Web Scraping
It is important to respect the property rights of web site owners and abide by their terms and conditions for use. This Wikipedia article on Fair Use provides a good overview of using copyright material.
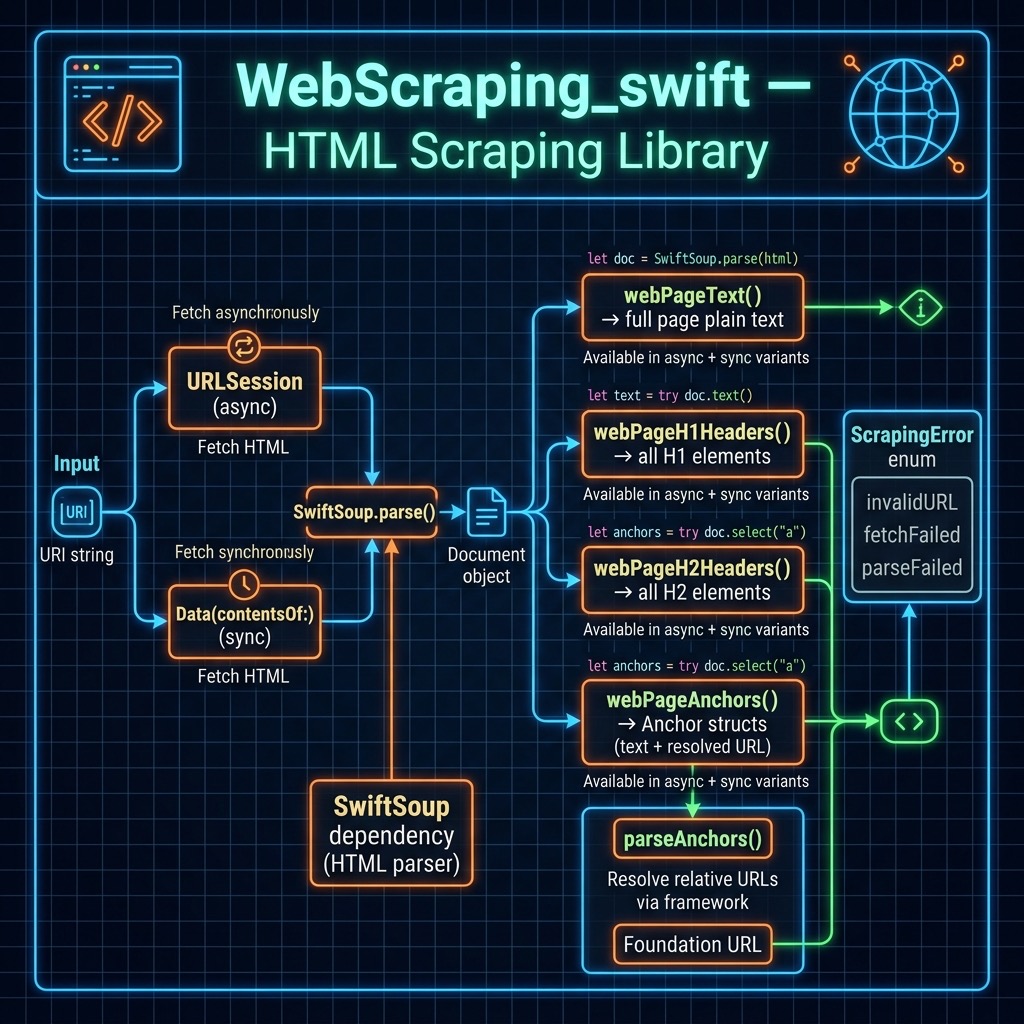
The web scraping code we develop here uses the Swift library SwiftSoup that is loosely based on the BeautifulSoup libraries available in other programming languages.
For my work and research, I have been most interested in using web scraping to collect text data for natural language processing but other common applications include writing AI news collection and summarization assistants, trying to predict stock prices based on comments in social media which is what we did at Webmind Corporation in 2000 and 2001, etc.
I wrote a simple web scraping library that is available in source-code/WebScraping_swift.
