Overview of Recommendation Systems (Optional Material)
Recommendation systems are a type of information filtering system that utilize historical data, such as past user behavior or interactions, to predict the likelihood of a user’s interest in certain items or products. As an example application: if a product web site has 100K products that is too many for customers to browse through. Based on a customer’s past purchases, finding other customers with similar purchases, etc. it is possible to filter the products shown to a customer.
Note: This is an advanced topic and you will need to reference the linked documentation resources to fully understand the material.
Writing recommendation systems is a common requirement for almost all businesses that sell products to customers. Before we get started we need to define two terms that you may not be familiar with: Collaborative filtering: uses both similarities between users and items to calculate recommendations. This linked Wikipedia article also discusses content-based filtering which uses user and item features.
The Movie Lens dataset created by the GroupLens Research organization uses the user movie preference https://movielens.org dataset. This dataset is a standard for developing and evaluating recommendation system algorithms and models.
There are at least three good approaches to take:
- Use a turnkey recommendation system like Amazon Personalize that is a turn-key service on AWS.
- Use one of the standard libraries or TensorFlow implementations for the classic approach using Matrix Factorization for collaborative filtering.
- Use the TensorFlow Recommenders library that supports multi-tower deep learning models.
In this chapter we build two recommendation systems from scratch in TypeScript: an item-based collaborative filter using adjusted cosine similarity, and an embedding-based matrix factorization model trained with stochastic gradient descent. No external ML libraries are required.
The examples for this chapter are in the directory source-code/deep_learning_recommendation.
TensorFlow Recommenders
I used Google’s TensorFlow Recommenders library for a work project. I recommend it because it has very good documentation, many examples using the Movie Lens dataset, and is fairly easy to adapt to general user/product recommendation systems.
We will refer to the documentation and examples at https://www.tensorflow.org/recommenders.
There are several types of data that could be used for recommending movies:
- User interactions (selecting movies).
- User data.
- Movie data based on text embedding of movie titles.
The TensorFlow Recommenders approach uses a multi-tower architecture. The query tower processes user features and the candidate tower processes item features. During training, the model learns to bring the embeddings of users and their preferred items closer together in the embedding space.
While TensorFlow Recommenders is a Python library, the concepts apply to any language. In this chapter we implement the core ideas in TypeScript:
- An item-based collaborative filtering engine that uses adjusted cosine similarity.
- An embedding matrix factorization model that learns dense user and item vectors via SGD, the same fundamental approach used inside TensorFlow Recommenders’ retrieval models.
Project Structure
The code is split into two TypeScript files:
1 deep_learning_recommendation/
2 ├── package.json
3 ├── collaborative_filtering.ts // Item-based CF engine + evaluation
4 ├── recommendation_demo.ts // Embedding MF model + full demo
5 └── README.md
Item-Based Collaborative Filtering
The simpler of our two approaches. The idea: if two movies tend to be rated similarly by the same users, those movies are similar. To recommend movies for a user, find movies similar to what they already liked.
Cosine Similarity
Two users’ rating vectors can be compared using cosine similarity, the cosine of the angle between them. Vectors pointing in the same direction (similar taste) produce values near 1; orthogonal vectors produce 0:
1 export function cosineSimilarity(
2 a: Map<string, number>,
3 b: Map<string, number>,
4 ): number {
5 let dot = 0, normA = 0, normB = 0;
6 for (const [key, valA] of a) {
7 const valB = b.get(key);
8 if (valB !== undefined) dot += valA * valB;
9 normA += valA ** 2;
10 }
11 for (const [, valB] of b) normB += valB ** 2;
12 return normA > 0 && normB > 0
13 ? dot / (Math.sqrt(normA) * Math.sqrt(normB))
14 : 0;
15 }
We use Map<string, number> as a sparse vector: keys are movie IDs, values are ratings. The function accumulates the dot product only over keys that appear in both maps (movies rated by both users). The denominator normalizes by each vector’s magnitude, producing a value in [-1, 1].
