Zorgen en Risico’s Rond AI
 |
De zorgen rond AI zijn serieus. De risico’s zijn echt. Soms worden ze op hysterische manieren geuit, maar als je dieper graaft, heeft de impact van AI de potentie om enorm destructief te zijn. |
Er zijn zoveel kwesties en zorgen rondom AI, dat ze op zichzelf volumes vullen. Hier is een woordwolk van de onderwerpen die ik in de gaten hou. Ik weet zeker dat ik er een paar mis.

Er is veel informatie beschikbaar over elk van deze onderwerpen, en ik moedig je aan om zo diep mogelijk te lezen. Het is mogelijk dat je concludeert dat de risico’s zwaarder wegen dan de voordelen, en dat je het gebruik van AI niet wilt nastreven, of het nu persoonlijk is of binnen je organisatie. Die beslissing brengt zijn eigen risico’s met zich mee; het gebruikelijke, om achter te blijven. Maar het is een persoonlijke keuze.
Als je googelt op “boeken over de risico’s van AI” vind je een selectie van waardevolle volumes. Een recente podcast die ik bijzonder huiveringwekkend vond, was Ezra Klein’s gesprek met Dario Amodei, medeoprichter en CEO van Anthropic (het bedrijf dat Claude.ai ontwikkelt). Je leert dat deze bedrijven zich bewust zijn van de risico’s. Amodei verwijst naar een intern risicoclassificatiesysteem genaamd A.S.L., voor “AI Safety Levels” (niet American Sign Language). We bevinden ons momenteel op ASL 2, “systemen die vroege tekenen van gevaarlijke capaciteiten vertonen — bijvoorbeeld het vermogen om instructies te geven over hoe biowapens te bouwen.” Hij beschrijft ASL 4 als “het in staat stellen van staatsactoren om hun capaciteit aanzienlijk te vergroten… waarbij we ons zorgen maken dat Noord-Korea of China of Rusland hun offensieve capaciteiten op verschillende militaire gebieden aanzienlijk kunnen verbeteren met AI op een manier die hen een aanzienlijk voordeel zou geven op geopolitiek niveau.” Huiveringwekkende zaken.
Binnen deze sombere context zal ik de meest relevante kwesties voor schrijvers en uitgevers benadrukken.
Auteursrecht geschonden?
|
De kwesties rond auteursrecht zijn een wirwar van complexiteit en dubbelzinnigheid. Het lijkt zeker dat sommige boeken die nog onder auteursrecht vallen, zijn opgenomen in de training van sommige LLM’s. Maar het is zeker niet het geval, zoals sommige auteurs vrezen, dat al hun werk is opgenomen in elk van de grote taalmodellen. |
De auteursrechtelijke kwesties zijn zowel specifiek als breed. Het is algemeen bekend dat alle LLM’s zijn getraind op het open web - alles wat kan worden geschraapt van de 1,5 miljard sites op het web vandaag de dag, of het nu gaat om krantenartikelen, berichten op sociale media, webblogs en, blijkbaar, transcripties van YouTube-video’s.
Het is aantoonbaar dat ten minste één van de LLM’s de feitelijke tekst van duizenden boeken heeft opgenomen die niet in het publieke domein vallen.
Was het legaal om al deze tekst te gebruiken om miljardenbedrijven in AI te helpen bouwen, zonder enige compensatie voor de auteurs? De AI-bedrijven voeren hun argument rond fair use; de rechtbanken zullen uiteindelijk beslissen. Zelfs als het legaal was, was het dan ethisch of moreel? De ethiek lijkt minder complex dan de juridische overwegingen. Jij beslist.
De wetten rond auteursrecht voorzagen duidelijk niet in de unieke uitdagingen die AI met zich meebrengt, en het zoeken naar juridische oplossingen zal tijd kosten, misschien jaren. (Als je verder wilt ingaan op waarom de wetten ongeschikt zijn voor het specifieke probleem, lees het uitstekende artikel van A. Feder Cooper en James Grimmelmann genaamd “The Files are in the Computer: Copyright, Memorization, and Generative AI.”)
Hier is een lijst van dertien van de meest prominente rechtszaken, niet allemaal met betrekking tot boeken; ook afbeeldingen en muziek. En hier is nog een lijst die de status van alle rechtszaken bijwerkt.
