Deep Learning
Most of my professional career since 2014 has involved Deep Learning, mostly with TensorFlow using the Keras APIs. In the late 1980s I was on a DARPA neural network technology advisory panel for a year. I wrote the first prototype of the SAIC ANSim neural network library commercial product, and I wrote the neural network prediction code for a bomb detector my company designed and built for the FAA for deployment in airports. More recently I have used GAN (generative adversarial networks) models for synthesizing numeric spreadsheet data and LSTM (long short term memory) models to synthesize highly structured text data like nested JSON and for NLP (natural language processing). I have 55 USA and several European patents using neural network and Deep Learning technology.
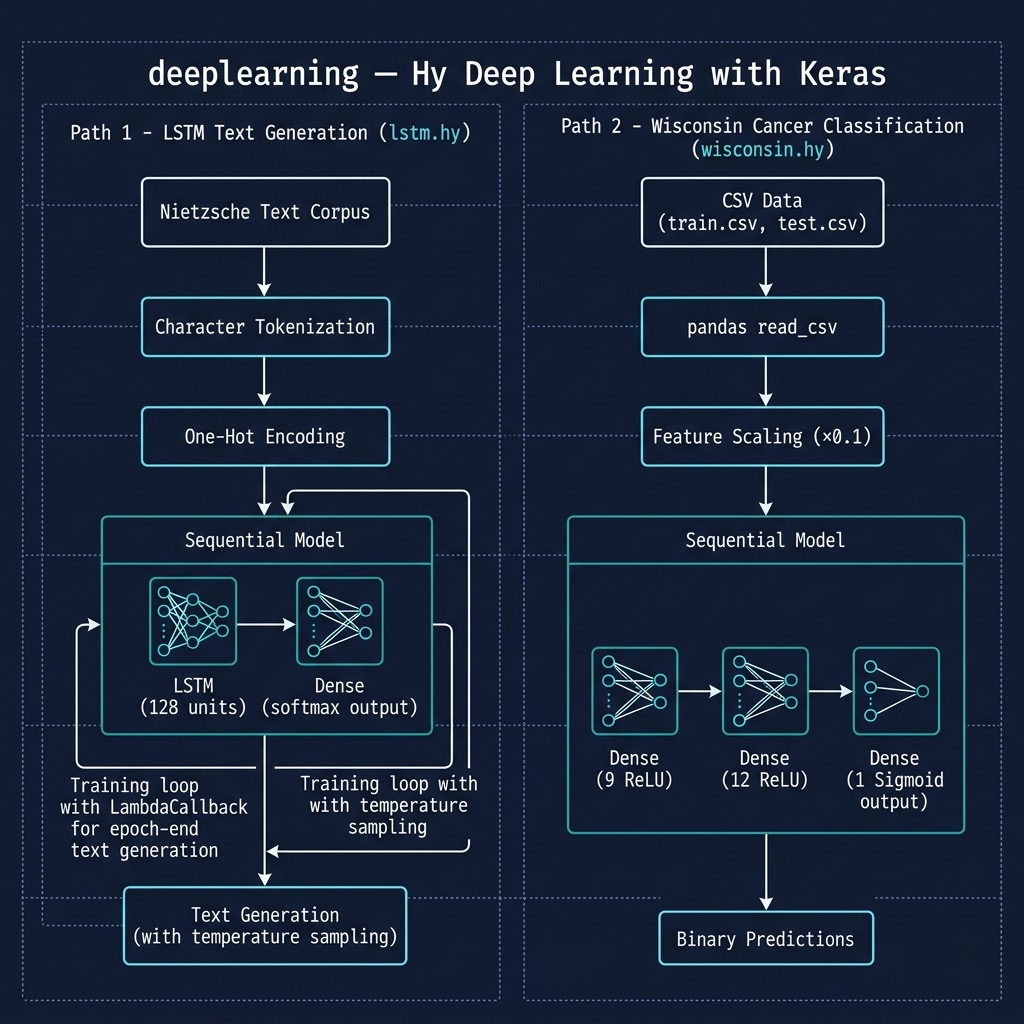
The Hy language utilities and example programs we develop here all use TensorFlow and Keras “under the hood” to do the heavy lifting. Keras is a simpler to use API for TensorFlow and I usually use Keras rather than the lower level TensorFlow APIs.
There are other libraries and frameworks that might interest you in addition to TensorFlow and Keras. I particularly like the Flux library for the Julia programming language. Currently Python has the most comprehensive libraries for Deep Learning but other languages that support differential computing (more on this later) like Julia and Swift may gain popularity in the future.
Here we will learn a vocabulary for discussing Deep Learning neural network models, look at possible architectures, and show two Hy language examples that should be sufficient to get you familiar to using Keras with the Hy language. If you already have Deep Learning application development experience you might want to skip the following review material and go directly to the Hy language examples.
If you want to use Deep Learning professionally, there are two specific online resources that I recommend: Andrew Ng leads the efforts at deeplearning.ai and Jeremy Howard leads the efforts at fast.ai. Here I will show you how to use a few useful techniques. Andrew and Jeremy will teach you skills that may lead a professional level of expertise if you take their courses.
There are many Deep Learning neural architectures in current practical use; a few types that I use are:
- Multi-layer perceptron networks with many fully connected layers. An input layer contains placeholders for input data. Each element in the input layer is connected by a two-dimensional weight matrix to each element in the first hidden layer. We can use any number of fully connected hidden layers, with the last hidden layer connected to an output layer.
- Convolutional networks for image processing and text classification. Convolutions, or filters, are small windows that can process input images (filters are two-dimensional) or sequences like text (filters are one-dimensional). Each filter uses a single set of learned weights independent of where the filter is applied in an input image or input sequence.
- Autoencoders have the same number of input layer and output layer elements with one or more hidden fully connected layers. Autoencoders are trained to produce the same output as training input values using a relatively small number of hidden layer elements. Autoencoders are capable of removing noise in input data.
- LSTM (long short term memory) process elements in a sequence in order and are capable of remembering patterns that they have seen earlier in the sequence.
