Eingaben
Interaktivität wird in der Regel damit verbunden, dass ein Computersystem innerhalb kürzester Zeit auf Eingaben reagiert. Bevor wir uns jedoch im nachfolgenden Kapitel Rückmeldungen damit befassen, welche Forderungen daran zu stellen sind, untersuchen wir zunächt einmal, welche Forderungen an die Eingaben selbst zu stellen sind.
Eingaben sind vielfältiger Natur. Es können Zahlen, Namen oder auch Passwörter sein oder auch die Bestätigung einer Systemmeldung. Aus technischer Sicht sind alle Handlungen an einem Computer, die er bearbeiten kann, Eingaben. Wenn eine auf dem Tisch liegende Maus durch einen Stups bewegt wird und deshalb der Mauszeiger um einige Pixel seine Position ändert, dann ist das eine Eingabe in das System, auf das dieses mit einer Rückmeldung reagiert: der Mauszeiger wird an einer anderen Stelle auf den Bildschirm gezeichnet. Jede Mausbewegung ist eine Eingabe, jeder Tastenanschlag ist eine Eingabe ebenso wie jedes Berühren eines sensitiven Smartphone-Bildschirms.
In grafischen Nutzungsschnittstellen sind Eingaben in aller Regel mit expliziten räumlichen Eingabeelementen verbunden1. Deshalb lassen sich die im vorherigen Kapitel angestellten Überlegungen zur Kopplung von Reihenfolgen und Abfolgen auf die Anordnung der Eingabeelemente übertragen. Insbesondere die Betrachtungen zum Handlungsabschluss sind ein gutes Beispiel dafür. Dasselbe gilt für typische Navigationselemente. Buttons zum Blättern, wie zum Beispiel „Weiter“, sollten rechts, unten oder rechts unten platziert werden. Entsprechend gilt für das Zurückblättern die Anordnung links, oben oder links oben.
Ein eigenartiger Konflikt entsteht bei Nutzungsschnittstellen, die so aufgebaut sind, dass alle aktuellen Elemente zuoberst angezeigt werden. Dies trifft zum Beispiel oft auf Verlagswebseiten zu, bei denen die jeweils aktuellen Meldungen bezogen auf die Leserichtung zuerst und damit räumlich oben erscheinen. Das gleiche gilt auch für Blogs. Das Einfügen zu Beginn bedeutet, dass die weiteren Seiten frühere Inhalte anzeigen. Wo bringt man nun das Weiterblättern unter? Es entsteht eine inhärente Inkonsistenz. Da es sich um frühere Inhalte handelt, lässt sich eine Positionierung links rechtfertigen, Weiterblättern jedoch legt eine Positionierung rechts nahe. Der Konflikt ist schwer zu lösen. Vermeiden sollten Sie auf jeden Fall, auf der linken Seite „weiterblättern“ und auf der rechten Seite „zurückblättern“ zu schreiben. Wenn Sie sich für diese Aufteilung entscheiden, verwenden Sie „frühere Inhalte“ und „neuere Inhalte“. Letztere beziehen sich auf die zeitliche Reigenfolge der Inhalte und nicht auf ihre räumliche Platzierung und charakterisieren daher besser den intendierten Handlungsabschluss.
Auch das Prinzip der räumlichen Zuordnung lässt sich auf inhärent räumliche Eingaben übertragen, also Eingaben, bei denen Elemente im Raum bewegt oder anderweitig manipuliert werden. Das damit verbundene Problem der Kopplung translatorischer Bewegungsformen zu Lage- und Zustandsänderungen ist auch schon in der klassischen Ergonomie untersucht worden: Was passiert bzw. welche Erwartungen sind damit verbunden, wenn ein Schieber nach rechts oder links, nach oben oder unten oder auch nach hinten oder vorne geschoben wird?
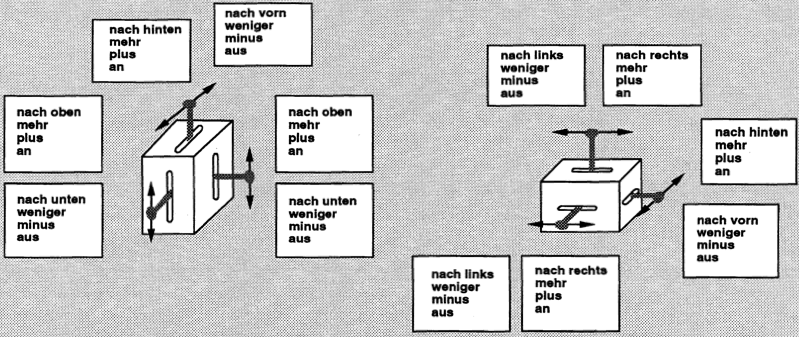
Manche Erkenntnisse aus diesen Untersuchungen können wir auf Slider und Anzeigeelemente in grafischen Nutzungsschnittstellen übertragen: Rechts wird stets mit mehr (größer, später, lauter, heller, …), links entsprechend mit weniger (kleiner, früher, leiser, dunkler, …) verbunden. Ebenso entspricht eine Bewegung nach oben einem „Mehr“ und nach unten einem „Weniger“. Diese Erkenntnis hilft uns bei der Gestaltung von Scrollbars und Einstellfeldern für Lautstärken und Helligkeiten, ebenso wie bei der schon angesprochenen Positionierung von Elementen zum Blättern.
Eingabenotwendigkeiten verringern
Da Eingaben allgegenwärtig sind, birgt eine ungeschickte Gestaltung ein großes Potenzial an erzwungener Sequenzialität. Wenn zum Erreichen eines Ziels Eingaben vom System gefordert werden, die für die Zielerreichung nicht notwendig sind, verkörpern diese erzwungene Sequenzialität. Doch wann ist eine Eingabe nicht notwendig? Bei einem Programm zur Addition zweier Zahlen wird man nicht umhinkommen, diese Zahlen zuvor einzugeben. Handlungsspielraum besteht aber sehr wohl bei den zusätzlichen Eingaben, die das Programm verlangt. Betrachten wir dazu zwei alternative, fiktive Gestaltungen. Die erste Variante erzwingt das Drücken eines Buttons, um den Vorgang zu starten. Dann erscheint ein Fenster, in das die erste Zahl einzugeben ist. Sobald dies geschehen ist, muss durch Drücken des Buttons „Fertig“ ein weiteres Eingabefeld für die Eingabe des zweiten Operanden geöffnet werden. Nachdem auch dieser Vorgang mit „Fertig“ abgeschlossen worden ist, erscheint ein Meldungsfenster, das die beiden Werte und das Ergebnis anzeigt. Für die Addition der zwei Zahlen 55 und 44 wäre die Eingabesequenz in dieser Design-Variante: Startbutton + Taste 5 + Taste 5 + Fertigbutton + Taste 4 + Taste 4 + Fertigbutton.
Nun eine alternative Gestaltung: Beide Eingabefelder und das Ausgabefeld sind direkt nach dem Programmstart zu sehen. Das erste Eingabefeld ist vorausgewählt, sodass unmittelbar ein Operand eingetippt werden kann. Um den zweiten Operanden eingeben zu können, kann entweder mit der Maus auf das zweite Eingabefeld geklickt oder durch das Drücken der Tabulator- oder Return-Taste ins zweite Feld gewechselt werden. Dort wird nun die zweite Zahl eingegeben2. Schon während der Eingabe wird ständig die Addition durchgeführt und in der Ausgabezeile darunter angezeigt. Die Eingabesequenz für die gleiche Addition sieht in diesem Programm wie folgt aus: Taste 5 + Taste 5 + Wechseloperation + Taste 4 + Taste 4.
Die Handlungssequenz in dieser zweiten Gestaltungsvariante ist kürzer, die Anzahl der von der Nutzungsschnittstelle notwendigerweise verlangten Eingabeschritte ist so weit reduziert worden, dass nur noch die der Aufgabe inhärente Sequenzialität verbleibt. Wir nennen dies „eingabeminimal“. Entsprechend ist für eine ergonomische Gestaltung die Forderung nach Eingabeminimalität zu erfüllen:
Im obigen Fall haben wir die Eingabeminimalität erfüllt. In den meisten Softwareprodukten wird das nicht so ohne weiteres gelingen, da nicht immer präzise und ausreichend umrissen werden kann, welche verschiedenen Nutzungsmöglichkeiten vorhanden sind und welche Eingaben jeweils dafür erforderlich sind. Eingabeminimalität zielt daher darauf ab, möglichst viele Eingaben zu identifizieren, die ohne Einschränkungen der Funktionalität oder der Handlungsmöglichkeiten reduziert werden können. Ob das Minimum jeweils erreicht wird, ist in der Regel nicht festzustellen und hängt nicht zuletzt auch von Innovationen und technischen Randbedingungen ab. Je mehr Eingaben aber reduziert werden können, desto besser die ergonomische Qualität.
Um Eingabeminimalität in diesem Sinne zu erreichen, gilt es, hilfreiche Techniken wie zum Beispiel inkrementelle Rückmeldung anzuwenden. Sie sorgt im obigen Beispiel dafür, dass das Ergebnis ständig neu berechnet wird und daher am Ende der Eingabe der Schritt zum Start der Berechnung gespart werden kann. Außerdem gilt es, eine Reihe von typischen Fehlern zu vermeiden, die in jedem Falle für übermäßig lange Eingabesequenzen sorgen.
Informationslose Eingaben vermeiden!
Eine vom System geforderte Eingabe sollte immer eine zusätzliche Information anfordern, um einen Sachverhalt genauer zu spezifizieren, etwas zu vervollständigen oder für eine Statusänderung an einem Objekt zu sorgen. Die Nutzungsschnittstellen-Handlungen, die dieses Kriterium nicht erfüllen, sind überflüssig und ein guter Kandidat, um entfernt zu werden.
Bestätigung von Optionsauswahl vermeiden!
Eine typischer Fall, in dem eine Eingabe minimiert werden kann, ist das Entfernen eines expliziten Bestätigungs-Buttons aus einer Auswahl von Optionen. Typisch sind solche Bestätigungs-Buttons etwa in Einstellungsfenstern, wo mehrere Änderungen zusammen mit einem Button übernommen und mit einem anderen verworfen werden können. Bei Fenstern, in denen komplexe oder umfangreiche Einstellungen vorgenommen werden können, geht das auch in Ordnung, denn es ermöglicht es, zunächst alle Einstellungen im Zusammenhang vorzunehmen, bevor sie jeweils bestätigt werden müssen.
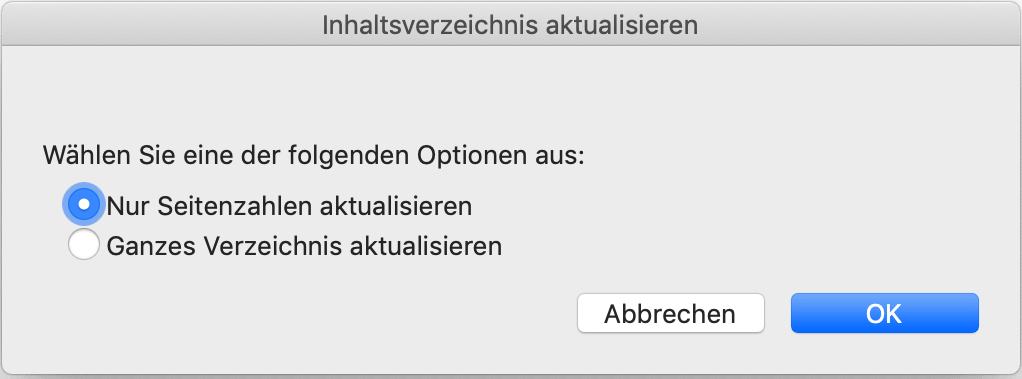
Eine Bestätigung dieser Art ist aber dann überflüssig, wenn es sich um die exklusive Auswahl eines einzigen Elements oder einer einzigen Option handelt. Ein schönes Beispiel für eine derart überflüssige Bestätigung einer exklusiven Auswahl findet sich in Microsoft Word. Das abgebildete Meldungsfenster erscheint, wenn das Inhaltsverzeichnis eines Dokuments aktualisiert werden soll. Es fordert dazu auf sich zu entscheiden, ob das gesamte Verzeichnis neu erzeugt werden soll oder nur die Seitenzahlen aktualisiert werden müssen. Die Entscheidung wird durch die Auswahl einer der beiden Optionen getroffen. Diese beiden Optionen sind exklusiv, schließen einander also aus. Man kann nur das eine oder das andere tun, nicht beides. Nachdem man sich entschieden hat, muss die Auswahl nochmal durch einen Klick auf „OK“ bestätigt werden. Diese Bestätigung trägt aber keinerlei neue Information bei. Sie ist ein nutzloser zusätzlicher Schritt, mit dem lediglich entschieden wird, ob die zuvor getätigte Auswahl auch angewandt werden soll.
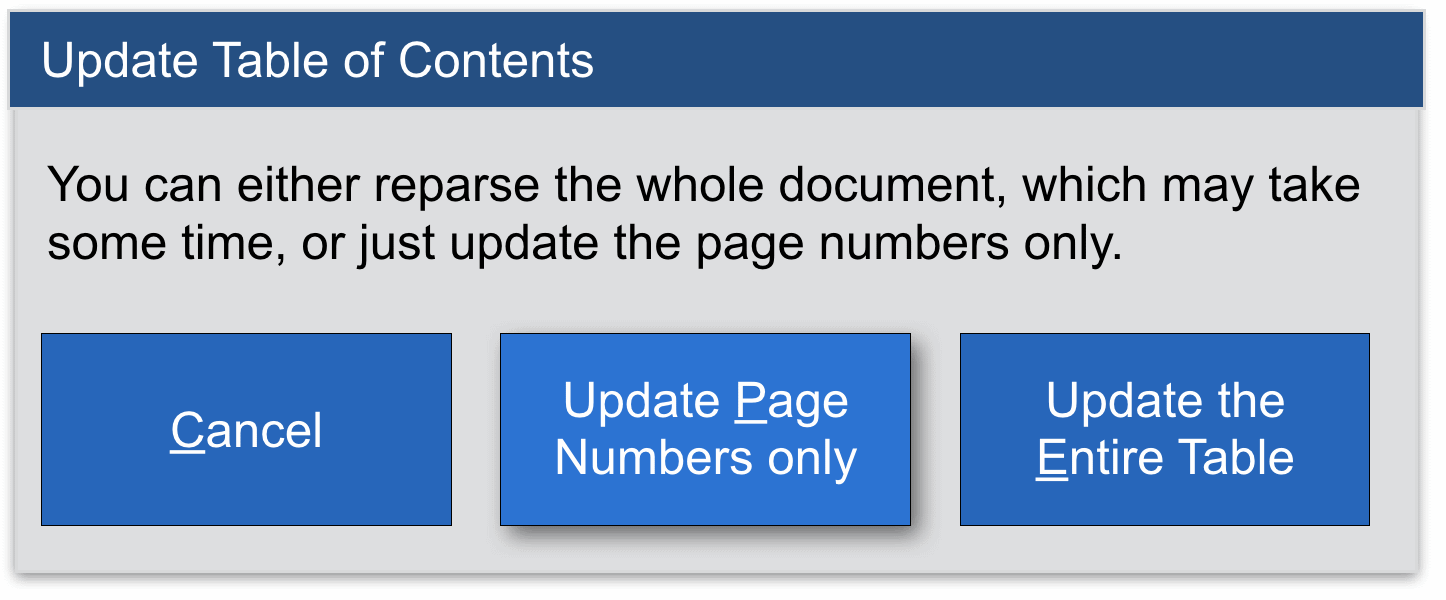
Im Beispiel gibt es genau drei Möglichkeiten der Handlung: Man kann nichts tun (abbrechen), nur die Seitenzahlen anpassen oder das Inhaltsverzeichnis komplett aktualisieren. Diese Alternativen kann man direkt in Form von Buttons anbieten. Die Überarbeitung ist übersichtlicher als vorher, da weniger Elemente auf dem Bildschirm zu sehen sind. Sie ist direkt auf die Aktion ausgerichtet, also auch mental einfacher zu bewältigen, und sie spart im besten Fall einen Klick ein. Die ursprüngliche Meldung hat übrigens noch ein weiteres Problem, das wir an dieser Stelle gleich mitbehoben haben: Das von Microsoft gestaltete Auswahlfenster schweigt sich nämlich dazu aus, was es mit der Auswahl überhaupt auf sich hat, warum sie also erscheint. Dies verletzt unsere Forderung nach Differenziertheit, die wir im folgenden Kapitel besprechen werden.
