Praktische Fragen
Wie ermittle ich meine persönlichen Anforderungen?
Bevor ich Zeit in ein Projekt mit einem OpenWrt Router investiere, ist es sinnvoll, dass ich meine ganz persönlichen Anforderungen definiere. Das kann mir später unliebsame Überraschungen ersparen, wenn ich rechtzeitig merke, dass mein Wunschgerät doch nicht geeignet ist. Selbst wenn ich es erst spät merke, dass meine Vorstellungen nicht erreichbar sind, fällt es mir leichter, die Positionen zu identifizieren, bei denen ich Kompromisse machen kann, wenn ich meine ursprünglichen Ziele dokumentiert und vielleicht sogar priorisiert habe.
Im Wesentlichen muss ich mir über drei Fragenkomplexe Gedanken machen:
- Wofür will ich das System einsetzen?
- Wieviel Geld und Zeit will ich investieren?
- Mit welchem Datenaufkommen rechne ich?
Wofür will ich das System einsetzen?
Soll es ein einfacher filternder Router sein, ein Captive Portal für ein WLAN oder sollen weitere Dienste darauf laufen? Wenn noch zusätzliche Dienste darauf laufen sollen, dann welche?
Wieviel Geld und Zeit will ich investieren?
Wenn das Projekt nur zum Lernen ist, will ich vielleicht weniger Geld in die Hand nehmen, dafür aber mehr Zeit damit verbringen. Habe ich einen konkreten Einsatzzweck, bestimmt dieser mein Budget.
Da OpenWrt nahezu kostenlos erhältlich ist, wird das meiste Geld vermutlich in die Hardware gehen. Bei deren Auswahl lasse ich mich von der Tabelle der unterstützten Hardware leiten.
Vielleicht will ich auch etwas Geld in die Hand nehmen und jemand beauftragen, der mir beim Zusammenstellen des Systems hilft.
Mit welchem Datenaufkommen rechne ich?
Diese Frage bestimmt, welche Hardware überhaupt für mein Vorhaben geeignet ist. Und darüber dann, wieviel Geld ich in die Hand nehmen muss. Ich kann OpenWrt auf kleinen WLAN-Routern für wenige Euro einsetzen, die vielleicht gerade mal ein paar MBit pro Sekunde schaffen und für bestimmte Einsatzzwecke ausreichen. Benötige ich mehr Durchsatz, gibt es Geräte mit Gigabit-Schnittstellen und mehreren Prozessorkernen, die recht wenig elektrische Leistung benötigen und somit problemlos im Dauerbetrieb laufen können. Will ich nur wenige Rechner über eine DSL-Leitung von mehreren Kilometern Länge anschließen, reicht vielleicht das erste. Möchte ich hingegen einen Streaming-Server mit mehreren Clients verbinden, benötige ich eher etwas Schnelleres.
Von Vorteil ist, wenn ich meine persönlichen Anforderungen nicht nur notiere, sondern gleich vermerke, bis zu welchem Grad ich bei den einzelnen Positionen zu Kompromissen bereit bin.
Alle drei Komplexe sind von einander abhängig. Während die erste Frage im Allgemeinen harte Kriterien für die spätere Auswahl eines Gerätes liefert, sind die Kriterien Geld und Leistungsfähigkeit eher fließend. Hier ist es nicht so einfach, zu einer Entscheidung zu kommen.
Es empfiehlt sich, ähnlich wie allgemein beim Rechnerkauf nur soviel Leistung zu kaufen, wie im Moment benötigt wird, zuzüglich einer Reserve für den Ausfall von Geräten und kurzfristige Leistungsspitzen. Später lohnt es sich mitunter, die dann aktuellen Preise und Geräte erneut zu untersuchen.
Auswahl von Hardware und Software
Nachdem ich mir Gedanken über meine Anforderungen an das Projekt gemacht habe, ist der nächste Schritt, geeignete Hardware und Software auszuwählen.
Hardware
Ein erster Anlaufpunkt für die Auswahl der Hardware ist der Buyer’s Guide von OpenWrt. Darin finde gleich am Anfang drei Hinweise, die den Auswahlprozess kurz und prägnant zusammenfassen:
- Es gibt keine beste Hardware, kaufe das, was Deinen Anforderungen genügt.
- Informiere Dich selbst über den aktuellen Hardware-Support und frag andere Benutzer nach Empfehlungen.
- Meide überteuerte Produkte, Hardware für OpenWrt kann sehr billig sein.
Mit diesen Ratschlägen im Hinterkopf kann ich mich auf die Kenndaten der Hardware konzentrieren.
LAN - Ethernet
Üblicherweise - und insbesondere bei Projekten, die starken Gebrauch vom Linux-Paketfilter machen - arbeite ich mit IP-Netzwerken und Ethernet.
So gut wie alle Hardware, auf die OpenWrt portiert ist, hat Anschlüsse für Ethernet. Hier interessiert mich einerseits die Anzahl dieser Anschlüsse und andererseits, wie schnell diese arbeiten können.
WLAN - drahtlose Netze
Bei WLAN interessiert mich natürlich ebenfalls die Anzahl der Anschlüsse, wobei für die meisten Anwendungen einer ausreichen dürfte.
Außerdem schaue ich nach, welche Substandards aus der IEEE-802.11-Familie die Adapter unterstützen.
Besonders wichtig ist, wie gut die Adapter mit Treibern unterstützt werden. Wenn es gute quelloffene Treiber gibt, ziehe ich diese proprietären Treibern vor. Allzuoft halten proprietäre Treiber nicht mit der Entwicklung des Kernels Schritt und werden dann von neueren Kernels nicht mehr unterstützt. Damit wäre mein Projekt auf eine bestimmte Version des Kernels festgenagelt und könnte nicht von der Weiterentwicklung des Kernels profitieren.
Eine weiterer wichtiger Aspekt kann die Möglichkeit sein, externe Antennen anschließen zu können. Das hängt vom Projekt ab.
Prozessor und Speicher
Die Leistung des Prozessors und der Speicherplatz sind zwei Kriterien, die ich vor allem bei ambitionierten Projekten berücksichtigen muss, wenn noch weitere Dienste auf dem Gerät laufen sollen.
Beim Speicher geht es dabei einerseits um den für die Prozesse zur Verfügung stehenden RAM sowie andererseits um den Platz auf dem Flash-Speicher für die Programme und Daten. Letzterer lässt sich möglicherweise über USB-Anschlüsse oder eingebaute Kartenleser erweitern, falls diese eingebaut sind.
Der Prozessor sollte auf jeden Fall schnell genug sein, um sämtliche Netzwerkschnittstellen zu bedienen. Für zusätzliche Dienste und / oder kryptographische Anwendungen wie VPNs oder TLS-Server sollte noch genügend Reserve da sein.
Anschlüsse
Je nach Einsatzfall benötige ich vielleicht zusätzliche Anschlüsse am Gerät.
Mit einem USB-Anschluss kann ich es universell erweitern und sowohl zusätzlichen Speicherplatz wie auch weitere Netzwerkkarten und andere Peripherie anschließen.
Einen seriellen Anschluss kann ich als Konsole nutzen oder zur Ansteuerung von externen Geräten.
Knöpfe, Schalter, Anzeigen
Bedienelemente erlauben das Gerät auch ohne Netzanschluss zu manipulieren, zum Beispiel um in den OpenWrt Failsave Modus zu starten.
Eine Anzeige kann mir Auskunft über aktuelle Betriebszustände geben.
Preis
Ein weiteres Kriterium für die Auswahl der Hardware ist der Preis. Insbesondere, wenn ich mir noch nicht klar über die genauen Anforderungen bin, kann ich zunächst zu billiger Hardware greifen, um über Monitoring die benötigten Parameter zu ermitteln und dann gezielt meine Kriterien anzupassen.
Der OpenWrt Buyer’s Guide verlinkt für einige Länder auf spezielle Filter bei Preisvergleichsportalen, die helfen, preiswerte aktuelle Hardware für OpenWrt zu finden.
Software
Ein Hauptkriterium bei der Auswahl der Software ist ihre Eignung für den Einsatzzweck.
OpenWrt verfügt zur Zeit über ein Repository mit etwa 2000 Softwarepaketen. Bei der Auswahl daraus lasse ich mich vom Einsatzzweck und dem Ressourcenbedarf der Software leiten.
Finde ich nicht das Richtige für mich, muss ich mich daran setzen und eine geeignete Software selbst schreiben oder anpassen. Dabei hilft mir die Dokumentation zu OpenWrt und eine Suche im Internet zum Thema.
Wenn ich für mein Projekt kein Standard-Image für die verwendete Hardware einsetze, habe ich die Möglichkeit, zusätzliche Software gleich im Image des Betriebssystems zu integrieren anstatt sie nachträglich mit dem Software-Paketmanager opkg zu installieren.
Das hat den Vorteil, dass der Platz besser ausgenutzt wird. Außerdem benötigt das Gerät keine Verbindung zu einem Software-Repository, bevor es für den Einsatzzweck konfiguriert werden kann.
Andererseits muss ich dann das komplette Image des Betriebssystems auswechseln, wenn ich nur eines der installierten Programme auswechseln will.
