
Table of Contents
- Requiem for an unfinished book
- 1. Management Heuristics
- 2. Teams Heuristics
- 3. Nature of the team
- 4. Constraining Laws for Teams
- 5. Team composition
-
6. Bug management strategies
- 6.1 Characteristics of bugs
- 6.2 Strategy #1: Prevent at source
- 6.3 Strategy #2: Fix close to origin
- 6.4 Strategy #3: Quick decision, quick fix
- 6.5 Strategy #4: Active bug management
- 6.6 Strategy #5: Bug fixing sub-team
- 6.7 Strategy #6: Fix within team
- 6.8 To estimate or not to estimate?
- 6.9 Choosing between strategies
- 6.10 Other strategies
- 6.11 Why not?
- 6.12 Finally
- 6.13 References
- Version History
Requiem for an unfinished book
Xanpan 2 is an unfinished book, a book that never will be finished. Well thats why the way I see it but I see the vision for the book I started to write, you dear reader see a collection of essays that may, or may not, constitute a book.
Indeed for sometime I’ve been troubled by the question “What is a book?”
I’ve written two books which are undoubtedly books: Changing Software Development and Business Patterns for Software Developers are traditional books, they are had print runs of several thousand copies with a traditional publisher - John Wiley and Sons. In writing them I had a contract: it contained a draft table of content, synopsis and approximate number of works, and it stipulated a end date.
These books were written to be printed but even as I was writing them the electronic book revolution was taking place. Both became available later as eBooks.
And then I wrote Xanpan, or rather the first Xanpan. This was self published using the LeanPub system. For a while it was only available as an eBook and on the LeanPub system. Gradually it acquired all the trapping of a traditional book: a nice cover, a copy edit, printed versions and even an ISBN code before it became available on Amazon - where most books sell today.
Xanpan looks like a book, is smells like a book, so, I guess it is a book.
The problem was, in writing Xanpan I didn’t know when to stop. There came a point where I wanted to “finish” it. I had more to say - I always do! - but I needed to move on.
Xanpan 2 was started in the glow of Xanpan and set out to say a lot of things which went beyond the original thesis. But Xanpan 2 stalled. Drafts chapters were written but never edited, my attention went elsewhere - other book projects like Little Book of User Stories and 50 Shades of Scrum took my attention.
Now, a little over a year after officially starting Xanpan 2 I feel I need to terminate it. Terminate rather than finish because it falls were short of the finish line I imagined. What is here is here, what is not… well I would like to add more but other ideas are pressing, other initiatives are squeezing it out.
Many of the ideas I wanted to express in Xanpan 2 have moved forward and some of the existing content should be updated to make it a book. But these ideas now cluster around another name, probably No Projects or Stream Based Development. Xanpan was Xanpan, Xanpan expresses the way I think agile software development works. Xanpan 2 expands on those ideas but… it will never be complete.
With a publisher a book is either completed or not, and if it is not then eventually the publisher calls time and the book and content never see the light of day. With LeanPub style publishing, were early version of the book have been sold I can’t pretend the book never happened - not least to myself and those who paid money for it.
I need to finish Xanpan 2 so that the ideas I want to express can emerge in the right way. I need to end Xanpan 2 to save those ideas.
So Xanpan 2 is, and always will be, an unfinished book. It will never be copy edited, it will never acquire a nice cover or an ISBN. Xanpan 2 is therefore more of an appendix to Xanpan than a sequel. An appendix yes, and a name change is probably appropriate: “Xanpan Appendix: Notes on teams.”
To those who paid, and may still pay, money for Xanpan 2: thank you for your faith, I’m sorry, I intend to find some way to make it up to you.
allan kelly allan@allankelly.net
London, March 2016
1. Management Heuristics
“In many ways, managing a large computer programming project is like managing any other large undertaking - in more ways than most programmers believe. But in many other ways it is different - in more ways than most professional managers expect.” (Brooks 1975)
“Some readers have found it curious that The Mythical Man Month devotes most of the essays to the managerial aspects of software engineering, rather than the many technical issues. This bias … sprang from [my] conviction that the quality of the people on a project, and their organization and management, are much more important factors in the success than are the tools they use or the technical approaches they take.” (Brooks 1995)
“It should be noted in conclusion that management has a much greater impact on both companies and projects than almost any other measured phenomenon. The leading-edge companies that know this, such as IBM, tend to go to extraordinary lengths to select managers carefully and to provide them with adequate training and support once they have been selected.” (Jones 2008)
There are those in the Agile community who argue that Agile working removes the need for managers. They may be right, although while I see how some Agile practices may reduce the role of managers I agree with Brooks and Jones: management makes a great impact. Management may well be the single biggest differentiator in the performance of software teams, for better or worse.
I believe much of the dislike, even distrust, of managers in Agile community (and wider software development community) is not a reaction to management itself but rather to poor management. At times it appears managers and programmers are locked in an existential struggle: managers long to automate programming while programmers hope to self-organise managers away.
Teams might well be better off without any manager rather than with a poor manager. After all the bulk of the work is technical, the engineers are clever people and self-organization can be very effective.
The challenge for those who aspire to manage software development work is to ensure they make a positive contribution and do not get in the way.
Nor should one make the mistake of thinking management is only done by those with the word “manager” in their title. Many of those who work in software development take on management work and management responsibilities but they may go by the title of Team Leader, Architect, Technical Lead, Senior Developer, Senior Tester, Release Engineer, Scrum Master, Business Analyst, or some other title.
I am sometimes reminded of the military differentiation between commissioned officers and non-commissioned officers - corporals and sergeants. The commissioned managers (with manager in their title) may nominal hold responsibility but without the, usually more numerous non-commissioned officers the organization would not work day-to-day.
While managers do at time seem to make more work for more managers removing managers altogether does not remove the need for management work. Indeed the work that remains must now be undertaken by a broader group of people, all of whom need to understand management and who need to co-ordinate about their management responsibilities.
1.1 Management focus on teams
This book focus on teams because teams are a major part of management work: deciding what teams there should be, who should be on the team, how the teams should be tasked, organised and so on. Teams are the central unit of work in an Agile processed. As it says in the title: the means of production.
Managing modern software development is to manage teams. Creating a large piece of software demands one, if not many, teams.
This book attempts to set the management philosophy about teams. By implication this sets the management approach to individuals - they are team members. And by placing teams, and team members, - not projects, budgets, or anything else - centre stage much else either falls.
Why place teams at the centre? Because the team is the means of production. Getting teams right creates stability. In an ever changing world managers need points of stability around which they can manage. This is not to say teams and team structures never change, they will, but that when do right there is more stability here than anywhere else.
Agility comes not from having ever fluid resources but from effective units of production, teams.
