Using Ollama to Run Local LLMs
Ollama is a program and framework written in Go that allows you to download, run models on the command line, and call using a REST style interface. You need to download the Ollama executable for your operating system at https://ollama.com.
Similarly to our use of a third party for accessing the Anthropic Claude models, here we will not write a wrapper library. The example code for this chapter is in the directory source-code/Ollama_swift_examples.
We use the library in the GitHub repository https://github.com/mattt/ollama-swift.
Running the Ollama Service
Assuming you have Ollama installed, download the following model:
When the model is downloaded it is also cached for future use on your laptop.
The OllamaService Actor Library
The library wraps the raw Ollama.Client in a Swift actor to provide safe concurrent access. It supports basic chat, streaming chat, and optional tool calling:
import Ollama
import Foundation
import JavaScriptCore
/// A service to interact with Ollama models using modern Swift concurrency.
public actor OllamaService {
private let client: Ollama.Client
private let model: Model.ID
@MainActor
public init(model: Model.ID = "qwen3:1.7b",
client: Ollama.Client? = nil) {
self.model = model
self.client = client ?? .default
}
/// Performs a chat request with optional tools.
public func chat(
messages: [Ollama.Chat.Message],
tools: [any Ollama.ToolProtocol] = []
) async throws -> Ollama.Client.ChatResponse {
return try await client.chat(
model: model, messages: messages, tools: tools
)
}
/// Performs a streaming chat request with optional tools.
public func chatStream(
messages: [Ollama.Chat.Message],
tools: [any Ollama.ToolProtocol] = []
) -> AsyncThrowingStream<Ollama.Client.ChatResponse,
any Error> {
AsyncThrowingStream { continuation in
Task {
do {
for try await chunk in try await
client.chatStream(
model: model,
messages: messages,
tools: tools) {
continuation.yield(chunk)
}
continuation.finish()
} catch {
continuation.finish(throwing: error)
}
}
}
}
}
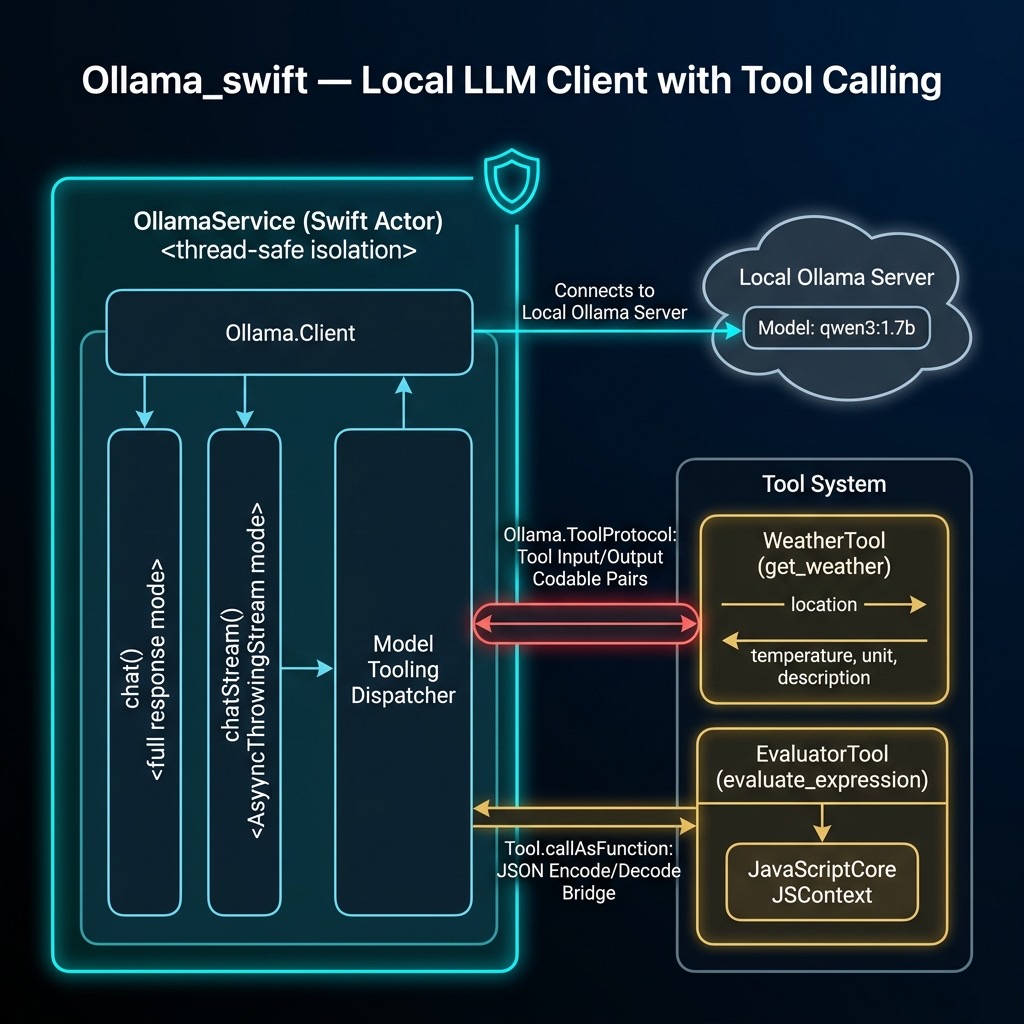
Tool Definitions
One of the most powerful features of modern LLMs is tool calling — the model can decide to invoke external functions to answer a question. The ollama-swift library provides a Tool type that defines the function schema and implementation. Here we define two tools: a weather lookup stub and a math expression evaluator.