Härten des Systems
Ein wichtiger Aspekt beim Betrieb eines jeden Rechners ist das Härten des Systems, damit ich meine Geräte kontrolliere und nicht jemand anders.
Für das konkrete Absichern eines OpenWrt-Systems finde ich Informationen im Wiki. Außerdem kann ich auf allgemeine Tipps zum Härten von Linux-Systemen zurückgreifen, die ich entsprechend der Situation an meinem Gerät adaptiere.
Allgemeine Hinweise
In [ctKaps2014] finden sich allgemeine Hinweise um automatisierten Angriffen auf Routern vorzubeugen, die sich auch für Geräte mit OpenWrt bewähren:
- Keine Konfiguration über Internet, oder
- wenn dann nur mit geänderten Ports und
- Verschlüsselung.
- Geänderte Kennworte und,
- wenn möglich, geänderte Anmeldenamen sowie
- geänderte interne Netzbereiche und darin
- geänderte Routeradressen.
Das sind einfache grundlegende Maßnahmen, die nicht viel gegen einen gezielten Angriff ausrichten können, aber dafür sorgen, dass einfach gestrickte Skripts ins Leere laufen.
Den Zugang sichern
Eine der ersten Maßnahmen ist die Absicherung des Zugangs zum Gerät. Dabei geht es um die Art und Weise der Anmeldung selbst.
Das OpenWrt-Wiki unterscheidet vier Arten, sich am System anzumelden, die von völlig unsicher bis ziemlich sicher reichen.
- Frag nach gar nichts
- Frag nach Benutzername und Kennwort über eine ungesicherte Verbindung
- Frag nach Benutzername und Kennwort über eine gesicherte Verbindung
- Frag nach Benutzername und einer Signatur anstelle eines Kennworts
1. Frag nach gar nichts
Jeder, der diesen Zugang erreichen kann, kann alles mit dem System machen, ohne sich anmelden zu müssen. Offensichtlich ist das für feindliche Umgebungen wie das Internet völlig ungeeignet.
In vertrauenswürdigen Umgebungen ist so ein Zugang vielleicht tolerabel, wenn absolut nichts von der Sicherheit des Gerätes abhängt. Das kann zum Beispiel eine Testumgebung sein, in der vor jedem Test der OpenWrt-Router automatisch konfiguriert wird.
2. Frag nach Benutzername und Kennwort über eine ungesicherte Verbindung
Das entspricht der Administration via Telnet oder HTTP. Es ist etwas besser als Variante 1. Bevor jemand anderes das Gerät manipulieren kann, muss er sich die Zugangsdaten besorgen.
Dazu reicht es allerdings, wenn er die Möglichkeit hat, den Datenverkehr zwischen Administrator und Gerät genau dann mitschneiden kann, wenn der Administrator sich anmeldet.
Da entsprechende Software bereits seit vielen Jahren verfügbar ist, reduziert sich der Aufwand für den Angreifer auf das Installieren und Starten eines solchen Programms auf einem geeigneten Rechner zwischen Administrator und OpenWrt-Gerät.
3. Frag nach Benutzername und Kennwort über eine gesicherte Verbindung
Hier verwende ich SSH oder HTTPS für die Administration. Damit ist das System relativ sicher.
Natürlich kann die Verschlüsselung gebrochen werden. Der Aufwand dafür hängt von den verwendeten Algorithmen, der Länge der Schlüssel und der Stärke des Kennworts ab.
Ein Angreifer muss hier den Datenverkehr mitschneiden und entschlüsseln, um an das Kennwort zu kommen.
Alternativ kann er versuchen die korrekte Kombination von Benutzername und Kennwort mit einem Brute-Force-Angriff zu erraten.
4. Frag nach Benutzername und einer Signatur anstelle eines Kennworts
Das entspricht der Anmeldung via SSH mit Public-Key-Authentication beziehungsweise HTTPS mit Client-Zertifikat.
Beim Public-Key-Verfahren verwende ich einen privaten Schlüssel, um mich am Gerät anzumelden. Den zugehörigen öffentlichen Schlüssel habe ich auf dem Gerät hinterlegt.
Ein Angreifer kann keine Passworte erraten, da keine für die Anmeldung verwendet werden. Um Zugang zu dem Gerät zu bekommen, muss er in den Besitz des privaten Schlüssels gelangen. Damit ist die Hürde für ihn noch etwas höher.
Allerdings muss ich nun aufpassen, dass mir der private Schlüssel nicht abhanden kommt. Und das sowohl in dem Sinne, dass jemand der den Schlüssel bekommt, Zugang zum OpenWrt-Gerät erhält, als auch in dem Sinne, dass ich ohne den Schlüssel keinen Zugang habe.
Neben diesen vier Arten, wie der Zugang zum Gerät geregelt ist, gibt es begleitende Maßnahmen, die die Sicherheit erhöhen können.
Mittels Paketfilterregeln kann ich den Zugang zur Administrator-Schnittstelle auf vertrauenswürdige IP-Adressen beschränken. Das ist ein starker Schutz, wenn die freigegebenen IP-Adressen wirklich zu vertrauenswürdigen Geräten führen.
Wenn ich einen anderen Benutzernamen als root verwende, mache ich Brute-Force-Attacken, die nur auf diesen Benutzernamen abzielen, wirkungslos.
Mit starken Kennworten erschwere ich Brute-Force-Attacken, die auf Wörterbüchern aufbauen.
Als weitere Schutzmaßnahme kann ich die Administrator-Zugänge auf andere Ports verlegen, anstelle von 22 für SSH und 443 für HTTPS. Damit schütze ich mich vor Skripts, die nach Services an diesen Ports suchen um anschließend Brute-Force-Attacken darauf zu beginnen.
System härten
Der nächste Schritt ist die Härtung des Systems selbst. Das ist vor allem dann wichtig, wenn das Gerät nicht nur als Router arbeitet, sondern zusätzlich weitere Dienste anbietet.
Der erste Punkt ist, so wenig wie möglich Software auf dem Gerät zu installieren und zu starten. Nur das, was wirklich nötig ist.
Falls ich Dienste auf dem Gerät anbiete, die als Einfallstor für Angreifer dienen können, kann ich mit SELinux den Schaden im Fall eines erfolgreichen Angriffs in Grenzen halten. SELinux ist für OpenWrt verfügbar. Da das Thema aber sehr umfangreich ist, gehe ich hier nicht weiter darauf ein.
Ein weiterer Punkt, der bereits bei der Absicherung des Zugangs angedeutet war, ist das Verwenden von anderen Benutzernamen. Prinzipiell brauche ich nur das Paket sudo um den Zugang zu privilegierten Diensten für die einzelnen Benutzer zu steuern. Das Paket shadow-useradd erleichtert das Einrichten von weiteren Benutzern, erfahrene Unix-Administratoren können weitere Benutzer aber auch ohne dieses anlegen. Für die Public-Key-Authentication bei SSH kopiere ich für jeden Benutzer die zugelassenen Schlüssel in die Datei $HOME/.ssh/authenticated_keys.
Mit individuellen Zugängen für die einzelnen Administratoren kann ich auch einfacher nachvollziehen, wer wann am Gerät administriert hat. Außerdem ist es einfacher, kompromittierte Zugänge zu sperren, ohne gleich alle Administratoren auszusperren.
Netzwerk härten
Ein wichtiger Punkt ist, keinen Port am externen Interface des Routers (WAN) zu öffnen. Generell. Auch, wenn ich Dienste auf dem Gerät betreibe.
Dienste, die ich nach außen anbiete, sollten auf dedizierten Servern, am besten in einem dedizierten Netz (DMZ) laufen.
Natürlich können auf dem Router laufende Dienste auch aus dem internen Netz angegriffen werden. Nur ist die Wahrscheinlichkeit, dass das aus einem öffentlichen Netz geschieht, um viele Größenordnungen höher.
Ein kompromittierter Server ist auch in einem dedizierten Netz problematisch. Ein kompromittierter Router gibt das ganze Netz dahinter preis.
Eine Ausnahme kann man für den Endpunkt eines VPN machen, das auf dem OpenWrt-Gerät endet. Hier kann ich den Zugriff auf die Adressen aus dem VPN beschränken und für alle anderen sperren.
Um einzelne Ports für einzelne Adressen freizugeben, kann ich Port-Knocking verwenden. Dafür gibt es bei OpenWrt das Paket knockd.
Eine weitere Möglichkeit, beliebige, vorher definierte Aktionen auf dem Gerät aus der Ferne zu starten ist Ostiary, für das es ebenfalls ein Paket bei OpenWrt gibt und Client-Programme für sehr viele Betriebssysteme. Damit lassen sich ebenfalls Ports für einzelne IP-Adressen freischalten.
Mit fail2ban kann ich Brute-Force-Attacken, die von einzelnen Adressen ausgehen, abbrechen. Ähnliches kann ich mit dem Programm logtrigger selbst implementieren.
Bei der Absicherung des Zugangs schrieb ich bereits, dass ein verschlüsselter Administrator-Zugang sicherer ist, als ein unverschlüsselter. Für SSH anstelle von Telnet ist das einfach zu installieren, und mittlerweile meist sowieso schon eingerichtet.
