Responsible Web Scraping
I put the word “Responsible” in the chapter title to remind you that just because it is easy (as we will soon see) to pull data from web sites, it is important to respect the property rights of web site owners and abide by their terms and conditions for use. This Wikipedia article on Fair Use provides a good overview of using copyright material.
The web scraping code we develop here uses the Python BeautifulSoup and URI libraries.
For my work and research, I have been most interested in using web scraping to collect text data for natural language processing but other common applications include writing AI news collection and summarization assistants, trying to predict stock prices based on comments in social media which is what we did at Webmind Corporation in 2000 and 2001, etc.
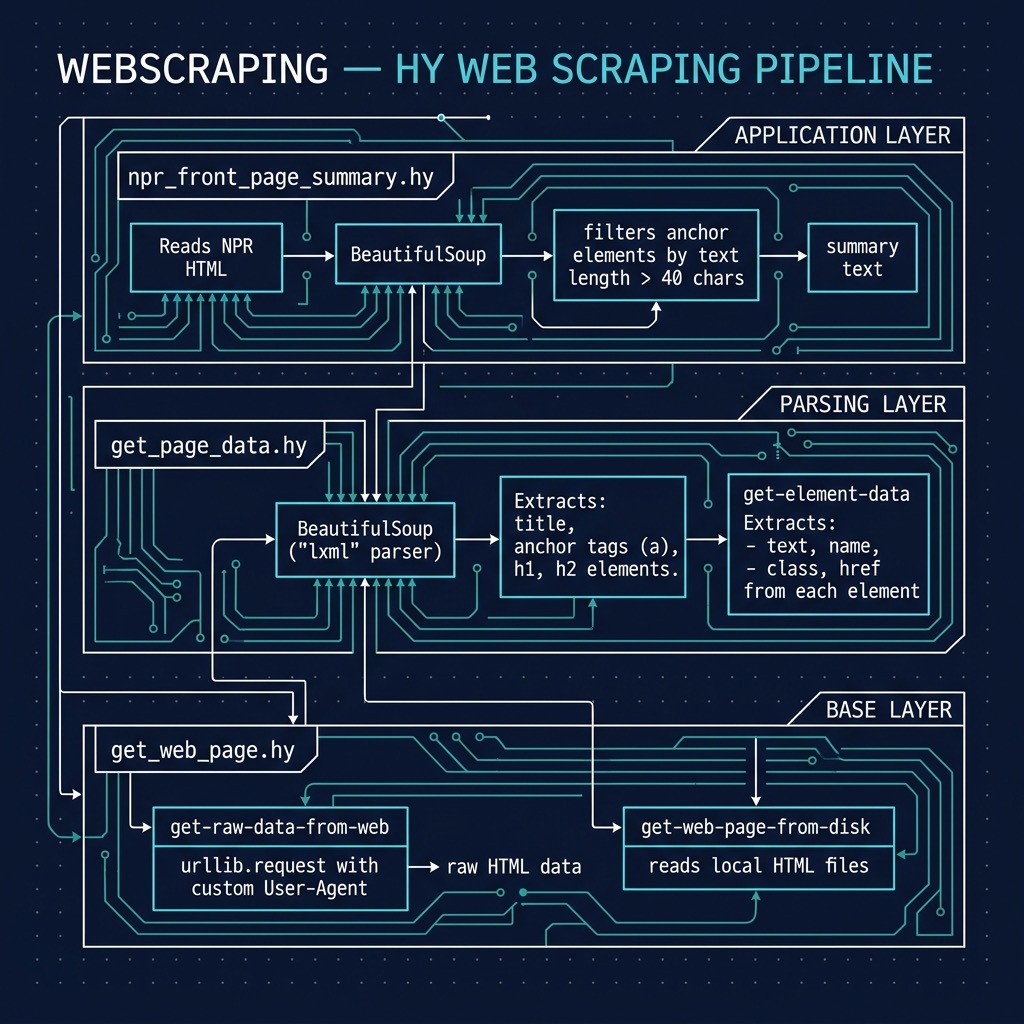
Using the Python BeautifulSoup Library in the Hy Language
There are many good libraries for parsing HTML text and extracting both structure (headings, what is in bold font, etc.) and embedded raw text. I particularly like the Python Beautiful Soup library and we will use it here.
In line 4 for the following listing of file get_web_page.hy, I am setting the default user agent to a descriptive string “HyLangBook” but for some web sites you might need to set this to appear as a Firefox or Chrome browser (iOS, Android, Windows, Linux, or macOS). The function get-raw-data gets the entire contents of a web site as a single string value.
1 (import urllib.request [Request urlopen])
2
3 (defn get-raw-data-from-web [aUri [anAgent {"User-Agent" "HyLangBook/1.0"}]]
4 (setv req (Request aUri :headers anAgent))
5 (setv httpResponse (urlopen req))
6 (setv data (.read httpResponse))
7 data)
Let’s test this function in a REPL:
1 $ uv run hy
2 Hy 1.1.0 (Business Hugs) using CPython(main) 3.12.0 on Darwin
3 => (import get-page-data [get-raw-data-from-web])
4 => (get-raw-data-from-web "http://knowledgebooks.com")
5 b'<!DOCTYPE html><html><head><title>KnowledgeBooks.com - research on the Knowledge M\
6 anagement, and the Semantic Web ...'