Managing around teams allows managers to concentrate on bigger issues. Gather than finding their time taken up by never ending resource discussions they can focus on those things that are not stable, where their skills, experience and authority can have the most effect.
This book is concerned with the organization and tasking of teams, in other words the structure of teams and the organization they exists in. This book does not concern itself with interpersonal issues within teams and between team members. This is not because these issues are not important, they are. Rather this is because I feel the structure and organization of software development teams is a neglected area. There is more than enough to say on this topic to fill on book.
1.2 Managers or management?
However removing managers and removing management are two different things. Whether a team or company has managers or not there are still things to manage - or at least administer. Some Agile practices may reduce the amount of management work to be done but, paradoxically perhaps, without managers more people will need to engage in management work.
Removing the specialist - the manager - will itself only remove management work in so much as managers create work for other managers -not always an insignificant amount of work! Without specialist managers the work that remains will fall on a wider set of people.
Consequently more people need to be versed in management - the skills, considerations and decision making mechanisms which would otherwise be concentrated in the specialist manager. When management work is distributed there is a greater need for shared understanding and shared learning because more individuals need to be involved in making decisions and execute consistently.
Since more people will be engaged in some way with management work the danger of poor management multiplies. More people need to understand management, understand how a team works and share the common understanding.
Therefore whether one believes managers are needed or not in an Agile environment there will still be people who need to engage in management type thinking. This volume is intended both for the dedicated specialist manager and for the far large group who need to understand management of software development.
1.3 Management is not strategy
There is a surprisingly wide spread view that managers should, even perhaps do, spend their time above the daily grind. They should/do spend their time planning, formulating strategy, engaging in high-level directing and co-ordinating.
Indeed managers - particularly new managers - own belief that this is what they should be doing leads to plenty of guilt, angst and cognitive dissonance. While there may be a few managers who can elevate themselves away from day-to-day fire-fighting, decision making and daily grind the overwhelming majority do not.
Those who have taken the time to study and research just what managers do find there the difference between what non-managers think managers do and what manager do. There may even be a difference between what managers - particularly new managers - think they should be doing as managers and what manager actually do do.
One of these is Professor Henry Mintzberg of McGill University who has spent much of his career trying to understand just what managers actually do. If I may quote from one of his more recent books:
“Henri Fayol saw managing as controlling, while Tom Peters has seen it as doing … On Wall Street, of course, managers ‘do deals.’ Michael Porter has instead equated managing with thinking, specifically analyzing … Others, such Warren Bennis, have built their reputations among managers by describing their work as leading, while Hubert Simon built his amoung academics by describing it as decision making.”
“Each of them is wrong because all of them are right. Managing is not one of these things but all of them: it is controlling and doing and dealing and thinking and leading and deciding and more, not added up but blended together.” (Mintzberg 2013)
Those who are still tempted to see managing as above the fray would be advised to pause and read on of Mintzberg’s books: Simply Managing is probably the place to start (being a summary of his earlier Managing (Mintzberg 2009)). But for those who still believe managers engage in strategy planning The Rise and Fall of Strategic Planning (Mintzberg 1994) represents a tour de force destroying the myth of planned strategy.
It is because managers are part of the daily work that they can think about formulating strategy - prospectively or retrospectively. Strategy and action are not to disjoint activities. It is by being involved in action - decision making and such - that informs strategy.
More importantly strategy can only be executed by day-to-day involvement. Only by being in field, in action, in the detail, can managers have any hope of ensuring that “big decisions” actually get en acted.
1.4 1000 decisions a day
Managers do engage in strategy planning, or at least strategic thinking. They do, from time to time, make big decisions. However much that is written about management tends to focus on the few occasional “big decisions.” In reality managers make hundreds, if not thousands, of small decisions every day.
It is these small decisions which constitute the guts of managing.
“the job of managing is significantly one of information processing, especially through a great deal of listening, seeing and feeling, besides just talking” (Mintzberg 2013)
It is the many small decisions which implement the few big decisions.
It is the small decisions which cummulatively make the big differences.
True, a few big decisions can be helpful to ensure that the small decisions are aligned, that they collectively make sense and are consistent. But perhaps even more important it the managers’ own beliefs, values, philosophy and logic which inform these decisions - some of which need to be made under extreme pressure and without the benefit of hard data or time to think.
1.5 Why management heuristics?
Management occurs within a context. It is not based on a set of if…then rules, or rather, management might be ruled based but the number of considerations, forces, pressures and constraints which must be examined is so large as to be beyond comprehension.
This then is an environment in which heuristics, rules of thumb, can be helpful. Such rules of thumb should guide decision making but they should not bind it. The heuristics should bring about consistency but they are not complete. Judgement and intuition need to be applied too.
There are so many variables in management work that it is rarely possible to formulate firm and fast rules. Indeed the time required to do so would probably make it a never ending task.
However there are common variables, common pressures, common forces and common environments. Within a software development environment there are decisions which crop up again and again.
Management cannot be programmed. It is not possible to give invariant rules but it is possible to give heuristics.
And, perhaps more importantly, it is possible to share ones own philosophy in the hope of educating another. At the very least the stories and heuristics in this volume should help those who practice management reflect on their own decisions.
1.6 Why Xanpan?
I have chosen to name this book “Xanpan Book 2” I could easily have named it “Agile Team Management Heuristics” or just “Heuristics for Managing Software Teams.” Instead I have chosen to make an explicit link to Xanpan. While this has certain marketing advantages the main reason for doing this is to provide a base for the book. By building on this base I can avoid digressions into discussions of iterations, quality, etc.
Many of the issues which I intend to discuss in this book have already been discussed in one form or another in “Xanpan: Team Centric software development” (shortly to be renamed “Xanpan Book 1”). This book builds on that base.
Although it is not essential for the reader to be familiar with “Xanpan Book 1” those who are not may find themselves needing to reference it from time to time - the alternative is for me to repeat myself.
Indeed I believe many of the heuristics presented here about managing software development are applicable whether a team is following Xanpan, generic Agile, Scrum, XP, Kanban or even a traditional “Waterfall” type development process.
That said, those who already “think Agile” will find the book easier to read; and those who “think Xanpan” will find it easiest of all.
1.7 Finally: Heuristics and philosophy
This volume strives to offer a set of heuristics for anyone involved with managing software development. These heuristics might not be the most important - although I hope they are. These heuristics might not address the most common areas - although I think they may well do. These heuristics are drawn from the conversations I have again and again with managers of software development.
Heuristics are useful, however the first heuristic for anyone charged with managing software development must be:
Develop your own philosophy of software development.
My own philosophy has already been laid out in Changing Software Development: Learning to be Agile (Kelly 2008). Those who have yet to develop their own philosophy are advised to read widely and reflect personally and with others.