- GAN (generative adversarial networks) models comprise two different and competing neural models, the generator and the discriminator. GANs are often trained on input images (although in my work I have applied GANs to two-dimensional numeric spreadsheet data). The generator model takes as input a “latent input vector” (this is just a vector of specific size with random values) and generates a random output image. The weights of the generator model are trained to produce random images that are similar to how training images look. The discriminator model is trained to recognize if an arbitrary output image is original training data or an image created by the generator model. The generator and discriminator models are trained together.
The core functionality of libraries like TensorFlow are written in C++ and take advantage of special hardware like GPUs, custom ASICs, and devices like Google’s TPUs. Most people who work with Deep Learning models don’t need to even be aware of the low level optimizations used to make training and using Deep Learning models more efficient. That said, in the following section I am going to show you how simple neural networks are trained and used.
Simple Multi-layer Perceptron Neural Networks
I use the terms Multi-layer perceptron neural networks, backpropagation neural networks and delta-rule networks interchangeably. Backpropagation refers to the model training process of calculating the output errors when training inputs are passed in the forward direction from input layer, to hidden layers, and then to the output layer. There will be an error which is the difference between the calculated outputs and the training outputs. This error can be used to adjust the weights from the last hidden layer to the output layer to reduce the error. The error is then backprogated backwards through the hidden layers, updating all weights in the model. I have detailed example code in any of my older artificial intelligence books. Here I am satisfied to give you an intuition to how simple neural networks are trained.
The basic idea is that we start with a network initialized with random weights and for each training case we propagate the inputs through the network towards the output neurons, calculate the output errors, and back-up the errors from the output neurons back towards the input neurons in order to make small changes to the weights to lower the error for the current training example. We repeat this process by cycling through the training examples many times.
The following figure shows a simple backpropagation network with one hidden layer. Neurons in adjacent layers are connected by floating point connection strength weights. These weights start out as small random values that change as the network is trained. Weights are represented in the following figure by arrows; in the code the weights connecting the input to the output neurons are represented as a two-dimensional array.
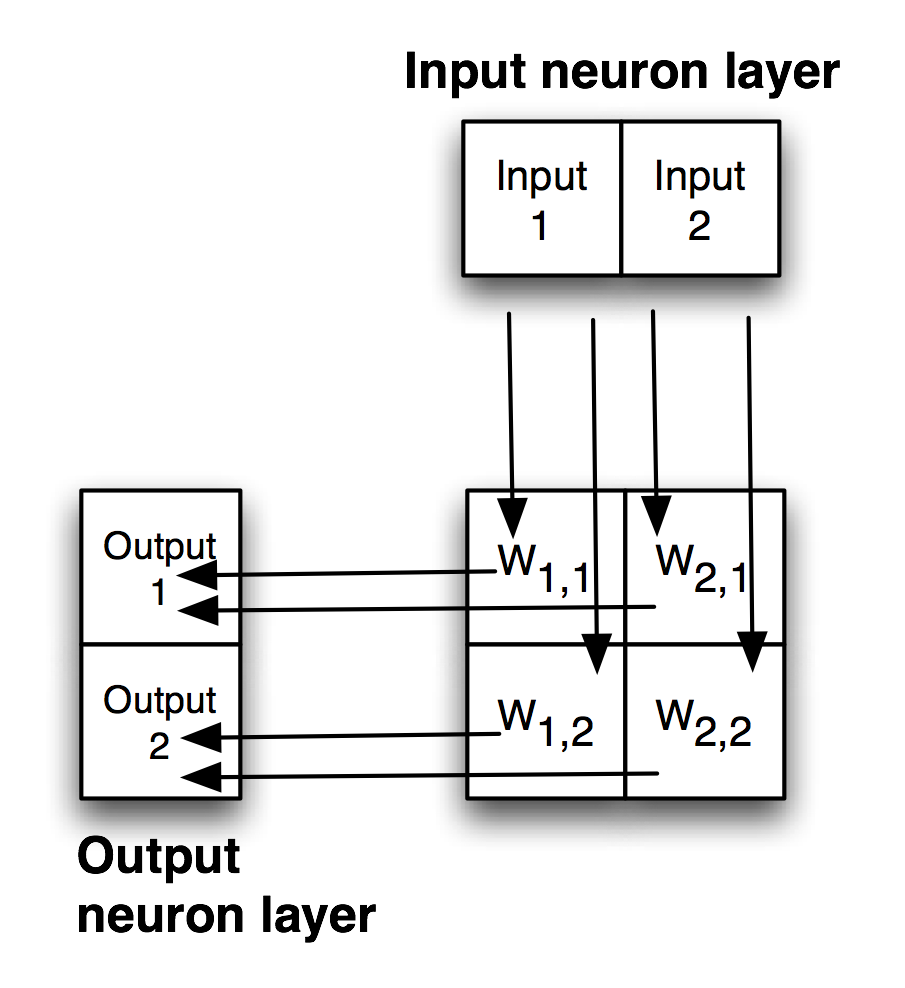
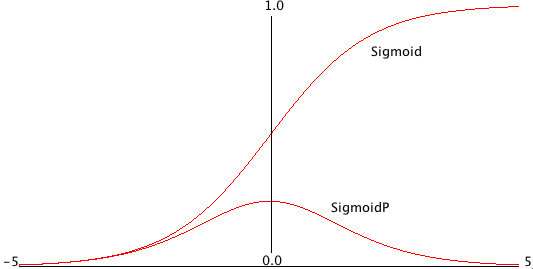
Each non-input neuron has an activation value that is calculated from the activation values of connected neurons feeding into it, gated (adjusted) by the connection weights. For example, in the above figure, the value of Output 1 neuron is calculated by summing the activation of Input 1 times weight W1,1 and Input 2 activation times weight W2,1 and applying a “squashing function” like Sigmoid or Relu (see figures below) to this sum to get the final value for Output 1’s activation value. We want to flatten activation values to a relatively small range but still maintain relative values. To do this flattening we use the Sigmoid function that is seen in the next figure, along with the derivative of the Sigmoid function which we will use in the code for training a network by adjusting the weights.
