Potenziale interaktiver Nutzungsschnittstellen
Im vorhergehenden Kapitel haben wir das Konzept der Differenzerfahrung eingeführt und beschrieben, wie mithilfe von Denkzeugen der Bereich des Wahrnehmbaren und damit auch des Bedenkbaren stark erweitert werden kann. Dieses Potenzial geht in der Regel mit einer kognitiven Entlastung einher, denn diese Mittel zur Differenzerfahrung überdauern als physische Objekte meist den Prozess der Erzeugung und ermöglichen dadurch Differenzerfahrungen über verschiedene Orte hinweg (Übertragung) als auch Differenzerfahrungen über die Zeit (externes Gedächtnis). Wir wollen nun diese Ideen möglichst konstruktiv auf die Gestaltung von Nutzungsschnittstellen übertragen. Anhand einer kurzen rückblickenden Betrachtung der Entstehung heutiger Nutzungsschnittstellen werden wir die technischen Prinzipien und Konzepte verdeutlichen, bevor wir dann im Hauptteil diese Einsichten zu einem konkreten Gestaltungsansatz verdichten. Damit können wir zugleich auch den Begriff der Interaktivität aus technischer Sicht präzisieren und einige irreführende Annahmen geraderücken.
Nach unserem Verständnis umfasst eine Nutzungsschnittstelle alle wahrnehmbaren und manipulierbaren Objekte, also z. B. auch Dateien und Ordner im Explorer oder Texte und grafische Objekte in einem Präsentationsprogramm. All diese Objekte existieren nur durch die Ausführung eines Programms. Denn nur innerhalb einer Software wie PowerPoint oder Keynote gibt es beispielsweise die Elemente einer Folienpräsentation, also Grafiken und Texte, als sichtbare und manipulierbare Objekte. Unter der Nutzungsoberfläche existieren sie als Datenstruktur und darunter schließlich als Konfigurationen von Zuständen. Erst eine explizit programmierte Nutzungsschnittstelle erzeugt die Objekte auf dem Bildschirm, macht sie ansprechbar und manipulierbar. Zwingend notwendig sind in all diesen Fällen weitere Objekte wie Buttons oder Menüs, deren einziger Zweck das Zugänglichmachen von Programmfunktionen ist. Jacob Nielsen bezeichnet solche Objekte als Chrome11.
Sowohl dieses Chrome als auch die Datenobjekte entstehen durch die Programmierung der Nutzungsoberfläche. Bruce Tognazzini beschreibt in seinem Buch „Tog on Interface“12 von 1992 die Benutzungsoberfläche des Apple Macintosh als eine „fanciful illusion“, deren Charakter anders sei als das darunter liegende Betriebssystem. Tognazzini zielt mit dieser Beschreibung zwar auf die grafische Nutzungsschnittstelle des Macintosh ab, sein Gedanke trägt aber für Nutzungsschnittstellen generell, denn auch wenn auf einem Unix-System eine Datei auf der Festplatte mit den Befehlen ls gelistet und mit cat ausgegeben wird, geht das nur, weil eine programmierte Nutzungsschnittstelle die Datei als Objekt zur Verfügung stellt. Wenn Sie einen Computer zerlegen, würden Sie keine Dateien finden, selbst wenn Sie die Magnetisierungen auf einer Festplatte oder die Zustände der Bits eines Speichermediums direkt wahrnehmen könnten. Das Betriebssystem liegt als Zwischenschicht13 zwischen der Nutzung und der gerätetechnischen Umsetzung. Es sorgt dafür, dass man sich nicht mit den gerätespezifischen Aspekten der Datei und Speicherverwaltung befassen muss. Ebenso sorgt das Betriebssystem dafür, dass ein Programm nicht etwa unter Angabe einer physikalischen Adresse in den Speicher kopiert werden muss, sondern dass das Programm mit einem Bezeichner angesprochen werden kann und dann automatisch geladen wird. Gemäß dieser Kapselung der technischen Realitäten und der gleichzeitigen Bereitstellung virtueller Objekte für die Nutzung sind in unserer Sichtweise große Teile des Betriebssystems auch Teil der Nutzungsschnittstelle eines Computers.
Bei den frühen Computern, die in den 1930er, 1940er und 1950er Jahren gebaut wurden, gibt es noch keine Nutzungsschnittstelle als Zwischenschicht. Die Schnittstellen des Rechners, meist große Bedienkonsolen mit vielen Knöpfen und Lämpchen, entsprachen genau den Hardwarezuständen der Maschine. Es handelte sich um Schnittstellen zur Maschinenüberwachung und -steuerung, nicht um von laufenden Programmen erzeugte virtuelle Objekte. Solche Objekte, die von einem Computer angezeigt und direkt mit dem Computer manipuliert werden können, bedürfen eines interaktiven[^interaktiv] Computers. In diesem Kapitel zeichnen wir anhand der Entwicklung interaktiver Nutzungsoberflächen nach, welche technischen Potenziale diese eröffnen und welche technischen Voraussetzungen gegeben oder entwickelt werden mussten, um sie zu verwirklichen.
Ein Hinweis zur Begriffswahl: Der Begriff „Interaktivität“ wird zwar vielfach verwendet, ist aber kaum definiert. Einen kurzen Überblick über verschiedene Definitionsversuche finden Sie in der Dissertation von Felix Winkelnkemper „Responsive Positioning – A User Interface Technique Based on Structured Space“ auf den Seiten 9 bis 14. Für unsere Zwecke ist es nicht wichtig, eine genaue Definition zu finden, sondern die Eigenschaften der Nutzungsoberflächen herauszuarbeiten, die wir interaktiv nennen. Das ist kein Selbstzweck, sondern die genauere Betrachtung der „Evolution“ der Nutzungsschnittstellen gibt uns wichtige Hinweise auf Gestaltungspotenziale. Potenziale verkörpern immer nur Möglichkeiten, keine Zwangsläufigkeiten. Sie können einen Mehrwert entfalten, müssen dies aber nicht. Manchmal ist das auch nicht gefragt oder gewollt. Oft jedoch entsteht aus dem verschenkten Potenzial ein ergonomisches Problem. Viele der Anforderungen der Kapitel Rückmeldung, Eingabeminimalität und Übergänge, die wir später behandeln werden, können beispielsweise direkt aus solchen Potenzialen abgeleitet werden.
Wir erarbeiten in diesem Kapitel die besagten Potenziale digitaler Nutzungsschnittstellen durch eine Betrachtung ihrer Entstehungsgeschichte. Das kann an dieser Stelle nur schlaglichtartig erfolgen. Es gäbe zur Computergeschichte gerade unter dem Aspekt der Entwicklung von Nutzungsschnittstellen noch viel mehr zu sagen. Wenn Sie das Thema interessiert, können wir Ihnen das Buch „Interface Evolution“14 empfehlen, welches die Thematik sehr viel umfangreicher behandelt und vor allem auch die Entwicklung der Nutzungsschnittstelle des PCs einbezieht; sie muss an dieser Stelle außen vor bleiben. Für unsere Zwecke reicht es zu skizzieren, welche Ziele und Vorteile jeweils mit der nächsten Entwicklungsstufe des Computers verbunden waren, um darüber die technischen Potenziale zu bestimmen, die wir in Gestaltungskonzepte umsetzen können. Dabei möchten wir zugleich verdeutlichen, wie durch technische Innovationen unnötige Arbeitsschritte eingespart werden können, die weder explizit gefordert werden noch zur Erledigung der jeweiligen Aufgabe erforderlich sind. Vielmehr sind sie der Wahl des jeweiligen Denkzeugs bzw. seiner Ausgestaltung geschuldet. In diesem Sinne bedeutet ergonomische Gestaltung für uns zweierlei: zum einen Belastungen zu vermeiden, zum anderen neue Handlungsmöglichkeiten zu erschließen.
Programmierung durch Verkabelung
Des amerikanische ENIAC wird oft als erster digitaler Computer aufgeführt. Dieser von 1943 bis 1945 für das amerikanische Militär gebaute Rechner war dreißig Tonnen schwer, füllte eine Halle und hatte eine Leistungsaufnahme von sage und schreibe 150 kW. Er war unter anderem für komplexe Berechnungen wie etwa ballistische Flugbahnen konzipiert worden. Seine auffälligste Eigenheit war jedoch, dass er per Verkabelung programmiert wurde und dass Werte unter anderem durch das Stellen von Drehschaltern eingegeben wurden.

