie synchronisiert werden. Die bekanntesten Vertreter solcher Clouds sind Dropbox und OneDrive.
FTP, der Urahn der netzbasierten Dateiablage
Zugriff auf im Netz gespeicherte Daten ist prinzipiell nicht neu. Im Internet-Vorgänger ARPAnet gab es bereits seit 1971 den FTP-Dienst. Mit FTP (File Transport Protocol) konnte man sich bereits damals auf einem entfernten Computer anmelden, durch die dort freigegebenen Verzeichnisse stöbern und dann Daten auf den eigenen Rechner herunterladen oder von dort aus hochladen. Der Dienst wird auch heute noch bei manchem Webhoster verwendet, um Dateien auf den Server zu laden, die dann über einen Webserver abgerufen werden können. Im Gegensatz zu den 1970ern und 1980ern geschieht dies heute in der Regel mittels einer Software mit grafischer Nutzungsschnittstelle, die oft ziemlich ähnlich aussieht, wie die Dateimanager der Betriebssysteme. FTP erfüllt sicherlich seinen Zweck, ist aber nicht besonders praktisch, denn das Prinzip ist recht umständlich: Ist auf einem FTP-Server ein Dokument einer Textverarbeitung gespeichert, das man gerne bearbeiten will, kann man das nicht einfach so öffnen und bearbeiten, sondern muss das Dokument erst auf den eigenen Rechner herunterladen, kann es dort öffnen und bearbeiten, um es dann explizit wieder hochzuladen. Moderne FTP-Programme haben häufig das Feature, dies zu automatisieren. Ein Doppelklick auf eine Datei lädt diese herunter, öffnet sie mit dem verknüpften Programm und lädt das ganze nach Speichern auch automatisch wieder hoch. Das ist besser als nichts, aber doch behalten die per FTP zugreifbaren Dateien eine andere Charakteristik als die lokal gespeicherten. Sie erscheinen nicht im Explorer oder Finder und auch über die Funktionen zum Öffnen und Speichern in Programmen lässt sich meist auf keine Dateien per FTP zugreifen.
Dateifreigaben im lokalen Netz
In den 1980er Jahren kamen im Bereich kleinerer Netzwerke in Unternehmen Techniken zur Dateifreigabe auf: 1984 etwa das Network File System (NFS) in den Unix-Systemen von Sun Microsystems und bereits 1983 das SMB-Protokoll von IBM sowie Netware von Novell für IBM-kompatible PCs. Gerade letzteres erfreute sich im Bereich von Firmennetzwerken großer Beliebtheit. In allen genannten Fällen mussten Dateien nicht, wie bei FTP, händisch hoch- oder heruntergeladen werden. Vielmehr wurden Verzeichnisse, die auf einem Server gespeichert wurden, im lokalen System so eingebunden, als ob sie lokal vorlägen. Eine Freigabe von Novell Netware erschien unter MS-DOS als Laufwerk mit eigenem Laufwerksbuchstaben, also wie eine Festplatte oder ein Diskettenlaufwerk. Netzwerke dieser Art konnten klein sein, bestanden beispielsweise aus zwei oder drei PCs, oder wurden allen Rechnern einer Firma verfügbar gemacht. Privat betrieb man 1983 hingegen noch keine Netzwerke. Die meisten privaten Nutzer von Computern hatten zu diesem Zeitpunkt noch nicht einmal eine Festplatte.
Techniken wie Novell Netware, SMB oder NFS sind grundsätzlich auch in größeren Netzwerkverbünden wie dem Internet anwendbar. Rein technisch ist das kein Problem. Die Nützlichkeit ist jedoch eingeschränkt. Greift nämlich ein Programm auf eine Datei auf einem Netzlaufwerk zu, ist dies für das Programm genau so, als handele es sich um eine lokal auf dem Rechner gespeicherte Datei. Der Zugriff auf eine Datei im Netz ist natürlich langsamer, als wenn die Datei auf der Festplatte liegt. Im lokalen Netzwerk ist er aber immerhin schnell genug, damit eine sinnvolle Nutzung noch möglich ist. Ist man mit dem Server allerdings über eine sehr langsame Leitung per Internet verbunden, funktioniert das meist nicht mehr vernünftig. Das Laden und Speichern einer Datei dauert dann sehr lange – und wenn ein Programm die Datei zwischenzeitlich speichert, was ja zu empfehlen ist, muss man als Nutzer warten, bis man weiterarbeiten kann.