Auteursrecht en AI voor auteurs
|
Auteurs worden geconfronteerd met aanvullende kwesties rond de auteursrechtelijkheid van door AI gegenereerde inhoud. |
Het standpunt van het U.S. Copyright Office over de auteursrechtelijkheid van door AI gegenereerde inhoud stelt dat AI alleen geen auteursrecht kan bezitten omdat het de juridische status van een auteur mist. Dat is logisch. Maar dit gaat ervan uit dat 100% van het werk door AI is gegenereerd. Zoals elders besproken, zullen weinig auteurs AI een heel boek laten genereren. Meer waarschijnlijk zal het 5%, of 10% of… En hier struikelt het Copyright Office (zoals ik zou doen).
In een recentere uitspraak concludeerde het Office dat een grafische roman bestaande uit door mensen geschreven tekst gecombineerd met afbeeldingen gegenereerd door de AI-dienst Midjourney een auteursrechtelijk beschermbaar werk vormde, maar dat de afzonderlijke afbeeldingen zelf niet door auteursrecht beschermd konden worden.“ Jeez!
|
Voldoende om te zeggen dat auteurs en uitgevers alert moeten blijven op de evoluerende auteursrechtelijke kwesties, op meerdere fronten. |
Wat zijn de langetermijnimplicaties?
Sommigen vergelijken de huidige rechtszaken met de Google-boekenrechtszaak, die 10 jaar duurde om juridisch op te lossen. Wie weet hoe lang het beroepsproces zal aanslepen voor deze zaken. In de tussentijd is het verstandig voor uitgevers om te handelen alsof de AI-bedrijven zullen verliezen, wat, althans theoretisch, iedereen die Chat AI licentieert of misschien zelfs gebruikt, blootstelt aan een soort van voorwaardelijke aansprakelijkheid.
Maar dat is niet het meest ernstige probleem voor een uitgever. Het is perceptie. Voor veel auteurs, sommigen prominent, sommigen obscuur, is de bron vergiftigd. AI is radioactief binnen de schrijf- en uitgeversgemeenschap. Alles wat ook maar enigszins naar AI ruikt, trekt intense kritiek.
Er zijn talloze voorbeelden. In een recent incident kondigde Angry Robot, een Britse uitgever “gewijd aan het beste in moderne volwassen sciencefiction, fantasy en WTF,” aan dat het AI-software, genaamd Storywise, zou gebruiken om een verwachte grote hoeveelheid manuscriptinzendingen te sorteren. Het duurde slechts vijf uur voor het bedrijf om het plan te laten vallen en terug te keren naar de “oude inbox.“
Het ondraaglijke dilemma voor handelsuitgevers bij het intern gebruik van AI-tools: als je auteurs erachter komen, zul je moeite hebben om de storm die daaruit voortvloeit te doorstaan. Ik geloof dat uitgevers geen andere keuze hebben dan moedig te zijn, (ten minste enkele van) de tools te adopteren, duidelijk uit te leggen hoe die tools worden getraind en hoe ze worden gebruikt, en door te gaan.
In het Verenigd Koninkrijk neemt The Society of Authors een harde lijn: “Vraag uw uitgever te bevestigen dat hij geen substantieel gebruik zal maken van AI voor welk doel dan ook in verband met uw werk - zoals proeflezen, redigeren (inclusief authenticiteitslezingen en fact-checking), indexeren, juridische controle, ontwerp en lay-out, of iets anders zonder uw toestemming. U kunt willen verbieden dat audioboekvertellingen, vertalingen en omslagontwerpen door AI worden uitgevoerd.”
De Authors Guild lijkt te accepteren dat “uitgevers beginnen met het verkennen van het gebruik van AI als een hulpmiddel in de normale gang van zaken, inclusief redactionele en marketingtoepassingen.” Ik denk niet dat veel leden van de Guild zo begripvol zijn.
Het licenseren van inhoud aan AI-bedrijven
De meeste uitgevers en veel auteurs zijn op zoek naar manieren om inhoud te licenseren aan AI-bedrijven. Iedereen heeft een ander idee over wat de licentievoorwaarden zouden moeten zijn en hoeveel hun inhoud waard is, maar in ieder geval zijn de gesprekken aan de gang.
