Unix und Linux
In meinen bisherigen Darstellungen der Entwicklung von Nutzungsschnittstellen habe ich das Betriebssystem Unix zwar dann und wann erwähnt, aber im Großen und Ganzen ignoriert. Tatsächlich hatte ich ursprünglich vor, es auch dabei zu belassen, denn Unix kam zum einen als Vertreter der textbasierten Time-Sharing-Betriebssysteme relativ spät auf den Markt und ist zum anderen, was die grafischen Nutzungsschnittstellen angeht, zumindest im Bereich der PC-Betriebssysteme nicht verbreitet. Man findet es wohl sehr oft auf Rechnern, die nicht direkt von Endnutzern verwendet werden, sondern Dienste im Hintergrund bereitstellen. Solche Rechner nennt man im Allgemeinen „Server“. Nahezu alle Websites, die Sie heute aufrufen können, laufen unter einem unix-artigen Betriebssystem, doch kann das dem Nutzer des Computers, auf dem der Webbrowser läuft, letztlich egal sein. Im Laufe der Recherche für viele der anderen Kapitel dieses Buches habe ich dann entschieden, dass es doch ein eigenes Unix-Kapitel braucht, denn das Betriebssystem hatte zum einen starken Einfluss auf andere Betriebssysteme und zum anderen werden im Unix-Bereich Nutzungsschnittstellen entwickelt, die zwar wenig genutzt werden, die aber dennoch teils so interessante Eigenschaften haben, dass man sie nicht einfach unter den Tisch fallen lassen sollte.
Von Multics zu Unics – Die Frühgeschichte
Lassen Sie mich mit der Geschichte von Unix etwa fünf Jahre vor dem Zeitpunkt beginnen, an dem das System das erste Mal in Erscheinung getreten ist, denn die Vorgeschichte des Systems erklärt manche der typischen Unix-Eigenheiten. Nachdem wir im vorherigen Kapitel schon in der Gegenwart angekommen sind, machen wir also einen Sprung weit zurück ins Jahr 1964, etwa zehn Jahre vor dem Aufkommen der ersten Personal Computer, in die Zeit, in der im großen Stile an der Time-Sharing-Technik entwickelt und geforscht wurde. In diesem Jahr 1964 begannen das Massachusetts Institute of Technology (MIT), die Firma General Electric (GE), damals ein Hersteller von Computern, und die Bell Labs mit der Entwicklung eines komplexen Time-Sharing-Systems. Wichtig für die Geschichte von Unix ist hier vor allem die Beteiligung des Forschungslabors Bell Labs. Diese Einrichtung war Teil des damaligen amerikanischen Telefon-Monopolisten AT&T, ein Fakt, der für die weitere Geschichte noch wichtig werden sollte.
MIT, GE und Bell Labs begannen im Jahr 1964 mit der Entwicklung eines Time-Sharing-Betriebssystems namens Multiplexed Information and Computer Service, kurz Multics. Das Betriebssystem war für die damalige Zeit extrem modern und mit Eigenschaften ausgestattet, die gerade im Einsatz in einer großen Rechenanlage mit vielen zugreifenden Nutzern sehr sinnvoll waren. Hierzu gehörte zum Beispiel die Verwaltung von Massenspeichern wie Festplatten, Magnetbändern oder Wechselplatten. Das System hatte in Sachen Datenträgerverwaltung interessante Konzepte. Heutige PC-Betriebssysteme wie Windows oder MacOS verwalten Datenträger in den meisten Fällen als unabhängige Einheiten. Wenn Sie etwa eine externe Festplatte oder einen USB-Stick an den Rechner anschließen, erscheint ein neuer Datenträger im System. Sie können nun darauf zugreifen und etwa Dateien herauf- oder herunterkopieren. Die Organisation, was auf welchem Datenträger gespeichert ist, müssen Sie aber selbst durchführen. Ist Ihnen die Festplatte in Ihrem Rechner zu klein und Sie bauen eine weitere ein, müssen Sie sich selbst darum kümmern, welche Dateien Sie auf welcher Festplatte abspeichern. Bei Multics war das anders: Dort vergrößerte eine neue, angeschlossene Festplatte oder ein eingelegtes Band die Menge des zur Verfügung stehenden Massenspeichers. Das System schichtete die gespeicherten Dateien automatisch so um, dass sich die häufig genutzten Dateien auf einem schnelleren Speichermedium befanden, etwa einer schnellen Festplatte, während die weniger genutzten auf langsame Medien wie Wechselplatten oder Magnetbänder umgelagert wurden. Diese Platten und Bänder mussten nicht dauerhaft vorgehalten werden. Operatoren im Rechenzentrum konnten Platten und andere Medien nahezu beliebig hinzufügen und entfernen. Würden Sie das bei einem heutigen System machen, würden im Normalfall Dateien und Verzeichnisse verschwinden oder wie von Geisterhand erscheinen. Das Dateisystem von Multics machte diese technische Realität der Speichermedien jedoch für den Nutzer vollständig unsichtbar. Nehmen wir einmal an, ein Nutzer hatte Monate zuvor eine Datei angelegt, diese aber seitdem nicht wiederverwendet. Zwischenzeitlich wurde sie vom System auf ein Magnetband umkopiert und archiviert. Wollte unser Nutzer nun auf diese Datei erneut zugreifen, war das kein Problem. Sie wurde ihm nach wie vor als vorhanden angezeigt. Sollte sie nun geladen oder ausgegeben werden, ging das nicht sofort. Der Benutzer wurde zunächst mit einer Systemmeldung vertröstet, während dem Operator im Rechenzentrum angezeigt wurde, dass er ein bestimmtes Magnetband einlegen sollte. Sobald er das tat, stand die Datei wieder zur Verfügung und wurde gegebenenfalls automatisch wieder auf ein schnelleres Speichermedium verschoben. Niemand musste händisch die Datei vom Magnetband auf eine Arbeitsfestplatte kopieren oder ähnliches. Diese Aufgabe wurde vollständig vom System selbst übernommen.
Das Multics-System war groß und komplex und verfügte über viele Funktionen für große Time-Sharing-Rechenanlagen, von der gerade beschriebenen Datenträgerverwaltung bis hin zu einer ausgefeilten Nutzerverwaltung. Die Weiterentwicklung zog sich hin, was nicht allen am Projekt Beteiligten zusagte. Im Jahre 1969 zogen sich die Bell Labs daher aus dem Projekt zurück. Dies setzte einerseits Ressourcen frei, führte aber andererseits zum Problem, dass für die eigenen Computer nun andere Betriebssysteme gefunden oder entwickelt werden mussten. Ken Thompson und Dennis Ritchie, zwei Techniker bei Bell Labs begannen daher, einfach aus der Notwendigkeit heraus, mit der Entwicklung eines eigenen, kleineren Betriebssystems für die am Bell Labs eingesetzten Minicomputer PDP-7 und später PDP-11/20 von DEC. Im Jahre 197023 wurde das System als Verballhornung von Multics zunächst Unics (Uniplexed Information and Computer Service) getauft. Der Name wurde später in „Unix“ geändert, wobei heute nicht mehr genau zu klären ist, wann die Umbenennung stattfand und wer dafür verantwortlich war. Die frühen Unix-Versionen wurden in der maschinennahen Assembler-Programmiersprache für die PDP-7 und die PDP-11 geschrieben, liefen also auch nur auf diesen Computern. Ab 1973 änderte sich das, denn große Teile des Systems wurden in der von Dennis Ritchie entwickelten Programmiersprache C, die auch heute noch weithin genutzt wird, neu geschrieben. Dieser Schritt erhöhte nicht nur die Wartbarkeit des Betriebssystems von Seiten der Entwickler, sondern erlaubte später auch die Portierung des Systems auf andere Hardware-Architekturen.
