LLMs with Public APIs
The fastest way to use large language models is through cloud APIs. Google, OpenAI, and Anthropic, all offer APIs that give you access to their most capable proprietary models with just a few lines of Python code. Fireworks.ai is an inference provider in the USA that offers fast inferencing for many open weight models. You don’t need a GPU, you don’t need to download model weights, and you can start building applications in minutes.
In this chapter we work through practical examples using the Google Gemini API, the OpenAI API, and the Fireworks.ai API. Each provides Python client libraries (or compatibility layers) that handle authentication, request formatting, and response parsing. The patterns you learn here apply to other API providers as well — the core concepts of sending prompts, receiving completions, and managing conversations are the same across providers.
The examples for this chapter are in the directory source-code/llm_public_apis.
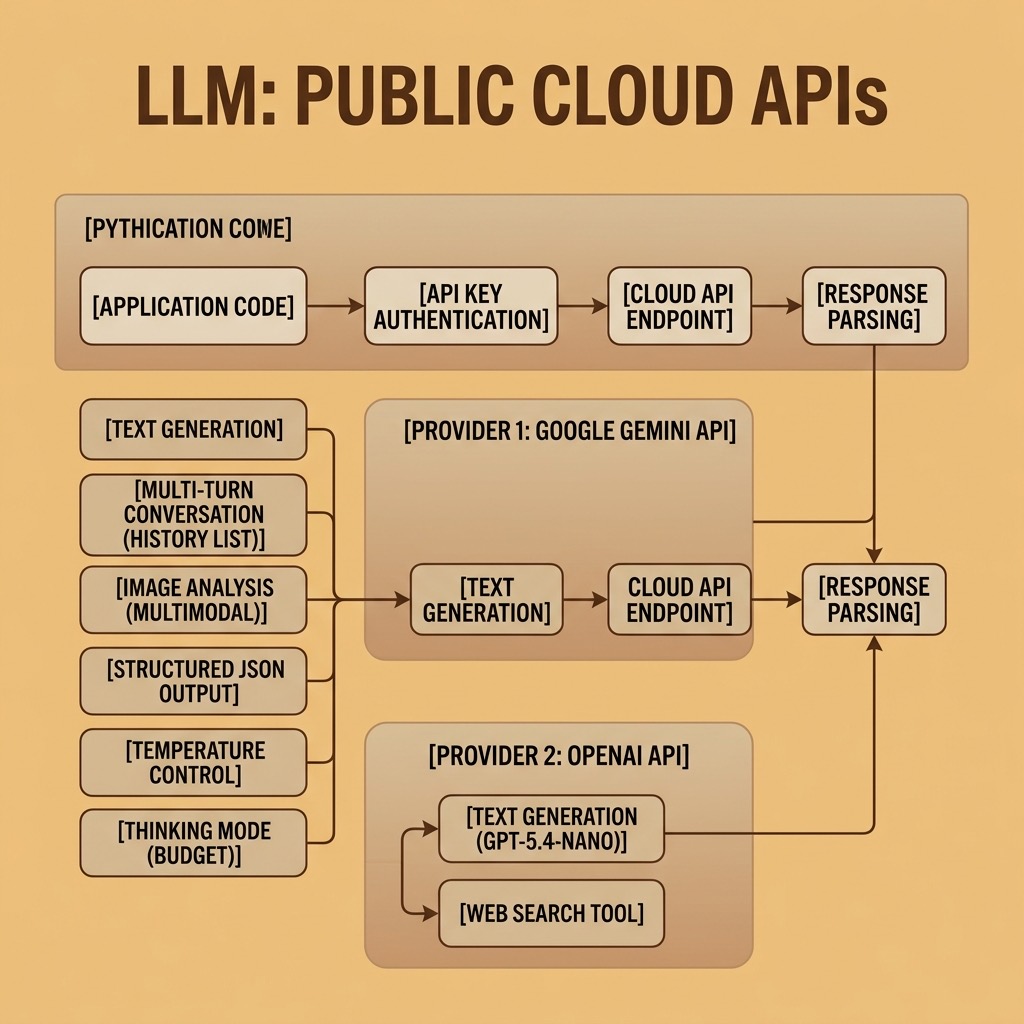
Setup and Authentication
Google Gemini
Google’s Gemini models are accessed through the Google AI API using the google-genai Python SDK. You need a free API key from Google AI Studio.
