Overview of Reinforcement Learning (Optional Material)
Reinforcement Learning has been used in various applications such as robotics, game playing, recommendation systems, and more. Reinforcement Learning (RL) is a broad topic and we will only cover basic aspects of RL.
No external libraries are required for this chapter, we implement Q-learning from scratch in TypeScript.
The examples for this chapter are in the directory source-code/reinforcement_learning.
Overview
Reinforcement Learning is a type of machine learning that is concerned with decision-making in dynamic and uncertain environments. RL uses the concept of an agent which interacts with its environment by taking actions and receiving feedback in the form of rewards or penalties. The goal of the agent is to learn a policy which is a mapping from states of the environment to actions with the goal of maximizing the expected cumulative reward over time.
There are several key components to RL:
- Environment: the system or “world” that the agent interacts with.
- Agent: the decision-maker that chooses actions based on its current state, the current environment, and its policy.
- State: a representation of the current environment, the parameters and trained policy of the agent, and possibly the visible actions of other agents in the environment.
- Action: a decision taken by the agent.
- Reward: a scalar value that the agent receives as feedback for its actions.
Reinforcement learning algorithms can be divided into two main categories: value-based and policy-based. In value-based RL the agent learns an estimate of the value of different states or state-action pairs which are then used to determine the optimal policy. In contrast, in policy-based RL the agent directly learns a policy without estimating the value of states or state-action pairs.
If you enjoy the overview material in this chapter I recommend that you consider investing the time in the Coursera RL specialization https://www.coursera.org/learn/fundamentals-of-reinforcement-learning taught by Martha and Adam White.
My favorite RL book is “Reinforcement Learning: An Introduction, second edition” by Richard Sutton and Andrew Barto, that can be read online for free at http://www.incompleteideas.net/book/the-book-2nd.html.
An Introduction to Markov Decision Process
Before we can write a reinforcement learning agent, we need to understand the mathematical framework that RL is built upon: the Markov Decision Process (MDP). An MDP provides a formal way to model sequential decision-making problems where outcomes are partly random and partly under the control of a decision-maker.
Let’s start by defining the key terms:
- Sequential decision problem: a problem where decisions are made in sequence over time, and each decision affects future states and rewards.
- Fully observable: the agent can see the complete state of the environment at each step.
- Stochastic environment: transitions between states are not deterministic.
- Markov property: the future depends only on the current state and action, not on the history.
- Bellman equation:
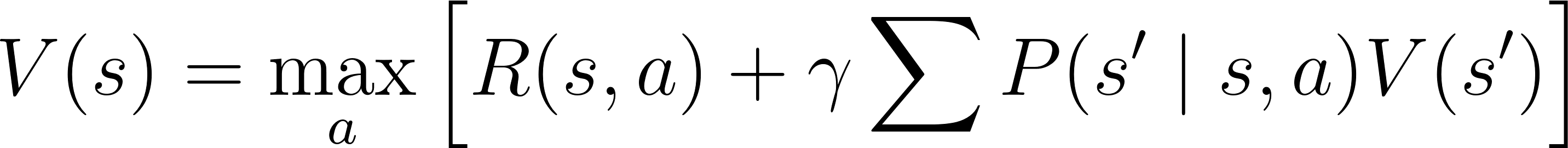 where
where 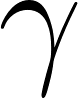 (gamma) is the discount factor.
(gamma) is the discount factor.
The discount factor (between 0 and 1) controls how much the agent values future rewards versus immediate rewards.