Beim Web-Interface muss ich oft noch selbst Hand anlegen, die notwendige Software installieren, konfigurieren und aktivieren. Das geht so:
Bei px5g handelt es sich um den Zertifikatsgenerator. Dieser wird nur zum Erzeugen eines Zertifikats für den Webserver benötigt und kann am Ende wieder entfernt werden.
Alternativ kann ich das Web-Interface auch durch einen SSH- oder OpenVPN-Tunnel verwenden.
Allgemeine Hinweise
Im Internet finden sich etliche Seiten mit Hinweisen, wie ein Linux-System gehärtet werden kann. Einige dieser Hinweise lassen sich für das Härten eines OpenWrt-Systems adaptieren.
Minimiere die Anzahl der Software-Pakete, ist immer sinnvoll, da dadurch die Angriffsfläche reduziert wird. Nun ist auf vielen OpenWrt-Systemen sowieso wenig Platz, so dass dieser Punkt ohnehin schon in den meisten Fällen berücksichtigt ist. Bei Standard-Images sollte man nur das nachinstallieren, was wirklich benötigt ist. Und bei selbst erstellten Images erst gar nichts überflüssiges hinein nehmen.
Kontrolliere die offenen Ports.
Damit vergewissere ich mich, dass ich keinen Dienst vergessen habe,
abzuschalten beziehungsweise zu sperren.
Von außen kann ich das mit dem Programm nmap auf einem benachbarten Rechner
machen.
Bei einem Zugangs-Router kann ich einen der vielen Dienstleister im Internet,
die solche Scans anbieten, bemühen.
Von innen, also auf dem Gerät selbst zeigt mir der Befehl netstat -aunt
alle offenen TCP- und UDP-Ports an.
Halte das System aktuell. ist immer wichtig, da ständig Programmfehler gefunden und beseitigt werden. Aber nur, wenn ich mein System auch aktualisiere.
Schaue regelmäßig in die Logs, ist ein sehr guter Rat. Nicht nur, weil ich dann Einbruchsversuche sehen und nötigenfalls Gegenmaßnahmen ergreifen kann, sondern auch, weil sich System- und Hardware-Fehler oft dort bemerkbar machen. Sehr komfortabel kann ich in die Logs schauen, wenn ich einen zentralen Log-Server mit Software zur Auswertung der Protokolle habe und diese vom OpenWrt-Gerät dorthin sende.
Beobachte das System mit IDS und Monitoring-Systemen. Während Logs meist erst nach dem Vorfall konsultiert werden, melden sich diese Systeme sofort, wenn sie Anomalien entdecken.
Ein Netzwerk-Service pro System. Dieser Grundsatz hat mehrere Vorteile. Vom Standpunkt der Sicherheit fällt nur ein Dienst aus, wenn das System ausfällt. Und als Administrator muss ich mich bei einem Ersatz oder Upgrade eines Systems nur auf einen Dienst konzentrieren, was die Sache sehr erleichtert.
Deaktiviere den Zugang für root. Das ist bei Embedded Systems eher nicht die Norm, da sich im Normalfall keine Benutzer anmelden. OpenWrt bietet jedoch die Möglichkeit und wenn sowieso schon verschiedene Zugänge für Revision und Operating existieren, sind die Hürden gering, den root-Zugang ganz zu deaktivieren.
Testen der Firewall
All das Wissen um die Paketfilter-Firewall nützt mir recht wenig, wenn ich mich nicht überzeugen kann, dass meine Kenntnisse zutreffen und meine damit getroffenen Einstellungen ihren Zweck erfüllen. Diesem Zweck dienen die Tests des Paketfilters.
Generell kann ich mich mit verschiedenen Arten von Tests an Firewalls herantasten:
- Penetrationstests,
- Tests der Firewall-Implementierung, das heisst, der Software, und
- Tests der Paketfilter-Regeln.
Mit Penetrationstests suche ich nach Sicherheitsproblemen in produktiven Netzwerken, indem ich diese attackiere. Der Paketfilter ist dabei nur ein Testobjekt unter mehreren. Probleme, die ich hierbei aufdecke, haben nicht notwendigerweise mit ihm zu tun. Da die untersuchten Netzwerke produktiv verwendet werden, muss ich besonders verantwortungsbewusst vorgehen und mir vor allem die Zustimmung des Besitzers der betroffenen Netzwerke holen. Das ist ganz bestimmt keine Arbeit für jemand, der sich erst in die Materie einarbeiten will.
Bei Tests der Firewall-Implementierung geht es um Fehler im Betriebssystem und der Paketfilter-Software. Probleme, die ich hierbei aufdecke, betreffen alle Paketfilter des betreffenden Typs, das heißt in unserem Fall OpenWrt in der getesteten Version. Dann ist es sinnvoll, eine Fehlermeldung in den Bug-Tracker zu stellen, damit das Problem für alle gelöst werden kann. Manchmal will ich mich auch direkt an die Entwickler wenden, wenn das entdeckte Problem sensible Bereiche betrifft.
Tests der Firewallregeln sollen nachweisen, dass die Paketfilter-Regeln die Sicherheitsrichtlinie korrekt umsetzen. Probleme, die ich hierbei aufdecke, betreffen den konkreten Paketfilter an dieser Stelle im Netz und die dafür geltende Sicherheitsrichtlinie.
In diesem Kapitel konzentriere ich mich auf Tests der Implementierung und der Regeln. Diese Tests kann ich abseits des produktiven Netzes in einer sicheren Testumgebung ausführen und muss mir keine Gedanken darüber machen, dass die Tests die Umgebung nicht stören dürfen beziehungsweise, dass letztere die Tests beeinflussen kann.
Testumgebung
Testmaschinen
Die Testumgebung besteht im einfachsten Fall aus dem zu testenden Paketfilter und je einem Rechner an jedem Anschluß dieses Paketfilters. Das heißt, ich benötige mindestens drei Geräte.
Mit einem X86-Image von OpenWrt kann ich alle Geräte als virtuelle, miteinander verbundene Maschinen betreiben. Dann kann ich die gesamte Testumgebung auf meiner Arbeitsstation vorhalten und benötige keine zusätzliche Hardware.
Will ich die mit der virtuellen Maschine gewonnenen Erkenntnisse auf ein OpenWrt-System mit anderer Hardware übertragen, benötige ich für einige Tests vielleicht trotzdem diese Hardware. Ein WLAN-Netzwerk, zum Beispiel, lässt sich nicht einfach simulieren.
Software
Neben den Testmaschinen benötige ich geeignete Software um die Testdaten zu erzeugen und die Datenpakete mitzuschneiden.
Zum Erzeugen von Datenpaketen stehen mir etliche Programme und Bibliotheken zur Verfügung, zum Beispiel:
- Nmap (Network Mapper) ist ein freies Werkzeug, um Netzwerke zu erkunden. Damit kann ich sehr einfach der Firewall Datagramme mit unterschiedlichen gesetzten Optionen senden.
- Hping ist dem Ping-Befehl ähnlich, unterstützt aber auch TCP, UDP, ICMP und andere IP-Protokolle, so dass ich die Reaktion des Paketfilters auf diese Datagramme testen kann.
- Tcpreplay erlaubt es, aufgezeichneten Datenverkehr erneut in das Netzwerk einzuspeisen. Damit kann ich zum Beispeil Datenverkehr aus dem Produktivnetz in das Testnetz einspielen und sehen, wie der Paketfilter reagiert.
- Network Expect ist ein Framework, das vom Programm Expect von Don Libes beeinflusst wurde. Damit kann ich “interaktive” Netzwerkprogramme mit Skripts schreiben, ohne zum Compiler greifen zu müssen.
- Mit libnet kann ich relativ einfach Anwendungen in C schreiben, die Datenpakete erzeugen. Diese verwende ich, wenn ich mit den anderen Werkzeugen nicht mehr weiterkomme.
Auch für das Mitschneiden des Datenverkehrs und die spätere Analyse kann ich unter verschiedenen Werkzeugen auswählen:
- Tcpdump ist weit verbreitet und für mich oft das Mittel der Wahl, um Datenverkehr mitzuschneiden.
- Snort basiert, wie tcpdump, auf der Bibliothek libpcap und kann als leichtgewichtiges IDS verwendet werden. Beim Testen von Firewalls kann es als Indikator dienen, ob bestimmte Datenpakete vorkommen. Das ist von Vorteil, wenn die mich interessierenden Daten in einer großen Menge anderer Datenpakete versteckt sind.
- Mit Libpcap kann ich wiederum eigene Werkzeuge in C programmieren, wenn ich kein geeignetes Werkzeug für meine Fragestellung finde.
- Libtrace ist eine Bibliothek wie libpcap. Ein Vorteil gegenüber letzterer ist, dass libtrace sehr viele Datenformate von fremden Paketsniffern lesen kann.
- Wireshark ist ein GUI-Programm zum Mitschneiden von Datenverkehr und zum bequemen Auswerten der Mitschnitte.