Install the SDK:
1 uv pip install google-genai
Store your API key in an environment variable:
1 export GOOGLE_API_KEY="your-api-key-here"
Here is the simplest possible example — send a prompt to Gemini and print the response:
1 # gemini_text.py - Basic text generation with Google Gemini
2
3 import os
4 from google import genai
5
6 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
7
8 response = client.models.generate_content(
9 model="gemini-3-flash-preview",
10 contents="Briefly explain what a transformer model is in AI."
11 )
12
13 print(response.text)
The output will be a concise explanation of transformer models. Each call to generate_content sends a request to Google’s servers, which run the model and return the generated text.
OpenAI
OpenAI’s GPT models are accessed through the openai Python SDK. You need an API key from OpenAI’s platform.
Install the SDK:
1 uv pip install openai
Store your API key:
1 export OPENAI_API_KEY="your-api-key-here"
Here is the equivalent example using OpenAI:
1 # openai_text.py - Basic text generation with OpenAI
2
3 from openai import OpenAI
4
5 client = OpenAI() # reads OPENAI_API_KEY from environment
6
7 response = client.responses.create(
8 model="gpt-5.4-nano",
9 input="Briefly explain what a transformer model is in AI."
10 )
11
12 output_items = list(response.output)
13 for item in reversed(output_items):
14 if getattr(type(item), "__name__", "") == "ResponseOutputMessage":
15 for content in item.content:
16 if type(content).__name__ == "ResponseOutputText":
17 print(content.text)
18 break
Both APIs follow the same pattern: create a client, send a prompt, and extract the generated text from the response.
Fireworks.ai
Fireworks.ai provides fast, cost-effective access to open-weight models through an OpenAI-compatible API. This means you can use the openai Python SDK you already installed — just point it at Fireworks’ endpoint. DeepSeek V4 Flash, the default model we use here, delivers strong performance at a fraction of the cost of proprietary models.
Get a free API key from fireworks.ai and set it as an environment variable:
1 export FIREWORKS_API_KEY="your-api-key-here"
The simplest Fireworks example looks nearly identical to OpenAI’s chat completions pattern:
1 # fireworks_text.py - Basic text generation with Fireworks.ai
2
3 import os
4 from openai import OpenAI
5
6 client = OpenAI(
7 base_url="https://api.fireworks.ai/inference/v1",
8 api_key=os.getenv("FIREWORKS_API_KEY"),
9 )
10
11 response = client.chat.completions.create(
12 model="accounts/fireworks/models/deepseek-v4-flash",
13 messages=[
14 {"role": "user", "content": "Briefly explain what a transformer model is in AI."}
15 ],
16 )
17
18 print(response.choices[0].message.content)
The output is a concise explanation of transformer models. The key difference from the standard OpenAI setup is the base_url parameter, which redirects the SDK to Fireworks’ servers. The messages format uses the familiar Chat Completions API structure with role-based message objects.
Text Generation
Text generation is the most fundamental LLM capability. You provide a prompt and the model generates a continuation or response.
Controlling Output with Temperature
The temperature parameter controls how creative or deterministic the output is. A temperature of 0 produces the most predictable output (the model always picks the highest-probability next token). Higher temperatures (up to 1.0 or 2.0) produce more varied and creative output.
1 # gemini_temperature.py - Effect of temperature on text generation
2
3 import os
4 from google import genai
5 from google.genai import types
6
7 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
8
9 prompt = "Write a one-sentence tagline for a coffee shop."
10
11 # Low temperature: deterministic, predictable
12 response_low = client.models.generate_content(
13 model="gemini-3-flash-preview",
14 contents=prompt,
15 config=types.GenerateContentConfig(temperature=0.0)
16 )
17 print(f"Temperature 0.0: {response_low.text}")
18
19 # High temperature: creative, varied
20 response_high = client.models.generate_content(
21 model="gemini-3-flash-preview",
22 contents=prompt,
23 config=types.GenerateContentConfig(temperature=1.5)
24 )
25 print(f"Temperature 1.5: {response_high.text}")
For most practical applications — code generation, data extraction, question answering — use a low temperature (0.0 to 0.3). For creative writing and brainstorming, higher temperatures (0.7 to 1.5) produce more interesting results.
