RAG Using zvec Vector Datastore and Local Model
The zvec library implements a lightweight, lightning-fast, in-process vector database. Allibaba released zvec in February 2026. We will see how to use zvec and then build a high performance RAG system. We will use the tiny model qwen3:1.7b as part of the application.
The Agentic RAG implementation in this chapter is based on the Google Research blog post/paper “Unlocking dependable responses with Gemini: Enterprise Agent Platforms & Agentic RAG”.
Note: The source code for this example can be found in Ollama_in_Action_Book/source-code/RAG_zvec/app.py. Not all the code in this file is listed here.
Introduction and Architecture
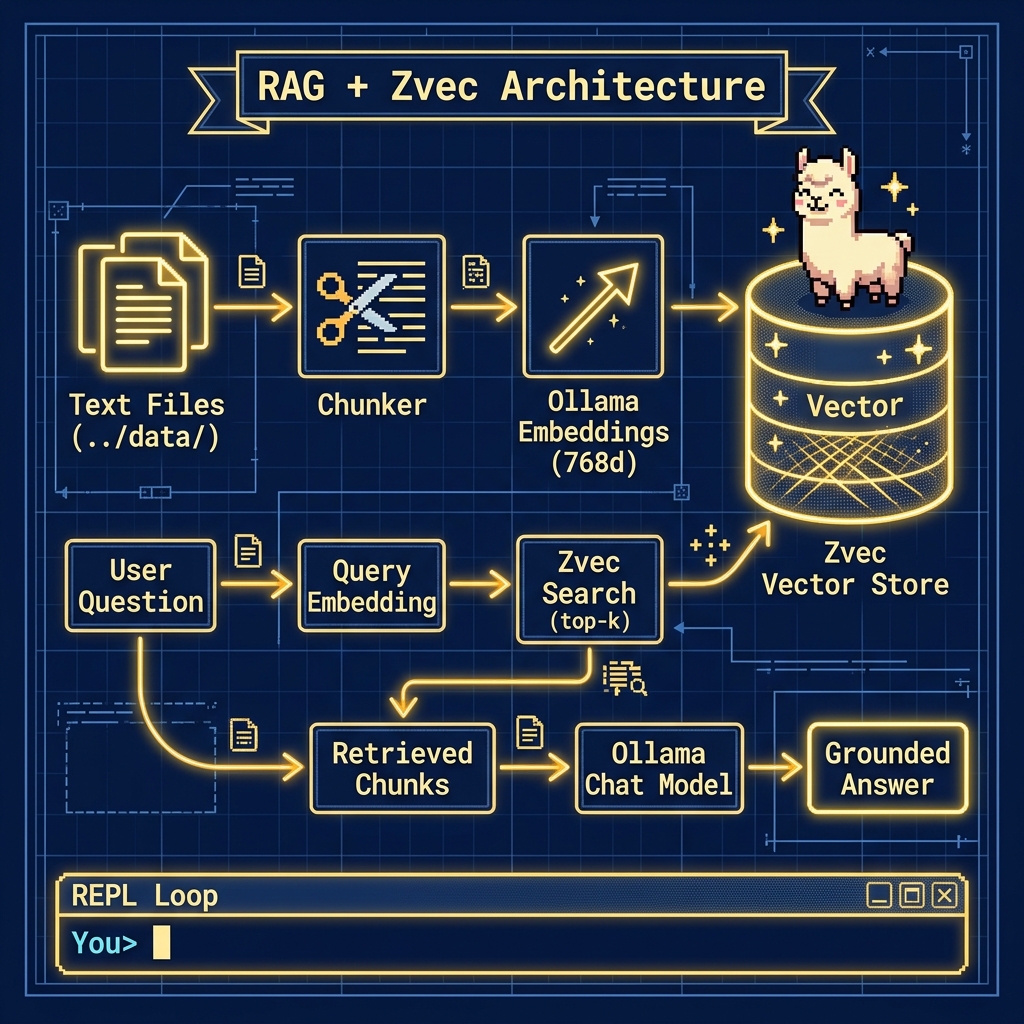
Building a Retrieval-Augmented Generation (RAG) pipeline entirely locally ensures absolute data privacy, eliminates API latency costs, and provides full control over the embedding and generation models. In this chapter, we construct a fully offline Agentic RAG system using local Ollama models for embedding (embeddinggemma) and inference (such as nemotron-3-nano:4b or qwen3:1.7b), paired with zvec, a lightweight, high-performance local vector database.
