Grundlagen Netzwerkprotokolle
Aufgaben eines Paketfilters
Ich mache mir zunächst die Aufgaben eines Paketfilters klar, um dann seine Bestandteile unter diesen Aspekten - den Aufgaben - zu betrachten und so besser zu verstehen.
Die Hauptaufgabe eines Paketfilters ist das Filtern des Datenverkehrs an Hand von vorgegebenen Regeln für die im Netz vorkommenden Protokolle. Dabei trifft der Paketfilter seine Entscheidungen normalerweise basierend auf den Kopfdaten der Datagramme und nicht ihrem Inhalt. Eine Ausnahme bilden einige Connection-Tracking-Module, wie zum Beispiel für FTP, die aus dem Datenstrom der Verbindung zu Port 21 die Ports der zugehörigen Datenverbindungen ermitteln.
An den Grenzen von Netzwerken kommt oft zusätzlich noch die Adressübersetzung, das heißt das Ändern von Quell- und / oder Zieladresse sowie der Ports bei TCP und UDP als Aufgabe dazu. Diese Umsetzung findet sich vorwiegend bei IPv4-Netzen, weil bei diesen die Anzahl der frei verfügbaren global eindeutigen Adressen seit langem nicht mehr den Bedarf decken kann und daher Adressen mehrfach verwendet werden.
Die Adressübersetzung dient zwei Zielen: das eine ist das Verbergen ganzer Netze hinter einzelnen Adressen (Masquerading), das andere das Ermöglichen der Kommunikation von Rechnern in verschiedenen Netzen, die den gleichen Präfix verwenden.
Masquerading finde ich häufig bei SOHO-Umgebungen, die von ISP eine IP-Adresse bekommen haben und hinter dieser verschiedene Endgeräte verbergen, die alle eine Verbindung in das Internet benötigen. Da mehrere interne Adressen auf eine externe Adresse gebündelt werden, geht es nicht ohne Änderung der TCP- und UDP-Ports ab. Von der externen Seite sind die internen Rechner nicht direkt adressierbar, da von außen nur eine IP-Adresse sichtbar ist.
Ein Beispiel für die Adressübersetzung ganzer Netzwerk-Präfixe ist ein Zusammenschluß zweier Netze, die bisher die gleichen privaten Netzwerkadressen verwendet haben. Da ich hier für die Umsetzung mit gleich großen Netzwerk-Präfixen arbeiten kann, müssen die Ports nicht zwingend geändert werden und außerdem sind alle internen Rechner von extern - über die umgesetzte Adresse - direkt adressierbar.
Kommen wir zurück auf das Filtern des Datenverkehrs, das dem Schutz vor Angreifern dient. Ich kann einzelnen Geräten eingeschränkten Zugang zu anderen Netzen gewähren oder Port-Scans verhindern, mit Port-Knocking auch für verfügbare Dienste. Unter bestimmten Voraussetzungen kann ich mit Rate-Limiting DoS-Angriffe entschärfen und gefährliche Datenpakete blockieren.
Formal dient die Filterung des Datenverkehrs der Durchsetzung einer Policy, welche den erlaubten und den verbotenen Datenverkehr in einem Netzwerk definiert.
Natürlich beschreibt eine Policy nicht direkt, welcher Datenverkehr erlaubt oder verboten ist. Dann müsste sie bei jeder Änderung im Netzwerk angepasst werden. Stattdessen drückt die Policy abstrakt die Ziele aus, von denen ausgehend ich, mit Kenntnis der im Netz eingesetzten Adressen und Protokolle, Regeln für den Paketfilter ableiten muss.
Eine weitere Aufgabe eines Paketfilters ist der Schutz vor unerwünschtem Datenabfluss. Natürlich kann ein Paketfilter nicht davor schützen, dass Daten durch Ausnutzen der erlaubten Verbindungen das Netz verlassen. Er kann jedoch den Datenverkehr in Bahnen lenken, auf denen ich mit anderen Mitteln dem Abfluss von Daten entgegenwirken kann.
Der Paketfilter hat dabei lediglich unterstützende Funktion, indem er den Datenverkehr umleitet zu einem Proxy, welcher den Datenverkehr bewertet und geeignete Entscheidungen trifft.
Neben dem absichtlichen Datenabfluss kann mich ein Paketfilter auch vor unbeabsichtigter, versehentlicher Preisgabe von sensiblen Informationen schützen. Dazu muss ich die Schwächen der in meinem Netz verwendeten Protokolle kennen und in manchen Fällen die Reichweite dieser Protokolle einschränken. So sendet beispielsweise MS Windows unter Umständen den NTLM-Hash des angemeldeten Nutzers an beliebige SMB-Server. Diese Information genügt, um sich in Windows-Netzen auszuweisen und Dienste zu nutzen. Um mich vor der versehentlichen Preisgabe dieser Information zu schützen, muss ich die Ports 139 und 445 für UDP und TCP abgehend sperren, auch wenn ich auf Grund einer permissiven Policy abgehenden Datenverkehr eigentlich erlauben würde.
Schließlich kann der Paketfilter noch die Authentisierung und Authorisierung von Netzwerk-Geräten unterstützen, indem er HTTP-Anfragen zunächst zu einem Captive Portal umleitet und den Datenverkehr erst nach Anmeldung am Portal freigibt.
Chance - Risiko - Policy - Firewall - Paketfilter
Bevor ich mich weiter in Details verliere, will ich kurz auf ein paar Begriffe und Zusammenhänge eingehen.
Vom wirtschaftlichen Standpunkt ausgehend, wäge ich die Chancen eines Systems (den Gewinn, den ich damit erziele) ab gegen die Risiken (die Verluste, die ich damit erleide). Ist das betrachtete System die IT-Infrastruktur einer Firma, wende ich mich wegen dieser Zahlen an die Geschäftsführung. Ist es mein persönliches Netz zu Hause, muss ich die Zahlen selbst bestimmen. Konkret geht es um den Nutzen oder Gewinn, den ich mit Hilfe des betrachteten Systems erreiche und die Verluste, die bei der Benutzung des Systems entstehen. Das Ermitteln dieser Zahlen benötigt betriebswirtschaftliche Kenntnisse.
Mit einer Security Policy (Sicherheitsrichtlinie) kann ich nur Verluste reduzieren. Die ermittelten finanziellen Werte geben den finanziellen Rahmen vor, innerhalb dessen sich meine Security Policy und die von ihr abgeleiteten Maßnahmen bewegen müssen, damit ich mich nicht langfristig zugrunde richte. So kann ich den Aufwand schätzen, den ich sinnvollerweise betreibe, um das System zu schützen.
Als nächstes ermittle ich die Schwachstellen des Systems und wie diese ausgenutzt werden können. Davon ausgehend lege ich Richtlinien - eine Policy - fest, die das Ausnutzen dieser Schwachstellen im besten Fall verhindert, zumindest aber erschwert. Das heißt, die Policy legt dem Gesamtsystem Beschränkungen auf, die einerseits die Ausnutzung von vorhandenen Schwachstellen verhindern, andererseits aber immer noch die Nutzung des Systems für seinen eigentlichen Zweck zulassen sollen. Hier muss ich eine Balance finden, wobei mir der oben erwähnte finanzielle Rahmen hilft.
Um die Policy durchzusetzen, kann ich - neben anderen Maßnahmen - für Rechnernetze eine Firewall verwenden. Diese besteht aus verschiedenen Komponenten: Paketfiltern, die den Datenverkehr auf den unteren Ebenen des OSI-Modells regulieren, Application Gateways, die sich um die oberen Ebenen des OSI-Modells kümmern und Intrusion Detection Systeme, die überwachen, ob die Policy eingehalten wird. Intrusion Prevention Systeme schließlich können bei einer erkannten Verletzung der Policy weitere Maßnahmen einleiten. In diesem Buch geht es vor allem um Paketfilter.
Die Policy sollte als erstes festlegen, ob ich grundsätzlich alles erlaube und nur bestimmten Datenverkehr verbiete - ein permissiver Ansatz - oder ob ich nur bestimmten Datenverkehr erlaube und alles andere verbiete - ein prohibitiver Ansatz. Die Antwort darauf kann in verschiedenen Bereichen eines Netzwerks unterschiedlich ausfallen. Anschließend sollte die Policy den erlaubten und / oder den verbotenen Datenverkehr beschreiben.
Habe ich meine Policy, ermittle ich im nächsten Schritt die Protokolle und Netzwerkadressen, die ich zulassen oder sperren muss und die Art von Application Gateways, die ich einsetzen muss, um die Ziele der Policy zu erreichen.
OSI Modell
Um den Paketfilter und die Application Gateways richtig einzuordnen, greife ich auf das Open Systems Interconnection (OSI) Modell zurück. Dieses Modell dient seit vielen Jahren als Referenzmodell für Netzwerkprotokolle.
Es ist als Schichtenmodell ausgeführt, bei dem jede Schicht genau definierte Aufgaben hat, die Dienste der darunterliegenden nutzt und seine Dienste den darüber liegenden zur Verfügung stellt. Es gibt in diesem Modell die folgenden sieben Schichten:
| deutsch | englisch | |
|---|---|---|
| 7 | Anwendungsschicht | application layer |
| 6 | Darstellungsschicht | presentation layer |
| 5 | Sitzungsschicht | session layer |
| 4 | Transportschicht | transport layer |
| 3 | Vermittlungsschicht | network layer |
| 2 | Sicherungsschicht | data link layer |
| 1 | Bitübertragungsschicht | physical layer |
Reale Protokolle können mehrere Schichten des OSI Modells abbilden, zum Beispiel:
- Ethernet die Schichten 1 und 2
- IP, ICMP, IGMP die Schicht 3
- TCP, UDP die Schicht 4
- HTTP, SMTP die Schichten 5, 6 und 7
Paketfilter arbeiten auf den OSI Schichten 1 bis 4. Habe ich verschlüsselten Datenverkehr, kann der Paketfilter nur bis zur Schicht 3, den IP-Adressen, arbeiten.
Für Protokolle der Ebenen 5 bis 7 muss ich entweder auf Application Gateways setzen und mit Paketfiltern erzwingen, dass diese genutzt werden. Oder ich untersuche den Datenverkehr mittels Deep Packet Inspection (DPI) und steuere mit den gewonnenen Erkenntnissen den Paketfilter und damit den Datenverkehr.
Reaktive Schutzmaßnahmen
Eine Möglichkeit, einen Server mittels Paketfilter zu schützen, besteht darin, die Log-Nachrichten des Servers auszuwerten und unerwünschten Datenverkehr zu unterbinden.
