IPv4 für den Firewall-Administrator
IPv4 wird auf längere Zeit noch eine große Rolle spielen. Darum gehe ich in diesem Kapitel auf wichtige Aspekte dieses und der damit verbundenen Protokolle ein.
Internet Protokoll Version 4
Im OSI-Modell finden wir das Internet Protokoll in Schicht 3, direkt auf Ethernet aufsetzend, welches wiederum die Funktionen der Schichten 1 und 2 bereitstellt.

Natürlich kann man IP auch mit anderen Protokollen übertragen, jedoch werden wir es wohl am häufigsten mit Ethernet oder WLAN zusammen sehen. In einem Datagramm finden wir den IP-Header folglich hinter dem Ethernet-Header und vor den Headern der Protokolle aus den höheren Schichten.
RFC 791 beschreibt IPv4. Daraus habe ich die die folgende ASCII-Graphik des IP-Headers entnommen, die 32 Bit pro Zeile anzeigt.

Die ersten fünf 32-Bit-Worte sind in jedem IPv4-Datagramm obligatorisch, die Optionen können weggelassen werden. Das Feld IHL zeigt die Länge des IPv4-Headers in 32-Bit-Worten, die minimale Länge ist 5.
Der RFC beschreibt die einzelnen Felder und die Bedeutung ihrer Werte recht ausführlich, so dass ich hier nicht weiter darauf eingehen will. Für den Firewall-Betrieb sind vor allem die folgenden Informationen im Header von IPv4 relevant:
- ToS (Type of Service)
Neben der Standard-Definition in RFC 791 gibt es Ergänzungen für die Bedeutung dieses Feldes in den RFCs 2474 (DCSP) und 3168 (ECN). - Flags
Diese zeigen unter anderem an, ob das IP-Paket fragmentiert werden darf oder bereits ist. Da Fragmentierung das Filtern erschweren kann, ist es ratsam, bei einem Paketfilter fragmentierte Pakete entweder zu verwerfen oder vor der Entscheidung zusammenzubauen. - Protocol
Dieses Feld gibt an, welches Protokoll im IP-Datagramm eingebettet ist, das heißt, wie die nachfolgenden Daten zu interpretieren sind. Seit RFC 3232 führt die IANA eine Online-Datenbank unter http://www.iana.org/. Auf einem Linux-Rechner finden sich die Nummern und Namen dieser Protokolle in der Datei /etc/protocols: so zum Beispiel 1 für ICMP, 2 für IGMP, 6 für TCP und 17 für UDP. Will ich am Paketfilter nach Protokollen diskriminieren, muss ich dieses Feld beachten. - Quell- und Zieladresse
Mit je 32 Bit dienen die Adressen in den meisten Regeln als Merkmale für die Entscheidung. Verwende ich NAT bei der Firewall, muss ich beachten, an welcher Stelle im Netfilter-Code die Regel greift und an welcher NAT, um dann entweder die originale oder die umgesetzte Adresse zu filtern.
Internet Control Message Protocol (ICMP)
ICMP wird zwar, genau wie IP, der OSI-Schicht 3 zugeordnet, es nutzt aber das Internet Protokoll für den Transport. Daher finden wir den ICMP-Header direkt hinter dem IP-Header.

RFC 792 beschreibt das Protokoll. Daraus habe ich die folgende ASCII-Graphik der Kopfdaten entnommen, die ebenfalls 32 Bit pro Zeile zeigt.

Der ICMP-Header folgt unmittelbar auf den IPv4-Header.
ICMP ist für viele Firewall-Administratoren eine Problemzone. Um das Jahr 2000 herum brachte Ofir Arkin seine Untersuchungsergebnisse über den Gebrauch von ICMP für das Scannen von Netzwerken heraus. Konnten zuvor in den meisten Firewalls ICMP-Pakete freizügig passieren, so wurden sie danach in vielen Konfigurationen rigoros gesperrt. Leider gibt es einige ICMP-Datagramme, die keinesfalls gesperrt werden sollten, um den regulären Netzbetrieb nicht zu behindern. Hier muss der Firewall-Administrator sehr gut Bescheid wissen, so dass ich ICMP in einem eigenen Kapitel intensiver behandle.
Transmission Control Protocol (TCP)
Auch den TCP-Header finden wir in einem Datagramm hinter dem IP-Header. Interessant ist, das zur eindeutigen Identifizierung einer TCP-Sitzung sowohl Informationen aus dem TCP-Header als auch aus dem IP-Header herangezogen werden.