1.8 References
Brooks, F. 1975. The Mythical Man Month: Essays on Software Engineering. Addison-Wesley.
———. 1995. The Mythical Man Month: Essays on Software Engineering. Anniversary edition. Addison-Wesley.
Jones, C. 2008. Applied Software Measurement. McGraw Hill.
Kelly, A. 2008. Changing Software Development: Learning to Become Agile. John Wiley & Sons.
Mintzberg, H. 1994. The Rise and Fall of Strategic Planning. FT Prentice Hall.
———. 2009. Managing. San Francisco: Berrett-Koehler Publishers Inc.
———. 2013. Simply Managing. FT Publishing.
2. Teams Heuristics
As stated in Xanpan book 1:
Xanpan is team-centric: the team is the production unit, need goes in, working - even valuable - software comes out. This is the machine, the goose that lays the Golden Egg.
In a software development organization - and many others - the means of production is the team. Thus teams need to be considered in more depth.There are several heuristics which can be applied when thinking about team:
- Teams should stay together, teams need to be stable and enduring. A team may grow or shrink over time. Once in a while a team may be dissolved and occasionally a new one be created. Like successful sports teams the nucleus of the team stays together.
- Teams need to have a sense of purpose and responsibility for delivering towards that purpose. When forming new teams they should be built around the purpose.
- Teams should contain all the skills required to do the work they are expected to do: every time they must “call out” for work to be done dependencies occur, delays arise, complexity rises and responsibility for doing the work becomes opaque.
- Devolving authority to the teams and team members will improve the flow of work through the system: decision can be made in a timely fashion by those who are closest to the work and who know the most about the details.
- Team members may have specialisms but are encouraged to work outside of specialism on the highest priority item. The more team members are able to cross specialisms the better the work will flow. Yet when deep technical knowledge is needed specialists are needed - this might be a reason to avoid such technologies.
- Specialists - in particular Software Testers and requirements experts (be they analysts, product managers or others) - should be embedded in the team. These are first class members, no team members should be considered second class (as unfortunately happens sometimes with software testers.)
- Flow the work to the team: the team is the unit of production, teams can work on more than one stream of work, or project, at a time as long as priorities between the competing streams can be reconciled without introducing delay.
- Align teams with business lines (products and services): it is no longer just software product companies which live or die by the quality of their software. Increasingly companies offer products and services which are dependent on software. Without the software the company has nothing. Every company is a software company.
- Teams should be sized and staffed according to business priorities and strategy rather than the effort required to do any particular piece of work.
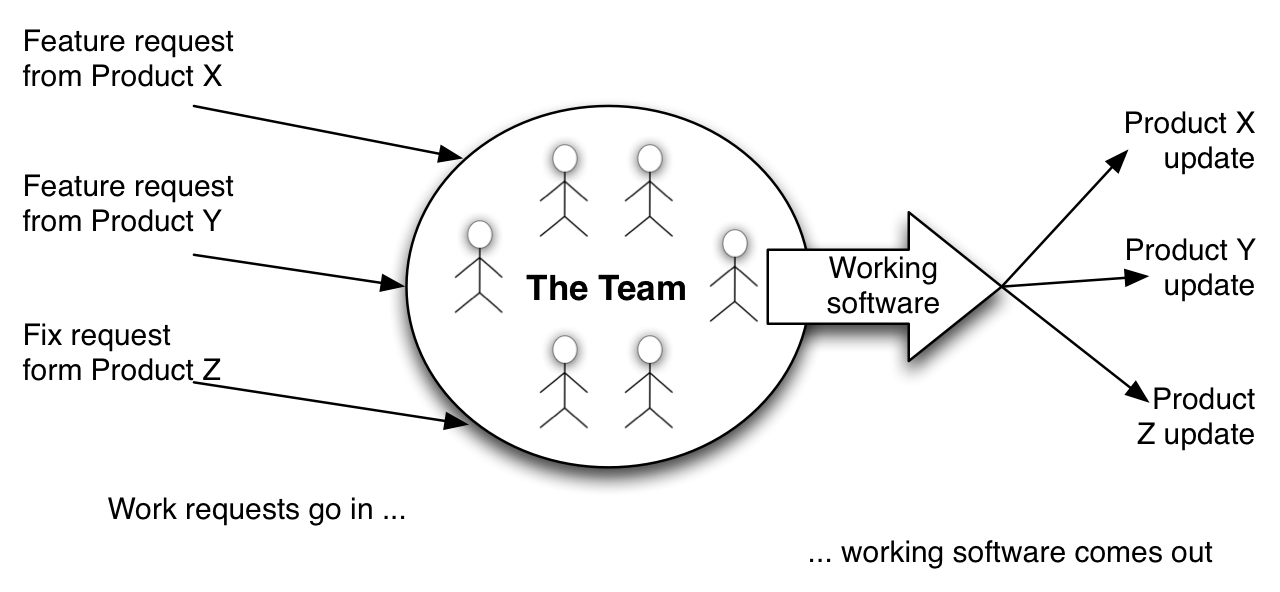
The days of managers allocating individuals to work, and occasionally intervening to move individuals from Project X to Project Y, should be history. Managers are busy people, too busy to be involved in details like who’s doing what. Team members will be more motivated if instead of being assigned tasks they have a part in both deciding what the tasks and deciding which tasks they will work on.
Managers need to deal with bigger concepts. They form the teams, teams are given a goal, managers leave the teams to do what needs to be done. Sure they review work - a portfolio review or similar - but that doesn’t happen every week and they review complete work, not small pieces. Once in a while they may become involved to rebalance teams as company priorities, objectives and strategies change but that doesn’t happen every month.
The rest of this chapter, and the following chapters will expand on these heuristics.
2.1 Teams over projects
Xanpan is project agnostic. There is a team, there is work to be done, the flow of work needs to be regulated and controlled so that the team can a) work efficiently, b) deliver with some degree of predictability. Teams and managers frequently use the language of projects and project management to describe ongoing programmes of work. This leads to confusion.
In the simplest model one team works on one project. In this case all the work undertaken by the team relates to the project. The team comes into being to undertake the project and is dissolved at the end.
A more common scenario is that a team exists and undertakes work on an existing and continuing product. While some of this work, and periods of time, may be assigned to a particular project this is an accounting convention. More likely than not the team and the product will continue to exist beyond this project, the work will simply be counted for under a different project label or a “business as usual” label.
Another common scenario is that a team exists to work on a project but must undertake ad hoc work for other projects or on other products. Rather than being dedicated to a single stream of work the team, or just individuals on the team, must slice their time between different streams of work.
Xanpan focus on the team and the flow of work through the team. Whether this work comes from one or more projects, programmes or business as usual (BAU) is unimportant. Part of the role of managing the team is to ensure that work is correctly accounted for and stakeholder expectations are managed.