The Fireworks API works the same way. Since Fireworks uses the OpenAI Chat Completions format, temperature is passed as a top-level parameter:
1 # fireworks_temperature.py - Effect of temperature on text generation
2
3 import os
4 from openai import OpenAI
5
6 client = OpenAI(
7 base_url="https://api.fireworks.ai/inference/v1",
8 api_key=os.getenv("FIREWORKS_API_KEY"),
9 )
10
11 prompt = "Write a one-sentence tagline for a coffee shop."
12
13 response_low = client.chat.completions.create(
14 model="accounts/fireworks/models/deepseek-v4-flash",
15 messages=[{"role": "user", "content": prompt}],
16 temperature=0.0,
17 )
18 print(f"Temperature 0.0: {response_low.choices[0].message.content}")
19
20 response_high = client.chat.completions.create(
21 model="accounts/fireworks/models/deepseek-v4-flash",
22 messages=[{"role": "user", "content": prompt}],
23 temperature=1.5,
24 )
25 print(f"Temperature 1.5: {response_high.choices[0].message.content}")
You’ll see the same pattern as Gemini: temperature 0.0 produces a safe, predictable tagline, while 1.5 yields something more surprising and original.
Thinking Models
Some models can engage in extended internal reasoning before producing a response. Google’s Gemini 2.5 Flash supports a thinking budget that controls how much computation the model devotes to reasoning through the problem before answering.
1 # gemini_thinking.py - Using Gemini's thinking mode for complex reasoning
2
3 from google import genai
4 from google.genai import types
5 import os
6
7 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
8
9 prompt = """
10 A farmer has a fox, a chicken, and a bag of grain. He needs to cross
11 a river in a boat that can only carry him and one item at a time.
12 If left alone, the fox will eat the chicken, and the chicken will eat
13 the grain. How does the farmer get everything across safely?
14 """
15
16 response = client.models.generate_content(
17 model="gemini-3-flash-preview",
18 contents=prompt,
19 config=types.GenerateContentConfig(
20 thinking_config=types.ThinkingConfig(
21 thinking_budget=1000 # allow up to 1000 tokens of reasoning
22 )
23 )
24 )
25
26 print(response.text)
The thinking budget is specified in tokens. A budget of 0 disables thinking entirely (useful for simple tasks where speed matters). Higher budgets allow the model to reason through more complex problems but increase latency and cost.
Fireworks’ DeepSeek models also support thinking mode. When enabled, the model performs internal chain-of-thought reasoning before producing its final answer, and the reasoning tokens are returned separately:
1 # fireworks_thinking.py - Extended reasoning with DeepSeek thinking mode
2
3 import os
4 from openai import OpenAI
5
6 client = OpenAI(
7 base_url="https://api.fireworks.ai/inference/v1",
8 api_key=os.getenv("FIREWORKS_API_KEY"),
9 )
10
11 prompt = """
12 A farmer has a fox, a chicken, and a bag of grain. He needs to cross
13 a river in a boat that can only carry him and one item at a time.
14 If left alone, the fox will eat the chicken, and the chicken will eat
15 the grain. How does the farmer get everything across safely?
16 """
17
18 response = client.chat.completions.create(
19 model="accounts/fireworks/models/deepseek-v4-flash",
20 messages=[{"role": "user", "content": prompt}],
21 extra_body={"thinking": {"type": "enabled"}},
22 )
23
24 message = response.choices[0].message
25 if hasattr(message, "thinking") and message.thinking:
26 print("--- Thinking ---")
27 print(message.thinking)
28 print("--- Answer ---")
29 print(message.content)
The extra_body parameter passes the thinking configuration directly to the Fireworks API. DeepSeek’s approach differs from Gemini’s thinking budget — instead of controlling how many tokens to spend on reasoning, you simply enable or disable thinking mode. The reasoning trace is available via message.thinking, which is useful for debugging and understanding the model’s logic.