Adjusted Cosine Similarity
Plain cosine similarity has a problem: some users are consistently generous (rating everything 4-5) while others are harsh (rating everything 1-3). This inflates similarity between items that happen to be rated by the same generous users.
Adjusted cosine solves this by subtracting each user’s mean rating before computing the similarity:
1 export function adjustedCosineSimilarity(
2 itemA: string,
3 itemB: string,
4 userRatings: Map<string, Map<string, number>>,
5 userMeans: Map<string, number>,
6 ): number {
7 let dot = 0, normA = 0, normB = 0;
8 for (const [userId, ratings] of userRatings) {
9 const rA = ratings.get(itemA), rB = ratings.get(itemB);
10 if (rA === undefined || rB === undefined) continue;
11 const mean = userMeans.get(userId) ?? 0;
12 const adjA = rA - mean, adjB = rB - mean;
13 dot += adjA * adjB;
14 normA += adjA ** 2;
15 normB += adjB ** 2;
16 }
17 return normA > 0 && normB > 0
18 ? dot / (Math.sqrt(normA) * Math.sqrt(normB))
19 : 0;
20 }
The key line is const adjA = rA - mean. If a user’s mean is 4.0 and they rate movie A as 5, the adjusted rating is +1 (above average, they liked it). If they rate movie B as 3, the adjusted rating is -1 (below average, they didn’t). This correctly captures that the user preferred A over B, regardless of their overall rating tendency.
The Recommender Class
The ItemBasedRecommender class ties everything together:
1 export class ItemBasedRecommender {
2 private userRatings = new Map<string, Map<string, number>>();
3 private itemRatings = new Map<string, Map<string, number>>();
4 private userMeans = new Map<string, number>();
5 private itemSimilarity = new Map<string, SimilarityEntry[]>();
6
7 constructor(private topK: number = 20) {}
It maintains four lookup maps: user-to-item ratings, item-to-user ratings, per-user mean ratings, and a pre-computed similarity index. The topK parameter controls how many similar items are stored per movie, a higher value captures more relationships but uses more memory.
The fit method ingests ratings and pre-computes all similarities:
1 fit(ratings: Rating[]): void {
2 // Build user→{item→score} and item→{user→score} lookup maps
3 for (const { userId, itemId, score } of ratings) {
4 if (!this.userRatings.has(userId))
5 this.userRatings.set(userId, new Map());
6 this.userRatings.get(userId)!.set(itemId, score);
7
8 if (!this.itemRatings.has(itemId))
9 this.itemRatings.set(itemId, new Map());
10 this.itemRatings.get(itemId)!.set(userId, score);
11 }
12
13 // Compute per-user mean rating (used for adjusted cosine)
14 for (const [userId, items] of this.userRatings) {
15 let sum = 0;
16 for (const [, s] of items) sum += s;
17 this.userMeans.set(userId, sum / items.size);
18 }
19
20 // Pre-compute top-K most similar items for every item
21 const allItems = [...this.itemRatings.keys()];
22 for (const itemA of allItems) {
23 const sims: SimilarityEntry[] = [];
24 for (const itemB of allItems) {
25 if (itemA === itemB) continue;
26 const sim = adjustedCosineSimilarity(
27 itemA, itemB, this.userRatings, this.userMeans,
28 );
29 if (sim > 0) sims.push({ itemId: itemB, similarity: sim });
30 }
31 sims.sort((a, b) => b.similarity - a.similarity);
32 this.itemSimilarity.set(itemA, sims.slice(0, this.topK));
33 }
34 }
The algorithm compares every pair of items and keeps the top-K most similar for each. This is an O(items² × users) operation, which is fine for our dataset but would need approximate nearest-neighbor techniques for millions of items.
