LLMs with Local Models
Running language models on your own hardware gives you privacy, zero per-token cost, and the ability to work offline. The tradeoff is that local models are generally smaller and less capable than the frontier models available through cloud APIs, and running larger models requires significant GPU memory or Apple Silicon unified memory.
In this chapter we focus on Ollama, the most popular tool for running local models. Ollama handles model downloading, quantization, GPU acceleration, and exposes a simple API — you can go from zero to a running local LLM in minutes. We also briefly mention alternative tools at the end of the chapter.
If you want to go deeper into Ollama, including tool use, agents, RAG, and advanced configuration, see my book Ollama in Action.
The examples for this chapter are in the directory source-code/llm_local_models.
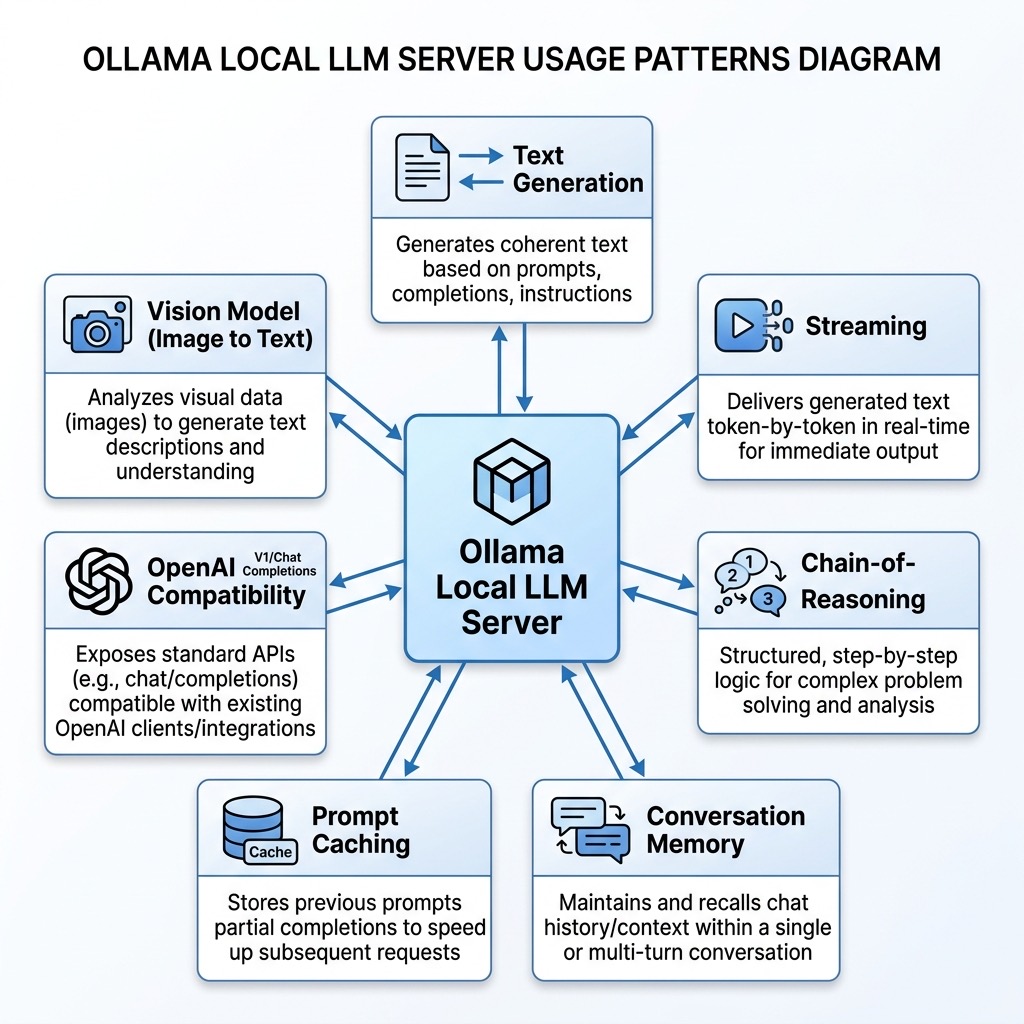
Installing Ollama
Ollama is available for macOS, Linux, and Windows. On macOS:
1 brew install ollama
Or download the installer from ollama.com. After installation, start the Ollama service:
1 ollama serve
This starts a local server on port 11434. The service runs in the background and manages model loading, GPU memory, and request handling.