Multi-Turn Conversations
Real applications often involve multi-turn conversations where the model needs to remember previous exchanges. Both APIs support this by passing conversation history with each request.
1 # gemini_conversation.py - Multi-turn conversation with Gemini
2
3 import os
4 from google import genai
5 from google.genai import types
6
7 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
8
9 # Build a conversation as a list of content parts
10 conversation = []
11
12 def chat(user_message):
13 """Send a message and get a response, maintaining conversation history."""
14 conversation.append(
15 types.Content(role="user", parts=[types.Part(text=user_message)])
16 )
17 response = client.models.generate_content(
18 model="gemini-3-flash-preview",
19 contents=conversation
20 )
21 conversation.append(
22 types.Content(role="model", parts=[types.Part(text=response.text)])
23 )
24 return response.text
25
26 # A multi-turn conversation
27 print(chat("What is the capital of France?"))
28 print(chat("What is its population?")) # "its" refers to Paris from context
29 print(chat("What are the top 3 tourist attractions there?"))
Notice that the second and third messages use pronouns (“its”, “there”) that only make sense given the conversation history. The model resolves these references correctly because it sees the full conversation with each request.
The same pattern works with Fireworks using the Chat Completions message list format. Instead of building Gemini Content/Part objects, you append plain dicts to the messages array:
1 # fireworks_conversation.py - Multi-turn conversation with Fireworks
2
3 import os
4 from openai import OpenAI
5
6 client = OpenAI(
7 base_url="https://api.fireworks.ai/inference/v1",
8 api_key=os.getenv("FIREWORKS_API_KEY"),
9 )
10
11 messages = []
12
13 def chat(user_message):
14 """Send a message and get a response, maintaining conversation history."""
15 messages.append({"role": "user", "content": user_message})
16 response = client.chat.completions.create(
17 model="accounts/fireworks/models/deepseek-v4-flash",
18 messages=messages,
19 )
20 reply = response.choices[0].message.content
21 messages.append({"role": "assistant", "content": reply})
22 return reply
23
24 print(chat("What is the capital of France?"))
25 print(chat("What is its population?"))
26 print(chat("What are the top 3 tourist attractions there?"))
The Fireworks implementation is notably simpler than the Gemini version — the Chat Completions format uses standard dicts for messages rather than typed objects, which makes message history management straightforward.
Multimodal Input: Analyzing Images
Modern LLMs can process images alongside text. This enables applications like image description, document analysis, chart reading, and visual question answering.
1 # gemini_image.py - Analyzing an image with Gemini
2
3 from google import genai
4 from google.genai import types
5 from PIL import Image
6 import os
7
8 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
9
10 # Load an image from disk
11 image = Image.open("photo.jpg")
12
13 prompt = "Describe what you see in this image. Be specific about people, objects, and setting."
14
15 response = client.models.generate_content(
16 model="gemini-3-flash-preview",
17 contents=[prompt, image],
18 config=types.GenerateContentConfig(
19 thinking_config=types.ThinkingConfig(
20 thinking_budget=0 # no thinking needed for simple description
21 )
22 )
23 )
24
25 print(response.text)
The key detail is that contents accepts a list containing both text and image objects. The model processes them together, understanding the image in the context of the text prompt.
Web Search with LLMs
Some API providers allow the model to search the web as part of generating a response, which gives it access to current information beyond its training data.
Here is an example using OpenAI’s web search tool:
1 # openai_search.py - Web search with OpenAI
2
3 from openai import OpenAI
4
5 client = OpenAI()
6
7 response = client.responses.create(
8 model="gpt-5.4-nano",
9 tools=[{"type": "web_search_preview"}],
10 input="What were the major AI announcements at Google I/O 2025?"
11 )
12
13 output_items = list(response.output)
14 for item in reversed(output_items):
15 kind = getattr(type(item), "__name__", "")
16 if kind == "ResponseOutputMessage" and getattr(item, "role", None) == "assistant":
17 for content in item.content:
18 if type(content).__name__ == "ResponseOutputText":
19 print(content.text)
20 break
The tools parameter tells the model it can use web search to answer the question. The model decides whether to search based on the query — factual questions about recent events will trigger a search, while questions about well-known topics may not.