Das obige Bild zeigt eine typische Ansicht des ENIAC. Auf der linken Seite sehen Sie das Programm in Form der Verkabelung der Hardwaremodule des Rechners. Auf der rechten Seite sind auf fahrbaren Gestellen angebrachte Anordnungen von Drehschaltern zu sehen, mit denen Werte eingestellt werden konnten. Programmieren bedeutete beim ENIAC etwas anderes, als man es sich heute vorstellt. Der ENIAC war ohne Programm, also ohne gesteckte Kabel, einfach nur eine Sammlung von Hardwaremodulen wie einem Taktgeber, Akkumulatoren, Multiplikatoren, Dividierern, Einstellfeldern sowie Druckern, Lochkartenlesern und -stanzern für die Ein- und Ausgabe. Den ENIAC zu programmieren bedeutete, diese Module der gewünschten Berechnung entsprechend miteinander zu verbinden. Ein Programm beim ENIAC war also nicht mit dem erst etwas später eingeführten Begriff „Programm“ im heutigen Sinne zu vergleichen. Gemäß der Konzeption von John von Neuman (1945) wird unter einem Programm eine Folge von Anweisungen verstanden, die dazu dient, den Computer zu steuern. Ein Programm wird Anweisung für Anweisung abgearbeitet. Beim ENIAC kann man das nicht sagen, denn er verarbeitete kein Programm und das Programm steuerte auch nicht den ENIAC. Er verkörperte vielmehr einen Bausatz, der für jedes Programm neu zusammensetzt werden musste. Der ENIAC, der die Funktion A ausführen konnte, war also genau genommen nicht der gleiche Computer wie der, der die Funktion B ausführen konnte.
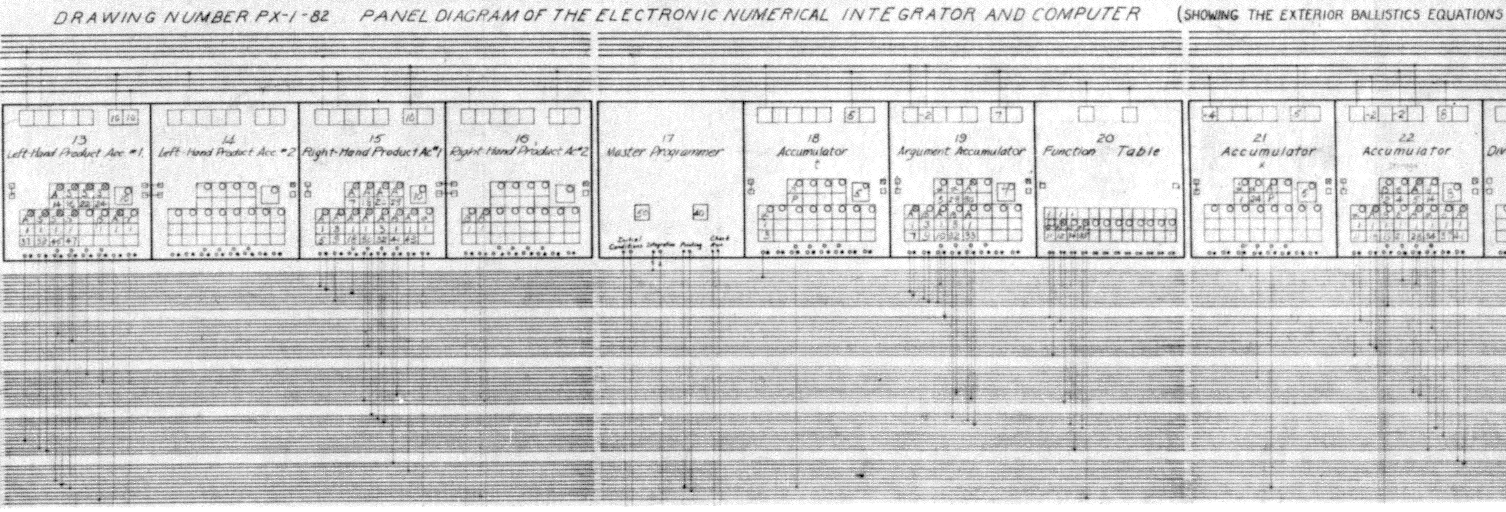
Ein Programm für den ENIAC, also seine Verkabelung zum Ausführen einer speziellen Berechnung, wurde auf Papier geplant. Oben ist ein Ausschnitt aus einem solchen „Panel Diagram“ abgebildet. Das Erstellen solcher Pläne dauerte oft Wochen, das Programmieren des Rechners durch das Stecken von Kabeln dauerte mehrere Tage. Die eigentliche Berechnung erfolgte, wenn er bestimmungsgemäß funktionierte und bei der Planung und der Verkabelung kein Fehler passiert war. Innerhalb weniger Minuten oder Stunden war eine Berechnung erledigt.
Computernutzung ohne Computerkontakt
Eine Programmierung durch Konfiguration und Verkabelung von Hardware-Bausteinen war nicht komfortabel und in Bezug auf mögliche Differenzerfahrungen äußerst unzureichend. Spätere Computer (und auch manch frühere) funktionierten deshalb auch nicht mehr auf diese Art und Weise. Um sie zu programmieren, wurde nicht mehr neu verkabelt, sondern ein symbolisches Programm im modernen Sinne wurde von einem Medium eingelesen und zumeist im internen Speicher abgelegt. Typische Medien für Programme waren zunächst Lochstreifen und Lochkarten.

Lochstreifen sind, wie oben zu sehen ist, Papierstreifen mit einer Perforation für den Transport durch einen entsprechenden Leser oder Stanzer. Auf diesen Streifen werden Reihen von Löchern gestanzt. Eine solche Reihe ist jeweils eine binäre Codierung eines Zeichens, also eine Codierung in Ja und Nein, 1 und 0 oder wie in diesem Fall Loch und Nicht-Loch. Typische Lochstreifen ermöglichten pro Zeile 5 oder 8 Löcher je nach eingesetztem System. Die wichtigste Alternative zu Lochstreifen waren Lochkarten. Das Prinzip einer Lochkarte ist dem eines Lochstreifens grundsätzlich sehr ähnlich. Statt eines kontinuierlichen Papierstreifens wurde jedoch eine Vielzahl von Papierkarten verwendet. Ein Lochkartenleser liest einen Lochkartenstapel Karte für Karte ein. Beschrieben werden können Lochkarten mithilfe von Lochkartenstanzern. Üblicherweise entsprach eine Karte einem Datensatz oder, im Falle der Programmierung, einer einzelnen Programmzeile, so etwa auch im unten abgebildeten Beispiel, das zugleich einen weiteren Vorteil offenbart: Neben dem Stanzcode ermöglicht das Trägermedium auch die äquivalente symbolische Beschriftung (im Bild am oberen Rand). Ein weiterer wichtiger Vorteil von Lochkarten war, dass das Trägermedium nicht ein einziges (langes) Artefakt war, sondern feingranularer aufgebaut ist. Dadurch wurden nicht nur lokale Änderungen erheblich vereinfacht, sondern auch die Möglichkeiten, einzelne Karten räumlich oder zeitlich verteilt zu erstellen, sie zusammenzuführen und ihre Reihenfolge zu ändern.

Mit Ausnahme weniger früher Computer wurde bei den meisten Geräten das Programm vor der Ausführung komplett eingelesen und in den internen Speicher des Computers übertragen. Um einen solchen „Stored Program Computer“ zu nutzen, mussten sowohl das Programm als auch alle Eingabedaten vor dem Programmablauf vorliegen. Wenn ein neues Programm geschrieben wurde, geschah dies in einem umständlichen und aufwändigen Prozess:
- Das Programm wurde auf Papier in einer Assembler-Sprache sehr nah am Maschinencode ausgearbeitet. Auch höhere Programmiersprachen waren möglich. Diese kamen aber erst Anfang der 1960er Jahre auf.
- Aus dem Assembler-Code musste das Programm in die Maschinensprache umcodiert werden. Aus Befehlen, die aus kurzen Buchstabenfolgen bestanden, etwa JMP für den Sprungbefehl, wurden Zahlenwerte, die der Computer direkt verarbeiten konnte.