Synchronisation mit lokalen Kopien.
Noch schlimmer wird das Problem mit den Netzlaufwerken dann, wenn die Netzwerkverbindung gar nicht dauerhaft besteht. Das ist selbst in Firmennetzwerken mitunter der Fall, etwa wenn man ein Laptop verwendet und damit die Firma verlässt. Unter Windows kann man daher etwa einstellen, dass die Dateien eines Netzlaufwerks offline vorgehalten werden. Das Praktische daran ist, dass es für die Arbeit auf dem Rechner gar keinen Unterschied macht, ob man gerade eine Netzwerkverbindung hat oder nicht. Bearbeitet man ein Dokument, ohne dass es eine Verbindung gibt, bearbeitet man lediglich eine lokale Kopie. Sobald die Netzwerkverbindung wieder vorliegt, wird die Kopie ins Netzwerk übertragen. Um all dies braucht man sich als Nutzer nicht selbst zu kümmern. Laden, Bearbeiten und Speichern laufen genauso ab wie immer. Dieses Prinzip lässt sich auch auf im Internet gespeicherte Dateien anwenden, denn dann spielt das langsame Netz keine so große Rolle mehr. Populär wurde das mit dem Dienst Dropbox, den es seit 2007 gibt. Ganz so wie in Dateifreigaben bei Windows werden bei Dropbox und vergleichbaren Diensten die Dateien lokal auf den eigenen Computer synchronisiert. Man kann sie dort ganz normal verwenden, was auch daran liegt, dass es sich ja in der Tat um lokal auf der Festplatte gespeicherte Dateien handelt. Im Hintergrund werden die Dateien bei Änderungen mit den Kopien im Netz synchronisiert – eine vorhandene Netzwerkverbindung natürlich vorausgesetzt.
Probleme entstehen in beiden Fällen, wenn mehrere Personen gleichzeitig an den Dateien arbeiten. Bei im Netzwerk gespeicherten Dateien, die man oft ja gerade aus dem Grund dort ablegt, um sie gemeinsam verwenden zu können, kann genau eine solche gleichzeitige Bearbeitung natürlich schnell vorkommen. Es gibt dann zwei Versionen der gleichen Datei, die nicht automatisch synchronisiert werden können. Man muss sich als Nutzer explizit für eine der beiden Dateien entscheiden oder diese händisch zusammenführen.
Gemeinsame Objekte
Nehmen wir einmal an, Sie besitzen eine Datei mit einer Folienpräsentation. Sie sind dafür zuständig, die Folien 6 bis 10 zu überarbeiten, ihr Kollege kümmert sich um die Folien 1 bis 5. Wenn Sie versuchen, die Überarbeitung mit den genannten Dateiablagediensten zusammenzuführen, kommt es zu einem Synchronisationskonflikt, den Sie natürlich nicht sinnvoll dadurch lösen können, dass Sie sich entweder für Ihre Datei oder die Ihres Kollegen entscheiden. Sie würden dann immer entweder Ihre eigene Arbeit oder die Ihres Kollegen in den Müll werfen. Das Problem ist hier die zu grobe Granularität. Dateifreigaben und auch cloudbasierte Dateiablagen wie Dropbox arbeiten auf Dateiebene. Von den einzelnen Folien oder gar die einzelnen Elemente auf den Folien wissen diese Dienste nichts. Sie können die Präsentation also nicht auf dieser feinen Granularitätsstufe synchronisieren.
Anders sieht das aus, wenn man Software nutzt, die über das Netzwerk synchronisiert Zugriff auf gemeinsame Objekte bietet. Google Docs ist ein modernes Beispiel für eine solche Software. Sie können damit Texte gleichzeitig mit mehreren Mitstreitern online bearbeiten. Alle arbeiten gleichzeitig am gleichen Text. Es ist kein Hin-und-her-Schicken und keine explizite Synchronisierung notwendig. Natürlich müssen solche Dienste nicht zwangsweise internetbasiert sein. Wenn Sie Apple-Nutzer sind, können Sie sich zum Beispiel das Programm SubEthaEdit herunterladen und haben damit einen Texteditor, mit dem Sie im lokalen Netzwerk gemeinsam an Dateien arbeiten können.