7 =>
8 => (import get-page-data [get-page-html-elements])
9 => (get-page-html-elements "http://knowledgebooks.com")
10 {'title': [<title>KnowledgeBooks.com - research on the Knowledge Management, and the\
11 Semantic Web </title>],
12 'a': [<a class="brand" href="#">KnowledgeBooks.com </a>, ...
13 =>
This REPL session shows the the function get-raw-data-from-web defined in the previous listing returns a web page as a string. In line 9 we use a function get-page-html-elements to find all elements in a string containing HTML. This function is defined in the next listing and shows how to parse and process the string contents of a web pages. Note: you will need to install the lxml library for this example (using pip or pip3 depending on your Python configuration):
1 pip install lxml
The following listing of file get_page_data.hy uses the Beautiful Soup library to parse the string data for HTML text from a web site. The function get-page-html-elements returns names and associated data with each element in HTML represented as a string (the extra code on lines 20-24 is just debug example code):
1 (import get_web_page [get-raw-data-from-web])
2
3 (import bs4 [BeautifulSoup])
4
5 (defn get-element-data [anElement]
6 {"text" (.getText anElement)
7 "name" (. anElement name)
8 "class" (.get anElement "class")
9 "href" (.get anElement "href")})
10
11 (defn get-page-html-elements [aUri]
12 (setv raw-data (get-raw-data-from-web aUri))
13 (setv soup (BeautifulSoup raw-data "lxml"))
14 (setv title (.find_all soup "title"))
15 (setv a (.find_all soup "a"))
16 (setv h1 (.find_all soup "h1"))
17 (setv h2 (.find_all soup "h2"))
18 {"title" title "a" a "h1" h1 "h2" h2})
19
20 (setv elements (get-page-html-elements "http://markwatson.com"))
21
22 (print (get elements "a"))
23
24 (for [ta (get elements "a")] (print (get-element-data ta)))
The function get-element-data defined in lines 5-9 accepts as an argument an HTML element object (as defined in the Beautiful soup library) and extracts data, if available, for text, name, class, and href values. The function get-page-html-elements defied in lines 11-18 accepts as an argument a string containing a URI and returns a dictionary (or map, or hash table) containing lists of all a, h1, h2, and title elements in the web page pointed to by the input URI. You can modify get-page-html-elements to add additional HTML element types, as needed.
Here is the output (with many lines removed for brevity):
1 {'text': 'Mark Watson artificial intelligence consultant and author',
2 'name': 'a', 'class': ['navbar-brand'], 'href': '#'}
3 {'text': 'Home page', 'name': 'a', 'class': None, 'href': '/'}
4 {'text': 'My Blog', 'name': 'a', 'class': None,
5 'href': 'https://mark-watson.blogspot.com'}
6 {'text': 'GitHub', 'name': 'a', 'class': None,
7 'href': 'https://github.com/mark-watson'}
8 {'text': 'Twitter', 'name': 'a', 'class': None, 'href': 'https://twitter.com/mark_l_\
9 watson'}
10 {'text': 'WikiData', 'name': 'a', 'class': None, 'href': 'https://www.wikidata.org/w\
11 iki/Q18670263'}
Getting HTML Links from the DemocracyNow.org News Web Site
I financially support and rely on both NPR.org and DemocracyNow.org news as my main sources of news so I will use their news sites for examples here and in the next section. Web sites differ so much in format that it is often necessary to build highly customized web scrapers for individual web sites and to maintain the web scraping code as the format of the site changes in time.
Before working through this example and/or the example in the next section use the file Makefile to fetch data:
make data
This should copy the home pages for both web sites to the files:
- democracynow_home_page.html (used here)
- npr_home_page.html (used for the example in the next section)
The following listing shows democracynow_front_page.hy
1 (import get-web-page [get-web-page-from-disk])
2 (import bs4 [BeautifulSoup])
3
4 ;; you need to run 'make data' to fetch sample HTML data for dev and testing
5
6 (defn get-democracy-now-links []
7 (setv test-html (get-web-page-from-disk "democracynow_home_page.html"))
8 (setv bs (BeautifulSoup test-html :features "lxml"))
9 (setv all-anchor-elements (.findAll bs "a"))
10 (lfor e all-anchor-elements
11 :if (> (len (.get-text e)) 0)
12 (, (.get e "href") (.get-text e))))
13
14 (when (= __name__ "__main__")
15 (for [[uri text] (get-democracy-now-links)]
16 (print uri ":" text)))
This simply prints our URIs and text (separated with the string “:”) for each link on the home page. On line 13 we discard any anchor elements that do not contain text. On line 14 the comma character at the start of the return list indicates that we are constructing a tuple. Lines 16-18 define a main function that is used when running this file at the command line. This is similar to how main functions can be defined in Python to allow a library file to also be run as a command line tool.
