RAG Using zvec Vector Datastore and Local Model
The zvec library implements a lightweight, lightning-fast, in-process vector database. Allibaba released zvec in February 2026. We will see how to use zvec and then build a high performance RAG system. We will use the tiny model qwen3:1.7b running localling using Ollama as part of the application.
Note: The source code for this example can be found in hy-lisp-python-book/source_code_for_examples/RAG_zvec/app.hy. Not all the code in this file is listed here.
Note: This chapter was derived from a chapter with the same name from my Python book Ollama in Action.
Introduction and Architecture
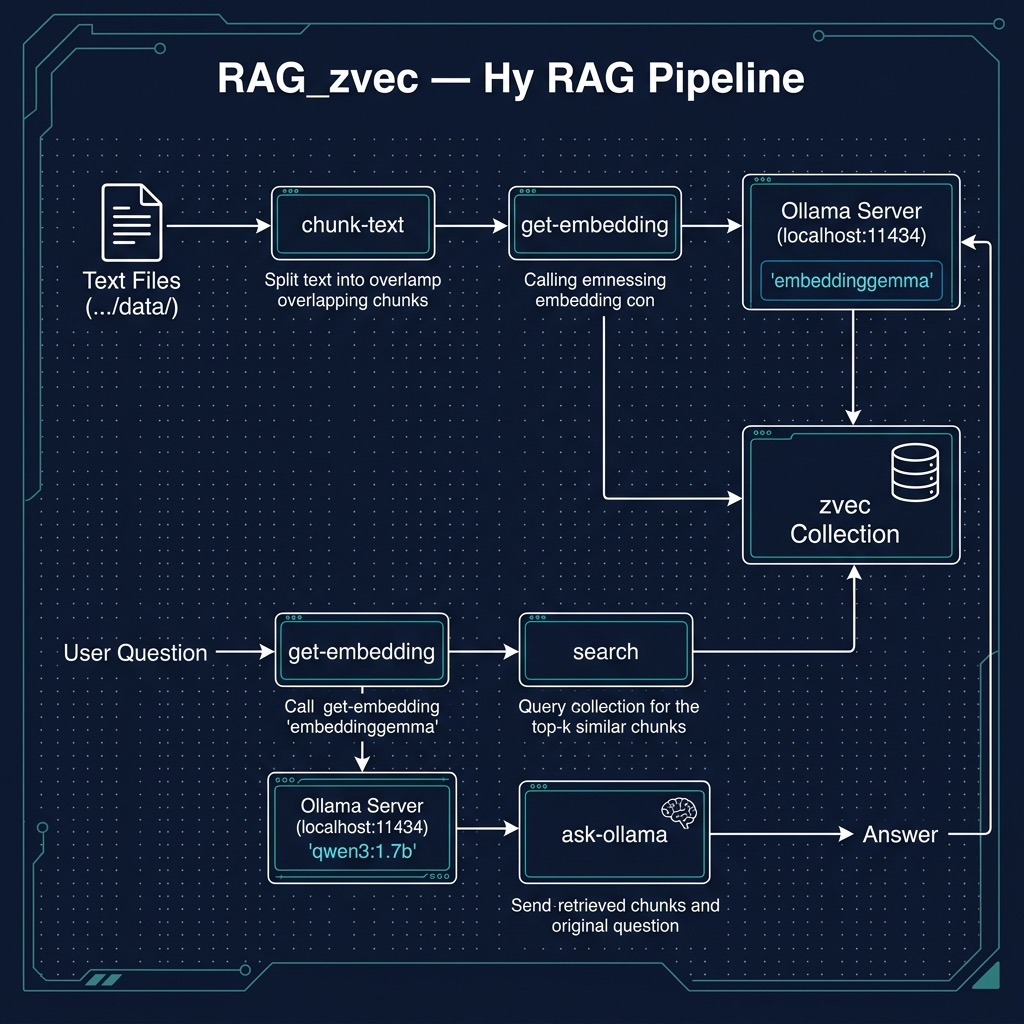
Building a Retrieval-Augmented Generation (RAG) pipeline entirely locally ensures absolute data privacy, eliminates API latency costs, and provides full control over the embedding and generation models. In this chapter, we construct a fully offline RAG system utilizing Ollama for both embeddings (embeddinggemma) and inference (qwen3:1.7b), paired with zvec, a lightweight, high-performance local vector database.