Solving MDPs: Value Iteration in TypeScript
We implement value iteration for a simple 3×3 grid world:
1 // mdp_demo.ts - Markov Decision Process with Value Iteration
2
3 function valueIteration(
4 nS: number, nA: number,
5 P: number[][][], R: number[][],
6 gamma = 0.9, threshold = 1e-6,
7 ) {
8 let V = new Array(nS).fill(0), policy = new Array(nS).fill(0), iterations = 0;
9 while (true) {
10 iterations++;
11 const newV = new Array(nS).fill(0);
12 let maxDelta = 0;
13 for (let s = 0; s < nS; s++) {
14 let bestVal = -Infinity, bestA = 0;
15 for (let a = 0; a < nA; a++) {
16 let val = R[s][a];
17 for (let sp = 0; sp < nS; sp++) val += gamma * P[a][s][sp] * V[sp];
18 if (val > bestVal) { bestVal = val; bestA = a; }
19 }
20 newV[s] = bestVal; policy[s] = bestA;
21 maxDelta = Math.max(maxDelta, Math.abs(newV[s] - V[s]));
22 }
23 V = newV;
24 if (maxDelta < threshold) break;
25 }
26 return { policy, V, iterations };
27 }
28
29 // --- 3×3 Grid World ---
30 const [nS, nA] = [9, 4];
31 const P = Array.from({ length: nA }, () => Array.from({ length: nS }, () => new Array(nS).fill(0)));
32 const dirs = [[-1, 0], [0, 1], [1, 0], [0, -1]];
33
34 for (let s = 0; s < nS; s++) {
35 const [r, c] = [Math.floor(s / 3), s % 3];
36 for (let a = 0; a < nA; a++) {
37 const nr = r + dirs[a][0], nc = c + dirs[a][1];
38 P[a][s][(nr >= 0 && nr < 3 && nc >= 0 && nc < 3) ? nr * 3 + nc : s] = 1;
39 }
40 }
41
42 const R = Array.from({ length: nS }, () => new Array(nA).fill(0));
43 for (let a = 0; a < nA; a++) { R[8][a] = 10; R[5][a] = -5; }
44
45 const { policy, V, iterations } = valueIteration(nS, nA, P, R, 0.9);
46 const arrows = ["↑", "→", "↓", "←"];
47
48 console.log("=== Custom 3×3 Grid World ===\nOptimal policy:");
49 for (let r = 0; r < 3; r++)
50 console.log(Array.from({ length: 3 }, (_, c) => ` ${arrows[policy[r * 3 + c]]} `).join(""));
51 console.log(`\nValue function: [${V.map(v => v.toFixed(2)).join(", ")}]`);
52 console.log(`Iterations: ${iterations}`);
A Concrete Example: Q-Learning
When the transition and reward models are unknown, the agent must learn through trial and error. Q-learning is one of the simplest and most widely used model-free RL algorithms.
The Q-learning update rule is:
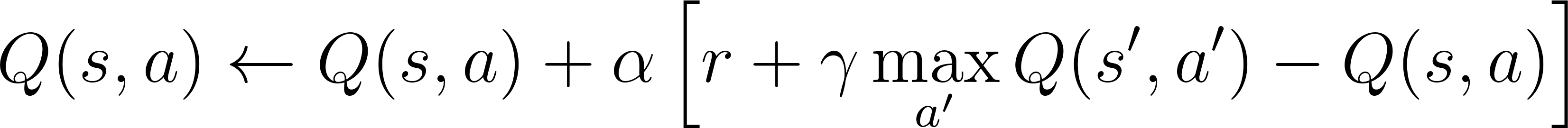
We implement a FrozenLake-style environment and Q-learning agent entirely in TypeScript:
1 // frozen_lake_qlearning.ts - Q-Learning on FrozenLake from scratch
2
3 class FrozenLake {
4 private state = 0;
5 private map = ["S","F","F","F", "F","H","F","H", "F","F","F","H", "H","F","F","G"];
6 nStates = 16; nActions = 4;
7
8 constructor(private slippery = true) {}
9 reset() { return this.state = 0; }
10
11 step(action: number) {
12 let a = action;
13 if (this.slippery && Math.random() < 0.667) a = (action + (Math.random() < 0.5 ? -1 : 1) + 4) % 4;
14 const [r, c] = [Math.floor(this.state / 4), this.state % 4];
15 const dirs = [[-1, 0], [0, 1], [1, 0], [0, -1]];
16 const nr = Math.max(0, Math.min(3, r + dirs[a][0]));
17 const nc = Math.max(0, Math.min(3, c + dirs[a][1]));
18 this.state = nr * 4 + nc;
19 const cell = this.map[this.state];
20 return { nextState: this.state, reward: cell === "G" ? 1.0 : 0.0, done: cell === "H" || cell === "G" };