Er zijn verschillende startups die willen samenwerken met uitgevers (en, in sommige gevallen, individuele auteurs). Calliope Networks en Created by Humans zijn beide interessant in dit opzicht.
Midden juli kondigde Copyright Clearance Center, al lange tijd de belangrijkste speler in collectieve auteursrechtlicenties in de industrie, de beschikbaarheid van “kunstmatige intelligentie (AI) hergebruikrechten binnen zijn Annual Copyright Licenses (ACL), een bedrijfsbrede contentlicentieoplossing die rechten biedt van miljoenen werken aan bedrijven die zich abonneren.”
Publishers Weekly besprak de aankondiging en citeerde Tracey Armstrong, president en CEO van CCC, die zei: “Het is mogelijk om pro-AI en pro-auteursrecht te zijn, en om AI te koppelen aan respect voor makers.”
Hoewel niet allesomvattend, is dit waarschijnlijk een doorbraak in het dichter bij elkaar brengen van de uitgeverswereld en de ontwikkelaars van grote taalmodellen.
Het is te laat om AI te vermijden
|
Voor auteurs en uitgevers die liever geen gebruik maken van AI, is het nieuws slecht: je gebruikt vandaag de dag AI, en je hebt het al jaren gebruikt. |
Kunstmatige intelligentie, in verschillende vormen, is al geïntegreerd in de meeste softwaretools en -diensten die we dagelijks gebruiken. Mensen vertrouwen op AI-gestuurde spellings- en grammaticacontroles in programma’s zoals Microsoft Word of Gmail. Microsoft Word en PowerPoint passen AI toe om schrijfsuggesties te geven, ontwerp- en lay-outaanbevelingen te doen, en meer. Virtuele assistenten zoals Siri en Alexa gebruiken natuurlijke taalverwerking om spraakopdrachten te begrijpen en vragen te beantwoorden. E-maildiensten gebruiken AI om berichten te filteren, spam te detecteren en waarschuwingen te verzenden. AI drijft klantenservice-chatbots aan en genereert productaanbevelingen op basis van je aankoopgeschiedenis.
En veel hiervan is gebaseerd op Grote Taakmodellen, zoals bij ChatGPT.
Voor een auteur of redacteur om te zeggen: “Ik wil geen AI op mijn manuscript,” is, algemeen gesproken, bijna onmogelijk, tenzij zowel zij als hun redacteuren werken met typemachines en potloden.
Ze zouden kunnen proberen te zeggen: “Ik wil geen generatieve AI” op hun boek. Maar dat is moeilijk te onderscheiden. Grammaticacontrolesoftware is oorspronkelijk niet gebouwd op generatieve AI. Grammarly heeft het als ingrediënt aan zijn product toegevoegd, net als alle andere spelling- en grammaticacontroles. Generatieve AI is ook kern van de marketingsoftware die wordt aangeboden.
Wanneer auteurs AI gebruiken
Een ander aspect van auteurs en het gebruik van AI heeft overeenkomsten met het hierboven besproken auteursrechtprobleem. In het extreme zien we 100% AI-gegenereerde inhoud die op Amazon wordt gepubliceerd. De meeste (alle?) hiervan is van vreselijke kwaliteit, maar dat weerhoudt het er niet van om gepubliceerd te worden. (Zie ook de Amazon-sectie.) Meer zorgwekkend voor uitgevers zijn AI-gegenereerde inzendingen. Ja, AI verhoogt de kwantiteit, maar grote uitgevers hebben al een filter voor kwantiteit. De filters worden agenten genoemd. Zij zijn degenen die moeten uitzoeken hoe ze het kwantiteitsprobleem moeten aanpakken, en blijkbaar moeten ze een oplossing vinden die geen gebruik maakt van AI.
Het is een soort existentiële vraag - wil ik een boek uitgeven dat is geschreven door ‘een machine’? Voor de meeste uitgevers is dat een ondubbelzinnig ‘nee’. Makkelijk zat. Maar wat als 50% van de inhoud van een boek is gegenereerd door een LLM, onder toezicht van een capabele auteur? Hmm, laten we daar ook maar een ‘nee’ op proberen. OK: wat dan als het 25%, of 10%, of 5% is? Waar trek je de grens?
