Yapay Zeka Etrafındaki Endişeler ve Riskler
 |
Yapay zeka etrafındaki endişeler ciddidir. Riskler gerçektir. Bazen histerik şekillerde ifade edilirler, ancak derinine incelediğinizde, yapay zekanın etkisi son derece yıkıcı olabilir. |
Yapay zeka etrafında o kadar çok sorun ve endişe var ki, kendi başlarına ciltler dolduruyorlar. İşte izlediğim konuların bir kelime bulutu. Eminim birkaçını kaçırıyorumdur.

Bu konular hakkında çok fazla bilgi mevcut ve mümkün olduğunca derinlemesine okumanızı teşvik ediyorum. Risklerin faydalardan daha ağır bastığına ve yapay zekayı, kişisel veya organizasyonunuz içinde kullanmak istemediğinize karar verebilirsiniz. Bu karar kendi risklerini getirir; genellikle, geride kalma riski. Ama bu kişisel bir seçimdir.
“Eğer yapay zekanın riskleri ile ilgili kitaplar” diye google’larsanız, değerli ciltlerden oluşan bir seçki bulacaksınız. Son zamanlarda özellikle ürpertici bulduğum bir podcast, Ezra Klein’ın Dario Amodei ile sohbetiydi, Anthropic’in kurucu ortağı ve CEO’su (Claude.ai’yi geliştiren şirket). Bu şirketlerin risklerin farkında olduğunu öğreniyorsunuz. Amodei, “AI Güvenlik Seviyeleri” (American Sign Language değil) için ASL olarak adlandırılan bir iç risk sınıflandırma sisteminden bahsediyor. Şu anda ASL 2 seviyesindeyiz, “tehlikeli yeteneklerin erken belirtilerini gösteren sistemler—örneğin biyolojik silahlar yapma talimatları verme yeteneği.” ASL 4’ü “devlet düzeyindeki aktörlerin yeteneklerini büyük ölçüde artırmalarını sağlama… Kuzey Kore, Çin veya Rusya’nın AI ile çeşitli askeri alanlarda saldırı yeteneklerini büyük ölçüde artırarak jeopolitik düzeyde önemli bir avantaj elde etmelerinden endişe ederdik.” Ürpertici şeyler.
Bu kasvetli bağlam içinde, yazarlar ve yayıncılar için en önemli sorunları vurgulayacağım.
Telif hakkı ihlali mi?
|
Telif hakkı sorunları karmaşıklık ve belirsizlik içinde bir sis bulutudur. Bazı telif hakkı altındaki kitapların bazı Büyük Dil Modelleri’nin eğitiminde kullanıldığı kesin gibi görünüyor. Ancak bazı yazarların korktuğu gibi, tüm eserlerinin her büyük dil modeli tarafından tamamen tüketildiği kesinlikle doğru değil. |
Telif hakkı sorunları hem spesifik hem de geniştir. Tüm Büyük Dil Modelleri’nin açık web üzerinde eğitildiği iyi bilinmektedir - bugün web’deki 1,5 milyar siteden kazınabilecek her şey, ister gazete makaleleri, sosyal medya gönderileri, web blogları ve görünüşe göre YouTube videolarının transkriptleri olsun.
En az bir Büyük Dil Modeli’nin kamuya açık olmayan binlerce kitabın gerçek metnini tükettiği kanıtlanabilir.
Bu metnin tamamını milyar dolarlık yapay zeka şirketleri oluşturmak için tazminatsız olarak tüketmek yasal mıydı? Yapay zeka şirketleri adil kullanım etrafında argümanlarını yapıyorlar; mahkemeler nihai kararı verecek. Yasal olsa bile, etik veya ahlaki miydi? Etik hususlar, yasal değerlendirmelerden daha az karmaşık görünmektedir. Karar sizin.
Telif hakkı ile ilgili yasalar, açıkça yapay zekanın getirdiği benzersiz zorlukları öngörmemiştir ve yasal çözümler aramak zaman alacak, belki yıllar. (Yasaların eldeki belirli probleme neden uygun olmadığını daha derinlemesine incelemek isterseniz, A. Feder Cooper ve James Grimmelmann’ın mükemmel makalesini “Dosyalar Bilgisayarda: Telif Hakkı, Hafıza ve Üretken Yapay Zeka” adlı makalesini okuyun.)