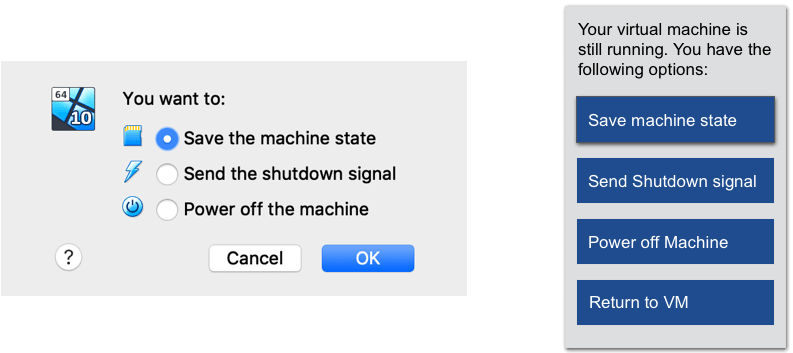
Word steht mit der Einforderung einer unnötigen Auswahlbestätigung nicht alleine da. Die oben abgebildete Auswahl erscheint, wenn in VirtualBox eine virtuelle Maschine beendet wird. Sie offenbart mehr als ein ergonomisches Problem: Der einleitende Text beispielsweise ist sinnlos. Auch auf die Titelzeile „You want to:“ hätte man verzichten können, denn sie liefert keine Zusatzinformation und spekuliert über die Absichten der Person vor dem Bildschirm. Ob ihr die angebotenen Optionen erwünscht erscheinen, ist an dieser Stelle nicht relevant. Abgesehen von dieser Eigenartigkeit tritt auch in diesem Beispiel das Problem der notwendigen Bestätigung der exklusiven Auswahl auf: Es gibt eine Auswahl, die dann nochmal per „OK“ bestätigt werden muss. Auch in diesem Fall können die Alternativen direkt als Buttons angeboten werden.
Wahrscheinlichkeit für Eingabenotwendigkeit verringern
In den obigen Beispielen ist der Schritt der Eingabebestätigung in jedem Fall überflüssig. Es gibt keinen Grund, die Alternativen jemals mit diesem Zusatzschritt zu gestalten. Eine solche Eindeutigkeit ist aber selten. In vielen Situationen wird es nicht verlässlich möglich sein, Eingabesequenzen zu verkürzen, da nicht alle Nutzungskonstellationen vorhersehbar sind. Es gibt aber Möglichkeiten, das Auftreten einer unnützen Eingabe zu verringern.
Die Notwendigkeit von Eingaben lässt sich prinzipiell senken, wenn die Objekte am Bildschirm schon in einem gut passenden Zustand sind, wenn also dem Angezeigten nichts oder nur wenig hinzugefügt werden muss. Es gibt verschiedene Techniken, um dies zu erreichen.
Standardwerte
Gut gewählte Standardwerte verringern die Notwendigkeit einer Eingabe und damit auch erzwungene Sequenzialität, da ein Standardwert, wenn er gut gewählt ist, mit hoher Wahrscheinlichkeit nur bestätigt oder geringfügig angepasst werden muss. Standardwerte sind abhängig von den jeweiligen Aufgaben und müssen im Rahmen der Gebrauchstauglichkeit erarbeitet werden. Wenn es jedoch aufgrund von sehr heterogenen Nutzungsumgebungen nicht möglich sein sollte, für alle Situationen gleichermaßen passende Standardwerte zu ermitteln, gibt es noch einige Möglichkeiten, die Misere zu lindern.
- Konfigurierbare Standardwerte: Standardwerte können anpassbar gestaltet werden, womit aber zugleich die Komplexität erhöht wird. Außerdem kann nicht vorausgesetzt werden, dass die Möglichkeiten zur Anpassung von Standardwerten bei der Nutzung bekannt sind. Wichtiger aber noch ist, dass verlässliches Wissen vorhanden ist, dass angemessene Anpassungen von der Software generiert werden können. Weiteres dazu findet sich in unseren Hinweisen zur Anpassbarkeit)
- Zurückgreifen auf das zuletzt verwendete Objekt oder den zuletzt verwendeten Wert: In vielen Anwendungssituationen kann es schon eine große Erleichterung sein, wenn eine zuletzt gewählte Option direkt wieder zur Verfügung steht. Eine dynamischere Variante erlaubt eine Auswahl der zuletzt gewählten Eingaben (Verlaufsgeschichte). Zu bedenken ist, dass es bei gemeinsamer Computernutzung zu einem Datenschutzproblem oder einem Privatsphärenproblem kommen kann. Diese Art der Standardwertbestimmung sollte deshalb mit größter Zurückhaltung eingesetzt werden.
- Zurückgreifen auf das am häufigsten verwendete Objekt oder den zuletzt verwendeten Wert: Dem letzten Punkt sehr ähnlich ist die Bestimmung eines Standardwerts gemäß der Häufigkeit der vorangegangenen Eingaben. In diesem Fall kommt aber hinzu, dass sich der Standardwert dann ohne direkte vorherige Handlung ändern kann, was unter Umständen schwer nachvollziehbar ist. (Siehe hierzu unsere Hinweise zur Adaptivität im Zusammenhang mit der Anpassbarkeit.)
Ein Standardwert und die mit ihm verbundene Reduzierung von Sequenzialität können übrigens auch zu einem Problem werden. Dies gilt beispielsweise beim Einsatz von medizinischen Geräten, wo durch eine Fehleinstellung von Werten gravierende Schäden verursacht werden können. Wo immer dies der Fall ist, sollten keine Standardwerte vorgegeben werden. Das erhöht zwar den Eingabeaufwand, der in diesen Fällen jedoch gerechtfertigt ist, weil er die Aufmerksamkeit auf den einzugebenden Wert lenkt.
Fill-By-Click
Standardwerte zu verwenden bedeutet, die Eingabewahrscheinlichkeit zu senken, indem auf eine frühere gespeicherte Eingabe referenziert wird. Auf ähnliche Art und Weise funktioniert die „Fill-By-Click“-Technik. Allerdings liegt die Referenz, aufgrund derer ein Feld ausgefüllt wird oder ein Objekt vorausgewählt wird, nicht in der weiteren Vergangenheit, sondern in einer gerade erst getätigten Eingabe. Ein typisches Beispiel für Fill-By-Click ist das Ausfüllen von Bestellformularen. Neben weiteren Daten muss auch eine Lieferadresse angegeben werden. Zusätzlich ist vor dem Abschluss der Bestellung die Rechnungsadresse gefragt. In vielen Fällen sind diese identisch. Fill-By-Click bedeutet, dass mit nur einem Klick die Lieferadresse als Rechnungsadresse übernommen werden kann, statt gezwungen zu sein, die gleichen Daten erneut einzugeben.
Fill-By-Click verdeutlicht auch, dass potenzielle Eingabeaufwände in verschiedenen Situationen gegeneinander abgewogen werden müssen. In der gerade geschilderten Implementierung verringert sich die erneute aufwändige Eingabe der Adresse bestenfalls auf einen Klick. Gesetzt den Fall, dass eine andere Adresse eingegeben werden soll, hilft das zwar nicht, doch entsteht auch kein Zusatzaufwand (lediglich etwas Platz für die Unterbringung der Klickbox). Würde die Adresse automatisch ohne den zusätzlichen Klick direkt übernommen, könnte im besten Fall zwar ein Klick mehr eingespart werden, aber der Eingabeaufwand für die abweichende Adresse wird deutlich größer und fehleranfälliger, weil auch der angezeigte nicht passende Text jetzt bearbeitet werden muss.
Voneinander abhängige Eingaben automatisieren
Die automatische Übernahme von Daten ist also nicht immer geboten. Es ist jedoch dann problemlos möglich und auch gefordert, wenn sich eine Eingabe direkt und zwangsläufig aus einer anderen Eingabe ableiten lässt.
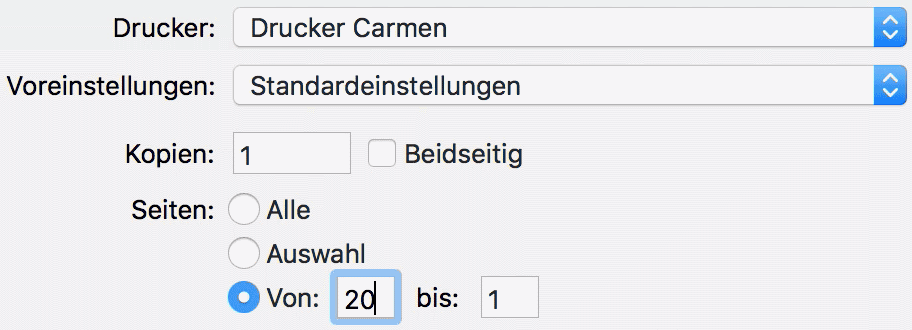
Die Abbildung zeigt einen solchen Fall: die Einstellungen für eine Druckerausgabe. Interessant für uns sind die Felder „Von“ und „bis“. Im aktuellen Zustand stehen beide Werte auf 1. Setzen Sie bei „bis“ eine 5 ein, passiert nichts. Erhöhen Sie nun den „Von“-Wert auf 10, wird auch der „bis“-Wert auf 10 gesetzt. Ändern Sie dann „Von“ wieder auf 3, passiert wiederum nichts. Der „bis“-Wert wird in Abhängigkeit vom „Von“-Wert automatisch ausgefüllt, aber eben nur dann, wenn der „Von“-Wert über den bisherigen „bis“-Wert erhöht wird. Das Resultat ist, dass die Wahrscheinlichkeit für eine notwendige Eingabe sinkt und zugleich ungültige Angaben wie „Von 10 bis 3“ abgefangen werden. Somit wird auch der Aufwand für notwendige Fehlerkorrekturen verringert.
Ein anderes Beispiel tritt bei der Eingabe von Adress- oder Bankdaten auf, wenn bei der Eingabe einer IBAN oder einer Bankleitzahl zusätzlich noch der Name der Bank eingegeben werden muss. Da die IBAN bereits den Namen der Bank eindeutig festlegt, handelt sich zum einen um eine unnötige Eingabe. Zum anderen unterstützt das automatische Anzeigen des Banknamens das Erkennen einer nicht korrekten IBAN, denn in diesem Fall wird kein Bankname angezeigt. Die Einsicht, dass die IBAN in diesem Fall nicht stimmen kann, spart gegenüber einer erst später auftretenden Fehlerdiagnose zusätzliche Schritte beim Korrigieren ein. Die Reduzierung erzwungener Sequenzialität reduziert in solchen Fällen also nicht nur Schritte zur Eingabe von Daten, sondern reduziert durch die unmittelbare Auswertung der Eingabe auch den Zusatzaufwand, der zur Korrektur derselben zu einem späteren Zeitpunkt erforderlich würde.
Optionen einschränken
Standardwerte, Fill-By-Click und das automatische Ausfüllen sorgen dafür, dass Eingaben nicht gemacht werden müssen, weil sie vorausgewählt oder die entsprechenden Felder bereits mit Werten ausgefüllt sind, die mit großer Wahrscheinlichkeit nicht geändert werden müssen. Es gilt jedoch, die Flexibilität zu erhalten, denn jeder Wert kann immer noch geändert werden. In Fällen, in denen aufgrund der jeweiligen Anwendungssemantik bestimmte Eingaben nicht zulässig sind, verbessern diese Techniken nicht nur die Eingabeminimalität, sondern verringern auch die Wahrscheinlichkeit von Fehleingaben und den Aufwand zu ihrer späteren Korrektur.
Aufgabenspezifische Eingabebeschränkungen
Dieser Effekt lässt sich durch die Einschränkung der möglichen Eingaben verstärken. Ein typisches Beispiel dafür ist, eine Altersangabe nicht über ein Freitextfeld zu erfassen, sondern einen Feldtyp zu nutzen, in dem nur Zahlen eingegeben werden können. Auch durch die Nutzung eines Auswahlfeldes, in dem alle möglichen Eingaben angeboten werden, trägt zur Reduktion von Korrektureingaben bei, kann aber auch zu Designkonflikten führen, da der Aufwand zur Präsentation von mehr als hundert möglichen Geburtsjahren entsprechend Platz verbraucht und die Auswahloperation zusätzlichen Bewegungsaufwand verursacht. In diesen Fällen müssen im Rahmen der Gebrauchstauglichkeit entsprechende Prioritäten ermittelt werden.

Diese Abbildung zeigt ein gutes Beispiel für eine Eingabebeschränkung dieser Art. Bestimmte Zeichen sind in Dateinamen unter Windows, wie in den meisten Betriebssystemen, nicht zulässig. Windows nimmt die Eingabe eines der verbotenen Zeichen gar nicht erst an. Es kommt also nie dazu, dass der gerade angezeigte Dateiname ungültig ist. Stattdessen wird die Eingabe des nicht akzeptablen Zeichens verworfen und gleichzeitig direkt an Ort und Stelle eine Fehlermeldung eingeblendet, die über diesen Umstand informiert.