En, nu je eenmaal in de grensbepaling bent gestapt, hoe los je het dilemma op dat spelling- en grammatica-tools nu, althans gedeeltelijk, afhankelijk zijn van generatieve AI? Wat te denken van AI-gedreven transcriptietools, zoals Otter.ai, of de transcriptiefunctie in Microsoft Word?
Ik kan geen enkele vakuitgever vinden die verklaard heeft dat ze geen werk willen publiceren met een vooraf gespecificeerd aantal AI-gegenereerde teksten. Hier is wat de Authors Guild erover zegt:
“Als een merkbaar deel van de tekst, karakters of plot in uw manuscript door AI is gegenereerd, moet u dit aan uw uitgever melden en moet u dit ook aan de lezer bekendmaken. Wij vinden het niet noodzakelijk dat auteurs het gebruik van generatieve AI bekendmaken wanneer het slechts wordt gebruikt als hulpmiddel voor brainstormen, ideeëngeneratie of voor copy-editing.”
Natuurlijk is ‘merkbaar’ niet gedefinieerd (Oxford definieert het als “groot genoeg om opgemerkt of belangrijk geacht te worden”), maar de post gaat verder met uit te leggen dat de opname van meer dan “de minimis AI-gegenereerde tekst” de meeste uitgeefcontracten zou schenden. De minimis, in juridische termen, is niet precies gespecificeerd, maar betekent over het algemeen hetzelfde als merkbaar.
Kan AI in schrijven worden gedetecteerd?
Ik heb in mei 2024 een webinar over AI-detectie georganiseerd, gesponsord door BISG. De herhaling is online op YouTube. Jane Friedman bood een uitgebreide samenvatting van het webinar in haar Hot Sheet nieuwsbrief.
Voor veel auteurs betekent de toxiciteit van AI dat ze het ver van hun woorden vandaan houden. Uitgevers dragen een speciale last - ze creëren de tekst niet, maar, eenmaal gepubliceerd, dragen ze een aanzienlijke verantwoordelijkheid voor de tekst. We hebben veel dynamiet zien afgaan bij brandbare boeken, of het nu gaat om de sociale implicaties van de inhoud, of het plagiaat van de woorden en ideeën van andere schrijvers. Met AI worden we nu geconfronteerd met een geheel nieuwe reeks ethische en juridische kwesties, waarvan geen enkele werd besproken op de uitgeverijschool.
Een deel ervan lijkt op waar mensen zich zorgen over maken bij studenten, dat het gebruik van AI op de een of andere manier valsspelen is, vergelijkbaar met het overnemen van een Wikipedia-artikel, of misschien gewoon een vriend vragen om je essay te schrijven.
Een van onze webinarsprekers, een opvoeder, José Bowen, deelde zijn openbaarmaking voor studenten. Het is niet precies wat je gebruikt voor een auteur, maar het toont een soort van “risiconiveaus” van AI-gebruik.
Openbaarmakingsovereenkomst voor Studenten
Ik heb al dit werk zelf gedaan zonder hulp van vrienden, tools, technologie of AI.
-
Ik deed de eerste versie, maar vroeg daarna vrienden/familie, AI parafraseer/grammatica/plagiaatsoftware om het te lezen en suggesties te doen. Ik maakte de volgende veranderingen na deze hulp:
Spelling en grammatica verbeterd
De structuur of volgorde veranderd
Hele zinnen/paragrafen herschreven
Ik liep vast op problemen en gebruikte een thesaurus, woordenboek, belde een vriend, ging naar het helpcentrum, gebruikte Chegg of een andere oplossingsaanbieder.
Ik gebruikte AI/vrienden/tutor om me te helpen ideeën te genereren.
Ik gebruikte hulp/tools/AI om een schema/eerste versie te maken, die ik daarna heb bewerkt. (Beschrijf de aard van uw bijdrage.)
En dus zou een uitgever iets dergelijks voor hun auteurs kunnen opstellen. Laten we zeggen dat de auteur het hoogste niveau openbaar maakt: ik gebruikte AI uitgebreid, en bewerkte daarna de resultaten. Wat dan? Wijs je het manuscript automatisch af? Zo ja, waarom?