İşte en öne çıkan 13 davanın bir listesi, hepsi kitaplarla ilgili değil; aynı zamanda görüntüler ve müzikler de var. Ve tüm davaların durumunu güncelleyen başka bir liste.
Yazarlar için Telif Hakkı ve Yapay Zeka
|
Yazarlar, yapay zeka tarafından üretilen içeriğin telif hakkı alabilirliği ile ilgili ek sorunlarla karşı karşıya. |
ABD Telif Hakkı Ofisi’nin yapay zeka tarafından üretilen içeriğin telif hakkı alabilirliği konusundaki konumu, yapay zekanın yazarın yasal statüsünden yoksun olduğu için tek başına telif hakkı sahibi olamayacağını belirtiyor. Bu mantıklı. Ancak bu, çalışmanın %100’ünün yapay zeka tarafından üretildiği varsayımına dayanıyor. Başka yerlerde tartışıldığı gibi, birkaç yazar yapay zekanın bir kitabın tamamını üretmesine izin verecektir. Daha olası olan %5, %10 veya… Ve burada Telif Hakkı Ofisi tökezliyor (ben de öyle).
Daha yakın bir kararda Ofis, insan tarafından yazılmış metinlerin yapay zeka hizmeti Midjourney tarafından üretilen görüntülerle birleştiği bir grafik romanın telif hakkına sahip olabileceğine, ancak bireysel görüntülerin telif hakkı koruması altına alınamayacağına karar verdi. Aman Tanrım!
|
Yazarlar ve yayıncıların, birçok cephede gelişen telif hakkı sorunlarına karşı uyanık olmaları gerektiğini söylemek yeterli olacaktır. |
Uzun vadeli sonuçlar nelerdir?
Bazıları mevcut davaları Google kitap davası ile karşılaştırıyor, bu da yasal olarak çözülmesi 10 yıl aldı. Bu başvuruların temyiz sürecinin ne kadar süreceği kim bilir. Bu arada, yayıncılar, yapay zeka şirketlerinin kaybedeceği varsayımıyla hareket etmekte temkinlidir, bu da en azından teorik olarak, Chat AI lisansı veren veya hatta kullanan herkesi bir tür olası yükümlülüğe maruz bırakır.
Ancak bu, bir yayıncının en ciddi sorunu değil. Bu algıdır. Birçok yazar için, bazıları ünlü, bazıları bilinmeyen, kuyu zehirlenmiştir. Yapay zeka, yazma ve yayınlama topluluğu içinde radyoaktif hale geldi. Yapay zekayı çağrıştıran herhangi bir şey yoğun eleştiri alıyor.
Birçok örnek var. Yakın zamanda meydana gelen bir olayda, “modern yetişkin bilim kurgu, fantezi ve WTF’de en iyisine adanmış” bir İngiliz yayıncı Angry Robot, büyük bir el yazması gönderisi yığınıyla başa çıkmak için Storywise adlı bir yapay zeka yazılımı kullanacağını duyurdu. Şirketin planı bırakması ve eski gelen kutusuna dönmesi sadece beş saat sürdü.
Yayıncılar için AI araçlarını dahili olarak kullanmanın katlanılmaz ikilemi: yazarlarınız bunu öğrenirse, ortaya çıkacak fırtınaya dayanmakta zorlanacaksınız. Yayıncıların cesur olmaktan başka seçeneği olmadığını, araçları (en azından bazılarını) benimsemeleri, bu araçların nasıl eğitildiğini ve nasıl kullanıldığını açıkça açıklamaları ve devam etmeleri gerektiğine inanıyorum.
Birleşik Krallık’ta, Yazarlar Derneği sert bir tutum sergiliyor: “Yayıncınızdan, eserinize ilişkin herhangi bir amaçla yapay zekayı önemli ölçüde kullanmayacağını teyit etmesini isteyin - örneğin, düzeltme, düzenleme (otantiklik okumaları ve gerçek kontrolü dahil), dizinleme, yasal inceleme, tasarım ve düzen veya başka herhangi bir şey için sizin izniniz olmadan. Yapay zeka tarafından gerçekleştirilen sesli kitap anlatımını, çeviriyi ve kapak tasarımını yasaklamak isteyebilirsiniz.”