Google’s Gemini also supports grounding with Google Search through a similar mechanism. Refer to the Google AI documentation for the current syntax, as this feature is actively evolving.
Structured Output
For many applications you need the model to return data in a specific format — JSON, CSV, or a particular schema. LLMs can be instructed to produce structured output through careful prompting.
1 # gemini_structured.py - Getting structured JSON output from Gemini
2
3 import os
4 import json
5 from google import genai
6 from google.genai import types
7
8 client = genai.Client(api_key=os.getenv("GOOGLE_API_KEY"))
9
10 prompt = """Extract the following information from the text below and return
11 it as a JSON object with keys: "name", "company", "role", "years_experience".
12
13 Text: "Jane Smith has been working as a Senior Data Scientist at Acme Corp
14 for the past 7 years. She specializes in NLP and recommendation systems."
15 """
16
17 response = client.models.generate_content(
18 model="gemini-3-flash-preview",
19 contents=prompt,
20 config=types.GenerateContentConfig(temperature=0.0)
21 )
22
23 # Parse the JSON from the response
24 result = json.loads(response.text.strip().removeprefix("```json").removesuffix("```").strip())
25 print(json.dumps(result, indent=2))
Using temperature 0.0 is important for structured output — you want the model to be deterministic and precise rather than creative. Some APIs also support specifying a JSON schema directly in the request, which guarantees the output conforms to a specific structure.
The Fireworks version uses the same prompting strategy. The code differs only in how the client is configured and how the response text is accessed:
1 # fireworks_structured.py - Getting structured JSON output from Fireworks
2
3 import os
4 import json
5 from openai import OpenAI
6
7 client = OpenAI(
8 base_url="https://api.fireworks.ai/inference/v1",
9 api_key=os.getenv("FIREWORKS_API_KEY"),
10 )
11
12 prompt = """Extract the following information from the text below and return
13 it as a JSON object with keys: "name", "company", "role", "years_experience".
14
15 Text: "Jane Smith has been working as a Senior Data Scientist at Acme Corp
16 for the past 7 years. She specializes in NLP and recommendation systems."
17 """
18
19 response = client.chat.completions.create(
20 model="accounts/fireworks/models/deepseek-v4-flash",
21 messages=[{"role": "user", "content": prompt}],
22 temperature=0.0,
23 )
24
25 raw = response.choices[0].message.content.strip()
26 raw = raw.removeprefix("```json").removesuffix("```").strip()
27 result = json.loads(raw)
28 print(json.dumps(result, indent=2))
The output is identical to the Gemini version — a clean JSON object with the extracted fields. The JSON cleanup logic (stripping markdown code fences) is the same because all LLMs tend to wrap code blocks in backticks.
Practical Considerations
Cost
API calls are billed per token. Input tokens (your prompt) and output tokens (the model’s response) are priced separately, with output tokens typically costing 2-4x more. Prices vary significantly between providers and models:
- Smaller, faster models (Gemini 2.5 Flash, GPT-5.4-nano) are very inexpensive — often under $0.10 per million input tokens
- Frontier models (Gemini 2.5 Pro, GPT-5.4, Claude Opus) cost 10-50x more but offer superior reasoning
For most applications, start with a fast, inexpensive model and only upgrade to a frontier model for tasks that require it.
Rate Limits
All API providers enforce rate limits — maximum requests per minute, tokens per minute, and tokens per day. Free tiers have lower limits. If you’re building a production application, you’ll need to implement retry logic with exponential backoff and consider batching requests where possible.
Latency
API calls involve network round-trips and model inference time. Simple completions with small models return in under a second. Complex reasoning with frontier models can take 10-30 seconds or more. For interactive applications, consider streaming responses (both Gemini and OpenAI support this) so users see output as it’s generated rather than waiting for the complete response.
Privacy
Any data you send to an API is transmitted to the provider’s servers. For sensitive data — medical records, financial information, proprietary code — review the provider’s data usage policies carefully. Some providers offer data residency guarantees and opt-out options for training. For maximum privacy, consider using local models instead, as covered in the next chapter.