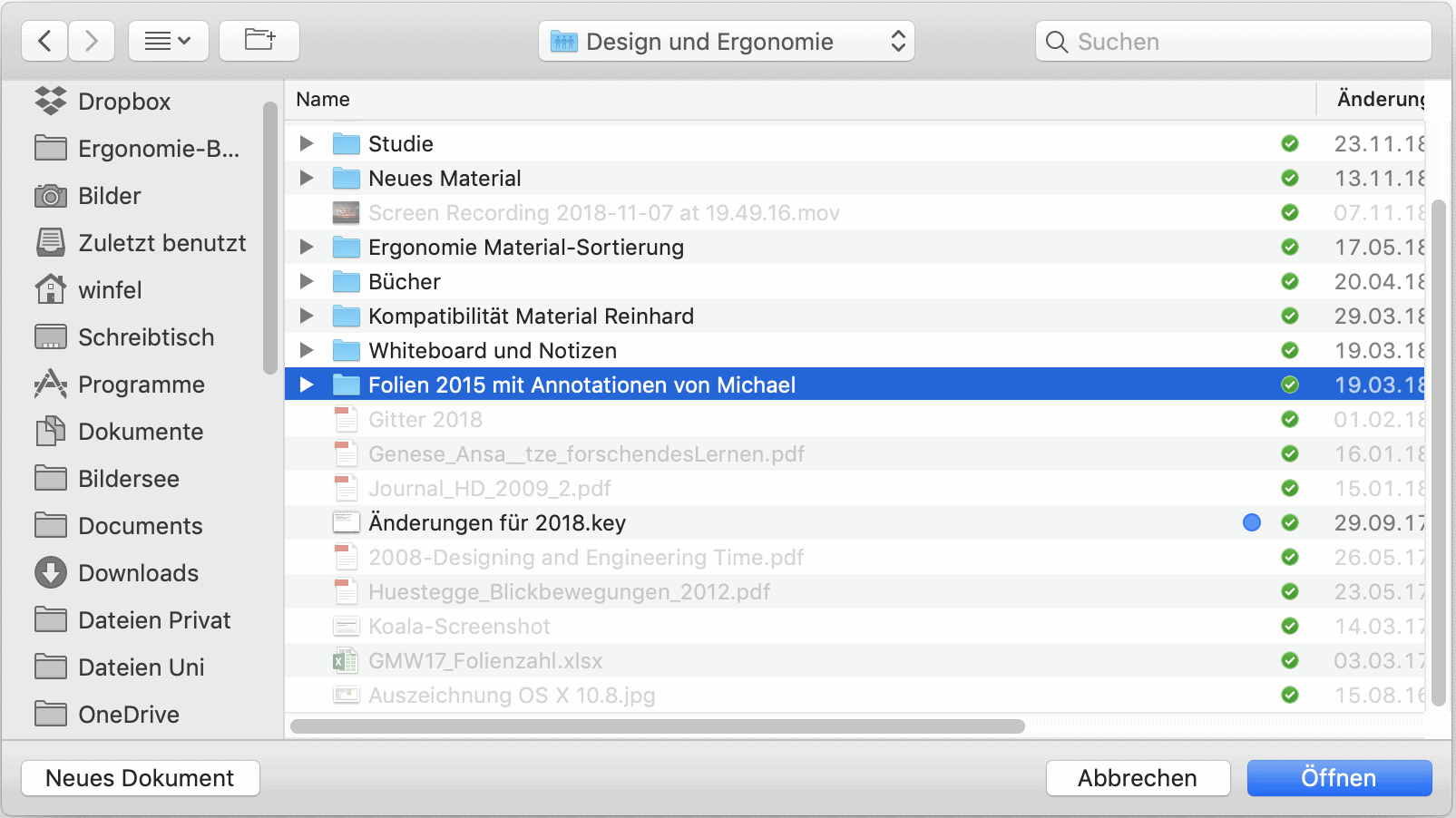
Eine weitere Möglichkeit zur Einschränkung von Fehleingaben zeigt dieses Fenster zum Öffnen von Dateien. Über den Datei-Öffnungs-Dialog werden alle Dateien wie im Dateimanager angezeigt und damit erreichbar, was die Orientierung unterstützt. Nur die Dateien, die von der Software auch geöffnet werden können, sind jedoch auswählbar. Alle anderen Elemente werden ausgegraut dargestellt und sind weder mit der Maus noch über die Tastatur anwählbar. Das verringert die Möglichkeit von Fehleingaben und, vor allem bei der Auswahl per Pfeiltasten, die Anzahl der Eingaben zum Erreichen eines Objekts, da alle ausgegrauten Einträge übersprungen werden.
Anschlusshandlungen erleichtern
Welche Handlungsschritte in welcher Abfolge durchgeführt werden, ist maßgeblich von der zu erledigenden Aufgabe anhängig, aber auch vom Wissen und von individuellen Vorlieben bei der Nutzung. Eine große Vielfalt von Alternativen hat zur Folge, dass manche Wege zum Ziel lang und nicht offensichtlich sind. Die daraus resultierenden Handlungsfolgen können verkürzt werden, indem einzelne Handlungsschritte, die mit hoher Wahrscheinlichkeit aufeinander folgen, so abgebildet werden, dass sie ohne großen Eingabeaufwand und ohne Sucherfordernisse direkt angeschlossen werden können.
Angebot häufig genutzter (Neben-)Handlungen
Eine Möglichkeit einer solchen Verkürzung ist das direkte Anbieten von Nebenhandlungen, die in einer bestimmten Situation bekanntermaßen häufig genutzt werden.
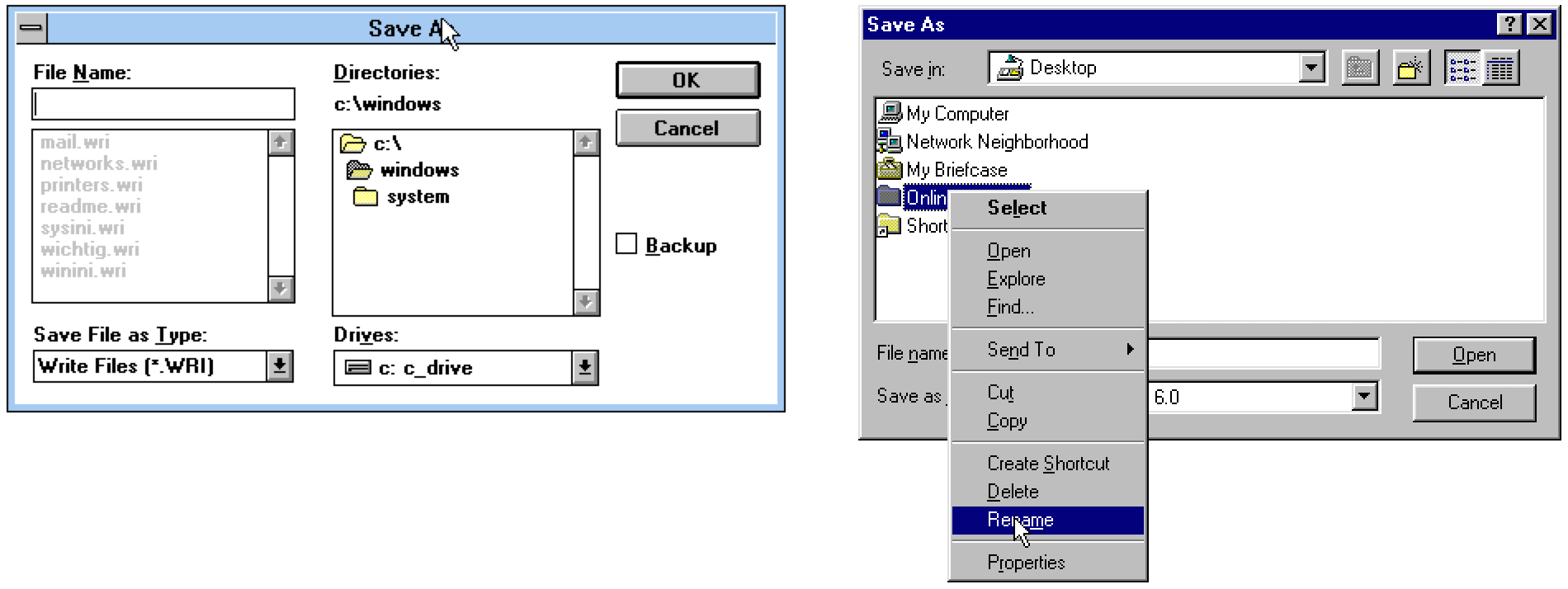
Diese Abbildungen zeigen eine Gegenüberstellung von typischen Datei-Speichern-Dialogen von Windows 3.1 und Windows 95. Die Variante in Windows 3.1 erfüllt ihren eigentlichen Zweck. Ein Verzeichnis zum Speichern kann ausgewählt und ein Dateiname eingegeben werden. Diese Funktionalität reicht aus, eine Datei in einem vorhandenen Ordner abzuspeichern. Die Windows-95-Variante bietet aber weitaus mehr Funktionen. Sie trägt dem Umstand Rechnung, dass oftmals erst beim Speichern deutlich wird, dass die Ordnerstruktur nicht optimal ist oder die zu speichernde Datei besser in einem neuen, noch nicht bestehenden Ordner abgelegt werden sollte. Es ist daher möglich, direkt innerhalb des Speichern-Dialogs einen neuen Ordner anzulegen, indem auf ein Icon in der Toolbar geklickt oder das Kontext-Menü per rechtem Mausklick geöffnet wird. Genauso einfach ist es möglich, Ordner und andere Dateien umzubenennen oder zu löschen. Im Fall von Windows 3.1 müsste man dazu die Speicherhandlung unterbrechen, das Programm wechseln, um im Dateimanager die Änderungen vorzunehmen, um dann wieder zurückzukehren und die eigentliche Speicherung vorzunehmen. Alternativ hätte man die Datei zunächst am unpassenden Speicherort ablegen und dann später die gewünschte Ordnerstruktur herstellen können. In beiden Fällen kann man das Ziel erreichen, nur ist der Aufwand im Windows-95-Fall erheblich geringer und erfordert inbesondere keinen Wechsel in ein anderes Programm.
Der Speichern-Dialog von Windows 95 bietet häufig erforderliche Dateisystemoperationen an Ort und Stelle an. Verallgemeinert kann man daraus schließen: Immer dann, wenn im Laufe einer Handlungsfolge bestimmte Nebenhandlungen sehr häufig ausgeführt werden müssen, sollten diese Nebenhandlungen auch direkt angeboten werden. Die Voraussetzung dafür ist, dass die Nebenhandlungen bekannt oder angemessen erhoben worden sind.
Direktes Angebot aller intendierten Handlungsoptionen
Eng verwandt mit dem Angebot häufig genutzter Nebenhandlungen ist das direkte Angebot aller durch die Software ermöglichten Handlungsoptionen. Dabei geht es nicht, wie oben, um das Anbieten von Nebenhandlungen, die nur lose mit der eigentlichen Handlung verbundenen sind, sondern um die Handlungsoperationen direkt anzubieten, die im Handlungsverlauf ohnehin notwendig sind. Das spart lästige Umwege.
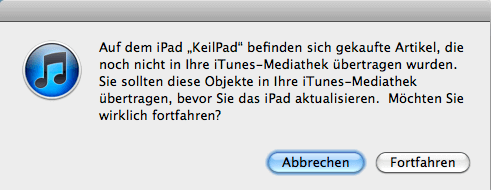
Das Beispiel aus Apples Medienverwaltung iTunes verdeutlicht dieses Problem. Das Meldungsfenster informiert darüber, dass zunächst Objekte von einem angeschlossenen iPad übertragen werden sollten, bevor man fortfährt. Um dies zu tun, muss man zuerst auf „Abbrechen“ drücken, dann in der Anwendung die Übertragungsfunktion suchen und diese schließlich starten. Es wird präzise gesagt, was zu tun ist, ohne diese Möglichkeit direkt anzubieten. Wenn der folgende Schritt aber derart klar ist, ist es auf jeden Fall erzwungene Sequenzialität, ihn nicht anzubieten. Dies könnte direkt an Ort und Stelle innerhalb der Warnmeldung durch das Hinzufügen eines weiteren Buttons erfolgen.

Meldungen dieser Art gibt es erstaunlich oft. In dieser Meldung wird genau beschrieben, welche Menüpunkte anzuklicken sind, um das Dokument wie gewünscht mit Hilfe von „Speichern unter“ abzulegen. Auch hier sollte also die jeweilige Funktion direkt aufrufbar sein. Man könnte sogar noch einen Schritt weiter gehen und gleich an Ort und Stelle einen Dateinamen zur Speicherung erfragen.
Dieses unten abgebildete Beispiel von Ende der 1980er Jahre des Editors Tempus, der auf dem Atari ST lief, zeigt sehr schön, wie man es besser machen kann. Die Meldung erscheint, wenn mit der Funktion „Speichern unter“ ein bereits existierender Dateiname ausgewählt worden ist. In der Meldung werden die nun möglichen Handlungen nicht nur beschrieben, sondern auch direkt angeboten. „Abbrechen“ muss also in der Tat nur gedrückt werden, wenn man nicht speichern will. Etwas verwirrend ist allerdings die Option „Umbenennen“, aus der nicht hervorgeht, ob ein neuer Dateiname für die gerade zu speichernde Datei gewählt oder ob die bereits vorhandene Datei umbenannt werden soll.

Interaktive Potenziale nutzen
Im Grundlagenteil unseres Buchs haben wir die Potenziale interaktiver Nutzungsschnittstellen beschrieben und gezeigt, dass interaktive, digitale Systeme viele Einschränkungen analoger Medientechniken ebenso wie auch nicht interaktiver Datenverarbeitung überwinden können. Werden diese Potenziale nicht ausgeschöpft, können daraus ergonomische Probleme folgen, weil unnötige Eingaben erzwungen werden, um das zu erreichen, was auch ohne weitere Eingaben möglich wäre.
Flexible Granularität
Analoge Medien erzwingen grundsätzlich eine Entscheidung, ob ein Arrangement bearbeitbar ist oder ob es einen fixen, persistenten Charakter hat. Moderationstechniken beispielsweise nutzen kleine Karten zur individuellen Beschriftung, die dann in einem Gruppenprozess an Stelltafeln festgesteckt, gruppiert und annotiert werden. Will man das Ergebnis zu einem späteren Zeitpunkt oder an einem anderen Ort nutzen, kann man entweder versuchen, jeweils die Stelltafeln mit ihren Karten und Annotationen aufzubewahren bzw. zu transportieren oder man fotografiert das gesamte Arrangement. Im ersten Fall haben wir viele kleine Objekte in einem fragilen Arrangement, das auch weiterbearbeitet werden kann, im zweiten Fall nur ein monolithisches Objekt mit einer festen Anordnung der Elemente. Das Foto kann zwar einfach vervielfältigt und übertragen, jedoch nicht mehr verändert werden. Der damit verbundene Konflikt „Persistenz versus Bearbeitbarkeit“ kann in digitalen Systemen, angepasst an die Aufgabe und die Situation, flexibel aufgelöst werden.
Digitale Medien erlauben es, Objekte sowohl bearbeitbar als auch persistent zu halten. Sie ermöglichen auch, Objekte flexibel mal als Einzelobjekt und mal als Teil eines umfassenden Gesamtobjekts zu bearbeiten. Dieses Potenzial digitaler Medien ist die Voraussetzung dafür, dass die Objektgranularität nicht von vornherein festgelegt werden muss. Die flexible Granularität erweist sich beispielsweise bei der Gruppierung von Objekten in einer Präsentations-Software als besonders hilfreich. Die Folienobjekte können zeitweise zu einem einzigen Objekt verschmolzen, aber auch wieder auseinandergenommen und weiter einzeln bearbeitet werden. Diese Flexibilität stellt aber hohe Anforderungen an die Nutzungsschnittstelle, die für alle Operationen, die die Granularität verändern, entsprechende Funktionen bereithalten muss, die dann ihrerseits wieder Eingabeaufwand erzeugen.
Viel Eingabeaufwand beim Erstellen und Auflösen von Objektgruppen lässt sich sparen, wenn Objekte ohne granularitätsverändernde Operation sowohl als Teil eines Gesamtobjekts als auch als Einzelobjekt ansprechbar und bearbeitbar sind. Gelegentlich will man etwa Teilobjekte eines zusammengesetzten Objekts ändern, ohne dass sich die anderen Teile der Gruppe ändern. Wenn das nur möglich ist, indem zuvor die Gruppe aufgelöst wird, entsteht viel erzwungene Sequenzialität: das Gesamtobjekt auswählen, die Gruppierung aufheben, das Teilobjekt selektieren, die Änderung durchführen, alle durch die Aufhebung entstandenen Teilobjekte wieder auswählen und die Gruppe erneut erstellen. Abgesehen davon, dass dies aufwändig ist und dass sich beim Neuerstellen einer Gruppierung leicht Fehler einschleichen können, kommt noch hinzu, dass das ursprüngliche Gesamtobjekt ja zwischenzeitlich zerschlagen wird, sodass auch alle Attribute und Eigenschaften des Gesamtobjekts erneut hergestellt werden müssen. Das ist beispielsweise der Fall, wenn das Gesamtobjekt mit Animationsfeatures versehen ist.
