Obawy i ryzyka związane z AI
 |
Obawy dotyczące AI są poważne. Ryzyka są realne. Czasami wyrażane są w sposób histeryczny, ale gdy się im dokładnie przyjrzymy, wpływ AI ma potencjał być ogromnie destrukcyjny. |
Jest tak wiele problemów i obaw związanych ze sztuczną inteligencją, że wypełniają one całe tomy książek. Oto chmura słów z tematami, które monitoruję. Jestem pewien, że brakuje kilku.

Na każdy z tych tematów dostępnych jest mnóstwo informacji, i zachęcam, abyś czytał/a tak głęboko, jak tylko możesz. Możliwe, że dojdziesz do wniosku, iż ryzyka przewyższają korzyści i nie chcesz korzystać ze sztucznej inteligencji, ani osobiście, ani w swojej organizacji. Ta decyzja niesie ze sobą własne ryzyka; zwykłe, czyli pozostanie w tyle. Ale to osobisty wybór.
Jeśli wpiszesz w Google “książki dotyczące ryzyk związanych ze sztuczną inteligencją”, znajdziesz wybór wartościowych tomów. Ostatni podcast, który wydał mi się szczególnie przerażający, to rozmowa Ezry Kleina z Dario Amodei, współzałożycielem i CEO Anthropic (firmy, która rozwija Claude.ai). Dowiesz się, że te firmy są świadome ryzyk. Amodei odnosi się do wewnętrznego systemu klasyfikacji ryzyk o nazwie A.S.L., dla “Poziomów Bezpieczeństwa AI” (nie American Sign Language). Obecnie znajdujemy się na poziomie ASL 2, “systemy, które wykazują wczesne oznaki niebezpiecznych możliwości - na przykład zdolność do udzielania instrukcji, jak zbudować broń biologiczną.” Opisuje poziom ASL 4 jako “umożliwienie aktorom państwowym znacznego zwiększenia swoich zdolności… gdzie martwilibyśmy się, że Korea Północna, Chiny lub Rosja mogłyby znacznie zwiększyć swoje ofensywne zdolności w różnych obszarach wojskowych dzięki AI w sposób, który dałby im znaczną przewagę na poziomie geopolitycznym.” Przerażające rzeczy.
W tym ponurym kontekście, podkreślę najbardziej istotne kwestie dla pisarzy i wydawców.
Naruszenie praw autorskich?
|
Problemy związane z prawami autorskimi to miasma złożoności i niejasności. Wydaje się pewne, że niektóre książki wciąż objęte prawami autorskimi zostały uwzględnione w szkoleniu niektórych LLM. Ale z pewnością nie jest tak, jak niektórzy autorzy się obawiają, że całe ich dzieło zostało wciągnięte do każdego z dużych modeli językowych. |
Problemy z prawem autorskim są zarówno specyficzne, jak i szerokie. Powszechnie wiadomo, że wszystkie LLM-y są szkolone na otwartym internecie - wszystko, co można zgarnąć z 1,5 miliarda stron w sieci dzisiaj, czy to artykuły prasowe, posty w mediach społecznościowych, blogi internetowe i, najwyraźniej, transkrypcje filmów z YouTube.
Jest to udowodnione, że przynajmniej jeden z LLM-ów przyswoił rzeczywisty tekst tysięcy książek, które nie są w domenie publicznej.
Czy było legalne przyswajanie całego tego tekstu w celu budowania firm AI wartych miliardy dolarów, bez żadnego wynagrodzenia dla autorów? Firmy AI argumentują to w kategoriach dozwolonego użytku; sądy w końcu zdecydują. Nawet jeśli to było legalne, czy było etyczne lub moralne? Etyka wydaje się mniej skomplikowana niż kwestie prawne. Ty decydujesz.
Prawa dotyczące prawa autorskiego oczywiście nie przewidziały unikalnych wyzwań, jakie AI wnosi do problemu, a poszukiwanie rozwiązań prawnych zajmie czas, być może lata. (Jeśli chcesz zgłębić, dlaczego prawa nie są odpowiednie do konkretnego problemu, przeczytaj doskonały artykuł A. Feder Coopera i Jamesa Grimmelmanna zatytułowany “Pliki są w komputerze: Prawo autorskie, zapamiętywanie i generatywne AI.”)