Vorgehen
Testplan
Spätestens, wenn ich mein Testsystem und die benötigte Software habe, wird es Zeit, einen Testplan aufzustellen. Dafür gibt es mindestens zwei Methoden: Ich kann nach einer Checkliste testen, oder ich erstelle meinen Testplan entsprechend dem Entwurf der Paketfilterregeln (entwurfsorientiert).
Tests nach Checkliste haben den Vorteil, dass ich sie schnell erstellen kann und nichts vergesse, was auf der Checkliste steht. Sie sind geeignet, wenn ich die Software der Firewall testen will, zum Beispiel zwischen zwei Versionen einer Firewall, als Regressionstest nach einer Fehlermeldung oder wenn ich ein Firewall-Produkt auswählen und vor dem Einsatz testen will, ob es überhaupt geeignet ist. Auch bei Tests von vorgegebenen Firewall-Regeln eignen sich Checklisten.
Was Tests nach Checkliste oft nicht berücksichtigen, sind die Beziehungen zwischen den Firewall-Regeln und der Sicherheitsrichtlinie.
Beim entwurfsorientierten Entwurf des Testplans gehe ich von der Sicherheitsrichtlinie aus. Ich überlege, wie eine Firewall-Konfiguration die Sicherheitsrichtlinie umsetzen könnte und entwickle daraus die Testfälle, die mir diese Überlegungen bestätigen oder widerlegen. Damit gelange ich zu Tests die relevant sind für den konkreten Paketfilter am Einsatzort.
Ein großes Problem beim entwurfsorientierten Entwurf der Tests ist, dass er schwierig ist. Schwieriger als der Entwurf von Firewall-Regeln für einen konkreten Paketfilter aus der Sicherheitsrichtlinie. Mit dem Entwurf der Paketfilter-Regeln stelle ich eine Behauptung auf: dass diese Paketfilter-Regeln die Sicherheitsrichtlinie erfüllen. Mit den Tests für die Überprüfung der Firewall versuche ich, diese Behauptung zu widerlegen.
Da es mir - und ich glaube den meisten Menschen - schwer fällt, eine eigene Behauptung zu widerlegen, ist es sinnvoll, wenn die Tests nicht von der gleichen Person entworfen werden, wie die Paketfilter-Regeln. Geht das nicht, hilft es, wenn ich die Regeln und die Tests im Abstand von einigen Tagen oder Wochen entwickle.
Tests durchführen
Neben den konzeptionellen Problemen beim Erstellen eines Testplans gibt es noch das Problem, dass ich bei seiner Umsetzung Fehler machen kann.
Das bedeutet, ich will nicht nur mit den Tests nachweisen, ob eine Filterregel korrekt ist oder nicht. Zusätzlich muss ich auch sicher sein können, dass die Tests wirklich funktionieren.
Dazu führe ich die Tests mindestens zweimal durch: einmal mit deaktivierten Regeln, die der Test prüfen soll und einmal mit aktiven Paketfilter-Regeln. Dabei sollte ich normalerweise in einem Fall die zugehörigen Datenpakete sehen und im anderen Fall nicht.
So kann ich sicher sein, dass die betrachteten Datenpakete durch die Firewall-Regeln blockiert werden und nicht auf Grund von anderen Phänomenen im Netz.
Neben der rein funktionalen Überprüfung des Paketfilters, ob die Regeln den Anforderungen der Sicherheitsrichtlinie für den konkreten Einsatzzweck genügen, steht als weiterer Aspekt die Leistungsfähigkeit des Paketfilters.
Diese hängt überwiegend von der eingesetzten Hardware und dem Betriebssystem ab, kann aber durch die Konfiguration des Paketfilters und der Regeln beeinflusst werden.
So kann durch zu großzügige Freigaben für ganze Netze die ARP-Tabelle bzw. der Neighbor-Cache des Paketfilters bei einem Netzwerk-Scan überlaufen, was dann zu erhöhtem Aufwand für reguläre Verbindungen führen kann, weil jedesmal eine neue ARP-Anfrage oder Neighbor-Detection nötig ist.
Auch können sich bestimmte Regel-Konfigurationen nachteilig auf die Performance des Paketfilters auswirken. Hier kann ich mit tcpreplay die Auswirkungen verschiedener Konfigurationen auf die Performance testen und anschließend mit einem funktionalen Test verifizieren, dass die performantere Konfiguration noch der Sicherheitsrichtlinie genügt.
Weitere Hinweise
Einen allgemeinen Einblick in die Vorgehensweise beim Test von Firewall-Paketfiltern gibt die Diplomarbeit von Gerhard Zaugg an der ETH Zürich von 2004. An den dort und in der referenzierten Literatur dargelegten Konzepten hat sich nichts Wesentliches geändert.
Für IPv6 verweise ich auf das Forschungsprojekt IPv6 Intrusion Detection im Rahmen dessen die Test-Suite ft6 entstanden ist.
Weitere Werkzeuge für IPv6 sind
- das IPv6-Angriffstoolkit thc-ipv6,
- die Testsuite zum Detektieren von Einbruchsversuchen
- das IPv6 Toolkit von Fernando Gont
Monitoring
Bei der Überwachung eines Paketfilters interessieren mich neben den Vitaldaten, wie CPU- und Speicher-Auslastung sowie Durchsatz vor allem zwei Dinge:
- Kein unerwünschter Datenverkehr soll den Paketfilter passieren.
- Kein erwünschter Datenverkehr soll durch den Paketfilter blockiert werden.
Was erwünschter und unerwünschter Datenverkehr ist, sollte inzwischen hinreichend klar sein.
Blockieren von unerwünschtem Datenverkehr
Um zu kontrollieren, dass kein unerwünschter Datenverkehr den Paketfilter passiert, bietet sich ein Intrusion Detection System (IDS) an.
Habe ich die Funktion des Paketfilters vor der Inbetriebnahme in einer Testumgebung geprüft, dann verfüge ich bereits über die Informationen, mit denen ich das IDS konfigurieren muss, damit es mir anzeigt, ob unerwünschter Datenverkehr durchkommt.
Passieren von erwünschtem Datenverkehr
Schwieriger ist das Monitoring für den erwünschten Datenverkehr. Das Hauptproblem ist, dass ich nicht vorhersagen kann, wann erwünschter Datenverkehr auftritt, um mich dann hinter dem Paketfilter zu überzeugen, dass er nicht blockiert wird. Ein weiteres Problem ist, dass der erwünschte Datenverkehr von verschiedenen Stellen im Netz kommen kann, was das gezielte Hervorbringen nicht erleichtert.
Typischerweise kann ich nur bei abgehendem Verkehr beeinflussen, wann dieser auftritt. Bei ankommendem Verkehr kann ich das nicht vorhersagen.
Hier habe ich zwei Möglichkeiten aktiv einzugreifen:
- Ich kann an repräsentativen Stellen außerhalb meines Netzes Sonden platzieren, mit denen ich regulären Datenverkehr gezielt hervorrufen kann. Dazu muss ich genügend Rechner außerhalb meines Netzes beinflussen können.
- Alternativ könnte ich einen Paketgenerator unmittelbar außerhalb des Paketfilters platzieren, der den gewünschten Datenverkehr simuliert, wie im Testnetz. Das Hauptproblem bei diesem Ansatz ist, dass die Antwortdaten bei bidirektionalem Datenverkehr zum einen den Paketgenerator erreichen und zum anderen nicht darüber hinausgehen sollten, um andere Netze und Rechner nicht zu stören. Daher ist dieser Ansatz nur in Ausnahmefällen geeignet.
Will ich rein passiv arbeiten kann ich beim Monitoring-System den letzten Zeitpunkt des erwünschten Datenverkehrs registrieren und auf ein mögliches Problem hinweisen, wenn der letzte Zeitpunkt zu weit in der Vergangenheit liegt.
Vitaldaten
Neben diesen beiden Hauptfunktionen des Paketfilters will ich in den meisten Fällen noch einige Vitaldaten beobachten, wie zum Beispiel:
- CPU-Last
- Speicherauslastung
- Temperatur
- Menge des Datenverkehrs
Während ich bei den Hauptfunktionen nur an der Aussage geht oder geht nicht interessiert bin, brauche ich von den Vitaldaten Zeitreihen. Damit kann ich zum einen über Korrelationen auf Zusammenhänge schließen und zum anderen Argumente sammeln, wenn sich abzeichnet, dass das aktuell eingesetzte Gerät nicht mehr den Anforderungen gewachsen ist.
Diese Daten frage ich über die Kommandozeile oder einen installierten SNMP-Dämon ab und speise sie in ein geeignetes Monitoring System ein.
Die Zeitreihen, die ich in der Webschnittstelle von OpenWrt sehen kann, helfen mir bei Problemen eher selten weiter, weil ich dann oft keine Daten habe, mit denen ich die aktuellen Werte vergleichen kann.
Kann ich Paketfilter umgehen?
Weiß ich, auf welche Art und Weise ein Paketfilter umgangen werden kann, hilft mir dass beim Entwurf von Paketfilterregeln, beim Testen und Monitoring. Darum schaue ich in diesem Kapitel, wie ich Informationen an einem Paketfilter vorbei übertragen kann.