Fail2ban ist eine Software, die so etwas macht: sie wertet die Systemprotokolle aus und sperrt nach einer bestimmten Anzahl von Fehlversuchen die IP-Adresse über den Paketfilter. Damit kann ich Brute-Force-Attacken auf Login-Dienste verlangsamen und so unbrauchbar machen.
Das funktioniert jedoch nur, wenn der fail2ban-Dämon die benötigten Log-Nachrichten erhält und der Datenstrom über diesen Rechner läuft. Für lokale Dienste ist das leicht zu realisieren.
Auf einem separaten Paketfilter benötige ich dafür ein komplexes System, das die Log-Nachrichten zentral auswertet und die Paketfilter steuert.
Port-Knocking und TCP-Stealth
Eine weitere Möglichkeit, bei der ein Paketfilter einen Server schützt, ist Port-Knocking. Bei diesem Verfahren unterbindet der Paketfilter zunächst jeglichen Datenverkehr. Erst wenn die Software auf dem Server, die den Datenverkehr beobachtet, eine bestimmte Signatur in den Datenpaketen erkennt, veranlasst sie den Paketfilter, den Datenverkehr vom Sender der Signatur zuzulassen.
Damit lassen sich Zugänge zu einem System so verbergen, dass ein Angreifer den kompletten Datenverkehr des Systems beobachten und analysieren müsste, um den geschützten Dienst zu finden und die Signatur zu ermitteln. Dieses Verfahren ist sicherer als das nachträgliche Sperren bei Fehlversuchen, aber nur für einen begrenzten Personenkreis geeignet, dem die Signatur bekannt sein und die Software zur ihrer Erzeugung zur Verfügung stehen muss.
TCP-Stealth funktioniert, oberflächlich betrachtet, ähnlich. Es ist aber direkt im TCP-Stack implementiert und arbeitet ohne den Paketfilter. Die Signatur befindet sich hier direkt in den Datagrammen, welche die TCP-Verbindung aufbauen. Damit ist TCP-Stealth noch schwerer zu entdecken, als Port-Knocking, welches für die Signatur zusätzliche Datagramme verwendet, die nichts mit der eigentlichen Verbindungsaufnahme zu tun haben und dadurch einem aufmerksamen Beobachter auffallen können. In [ixGK2014] und [ctKGEAPM2014] finden sich nähere Informationen dazu.
Um welche Protokolle geht es?
Welche Netzwerkprotokolle sind für mich interessant, wenn ich eine Paketfilter-Firewall betreiben will? Auf einer Seite gehen Datenpakete hinein, auf der anderen Seite sollen sie herauskommen oder auch nicht. Das kann doch nicht so viel sein, könnte man meinen. Erstaunlicherweise sind es recht viele Protokolle, von denen ich mehr wissen muss, als nur den Namen und wofür es verwendet wird.
Betrachten wir den Bereich IPv4, dann haben wir IPv4 selbst, ICMP und IGMP. Dazu kommen TCP und UDP auf denen die meisten Protokolle der höheren OSI-Schichten aufsetzen.
Mit ARP werden bei IPv4 die Ethernet-Adressen den IP-Adressen zugeordnet. Dieses Protokoll interessiert mich, wenn ich meinen Paketfilter als Ethernet-Bridge betreibe.
Im Bereich IPv6 muss ich das Protokoll IPv6 selbst und ICMPv6 kennen. Bei TCP und UDP muss ich nicht viel gegenüber IPv4 dazu lernen. Die Funktionen von ARP und IGMP übernimmt ICMPv6.
Das sind die wichtigsten Protokolle der OSI-Schichten 1-4, die ich beim Paketfilter beachten muss.
Die Protokolle der Schichten 5-7 setzen oft auf TCP oder UDP auf. Bei diesen muss ich oft nur wissen, welche Ports verwendet werden und welche Seite die Verbindung aufbaut.
Es gibt unter diesen Protokollen jedoch einige, wie zum Beispiel FTP, die mit mehr als einer Verbindung arbeiten. Andere, wie zum Beispiel TFTP, verwenden im Laufe einer Sitzung verschiedene Ports. Werde ich mit solchen Protokollen konfrontiert, muss ich deren Eigenheiten kennen.
Die meisten dieser Protokolle werden in RFCs beschrieben, welche ich im Internet von http://tools.ietf.org/ beziehen kann. Nachfolgend gehe ich kurz auf einige davon ein.
Ethernet
Die RFCs 894, 1042 und 2464 beschreiben, wie IPv4 und IPv6 Datenpakete in Ethernet- und 802.3-Frames eingebettet werden. Oft interessieren mich zum Filtern nur die MAC-Adressen. Arbeitet der Paketfilter jedoch als Ethernet-Bridge und nicht als Router, muss ich mich auch mit diesen Protokollen auseinandersetzen.
ARP, das Address Resolution Protocol finde ich in RFC 826 beschrieben. RFC 5227 aktualisiert es beim Thema Erkennung von Adresskonflikten. Das Protokoll spielt eine wesentliche Rolle bei Bonjour, der automatischen Netzwerk-Konfiguration von Apple-Rechnern sowie bei APIPA (Automatic Private IP Adressing) von Windows-Rechnern.
RFC 3927 beschreibt die automatische Konfiguration von link-lokalen IPv4-Adressen. Dabei wird ARP verwendet, um zu ermitteln, ob eine Adresse bereits belegt ist oder um eine IP-Adresse zu reklamieren. Auf diese Art konfigurierte IP-Adressen erkenne ich am Prefix 169.254/16. Datagramme mit dieser Absenderadresse dürfen nicht geroutet werden, da sie nur im lokalen Netzwerksegment gültig sind.
Bei IPv6 übernimmt Neighbor Discovery (ND) via ICMPv6 diese Funktion. Diese ist in RFC 4861 beschrieben. RFC 5942 aktualisiert ND in Bezug auf das IPv6-Subnetz-Modell, speziell für das Verhältnis zwischen Links und Subnetz-Präfixen. RFC 6980 geht auf die Auswirkungen von IPv6-Fragmentierung auf Neighbor Discovery ein.
IPv4
RFC 791 beschreibt das Internet Protokoll in Version 4. RFC 1349 ändert und erläutert einige Aspekte des Type of Service (TOS) Felds im IP-Header. RFC 2474 definiert das Differentiated Services (DS) Feld und RFC 6864 aktualisiert die Definition des ID-Feldes.
Da dieses Protokoll eines der wichtigsten für Firewall-Administratoren ist, gehe ich in einem eigenen Kapitel intensiver darauf ein.
IPv6
IPv6 wurde erstmals 1995 in RFC 1883 beschrieben. 1998 löste RFC 2460 diese inzwischen veraltete Beschreibung ab.
RFC 4303 “IP Encapsulation Security Payload (ESP)” beschreibt die IPv6 Header Extensions für IPsec.
Da dieses Protokoll immer wichtiger für Firewall-Administratoren wird, gehe ich in einem eigenen Kapitel intensiver darauf ein.
ICMP
Das Internet Control Message Protocol ist in RFC 792 beschrieben. RFC 4884 erweitert ICMP für Multipart-Nachrichten.
RFC 6633 und RFC 6918 begründen die Ablehnung von wenig genutzten ICMP-Nachrichten. Damit helfen mir diese beiden RFCs bei der Entscheidung für oder gegen diese Datagramme.
Auch auf dieses Protokoll gehe ich in einem eigenen Kapitel intensiver ein, da gerade hier sehr viele Nuancen stecken, bei denen durch unbedachte Sperrung oder Freigabe potentiell Schaden angerichtet werden kann.
ICMPv6
Das Internet Control Message Protocol for IPv6 wurde erstmals 1995 in RFC 1885 beschrieben. 1998 wurde dieses RFC durch RFC 2463 obsolet, welches dann im Jahr 2006 durch RFC 4443 abgelöst wurde. RFC 4884 aktualisiert und ergänzt diesen Draft Standard.
Für mich als Firewall-Administrator ist RFC 4890 “Recommendations for Filtering ICMPv6 Messages in Firewalls” interessant, welches begründete Empfehlungen für die Behandlung von ICMPv6 gibt.
Auch bei diesem Protokoll gehe ich auf wesentliche Punkte in einem eigenen Kapitel intensiver ein.
IGMP
RFC 1112 beschreibt Host Extensions for Multicasting und in seinem Anhang Version 1 von IGMP.
Version 2 des Internet Group Management Protocol ist in RFC 2236 beschrieben. Diese Version erlaubt es, dem Router die Beendigung der Gruppenmitgliedschaft mitzuteilen, was Vorteile bei Multicast-Gruppen mit hoher Bandbreite bringt.
RFC 3376 beschreibt Version 3. Diese ergänzt das Protokoll um Quellenfilterung, das heisst ein Mitglied einer Multicast-Gruppe kann dem Router mitteilen, dass es nur an Datagrammen von bestimmten Routern oder nicht an solchen interessiert ist.
Bei IPv6 übernimmt ICMPv6 die Steuerung der Multicast-Zugehörigkeit.
TCP
RFC 793 beschreibt das Transmission Control Protocol. RFC 1122 erläutert die Anforderungen für Internet-Hosts und geht dabei auch näher auf TCP, UDP, ICMP und IP ein. Explicit Congestion Notification (ECN) und deren Anwendung bei TCP ist in RFC 3168 beschrieben.
UDP
RFC 768 beschreibt das User Datagram Protocol bereits seit 1980. Das Protokoll ist so simpel, dass drei Seiten für die Beschreibung und weiterführende Referenzen ausreichen.
Für IPv6 ergab sich lediglich die Notwendigkeit, die UDP-Checksumme obligatorisch zu machen, da im IPv6-Header keine Checksumme enthalten ist. RFC 768 erlaubt noch das Senden von UDP-Datagrammen ohne Checksumme.
Tunnelprotokolle
Für die Übergangszeit, in der sowohl IPv4 als auch IPv6 nebeneinander existieren, gibt es verschiedene Protokolle, mit denen IPv6-Datagramme über IPv4-Netze übertragen werden können und umgekehrt. Diese muss ich kennen, wenn ich sie im Paketfilter regulieren will.
6to4 ist ein Protokoll, bei dem IPv6-Datagramme in einem Tunnel durch IPv4-Netze übertragen werden. Es ist in RFC 3056 beschrieben.
6rd (IPv6 Rapid Deployment on IPv4 Infrastructures) baut auf 6to4 auf und ist in RFC 5569 und RFC 5969 beschrieben.
ISATAP (Intra-Site Automatic Tunnel Addressing Protocol) ist in RFC 5214 beschrieben.