Unlike standard (or “Vanilla”) RAG, which follows a linear pipeline (query -> retrieve -> generate), our Agentic RAG pattern uses multiple specialized agents that plan, rewrite queries, and evaluate context sufficiency iteratively to guarantee grounding and avoid hallucination:
- Ingestion: Parse local text files, chunk the content, generate embeddings via Ollama, and index them into
zvec. - Planning & Query Rewriting: An orchestrator agent analyzes the user’s question, drafts a search plan, and generates multiple sub-queries to capture all facets of a multi-hop or complex question.
-
Iterative Retrieval & Sufficiency Assessment:
- The vector retriever searches
zvecfor the sub-queries and aggregates unique snippets. - The Sufficient Context Agent acts as a quality inspector: it drafts a response, evaluates whether the retrieved snippets contain enough information, and flags any missing pieces as feedback.
- If context is insufficient, the rewriter uses the feedback to formulate new queries, retrieving more snippets. This loop runs up to 3 times.
- Synthesis: The Synthesis Agent compiles the final answer using the accumulated context. If context remains insufficient after iterations, it clearly states what is missing rather than guessing.
Design Analysis: Dependency Minimization
A notable design choice in our implementation is the reliance on Python’s standard library for network calls. By utilizing urllib.request instead of third-party libraries like requests, the dependency footprint is minimized exclusively to zvec. This reduces virtual environment overhead and potential version conflicts, prioritizing a lean deployment.
Implementation Walkthrough
Here we look at some of the code in the source file app.py.
Embedding and Chunking Strategy
The ingestion phase relies on a fixed-size overlapping window strategy. Here is an implementation of a chunking strategy:
1 def chunk_text(text, chunk_size=500, overlap=50):
2 """Split text into overlapping chunks."""
3 chunks = []
4 start = 0
5 while start < len(text):
6 end = start + chunk_size
7 chunks.append(text[start:end])
8 start = end - overlap
9 return chunks
Analysis of code:
- Chunk Size (500 chars): This relatively small chunk size yields high-granularity embeddings. It reduces the risk of retrieving “diluted” context where a single chunk contains multiple disparate concepts.
- Overlap (50 chars): Crucial for preventing context loss at the boundaries of chunks. It ensures that a semantic concept bisected by a hard character limit is still captured cohesively in at least one chunk.
- Embedding Model: The system uses
embeddinggemma. The Ollama API endpoint (/api/embeddings) is called directly. If the server fails to respond, a fallback zero-vector[0.0] * 768is returned to prevent pipeline crashes.
Vector Storage with zvec
The zvec integration demonstrates a strictly typed, schema-driven approach to local vector storage.
1 schema = zvec.CollectionSchema(
2 name="example",
3 vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 768),
4 fields=zvec.FieldSchema("text", zvec.DataType.STRING),
5 )
Analysis of code:
- Dimensionality Matching: The vector schema is hardcoded to 768 dimensions (FP32), which strictly matches the output tensor of the
embeddinggemmamodel. Any change to the embedding model in the configuration must be accompanied by a corresponding update to this schema. - Storage Path: The database is initialized locally at
./zvec_example. The implementation includes a defensive teardown (shutil.rmtree) of existing databases on startup. This is excellent for testing and iterative development, though destructive in a persistent production environment.
