Grundlagen OpenWrt Paketfilter
Netfilter: Kernel-Komponenten
Das Netfilter-Framework besteht aus drei Komponenten: iptables, ebtables und arptables.
Iptables
Der Teil des Netfilter-Frameworks, der sich mit der Filterung und Manipulation von IPv4-Datagrammen befasst ist Iptables. Sein Pendant für IPv6 ist Ip6tables.
Iptables enthält mehrere unabhängige Tabellen mit Regelketten, in welchen die Paketfilter-Regeln gruppiert sind. Jede Tabelle enthält fest eingebaute Regelketten und kann zusätzlich benutzerdefinierte Regelketten aufnehmen.
Jede Regelkette ist eine Liste von Regeln, die jeweils für bestimmte Datagramme gelten und festlegen, was mit diesen Datagrammen passieren soll. Eingebaute Regelketten besitzen darüber hinaus eine Policy, die bestimmt, was mit einem Datagramm passieren soll, auf das keine Regel passt. Wenn keine Regel in einer benutzerdefinierten Kette passt, geht es mit der nächsten Regel derjenigen Kette weiter, aus der die benutzerdefinierte Kette angesprungen wurde.
Jede Regel besteht aus zwei Teilen: einer Beschreibung der Datagramme, für die diese Regel zuständig ist (Match) und einer Aktion, die auf diese Datagramme anzuwenden ist (Target).
Netfilter-Tabellen
Die Tabellen haben verschiedene Aufgaben.
- Die Tabelle filter ist zuständig für die Entscheidung, ob ein Datagramm weitergeleitet oder verworfen wird. Wenn ich keine Tabelle explizit angebe, arbeiten die Benutzerprogramme mit dieser. Hier gibt es die eingebauten Ketten INPUT, FORWARD und OUTPUT.
- Die Tabelle nat ist für die Adressumsetzung zuständig. Sie wird konsultiert, wenn ein Datagramm eine neue Verbindung aufbaut. Hier gibt es die eingebauten Ketten PREROUTING, OUTPUT und POSTROUTING.
- Die Tabelle mangle ist für spezielle Manipulationen der Datagramme zuständig. Hier gibt es die eingebauten Ketten PREROUTING, OUTPUT, INPUT, FORWARD und POSTROUTING.
- Mit der Tabelle raw kann ich Datagramme von der Verarbeitung durch die anderen Tabellen ausnehmen. Diese Tabelle wird vor ip_conntrack konsultiert. Hier gibt es die eingebauten Ketten PREROUTING und OUTPUT.
- Die Tabelle security ist für Mandatory Access Control (MAC) Netzwerk-Regeln zuständig. Hier gibt es die eingebauten Ketten INPUT, FORWARD und OUTPUT.
Welche der genannten Tabellen zur Verfügung stehen, hängt von den Optionen bei der Konfiguration des Kernels ab und welche Kernel-Module geladen sind.
Targets
Die Aktionen für Datagramme, auf die eine Paketfilter-Regel zutrifft,
werden Target genannt.
Beim Programm iptables werden sie mit der Option -j beziehungsweise
--jump angegeben.
Wenn eine Regel nicht auf ein Datagramm passt, wird die nächste Regel derselben Kette untersucht. Passt eine Regel auf ein Datagramm, bestimmt das Target, welche Regel als nächstes angewendet wird.
Target kann eines der folgenden sein:
- der Name einer benutzerdefinierten Regelkette: dann werden als nächstes die Regeln dieser Kette angewendet,
- ACCEPT: das Datagramm wird durchgelassen und keine weitere Regel mehr angewendet,
- DROP: das Datagramm wird verworfen und keine weitere Regel angewendet,
- QUEUE: das Datagramm wird an ein Programm im Userspace zur Begutachtung übergeben
- RETURN: in einer benutzerdefinierten Regelkette geht es zurück zur Kette, aus der diese angesprungen wurde, in einer eingebauten Kette wird die Policy auf das Datagramm angewendet.
Ist das Ende der eingebauten Regelkette erreicht und passte keine Regel mit endgültigem Target, wird die Policy der Kette auf das Datagramm angewendet. Die Policy darf kein Sprung zu einer anderen Regelkette und nicht RETURN sein.
Iptables-Extension-Module stellen weitere Targets sowie zusätzliche Match-Optionen für die Regeln bereit.
Einsprungspunkte für Paketfilterregeln
Die Kernel-Komponenten des Netfilter-Frameworks bestehen aus verschiedenen Einsprungspunkten im Kernel-Code zur Verarbeitung und Weiterleitung von Datagrammen, verschiedenen Regelketten nebst in ihnen enthaltenen Regeln sowie Kernel-Modulen mit dem Code für die Aktionen, die sich aus den Regeln ergeben.
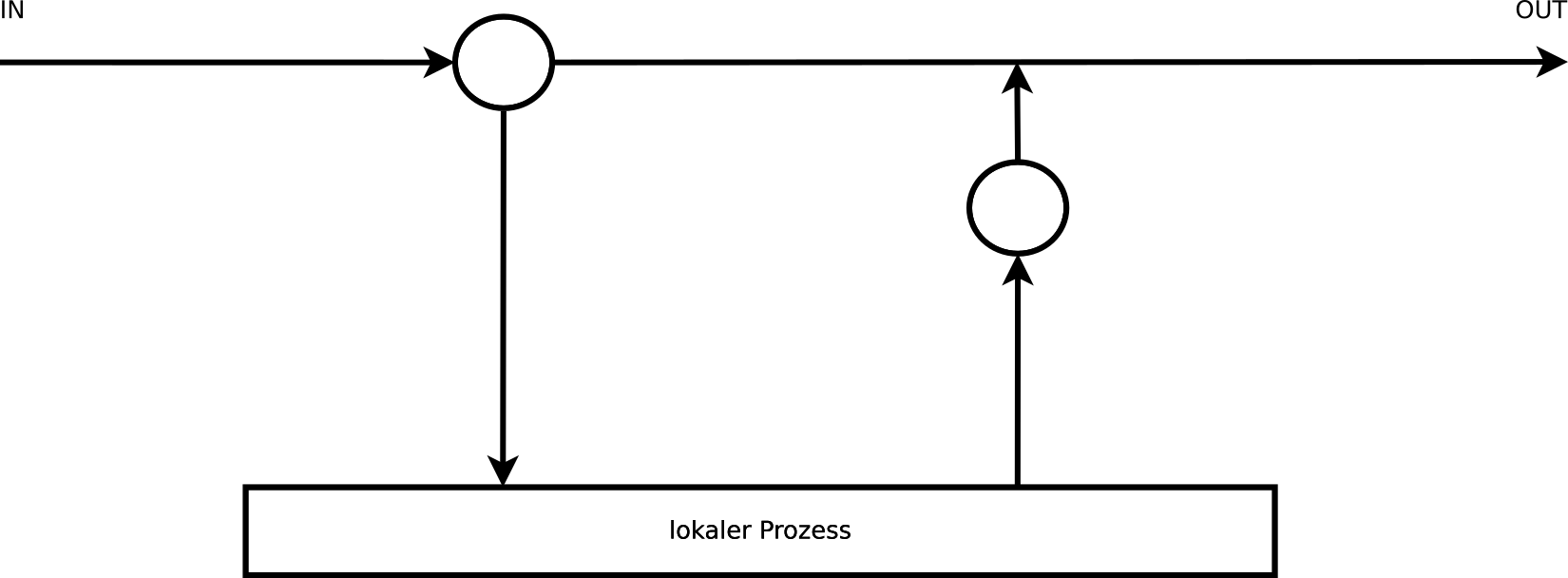
Um die Einsprungspunkte zuordnen zu können, betrachte ich zunächst abstrakt den Weg, den ein Datagramm durch den Kernel zurücklegt. Dieses kann auf zwei Möglichkeiten in den Netzwerk-Code gelangen: über ein Netzwerkinterface (IN) oder wenn ein lokaler Prozess ein neues Datagramm erzeugt.
Bei einem Datagramm, das über einen Netzwerkadapter angekommen ist, wird eine Routing-Entscheidung getroffen und dann das Datagramm an einen lokalen Prozess ausgeliefert, oder über einen - meist anderen - Netzwerkadapter (OUT) versendet.
Ein lokal erzeugtes Datagramm wird nach der Routing-Entscheidung über den ermittelten Netzwerkadapter (OUT) versendet oder, falls es an einen anderen lokalen Prozess geht, an diesen ausgeliefert.
Es gibt fünf Einsprungspunkte für das Netfilter-Framework, deren Name im nachfolgenden Bild der entsprechenden Regelkette des Paketfilters entspricht.
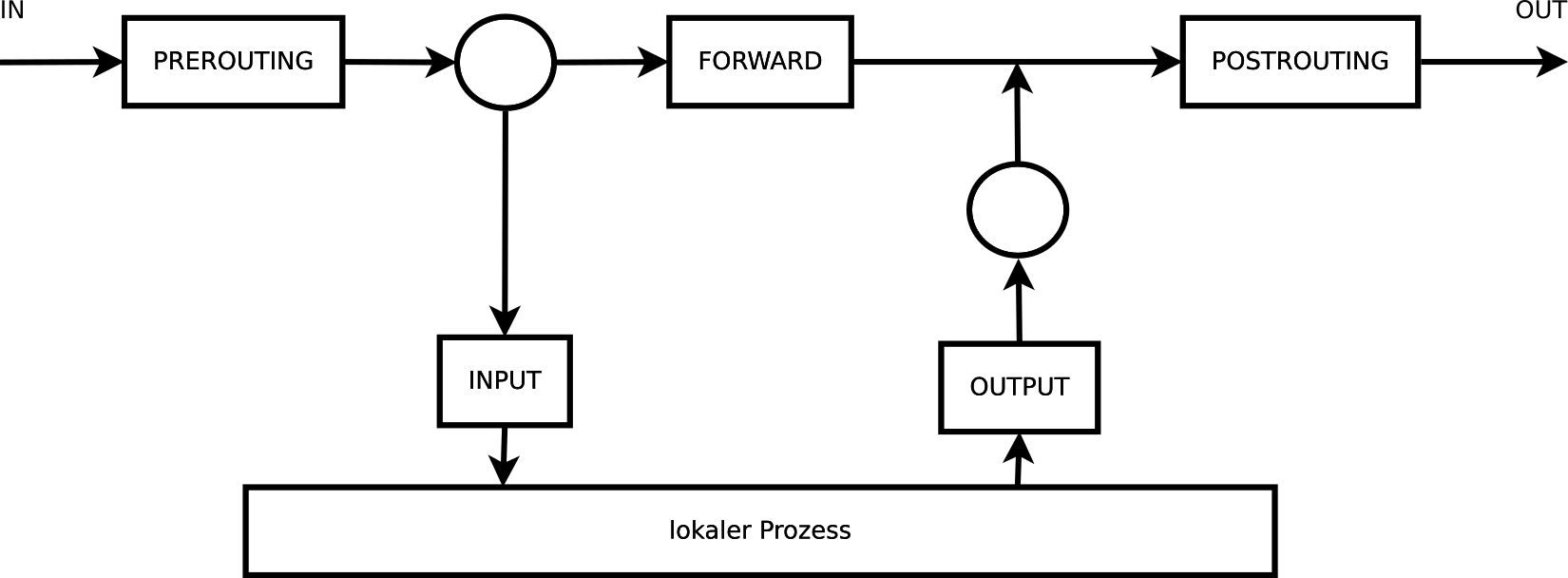
Die erste Regelkette, die ein von außen kommendes Datagramm passiert ist PREROUTING. Diese Regelkette gibt es bei den Tabellen nat, mangle und raw.