A few lines of output from today’s front page is:
/2020/1/7/the_great_hack_cambridge_analytica : Meet Brittany Kaiser, Cambridge Analy\
tica Whistleblower Releasing Troves of New Files from Data Firm
/2019/11/8/remembering_orangeburg_massacre_1968_south_carolina : Remembering the 196\
8 Orangeburg Massacre When Police Shot Dead Three Unarmed Black Students
/2020/1/15/democratic_debate_higher_education_universal_programs : Democrats Debate \
Wealth Tax, Free Public College & Student Debt Relief as Part of New Economic Plan
/2020/1/14/dahlia_lithwick_impeachment : GOP Debate on Impeachment Witnesses Intensi\
fies as Pelosi Prepares to Send Articles to Senate
/2020/1/14/oakland_california_moms_4_housing : Moms 4 Housing: Meet the Oakland Moth\
ers Facing Eviction After Two Months Occupying Vacant House
/2020/1/14/luis_garden_acosta_martin_espada : “Morir Soñando”: Martín Espada Reads P\
oem About Luis Garden Acosta, Young Lord & Community Activist
The URIs are relative to the root URI https://www.democracynow.org/.
Getting Summaries of Front Page from the NPR.org News Web Site
This example is similar to the example in the last section except that text from home page links is formatted to provide a daily news summary. I am assuming that you ran the example in the last section so the web site home pages have been copied to local files.
The following listing shows npr_front_page_summary.hy
1 (import get-web-page [get-web-page-from-disk])
2 (import bs4 [BeautifulSoup])
3
4 ;; you need to run 'make data' to fetch sample HTML data for dev and testing
5
6 (defn get-npr-links []
7 (setv test-html (get-web-page-from-disk "npr_home_page.html"))
8 (setv bs (BeautifulSoup test-html :features "lxml"))
9 (setv all-anchor-elements (.findAll bs "a"))
10 (setv filtered-a
11 (lfor e all-anchor-elements
12 :if (> (len (.get-text e)) 0)
13 #((.get e "href") (.get-text e))))
14 filtered-a)
15
16 (defn create-npr-summary []
17 (setv links (get-npr-links))
18 (setv filtered-links (lfor [uri text] links :if (> (len (.strip text)) 40) (.strip\
19 text)))
20 (.join "\n\n" filtered-links))
21
22 (when (= __name__ "__main__")
23 (print (create-npr-summary)))
In lines 12-15 we are filtering out (or removing) all anchor HTML elements that do not contain text. The following shows a few lines of the generated output for data collected today:
January 16, 2020 Birds change the shape of their wings far more than
planes. The complexities of bird flight have posed a major design challenge
for scientists trying to translate the way birds fly into robots.
FBI Vows To Warn More Election Officials If Discovering A Cyberattack
January 16, 2020 The bureau was faulted after the Russian attack on the
2016 election for keeping too much information from state and local
authorities. It says it'll use a new policy going forward.
Ukraine Is Investigating Whether U.S. Ambassador Yovanovitch Was Surveilled
January 16, 2020 Ukraine's Internal Affairs Ministry says it's asking the
FBI to help determine whether international laws were broken, or "whether it
is just a bravado and a fake information" from a U.S. politician.
Electric Burn: Those Who Bet Against Elon Musk And Tesla Are Paying A Big Price
January 16, 2020 For years, Elon Musk skeptics have shorted Tesla stock, confident \
the electric carmaker was on the brink of disaster. Instead, share value has skyrock\
eted, costing short sellers billions.
TSA Says It Seized A Record Number Of Firearms At U.S. Airports Last Year
The examples seen here are simple but should be sufficient to get you started gathering text data from the web.
Optional Practice Problems
Here are a few optional practice problems to help you build confidence modifying the web scraping code:
-
Extract Image Meta-Data:
Modify the function
get-page-html-elementsinget_page_data.hyto also extract all<img>tags. Extendget-element-datato handle image elements by extracting thesrcandaltattributes.Hint: In Hy, you can add key-value pairs to the returned dictionary for
<img>tags. For example, your updatedget-element-datamight look like:hylang (defn get-element-data [anElement] {"text" (.getText anElement) "name" (. anElement name) "class" (.get anElement "class") "href" (.get anElement "href") "src" (.get anElement "src") "alt" (.get anElement "alt")}) -
Normalize Relative Links:
In
democracynow_front_page.hy, many extracted links are relative paths (e.g.,/2020/1/7/...). Modify the list comprehension (lfor) inget-democracy-now-linksto normalize these links. If a link starts with/, prependhttps://www.democracynow.orgto it.Hint: Use a helper function or an inline
ifexpression to check if the URI starts with/. In Hy, that might look like:hylang (defn normalize-url [url base-url] (if (.startswith url "/") (+ base-url url) url)) -
Keyword Filtering for Summaries:
Modify
create-npr-summaryinnpr_front_page_summary.hyso that it filters the headlines based on a set of target keywords (e.g., “Election”, “Climate”, “Musk”). The function should only include items where the text contains one of the user-specified keywords (case-insensitively).Hint: You can write a helper function
contains-any-keyword?usinganyand a list comprehension:hylang (defn contains-any-keyword? [text keywords] (any (lfor kw keywords (in (.lower kw) (.lower text)))))