In gängigen Präsentationsprogrammen ist der Aufwand zur Entgruppierung und Neugruppierung nicht mehr nötig, da für die Bearbeitung eines Teilobjekts nicht mehr die Auflösung der umfassenden Gruppe erforderlich ist. Die zusätzlich erforderliche Spezifikation, auf welches Objekt sich eine Selektion jeweils bezieht, ist gegenüber der eingesparten erzwungenen Sequenzialität vernachlässigbar klein. Es kann dafür eine Zusatzoperation wie zum Beispiel ein Dreifachklick, eine konsekutive Selektion, bei der zuerst das Gesamtobjekt und mit der anschließenden Selektion das Teilobjekt angesprochen wird, oder eine Modus-Taste festgelegt werden. Allerdings sind bezüglich des Einsatzes von Modi besondere Randbedingungen zu beachten, auf die wir im Kapitel Modusgestaltung eingehen.
Wiederverwendbare Ein- und Ausgaben
Eines der wichtigsten Potenziale interaktiver Schnittstellen ist, dass eine Ausgabe zu einer Eingabe werden kann. Dies war, wie wir schon beschrieben haben, ein essenzieller Punkt für die Entwicklung interaktiver Systeme. Es war das Ziel, den durch die organisatorische, räumliche und zeitliche Trennung von Ein- und Ausgaben bedingten Aufwand zu reduzieren, indem sowohl die Eingaben als auch die Ausgaben unmittelbar und direkt am Computer weiterverarbeitet werden können. Diese Art der Wiederverwendbarkeit erfordert, dass jede Eingabe und jede Ausgabe ein Objekt verkörpern, das an anderer Stelle und zu einem anderen Zeitpunkt weiterverwendet werden kann. Anders formuliert: Etwas, das schon einmal in den Computer eingegeben oder von ihm ausgegeben worden ist, muss nicht erneut eingegeben werden, unabhängig davon, um was für einen Typ (Text, Datei, Grafik usw.) es sich handelt.

Es gibt in der Praxis immer noch viele Fälle, in denen eine Ausgabe des Systems nicht direkt als Eingabe an anderer Stelle zur Verfügung steht, sondern neu getätigt werden muss. Wir beginnen mit dem Klassiker dieses Problems, das bei der Arbeit mit einer Kommandozeile auftritt. Die Ausgabe eines Befehls, also die Dateinamen, die mit dem ls-Befehl aufgelistet werden, stehen nicht als Objekt zur Verfügung. Sie müssen im nächsten Schritt erneut eingegeben werden. Mit Techniken moderner Nutzungsschnittstellen ist das nicht mehr erforderlich, denn es ist vom Grundsatz her möglich, eine händische Eingabe zu ersetzen, indem auf eine vorherige Eingabe oder eine vorherige Ausgabe verwiesen wird. Nehmen wir als Beispiel das Buchungssystem einer Bahngesellschaft. Wir suchen dort eine Verbindung durch die Eingabe von Start und Ziel. Das gewählte Ziel, beispielsweise Frankfurt, ist nicht eindeutig. Das System reagiert darauf, indem es mehrere Ziele, zum Beispiel Frankfurt an der Oder und Frankfurt am Main, zur Auswahl anbietet. Die auf dem Bildschirm befindliche Ausgabe kann nun automatisch durch Klicken auf „Frankfurt am Main Hbf“ in eine neue Eingabe verwandelt werden.
Bei der Wiederverwendung von Ein- und Ausgaben muss einschätzbar sein, welche Ausgaben und welche Eingaben potenziell wiederverwendet werden sollen. Innerhalb einer Anwendung, bei der man den Bearbeitungsprozess gut einschätzen kann, ist das noch relativ gut möglich. Problematisch wird es, wenn verschiedene Anwendungsprogramme zum Einsatz kommen. Um dann Wiederverwendbarkeit zu gewährleisten, müssten alle Anwendungsprogramme beliebige Ein- und Ausgaben in einer anderen Anwendung referenzieren können. Das wird so einfach nicht funktionieren, denn Anwendungsprogramme erzeugen durch ihre Programmierung eine eigene virtuelle Objektwelt, die oft nur in diesem Anwendungskontext existiert. Erst durch diese Programmierung werden Datenstrukturen innerhalb des Speichers zu Objekten, die wahrgenommen und manipuliert werden können. Wenn nun über Anwendungsgrenzen hinweg Ausgaben und vorherige Eingaben als neue Eingaben verwendet werden sollen, müssen die Anwendungsprogramme über eine kompatible Programmierung mit entsprechenden Datenstrukturen verfügen, denn nur dann ist das, was in einem Programm ein Objekt verkörpert, auch ein Objekt in anderen Programmen.
Diesem grundsätzlichen Problem kann nur mit übergreifenden Standards begegnet werden. Relevante Standards fangen schon bei so grundlegenden Aspekten wie der Zeichencodierung an. Nur dadurch, dass ein Editor eine gespeicherte Zahlenfolge auf gewisse Art und Weise interpretiert, entsteht ein Wort als manipulierbares Objekt am Bildschirm. Dieses Wort lässt sich je nach Blickwinkel als frühere Eingabe oder als Ausgabe interpretieren. Soll es in einem anderen Programm zur Eingabe werden, ist die Grundvoraussetzung, dass die gleiche Zeichencodierung verwendet oder zumindest als Eingabe akzeptiert werden kann. Glücklicherweise hat sich die Computerwelt in eine Richtung entwickelt, in der es viele Standardformate auf unterschiedlichen Ebenen gibt, angefangen bei Unicode über Containertechnologien wie Microsofts Object Linking and Embedding (OLE) bis hin zu einer jeweils systemweiten Zwischenablage. Diese Techniken ermöglichen es Objekten, die Anwendungsgrenzen relativ gut zu überwinden.
Klassische generische Lösung: Kopieren, Ausschneiden, Einfügen
Die Zwischenablage und die mit ihr verbundenen Funktionen Kopieren, Ausschneiden und Einfügen ermöglichen es, Objekte ziemlich flexibel sowohl innerhalb von Anwendungen als auch zwischen Anwendungen zu verschieben und zu kopieren. Kopieren und Ausschneiden sind in der Computernutzung so allgegenwärtig, dass aus dem Blickfeld gerät, dass es sich eigentlich oft um eine Rückfalllösung handelt, wenn es anders nicht möglich ist. Warum das so ist, wird an der bereits von uns vorgestellten Lösung des Fill-By-Click deutlich. Zur Erinnerung: In einem digitalen Formular, in das bereits eine Lieferanschrift eingegeben worden ist, kann diese durch einen Klick auf einen Button auch als Eingabe für die Rechnungsanschrift übernommen werden. Wir haben, als wir diese Technik vorstellt haben, noch nicht von „wiederverwendbaren Ein- und Ausgaben“ gesprochen, doch genau um solche handelt es sich. Die vorherige Eingabe der Adresse kann direkt wieder als Eingabe übernommen werden. Wäre diese Möglichkeit bei der Entwicklung nicht bedacht worden, könnte man immer noch die Neueingabe erheblich erleichtern, indem die Adresse Feld für Feld erst kopiert und dann an der neuen Stelle einfügt wird. Dieser Umweg über die Zwischenablage ist sehr hilfreich, aber doch immer noch ein Umweg, den man vermeiden kann.
Kopieren und Einfügen sind eine gute Lösung, wenn es nicht absehbar ist, wo und wie die Übernahme ablaufen wird. In diesem Fall spielt die Zwischenablage ihre große Stärke aus, prinzipiell generisch zu sein und potenziell alles mit allem verbinden zu können. Die klassische Implementierung der Zwischenablage hat übrigens das große Manko, dass immer nur das zuletzt in die Zwischenablage Kopierte zur Verfügung steht. Somit sind frühere Eingaben oder frühere Ausgaben, die in der Zwischenablage gelandet sind, oft nach kurzer Zeit wieder verloren, obwohl sie noch gebraucht werden könnten. Microsoft versucht momentan, ab Windows 10 diesem Manko durch die Einführung einer komplexeren Zwischenablage abzuhelfen.
Möglichst jede Eingabe und Ausgabe wiederverwendbar machen
Zur Erfüllung der Forderung, möglichst jede Ein- und Ausgabe wiederverwenden zu können, ist eine Zwischenablage zusammen mit den Funktionen Kopieren und Einfügen eine gute Technik. Allerdings müssen die Voraussetzungen innerhalb der Software geschaffen werden, dass sie auch anwendbar sind. Entsprechend müssen Ein- und Ausgaben so gestaltet sein, dass sie in die Zwischenablage kopiert werden können. In Bezug auf die Eingabe ist das in der Regel kein Problem, doch viele Ausgaben sind so gestaltet, dass sie nicht kopiert werden können. Dies betrifft zum Beispiel Fehlermeldungen in nativen Anwendungen. Der Text der Fehlermeldung kann oft weder komplett noch auszugsweise in die Zwischenablage kopiert werden. Doch auch eine Fehlermeldung ist eine Ausgabe des Systems, die an anderer Stelle zur Eingabe werden könnte, wenn sie beispielsweise in der schriftlichen Kommunikation für ein Hilfeersuchen benötigt wird.
Auch Fehleingaben erhalten!
Kopieren und Einfügen funktioniert so lange, wie die Inhalte, die wiederverwendet werden sollen, noch am Bildschirm verfügbar sind oder zumindest verfügbar gemacht werden können. Ein Problemfall, in dem das nicht mehr gegeben ist, sind Eingaben, die im Kontext der Software fehlerhaft gewesen sind. Diese werden von Nutzungsschnittstellen häufig direkt verworfen. Oft ist aber der Aufwand geringer, die Fehleingabe in eine richtige Eingabe umzuwandeln, als die Eingabe komplett zu wiederholen. Ein klassisches Beispiel ist eine Abfrage von Anmeldeinformationen. Werden diese nach Bestätigung vom System als falsch eingestuft, erscheint in mancher Software wieder eine leere Eingabemaske. Sämtliche Informationen müssen noch einmal eingegeben werden. Liegt zum Beispiel ein Tippfehler in einem Namen vor, ist das unnützer Eingabeaufwand, denn es wäre sicher einfacher, den Fehler zu korrigieren als die gesamte Eingabe zu wiederholen.

Auch in diesem Beispiel geht es um das Problem einer verworfenen Fehleingabe. Die Abbildung zeigt einen Verzeichnisinhalt im Finder von MacOS. Eine Datei, die zuvor noch „K96.pdf“ hieß, wird gerade umbenannt. Dazu ist ein sehr umfangreicher Dateiname gewählt worden, um schnell erkennen zu können, was der jeweilige Inhalt sein könnte. Leider enthält er mit dem Doppelpunkt ein Zeichen, das in Dateinamen am Mac nicht vorkommen darf. Bestätigt man den Dateinamen nun, gibt das Betriebssystem daher eine Fehlermeldung aus. Wird diese geschlossen, erscheint wieder der Name „K96.pdf“. Die komplette Eingabe, die ja nur in einem einzigen Zeichen hätte korrigiert werden müssen, ist verloren und muss wiederholt werden.
Weitergehende Beispiele: Screenshot und Farblupe
Die Forderung, Ein- und Ausgaben des Systems später wieder als Eingaben verwenden zu können, beschränkt sich nicht auf textuelle Inhalte oder Anwendungsobjekte, die mittels direkter Funktionalität oder über den Umweg Zwischenablage übertragen werden können. Auch das am Monitor angezeigte Bild selbst verkörpert eine Ausgabe des Systems. Es sollte vollständig oder in Teilen an anderer Stelle wieder zur Eingabe genutzt werden können. Eine Möglichkeit, dies umzusetzen, ist das Erstellen eines Screenshots. Das Buch, das Sie gerade lesen, lebt regelrecht davon, dass die Ausgaben eines Systems, nämlich die Nutzungsschnittstellen verschiedener Programme, zur Eingabe für den Buchinhalt werden konnten. Die Screenshots wurden in Dateien abgespeichert und in den Buchtext eingebunden.
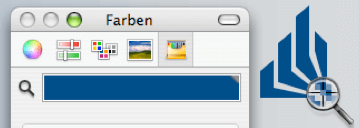
Auf einer anderen Granularitätsebene können Sie jedes einzelne Bildschirmpixel als Ausgabe des Systems auffassen. Diese Ausgabe sollte wieder zur Eingabe werden können. Diese Anforderung mag zunächst etwas überspitzt klingen, doch der oben dargestellte Farbauswahldialog erlaubt genau das. Die aus vielen Grafikprogrammen bekannte Farbpipette, die dazu dient, von einer beliebigen Stelle in einem Bild die Farbwerte abzunehmen, funktioniert hier als Farblupe systemweit. Wenn die Lupe aktiviert wird, kann sie von einem beliebigen Punkt des Bildschirms eine Farbe abnehmen, unabhängig davon, ob sie zur gerade laufenden Anwendung gehört. Der Farbwert kann ermittelt und übertragen werden.
Inkrementelle Rückmeldung
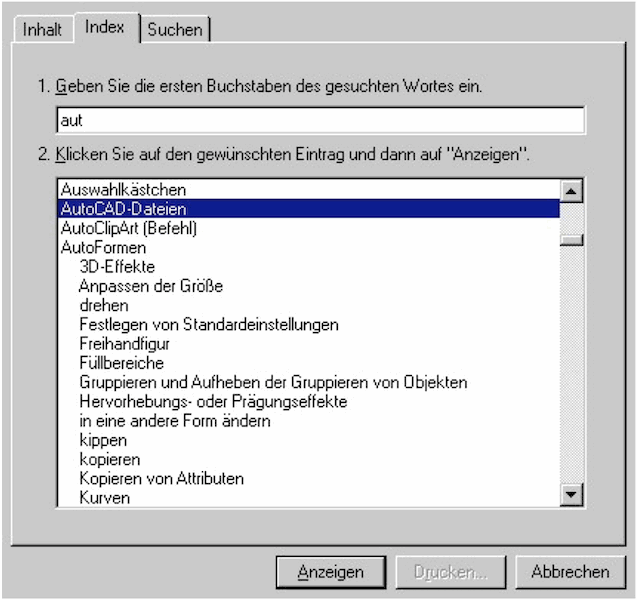
Eine wichtige Möglichkeit zur Reduzierung der Anzahl notwendiger Eingaben ist die frühzeitige Rückmeldung. Sobald bereits nach der Eingabe der ersten Zeichen die Ausgabe angezeigt wird, sprechen wir von „inkrementeller Rückmeldung“. Dies wollen wir am Beispiel des Hilfesystems von Windows 95 illustrieren. Das System bietet unter anderem das Anwählen von Stichworten in einem Index an. Um die Anzahl der Elemente in einem Index zu beherrschen, können Suchergebnisse über Filter eingeschränkt werden. Das Beispiel zeigt, dass bereits nach einigen Buchstaben anhand der Ausgabe erkennbar ist, ob der Eintrag entweder nicht vorhanden ist oder ob er nach weiteren Eingaben noch prinzipiell auffindbar sein könnte. Im besten Fall zeigt das selektierte Ausgabefeld bereits den gewünschten Eintrag an. In allen drei Fällen können durch diese inkrementelle Rückmeldung etliche Eingaben eingespart werden, denn Stichwörter müssen nicht immer komplett eingegeben und Schreibfehler können frühzeitig erkannt und korrigiert werden. Das setzt allerdings voraus, dass der Index geordnet ist, also eine (meist textuelle) Eingabe mit ihrer Länge „inkrementiert“, das heißt spezifischer wird.