- Dieses Maschinensprachenprogramm musste nun auf Lochkarten oder Lochstreifen übertragen werden.
- Die Lochkarten oder Lochstreifen mit dem Programm und allen Eingabedaten wurden einem Operator übergeben. Der Operator verwaltete eine Warteschlange von Programmen, die vor dem eigenen noch abzuarbeiten waren.
- Wenn das eigene Programm an der Reihe war, ließ der Operator es einlesen, legte die Eingabedaten in den Lochstreifen- oder Lochkartenleser und startete das Programm.
- Resultate des Programms wurden auf einem Drucker ausgegeben.
- Der Operator legte das Programm, die Eingabedaten und die ausgedruckten Ausgaben des Programms in einem Ausgabefach bereit, wo sie abgeholt werden konnten.
Charakteristisch für diese Arbeitsweise ist, dass die Prozesse der Entwicklung und des Ausführens von Programmen personell und räumlich getrennt waren. Ein Programm musste korrekt in Assembler-Sprache auf Papier programmiert, ggf. fehlerfrei in Maschinencode übertragen und dann auch noch korrekt abgelocht worden sein. Auf all diesen Ebenen konnten Fehler passieren, die sich aber erst während der Ausführung offenbarten. Zudem war es bei dieser Art der Computernutzung nicht möglich, ein Programm zu schreiben, bei dem abhängig vom Programmablauf Entscheidungen getroffen wurden. Alle Entscheidungen mussten vor Beginn der Programmausführung getroffen werden. Die zugrundeliegenden Prinzipien sind unter dem Namen John von Neumanns veröffentlicht. In diesem „First Draft Report on the EDVAC“15 von 1945 wird ausgeführt:
An automatic computing system is a (usually highly composite) device, which can carry out instructions to perform calculations of a considerable order of complexity — e.g. to solve a non-linear partial differential equation in 2 or 3 independent variables numerically. The instructions which govern this operation must be given to the device in absolutely exhaustive detail. They include all numerical information which is required to solve the problem under consideration: Initial and boundary values of the dependent variables, values of fixed parameters (constants), tables of fixed functions which occur in the statement of the problem. These instructions must be given in some form which the device can sense: Punched into a system of punchcards or on teletype tape, magnetically impressed on steel tape or wire, photographically impressed on motion picture film, wired into one or more fixed or exchangeable plugboards—this list being by no means necessarily complete. All these procedures require the use of some code to express the logical and the algebraical definition of the problem under consideration, as well as the necessary numerical material.
Once these instructions are given to the device, it must be able to carry them out completely and without any need for further intelligent human intervention. At the end of the required operations the device must record the results again in one of the forms referred to above. The results are numerical data; they are a specified part of the numerical material produced by the device in the process of carrying out the instructions referred to above. (Hervorhebung nicht im Original)
Von Neumann beschreibt hier einen Computer, bei dem Programme „without any need for further intelligent human intervention“ ablaufen. Von einer Nutzungsschnittstelle spricht er an keiner Stelle. Auch Computer, wie von Neumann sie charakterisierte, brauchten einige Bedienelemente. Dazu gehörten unter anderem Knöpfe zum Ein- und Ausschalten, zum Starten und Unterbrechen der Operation und zum Einlesen des Programms und der Daten vom Lochkarten- bzw. Lochstreifenleser. In der Tat gab es aber für die eigentliche Funktion des Computers, das Programm selbst, keinerlei Nutzungsschnittstelle. Das Programm lief völlig ohne menschliche Intervention ab. Zwar wurde bei dieser Art von Computern nicht mehr neu verkabelt, um zu programmieren, doch waren Bedienelemente und Anzeigen unabhängig von der jeweiligen Anwendung. Sie zeigten die Funktion von Systemkomponenten an oder gaben direkt den Inhalt von Registern und Akkumulatoren aus und erlaubten deren Manipulation zum Zweck der Fehlerbeseitigung. Sie dienten nicht zur Steuerung des Programmablaufs oder der Eingabe zusätzlicher Daten.
Während das Personal der Rechenzentren in der Frühzeit der Computer noch mit den Datenträgern der Programme und Daten in Kontakt kam, wurden im Laufe der nächsten Jahre die Abläufe zunehmend verkürzt und vereinfacht. Computer wurden im sogenannten Batch-Modus betrieben. Ein Rechenauftrag, üblich war der Ausdruck „Job“, wurde mittels einer vorgelagerten Maschine zunächst auf Magnetbänder übertragen. Der eigentliche Hauptcomputer arbeitete diesen Stapel von Jobs, den „Batch“, nach und nach ab. Ausgaben wurden wiederum auf Magnetbänder geschrieben, die später in eine nachgelagerte Maschine eingelesen wurden, die die Daten auf Papier druckte. Auf diese Art und Weise wurde der Rechenablauf optimiert, da die teure Recheneinheit nicht mehr darauf warten musste, dass neue Lochkarten oder Lochstreifen von langsamen Lesegeräten eingelesen oder Zeichen auf langsamen Ausgabegeräten gedruckt werden mussten. Personen, die die Jobs programmierten, konnte die Optimierung der Zuführung von Programm und Daten egal sein, denn sie kamen mit dem Computer ohnehin nicht direkt in Berührung. Der komplette Programmierprozess war nach wie vor vorgelagert und fand nur mit analogen, mechanischen Mitteln statt. Programmiert wurde auf sogenannten „Codierbögen“. Dies geschah üblicherweise nicht direkt im Maschinencode des Computers, sondern zumindest in Assembler-Code, zumeist aber in einer höheren Programmiersprache wie Fortran, Algol, COBOL oder LISP.
Die große Verzögerung zwischen Programmabgabe und der Ergebnispräsentation stellte ein gravierendes Problem dar, da es kaum jemals gelingt, ein komplexes Programm auf Anhieb korrekt zu schreiben. Meist gibt es Fehler, sowohl syntaktischer als auch semantischer Art. Gerade die semantischen Fehler sind die problematischen, denn bei ihnen kann das Programm durchaus syntaktisch korrekt ausgeführt werden, es tut aber nicht, was man von ihm erwartet. Weil Fehler jedoch erst nach Stunden offenbar wurden, erforderte die Fehlerbeseitigung zusätzlichen organisatorischen und mentalen Aufwand. Heute dagegen ist es möglich, ein Programm bei einem auftretenden Fehler schnell zu korrigieren. Das heute übliche Programmieren durch schrittweises Annähern an die gesuchte Lösung hätte damals Tage bis Wochen gedauert.
Responsivität: Echtzeit-Computer
Die Probleme, die durch die sehr langen Zeiten zwischen Programmabgabe und Aushändigung des Ergebnisses entstanden, sowie der Nachteil, auf Lochkarten und Lochstreifen programmieren zu müssen, ohne den Computer selbst zur Fehlerbehebung und Bearbeitung nutzen zu können, waren offensichtlich. Benötigt wurden Computer im Echtzeitbetrieb, bei denen Eingaben direkt verarbeitet und Ausgaben direkt erzeugt werden konnten. Solche Computer gab es bereits früher, als man meinen sollte. Computer wie die IBM 305 RAMAC oder der Librascope LGP-30 ermöglichten bereits in den 1950er Jahren, einen Computer in gewisser Weise interaktiv zu nutzen. Die RAMAC-Machine etwa wurde für Buchhaltungs- und Verwaltungsaufgaben eingesetzt. Dabei wurden keine hohen Anforderungen an die Rechenleistung gestellt, nur wenige Personen verwendeten den Rechner und auch die Menge der verschiedenen Programme war überschaubar. Unter solchen Bedingungen konnte eine Betriebsart, in der z. B. Lagerstände abgefragt werden konnten und das System zeitnah die Antworten lieferte, durchaus verantwortet werden.