Oto lista trzynastu najbardziej znanych spraw, nie wszystkie dotyczą książek; także obrazów i muzyki. A oto inna lista, która aktualizuje status wszystkich spraw sądowych.
Prawo autorskie i AI dla autorów
|
Autorzy stają przed dodatkowymi problemami związanymi z możliwością objęcia prawem autorskim treści generowanych przez AI. |
Stanowisko Urzędu ds. Praw Autorskich USA dotyczące możliwości objęcia prawem autorskim treści generowanych przez AI stwierdza, że AI nie może samodzielnie posiadać praw autorskich, ponieważ brakuje mu statusu prawnego autora. To ma sens. Ale to zakłada, że 100% pracy jest generowane przez AI. Jak omówiono gdzie indziej, niewielu autorów pozwoli AI wygenerować całą książkę. Bardziej prawdopodobne jest, że będzie to 5%, 10% lub… I tutaj Urząd ds. Praw Autorskich napotyka trudności (jak i ja).
W niedawnym orzeczeniu Urząd stwierdził, że powieść graficzna składająca się z tekstu napisanego przez człowieka i obrazów wygenerowanych przez usługę AI Midjourney stanowi utwór podlegający prawu autorskiemu, ale same obrazy nie mogą być chronione prawem autorskim.“ Jejku!
|
Wystarczy powiedzieć, że autorzy i wydawcy muszą być czujni na zmieniające się kwestie związane z prawem autorskim, w wielu aspektach. |
Jakie są długoterminowe implikacje?
Niektórzy porównują obecne postępowania sądowe do procesu Google Books, który trwał 10 lat, zanim został prawnie rozstrzygnięty. Kto wie, jak długo potrwa proces apelacyjny w tych sprawach. W międzyczasie wydawcy rozsądnie działają, zakładając, że firmy AI przegrają, co teoretycznie naraża każdego, kto udziela licencji lub nawet używa Chat AI, na pewną formę odpowiedzialności warunkowej.
Ale to nie jest najpoważniejszy problem wydawców. To percepcja. Dla wielu autorów, zarówno znanych, jak i mniej znanych, studnia została zatruta. AI jest radioaktywne w społeczności pisarskiej i wydawniczej. Wszystko, co choćby przypomina AI, spotyka się z intensywną krytyką.
Jest wiele przykładów. W niedawnym incydencie Angry Robot, brytyjski wydawca “dedykowany najlepszej współczesnej literaturze science fiction, fantasy i WTF,” ogłosił, że będzie używał oprogramowania AI o nazwie Storywise, aby przesiać spodziewaną dużą partię zgłoszeń rękopisów. Wystarczyło tylko pięć godzin, aby firma porzuciła plan i powróciła do “starej skrzynki mailowej.“
Nie do zniesienia dylemat wydawców branżowych w korzystaniu z narzędzi AI wewnętrznie: jeśli twoi autorzy się dowiedzą, trudno będzie przetrwać burzę, która nastąpi. Wierzę, że wydawcy nie mają wyboru, muszą być odważni, przyjąć (przynajmniej niektóre z) narzędzi, jasno wyjaśnić, jak te narzędzia są szkolone i jak są wykorzystywane, i iść dalej.
W Wielkiej Brytanii, The Society of Authors przyjmuje twarde stanowisko: “Poproś swojego wydawcę, aby potwierdził, że nie będzie znacząco wykorzystywał AI do żadnych celów związanych z twoją pracą - takich jak korekta, redakcja (w tym autentyczność i sprawdzanie faktów), indeksowanie, ocena prawna, projektowanie i układ, czy cokolwiek innego bez twojej zgody. Możesz chcieć zakazać narracji audiobooka, tłumaczenia i projektowania okładki wykonanego przez AI.”
The Authors Guild appears to accept that “publishers are starting to explore using AI as a tool in the usual course of their operations, including editorial and marketing uses.” I don’t think that many members of the Guild are as understanding.
Licencjonowanie treści dla firm AI
Większość wydawców i wielu autorów szuka sposobów na licencjonowanie treści dla firm zajmujących się sztuczną inteligencją. Każdy ma inne zdanie na temat warunków licencjonowania i wartości swoich treści, ale przynajmniej rozmowy się rozpoczęły.
Istnieje kilka startupów, które chcą współpracować z wydawcami (a w niektórych przypadkach także z indywidualnymi autorami). Calliope Networks i Created by Humans są w tym kontekście interesujące.