Geht das Datagramm nach der Routing-Entscheidung an einen lokalen Prozess, passiert es als nächstes die Regelkette INPUT, die es bei den Tabellen filter, mangle und security gibt.
Geht das Datagramm stattdessen zu einer anderen Schnittstelle, um wieder versendet zu werden, passiert es als nächstes die Regelkette FORWARD, die es ebenfalls bei den Tabellen filter, mangle und security gibt.
Ein von einem lokalen Prozess erzeugtes Datagramm passiert als erstes die Regelkette OUTPUT, die es bei allen Tabellen gibt, und geht dann nach der Routing-Entscheidung zur sendenden Schnittstelle.
Unmittelbar vor dem Versenden passiert ein Datagramm die Regelkette POSTROUTING, die es bei den Tabellen nat und mangle gibt.
Bei der Behandlung eines Datagramms im Kernel konsultiert der Netfilter-Code an den verschiedenen Einsprungstellen die zugehörigen Regelketten und verfährt mit den Datagrammen entsprechend der darin enthaltenen Regeln.
Außer den vordefinierten Regelketten, deren Name den Einsprungspunkten entspricht, kann es benutzerdefinierte Regelketten geben, die über Sprunganweisungen in den Regeln erreicht werden. Diese Regelketten können beliebige Namen mit bis zu 31 Buchstaben haben. Es empfiehlt sich, hierfür Kleinbuchstaben zu verwenden, um die benutzerdefinierten Ketten von den vordefinierten leichter unterscheiden zu können.
Diese benutzerdefinierten Regelketten können die Regeln zusammenfassen und einfacher strukturieren, so dass die Firewall einfacher zu verstehen ist. Dazu muss man jedoch das Modell kennen, nach dem diese Regelketten verknüpft sind. Für OpenWrt beschreibe ich das Modell der Regelketten in einem der folgenden Kapitel.
Connection Tracking
Will ich meinen Paketfilter zustandsbezogen (stateful) betreiben, verwende ich die conntrack Module.
Diese haben den Vorteil, dass ich meine Regeln genauer bestimmen und trotzdem einfacher halten kann. Bestimmte Anwendungen, wie das automatische Freischalten von FTP-Datenverbindungen, gehen nicht ohne diese Module.
Ein Nachteil von zustandsbezogenen Paketfilter ist, dass sie für die zusätzlichen Informationen mehr Speicherplatz benötigen. Deshalb muss ich mir gegebenenfalls Gedanken machen, wie ich die Zustandstabellen vor Überlauf schützen kann.
Beim zustandsbezogenen Filtern kann ich die Datenpakete neben den anderen Kriterien noch nach dem Zustand der zugehörigen Verbindung diskriminieren. Diese Zustände sind:
- NEW
- für ein Paket, das eine neue Verbindung aufbaut.
- ESTABLISHED
- für Pakete, die zu einer bereits existierenden Verbindung gehören.
- RELATED
- für Datagramme, die zu einer bestehenden Verbindung gehören, aber nicht Teil dieser sind. Das kann ein Paket sein, das eine Datenverbindung zu einer bestehenden FTP-Verbindung aufbaut oder eine ICMP-Fehlermeldung.
- INVALID
- für ein Paket, das nicht identifiziert oder zugeordnet werden kann. Zum Beispiel ICMP-Fehlermeldungen oder TCP-Pakete, die zu keiner bekannten Verbindung passen.
Dabei muss ich beachten, dass der Status einer Verbindung bei Iptables nicht äquivalent zum Status einer TCP-Verbindung sein muss. So hat das SYN-ACK-Paket beim Aufbau einer TCP-Verbindung bei Iptables den Status ESTABLISHED, während die TCP-Verbindung erst mit dem dritten Datagramm als established angesehen wird.
Bei ICMP können nur vier Typen den Status NEW oder ESTABLISHED haben:
- Echo (0,8)
- Timestamp (13,14)
- Information (15,16)
- Adressmask (17,18)
Alle anderen ICMP-Nachrichten können maximal den Status RELATED haben.
Iptables-Extensions
Für einige Protokolle und andere nützliche Sachen gibt es sogenannte Match-Erweiterungen, für die zum Teil zusätzliche Kernel-Module geladen werden müssen.
Das sind beispielsweise Erweiterungen für die Protokolle ICMP, TCP und UDP,
mit denen ich die Regeln genauer an die Erfordernisse dieser Protokolle
anpassen kann.
Diese aktiviere ich mit der Option -p beim Aufruf von iptables.
Andere Erweiterungen beziehen sich auf die MAC-Adresse, die Limitierung von Datagrammen oder den Benutzer oder Prozess, der ein lokal erzeugtes Datagramm verursacht hat.
Weitere Erweiterungen, erlauben mir zusätzliche Targets, das heißt Aktionen, in den Regeln, wie zum Beispiel:
- LOG für das Protokollieren von Datagrammen
- REJECT um Fehlermeldungen für Datagramme zu generieren
- SNAT, DNAT, MASQUERADE um die Adressen zu manipulieren
- REDIRECT um eine Verbindung umzuleiten
- TOS und MARK um QoS zu unterstützen
Ebtables
Dieser Teil der Netfilter-Frameworks behandelt die Administration der Ethernet-Bridges.
Hier gibt es drei Tabellen mit vordefinierten Regelketten:
- Die Tabelle filter entscheidet über die Weiterleitung von Ethernet-Frames.
- Die Tabelle nat dient der Manipulation von Ethernet-Frames.
- In der Tabelle broute wird entschieden, ob ein Ethernet-Frame anhand der Layer-2-Informationen weiter geleitet werden soll (Bridge) oder anhand der Layer-3-Informationen geroutet werden soll. Das ist bei einem reinen IP-Betrieb kaum mehr notwendig. Falls im Netz jedoch anderer Traffic (zum Beispiel NetBEUI oder IPX) vorkommt, kann man damit einen sogenannten Brouter realisieren.
Arptables
Das Programm arptables wird verwendet, um die ARP-Regeln im Linux-Kernel zu
verwalten.
Diese Regeln inspizieren die ARP-Datagramme.
Es gibt nur eine Regeltabelle: filter. Diese enthält drei Regelketten:
- INPUT für Datagramme, die an diesen Rechner gehen,
- OUTPUT für Datagramme, die von diesem Rechner erzeugt wurden und
- FORWARD für Datagramme, die vom Bridge-Code weitergeleitet werden. Diese Kette gibt es beim Kernel 2.4 nicht.
Wenn eine Regel zutrifft, gibt es die folgenden Targets (Aktionen):
- ACCEPT, um das Datagramm durchzulassen.
- DROP, um das Datagramm zu verwerfen.
- CONTINUE, um die nächste Regel zu prüfen.
- RETURN um aus der aktuellen benutzerdefinierten Kette zurückzuspringen.
Daneben gibt es Target-Erweiterungen, die es erlauben, ARP-Datagramme zu manipulieren, indem die MAC- oder IP-Adressen geändert werden.
Netfilter: Benutzerprogramme
Im Netfilter-Framework gibt es vier Gruppen von Userspace-Programmen, die sich um verschiedene Belange bei der Paketfilterung kümmern:
- iptables ist zuständig für die Filterung und Manipulation von IPv4-Traffic,
- ip6tables kümmert sich um IPv6,
- ebtables ist für die die Filterung und Manipulation von Datagrammen auf OSI-Schicht 2, also bei Netzwerk-Bridges zuständig, und
- arptables kümmert sich um ARP, das heißt die Zuordnung von Ethernet-Adressen zu IPv4-Adressen.
Auf alle vier gehe ich im folgenden nur kurz ein, für detailliertere Erläuterungen verweise ich auf die Handbuchseiten.
iptables
Hier habe ich es mit insgesamt vier Programmen zu tun:
-
iptablesverwende ich, wenn ich einzelne Paketfilterregeln von Hand oder in einem Skript explizit ändern will.Konkret nutze ich es für die Verwaltung von Regelketten:
- Anlegen und Löschen von benutzerdefinierten Ketten,
- Vorgabe einer Policy,
und für die Verwaltung der Regeln:
- Anlegen, Ändern und Löschen von Regeln,
- Abfragen, Setzen und Löschen von Zählerständen,
- Aktivierung von Match-Erweiterungen und Modulen für das Connection Tracking.
- Mit
iptables-savekann ich komplette Regelsätze sichern.Durch die kompakte Form als Textdatei mit jeweils allen Optionen von
iptablesfür die betreffende Regel in einer Zeile eignet sich die Ausgabe voniptables-savesehr gut zur Analyse eines Paketfilters. Darauf komme ich in einem späteren Kapitel zurück. -
iptables-restorenimmt die Ausgabe voniptables-saveund installiert alle Regeln im Kernel. Dieses Programm wird in den Skripts beim Systemstart verwendet, um die vor dem Herunterfahren gesicherten Regeln beim Neustart des Rechners wiederherzustellen. -
iptables-save-xmlnimmt die Ausgabe voniptables-saveund wandelt sie in XML für die weitere maschinelle Verarbeitung um.Bis jetzt habe ich für dieses Programm noch keine Verwendung gefunden.
ip6tables
Hier gilt das für iptables gesagte. Es gibt die drei Programme
-
ip6tableszur Manipulation von Regeln und Regelketten, -
ip6tables-savezum Speichern des gesamten IPv6-Regelsatzes und -
ip6tables-restorezum Wiederherstellen des Regelsatzes mit einem Befehl.
ebtables
Für die Administration der Ethernet Bridging Tables gibt es das Programm
ebtables, das ich nur benötige, wenn ich eine Ethernet-Bridge betreibe.
Die Bridge kann echte Ethernet-Adapter verbinden oder virtuelle Maschinen.
Ein Einsatzfall, für den ich ebtables verwende, ist eine Bridge,
die zusätzlich als Router, zum Beispiel für ein VPN arbeiten soll.