Jedem sein Unix – Die Zersplitterung
Das neue Betriebssystem Unix wurde zunächst nur innerhalb von AT&T verwendet und entwickelt. Das System wuchs dabei in Funktionalität und Komplexität natürlich an, von einem einfachen Single-Tasking-Betriebssystem noch auf der PDP-7 zu einem Multi-User-Multi-Tasking-Betriebssystem, das es auch noch heute ist. Der Entwickler Bell Labs war, wie bereits angedeutet, Teil des damaligen Telefonmonopolisten AT&T. Eine der Bedingungen dafür, dass AT&T sein Monopol haben durfte, war, dass sich der Konzern auf Telefondienstleistungen und Kommunikation beschränkte und mit seinem Angebot nicht etwa auch in verwandte Wirtschaftsbereiche ausuferte. Der Verkauf von Computern und Betriebssystemen war damit für die Firma ein Tabu. Natürlich konnte niemand AT&T verbieten, für interne Zwecke ein Betriebssystem zu entwickeln. Lediglich verkaufen durfte AT&T ein solches System nicht. Was allerdings erlaubt war, und auch intensiv betrieben wurde, war die Lizensierung des Systems an Interessenten. Computerhersteller, die ein Betriebssystem suchten, konnten bei AT&T eine Lizenz erwerben und erhielten damit Zugriff auf den Programmcode des Systems, den sie relativ frei verwenden und für ihre Belange anpassen konnten. Besonders attraktiv war diese Lizenzierung für Bildungseinrichtungen und Universitäten, die für die Lizenz nur einmalig 200 Dollar bezahlen mussten. Einer dieser Lizenznehmer war die University of Berkeley. Informatiker und Studierende der Universität passten das System von AT&T für ihre Forschungszwecke an, erweiterten die Netzwerkfunktionalitäten und verbesserten die Performanz. Das daraus entstehende System wurde BSD (Berkeley Software Distribution) genannt. Nachfolger dieses Systems sind in der Form von FreeBSD und NetBSD noch heute verbreitet.
Dass Lizenznehmer von Unix das System ihren eigenen Bedürfnissen anpassen konnten, führte dazu, dass es kein einheitliches Unix mehr gab. Es gab das UNIX von AT&T, das in der Regel in Großbuchstaben geschrieben wurde. Daneben gab es viele andere Unixe, etwa das BSD der University of Berkeley, SunOS von Sun Microsystems, Xenix von Microsoft, AIX von IBM und viele andere mehr. All diese Systeme waren irgendwie jeweils Unix, aber sie waren doch verschieden. Das war natürlich einerseits der Charme des Projektes, denn jedes Unix war für seinen Einsatzzweck optimiert, andererseits brachte diese Zersplitterung die Gefahr, dass ein absolutes Chaos entsteht. Um ebendieses zu vermeiden, wurde ab 1985 eine Standardisierung angestrebt, die heute unter dem Begriff „POSIX-Standard“ bekannt ist. Der Standard beschreibt eine Art Mindestanforderung für Unix-Systeme, die bei allen Derivaten gleich sein soll.
Das Telefonmonopol von AT&T wurde in den 1980er Jahren zerschlagen. Ab dem Jahr 1984 durfte das an den Bell Labs entwickelte System daher auch als Produkt verkauft werden. AT&T verschärfte fortan die Lizenzpolitik. Neue Versionen des UNIX von AT&T konnten nicht mehr so günstig lizenziert und angepasst werden. Dieser Schritt sorgte natürlich für Gegenreaktionen. Unix war an Universitäten weit verbreitet und dort wegen seiner Flexibilität sehr geschätzt. Die University of Berkeley mit ihrem wichtigen Unix-Derivat BSD schrieb alle vorhandenen AT&T-Teile aus ihrem System heraus und ersetzte sie durch funktionsgleichen, also zum POSIX-Standard kompatiblen, eigenen Code. Ab 1991 stand BSD dann AT&T-frei unter einer Open-Source-Lizenz zur Verfügung. „Open Source“ bedeutet, sehr einfach formuliert, dass jeder sich den Quellcode beschaffen und nach Lust und Laune für eigene Projekte anpassen kann, ohne Lizenzgebühren bezahlen zu müssen. Nach diesem Prinzip funktioniert heute sehr viel Software, etwa der Browser Firefox, die Grundlage des Browsers Chrome und die Office-Programme LibreOffice und OpenOffice.
Die quelloffenen BSD-Versionen von 1989 und 1991 waren nicht der erste Versuch, ein Unix ohne AT&T-Abhängigkeit zu erzeugen. Bereits 1983 startete Richard Stallman eigens zu diesem Zweck das GNU-Projekt. Das Ziel Stallmans war freie Software24 – und hier im Speziellen ein UNIX-kompatibles Betriebssystem ohne eine einzige Zeile des Original UNIX-Codes von AT&T. Die Abkürzung GNU steht daher auch vielsagend für „GNU is Not UNIX!“. GNU als Komplett-Betriebssystem ist bis heute noch nicht fertig. Aus dem Projekt hervorgegangen sind aber eine ganze Menge wichtiger Tools und Programmpakete, darunter der Kommandozeilen-Interpreter „bash“, der weit verbreitet ist und in vielen Unixen und darüber hinaus genutzt wird. Die ganze Palette der GNU-Software-Werkzeuge bildete zusammen mit einem von Linus Torwalds Anfang der 1990er Jahre entwickelten Open-Source-Betriebssystemkern vor allem aber die Grundlage für das Betriebssystem Linux25.