Here is the main implementation file for the library:
1 import Foundation
2 import SwiftSoup
3
4 public enum ScrapingError: Error {
5 case invalidURL(String)
6 case fetchFailed(Error)
7 case parseFailed(Error)
8 }
9
10 public struct Anchor: Equatable {
11 public let text: String
12 public let url: URL
13 }
14
15 /// Helper to parse HTML data into a SwiftSoup Document.
16 private func parse(data: Data, uri: String) throws -> Document {
17 guard let html = String(data: data, encoding: .utf8) else {
18 throw ScrapingError.parseFailed(
19 NSError(
20 domain: "WebScraping",
21 code: 1,
22 userInfo: [
23 NSLocalizedDescriptionKey:
24 "Failed to decode UTF-8 data"
25 ]
26 )
27 )
28 }
29
30 do {
31 return try SwiftSoup.parse(html, uri)
32 } catch {
33 throw ScrapingError.parseFailed(error)
34 }
35 }
36
37 /// Fetches the HTML document from a given URI and parses it asynchronously.
38 private func fetchDocument(uri: String) async throws -> Document {
39 guard let url = URL(string: uri) else {
40 throw ScrapingError.invalidURL(uri)
41 }
42
43 let data: Data
44 do {
45 (data, _) = try await URLSession.shared.data(from: url)
46 } catch {
47 throw ScrapingError.fetchFailed(error)
48 }
49
50 return try parse(data: data, uri: uri)
51 }
52
53 /// Fetches the HTML document from a given URI and parses it synchronously.
54 private func fetchDocument(uri: String) throws -> Document {
55 guard let url = URL(string: uri) else {
56 throw ScrapingError.invalidURL(uri)
57 }
58
59 let data: Data
60 do {
61 data = try Data(contentsOf: url)
62 } catch {
63 throw ScrapingError.fetchFailed(error)
64 }
65
66 return try parse(data: data, uri: uri)
67 }
68
69 /// Returns the plain text content of a web page (asynchronous).
70 public func webPageText(uri: String) async throws -> String {
71 let doc = try await fetchDocument(uri: uri)
72 return try doc.text()
73 }
74
75 /// Returns the plain text content of a web page (synchronous).
76 public func webPageText(uri: String) throws -> String {
77 let doc = try fetchDocument(uri: uri)
78 return try doc.text()
79 }
80
81 /// Helper for headers (asynchronous).
82 private func webPageHeadersHelper(
83 uri: String,
84 headerName: String
85 ) async throws -> [String] {
86 let doc = try await fetchDocument(uri: uri)
87 let headers = try doc.select(headerName)
88 return try headers.map { try $0.text() }
89 }
90
91 /// Helper for headers (synchronous).
92 private func webPageHeadersHelper(
93 uri: String,
94 headerName: String
95 ) throws -> [String] {
96 let doc = try fetchDocument(uri: uri)
97 let headers = try doc.select(headerName)
98 return try headers.map { try $0.text() }
99 }
100
101 /// Returns all H1 headers on the page (asynchronous).
102 public func webPageH1Headers(uri: String) async throws -> [String] {
103 return try await webPageHeadersHelper(uri: uri, headerName: "h1")
104 }
105
106 /// Returns all H1 headers on the page (synchronous).
107 public func webPageH1Headers(uri: String) throws -> [String] {
108 return try webPageHeadersHelper(uri: uri, headerName: "h1")
109 }
110
111 /// Returns all H2 headers on the page (asynchronous).
112 public func webPageH2Headers(uri: String) async throws -> [String] {
113 return try await webPageHeadersHelper(uri: uri, headerName: "h2")
114 }
115
116 /// Returns all H2 headers on the page (synchronous).
117 public func webPageH2Headers(uri: String) throws -> [String] {
118 return try webPageHeadersHelper(uri: uri, headerName: "h2")
119 }
120
121 /// Returns all anchors (links) found on the page as `Anchor` objects (asynchronous).
122 public func webPageAnchors(uri: String) async throws -> [Anchor] {
123 let doc = try await fetchDocument(uri: uri)
124 return try parseAnchors(doc: doc, uri: uri)
125 }
126
127 /// Returns all anchors (links) found on the page as `Anchor` objects (synchronous).