En ondertussen, als je oplet, leer je dat het manuscript dat je net hebt gelezen en waar je van hield, waarvan de auteur zwoer dat het niet eens door Grammarly was gecontroleerd, in feite voor 90% door AI gegenereerd kon zijn, door een auteur die bedreven is in het verbergen van het gebruik ervan.
Je wordt dan gedwongen de vraag opnieuw te overdenken. Het wordt: “Waarom ben ik zo verdomd vastbesloten om dit ding te detecteren dat ondetecteerbaar is?”
Deels is het de alarmistische bezorgdheid rond de auteursrechtelijkheid van door AI gegenereerde tekst. Het auteursrechtkantoor biedt geen auteursrechtbescherming voor 100% door AI gegenereerde tekst (of muziek, of afbeeldingen, enz.). Maar wat als de tekst voor 50% door AI is gegenereerd? Welnu, we zouden alleen de 50% dekken die door de auteur is gegenereerd. En hoe zou je weten welke helft? Daar komen we later op terug.
Zou het niet geweldig zijn als je elk manuscript gewoon in software kunt invoeren die je vertelt of AI is gebruikt bij het maken van de tekst?
Afgezien van het feit dat de enige manier om dit te doen het gebruik van AI-tools zou zijn, is de belangrijkere vraag, zou de software (voldoende) nauwkeurig zijn? Kan ik erop vertrouwen dat het me vertelt of AI is gebruikt bij het maken van een manuscript? En kan ik erop vertrouwen dat het geen “vals-positieven” produceert—aangeeft dat AI is gebruikt, terwijl dat in feite niet het geval is?
Er is nu veel software op de markt die deze uitdagingen aanpakt. Veel van de academische studies die deze software evalueren wijzen op de onbetrouwbaarheid ervan. Door AI gegenereerde tekst glipt erdoorheen. Erger nog, tekst die niet door een AI is gegenereerd, wordt ten onrechte bestempeld als besmet.
Maar boekuitgevers willen enige vorm van beveiliging hebben. Het lijkt erop dat deze tools je in het beste geval kunnen waarschuwen voor mogelijke zorgen, maar je moet altijd dubbel controleren. Dus misschien kan het je waarschuwen voor teksten die zorgvuldiger moeten worden onderzocht dan andere? Is dit een efficiëntie?
Werkelijke efficiëntie zal worden gevonden door verder te gaan dan zorgen over de oorsprong van een tekst, in plaats daarvan onze bestaande criteria voor de kwaliteit ervan te handhaven.
Baanverlies
“Je wordt niet vervangen door AI. Je wordt vervangen door iemand die weet hoe AI te gebruiken.” —Anoniem
Baanverlies door AI-adoptie zou ernstig kunnen zijn. De schattingen lopen uiteen, maar de cijfers zijn somber. Er zijn duidelijke voorbeelden: de zelfrijdende taxi’s van San Francisco elimineren… taxi- en rideshare-chauffeurs. Door AI ondersteunde diagnoses zouden de behoefte aan medische technici kunnen verminderen.
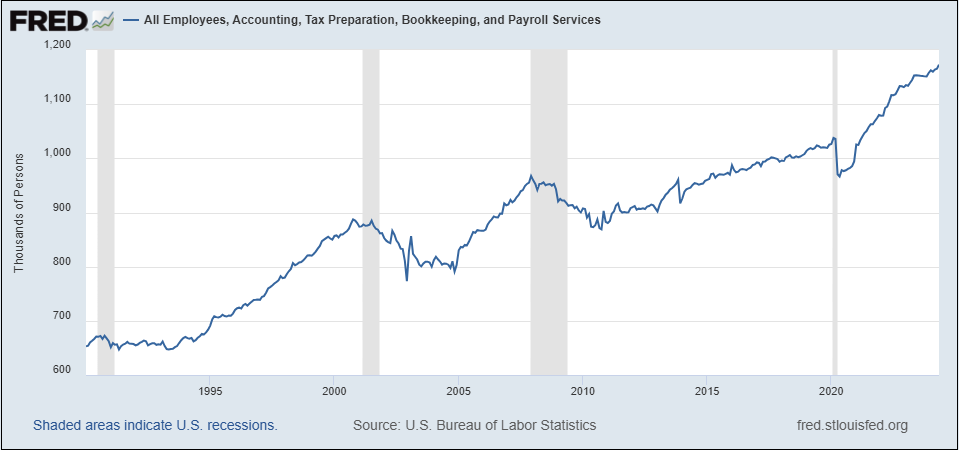
De optimist in mij wijst op, als één voorbeeld, de introductie van de spreadsheet en de impact daarvan op de werkgelegenheid. Zoals je in de onderstaande grafiek ziet, is de werkgelegenheid in “Accounting, Tax Preparation, Bookkeeping, and Payroll Services” sinds 1990 bijna verdubbeld—nauwelijks een aanklacht tegen spreadsheets en andere technologieën die deze taken grotendeels hebben geautomatiseerd.