Teredo tunnelt Pakete via UDP und funktioniert damit auch via NAT. RFC 4380 beschreibt dieses Protokoll.
GRE (Generic Routing Encapsulation) erlaubt es, beinahe beliebige Protokolle in beliebigen anderen Protokollen zu kapseln. In RFC 2748 finde ich Informationen dazu.
IP Encapsulation within IP erlaubt ebenfalls beinahe beliebige IP-Protokolle zu kapseln indem vor den inneren IP-Header ein äußerer gesetzt wird. RFC 2003 beschreibt das Verfahren für die Kapselung von IPv4 in IPv4. RFC 4213 beschreibt es für die Kapselung von IPv6 in IPv4. Auf BSD-Systemen ist diese Art der Kapselung als GIF-Interface (generic tunnel interface) bekannt.
IPv4 für den Firewall-Administrator
IPv4 wird auf längere Zeit noch eine große Rolle spielen. Darum gehe ich in diesem Kapitel auf wichtige Aspekte dieses und der damit verbundenen Protokolle ein.
Internet Protokoll Version 4
Im OSI-Modell finden wir das Internet Protokoll in Schicht 3, direkt auf Ethernet aufsetzend, welches wiederum die Funktionen der Schichten 1 und 2 bereitstellt.

Natürlich kann man IP auch mit anderen Protokollen übertragen, jedoch werden wir es wohl am häufigsten mit Ethernet oder WLAN zusammen sehen. In einem Datagramm finden wir den IP-Header folglich hinter dem Ethernet-Header und vor den Headern der Protokolle aus den höheren Schichten.
RFC 791 beschreibt IPv4. Daraus habe ich die die folgende ASCII-Graphik des IP-Headers entnommen, die 32 Bit pro Zeile anzeigt.

Die ersten fünf 32-Bit-Worte sind in jedem IPv4-Datagramm obligatorisch, die Optionen können weggelassen werden. Das Feld IHL zeigt die Länge des IPv4-Headers in 32-Bit-Worten, die minimale Länge ist 5.
Der RFC beschreibt die einzelnen Felder und die Bedeutung ihrer Werte recht ausführlich, so dass ich hier nicht weiter darauf eingehen will. Für den Firewall-Betrieb sind vor allem die folgenden Informationen im Header von IPv4 relevant:
- ToS (Type of Service)
Neben der Standard-Definition in RFC 791 gibt es Ergänzungen für die Bedeutung dieses Feldes in den RFCs 2474 (DCSP) und 3168 (ECN). - Flags
Diese zeigen unter anderem an, ob das IP-Paket fragmentiert werden darf oder bereits ist. Da Fragmentierung das Filtern erschweren kann, ist es ratsam, bei einem Paketfilter fragmentierte Pakete entweder zu verwerfen oder vor der Entscheidung zusammenzubauen. - Protocol
Dieses Feld gibt an, welches Protokoll im IP-Datagramm eingebettet ist, das heißt, wie die nachfolgenden Daten zu interpretieren sind. Seit RFC 3232 führt die IANA eine Online-Datenbank unter http://www.iana.org/. Auf einem Linux-Rechner finden sich die Nummern und Namen dieser Protokolle in der Datei /etc/protocols: so zum Beispiel 1 für ICMP, 2 für IGMP, 6 für TCP und 17 für UDP. Will ich am Paketfilter nach Protokollen diskriminieren, muss ich dieses Feld beachten. - Quell- und Zieladresse
Mit je 32 Bit dienen die Adressen in den meisten Regeln als Merkmale für die Entscheidung. Verwende ich NAT bei der Firewall, muss ich beachten, an welcher Stelle im Netfilter-Code die Regel greift und an welcher NAT, um dann entweder die originale oder die umgesetzte Adresse zu filtern.
Internet Control Message Protocol (ICMP)
ICMP wird zwar, genau wie IP, der OSI-Schicht 3 zugeordnet, es nutzt aber das Internet Protokoll für den Transport. Daher finden wir den ICMP-Header direkt hinter dem IP-Header.

RFC 792 beschreibt das Protokoll. Daraus habe ich die folgende ASCII-Graphik der Kopfdaten entnommen, die ebenfalls 32 Bit pro Zeile zeigt.

Der ICMP-Header folgt unmittelbar auf den IPv4-Header.
ICMP ist für viele Firewall-Administratoren eine Problemzone. Um das Jahr 2000 herum brachte Ofir Arkin seine Untersuchungsergebnisse über den Gebrauch von ICMP für das Scannen von Netzwerken heraus. Konnten zuvor in den meisten Firewalls ICMP-Pakete freizügig passieren, so wurden sie danach in vielen Konfigurationen rigoros gesperrt. Leider gibt es einige ICMP-Datagramme, die keinesfalls gesperrt werden sollten, um den regulären Netzbetrieb nicht zu behindern. Hier muss der Firewall-Administrator sehr gut Bescheid wissen, so dass ich ICMP in einem eigenen Kapitel intensiver behandle.
Transmission Control Protocol (TCP)
Auch den TCP-Header finden wir in einem Datagramm hinter dem IP-Header. Interessant ist, das zur eindeutigen Identifizierung einer TCP-Sitzung sowohl Informationen aus dem TCP-Header als auch aus dem IP-Header herangezogen werden.

Beschrieben in RFC 793, ist TCP eines der am häufigsten verwendeten Protokolle im Internet. Die folgende ASCII-Graphik ist dem RFC entnommen und lässt bereits die Komplexität des Protokolls erahnen.
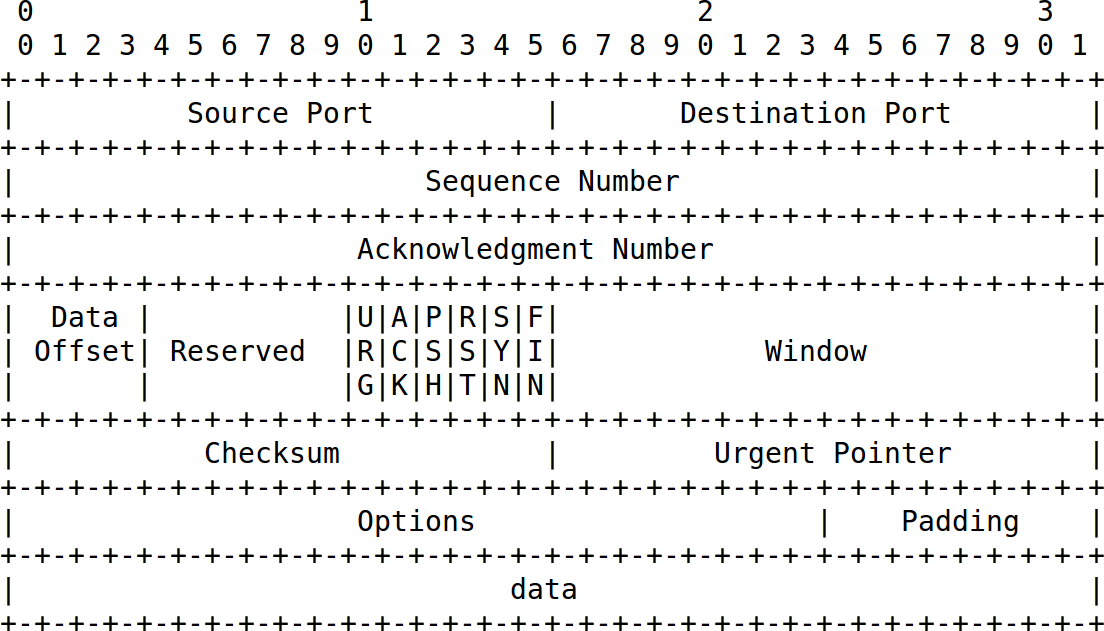
Der TCP-Header kann aufgrund der Optionen unterschiedliche Längen haben. Das Feld Data Offset gibt seine Länge in 32-Bit-Worten an. Das Feld data in der ASCII-Graphik steht für die transportierten Daten und gehört nicht mehr zum TCP-Header.
Eine TCP-Verbindung wird durch folgende fünf Angaben eindeutig identifiziert:
- Quell- und Zieladresse sowie Protokollfeld im IP-Header
- Quell- und Zielport im TCP-Header
TCP-Verbindungen sind bidirektional, Quell- und Zieladresse sowie Quell- und Zielport von Datagrammen einer Sitzung sind paarweise vertauscht, je nach der Richtung, in der sie gesendet werden.
Jede TCP-Sitzung befindet sich in einem Zustand, den die Firewall am TCP-Header erkennen kann: an den Flags, der Sequenz- und Acknowledge-Nummer sowie am Receive-Window.
Bei einer zustandslosen Regel muss die Firewall den Zustand ausschließlich an Hand des aktuellen Datenpakets erraten und entsprechend reagieren. Dann ist es bei einer bestehenden Verbindung nicht mehr möglich, zu erkennen, welche Seite die Verbindung ursprünglich initiiert hatte.
Demgegenüber verfolgt die Firewall bei zustandsbehafteten Regeln die Sitzung und ist auf diese Weise zum Teil in der Lage, gefälschte Datenpakete zu erkennen und zu unterdrücken. Das braucht allerdings mehr Ressourcen, vor allem Speicherplatz, von der Firewall.
TCP enthält einen Mechanismus, mit dem es die maximale Größe von Datagrammen auf der Verbindungsstrecke ermitteln kann. Dafür setzt es das Don’t Fragment Bit im IP-Header und ist darauf angewiesen, dass ICMP-Unreachable-Pakete zurückkommen können, die dem Sender sagen, wann ein Datagramm zu groß ist. Moderne TCP-Stacks können mit Heuristiken auch ohne ICMP erkennen, wenn die Path-MTU kleiner als die MTU des Interfaces ist und senden dann kleinere Datenpakete. Diese Heuristiken sind jedoch zeitaufwendig - sie arbeiten mit Timeouts - und verschwenden Bandbreite, weil sie nicht mit der maximal möglichen MTU arbeiten sondern meist mit kleineren.
Gehen Datenpakete verloren, wiederholt TCP automatisch bereits gesendete Datagramme. Diese wiederholt gesendeten Datagramme sollten problemlos durch die Firewall gehen, wenn die Verbindung legitim ist. Bei zustandsbehafteten Regeln kann die Firewall Replay-Attacken erkennen, wenn die Sequenznummer eines Datagramms wesentlich kleiner ist, als die letzte Acknowledge-Nummer der Gegenrichtung.
User Datagram Protocol (UDP)
Kommen wir nun zu UDP, dem letzten der Protokolle, auf die ich im Rahmen von IPv4 kurz eingehen will.