Predicting Ratings and Generating Recommendations
To predict how a user would rate an unseen movie, we find the most similar movies that the user has rated, and compute a weighted average:
1 predict(userId: string, itemId: string): number {
2 const userItems = this.userRatings.get(userId);
3 if (!userItems) return 0;
4 const neighbors = this.itemSimilarity.get(itemId) ?? [];
5
6 let weightedSum = 0, simSum = 0;
7 for (const { itemId: neighborId, similarity } of neighbors) {
8 const rating = userItems.get(neighborId);
9 if (rating === undefined) continue;
10 weightedSum += similarity * rating;
11 simSum += Math.abs(similarity);
12 }
13 return simSum > 0 ? weightedSum / simSum : 0;
14 }
The weighting by similarity means that more similar movies have more influence on the prediction. If a user loved “The Matrix” (cosine 0.9 with “Inception”) and disliked “The Notebook” (cosine 0.1 with “Inception”), the high similarity to “The Matrix” dominates the prediction for “Inception.”
The recommend method simply predicts scores for all unrated items and returns the top N:
1 recommend(userId: string, n: number = 5): Recommendation[] {
2 const rated = this.userRatings.get(userId);
3 if (!rated) return [];
4
5 const candidates: Recommendation[] = [];
6 for (const itemId of this.itemRatings.keys()) {
7 if (rated.has(itemId)) continue;
8 const predictedScore = this.predict(userId, itemId);
9 if (predictedScore > 0)
10 candidates.push({ itemId, predictedScore });
11 }
12 candidates.sort((a, b) => b.predictedScore - a.predictedScore);
13 return candidates.slice(0, n);
14 }
Evaluation Metrics
We evaluate recommendation quality using three metrics computed on held-out test ratings:
1 export function evaluate(
2 recommender: ItemBasedRecommender,
3 testRatings: Rating[],
4 ): EvalResult {
5 let sumAbsErr = 0, sumSqErr = 0, predicted = 0;
6 for (const { userId, itemId, score } of testRatings) {
7 const pred = recommender.predict(userId, itemId);
8 if (pred > 0) {
9 sumAbsErr += Math.abs(pred - score);
10 sumSqErr += (pred - score) ** 2;
11 predicted++;
12 }
13 }
14 return {
15 mae: predicted > 0 ? sumAbsErr / predicted : 0,
16 rmse: predicted > 0 ? Math.sqrt(sumSqErr / predicted) : 0,
17 coverage: testRatings.length > 0 ? predicted / testRatings.length : 0,
18 };
19 }
- MAE (mean absolute error): average distance between predicted and actual ratings. Lower is better.
- RMSE (root-mean-square error): similar to MAE but penalizes large errors more heavily.
- Coverage: fraction of test ratings the model could make a prediction for. A model that can’t predict anything is useless regardless of accuracy.
Embedding Matrix Factorization
The collaborative filtering approach above works well but has a limitation: it can only compare items that share users who rated both. The embedding matrix factorization approach solves this by learning dense vector representations (embeddings) for every user and item.
This is the same core technique used in deep learning recommendation systems. TensorFlow Recommenders’ retrieval models, for example, learn user and item embeddings in exactly this way, they just add more layers on top.
How It Works
The idea is elegant: represent each user as a vector of k numbers and each item as another vector of k numbers. The predicted rating is the dot product of these vectors, plus bias terms:
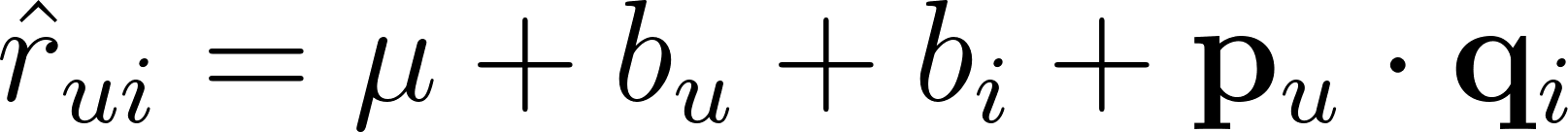
Where:
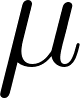 is the global mean rating
is the global mean rating
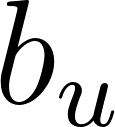 is the user bias (does this user rate things high or low?)
is the user bias (does this user rate things high or low?)