Will ich in einem bestehenden Netzwerk minimal invasiv nachträglich einen
VPN-Router einsetzen, ohne die Rechner oder den Zugangs-Router
neu zu konfigurieren, dann kann ich den VPN-Router als Bridge zwischen dem
vorhandenen Router und den Rechnern im Netz platzieren.
Damit die Datagramme, die durch das VPN geleitet werden sollen, auch
wirklich dort ankommen, muss der IP-Stack des VPN-Routers sie zu “sehen”
bekommen.
Dafür nehme ich mit ebtables diese Datagramme von der Weiterleitung durch
die Bridge aus und führe sie dem IP-Stack zu.
arptables
Hier habe ich es ebenfalls mit drei Programmen zu tun:
-
arptablessetzt die Regeln zum Inspizieren und Manipulieren von Datagrammen des Address Resolution Protocol (ARP), -
arptables-savesichert alle Regeln und -
arptables-restorestellt alle wieder her.
Zwar kann ich mit arptables auch einen einzelnen Rechner schützen, doch
werde ich dieses vorwiegend bei einer Bridge einsetzen.
Die Regeln und Optionen von arptables sind auf das Protokoll ARP
abgestimmt, Details finden sich in den Handbuchseiten.
Netfilter erweitern
Falls mir die Funktionalität des Netfilter-Frameworks nicht ausreicht, kann ich dieses um eigene Funktionen ergänzen.
Dafür gibt es verschiedene Wege. Ich kann ein Kernel-Modul schreiben, das an den nötigen Hooks eingehängt und von einem Userspace-Programm gesteuert wird.
Alternativ kann ich mit libipq die entsprechende Funktionalität auch im Userspace realisieren.
Für Experimente und Tests würde ich die Filterung im Userspace vorziehen, bei hohen Anforderungen an die Performance den Weg über das Kernel-Modul.
Einen Einstieg in dieses Thema bietet das Linux netfilter hacking HOWTO
Besonderheiten des Linux-Kernels
Der Linux-Kernel bietet viele Einstellmöglichkeiten über das proc
Dateisystem.
Dieses spezielle Dateisystem, das im Verzeichnisbaum unter /proc
eingehängt ist, enthält Pseudo-Dateien, aus denen Kernelparameter
ausgelesen werden können.
Durch Schreiben in diese Dateien kann ich die Kernelparameter setzen.
Die für das Netzwerk und damit für Paketfilter und Firewalls interessanten Parameter sind im Verzeichnis /proc/sys/net/ zu finden.
Ich kann diese Parameter mit cat oder less auslesen und mit
echo $wert > /proc/sys/net/$parameter setzen.
Einfacher geht das jedoch mit dem Programm sysctl, dem ich den Namen des
Parameters und den Wert in der Kommandozeile oder in der
Datei /etc/sysctl.conf mitgeben kann.
Dabei gilt die Besonderheit beim Namen des Parameters, dass dieser dem
Pfadnamen der Datei unterhalb von /proc/sys/ entspricht,
wobei statt der ‘/’ im Dateisystem ‘.’ im Namen des Parameters gesetzt wird.
So entspricht die Datei /proc/sys/net/ipv4/ip_forward dem Parameter
net.ipv4.ip_forward in der Kommandozeile von sysctl beziehungsweise in
der Datei /etc/sysctl.conf.
Die Dokumentation zu den Variablen findet sich bei den Linux Kernelquellen im Verzeichnis Documentation. Die für das Netzwerk und Paketfilter wichtigen Parameter sind dort in der Datei sysctl/net.txt sowie in den Dateien im Verzeichnis networking beschrieben.
Damit genug der Vorrede, kommen wir zu den für Paketfilter interessanten Variablen.
- net.core.bpf_jit_enable
- Für die Architektur x86_64 gibt es ein Framework, das die Paketfilterung beschleunigen kann. Dieses wird mit diesem Parameter aktiviert.
- net.ipv4.ip_forward
- Diese Variable entscheidet, ob eine Maschine mit mehreren Netzwerkschnittstellen als Router arbeitet und Pakete zwischen den Schnittstellen weiterleitet. In Skripts setzt man diesen Parameter oft auf 0, bevor die Regeln des Paketfilters gesetzt werden und aktiviert die Weiterleitung mit einem von 0 verschiedenen Wert nach dem Setzen der Regeln.
- net.ipv4.ipfrag_ *
- Diese Gruppe von Variablen steuert das Zusammensetzen von IP-Fragmenten. Will ich auf dem Paketfilter ankommende Fragmente zusammensetzen, muss ich diese Variablen näher anschauen.
- net.ipv4.tcp_mtu_probing
- Damit kann ich Path-MTU-Probing, wie in RFC 4821 beschrieben, für TCP einstellen. Drei Werte sind möglich: 0 deaktiviert PMTU-Probing, 1 aktiviert es, wenn ein ICMP-Blackhole entdeckt wird und 2 aktiviert es ständig und nutzt die MSS von net.ipv4.tcp_bas_mss.
- net.ipv4.icmp_echo_ignore_all
- Wenn diese Option ungleich 0 gesetzt ist, ignoriert der Kernel alle ICMP-Echo-Requests, die an ihn gerichtet sind.
- net.ipv4.icmp_echo_ignore_broadcasts
- Wenn diese Option ungleich 0 gesetzt ist, ignoriert der Kernel alle ICMP-Echo-Requests, die ihn via Multicast oder Broadcast erreichen.
- net.ipv4.icmp_errors_use_inbound_ifaddr
- Ist diese Option auf 0 gesetzt, sendet ein Router ICMP-Fehlermeldungen mit der primären Adresse der abgehenden Schnittstelle. Mit dem Wert 1 nimmt er die primäre Adresse der Schnittstelle auf der das Paket ankam, welches den Fehler verursacht hat.
- net.ipv4.icmp_ratelimit
- Diese Variable bestimmt die Rate, mit der bestimmte ICMP-Nachrichten gesendet werden. Der Wert gibt den minimalen Abstand in Millisekunden zwischen zwei ICMP-Nachrichten an, 0 bedeutet dementsprechend keine Beschränkung. Welche ICMP-Nachrichten limitiert werden, steht in der Variable net.ipv4.icmp_ratemask.
- net.ipv4.icmp_ratemask
- Diese Variable legt in einer Bitmap fest, welche ICMP-Nachrichten von der Beschränkung durch net.ipv4.icmp_ratelimit betroffen sind. Die Default-Bitmap ist 6168, bei der die Nachrichten “Destination Unreachable”, “Source Quench”, “Time Exceeded” und “Parameter Problem” beschränkt werden.
Unter /proc/sys/net/ipv4/conf/ gibt es die Unterverzeichnisse all und default sowie je ein Unterverzeichnis für jede Netzwerk-Schnittstelle. Darin werden Parameter gesetzt, die für alle Schnittstellen gelten (unter all), für einzelne Schnittstellen (unter den Schnittstellen-Verzeichnissen) oder für alle Schnittstellen, für die nichts explizit eingestellt ist (unter default). Nachfolgend nenne ich die Variablen unter net.ipv4.conf.default, die exemplarisch für die anderen Verzeichnisse gelten.
- net.ipv4.conf.default.accept_redirects
- Damit kann ich festlegen, ob der Rechner ICMP-Redirect-Nachrichten akzeptiert oder ignoriert. In den meisten Fällen sollten diese von Hosts akzeptiert und von Routern ignoriert werden.
- net.ipv4.conf.default.accept_source_route
- Diese Variable legt fest, ob Pakete mit Source-Route-Option akzeptiert oder ignoriert werden. Per Default werden diese von Routern akzeptiert und von Hosts ignoriert.
- net.ipv4.conf.default.arp_accept
- Diese Variable steuert das Verhalten bei Gratuitous-ARP-Paketen, konkret für IP-Adressen, die noch nicht in der ARP-Tabelle sind. Mit dem Wert 0 werden keine neuen Einträge erzeugt, mit dem Wert 1 wird die ARP-Tabelle sowohl für ARP-Requests als auch für ARP-Replies aktualisiert.
- net.ipv4.conf.default.forwarding
- Aktiviert die Weiterleitung von Datagrammen für die betreffende Schnittstelle.
- net.ipv4.conf.default.log_martians
- Ein Wert ungleich 0 aktiviert die Protokollierung von IP-Paketen mit nichtroutbarer Absenderadresse.
- net.ipv4.conf.default.rp_filter
- Dieser Integerwert steuert die Reverse-Path-Validierung entsprechend RFC 3704. Mit Wert 0 wird die Absenderadresse eines Datagramms nicht validiert. Der Wert 1 entspricht der Strict Mode nach RFC 3704: wenn die ankommende Schnittstelle nicht die beste Route zur Absenderadresse hat, wird das Datagramm verworfen. Der Wert 2 entspricht der Loose Mode nach RFC 3704: nur wenn es überhaupt keine Route zurück zur Absenderadresse gibt, wird das Datagramm verworfen. Loose Mode empfiehlt sich bei asymmetrischem Routing.
Für IPv6 gilt das gleiche, wie für IPv4: die Dateien und Verzeichnisse unter /proc/sys/net/ipv6/conf erlauben Einstellungen für einzelne oder alle Schnittstellen.
- net.ipv6.conf.default.disable_ipv6
- Damit kann ich IPv6 selektiv an einzelnen Schnittstellen abschalten.
- net.ipv6.conf.default.forwarding
- Auch das Weiterleiten von Datagrammen kann ich für einzelne Schnittstellen an- oder abschalten.
- net.ipv6.conf.default.suppress_frag_ndisc
- Damit kann ich das Verhalten nach RFC 6980 steuern. Mit dem Defaultwert von 1 verwirft der Kernel fragmentierte Neighbor-Discovery-Datagramme, mit dem Wert 0 erlaubt er sie.
- net.ipv6.conf.default.use_tempaddr
- Mit dieser Variable kann ich die Privacy Extensions für IPv6 einschalten.
- net.ipv6.icmp.ratelimit
- Diese Variable bestimmt die Rate, mit der ICMPv6-Datagramme gesendet werden.
Ein Modell der Firewall-Regeln bei OpenWrt
Um den Paketfilter bei OpenWrt zu verstehen, rufe ich mir den Weg eines Datagramms durch die Regelketten des Netfilter Frameworks, wie im Kapitel “Netfilter: Kernel-Komponenten” beschrieben, in das Gedächtnis zurück. Dieses Modell liefert mir die Einsprungspunkte in die Paketfilter-Tabellen beim Weg eines Datagramms durch den Netzwerkcode des Kernel. Die Einsprungspunkte in dem Modell liefern die Reihenfolge, in der die Tabellen des Netfilter-Frameworks befragt werden.