Auch hier finden wir die Kopfdaten direkt hinter dem IP-Header. Und wie bei TCP werden auch bei UDP Informationen aus dem IP-Header zur vollständigen Identifizierung einer UDP-Sitzung herangezogen.

Beschrieben in RFC 768, ist UDP ein zustandsloses Protokoll. Die folgende ASCII-Graphik aus dem RFC lässt bereits erahnen, dass es sich um ein sehr einfaches Protokoll handelt.
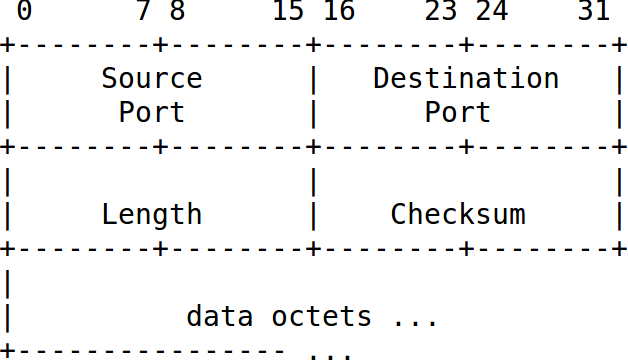
Das Längenfeld gibt die Länge des UDP-Headers und der Daten in Oktetts an.
Eine UDP-Verbindung wird, ähnlich wie bei TCP, durch folgende Informationen identifiziert:
- Quell- und Zieladresse sowie Protokollfeld im IP-Header
- Quell- und Zielport im UDP-Header
Einige auf UDP aufsetzende Protokolle verwenden mehrere dieser eindeutigen UDP-IDs in einer Sitzung, zum Beispiel TFTP. Das muss ich als Firewall-Administrator berücksichtigen, wenn diese Protokolle über die Firewall laufen.
Will ich UDP mit stateful Regeln überwachen, muss die Firewall mit Timern arbeiten. Das bedeutet für die Anwendungen, dass sie regelmäßig Daten senden müssen, bevor der Timer abläuft, wenn sie die Verbindung für die Firewall aktiv halten wollen. Alternativ kann ich auch den Timeout bei der Firewall etwas größer ansetzen, wenn die Firewall Probleme mit einzelnen Verbindungen bereitet.
Network Address Translation (NAT)
Mit NAT kann man die bei IPv4 mittlerweile nicht mehr ausreichenden eindeutigen Adressen mehrfach verwenden. Bei IPv4-Firewalls muss ich jederzeit damit rechnen, mit NAT konfrontiert zu werden.
Es gibt verschiedene Einteilungen von NAT, je nachdem, welchen Aspekt ich betrachte. So gibt es NAT bei dem
- mehrere Adressen eines Netzes auf genau so viele Adressen eines anderen Netzes umgesetzt werden, oder
- mehrere Adressen eines Netzes auf weniger - im Extremfall genau eine - Adresse umgesetzt werden. Letzteres wird auch als Masquerading bezeichnet.
Da NAT sehr häufig an Perimeter-Routern eingesetzt wird, bezeichnet man die beiden Seiten des Routers oft mit innen und außen. Werden die Adressen eins-zu-eins zwischen verschiedenen Adressbereichen umgesetzt, ist es möglich, Verbindungen gezielt von der äußeren zur inneren Seite aufzubauen, wenn die Adresszuordnung feststehend ist.
Insbesondere im SOHO-Bereich stehen auf der äußeren Seite oft weniger Adressen zur Verfügung als auf der inneren Seite verwendet werden. Bei einer Umsetzung von vielen inneren Adressen auf wenige äußere ist es ohne explizite Konfiguration schwierig, eine Verbindung von außen nach innen aufzubauen.
Das ist genau dann problematisch, wenn zwei Rechner hinter zwei solchen NAT-Routern ein direkte Verbindung wünschen, zum Beispiel für VoIP oder Videokonferenzen. In diesem Fall ist es ratsam sich mit dem Thema NAT-Traversal auseinander zu setzen. NATBlaster und STUN sind zwei Verfahren, mit denen direkte Verbindungen über zwei NAT-Router hinweg etabliert werden können. Diese sind auf die Kooperation der Firewall angewiesen.
Schließlich behindert NAT IPsec, da letzteres die IP-Adressen verifiziert und durch die Änderung der Adressen die Datagramme ungültig werden. Hier muss man auf UDP Encapsulation of IPsec ESP Packets, beschrieben in RFC 3948 ausweichen.
Da das Thema NAT sehr komplex ist und sehr viele Facetten enthält, gehe ich in einem späteren Kapitel noch einmal ausführlich darauf ein.
Fragmentierung
Prinzipiell kann ich auch fragmentierte Datagramme filtern, ohne sie vorher zusammen zu setzen. In diesem Fall müsste ich alle Fragmente ohne Header-Informationen durchlassen und die Filter-Regeln nur auf die ersten Fragmente mit den Header-Informationen anwenden.
Sind die ersten Fragmente zu klein, so dass sie nicht genügend Informationen enthalten, verwerfe ich sie. Was zu klein ist, hängt von den Regeln und den Protokollen ab, nach denen ich filtere.
Bei Connection Tracking muss ich fragmentierte Datagramme auf jeden Fall zusammensetzen, da die benötigten Informationen, zum Beispiel für FTP, in den Nutzdaten stehen.
IPv6 für den Firewall-Administrator
Mit IPv6 trat 1998 ein weiterer Akteur auf die Bühne der Transport-Protokolle. Die Adoption verlief anfangs sehr schleppend, hat in den letzten Jahren aber an Fahrt aufgenommen. Inzwischen kann man IPv6 als Firewall-Administrator nicht mehr ignorieren.
Obwohl mittlerweile alle weitverbreiteten Betriebssystem IPv6 gut unterstützen, ist es noch notwendig, IPv6-Projekte vor dem produktiven Einsatz gründlich zu testen.
Einer der Hauptvorteile von IPv6 ist der riesige Adressraum, der NAT überflüssig macht. Was nicht heißen soll, dass NAT bei IPv6 unmöglich wäre.
Zwar hat die IETF beim Entwurf von IPv6 nicht am grünen Tisch angefangen, sondern bewährte Dinge von IPv4 übernommen. Doch sind viele Dinge hinzugekommen und andere weggefallen.
TCP und UDP verhalten sich hier wie von IPv4 gewohnt, daher füge ich dem dort genannten nichts weiter hinzu, als dass UDP bei IPv6 zwingend eine Prüfsumme berechnen muss. Der IPv6-Header hat keine Prüfsumme.
Paket-Header
Mit 40 Byte ist der IPv6-Header recht klein, davon gehen bereits 32 Byte für die Adressen von Sender und Empfänger drauf. Alle zusätzlich benötigten Informationen gehen in Extension-Header, die zwischen dem IP-Header und dem Header des höheren Protokolls (zum Beispiel TCP oder UDP) Platz finden. Durch die Extension-Header kann der IPv6-Header auf maximal 60 Byte anwachsen.
Zur Zeit sind sechs Extension-Header spezifiziert, die von allen IPv6-Knoten unterstützt werden müssen:
- Hop-by-Hop Options Header, RFC 2460
- Routing Header, RFC 2460
- Fragment Header, RFC 2460
- Destination Options Header, RFC 2460
- Authentication Header, RFC 4303
- Encapsulating Security Payload Header, RFC 4303
Es können kein, einer oder mehrere Extension-Header in einem IPv6-Paket vorkommen. RFC 2460 gibt eine Reihenfolge vor, die bei mehreren Extension-Headern in einem Datenpaket eingehalten werden soll. Jeder Header wird durch das Next-Header-Feld des vorherigen identifiziert. Extension-Header werden genau in der Reihenfolge verarbeitet, in der sie im Datenpaket vorkommen.
Normalerweise beachten nur die Knoten mit der Zieladresse die Extension-Header. Eine Ausnahme dazu bildet der Hop-by-Hop-Options-Header, der von allen Geräten beachtet wird, die das Datagramm durchläuft.
Adressierung
Aufgrund des riesigen Adressraums, und um es einfacher zu handhaben, verwendet man in einer Layer-2-Domain (früher als Broadcast-Domain bezeichnet) 64 Bit als Netzmaske, so dass 2 hoch 64 Adressen für die Knoten in diesem Segment verbleiben.
Broadcast gibt es nicht mehr. Die Funktionen, die Broadcast verwendeten, müssen nun mit Multicast arbeiten. Dementsprechend muss jeder IPv6-Knoten Multicast beherrschen.
IGMP, das bei IPv4 für die Verwaltung der Multicast-Gruppen zuständig ist, entfällt ebenfalls. Seine Aufgaben übernimmt ICMPv6.
Ebenfalls entfallen ist ARP, mit dem bei IPv4 Ethernet-Adressen und IP-Adressen verknüpft werden. Auch diese Aufgabe übernimmt ICMPv6.
Neu gegenüber IPv4 ist Stateless Address Autoconfiguration (SLAAC). Diese erspart dem Netzwerk-Administrator einiges an Arbeit. Für IPv4 ist in RFC 3927 mittlerweile ein ähnliches Verfahren beschrieben. Der Artikel [ctSKL2012] erläutert die IPv6-Autokonfiguration mittels SLAAC sowie mit DHCPv6.
Ebenfalls neu sind die Privacy Extensions bei IPv6, mit denen ein Client-Rechner in bestimmten Abständen neue Adressen für sich bestimmt und diese statt der alten Adressen für neue Verbindungen verwendet. Für Server machen diese Extensions keinen Sinn, denn der Server soll ja gefunden werden. Für den Firewall-Administrator bedeutet das, dass er nicht mit festen IP-Adressen für diese Client-Rechner arbeiten kann, sondern nur mit ganzen Subnetzen. Dem muss er in den Richtlinien und Regeln Rechnung tragen.
Aber auch Server mit festen IP-Adressen haben mehrere Adressen. So hat jeder IPv6-Knoten mindestens eine link-lokale Adresse an jedem Interface. Über diese link-lokalen Adressen kommunizieren die Knoten in einer Layer-2-Domain und darüber geben Router den Netzwerk-Präfix für dieses Segment bekannt. Aus diesem Präfix und der link-lokalen Adresse bildet jeder Knoten seine global eindeutige Adresse. Damit hat jeder Host schon mindestens zwei Adressen, mit denen er über das Netz erreicht werden kann. Hinzu kommen noch einige Multicast-Adressen, auf die er reagieren muss.
Vereinfachungen für Router
Für Router gibt es einige Vereinfachungen bei IPv6.