Time-Sharing
Im Bereich großer Rechenanlagen wurde die Lösung des Problems der langen Zeiten zwischen Programmabgabe und Aushändigung der Ergebnisse und vor allem auch der mangelnden Eingriffsmöglichkeiten während des Programmierprozesses selbst im Time-Sharing gefunden. Die theoretischen Vorarbeiten hierzu begannen schon Mitte der 1950er Jahre. Das erste kommerzielle Time-Sharing-System wurde 1964 am Dartmouth College in Betrieb genommen. Ab Mitte der 1960er Jahre folgten dann viele weitere Systeme. Hinter Time-Sharing steckt die Idee, die Ressourcen des Computers zu teilen. Der Computer ist durchgehend in Betrieb und wird über ein mit ihm verbundenes Terminal genutzt. Meist diente dazu ein Fernschreiber oder eine elektrische Schreibmaschine. Es arbeitet aber nicht nur eine einzige Person mit der Maschine, sondern viele gleichzeitig. Sie werden im Rundumverfahren bedient. Wenn die Geschwindigkeit unterhalb der Wahrnehmungsschwelle liegt, entsteht für alle Beteiligten die Illusion, den Computer jeweils nur für sich allein zu nutzen.
Wenn beim Time-Sharing viele Programme gleichzeitig verarbeitet werden, wird die Abarbeitung eines einzelnen Programms langsamer als vorher, denn der Computer wechselt zwischen den Programmen hin und her. Ein Programm wird also nur in kurzen Schüben ausgeführt. Obwohl sich dadurch die Laufzeit eines Programms verlängerte, war der Verarbeitungsprozess insgesamt viel schneller, weil die enormen Wartezeiten im Batch-Prozess entfielen. Die Zeit von einer Programmkorrektur bis zur Überprüfung, ob die Korrektur zum richtigen Ergebnis führte, dauerte mit dem Time-Sharing nicht mehr Tage oder Stunden, sondern nur noch Minuten oder Sekunden. Mit dem Time-Sharing änderten sich auch die Ein- und Ausgabemedien. Statt Lochkartenstapel abzugeben und als Ergebnis die Lochkarten und den Ergebnisausdruck zurückzuerhalten, wurden nun Befehle per Texteingabe über die Tastatur eines Fernschreibers an den Computer gegeben. Durch die Abschaffung der damit einhergehenden Medienwechsel konnte der Zusatzaufwand für die Behandlung unterschiedlicher Formate und Codierungen sowie der Trägermedien entfallen. Er war allein den mangelnden technischen Möglichkeiten geschuldet und nicht den zu erledigenden Arbeitsaufgaben.
Time-Sharing eröffnete das Potenzial der Responsivität, erhielt aber die komplette Flexibilität der individuellen Programmierung und Datenverarbeitung. Nach wie vor konnten mehrere Personen unabhängig voneinander ihr eigenes Programm erstellen und laufen lassen.
Responsivität bedeutet, dass auf Eingaben innerhalb kurzer Zeit eine Ausgabe erfolgt. Responsivität fördert einen iterativen Stil bei der Problemlösung und ermöglicht es, Lösungsmöglichkeiten durch Probehandeln zu erarbeiten.
Mit dem Übergang zum Time-Sharing ging der Übergang von Konsolen zur Steuerung und Überwachung der Maschine zu eigens programmierten Nutzungsschnittstellen einher. Die Konsolen boten Zugriff auf die Hardware des Rechners, auf interne Zustände und Speicherregister. Von Interesse bei der Nutzung sind jedoch nicht interne Maschinenzustände und Speicheradressen, sondern die Möglichkeiten, die jeweils interessierenden Daten, Funktionen und Objektstrukturen anzusprechen und manipulieren zu können.
Interaktiver Editor
Eine große Errungenschaft der Einführung der Time-Sharing-Technik war die Möglichkeit, Programme direkt am Computer zu programmieren und über den Erfolg der Programmierung zeitnah Rückmeldung zu bekommen. Mittels eines Fernschreibers, der an einen zentralen Computer angeschlossen war, war das grundsätzlich möglich, wenn das Computersystem über einen Editor verfügte, der es erlaubte, ein Programm im interaktiven Betrieb zu schreiben, zu bearbeiten und jederzeit abzuspeichern. Diese Möglichkeit, Programme unter direkter Nutzung des Computers zu bearbeiten und auf diese Weise die Misslichkeiten der Programmierung mit Lochkarten und Lochstreifen hinter sich zu lassen, war eine der Hauptantriebskräfte hinter der Entwicklung von Time-Sharing-Systemen. Dass mit diesen Systemen nun auch Programme möglich waren, die interaktiv gesteuert werden konnten, wurde zwar gesehen, stand aber nicht unbedingt im Vordergrund und war auch nicht in jedem Time-Sharing-System von Beginn an möglich.
Ein Editor zur damaligen Zeit entsprach jedoch nicht unseren heute gebräuchlichen Editoren. Der Grund dafür liegt darin, dass mit Schreibgeräten wie Fernschreibern, Schreibmaschinen oder auch Druckern nur Inschriften produziert werden können. Einmal geschrieben ist der Text fixiert und es lässt sich immer nur etwas Weiteres dazuschreiben. Die Aufgabe eines Editors ist jedoch, einen im Computer befindlichen Text bearbeiten, also ändern zu können. Was auf dem Papier steht, lässt sich aber nicht mehr ändern. Es gibt bei Fernschreibern, ebenso wie bei Schreibmaschinen kein Löschen16, kein Backspace im heutigen Sinne und keine Möglichkeit, einen Cursor im Text zu positionieren, um etwas an dieser Stelle einzufügen oder zu ersetzen. Diese Aufgaben können nur erledigt werden, wenn es zusätzliche Befehle gibt, die beschreiben, wie ein Text angepasst werden kann.
Diese Funktionsweise früher Editoren lässt sich noch an heutigen Linux- oder Unix-System (inklusive MacOS) nachvollziehen. Der in diesen Systemen enthaltene Zeileneditor „ed“ stammt aus der Frühzeit des Betriebssystems Unix Anfang der 1970er Jahre, aus einer Zeit also, in der viele Computer noch per Fernschreiber genutzt wurden. Wird der Editor durch die Eingabe von „ed“ in der Kommandozeile gestartet, passiert zunächst nichts, außer dass ein Zeilenvorschub ausgelöst wird (oder im modernen Bildschirm-Terminal der Cursor in die nächste Zeile wandert). Tippen Sie nun nacheinander H und P jeweils gefolgt von „Enter“. Diese beiden Befehle sorgen dafür, dass Fehlermeldungen ausgegeben werden und dass mit einem * angezeigt wird, wenn Sie eine Befehlseingabe machen können. Nun kann eine Datei zur Bearbeitung geladen werden. Mit der Eingabe von r textfile.txt wird die Datei mit besagtem Namen „textfile.txt“ eingelesen. Der Editor antwortet mit der Anzahl der gelesenen Bytes, in unserem Beispiel 86. Da die Datei nicht groß ist, können Sie sie in ganzer Länge ausgeben. Dies geschieht durch die Eingabe des Befehls ,l (hierbei handelt es sich um ein kleines L und nicht um die Zahl 1).
Wie Sie sehen, handelt es sich um einen einfachen Text, bestehend aus zwei Zeilen. Das Dollarzeichen steht jeweils für ein Zeilenende. Sie können diesen Text nun bearbeiten, indem Sie entsprechende Befehle eingeben. Im Beispiel werden wir zum einen unterhalb der Überschrift eine Zeile mit Plus-Zeichen einfügen, um sie besser abzusetzen, und zum anderen das Wort „hree“ – wohl ein Tippfehler – durch das korrekte Wort „here“ ersetzen.
Um die Pluszeichen hinzuzufügen, müssen Sie dem Editor mitteilen, dass Sie in Zeile 2 etwas einfügen wollen. Dies geschieht durch den Befehl 2i. Nun können Sie den neuen Text eingeben. Um die Eingabe abzuschließen, schreiben Sie einen einzelnen Punkt in eine Zeile:
Die ehemalige Zeile 2 müsste durch das Einfügen einer weiteren Zeile jetzt zur Zeile 3 geworden sein. Sie können das überprüfen, indem Sie die Zeile 3 mit dem Befehl ,3 ausgeben lassen.
Nun geben Sie den Befehl ein, in Zeile 3 das erste Vorkommen von „hree“ durch „here“ zu ersetzen und geben anschließend den kompletten berichtigten Text nochmals aus.
Hiermit sind die beabsichtigten Änderungen abgeschlossen. Abschließend können Sie den verbesserten Text mit w besser.txt abspeichern. Der Editor quittiert das wiederum durch die Angabe der geschriebenen Bytes. Die Eingabe des Befehls q beendet dann den Editor.