Teams will be most effective when the variety of work is the smallest, i.e. all team members work on the same code base under the same project focus. This set up will also provide the greatest degree of predictability when forecasting deliverables and schedule. The greater the variety of work the less efficient and less predictable the work will be.
Organizations need to determine whether they wish to optimise work for effectiveness and predictability or for flexibility and responsiveness.
As a general principle, for projects and similar types of work it should be arranged as a sequence of short-fat projects rather than parallel streams of long-thin projects.
While team members completely fungible the aims of favouring short-fat over long-thin are:
- To deliver value early, i.e. the first short-fat project to complete can be released and start generating value which the second is in development.
- Remove bottlenecks when multiple parallel streams require the same resource, e.g. four streams complete at the same time and content for test resource.
2.2 Clear benefits and purpose
Teams need clear sight of how their work brings benefits to customers, users and the business. Team are organised along business lines rather than functionally. There is no database or user interface team. Teams deliver a product or service to the business. A saleable thing in its own right, or tools to support a line of business.
Businesses increasing deliver products and services which are inherently software dependent or which could not be delivered without software, as a result all businesses increasingly resemble software businesses. The business is software. Business folks need to learn more about IT and to work with IT people.
Think of teams like amoeba, they are the cells that make up the bigger organization. Indeed Kyocera has pioneered and approach called Amoeba Management (Inamori 2013).
Kyocera’s Amoeba management was invented for a different knowledge based industry: specialists ceramics research, development and production development but there are lessons here for software teams.
The amoebas also holds the key to growth - or shrinkage. Amoebas grow and expand in size up to a point where they split, cell-like, into two independent entities. (This topic will be discussed in more detail later.)
Many software teams - particularly in corporate IT departments - find themselves buried somewhere inside the organization without any idea - let a clear idea - of how their work benefits the wider organization. This is not good for morale. And it is not good for resolving conflicts and deciding trade-offs.
Kyocera’s amoebas produce their own efficiency reports showing profit and loss. Each amoeba - no matter how deep inside the company - is a stand alone profit centre. Each amoeba measures its own costs and revenue. The company has created a series of conventions that allow amoeba to be customers of one another.
This approach allows each amoeba to make decisions to optimise its own performance and gives all employees clear sight of how their actions impact profit - or loss. This does not mean Kyocera teams run in different directions, that the company lacks a strategy or the company sub-optimises. The company has other mechanisms in place for those things - largely based on a shared culture. But it does mean each amoeba takes on responsibility.
Teams, amoebas, need to have a sense of purpose, a sense that the team - and individuals on the team - make a difference. Therefore the team members need to be able to see the impact their work makes. At a very minimum this should be visible on a financial report, better still they should be able to see difference their products make.
2.3 Stability
Teams need stability. This does not mean people never leave a team or that teams don’t obtain new recruits but it does mean that these are occasional, not regular events.
At a mundane level team stability is needed to provide continuity in data. If a development organization is to be run in a rational manor then data on past performance, or rather capacity, will prove useful. If a team has never worked together there will be no data so it is not possible to assess what might be achieved. Only with stable teams can past performance provide the data required to product accurate forecasts of future work.
Many people will have heard of the Storming-Norming-Forming and Performing model (Tuckman 1965) which described the stages a team passes through when becoming productive. Before a team can get to the performing state time (and therefore money) must be expended. Thus new teams cannot be expected to suddenly meet and “hit the ground running”. Team start-up time and costs must be factored into any work.
(The “hit the ground running” metaphor must be one of the most poisonous ever invented. I fail to think of any animal, sport or military team which can actually do it.)
At the other end of the cycle disbanding a team makes little sense. Once a team is performing why break them up when there is more work to do? The organization which owns the team has paid the storming-forming-norming and performing price and now has valuable data on capacity so why dispose of these assets?
Frequently former members of team will find themselves sought by those now charged with maintaining software either to undertake work or to share their knowledge. Since software survives it makes sense to keep the creators together to service the software as need be.
When teams have been disbanded finding former members may be the only option available to those who need to make changes. Consequently past work has a habit of following people and disrupting their new work.
Knowledge is the reason why team member are sought. Teams may see documentation as a solution to this problem, they believe that leaving documents behind will allow the next generation to obtain this knowledge. But documentation is rarely done and when it is done it frequently fails to describe what is needed - why would it?
Those writing the document can only guess at what the future readers will want to know. Frequently documentation is left to the end of a team’s allotted time. Time for documentation is squeezed, few people are enthusiastic about writing documentation and what is produced may be of low quality.
Worse still documentation may be written before any code is cut, it describes what is expected and may consequently not represent what actually comes to pass. Sometime teams get stuck creating great documentation, perfect designs, rather than actually producing useful software.
Stable teams contain this knowledge. There is no need to pay the price of writing the documents, no need to hunt down members and no need to disrupt their current work.
When people join teams they bring their knowledge, they also bring baggage: knowledge of past work. When they remain in the same organization they may be hunted down for this knowledge, they may be asked to help those who have “replaced” them. Attempts to resist these requests - perhaps by ring fencing individuals or time - create conflict and tension - both for the individuals and their managers. And as mentioned above these requests disrupt the new work.
A team centric approach accepts these requests and works to service either directly (by doing the work, absorbing these responsibilities into the team) or indirectly (by helping the replacements). By tracking and understanding this work measures can then be taken to manage this work.
Individuals who move to new organizations will bring less direct baggage - the previous employer is unlikely to come asking questions. But mentally the individuals will bring much of their mindset from the previous employer.
Of course teams will change - people sometimes retire or get ill. And teams will need to add new members - if only to replace those who leave. However these changes should be gradual and over time. Rapidly adding people to a team - something I call “fois gras” recruitment - will undermine the teams productive capacity.
It is 40 years since Fred Brooks coined his famous law:
“Adding people to a late project makes it later” (Brooks 1975)
This may be generalised as:
“Adding people to a work effort slows it down”
Teams may at times need to expand to take on a lot of new work, and they may shrink when peak work is done. Such transitions need to be managed carefully. It may make sense to think of a core team which stays together and services a number of products and may, when necessary, expand to cope with more work. Time will tell if the team shrinks back to the same size when the work is done.
But rather than regularly changing team composition to cope with changing demands stable teams can look for other solutions. They seek mechanisms to reshape demand - perhaps by moving work from high demand periods to low demand periods. Or by shedding low value work. Or finding creative synergies in requests. Or some other technique yet to be invented.
Optimisation
Because the team continue to work together they can also optimise their thinking. This might be thinking around technology, application or processes. The team is the unit of production and they should seek to improve their productive capability, i.e. optimise themselves!