So können die Adressbereiche großzügig an ISPs und deren Kunden aufgeteilt werden, so dass die Routing-Tabellen der Core-Router klein bleiben können.
Router dürfen IPv6-Pakete grundsätzlich nicht fragmentieren. Ist Fragmentierung notwendig, muss der sendende Host fragmentieren und erst der empfangende Host baut das Datagramm wieder zusammen. Natürlich wird jede DPI-Firewall, die etwas auf sich hält, das auch machen. Da aber die MTU für IPv6 auf allen Segmenten mindestens 1280 Bytes beträgt, ist das für eine simple Firewall nicht nötig, denn im ersten Datagramm sind alle Informationen für die Entscheidung enthalten.
Da der IPv6-Header keine Prüfsumme enthält, müssen Router diese auch nicht neu berechnen, wenn sie das Hop-Limit-Feld reduzieren.
Gleichzeitiger Betrieb von IPv4 und IPv6
Wenn ich in meinem Netz gleichzeitig IPv4 und IPv6 betreibe, kommen zusätzliche Herausforderungen auf mich als Firewall-Administrator zu. Darum geht es in diesem Kapitel. Zunächst betrachte ich verschiedene Arten des gleichzeitigen Betriebs von IPv4 und IPv6, dann gehe ich auf einige Aspekte zur Sicherheit ein.
Ich unterscheide drei Arten, IPv4 und IPv6 gleichzeitig zu betreiben:
- Dual-Stack-Betrieb, bei dem im Netz und bei den Rechnern beide Protokolle gleichzeitig verwendet werden.
- Tunnel-Techniken, bei denen IPv6-Pakete in IPv4-Paketen transportiert werden oder umgekehrt.
- Netzwerk Adress- und Protokollübersetzung, bei der an einer Stelle im Netz IPv4-Pakete in IPv6 umgesetzt werden und umgekehrt.
Dual-Stack-Betrieb
Beim Dual-Stack-Betrieb verwende ich IPv4 und IPv6 gleichberechtigt.
Die Rechner müssen beide Protokolle vollständig benutzen können und verwenden je nach Kommunikationspartner oder Voreinstellung das eine oder das andere Protokoll.
Alle Switche, Router und Paketfilter müssen beide Protokolle unterstützen, damit das reibungslos funktioniert.
Der Dual-Stack-Betrieb ist einfach zu benutzen und flexibel. Er ist oft die beste Option für den gleichzeitigen Betrieb von IPv4 und IPv6.
Vom Standpunkt der Firewall habe ich zwei Zugänge zum Netzwerk, für die ich zwei - dem jeweiligen Protokoll angepasste - Sicherheitskonzepte benötige.
Natürlich hat der Dual-Stack-Betrieb auch Nachteile.
So benötigt das Equipment, welches im Dual-Stack-Modus läuft, mehr RAM und aktiven Programmcode, da es die Funktionen und Status-Informationen für zwei Protokolle vorhalten muss.
Ich benötige sowohl für IPv4 als auch für IPv6 Routing-Informationen und gegebenenfalls zwei Routing-Protokolle.
Auch die Fehlersuche wird komplizierter, weil ich in Betracht ziehen muss, dass ein Host versucht, einen Dienst mit dem falschen Protokoll zu erreichen, oder dass IPv4- und IPv6-Datagramme unterschiedliche Wege gehen.
Tunnel
Bei einem Tunnel leite ich IPv6-Pakete über IPv4-Netze weiter oder umgekehrt. Dabei muss ich drei wesentliche Punkte betrachten:
- das Verpacken der Pakete am Eingang des Tunnels,
- das Auspacken der Pakete am Ausgang des Tunnels und
- die Verwaltung des Tunnels.
Es gibt manuell und automatisch konfigurierte Tunnel. Außerdem unterscheiden sich die Tunnel nach der Art der gekapselten Daten und des Transports.
Tunnel erlauben es mir, genau in dem Tempo IPv4 zu IPv6 zu migrieren, dass ich im Moment gehen kann. Habe ich kein Dual-Stack-Netzwerk und möchte zwei IPv6-Inseln über ein IPv4-Netzwerk verbinden, kann ich das sofort machen und muss nicht warten, bis der Backbone IPv6 übertragen kann. Ich kann einzelne Hosts oder ganze Netzsegmente umstellen und muss mich nicht an eine bestimmte Reihenfolge halten.
Natürlich haben auch Tunnel Nachteile.
Sie erzeugen zusätzliche Last auf dem Router, der als Endpunkt für den Tunnel arbeitet.
Die Endpunkte des Tunnels benötigen Zeit um die Daten ein- und auszupacken, wodurch sich die Latenz erhöht.
Selbst wenn die Datenpakete den gleichen Weg nehmen wie ungetunnelte, geht etwas Bandbreite für die Header des Tunnelprotokolls verloren. Durch die zusätzlichen Header verringert sich die MTU des Datenpfades.
Auch die Fehlersuche wird komplexer, da Probleme mit dem Hop-Count, der Path-MTU und Fragmentierung hinzukommen können. Bei Problemen mit der Verbindung muss ich sowohl das Tunnelprotokoll als auch das getunnelte Protokoll in Betracht ziehen.
Vom Standpunkt der Sicherheit sind insbesondere automatisch aufgebaute Tunnel problematisch, da ich sicherstellen muss, dass auch getunnelte Daten von einer Firewall gefiltert werden, die unter meiner Kontrolle steht. Falls durch meinen Paketfilter getunnelte Daten laufen, trage ich dafür Sorge, dass nur Daten durchgehen, die von einem zugelassenen Tunnel-Endpunkt kommen und dass an diesem Endpunkt ebenfalls gefiltert wird.
Als Firewall-Administrator muss ich mich kundig machen, welche Tunnel in meinem Netzwerk zugelassen sind. Gegebenenfalls muss ich unerwünschte Tunnel erkennen und sperren.
Hier habe ich eine Liste von gängigen Techniken für Tunnel und Quellen für Informationen dazu als Einstieg für interessierte Administratoren zusammengetragen.
6to4
ist ein Verfahren, bei dem jede IPv4-Adresse auf ein IPv6-Netz mit der Netzmaske /48 abgebildet wird. Die IPv6-Adresse setzt sich aus dem Präfix 2002 und der hexadezimal notierten IPv4-Adresse zusammen
Das Verfahren ist in RFC 3056 beschrieben.
6rd (IPv6 Rapid Deployment)
erlaubt einem Provider seinen Kunden bereits IPv6 anzubieten, auch wenn seine eigene Infrastruktur noch nicht vollständig auf IPv6 umgestellt ist. Es basiert auf den Ideen von 6to4 nutzt im Gegensatz zu diesem jedoch keinen speziellen Adressbereich sondern den des Providers.
6rd ist in den RFCs 5569 und 5969 beschrieben.
ISATAP (Intra-Site Automatic Tunnel Addressing Protocol)
ist eine Variante des 6to4-Verfahrens, bei der Tunnel automatisch aufgebaut werden.
Das Verfahren ist in RFC 5214 beschrieben.
Teredo
tunnelt Pakete via UDP und funktioniert damit auch via NAT. Es ist in RFC 4380 beschrieben.
Tunnel Broker
sind IPv6 Provider für Netze, die nur eine IPv4-Verbindung zum Internet haben. Sie sind in RFC 3053 beschrieben.
GRE (Generic Routing Encapsulation)
erlaubt es, beliebige Protokolle in beliebigen anderen Protokollen zu kapseln. Es ist in RFC 2784 beschrieben.
Netzwerk Adress- und Protokollumsetzung (NAPT)
Diese Lösung setze ich nur ein, wenn keine andere verfügbar ist. Sie unterstützt nicht die fortgeschrittenen Möglichkeiten von IPv6.
Der Vorteil von NAPT ist die damit mögliche “direkte” Kommunikation eines IPv4-Hosts mit einem IPv6-Host. Bei allen anderen Lösungen müssen beide Rechner das gleiche Protokoll verwenden.
Nachteile sind begrenzte Topologie-Optionen, da ich einen NAPT-Router, der die Protokolle umsetzt, im Netzwerk-Pfad benötige. Protokolle, die in den Datenpaketen Informationen über die beteiligten Adressen senden, funktionieren nur mit zusätzlichem Aufwand oder gar nicht.
Secure Shell (SSH)
erlaubt über Port-Weiterleitungen einen verschlüsselten Tunnel für die Datenpakete und kann dabei das Protokoll umsetzen, wenn der SSH-Rechner im Dual-Stack-Betrieb arbeitet.
Sicherheitserwägungen
Beim gleichzeitigen Betrieb von IPv4 und IPv6 muss ich mehrere Zugänge zum Netz in den Richtlinien berücksichtigen.
Ich muss dafür Sorge tragen, dass Datenpakete, die mein Netzwerk über einen Tunnel erreichen oder verlassen, ebenfalls gefiltert werden.
RFC 4942 “IP6 Transition / Coexistence Security Considerations” geht auf dieses Thema ein.
RFC 3964 “Security Considerations for 6to4” geht auf den Tunnelbetrieb ein.
Auch die anderen RFCs zu den verschiedenen Verfahren muss ich studieren, wenn ich diese einsetzen will oder erkennen will, ob sie bereits eingesetzt werden.
ICMP und IGMP
ICMP
Bereits 1981 beschrieb Jon Postel in RFC 792 das Internet Control Message Protocol. Später kamen Ergänzungen in den RFCs 950, 4884, 6633 und 6918 hinzu. Es dient vor allem zur Kommunikation von Fehlerzuständen, aber auch um Informationen zum Zustand des Netzwerks auszutauschen.
Als Firewall-Administrator muss ich den grundlegenden Aufbau von ICMP-Nachrichten kennen und wissen, welche Datagramme ich unbedingt durchlassen sollte, welche ich auf jeden Fall sperren kann und warum ich mich bei den restlichen für die eine oder andere Art der Behandlung entscheide.
ICMP-Pakete nutzen IPv4 zum Transport, haben also ebenfalls einen IP-Header. Im darauf folgenden ICMP-Header werden die Datagramme nach dem Typ der ICMP-Nachricht und einem zu dem Typ gehörenden Code unterschieden. Da viele ICMP-Nachrichten als Reaktion auf Probleme mit bestimmten Datagrammen generiert werden, enthalten sie oft im Anhang den Anfang des Datagramms, auf das sich die ICMP-Nachricht bezieht.