The following function builds the index using an embedding model for the local Ollama server:
1 def build_index():
2 """Index all text files from the data directory into zvec."""
3 # Define collection schema (embeddinggemma: 768 dimensions)
4 schema = zvec.CollectionSchema(
5 name="example",
6 vectors=zvec.VectorSchema("embedding", zvec.DataType.VECTOR_FP32, 768),
7 fields=zvec.FieldSchema("text", zvec.DataType.STRING),
8 )
9
10 db_path = "./zvec_example"
11 if os.path.exists(db_path):
12 import shutil
13 shutil.rmtree(db_path)
14
15 collection = zvec.create_and_open(path=db_path, schema=schema)
16
17 docs = []
18 doc_count = 0
19 for root, _, files in os.walk(config["data_dir"]):
20 for file in files:
21 if file.lower().endswith(config["extensions"]):
22 try:
23 file_path = Path(root) / file
24 with open(file_path, "r", encoding="utf-8") as f:
25 content = f.read()
26 chunks = chunk_text(content)
27 for i, chunk in enumerate(chunks):
28 embedding = get_embedding(chunk)
29 docs.append(zvec.Doc(
30 id=f"{file}_{i}",
31 vectors={"embedding": embedding},
32 fields={"text": chunk},
33 ))
34 doc_count += len(chunks)
35 except Exception as e:
36 pass
37
38 if docs:
39 collection.insert(docs)
40 print(f"Indexed {doc_count} chunks from {config['data_dir']}")
41 return collection
This function build_index initializes a local vector database and populates it with document embeddings. Specifically, it executes four main operations:
- Schema & Storage Initialization: Defines a strict schema for zvec (768-dimensional FP32 vectors and a string metadata field) and recreates the local database directory (
./zvec_example). - File Traversal: Recursively walks a configured target directory to locate specific file types.
- Transformation & Embedding: Reads each file, splits it into overlapping chunks, and retrieves the vector embedding for each chunk via
get_embedding. - Batch Insertion: Accumulates all processed chunks and their embeddings, then performs a bulk insert.
Multi-Query Retrieval and Deduplication
To support queries that target multiple concepts, we define a wrapper search_multi_queries that performs Top-K retrieval across multiple queries and aggregates only unique snippets to avoid context bloat:
1 def search_multi_queries(collection, queries, topk=3):
2 """Search the zvec collection for multiple queries, aggregating and deduplicating chunks."""
3 all_chunks = []
4 seen = set()
5 for query in queries:
6 chunks = search(collection, query, topk=topk)
7 for chunk in chunks:
8 cleaned = chunk.strip()
9 if cleaned and cleaned not in seen:
10 seen.add(cleaned)
11 all_chunks.append(chunk)
12 return all_chunks
Agentic RAG Multi-Agent Components
To implement the multi-agent planning and sufficiency check, we define helpers to make structured chat calls to Ollama using its built-in JSON constraint parameter ("format": "json"), and parse the outputs reliably.
1 def call_llm(system_prompt: str, user_prompt: str, json_format: bool = False) -> str:
2 """Helper to send a prompt to the Ollama chat model, optionally enforcing JSON format."""
3 url = f"{OLLAMA_BASE}/api/chat"
4 payload = {
5 "model": config["chat_model"],
6 "stream": False,
7 "messages": [
8 {"role": "system", "content": system_prompt},
9 {"role": "user", "content": user_prompt},
10 ],
11 "options": {
12 "temperature": 0.1, # Low temperature for deterministic behavior
13 }
14 }
15 if json_format:
16 payload["format"] = "json"
17
18 req = _make_request(url, payload)
19 try:
20 with urllib.request.urlopen(req) as res:
21 body = json.loads(res.read().decode("utf-8"))
22 return body["message"]["content"]
23 except Exception as e:
24 print(f"Error calling Ollama chat: {e}")
25 return ""
Using this foundation, we implement the individual agents:
Planner Agent
Generates a plan and breaks down the user query into multiple specific search queries.