Beschrieben in RFC 793, ist TCP eines der am häufigsten verwendeten Protokolle im Internet. Die folgende ASCII-Graphik ist dem RFC entnommen und lässt bereits die Komplexität des Protokolls erahnen.
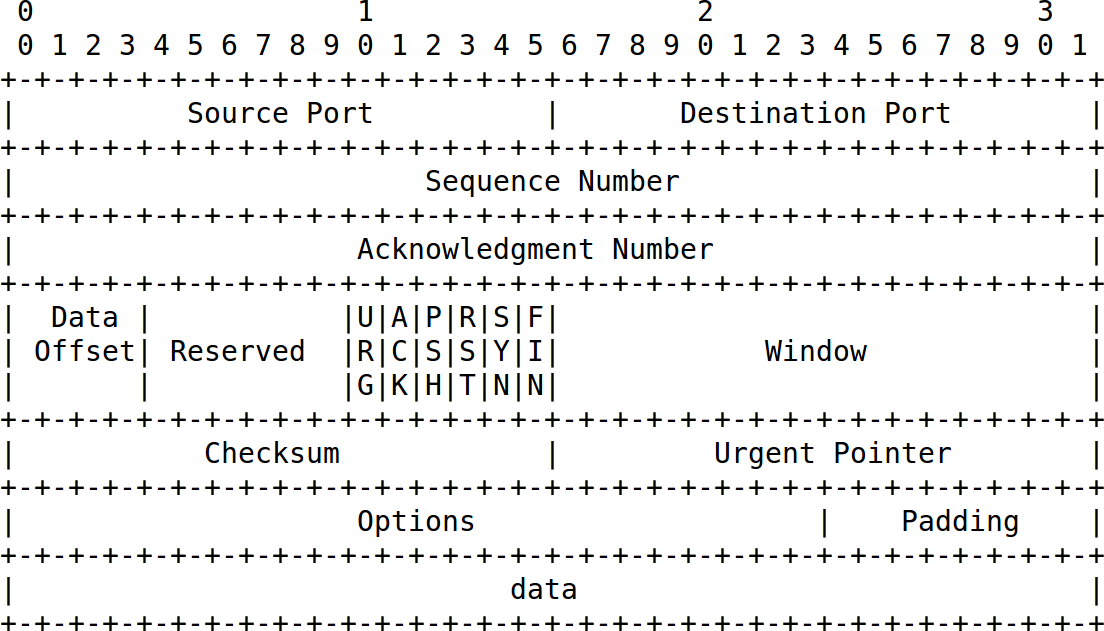
Der TCP-Header kann aufgrund der Optionen unterschiedliche Längen haben. Das Feld Data Offset gibt seine Länge in 32-Bit-Worten an. Das Feld data in der ASCII-Graphik steht für die transportierten Daten und gehört nicht mehr zum TCP-Header.
Eine TCP-Verbindung wird durch folgende fünf Angaben eindeutig identifiziert:
- Quell- und Zieladresse sowie Protokollfeld im IP-Header
- Quell- und Zielport im TCP-Header
TCP-Verbindungen sind bidirektional, Quell- und Zieladresse sowie Quell- und Zielport von Datagrammen einer Sitzung sind paarweise vertauscht, je nach der Richtung, in der sie gesendet werden.
Jede TCP-Sitzung befindet sich in einem Zustand, den die Firewall am TCP-Header erkennen kann: an den Flags, der Sequenz- und Acknowledge-Nummer sowie am Receive-Window.
Bei einer zustandslosen Regel muss die Firewall den Zustand ausschließlich an Hand des aktuellen Datenpakets erraten und entsprechend reagieren. Dann ist es bei einer bestehenden Verbindung nicht mehr möglich, zu erkennen, welche Seite die Verbindung ursprünglich initiiert hatte.
Demgegenüber verfolgt die Firewall bei zustandsbehafteten Regeln die Sitzung und ist auf diese Weise zum Teil in der Lage, gefälschte Datenpakete zu erkennen und zu unterdrücken. Das braucht allerdings mehr Ressourcen, vor allem Speicherplatz, von der Firewall.
TCP enthält einen Mechanismus, mit dem es die maximale Größe von Datagrammen auf der Verbindungsstrecke ermitteln kann. Dafür setzt es das Don’t Fragment Bit im IP-Header und ist darauf angewiesen, dass ICMP-Unreachable-Pakete zurückkommen können, die dem Sender sagen, wann ein Datagramm zu groß ist. Moderne TCP-Stacks können mit Heuristiken auch ohne ICMP erkennen, wenn die Path-MTU kleiner als die MTU des Interfaces ist und senden dann kleinere Datenpakete. Diese Heuristiken sind jedoch zeitaufwendig - sie arbeiten mit Timeouts - und verschwenden Bandbreite, weil sie nicht mit der maximal möglichen MTU arbeiten sondern meist mit kleineren.
Gehen Datenpakete verloren, wiederholt TCP automatisch bereits gesendete Datagramme. Diese wiederholt gesendeten Datagramme sollten problemlos durch die Firewall gehen, wenn die Verbindung legitim ist. Bei zustandsbehafteten Regeln kann die Firewall Replay-Attacken erkennen, wenn die Sequenznummer eines Datagramms wesentlich kleiner ist, als die letzte Acknowledge-Nummer der Gegenrichtung.
User Datagram Protocol (UDP)
Kommen wir nun zu UDP, dem letzten der Protokolle, auf die ich im Rahmen von IPv4 kurz eingehen will.
Auch hier finden wir die Kopfdaten direkt hinter dem IP-Header. Und wie bei TCP werden auch bei UDP Informationen aus dem IP-Header zur vollständigen Identifizierung einer UDP-Sitzung herangezogen.