128 public func webPageAnchors(uri: String) throws -> [Anchor] {
129 let doc = try fetchDocument(uri: uri)
130 return try parseAnchors(doc: doc, uri: uri)
131 }
132
133 /// Shared anchor parsing logic.
134 private func parseAnchors(doc: Document, uri: String) throws -> [Anchor] {
135 let anchors = try doc.select("a")
136 let baseURL = URL(string: uri)
137
138 return try anchors.compactMap { a -> Anchor? in
139 let text = try a.text()
140 let href = try a.attr("href")
141
142 // Use Foundation's URL resolution for relative/fragment links.
143 guard let resolvedURL = URL(string: href, relativeTo: baseURL) else {
144 return nil
145 }
146
147 return Anchor(text: text, url: resolvedURL.absoluteURL)
148 }
149 }
This Swift code defines several functions that can be used to scrape information from a web page located at a given URI.
The library uses modern Swift concurrency (async/await) throughout. A ScrapingError enum provides typed error handling for invalid URLs, network failures, and parsing failures. The Anchor struct replaces the old [[String]] return type and holds a resolved URL alongside the link text.
The private fetchDocument helper does the shared heavy lifting: it validates the URI, fetches the raw data with URLSession.shared.data(from:) (async), decodes it as UTF-8, and returns a parsed SwiftSoup Document.
The webPageText function takes a URI as input and returns the plain text content of the web page located at that URI. It delegates to fetchDocument and then calls SwiftSoup’s doc.text() to extract all plain text.
The webPageH1Headers and webPageH2Headers functions use the private webPageHeadersHelper function to extract the H1 and H2 header texts respectively from the web page. The helper uses doc.select(headerName) on the parsed document and maps each element to its text content.
The webPageAnchors function extracts all anchor tags <a> from the web page and returns them as an array of Anchor values. It resolves relative and fragment URLs against the page’s base URL using Foundation’s URL(string:relativeTo:), discarding any links that cannot be resolved.
Overall, these functions provide a simple, modern way to scrape information from a web page and extract specific information such as plain text, header texts, and anchors.
I wrote these utility functions to get the plain text from a web site, HTML header text, and anchors. You can clone this library and extend it for other types of HTML elements you may need to process.
The test program shows how to call the APIs in the library:
1 import XCTest
2 import Foundation
3 import SwiftSoup
4
5 @testable import WebScraping_swift
6
7 final class WebScrapingTests: XCTestCase {
8 func testGetWebPage() {
9 let text = webPageText(uri: "https://markwatson.com")
10 print("\n\n\tTEXT FROM MARK's WEB SITE:\n\n", text)
11 }
12
13 func testToShowSwiftSoupExamples() {
14 let myURLString = "https://markwatson.com"
15 let h1_headers = webPageH1Headers(uri: myURLString)
16 print("\n\n++ h1_headers:", h1_headers)
17 let h2_headers = webPageH2Headers(uri: myURLString)
18 print("\n\n++ h2_headers:", h2_headers)
19 let anchors = webPageAnchors(uri: myURLString)
20 print("\n\n++ anchors:", anchors)
21 }
22
23 static var allTests = [("testGetWebPage", testGetWebPage),
24 ("testToShowSwiftSoupExamples",
25 testToShowSwiftSoupExamples)]
26 }
This Swift test program tests the functionality of the WebScraping_swift library. It defines two test functions: testGetWebPage and testToShowSwiftSoupExamples.
The testGetWebPage function uses the webPageText function to retrieve the plain text content of my website located at “https://markwatson.com”. It then prints the retrieved text to the console.
The testToShowSwiftSoupExamples function demonstrates the use of webPageH1Headers, webPageH2Headers, and webPageAnchors functions on the same website. It extracts and prints the H1 and H2 header texts and anchor tags of the same website.
The allTests variable is an array of tuples that map the test function names to the corresponding function references. This variable is used by the XCTest framework to discover and run the test functions.
Overall, this Swift test program demonstrates how to use the functions defined in the WebScraping_swift library to extract specific information from a web page.