W połowie lipca Copyright Clearance Center, od dawna główny gracz w branży kolektywnego licencjonowania praw autorskich, ogłosiło dostępność „praw do ponownego wykorzystania sztucznej inteligencji (SI) w ramach swoich Annual Copyright Licenses (ACL), kompleksowego rozwiązania do licencjonowania treści oferującego prawa do milionów utworów dla firm, które subskrybują.”
Publishers Weekly relacjonował ogłoszenie, cytując Tracey Armstrong, prezes i CEO CCC, mówiącą: “Możliwe jest być pro-SI i pro-prawa autorskie, łącząc SI z szacunkiem dla twórców.”
Chociaż nie jest to wszechstronne rozwiązanie, prawdopodobnie jest to przełom w zbliżaniu wydawnictw do pewnego stopnia współpracy z twórcami dużych modeli językowych.
Jest za późno, aby uniknąć SI
|
Dla autorów i wydawców, którzy wolą nie mieć nic wspólnego z SI, wiadomości są złe: używacie SI dziś i używaliście go od lat. |
Sztuczna inteligencja, w różnych formach, została już zintegrowana z większością narzędzi programowych i usług, z których korzystamy na co dzień. Ludzie polegają na narzędziach do sprawdzania pisowni i gramatyki opartych na SI w programach takich jak Microsoft Word czy Gmail. Microsoft Word i PowerPoint wykorzystują SI do sugestii pisania, rekomendacji projektów i układów oraz innych funkcji. Wirtualni asystenci, tacy jak Siri i Alexa, używają przetwarzania języka naturalnego do rozumienia poleceń głosowych i odpowiadania na pytania. Usługi e-mail wykorzystują SI do filtrowania wiadomości, wykrywania spamu i wysyłania alertów. SI napędza chatboty obsługi klienta i generuje rekomendacje produktowe na podstawie historii zakupów.
I wiele z tego opiera się na Dużych Modelach Językowych, jak w przypadku ChatGPT.
Dla autora lub redaktora, który mówi: “Nie chcę, aby SI była używana w moim manuskrypcie,” jest to, ogólnie rzecz biorąc, prawie niemożliwe, chyba że oni i ich redaktorzy pracują na maszynach do pisania i ołówkach.
Mogliby spróbować powiedzieć: “Nie chcę, aby generatywna SI” była używana w ich książce. Ale to trudne do rozdzielenia. Oprogramowanie do sprawdzania gramatyki nie było pierwotnie oparte na generatywnej SI. Grammarly dodało ją jako składnik do swojego produktu, podobnie jak wszystkie inne narzędzia do sprawdzania pisowni i gramatyki. Generatywna SI jest również kluczowym elementem oferowanego oprogramowania marketingowego.
Kiedy autorzy używają SI
Inny aspekt autorów i używania SI ma podobieństwa do omówionego powyżej problemu z prawami autorskimi. W skrajnych przypadkach widzimy 100% treści generowanej przez SI publikowanej na Amazonie. Większość z tego (wszystko?) jest kiepskiej jakości, ale to nie zapobiega jej publikacji. (Zobacz także sekcję Amazon.) Bardziej niepokojące dla wydawców są zgłoszenia generowane przez SI. Tak, SI zwiększa ilość, ale duzi wydawcy już mają filtr na ilość. Filtry nazywane są agentami. To oni będą musieli wymyślić, jak poradzić sobie z problemem ilości, i najwyraźniej będą musieli znaleźć rozwiązanie, które nie wykorzystuje SI.
Jest to coś w rodzaju egzystencjalnego problemu - czy chcę opublikować książkę napisaną przez ‘maszynę’? Dla większości wydawców to jednoznaczne ‘nie.’ Proste. No dobrze, a co z książką, gdzie 50% treści zostało wygenerowane przez Duży Model Językowy, pod nadzorem kompetentnego autora? Hmm, spróbujmy też z ‘nie.’ OK: a co z 25%, 10% lub 5%? Gdzie ustawić granicę?
A teraz, kiedy już zaczęliście wyznaczać granice, jak rozwiązać dylemat, że narzędzia do sprawdzania pisowni i gramatyki teraz polegają, przynajmniej częściowo, na generatywnej SI? Co z narzędziami do transkrypcji napędzanymi przez SI, takimi jak Otter.ai, czy funkcją transkrypcji wbudowaną w Microsoft Word?