Diese Daten am Ende der ICMP-Nachricht können für versteckte Kommunikation verwendet werden, deshalb sollte ich ICMP-Datagramme nicht wahllos durchlassen. Ein weiterer Grund ist, dass die ICMP-Nachrichten selbst sehr viele Informationen über IP-Netze preisgeben.
Immer durchlassen sollte ich ICMP-Datagramme vom Typ 3 “Destination Unreachable” mit Code 4 “Fragmentation Needed”. Diese werden für die Path-MTU-Discovery bei TCP benötigt. Ein Blockieren dieser Nachricht führt nicht automatisch zum Blockieren aller TCP-Verbindungen, kann bei manchen Verbindungen aber Fehler hervorrufen, die für unerfahrene Administratoren schwer einzugrenzen sind. Selbst wenn das Problem erkannt ist - zu geringe MTU auf einem Teilstück der Verbindung - ist die Abhilfe oft ineffizient.
Die RFCs 6633 und 6918 diskutieren ICMP-Nachrichten, die ich bedenkenlos sperren kann. Das sind ICMP-Nachrichten, für die es keine weitverbreiteten Implementierungen gibt, deren Aufgaben anderweitig besser gelöst sind oder die eher schädlich als nützlich sind. Konkret kann ich die folgenden ICMP-Nachrichten unterdrücken:
- Typ 4 “Source Quench” (Deprecated in RFC 6633): Dieser Typ diente der Signalisierung von Überlast bei Routern. Die Nachrichten erwiesen sich als ineffektives Mittel gegen Überlast und gelten bereits seit 1995 bei Routern als veraltet. Seit etwa 2005 berücksichtigt kaum noch ein Betriebssystem diese Nachrichten.
- Typ 15 “Information Request” und Typ 16 “Information Reply”, Typ 17 “Address Mask Request” und Typ 18 “Address Mask Reply”, Typ 30 “Traceroute” bis Typ 39 “SKIP” (Deprecated in RFC 6918). Diese Typen sind in der Praxis technisch überholt und in genanntem RFC förmlich missbilligt. Dort steht auch eine Diskussion zu den einzelnen Typen.
Bleibt als dritte Gruppe die ICMP-Nachrichten, bei denen ich von Fall zu Fall entscheiden muss, ob ich sie durchlasse. Gehen wir diese der Reihe nach durch.
Typ 0 “Echo Reply” ist die Antwort zu Typ 8 “Echo Request”.
Innerhalb meiner Netze will ich diese Datagramme durchlassen, weil damit
einfache Tests auf Erreichbarkeit mit dem Programm ping möglich sind.
Aus meinem Netz in andere Netze will ich das auch, wenn ich die
Erreichbarkeit von Rechnern in diesen Netzen mit ping prüfen will.
Dann lasse ich Typ 8 von innen (meinem Netz) nach außen (dem fremden Netz)
und Typ 0 von außen nach innen zu.
Will ich auch Rechner in meinem Netz von außen prüfen lassen,
gebe ich die beiden Typen auch in der anderen Richtung frei, eventuell
beschränkt auf bekannte Netze oder Adressen.
Bei Typ 3 “Destination Unreachable” gibt es außer Code 4 “Fragmentation needed and DF bit set”, den ich immer freigeben will, noch die Codes 0 “Network unreachable”, 1 “Host unreachable”, 2 “Protocol unreachable” und 3 “Port unreachable”, die Hinweise bei der Fehlersuche im Netz liefern. Diese will ich im internen Netz auf jeden Fall haben. Von außen nach innen will ich diese Nachrichten auch. Von innen nach außen will ich diese Nachrichten aber höchstens an jemand senden, der mein Netz analysieren darf. Wer das ist, sollte in einer Policy festgelegt sein.
Code 5 “Source route failed” tritt nur bei Source Routing auf. Verwende ich dieses nicht, kann ich getrost auch die ICMP-Nachrichten sperren.
Code 13 “Administratively prohibited” wird von Firewalls generiert. Das ist eine klare Ansage an jemanden, der probiert, ob bestimmte Rechner oder Dienste erreichbar sind. Es hat den Vorteil, dass Verbindungsversuche von normalen Programmen sofort beendet werden, die bei einfachem Verwerfen der Anfragen automatisch weitere Versuche unternommen hätten. Der Mehrwert dieser ICMP-Nachricht für einen Angreifer, der systematisch Netzwerkadressen ausprobiert, ist gering. Bei einer großen Anzahl derartiger Tests sollte ich allerdings ein Rate-Limit aktiviert haben, insbesondere bei einer asymmetrischen Anbindung. Wichtig ist, dass diese Nachrichten nur vom Border-Gateway generiert und nicht durchgeleitet werden, da sonst die TTL Informationen zur internen Netzwerkstruktur preisgibt.
Nachrichten vom Typ 5 “Redirect” werden regulär vom Router an Hosts in einem direkt angeschlossenen Netz gesendet, wenn diese für bestimmte Verbindungen ein anderes Gateway verwenden soll. Ein Host sollte diese Nachrichten von seinem Default-Gateway akzeptieren, wenn es mehrere Router in dem Netzsegment gibt. Gibt es nur ein Gateway, sollten Hosts diese Nachrichten ignorieren.
Typ 8 hatte ich bereits bei Typ 0 abgehandelt.
Typ 9 “Router Advertisement” und Typ 10 “Router Solicitation” benötige ich nur, wenn die Hosts in einem Netzsegment ihr Gateway nicht kennen. Kann ich die Hosts auf andere Art konfigurieren, benötige ich diese Nachrichten nicht. Das Problem mit diesen beiden Typen und Typ 5 ist, dass ein Rechner damit Datenverkehr auf sich umleiten und dann MITM-Angriffe gegen andere Rechner ausführen kann. Aus diesem Grund muss ich, wenn ich mit solchen Angriffen rechne, mein Netz nicht nur mit Paketfiltern schützen, sondern auch mit IDS auf Anomalien überwachen. Das ist aber nicht Thema dieses Buches.
Typ 11 “Time Exceeded” wird zum Beispiel vom traceroute Programm
ausgewertet, um die Topologie eines Netzes zu erkunden.
Innerhalb meiner eigenen Netze will ich das in den meisten Fällen, weil es
bei der Fehlersuche helfen kann.
Von außen nach innen will ich diese ICMP-Nachrichten auch, von innen nach
außen nicht, wenn ich die Struktur meines internen Netzes
nicht preisgeben will.
Typ 12 “Parameter Problem” kann bei der Fehlersuche helfen. Es verweist auf Probleme mit dem ursprünglich gesendeten Datagramm. Nach außen will ich diese Information nicht geben, weil sie Eigenschaften des IP-Stacks auf dem sendenden Rechner preisgeben.
Typ 13 “Timestamp Request” und Typ 14 “Timestamp Reply” können zur Synchronisation der Uhren von Rechnern verwendet werden. Wenn andere Protokolle für die Synchronisation der Uhren verfügbar sind, sehe ich kein Problem darin, diese Datagramme zu sperren.
IGMP
Das Internet Group Management Protocol ermöglicht die Verwaltung von IPv4-Multicast-Gruppen. Die Gruppen werden dabei in den Routern verwaltet, an denen die Empfänger angeschlossen sind. Es gibt drei Versionen von IGMP:
- IGMPv1 (RFC 1112) erlaubt einem Host, einer Gruppe beizutreten. Seine Mitgliedschaft erlischt automatisch nach einem Timeout, wenn er sie nicht erneuert.
- Mit IGMPv2 (RFC 2236) kann ein Host eine Gruppe mit einer “Leave Group” Nachricht verlassen, so dass ein Router eher mitbekommen kann, ab wann er Datagramme für eine Gruppe nicht mehr senden braucht.
- ICMPv3 (RFC 3376) erlaubt es, Multicast-Gruppen mit bestimmten Quellen beizutreten.
Üblicherweise verwaltet der IP-Stack des Routers die Mitgliedschaft in Multicast-Gruppen. Als Firewall-Administrator entscheide ich lediglich, ob ich Multicast über Router überhaupt zulasse oder nicht.
Einen Sonderfall stellt Multicast-DNS (mDNS) dar. Dieses ist beschränkt auf das lokale Netzsegment und wird unter anderem von Bonjour verwendet, der automatischen Netzwerk-Konfiguration von Apple-Rechnern. Normalerweise habe ich bei einem Paketfilter nichts mit diesem Protokoll zu tun, da es nicht geroutet wird. Betreibe ich meinen Paketfilter jedoch als Bridge, dann muss ich mich entscheiden, ob ich Bonjour darüber unterstützen will oder nicht.
Multicast-DNS verwendet die Adresse 224.0.0.51 bei IPv4 sowie FF02::FB bei IPv6 und den UDP-Port 5353. Im Gegensatz zum normalen DNS, bei dem die Antworten von einer überschaubaren Anzahl von DNS-Servern kommen können, antwortet bei mDNS üblicherweise der Rechner, der den entsprechenden Record für sich beansprucht. Das muss ich berücksichtigen, wenn ich mDNS regulieren will.
Will ich einzelne Gruppen oder Quellen sperren, muss ich die IGMP-Nachrichten analysieren und selektiv sperren.
ICMPv6 für den Firewall-Administrator
ICMPv6 macht für IPv6, was ICMP für IPv4 macht und noch einiges mehr. So ist die Zuordnung von Link-Layer-Adressen (Adressen der OSI-Schicht 2), für die bei IPv4 die Protokolle ARP und RARP zuständig sind, Bestandteil von ICMPv6 und als Neighbor Discovery in RFC 4861 beschrieben. Die Verwaltung von Multicast-Gruppen, für die es bei IPv4 das Protokoll IGMP gibt, ist ebenfalls Aufgabe von ICMPv6.
RFC 4443 beschreibt das Protokoll. Für den Firewall-Administrator gibt es mit RFC 4890 “Recommendations for Filtering ICMPv6 Messages in Firewalls” handfeste Empfehlungen für die Behandlung von ICMPv6.