Simple neural network architectures with just one or two hidden layers are easy to train using backpropagation and I have examples of from-scratch code for this several of my previous books. You can see Java and Common Lisp from-scratch implementations in two of my books that you can read online: Practical Artificial Intelligence Programming With Java and Loving Common Lisp, or the Savvy Programmer’s Secret Weapon. However, here we are using Hy to write models using the TensorFlow framework which has the huge advantage that small models you experiment with on your laptop can be scaled to more parameters (usually this means more neurons in hidden layers which increases the number of weights in a model) and run in the cloud using multiple GPUs.
Except for pedantic purposes, I now never write neural network code from scratch, instead I take advantage of the many person-years of engineering work put into the development of frameworks like TensorFlow, PyTorch, mxnet, etc. We now move on to two examples built with TensorFlow.
Deep Learning
Deep Learning models are generally understood to have many more hidden layers than simple multi-layer perceptron neural networks and often comprise multiple simple models combined together in series or in parallel. Complex architectures can be iteratively developed by manually adjusting the size of model components, changing the components, etc. Alternatively, model architecture search can be automated. At Capital One I used Google’s AdaNet project that efficiently searches for effective model architectures inside a single TensorFlow session. The model architecture used here is simple: one input layer representing the input values in a sample of University of Wisconsin cancer data, one hidden layer, and an output layer consisting of one neuron whose activation value will be interpreted as a prediction of benign or malignant.
The material in this chapter is intended to serve two purposes:
- If you are already familiar with Deep Learning and TensorFlow then the examples here will serve to show you how to call the TensorFlow APIs from Hy.
- If you have little or no exposure with Deep Learning then the short Hy language examples will provide you with concise code to experiment with and you can then decide to study further.
Once again, I recommend that you consider taking two online Deep Learning course sequences. For no cost, Jeremy Howard provides lessons at fast.ai that are very good and the later classes use PyTorch which is a framework that is similar to TensorFlow. For a modest cost Andrew Ng provides classes at deeplearning.ai that use TensorFlow. I have been working in the field of machine learning since the 1980s, but I still take Andrew’s online classes to stay up-to-date. In the last eight years I have taken his Stanford University machine learning class twice and also his complete course sequence using TensorFlow. I have also worked through much of Jeremy’s material. I recommend both course sequences without reservation.
Using Keras and TensorFlow to Model The Wisconsin Cancer Data Set
The University of Wisconsin cancer database has 646 samples. Each sample has 9 input values and one output value:
- Cl.thickness: Clump Thickness
- Cell.size: Uniformity of Cell Size
- Cell.shape: Uniformity of Cell Shape
- Marg.adhesion: Marginal Adhesion
- Epith.c.size: Single Epithelial Cell Size
- Bare.nuclei: Bare Nuclei
- Bl.cromatin: Bland Chromatin
- Normal.nucleoli: Normal Nucleoli
- Mitoses: Mitoses
- Class: Class (0 for benign, 1 for malignant)
Each row represents a sample with different measurements related to cell properties, and the final column ‘Class’ indicates whether the sample is benign (0) or malignant (1).
Let’s perform some basic analysis on this data:
- Check for missing values.