Der Minimierung der Eingabe durch inkrementelle Rückmeldung steht der Nachteil einer potenziellen Ablenkung gegenüber, denn wenn eine Eingabe schon ausgewertet wird, bevor sie abgeschlossen ist, ändert sich während der Eingabe das Objektarrangement am Bildschirm und schafft dadurch eine unruhige Atmosphäre, vor allem, wenn sich diese Änderungen im peripheren Wahrnehmungsfeld vollziehen. Es muss also die Eingabeminimalität gegen die Ablenkungsfreiheit austariert werden, indem man festlegt, wann und in welchem Umfang bereits während der Eingabe solche Auswertungen stattfinden.
Handlungen handhabbar machen
Die bisherigen Hinweise zur Eingabeminimalität zielten darauf ab, die Menge der notwendigen Eingaben zu verringern. Diese Art der Minimierung ist jedoch nur die halbe Miete, denn auch wenn die Eingabemenge selbst reduziert wird, kann es immer noch zu allerlei Problemen kommen, wenn eine Eingabe nicht hinreichend präzise durchgeführt werden kann, wenn die Eingabe so kleinteilig erfolgen muss, dass sie viel Zeit beansprucht, oder wenn die Eingabemöglichkeit so ungünstig gestaltet ist, dass es zu vielen Fehleingaben kommt. Es gilt also, Eingaben nicht nur zu vermeiden, sondern nötige Eingaben so zu gestalten, dass sie präzise und effizient durchgeführt werden können.
Die erste Forderung an diese Eingabemöglichkeiten ist die Eingabepräzision:
Die Erfüllung dieser Forderung verlangt, dass Handlungen zügig mit der für die Erledigung der Aufgabe erforderlichen Präzision durchgeführt werden können. Das erfordert auch, die Granularität der Eingabeoperationen der Granularität der zu lösenden Aufgabe anzupassen.
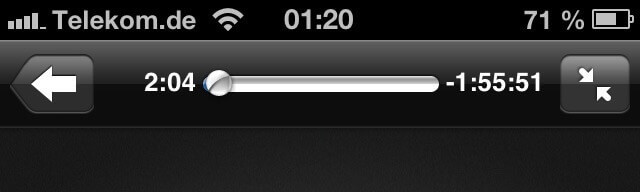
Dieses Beispiel zeigt eine Verletzung der Forderung nach Eingabepräzision. Zu sehen ist eine Fernsteuerungs-App auf dem iPhone, mit der man den auf einem Rechner installierten Medienplayer iTunes fernsteuern kann. Die Anzeige besagt, dass ein Film mit einer Länge von annähernd zwei Stunden abgespielt wird. Will man nun zu einer bestimmten Position springen, sagen wir zum Punkt 1:05:32, muss dazu der obere Slider an die entsprechende Position bewegt werden. Dies wird jedoch selbst bei einem vorsichtigen Vorgehen kaum gelingen, weil der Slider schlicht zu klein ist, um den Punkt präzise treffen zu können. Es fehlt an der notwendigen, technisch jedoch möglichen Eingabepräzision für diese Aufgabe3. Die räumliche Länge des Sliders lässt sich motorisch nicht präzise auf die zeitliche Länge des Films abbilden.
Eingabepräzision versus Platzbedarf (Übersichtlichkeit, Strukturiertheit)
Ein Slider, der ein präzises Springen im gesamten Film ermöglicht, müsste deutlich länger ausfallen. Dieser Platz ist aber in der Nutzungsschnittstelle eines Smartphones nicht vorhanden. Doch auch wenn er vorhanden wäre, sprechen unsere Forderungen nach Übersichtlichkeit und Strukturiertheit dagegen, derart große Eingabeelemente anzubieten. Für diese Art von Konflikten ist die Technik der lokalen Vergrößerung eine gute Lösung. Auf einige Spielarten dieser Technik kommen wir noch zu sprechen. Hier geht es erstmal um die Lösung für das Beispiel des Springens innerhalb des Films, die YouTube bei Filmen mit einer Laufzeit von mehr als einer Stunde anbietet.
Will man in dem Beispiel etwa auf die Position 38:33 springen, wählt man zunächst auf der groben Skala eine ungefähre Position und zieht die Positionsmarke dann nach oben. Dabei spreizt sich die Skala, sodass nun im Lokalen sehr genau die gewünschte Position gefunden werden kann. Die lokale Vergrößerung ermöglicht trotz des geringen Platzes ein hinreichend präzises Arbeiten. Erkauft wird die Möglichkeit durch eine zusätzliche Operation zur Aktivierung der Vergrößerung. Mangelnder Platzbedarf wird durch erzwungene Sequenzialität aufgelöst. Problematisch ist in diesem Zusammenhang auch, dass es keinerlei wahrnehmbaren Hinweis auf diese Vergrößerung gibt. Man muss die Funktionalität kennen oder aber sie zufällig entdecken. Derartige Probleme werden wir in der Forderung nach Erschließbarkeit in kommenden Kapiteln behandeln.
Schnelligkeit versus Sicherheit
Die Forderung nach Eingabepräzision offenbart noch einen weiteren Gestaltungskonflikt, denn es geht nicht nur um die Frage, ob eine Handlung zielgenau ausgeführt werden kann, sondern auch wie schnell. Anders ausgedrückt: Welcher Grad an bewusster Konzentration ist erforderlich bzw. wie routiniert kann eine Handlung ausgeführt werden, ohne dass die Wahrscheinlichkeit von Fehlhandlungen steigt? In der Softwareergonomie führen die Forderungen nach Schnelligkeit und Sicherheit von Eingaben meist zur Frage nach der Positionierung und Größe von Eingabeelementen auf dem Bildschirm zum Zwecke der räumlichen Positionierung per Maus, Stift- oder Berührungseingabe. Um diese Probleme lösen zu können, sind einige grundsätzliche Überlegungen nötig.
Motorische Handlungen lassen sich gut als Bewegung modellieren, bei denen von einem Startpunkt ausgehend ein kontinuierlicher Abgleich zwischen Ist-Position und Soll-Position stattfindet. Experimentelle Untersuchungen zeigen einige Besonderheiten solcher Handlungen auf, die, ebenso wie die Architektur der Wahrnehmung, bei der Gestaltung berücksichtigt werden müssen.
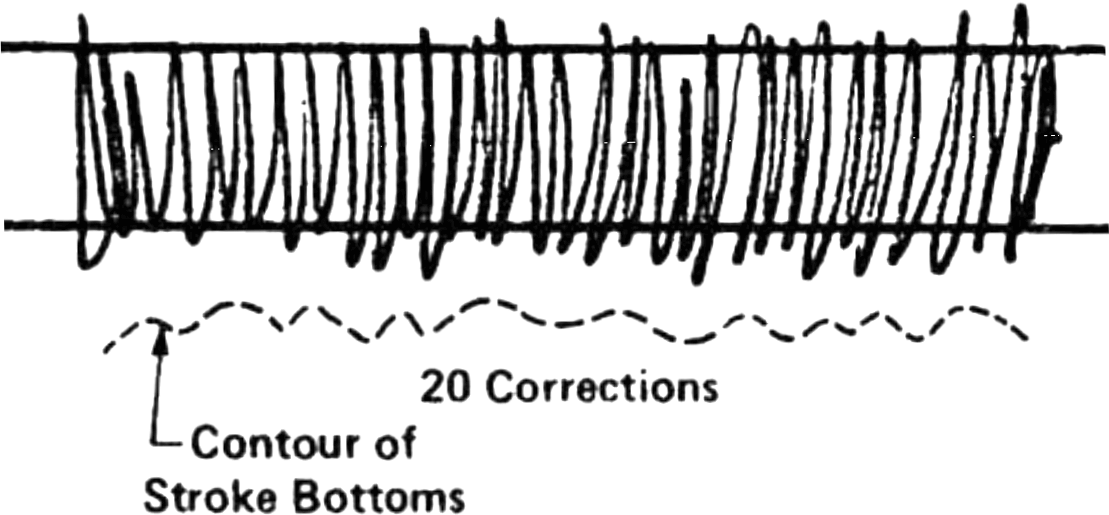
Die Abbildung zeigt eine Aufgabe aus einem wissenschaftlichen Experiment, bei der es darum ging, fünf Sekunden lang so schnell wie möglich zwischen geraden Grenzlinien hin und her zu zeichnen und dabei die Linien möglichst wenig zu überschreiten. Man erkennt in der Abbildung anhand der vielfach überschrittenen Linien, dass es kaum möglich ist, Geschwindigkeit und Genauigkeit gleichermaßen zu erreichen. Schaut man sich den Verlauf von links nach rechts etwas genauer an, stellt man fest, dass die Überschreitungen nicht gleichmäßig verteilt sind: Eine Versuchsperson zeichnet ein Zackenmuster und überschreitet an einigen Stellen die Begrenzungslinien. Nach einiger Zeit wird dies bemerkt und das Verhalten korrigiert. Die Zacken liegen nun wieder deutlicher innerhalb der Begrenzungslinien, teilweise deutlich darunter. Eine erneute Korrektur stand an. Doch warum gelingt es nicht, den Fehler schon mit dem Zeichnen der jeweils nächsten Zacke zu korrigieren? Offensichtlich gibt es eine Diskrepanz zwischen Erkennen und Handeln. Das Zusammenspiel aus Wahrnehmung und Motorik ist zu langsam, um Korrekturen schnell genug bewerkstelligen können. In der gezeigten Abbildung hat es die Versuchsperson geschafft, in fünf Sekunden 68 Zacken zu zeichnen. Das heißt, für jede Zacke hat sie nur 73,53 Millisekunden benötigt. In weiteren ähnlichen Experimenten konnte ermittelt werden, dass die Zeit, die für die visuelle Rückkopplung des Gezeichneten benötigt wird, etwa bei 240 Millisekunden liegt. Teilt man die 5 s durch 240 ms ergibt sich, dass ein Mensch in fünf Sekunden seine motorische Handlung etwa 21-mal korrigieren kann. Die Versuchsperson in unserem Beispiel liegt mit ihren 20 Korrekturen also gut im Durchschnitt.
Was lehrt uns dieses Experiment? Die Hand-Auge-Koordination erfolgt nicht synchron und deshalb auch nicht beliebig genau. Während ein Fehler wahrgenommen wird, geht die Handlung weiter. Bis er dann verarbeitet worden ist und in eine Korrektur einmündet, ist die Situation schon wieder eine andere.
Fitts‘s Law
Genau diese Erkenntnis steht auch im Zentrum des vielleicht bekanntesten Beitrags der Psychologie zur Ergonomie: das Gesetz von Fitts, meistens in seiner englischen Form als Fitts’s Law4 bezeichnet. Dieses „Gesetz“ geht auf die Untersuchungen des amerikanischen Psychologen Paul M. Fitts zurück. Fitts hat in der Psychologieabteilung des Air Force Research Laboratory gearbeitet. Seine Untersuchungen haben also, zumindest im weitesten Sinne, die Verbesserung der Flugsicherheit zum Ziel und werden deshalb als ergonomische Studien betrachtet. Die Untersuchung, deren Ergebnis heute „Fitts’s Law“ genannt wird, hat Fitts bereits im Jahre 19545 veröffentlicht. Dass seine Erkenntnisse Anfang der 1980er Jahre Eingang in die Softwareergonomie gefunden haben, hat er selbst nicht mehr erlebt. Aufgrund der besonderen Aufmerksamkeit, die diesem Gesetz zuteilgeworden ist, und der speziellen Schwierigkeiten, es anzuwenden, wollen wir es nachfolgend ausführlicher behandeln.
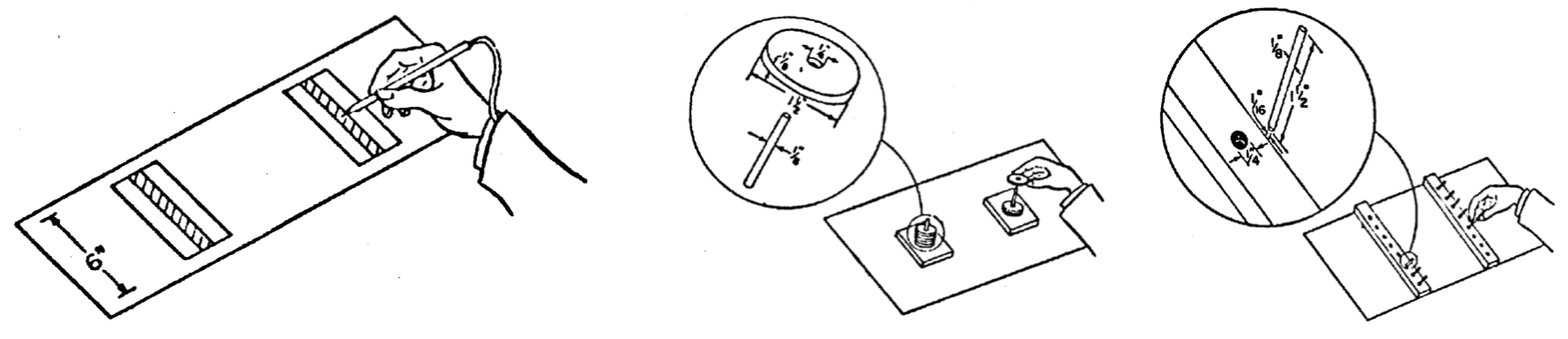
Die Veröffentlichung von Fitts beschreibt den Aufbau, die Durchführung und die Ergebnisse einer Reihe von Experimenten, von denen einige abgebildet sind. Im linken Experiment haben die Probanden vor sich zwei Strukturen, die jeweils einen inneren und einen äußeren Bereich haben. Mit dem Stift sollen sie nun möglichst schnell, aber auch möglichst ohne Fehler zu machen, abwechselnd jeweils in den linken und rechten inneren Bereich tippen. Tippen Sie daneben und geraten in den äußeren Bereich, wird ein Stromkreis geschlossen und ein Fehlerzähler erhöht. Beim mittleren Experiment geht es darum, auf einen Stift aufgesteckte Unterlegscheiben eine nach der anderen von einer Seite auf die andere Seite zu bringen. Ähnlich ist es beim rechten Experiment, bei dem Stifte aus einem Brett nacheinander in die Löcher des jeweils anderen Bretts gesteckt werden müssen.
Was aus Fitts‘ Überlegungen und seinen Ergebnissen abgeleitet werden kann, lässt sich auf verschiedene Weise ausdrücken und mathematisch formulieren. Die in der Mensch-Maschine-Interaktion übliche Interpretation, die man auch in der deutschen Wikipedia findet, lautet: „[Fitts’s Law] besagt, dass die benötigte Zeit, um eine Zielfläche zu erreichen, eine Funktion der Distanz zu dieser Fläche und deren Größe ist.“ Wenn man die Veröffentlichung von Fitts liest, findet man diese Aussage in der Form jedoch nicht. Fitts formuliert wie folgt:
If the amplitude and tolerance limits of a task are controlled by E6, and S7 is instructed to work at his maximum rate, then the average time per response will be directly proportional to the minimum average amount of information per response demanded by the particular conditions of amplitude and tolerance.
