Manipulando dados no R
No capítulo passado aprendemos a usar as funções estatísticas para calcular os pontos centrais e a dispersão dos dados:
- média - mean()
- mediana - median()
- amplitude - range()
- quantiles (percentis) - quantile()
- variância - var()
- desvio padrão - sd()
O conjunto de pacotes tidyverse
Precisamos agora aprender a usar as funções de manipulação de dados do pacote dplyr. Instalar o tidyverse é o modo mais fácil de ter acesso a esse pacote, pois o dplyr faz parte do conjuto de pacotes do tidyverse.
A primeira etapa é instalar o pacote tidyverse, caso ainda não tenha feito isso. Se você já instalou esse pacote, passe para a próxima etapa. Lembre-se, que um pacote só precisa ser instalado uma única vez.
A segunda etapa é carregar o pacote na sessão. Isso é feito com o comando library(). O carregamento dos pacotes necesssários deve ser feito sempre no início de seu script.
1 library(tidyverse)
O pacote dplyr
O dplyr é um pacote para manipulação de dados, escrito e mantido por Hadley Wickham, com funções úteis e fáceis de usar para exploração dos dados. As principais funções desse pacote são:
| função | ação |
|---|---|
| filter() | seleciona linhas de acordo com argumentos lógicos |
| select() | seleciona variáveis (colunas) |
A função `filter()
As linhas de um data frame representam as diferentes observações. Por exemplo, em pesquisas na área de saúde, geralmente cada linha representa um participante da pesquisa.
Frequentemente precisamos acessar subgrupos desse grande conjunto de participantes, ou seja, precisamos selecionar subgrupos nos quais desejamos fazer nossa análise. Isso é feito no R com a função filter() do pacote {dplyr}.
O modo de usar a função filter()é muito simples: o primeiro argumento é o data frame a ser usado, em seguida as expressões lógicas para filtrar/selecionar as linhas do data.frame, como mostaremos a seguir, usando novamente o dataset mpg do pacote ggplot2 (Esse pacote também faz parte do tidyverse).
Vamos carregar esses dados com a função data():
1 data(mpg)
Relembrando o significado de cada variável:
| variável | significado |
|---|---|
| manufacturer | marca |
| model | modelo |
| displ | cilindradas (Engine Displacement) |
| year | ano de fabricação |
| cyl | número de cilindros |
| trans | tipo de marcha: automática / manual |
| drv | tração: f=frontal, r=traseira, 4=4x4 |
| cty | milhas por galão na cidade |
| hwy | milhas por galão na estrada |
| fl | tipo de combustível: r=regular, p=premium, d=diesel, e=ethanol, c=CNG (gás) |
| class | tipo de carro |
Sabemos que para acessar uma variável de um data frame usamos o operador $ e que a variável com os nomes das montadores é manufacturer. Vamos então checar quais são as montadoras dos carros dessa pacote com o comando unique().
1 unique(mpg$manufacturer)
O resultado do comando acima é a lista de todos as montadoras no dataset, sem repetição:
1 > unique(mpg$manufacturer)
2 "audi" "chevrolet" "dodge" "ford"
3 "honda" "hyundai" "jeep" "land rover"
4 "lincoln" "mercury" "nissan" "pontiac"
5 "subaru" "toyota" "volkswagen"
Como podemos ver, esse banco de dados tem carros de várias montadoras. Em análises estatísticas que é frequentemente necessário separar os dados de acordo com alguma regra, por exemplo, de acordo com a montadora.
Para separar um grupo, com base em alguma regra, usamos a função filter(). Podemos, por exemplo querer analisar apenas os carros das montadoras audi, toyota, ford, chevrolet. Vamos fazer um novo data frame com cada uma dessas montadoras e calcular a média e o desvio padrão do desempenho/consumo na cidade (milhas percorridas com um galão) de cada uma dessas montadoras.