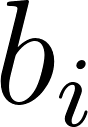 is the item bias (is this movie generally well-liked?)
is the item bias (is this movie generally well-liked?)
 is the user embedding vector
is the user embedding vector
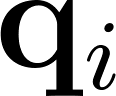 is the item embedding vector
is the item embedding vector
The model learns all of these parameters by minimizing the squared error on training ratings plus L2 regularization to prevent overfitting:
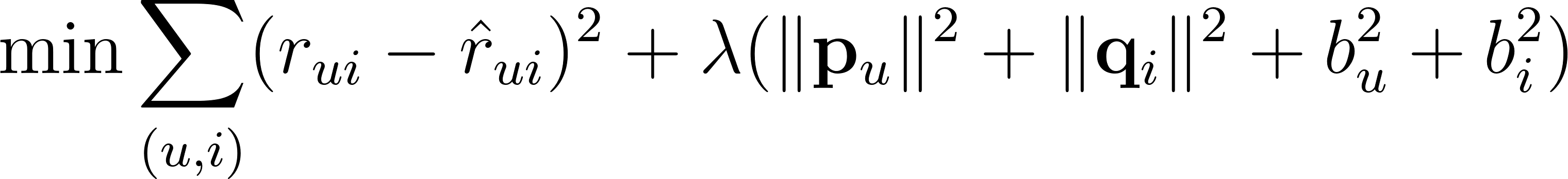
The Training Loop
We train with stochastic gradient descent (SGD): for each rating in the training set, compute the prediction error and nudge the embeddings in the direction that reduces that error:
1 export class EmbeddingRecommender {
2 private userEmbeddings = new Map<string, number[]>();
3 private itemEmbeddings = new Map<string, number[]>();
4 private userBias = new Map<string, number>();
5 private itemBias = new Map<string, number>();
6 private globalMean = 0;
7
8 constructor(
9 private k: number = 8, // embedding dimension
10 private lr: number = 0.005, // learning rate
11 private reg: number = 0.02, // L2 regularization
12 private epochs: number = 50,
13 ) {}
The constructor takes four hyperparameters: the embedding dimension k controls how many latent factors are learned (8 means each user and movie is described by 8 numbers); the learning rate lr controls the step size during gradient descent; the regularization strength reg prevents overfitting; and epochs controls how many passes over the data.
The core SGD update inside the fit method:
1 for (const { userId, itemId, score } of shuffled) {
2 const uEmbed = this.userEmbeddings.get(userId)!;
3 const iEmbed = this.itemEmbeddings.get(itemId)!;
4 const uBias = this.userBias.get(userId)!;
5 const iBias = this.itemBias.get(itemId)!;
6
7 // Predicted rating = dot product + biases + global mean
8 let pred = this.globalMean + uBias + iBias;
9 for (let d = 0; d < this.k; d++) pred += uEmbed[d] * iEmbed[d];
10
11 const error = score - pred;
12 totalLoss += error ** 2;
13
14 // Update biases
15 this.userBias.set(userId, uBias + this.lr * (error - this.reg * uBias));
16 this.itemBias.set(itemId, iBias + this.lr * (error - this.reg * iBias));
17
18 // Update embeddings
19 for (let d = 0; d < this.k; d++) {
20 const uOld = uEmbed[d], iOld = iEmbed[d];
21 uEmbed[d] += this.lr * (error * iOld - this.reg * uOld);
22 iEmbed[d] += this.lr * (error * uOld - this.reg * iOld);
23 }
24 }
Let’s trace through one update step:
- Compute the predicted rating as the dot product of user and item embeddings, plus biases and the global mean.
- Compute
error = actual - predicted. - Update the biases: move them toward reducing the error, with a small regularization pull toward zero.
- Update the embeddings: this is the key step. Each dimension of the user embedding is nudged by
lr * (error * itemEmbed[d]), the user vector moves toward the item vector when the error is positive (we under-predicted, the user liked this more than expected) and away when negative. The item embedding is updated symmetrically.
Notice the careful use of uOld and iOld: we save the values before updating because both the user and item embeddings depend on each other’s pre-update values.
What the Embeddings Capture
After training, the learned embeddings capture latent factors, abstract properties that the model discovers on its own. In a movie dataset, these might correspond to genre preferences, mood, era, or other patterns that humans might not explicitly label.