Linux steht somit in der Unix-Tradition, aber ist Linux damit auch ein Unix? Man kann die Frage nur mit einer Gegenfrage beantworten: Ist BSD ein Unix, obwohl explizit alle Programmcodes von AT&T entfernt wurden? Woran will man das festmachen? Eine Möglichkeit wäre der oben genannte POSIX-Standard, denn der beschreibt unix-artige (oder auch „unixoide“) Betriebssysteme. Bezeichnet man alle Betriebssysteme, die diesen Standard vollständig oder zumindest großteils erfüllen, als Unix, müsste man, wenn man die aktuellen Varianten von BSD (FreeBSD, OpenBSD) als ein Unix bezeichnet, auch Linux als ein Unix ansehen. In der Praxis wird das jedoch oft nicht gemacht. Ganz im Gegenteil: Wenn Sie eine Linux-Distribution nutzen und diese als Unix bezeichnen, werden Sie viele Informatiker zurechtweisen. Wir haben hier einmal wieder so einen Streit, den ich an dieser Stelle nicht auflösen kann, nicht auflösen will und glücklicherweise auch nicht auflösen muss, denn ich habe mir ja die Nutzungsschnittstellen-Brille ausgesucht, um die Computergeschichte zu beschreiben und aus dieser Perspektive gibt es keinen nennenswerten Unterschied zwischen einem FreeBSD, also einem Unix, und einem Linux. Ein kommandozeilenorientiertes BSD und ein kommandozeilenorientiertes Linux können Sie kaum unterscheiden und das Gleiche gilt für Unixe oder Linuxe mit den grafischen Nutzungsschnittstellen wie KDE oder Gnome. Sie sehen sehr ähnlich aus, verhalten sich ähnlich und sind daher, zumindest aus meiner Sicht, auch ähnlich genug, um sie beide unter „Unix“ zusammenzufassen.
Die Macht der Kommandozeile – Die Unix-Shell
Ich habe Ihnen nun viel über die Geschichte des Systems erzählt, aber noch kein Wort darüber verloren, wie sich Unix in der Nutzung darstellt. Beginnen wir mit dem Grundkonzept, den wichtigsten Objektarten, mit denen ein Unix-Nutzer umgehen muss. Unix ist an dieser Stelle sehr einfach. Die wichtigsten Objekte sind Dateien und Verzeichnisse bzw. Unterverzeichnisse. Heute wird ein Unterverzeichnis gerne als „Ordner“ bezeichnet. Das ist für Unix aber eigentlich anachronistisch, denn dieser Ausdruck entstammt dem Begriffsrepertoire der grafischen Nutzungsschnittstellen der 1980er Jahre. Im Jahre 1970 stellten sich die meisten Computernutzer ihr Dateisystem noch nicht als Analogie zu Büros mit Dokumenten und Ordnern vor. Sie sahen viel eher Dateien, die in einem Index aufgelistet wurden. Dieser Index wurde „Verzeichnis“ oder, auf Englisch, „Directory“ genannt. Unix ist ein Betriebssystem, das um das Dateisystem herum entwickelt wurde. Das Grundkonzept der Unix-Dateiablage, eine hierarchische Verzeichnisstruktur, wurde von Multics übernommen. „Hierarchisch“ bedeutet, dass ein Verzeichnis nicht nur Dateien, sondern auch seinerseits Verzeichnisse beinhalten kann. In einem solchen Dateisystem kann jede Datei durch die Angabe eines Pfades identifiziert werden. Dieser beginnt an einer allgemeinen Wurzel und folgt dann den Unterverzeichnissen bis zur Datei. Ein / wird als Trennzeichen verwendet. Ein typischer Unix-Pfad ist etwa /home/User/texts/history.txt.
Die Interaktion mit dem Unix-Betriebssystem erfolgt klassischerweise mit einem Kommandozeilen-Interpreter. Im Unix-Bereich wird dieser meist „Shell“ genannt. Nutzer der Shell befinden sich zu einem Zeitpunkt immer in einem bestimmten Pfad der Dateisystem-Hierarchie und können diese Position mit Hilfe des Befehls cd ändern. cd dirname wechselt etwa ins Unterverzeichnis dirname. Die Zeichenfolge .. steht für das übergeordnete Verzeichnis, auch Elternverzeichnis genannt. cd .. wechselt also in das Verzeichnis, das das Verzeichnis enthält, in dem man sich gerade befindet. Dieses Konzept, inklusive des Befehls cd und des Parameters .. für das Elternverzeichnis wurde auch in andere Betriebssysteme übernommen. Microsoft portierte sie schon 1983 in die zweite Version seines DOS. Lediglich das Trennzeichen im Pfad drehte Microsoft um und verwendete den Rückschrägstrich, meist „Backslash“ genannt. In einer aktuellen Eingabeaufforderung von Windows können Sie sowohl \ als auch / als Trennzeichen verwenden.
In der Nutzungswelt von Unix erscheint eigentlich alles als Datei. Selbst an den Computer angeschlossene Geräte werden als Datei dargestellt und haben dementsprechend einen Pfad im Dateisystem. Das hat für den modernen Nutzer eigentümliche Konsequenzen. Man kann zum Beispiel eine Datei auf einem angeschlossenen Drucker ausdrucken lassen, indem man sie auf den Drucker kopiert. Der Befehl dafür lautete zum Beispiel cp ./test.txt /dev/lp0. Mit einem ähnlichen Befehl kann man die Datei aber auch an die Soundkarte schicken oder auf dem Bildschirm eines anderen angemeldeten Nutzers ausgeben, denn all diese Ressourcen stehen genauso als Dateien, also über einen Dateipfad, zur Verfügung.
Unix ist sehr modular aufgebaut. Nahezu jede Komponente kann durch eine andere ersetzt werden. Es gibt zum Beispiel nicht den einen Kommandozeilen-Interpreter, sondern mehrere Alternativen, die eingesetzt werden können. Sehr verbreitet ist heute zum Beispiel die bash aus dem GNU-Repertoire. Auch die zur Verfügung stehenden Befehle können ausgetauscht und erweitert werden, denn sie sind, von wenigen Ausnahmen abgesehen, nicht wie bei MS-DOS in den Kommandozeilen-Interpreter eingebaut, sondern liegen als kleine ausführbare Programme vor. Über alle Unix-Derivate hinweg, so unterschiedlich sie auch sein mögen, gibt es aber einen typischen Satz an kleinen Tools und Shell-Befehlen. Dazu gehören etwa:
-
lszur Ausgabe einer Liste der Einträge in einem Verzeichnis -
catzur Ausgabe eines Dateiinhalts -
cpzum Kopieren von Dateien -
mvzum Verschieben oder Umbenennen von Dateien -
rmzum Löschen von Dateien -
mkdirzum Erstellen von Verzeichnissen -
cdzum Wechseln in Verzeichnisse
Die meisten dieser Befehle ergeben für sich allein stehend keinen Sinn. cat etwa muss man zumindest noch mitgeben, welche Datei es ist, die man angezeigt haben will und wenn man cp eingibt, muss man zumindest sagen, welche Datei man wohin kopieren möchte. Diese zusätzlichen Angaben werden „Parameter“ genannt. Sehr typisch für Unix-Systeme ist die oft sehr große Zahl möglicher Parameter. Der Befehl ls etwa gibt, für sich allein stehend, alle nicht versteckten Dateien im aktuellen Verzeichnis als einfache Liste aus. Gibt man den Parameter a hinzu, also ls -a, werden auch versteckte Dateien angezeigt. Gibt man hingegen ls -l an, wird eine umfangreichere Liste ausgegeben, die auch Dateigröße, Erstellungsdatum usw. beinhaltet. Will man, dass in dieser Liste auch die versteckten Dateien enthalten sind, kann man beides durch ls -a -l oder auch ls -al kombinieren. Diese beiden Parameter sind bei Weitem nicht die einzig möglichen. Alle Parameter von ls lassen sich im in die meisten Unix-Systeme integrierten Hilfesystem, den sogenannten „man-pages“ nachlesen. Bei einem BSD-Unix steht dort dann zum Beispiel ls [-ABCFGHLOPRSTUW@abcdefghiklmnopqrstuwx1] [file ...]. Jeder Buchstabe steht für einen möglichen Parameter.