- Get the summary statistics of the dataset.
- Check the balance of the classes (benign and malignant).
Here’s the analysis:
- Missing Values: There are no missing values in the dataset. Each column has complete data.
- Summary Statistics: The mean and median (50%) values of most features are quite different, indicating that the data distribution for these features might be skewed.
- The range (min to max) for all features is from 1 to 10, indicating that the measurements are likely based on a scale or ranking system of 1 to 10.
- Class Balance: The dataset is somewhat imbalanced. Approximately 65% of the samples are benign (0) and 35% are malignant (1). This imbalance might influence the performance of machine learning models trained on this data.
Now, it would be beneficial to visualize the data to get a better understanding of the distribution of each feature and the relationship between different features:
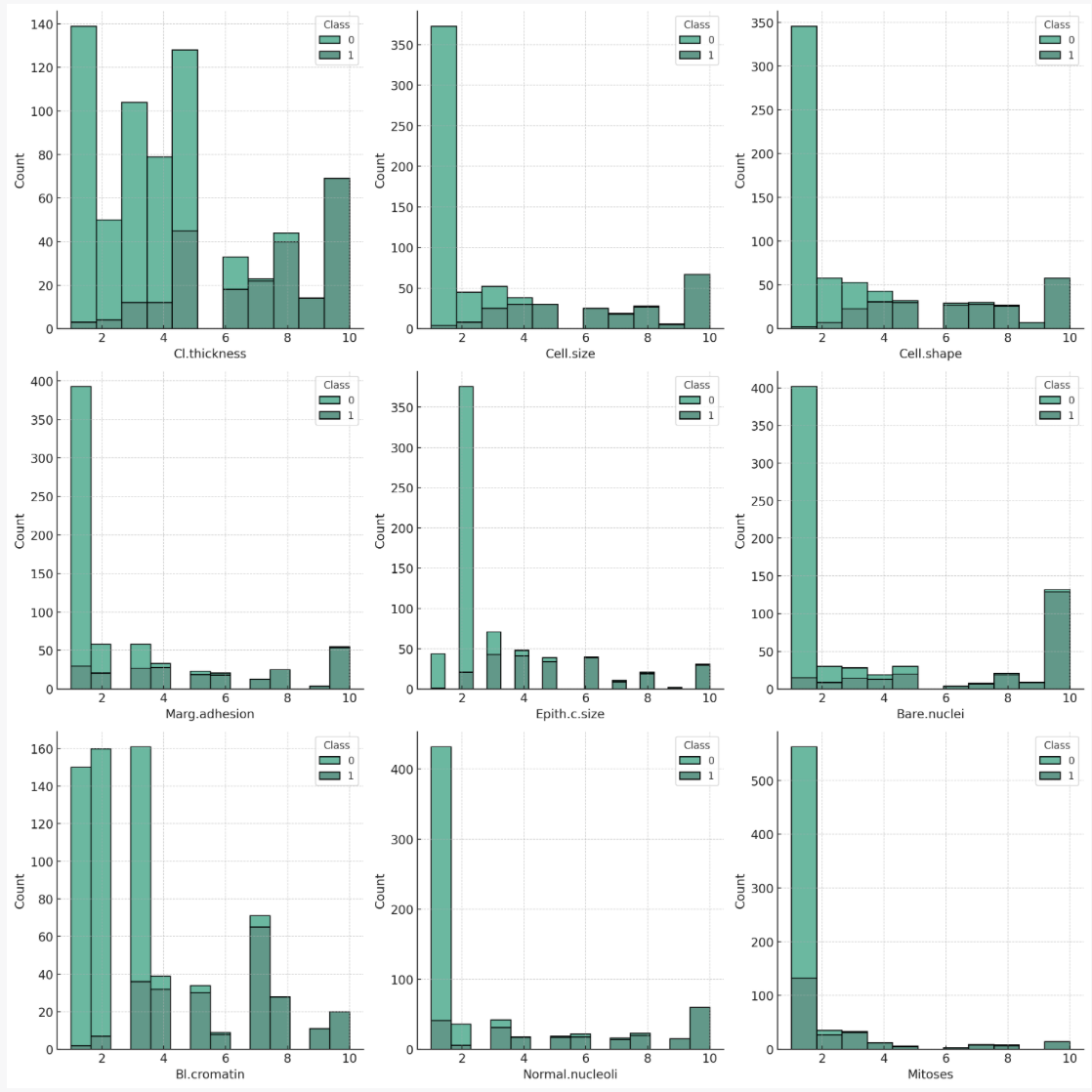
Here are histograms of each feature, broken down by class (benign or malignant). Some observations:
Cl.thickness, Cell.size, Cell.shape, Marg.adhesion, Epith.c.size, Bare.nuclei, Bl.cromatin, Normal.nucleoli: For these features, higher values seem to be associated with the malignant class. This might suggest that these characteristics are significant in the determination of malignancy. Mitoses: This feature shows a different trend, with a majority of both benign and malignant cases having low mitoses values. However, there are more malignant cases with higher mitoses values than benign cases.
We will use separate training and test files hy-lisp-python/deeplearning/train.csv and hy-lisp-python/deeplearning/test.csv. Here are a few samples from the training file:
6,2,1,1,1,1,7,1,1,0
2,5,3,3,6,7,7,5,1,1
10,4,3,1,3,3,6,5,2,1
6,10,10,2,8,10,7,3,3,1
5,6,5,6,10,1,3,1,1,1
1,1,1,1,2,1,2,1,2,0
3,7,7,4,4,9,4,8,1,1
1,1,1,1,2,1,2,1,1,0
After you look at this data, if you did not have much experience with machine learning then it might not be obvious how to build a model to accept a sample for a patient like we see in the Wisconsin data set and then predict if the sample implies benign or cancerous outcome for the patient. Using TensorFlow with a simple neural network model, we will implement a model in about 40 lines of Hy code to implement this example.
Since there are nine input values we will need nine input neurons that will represent the input values for a sample in either training or separate test data. These nine input neurons (created in lines 9-10 in the following listing) will be completely connected to twelve neurons in a hidden layer. Here, completely connected means that each of the nine input neurons is connected via a weight to each hidden layer neuron. There are 9 * 12 = 108 weights between the input and hidden layers. There is a single output layer neuron that is connected to each hidden layer neuron.
Notice that in lines 12 and 14 in the following listing that we specify a relu activation function while the activation function connecting the hidden layer to the output layer uses the sigmoid activation function that we saw plotted earlier.
There is an example in the git example repo directory hy-lisp-python/matplotlib in the file plot_relu.hy that generated the following figure:
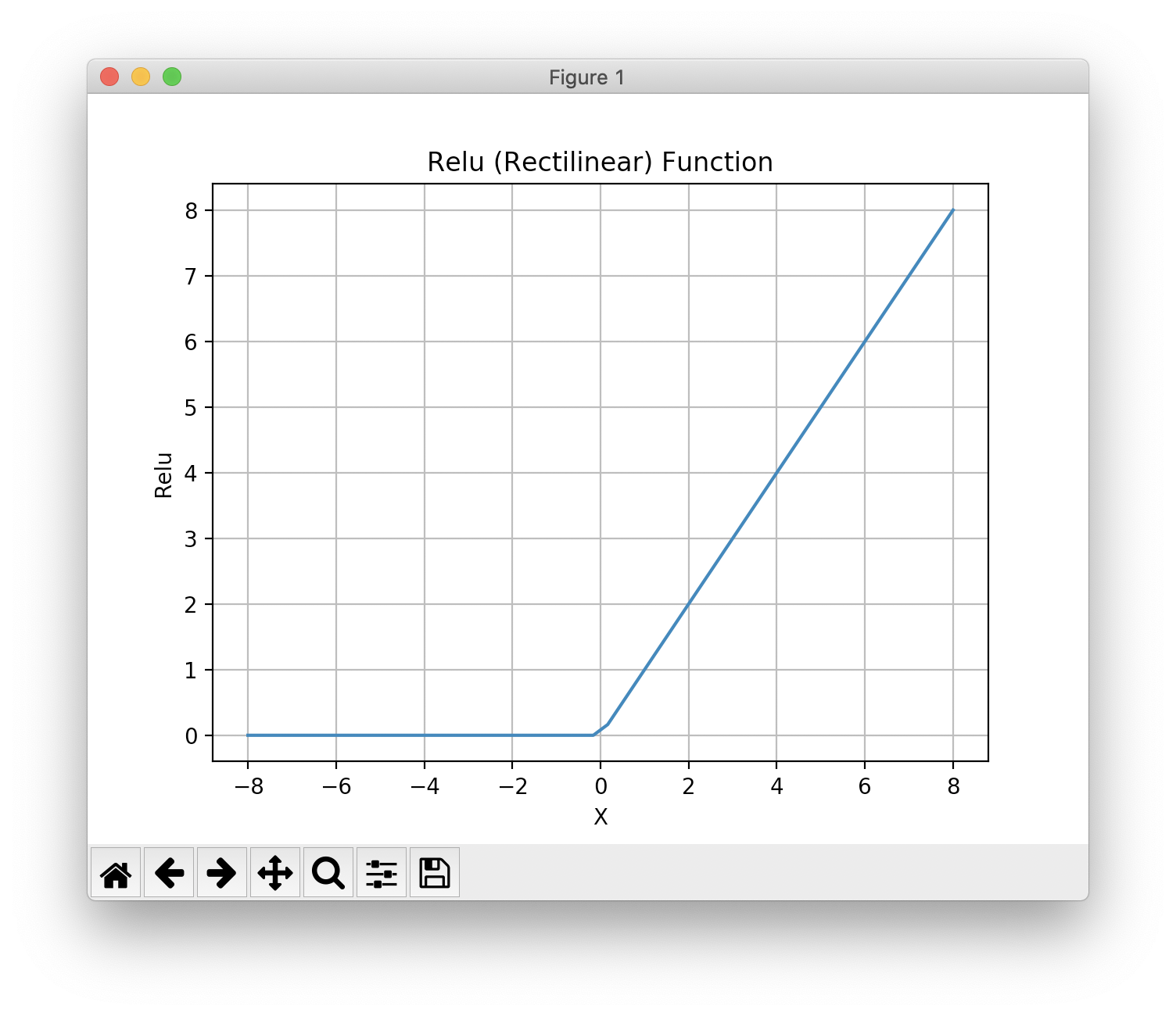
The following listing shows the use of the Keras TensorFlow APIs to build a model (lines 9-19) with one input layer, two hidden layers, and an output layer with just one neuron. After we build the model, we define two utility functions train (lines 21-23) to train a model given training inputs (x argument) and corresponding training outputs (y** argument), and we also define predict (lines 25-26) using a trained model to make a cancer or benign prediction given test input values (x-data argument).