Yazarlar Birliği, “yayıncıların operasyonlarının olağan seyrinde, editoryal ve pazarlama kullanımları dahil olmak üzere yapay zekayı bir araç olarak kullanmayı keşfetmeye başladığını” kabul ediyor gibi görünüyor. Birliğin birçok üyesinin bu kadar anlayışlı olduğunu düşünmüyorum.
AI şirketlerine içerik lisanslama
Çoğu yayıncı ve birçok yazar, AI şirketlerine içerik lisanslamanın yollarını arıyor. Herkes lisanslama koşullarının ne olması gerektiği ve içeriklerinin ne kadar değerli olduğu konusunda farklı bir fikre sahip, ancak en azından tartışmalar başladı.
Yayıncılarla (ve bazı durumlarda bireysel yazarlarla) çalışmak isteyen birkaç girişim var. Calliope Networks ve Created by Humans bu konuda ilginç.
Temmuz ortasında, uzun zamandır kolektif telif hakkı lisanslamasında sektörün ana oyuncusu olan Copyright Clearance Center, “yapay zeka (AI) yeniden kullanım haklarının Yıllık Telif Hakkı Lisansları (ACL) kapsamında sunulacağını” duyurdu. Bu, milyonlarca eserden işletmelere abonelik sunan bir kurumsal içerik lisanslama çözümüdür.
Publishers Weekly, duyuruyu haber yaptı ve CCC Başkanı ve CEO’su Tracey Armstrong’un şu sözlerine yer verdi: “AI’ye ve telif hakkına karşı olmak mümkün ve yaratıcıları saygıyla AI ile birleştirmek de mümkün.”
Tam kapsamlı olmasa da, bu, yayıncılığı büyük dil modeli geliştiricileriyle belirli bir işbirliği düzeyine yaklaştırmada muhtemelen bir atılımdır.
AI’dan kaçınmak için çok geç
|
AI ile kirlenmek istemeyen yazarlar ve yayıncılar için haberler kötü: bugün AI kullanıyorsunuz ve yıllardır kullanıyordunuz. |
Yapay zeka, farklı biçimlerde, günlük olarak kullandığımız yazılım araçlarının ve hizmetlerin çoğuna zaten entegre edilmiştir. İnsanlar, Microsoft Word veya Gmail gibi programlarda AI destekli yazım ve dilbilgisi denetimine güveniyor. Microsoft Word ve PowerPoint, yazma önerileri sunmak, tasarım ve düzen önerileri sağlamak ve daha fazlası için AI kullanır. Siri ve Alexa gibi sanal asistanlar, sesli komutları anlamak ve sorulara yanıt vermek için doğal dil işleme kullanır. E-posta hizmetleri, mesajları filtrelemek, spam tespit etmek ve uyarılar göndermek için AI kullanır. AI, müşteri hizmetleri sohbet botlarını güçlendirir ve satın alma geçmişinize dayalı ürün önerileri oluşturur.
Ve bunların çoğu, ChatGPT ile olduğu gibi, Büyük Dil Modellerine dayanmaktadır.
Bir yazar veya editörün, “Manuskriptime AI kullanılmasını istemiyorum” demesi, genel anlamda, neredeyse imkansızdır, çünkü hem onlar hem de editörleri daktilo ve kalemle çalışmadıkları sürece.
Kitaplarında “üretici yapay zeka” kullanılmasını istemediklerini söylemeyi deneyebilirler. Ancak bu zor bir durum. Dilbilgisi denetleme yazılımı başlangıçta üretici yapay zeka üzerine inşa edilmemişti. Grammarly, ürününe bir bileşen olarak ekledi ve diğer tüm yazım ve dilbilgisi denetleyicileri de ekleyecek. Üretici yapay zeka, pazarlama yazılımının da temelidir.