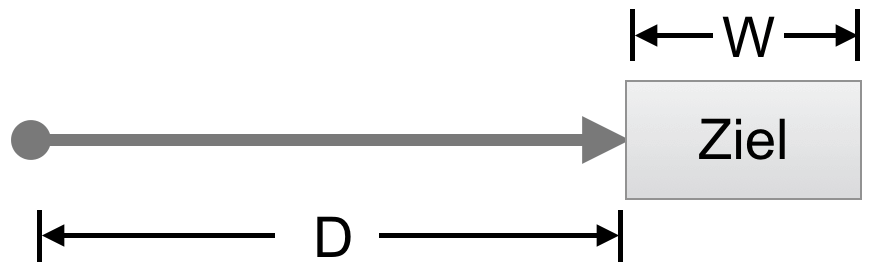
Fitts bezieht sich mit seinen ungewöhnlich klingenden Formulierungen auf die Konzepte der Shannon’schen Informationstheorie. Wir wollen diese Hypothese in verständlichere Ausdrücke übersetzen, auch wenn wir damit einen kleinen Verlust an Präzision in Kauf nehmen müssen. Nehmen wir als Beispiel einen Mauszeiger und ein Objekt auf dem Bildschirm. Das Ziel ist, das Zielobjekt mit dem Mauszeiger zu erreichen, um es beispielsweise anklicken zu können.
Wir wenden nun Fitts’s Law auf diese Situation an. Dafür können wir den Begriff „amplitude“ in Distanz vom Mauszeiger zum Ziel übersetzen, denn die Amplitude steht für die Bewegungsreichweite, die genau dieser Distanz entspricht. Die „tolerance limits“, von denen Fitts spricht, bezeichnen die mögliche Ungenauigkeit beim Zeigen. Beim Button entspricht das seiner Ausdehnung in der Bewegungsrichtung des Mauszeigers. Die „average time per response“ ist die durchschnittliche Zeit, um auf das Ziel zu zeigen. Die „minimum average amount of information per response“ bezeichnet Fitts an anderer Stelle selbst als „index of difficulty“, also Schwierigkeitsgrad. Er beziffert die Schwierigkeit, um auf das Ziel zu zeigen. Wenden wir das alles an, kommt Folgendes heraus:
Die durchschnittliche Zeit, um fehlerfrei auf ein Ziel zu zeigen, hängt direkt proportional von der Schwierigkeit ab, darauf zu zeigen. Diese Schwierigkeit wird bestimmt von der Entfernung zum Ziel und der Toleranz, darauf zu zeigen.
Das von uns hier hinzugefügte „fehlerfrei“ steckt in den Untersuchungen von Fitts in der Aufgabenstellung, bei der beim ersten Experiment etwa die Probanden aufgerufen waren, die Aufgabe möglichst schnell ohne Fehler durchzuführen. Die tatsächlich geringen Fehlerzahlen in den Experimenten interpretiert Fitts dementsprechend als Anpassung der Geschwindigkeit an die Schwierigkeit der Aufgabe seitens der Versuchspersonen.
Wenn man obige Definition auf einen typischen Button anwendet, entspricht die Interpretation jener, die bei Wikipedia zu finden ist. Dies ist aber nur ein sehr spezieller Fall. Wir möchten mit unserer Formulierung daher gerne den Blickwinkel auf zwei Konstrukte in der Argumentation lenken, zum einen dem Schwierigkeitsgrad und zum anderen dem allgemeineren Konzept der Zieltoleranz.
Fitts’s Law wird heute meist mit der Formel
MT = a + b * log2(D / W + 1)
angegeben. Ersetzen wir das konkrete W für die Objektgröße durch T für die Zieltoleranz, bleibt:
MT = a + b * log2(D / T + 1).
Der hintere Term ist der Schwierigkeitsindex in der sogenannten Shannon-Form8:
ID = log2(D / T + 1).
MT steht für die durchschnittliche Zeit, ID für den Schwierigkeitsgrad, D für die Objektentfernung und T für die Zieltoleranz. Die Konstanten a und b hängen vom individuellen Handelnden und den Umständen der Handlung ab und müssen separat ermittelt werden.
Die Aussage von Fitts’s Law kann nun auf vielfältige Art und Weise zu Aussagen umgeformt werden wie: „Soll es schneller gehen, muss entweder die Schwierigkeit sinken oder es muss von Fehlern ausgegangen werden.“ oder: „Ist eine schwierige Zeigeoperation notwendig, bedarf es mehr Zeit, sie durchzuführen.“ Zentral ist jeweils die Schwierigkeit. Diese gilt es im Sinne der Reduzierung erzwungener Sequenzialität zu verringern. Dies ist nach Fitts’s Law durch Änderung der Entfernung zum Ziel oder der Toleranz, das Ziel zu treffen, möglich. Wird die Entfernung zum Ziel verringert, wird es einfacher, ebenso wenn die Größe des Objekts zunimmt oder man das Ziel nicht genau treffen muss.
Wichtig ist der Logarithmus in der Formel. Es handelt sich bei der Schwierigkeit nicht um ein lineares Verhältnis zu den beeinflussenden Größen, sondern um ein logarithmisches: Die größte Steigerung hat der Logarithmus bei D/T nahe Null. Die niedrigsten Schwierigkeitsgrade erhalten wir also im Bereich der Verhältnisse kleiner D-Werte zu großen T-Werten. Folglich bringt die Verkleinerung bereits kurzer Distanzen im Verhältnis mehr ein als die Verkleinerung großer Distanzen. Noch wichtiger ist für uns aber die Erkenntnis bezüglich des T: Die Vergrößerung kleiner Toleranzen bringt im Verhältnis mehr ein als die Vergrößerung großer Toleranzen. In vielen Fällen hat man in der Gestaltungspraxis nicht die Freiheiten, beide Größen optimieren zu können. Wenn das T klein sein muss, weil zum Beispiel kleine Buttons genutzt werden müssen, da wenig Platz zur Verfügung steht, sollte für einen kleinen Schwierigkeitsgrad das D klein gehalten werden. Wenn D groß ist oder, wie wir sehen werden, nicht eingeschätzt werden kann und damit potenziell groß sein könnte, kann der Schwierigkeitsgrad nur dadurch verringert werden, dass eine große Toleranz gewählt wird.
Einschränkungen von Fitts’s Law für die Gestaltungspraxis
Nun gilt es genauer zu betrachten, inwieweit Fitts’s Law als Grundlage zum Austarieren von Design-Konflikten und daraus resultierenden Gestaltungsanforderungen geeignet ist. Aber nicht jeder Aspekt des Gesetzes ist für uns interessant. Da wir nicht daran interessiert sind auszurechnen, wie lange eine Zeigeoperation tatsächlich dauert, berücksichtigen wir die Konstanten a und b nicht weiter. Unser Interesse gilt nur dem Schwierigkeitsindex und seiner Minimierung. Fitts’s Law legt zwei Ansatzpunkte nahe, wobei die Erkenntisse bezüglich der Toleranz die wichtigeren sind, denn bezüglich der Verringerung des Abstands zur Beschleunigung der Zeigeoperation können wir kaum etwas erreichen, weil wir auf diesen Abstand oft keinen Einfluss haben.
Um das zu verdeutlichen, betrachten wir den Start-Button von Windows und stellen uns die Aufgabe, ihn durch die Optimierung der Entfernung zum Mauszeiger schneller erreichbar zu machen. Wie soll das gehen? Wir können schlichtweg nicht allgemein aussagen, wo sich der Mauszeiger auf dem Bildschirm gerade befindet, wenn die Entscheidung fällt, das Startmenü aufzurufen; die Distanz ist also eine Unbekannte.

Es gibt Situationen, in denen bekannt oder mit hoher Wahrscheinlichkeit vermutet werden kann, wo sich der Mauszeiger befindet. Das kann der Fall sein, wenn es inhaltliche Abhängigkeiten zwischen den Objekten gibt oder die Arbeitsaufgabe eine Reihenfolge nahelegt. Der Webeditor CKEditor 5 etwa bietet die Manipulationsmöglichkeiten jeweils in direkter Nähe zum Objekt an. Durch diese Platzierung sind die Mauswege kurz und damit schnell. Fitts’s Law wird aber nicht benötigt, um die Nähe der Einblendung zur Textmarkierung zu begründen. Unsere Forderungen nach Strukturiertheit (aufeinander Bezogenes auch beieinander platzieren) und Lokalität (Rückmeldungen am Ort der Handlung) würden eine solche Gestaltung ohnehin bereits fordern.
Während die Entfernung für uns aus den genannten Gründen nicht im Fokus steht, können wir bei der Zieltoleranz gut ansetzen: Gerade durch die Vergrößerung sehr kleiner Objekte lässt sich eine gute Verringerung der Schwierigkeit bewirken und das unabhängig davon, wo eine Zeigeoperation startet.
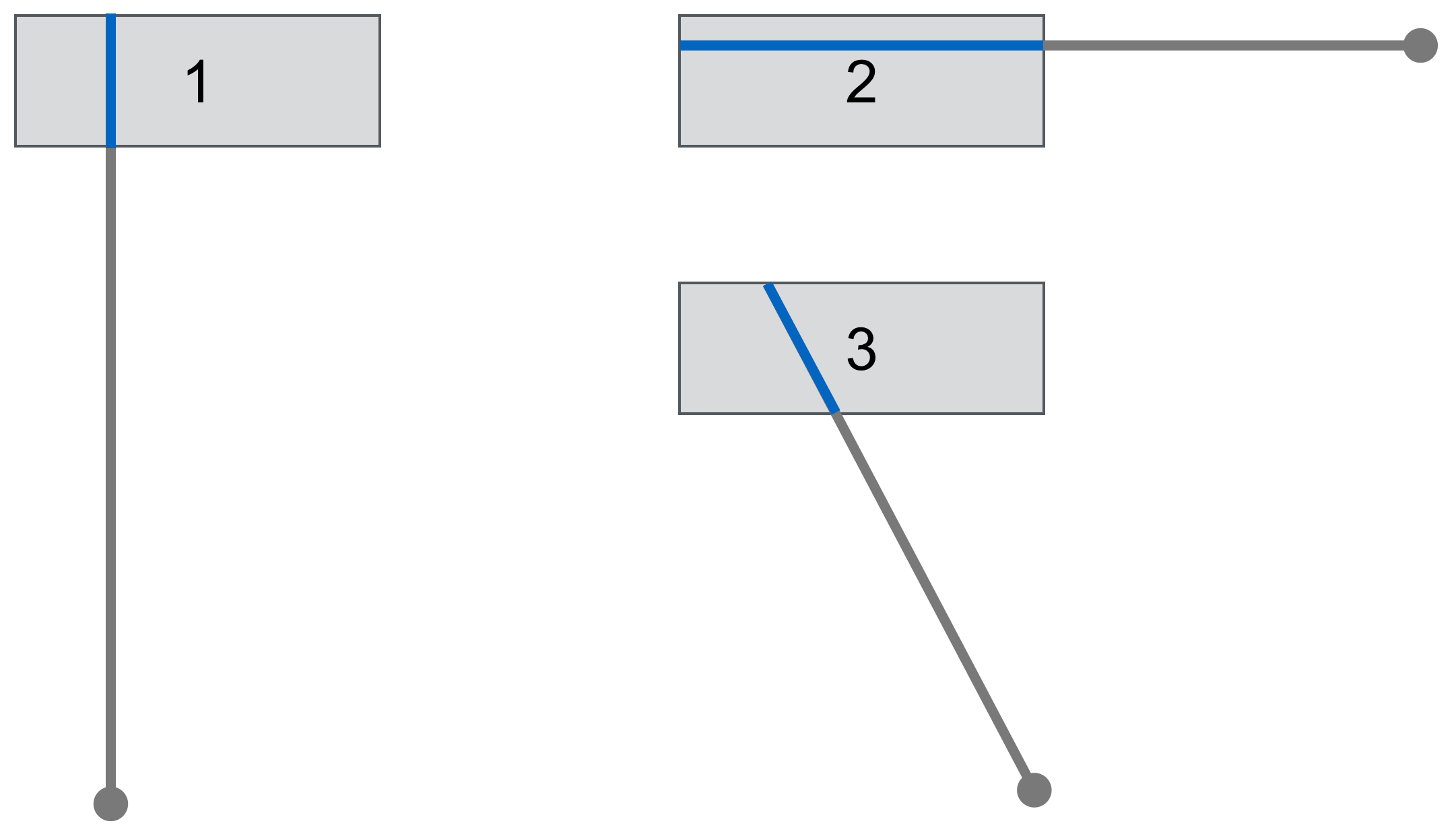
Entscheidend für den Toleranz- bzw. Größenaspekt ist die Toleranz oder Objektausdehnung in der Bewegungsrichtung. Sie sehen auf der Abbildung, dass der Button in den Fällen 1 und 3 gemäß Fitts’s Law erheblich kleiner ist als im Fall 2. Da aus den zuvor schon genannten Gründen nicht vorhersehbar ist, von welcher Position aus ein Objekt angesteuert wird, ist somit die kleinste mögliche Zielgröße für unsere Überlegung relevant. Bei rechteckigen Objekten, mit denen wir es am Bildschirm überwiegend zu tun haben, ist das also die kleinste Seite.
In der Praxis sind es meistens die Objekthöhen, die problematisch sind. Beim Editor Notepad von Windows 10 ist das zielgerichtete Anvisieren der Menüpunkte „Datei“, „Bearbeiten“ etc. einigermaßen schwierig und damit auch langsam und fehlerträchtig. Möglicherweise ist das einer der Gründe, warum dieses klassische Menü bei Windows momentan auf dem Rückzug ist und es immer mehr Anwendungen ohne diese Art von Menü gibt.
Folgerungen für die Gestaltung
Große Zielflächen
Wenn Sie bei der Gestaltung von Zeigeoperationen die Schwierigkeit senken und damit erzwungene Sequenzialität reduzieren wollen, müssen Sie die Zieltoleranz erhöhen. Am einfachsten erfolgt dies über die Vergrößerung der Zielobjekte. Große Objekte sind sowohl schneller als auch sicherer zu treffen.
Besonders wichtig ist das Vergrößern von Zielflächen beim Einsatz von Touch-Bildschirmen. Icons, Buttons und andere Elemente, die Sie bei Maus- oder Trackpad-Nutzung anklicken würden, werden beim Einsatz solcher Bildschirme nicht angeklickt, sondern angetippt. Der Unterschied in der Interaktion scheint auf den ersten Blick gering, ist aber tatsächlich sehr groß. Touch-Interaktion wird geschätzt, weil sie direkter ist als das Interagieren mit einem Eingabegerät und einem Mauszeiger. Das Anklicken per Zeiger hat aber den großen Vorteil, dass die Objektanwahl durch das Bewegen des Zeigers zum Zielort unabhängig von der Auslösung einer Funktion durch das Klicken geschieht. Selbst wenn man ungeschickt mit der Maus umgeht oder das Gerät nicht besonders gut funktioniert, ist die Handlung wenig fehleranfällig, weil die Ansteuerung durch zwei verschiedene Operationen erfolgt: Die Bewegung des Mauszeigers durch Schieben und das Auslösen der Funktion durch einen Klick sind voneinander entkoppelt. Erst wenn der Zeiger an die passende Position bewegt worden ist, wird durch einen Klick die Funktion ausgelöst. Dabei kann man das Anvisieren auch beliebig verlangsamen. Beim Touch-Bildschirm geht das nicht, da beide Operationen in einer Geste zusammenfallen. Die Positionierung muss also gleich beim ersten Mal passen, was die Gefahr einer versehentliche Fehleingabe stark erhöht, zumal beim Auslösen einer Funktion mit einem Finger das Zielobjekt teilweise verdeckt wird. Um das zu vermeiden, muss man, beispielsweise durch die Vergrößerung der Buttons, die Zieltoleranz erhöhen.