Lines 28-33 show a utility function load-data that loads a University of Wisconsin cancer data set CSV file, scales the input and output values to the range [0.0, 1.0] and returns a list containing input (x-data) and target output data (y-data). You may want to load this example in a REPL and evaluate load-data on one of the CSV files.
The function main (lines 35-45) loads training and test (evaluation of model accuracy on data not used for training), trains a model, and then tests the accuracy of the model on the test (evaluation) data:
1 #!/usr/bin/env hy
2
3 (import argparse)
4 (import os)
5 (import keras.models [Sequential])
6 (import keras.layers [Dense])
7 (import keras.optimizers [RMSprop])
8
9 (import pandas [read-csv])
10 (import pandas)
11
12 (defn build-model []
13 (setv model (Sequential))
14 (.add model (Dense 9
15 :activation "relu"))
16 (.add model (Dense 12
17 :activation "relu"))
18 (.add model (Dense 1
19 :activation "sigmoid"))
20 (.compile model :loss "binary_crossentropy"
21 :optimizer (RMSprop))
22 model)
23
24 (defn first [x] (get x 0))
25
26 (defn train [batch-size model x y]
27 (for [it (range 50)]
28 (.fit model x y :batch-size batch-size :epochs 10 :verbose False)))
29
30 (defn predict [model x-data]
31 (.predict model x-data))
32
33 (defn load-data [file-name]
34 (setv all-data (read-csv file-name :header None))
35 (setv x-data10 (. all-data.iloc [#((slice 0 10) [0 1 2 3 4 5 6 7 8])] values))
36 (setv x-data (* 0.1 x-data10))
37 (setv y-data (. all-data.iloc [#((slice 0 10) [9])] values))
38 [x-data y-data])
39
40 (defn main []
41 (setv xyd (load-data "train.csv"))
42 (setv model (build-model))
43 (setv xytest (load-data "test.csv"))
44 (train 10 model (. xyd [0]) (. xyd [1]))
45 (print "* predictions (calculated, expected):")
46 (setv predictions (list (map first (predict model (. xytest [0])))))
47 (setv expected (list (map first (. xytest [1]))))
48 (print
49 (list
50 (zip predictions expected))))
51
52
53 (main)
The following listing shows the output:
1 $ uv run hy wisconsin.hy
2 * predictions (calculated, expected):
3 [(0.9998953, 1), (0.9999737, 1), (0.9172243, 1), (0.9975936, 1), (0.38985246, 0), (0\
4 .4301587, 0), (0.99999213, 1), (0.855, 0), (0.3810781, 0), (0.9999431, 1)]
Let’s look at the first test case: the “real” output from the training data is a value of 1 and the calculated predicted value (using the trained model) is 0.9759052. In making predictions, we can choose a cutoff value, 0.5 for example, and interpret any calculated prediction value less than the cutoff as a Boolean false prediction and calculated prediction value greater to or equal to the cutoff value is a Boolean true prediction.
Using a LSTM Recurrent Neural Network to Generate English Text Similar to the Philosopher Nietzsche’s Writing
We will translate a Python example program from Google’s Keras documentation (listing of LSTM.py that is included with the example Hy code) to Hy. This is a moderately long example and you can use the original Python and the translated Hy code as a general guide for converting other models implemented in Python using Keras that you want use in Hy. I have, in most cases, kept the same variable names to make it easier to compare the Python and Hy code.
Note that using the nietzsche.txt data set requires a fair amount of memory. If your computer has less than 16G of RAM, you might want to reduce the size of the training text by first running the following example until you see the printout “Create sentences and next_chars data…” then kill the program. The first time you run this program, the training data is fetched from the web and stored locally. You can manually edit the file ~/.keras/datasets/nietzsche.txt to remove 75% of the data by:
1 pushd ~/.keras/datasets/
2 mv nietzsche.txt nietzsche_large.txt
3 head -800 nietzsche_large.txt > nietzsche.txt
4 popd
The next time you run the example, the Keras example data loading utilities will notice a local copy and even though the file now is much smaller, the data loading utilities will not download a new copy.
When I start training a new Deep Learning model I like to monitor system resources using the top command line activity, watching for page faults when training on a CPU which might indicate that I am trying to train too large a model for my system memory. If you are using CUDA and a GPU then use the CUDA command line utilities for monitoring the state of the GPU utilization. It is beyond the scope of this introductory tutorial, but the tool TensorBoard is very useful for monitoring the state of model training.