Software von verbreiteten Betriebssystemen wie Windows oder auch MS-DOS unterscheidet sich stark von typischer Unix-Software. Eine typische DOS- oder Windows-Anwendung ist interaktiv, verfügt über eine eigene Nutzungsschnittstelle und deckt in der Regel einen großen Funktionsbereich ab. Unter Unix hingegen sind Programme meist recht kleine Werkzeuge, die eine bestimmte Aufgabe ohne weitere Nutzerinteraktion besonders gut machen, jedoch nicht darüber hinaus gehen. Diese kleinen Programme kann man kombinieren, indem man die Ausgabe des einen Programms zur Eingabe des anderen Programms macht. Neben Dateien sind damit auch Datenströme ein Grundkonzept des Betriebssystems. Um diese zu verstehen, hilft es, sich wieder in die Urgeschichte des Computers zurückzuversetzen. Stellen Sie sich jedes kleine Unix-Tool als einen kleinen Computer vor, der mit einem Lochstreifenleser und einem Lochstreifenstanzer ausgestattet ist. Wenn Sie einen solchen Computer nun loslaufen lassen, wird ein Eingabe-Lochstreifen gelesen und dabei ein Ausgabe-Lochstreifen erzeugt. Diesen Ausgabe-Lochstreifen könnten Sie nun einem anderen kleinen Computer mit einem anderen Programm als Eingabe-Lochstreifen geben. Wenn Sie den dann laufen lassen, wird die vorherige Ausgabe als Eingabe aufgefasst und wiederum ein neuer Ausgabe-Lochstreifen erzeugt. Auf genau diese Art und Weise funktionieren im Prinzip die Unix-Tools. Nehmen wir den Befehl cat ./events.log. Dieser Befehl gibt die Datei „events.log“ aus dem aktuellen Verzeichnis aus – in unserem eben angestellten Gedankenspiel erzeugt sie einen Lochstreifen mit dem Inhalt der Datei. Diesen Lochstreifen geben wir nun einem anderen unserer kleinen Computer als Eingabe. Auch zu diesem gehört natürlich ein Befehl, nämlich grep ERROR. Wenn Sie diesen Befehl so für sich eingeben – versuchen Sie es ruhig einmal, wenn sie ein MacOS oder ein Linux zur Verfügung haben –, passiert erst einmal wenig. grep erwartet eine Eingabe, und da Sie keine Eingabe zur Verfügung gestellt haben, erwartet das Tool, dass Sie sie selbst machen. Tippen Sie zum Beispiel „Hallo Welt!“ und drücken Sie die Eingabetaste, passiert, außer dass dieser Text auf dem Bildschirm steht, nichts. Schreiben Sie aber „Dies ist ein ERROR!“ und drücken auf Enter, passiert etwas. Die Zeile steht nun zweimal am Bildschirm. Was grep ERROR nämlich tut, ist, die Zeilen der Eingabe, die das angegebene Wort, also ERROR enthalten, in die Ausgabe zu übernehmen. Alle anderen Zeilen werden verworfen.
Nun haben Sie schon zwei kleine Computer. Der eine erzeugt einen Lochstreifen mit dem Inhalt der Datei „events.log“ und der andere arbeitet als Filter, indem er alle eingegebenen Zeilen, die das Wort „ERROR“ enthalten auf den Ausgabe-Lochstreifen übernimmt und alles andere ignoriert. Nun müssen Sie dem System noch mitteilen, dass der Ausgabe-Lochstreifen des ersten Computers der Eingabe-Lochstreifen des zweiten werden soll. Hierzu dient bei Unix der senkrechte Strich, entsprechend dem Namen der Technik auch „Pipe-Zeichen“ genannt. Mit dem | erzeugen Sie eine Verbindung, eine Pipe, zwischen der Ausgabe eines Tools und der Eingabe des anderen. Das Resultat cat ./events.log|grep ERROR gibt also alle Zeilen aus der Datei „events.log“ aus, die das Wort „ERROR“ enthalten. Mit einer besonderen Art von Pipe können Sie dafür sorgen, dass diese Ausgabe nicht einfach auf dem Bildschirm steht, sondern wieder in eine Datei geschrieben wird. Dies geht mit dem „Größer“-Zeichen gefolgt vom Dateinamen. Der Befehl cat ./events.log|grep ERROR>errors.log erzeugt also eine Datei „errors.log“ mit den ausgefilterten Zeilen der Datei „events.log“.
Mit dem Piping kann man, wenn man es erst einmal verstanden hat, die vielen kleinen Tools von Unix auf geschickte Weise miteinander kombinieren. Manche Aufgaben sind aber komplexer, als dass man sie als einfaches Hintereinander-Ausführen mehrerer Programme bei gleichzeitiger Weitergabe der Ausgabe verstehen könnte. Als Beispiel soll hier einmal das Problem des Umbenennens von Dateien gelten. Erstaunlicherweise ist Unix an dieser Stelle nicht besonders gut ausgestattet. Stellen Sie sich einmal vor, Sie haben einen Ordner voll mit Bilddateien, die „bild001.jpg“, „bild002.jpg“ und so weiter heißen. Sie wollen diese Dateien nun so umbenennen, dass „image001.jpg“, „image002.jpg“ und so weiter herauskommt. Wenn Sie Windows-Nutzer sind und die Eingabeaufforderung verwenden, geht das ganz einfach mit einem einzigen Befehl ren bild*.* image*.*. Unter Unix geht es leider nicht so einfach. Warum das so ist, hängt damit zusammen, wie die Sternchen, die für beliebige weitere Zeichen stehen, aufgelöst werden. Ich spare mir an dieser Stelle eine genaue Erklärung, denn ich nutze das Umbenennen nur als Beispiel und nehme nicht an, dass Sie mein Buch verwenden wollen, um in die Geheimnisse der Unix-Shells tiefer einzusteigen.
Um das Umbenennen auch unter Unix hinzubekommen, kann man sich ein kleines Programm, ein Shell-Script, schreiben. Das könnte zum Beispiel26 wie folgt aussehen. Die hier abgedruckten Zeilennummern dienen nur der folgenden Beschreibung. Sie sind nicht Teil des Shell-Scripts.