The architecture follows a classic two-phase RAG pattern, adding an additional third step to improve the user experience:
- Ingestion: Parse local text files, chunk the content, generate embeddings via Ollama, and index them into zvec.
- Retrieval & Generation: Embed the user query, perform a similarity search in zvec, and save the retrieved top-k chunks for processing by a local Ollama chat model.
- Use a small LLM model (qwen3:1.7b) to process the retrieved chunks and taking into account the user’s original query and then format a subset of the text in the returned chunks for the user to read.
Design Analysis: Dependency Minimization
A notable design choice in our implementation is the reliance on Python’s standard library for network calls. By utilizing urllib.request instead of third-party libraries like requests or the official ollama-python client library, the dependency footprint is minimized exclusively to zvec. This reduces virtual environment overhead and potential version conflicts, prioritizing a lean deployment.
Implementation Walkthrough
Here we look at some of the code in the source file app.hy.
Embedding and Chunking Strategy
The ingestion phase relies on a fixed-size overlapping window strategy. Here is an implementation of a chunking strategy:
1 (defn chunk-text [text [chunk-size 500] [overlap 50]]
2 "Split text into overlapping chunks."
3 (setv chunks [])
4 (setv start 0)
5 (while (< start (len text))
6 (setv end (+ start chunk-size))
7 (.append chunks (cut text start end))
8 (setv start (- end overlap)))
9 chunks)
Analysis of code:
- Chunk Size (500 chars): This relatively small chunk size yields high-granularity embeddings. It reduces the risk of retrieving “diluted” context where a single chunk contains multiple disparate concepts.
- Overlap (50 chars): Crucial for preventing context loss at the boundaries of chunks. It ensures that a semantic concept bisected by a hard character limit is still captured cohesively in at least one chunk.
- Embedding Model: The system uses embeddinggemma. The Ollama API endpoint (/api/embeddings) is called directly. If the server fails to respond, a fallback zero-vector [0.0] * 768 is returned to prevent pipeline crashes, though logging or raising an exception might be preferred in production.
Vector Storage with zvec
The zvec integration demonstrates a strictly typed, schema-driven approach to local vector storage.
Design notes for code:
- Dimensionality Matching: The vector schema is hardcoded to 768 dimensions (FP32), which strictly matches the output tensor of the embeddinggemma model. Any change to the embedding model in the configuration must be accompanied by a corresponding update to this schema.
- Storage Path: The database is initialized locally at ./zvec_example. The implementation includes a defensive teardown (shutil.rmtree) of existing databases on startup. This is excellent for testing and iterative development, though destructive in a persistent production environment.
The following function builds the index using an embedding model for the local Ollama server:
1 (defn build-index []
2 "Index all text files from the data directory into zvec."