1 def plan_and_rewrite(question: str) -> dict:
2 """Planner Agent: Analyzes the question, generates a plan and search queries."""
3 system_prompt = (
4 "You are a Plan and Query Rewriter agent. Your task is to analyze the user's question, "
5 "create a brief search plan, and generate 1 to 3 distinct search queries to retrieve relevant "
6 "information from a vector database.\n"
7 "You must respond ONLY with a JSON object in this format:\n"
8 "{\n"
9 ' "plan": "brief explanation of what to search for",\n'
10 ' "queries": ["query 1", "query 2"]\n'
11 "}\n"
12 "Do not include any other text."
13 )
14 user_prompt = f"Question: {question}"
15 res_text = call_llm(system_prompt, user_prompt, json_format=True)
16 res_json = parse_json_response(res_text)
17
18 if not res_json or "queries" not in res_json:
19 res_json = {
20 "plan": f"Direct search for: '{question}'",
21 "queries": [question]
22 }
23 return res_json
Sufficient Context Agent
Evaluates if the retrieved snippets contain enough information to fully address the query. If not, it outputs is_sufficient: false and logs exactly what facts are missing.
1 def evaluate_context(question: str, snippets: list) -> dict:
2 """Sufficient Context Agent: Evaluates whether the retrieved snippets contain enough info."""
3 context_str = "\n\n---\n\n".join(snippets)
4 system_prompt = (
5 "You are a Sufficient Context Agent. Your job is to review the user's question, "
6 "the retrieved context snippets, and determine if the snippets contain all the "
7 "necessary information to answer the question fully.\n"
8 "First, mentally draft a potential answer. Then assess if any parts of the question "
9 "are unanswered or if any crucial information is missing.\n"
10 "You must respond ONLY with a JSON object in this format:\n"
11 "{\n"
12 ' "is_sufficient": true or false (boolean),\n'
13 ' "draft_answer": "a rough draft answer based on the current context",\n'
14 ' "reason": "explanation of what is present or what is missing from the snippets",\n'
15 ' "feedback": "if is_sufficient is false, detailed feedback of what specific keywords, topics, or facts are missing and should be searched for next. If is_sufficient is true, leave this empty."\n'
16 "}\n"
17 "Do not include any other text."
18 )
19 user_prompt = (
20 f"Question: {question}\n\n"
21 f"Retrieved Snippets:\n{context_str}"
22 )
23 res_text = call_llm(system_prompt, user_prompt, json_format=True)
24 res_json = parse_json_response(res_text)
25
26 if not res_json or "is_sufficient" not in res_json:
27 res_json = {
28 "is_sufficient": True,
29 "draft_answer": "No draft available.",
30 "reason": "Failed to parse sufficiency evaluation, defaulting to sufficient.",
31 "feedback": ""
32 }
33 return res_json
Synthesis Agent
Generates the final response grounded in the accumulated context. If context sufficiency failed, it explicitly reports the missing details.
1 def synthesize_answer(question: str, snippets: list, is_fully_sufficient: bool, sufficiency_reason: str) -> str:
2 """Synthesis Agent: Generates final grounded response using retrieved context."""
3 context_str = "\n\n---\n\n".join(snippets)
4 if is_fully_sufficient:
5 system_prompt = (
6 "You are a Synthesis Agent. Write a clear, comprehensive, and accurate final answer "
7 "to the user's question using ONLY the provided context. Do not extrapolate or assume facts.\n"
8 f"Context:\n{context_str}"
9 )
10 user_prompt = f"Question: {question}"
11 else:
12 system_prompt = (
13 "You are a Synthesis Agent. The retrieved context was NOT fully sufficient to answer the question. "
14 "Answer what you can from the provided context, and clearly note what information is missing "
15 "or could not be retrieved from the database. Do not make up any information.\n"
16 f"Reason for insufficiency: {sufficiency_reason}\n\n"
17 f"Context:\n{context_str}"
18 )
19 user_prompt = f"Question: {question}"
20
21 return call_llm(system_prompt, user_prompt, json_format=False)
Example Run
To run the pipeline, ensure the Ollama daemon is running locally on port 11434 and that both models (embeddinggemma and qwen3:1.7b) have been pulled. Place your .txt files in the ../data directory and execute the script. The system will build the index and immediately drop you into a REPL loop for interactive querying.