Gehen wir das Programm kurz durch: Die ersten drei Zeilen sind im Grunde nur Kommentare, die dazu dienen, dass man auf die Schnelle erkennen kann, was dieses Shell-Script macht. Eine besondere Rolle kommt dabei der ersten Zeile zu, denn dort steht, welcher Kommandozeilen-Interpreter dieses Shell-Script ausführen soll. Es handelt sich hier um die schon angesprochene bash-Shell aus dem GNU-Projekt. Die Zeilen 5 bis 7 dienen vor allem der besseren Lesbarkeit des Programms. Hier werden die Parameter, die dem Script mitgegeben werden, in Variablen mit sinnvollen Namen gespeichert. Startet ein Nutzer das Script mit dem Aufruf rename.sh *.jpg bild image, wird an dieser Stelle *.jpg in criteria gespeichert, die Variable re_match erhält den Wert bild und entsprechend findet sich image in der Variablen replace. Das eigentliche Programm beginnt erst in Zeile 9. Betrachten Sie zunächst einmal, was dort innerhalb der Klammer steht. Dort wird der Befehl ls aufgerufen, der, wie Sie inzwischen wissen, für das Ausgeben eines Verzeichnisinhalts verantwortlich ist. Hier im Script wird das Ergebnis aber nicht ausgegeben, sondern in einer Variablen gespeichert. Vor der Klammer steht for i in. Hierbei handelt es sich um eine der typischsten Strukturen eines jeden Computerprogramms, nämlich um eine sogenannte „Schleife“. Alles zwischen do in Zeile 10 und done in Zeile 14 wird nicht nur einmal, sondern mehrfach ausgeführt, und zwar genau so oft, wie das Verzeichnislisting aus der Klammer lang ist. Das Listing wird also Zeile für Zeile durchgegangen. In einer Variablen namens i steht dann jeweils der aktuelle Dateiname. Was innerhalb der Schleife passiert, ist im Grundsatz ganz einfach. In Zeile 11 wird der ursprüngliche Dateiname, also der, der aus dem Listing gerade dran ist, in eine Variable src gespeichert. In Zeile 12 wird bestimmt, wie der neue Dateiname lauten soll. Das Ergebnis wird in der Variablen tgt gespeichert. In Zeile 13 wird nun die Datei unter Zuhilfenahme des Befehls mv umbenannt.
Trickreich ist die Zeile 12, denn hier greifen wieder die Unix-Tools ineinander. Schauen wir uns zunächst an, was innerhalb der Klammer passiert. Zunächst steht hier einmal der Befehl echo. Diesen Befehl kann man zum Beispiel dafür benutzen, um in einem Script etwas auf dem Bildschirm auszugeben, denn echo erzeugt genau das: ein Echo. Tippen Sie in einer Linux-Konsole echo Hallo, wird in der Zeile darunter Hallo ausgegeben. Im Script wird hier natürlich nicht Hallo ausgegeben, sondern der Inhalt der Variablen i, also des Dateinamens, der angepasst werden soll. echo schreibt in diesem Fall auch nicht auf den Bildschirm, denn dahinter steht das schon bekannte Pipe-Zeichen. Die Ausgabe wird also zur Eingabe für ein anderes Unix-Tool. Dieses Tool ist der Editor „sed“. „Sed“ steht für „stream editor“. Er funktioniert ähnlich wie der „ed“, den wir in einem früheren Kapitel besprochen haben, kennt im Gegensatz zu diesem aber kein Konzept von Zeilen. Eine Textdatei ist in „sed“ einfach eine lange Folge von Zeichen. Als praktischer Editor ist „sed“ damit ziemlich nutzlos, doch für den Zweck der automatisierten Verarbeitung ist er ideal. „Sed“ bekommt den soeben mit echo ausgegebenen Dateinamen als Eingabe. Nehmen wir einmal an, diese Eingabe sei einbildung.jpg. „Sed“ wurde mit dem Parameter -e gestartet. Hinter diesem befindet sich ein sogenannter „regulärer Ausdruck“. Diese Zeichenfolgen sind Befehle, um in einem Text etwas zu finden und gegebenenfalls auch darin etwas zu verändern. Der hier angegebene Ausdruck sucht nach dem, was in der Variablen re_match steht und ersetzt es durch das, was in replace steht. In unserem Beispiel wird also in einbildung.jpg nach bild gesucht und dieses Vorkommen in image geändert. Im Normalfall würde das Ergebnis einimageung.jpg wieder auf dem Bildschirm landen, aber hier im Shell-Script landet es stattdessen in der Variablen tgt.
Unix ist nicht das einzige Betriebssystem, das Shell-Scripte unterstützt, und auch die Technik des Piping ist nicht auf Unix beschränkt. Microsoft übernahm beide Techniken bereits 1983 für seine zweite Version des DOS. Scripte sind dort unter dem Namen „Batch-File“ oder auch „Batch-Datei“ bekannt. Der Begriff hat nicht besonders viel mit dem Batch-Processing aus der Lochkartenzeit zu tun. Der Name ist in vielen Fällen auch einigermaßen irreführend, denn natürlich kann ein solches Script dafür genutzt werden, um viele Dateien oder Datensätze in einem Rutsch, also als einen Stapel zu bearbeiten. Genau so ein Beispiel haben Sie gerade gesehen. Nicht jedes Shell-Script und schon gar nicht jede Batch-Datei von DOS oder Windows erfüllt aber diese Eigenschaft. Oft handelte es sich einfach nur um fünf Befehle, die hintereinander ausgeführt werden sollten, und deren ewige Wiederholung eingespart werden sollte oder es handelte sich, gerade bei DOS, um einfache Menüstrukturen, die sich viele Nutzer bastelten, um schnell die Programme ihrer Wahl starten zu können, ohne Befehle auf der Kommandozeile eingeben zu müssen.
Piping und Shell-Scripting ist unter Unix aufgrund der vielen kleinen Tools sehr mächtig. In Systemen wie DOS oder der Windows-Eingabeaufforderung sind ähnliche Techniken zwar möglich, aber bei Weitem nicht so verbreitet und so oft eingesetzt. Unix ist mit seiner Shell ein sehr leistungsfähiges Betriebssystem. Die Nutzungsschnittstellen-Welt von Unix ist aber ganz anders als die, die Nutzer aktueller Betriebssysteme meist gebrauchen. Es herrscht nach wie vor ein fernschreiberartiger Terminal-Stil. Die einzig wirklich interaktiven Programme, die man bei einem klassischen Unix braucht, sind die Shell selbst und ein Editor. Außer diesem Editor braucht es in der Unix-Welt im Prinzip keine Software, die die Räumlichkeit des Bildschirms ausnutzen würde. Zwar sind in der Unix-Welt Dateien die zentralen Objekte der Interaktion, es ist aber für das Piping auch eine datenstromorientierte Denkweise notwendig. Gerade diese Denkweise, die ich Ihnen oben durch die Metaphorik mit den vielen kleinen Computern und den Lochstreifen zu erklären versucht habe, ist für Nutzer heutiger Systeme, zumindest wenn sie nicht auch Programmierer sind, nur schwer verständlich, denn sie ist sehr technisch. Die Genialität der klassischen Unix-Schnittstelle liegt dann auch nicht in ihrer Einfachheit, sondern in der unerreichten Flexibilität, denn mit Shell, Dateisystem, Piping und Scripting kann man sich die vielen kleinen Unix-Tools stets so zusammensetzen, wie man es gerade braucht.