Because the team are staying together they have reason to improve their technology and processes and because they are staying together they will see the benefits form their efforts. If a team is destined to be broken up at the end of a piece of work why would it strive to improve their methods of working and productive capacity?
The closer a team gets to “the end” the less attractive it will be to invest any time in team and productivity improvement. Indeed it might be more sensible to for team members to impede their productive capacity in order to prolong the time they spent together.
When managers intervene to optimise a team by moving people around the result is often counter-productive. First it reduces the incentive for team members to improve their practices if they know managers will ride to the rescue with more resources. Second by removing responsibility from the team to solve their problems it also removes the impetus and authority to solve the problems.
Adding people to the team may increase capacity - after a lag - but it will not improve efficiency. And since those people need to come from somewhere other teams suffer as people are moved.
Expanding a team through recruitment will reduce productive capacity long before any new employee starts work. Decision makers need to be lobbies to agree recruitment, bob specs need to be written, approved and issues, resumes or CVs filtered, interviews conducted, etc. etc. Doing this work removes productive capacity.
When a recruit starts work they need help learning their way around. It can be several weeks if not months before they are productive.
It is not unusual to hear of recruitment taking three months, and that is often regarded as quick. Hiring new people is a time consuming process and reduces productive capacity for many months.
Camaraderie
Teams which work together over time develop a camaraderie - a friendship, an empathy for each other. They share success, they share failure, success for one is a success for all and when one has difficulty others will rally round to help. Building such camaraderie is part of the storming norming forming and performing process. But no amount of team building causes can substitute for years of shared experience, pain and joy.
When a team shares success each member also shares responsibility for bring that success about - and they share in the joy when success is achieved. This way team members can see how their work, and their relationships, make a difference.
Keeping teams together allows camaraderie to build and allows the team, and their wider organization, to benefit from these shared bonds.
Unfortunately team which are too stable and lack diversity can suffer from a phenomenon of group think. When this happens team members search for harmony leads them to stop raising objections. To some degree stable teams can offset this by encoring diversity in the recruitment process. Still, completely stable teams are probably not the best idea.
Flow the work to the team
If the team are considered stable, how can a company match the work to be done with the resource available to do work?
The answer is to flow the work to a team. Teams already exists, an organization may have several teams, work comes and goes, unlike a team work is transient. Therefore work needs to be directed to the team that will do the work. If a team is experiencing a surge in the amount of work it is asked to do then expanding the team can be justified. Equally if a team is not receiving very much work it might be shrink. And teams may merge and teams may split.
Since the team has an area - or areas - of speciality and responsibility - one hopes it will become obvious where work will flow to.
Think of a team as a sausage machine: sausage meat going in, sausages come out; requests for work go in, working software comes out. If pork meat goes in port sausages come out, if chicken meat goes in chicken sausages come out. Software teams specialise in certain products but they work they do at anyone time depends on the requests which go in.
2.4 Area of speciality
Teams should have an area of speciality. Preferably this area of speciality is related to a business function, i.e. a business capability that produces revenue for the business. As such the team will have some skills and knowledge related to the business domain they are working in.
Since software exhibits continuity the team will have experience and knowledge of the software products which service this business function. And thus the team will have knowledge and experience of the technologies that are used in those software products.
Business domain knowledge - sometimes called the application or problem domain - and technical knowledge - sometimes called solution domain - go hand in hand. The individuals on a particular team will have both and they will support each other in their knowledge.
New team members are often recruited because of their knowledge and experience of some subset of this knowledge, usually the solution technolgies. For example, a team working on an accounts payable system written in Java and Oracle SQL may be able to hire a programmer with Java and Oracle SQL knowledge. While they may even have some knowledge of accounts payable they will not have knowledge of the actual application and the existing code because this is unique. (Unless of course the team can hire someone who previously left the team!).
2.5 Area of responsibility
Hand-in-hand with an speciality goes responsibility. When a team specialise in an area they are also responsible for it. They know - because of stability - that they will be responsible for it next month, next year and into the future. Therefore they have a reason to look after the area, to improve it, to help the business benefit from it.
The area of responsibility is largely implied by the purpose of the team and benefits the team are entrusted to deliver. Together purpose and responsibility allow teams to have pride, to derive pleasure and self-respect from their work.
Teams may have more than one area of responsibility. The greater the similarities between the areas the more effectively this will work. Imagine our accounts payable Java Oracle SQL team. The same team may hold responsibility for the fixed assets part of the system too. It is going to be a lot easier to maintain this responsibility if fixed assets is also implemented in Java and Oracle SQL.
The greater the variance in technologies, differences in business domains and variety of users the greater the difficulty in keeping multiple responsibilities in the same team. This is a particular consideration when teams need to shrink.
2.6 Strategic sizing
Obviously if a team is to be stable people are not going to be regularly looking at work arising and saying “How long will this take? How many people do we need?”. Rather they will be deciding is work arising is beneficial, directing it to the appropriate team and balancing priorities within that team.
And since each team will have its own areas of specialisation and responsibility there are going to be few questions about moving work between teams to balance the load. Occasional personnel moves are normal and should be expected, but when frequent team changes are disruptive and destroy capacity.
Indeed, since the teams will have their own areas and will have analysts and other requirements people in the teams they may well be identifying and generating their own work to produce business benefit.
So, given all of this, how is an organization to decide how many people to put in each team?
How are they to know when to expand teams?
And known when to shrink or merge teams?
The aim, for the sake of stable teams, is to get away from a position which so many software managers find themselves in: the constant, ongoing discussion of who’s on which team or project.
It sometimes seems that software managers only have one lever with which to control work: team resources. One team is slow so they pull the lever and someone moves from another team to the slow one. In so doing they sow the seeds of the next crisis when the same lever will be used again.
The answer lies in moving away from the piecework approach of constantly looking at incoming work, estimating the size and assigning individuals and teams to undertake the work. As discussed in Xanpan volume 1 this approach is fundamentally flawed because humans are very bad at estimating work.
Estimating the work without reference to who will do it is akin asking “How long will it take to get from London to New York?” and being told “It is 5500km between London and New York” without reference to the mode of transport. Estimates are inherently tired to who (which team) undertakes the work and to have any hope of accuracy requires knowledge of past performance. Even then accuracy is far from guaranteed.
Rather than work on a piecework/estimation basis teams need to be staffed strategically by reference to the value their product holds to the wider business and their past record of delivery. Thus the team are tied to the business they serve.
Should the company in our earlier example determine that the accounts payable system lacks business value they should act to reduce the capacity (and therefore costs) of the team. Similarly if they determine that the online retail system is the source of growth and therefore valuable then it makes sense to increase staffing in this area. Such decisions may mean that it takes longer to get changes to accounts payable but so be it, that is the strategy. It would be foolish to limit the online system if this is where the business sees growth.