Ethan Mollick’s studie met de Boston Consulting Group (BCG) was een experiment dat bedoeld was om AI’s impact op werk beter te begrijpen, vooral op complexe en kennisintensieve taken. De studie betrof 758 BCG-adviseurs, willekeurig toegewezen om wel of niet OpenAI’s GPT-4 te gebruiken voor twee taken: creatieve productinnovatie en zakelijke probleemoplossing. De studie mat de prestaties, het gedrag en de houding van de deelnemers, evenals de kwaliteit en kenmerken van de AI-output.
Een van de bevindingen was dat “AI werkt als een vaardigheidsnivelleerder. De adviseurs die het slechtst scoorden toen we hen aan het begin van het experiment beoordeelden, maakten de grootste sprong in hun prestaties, 43%, toen ze AI mochten gebruiken. De topadviseurs kregen nog steeds een boost, maar minder.” Het volledige artikel is onthullend, en zoals bij al Mollick’s werk, provocerend maar toegankelijk.
Onderwijs
Onderwijs heeft centraal gestaan in de voor- en nadelen debatten over AI. De introductie van AI in klaslokalen wordt grotendeels gezien als een vloek, of op zijn minst een uitdaging. Andere opvoeders, zoals PW’s hoofdspreker Ethan Mollick, omarmen AI als een opmerkelijk nieuw hulpmiddel voor opvoeders; Mollick staat erop dat zijn studenten werken met ChatGPT.
Het beste boek over dit onderwerp is Teaching with AI: A Practical Guide to a New Era of Human Learning door José Antonio Bowen en C. Edward Watson.
Ik ga in dit boek niet dieper in op educatief uitgeven—het is een enorm onderwerp dat een apart rapport vereist. Aannemelijk wordt publiceren van ondergeschikt belang binnen het onderwijs: AI-tools zijn software, geen inhoud, per se.
De toekomst van zoeken
|
Zoeken is een beladen onderwerp in AI. Ik moedig je aan om perplexity.ai en You.com te bezoeken om een glimp op te vangen van waar het heen gaat. De volgende paar keer dat je van plan bent een Google-zoekopdracht te starten, ga in plaats daarvan naar Perplexity. Het zal niet dramatisch anders aanvoelen—het lijkt op de kennisgrafieken die Google vaak aan de rechterkant van een zoekscherm plaatst, of soms bovenaan de zoekresultaten. In plaats van op een link te hoeven klikken, staat de informatie daar direct voor je. |
Perplexiteit gaat een stap verder, door de informatie die het verzamelt uit meerdere bronnen zo te herformuleren dat je echt niet op een link hoeft te klikken. Het biedt links naar zijn bronnen, maar het is meestal onnodig om erop te klikken - je hebt het antwoord op je vraag al.
Deze ogenschijnlijk bescheiden verschuiving heeft grote gevolgen voor elk bedrijf en elk product dat, op zijn minst gedeeltelijk, afhankelijk is van gevonden worden via zoekmachines. Als zoekers niet langer naar jouw site worden gestuurd, hoe kun je ze dan betrekken en omzetten in klanten? Simpel antwoord, dat kan niet.
Joanna Penn staat vooraan in het denken over de impact van nieuwe technologieën op schrijven en uitgeven. Ze behandelde dit complexe onderwerp in haar podcast en blog afgelopen december.
Het is nog steeds vroeg voor AI en de transformatie van zoeken.