Konkret hat ICMPv6 die folgenden Aufgaben:
- Fehlermeldungen an den Absender von Datagrammen senden
- Verbindungen überprüfen
- das Netzwerk erkunden:
- Nachbarn im gleichen Netzsegment finden und ihre IP- und Link-Layer-Adresse bestimmen
- Die Erreichbarkeit von Nachbarn überwachen
- Router finden und die Netzwerk-Konfiguration von diesen übernehmen
- Informationen wie Netzwerkpräfixe und MTU von Routern an Hosts senden
- Authentifizieren von Nachbarn mit SEND
- Bestimmen der Path-MTU für Verbindungen
- IPv6-Adressen für Link-Layer-Adressen bestimmen
- Multicast-Gruppenmitgliedschaften verwalten
- Multicast-Router finden
- Rekonfiguration
- Weiterleitung zu anderen Routern mit Redirect-Nachrichten
- Unterstützung der Umnummerierung von Netzen
- Unterstützung von Mobile IPv6
- experimentelle Erweiterungen
Klassifizierung von ICMPv6-Nachrichten
ICMPv6-Nachrichten können nach verschiedenen Kriterien klassifiziert werden. In RFC 4890 finden sich die folgenden:
- Fehler- und Informationsnachrichten
ICMPv6-Nachrichten mit Typ 0 bis 127 sind Fehlermeldungen, die in den meisten Fällen erlaubt sein sollten. Nachrichten mit Typ 128 bis 255 sind Informationsnachrichten, die eher einer Policy unterliegen sollten.
- Adressen
Die Absenderadresse einer ICMPv6-Nachricht ist üblicherweise eine Unicast-Adresse. Während der Autokonfiguration des Interfaces und bevor eine gültige IPv6-Adresse konfiguriert wurde, können ICMPv6-Nachrichten mit unspezifizierter Adresse [::] gesendet werden. Die Zieladresse ist bei Fehler-Nachrichten eine Unicast-Adresse, bei Informationsnachrichten kann es eine Unicast- oder Multicast-Adresse sein.
- Netzwerktopologie und Geltungsbereich der Adresse
Einige ICMPv6-Nachrichten sind nur für den lokalen Link bestimmt, wie zum Beispiel bei der Neighbor Discovery, während andere über mehrere Links gesendet werden können, wie die meisten Fehlermeldungen.
- Rolle beim Aufbau und der Aufrechterhaltung von Kommunikation
Neighbor Discovery und Stateless Automatic Address Configuration arbeiten mit ICMPv6 Paketen. Die ICMPv6-Nachricht mit Type 2 “Packet Too Big” sind entscheidend für eine erfolgreiche Verbindung über Pfade mit kürzerer MTU.
Sicherheitsüberlegungen
Während es bei IPv6 generell möglich ist, Datenpakete kryptographisch abzusichern, trifft das auf ICMPv6 nur bedingt zu. Dadurch, dass legitime ICMPv6-Nachrichten von beliebigen Hosts oder Routern im Internet kommen können, ist es nicht möglich, zu allen Sendern von ICMPv6-Nachrichten Security Associations aufzubauen.
Aus diesem Grund ist die Filterung von ICMPv6-Nachrichten der häufigste Weg, mit diesem Problem umzugehen. Dabei muss ich eine Balance finden zwischen dem Verwerfen von Datagrammen um die Site zu schützen und dem Zulassen von Datagrammen um sicherzustellen, dass effiziente Kommunikation möglich ist.
Wenn ich ICMPv6 mit einer Firewall kontrolliere, habe ich dabei die folgenden Sicherheitsbedenken im Sinn:
Denial of Service Attacken (DoS)
ICMPv6 kann auf zwei Arten für DoS verwendet werden: es können einfach übermäßig viele ICMPv6-Nachrichten geschickt werden oder es wird versucht, durch Konfigurationsnachrichten legitime Adressen ungültig zu machen oder Interfaces zu deaktivieren.
Probing
Angreifer können mit Datagrammen, die ICMPv6-Fehlermeldungen provozieren, die Topologie des Netzes erkunden und so Ziele für weitere Attacken finden. Dieser Ansatz ist durch den riesigen Adressraum von IPv6 allerdings nicht so effektiv wie bei IPv4. In RFC 4890 wird dieses Thema weiter ausgeführt.
Redirection
Durch Umleitung des Datenverkehrs kann ein Angreifer Man-in-the-middle-Angriffe aufsetzen. Diese Angriffe erfolgen häufig lokal, wenn der Angreifer bereits Zugang zum Netz hat.
Als Administrator muss ich einschätzen, ob die Effizienzverbesserung durch Redirect-Nachrichten das Risiko eines derartigen Angriffes wert ist. Bei dieser Entscheidung ist die Sicherheit der Verkabelung, des Gebäudes und der anderen Hosts im Netzwerk ebenso zu berücksichtigen, wie die Komplexität der Adressen und Routen.
Renumbering
Nachrichten zur Umnummerierung des Netzes können ein Netzsegment unerreichbar machen. Diese Nachrichten will ich auf jeden Fall am Border-Router filtern. RFC 2894 beschreibt das Verfahren.
Probleme durch ICMPv6-Transparenz
Da ICMPv6-Nachrichten in beiden Richtungen zugelassen werden müssen, können diese für verdeckte Kommnikationskanäle benutzt werden. Diesem kann ich mit Connection Tracking begegnen, um sicherzustellen, dass die ICMP-Nachrichten zu legitimen Datenverkehr gehören.
Empfehlungen zur Filterung
RFC 4890 teilt Filter-Regeln für ICMPv6 in zwei Klassen ein:
- Regeln für Datenverkehr, der die Firewall passiert
- Regeln für Datenverkehr, der an die Firewall gerichtet ist.
Innerhalb dieser Klassen werden die Regeln für ICMPv6 Datagramme kategorisiert in Regeln für Nachrichten, die
- nicht verworfen werden dürfen,
- nicht verworfen werden sollten, es sei denn, es gibt einen triftigen Grund,
- verworfen werden können, aber aus anderen Gründen sowieso nicht akzeptiert werden,
- entsprechend einer Richtlinie verworfen werden können oder nicht,
- immer verworfen werden sollten.
Generell sollten Firewalls, die als Bridge in einem Netzsegment arbeiten, link-lokale ICMPv6-Nachrichten beachten, während Firewall-Router diese einfach ignorieren können.
Eine Host-Firewall kann man sich als Spezialfall einer Firewall-Bridge vorstellen, die aus dem Netz nur Pakete für das eigene Interface durchläßt.
Empfehlungen für Transitverkehr
Unbedingt durchgehen sollten die folgenden Fehlernachrichten:
- Destination Unreachable (Typ 1), alle Codes
- Packet Too Big (Typ 2)
- Time Exceeded (Typ 3), Code 0
- Parameter Problem (Typ 4), Codes 1 und 2
Außerdem diese Nachrichten für Verbindungstests:
- Echo Request (Typ 128)
- Echo Reply (Typ 129)
Bei IPv4 werden die Nachrichten zur Verbindungstests oft gesperrt, um einen Netzwerk-Scan zu verhindern. Bei IPv6 ist das Risiko eines Netzwerk-Scans sehr viel geringer. In RFC 4890 wird das Thema ausführlicher betrachtet.
Die folgenden Fehlernachrichten sollten normalerweise nicht verworfen werden, wenn nicht gute Gründe für das Verwerfen sprechen:
- Time Exceeded (Typ 3), Code 1
- Parameter Problem (Typ 4), Code 0
Außerdem die folgenden Nachrichten zur Unterstützung von mobile IP (RFC 6275):
- Home Agent Address Discovery Request (Typ 144)
- Home Agent Address Discovery Reply (Typ 145)
- Mobile Prefix Solicitation (Typ 146)
- Mobile Prefix Advertisement (Typ 147)
Hier kann ich selektive Regeln verwenden, je nachdem, ob ich mobiles IP für eigene oder fremde Knoten unterstützen will.
Die folgenden Nachrichten verwirft ein Router sowieso, hier ist keine zusätzliche Maßnahme nötig:
Nachrichten zur Konfiguration und Auswahl des Routers (RFC 4620, 4861):
- Router Solicitation (Typ 133)
- Router Advertisement (Typ 134)
- Neighbor Solicitation (Typ 135)
- Neighbor Advertisement (Typ 136)
- Redirect (Typ 137)
- Inverse Neighbor Discovery Solicitation (Typ 141)
- Inverse Neighbor Discovery Advertisement (Typ 142)
Nachrichten für link-lokale Multicast-Empfänger (RFC 2710):
- Multicast Listener Query (Typ 130)
- Multicast Listener Report (Typ 131)
- Multicast Listener Done (Typ 132)
SEND Certificate Path Notification Messages (RFC 3791):
- Certification Path Solicitation (Typ 148)
- Certification Path Advertisement (Typ 149)
Nachrichten für Multicast-Router (RFC 4286)
- Multicast Router Advertisement (Typ 151)
- Multicast Router Solicitation (Typ 152)
- Multicast Router Termination (Typ 153)
Für die folgenden Datagramme sollte in einer Policy festgelegt sein, ob sie durchgelassen oder verworfen werden:
- Seamoby Experimental (Typ 150), siehe RFC 4065
- momentan nicht verwendete Fehlernachrichten (Typ 5-99, 102-126)
- momentan nicht verwendete Informationsnachrichten (Typ 154-199, 202-254)
Die folgenden Nachrichten sollten verworfen werden, wenn nicht triftige Gründe für das Weiterleiten sprechen:
- Node Information Query (Typ 139), siehe RFC 4620
- Node Information Response (Typ 140), siehe RFC 4620
- Router Renumbering (Typ 138), siehe RFC 2894
- Private Experimentation (Typ 100, 101, 200, 201), siehe RFC 4443
- Reserved for Expansion (Typ 127, 255), siehe RFC 4443
Empfehlungen für lokalen ICMPv6-Verkehr
Die folgenden Datagramme dürfen an Host-Firewalls nicht verworfen werden:
Fehlermeldungen (RFC 4443):
- Destination Unreachable (Typ 1), alle Codes
- Packet Too Big (Typ 2)
- Time Exceeded (Typ 3), Code 0
- Parameter Problem (Typ 4), Code 1 und 2
Nachrichten zur Verbindungsüberprüfung (RFC 4443):
- Echo Request (Typ 128)
- Echo Reply (Typ 129)
Nachrichten zur Konfiguration und Routerauswahl (RFC 3122, 4861):
- Router Solicitation (Typ 133)
- Router Advertisement (Typ 134)
- Neighbor Solicitation (Typ 135)
- Neighbor Advertisement (Typ 136)
- Inverse Neighbor Detection Solicitation (Typ 141)
- Inverse Neighbor Detection Advertisement (Typ 142)
Nachrichten für link-lokale Multicast-Empfänger (RFC 2710, 3810):
- Multicast Listener Query (Typ 130)
- Multicast Listener Report (Typ 131)
- Multicast Listener Done (Typ 132)
- Version 2 Multicast Listener Report (Typ 143)
SEND Certification Path Notification (RFC 3971):
- Certification Path Solicitation (Typ 148)
- Certification Path Advertisement (Typ 149)
Multicast Router Discovery (RFC 4286):
- Multicast Router Advertisement (Typ 151)
- Multicast Router Solicitation (Typ 152)
- Multicast Router Termination (Typ 153)
Die folgenden Datagramme sollten normalerweise nicht verworfen werden:
- Time Exceeded (Typ 3), Code 1
- Parameter Problem (Typ 4), Code 0
Die folgenden Datagramme werden sowieso verworfen, dafür ist keine besondere Aufmerksamkeit nötig:
- Router Renumbering (Typ 138), RFC 2894
Mobile IP-Nachrichten (RFC 6275):
- Home Agent Address Discovery Request (Typ 144)
- Home Agent Address Discovery Reply (Typ 145)
- Mobile Prefix Solicitation (Typ 146)
- Mobile Prefix Advertisement (Typ 147)
Diese experimentelle Nachricht wird verworfen, wenn das Protokoll nicht unterstützt wird:
- Seamoby Experimental (Typ 150), siehe RFC 4065
Die folgenden Datagramme sollten in einer Policy berücksichtigt werden:
Redirect-Nachrichten (RFC 4861) stellen ein erhebliches Sicherheitsrisiko dar. Als Administrator muss ich daher von Fall zu Fall entscheiden ob die Vorteile dieser Nachricht den potentiellen Schaden bei einem Missbrauch überwiegen.