Sie können Zielflächen auch vergrößern, ohne sie optisch groß darzustellen. In diesen drei Beispielen ist die Zielfläche jeweils deutlich größer als das eigentlich dargestellte Objekt. Die Icons in der Menüleiste von LibreOffice (links) haben, wie an dem umrahmten Icon zu sehen ist, einen viel größeren Selektionsbereich als das eigentliche Bild. Bei der Drop-down-Liste in der Mitte kann die gesamte Fläche zum Aufklappen genutzt werden, nicht nur das eigentliche Aufklappfeld rechts. Bei den Radio-Buttons9 auf der rechten Seite ist der komplette Text, der zu einem Optionspunkt gehört, Teil der Zielfläche. Aktuelle Betriebssysteme besorgen diese Art von Eingabeerleichterungen selbst. Falls man aber, etwa in einer Webanwendung, diese Nutzungsschnittstellen-Elemente selbst gestalten muss, sollte die Vergrößerung der Zielflächen über die sichtbaren Interaktionselemente hinaus mitbedacht werden, wenn nicht ohnehin große Elemente erzeugt werden sollen.
Große Toleranzen für Zeigeoperationen zu implementieren führt zu Konflikten, da zwangsläufig die Anzahl der gleichzeitig selektierbaren Elemente sinkt, wenn die Zielflächen einander nicht überlappen. Es ist also notwendig, entweder die Anzahl der möglichen Optionen einer Software zu beschränken oder die Nutzungsschnittstelle auf mehrere Bildschirmseiten aufzuteilen. Im letzten Fall entstehen Probleme mit der Erschließbarkeit der Software, denn es ist jetzt aufwändiger, alle vorhandenen Möglichkeiten zu erfassen. Wir werden uns im Kapitel Orientierung eingehender mit diesem Problem beschäftigen.
Ausnutzen der Bildschirmränder
Bei Zeigeoperationen mit Maus oder Touchpad kommt den Bildschirmrändern und Bildschirmecken eine besondere Rolle zu. Im Gegensatz zum Finger bei einer Touch-Eingabe ist der Mauszeiger innerhalb des Bildschirms gefangen. Wenn man den Zeiger gegen den Bildschirmrand bewegt, kann man die Maus zwar darüber hinaus bewegen, der Zeiger bleibt jedoch stehen. Diese Eigenschaft können wir ausnutzen.
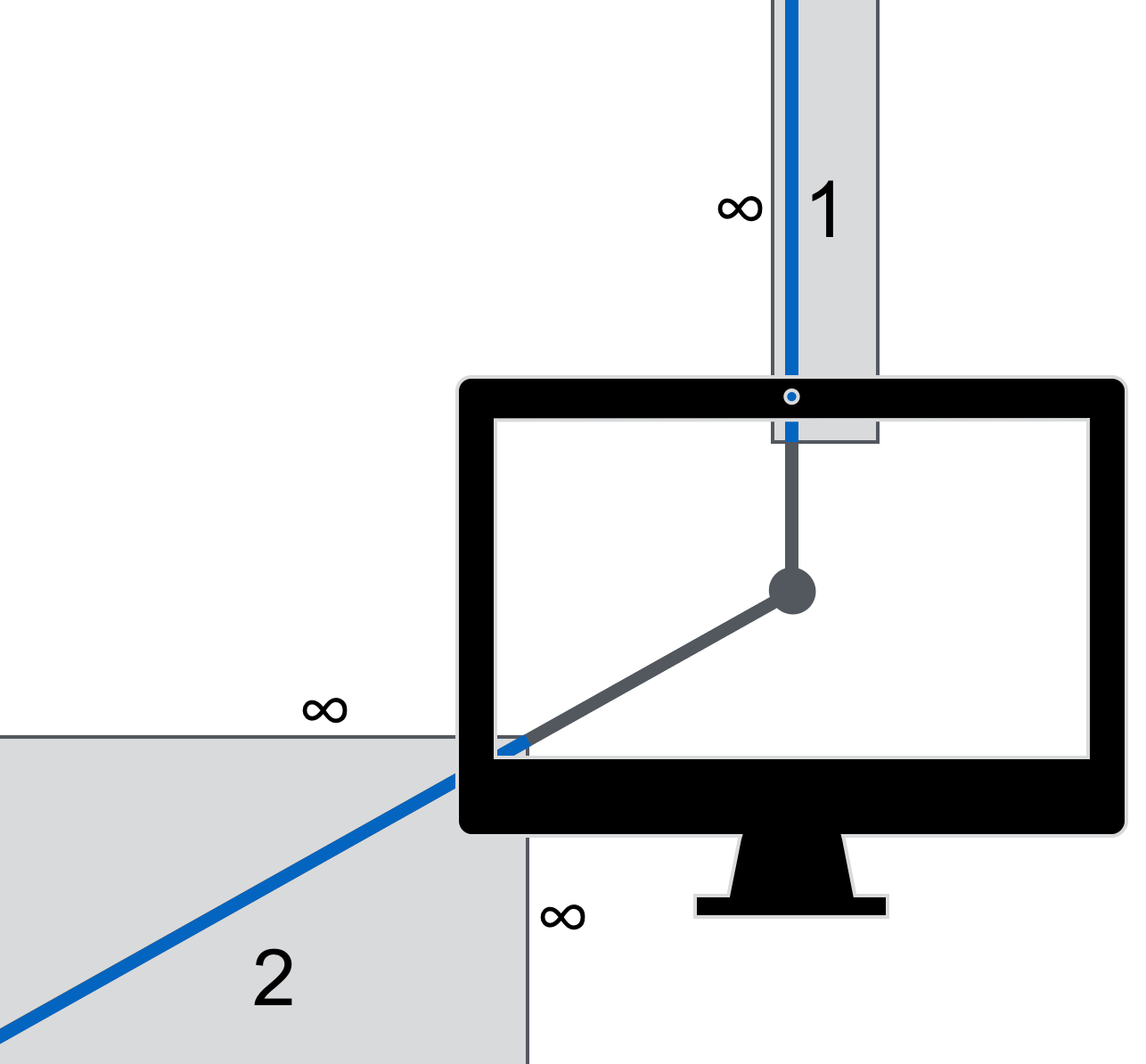
Diese Abbildung verdeutlicht die Konsequenz der Objektpositionierung am Bildschirmrand. Objekte, die so angeordnet sind, dass sie mit dem oberen Bildschirmrand abschließen, haben, wenn man sie gemäß Fitts’s Law interpretiert, eine unendliche Zieltoleranz in dieser Richtung. Bei einem Button würde das quasi einer unendlichen Ausdehnung entsprechen. Es ist also besonders schnell und vor allem auch besonders einfach, ihn in dieser Hinsicht zu treffen. Dies ist auch der Grund dafür, warum bei Apple schon seit der Veröffentlichung der Lisa10 im Jahr 1983 die Menüleiste am oberen Bildschirmrand angebracht ist. Ihre Objekte sind im Gegensatz zu den alten Windows-Menüleisten (siehe oben) einfacher zu treffen.
Der Effekt potenziert sich in den vier Ecken des Bildschirms. Diese sind schnell und sehr einfach zu erreichen. Jede Bewegung, die auch nur ansatzweise nach links und unten gerichtet ist, landet beispielsweise, wenn sie nur lange genug ausgeführt wird, zwangsläufig in der linken, unteren Ecke. Dies haben sich die Betriebssystemhersteller zunutze gemacht.
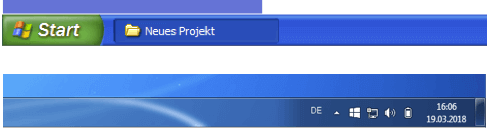
In den gezeigten Ausschnitten aus den Taskleisten von Windows XP oben und von Windows 7 unten wird die unendliche Zielfläche ausgenutzt. Sowohl der Startknopf unten links als auch die Fläche zum Anzeigen des Desktops unten rechts sind mit der Maus sehr einfach zu erreichen.
Leider wird man das Prinzip der unendlichen Zielflächen am Bildschirmrand nur selten in der Gestaltung eigener Software einsetzen können, denn das wäre nur möglich, wenn damit die Kontrolle des kompletten Bildschirms verbunden ist, also das Programm im Vollbild läuft. Dann sind die Plätze an den Bildschirmrändern und in den Bildschirmecken sehr wertvoll. Wenn aber eine Anwendung zu gestalten ist, die in einem Fenster läuft, würde ein Positionieren von Objekten am Fensterrand eher für Probleme sorgen, denn es besteht die Gefahr, dass beim Versuch, dort ein Element zu treffen, versehentlich am Fenster vorbei geklickt und dadurch ungewollt die Anwendung gewechselt wird. Eine Positionierung von Elementen am Rand würde somit der Eingabesicherheit stark widersprechen.
Positionierungshilfen
Räumliches Positionieren in grafischen Nutzungsoberflächen erlaubt eine sehr genaue Positionierung bis auf die Pixelebene. Eine so genaue Positionierung ist aber schwierig auszuführen und damit nach Fitts’s Law langsam bzw. fehlerträchtig. Zur Eingabeunterstützung bieten sich in solchen Fällen Positionierungshilfen wie Raster oder Magnetlinien an.

Die abgebildete Positionierungshilfe aus dem Präsentationsprogramm „Keynote“ von Apple trägt dem Umstand Rechnung, dass Objekte oft an anderen Objekten ausgerichtet werden. Ziel der räumlichen Manipulation dieses Textobjekts ist es, dieses auf die gleiche Höhe wie ein anderes, schon positioniertes Textobjekt zu bringen. Diese Höhe auf Anhieb ohne Unterstützung zu treffen ist sehr schwer, vor allem wenn die beiden auszurichtenden Objekte nicht direkt nebeneinander stehen. Die Positionierung wird durch die Positionierungshilfe dadurch erleichtert, dass das Textobjekt auf der passenden Höhe – ähnlich wie beim Bildschirmrand – quasi hängen bleibt. Die relative Ausrichtung wird durch die Einblendung einer Hilfslinie angezeigt. Man muss also nicht pixelgenau positionieren, sondern kann mit einer deutlich größeren Zieltoleranz besser arbeiten.
Positionierungshilfen dieser Art sind immer dann möglich und sinnvoll, wenn eine Positionierung in Relation zu einem Rand, einem Raster, einem anderen Objekt oder einem explizit angegebenen Bereich mit hoher Wahrscheinlichkeit angenommen werden kann. Ein Einrasten wie oben beschrieben macht es jedoch nahezu unmöglich, absichtlich eine leicht versetzte Positionierung zu erzeugen. In manchen Fällen, etwa bei einem Raster für Icons, ist das auch nicht notwendig, in anderen Fällen ist es wichtig, dass die Positionierungshilfen für diese Fälle ausschaltbar sind, etwa durch das Drücken einer Modifikatortaste wie ALT oder SHIFT während der Positionierung. Würden Sie nicht für diese Möglichkeit sorgen, hätten Sie durch Ihre gut gemeinte Verringerung der Zieltoleranz die Forderung nach Eingabegenauigkeit verletzt.
Lokale Vergrößerungen
In Gestaltungsprozessen schränken viele Vorgaben und Randbedingungen die Umsetzung ergonomischer Forderungen ein. So kann es sein, dass die Anzahl der anzuzeigenden Elemente, von denen eines auszuwählen ist, sehr groß sein muss. In anderen Situationen lässt sich die Größe der Bildschirmobjekte oder der Zielflächen frei gestalten, weil es sich zum Beispiel um Objekte handelt, die erst während der Nutzung erzeugt oder angezeigt werden oder weil es sich um Inhalte handelt, die ursprünglich für ein anderes Ausgabemedium gedacht waren.

In solchen Fällen kann eine lokale Vergrößerung helfen, wie das Beispiel eines Docks für Programme zeigt. Je mehr Elemente das Dock enthalten soll, desto kleiner müssen die Objekte werden, wenn sie vollzählig angezeigt werden sollen. Ab einer bestimmten Anzahl würde der Schwierigkeitsgrad, sie verlässlich zu treffen, zu groß. Das Dock kann aber so eingestellt werden, dass die Objekte in dem Bereich, in dem man sich mit dem Mauszeiger befindet, deutlich größer dargestellt werden als die umliegenden. Im vergrößerten Bereich ist es dadurch möglich, das jeweils gewünschte Objekt verlässlich anzuwählen.
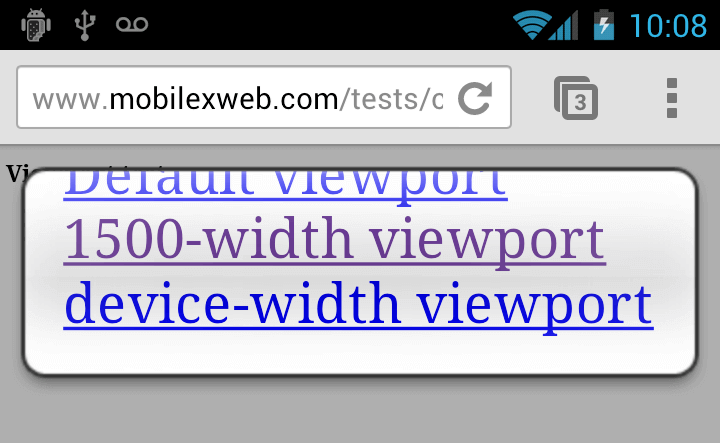
Auch diese Nutzungsschnittstelle verwendet eine lokale Vergrößerung. In einem mobilen Browser wird eine Website dargestellt, die nicht für Mobilgeräte mit Touch-Bedienung angepasst worden ist. Die Links werden entsprechend sehr klein dargestellt und sind gerade dann, wenn sie nebeneinander angeordnet sind, schwer zu treffen. Chrome zeigt beim Tippen in die Region, in der sich diese Links befinden, ein „Link Disambiguation Pop-up“ an, das die Auswahl der Links vergrößert darstellt. Auf diese Weise wird eine präzise Auswahl ermöglicht11.
Behandlung von Überlappungen
Idealerweise ist die Auswahl durch das Klicken oder Tippen auf ein Objekt eindeutig. Die Objekte der Nutzungsschnittstelle sollten einander nicht überlappen, hinreichend groß und mit angemessenem Abstand zueinander gestaltet werden. Wenn jedoch zum Beispiel eine Anwendung das freie Positionieren von Icons ermöglicht, kann es passieren, dass sich die Icons überlappen. Dadurch kann das Auswählen eines Objekts zu einem Problem werden. Eine zufällige bzw. nicht nachvollziehbare Auswahl ist in solchen Fällen nicht hilfreich. Software sollte auch für diese Fälle robust gestaltet sein, indem Mechanismen angeboten werden, um Mehrdeutigkeiten aufzulösen, die durch die Nutzung entstehen können. Vielmehr sollte die Nutzungsschnittstelle es ermöglichen, die möglichen Alternativen zu durchlaufen und eine auszuwählen.
Lift-Off-Techniken
Die Genauigkeit bei der Interaktion mit Fingern auf Touch-Geräten scheint sehr gering zu sein. Im Gegensatz zu einem Stift ist ein Finger viel breiter, sodass er einerseits mehr Bildschirminhalte verdeckt und andererseits die rundliche Fingerkuppe im Vergleich zu einem spitzen Stift eine relativ große Auflagefläche besitzt, die zudem beim Landen auf der Oberfläche grundsätzlich verdeckt ist. Doch auch bei Fingereingaben auf Touch-Oberflächen kann man sehr wohl eine eindeutige Auswahl treffen oder eine Position präzise ansteuern. Wäre dem nicht so, wäre auch das Trackpad eines Laptops nicht brauchbar. Das Problem liegt nicht in der Eingabegenauigkeit, sondern in der Kopplung der Eingabehandlungen: Wie schon erwähnt, sind bei diesen Gesten die Bewegung und das Auslösen der Aktion nicht getrennt, sodass es keine Möglichkeit gibt, die Bewegung zum Zielobjekt und das Auslösen der Funktion zu entkoppeln. Dieses Problem lässt sich in vielen Fällen durch die Verwendung einer „Lift-Off“-Strategie mindern12.