The weather tool uses Codable structs for its input and output, and returns a hardcoded stub response. In a real application you would call a weather API:
public struct WeatherInput: Codable {
public let location: String
}
public struct WeatherOutput: Codable {
public let temperature: Double
public let unit: String
public let description: String
}
public let weatherTool =
Ollama.Tool<WeatherInput, WeatherOutput>(
name: "get_weather",
description: "Get the current weather for a location",
parameters: [
"location": [
"type": "string",
"description":
"The city and state, e.g. San Francisco, CA"
]
],
required: ["location"]
) { input in
// Stub implementation
return WeatherOutput(
temperature: 72,
unit: "Fahrenheit",
description: "Sunny")
}
The evaluator tool uses JavaScriptCore to safely evaluate math expressions. We use JSContext rather than NSExpression because NSExpression has known security risks when used with untrusted input:
public struct EvaluatorInput: Codable {
public let expression: String
}
public struct EvaluatorOutput: Codable {
public let result: String
}
public let evaluatorTool =
Ollama.Tool<EvaluatorInput, EvaluatorOutput>(
name: "evaluate_expression",
description: "Evaluate a mathematical expression " +
"(arithmetic and basic algebra)",
parameters: [
"expression": [
"type": "string",
"description":
"The expression to evaluate, e.g. '2 + 2'"
]
],
required: ["expression"]
) { input in
let context = JSContext()!
if let value = context.evaluateScript(input.expression),
!value.isUndefined, !value.isNull {
return EvaluatorOutput(result: value.toString())
} else {
return EvaluatorOutput(
result: "Error: Could not evaluate expression")
}
}
We also add an extension on Ollama.Tool that allows calling a tool directly with the arguments dictionary returned by the model:
extension Ollama.Tool {
public func callAsFunction(
_ arguments: [String: Ollama.Value]
) async throws -> Output {
let data = try JSONEncoder().encode(
Ollama.Value.object(arguments))
let input = try JSONDecoder().decode(
Input.self, from: data)
return try await self(input)
}
}
Example Tests
The tests use Swift’s modern Testing framework rather than XCTest. Here is the test/example code we will run:
import Testing
import Ollama
import Foundation
@testable import Ollama_swift_examples
@Suite("Ollama Service Tests")
@MainActor
struct OllamaServiceTests {
let service = OllamaService(model: "qwen3:1.7b")
@Test("Basic Chat Functionality")
func testBasicChat() async throws {
let messages: [Ollama.Chat.Message] = [
.system("You are a helpful assistant."),
.user("What is the capital of Germany?")
]
let response = try await service.chat(
messages: messages)
#expect(!response.message.content.isEmpty)
print("Response: \(response.message.content)")
}
@Test("Weather Tool Functionality")
func testWeatherTool() async throws {
var messages: [Ollama.Chat.Message] = [
.system("You are a helpful assistant that " +
"can check the weather."),
.user("What is the weather in San Francisco?")
]
let response = try await service.chat(
messages: messages, tools: [weatherTool])
if let toolCalls = response.message.toolCalls {
for toolCall in toolCalls {
#expect(
toolCall.function.name == "get_weather")
let result = try await weatherTool(
toolCall.function.arguments)
let resultString = String(
data: try JSONEncoder().encode(result),
encoding: .utf8)!
messages.append(response.message)
messages.append(.tool(resultString))
let finalResponse = try await service.chat(
messages: messages)
#expect(
!finalResponse.message.content.isEmpty)
print("Weather Final Response: " +
"\(finalResponse.message.content)")
}
} else {
print("Model did not call the weather tool.")
}
}
@Test("Evaluator Tool Functionality")
func testEvaluatorTool() async throws {
var messages: [Ollama.Chat.Message] = [
.system("You are a helpful assistant that " +
"can evaluate math expressions."),
.user("What is (15 * 3) + 7?")
]
let response = try await service.chat(
messages: messages, tools: [evaluatorTool])
if let toolCalls = response.message.toolCalls {
for toolCall in toolCalls {
#expect(toolCall.function.name ==
"evaluate_expression")
let result = try await evaluatorTool(
toolCall.function.arguments)
let resultString = String(
data: try JSONEncoder().encode(result),
encoding: .utf8)!
messages.append(response.message)
messages.append(.tool(resultString))
let finalResponse = try await service.chat(
messages: messages)
#expect(
finalResponse.message.content
.contains("52"))
print("Evaluator Final Response: " +
"\(finalResponse.message.content)")
}
} else {
print("Model did not call the evaluator tool.")
}
}
@Test("Streaming Chat Functionality")
func testStreamingChat() async throws {
let messages: [Ollama.Chat.Message] = [
.user("Tell me a very short joke.")
]
var fullResponse = ""
for try await chunk in await service.chatStream(
messages: messages) {
fullResponse += chunk.message.content
}
#expect(!fullResponse.isEmpty)
print("Streaming Response: \(fullResponse)")
}
}
The output for the basic chat test looks like:
Response: The capital of Germany is Berlin.
Ollama Wrap Up
I do over half my work with LLMs running locally on my laptop using Ollama, with the rest of my work using OpenAI, Anthropic, and Google commercial APIs. Running models locally is appealing for privacy, offline use, and avoiding per-token costs. The ollama-swift library also supports structured outputs (since version 1.2.0) which lets you constrain the model’s response to a specific JSON schema — a very useful feature for building reliable tool-calling pipelines.