Betrachte ich ein Datagramm, das auf einem Interface ankommt und auf Grund seiner Zieladresse auf einem anderen Interface versendet werden soll, dann durchläuft es nacheinander die folgenden Stationen:
- Tabelle raw, Kette PREROUTING
- Connection Tracking Module
- Tabelle mangle, Kette PREROUTING
- Tabelle nat, Kette PREROUTING
- Entscheidung über das Routing
- Tabelle mangle, Kette FORWARD
- Tabelle filter, Kette FORWARD
- Tabelle mangle, Kette POSTROUTING
- Tabelle nat, Kette POSTROUTING
Damit weiß ich, in welcher Reihenfolge ich die genannten Regelketten konsultieren muss, um zu analysieren, was das Netfilter-Framework mit diesem Datagramm macht.
Nun erlaubt das Netfilter-Framework beliebige Regelketten anzulegen, die aus den Einsprungsketten über Jump-Aktionen erreicht werden können. Diese Regelketten können das Arbeiten effizienter und übersichtlicher machen, sie können mich aber auch verwirren, wenn ich die zugrundeliegende Struktur nicht kenne.
Dazu begebe ich mich auf eine andere Abstraktionsebene und betrachte die
Regelketten der Tabellen als Folgen von Anweisungen, um zu einer Aussage zu
kommen, was mit einem Datagramm passieren soll, das bei einer vordefinierten
Regelkette ankommt.
Mit iptables-save beziehungsweise ip6tables-save erhalte ich alle
Regelketten und Tabellen in einer Textdatei mit einer Regel pro Zeile.
Diese Textdatei ohne Hilfsmittel auszuwerten, ist mühsam, da ich
ohne Vorwissen immer bei den Standard-Regelketten anfangen muss,
diese nacheinander betrachte und bei einer Jump-Aktion an anderer Stelle
weiter mache, bis ich zu einer endgültigen Aktion komme, oder das
Ende der vordefinierten Regelkette erreiche.
Hier hilft es mir, die Regelketten als gerichteten Graphen zu betrachten, dessen Knoten die Regelketten sind und dessen Kanten die Sprunganweisungen. Das funktioniert für einfache Firewalls mit wenigen Regeln und Regelketten recht gut, da kann ich dem Verlauf mit dem Finger auf einem genügend großen Ausdruck folgen.
Bei komplexeren Paketfiltern wird aber auch dass schon zu unübersichtlich. Hier betrachte ich nur die Regelketten und die zwischen ihnen existierenden oder möglichen Sprünge.
Die benutzerdefinierten Regelketten sind bei OpenWrt gut strukturiert, das Modell dafür hatte ich in [Weidner2012] bereits für die damals aktuelle Version grob beschrieben. Inzwischen hat sich OpenWrt weiterentwickelt und auch das Modell der Regelketten geändert. Darum gehe ich hier noch einmal detailliert auf die verschiedenen Tabellen der momentan aktuellen Version Barrier Breaker ein.
Einen guten Einstieg bietet die Dokumentation zur Firewall-Konfiguration im Wiki. Dort werden die Regelketten nach drei Typen unterschieden:
- system: sind die vordefinierten Regelketten des Netfilter-Frameworks wie INPUT, OUTPUT, FORWARD, …
- internal: sind Regelketten, die von der OpenWrt-Firewall intern verwendet werden. Diese enthalten Sprünge zu den anderen Regelketten oder Regeln, die via LuCI oder UCI konfiguriert wurden.
- user: sind frei verfügbar und zunächst leer. Regeln für diese Ketten kann ich in der Datei /etc/firewall.user definieren.
Tabelle filter
Das nachfolgende Bild zeigt ein allgemeines Modell der Regelketten dieser Tabelle. Ganz links stehen die vordefinierten Regelketten, die den Einsprungspunkten in Kapitel “Netfilter: Kernel-Komponenten” entsprechen.
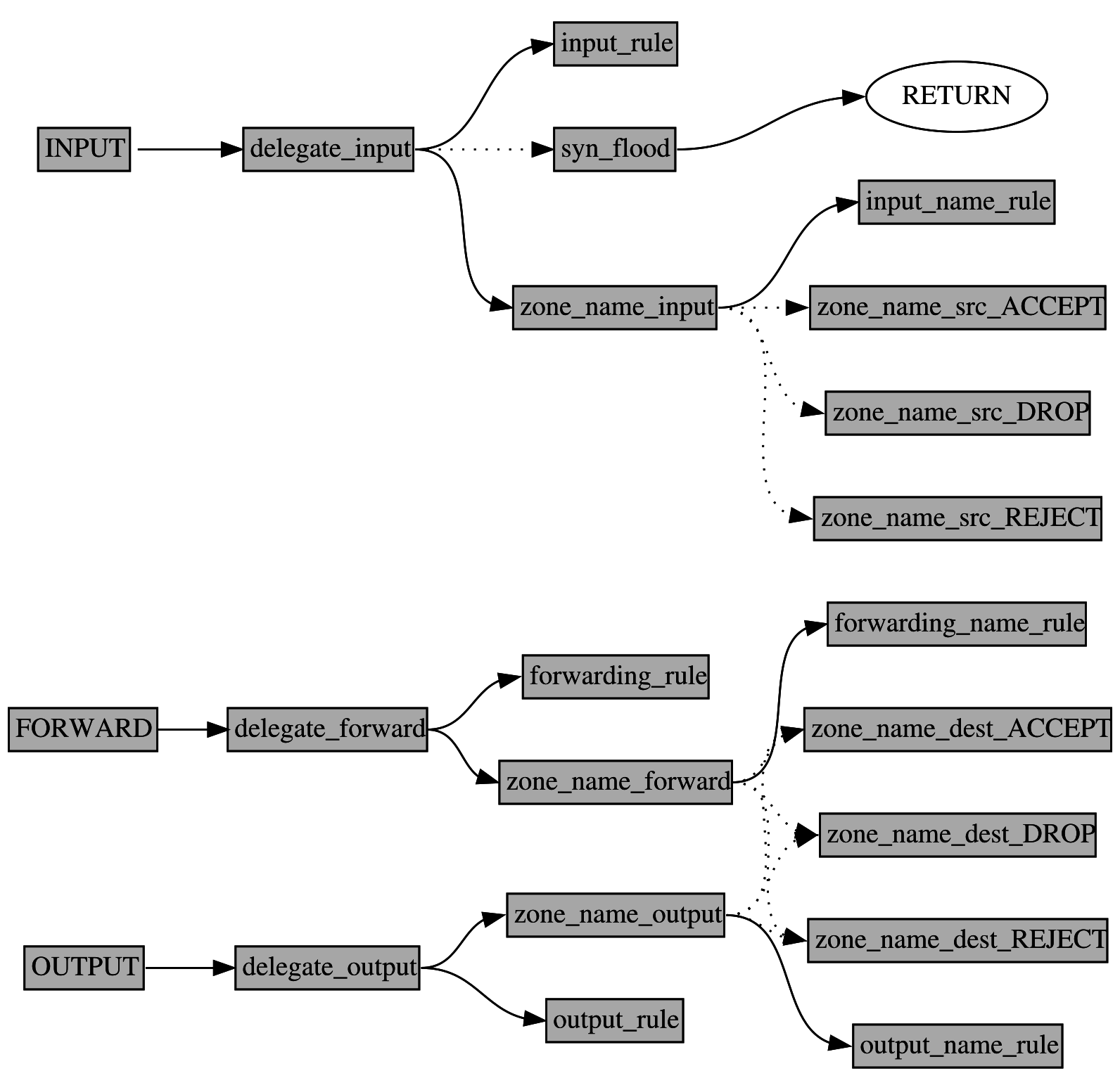
Die Namen der Regelketten folgen einem festen Schema, dem die Namen der Knoten im Graphen entsprechen. Dabei steht der Wortteil name für die entsprechende Zone bei der Netzkonfiguration des Routers. Das heißt, wenn zwei Zonen (zum Beispiel LAN und WAN) definiert sind, dann gibt es für den Knoten zone_name_forward im Modell, die beiden Regelketten zone_lan_forward und zone_wan_forward in der Tabelle filter, die die gleiche Funktion, wie im Modell haben, deren Regeln aber nur für die betreffende Zone gelten.
Gehen wir die einzelnen Ketten und deren Funktion durch.
Ich beginne bei der Kette INPUT.
Von hier aus geht es zur Kette delegate_input (system).
Wie der Name verrät, delegiert diese zu verschiedenen anderen Ketten und
zwar zu input_rule, syn_flood und zu zone_name_input.
Außerdem enthält diese Kette einige hoch priorisierte Regeln, wie zum
Beispiel -i lo -j ACCEPT, die dafür sorgt, dass lokaler Datenverkehr
über Adresse 127.0.0.1 immer durchkommt.
Die erste angesprungene Kette ist input_rule (user). Diese Kette ist reserviert für benutzerdefinierte Regeln für Verbindungen zum Router, die über die Datei /etc/firewall.user konfiguriert werden.
Zur Kette syn_flood (internal) geht es nicht immer, sondern nur, wenn in der Konfiguration “SYN flood protection” aktiviert wurde. Genau dann wird in INPUT eine Regel eingefügt, die für alle TCP-Pakete mit gesetztem SYN-Flag zu dieser Kette springt. In der Kette sind zwei Regeln: eine, die ein Limit prüft und zur aufrufenden Regelkette zurückspringt und eine, die alle Datagramme, welche über dem Limit liegen, verwirft.
Die letzte Ketten, die von delegate_input aus angesprungen werden, sind im Modell mit zone_name_input (internal) bezeichnet. Wie viele Ketten das genau sind, hängt von den Firewall-Zonen ab, ich definiert habe Als erstes verzweigen diese Ketten zu den entsprechenden Ketten namens input_name_rule. Dann folgen die Regeln, die in LuCI oder UCI für die betreffende Zone konfiguriert wurden sowie einige automatisch generierte Regeln wie zum Beispiel die Regeln, die konfigurierte Port-Weiterleitungen zulassen. Als letztes verzweigen diese Ketten je nach gewählter Policy für die betreffende Zone zu einer der drei Ketten zone_name_src_ACCEPT, zone_name_src_DROP oder zone_name_src_REJECT.
Die Ketten zone_name_src_ACCEPT (internal), zone_name_src_DROP (internal) und zone_name_src_REJECT (internal) sind Policy-Ketten. Diese lösen die entsprechende Reaktion für Datagramme aus der betreffenden Zone aus, wenn bis dahin noch keine Entscheidung getroffen wurde.
Die Ketten zone_name_dest_REJECT und zone_name_src_REJECT enthalten jeweils einen Sprung zur Kette reject. Diesen habe ich im Modell nicht aufgenommen, um es nicht unnötig zu komplizieren. In der Kette reject werden alle Datagramme zurückgewiesen, und zwar mit TCP-Reset für TCP-Pakete und mit ICMP-Port-Unreachable für alle anderen.
Auf den ersten Blick mag das recht willkürlich erscheinen, es offenbart jedoch ein grundlegendes Design-Prinzip: Jede Regelkette hat einen ganz speziellen Zweck, auf den sich die darin enthaltenen Regeln konzentrieren.