Nicht alle der hier vorgestellten Möglichkeiten sind von vornherein illegitim oder schädlich. Jede einzelne muss ich im konkreten Kontext betrachten, in dem ich den Paketfilter einsetze.
Stateless Firewallregeln
Eine Möglichkeit, die Firewall zu umgehen beziehungsweise zu überwinden, findet sich bei stateless Firewalls, das heißt, wenn die Conntrack-Module nicht aktiv sind.
Ich kann mit einer stateless Firewall TCP-Verbindungen in einer Richtung sperren und in der anderen Richtung offen lassen, indem ich Datagramme ohne gesetztes ACK-Bit nur in einer Richtung erlaube.
Zwar kann man dann aus der anderen Richtung keine Verbindung aufbauen,
jedoch ist es möglich, Informationen über die Rechner hinter dem Paketfilter
zu erlangen.
Kommt ein Datenpaket mit gesetztem ACK-Bit an einem Rechner hinter dem
Paketfilter an, dann antwortet dieser mit TCP-Reset, falls ein Socket an den
Zielport gebunden ist und mit ICMP-Unreachable-Port, wenn nicht.
Diese Antworten gehen oft durch die Firewall und teilen dem
Angreifer auf diese Art mit, ob der Port offen ist.
Das Programm nmap scannt bei gesetzter Option -PA mit dieser Methode.
Bei einer stateful Firewall wäre das nicht möglich, weil diese erkennen würde, dass das erste Datagramm zu keiner gültigen Verbindung gehört und es gleich verwerfen würde.
Normalerweise ziehe ich als Firewall-Administrator daher stateful Paketfilterregeln vor. Lediglich bei speziellen Performance-Problemen kann es nötig sein auf stateless Regeln auszuweichen.
Fehlerhafte IP-Optionen
Lässt der Paketfilter ICMP-Pakete durch, entweder auf Grund der Policy, oder weil er als stateless Filter bestimmte ICMP-Pakete durchlassen muss, um die Funktionalität des Netzes nicht zu behindern, dann kann ich das ausnutzen um das Netz hinter dem Paketfilter zu erkunden.
Dazu sende ich ICMP-Pakete mit ungültigem IP-Header oder ICMPv6-Pakete mit ungültigem Extension-Header.
RFC 792 definiert für ICMP die Nachricht vom Typ 12 “Parameter Problem Message”, die ein Host oder Gateway sendet, wenn er ein Datagramm nicht verarbeiten kann. Für IPv6 definiert RFC 4443 in Abschnitt 3.4 die ICMPv6 Nachricht “Parameter Problem”, bei Datagrammen mit ungültigen Extension Headern.
Um das auf dem Paketfilter zu unterbinden, kann ich fehlerhafte Datagramme verwerfen.
Dynamisch ausgehandelte Protokolle
Dynamisch ausgehandelte Protokolle arbeiten mit einer Kombination von festgelegten und dynamisch ausgehandelten Ports, wie zum Beispiel FTP, TFTP oder SiP. Ohne Connection Tracking muss ich hier ganze Bereiche von Ports freigeben, so dass ich im ungünstigsten Fall auch unerwünschte Datenverbindungen in Kauf nehmen muss.
Will ich diese Protokolle über den Paketfilter regulieren, werde ich daher auf jeden Fall mit stateful Regeln und Connection Tracking arbeiten und dafür nötigenfalls leistungsfähigere Hardware einsetzen.
Beim Einsatz von Connection Tracking muss ich allerdings einige Feinheiten beachten. So ist es sinnvoll, die dynamisch ausgehandelten Verbindungen, die den Zustand RELATED bekommen, wenn möglich an fest vorgegebene IP-Adressen zu binden, zum Beispiel an die des FTP-Servers, wenn ich FTP zu einzelnen Servern freischalte.
Wenn ein Session Helper auf einem anderen als dem Stardard-Port arbeiten soll, kann ich mit dem CT Target in den Regeln der Tabelle raw den entsprechenden Port einstellen.
Dabei muss ich aber beachten, dass der Session Helper nicht mehr an den Standard-Ports lauschen darf, da sonst darüber unerwünschte Verbindungen freigeschaltet werden können.
Zu diesem Zweck deaktiviere ich das Parsen der Verbindungen per Default und aktiviere es für jede gewünschte Verbindung mit dem CT Target.
Schließlich muss ich im Hinterkopf behalten, dass Session Helpers die Daten in IP-Datagrammen inspizieren und selbst keine Prüfungen auf Gültigkeit der Datagramme vornehmen wie der Rest der Connection Tracking Module. Es ist daher möglich, durch gespoofte Datagramme Verbindungen über Session Helper freizuschalten, indem ich ein passendes Datagramm über ein anderes Interface einspeise. Dem muss ich mit Anti-Spoofing-Maßnahmen begegnen, zum Beispiel mit dem rpfilter Modul.
Der Webartikel Secure use of iptables and connection tracking helpers geht näher auf diese Problematik ein.
Application Level Gateways
Application Level Gateways (ALG) erlauben es, Paketfilter zu umgehen. Ihre Aufgabe ist es, explizit den Datenverkehr zu kontrollieren und zu steuern, der mit einfachen Paketfiltern nicht kontrolliert werden kann. Das sind meist Protokolle der oberen vier OSI-Schichten. Damit liegen Application Level Gateways außerhalb des Themas dieses Buches. Ich behalte aber im Hinterkopf, dass ALG einen Weg bieten können, auf dem Daten mein Netz unkontrolliert erreichen oder verlassen.
Virtual Private Networks
Das gleiche gilt für VPN, seien diese mit IPsec, OpenVPN, SSH-Tunneln oder auf andere Art und Weise realisiert. Diese kann ich nur an den Endpunkten, den VPN-Gateways, kontrollieren.
Habe ich Bedenken bezüglich des Verkehrs, der durch die VPN geht, dann platziere ich einen Paketfilter direkt auf dem VPN-Gateway. Alternativ lasse ich den Datenverkehr aus dem VPN nicht direkt in mein Netz sondern nur über einen vorgeschalteten Paketfilter, zum Beispiel den der DMZ, indem ich das VPN-Gateway genau dort platziere.
Zusätzlich sperre ich allen anderen VPN-Datenverkehr mit den Paketfiltern, so dass deren Regeln auf diese Art nicht umgangen werden können.
NAT Traversal
NAT Traversal ist, je nach Gegebenheit, eine möglicherweise gewünschte Methode, einen Paketfilter zu passieren. Dabei geht es darum, einen direkte TCP- oder UDP-Verbindung zwischen zwei Rechnern aufzubauen, die sich beide hinter einer NAT-Box befinden. VoIP-Verbindungen oder Peer-to-Peer-Netze, die geringe Latenz benötigen, sind mögliche Anwendungen.
Das Problem besteht darin, dass Rechner hinter NAT-Boxen nicht direkt adressiert werden können. Sitzt nur ein Partner hinter einer NAT-Box, kann dieser die Verbindung zum anderen aufbauen. Sitzen beide Partner hinter NAT-Boxen ist eine unmittelbare direkte Verbindung nicht möglich.
Dann kann man sich mit einem Rendezvous-Server behelfen, zu dem sich beide Partner verbinden und der die nötigen Informationen weiterleitet, damit die Partner eine direkte Verbindung aufbauen können. Dafür gibt es verschiedene Lösungen, die mit unterschiedlichen NAT-Boxen umgehen können.
Je nachdem, ob solch direkter Verkehr in meiner Sicherheitsrichtlinie erlaubt ist oder nicht, muss ich meine Paketfilter-Regeln entsprechend anpassen.
Netzwerk Topologie
Eine weitere Möglichkeit, Paketfilter zu überwinden, ist, diese zu umgehen, wenn es mehrere Wege zum Ziel gibt. Das kann ein vermaschtes Netz sein, eine zweite Verbindung zum Internet oder Daten, die über das Netz eines Kooperationspartners laufen.
Daher muss ich bei der Umsetzung einer Sicherheitsrichtlinie immer die komplette Topologie des Netzes, in dem diese gelten soll, kennen.
Fragmentierung
Mit fragmentierten Paketen ist es gelegentlich möglich, simpel gestrickte Paketfilter auszutricksen, wenn die Fragmente nicht genug Informationen für eine korrekte Identifizierung enthalten.
Die Abhilfe dafür ist einfach: ich kann die Datenpakete direkt am Paketfilter zusammensetzen oder, falls das zu Performanceproblemen führt, die Fragmente gleich verwerfen.
Verdeckte Kanäle
Schließlich gibt es noch die Möglichkeit, Daten unkontrolliert über verdeckte Kanäle zu versenden, die sich in anderen Protokollen verbergen.
Das können IP-Daten sein, die sich in DNS-Datagrammen oder ICMP-Datagrammen verbergen. Oder in beliebigen anderen Protokollen, die Nutzerdaten transportieren können.
Bei ICMP habe ich das Problem, dass zumindest einige dieser Datagramme für das korrekte Funktionieren des Netzes erforderlich sind. Hier kann ich mit Rate-Limits und stateful Paketfilter-Regeln arbeiten.