Beschrieben in RFC 768, ist UDP ein zustandsloses Protokoll. Die folgende ASCII-Graphik aus dem RFC lässt bereits erahnen, dass es sich um ein sehr einfaches Protokoll handelt.
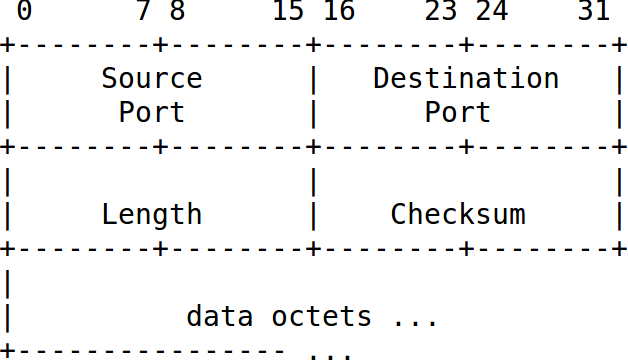
Das Längenfeld gibt die Länge des UDP-Headers und der Daten in Oktetts an.
Eine UDP-Verbindung wird, ähnlich wie bei TCP, durch folgende Informationen identifiziert:
- Quell- und Zieladresse sowie Protokollfeld im IP-Header
- Quell- und Zielport im UDP-Header
Einige auf UDP aufsetzende Protokolle verwenden mehrere dieser eindeutigen UDP-IDs in einer Sitzung, zum Beispiel TFTP. Das muss ich als Firewall-Administrator berücksichtigen, wenn diese Protokolle über die Firewall laufen.
Will ich UDP mit stateful Regeln überwachen, muss die Firewall mit Timern arbeiten. Das bedeutet für die Anwendungen, dass sie regelmäßig Daten senden müssen, bevor der Timer abläuft, wenn sie die Verbindung für die Firewall aktiv halten wollen. Alternativ kann ich auch den Timeout bei der Firewall etwas größer ansetzen, wenn die Firewall Probleme mit einzelnen Verbindungen bereitet.
Network Address Translation (NAT)
Mit NAT kann man die bei IPv4 mittlerweile nicht mehr ausreichenden eindeutigen Adressen mehrfach verwenden. Bei IPv4-Firewalls muss ich jederzeit damit rechnen, mit NAT konfrontiert zu werden.
Es gibt verschiedene Einteilungen von NAT, je nachdem, welchen Aspekt ich betrachte. So gibt es NAT bei dem
- mehrere Adressen eines Netzes auf genau so viele Adressen eines anderen Netzes umgesetzt werden, oder
- mehrere Adressen eines Netzes auf weniger - im Extremfall genau eine - Adresse umgesetzt werden. Letzteres wird auch als Masquerading bezeichnet.
Da NAT sehr häufig an Perimeter-Routern eingesetzt wird, bezeichnet man die beiden Seiten des Routers oft mit innen und außen. Werden die Adressen eins-zu-eins zwischen verschiedenen Adressbereichen umgesetzt, ist es möglich, Verbindungen gezielt von der äußeren zur inneren Seite aufzubauen, wenn die Adresszuordnung feststehend ist.
Insbesondere im SOHO-Bereich stehen auf der äußeren Seite oft weniger Adressen zur Verfügung als auf der inneren Seite verwendet werden. Bei einer Umsetzung von vielen inneren Adressen auf wenige äußere ist es ohne explizite Konfiguration schwierig, eine Verbindung von außen nach innen aufzubauen.
Das ist genau dann problematisch, wenn zwei Rechner hinter zwei solchen NAT-Routern ein direkte Verbindung wünschen, zum Beispiel für VoIP oder Videokonferenzen. In diesem Fall ist es ratsam sich mit dem Thema NAT-Traversal auseinander zu setzen. NATBlaster und STUN sind zwei Verfahren, mit denen direkte Verbindungen über zwei NAT-Router hinweg etabliert werden können. Diese sind auf die Kooperation der Firewall angewiesen.
Schließlich behindert NAT IPsec, da letzteres die IP-Adressen verifiziert und durch die Änderung der Adressen die Datagramme ungültig werden. Hier muss man auf UDP Encapsulation of IPsec ESP Packets, beschrieben in RFC 3948 ausweichen.
Da das Thema NAT sehr komplex ist und sehr viele Facetten enthält, gehe ich in einem späteren Kapitel noch einmal ausführlich darauf ein.
Fragmentierung
Prinzipiell kann ich auch fragmentierte Datagramme filtern, ohne sie vorher zusammen zu setzen. In diesem Fall müsste ich alle Fragmente ohne Header-Informationen durchlassen und die Filter-Regeln nur auf die ersten Fragmente mit den Header-Informationen anwenden.
Sind die ersten Fragmente zu klein, so dass sie nicht genügend Informationen enthalten, verwerfe ich sie. Was zu klein ist, hängt von den Regeln und den Protokollen ab, nach denen ich filtere.
Bei Connection Tracking muss ich fragmentierte Datagramme auf jeden Fall zusammensetzen, da die benötigten Informationen, zum Beispiel für FTP, in den Nutzdaten stehen.