There are a few things that make the following example code more complex than the example using the University of Wisconsin cancer data set. We need to convert each character in the training data to a one-hot encoding which is a vector of all 0.0 values except for a single value of 1.0. I am going to show you a short REPL session so that you understand how this works and then we will look at the complete Hy code example.
1 $ hy
2 => (import keras.callbacks [LambdaCallback])
3 Using TensorFlow backend.
4 => (import keras.src.callbacks [LambdaCallback])
5 => (import keras.src.models [Sequential])
6 => (import keras.src.layers [Dense LSTM])
7 => (import keras.src.optimizers [RMSprop])
8 => (import keras.src.utils [get_file])
9 => (import numpy :as np) ;; note the syntax for aliasing a module name
10 => (import random sys io)
11 => (with [f (io.open "/Users/markw/.keras/datasets/nietzsche.txt" :encoding "utf-8")]
12 ... (setv text (.read f)))
13 => (cut text 98 130)
14 'philosophers, in so far as they '
15 => (setv chars (sorted (list (set text))))
16 => chars
17 ['\n', ' ', '!', '"', "'", '(', ')', ',', '-', '.', '0', '1', '2', '3', '4', '5', '6\
18 ', '7', '8', '9', ':', ';', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', '\
19 K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', '_', 'a', \
20 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r',\
21 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
22 => (setv char_indices (dict (lfor i (enumerate chars) (, (last i) (first i)))))
23 => char_indices
24 {'\n': 0, ' ': 1, '!': 2, '"': 3, "'": 4, '(': 5, ')': 6, ',': 7, '-': 8, '.': 9, '0\
25 ': 10, '1': 11, '2': 12, '3': 13, '4': 14, '5': 15, '6': 16, '7': 17, '8': 18, '9': \
26 19, ':': 20, ';': 21, '?': 22, 'A': 23, 'B': 24, 'C': 25, 'D': 26, 'E': 27, 'F': 28,\
27 'G': 29, 'H': 30, 'I': 31, 'J': 32, 'K': 33, 'L': 34, 'M': 35, 'N': 36, 'O': 37, 'P\
28 ': 38, 'Q': 39, 'R': 40, 'S': 41, 'T': 42, 'U': 43, 'V': 44, 'W': 45, 'X': 46, 'Y': \
29 47, '_': 48, 'a': 49, 'b': 50, 'c': 51, 'd': 52, 'e': 53, 'f': 54, 'g': 55, 'h': 56,\
30 'i': 57, 'j': 58, 'k': 59, 'l': 60, 'm': 61, 'n': 62, 'o': 63, 'p': 64, 'q': 65, 'r\
31 ': 66, 's': 67, 't': 68, 'u': 69, 'v': 70, 'w': 71, 'x': 72, 'y': 73, 'z': 74}
32 => (setv indices_char (dict (lfor i (enumerate chars) i)))
33 => indices_char
34 {0: '\n', 1: ' ', 2: '!', 3: '"', 4: "'", 5: '(', 6: ')', 7: ',', 8: '-', 9: '.', 10\
35 : '0', 11: '1', 12: '2', 13: '3', 14: '4', 15: '5', 16: '6', 17: '7', 18: '8', 19: '\
36 9', 20: ':', 21: ';', 22: '?', 23: 'A', 24: 'B', 25: 'C', 26: 'D', 27: 'E', 28: 'F',\
37 29: 'G', 30: 'H', 31: 'I', 32: 'J', 33: 'K', 34: 'L', 35: 'M', 36: 'N', 37: 'O', 38\
38 : 'P', 39: 'Q', 40: 'R', 41: 'S', 42: 'T', 43: 'U', 44: 'V', 45: 'W', 46: 'X', 47: '\
39 Y', 48: '_', 49: 'a', 50: 'b', 51: 'c', 52: 'd', 53: 'e', 54: 'f', 55: 'g', 56: 'h',\
40 57: 'i', 58: 'j', 59: 'k', 60: 'l', 61: 'm', 62: 'n', 63: 'o', 64: 'p', 65: 'q', 66\
41 : 'r', 67: 's', 68: 't', 69: 'u', 70: 'v', 71: 'w', 72: 'x', 73: 'y', 74: 'z'}
42 => (setv maxlen 40)
43 => (setv s "Oh! I saw 1 dog (yesterday)")
44 => (setv x_pred (np.zeros [1 maxlen (len chars)]))
45 => (for [[t char] (lfor j (enumerate s) j)]
46 ... (setv (get x_pred 0 t (get char_indices char)) 1))
47 => x_pred
48 array([[[0., 0., 0., ..., 0., 0., 0.],
49 [0., 0., 0., ..., 0., 0., 0.],
50 [0., 0., 1., ..., 0., 0., 0.], // here 1. is the third character "!"
51 ...,
52 [0., 0., 0., ..., 0., 0., 0.],
53 [0., 0., 0., ..., 0., 0., 0.],
54 [0., 0., 0., ..., 0., 0., 0.]]])
55 =>
For lines 48-54, each line represents a single character one-hot encoded. Notice how the third character shown on line 50 has a value of “1.” at index 2, which corresponds to the one-hot encoding of the letter “!”.
Now that you have a feeling for how one-hot encoding works, hopefully the following example will make sense to you. We will further discuss one-hot-encoding after the next code listing. For training, we take 40 characters (the value of the variable maxlen) at a time, and using one one-hot encode a character at a time as input and the target output will be the one-hot encoding of the following character in the input sequence. We are iterating on training the model for a while and then given a few characters of text, predict a likely next character - and keep repeating this process. The generated text is then used as input to the model to generate yet more text. You can repeat this process until you have generated sufficient text.
This is a powerful technique that I used to model JSON with complex deeply nested schemas and then generate synthetic JSON in the same schema as the training data. Here, training a model to mimic the philosopher Nietzsche’s writing is much easier than learning highly structured data like JSON:
1 #!/usr/bin/env hy
2
3 ;; This example was translated from the Python example in the Keras
4 ;; documentation at: https://keras.io/examples/lstm_text_generation/ that
5 ;; was written with very old versions of tensorflow and keras.