Yazarlar AI kullandığında
Yazarlar ve AI kullanımı konusunun bir başka yönü, yukarıda tartışılan telif hakkı sorunuyla benzerlikler taşır. Aşırı durumda, yüzde 100 AI tarafından oluşturulan içeriğin Amazon’da yayımlandığını görüyoruz. Çoğu (hepsi?) berbat kalitede, ama bu yayımlanmasını engellemiyor. (Ayrıca Amazon bölümüne bakın.) Yayıncılar için daha endişe verici olan AI tarafından oluşturulan başvurulardır. Evet, AI miktarı artırıyor, ancak büyük yayıncılar zaten miktar filtresine sahip. Bu filtreler ajanlardır. Miktar sorununu nasıl çözeceklerini bulmak zorunda olanlar onlar ve görünüşe göre AI kullanmayan bir çözüm bulmak zorundalar.
Bu bir tür varoluşsal sorun—‘bir makine’ tarafından yazılmış bir kitabı yayınlamak istiyor muyum? Çoğu yayıncı için bu kesin bir ‘hayır.’ İşte bu kadar basit. Peki, yetenekli bir yazarın gözetiminde içeriğin %50’si bir LLM tarafından üretilmiş bir kitap hakkında ne düşünüyorsunuz? Hmm, buna da bir ‘hayır’ deneyelim. Tamam: o zaman %25, %10 veya %5 hakkında ne düşünüyorsunuz? Çizgiyi nereye çekersiniz?
Ve şimdi çizgi çekme işine girdiğinize göre, yazım ve gramer araçlarının artık en azından kısmen yapay zeka üretimine dayandığı ikilemini nasıl çözeceksiniz? Peki ya Otter.ai gibi AI destekli transkripsiyon araçları veya Microsoft Word’e entegre edilen transkripsiyon özelliği?
Önceden belirlenmiş bir miktarda yapay zeka üretimi metin içeren bir eseri yayınlamayacaklarını belirten hiçbir ticari yayıncı bulamıyorum. İşte Authors Guild konuyla ilgili olarak şunları söylüyor:
“Eğer el yazmanızda dikkate değer miktarda yapay zeka üretimi metin, karakter veya olay örgüsü bulunuyorsa, bunu yayıncınıza açıklamalısınız ve ayrıca okuyucuya da açıklamalısınız. Beyin fırtınası, fikir üretimi veya düzeltme amacıyla yapay zeka kullanımı söz konusu olduğunda yazarların bunu açıklamasının gerekli olduğunu düşünmüyoruz.”
Söylemeye gerek yok, ‘dikkate değer’ tanımlanmamış (Oxford bunu “farkedilecek veya önemli sayılacak kadar büyük” olarak tanımlar), ancak gönderi, “de minimis yapay zeka üretimi metin” içermenin çoğu yayın sözleşmesini ihlal edeceğini açıklamaya devam ediyor. Hukuki terimlerle, de minimis tam olarak belirtilmemiştir, ancak genel olarak, dikkate değer ile aynı anlama gelir.
Yapay zeka yazıda tespit edilebilir mi?
2024 Mayıs ayında BISG sponsorluğunda bir yapay zeka tespit webinarı düzenledim. Tekrarı YouTube’da çevrimiçi. Jane Friedman, Hot Sheet bülteninde webinarın kapsamlı bir özetini sundu.
Birçok yazar için, yapay zekanın toksisitesi, onu kelimelerinden uzak tutmak anlamına gelir. Yayıncılar özel bir yük taşır—metni yaratmazlar, ancak bir kez yayınlandığında, metne büyük bir yükümlülük taşırlar. İçeriğin sosyal etkileri veya diğer yazarların kelimelerinin ve fikirlerinin intihal edilmesi etrafında olsun, patlayıcı kitapların yakınında çok fazla dinamit patladığını gördük. Şimdi yapay zeka ile karşı karşıya olduğumuz yeni bir dizi etik ve hukuki sorun var, bunların hiçbiri yayıncılık okulunda anlatılmadı.
Bunun bir kısmı, öğrenciler için endişe edilen şeylere benziyor; yapay zeka kullanmanın bir şekilde hile yapmak olduğu, Wikipedia makalesinden kopya çekmek gibi ya da belki sadece bir arkadaşa makalenizi yazmasını istemek gibi.