Downloading and Running Models
Ollama uses a Docker-like model for pulling and running models. To download a model:
1 ollama pull llama3.2:3b
This downloads Meta’s Llama 3.2 with 3 billion parameters, quantized to about 2 GB. You can interact with it immediately from the command line:
1 ollama run llama3.2:3b "What is the capital of France?"
Some recommended models to start with:
| Model | Size | Strengths |
|---|---|---|
| llama3.2:3b | 2 GB | Fast, good general purpose |
| gemma3:4b | 3 GB | Google’s small model, strong reasoning |
| qwen3:4b | 2.6 GB | Excellent multilingual and coding |
| deepseek-r1:7b | 4.7 GB | Strong reasoning with explicit chain-of-thought |
| llava:7b | 4.7 GB | Vision model — can analyze images |
Using Ollama from Python
The ollama Python SDK provides a clean interface to the local Ollama service.
1 uv pip install ollama
Basic Text Generation
The simplest use of the Ollama SDK — send a prompt and print the response:
1 # ollama_text.py - Basic text generation with a local model
2
3 import ollama
4
5 response = ollama.chat(
6 model="llama3.2:3b",
7 messages=[
8 {"role": "user", "content": "Briefly explain what a neural network is."}
9 ]
10 )
11
12 print(response.message.content)
This is similar in structure to the cloud API examples from the previous chapter, but the request never leaves your machine.
Streaming Responses
For interactive applications, streaming lets users see output as it’s generated rather than waiting for the complete response:
1 # ollama_streaming.py - Streaming responses for real-time output
2
3 import ollama
4
5 stream = ollama.chat(
6 model="llama3.2:3b",
7 messages=[
8 {"role": "user", "content": "Write a short poem about programming."}
9 ],
10 stream=True
11 )
12
13 for chunk in stream:
14 print(chunk.message.content, end="", flush=True)
15 print() # final newline
Each chunk contains a small piece of the response. The flush=True argument ensures text appears immediately rather than being buffered.
Reasoning with Local Models
Some local models support explicit chain-of-thought reasoning, where the model shows its thinking process before providing a final answer. DeepSeek-R1 is particularly good at this.
First pull the model:
1 ollama pull deepseek-r1:7b
Here is an example that extracts both the reasoning trace and the final answer:
1 # ollama_reasoning.py - Chain-of-thought reasoning with DeepSeek-R1
2
3 import ollama
4 import json
5
6 def reason_about(question: str, model: str = "deepseek-r1:7b") -> dict:
7 """Ask a question and extract both reasoning and final answer."""
8 response = ollama.chat(
9 model=model,
10 messages=[
11 {"role": "user", "content": question}
12 ]
13 )
14 content = response.message.content
15
16 # DeepSeek-R1 wraps reasoning in <think>...</think> tags
17 reasoning = ""
18 answer = content
19 if "<think>" in content and "</think>" in content:
20 reasoning = content.split("<think>")[1].split("</think>")[0].strip()
21 answer = content.split("</think>")[1].strip()
22
23 return {"reasoning": reasoning, "answer": answer}
24
25
26 question = (
27 "A bakery sells 3 types of bread. Each type comes in 2 sizes. "
28 "How many different bread options are available? "
29 "Respond with just the number and a brief explanation."
30 )
31
32 result = reason_about(question)
33
34 if result["reasoning"]:
35 print("=== Reasoning ===")
36 print(result["reasoning"])
37 print()
38
39 print("=== Answer ===")
40 print(result["answer"])
The model’s reasoning trace shows each step of its thinking, making the output more transparent and debuggable than a black-box answer. This is especially valuable for math, logic, and planning tasks.
Conversation Memory with Ollama
Cloud APIs handle conversation history by passing the full message list with each request. With local models the same pattern applies, but since there are no per-token costs, you can maintain longer conversations without worrying about expense.