Error Handling
API calls can fail for many reasons: network errors, rate limiting, content filtering, malformed requests, or service outages. Production code should handle these gracefully:
1 import time
2
3 def generate_with_retry(client, prompt, max_retries=3):
4 """Call the Gemini API with exponential backoff on failure."""
5 for attempt in range(max_retries):
6 try:
7 response = client.models.generate_content(
8 model="gemini-3-flash-preview",
9 contents=prompt
10 )
11 return response.text
12 except Exception as e:
13 if attempt < max_retries - 1:
14 wait = 2 ** attempt # 1s, 2s, 4s
15 print(f"Attempt {attempt + 1} failed: {e}. Retrying in {wait}s...")
16 time.sleep(wait)
17 else:
18 raise
Summary
Using LLMs through public APIs is the fastest path from idea to working application. The core pattern is simple across all providers: create a client, send a prompt, process the response. The richness comes from features like multi-turn conversations, multimodal input, web search, structured output, and thinking modes.
The main tradeoffs of the API approach are cost (per-token pricing), privacy (data leaves your machine), and dependence on the provider’s availability. For applications where these tradeoffs are acceptable, public APIs give you access to the most capable models available.
In the next chapter we cover the alternative approach: running open-weights models locally on your own hardware, which offers privacy, no per-token cost, and offline operation at the expense of model capability and the need for suitable hardware.
Optional Practice Problems
To help solidify the concepts covered in this chapter, try implementing the following exercises. You can create these scripts in your local workspace to extend the existing code examples.
1. Easy: Dynamic Tagline Generator
Modify the gemini_temperature.py example to create a command-line script that:
- Prompts the user to enter a business type (e.g., “coffee shop”, “dog walking service”, “indie game studio”).
- Prompts the user to enter a target audience (e.g., “college students”, “busy professionals”, “hardcore gamers”).
- Generates three different taglines using three distinct temperature values (e.g.,
0.0for deterministic/professional,0.7for balanced, and1.5for highly creative/unconventional). - Displays the temperature alongside the generated tagline so you can compare the direct effects of the temperature parameter on creativity.
2. Medium: CLI Chatbot with System Instructions
Using the gemini_conversation.py script as a starting point, build a fully interactive command-line chatbot:
- When the script starts, prompt the user to input a “persona” or system instructions (e.g., “You are a helpful assistant who answers exclusively in pirate speak” or “You are an encouraging coding mentor”).
- Configure the client or prompt structure to enforce this persona. (Hint: In the Gemini API, you can pass system instructions via
types.GenerateContentConfig(system_instruction="...")). - Enter a loop that repeatedly prompts the user for input (
input("You: ")). - Exit the loop gracefully if the user types
exitorquit. - Print the assistant’s responses and append each turn to the conversation history to maintain context.
3. Medium: Structured Multimodal Data Extractor
Combine the concepts from gemini_image.py and gemini_structured.py to extract structured information from a document image:
- Find or capture an image containing unstructured text (e.g., a photo of a restaurant receipt, a business card, or a book cover).
- Load the image using
Pillowand write a script that sends the image along with a prompt requesting the model to extract key details. - Instruct the model to return a structured JSON response (e.g., for a book cover, extract
"title","author","publisher", and"estimated_publication_year"). - Parse the JSON response in Python and display the extracted keys and values in a formatted terminal printout.
4. Hard: High-Availability Structured Parser with Retry and Fallback
Create a robust text processing pipeline that extracts structural sentiment analysis from product reviews:
- Write a script that takes a list of raw user reviews (e.g.,
"The battery life is amazing, but the screen is a bit dim."). - Define a target schema for the output containing:
sentiment(must be one ofPositive,Negative, orNeutral),sentiment_score(a float between0.0and1.0), and a list ofprosandcons. - Implement a function to call the Gemini API using
gemini-3-flash-previewto perform this extraction, ensuring temperature is set to0.0. - Integrate the exponential backoff retry logic described in the Error Handling section of this chapter. If a call fails, retry up to 3 times with progressive delays.
- Add a Fallback Provider: If the Gemini API call still fails after 3 retries (due to rate limits, quota limits, or API outage), catch the exception, print a warning, and fall back to the OpenAI API using
gpt-5.4-nanoto process that specific review.