Filtrando os carros da Audi:
1 audi <- filter(mpg, manufacturer == "audi")
2 mean(audi$cty)
3 sd(audi$cty)
O resultado dos comandos acima é:
1 > mean(audi$cty)
2 [1] 17.61111
3
4 > sd(audi$cty)
5 [1] 1.974511
Filtrando os carros da Toyota:
1 toyota <- filter(mpg, manufacturer == "toyota")
2 mean(toyota$cty)
3 sd(toyota$cty)
O resultado dos comandos acima é:
1 > mean(toyota$cty)
2 [1] 18.52941
3
4 > sd(toyota$cty)
5 [1] 4.046961
Filtrando os carros da Ford:
1 ford <- filter(mpg, manufacturer == "ford")
2 mean(ford$cty)
3 sd(ford$cty)
O resultado dos comandos acima é:
1 > mean(ford$cty)
2 [1] 14
3
4 > sd(ford$cty)
5 [1] 1.914854
Filtrando os carros da Chevrolet:
1 chev <- filter(mpg, manufacturer == "chevrolet")
2 mean(chev$cty)
3 sd(chev$cty)
O resultado dos comandos acima é:
1 > mean(chev$cty)
2 [1] 15
3
4 > sd(chev$cty)
5 [1] 2.924988
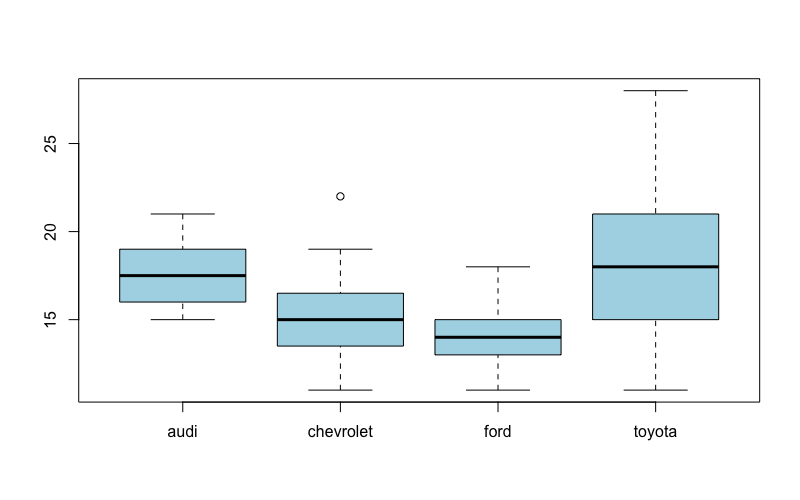
Podemos ver com essa análise inicial que os carros da Audi e da Toyota percorrem mais milhas com um galão que os carros da Chevrolet e da Ford. Podemos ver também que os carros da Audi, apesar de terem uma média de milhas percorridas menor que os carros da Toyota, a performance da Audi tem um desvio padrão menor, indicando que seus carros estão com o consumo consistentemente perto da média. A Toyota, por outro lado, tem um desvio padrão maior, o que indica que alguns carros tem um consumo bem mais inferior que a média e outros carros tem um consumo bem maior que a média.
É interessante também podermos comparar visualmente essas quatro marcas que foram nosso interesse. Para isso vamos usar a função filter() novamente, dessa vez construindo um único data frame com essas quatro montadoras, que nomearei de atfc (iniciais de audi, toyota, ford e chevrolet). Para isso devemos substituir o operador de igualdade (==)
pelo operador (%in%) e criar um vetor com as montadoras que quero no meu novo data frame:
1 atfc <- filter(mpg, manufacturer %in% c("audi", "toyota", "ford", "chevrolet"))
2 boxplot(cty~manufacturer, data=atfc, col="lightblue")
Podemos usar o comando filter() para filtramos os dados de acordo com regras numéricas. Podemos por exemplo separar os carros abaixo de 2.0 cilindradas, aqueles entre 2.0 e 3.0 cilindradas e os carros com 4.0 ou mais cilindradas. Vamos ver se as cilindradas influenciam no quanto um carro é capaz de percorrer com um galão. Lembre-se de que as cilindradas estão na variável displ, que é uma abreviação de Engine Displacement.