Here is an example that maintains a conversation with memory across multiple exchanges and uses a system prompt to shape the assistant’s personality:
1 # ollama_memory.py - Conversation with persistent memory
2
3 import ollama
4
5 class LocalAssistant:
6 """A simple conversational assistant that maintains message history."""
7
8 def __init__(self, model: str = "llama3.2:3b", system_prompt: str = ""):
9 self.model = model
10 self.messages = []
11 if system_prompt:
12 self.messages.append({"role": "system", "content": system_prompt})
13
14 def chat(self, user_message: str) -> str:
15 """Send a message and get a response, maintaining conversation history."""
16 self.messages.append({"role": "user", "content": user_message})
17 response = ollama.chat(model=self.model, messages=self.messages)
18 reply = response.message.content
19 self.messages.append({"role": "assistant", "content": reply})
20 return reply
21
22 def message_count(self) -> int:
23 """Return the number of messages in the conversation history."""
24 return len(self.messages)
25
26
27 # Create an assistant with a specific personality
28 assistant = LocalAssistant(
29 system_prompt="You are a concise technical writing assistant. "
30 "Keep answers under 3 sentences."
31 )
32
33 # Multi-turn conversation — the model remembers prior context
34 print("Q:", "What is gradient descent?")
35 print("A:", assistant.chat("What is gradient descent?"))
36 print()
37
38 print("Q:", "How does the learning rate affect it?")
39 print("A:", assistant.chat("How does the learning rate affect it?"))
40 print()
41
42 print("Q:", "What happens if I set it too high?")
43 print("A:", assistant.chat("What happens if I set it too high?"))
44 print()
45
46 print(f"(Conversation has {assistant.message_count()} messages)")
Note that unlike cloud APIs, keeping long conversation histories in local models is free — there are no per-token costs. The main constraint is the model’s context window size, which varies by model (typically 4K to 128K tokens).
Prompt Caching for Performance
When you send the same long context (a document, a knowledge base, or a detailed system prompt) with multiple questions, Ollama can cache the prompt processing to dramatically speed up subsequent requests. This happens automatically when the prefix of the prompt is identical across requests.
Here is an example that demonstrates the speedup:
1 # ollama_caching.py - Prompt caching benchmark
2
3 import requests
4 import time
5
6 OLLAMA_URL = "http://localhost:11434/api/generate"
7 MODEL = "llama3.2:3b"
8
9 # A long static context that stays the same across queries
10 CONTEXT = """
11 The Python programming language was created by Guido van Rossum and first
12 released in 1991. Python's design philosophy emphasizes code readability
13 with its notable use of significant whitespace. Python is dynamically typed
14 and garbage-collected. It supports multiple programming paradigms, including
15 structured, object-oriented, and functional programming.
16
17 Python consistently ranks as one of the most popular programming languages.
18 It is widely used in web development, data science, machine learning,
19 automation, and scientific computing. The language's large standard library
20 and extensive ecosystem of third-party packages make it suitable for a
21 wide range of applications.
22 """ * 20 # repeat to create a substantial context
23
24
25 def timed_query(question: str, label: str) -> float:
26 """Send a query with the shared context and measure prompt processing time."""
27 payload = {
28 "model": MODEL,
29 "keep_alive": "60m", # keep model and cache in memory
30 "prompt": f"{CONTEXT}\n\nQuestion: {question}",
31 "stream": False,
32 "options": {"num_ctx": 4096}
33 }
34 start = time.time()
35 resp = requests.post(OLLAMA_URL, json=payload)
36 elapsed = time.time() - start
37 data = resp.json()
38
39 # prompt_eval_duration is in nanoseconds
40 eval_ms = data.get("prompt_eval_duration", 0) / 1_000_000
41 print(f"[{label}] Wall time: {elapsed:.2f}s | Prompt eval: {eval_ms:.0f}ms")
42 return eval_ms
43
44
45 # First request: cold start, processes the full context
46 time_a = timed_query("When was Python created?", "Cold start")
47
48 # Second request: same context prefix, different question — cache hit
49 time_b = timed_query("What paradigms does Python support?", "Cache hit")
50
51 if time_a > 0 and time_b > 0:
52 print(f"\nSpeedup: {time_a / time_b:.1f}x faster on cached prompt")
The key settings for prompt caching:
- keep_alive: Set to a long duration (e.g., “60m”) so the model and its KV cache stay in memory between requests.