Bei allen anderen Protokollen können Application Level Gateways helfen, wenn ich auf diesen den Verkehr für die entsprechenden Protokolle kontrolliere.
Wo platziere ich ein Tunnel-Gateway?
Nachdem ich in anderen Kapiteln bereits darauf eingegangen war, welche Besonderheiten der Einsatz von Tunneln und VPNs für den Paketfilter mit sich bringt, gehe ich in diesem Kapitel intensiver darauf ein, wo ich ein Tunnel-Gateway in meinem Netz platziere. Dabei ist es egal, ob der Tunnel ein VPN ist, ein IPv6-Tunnel durch ein IPv4-Netz oder umgekehrt.
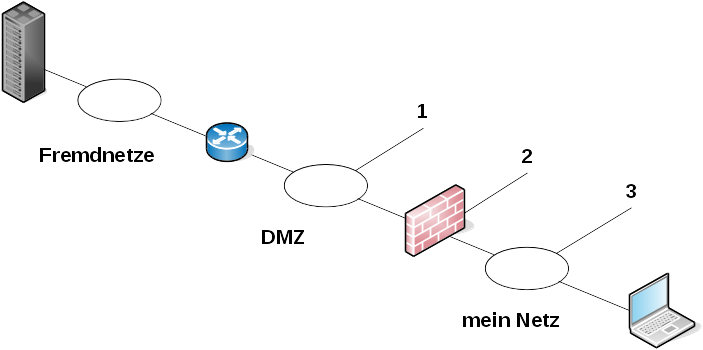
Dabei unterscheide ich grundsätzlich drei Möglichkeiten, das Tunnel-Gateway zu platzieren:
- vor der Firewall
- auf der Firewall
- hinter der Firewall
Jede der drei Positionen bringt Vor- und Nachteile, die ich nachfolgend gegenüberstellen möchte.
Gateway vor der Firewall
Vor der Firewall heißt, aus Sicht eines Fremdnetzes kommt zuerst das Tunnel-Gateway, dann der Paketfilter, dann mein Netzwerk.
Das hat verschiedene Vorteile:
- Die Firewall kann den Traffic aus dem Tunnel filtern.
- Die Sicherheit des Tunnel-Gateway ist weniger kritisch für die Sicherheit meines Netzes hinter der Firewall.
- Ich kann die Konfiguration von Gateway und Firewall relativ einfach halten.
- Die Konfiguration des Gateways ist getrennt von der Konfiguration der Firewall. Damit kann das ein anderer Personenkreis machen und es skaliert besser, wenn ich viele Tunnel zu konfigurieren habe.
- Ich kann das Einrichten in Teilschritte zerlegen.
- Ich kann Gateway und Firewall unabhängig voneinander aktualisieren oder ersetzen.
- Die Fehlersuche ist einfacher, wenn ich die Netzstruktur kenne.
Dem stehen einige Nachteile gegenüber:
- Ich brauche mindestens zwei Geräte.
- Die Konfiguration erfolgt an mehreren Stellen und muss in Teilschritte zerlegt werden, die zueinander passen.
- Das Routing muss stimmen.
Was mache ich, wenn ich mein Tunnel-Gateway vor der Firewall platzieren will?
- Falls NAT nötig ist, mache ich das auf dem Gateway. Damit kann ich die Regeln auf der Firewall einfacher halten, was der Sicherheit zugute kommt und die Fehlersuche vereinfacht.
- Ich muss das Routing für den Tunnel anpassen. Dabei muss ich den Überblick über die Subnetze behalten. Hier macht sich eine gute Netzplanung bezahlt.
- Beim Einrichten eines neuen Tunnels muss ich die Konfiguration zwischen Firewall und Gateway koordinieren.
- Ich muss die Dokumentation von Gateway und Firewall für jeden einzelnen Tunnel zusammenführen. Das erleichtert mir später die Fehlersuche.
Gateway auf der Firewall
Auch das Platzieren des Tunnel-Gateways direkt auf der Firewall hat Vorteile:
- Ich brauche nur ein Gerät und kann damit, insbesondere bei wenig Traffic im Tunnel, einiges an Kosten sparen.
- Die Konfiguration erfolgt an einer Stelle.
- Das Routing ist etwas einfacher.
- Die Firewall sieht den Traffic aus dem Tunnel und kann ihn filtern.
Dem stehen einige Nachteile gegenüber
- Die Kombination aus Tunnel-Gateway und Firewall wird zum Single Point of Failure.
- Will oder muss ich das System ersetzen, muss das neue System alles können, was das alte konnte. Ich bekomme hier sehr leicht einen Vendor-Lock-In.
- Die Konfiguration ist komplizierter als bei den anderen Varianten.
- Die Fehlersuche ist schwieriger.
Worauf achte ich also, wenn ich das Tunnel-Gateway auf der Firewall betreibe?
- Ich achte darauf, dass ich genügend Ersatzgeräte zur Hand habe, so dass ich bei einem Ausfall schnell die alte Konfiguration wieder einspielen und damit weiterarbeiten kann.
- Ich dokumentiere nicht einfach nur die Konfiguration der Tunnels als Prosa, sondern auch aussagekräftige Diagramme, die mir das ganze System bei der Fehlersuche verständlicher machen. Diese Art der Dokumentation ist auch bei den anderen Varianten nützlich, hier ist sie essentiell.
Gateway hinter der Firewall
Auch diese Variante hat Vorteile:
- Die Daten werden durch mein Netz getunnelt, somit kann meine Netzstruktur über den Tunnel nicht mit Traceroute oder Ping erkundet werden. Das ist - zugegeben - ein schwacher Vorteil, da ich mit einem Tunnel meist vertrauenswürdigen Partnern Zugriff auf Teile meines Netzwerks gestatte.
- Ich kann das Routing zum Tunnel auf die Geräte beschränken, die diesen nutzen. Auch das ist nur ein schwacher Vorteil.
- Bei einem Layer-2-Tunnel benötige ich überhaupt keine zusätzlichen Routen.
- Firewall und Gateway werden separat konfiguriert wie in der ersten Variante.
- Ich kann die Geräte wie in der ersten Variante unabhängig voneinander auswechseln.
Dem stehen die folgenden Nachteile gegenüber:
- Die Firewall kann den Traffic im Tunnel nicht filtern, ich bin auf die Sicherheitsvorkehrungen angewiesen, die ich am Tunnel-Gateway einstellen kann.
- Die Konfiguration erfolgt an verschiedenen Stellen und muss koordiniert werden.
- Verwende ich einen gerouteten Tunnel, brauche ich extra Routingeinträge zumindest bei den Rechnern, die diesen nutzen.
Worauf muss ich bei dieser Variante achten?
- Wenn möglich, filtere ich den Traffic des Tunnels auf dem Gateway.
- Bei einem gerouteten Tunnel (Layer 3) muss ich die nötigen Routen eintragen, entweder auf dem nächsten Gateway oder auf den Rechnern, die den Tunnel nutzen.
- Für jeden Tunnel muss ich die Konfiguration von Gateway, Firewall und Routing zusammen dokumentieren.
Wo also platziere ich das Tunnel-Gateway?
Aus den genannten Vor- und Nachteilen ergibt sich für mich folgendes: ich platziere das Gateway vor der Firewall,
- wenn ich mehrere Tunnel betreiben und dafür ein spezielles Gerät anschaffen will,
- wenn ich die separate Konfiguration von Tunnel und Firewall haben will und das koordinieren kann und
- wenn ich den Traffic restriktiv mit der Firewall regulieren will.
Ich platziere das Gateway auf der Firewall,
- wenn ich nur ein Gerät einsetzen kann oder will,
- wenn ich den Tunnel-Traffic mit der Firewall filtern will,
- wenn ich mit der höheren Komplexität umgehen kann und
- wenn die Sicherheitsanforderungen nicht so hoch sind
- weil nicht so viel auf dem Spiel steht oder
- weil ich das Risiko auf andere Weise reduziere.
Ich platziere das Gateway hinter der Firewall,
- wenn ich eine Layer-2-Verbindung brauche und keine Layer-2-Firewall habe,
- wenn ich den Tunnel-Verkehr vor dem restlichen Netz (und der Firewall) verbergen will,
- wenn ich mir der Implikationen für die Sicherheit bewusst bin und damit umgehen kann
Das heißt, ich betrachte die Frage der Platzierung des Tunnel-Gateways jedes Mal aufs Neue unter Berücksichtigung der oben genannten Punkte.
Wie dokumentiere ich das System?
In gewissem Sinne dokumentiert sich eine Firewall selbst in ihren Regeln. Um den Paketfilter konfigurieren zu können, muss ich wissen, welche Regel was bewirkt. Also kann ich aus den Regeln und Einstellungen des Kernels ableiten, was diese und damit die Firewall für einen Zweck haben. Diese Einstellung ist bei manchen Leuten schwer zu widerlegen. Sie ähnelt der Einstellung einiger Autoren von Open Source Software, dass der Quellcode die ultimative und leider mitunter auch die einzige Dokumentation ist.
Damit keine Missverständnisse aufkommen: die Liste der Regeln, die
iptables-save ausgibt, dokumentiert tatsächlich die Firewall.