Das Bearbeiten eines Textes ist auf diese Art und Weise sehr umständlich, denn man bearbeitet den Text nur indirekt. Der Text liegt zwar im Computer als bearbeitbares Objekt vor, aber man kann ihn nicht als Objekt sehen und auch nicht als Objekt an Ort und Stelle bearbeiten. Vielmehr muss man stattdessen Befehle zur Bearbeitung eingeben und den aktuellen Zustand des Textes immer wieder vollständig oder in Ausschnitten abfragen. Das entspricht einer Arbeitsweise, bei der man eine Person anruft, die einen Text vor sich liegen hat und diesen immer in Teilen durchgibt. Dieser Person könnte man nun die Änderungen beschreiben, die man vornehmen will, und dann jeweils den aktuellen Zustand des Textes erfragen, um zu sehen, ob auch das Ergebnis den Absichten entspricht. Das Beispiel verdeutlicht, dass der Begriff „Dialogsystem“ von Beginn an irreführend war und das eigentliche Potenzial in der Bereitstellung einer interaktiv nutzbaren Arbeitsumgebung besteht. Wir gehen darauf noch einmal im Abschnitt Dialog in den Exkursen ein.
Manipulierbare virtuelle Objekte
Auch wenn ein solcher Editor heute unpraktisch erscheinen mag, führte er damals ein neues Konzept ein, das zuvor nicht möglich und auch nicht nötig war. Der Editor stellt den Text nicht in seiner internen Repräsentation als Bitstrom oder als lange Zeichenkette dar, sondern erzeugt in der Nutzungsoberfläche für die Nutzung verständliche, selektierbare, wahrnehmbare und veränderbare Objekte. Beim einfachen „ed“ sind dies nur Zeilen und Worte. Denkbare Objekte wären auch Absätze oder Seiten. Würde „ed“ nicht über diese Objekte verfügen, wäre es noch viel umständlicher, denn dann könnte man sich nicht auf Zeilen beziehen, sondern müsste Bytes innerhalb des Datenstroms adressieren und manipulieren.
Nutzungsoberflächen für Echtzeitsysteme erzeugen virtuelle Objekte, auf die sich die Nutzung beziehen kann. Bei „ed“ sind es Zeilen, auf der Ebene des Kontrollprogramms – der Shell oder Eingabeaufforderung – sind es Programme und Dateien; verwenden Sie ein Terminprogramm, sind es Kalendereinträge. In all diesen Fällen beziehen Sie sich auf ein Objekt der Nutzungsschnittstelle, statt auf Adressbereiche und Maschinenoperationen. Auch wenn dies eine einfache Nutzungsschnittstelle ist, die einem sehr technisch vorkommen mag, wird sie durch den Computer explizit für die Nutzung erzeugt, statt nur eine Schnittstelle für den Computer zu sein. Programme auf Echtzeitcomputern erzeugen die Steuerungselemente selbst, mithilfe derer sie genutzt werden können. Was auf der anderen Seite der Nutzungsschnittstelle steckt, also die technische Implementierung der Software, ist für die Nutzung in dieser Sichtweise nicht von Belang.
Die von einem interaktiven Programm erzeugten Entitäten, die per Name ansprechbar sind und mithilfe von Befehlen manipuliert werden können, bezeichnen wir als virtuelle Objekte. Zu diesen zählen nicht nur die Objekte der Nutzungsschnittstelle im engeren Sinne, sondern auch die von den jeweiligen Anwendungsprogrammen erzeugten Objekte, mit deren Hilfe die zu erledigenden Aufgaben unabhängig von technischen Interna bearbeitet werden können. Insofern lassen sich viele unserer Betrachtungen zur Ergonomie von Nutzungsschnittstellen auch auf Fragen der Anwendungsgestaltung übertragen. Solche Übertragungen gehören in den Bereich der Gebrauchstauglichkeit und erfordern einen engen Bezug zum Einsatzkontext, den wir in diesem Buch bis auf ein paar allgemeine, weitgehend kontextunabhängige Überlegungen (vgl. u. a. den Abschnitt Übergänge) nicht behandeln.
Räumliche Objektarrangements
Wenngleich Time-Sharing das Bearbeiten von Programmen und Daten vereinfacht, indem der Computer selbst für diese Aufgabe genutzt werden kann und dadurch die Rücklaufzeiten stark verkürzt werden, sind die oben beschriebenen Nachteile der Nutzung per Fernschreiber oder einer elektrischen Schreibmaschine offensichtlich. Mit der Verwendung von Terminals mit Bildschirm und Tastatur konnten diese Nachteile abgebaut werden.

Die Abbildung zeigt das verbreitete Terminal ADM-3A von Lear Siegler von 1976. Ein solches Terminal konnte anstelle eines Fernschreibers an einen Computer angeschlossen werden und dann zunächst genauso wie dieser verwendet werden. Anstelle eines Ausdrucks wurden die Zeichen aber auf dem Bildschirm ausgegeben. Zeilen rutschten automatisch nach oben. Terminals mit zusätzlichem Speicher erlaubten auch das Scrollen nach oben, um das in der Vergangenheit Ausgegebene ansehen zu können. Ein Terminal konnte also prinzipiell wie ein Fernschreiber verwendet werden. Scherzhaft wurde in so einem Fall der Begriff „Glass Teletype“ verwendet, denn das Terminal ist in diesem Fall funktionsidentisch mit einem Fernschreiber, bei dem das Papier durch eine rasend schnell änderbare Fluoreszenzschicht ersetzt wird, deren Anzeige durch permanentes Neu(ein-)schreiben den Eindruck von Persistenz vermittelt.
Ein Terminal anstelle eines Fernschreibers zu verwenden, sparte Papier und war auch weniger laut. Der eigentliche Vorteil von Terminals wie dem ADM-3A lag aber nicht darin, sondern in der Möglichkeit, Zeichen nicht nur ausgeben, sondern auch löschen und vor allem einen Cursor frei auf dem Bildschirm positionieren zu können. Dadurch wurde es möglich, die Buchstaben auf dem Bildschirm zu arrangieren und dieses Arrangement flexibel zu aktualisieren. Terminals, bei denen mit Steuerzeichen der Bildschirminhalt gelöscht und Ein- und Ausgabecursor frei positioniert werden konnten, bildeten die Grundlage für die Aktualisierung von Statusanzeigen, Formularen am Bildschirm, Menüs oder auch Editoren, bei denen der bearbeitete Text am Bildschirm kontinuierlich zu sehen ist.
Screen-Editing: Von „ed“ zu „vi“
Der oben abgebildete UNIX-Editor „vi“ aus dem Jahr 1976 – „vi“ steht für visual – ist dem Editor „ed“ bezüglich der Funktionsweise nicht unähnlich. Im Gegensatz zu „ed“ sieht man bei „vi“ aber einen Ausschnitt des Textes dauerhaft am Bildschirm. „Vi“ erlaubt es, einen Cursor im Text zu positionieren, dann in einen Einfügemodus zu wechseln und neue Textinhalte an der Stelle des Eingabecursors einzufügen. Im Befehlsmodus verhält sich „vi“ wie „ed“ und erlaubt die Eingabe von Befehlen in eine Befehlszeile am unteren Bildschirmrand. Im Gegensatz zu „ed“ werden die Resultate der dort befohlenen Manipulationen, zum Beispiel das Ersetzen eines Wortes durch ein anderes, in „vi“ aber sofort als Änderung des dargestellten Textes angezeigt. Die Bedienung von „vi“ ist für heutige Maßstäbe kryptisch und kompliziert, doch verwirklicht der Editor seinem Namen entsprechend das Potenzial mit dauerhaft am Bildschirm sichtbaren und zugleich bearbeitbaren Zeichen. Zwar erlaubt der Editor die Eingabe von Befehlen, doch müssen diese nicht mehr für das Einfügen genutzt werden; für die Ausgabe ist es zudem nicht mehr nötig, die Zeilennummer im Text zu kennen.