Here we run the unit tests (with much of the output not shown for brevity):
1 $ swift test
2
3 TEXT FROM MARK's WEB SITE:
4
5 Mark Watson: AI Practitioner and Polyglot Programmer | Mark Watson Read my Blog \
6 Fun stuff My Books My Open Source Projects Hire Me Free Mentoring \
7 Privacy Policy Mark Watson: AI Practitioner and Polyglot Programmer I am the author \
8 of 20+ books on Artificial Intelligence, Common Lisp, Deep Learning, Haskell, Clojur\
9 e, Java, Ruby, Hy language, and the Semantic Web. I have 55 US Patents. My customer \
10 list includes: Google, Capital One, Olive AI, CompassLabs, Disney, SAIC, Americast, \
11 PacBell, CastTV, Lutris Technology, Arctan Group, Sitescout.com, Embed.ly, and Webmi\
12 nd Corporation.
13
14 ++ h1_headers: ["Mark Watson: AI Practitioner and Polyglot Programmer", "The books t\
15 hat I have written", "Fun stuff", "Open Source", "Hire Me", "Free Mentoring", "Priva\
16 cy Policy"]
17
18 ++ h2_headers: ["I am the author of 20+ books on Artificial Intelligence, Common Lis\
19 p, Deep Learning, Haskell, Clojure, Java, Ruby, Hy language, and the Semantic Web. I\
20 have 55 US Patents.", "Other published books:"]
21
22 ++ anchors: [["Read my Blog", "https://mark-watson.blogspot.com"], ["Fun stuff", "ht\
23 tps://markwatson.com#fun"], ["My Books", "https://markwatson.com#books"], ["My Open \
24 Source Projects", "https://markwatson.com#opensource"], ["Hire Me", "https://markwat\
25 son.com#consulting"], ["Free Mentoring", "https://markwatson.com#mentoring"], ["Priv\
26 acy Policy", "https://markwatson.com/privacy.html"], ["leanpub", "https://leanpub.co\
27 m/u/markwatson"], ["GitHub", "https://github.com/mark-watson"], ["LinkedIn", "https:\
28 //www.linkedin.com/in/marklwatson/"], ["Twitter", "https://twitter.com/mark_l_watson\
29 "], ["leanpub", "https://leanpub.com/lovinglisp"], ["leanpub", "https://leanpub.com/\
30 haskell-cookbook/"], ["leanpub", "https://leanpub.com/javaai"],
31 ]
32 Test Suite 'All tests' passed at 2021-08-06 17:37:11.062.
33 Executed 2 tests, with 0 failures (0 unexpected) in 0.471 (0.472) seconds
Running in the Swift REPL
1 $ swift run --repl
2 [1/1] Build complete!
3 Launching Swift REPL with arguments: -I/Users/markw_1/GIT_swift_book/WebScraping_swi\
4 ft/.build/arm64-apple-macosx/debug -L/Users/markw_1/GIT_swift_book/WebScraping_swift\
5 /.build/arm64-apple-macosx/debug -lWebScraping_swift__REPL
6 Welcome to Apple Swift version 5.5 (swiftlang-1300.0.29.102 clang-1300.0.28.1).
7 Type :help for assistance.
8 1> import WebScraping_swift
9 2> try webPageText(uri: "https://markwatson.com")
10 $R0: String = "Mark Watson: AI Practitioner and Polyglot Programmer | Mark Watson \
11 Read my Blog Fun stuff My Books My Open Source Projects Privacy Policy \
12 Mark Watson: AI Practitioner and Polyglot Programmer I am the author of 20+ books on\
13 Artificial Intelligence, Common Lisp, Deep Learning, Haskell, Clojure, Java, Ruby, \
14 Hy language, and the Semantic Web. I have 55 US Patents. My customer list includes: \
15 Google, Capital One, Babylist, Olive AI, CompassLabs, Disney, SAIC, Americast, PacBe\
16 ll, CastTV, Lutris Technology, Arctan Group, Sitescout.com, Embed.ly, and Webmind Co\
17 rporation"...
18 3>
This chapter finishes a quick introduction to using Swift and Swift packages for command line utilities. The remainder of this book comprises machine learning, natural language processing, and semantic web/linked data examples.