6 ;; This Hy version is translated to use current versions of keras and
7 ;; tensorflow:
8
9 (import keras.src.callbacks [LambdaCallback])
10 (import keras.src.models [Sequential])
11 (import keras.src.layers [Dense LSTM])
12 (import keras.src.optimizers [RMSprop])
13 (import keras.src.utils [get_file])
14 (import numpy :as np) ;; note the syntax for aliasing a module name
15 (import random sys io)
16
17 (setv path
18 (get_file ;; this saves a local copy in ~/.keras/datasets
19 "nietzsche.txt"
20 :origin "https://s3.amazonaws.com/text-datasets/nietzsche.txt"))
21
22 (with [f (io.open path :encoding "utf-8")]
23 (setv text (.read f))) ;; note: sometimes we use (.lower text) to
24 ;; convert text to all lower case
25 (print "corpus length:" (len text))
26
27 (setv chars (sorted (list (set text))))
28 (print "total chars (unique characters in input text):" (len chars))
29 ;;(setv char_indices (dict (lfor i (enumerate chars) (, (last i) (first i)))))
30 (setv char_indices (dict (lfor i (enumerate chars) #((get i -1) (get i 0)))))
31 (setv indices_char (dict (lfor i (enumerate chars) i)))
32
33 ;; cut the text in semi-redundant sequences of maxlen characters
34 (setv maxlen 40)
35 (setv step 3) ;; when we sample text, slide sampling window 3 characters
36 (setv sentences (list))
37 (setv next_chars (list))
38
39 (print "Create sentences and next_chars data...")
40 (for [i (range 0 (- (len text) maxlen) step)]
41 (.append sentences (cut text i (+ i maxlen)))
42 (.append next_chars (get text (+ i maxlen))))
43
44 (print "Vectorization...")
45 (setv x (np.zeros [(len sentences) maxlen (len chars)] :dtype bool))
46 (setv y (np.zeros [(len sentences) (len chars)] :dtype bool))
47 (for [[i sentence] (lfor j (enumerate sentences) j)]
48 (for [[t char] (lfor j (enumerate sentence) j)]
49 (setv (get x i t (get char_indices char)) 1))
50 (setv (get y i (get char_indices (get next_chars i))) 1))
51 (print "Done creating one-hot encoded training data.")
52
53 (print "Building model...")
54 (setv model (Sequential))
55 (.add model (LSTM 128 :input_shape [maxlen (len chars)]))
56 (.add model (Dense (len chars) :activation "softmax"))
57
58 (setv optimizer (RMSprop 0.01))
59 (.compile model :loss "categorical_crossentropy" :optimizer optimizer)
60
61 (defn sample [preds &optional [temperature 1.0]]
62 (setv preds (.astype (np.array preds) "float64"))
63 (setv preds (/ (np.log preds) temperature))
64 (setv exp_preds (np.exp preds))
65 (setv preds (/ exp_preds (np.sum exp_preds)))
66 (setv probas (np.random.multinomial 1 preds 1))
67 (np.argmax probas))
68
69 (defn on_epoch_end [epoch [not-used None]]
70 (print)
71 (print "----- Generating text after Epoch:" epoch)
72 (setv start_index (random.randint 0 (- (len text) maxlen 1)))
73 (for [diversity [0.2 0.5 1.0 1.2]]
74 (print "----- diversity:" diversity)
75 (setv generated "")
76 (setv sentence (cut text start_index (+ start_index maxlen)))
77 (setv generated (+ generated sentence))
78 (print "----- Generating with seed:" sentence)
79 (sys.stdout.write generated)
80 (for [i (range 400)]
81 (setv x_pred (np.zeros [1 maxlen (len chars)]))
82 (for [[t char] (lfor j (enumerate sentence) j)]
83 (setv (get x_pred 0 t (get char_indices char)) 1))
84 ;; (setv preds (first (model.predict x_pred :verbose 0)))
85 (setv preds (get (model.predict x_pred :verbose 0) 0))
86 ;;;(print "** preds=" preds)
87 (setv next_index (sample preds diversity))
88 (setv next_char (get indices_char next_index))
89 (setv sentence (+ (cut sentence 1) next_char))
90 (sys.stdout.write next_char)
91 (sys.stdout.flush))
92 (print)))
93
94 (setv print_callback (LambdaCallback :on_epoch_end on_epoch_end))
95
96 (model.fit x y :batch_size 128 :epochs 60 :callbacks [print_callback])
We run this example using:
1 uv run hy lstm.hy
In lines 52-54 we defined a model using the Keras APIs and in lines 56-57 compiled the model using a categorical crossentropy loss function with an RMSprop optimizer.
In lines 59-65 we define a function sample that takes a first required argument preds which is a one-hot predicted encoded character that might look like (maxlen or 40 values):
[2.80193929e-02 6.78635418e-01 7.85831537e-04 4.92034527e-03 . . . 6.62320468e-04 9.14627407e-03 2.31375365e-04]
Now, here the predicted one hot encoding values are not strictly 0 or 1, rather they are small floating point numbers of a single number much larger than the others. The largest number is 6.78635418e-01 at index 1 which corresponds to a one-hot encoding for a “ “ space character.
If we print out the number of characters in text and the unique list of characters (variable chars) in the training text file nietzsche.txt we see:
corpus length: 600893
['\n', ' ', '!', '"', "'", '(', ')', ',', '-', '.', '0', '1', '2', '3', '4', '5', '6\
', '7', '8', '9', ':', ';', '=', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', '\
J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', \
'[', ']', '_', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',\
'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'Æ', 'ä', 'æ', 'é', 'ë'\
]
A review of one-hot encoding:
Let’s review our earlier discussion of one-hot encoding with a simpler case. It is important to understand how we one-hot encode input text to inputs for the model and decode back one-hot vectors to text when we use a trained model to generate text. It will help to see the dictionaries for converting characters to indices and then reverse indices to original characters as we saw earlier, some output removed:
char_indices:
{'\n': 0, ' ': 1, '!': 2, '"': 3, "'": 4, '(': 5, ')': 6, ',': 7, '-': 8, '.': 9, '\
0': 10, '1': 11, '2': 12, '3': 13, '4': 14, '5': 15, '6': 16, '7': 17, '8': 18, '9':\
19,
. . .