Here is an example run where we specify the use of model qwen3:1.7b:
1 $ export MODEL=qwen3:1.7b
2 $ uv run app.py
3 Building zvec index from text files …
4 Indexed 9 chunks from ../data
5
6 Agentic RAG chat ready (model: nemotron-3-nano:4b)
7 Type your question, or 'quit' to exit.
8
9 You> What are the main schools of economic thought?
10
11 🧠 [Planner] Analyzing question and generating search plan...
12 ↳ Plan: Search for a comprehensive list and description of the main schools of economic thought, such as Keynesian, Neoclassical, Marxist, Austrian, etc.
13 ↳ Initial Queries: ['main schools of economic thought', 'major schools of economics overview', 'schools of economic thought']
14 🔍 [Retriever] Searching vector store for queries...
15 ↳ Found 4 unique context snippet(s).
16 🤖 [Sufficiency Check] Evaluating context sufficiency (Iteration 1)...
17 ↳ Sufficiency: False
18 ↳ Reason: Only the Austrian School is described in the snippets; other major schools such as Keynesian, Neoclassical, Marxist, etc., are not mentioned.
19 🔄 [Rewriter] Context insufficient. Feedback: 'Missing information on Keynesian economics, neoclassical theory, Marxist economics, and possibly other contemporary schools. These should be searched for.'
20 Generating new queries based on feedback...
21 ↳ New queries: ['Keynesian economics overview', 'Neoclassical economic theory summary']
22 🔍 [Retriever] Retrieving additional context...
23 ↳ Found 2 new unique snippet(s). Total unique snippets: 6.
24 🤖 [Sufficiency Check] Evaluating context sufficiency (Iteration 2)...
25 ↳ Sufficiency: False
26 ↳ Reason: The snippets only describe the Austrian School in detail. They do not mention other significant schools of economic thought like Keynesian, Neoclassical, or Marxist, which are essential to a complete answer.
27 🔄 [Rewriter] Context insufficient. Feedback: 'Missing keywords: Keynesian, Neoclassical, Marxist, and possibly others such as Institutional economics.'
28 Generating new queries based on feedback...
29 ↳ New queries: ['Marxist economic theory summary', 'Institutional economics schools of thought']
30 🔍 [Retriever] Retrieving additional context...
31 ↳ Found 0 new unique snippet(s). Total unique snippets: 6.
32 🤖 [Sufficiency Check] Evaluating context sufficiency (Iteration 3)...
33 ↳ Sufficiency: False
34 ↳ Reason: The snippets only describe the Austrian School in detail. They do not mention or provide information about other significant schools of economic thought (e.g., Keynesian, Neoclassical, Marxist).
35 ⚠️ [Iteration Limit] Reached max iterations (3). Proceeding to synthesis with partial context.
36 ✍️ [Synthesis] Generating final response...
37
38 Assistant> **Answer based on the provided context**
39
40 - The **Austrian School** (also called the Vienna or Psychological School) is described in detail as one school of economic thought that emphasizes the spontaneous organizing power of the price mechanism, advocates a “laissez‑faire” approach, and stresses voluntary contractual agreements with minimal government intervention.
41
42 **What is missing / could not be retrieved**
43
44 - The context does **not** mention or provide any information about other significant schools of economic thought such as Keynesian economics, Neoclassical economics, Marxist economics, etc.