Nie mogę znaleźć żadnego wydawcy handlowego, który zadeklarowałby, że nie opublikuje pracy z określoną ilością tekstu generowanego przez SI. Oto, co na ten temat mówi Authors Guild:
“Jeśli znaczna ilość tekstu, postaci lub fabuły wygenerowanych przez sztuczną inteligencję zostanie włączona do twojego rękopisu, musisz to ujawnić wydawcy i powinieneś również ujawnić to czytelnikowi. Nie uważamy, że autorzy muszą ujawniać użycie generatywnej AI, gdy jest ona wykorzystywana jedynie jako narzędzie do burzy mózgów, generowania pomysłów lub do redagowania tekstu.”
Nie trzeba dodawać, że ‘znaczna’ nie jest zdefiniowana (Oxford definiuje to jako “wystarczająco duża, aby była zauważona lub uznana za ważną”), ale post idzie dalej, wyjaśniając, że włączenie więcej niż “de minimis tekstu wygenerowanego przez AI” naruszyłoby większość kontraktów wydawniczych. De minimis, w terminach prawnych, nie jest precyzyjnie określone, ale ogólnie rzecz biorąc, oznacza mniej więcej to samo co znaczna.
Czy można wykryć AI w pisaniu?
W maju 2024 roku zorganizowałem webinar na temat wykrywania AI, sponsorowany przez BISG. Powtórkę można obejrzeć online na YouTube. Jane Friedman przedstawiła obszerne podsumowanie webinaru w swoim newsletterze Hot Sheet.
Dla wielu autorów toksyczność AI oznacza trzymanie jej z daleka od ich słów. Wydawcy ponoszą szczególne brzemię - nie tworzą tekstu, ale po opublikowaniu ponoszą znaczną odpowiedzialność za tekst. Widzieliśmy wiele wybuchów w pobliżu zapalnych książek, czy to wokół społecznych implikacji treści, czy też plagiatowego przechwytywania słów i pomysłów innych pisarzy. Teraz, z AI, stajemy przed zupełnie nowym zestawem problemów etycznych i prawnych, które nie były omawiane w szkole wydawniczej.
Część z tego wydaje się podobna do tego, czym ludzie martwią się w przypadku studentów, że używanie AI jest w jakiś sposób oszustwem, podobnym do kopiowania artykułu z Wikipedii lub może po prostu poproszenia przyjaciela o napisanie eseju.
Jeden z naszych mówców webinaru, edukator, José Bowen, podzielił się swoim ujawnieniem dla studentów. To nie jest dokładnie to, co używasz dla autora, ale pokazuje pewne “poziomy ryzyka” użycia AI.
Szablon umowy ujawnienia dla studentów
Całą tę pracę wykonałem sam bez pomocy przyjaciół, narzędzi, technologii ani AI.
-
Zrobiłem pierwszy szkic, ale potem poprosiłem przyjaciół/rodzinę, oprogramowanie do parafrazowania/gramatyki/plagiatu AI, aby to przeczytali i zasugerowali. Po tej pomocy wprowadziłem następujące zmiany:
Naprawiono błędy ortograficzne i gramatyczne
Zmieniono strukturę lub kolejność
Przepisano całe zdania/akapit
Utknąłem na problemach i użyłem tezaurusa, słownika, zadzwoniłem do przyjaciela, poszedłem do centrum pomocy, użyłem Chegg lub innego dostawcy rozwiązań.
Użyłem AI/przyjaciół/tutora, aby pomogli mi wygenerować pomysły.
Użyłem wsparcia/narzędzi/AI do stworzenia zarysu/pierwszego projektu, który następnie edytowałem. (Opisz naturę swojego wkładu.)
I tak wydawca mógłby napisać coś takiego dla swoich autorów. Powiedzmy, że autor ujawnia najwyższy poziom: użyłem AI obszernie, a następnie edytowałem wyniki. Co wtedy? Czy automatycznie odrzucasz manuskrypt? Jeśli tak, to dlaczego?
A tymczasem, jeśli zwracasz uwagę, dowiadujesz się, że ten manuskrypt, który właśnie przeczytałeś i pokochałeś, który autor przysiągł, że nawet nie został sprawdzony pod kątem błędów przez Grammarly, mógł w rzeczywistości być w 90% wygenerowany przez AI, przez autora eksperta w ukrywaniu jego użycia.