Vergleicht man die Ur-Version von „vi“ mit der Funktionalität heutiger Text-Editoren, bemerkt man, dass eine heute grundlegende Eigenschaft fehlt: Der große Vorteil der Textbearbeitung an Terminals ist ja, dass der ausgegebene Text direkt an Ort und Stelle bearbeitet werden kann. Statt eines Befehls der Art „Füge in Zeile 20 nach dem 4. Wort ein Komma ein“ kann mit dem Cursor an diese Stelle navigiert und das Komma eingegeben werden. Jeder moderne Editor unterstützt diese Arbeitsweise – so auch „vi“. Was aber bei „vi“ noch nicht möglich war, ist die räumliche Markierung eines Textausschnitts und das Anwenden eines Manipulationsbefehls auf diesen Bereich. Wenn Sie heute dagegen auf einem Linux- oder Unix-basierten System „vi“ eingeben, öffnet sich ein Editor, den Sie wie „vi“ verwenden können. Es handelt sich aber in der Regel nicht mehr um den „vi“ aus den 1970er Jahren, sondern um eine erweiterte Version mit dem Namen „vim“ (für vi improved). „vim“ wurde Ende der 1980er Jahre entwickelt und besitzt einen Modus, der eine räumliche Selektion von Textteilen erlaubt. Die selektierten Textteile werden invertiert dargestellt. Das Selektieren unter „vim“ funktioniert dann wie folgt:
- Sicherstellen, dass Sie sich im Befehlsmodus befinden, den Einfügemodus gegebenenfalls durch ESC verlassen.
- Den Cursor am Beginn des Blocks positionieren.
- Durch Eingabe von SHIFT+v die komplette Zeile oder durch STRG+v den kompletten Block markieren oder
- v eingeben, um den Blockanfang festzulegen.
- Mit dem Cursor zum Blockende navigieren.
- d (delete) eingeben, um den Block auszuschneiden oder y (yank), um ihn zu kopieren.
- Mit dem Cursor zur Zielposition navigieren.
- p (paste) eingeben, um den Block an dieser Stelle einzufügen.
Statt der Notwendigkeit einer verbalen Formulierung von Position und Ausdehnung einer Auswahl ermöglicht die räumliche Selektion der auf dem Bildschirm angezeigten Elemente bei „vi“ und „vim“ eine „direkte” Manipulation. Üblicherweise wird der Begriff „direkte Manipulation“ mit Zeigegeräten wie Maus oder Stift und grafischen Darstellungen verbunden17. Grundsätzlich reicht aber ein Textterminal aus, insofern Objekte räumlich dargestellt und auch räumlich selektiert und manipuliert werden können. „Direkte Manipulation“ erfordert, dass Handlungs- und Wahrnehmungsraum gekoppelt sind bzw. genauer, dass Handlungsraum und Wahrnehmungsraum übereinstimmen. Objekte werden bei „vi“ an einem Ort am Bildschirm angezeigt, werden an eben diesem Ort selektiert und dann auch an Ort und Stelle manipuliert. Anders ist es, wenn „vi“ im Befehlsmodus verwendet wird. In diesem Fall werden die Anweisungen zur Manipulation in einer Befehlszeile eingegeben, wirken sich aber an anderer Stelle auf Objekte aus. Handlungs- und Wahrnehmungsraum fallen auseinander.
Direkte Manipulation
Im „vim“-Beispiel des vorherigen Abschnitts wurde ein Cursor mehrfach räumlich positioniert, um Objekte am Bildschirm zu selektieren. Eine solche Selektion per Cursortasten ist aber recht umständlich und indirekt. Die Auswahl eines Objekts in einem Smartphone, etwa eines Kontaktes aus einer Kontaktkiste, erfolgt deutlich direkter durch das Zeigen auf dieses Objekt. Interessanterweise war etwas Ähnliches bereits in den 1950er Jahren möglich. Jedoch erforderte dies ein Zusatzgerät, das direkt auf eine Position auf den Bildschirm gerichtet werden konnte, um dort ein Objekt zu selektieren.
Die Anfänge der direkten räumlichen Selektion liegen, wie so oft in der Computergeschichte, beim Militär, namentlich beim Whirlwind-Computer und dem darauf aufbauenden SAGE-Computer. SAGE steht für Semi-Automatic Ground Environment. Das Herzstück von SAGE waren zwei riesige von IBM hergestellte Computer, die dauerhaft eingehende Daten von Radarstellen auswerteten und mit den Daten bekannter und gemeldeter Flugbewegungen abglichen, um angreifende sowjetische Jets frühzeitig erkennen und darauf reagieren zu können. Das Ziel war nicht ein automatisches Abfangen, sondern, wie im Namen ersichtlich, ein halb-automatischer Umgang mit der Situation. SAGE verfügte daher über eine Schnittstelle, die aufbereitete Daten anzeigte und über Knöpfe und Schalter Eingaben entgegennahm. Zentrale Komponenten der Eingabekonsolen des Systems waren die „View Scopes“ genannten Bildschirme und die als „Lightgun“ bezeichneten Zeigegeräte.


SAGE war ein rein militärisches Projekt. In Zeiten des Kalten Krieges beflügelten sich zivile und militärische Forschung oft gegenseitig. Das Lincoln Lab des MIT, das auch Whirlwind baute und am SAGE-System beteiligt war, entwickelte 1955 bis 1956 einen experimentellen, auf den im Rahmen des SAGE-Systems entstandenen Konzepten aufbauenden Computer mit dem Namen TX-0. Genau wie das SAGE-System verfügte er über eine grafische Ausgabe mittels eines der Radartechnik entlehnten Bildschirms und wie beim SAGE-System konnte ein Gerät zur räumlichen Eingabe am Bildschirm genutzt werden. Im nicht militärischen Kontext wurde aber nicht von der Lightgun, sondern vom Lightpen gesprochen. Von der Funktionsweise her waren beide nahezu identisch. Es handelte sich im Prinzip um sehr einfache Gebilde. Sie bestanden im Großen und Ganzen nur aus einer einfachen Fotozelle, konnten also nur feststellen, ob es an der Spitze des Stifts oder der Pistole hell war oder nicht. Auf Bildschirmen, die mittels Kathodenstrahl ein Bild erzeugen, also den klassischen „Röhrenbildschirmen“, konnte auf diese Weise die Position auf dem Bildschirm festgestellt werden. Diese Technik basiert darauf, dass das Bild nicht gleichmäßig leuchtet, sondern auf sehr schnelle Art und Weise Punkt für Punkt, Zeile für Zeile aufgebaut wird. Der Zeitpunkt, an dem es unter dem Lightpen hell wird, kann mit der bekannten Ausrichtung des Kathodenstrahls zu diesem Zeitpunkt verrechnet und darüber die Position des Stifts auf dem Bildschirm bestimmt werden.
1958 wurde am Lincoln Lab als direkter Nachfolger des TX-0 der TX-2 in Betrieb genommen. An den Systemen TX-0 und TX-2 wurden bereits in den 1950er und 1960er Jahren an Handschrifterkennung, Texteditoren, interaktiven Debuggern, grafischen Schachprogrammen und Projekten der Künstlichen Intelligenz gearbeitet. Auch ein System namens „Sketchpad“ wurde am TX-2 entwickelt; es war wegweisend für heutige Nutzungsschnittstellen und Grafikprogramme.
Das Sketchpad-System, das 1963 von Ivan Sutherland im Rahmen seiner Doktorarbeit entwickelt wurde, war wegweisend für die Entwicklung von Nutzungsschnittstellen mit räumlich-grafischer Anzeige und Objektmanipulation. Das Foto zeigt Timothy Johnson vom MIT bei der Arbeit mit dem auf dem TX-2 laufenden Sketchpad-System. In der Hand hat er einen Lightpen. Mit diesem Stift konnten im System zum Beispiel neue Linienzüge auf dem Bildschirm erzeugt werden. Dies ging durch Zeigen auf einen Punkt und die Betätigung einer der Tasten auf der Tastatur auf der linken Seite. Auf diese Art und Weise konnten auf dem Bildschirm Strecken oder Kreise aufgezogen werden. Betrachten wir der Einfachheit halber zunächst einmal nur Strecken: Das System zeichnete während der Erzeugung der Strecke fortlaufend eine gerade Linie zwischen dem eben fixierten Punkt und der aktuellen Position des Stifts auf dem Bildschirm. Ein weiterer Tastendruck fixierte diesen Punkt, der dann wiederum zum Ausgangspunkt der nächsten Strecke wurde. Der Prozess konnte durch Knopfdruck oder durch Wegnehmen des Stifts vom Bildschirm abgebrochen werden.