Damit muss ich mir beim Hinzufügen von Regeln weniger Gedanken machen und kann mich ganz auf den Zweck der Regeln konzentrieren. Wenn ich die Policy für einen Bereich auswähle und damit den entsprechenden Sprung in der Kette zone_name_input festlege, muss ich nicht wissen, welche Interfaces dazugehören. Diese stehen in der entsprechenden Policy-Kette. Das gleiche gilt für die Input-Regeln der betreffenden Zone. Für diese werden die ankommenden Schnittstellen in der Kette delegate_input den Zonen zugeordnet.
Schauen wir uns als nächstes die FORWARD Regeln an.
Dort finden wir nur einen Sprung zur Kette delegate_forward (internal).
In dieser Kette geht es als erstes zur Kette forwarding_rule.
Danach kommen einige automatisch generierte Regeln, wie zum Beispiel
-m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT, die dafür sorgt,
dass Datagramme von bestehenden Verbindungen akzeptiert werden.
Danach folgen Sprünge zu den Regelketten zone_name_forward, die anhand
des Ingress-Interfaces ausgewählt werden.
Schließlich werden alle Datagramme, für die noch keine Entscheidung
gefällt wurde mit einem Sprung zur Regelkette reject abgewiesen.
Die Regelkette forwarding_rule (user) ist reserviert für Regeln, die ich in /etc/firewall.user definieren kann.
Die Ketten zone_name_forward (internal) enthalten einen Sprung zur Kette forwarding_name_rule sowie Regeln für die betreffende Zone. Da diese Regeln üblicherweise andere Zonen haben, gibt es hier Sprünge zu den Zonen zone_name_dest_ACCEPT, zone_name_dest_DROP und zone_name_dest_REJECT, die nur für Datagramme mit dem entsprechenden Egress-Interface greifen. Am Schluß der Kette zone_name_forward steht eine Policy-Regel, die bei Datagrammen greift, für die noch keine Entscheidung gefallen ist.
Bleiben als letztes die Regeln für den abgehenden Verkehr.
Von der vordefinierten Kette OUTPUT geht es zunächst zur Regelkette
delegate_output (internal), die zu den Regelketten output_rule und den
Ketten für die einzelnen Zonen zone_name_output verzweigt.
Außerdem enthält diese Kette Firewallregeln mit hoher Priorität, wie zum
Beispiel die Regel -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT,
dafür sorgt, dass Datenpakete von bestehenden Verbindungen – die an
anderer Stelle im Regelwerk erlaubt wurden – sofort durchgelassen
werden.
Die Regelkette output_rule (user) ist für benutzerdefinierte Regeln für abgehende Verbindungen vom Router reserviert. Diese können wir über die Datei /etc/firewall.user konfigurieren.
Die Regelketten zone_name_output (internal) enthalten einen zunächst einen Sprung zur zugehörigen Kette output_name_rule. Darauf folgen die Firewall-Regeln, die die entsprechende abgehende Zone betreffen und schließlich eine Policy-Regel für die betreffende Zone.
Die Kette output_name_rule (user) ist wie output_rule für benutzerdefinierte Regeln definiert, die ich in /etc/firewall.user angeben kann. Im Gegensatz zu output_rule sehen die Regeln in dieser Kette aber nur Datenverkehr, der zu einer bestimmten Zone hinausgeht.
Tabelle nat
Für die Tabelle nat ist das Modell einfacher. Hier haben wir im Netfilter-Framework die drei Einsprungspunkte PREROUTING, OUTPUT und POSTROUTING, von denen die Firewall von OpenWrt nur PREROUTING und POSTROUTING verwendet.
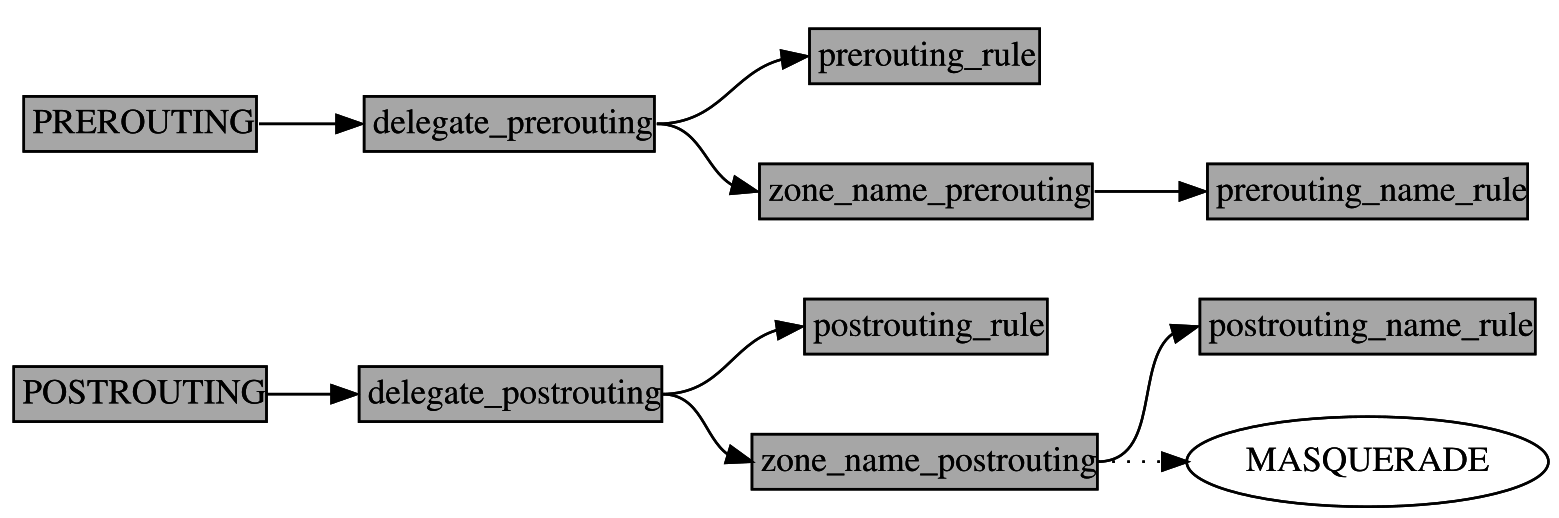
Von PREROUTING aus geht es in die Kette delegate_prerouting (internal). In dieser Kette finden wir einen Sprung zur Kette prerouting_rule, ein paar globale Pre-Routing-Regeln und die Verzweigungen zu den Ketten zone_name_prerouting für die einzelnen Firewall-Zonen.
Die Regelkette prerouting_rule (user) ist für benutzerspezifische Regeln, die ich in der Datei /etc/firewall.user spezifiziere.
Die Ketten zone_name_prerouting (internal) enthalten einen Sprung zur Kette prerouting_name_rule und die DNAT-Regeln, die ich mit LuCI oder UCI für die betreffende Zone.
Die Regelketten prerouting_name_rule wiederum können benutzerspezifische Regeln für die betreffende Zone aufnehmen, die in /etc/firewall.user spezifiziert werden.
Betrachten wir die Kette POSTROUTING, so finden wir dort nur einen Sprung zur Kette delegate_postrouting (internal). Darin finden wir einen Sprung zu postrouting_rule, globale Post-Routing-NAT-Regeln und Verzweigungen zu den Ketten zone_name_postrouting.
Die Regelkette postrouting_rule (user) ist für globale benutzerspezifische NAT-Regeln, die ich in der Datei /etc/firewall.user konfigurieren kann.
In den Ketten zone_name_postrouting (internal) finden wir einen Sprung zu postrouting_name_rule sowie NAT-Regeln für die betreffende Zone. Das sind SNAT- und MASQERADE-Regeln, wie im Graphen bereits angedeutet.
Die Regelkette postrouting_name_rule (user) kann ich in der Datei /etc/firewall.user nach eigenem Gutdünken mit NAT-Regeln für die betreffende Zone füllen.
Tabelle mangle
In dieser Tabelle gibt es nur zwei benutzerdefinierte Ketten.
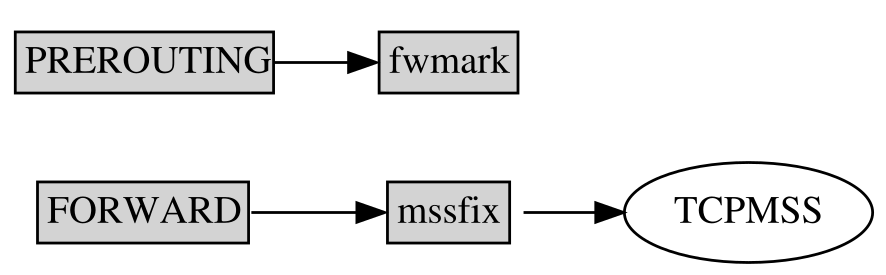
Von PREROUTING aus geht es zur Kette fwmark (internal), die für MARK-Regeln verwendet wird.
Von FORWARD aus geht es zur Kette mssfix (internal). In dieser Kette kann ich die TCPMSS-Regeln finden. Das sind Regeln, die bei Datagrammen, welche eine neue TCP-Verbindung aufbauen (mit gesetztem SYN-Bit) die TCP-Option MSS (Maximum Segment Size) auf die MTU der abgehenden Schnittstelle beschränkt. Damit wird die Path-MTU für TCP bei Verbindungen zu Netzen mit kleinerer MTU (zum Beispiel PPPoE-Verbindungen) automatisch angepasst.
Tabelle raw
Diese Tabelle wird nur für Datagramme genutzt, die vom Connection Tracking ausgenommen werden sollen.

Von PREROUTING aus geht es zur Kette delegate_notrack (internal), die ihrerseits zu den Ketten zone_name_notrack verzweigt.
Die Ketten zone_name_notrack (internal) enthalten für die entsprechende Zone Regeln für Datagramme, die vom Connection Tracking ausgenommen werden sollen.
Die Webschnittstelle LuCI
Ein Vorteil der browserbasierten Konfiguration ist, dass sie Leuten, die die Kommandozeile eher scheuen, die Administration von OpenWrt akzeptabel machen kann. Insbesondere, wenn man längere Zeit keine Router konfiguriert hat, liefert die Webschnittstelle genügend Kontext, um eine kleine Änderung mal eben schnell einzustellen.
In den meisten Fällen wird LuCI auf Englisch eingestellt sein. Will ich die Konfiguration in deutscher Sprache, muss ich unter System -> Software die Pakete luci-i18n-…-de installieren. Danach sollte sich die Webschnittstelle automatisch auf die in den Spracheinstellungen des Browser gemachten Vorgaben einstellen. Tut sie das nicht, kann ich unter System -> System im Reiter Language and Style die Einstellungen anpassen. In diesem Buch beziehe ich mich auf das englischsprachige Interface.