3 ;; Define collection schema (embeddinggemma: 768 dimensions)
4 (setv schema
5 (zvec.CollectionSchema
6 :name "example"
7 :vectors (zvec.VectorSchema "embedding" zvec.DataType.VECTOR-FP32 768)
8 :fields (zvec.FieldSchema "text" zvec.DataType.STRING)))
9
10 (setv db-path "./zvec_example")
11 (when (os.path.exists db-path)
12 (import shutil)
13 (shutil.rmtree db-path))
14
15 (setv collection (zvec.create-and-open :path db-path :schema schema))
16
17 (setv docs [])
18 (setv doc-count 0)
19 (for [[root _ files] (os.walk (get config "data_dir"))]
20 (for [file files]
21 (when (.endswith (.lower file) (get config "extensions"))
22 (try
23 (setv file-path (/ (Path root) file))
24 (with [f (open file-path "r" :encoding "utf-8")]
25 (setv content (.read f)))
26 (setv chunks (chunk-text content))
27 (for [[i chunk] (enumerate chunks)]
28 (setv embedding (get-embedding chunk))
29 (.append docs
30 (zvec.Doc
31 :id f"{file}_{i}"
32 :vectors {"embedding" embedding}
33 :fields {"text" chunk})))
34 (+= doc-count (len chunks))
35 (except [e Exception]
36 None)))))
37
38 (when docs
39 (.insert collection docs))
40 (print (.format "Indexed {} chunks from {}"
41 doc-count
42 (get config "data_dir")))
43 collection)
This function build_index initializes a local vector database and populates it with document embeddings. Specifically, it executes four main operations:
- Schema & Storage Initialization: Defines a strict schema for zvec (768-dimensional FP32 vectors and a string metadata field) and destructively recreates the local database directory (./zvec_example).
- File Traversal: Recursively walks a configured target directory (config[“data_dir”]) to locate specific file types.
- Transformation & Embedding: Reads each file, splits it into overlapping chunks, and retrieves the vector embedding for each chunk via an external call (get_embedding).
- Batch Insertion: Accumulates all processed chunks and their embeddings into a single memory list (docs), then performs a bulk insert into the zvec collection.
Retrieval and LLM Synthesis
The synthesis phase bridges the vector database and the Generative LLM. Function search identifies matching text chunks in the vector database:
1 (defn search [collection query [topk 5]]
2 "Search the zvec collection for chunks relevant to the query."
3 (setv query-vector (get-embedding query))
4 (setv results
5 (.query collection
6 (zvec.VectorQuery "embedding" :vector query-vector)
7 :topk topk))
8 (setv chunks [])
9 (for [res results]
10 (setv text
11 (if res.fields
12 (.get res.fields "text" "")
13 ""))
14 (when text
15 (.append chunks text)))
16 chunks)
Function search performs a Top-K retrieval. The default topk=5 retrieves roughly 2,500 characters of context. This easily fits within the context window of modern small models like qwen3:1.7b without causing attention dilution (“lost in the middle” syndrome).
System Prompt Engineering and Using a Small LLM to Prepare Output for a User
The ask_ollama function utilizes strict prompt constraints: “Answer the user’s question using ONLY the context provided below. If the context does not contain enough information, say so.” This significantly mitigates hallucination by forcing the model to ground its response exclusively in the retrieved data.
1 (defn ask-ollama [question context-chunks]
2 "Send retrieved chunks + user question to the Ollama chat model."
3 (setv context (.join "\n\n---\n\n" context-chunks))
4 (setv system-prompt
5 (.join ""
6 ["You are a helpful assistant. Answer the user's question using ONLY "
7 "the context provided below. If the context does not contain enough "
8 "information, say so. Be concise and accurate.\n\n"
9 f"Context:\n{context}"]))
10 (setv url f"{OLLAMA-BASE}/api/chat")
11 (setv payload
12 (.encode
13 (json.dumps
14 {"model" (get config "chat_model")
15 "stream" False
16 "messages"
17 [{"role" "system" "content" system-prompt}
18 {"role" "user" "content" question}]})
19 "utf-8"))
20 (setv req
21 (urllib.request.Request url :data payload
22 :headers {"Content-Type" "application/json"}))
23 (try
24 (with [res (urllib.request.urlopen req)]
25 (setv body (json.loads (.decode (.read res) "utf-8")))
26 (get (get body "message") "content"))
27 (except [e Exception]
28 f"Error calling Ollama chat: {e}")))
Function ask_ollama uses stateless execution: The /api/chat call sets “stream”: False and does not maintain a conversation history array across loop iterations. This makes it a pure Q&A interface rather than a continuous chat, ensuring each answer is cleanly tied to a fresh zvec retrieval.