45 - Therefore, I cannot list those schools or describe their characteristics from the given material.
46
47 **Conclusion**
48
49 From the supplied text, the only school explicitly described is the **Austrian School**. The existence and description of other major schools (e.g., Keynesian, Neoclassical, Marxist) are not present in the retrieved context.
50
51 You> who says that Economics is bullshit?
52
53 🧠 [Planner] Analyzing question and generating search plan...
54 ↳ Plan: Search for statements where someone calls Economics 'bullshit' and identify the speaker or source.
55 ↳ Initial Queries: ['economics is bullshit quote', 'who said economics is bullshit', 'criticism of economics bullshit']
56 🔍 [Retriever] Searching vector store for queries...
57 ↳ Found 3 unique context snippet(s).
58 🤖 [Sufficiency Check] Evaluating context sufficiency (Iteration 1)...
59 ↳ Sufficiency: True
60 ↳ Reason: The snippet explicitly states that Pauli Blendergast, who teaches at the University of Krampton Ohio and is famous for saying economics is bullshit, is the person who makes this claim.
61 ✅ [Sufficiency Check] Context is fully sufficient!
62 ✍️ [Synthesis] Generating final response...
63
64 Assistant> Pauli Blendergast, an economist who teaches at the University of Krampton, Ohio, is said to claim that “economics is bullshit.”
65
66 You> ^D
67 Goodbye!
Dear reader, notice that there was no information in the indexed text to answer the second example query and this program correctly refused to hallucinate (or make up) an answer.
Wrap Up for RAG Using zvec Vector Datastore and Local Model
In this chapter, we built a completely offline, privacy-preserving RAG architecture by bridging Alibaba’s recently released in-process vector database, zvec, with local Ollama inference. By intentionally minimizing external dependencies and utilizing a strictly typed, schema-driven datastore, we eliminated the network overhead and deployment bloat typical of client-server vector databases. The fixed-size overlapping chunking strategy, combined with the 768-dimensional embeddinggemma model, ensures high-fidelity semantic retrieval. Simultaneously, the compact qwen3:1.7b model demonstrates that a heavily constrained, prompt-engineered generation phase can effectively synthesize retrieved context without hallucination.
The resulting pipeline serves as a robust, lightweight foundation for edge-deployable AI applications. Because the entire storage and inference stack executes locally within the same process, the pattern is exceptionally portable, fast, and secure. Moving forward, this baseline implementation can be extended to handle more complex retrieval requirements, such as integrating dynamic semantic chunking, implementing Reciprocal Rank Fusion (RRF) for hybrid multi-vector queries, or introducing multi-turn conversational memory. Ultimately, combining embedded vector storage with small-parameter LLMs proves that high-performance, domain-specific RAG does not require massive cloud infrastructure.
Optional Practice Problems
Semantic Document Chunking. In
app.py, the document loading process uses a simple character-based overlapping split. Replace this mechanism with semantic chunking, where paragraphs are split on sentence boundaries and grouped together only if their embedding cosine similarity is above a threshold (e.g. 0.85). Verify if the retrieval accuracy changes for cross-paragraph information.Multi-Query Expansion. Currently, the Planner generates a plan and a single list of search queries. Modify the retriever stage to execute three separate search queries against
zvecfor every prompt, merge the returned results, and implement a de-duplication step based on chunk IDs or content hashes.Retrieved Context Sufficiency Threshold. The sufficiency evaluator in the loop uses a Yes/No classification. Modify the evaluator system prompt to return a score from 1 to 5 indicating sufficiency. Continue the retrieval iteration loop only if the score is less than 4. Write a script to output the sufficiency score of the retrieved passages at each step.
Web Search API Fallback. If the local
zvecvector store returns insufficient context after 3 retrieval iterations, configure the agent to call the Brave Web Search API as a fallback to fetch the missing details from the web, append those web snippets to the context, and pass the final aggregate context to the Synthesis Agent.