LuCI merkt sich Änderungen, die ich noch nicht aktiviert habe und zeigt dann oben rechts einen anklickbaren Hinweistext: “Unsaved Changes”. Klicke ich darauf, zeigt mir LuCI die noch nicht aktivierten Änderungen der Kommandozeilenoberfläche UCI. Dann kann ich diese anwenden oder verwerfen.
Auf der Kommandozeile kann ich diese Änderungen mit uci changes
anzeigen lassen, mit uci commit aktivieren oder mit uci revert ...
zurücknehmen.
Damit genug des Vorgeplänkels, kommen wir zur Konfiguration der Firewall mit LuCI.
Zuordnung der Netzwerke und Schnittstellen
Ich beginne, indem ich die Schnittstellen, die mein Gerät besitzt, den Netzwerken respektive Firewall-Zonen meiner Policy zuordne.
Bei OpenWrt habe ich verschiedene Möglichkeiten, die Schnittstellen zuzuordnen: eine Firewall-Zone kann eine Schnittstelle umfassen oder mehrere Schnittstellen, wobei eine Schnittstelle aus einem physischen Anschluss bestehen kann oder aus mehreren Anschlüssen, die zu einer Bridge zusammengefasst sind.
Für diese Zuordnung gehe ich in den Menüpunkt Network -> Interfaces und wähle eine Schnittstelle über den Schalter Edit aus, oder füge eine neue Schnittstelle mit dem Schalter Add new interface hinzu.
Im Reiter General Setup stelle ich bei Protokol ein, wie die Adressen konfiguriert werden (Statische Adresse, DHCP-Client, Ignoriert, …) und trage nötigenfalls die Netzwerk-Konfiguration selbst ein.
Im unteren Bereich habe ich die Möglichkeit einen DHCP-Server für diese Schnittstelle bereitzustellen.
Beim Reiter Advanced Settings vergewissere ich mich, dass die Schnittstelle während des Bootvorgangs aktiviert wird. Bei Use builtin IPv6-Management lasse ich den Haken gesetzt. Weiter kann ich hier bei Bedarf die MAC-Adresse, die MTU und die Gateway-Metrik vorgeben.
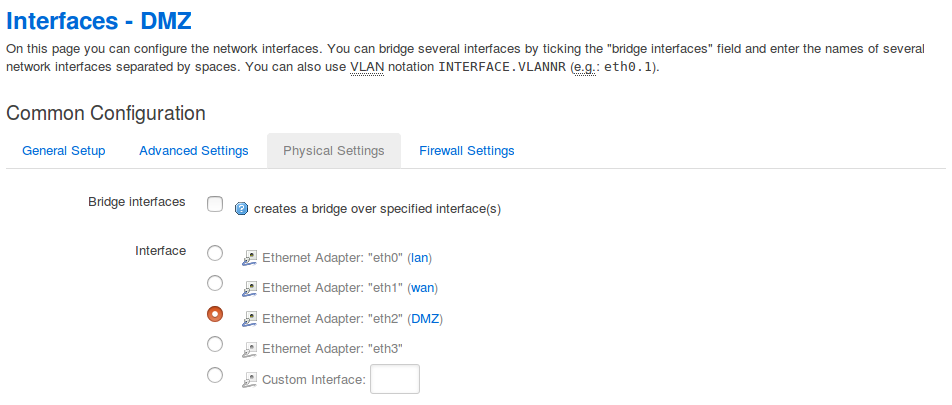
Beim Reiter Physical Settings kann ich die zu einer Bridge gehörenden Anschlüsse festlegen oder eine einzelne Schnittstelle auswählen, wenn ich keine Bridge in der Zone betreibe.
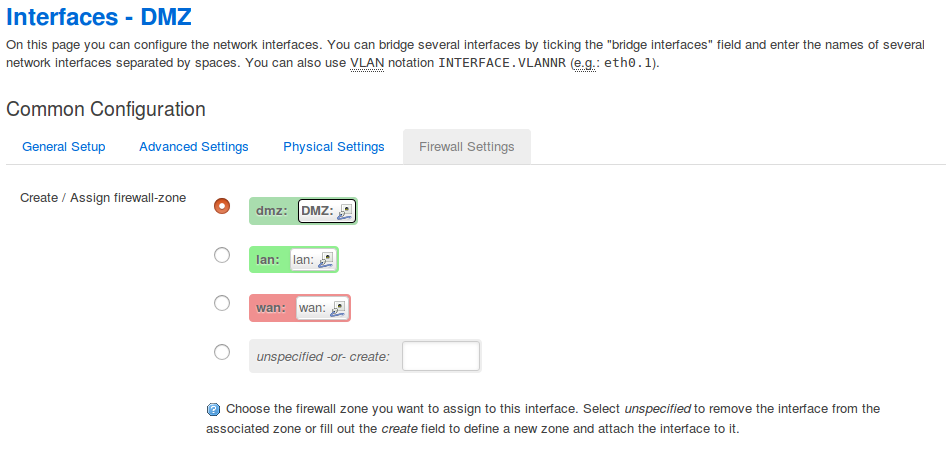
Beim ReiterFirewall Settings weise ich die Zonen für die Firewall zu oder lege eine neue Firewallzone an. Diese Zonen sind die Zonen im Modell aus dem vorigen Kapitel, die im Graphen unter “name” zusammengefasst sind.
Habe ich Netzwerke, die nicht direkt mit dem Gerät verbunden sind und verwende kein Routing-Protokoll, kann ich über den Menüpunkt Network -> Static Routes das Gateway dorthin angeben.
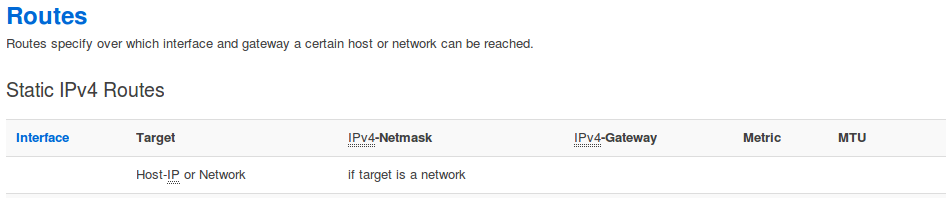
Routen für IPv6 kann ich auf der gleichen Seite eingeben.
Damit habe ich die grundlegenden Netzwerkeinstellungen und kann mich der eigentlichen Konfiguration der Firewall widmen.
Allgemeine Firewall-Einstellungen
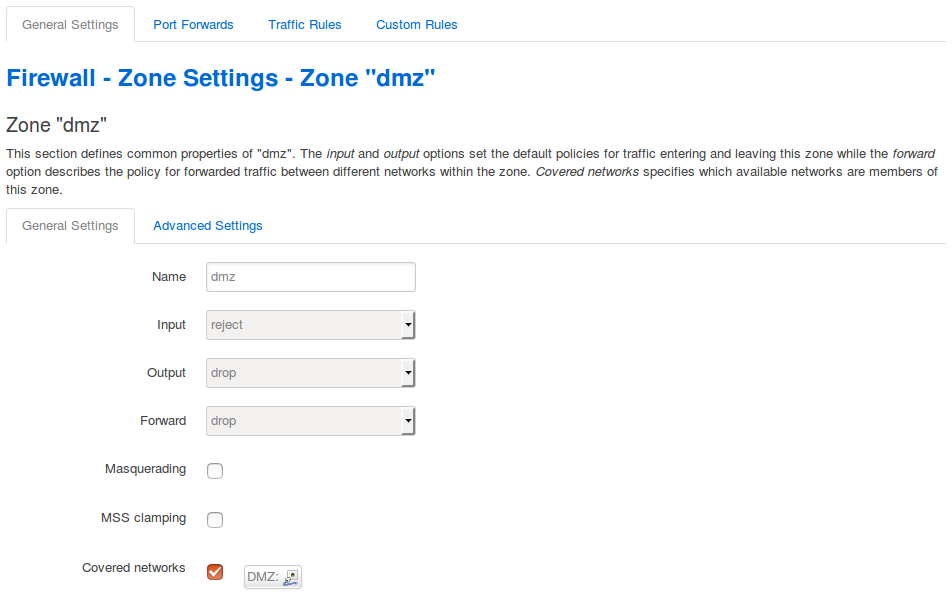
Ich beginne beim Menü Network -> Firewall im Reiter General Settings.
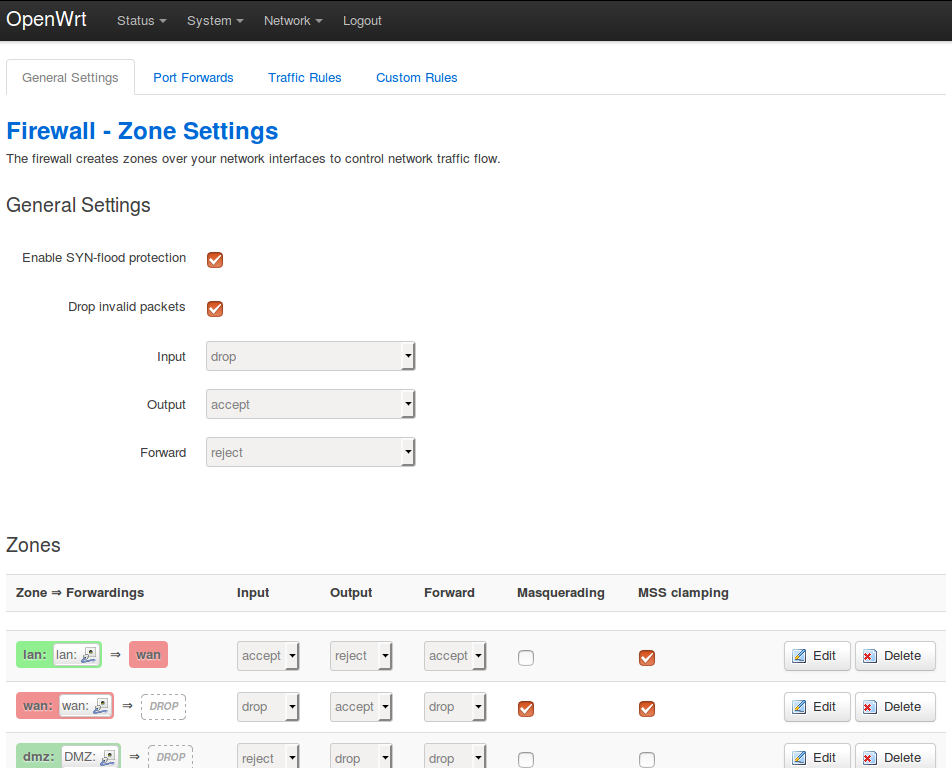
Mit einem Haken kann ich den Schutz vor SYN-Flood-Attacken aktivieren, was mir für TCP-Datagramme beim Verbindungsaufbau in der Iptables-Tabelle filter einen Sprung von der Regelkette delegate_input zur Kette syn_flood beschert. Das heißt, dieser Schutz gilt nur für Datagramme direkt an das Gerät und nicht für die Netze hinter der Firewall.