Jesteś wtedy zmuszony ponownie przemyśleć pytanie. Staje się ono: “Dlaczego jestem tak cholernie zdeterminowany, aby wykryć tę rzecz, która jest niewykrywalna?”
Częściowo to alarmistyczne obawy dotyczące ochrony praw autorskich dla tekstów generowanych przez AI. Urząd praw autorskich nie zaoferuje ochrony praw autorskich dla w 100% tekstów generowanych przez AI (lub muzyki, obrazów itp.). Ale co z tekstem wygenerowanym w 50% przez AI? Cóż, pokrylibyśmy tylko 50% wygenerowane przez autora. A skąd byś wiedział, która połowa? Wrócimy do Ciebie w tej sprawie.
Czy nie byłoby wspaniale, gdybyś mógł po prostu wprowadzić każdy manuskrypt do jakiegoś oprogramowania, które powiedziałoby ci, czy AI zostało użyte do tworzenia tekstu?
Pomijając kwestię, że jedynym sposobem na to byłoby użycie narzędzi AI, ważniejsze pytanie brzmi: czy oprogramowanie byłoby (wystarczająco) dokładne? Czy mógłbym na nim polegać, aby powiedziało mi, czy AI zostało użyte do tworzenia manuskryptu? I czy mógłbym polegać na tym, że nie wytworzy “fałszywych pozytywów” – wskazując, że AI zostało użyte, kiedy w rzeczywistości nie zostało?
Obecnie na rynku jest wiele oprogramowania, które zajmuje się tymi wyzwaniami. Wiele badań akademickich oceniających to oprogramowanie wskazuje na jego zawodność. Tekst generowany przez AI prześlizguje się. Gorzej, tekst, który nie został wygenerowany przez AI, jest błędnie oznaczany jako “skażony”.
Ale wydawcy książek będą chcieli mieć pewne zabezpieczenia. Wydaje się, że w najlepszym razie te narzędzia mogą ostrzegać o możliwych problemach, ale zawsze będzie trzeba to sprawdzić. Może więc będą ostrzegać o tekstach, które wymagają dokładniejszego zbadania niż inne? Czy to jest efektywność?
Prawdziwa efektywność zostanie osiągnięta, gdy przestaniemy martwić się o pochodzenie tekstu, zamiast tego utrzymując nasze istniejące kryteria dotyczące jego jakości.
Utrata pracy
“Nie zostaniesz zastąpiony przez AI. Zostaniesz zastąpiony przez kogoś, kto potrafi korzystać z AI.” —Anonimowy
Utrata pracy z powodu wdrożenia AI może być poważna. Szacunki są różne, ale liczby są ponure. Istnieją oczywiste przykłady: bezzałogowe taksówki w San Francisco eliminują… kierowców taksówek i usług współdzielenia przejazdów. Diagnostyka wspierana przez AI może zmniejszyć zapotrzebowanie na techników medycznych.
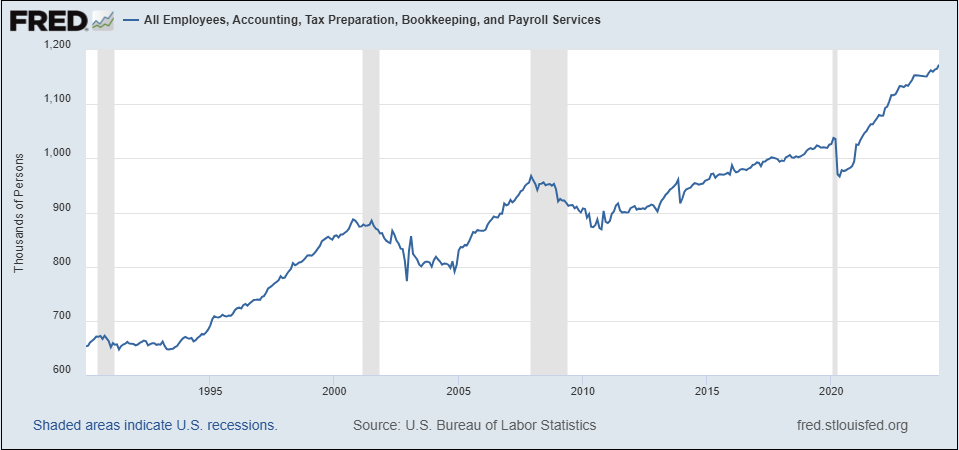
Optymista we mnie wskazuje, jako jeden z przykładów, wprowadzenie arkusza kalkulacyjnego i jego wpływu na zatrudnienie. Jak widać na poniższym wykresie, zatrudnienie w “Usługach księgowych, przygotowywania podatków, prowadzenia ksiąg rachunkowych i płac” niemal podwoiło się od 1990 r. - trudno tu o oskarżenia wobec arkuszy kalkulacyjnych i innych technologii, które w dużej mierze zautomatyzowały te zadania.