Webinar konuşmacılarımızdan biri, eğitimci José Bowen, öğrenciler için hazırladığı açıklamayı paylaştı. Bu, bir yazar için kullanacağınız şey değildir, ancak yapay zeka kullanımının bazı “risk seviyelerini” göstermektedir.
Öğrenciler İçin Şablon Açıklama Anlaşması
Bu çalışmanın tamamını arkadaşlar, araçlar, teknoloji veya yapay zeka yardımı olmadan kendi başıma yaptım.
-
İlk taslağı ben yaptım, ancak daha sonra arkadaşlarım/ailem, yapay zeka parafraz/granmer/ intihal yazılımına okutup önerilerde bulunmalarını istedim. Bu yardımdan sonra şu değişiklikleri yaptım:
Yazım ve gramer hatalarını düzelttim
Yapının veya sıralamanın değiştirilmesi
Bütün cümleleri/paragrafları yeniden yazmak
Sorunlarla karşılaştım ve bir tezaurus, sözlük kullandım, bir arkadaşı aradım, yardım merkezine gittim, Chegg veya başka bir çözüm sağlayıcı kullandım.
Fikir üretmek için yapay zeka/arkadaşlar/eğitmen kullandım.
Bir taslak/ilk taslak oluşturmak için yardım/araçlar/yapay zeka kullandım, ardından düzenledim. (Katkınızın doğasını açıklayın.)
Ve bir yayıncı, yazarları için buna benzer bir şey hazırlayabilir. Diyelim ki yazar en üst düzeyde açıklamada bulunuyor: Yapay zekayı yoğun olarak kullandım, ardından sonuçları düzenledim. Ne olur? Otomatik olarak el yazmasını reddeder misiniz? Öyleyse neden?
Ve bu arada, dikkat ediyorsanız, yazarın Grammarly tarafından bile yazım denetimi yapılmadığına yemin ettiği ve beğendiğiniz o el yazmasının aslında yapay zeka tarafından %90 oranında üretilmiş olabileceğini öğrenirsiniz ve yazar, kullanımını gizleme konusunda uzmandır.
Sonunda soruyu yeniden düşünmek zorunda kalıyorsunuz. Bu, “Bu tespit edilemez şeyi neden bu kadar lanet olası bir şekilde tespit etmeye kararlıyım?” haline gelir.
Kısmen Yapay Zeka tarafından üretilen metinlerin telif hakkına sahip olma konusundaki alarmist endişelerden kaynaklanıyor. Telif hakkı ofisi, %100 Yapay Zeka tarafından üretilen metinlere (veya müziklere, görüntülere, vb.) telif hakkı koruması sağlamayacaktır. Peki ya %50 Yapay Zeka tarafından üretilen metinler? Eh, sadece yazar tarafından üretilen %50’yi kapsayacağız. Ve hangi yarının hangisi olduğunu nasıl bileceksiniz? Bu konuda size geri döneceğiz.
Her el yazmasını bir yazılıma besleyip, metnin oluşturulmasında Yapay Zeka kullanılıp kullanılmadığını söyleyen bir yazılımın harika olmayacağını mı düşünüyorsunuz?
Bu işi yapmanın tek yolu Yapay Zeka araçlarını kullanmak olsa da, daha önemli soru şu ki, yazılım yeterince doğru olur mu? Bir el yazmasının oluşturulmasında Yapay Zeka kullanılıp kullanılmadığını bana güvenilir bir şekilde söyleyebilir mi? Ve Yapay Zeka kullanılmadığında bile “yanlış pozitifler” üretmeyeceğine güvenebilir miyim?
Şu anda piyasada bu zorluklarla başa çıkan birçok yazılım var. Bu yazılımları değerlendiren birçok akademik çalışma güvenilmezliğine işaret ediyor. Yapay Zeka tarafından üretilen metinler gözden kaçıyor. Daha da kötüsü, Yapay Zeka tarafından üretilmeyen metinler yanlış bir şekilde kontamine olarak etiketleniyor.