Beim Sketchpad-System konnten alle Punkte der Strecken auch im Nachhinein noch bearbeitet werden. Dafür musste ein Punkt zunächst ausgewählt werden. Dies geschah durch Zeigen mit dem Lightpen auf den Punkt. Der Punkt musste aber nicht genau getroffen werden. Das System unterstützte vielmehr die Auswahl dadurch, dass auch die unmittelbare Umgebung eines Punktes diesem zugeordnet wird. Auch wenn mit dem Stift also leicht neben den Punkt gezeigt wurde oder wenn die Abtastung nicht genau war, konnte ein Punkt verlässlich selektiert werden. War ein Punkt erst einmal selektiert, konnte er durch Betätigen einer Taste in einen Verschiebezustand gebracht werden, der wiederum per Tastendruck oder durch Wegnehmen des Stifts beendet werden konnte. Auch bei dieser Operation wurde während des kompletten Manipulationsvorgangs die Zeichnung laufend aktualisiert, sodass während der Nutzung von Sketchpad kontinuierlich die Konsequenzen einer Manipulation sichtbar waren. Diese enge Kopplung von Handlung und Wahrnehmung erzeugte den Eindruck, die Objekte tatsächlich in Echtzeit direkt zu erzeugen und zu manipulieren.
Direkte Manipulation bedeutet in diesem Fall, dass Objekte nicht durch textuelle Funktionsaufrufe erzeugt und verändert werden (zum Beispiel: Zeichne einen Kreis mit dem Radius R um den Mittelpunkt an der Koordinate X,Y), sondern durch die Manipulation ihrer Darstellung am Bildschirm.
Damit eine unmittelbare Manipulation möglich ist, muss eine Reihe von technischen Voraussetzungen erfüllt sein, die erst mit der Entwicklung schneller Prozessoren und Grafikkarten ökonomisch realisierbar wurden:
- Objekte müssen dauerhaft und stabil sichtbar sein. Hierfür bedarf es eines Bildschirms, der Zeichen oder Grafiken in so schneller Folge zur Anzeige bringt, dass sie wie stabile Objekte erscheinen.
- Die Objekte müssen räumlich selektiert werden können. Es bedarf also eines räumlichen Eingabegeräts, das sich auf Koordinaten am Bildschirm beziehen kann, sowie einer Programmierung, die diese Koordinaten den dort vorhandenen Objekten zuordnen kann.
- Die Bearbeitung der Objekte muss direkt an Ort und Stelle erfolgen. Änderungen der räumlichen Eingabe müssen dauerhaft und in hoher Frequenz verarbeitet und als Manipulationskommandos interpretiert werden.
- Die Konsequenzen einer Manipulation müssen umgehend und fortlaufend, also ohne ein explizit ausgelöstes Aktualisieren dargestellt werden. Nur so ist der Eindruck einer direkten räumlichen Manipulation erreichbar. Kommt es zu Verzögerungen, ist ein präzises Arbeiten nicht mehr möglich. Um die notwendige Schnelligkeit zu erreichen, bedarf es geeigneter Datenstrukturen und einer hohen Rechenleistung.
Responsive Manipulation
Die vier bislang von uns beschriebenen technischen Potenziale Responsivität, Virtuelle Objekte, Räumlichkeit und Direkte Manipulation ermöglichen den flexiblen Umgang mit Zeichen und Objekten, indem sie die Nachteile analoger Einschreibmedien aufheben. Bei letzteren kann einmal Geschriebenes weder verändert werden noch kann eine zeitnahe formale Auswertung eines Objekt- und Zeichenarrangements erfolgen. Mit interaktiven Systemen lassen sich Umgebungen kreieren, in denen Objekte flexibel manipuliert und arrangiert werden können. Durch die Kombination der Potenziale können wir aber noch einen Schritt weiter gehen: Der Computer ermöglicht es die Zeichen zu manipulieren, die Grundlage seiner Operationen sind. Beim interaktiven Programmieren beispielsweise wird der Quelltext bearbeitet und in der Folge ausgeführt.
In einem Artikel von 1997 mit dem Titel „Why Interaction is More Powerful Than Algorithms“18 beschreibt Peter Wegner die Vorteile interaktiver Systeme wie folgt:
Objects and robots have similar interactive models of computation; robots differ from objects only in that their sensors and effectors have physical rather than logical effects.
Wegner hatte bei seiner Aussage den Vorteil im Blick, den Programme mit Interventionen zur Nutzungszeit im Vergleich mit rein algorithmischen Programmen haben, bei denen also wie beim Batch-Betrieb das Programm ohne jegliche Intervention abläuft. Seine Beschreibung der Objekte mit Sensoren und Effektoren passt aber noch besser auf das, was wir „Responsive Manipulation“ nennen wollen. Virtuelle Objekte können, wie Roboter, so programmiert werden, dass sie auf Änderungen in ihrer Umgebung reagieren. Welche Möglichkeiten sich daraus ergeben, wollen wir kurz anhand der nachfolgenden Tabelle skizzieren:
| nicht-reflektiv | referenzierend | reflektiv | |
|---|---|---|---|
| explizit | Ausführung | Auswertung | Transformation |
| implizit | Responsive Auswertung | Responsive Manipulation |
Bezüglich der gewählten Begrifflichkeiten geht es uns darum, die Dimensionen der Kombination aus interaktiver Manipulation und responsiver Auswertung zu verdeutlichen. Wir verwenden dafür zwei Dimensionen: Zum einen unterscheiden wir, ob eine Auswertung explizit in Gang gesetzt werden muss oder nicht, zum anderen ist es ein großer Unterschied, ob das Ergebnis der Auswertung von Objekten am Bildschirm Einfluss auf diese Objekte selbst hat oder nicht. Die daraus resultierenden Ausführungen, Auswertungen und Manipulationen lassen sich wie folgt charakterisieren:
- Eine Ausführung liegt vor, wenn die Verarbeitung der Zeichen explizit gestartet wird und dann den Computer steuert, ohne dass sich das, was dann passiert oder erzeugt wird, auf die verarbeiteten Zeichen auswirkt. Es gibt in diesem Fall also ein Arrangement von Objekten, das den Computer in seiner Ausführung steuert, ohne dass es selbst dabei verändert würde. Ein klassisches Beispiel hierfür ist ein Programm-Code, der vom Computer zu seiner Steuerung ausgewertet wird.
- Bei einer Auswertung wird ein neues Zeichen- oder Objektarrangement erzeugt, das sich auf die verarbeiteten Zeichen bezieht. Eine Auswertung ändert das Objektarrangement selbst nicht, bezieht sich aber darauf. Auswertungen liegen zum Beispiel vor, wenn ein Compiler eine Reihe von Fehlermeldungen erzeugt, die auf Codestellen verweisen, oder wenn ein Programm einen Bericht über die Wortwahl in einem Text liefert, ohne diesen selbst zu verändern.
- Eine Responsive Auswertung wird, im Gegensatz zur oben beschriebenen Form, ohne expliziten Auslöser durchgeführt. Eine Textverarbeitung aktualisiert beispielsweise laufend die angezeigte Anzahl der Zeichen, Worte und Seiten in einem Dokument, ohne dass diese Aktualisierung durch einen expliziten Aufruf ausgelöst werden müsste.
- Explizit hingegen ist eine Transformation. Bei einer Transformation werden Objekte, ihre Eigenschaften und Positionen ausgewertet und diese dabei selbst verändert. Viele Aspekte der Textverarbeitung sind Transformationen. In der Programmierung zählt beispielsweise die Minimierung von Code oder das sogenannte „Pretty Printing“, also das gleichmäßige Einrücken von Code-Bestandteilen, zu den Transformationen.
- Die Responsive Manipulation ist die vielleicht interessanteste, aber auch die komplizierteste Form der Verarbeitung der Objekte und ihrer Anordnung, denn sie vereint Reflektivität und Implizität. Responsive Manipulation heißt, dass eine Manipulation eines Objekt- oder Zeichenarrangements durchgeführt und diese unmittelbar ausgewertet wird und dass das Resultat dieser Auswertung ebenso unmittelbar eine Veränderung des Objektarrangements bewirkt. Responsive Manipulationen sind noch selten. Beispiele, wie so etwas aussehen könnte, sind in der Dissertation „Responsive Positioning“ von Felix Winkelnkemper beschrieben.