Badanie Ethana Mollicka z Boston Consulting Group (BCG) było eksperymentem mającym na celu lepsze zrozumienie wpływu AI na pracę, zwłaszcza na zadania złożone i wymagające wiedzy. Badanie obejmowało 758 konsultantów BCG, losowo przydzielonych do używania lub nieużywania GPT-4 od OpenAI w dwóch zadaniach: innowacja produktów kreatywnych i rozwiązywanie problemów biznesowych. Badanie mierzyło wydajność, zachowanie i postawy uczestników, a także jakość i charakterystykę wyników AI.
Wśród ustaleń było to, że “AI działa jako wyrównywacz umiejętności. Konsultanci, którzy uzyskali najgorsze wyniki na początku eksperymentu, odnotowali największy wzrost wydajności, o 43%, gdy mogli korzystać z AI. Najlepsi konsultanci również uzyskali wzrost, ale mniejszy.” Pełny artykuł jest odkrywczy, a jak wszystkie prace Mollicka, prowokacyjny, ale przystępny.
Edukacja
Edukacja była w centrum debat na temat zalet i wad sztucznej inteligencji. Wprowadzenie AI do klas jest generalnie postrzegane jako przekleństwo, a przynajmniej wyzwanie. Inni edukatorzy, jak główny prelegent PW Ethan Mollick, przyjmują AI jako niezwykłe nowe narzędzie dla nauczycieli; Mollick nalega, aby jego studenci pracowali z ChatGPT.
Najlepszą książką na ten temat jest Teaching with AI: A Practical Guide to a New Era of Human Learning autorstwa José Antonio Bowen i C. Edward Watson.
Nie zamierzam zagłębiać się w publikacje edukacyjne w tej książce - to ogromny temat, wymagający osobnego raportu. Można argumentować, że publikacje stają się drugorzędnym zainteresowaniem w edukacji: narzędzia AI to oprogramowanie, a nie treść jako taka.
Przyszłość wyszukiwania
|
Wyszukiwanie to kontrowersyjny temat w AI. Zachęcam do odwiedzenia perplexity.ai i You.com, aby zobaczyć, dokąd zmierzają te technologie. Następnym razem, gdy będziesz myśleć o rozpoczęciu wyszukiwania w Google, zamiast tego odwiedź Perplexity. Nie będzie to wydawało się dramatycznie inne - jest podobne do grafów wiedzy, które Google często wyświetla po prawej stronie ekranu wyszukiwania lub czasem na górze wyników wyszukiwania. Zamiast klikać na link, informacje są bezpośrednio dostępne. |
Perplexity idzie o krok dalej, przekształcając informacje zebrane z wielu źródeł, abyś naprawdę nie musiał klikać linku. Dostarcza linki do swoich źródeł, ale klikanie ich jest zazwyczaj zbędne - już masz odpowiedź na swoje pytanie.
Ta pozornie skromna zmiana ma ogromne implikacje dla każdej firmy i każdego produktu, który opiera się przynajmniej częściowo na byciu odkrytym przez wyszukiwarki. Jeśli wyszukiwacze nie są już kierowani na twoją stronę, jak możesz ich zaangażować i przekształcić w klientów? Prosta odpowiedź, nie możesz.
Joanna Penn jest na czele myślenia o wpływie nowych technologii na pisanie i publikowanie. Podjęła ten skomplikowany temat w swoim podcastie i blogu w grudniu zeszłego roku.
To dopiero początki dla AI i transformacji wyszukiwania.