The similarItems method reveals what the model learned by computing cosine similarity between item embeddings:
1 similarItems(itemId: string, topK: number = 5): { id: string; sim: number }[] {
2 const target = this.itemEmbeddings.get(itemId);
3 if (!target) return [];
4 const results: { id: string; sim: number }[] = [];
5 for (const [id, emb] of this.itemEmbeddings) {
6 if (id === itemId) continue;
7 let dot = 0, nA = 0, nB = 0;
8 for (let d = 0; d < this.k; d++) {
9 dot += target[d] * emb[d];
10 nA += target[d] ** 2;
11 nB += emb[d] ** 2;
12 }
13 const sim = nA > 0 && nB > 0 ? dot / (Math.sqrt(nA) * Math.sqrt(nB)) : 0;
14 results.push({ id, sim });
15 }
16 results.sort((a, b) => b.sim - a.sim);
17 return results.slice(0, topK);
18 }
In our demo, the model correctly learns that “The Matrix” is most similar to “Mad Max: Fury Road” (both are sci-fi/action) and “Die Hard” (action), while being dissimilar to romance films, without ever being told about genres.
Synthetic Dataset
To make the demo self-contained and reproducible, we generate synthetic ratings with a deterministic PRNG:
1 function mulberry32(seed: number) {
2 return () => {
3 let t = (seed += 0x6D2B79F5);
4 t = Math.imul(t ^ (t >>> 15), t | 1);
5 t ^= t + Math.imul(t ^ (t >>> 7), t | 61);
6 return ((t ^ (t >>> 14)) >>> 0) / 4294967296;
7 };
8 }
Each synthetic user has random genre preferences. Their rating for a movie is 3 + genre_affinity + noise, clamped to [1, 5]. This creates realistic patterns: sci-fi fans rate sci-fi movies higher, romance fans prefer romance, and there is enough overlap that the models can discover these clusters.
Running the Examples
Install dependencies and run:
1 cd source-code/deep_learning_recommendation
2 npm install
3 npx tsx recommendation_demo.ts
Here is typical output:
1 === Embedding-Based Recommendation System ===
2
3 Dataset: 50 users × 15 movies
4 Training ratings: 346 Test ratings: 104
5
6 --- Part 1: Embedding Matrix Factorization (SGD) ---
7
8 Training:
9 Epoch 10: RMSE = 0.8454
10 Epoch 20: RMSE = 0.7917
11 Epoch 30: RMSE = 0.7639
12 Epoch 40: RMSE = 0.7485
13 Epoch 50: RMSE = 0.7392
14 Epoch 60: RMSE = 0.7325
15
16 Model: 50 users, 15 items, embedding dim = 8
17
18 Test set evaluation:
19 MAE = 0.6332
20 RMSE = 0.8379
21
22 Movies rated by user_0:
23 The Notebook → 2
24 Pulp Fiction → 2
25 Blade Runner 2049 → 3
26 Mad Max: Fury Road → 3
27 Arrival → 3
28 Die Hard → 3
29 When Harry Met Sally → 3
30
31 Top recommendations for user_0:
32 Interstellar (predicted: 3.04)
33 Casablanca (predicted: 2.83)
34 Pride & Prejudice (predicted: 2.78)
35 The Matrix (predicted: 2.78)
36 Amélie (predicted: 2.73)
37
38 Similar items to 'The Matrix' (by learned embedding):
39 Mad Max: Fury Road (cosine: 0.829)
40 Die Hard (cosine: 0.656)
41 Inception (cosine: 0.195)
42 The Notebook (cosine: 0.138)
43 Amélie (cosine: 0.063)
The training RMSE drops steadily as the model learns, and the test-set metrics confirm good generalization. The embedding-based model discovers that “The Matrix” is most similar to “Mad Max: Fury Road” and “Die Hard” (all action-heavy movies), a sensible result given the genre-based preferences in our synthetic data.