X-Window-System – Unix kann auch grafisch
Die klassische Unix-Schnittstelle, die ich Ihnen gerade beschrieben habe, finden Sie bei allen unixoiden Betriebssystemen. Egal, ob Sie ein Xenix aus den 1980ern nutzen oder unter einem Ubuntu-Linux oder unter MacOS ein Terminal starten: Sie befinden sich immer in der oben beschriebenen Nutzungsschnittstellen-Welt, die sich auch immer ganz ähnlich gibt. Natürlich ist die Entwicklung zu grafischen Nutzungsschnittstellen aber auch an der Unix-Welt nicht spurlos vorbeigezogen. Als Grundlage für die größere Verbreitung grafischer Nutzungsoberflächen unter Unix kann das X-Window-System des MIT angesehen werden, das seit 1987 in stabiler Version zur Verfügung steht. Ein Blick in die Computergeschichte offenbart durchaus auch frühere grafische Schnittstellen, doch blieben diese oft experimentell oder waren auf einzelne Unix-Derivate beschränkt. Die X-Window-Technik hingegen war ein allgemeiner Standard, der sich bis heute gehalten hat27. Wohl wegen der Namensähnlichkeit mit Microsofts Windows wird die X-Window-Technik mitunter selbst als grafische Nutzungsschnittstelle angesehen. Das ist jedoch eine Fehlcharakterisierung. X-Window stellt nur einen allgemeinen Mechanismus zur Verfügung, den laufende Programme dafür nutzen können, auf den Bildschirm zu zeichnen und Eingaben von Maus, Tastatur usw. zu erhalten. Wie das aussieht, wie die Nutzungsschnittstelle beschaffen ist, welche Objekte es gibt, und letztlich sogar, ob es überhaupt Fenster gibt, ist nicht der Gegenstand von X-Window.
Windows und MacOS sind mehr oder weniger monolithische Systeme. Sie bieten die Methoden zur Anzeige auf dem Bildschirm generell, bieten Bildschirmelemente wie Buttons, Eingabefelder etc. an und kümmern sich auch um die Verwaltung von Fenstern. Hinzu kommen noch Nutzungsschnittstellen zur Dateiverwaltung, zum Starten von Programmen und zum Wechseln zwischen diesen Programmen. Bei grafischen Nutzungsoberflächen unter Unix sind all diese Bereiche getrennt. Das sieht in etwa wie folgt aus:
- Die grundlegendste Ebene bildet der sogenannte X-Server. Er bietet Anwendungen Möglichkeiten, auf den Bildschirm zu zeichnen und die Maus- und Tastatur-Interaktionen des Nutzers zu empfangen. Die Begrifflichkeit „Server“ ist hier etwas verwirrend. Als Server bezeichnet man üblicherweise einen Computer im Netz oder ein Programm auf einem solchen Computer, das Dienste zur Verfügung stellt, die dann mittels Nutzungsschnittstellen-Programmen genutzt werden können. Diese nennt man üblicherweise „Clients“. Das Konzept des X-Servers stellt das ein bisschen auf den Kopf. Der X-Server ist es, der allgemeine Funktionalitäten zur räumlich-grafischen Ein- und Ausgabe zur Verfügung stellt. Die Software-Programme bedienen sich dieser Fähigkeiten und sind damit die Clients. Der Nutzer nutzt also die Clients mittels eines X-Servers.
- Nutzungsschnittstellen sind zusammengesetzt aus sehr grundlegenden Elementen wie Bildschirmbereichen, Buttons, Menüs und Eingabefeldern. Damit nicht jede Software-Anwendung hier das Rad neu erfinden muss, bedienen Entwickler sich Bibliotheken mit solchen Elementen. Diese werden Widget Toolkits genannt.
- Die grundlegende Funktionalität von Fenstern und ihrer Verwaltung obliegt den Window Managern. Der Umfang dieser Fenster-Manager ist unterschiedlich. Auf jeden Fall gehört zu ihnen die Möglichkeit des Fensterverschiebens sowie des Schließens von Fenstern. Die meisten Fenster-Manager setzen dafür die bekannten Methoden mit einem in der Größe veränderbaren Fensterrahmen und einer Reihe von Buttons zum Minimieren, Maximieren und Schließen um. Viele Fenster-Manager stellen auch einen Task Switcher zum Umschalten zwischen Fenstern und einen Application Launcher zum Starten von Programmen bereit.
- Die Kombination aus Window Manager, Widget Toolkits und so grundlegenden Programmen wie einem Datei-Manager und einem Application Launcher bildet ein sogenanntes Desktop Environment.
- Mit einem Betriebssystem wird üblicherweise auch ein Satz typischer Anwendungen ausgeliefert, der teilweise allgemein verfügbar, in anderen Fällen aber extra an das entsprechende System angepasst ist. Im Linux-Bereich werden diese Sammlungen installierter Software-Produkte und Verwaltungswerkzeuge Distribution genannt. Jede Distribution macht eine Vorauswahl bezüglich des Desktop Environments, der mitgelieferten Tools und Verwaltungswerkzeuge und passt diese entsprechend der Philosophie der Distribution an, fügt eigene Plug-Ins hinzu, tauscht Module aus und passt das Aussehen und die Einstellungen an.
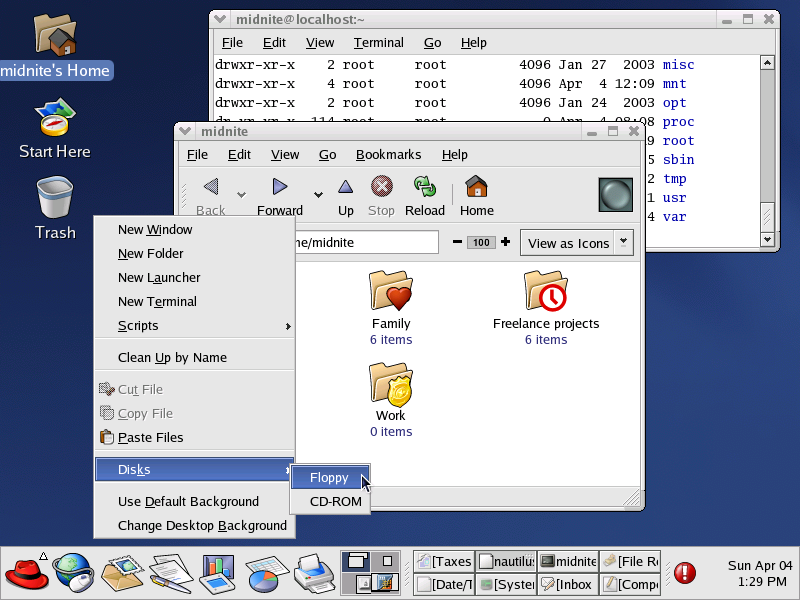
Die populäre Linux-Distribution Ubuntu beispielsweise verwendet, Stand 2021, die Desktop-Umgebung GNOME. Der Window-Manager von GNOME heißt „Mutter“, als Datei-Manager kommt „Nautilus“ zum Einsatz. Zu GNOME gehört auch das GTK-Toolkit, das Nutzungsschnittstellen-Elemente bereitstellt. Die Distribution openSUSE hingegen setzt auf die Desktop-Umgebung KDE Plasma mit dem Window-Manager KWin und dem Widget Toolkit qt. Der Datei-Manager von KDE nennt sich „Dolphin“. Linux Mint nutzt den Window Manager Cinnamon mit dem Datei-Manager Nemo, der eine Abspaltung (ein sogenannter „Fork“) einer früheren Nautilus-Version ist. Sie haben hier also dreimal Linux, aber dreimal gibt es sich anders, mit anderen Werkzeugen und mit einer anderen Nutzungsschnittstelle. Damit ist die Verwirrung aber noch nicht am Ende, denn Sie können nicht nur das Desktop Environment austauschen, sondern die Werkzeuge auch kreuz und quer verwenden. Auch wenn man also eine KDE Plasma-Umgebung einsetzt, kann man GNOME-Programme nutzen, insofern man die passenden Toolkits mitinstalliert hat, worum sich die Verwaltungswerkzeuge des Betriebssystems in aller Regel von selbst kümmern. Man kann also auch ein Nautilus unter KDE laufen lassen oder die teils umfassenden KDE-Anwendungen unter Linux Mint installieren. Diese große Flexibilität und Kompatibilität ist es, weswegen es schlichtweg nicht möglich ist, über die grafische Nutzungsschnittstelle von Unix und Linux allgemein zu sprechen. Man braucht, um überhaupt etwas sagen zu können, die Angabe der Distribution, die Version und letztlich eigentlich auch immer die Angabe aller Anpassungen, die ein Nutzer gemacht hat.