Example Run
To run the pipeline, ensure the Ollama daemon is running locally on port 11434 and that both models (embeddinggemma and qwen3:1.7b) have been pulled. Place your .txt files in the ../data directory and execute the script. The system will build the index and immediately drop you into a REPL loop for interactive querying.
Here is an example run:
1 $ uv run hy app.hy
2 Building zvec index from text files
3 Indexed 9 chunks from ../data
4
5 RAG chat ready (model: qwen3:1.7b)
6 Type your question, or 'quit' to exit.
7
8 You> who says economics is bullshit?
9
10 Assistant> The context mentions Pauli Blendergast, an economist at the University of\
11 Krampton Ohio, who is noted for stating that "economics is bullshit." No other indi\
12 viduals are explicitly cited in the provided text.
13
14 You> what procedures are performed in chemistry labs?
15
16 Assistant> The provided context does not contain information about procedures perfor\
17 med in chemistry labs. It focuses on economic concepts, microeconomics, macroeconomi\
18 cs, and related topics, but does not mention chemistry or laboratory procedures.
19
20 You> how do microeconomics and macroeconomics differ?
21
22 Assistant> Microeconomics focuses on individual agents (e.g., households, firms) and\
23 specific markets, analyzing decisions like pricing, resource allocation, and consum\
24 er behavior. Macroeconomics examines the entire economy, addressing broader issues s\
25 uch as unemployment, inflation, growth, and fiscal/money policy. While microeconomic\
26 s deals with "how" resources are used, macroeconomics focuses on "what" the economy \
27 produces and "how collectively" it functions.
28
29 You> quit
30 Goodbye!
Dear reader, notice that there was no information in the indexed text to answer the second example query and this program correctly refused to hallucinate (or make up) an answer.
Wrap Up for RAG Using zvec Vector Datastore and Local Model
In this chapter, we built a completely offline, privacy-preserving RAG architecture by bridging Alibaba’s recently released in-process vector database, zvec, with local Ollama inference. By intentionally minimizing external dependencies and utilizing a strictly typed, schema-driven datastore, we eliminated the network overhead and deployment bloat typical of client-server vector databases. The fixed-size overlapping chunking strategy, combined with the 768-dimensional embeddinggemma model, ensures high-fidelity semantic retrieval. Simultaneously, the compact qwen3:1.7b model demonstrates that a heavily constrained, prompt-engineered generation phase can effectively synthesize retrieved context without hallucination.
The resulting pipeline serves as a robust, lightweight foundation for edge-deployable AI applications. Because the entire storage and inference stack executes locally within the same process, the pattern is exceptionally portable, fast, and secure. Moving forward, this baseline implementation can be extended to handle more complex retrieval requirements, such as integrating dynamic semantic chunking, implementing Reciprocal Rank Fusion (RRF) for hybrid multi-vector queries, or introducing multi-turn conversational memory. Ultimately, combining embedded vector storage with small-parameter LLMs proves that high-performance, domain-specific RAG does not require massive cloud infrastructure.
Optional Practice Problems
-
Source Attribution & Metadata Retrieval:
Modify the schema in
build-indexto include a new string fieldsource_file. Update the ingestion logic to populate this field with the base filename of the text file being processed. Then, update thesearchandask-ollamafunctions so that when the assistant answers a question, it also prints or appends a list of the unique source files from which the retrieved chunks originated. -
Semantic Paragraph Chunking:
The current
chunk-textfunction splits documents blindly by character limits, which can cut sentences in half. Rewrite the chunking logic to split the input text by paragraphs (e.g., using\n\nas a delimiter). Ensure that chunks are grouped so they do not exceed a certain character count (e.g., 500 characters) while still keeping paragraphs intact where possible. -
Hybrid Search Configuration:
Extend the command-line interface or configuration dictionary to support running different local embedding models (such as
nomic-embed-textvsembeddinggemma). Note that different embedding models output different vector dimensions. Modify thebuild-indexfunction to dynamically determine the correct vector dimension (e.g., 768 or 1024) depending on the active model, and set thezvec.VectorSchemadimension parameter programmatically.