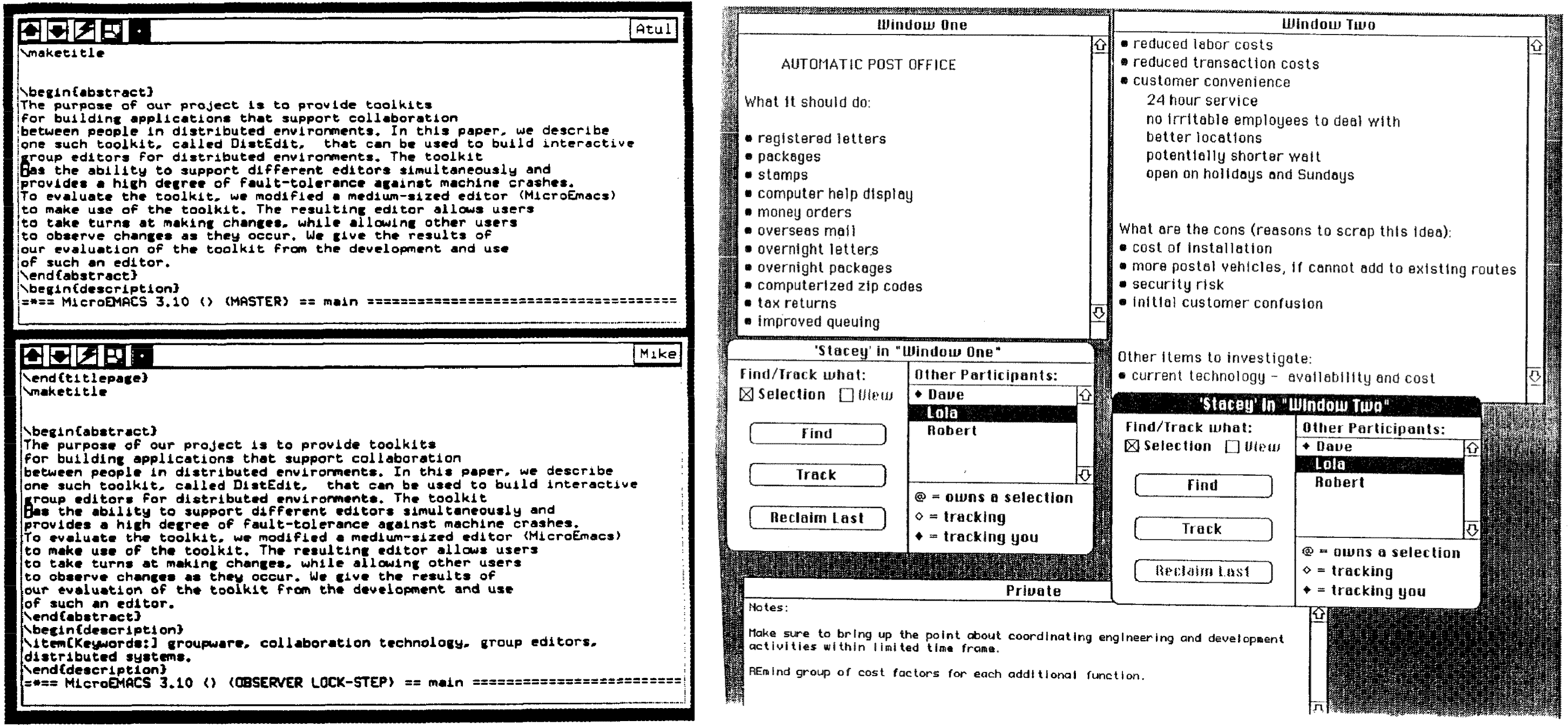
In dieser Abbildung sehen Sie zwei frühe Repräsentanten solcher Programme. Links zu sehen23 ist der Unix-Editor EMacs, der es in dieser Version erlaubt, jemandem über das Netz beim Bearbeiten eines Textes zuzusehen. Das Fenster oben zeigt den Master (in der letzten Zeile zu lesen), das untere den Observer, der zusehen, nicht aber selbst bearbeiten kann. Der Editor ShrEdit von 1994 auf der rechten Seite24 erlaubt bereits das gemeinsame, gleichzeitige Bearbeiten des Textes.