KDE Plasma
Eine Betrachtung der grafischen Unix-Nutzungsschnittstellen kann also nur exemplarisch sein, aber diese Beispiele können es stark in sich haben, denn es ist mit ihnen teils viel mehr möglich, als Windows und MacOS im Angebot haben. Um das zu belegen, zeige ich Ihnen einmal die Linux-Distribution Kubuntu 19.03 mit dem Desktop Environment KDE Plasma 5.
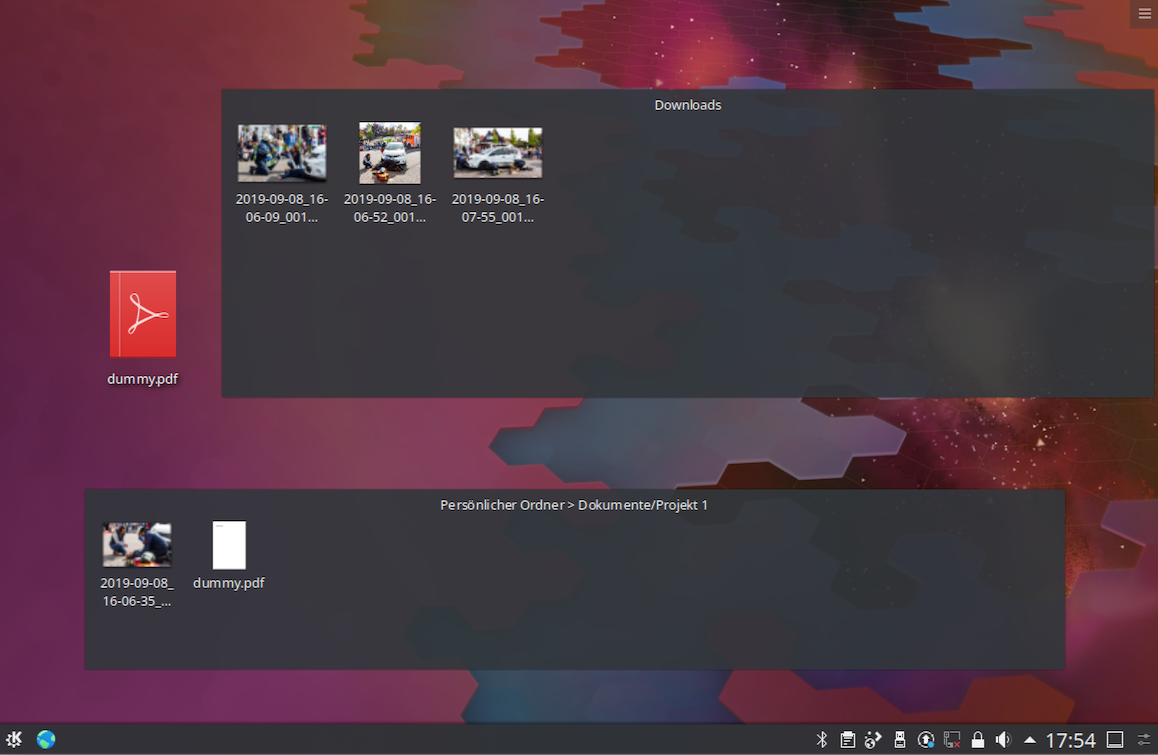
Die Nutzungsschnittstelle von KDE Plasma ist grundsätzlich ziemlich stark an die Nutzungsschnittstelle aktueller Windows-Versionen angelehnt. Es gibt einen Startbutton und ein Startmenü, eine Taskleiste und einen Desktop. Der Datei-Manager Dolphin wirkt wie eine Mischung aus Apples Finder und dem Explorer von Microsoft, hat allerdings interessante Features wie eine Split View, die es weder unter Windows noch auf dem Mac von Haus aus gibt. Spannend an der Nutzungsschnittstelle ist das Desktop-Konzept. Bei Windows und auch bei aktuellem MacOS ist der Desktop ein Ordner auf der Festplatte, dessen einzige besondere Eigenschaft es ist, dass seine Inhalte, also die enthaltenen Dateien und Ordner, großflächig als Hintergrund hinter allen Fenstern angezeigt werden. Bei KDE Plasma ist dies auch möglich und in Kubuntu ist diese Einstellung der Standard. Das Layout kann jedoch von „Ordneransicht“ auf „Arbeitsfläche“ umgeschaltet werden.
In der Arbeitsflächen-Ansicht können auf dem Desktop in jeweils eigenen Bereichen kleine aktive Komponenten untergebracht werden. Diese als „Widget“ bezeichneten Miniprogramme können allerlei Aufgaben erfüllen, von der Anzeige des aktuellen Wetters bis zur direkten Einbindung von Websites auf dem Desktop. Wenn Sie ein Android-Telefon besitzen, kennen Sie dieses Konzept, denn auch Android ermöglicht es, auf den Übersichtsbildschirmen nicht nur Icons zum Starten der gewünschten Anwendungen unterzubringen, sondern auch direkt Objekte auf diesen Bildschirmen zu haben, die etwas anzeigen und mit denen interagiert werden kann. Auch in Windows Vista konnte man sich kleine Progrämmchen auf den Desktop legen. Widgets allein wären daher noch nicht etwas, was mich dazu bewegen würde, Ihnen etwas vom KDE-Desktop vorzuschwärmen. Spannend wird die Sache aber dann, wenn man sich über die Möglichkeiten eines sehr einfachen Widgets ein wenig Gedanken macht, nämlich dem Widget, das die Inhalte eines Ordners zur Anzeige bringt. Oben sehen Sie ein Beispiel dafür. Zwei Ordner-Anzeige-Widgets zeigen jeweils einen Ordner an. Der obere Bereich zeigt den Inhalt des Download-Ordners, während der untere den Inhalt eines Ordners mit dem Namen „Projekt 1“ zeigt.