Ancak kitap yayıncıları bazı türden güvenlik önlemlerinin yerinde olmasını isteyecektir. Görünüşe göre, en iyi ihtimalle, bu araçlar size olası endişeler konusunda uyarabilir, ancak her zaman tekrar kontrol etmeniz gerekecektir. Belki de bu, diğerlerinden daha dikkatli incelenmesi gereken metinlere dikkat çekebilir mi? Bu bir verimlilik mi?
Gerçek verimlilik, bir metnin kökeni hakkındaki endişeleri aşarak, mevcut kriterlerimizi kalitesi konusunda koruyarak bulunacaktır.
İş kaybı
“Yapay Zeka tarafından değiştirilmek üzere değilsiniz. Yapay Zeka kullanmayı bilen biri tarafından değiştirileceksiniz.” —Anonim
Yapay Zeka benimsenmesinden kaynaklanan iş kaybı ciddi olabilir. Tahminler değişiklik gösterse de, rakamlar iç karartıcı. Belirgin örnekler var: San Francisco’nun sürücüsüz taksileri… taksi ve sürüş paylaşımı sürücülerini ortadan kaldırır. Yapay Zeka destekli teşhisler, tıbbi teknisyenlere olan ihtiyacı azaltabilir.
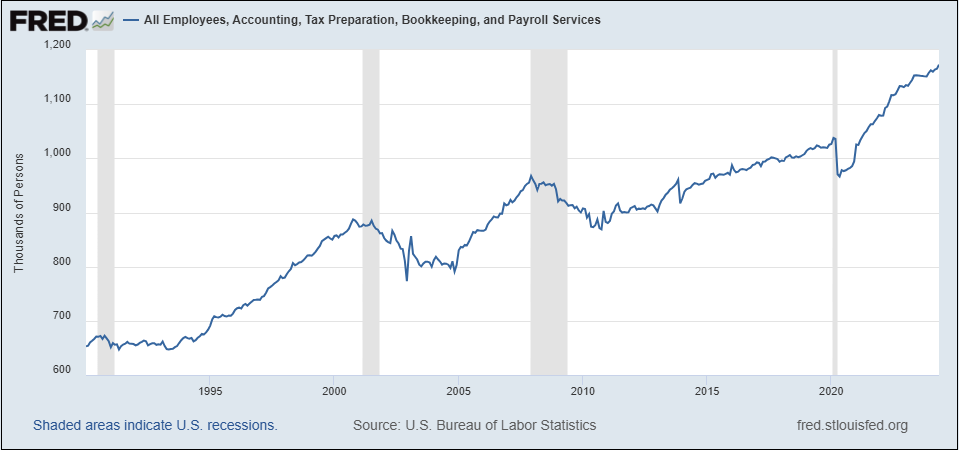
İyimser yanım, elektronik tablonun tanıtımı ve istihdam üzerindeki etkisi gibi bir örneğe işaret ediyor. Aşağıdaki grafikte gördüğünüz gibi, “Muhasebe, Vergi Hazırlama, Muhasebecilik ve Bordro Hizmetleri” ndeki istihdam 1990’dan bu yana neredeyse iki katına çıktı - bu görevleri büyük ölçüde otomatikleştiren elektronik tablolar ve diğer teknolojilerin bir iddianamesi değil.
Ethan Mollick’in Boston Consulting Group (BCG) ile yaptığı çalışma, Yapay Zeka’nın iş üzerindeki etkisini, özellikle karmaşık ve bilgi yoğun görevler üzerindeki etkisini daha iyi anlamayı amaçlayan bir deneydi. Çalışma, 758 BCG danışmanını, iki görev için OpenAI’nın GPT-4’ünü kullanmaya veya kullanmamaya rastgele atadı: yaratıcı ürün inovasyonu ve iş sorunlarını çözme. Çalışma, katılımcıların performansını, davranışlarını ve tutumlarını, ayrıca Yapay Zeka çıktısının kalitesini ve özelliklerini ölçtü.