Bei einer Lift-Off-Strategie wird ein Ereignis nicht beim Landen des Fingers auf der Touch-Oberfläche ausgelöst, sondern erst, wenn der Finger wieder abgehoben wird. Der Vorteil ist nun, dass mit dem Aufsetzen des Fingers eine Rückmeldung erfolgen kann, welches Objekt selektiert bzw. welche Funktion beim Abheben ausgelöst würde. Entspricht die angezeigte Wahl nicht dem Gewollten, besteht die Möglichkeit, durch Ziehen des Fingers den Selektionsbereich zu verlassen oder auch eine andere Selektion anzusteuern. In nahezu allen aktuellen Betriebssystemen funktionieren Buttons auf diese Art und Weise, und dies sowohl bei Touch- als auch bei Mausinteraktion. Beim schnellen Klicken oder Tippen in unkritischen Situationen ist dieser Unterschied kaum zu bemerken. Sind jedoch die Gefahren einer Fehleingabe hoch, etwa in einer Menüleiste, und ist diese eventuell noch mit gravierenden Konsequenzen verbunden, ermöglicht diese Technik, ein ungewolltes Auslösen zu verhindern, wenn man vorsichtig und langsam agiert. Voraussetzung dafür ist eine Rückmeldung während der Touchoperation. Ohne die zusätzliche Rückmeldung nach dem Aufsetzen fehlt die Differenzerfahrung, die erst die Selbstvergewisserung ermöglicht und damit das Ausprägen entsprechender Handlungsstrategien.
Technisch ist eine Lift-Off-Strategie bei einem Button leicht umzusetzen. In vielen Fällen übernimmt bereits das Betriebssystem diese Aufgabe. Wenn die Strategie jedoch erst noch implementiert werden muss, sollte man folgende Aspekte bedenken:
- Beim Mausklick oder beim Aufsetzen des Fingers muss es eine erkennbare Rückmeldung geben. Der Button sollte dann etwa aufleuchten oder eingedrückt wirken.
- Wird bei aufgesetztem Finger oder bei gedrückter Maustaste die Zielfläche des Buttons verlassen, ist die Aktion abgebrochen. Der Button muss wieder seine ursprüngliche Form annehmen.
- Nur wenn dies nicht geschehen ist und der Finger wieder hochgenommen bzw. die Maustaste losgelassen wird, ist die Funktion auszulösen.
Lift-Off ist eine effektive Technik, aber in dieser Form in erster Linie nur bei Buttons und bei Positionierungsaufgaben anwendbar, denn sie ist mit anderen typischen Interaktionstechniken nicht kompatibel. Bei der Selektion eines Datei-Icons würde Lift-Off zum Beispiel nur funktionieren, wenn man auf die Möglichkeit des Drag and Drop verzichten würde. Lift-Off und Drag and Drop lassen sich nicht kombinieren, denn sie sind in Bezug auf die Eingabe nicht unterscheidbar.
Lift-Off-Strategien sind gerade bei Touch-Interaktionen besonders interessant, weil im Gegensatz zu reinen Tipp-Aktionen mit Lift-Off eine genaue Positionierung möglich ist. Wenn Sie mit Ihrem Finger auf den Bildschirm tippen, dann ist es nicht einfach, genau eine bestimmte Position zu treffen, aber wenn Ihr Finger auf der Touch-Oberfläche liegt, dann können Sie sehr feinfühlig eine Position auswählen.
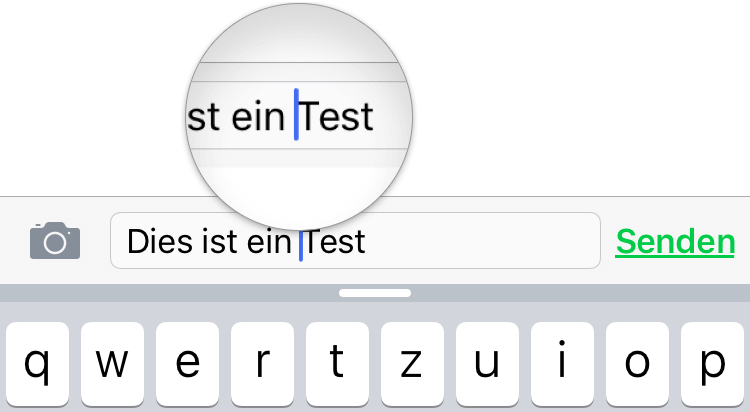
Ein gutes Beispiel ist die Cursor-Positionierung von iOS. Wenn der Cursor an eine genaue Stelle zwischen den Buchstaben positioniert werden soll, ist dies durch Tippen auf die passende Stelle nur schwer zu erreichen. Sehr oft landet man um einen oder mehrere Buchstaben neben dem gewünschten Punkt. Wenn aber, nachdem der Finger gelandet ist, eine lokale Vergrößerung des unmittelbar umgebenden Bereichs angezeigt wird, kann man durch Ziehen oder schon durch Neigen des Fingers genau positionieren. Die vergrößerte Darstellung in einer Lupe dient in diesem Fall dazu, den Cursor sichtbar zu machen, der sich ja unterhalb des Fingers befindet.
Eingabesicherheit: Die Rolle der Abstände
Bei der Forderung nach Eingabeschnelligkeit und bei der Betrachtung von Fitts’s Law haben wir unterstellt, dass Eingaben korrekt durchgeführt werden, es also nicht zu Eingabefehlern aufgrund von Genauigkeits- oder Schnelligkeitsproblemen kommt. Diese Fehler stellen jedoch eine ebenfalls mögliche Interpretation von Fitts’s Law dar: Erfolgt eine Eingabe schnell und sind die Zieltoleranzen zugleich klein, resultiert dies in mehr Eingabefehlern. Gemäß der Forderung nach Eingabesicherheit gilt es die Nutzungsschnittstelle so zu gestalten, dass Eingabefehler aufgrund hoher Schnelligkeit und geringer Zieltoleranz nicht zu Problemen führen.
Nicht alle ungenauen Eingaben sind gleichermaßen kritisch. Befände sich auf einem leeren Bildschirm an einer beliebigen Position ein kleines Icon ohne vergrößerte Zielfläche, würde es bei schneller Bedienung leicht zu einem Eingabefehler kommen, indem das Icon verfehlt wird. Da man in diesem Fall auf die leere Hintergrundfläche klicken würde, hätte dies keinerlei Effekt. Gibt es dagegen zwei kleine Icons unmittelbar nebeneinander, wäre das schon kritischer, weil die dahinterstehenden unterschiedlichen Funktionen zu gravierenden Konsequenzen führen können.
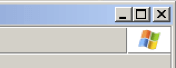
Tatsächlich treten solche Fälle häufiger auf, als wir erwarten würden. Beispiele finden sich bei nahezu allen Betriebssystemherstellern. Abgebildet sind die sogenannten Window-Controls von Windows 98. Es handelt sich um sehr kleine Icons, die sehr nah zueinander positioniert sind. Wenn man diese Icons sicher treffen will, ist das mühselig und mit der Gefahr versehentlicher Fehleingaben verbunden. Solch eine Fehleingabe kann unangenehme Folgen haben. Nehmen wir an, wir sind in einem Browser mit einem Buchungsvorgang befasst und wollen, um das komplexe Formular besser sehen zu können, das Fenster vergrößern. Durch einen Fehlklick wird jedoch aus Versehen das Fenster geschlossen. Das Gleiche kann bei den aktuellen Versionen von MacOS übrigens auch passieren, denn Apple verwendet genauso drei kleine Elemente, um das Fenster zu steuern.
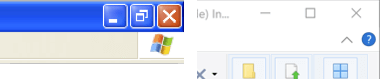
Bei Windows 95 ist der Schließen-Knopf von den anderen Controls um genau einen zsätzlichen Pixel abgesetzt. Dies dürfte wohl kaum versehentliche Fehleingaben verhindern. Wenn wir uns anschauen, wie sich die Gestaltung dieser Buttons in der Windows-Geschichte entwickelt hat, sehen wir von Version zu Version Verbesserungen. Im Design von Windows XP ist der Schließen-Knopf zwar gar nicht mehr abgesetzt, doch sind die Buttons nun erheblich größer. Unter Windows 10 wird eine Fehlbedienung nochmals unwahrscheinlicher, weil die Knöpfe nun erheblich weiter auseinander liegen. Sie versehentlich falsch zu treffen wird dadurch deutlich erschwert. Der Grund dafür dürfte in der Tatsache zu suchen sein, dass Windows 10 auch per Touch bedienbar sein soll. Hätte man die Mini-Buttons aus Windows 95 und 98 beibehalten, wären Fehlbedienungen kaum zu vermeiden.

Obwohl die Windows-10-Variante der Fenster-Operations-Knöpfe gelungen ist, zeigt uns ein Blick weiter zurück in die Geschichte, dass es schon mal eine bessere Lösung gab. Zu sehen ist die Titelzeile eines Fensters von Windows 3.1. Die Knöpfe sind recht groß, können also schon aus diesem Grund gut getroffen werden. Noch wichtiger aber ist das extreme Absetzen des Schließen-Buttons. Die Buttons zum Maximieren und Minimieren befinden sich auf der rechten Seite. Die Schließ-Operation befindet sich auf der anderen Seite des Fensters. Deshalb war es bei Windows 3.1 unmöglich, ein Fenster versehentlich zu schließen, statt es zu minimieren oder zu maximieren. Als zusätzliche Sicherheitsmaßnahme löste der Knopf auf der linken Seite nur bei einem Doppelklick das Schließen aus. Ein Einfachklick hingegen öffnete ein Menü.
Ob Microsoft diesen Knopf seinerzeit absichtlich deswegen abgesetzt hat, um Fehlbedienungen zu vermeiden, ist uns nicht bekannt. Dass sie es getan haben, war jedenfalls im Sinne unserer Forderung nach Eingabesicherheit eine gute Entscheidung.
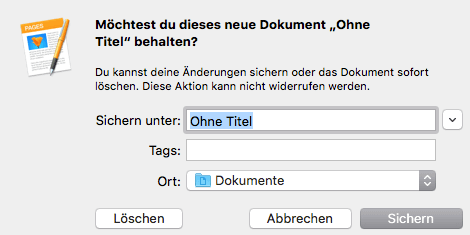
Unsere Betrachtungen der Window-Controls lassen sich verallgemeinern. Es ist in jedem Fall im Sinne der Eingabesicherheit eine gute Empfehlung, Optionen abzusetzen, die bei versehentlichem Auslösen zu größeren Problemen wie einem Datenverlust führen können.
Die Abbildung zeigt die Umsetzung bei MacOS. Es gehört zu den Design-Vorgaben des Betriebssystems, dass Auslöser für Aktionen, die zu einem Datenverlust führen können, von den anderen abgesetzt sind. Im Beispiel ist der Button für das Löschen von den anderen beiden abgesetzt. Selbst wenn man aus Versehen „Abbrechen“ oder „Sichern“ verfehlen sollte, landet man wohl kaum beim gefährlichen „Löschen“.
Eingabetechnikoptimierte Selektionstechniken
Schließen wir dieses Kapitel mit einem Thema ab, das verschiedene Charakteristika unterschiedlicher Eingabetechniken zusammenfasst. Schon in unseren Überlegungen zu Zieltoleranzen haben wir betont, dass es gewichtige Unterschiede zwischen der Eingabe mit Maus oder Trackpad im Vergleich zu einer Touch-Eingabe etwa auf einem Tablet oder einem Smartphone gibt. Als Folge sollten bei der Touch-Eingabe größere Zielflächen vorgesehen werden. Dies ist aber nicht die einzige Form der räumlichen Eingabe, die bei Touch-Nutzung anders gelöst werden muss als bei der klassischen Eingabemethode. Vor allem die Gestaltung der Objektselektion muss anders gelöst werden.
Gegenüber der Eingabe mit Maus und Tastatur sind die Möglichkeiten bei Touch-Eingaben stark eingeschränkt, weil die Positionierung des Zeigers und die Auslösung der Funktion nicht mehr voneinander getrennte Aktionen sind. Das könnte durch den Einsatz eines Zeigers zwar kompensiert werden, doch verschwände dann der große Vorteil des direkten Zeigens. Bei Maus-Interaktionen ist es überdies leicht, verschiedene Eingaben für die Selektion und Ausführung, etwa das Öffnen der Date, vorzusehen. Üblich ist ein einfacher Klick für eine Selektion und ein Doppelklick für die Auslösung der Funktion. Möglich wäre auch ein Rechtsklick für die Selektion und ein Linksklick für die direkte Ausführung. In Touch-Oberflächen gibt es nur eine Operation, nämlich die des Tippens. Denkbar wären allenfalls noch eine Selektion durch längeres Gedrückthalten oder der Rückgriff auf komplexe Multi-Touch-Gesten, bei denen auch die Anzahl der möglichen Touch-Punkte oder der Zeitabstand zwischen zwei aufeinanderfolgenden Klicks eine Rolle spielen.
Noch komplexer gestaltet sich die Umsetzung der Mehrfachselektion, also der Auswahl mehrerer Dateien: Bei der klassischen Eingabetechnik können durch Klicken und Ziehen über einen Bereich mehrere Objekte zugleich selektiert werden. Theoretisch ist dies auch auf Touch-Oberflächen möglich. Es funktioniert zum Beispiel recht problemlos unter Windows 10, wenn man den Rechner im Desktop-Modus betreibt. Das Berühren des Bildschirms und das anschließende Bewegen löst jedoch auf den meisten Systemen (Android, iOS und auch Windows 10 im Tablet-Modus) ein Scrollen des Inhalts aus, sodass auf das Markieren per „Gummiband“ in diesen Fällen verzichtet werden muss. Auch die Markierung mehrerer Dateien, indem die SHIFT-Taste gedrückt wird, während mehrere Dateien nacheinander angeklickt werden, lässt sich nicht auf die Touch-Bedienung übertragen, weil es keine Zusatztasten gibt.
Selektion ist also bei Touch-Interaktion ein Problem. Zufriedenstellend lösen kann man es nur durch die Einführung eines expliziten Selektionsmodus. Die Abbildung zeigt eine Objektliste aus iOS. Beim Tippen auf ein Objekt wird dieses in der zugeordneten App geöffnet. Klickt man jedoch oben rechts auf „Auswählen“, wechselt das System in einen anderen Modus, in dem die Objekte markiert und anschließend Operationen wie zum Beispiel „Löschen“ ausgewählt werden können.
Das Markieren von Objekten ist in diesem Falle mit zusätzlichen Sequenzialitäten verbunden, die in der Eingabetechnologie begründet sind. Mit klassischen Eingabetechniken geht die Selektion schneller von der Hand und kommt ohne Zusatzmodus aus. Bemerkenswert ist aber, dass die Technik der Selektion per Zusatzmodus zwar aufwändiger, aber leichter erschließbar ist (siehe Erschließbarkeit im Abschnitt Orientierung). Der Knopf, um in den Auswahlmodus zu wechseln, ist nämlich stets sichtbar. In der klassischen Variante hingegen muss man wissen, dass es die Möglichkeit gibt, ein Gummiband aufzuziehen oder dass man die SHIFT-Taste drücken kann, um eine Mehrfachselektion zu machen. Die Nutzungsoberfläche selbst gibt keinen Hinweis darauf.