- Identical prefix: The cached portion must be exactly the same. If even one character of the context changes, the cache is invalidated.
- Consistent num_ctx: The context window size must match between requests.
Prompt caching is especially valuable for applications like document Q&A, where you load a long document once and then answer many questions about it.
Image to Text Description (Vision Models)
Ollama also supports vision models, allowing you to pass an image along with your text prompt so the model can analyze the visual content. You just need to ensure you’re using a vision-capable model (like llava or qwen3.5) and include the image path in your message.
Here is the sample image we will use for this example:

Here is an example of asking a vision model to describe an image:
1 # image_to_text_description.py - Generating detailed image descriptions using a vision model
2
3 import ollama
4
5 # Specify the path to the image file to be analyzed
6 image_path = 'ticket.png'
7
8 # Send the image to the vision-capable model for a detailed description
9 response = ollama.chat(
10 model='qwen3.5:0.8b', # Ensure you use a vision-capable model
11 messages=[{
12 'role': 'user',
13 'content': 'Describe this image in detail',
14 'images': [image_path]
15 }],
16 think=False # Suppresses the <think> reasoning block
17 )
18
19 # Print the model's descriptive analysis of the image
20 print(response.message.content)
Here is abbreviated output from running this example:
1 $ uv run image_to_text_description.py
2 This image is an event ticket from **Northern Arizona
3 University (NAU)** for a performance called **"Fanfares
4 and Fireworks."**
5
6 **Event Details**
7 - **Event Name**: *Fanfares and Fireworks*
8 - **Event Date**: Friday, September 26, 2025
9 - **Time**: 7:30 PM (AZ)
10 - **Venue**: Ardrey Memorial Auditorium
11 - **Performance**: Flagstaff Symphony Orchestra
12
13 **Ticket Information**
14 - **Ticket Type**: *Early Bird Tickets* / *New Subscriber C3*
15 - **Ticket Price**: $53.00 (Service Fee: $0.00)
16 - **Section**: Main Level, Row M, Seat 31
17
18 A QR code is displayed on the right side of the ticket
19 for scanning at the venue.
Even this small 0.8B-parameter vision model extracts detailed structured information from the ticket image — event details, pricing, seating, and layout elements. This simple capability makes it easy to add image understanding to your local applications without needing complex computer vision pipelines.
OpenAI-Compatible API
Ollama exposes an OpenAI-compatible API endpoint, which means you can use the standard openai Python library to talk to local models. This is useful if you want to write code that can switch between cloud and local models by changing only the base URL:
1 # ollama_openai_compat.py - Using local Ollama with the OpenAI SDK
2
3 from openai import OpenAI
4
5 # Point the OpenAI client at the local Ollama server
6 client = OpenAI(
7 base_url="http://localhost:11434/v1",
8 api_key="not-needed" # Ollama doesn't require authentication locally
9 )
10
11 response = client.chat.completions.create(
12 model="llama3.2:3b",
13 messages=[
14 {"role": "system", "content": "You are a helpful assistant."},
15 {"role": "user", "content": "What is the difference between a list and a tuple in Python?"}
16 ],
17 temperature=0.7
18 )
19
20 print(response.choices[0].message.content)
This compatibility layer means you can prototype with local models and then switch to OpenAI, Gemini, or another provider by changing the client configuration — the rest of your code stays the same.
Alternative Tools for Running Local Models
While Ollama is the system I usually use for running local models, several alternatives exist:
llama.cpp: The C++ inference engine that Ollama is built on. Use it directly if you need maximum control over quantization, batching, or want to embed inference in a C/C++ application. Available at github.com/ggerganov/llama.cpp.