21 }
22 }
23
24 function evaluate(env: FrozenLake, Q: number[][], episodes = 100) {
25 let wins = 0;
26 for (let i = 0; i < episodes; i++) {
27 let s = env.reset(), done = false, steps = 0;
28 while (!done && steps++ < 100) {
29 const a = Q[s].indexOf(Math.max(...Q[s]));
30 const r = env.step(a);
31 s = r.nextState; done = r.done;
32 if (done && r.reward === 1) wins++;
33 }
34 }
35 return wins / episodes;
36 }
37
38 function qLearning(env: FrozenLake, episodes = 10000, alpha = 0.1, gamma = 0.99, eps = 1.0, decay = 0.999, minEps = 0.01) {
39 const Q = Array.from({ length: env.nStates }, () => new Array(env.nActions).fill(0));
40 for (let ep = 0; ep < episodes; ep++) {
41 let s = env.reset(), done = false, steps = 0;
42 while (!done && steps++ < 100) {
43 const a = Math.random() < eps ? Math.floor(Math.random() * env.nActions) : Q[s].indexOf(Math.max(...Q[s]));
44 const { nextState, reward, done: d } = env.step(a);
45 done = d;
46 Q[s][a] += alpha * (reward + gamma * Math.max(...Q[nextState]) - Q[s][a]);
47 s = nextState;
48 }
49 eps = Math.max(minEps, eps * decay);
50 if ((ep + 1) % 1000 === 0) console.log(` Episode ${String(ep + 1).padStart(5)}: success = ${evaluate(env, Q).toFixed(2)}`);
51 }
52 return Q;
53 }
54
55 const env = new FrozenLake(true);
56 console.log(`=== Q-Learning on FrozenLake ===\nStates: ${env.nStates}, Actions: ${env.nActions}\n\nTraining:`);
57 const Q = qLearning(env);
58
59 const arrows = ["↑", "→", "↓", "←"];
60 console.log("\nLearned policy:");
61 for (let r = 0; r < 4; r++)
62 console.log(" " + Array.from({ length: 4 }, (_, c) => arrows[Q[r * 4 + c].indexOf(Math.max(...Q[r * 4 + c]))]).join(""));
63
64 const finalRate = evaluate(env, Q, 1000);
65 console.log(`\nFinal success rate (1000 episodes): ${finalRate.toFixed(2)}`);
The qLearning function implements the core algorithm. The epsilon-greedy strategy decays from 1.0 (pure exploration) to 0.01 over time.
When learning RL, start with tabular methods (Q-learning on discrete environments) before moving to deep RL. The concepts transfer directly, but debugging is far easier when you can inspect every Q-value in a table.
Reinforcement Learning Wrap-up
In this chapter we covered:
- Markov Decision Processes: the mathematical foundation of RL, including states, actions, rewards, transition probabilities, the Bellman equation, and discount factors.
- Value Iteration: computing optimal policies for known MDPs.
- Q-learning: a model-free algorithm that learns from experience without needing transition probabilities, implemented from scratch in TypeScript.
- Exploration vs exploitation: controlled by the epsilon-greedy strategy with decaying epsilon.
If this chapter sparked your interest, I encourage you to work through the Coursera specialization by Martha and Adam White and the Sutton/Barto book.
I tagged this chapter as optional material because I believe most readers will get more immediate value from mastering deep learning and pre-trained models. But if you find yourself working on sequential decision-making problems, robotics, game AI, resource allocation, dynamic pricing, the RL toolkit becomes indispensable.