Mit dem Haken Drop invalid packets kommt in jede der Regelketten delegate_forward, delegate_input und delegate_output eine Regel, die ungültige Datagramme verwirft. Ungültige Datagramme sind Datagramme mit ungültigen Headern, Prüfsummen oder TCP-Flags, ungültige ICMP-Nachrichten und Pakete außer der Reihe, die zum Beispiel bei Attacken mit Vorhersage der Sequenznummer entstehen.
Bei den Richtlinien für Input, Output und Forward lege ich die Policy der drei System-Regelketten INPUT, OUTPUT und FORWARD fest, wie mit Datagrammen verfahren wird, für die es keine explizite Regel gibt.
Im Abschnitt Zones kann ich detaillierte Vorgaben machen. Hier finde ich die Firewall-Zonen aus den Netzwerkeinstellungen.
In der Tabelle Zone Forwardings gebe ich vor, zwischen welchen Zonen Daten ausgetauscht werden dürfen. Mit dem Schalter Add kann ich weitere Weiterleitungen definieren. Über den Schalter Edit kann ich bestehende Weiterleitungen modifizieren.
Hier kann ich - analog zu den globalen Richtlinien - festlegen, wie mit Datagrammen zwischen zwei Zonen verfahren wird, für die es keine explizite Regel gibt. Das heißt ich lege die Policy für den Datenverkehr zwischen diesen beiden Zonen fest.
Mit dem Haken bei Masquerading stelle ich dieses für abgehende Datagramme in dieser Zone ein. Bei SOHO-Routern setze ich diesen Haken üblicherweise am WAN-Interface beziehungsweise bei der zugehörigen Zone.
Der Haken bei MSS Clamping erzeugt in Iptables-Tabelle mangle eine Regel in der Kette mssfix, mit der beim Aufbau von TCP-Verbindungen die Maximum Segment Size (MSS) an die MTU der Zone anpasst. Das brauche ich zum Beispiel bei PPPoE-Verbindungen (DSL), bei denen ein Teil des Ethernet-Frames für Verwaltungsinformationen draufgeht und nur 1492 statt 1500 Byte für die IP-Datagramme zur Verfügung stehen.
Die Covered Networks entsprechen denen in den Netzwerkeinstellungen
Bei Inter-Zone-Forwarding stelle ich ein, zu beziehungsweise von welchen Zonen ich Datagramme weiterleiten möchte. Dabei bewirkt ein Haken bei den entsprechenden Zonen, dass ein Sprung in der Kette zone_quellname_forward zur Kette zone_zielname_dest_ACCEPT angelegt wird.
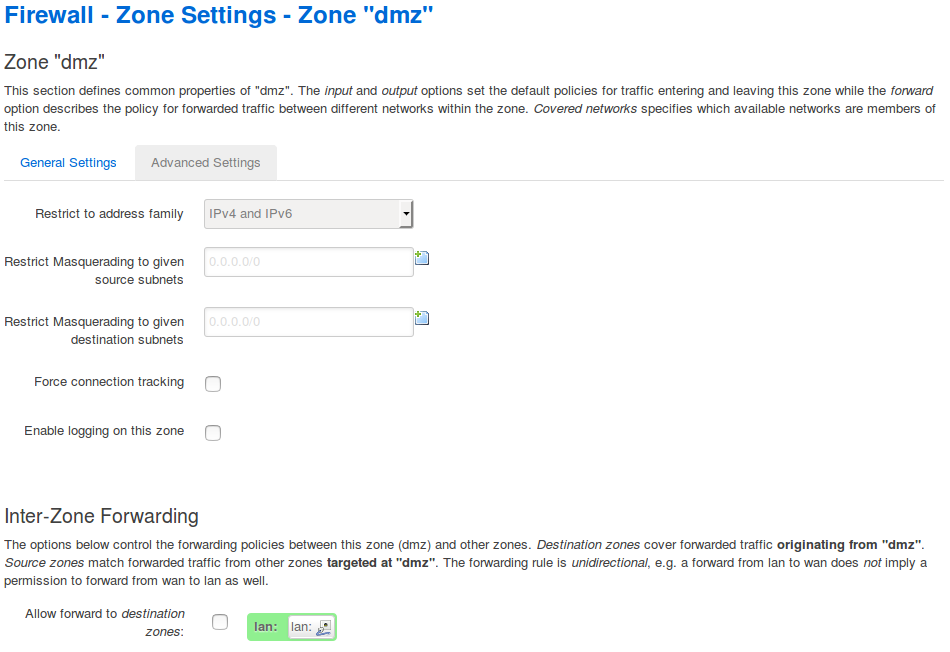
In den Advanced Settings kann ich die Zonen auf eine Adressfamilie (IPv4, IPv6) beschränken.
Weiterhin kann ich Masquerading auf bestimmte Quell- oder Zielnetze einschränken.
Connection Tracking ist nur bei NAT automatisch aktiv. Hier kann ich es gezielt einschalten, genauso wie das Logging für die Zone.
Port Forwards
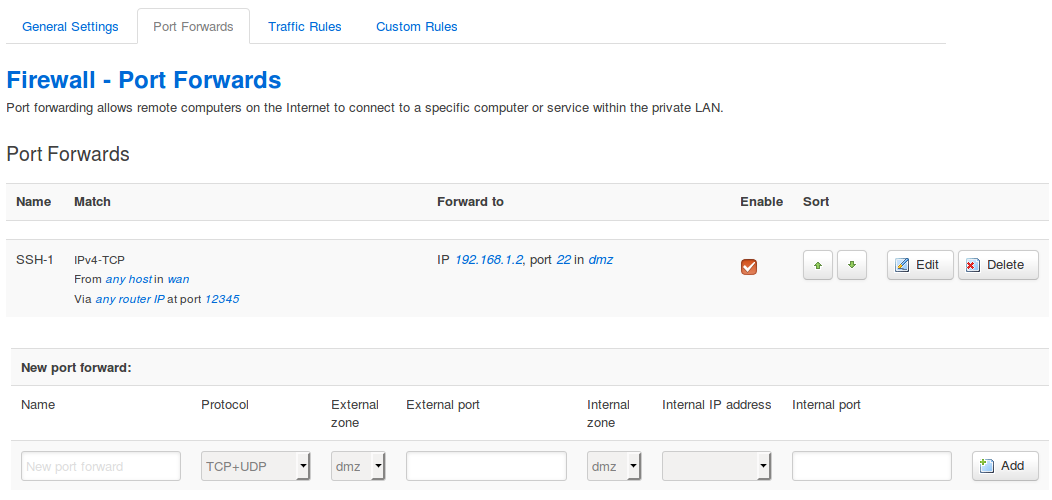
Insbesondere bei Masquerading, wie ich es in SOHO-Routern oft finde, habe ich keine Möglichkeit, von der externen Seite aus, einen Rechner auf der internen Seite zu erreichen, da der Router das einzige Gerät ist, dessen Adresse im externen Netz bekannt ist.
Hier helfe ich mir mit Port-Weiterleitungen zumindest für TCP und UDP weiter. Dabei gebe ich einen frei wählbaren Namen für die Weiterleitung an, das Protokoll, die externe Zone und den Port, sowie die interne Zone, Adresse und Port, an die die Datagramme weitergeleitet werden sollen. Über den Schalter “Add” füge ich eine Portweiterleitung hinzu.
Beim Protokoll habe ich die Auswahl zwischen:
- TCP+UDP: die Portweiterleitung gilt gleichermaßen für beide Protokolle
- TCP: nur für TCP
- UDP: nur für UDP
- Other: für andere Protokolle, zum Beispiel ICMP
Die Weiterleitung für andere Protokolle ist etwas kompliziert. Diese lässt sich am besten über den Schalter “Edit” einer bestehenden Weiterleitung einstellen. Auf jeden Fall muss ich die erzeugte Regel kontrollieren und ausprobieren.
Traffic Rules
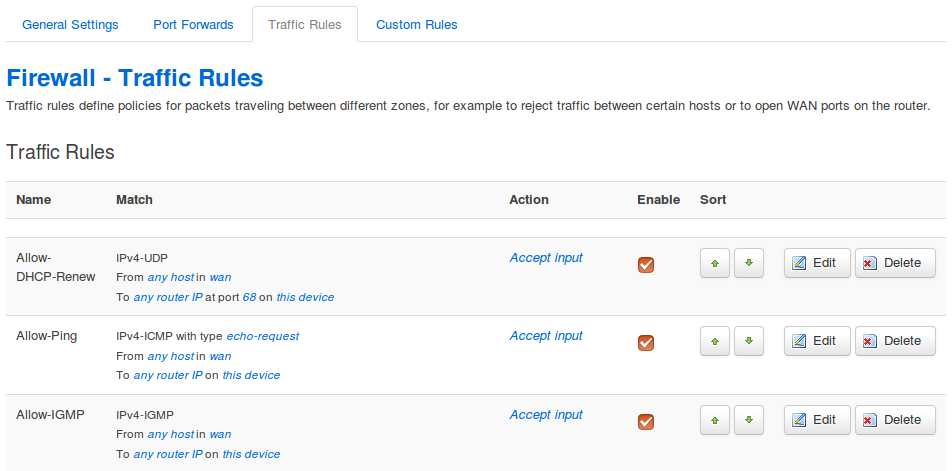
Beim Reiter Traffic Rules finde ich eine sortierte Liste von Regeln, in die ich meine eigenen einfügen kann.
Einige Regeln sind bereits vordefiniert, wie zum Beispiel
- Allow-DHCP-Renew
- Allow-Ping
- Allow-ICMP
- Allow-DHCPv6
- Allow-MLD
- Allow-ICMPv6-Input
- Allow-ICMPv6-Forward
- Regeln für das Durchlassen von IPsec-Tunneln
Diese Regeln kontrolliere ich, ob ich sie wirklich haben möchte, und deaktiviere die unerwünschten. Außerdem kann ich diese Regeln als Muster für meine eigenen verwenden.
Weiterhin kann ich hier Ports öffnen, falls ich lokale Dienste auf dem Router betreibe, Regeln für die Weiterleitung vorgeben oder mit Source NAT die volle Kontrolle über die Quelladressen auszuüben.
Custom Rules
Habe ich ein Problem, das ich mit LuCI nicht in entsprechende Regeln fassen kann, besteht die Möglichkeit, beliebige Iptables-Befehle in einem Shell-Skript aufzurufen. Das Skript wird mit jedem Neustart der Firewall, direkt nach dem Abarbeiten der Basis-Regeln abgearbeitet.