1 cilin.1a2 <- filter(mpg, displ<=2)
2 cilin.2a3 <- filter(mpg, displ>2 & displ<4)
3 cilin.4a7 <- filter(mpg, displ>=4)
Agora podemos calcular as médias das distâncias percorridas na cidade em cada um desses grupos:
1 mean(cilin.1a2$cty)
2 mean(cilin.2a3$cty)
3 mean(cilin.4a7$cty)
O resultado dos comandos acima é:
1 > mean(cilin.1a2$cty)
2 [1] 22.34884
3
4 > mean(cilin.2a3$cty)
5 [1] 17.79048
6
7 > mean(cilin.4a7$cty)
8 [1] 12.97674
Podemos ver que à medida que as cilindradas aumentam, diminui-se a distância percorridas com um galão de combustível. Isso pode ser mais facilmente visualizado num gráfico de dispersão, usualmente chamado de scatter plot:
1 ggplot(mpg, aes(x=displ, y=cty)) +
2 geom_jitter() +
3 geom_smooth(method = "lm")
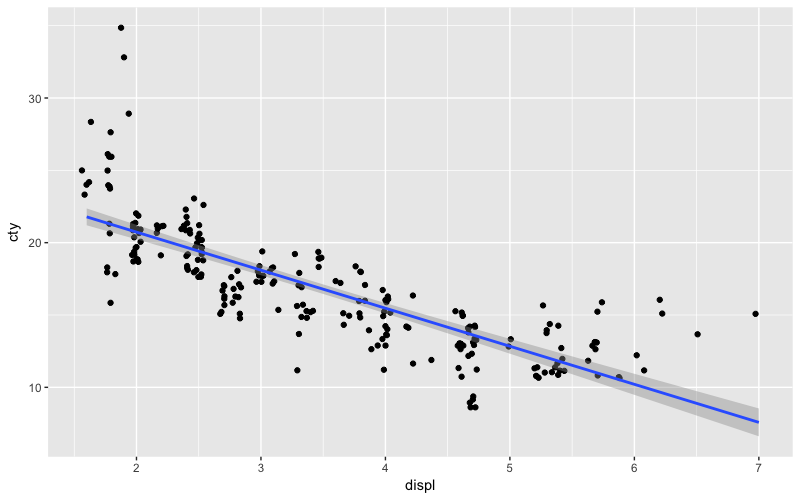
Com esse gráfico podemos ver que existe uma correlação negativa entre as cilindradas e a distância percorrida com um galão de combustível: quanto maior a cilindrada, menor a distância média percorrida. Em outras palavras: um carro 1.0 é mais econômico que um carro 4.0.
A função select()
A função select() possibilita selecionar as variáveis que interessam e criar novos data frames apenas com os dados selecionados. Como exemplo, vamos imaginar a situação na qual só interessam as variáveis modelo, distância percorrida na cidade e na estrada. Vamos criar um novo data frame chamado new.df só com essas variáveis. A função select() é usada da seguinte maneira:
select(data.frame, variável1, variável2, …)
1 new.df <- select(mpg, model, cty, hwy)
2 str(new.df)
1 Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 234 obs. of 3 variables:
2 $ model: chr "a4" "a4" "a4" "a4" ...
3 $ cty : int 18 21 20 21 16 18 18 18 16 20 ...
4 $ hwy : int 29 29 31 30 26 26 27 26 25 28 ...
Veja que esse novo data frame só tem 3 variáveis: model, cty e hwy.
Existem muitas outros modos de usar essa função, para mais detalhes digite ?select no console.