Strategic staffing aligns with stability because strategy, like teams, should be stable over more than the short run. Good strategies should last years, if they do not they are not really strategy - or at least, not good strategies.
However looking at the value to the business is not the whole story. Organizations should also examine the benefits delivered by a team and the potential benefit in so far as it can be seen. Partly this is good governance, if a team repeatedly fails to deliver benefit they see then something needs to be fixed.
At a strategic level it is one thing to say the organization should invest in an area but another to actually perform well in that area. To continue the example, deciding to invest in online retail and growing the team does not itself guarantee success. The team may find that while they can deliver software competitors are stealing customers and the anticipated benefits are not being achieved.
Competitors, the market, customers and many other factors mean that realising desired strategies can be hard work. On occasions it makes sense to reverse course or change strategy. Only by executing is it possible to determine such factors. On paper all plans look possible.
2.7 Conclusion
Teams are the unit of production, organizations should allocate their people to teams according to strategic priorities and aim to keep both stable over the longer term.
Constantly micro-managing teams to match resources to goals is counter productive. Changing team members, forming new teams, disbanding existing teams and changing goals not only reduces productive capacity but job workers of the continuity needed to foster responsibility, sense of purpose and pride.
Achieving quality, responsiveness and flexibility - what might be called agile - comes not from constant changes to teams but from stable teams. These changes make for more management work - as they rebalance the teams - but this work is superficial.
Setting strategy, setting teams to match strategy and staying the course requires less management but deeper management. Less knee-jerk changes and more strategic thinking.
2.8 References
Brooks, F. 1975. The Mythical Man Month: Essays on Software Engineering. Addison-Wesley.
Inamori, K. 2013. Amoeba Management. CRC Press - Taylor Francis Group.
Tuckman, B. 1965. “Developmental Sequence in Small Groups.” Psychological Bulletin 63 (6): 384–99. doi:10.1037/h0022100.
3. Nature of the team
Teams are the means of production. Teams create value. Organizations are made up of teams. The team are the capability to do work.
A team is like sausage machine, work requests go in, working software - or whatever it is you are building - comes out. Put in pork request you get pork sausages, put in chicken requests and you get chicken sausages1, put in horse meet and… well who knows!

The aim of the team is to be productive and to increase their productive capacity over time. The team work on products, they may be responsible for more than one product and therefore work on more than one code base.
The team is stable and productive. Work flows to the team. The team sits at the centre of their own little universe, that might make some people uncomfortable but since the teams are the means of production it is inevitable.
Thus the question for management, and the requirements specialists, is: what should the team be working on?
There are different ways to answer this question. One might choose to answer it from an efficiency point of view: “The team should be working to maximise their output and utilisation.”
One might answer it from a value point of view: “The team should maximise the value they deliver.”
One might answer it from a risk point of view: “The team should be working on the items of highest risk” - which, since profit is the return for risk, might also be profit point of view: “The team should be working on the most profitable items.”
One might even answer it from a political point of view: “The team should be working on the highest profile work.” Or as Tom Gilb likes to say “Work on the juicy bits first.”
How the question is answered depends on the priorities of the organization. The organisation is free to choose how it wants to answer the question. Unfortunately it is also free to change its answer. Sticking with an answer, at least for a few months, is more likely to produce the desired result.
3.1 Work flows to the team
Teams have areas of responsibility, whether that be business domain or a set of software products - ideally it would be a set of software products grouped around a common business domain. These products generate work - because people want changes. And the business domain generates work - because business is in a constant state of flux.
When work arises it is directed to the team. Where there are several teams the work is directed to the most appropriate team.
Some of this work may be small, some might be large. Some might be simple requests and some might be great big bundles of work or “projects.”
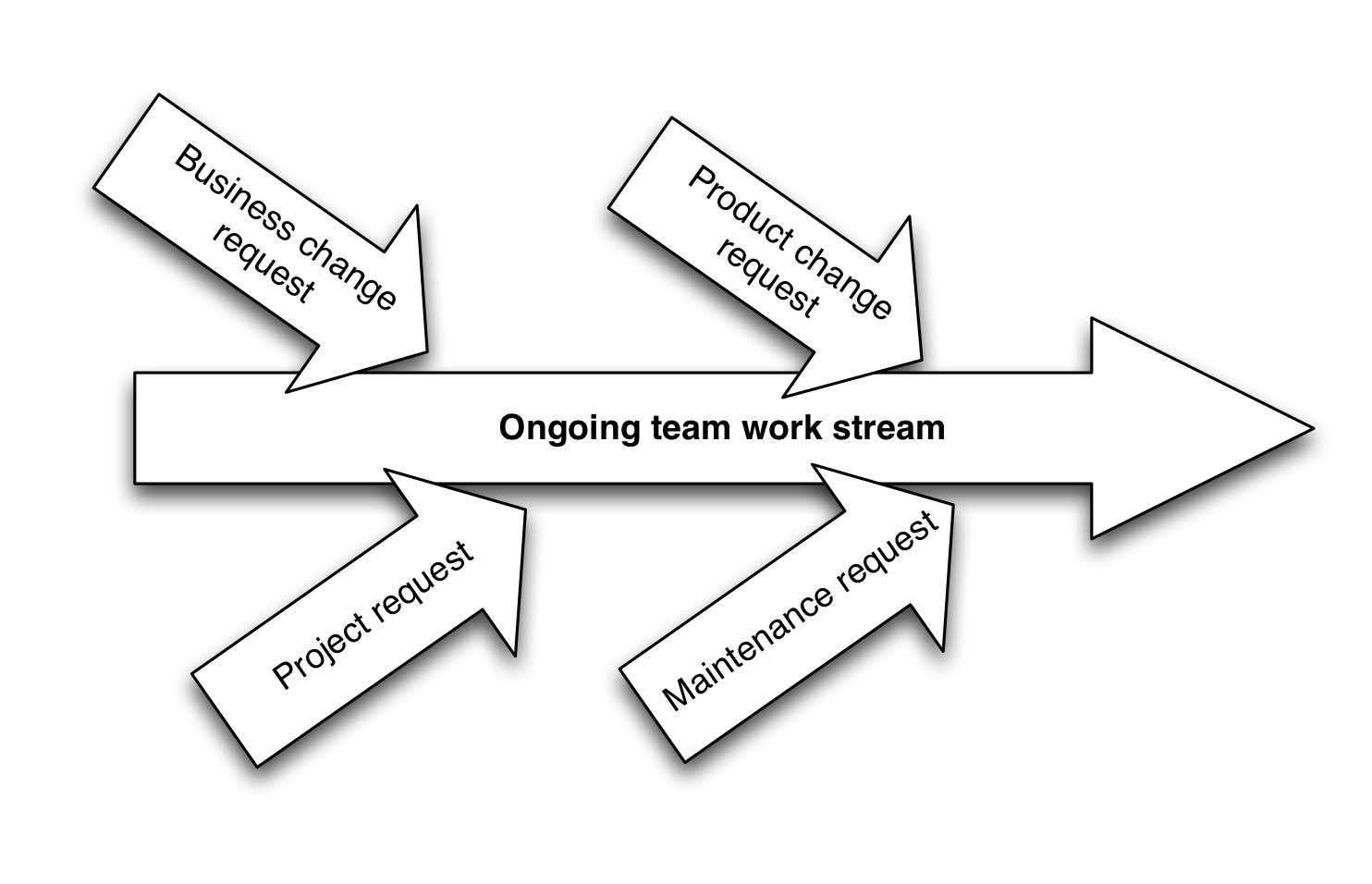
This approach follows the Work Flows Inward pattern described in Organizational Patterns of Agile Software Development (Coplien and Harrison 2004).