Diese Regeln sind am besten in den System-Regelketten oder den explizit als User-Regelketten ausgewiesenen Ketten aufgehoben. Vergleiche dazu die Ausführungen zum Modell der OpenWrt-Firewall im vorigen Kapitel.
Die zentrale Konfigurationsschnittstelle UCI
UCI steht für Unified Configuration Interface, die zentrale Schnittstelle für die Konfiguration von OpenWrt.
Es gibt ein Kommandozeilenprogramm (uci) sowie API-Bindungen für
verschiedene Programmiersprachen.
Das im vorigen Kapitel besprochene Webinterface LuCI verwendet UCI als
Backend für die Konfiguration.
Ich verwende UCI direkt über das Kommandozeilenprogramm,
- wenn kein Webinterface installiert ist,
- für die automatisierte Konfiguration und
- wenn ich bereits via SSH angemeldet bin und schnell etwas anpassen will.
Allgemeine Prinzipien
UCI arbeitet mit Konfigurationsdateien im Verzeichnis /etc/config. Jede dieser Dateien deckt einen Bereich der Konfiguration ab, wie zum Beispiel network für die Netzwerk-Einstellungen und firewall für die Firewall-Einstellungen.
Ich kann die Dateien mit einem beliebigen Texteditor bearbeiten oder mit dem
Kommandozeilenprogramm uci.
In eigenen Programmen kann ich auf die API für verschiedene
Programmiersprachen (C, Lua, Shell) zurückgreifen.
Damit eine Änderung in der Konfiguration wirksam wird, muss anschließend der entsprechende Dienst neu gestartet werden, zum Beispiel für die Firewall:
Manchmal heißen die Skripts zum Neustart eines Dienstes unter /etc/init.d/ genau wie die Konfigurationsdatei in /etc/config/. In einigen Fällen muss ich andere Skripts zum Neustart des Dienstes verwenden. Einen Hinweis, welches Skript zu welcher Konfiguration gehört, liefert die Datei /etc/config/lucitrack aus dem Paket luci-base.
Syntax der Konfigurationsdateien
Die Syntax der Dateien unter /etc/config/ ist recht einfach. Die Anweisungen stehen auf jeweils einer Zeile und beginnen mit einer Direktive auf die spezifische Argumente folgen.
Es gibt die folgenden Direktiven:
-
package $name- leitet einen Konfigurationsbereich ein.Fehlt diese Direktive, dient der Dateiname als Name für den Bereich.
Beispiel:
package network -
config $styp [ $sname ]- leitet eine neue Sektion in einem Bereich ein. Alle folgenden Direktiven bis zum nächstenconfiggelten für diese Sektion. Zur besseren Lesbarkeit sind diese oft eingerückt, das ist aber nicht notwendig.Beispiel:
config interface 'lan' -
option $oname $ovalue- weist in einer Sektion einem Bezeichner einen Wert zu. Die Bedeutung des Bezeichners und des Wertes hängt von der Sektion ab.Beispiel:
option ipaddr '192.168.1.1' -
list $lname $lvalue- weist einer Liste einen weiteren Wert zu. Ähnlich der Direktiveoptionist die Bedeutung vom Bereich und der Sektion abhängig.Beispiel:
list network 'wan1' list network 'wan2'
Als Boolesche Werte kann ich ‘1’, ‘on’, ‘yes’ beziehungsweise ‘0’, ‘off’, ‘no’ verwenden.
Alle anderen Werte können beliebige Zeichenketten sein. Enthalten diese Leerzeichen oder Tabulatoren, muss ich sie mit einfachen oder doppelten Anführungszeichen begrenzen.
Die Bezeichner und Dateinamen dürfen nur die Zeichen _, A-Z, a-z und 0-9 enthalten.
Das Kommandozeilenprogramm uci
An dieser Stelle gebe ich nur eine kurze Einführung in das Kommandozeilenprogramm. Dieses zeigt alle unterstützte Optionen und Befehle an, wenn man es ganz ohne Argumente aufruft.
Die wichtigsten Befehle sind für mich:
-
uci show [$config[.$section[.$option]]]Damit zeigt
ucidie spezifizierten Daten (oder alles) in der Form an, in der ich es mituci addoderuci setkonfigurieren kann. - `uci get $config.$section[.$option]
Dieser Aufruf liefert nur den Wert, den ich dann in einem Skript weiter verwenden kann.
Um zum Beispiel den DHCP-Dämon neu zu starten, kann ich folgendes aufrufen und brauche nicht zu wissen, dass das Init-Skript dnsmasq heißt:/etc/init.d/$(uci get ucitrack.@dhcp[0].init) restartBeim Aufruf von Hand bin ich wahrscheinlich schneller, wenn ich direkt in /etc/init.d/ nachsehe. Ein Skript wird damit jedoch robuster gegenüber Änderungen.
-
uci export [$config]Dieser Aufruf zeigt die Konfiguration in der Form, wie sie in den Konfigurationsdateien steht. Mit
uci importkann ich das wieder importieren, so dass sich diese beiden Befehle für Backup und Restore der Konfiguration eignen. -
uci importLiest den mit
uci exporterstellten Text wieder ein. -
uci changeslistet Änderungen, die noch nicht mit
uci commitbestätigt wurden. -
uci revert $config[.$section[.$option]]macht unbestätigte Änderungen rückgängig.
- `uci commit [$config]
bestätigt die Änderungen, indem es sie in die Konfigurationsdatei unter /etc/config/ schreibt.
-
uci add|delete|add_list|del_list|set ...sind für einzelne Änderungen.
Neben den genannten Befehlen interessiert mich noch die Option -p, mit
der ich einen Suchpfad für die variablen Konfigurationsdaten vorgeben kann.
So finden sich in /var/state/network Laufzeitinformation zur
Netzkonfiguration, die uci mir nur anzeigt, wenn ich den Suchpfad auf
/var/state lege:
Habe ich eine neue Listenoption angelegt, kann ich diese mit dem Index -1
referenzieren und muss mich nicht um die genaue Position in der Liste
kümmern:
Konfiguration der Firewall
Bei der Firewall kennt UCI die folgenden Sektionen:
- defaults
- zone
- rule
- include
- forwarding
- redirect
- ipset
Alle Sektionen sind Listeneinträge, das heißt ich greife darauf mit der Notation `firewall.@sektion[$index]’ zu.
Detaillierte Informationen finde ich auf der Wikiseite zur Firewall-Konfiguration
Sektion defaults
Ich kann mir die Einstellungen anzeigen lassen mit:
Es gibt nur einen Listeneintrag.
Hier kann ich die globalen Einstellungen treffen, die ich in LuCI bei der Startseite für die Firewall finde.
Den Schutz vor SYN-Flood-Atacken aktiviere ich mit
Um ungültige Datenpakete zu verwerfen gebe ich das folgende ein:
Entsprechend gebe ich die Policies für die drei Einsprungsketten vor:
Da iptables keine REJECT Policy kennt, landet in diesem Fall ein Sprung zur Kette reject in der Kette delegate_forward.
Sektion zone
Diese Liste enthält so viele Elemente, wie Zonen definiert sind.
Eine Übersicht über die Einstellungen aller Zonen bekomme ich mit
Ich kann in dieser Sektion die allgemeinen Einstellungen für eine Zone vorgeben. Um beispielsweise eine neue Zone für die WAN-Schnittstelle zu definieren würde ich das folgende eingeben:
Der erste Aufruf legt eine neue Zone an und der zweite benennt diese.
Die Optionen input, output und forward bestimmen die Policies für diese Zone.
Mit der Option masq kann ich bestimmen, dass alle Datagramme für diese Zone mit der selben Absenderadresse hinausgehen sollen.
Die Option mtu_fix sorgt dafür, dass die MSS beim TCP-Verbindungsaufbau an die MTU der Verbindung angepasst wird.
Die Option network schließlich bezeichnet die Interfaces in den Netzwerkeinstellungen, die dieser Firewall-Zone zugeordnet werden.
Sektion rule
In LuCI wird bei den Firewallregeln unterschieden nach
- Regeln, die einen Port am Router öffnen und
- Regeln für die Weiterleitung
Diese gebe ich auf unterschiedliche Art ein.
Regeln, die einen Port am Router öffnen
Um beispielsweise den SSH-Port auf der WAN-Seite zu öffnen, gebe ich folgendes ein:
Der erste Aufruf legt die Regel an und der zweite benennt sie.
Die Option target gibt an, wie mit den passenden Datagrammen zu verfahren ist, ACCEPT heißt zulassen.
Die Option src legt die Zone (wan) fest, proto (tcp) und dest_port (22) sind spezifisch für SSH.
Regeln für das Weiterleiten von Traffic
Um Datenverkehr in andere Zonen weiterzuleiten, muss ich sowohl die Quell- als auch die Ziel-Zone angeben, wie in folgendem Beispiel:
Sektion include
Diese Sektion enthält nur einen Eintrag: den Namen der Datei, in der ich eigene Regeln ablege, die ich mit UCI oder LuCI nicht einstellen kann.
Hier ist der Name /etc/firewall.user voreingestellt.
Habe ich eine experimentelle Konfiguration, zu der ich schnell umschalten will, dann kann ich das mit den folgenden Befehlen:
Dabei gehe ich davon aus, dass die experimentelle Firewall-Konfiguration in der Datei /etc/firewall.other abgelegt ist.
Ich kann auch mehrere Skript-Dateien angeben, die nacheinander aufgerufen werden.
Sektion forwarding
Die Sektion forwarding steuert den Datenverkehr zwischen den Zonen und kann MSS-Clamping in bestimmten Richtungen aktivieren.
Eine forwarding Regel deckt nur eine Richtung ab. Um den Verkehr in beiden Richtungen zu regulieren, muss ich daher zwei Regeln definieren.
Sektion redirect
In dieser Sektion landen die Regeln für die Adressumsetzung.
Section ipset
Die UCI firewall ab Version 3 kann mit IPsets umgehen. Das bietet die Möglichkeit, große Adress- und/oder Portlisten in einer einzigen Regel abzuhandeln. Damit wird die Firewall entlastet, da IPsets sehr effizient beim Behandeln von großen Listen sind. Außerdem kann ich über die IPsets dynamisch die Listen ändern, ohne jedesmal die Firewall neu konfigurieren zu müssen.
Um IPsets verwenden zu können, muss das Paket ipset installiert sein, entweder bereits im OpenWrt-Image oder mit:
Mit UCI kann ich IPsets lediglich anlegen beziehungsweise extern
angelegte IPsets referenzieren.
Um konkrete Adressen oder Ports zum IPset hinzuzufügen oder zu
entfernen, verwende ich den ipset Befehl direkt oder in einem Skript.
Dieses Skript kann ich über die Sektion include automatisch beim
Modifizieren der Firewall aufrufen lassen oder via cron, wenn das
Skript die Daten von externen Quellen holt.