Dass man auf diese Weise potenziell von unterschiedlichen Enden der Welt gemeinsam und gleichzeitig an einem Dokument arbeiten kann, wirkt heute fast selbstverständlich. Wenn man sich mal überlegt, was eigentlich dahintersteckt, kann man aber schon ins Staunen kommen, denn dieses gemeinsame Objekt, das Dokument, mit seinen Teilobjekten gibt es ja eigentlich gar nicht. Jeder sieht und bearbeitet eine eigene Kopie. Diese wird im Hintergrund so schnell mit den Kopien der anderen synchronisiert, dass der Eindruck eines gemeinsamen, geteilten Objekts entsteht. Dass das klappt, ist kein Pappenstiel, denn ein einfaches Synchronisieren des ganzen Dokuments würde ja nicht ausreichen. Zum einen würde das viel zu lange dauern. Ein komplexes großes Dokument könnte man wohl kaum mehrmals pro Sekunde per Netz durch die ganze Welt schicken. Das geht selbst bei den heutigen hohen Netzwerkgeschwindigkeiten nicht. Die Entwickler entsprechender Tools standen also vor der Aufgabe sich zu überlegen, wie man die Datenmenge stark reduzieren kann, etwa, indem man nur die Stellen des Dokuments versendet, die sich verändert haben, oder indem man die Änderungsoperationen als solche überträgt. Das allein reicht aber nicht, denn dann würden zwar die Änderungen der Mitarbeiter stets zügig sichtbar werden, der Überblick darüber, wer gerade wo arbeitet, könnte sich aber schwieriger gestalten. Es braucht also zusätzliche Informationen, die mit übertragen werden müssen. Dazu gehört etwa der Mauszeiger oder der Schreib-Cursor der Mitarbeiter zusammen mit der Anzeige ihrer Namen. Mit solchen Awareness- oder zu Deutsch Gewärtigkeitsinformationen gelingt die gemeinsame Arbeit erheblich einfacher. Trickreich bleibt es dennoch, denn bekannte Funktionalitäten wie Undo und Redo werden nun ziemlich kompliziert. Stellen Sie sich vor, wir würden gemeinsam an diesem Absatz arbeiten. Ich schriebe am Ende des Absatzes einen neuen Satz. Kurz danach korrigieren Sie einen Fehler am Beginn des Absatzes. Wenn ich dann auf “Undo” klicke, was passiert dann eigentlich? Wird meine Änderung zurückgenommen oder Ihre? Was würde man erwarten?
Halten wir an dieser Stelle mal inne. Wo sind wir jetzt angekommen? Wir arbeiten weltweit verteilt, gleichzeitig und gemeinsam an virtuellen Objekten. Eine Vielzahl von Entwicklern hat sich intelligente Dinge ausgedacht, damit das so funktioniert und wenn es funktioniert, dann ist alles super. Eigentlich ist es fast schon Zauberei, wenn es nicht so selbstverständlich geworden wäre. Dadurch, dass sich die technischen Hintergründe auf geschickte Art und Weise immer mehr der Wahrnehmung der Nutzer entziehen, sind Nutzungsformen möglich, die vorher undenkbar waren. Dieses Verstecken der Technik ist die Grundlage der Potenziale, die die digitale Technik bietet. Damit verbunden ist dann aber, dass man fast zwangsläufig als Nutzer und als Interessierter das technische System gar nicht mehr durchblicken kann und immer auf die bereits vorgefertigten Lösungen angewiesen ist. Bei einem Commodore 64 konnte man noch jeden einzelnen Chip ergründen, konnte das komplette auf einem Chip untergebrachte ROM analysieren und an Software und gegebenenfalls sogar an Hardware selbst Hand anlegen. Ein moderner Laptop ist mehrere tausend Mal potenter in jeder Hinsicht und bietet durch die Geschwindigkeit, die Vernetzung und durch geschickte Programmierung die geschilderten verteilten Wunderwelten mit gemeinsamen, persistenten Objekten, aber wirklich durchdringen kann man das alles nicht mehr.