The great management debate about “who will work on” a request is removed. Such debate is not a productive use of managers time anyway, using a team centric view managers might decide who is on a team but they need not have micro conversations about who will undertake a piece of work or when an individual will work on it. Discussions about whether Bill or Jim should work on something are gone because Bill, and Jim, work within teams. Work is directed to a team and not to an individual.
The team are the means of product. The team represent at the capability to do the work. As long as an organization does business in a particular area using a particular set of products then the team exists to service those products.
Generally it should be clear which team will work on any given request. There may be an occasional discussion about whether one team or another should undertake a particular request but these discussions happen at the team leave.
Internally the team might debate who is going to do a particular piece or work, or they might not, they might just have the next available person work on it when it rises to the top of the priority queue.
The company may decide to run down the use of the products and therefore reduce the size of the team, or it may decide to enhance those product further and that would require expand the team.
3.2 Vertical teams
Teams are staffed in vertically, that is to say the team contains all the skills needed to do a piece of work across the entire software stack or architecture.
In the past many teams have been organised along functional, or horizontal, lines:
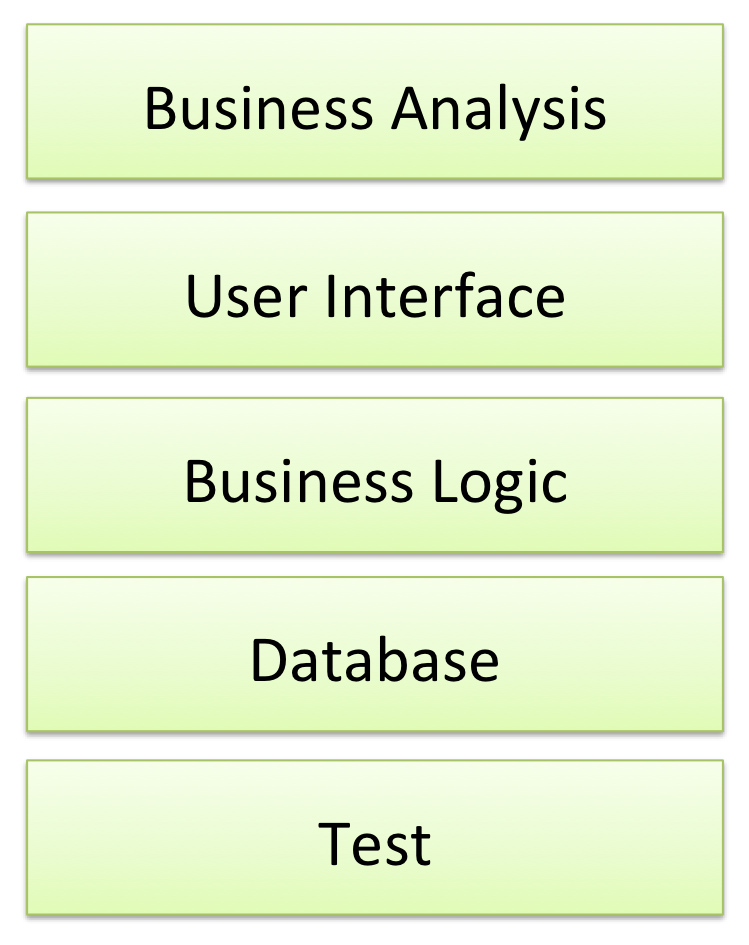
The problem here is that getting a piece of work done requires co-ordination between all the layers. Different teams were responsible for different functional items and getting anything the business would recognise delivered required each team doing its bit. And that might mean lots of co-ordination and even persuasion.
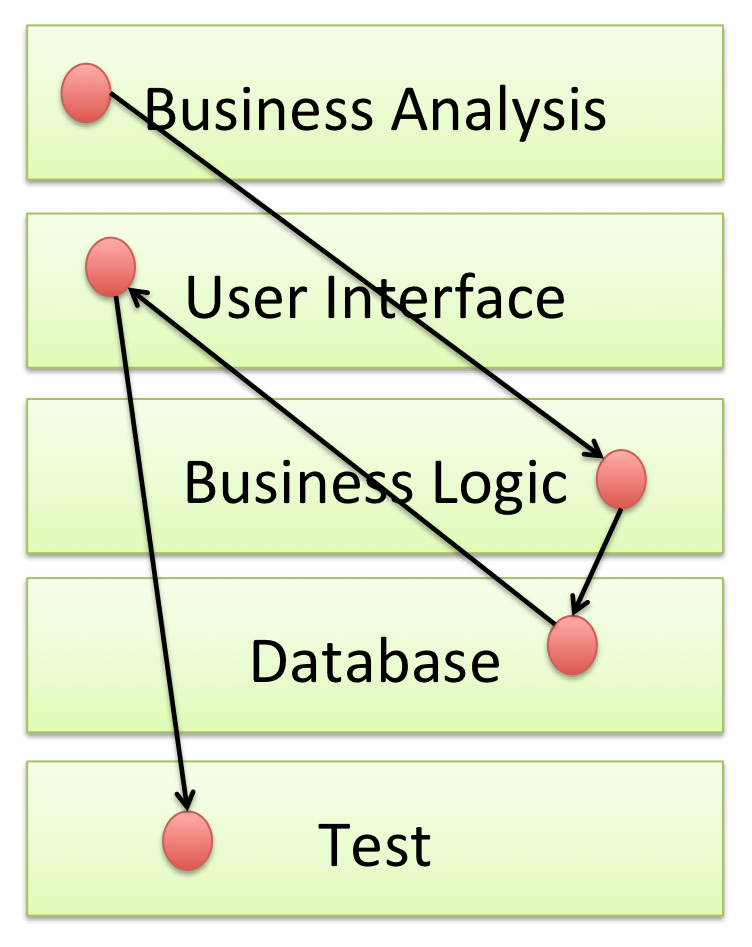
In a horizontal model delivery occurs at the pace of the slowest team. No matter how fast the other teams perform until the work of the slowest team is completed there is nothing that to be delivered. If a customer comes to ask “why is this late?” each team can point at the other teams. Such a situations does not generate responsibility and it is hard to hold anyone to account - except perhaps the person with the thankless task of co-ordinating all the different teams.