You can also run the standalone collaborative filtering demo with a small hand-crafted dataset:
1 npx tsx collaborative_filtering.ts
1 === Item-Based Collaborative Filtering Demo ===
2
3 Users: 6 Items: 8 Similarity pairs: 18
4
5 Recommendations for alice:
6 The Dark Knight (predicted: 5.00)
7 Pulp Fiction (predicted: 1.44)
8 Titanic (predicted: 1.00)
9
10 Recommendations for bob:
11 Interstellar (predicted: 4.39)
12 The Notebook (predicted: 4.00)
13
14 Recommendations for carol:
15 Pulp Fiction (predicted: 4.67)
16 Inception (predicted: 2.00)
17 Interstellar (predicted: 2.00)
Alice likes sci-fi (rated “The Matrix” and “Inception” as 5), so the system recommends “The Dark Knight”, it shares high similarity with her favorites because users who like sci-fi/action tend to like both. Carol prefers romance but hasn’t seen “Pulp Fiction”, it gets recommended because Dave (who has similar romance preferences) rated it well.
Comparing the Two Approaches
The demo’s model comparison section shows both models evaluated on the same test set:
1 --- Model Comparison ---
2
3 MAE RMSE
4 Embedding MF 0.6332 0.8379
5 Item-Based CF 0.5909 0.8004
On this small dataset, item-based CF edges ahead, it has enough direct rating overlap between items to make accurate predictions. However, the embedding model has key advantages that matter at scale:
- Generalization: embeddings can predict ratings for user-item pairs that share no direct rating overlap, by capturing latent patterns.
- Scalability: once trained, predictions are a simple dot product, O(k) per prediction, compared to scanning a similarity list.
- Extensibility: the embedding approach naturally extends to deep learning. By adding neural network layers on top of the embeddings, you get the multi-tower architectures used by TensorFlow Recommenders and production systems at Netflix, YouTube, and Alibaba.
Using the API in Your Own Code
You can use either recommender in your own TypeScript code:
1 import { ItemBasedRecommender } from "./collaborative_filtering.js";
2 import { EmbeddingRecommender } from "./recommendation_demo.js";
3
4 // Item-based collaborative filtering
5 const cfRec = new ItemBasedRecommender(20);
6 cfRec.fit(myRatings);
7 const recs = cfRec.recommend("user123", 10);
8
9 // Embedding matrix factorization
10 const embedRec = new EmbeddingRecommender(16, 0.005, 0.02, 100);
11 embedRec.fit(myRatings);
12 const ratedItems = new Set(myRatings
13 .filter(r => r.userId === "user123")
14 .map(r => r.itemId));
15 const topPicks = embedRec.recommend("user123", ratedItems, 10);
Both models expect an array of Rating objects: { userId: string, itemId: string, score: number }. Split your data into training and test sets before fitting, and use the evaluate functions to measure prediction quality.
Recommendation Systems Wrap-up
In this chapter we built two recommendation systems from scratch, demonstrating the progression from simple similarity-based methods to embedding-based matrix factorization, the foundation of modern deep learning recommendation systems.
The key ideas to take away:
- Collaborative filtering discovers user preferences from rating patterns: users who agreed in the past will agree in the future.
- Cosine similarity measures how aligned two rating vectors are; adjusted cosine corrects for per-user rating biases.
- Embedding matrix factorization learns dense vector representations that capture latent factors, enabling predictions even for user-item pairs with no direct rating overlap.
- SGD training iteratively reduces prediction error by nudging embeddings toward the observed ratings.
If you need to build a production recommendation system, consider these resources and alternatives:
- Consider using Amazon Personalize which is a turn-key service on AWS.
- Consider using Google’s turn-key Recommendations AI.
- For a deeper dive into embedding-based models, study the TensorFlow Recommenders tutorials, our
EmbeddingRecommenderimplements the same core mathematics. - For TypeScript-native solutions at scale, implement the models in this chapter using TensorFlow.js on Node.js to leverage GPU acceleration.
- A research idea: transform input training data to a textual representation for input to a Transformer model, based on the paper Behavior Sequence Transformer for E-commerce Recommendation in Alibaba.