Książki śmieciowe na Amazonie
|
Książki śmieciowe generowane przez AI na Amazonie stanowią problem, chociaż ich powaga może być bardziej odczuwalna niż literalna. Z jednej strony te książki spamują księgarnię internetową niskiej jakości i plagiatowaną treścią, czasami używając nazwisk prawdziwych autorów, aby oszukać klientów i wykorzystać ich reputacje. Książki te są nie tylko uciążliwe dla czytelników, ale także stanowią zagrożenie dla autorów, potencjalnie pozbawiając ich trudno zarobionych tantiem. Książki generowane przez AI wpływają również na ranking i widoczność prawdziwych książek i autorów na stronie Amazona, konkurując o te same słowa kluczowe, kategorie i recenzje. |

Amazon teraz wymaga od autorów ujawniania szczegółów dotyczących wykorzystania AI przy tworzeniu ich książek. Bez wątpienia można to nadużyć.
Spróbuj wyszukać na Amazonie “książki generowane przez AI”. Jest ich mnóstwo. Niektóre z wyników to podręczniki na temat wykorzystania AI do tworzenia książek. Ale inne są, bez skrupułów, generowane przez AI. “Śmieszne i słodkie zdjęcia kotów - Nie zobaczysz tego typu zdjęć na świecie - CZĘŚĆ-1” (stet) jest przypisane Rajasekarowi Kasi. Na stronie autora nie ma żadnych szczegółów dotyczących jego (?) biografii, ale sześć innych tytułów jest przypisanych do tego nazwiska. Książka, opublikowana 26 sierpnia 2023 roku, nie ma recenzji ani rankingu sprzedaży. Niegramatyczny tytuł ebooka nie pasuje do niegramatycznego tytułu na okładce drukowanej książki.
Ale inni autorzy wyraźnie używają AI w dużym stopniu przy tworzeniu swoich książek i nie ujawniają tego. Jak wspomniałem powyżej, wykrycie użycia AI jest prawie niemożliwe w przypadku wykwalifikowanych “fałszerzy”. Kolorowanki, dzienniki, książki podróżnicze i książki kucharskie są tworzone za pomocą narzędzi AI w ułamku czasu i wysiłku tradycyjnego wydawnictwa.
Wyszukaj „koreańska wegańska książka kucharska”, a znajdziesz tytuł numer jeden, autorstwa Joanne Lee Molinaro, na pierwszym miejscu. Ale tuż za nim są inne tytuły, które są oczywistymi podróbkami. „Koreańska książka kucharska dla wegan: Proste i pyszne tradycyjne i nowoczesne przepisy dla miłośników kuchni koreańskiej” ma dwie recenzje, w tym jedną, która zauważa „To nie jest wegańska książka kucharska. Wszystkie przepisy zawierają mięso i jajka”. Ale książka jest na #5,869,771 w rankingu sprzedaży, w porównaniu do oryginału, który zajmuje #2,852 na liście.
Trudno określić zakres wyrządzonych szkód. Nic dobrego z tego nie wyniknie, ale jak źle może być?
Amazon ma zasady, które pozwalają na usunięcie każdej książki, która nie „zapewnia pozytywnego doświadczenia klienta”. Wytyczne dotyczące treści Kindle zabraniają „opisowej treści mającej na celu wprowadzenie klientów w błąd lub nieodpowiednio przedstawiającej zawartość książki.” Mogą również zablokować „treści, które zazwyczaj rozczarowują klientów.” Czy to ogromna ilość treści pokonuje obserwatorów Amazonu? A może jest inny powód?
Stronniczość
LLM są trenowane na tym, co już zostało opublikowane w internecie. To, co zostało opublikowane w internecie, jest pełne stronniczości, więc LLM odzwierciedlają tę stronniczość. I oczywiście nie tylko stronniczość, ale także nienawiść, odzwierciedloną w ich naukach, a teraz potencjalnie w wynikach generowanych przez AI słowach i obrazach. Pornografia jest kolejnym naturalnym beneficjentem niezwykłej zdolności AI do tworzenia obrazów, a ostatnio pojawiły się niepokojące historie o młodych kobietach znajdujących sfabrykowane nagie zdjęcia, z ich męskimi kolegami jako prawdopodobnymi podejrzanymi. The New York Times donosił oddzielnie o wzroście liczby obrazów wykorzystywania seksualnego dzieci w sieci.
Autorzy i wydawcy muszą być świadomi tych wbudowanych ograniczeń podczas korzystania z narzędzi AI.