- Redirect (Typ 137)
Falls ein Knoten den Node Information Dienst (RFC 4620) unterstützt, muss ich entscheiden ob und an welchen Schnittstellen er auf entsprechende Anfragen reagieren soll. Wenn der Dienst deaktiviert oder nicht vorhanden ist, werden die Anfragen ignoriert und es ist keine Filterung notwendig.
- Node Information Query (Typ 139)
- Node Information Response (Typ 140)
Gegenwärtig nicht definierte Fehlermeldungen
- ICMPv6-Typ 5-99, 102-126
Die Spezifikation von ICMPv6 besagt, dass unbekannte ICMPv6-Fehlermeldungen an das Protokoll der höheren Ebene weitergereicht werden soll. Dieses höhere Protokoll wird aus dem in der ICMP-Nachricht enthaltenen Anfang des auslösenden Datagramms bestimmt. Es besteht die Möglichkeit, dass diese Nachrichten für einen versteckten Datenkanal benutzt werden.
Der folgende Datenverkehr sollte verworfen werden, wenn nicht triftige Gründe für seine Verwendung gefunden werden:
- Private Experimentation (Typ 100, 101, 200, 201)
- Reserved for Expansion (Typ 127, 255), siehe RFC 4443
- momentan nicht verwendete Informationsnachrichten (Typ 154-199, 202-254)
Network Address Translation
Der ursprüngliche Entwurf der Internet-Protokolle sah kein NAT vor. Er ging von “intelligenten” Endgeräten und einem “dummen” Netz aus, das lediglich wusste, wie es Datenpakete von A nach B transportieren kann. Die Endgeräte kümmerten sich um die Kontrolle der Datenströme und alle anderen Aspekte bis auf die Auswahl der Transportwege.
Diese Trennung der Zuständigkeiten trug einen wesentlichen Teil zur Entwicklung des Internet bei, weil sich Netz und Endgeräte auf ihren Teil konzentrieren und davon ausgehen konnten, dass der jeweils andere Teil seine Aufgabe erfüllt. Durch die globale Adressierung war gewährleistet, dass prinzipiell jedes Endgerät mit jedem anderen kommunizieren konnte.
Dieses Prinzip der Trennung von “dummem” Netz und “intelligenten” Endgeräten wurde im Laufe der Zeit auf verschiedene Art aufgebrochen. Während die Versuche seitens der Endgeräte, die Datenpfade durch Source-Routing zu kontrollieren, keine große Verbreitung fanden, sind im Netz immer mehr Funktionen dazugekommen, die das Netz “intelligenter” und damit schlechter vorhersehbar für die Endgeräte machen.
Eine Art das Netz “intelligenter” zu machen sind Middle-Boxes, die den Datenverkehr inspizieren, manipulieren und aussondern. Zu den Manipulationen zählt unter anderem die Netzwerk-Adressumsetzung, die einen schwerwiegenden Eingriff in die Datagramme darstellt.
Sende ich in einem Netz ohne Middle-Box ein Datagramm von Rechner A nach Rechner B, so kann ich damit rechnen, dass dieses Datagramm genauso beim Ziel ankommt, wie ich es abschicke. Lediglich die TTL wird vermindert und bei IPv4 die Prüfsumme mit der geänderten TTL neu berechnet.
Der Empfänger des Datagramms kann daraus selbst den Absender erkennen und seine Antwort direkt an diesen adressieren. Bei einer Zwei-Wege-Kommunikation ist damit immer klar, wer mit wem kommuniziert.
Sobald NAT dazu kommt, weiss manchmal die eine Seite, manchmal die andere und manchmal beide nicht, mit wem sie kommunizieren.
Das ist bei einer einfachen TCP-Verbindung, wie zum Beispiel beim Übertragen einer Datei via HTTP, unkritisch.
Es gibt jedoch Protokolle, die die Adressinformationen auswerten und verwenden. Sei es, wie bei FTP und TFTP, um eine weitere Verbindung mit einem anderen Port zur Datenübertragung zu öffnen. Oder dass die Nachricht inklusive der Adresse kryptographisch gesichert werden soll, wie bei IPsec. Im ersten Fall kann die NAT-Box durch Beobachten des Datenstroms die nötigen Umsetzungen für die zusätzliche Verbindung einrichten. IPsec hingegen funktioniert nicht über NAT, da die verschlüsselten Daten sich auf die unveränderten Adressen und Ports beziehen. In diesem Fall musste nachträglich eine Variante für IPsec via NAT geschaffen werden.
ICMP-Fehlermeldungen gelangen bei manchen NAT-Boxen nicht zum Absender der auslösenden Nachricht. Damit erschwert NAT dem Netzwerk-Administrator die Arbeit, weil er die umgesetzten Adressen bei seinen Analysen kennen und in Betracht ziehen muss.
Dem Nutzer des Endknotens erschwert es die Arbeit im Fehlerfall dadurch, dass er nicht weiß, an wen er sich wenden soll, beziehungsweise dadurch, dass er dem Mitarbeiter beim Support Adressen nennt, mit denen dieser nichts anfangen kann.
NAT wird nach verschiedenen Kriterien unterschieden. Ändern sich nur die IP-Adressen oder die Ports oder beides? Betrachte ich nur die Richtung, dann kann ich zwischen Source-NAT (SNAT) und Destination-NAT (DNAT) unterscheiden. Eine weitere Unterscheidung berücksichtigt, ob Adressen eineindeutig umgesetzt werden oder mehrere Adressen auf eine andere Adresse (Masquerading). Beim Masquerading macht es einen Unterschied, ob der gleiche Port bei verschiedenen Verbindungen desselben Netzknotens auf den selben oder einen anderen Port umgesetzt wird.
Insbesondere verhindert Masquerading die direkte Adressierbarkeit von Endgeräten. Während das in vielen Fällen gewünscht ist, weil zum Beispiel interne Rechner nicht direkt von extern angegriffen werden können, erschwert es die Arbeit mit Peer-to-Peer-Protokollen, zum Beispiel für VoIP oder Videotelefonie, die auf geringe Latenzen angewiesen sind.
In diesem Bereich haben sich daher verschiedene Verfahren etabliert, die sich mit dem Hole-Punching bei NAT-Boxen beschäftigen, dem automatischen Öffnen von Verbindungen zur direkten Kommunikation von zwei Rechnern, die sich beide hinter NAT-Boxen befinden. Diese Verfahren benötigen einen Rendezvous-Server, über den die Endgeräte die nötigen Informationen zum Partner bekommen und natürlich kooperierende NAT-Boxen.
Zwar könnten die beiden Endgeräte gleich über den Rendezvous-Server kommunizieren, anstelle sich mit den Eigenarten der beteiligten NAT-Boxen herumzuschlagen. Für die direkte Verbindung spricht jedoch zum einen die Latenz, die in den meisten Fällen kleiner ist als über die beiden Verbindungen zum Rendezvous-Server, der alle Datagramme umsetzen müsste. Außerdem ist es eine Frage der Vertraulichkeit, ob ich alle meine Daten über den Server schicken will, oder lieber direkt.
Ein weiteres Problem beim Hole-Punching stellt das Hair-Pinning dar, das auftritt, wenn zwei Rechner hinter derselben NAT-Box eine direkte Verbindung aufnehmen wollen. In diesem Fall teilt der Rendezvous-Server beiden Clients die gleiche NAT-Adresse mit und diese versuchen über die NAT-Box eine Verbindung in das private Netz zurück aufzubauen. Damit das funktioniert, muss es von der NAT-Box unterstützt werden. Sollten mehrere NAT-Boxen kaskadiert sein, muss zumindest die dem Rendezvous-Server zunächst gelegene NAT-Box Hair-Pinning unterstützen. RFC 2663, RFC 3022 und RFC 3303 gehen auf diese Aspekte ein.
Aus dem vorgenannten ist sicher zu erkennen, dass ich NAT eher für ein Übel als für einen Segen halte. Wenn es sich beim Entwurf des Netzes vermeiden lässt, würde ich auf jeden Fall darauf verzichten. Allgemein spricht nur die Knappheit der Adressen bei IPv4 für NAT. Konkret ist NAT notwendig, wenn zwei Netzbereiche mit überlappender Adressvergabe, zum Beispiel mit Adressen nach RFC 1918, verbunden werden sollen oder wenn ein Netzbereich mit Adressen nach RFC 1918 an das Internet angeschlossen werden soll.
Zwar gibt es einige, die den Standpunkt vertreten, dass NAT einen gewissen Schutz bietet, weil das Netz dahinter nicht von außen adressiert und somit das Netz auch ohne Firewall geschützt wäre. Doch kann NAT keine durchdachte und mit Hilfe einer Firewall durchgesetzte Policy ersetzen. Ist die Firewall einmal im Betrieb ist der zusätzliche Nutzen durch NAT nur noch marginal.
Demgegenüber steht die zusätzliche Rechenzeit, die für NAT aufgewendet werden muss. Setze ich NAT ein, muss der NAT-Router für jedes Datagramm das umgesetzt werden soll, in einer Tabelle nachschauen und die Adressen, Ports und Prüfsummen modifizieren. Ist die CPU des NAT-Routers nicht leistungsfähig genug, kann der mögliche Durchsatz erheblich sinken. In einem konkreten Fall hatte ich Unterschiede von mehr als 30 Prozent im maximalen Durchsatz mit und ohne NAT gemessen.