Diese Ordner-Widgets ermöglichen es, viel mehr als Windows und MacOS, dass man sich den Desktop zum eigenen Arbeitsplatz machen kann. Nutzt man KDE Plasma, kann man sich die Projekte, an denen man gerade arbeitet, als eigene Bereiche auf dem Desktop einrichten, mit den Dateien arbeiten und sie sogar zwischen den Ordnern hin und herschieben. Braucht man zwischenzeitlich einen weiteren Bereich direkt im Zugriff, richtet man sich einfach ein weiteres Widget ein. Ist ein Projekt abgeschlossen und nicht mehr relevant, kann man einfach das Widget entfernen. Die Dateien liegen dann nicht mehr auf dem Desktop, sind aber natürlich in der Dateiablage weiterhin vorhanden.
Ebenfalls sehr praktisch bei der Arbeit mit einer Vielzahl von Projekten ist die Funktion „Activities“. Mit ihr lassen sich verschiedene Desktops für verschiedene Aufgaben einrichten. Jeder Desktop hat seine eigene Einrichtung, mit eigenen Widgets, eigenem Hintergrundbild und auch eigenen geöffneten Anwendungen. Die Funktionalität, mehr als einen Desktop anzubieten und so mehrere Arbeitskontexte zu ermöglichen, ist gerade im Bereich der Unix-GUIs schon sehr alt. Inzwischen sind ähnliche Funktionen auch in MacOS und in Windows verfügbar. Ihre Umsetzung ist allerdings im Verhältnis zu den „Activities“ von KDE sehr eingeschränkt, denn weder unter Windows noch unter MacOS werden einem wirklich verschiedene Desktops mit verschiedenen Elementen bereitgestellt. Man kann lediglich zwischen Sätzen geöffneter Fenster wechseln. Anders bei KDE Plasma: Dort kann sich so etwa einen Heim-Desktop und einen Arbeits-Desktop einrichten und sich beiden Kontexten entsprechend anpassen, ohne dass die Objekte des einen Kontextes mit denen des anderen in Konflikt geraten. Braucht man die gleichen Elemente auf mehr als einem dieser Desktops, ist das mit der Widget-Einrichtung gar kein Problem, denn niemand hindert einen daran, für den gleichen Ordner der Festplatte jeweils ein Anzeige-Widget auf den Desktop zu schieben.
Die Anzahl der Leute, die Unix- oder Linux-Systeme mit grafischer Nutzungsschnittstelle bei sich zu Hause oder auf der Arbeit einsetzen, ist verschwindend gering, im niedrigen einstelligen Prozentbereich. Um so erstaunlicher ist es, dass, wie hier zum Beispiel bei KDE Plasma, sehr interessante Nutzungsschnittstellen für die Systeme entwickelt werden, und um so bedauerlicher ist es natürlich, dass kaum jemand in den Genuss dieser Nutzungsschnittstellen kommt. Warum das letztlich so ist, hat sicherlich viele Gründe, über die ich hier nur spekulieren kann. Manches hat sicherlich mit der Marktmacht der großen Firmen Microsoft und Apple und der damit zusammenhängenden großen Verbreitung ihrer Software-Infrastrukturen zu tun. Ein anderer gewichtiger Grund ist meiner Meinung nach aber auch, dass Unix und Linux sich mit ihrer grundsätzlichen Philosophie ein wenig selbst die Möglichkeit des Erfolgs verbauen. Die oben skizzierte Offenheit der Konfiguration und die Möglichkeit, nahezu alles mit allem zu kombinieren, scheint Entwickler durchaus zu beflügeln, neue innovative Funktionen einzubauen. Sie sorgt aber auch dafür, dass man sich als Linux- oder Unix-Nutzer bei Problemen immer noch ein wenig mehr alleine fühlt als andere. Wenn Sie mit Ihrem Windows 10 ein Problem haben, finden Sie sicher jemanden im Bekanntenkreis, der das Problem nachvollziehen und Ihnen helfen kann. Wenn Sie Linux nutzen, wird das aufgrund der Verbreitung schwieriger, aber selbst wenn Sie jemanden finden, der auch Linux nutzt, dann nutzt der wahrscheinlich eine andere Distribution mit anderen Fenster-Managern, anderen Einstellungen und anderen Systemtools.
Unix auf Smartphones?
Dass Unix und Linux im Endanwenderbereich geringe Verbreitung haben, gilt nur, wenn man nur den Bereich der Desktop-Betriebssysteme betrachtet und wenn man MacOS nicht als Unix, sondern als eigenes System zählt. Generell ganz anders sieht die Sache aus, wenn Sie Smartphones und Tablets mit hinzuzählen, denn Apples iOS basiert wie MacOS auf BSD-Unix und Android von Google verwendet unter der Haube Linux als Betriebssystem. Sollte ich Ihnen MacOS, Android und iOS nun also hier als Unix-Systeme vorstellen? Es gibt wie immer mehrere Sichtweisen. Meine ist die der Nutzungsschnittstellen-Welten. Es ergibt zum Beispiel Sinn, wie im vorherigen Kapitel dargelegt, Windows als etwas anderes als MS-DOS zu beschreiben, denn es hat seine ganz eigene Nutzungsschnittstellen-Welt. Wenn Sie einem erfahrenen Informatiker etwas vom Betriebssystem Windows 3.11 erzählen, wird er Sie aufklären, dass es sich bei Windows 3.11, genauso wie bei Windows 95, 98 und ME, nicht um eigenständige Betriebssysteme handelte, sondern um Erweiterungen für MS-DOS. Aus Sicht der Betriebssystemtechnologie mag das stimmen, doch für mich ist es schlichtweg egal. Die Nutzungswelten von reinem DOS mit nur einem gleichzeitig laufenden Programm, einer Kommandozeile und Anwendungen im Text-Modus, und von Windows, mit mehreren gleichzeitig laufenden Anwendungen, einem Programm-Manager und grafischen Objekten, die räumlich manipuliert werden können, sind ganz verschieden. Ein Windows-Nutzer nutzt nicht eigentlich immer noch DOS – zumindest nicht, wenn man die Nutzungsschnittstellen-Brille aufhat. Das Gleiche gilt noch viel stärker für Unix, Android und iOS. Auf der technischen Ebene der Prozess- und Datenträgerverwaltung mag das eine ein Aufsatz auf das andere sein, aber aus Sicht des Nutzers handelt es sich jeweils um eigene Nutzungsschnittstellen-Welten. Android und iOS stehen in einer ganz anderen Tradition als Unix und Linux. Sie sind nicht die Urenkel eines alten Time-Sharing-Systems, sondern Nachfolger der mobilen Personal Digital Assistants der 1990er Jahre und in diesem Zusammenhang will ich sie Ihnen im folgenden Kapitel auch beschreiben.