'f': 58, 'g': 59, 'h': 60, 'i': 61, 'j': 62, 'k': 63, 'l': 64, 'm': 65, 'n': 66, 'o\
': 67, 'p': 68, 'q': 69, 'r': 70, 's': 71, 't': 72, 'u': 73, 'v': 74, 'w': 75, 'x': \
76, 'y': 77, 'z': 78, 'Æ': 79, 'ä': 80, 'æ': 81, 'é': 82, 'ë': 83}
indices_char:
{0: '\n', 1: ' ', 2: '!', 3: '"', 4: "'", 5: '(', 6: ')', 7: ',', 8: '-', 9: '.', 1\
0: '0', 11: '1', 12: '2', 13: '3', 14: '4', 15: '5', 16: '6', 17: '7', 18: '8', 19: \
'9',
. . .
'o', 68: 'p', 69: 'q', 70: 'r', 71: 's', 72: 't', 73: 'u', 74: 'v', 75: 'w', 76: 'x\
', 77: 'y', 78: 'z', 79: 'Æ', 80: 'ä', 81: 'æ', 82: 'é', 83: 'ë'}
We prepare the input and target output data in lines 43-48 in the last code listing. Using a short string, let’s look in the next REPL session listing at how these input and output training examples are extracted for an input string:
1 $ uv run hy
2 => (setv text "0123456789abcdefg")
3 => (setv maxlen 4)
4 => (setv i 3)
5 => (cut text i (+ i maxlen))
6 '3456'
7 => (cut text (+ 1 maxlen))
8 '56789abcdefg'
9 => (setv i 4) ;; i is the for loop variable for
10 => (cut text i (+ i maxlen)) ;; defining sentences and next_chars
11 '4567'
12 => (cut text (+ i maxlen))
13 '89abcdefg'
14 =>
So the input training sentences are each maxlen characters long and the next-chars target outputs each start with the character after the last character in the corresponding input training sentence.
This script pauses during each training epoc to generate text given diversity values of 0.2, 0.5, 1.0, and 1.2. The smaller the diversity value the more closely the generated text matches the training text. The generated text is more realistic after many training epocs. In the following, I list a highly edited copy of running through several training epochs. I only show generated text for diversity equal to 0.2:
1 $ uv run hy wisconsin.hy
2 ----- Generating text after Epoch: 0
3 ----- diversity: 0.2
4 ----- Generating with seed: ocity. Equally so, gratitude.--Justice r
5 ocity. Equally so, gratitude.--Justice read in the become to the conscience the seen\
6 er and the conception that the becess of the power to the procentical that the becau\
7 se and the prostice of the prostice and the will to the conscience of the power of t\
8 he perhaps the self-distance of the all the soul and the world and the soul of the s\
9 oul of the world and the soul and an an and the profound the self-dister the all the\
10 belief and the
11
12 ----- Generating text after Epoch: 8
13 ----- diversity: 0.2
14 ----- Generating with seed: nations
15 laboring simultaneously under th
16 nations
17 laboring simultaneously under the subjection of the soul of the same to the subjecti\
18 on of the subjection of the same not a strong the soul of the spiritual to the same \
19 really the propers to the stree be the subjection of the spiritual that is to probab\
20 ly the stree concerning the spiritual the sublicities and the spiritual to the proce\
21 ssities the spirit to the soul of the subjection of the self-constitution and proper\
22 s to the
23
24 ----- Generating text after Epoch: 14
25 ----- diversity: 0.2
26 ----- Generating with seed: to which no other path could conduct us
27 to which no other path could conduct us a stronger that is the self-delight and the\
28 strange the soul of the world of the sense of the sense of the consider the such a \
29 state of the sense of the sense of the sense of such a sandine and interpretation of\
30 the process of the sense of the sense of the sense of the soul of the process of th\
31 e world in the sense of the sense of the spirit and superstetion of the world the se\
32 nse of the
33
34 ----- Generating text after Epoch: 17
35 ----- diversity: 0.2
36 ----- Generating with seed: hemselves although they could easily hav
37 hemselves although they could easily have been moral morality and the self-in which \
38 the self-in the world to the same man in the standard to the possibility that is to \
39 the strength of the sense-in the former the sense-in the special and the same man in\
40 the consequently the soul of the superstition of the special in the end to the poss\
41 ible that it is will not be a sort of the superior of the superstition of the same m\
42 an to the same man
Here we trained on examples, translated to English, of the philosopher Nietzsche. I have used similar code to this example to train on highly structured JSON data and the resulting LSTM bsed model was usually able to generate similarly structured JSON. I have seen other examples where the training data was code in C++.
How is this example working? The model learns what combinations of characters tend to appear together and in what order.
In the next chapter we will use pre-trained Deep Learning models for natural language processing (NLP).
Optional Practice Problems
-
Full Dataset Training and Model Tuning in wisconsin.hy
The training and test data loader in wisconsin.hy currently slices only the first 10 rows using
(slice 0 10)to speed up testing. Modify theload-datafunction to load the entire dataset fromtrain.csvandtest.csv. Additionally, experiment with:- Changing the hidden layer sizes or adding another
Denselayer. - Using the
Adamoptimizer instead ofRMSprop. - Modifying the activation functions (e.g., changing hidden layers to
tanhorelu).
- Changing the hidden layer sizes or adding another
-
Hyperparameter Tuning in lstm.hy
In lstm.hy, the sequence length
maxlenis set to 40, and the sampling step sizestepis set to 3. Modify these hyperparameters:- Decrease
maxlento 20 or increase it to 60. How does this affect text coherence and training time? - Change
stepto 1 or 5. How does this change the total number of sentences generated for training data, and what is the impact on memory usage?
- Decrease
-
Saving and Reloading the LSTM Model
Because training a character-level LSTM model takes a substantial amount of time, it is impractical to retrain it every time you want to generate text. Modify lstm.hy to:
- Save the model weights and structure to disk using
(.save model "nietzsche_lstm.keras")at the end of training. - Write a separate Hy script (e.g.,
generate.hy) that loads the saved model and generates text from a given seed without retraining.
- Save the model weights and structure to disk using