Rommelboeken op Amazon
|
Door AI gegenereerde rommelboeken op Amazon zijn een probleem, hoewel hun ernst misschien meer visceraal dan letterlijk is. Aan de ene kant spammen deze boeken de online boekwinkel met inhoud van lage kwaliteit en geplagieerde inhoud, soms onder de namen van echte auteurs om klanten te misleiden en hun reputatie te misbruiken. De boeken zijn niet alleen vervelend voor lezers, maar ook een bedreiging voor auteurs, omdat ze mogelijk hun zuurverdiende royalty’s afnemen. Door AI gegenereerde boeken beïnvloeden ook de rangschikking en zichtbaarheid van echte boeken en auteurs op de site van Amazon, omdat ze concurreren om dezelfde zoekwoorden, categorieën en recensies. |

Amazon vereist nu dat auteurs details van hun gebruik van AI bij het maken van hun boeken bekendmaken. Dit kan ongetwijfeld worden misbruikt.
Probeer op Amazon te zoeken naar “door AI gegenereerde boeken”. Er zijn er veel. Sommige van de resultaten zijn handleidingen over het gebruik van AI voor het maken van boeken. Maar anderen zijn, zonder schaamte, door AI gegenereerd. “Grappige en schattige kattenfoto’s-Je kunt deze soorten foto’s nergens in de wereld zien-DEEL-1” (stet) wordt toegeschreven aan Rajasekar Kasi. Er zijn geen details over zijn (?) bio op een auteurspagina, maar zes andere titels worden aan de naam toegeschreven. Het boek, gepubliceerd op 26 augustus 2023, heeft geen recensies en geen verkooprang. De ongrammaticale titel van het ebook komt niet overeen met de ongrammaticale titel op de omslag van het gedrukte boek.
Maar andere auteurs maken duidelijk uitgebreid gebruik van AI bij het maken van hun boeken en melden dit niet. Zoals ik hierboven bespreek, is het detecteren van AI-gebruik bijna onmogelijk met vaardige ‘vervalsers’. Kleurboeken, tijdschriften, reisboeken en kookboeken worden in een fractie van de tijd en moeite van traditionele uitgaven met AI-tools gegenereerd.
Zoek “Koreaanse veganistische kookboek” en je vindt de nummer één titel, door Joanne Lee Molinaro, op de eerste plaats. Maar direct daarachter staan andere titels die duidelijke imitaties zijn. “Het Koreaanse Veganistische Kookboek: Eenvoudige en heerlijke traditionele en moderne recepten voor liefhebbers van de Koreaanse keuken” heeft twee recensies, waaronder één die opmerkt “Dit is geen veganistisch kookboek. Alle recepten bevatten vlees en eieren.” Maar het boek staat op #5,869,771 in verkooprang, versus het origineel, dat op #2,852 op de lijst staat.
Het is moeilijk om de omvang van de schade te bepalen. Niets goeds kan hiervan komen, maar hoe erg is het?
Amazon heeft beleidsregels die het mogelijk maken om elk boek te verwijderen dat niet “een positieve klantervaring biedt.” Kindle-inhoudsrichtlijnen verbieden “beschrijvende inhoud die bedoeld is om klanten te misleiden of die de inhoud van het boek niet nauwkeurig weergeeft.” Ze kunnen ook “inhoud blokkeren die doorgaans teleurstellend is voor klanten.” Is het de pure hoeveelheid die de toezichthouders van Amazon overweldigt? Of is er een andere reden?
Vooringenomenheid
LLM’s worden getraind op wat al online is gepubliceerd. Wat online is gepubliceerd, zit vol met vooringenomenheid en dus weerspiegelen LLM’s die vooringenomenheid. En natuurlijk niet alleen vooringenomenheid, maar ook haat, weerspiegeld in hun leren, en nu een potentieel resultaat in door AI gegenereerde woorden en beelden. Porno is een andere natuurlijke begunstigde van de opmerkelijke faciliteit van AI met afbeeldingen, en er zijn recent verontrustende verhalen over jonge vrouwen die geconstrueerde naaktfoto’s van zichzelf vinden, met hun mannelijke klasgenoten als waarschijnlijke verdachten. The New York Times meldde afzonderlijk over een toename van online afbeeldingen van seksueel misbruik van kinderen.
Auteurs en uitgevers moeten zich bewust zijn van deze ingebouwde beperkingen bij het gebruik van AI-tools.