Bulgulardan biri, “Yapay Zeka bir beceri seviyelendirme aracı olarak çalışır. Deneyin başında değerlendirdiğimizde en kötü performans gösteren danışmanlar, Yapay Zeka kullanma fırsatı bulduklarında performanslarında %43’lük bir sıçrama yaşadılar. En iyi danışmanlar da bir artış yaşadı, ancak daha az bir artış.” Makalenin tamamı aydınlatıcıdır ve Mollick’in tüm çalışmaları gibi, kışkırtıcı ama erişilebilirdir.
Eğitim
Eğitim, Yapay Zeka hakkındaki lehte ve aleyhte tartışmalarda en ön planda yer aldı. Yapay Zeka’nın sınıflara girişi büyük ölçüde bir lanet veya en azından bir zorluk olarak görülüyor. Diğer eğitimciler, PW’nin ana konuşmacısı Ethan Mollick gibi, Yapay Zeka’yı eğitimciler için dikkate değer yeni bir araç olarak benimsiyor; Mollick, öğrencilerinin ChatGPT ile çalışmasını ısrar ediyor.
Bu konudaki en iyi kitap José Antonio Bowen ve C. Edward Watson tarafından yazılan Teaching with AI: A Practical Guide to a New Era of Human Learning.
Bu kitapta eğitim yayıncılığına dalmayacağım - bu geniş bir konu ve ayrı bir rapor gerektiriyor. Tartışmalı olarak, yayıncılık eğitim içinde ikincil bir ilgi alanı haline geliyor: Yapay Zeka araçları yazılımdır, içerik değil.
Aramanın geleceği
|
Arama, Yapay Zeka’da çetrefilli bir konudur. Perplexity.ai ve You.com sitelerini ziyaret etmenizi teşvik ediyorum, nereye gidildiğine bir göz atın. Bir dahaki sefere bir Google araması yapmayı düşündüğünüzde, bunun yerine Perplexity’ye gidin. Dramatik bir fark gibi görünmeyecek - Google’ın arama ekranının sağ tarafında veya bazen arama sonuç listelerinin üst kısmında sık sık açılan bilgi grafiklerine benzer. Bir bağlantıya tıklamak zorunda kalmadan, bilgi orada sizin için. |
Perplexity bir adım daha ileri gider, bilgiyi birçok kaynaktan toplayarak yeniden ifade eder, böylece bir bağlantıya tıklamak gerçekten zorunda kalmazsınız. Kaynaklarına bağlantılar sağlar, ancak genellikle tıklamanız gerekmez—sorunuzun cevabını zaten almış olursunuz.
Bu görünüşte mütevazı değişiklik, her şirket ve en azından kısmen arama motorları aracılığıyla keşfedilmekten yararlanan her ürün için büyük sonuçlar doğurur. Arayanlar artık sitenize yönlendirilmiyorsa, onlarla nasıl etkileşim kurabilir ve onları müşterilere dönüştürebilirsiniz? Basit cevap, yapamazsınız.
Joanna Penn, yazma ve yayıncılık üzerine yeni teknolojilerin etkisini düşünme konusunda ön plandadır. Bu karmaşık konuyu geçen Aralık ayında podcast ve blogunda ele aldı.
AI ve aramanın dönüşümü için hala erken günler.
Amazon’da Çöp Kitaplar
|
Amazon’da Yapay Zeka tarafından üretilmiş çöp kitaplar bir sorundur, ancak ciddiyetleri belki de daha çok duygusaldır. Bir yandan, bu kitaplar düşük kaliteli ve intihal edilmiş içerikle çevrimiçi kitapçıları spam yapıyor, bazen gerçek yazarların isimlerini kullanarak müşterileri kandırıyor ve itibarlarından faydalanıyorlar. Bu kitaplar sadece okuyucular için bir rahatsızlık değil, aynı zamanda yazarlar için de bir tehdit, zor kazanılmış telif haklarından mahrum bırakma potansiyeli taşıyorlar. Yapay Zeka tarafından üretilmiş kitaplar, Amazon’un sitesinde gerçek kitapların ve yazarların sıralamasını ve görünürlüğünü de etkiliyor, çünkü aynı anahtar kelimeler, kategoriler ve incelemeler için rekabet ediyorlar. |

Amazon artık yazarların kitaplarını oluştururken Yapay Zeka kullanım detaylarını açıklamalarını gerektiriyor. Şüphesiz bu suistimal edilebilir.