Und wenn ich Zweifel daran habe oder gar nicht weiß, wie UCIs Konfiguration
in Paketfilterregeln umgesetzt wird, bin ich mit der Ausgabe von
iptables-save tatsächlich am Besten aufgehoben.
Aber eine Firewall-Dokumentation ist das nicht.
Ich will zunächst etwas ausholen und darauf eingehen, welche Informationen überhaupt in eine Firewall-Dokumentation gehören, dann allgemeine Vorgehensweisen ansprechen um schließlich auf Techniken zu kommen, die ich bei der OpenWrt-Firewall verwenden kann.
Informationen in einer Firewall-Dokumentation
So, wie es bei einem Artikel oder einem Buch eine Einleitung gibt, die den Kontext als Rahmen für das folgende bestimmt, bin ich bei jeder Dokumentation gut beraten, wenn ich den Kontext dessen angebe, was ich dokumentiere.
Der Kontext einer Firewall besteht aus den Netzen und Endgeräten von denen Datagramme durch die und zur Firewall geschickt werden. Diesen Kontext kann ich der Netzwerk-Dokumentation entnehmen, wenn ich eine solche vorliegen habe. Dabei interessieren mich L1/L2-Netzpläne für direkt angeschlossene Geräte. L3-Netzpläne benötige ich, um zu wissen, welche Netze sich hinter welchen Gateways verbergen.
Idealerweise habe ich diese Pläne bereits vorliegen. Falls nicht, kann ich diese Informationen aus den ARP-Tabellen, Neighbor-Caches und Routing-Tabellen auslesen und aufbereiten. In diesem Fall kann ich jedoch bei den ARP-Tabellen und Neighbor-Caches nicht sicher sein, alle Geräte erfasst zu haben. Dann können mir die Informationen von managed Switches weiterhelfen.
Außer diesen Netzplänen hilft mir eine Inventarliste der beteiligten Systeme bei der Dokumentation der Firewall. Idealerweise enthält diese Liste die Namen und Adressen der Systeme, ihren Einsatzzweck und Hinweise auf ihre Klassifizierung in der Sicherheitsrichtlinie.
Die Sicherheitsrichtlinie selbst bestimmt ebenfalls den Kontext der Firewall und ist damit Bestandteil der Dokumentation, legt sie doch fest, warum bestimmte Regeln in der Firewall vorhanden sind.
Das sind die globalen oder Kontextinformationen, die ich in einer Firewall-Dokumentation zu finden hoffe. Es wird bereits deutlich, dass diese nicht aus einem einzigen Text bestehen kann.
In einer ausführlichen Dokumentation erwarte ich weitere Informationen zu jeder einzelnen Regel:
- Warum wurde diese Regel eingefügt. Zum Beispiel, weil ein Netz wegfiel oder hinzukam oder weil die Sicherheitsrichtlinie geändert wurde.
- Wer hat die Regel eingefügt, wer ist der technische Kontakt und vielleicht der geschäftliche Ansprechpartner, wenn die Regel einen Bereich der Sicherheitsrichtlinie mit geschäftlichen Hintergrund berührt.
- Was soll diese Regel oder Gruppe von Regeln bewirken.
- Wann wurde die Regel eingefügt? Wie lange soll die Regel enthalten sein? Gibt es ein Verfallsdatum? Damit kann ich bei den hoffentlich regelmäßig stattfindenden Audits einfach prüfen, ob ich eine Regel entfernen kann.
Diese Informationen kann ich zum Beispiel in einem Ticketsystem oder einer Configuration Management Database pflegen.
Allgemeine Verfahren
Stand der Technik, wenn auch noch lange nicht von jedem angewendet, ist ein Change Management, das zum einen Änderungen der Konfiguration abdeckt und zum anderen die Anpassungen der zugehörigen Dokumentation.
Ich will hier nicht auf einzelne Verfahren eingehen, wichtig ist nur, dass eines etabliert wird, bei dem sich Änderungen in der Konfiguration in der Dokumentation niederschlagen. Idealerweise dokumentiere ich die Änderung zuerst, setze sie dann um, prüfe die Umsetzung und dokumentiere schließlich auch das Prüfergebnis. Das kann sehr aufwendig werden, darum muss jeder für sich selbst entscheiden, wieviel Bürokratie er haben will und wie hoch der Nutzen daraus für ihn ist.
Ein weiterer Baustein sind periodische Reviews. Das bedeutet, in regelmäßigen Abständen kontrolliere ich, ob die Firewall-Konfiguration mit der Dokumentation übereinstimmt. Habe ich mehr Aufwand in das Change Management gesteckt, kann der Review schnell vor sich gehen, weil kaum Abweichungen zu finden sein werden. Sind Abweichungen da, muss ich entscheiden, ob ich die Dokumentation an die Firewall anpasse, die Firewall an die Dokumentation oder beides aneinander. Dabei muss ich prüfen, ob die Firewall noch korrekt im Sinne der Sicherheitsrichtlinie arbeitet.
Egal, wie ich die Firewall dokumentiere, ob nur die Regeln als solches oder weitere Informationen, wie am Anfang des Kapitels beschrieben, auf eines würde ich nie verzichten: ein Versionsverwaltungssystem, mit dem ich alle Änderungen erfassen und bei Bedarf einen älteren Stand wieder herstellen kann.
Abschließend halte ich technische Hilfsmittel für sinnvoll, die automatisch entweder die Regeln aus der Dokumentation oder aus den Regeln eine gut lesbare Dokumentation erzeugen.
Werkzeuge der ersten Art sind gut um die eigene Infrastruktur zu verwalten. Wenn alles korrekt eingestellt ist, liegt dann der größte mentale Aufwand im Bestimmen und Dokumentieren der Regeln, während die Umsetzung halb- oder vollautomatisiert erfolgen kann. Ich muss allerdings immer daran denken, dass Ad-hoc-Änderungen der Regeln im nächsten Update-Zyklus verschwinden, wenn sie nicht dokumentiert werden.
Werkzeuge der zweiten Art sind nützlich, wenn ich eine Firewall, die nicht oder schlecht dokumentiert ist, analysieren will.
Firewall-Dokumentation bei OpenWrt
Generell habe ich drei Wege, um auf die Firewall-Konfiguration bei OpenWrt für die Dokumentation zuzugreifen:
- das Web-Interface LuCI,
- das Kommandozeilen-Interface UCI und
-
iptables-save.
LuCI, das Web-Interface, ist am besten für Ad-Hoc-Konfiguration geeignet. Diese will ich im Rahmen eines Change Managements jedoch vermeiden.
Zwar ist es möglich, mit Web Bots einen OpenWrt-Rechner automatisch über das Web-Interface zu konfigurieren und dokumentieren, doch sind solche Lösungen zu komplex und vor allem zu anfällig im Hinblick auf Änderungen am Web-Interface.
Besser geeignet für die automatisierte Erfassung der Konfiguration sowie
für die Konfiguration selbst ist UCI.
Mit uci export kann ich eine vorhandene Konfiguration auslesen, mit uci
import eine neue einlesen.
Der Vorteil gegenüber LuCI ist, dass ich damit eine Softwareschicht ausgeschaltet habe, denn letztendlich verwendet auch LuCI im Hintergrund für die Konfiguration UCI.
Daher ist UCI mein Favorit für eine automatisierte Konfiguration.
Die dritte Möglichkeit, iptables-save, eignet sich nur für eine Analyse der
Paketfilterregeln selbst.
Hier fehlen unter anderem die Informationen zur Konfiguration der
Schnittstellen, die uci export mitliefert.
Der große Vorteil von iptables-save ist, dass ich die Firewall-Regeln sehr
einfach für die weitere Verarbeitung aufbereiten kann.
Zusätzliche Software
Manchmal reicht mir die Funktionalität nicht und ich benötige weitere Software, die im Firmware-Image von OpenWrt nicht enthalten ist.
Dann kann ich zunächst in den Software Repositories von OpenWrt nachschauen, ob ich dort etwas Passendes finde. Diese Repositories enthalten eine Vielzahl von Paketen, die schon aus Platzgründen nicht alle im Firmware-Image untergebracht werden können.
Finde ich auch dort nichts Geeignetes, gibt es zuweilen die gewünschte Software in Repositories von dritter Stelle. Bei diesen muss ich jedoch bedenken, dass ich damit mein Vertrauen in die Sicherheit der Software nun von OpenWrt auf den Anbieter dieser Software-Pakete ausdehnen und dass in meinen Sicherheitsüberlegungen berücksichtigen muss.
Eine Alternative zu Repositories Dritter ist, die Software selbst zu übersetzen. Diesen Weg muss ich sowieso gehen, wenn ich der Autor bin.
Nach der Frage, woher ich die benötigte Software bekomme, muss ich überlegen, wie ich sie auf den System installiere.
Hier gibt es mehrere Möglichkeiten:
- Ich integriere die Software in meinem Firmware-Image. Diesen Weg kann ich gehen, wenn ich sowieso schon das Firmware-Image selbst erzeugt habe. Dazu muss die Software im Buildroot integriert sein. Auf Details gehe ich hier nicht ein, im Wiki von OpenWrt liefert der Developer Guide Anleitungen dazu.