Fazit
Interessant ist, dass es bis heute keine präzise technische Definition grundlegender Begriffe wie Interaktivität gibt, die allgemein anerkannt und gebräuchlich ist. Ein entscheidender Punkt ist dabei die nahezu durchgängige Verwendung von Metaphern, die aus der Sphäre individuellen menschlichen Verhaltens und seiner sozialen Einbettung entlehnt sind. Solche Metaphern verleiten zu ungeeigneten Assoziationen, da sie eine funktionelle Äquivalenz zwischen menschlicher Informationsverarbeitung und maschineller Datenverarbeitung suggerieren.
Der Begriff „Dialogsystem“ ist ein markantes Beispiel dafür, denn selbst in den von uns skizzierten Systemen mit kommandoorientierten Eingaben geht es an keiner Stelle der Nutzungsschnittstelle um einen Dialog zwischen Mensch und Maschine als einer wechselseitigen Bezugnahme zum Zweck der gegenseitigen Verständnisbildung. Auch der Begriff „grafische Benutzungsoberflächen“ und damit zusammenhängend die Formulierung „Ein Bild sagt mehr als tausend Worte“, mit dem gelegentlich der Nutzen von Icons charakterisiert wird, lenkt, wie wir im Kapitel zur Icon-Gestaltung ausführlicher darstellen, vom eigentlichen Potenzial ab. Statt der Möglichkeit, Funktionen und Objekte räumlich platzieren zu können und dadurch einen Wahrnehmungs- und Handlungsraum zu schaffen, in dem Objekte angeordnet und arrangiert werden können, wird lediglich ihr Aussehen thematisiert.
Auf der Grundlage unserer Überlegungen zur Rolle von Denkzeugen für Differenzerfahrung haben wir die historische Entwicklung von Benutzungsschnittstellen rekonstruiert und die damit einhergehenden Nutzungspotenziale charakterisiert, die schließlich zu unseren heutigen Schnittstellen geführt haben:
- Das Konzept der Responsivität ermöglichte es, in die ursprünglich unterbrechungsfreie Ausführung eines Programms zur Laufzeit einzugreifen. Die Grundlage für Interaktivität war gelegt.
- Es wurden Techniken entwickelt, um virtuelle Objekte kontinuierlich anzeigen und über räumliche Positionen selektiv ansprechen zu können.
- Zusätzliche Eingabegeräte boten die Möglichkeit, Objekte der Wahrnehmung direkt anzusprechen und manipulieren zu können (direkte Manipulation).
- Die zunehmend verbesserte Kopplung von Handlungs- und Wahrnehmungsraum ermöglichte es, persistente räumliche Arbeitsumgebungen zu kreieren, in denen Bildschirmobjekte adressiert, arrangiert, verändert und ausgewertet werden konnten.
In all diesen Entwicklungsschritten wurden durch technische Innovationen
- zum einen Hindernisse abgebaut, die für den Nutzungszweck nicht relevant gewesen sind, sondern nur dem jeweils eingesetzten Mittel geschuldet waren,
- zum anderen die Handlungsspielräume zur Nutzungszeit durch das interaktive Eingreifen erheblich erweitert.
Sowohl in Bezug auf die Beseitigung von Hindernissen als auch auf das Eröffnen neuer Handlungsmöglichkeiten ist die möglichst enge Kopplung von Handlungs- und Wahrnehmungsraum entscheidend.
Technische Potenziale können, müssen sich aber nicht unmittelbar in der Nutzungsschnittstelle offenbaren. Wie wir beschrieben haben, liegt wischen der Nutzungswelt auf der einen und der technischen Welt auf der anderen Seite ein System von technischen Übersetzungsschichten. Es sind diese Schichten, die die technische Realisierung von den vorgestellten interaktiven Potenzialen auf der anderen Seite trennen. Diese Darstellung ist jedoch noch nicht vollständig, denn Computer können zum Beispiel miteinander vernetzt sein. Auch diese Vernetzung wird gemäß eines Protokolls in Schichten realisiert. Auf der untersten Schicht geht es um das Senden und Empfangen elektrischer oder elektromagnetischer Signale. Die darüber liegenden Schichten sorgen gemäß Protokoll dafür, dass auf beiden Seiten der vernetzten Geräte diese Signale auf dieselben Strukturen und Objekte abgebildet werden. Beispielsweise ermöglicht eine solche Vernetzung, auf einer entsprechenden Schicht von einem Computer aus auf die Dateien eines anderen Computers zuzugreifen. Der Zugriff selbst erfolgt gekapselt, d. h. ohne Intervention durch den Menschen und in der Regel so schnell, dass er nicht mehr wahrnehmbar ist. Das Netz verhält sich transparent. Dadurch kann der Eindruck entstehen, als lägen Dateien auf der lokalen Festplatte des eigenen Rechners. Da die Netzwerkkommunikation sich der Aufmerksamkeit entzieht, bedingt sie auch keinen mentalen Zusatzaufwand bei der Nutzung.
Das Potenzial des Zugriffs auf ein Objekt, dessen Daten nicht auf dem Gerät der Bearbeitung, sondern einem entfernten vorliegen, entfaltet sein größtes Potenzial bei der gemeinsamen Nutzung durch verschiedene (entfernte) Personen; sie können die gleiche Datei öffnen und gleichzeitig mit ihr arbeiten. Hier täuscht jedoch der Eindruck, denn tatsächlich arbeiten beide Personen mit einer lokalen Kopie. Durch geschickte, zeitlich unmittelbar ausgeführte Synchronisationsverfahren kann der Eindruck entstehen, an einem einzigen Objekt zu arbeiten. Auch hier ist die Schnittstelle transparent.
Ein weiteres Potenzial einer transparenten Vernetzung liegt dann vor, wenn die Nutzungsschnittstelle auf verschiedene Geräte verteilt ist. Zur Illustration nutzen wir folgendes Szenario: Eine digitale Tafel erlaubt das Erstellen und Positionieren von Objekten auf der Oberfläche. Eine Person nutzt die Tafel, indem sie die Objekte mit einem digitalen Stift erstellt und manipuliert. Die Eingabe vermittels eines digitalen Stifts ist aber nicht für alle Arten von Eingaben ideal. Auf dieser Tafel, die ja alle sehen können, nun einen Datei-Browser zu öffnen, sodass ein Foto ausgewählt werden kann, wäre unpraktisch. Die verteilte Nutzungsschnittstelle erlaubt es nun, dass an der Tafel das Objekt markiert wird und dann das Smartphone genutzt wird, um ein Foto auszuwählen oder um direkt ein Foto zu erstellen. Es erscheint dann an der entsprechenden Stelle auf der Tafel. Ähnliches kann man sich für Textfelder vorstellen. Diese könnten an der Tafel ausgewählt, dann aber von einem Laptop aus befüllt werden. Alle drei Geräte, die digitale Tafel, das Smartphone und der Laptop bilden die Nutzungsschnittstelle für die Bearbeitung derselben Objekte.
Die beiden genannten Potenziale, die gemeinsamen verteilten Objekte und die verteilte Nutzungsschnittstelle, bringen komplexe Gestaltungsanforderungen mit sich. Bei gleichzeitiger Nutzung eines gemeinsamen Objekts, zum Beispiel eines Textes, an dem gemeinsam geschrieben wird, muss zum Beispiel dafür gesorgt werden, dass jeder beteiligten Person die Änderungen der anderen Beteiligten vergegenwärtigt werden. Man spricht von Gewärtigkeits- oder Awareness-Informationen. Auch im Szenario der verteilten Nutzungsschnittstelle im Beispiel der digitalen Tafel besteht die Herausforderung darin, den Nutzenden die Möglichkeit der Eingabe an einem anderen Gerät bewusst zu machen und sie dabei zu unterstützen, die Objektzuordnung nicht zu verlieren. Wir behandeln diese speziellen Anforderungen deshalb nicht, weil, ebenso wie bei den sogenannten „natürlichen“ Nutzungsschnittstellen wie Touch, Gestik, Sprache usw., in diesen Fällen sehr spezifische und situationsabhängige Faktoren zu berücksichtigen sind, die über die zu vermittelnden allgemeinen Gestaltungskonzepte deutlich hinausgehen19. Unabhängig von diesen speziellen Anforderungen sind die gleichen grundsätzlichen Gestaltungsanforderungen zu erfüllen wie für grafische Nutzungsschnittstellen mit Bildschirm, Tastatur und Zeigegeräten, die wir im Weiteren behandeln.