LM Studio: A desktop application with a graphical interface for downloading, managing, and chatting with local models. Good for non-programmers or for quickly trying different models. Available at lmstudio.ai.
vLLM: A high-performance inference server optimized for throughput. Best suited for serving models to multiple users in production. Requires more GPU memory but can handle many concurrent requests efficiently. Available at github.com/vllm-project/vllm.
Hugging Face Transformers: The transformers Python library can load and run models directly. This gives you the most flexibility for fine-tuning and custom inference pipelines, but requires more setup and GPU memory management. Best for researchers and advanced users.
For most developers getting started with local models, Ollama provides the best balance of simplicity and capability.
Hardware Considerations
The amount of memory you need depends on the model size:
| Model Parameters | Quantized Size | Minimum RAM/VRAM |
|---|---|---|
| 1-3B | 1-2 GB | 8 GB RAM |
| 7-8B | 4-5 GB | 16 GB RAM |
| 14B | 8-9 GB | 16 GB RAM |
| 32-70B | 18-40 GB | 32-64 GB RAM |
On macOS with Apple Silicon (M1/M2/M3/M4), models run on the GPU using unified memory, which means your total system RAM is also your GPU memory. A MacBook with 16 GB of RAM can comfortably run 7-8B parameter models, and 32 GB or more enables larger models.
On Linux and Windows, a dedicated NVIDIA GPU with sufficient VRAM provides the best performance. Models can also run on CPU only, but inference is significantly slower (roughly 5-10x slower than GPU for most models).
Summary
Running LLMs locally with Ollama gives you a private, cost-free, offline-capable alternative to cloud APIs. The setup is straightforward — install Ollama, pull a model, and start making API calls from Python. Features like streaming, conversation memory, prompt caching, and reasoning models make local models practical for many real applications.
The main tradeoff is capability: the largest models that run locally (7-14B parameters on typical hardware) are less capable than frontier cloud models with hundreds of billions of parameters. For many tasks — code assistance, text summarization, data extraction, conversational interfaces — local models perform well enough, and the privacy and cost benefits make them the better choice.
Optional Practice Problems
Here are some exercises to help you apply the concepts from this chapter and extend the existing code examples.
1. Interactive Streaming Chat Loop (Easy)
- Objective: Extend ollama_streaming.py to create a command-line chat interface. Instead of a single hardcoded query, prompt the user for input in a loop, stream the model’s responses to the console in real-time, and exit when the user types
exitorquit. - Key Concepts: Input loops, real-time output streaming with
flush=True, basic text generation.
2. Context Window and History Management (Medium)
- Objective: Modify the LocalAssistant class in ollama_memory.py to handle context limits. Implement a maximum history size (e.g.,
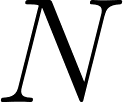 messages). When the conversation history exceeds this limit, the assistant should discard the oldest user/assistant exchanges. However, make sure that the original system prompt is always preserved at the beginning of the message history.
messages). When the conversation history exceeds this limit, the assistant should discard the oldest user/assistant exchanges. However, make sure that the original system prompt is always preserved at the beginning of the message history.
- Key Concepts: System prompt preservation, sliding window list management, message history truncation.
3. Extracting Structured JSON from Vision Models (Medium)
- Objective: Modify image_to_text_description.py to ask the local vision model to extract structured data from
ticket.pngas a raw JSON block. Instruct the model to return keys likeevent_name,date,time,venue, andprice. In your Python code, parse the model’s output using Python’s built-injsonmodule, print the resulting dictionary, and handle any parsing errors. - Key Concepts: Vision model prompting, structured output format directives, output parsing with JSON.
4. Multi-Model Answer Verification (Hard)
- Objective: Create a Python script that implements a multi-model validation pipeline. First, use reason_about from ollama_reasoning.py with
deepseek-r1:7bto solve a logic puzzle (such as a word riddle or math problem). Then, extract the<think>reasoning trace and final answer. Finally, query a smaller general-purpose model likellama3.2:3busing the Ollama API, passing it both the original question and the reasoning trace, and ask it to verify whether the final answer is logically correct based on the reasoning trace. - Key Concepts: Multi-model collaboration, chain-of-thought verification, automated self-correction/grading.