- Mit dem Software-Verwaltungsprogramm
opkgkann ich zusätzliche Software aus den Repositories von OpenWrt oder von dritter Stelle installieren. Nach der Installation der Firmware istopkgkorrekt konfiguriert, so dass ich sofort auf die Repositories von OpenWrt zugreifen kann.Für fremde Repositories muss ich die Konfiguration von
opkgerst anpassen.Eventuell muss ich mir Gedanken machen, wie ich auf meinem Gerät Platz für diese Software schaffe.
- Einfache Skripts, die von den installierten Interpretern (Shell, Lua, …) ausgeführt werden, kann ich einfach so auf das Gerät kopieren.
Der Software-Paketmanager opkg
In den meisten Fällen dürfte die einfachste Art, zusätzliche
Software zu installieren, der Paketmanager opkg sein.
Nach der Installation ist dieser normalerweise auf die Repositories von
OpenWrt für die verwendete Hardware eingestellt, so dass ich mir nur mit
opkg update die aktuelle Liste der verfügbaren Pakete holen muss.
Dabei gibt es drei Kategorien von Software-Paketen:
- Skripts, die von einem Interpreter wie der Shell abgearbeitet werden. Diese sind unabhängig von der Hardware-Architektur des Gerätes.
- Ausführbare Programme, die direkt vom Prozessor abgearbeitet werden können. Diese sind nur auf der spezifischen Hardware verwendbar, für die sie kompiliert wurden.
- Kernel-Module sind zusätzlich noch von der Version des Kernels im
Firmware-Image abhängig.
Gerade bei Firmware-Images aus dem Entwicklerzweig (Trunk)
muss ich bei der Aktualisierung der Pakete aufpassen, ob sie
noch zum laufenden Kernel passen und gegebenenfalls das Firmware-Image
mit
sysupgradeaktualisieren.
Platz für zusätzliche Software
Beim Installieren von Software mit opkg kann es
passieren, dass ich an die Grenze des verfügbaren Speichers gelange.
Bietet die Hardware die Möglichkeit, kann ich vielleicht zusätzlichen Speicher via USB oder Card Reader bereitstellen. Dafür benötige ich vielleicht zusätzliche Kernel-Module für USB und die Dateisysteme, die ich verwenden will.
Falls das Firmware-Image auf einem Wechseldatenträger (CompactFlash- oder SD-Card) untergebracht ist, kann ich vielleicht auf diesem noch freien Speicher nutzen. Dann benötige ich das Paket block-mount.
Anschließend muss ich opkg so konfigurieren, dass Software-Pakete in
dem zusätzlichen Speicher installiert werden.
Zusätzlich muss ich den Suchpfad für ausführbare Programme anpassen,
damit diese auch gefunden werden.
Details dazu gibt die technische Referenz OPKG Package Manager im
OpenWrt-Wiki.
Software portieren
Die dritte Möglichkeit, an benötigte Software zu gelangen, ist, diese selbst zu übersetzen.
Dazu muss ich diese, am besten mit dem Buildroot-System von OpenWrt, für
mein Gerät kompilieren.
Sinnvollerweise erzeuge ich gleich ein Paket, das ich mit opkg
installieren oder im Firmware-Image einbinden kann.
Dabei kann ich notwendige Abhängigkeiten von anderer Software gleich mit angeben, so dass diese automatisch mit installiert wird.
System aktualisieren
Auch bei OpenWrt muss ich mir Gedanken machen, wie ich mein System aktuell halte. Habe ich die Firmware aus dem Entwicklerzweig (Snapshot) genommen, kommt das häufiger vor, bei einem stabilen Zweig seltener.
Grundsätzlich muss ich dabei zwei Seiten betrachten: das Firmware-Image
selbst und nachträglich mit opkg installierte Software.
Hier gehe ich kurz auf beide ein.
Firmware-Image aktualisieren
Zum Aktualisieren der Firmware gibt es das Skript sysupgrade, welches die
notwendigen Schritte ausführt.
Im Wiki gibt es eine Anleitung, die beschreibt,
wie man das System von der Kommandozeile oder von der Webschnittstelle LuCI
aktualisiert.
Das Skript sysupgrade sichert dabei die Konfigurationsdateien über die
Aktualisierung, die in der Textdatei /etc/sysupgrade.conf aufgeführt sind.
Ich muss mich allerdings selbst informieren, ob die alten
Konfigurationsdateien noch mit der neuen Version der Firmware funktionieren.
Will ich mich nicht auf sysupgrade verlassen, kann ich diese Dateien
auch selbst auf einem anderen Rechner sichern.
Dazu schreibe ich mit folgendem Befehl eine Archiv-Datei, die ich
anschließend mit scp auf einen anderen Rechner kopiere:
Bei LuCI bekomme ich eine Liste mit Vorschlägen, welche Dateien gesichert werden sollten. Auf der Kommandozeile muss ich mir diese Liste selbst zusammenstellen.
Ein Blick in den Lua-Source-Code von LuCI verrät, woher es diese Vorschläge bezieht:
- die Dateien, die bereits in /etc/sysupgrade.conf aufgeführt sind,
- Dateien, die in den Textdateien unter /lib/upgrade/keep.d/ verzeichnet sind,
- die Ausgabe von
opkg list-changed-conffiles.
Damit kann ich mir selbst eine aktuelle Liste zusammenstellen. Konkret verwendet LuCI bei der Version Chaos Calmer die folgenden Shell-Befehle, um die Vorschlagsliste zu erstellen:
1 (
2 find $(sed -ne '/^[[:space:]]*$/d; /^#/d; p' \
3 /etc/sysupgrade.conf /lib/upgrade/keep.d/* \
4 2>/dev/null) -type f 2>/dev/null; \
5 opkg list-changed-conffiles
6 ) | sort -u
Um die Befehle zu verstehen, betrachtet man sie am Besten von außen nach innen.
Die Klammern in der ersten und letzten Zeile umfassen eine Subshell, deren
Ausgabe an sort geschickt wird, welches die Ausgabe sortiert und dabei
Duplikate entfernt.
In der Subshell haben wir einen find Befehl in den Zeilen 2-4 und den
Befehl opkg list-changed-conffiles in Zeile 5, die die zu sortierenden
Zeilen bereitstellen.
Der find Befehl gibt nur gefundene Dateien aus (-type f).
Wo find nach den Dateien sucht, bestimmt der Ausdruck $(sed ...) in den
Zeilen 2-4, der als Dateiliste an find übergeben wird.
Der dabei aufgerufene sed Befehl gibt den Inhalt der in Zeile 3
angegebenen Dateien aus, wobei er leere Zeilen und solche, die
mit '#' beginnen, auslässt.
Die sortierte Liste, die das Skript ausgibt, kann ich in eine Datei schreiben, nachbereiten und dann zum Sichern der Konfigurationsdateien verwenden.
Die eigentliche Aktualisierung läuft wie folgt ab:
- Ich prüfe, ob genügend Speicher (RAM) zur Verfügung steht und schaffe, wenn nötig, Platz.
- Ich kopiere das Upgrade-Image nach /tmp und prüfe die Integrität der Datei.
- Ich starte
sysupgrademit dem Namen der heruntergeladenen Datei als Argument.
Sollte sysupgrade mein Gerät noch nicht unterstützen, kann ich auf das
Programm mtd (Memory Technology Device) zurückgreifen, um das neue Image in
die Firmware zu schreiben.
Die Details dazu stehen im Wiki von OpenWrt.
Mit dem Programm mtd kann ich, bei extremem Speichermangel auch das Image
via Netzwerk mit netcat (nc) bereitstellen.
Diese Methode ist jedoch sehr riskant, weil hierbei mehr
Störstellen vorhanden sind (Netzkabel, Switch, Rechner, der das Image
sendet), so dass die Gefahr, ein defektes Image zu schreiben,
höher ist.
Speicher frei räumen
Etwas Speicher kann ich freigeben, indem ich die Listen von opkg lösche:
Da Linux automatisch verfügbaren Speicher als Cache verwendet, kann ich saubere Cache-Seiten freigeben um noch etwas Speicher zu bekommen:
Bei einem normalen Linux-System, kann ich vorher sync aufrufen, so dass
weitere Cache-Seiten freigegeben werden können.
Ob das bei OpenWrt wirksam ist, hängt davon ab, ob ich Dateisysteme
read-write eingehängt habe (zum Beispiel USB-Sticks).
Details dazu finden sich in der Kernel-Dokumentation, konkret in der Datei
Documentation/sysctl/vm.txt.
Zusätzlich installierte Software aktualisieren
Mit opkg kann ich zusätzliche Software auf einem OpenWrt-System
installieren.
Diese Software ist nicht Bestandteil des Firmware-Images und belegt
extra Platz auf dem Gerät.
Um sie zu aktualisieren, muss ich als erstes die Paketlisten von opkg
aktualisieren:
Danach kann ich mir anzeigen lassen, welche Pakete aktualisiert werden können:
Und genau diese schließlich aktualisieren:
Alternativ kann ich die Pakete auch einzeln aktualisieren.