Amazon’da “Yapay Zeka tarafından üretilmiş kitaplar” araması yapmayı deneyin. Çok sayıda var. Sonuçlardan bazıları, kitap oluşturmak için Yapay Zeka kullanımını anlatan nasıl yapılır kitaplarıdır. Ancak diğerleri açıkça Yapay Zeka tarafından üretilmiştir. “Komik ve sevimli kedi resimleri-Dünyada bu tür fotoğrafları göremezsiniz-BÖLÜM-1” Rajasekar Kasi’ye atfedilmiştir. Yazar sayfasında biyografisi hakkında hiçbir detay yoktur, ancak altı diğer başlık bu isme atfedilmiştir. Kitap, 26 Ağustos 2023’te yayımlandı, hiçbir incelemesi ve satış sıralaması yok. E-kitabın dil bilgisi hatalı başlığı, basılı kitabın kapağındaki dil bilgisi hatalı başlıkla uyuşmuyor.
Ancak diğer yazarlar kitaplarını oluştururken Yapay Zekayı yoğun bir şekilde kullanıyor ve bunu açıklamıyorlar. Yukarıda tartıştığım gibi, Yapay Zeka kullanımı tespit etmek, yetenekli ‘sahtekarlar’ ile neredeyse imkansızdır. Boyama kitapları, günlükler, seyahat kitapları ve yemek kitapları, geleneksel yayıncılığın zaman ve çabasının bir kısmıyla Yapay Zeka araçlarıyla üretiliyor.
“Koreli vegan yemek kitabı” araması yapın ve bir numaralı başlık olan Joanne Lee Molinaro’nun kitabını birinci sırada bulacaksınız. Ancak hemen arkasında, açıkça kopya olan diğer başlıklar gelmektedir. “The Korean Vegan Cookbook: Simple and Delicious Traditional and Modern Recipes for Korean Cuisine Lovers” iki incelemeye sahiptir, bunlardan biri “Bu bir vegan yemek kitabı değil. Tüm tariflerde et ve yumurta malzemeleri var.” diyerek belirtiyor. Ancak kitap satış sıralamasında #5,869,771, orijinal kitabın ise listede #2,852.
Zararın boyutunu belirlemek zor. Bundan iyi bir şey çıkmaz, ama ne kadar kötü?
Amazon’un, “olumlu bir müşteri deneyimi sunamayan” herhangi bir kitabı kaldırmasına izin veren politikaları vardır. Kindle içerik yönergeleri, “müşterileri yanıltmak amacıyla yazılmış veya kitabın içeriğini doğru bir şekilde temsil etmeyen açıklayıcı içerikleri” yasaklar. Ayrıca “müşterileri genellikle hayal kırıklığına uğratan” içerikleri de engelleyebilirler. Amazon’un gözlemcilerini yenilgiye uğratan şey, muazzam hacim mi? Yoksa başka bir sebep mi var?
Önyargı
LLM’ler, çevrimiçi olarak zaten yayınlanmış olanlarla eğitilir. Çevrimiçi olarak yayınlananlar önyargılarla doludur ve bu nedenle LLM’ler de bu önyargıları yansıtır. Elbette sadece önyargı değil, nefret de, öğrenimlerinde yansıtılır ve şimdi Yapay Zeka tarafından üretilmiş kelimeler ve görüntülerde potansiyel bir çıktıdır. Pornografi, Yapay Zeka’nın görüntülerle olan olağanüstü yeteneğinin doğal bir yararlanıcısıdır ve genç kadınların sahte çıplak görüntülerini bulan erkek sınıf arkadaşlarının olası şüpheliler olduğu son zamanlarda rahatsız edici hikayeler vardır. The New York Times ayrı olarak çocuk cinsel istismarının çevrimiçi görüntülerinde bir artış olduğunu bildirdi.
Yazarlar ve yayıncılar, Yapay Zeka araçlarını kullanırken bu yerleşik sınırlamaların farkında olmalıdır.