Because work must be passed from team to team, layer to layer, there are multiple hand-offs, each hand-off requires communication with adds to cost, takes time, which slows things down, and poses a potential risk - the hand-off misses, information is lost and so on. With each hand-off the distance to the end customer increases and responsibility is lost.
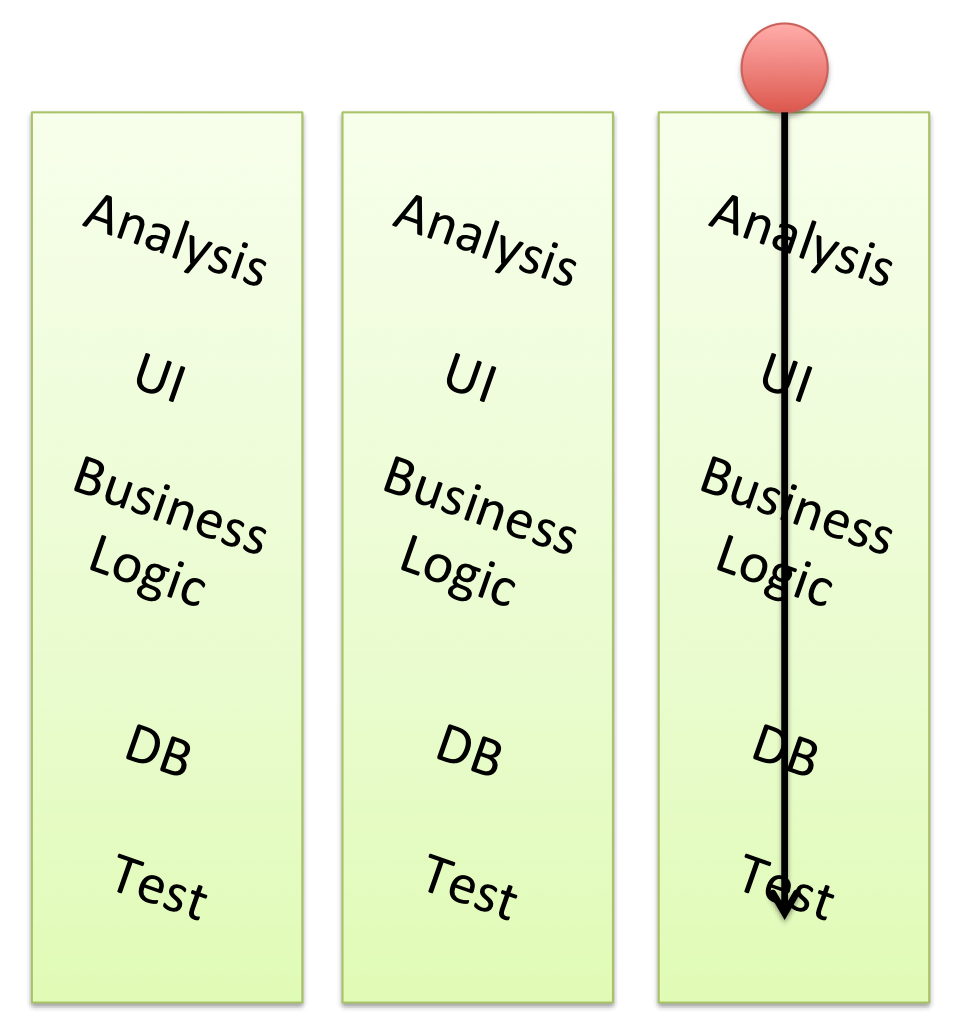
A vertical team works on complete items, things which are recognisable and valuable for the business. One team is responsible, one team accountable, and one team can take the glory. If work is delayed there then one team is talk to, and there is little need to co-ordinate the work of multiple teams. Each team is free to work as fast as it likes.
There may be hand-offs within the team but the team can work to minimise these, and since the work is within the team communication and risk are reduced.
This requires teams to be staffed with all the skills they need and the authority to use those skills. Even when team members are new to a skill set, or there are better people in other teams, the team take responsibility and does the work.
3.3 Only software?
In the context of software a vertical team probably makes one think: Java coders, front end developers (HTML, CSS, JavaScript perhaps), product specialists (a product manager or business analysts perhaps), testers, database SQL skills or similar. Indeed there are many vertical software teams staffed according to this model.
But this might not be the limit of the team. If the team delivers value then delivered completed software products might not be the end.
Technical operations, the capability to deploy software in the cloud, to monitor its use and so on would allow the team to measure the benefit delivered directly in terms of the service they are delivering. Including such skills the the basis of DevOps.
Teams could go further: the team might include outbound marketeers to tell people about the software service they are delivering. The team might include customer service staff to help with customer problems.
In fact the software engineers might be a small part of a much bigger business team or even business unit.
3.4 Deciding what to work on
Given all the request that might reach a team the question arises: how does the team know what to work on?
When work comes from multiple sources to a team it is critical that the team has a clear way of deciding what will be worked on next. Even if the prioritisation process is unclear or erratic some priority call still needs to be made, it is more important that prioritisation is how it is done.
Basically there are two ways in which the actual work gets decided: the team are told what the priority is (an external command) or the team are trusted to do what is needed (an internal decision.)
My preference is to endowed the team with the authority to make the decision internally. This power may well be vested in one, named, individual. Such a person might go by the title Team Leader, or Product Owner or Manager.
Alternatively the team might decide collectively what to work on. Even here there may be a role for a product specialist with the skills to identify the highest value items and evaluate the results.
When the power to make the decision is vested inside the team the team, or at least individuals, will need to explain their decisions. Putting the power to decide inside the team means that the team can be asked to justify their decisions - perhaps for governance. Specifically teams should be able to justify decisions not to work on something or to delay work on something so that a another piece of work (a higher priority) can be undertaken.
Over time teams will understand their own capacity to do work. As a result they may find their capacity is not enough, they may add more capacity (capacity) or they may need to refuse work.
The important thing is: work potentially arrives at the team from multiple sources and some prioritisation - and thus scheduling - happens within the team. If the team does not have an clear process for doing this, and do not communicate this well both inside and outside the team, then there will be confusion over what the team is working on.
Alternatively the decision over what the team are working on may be made externally to the team. While in theory the person making this decision could have access to all the same information about the team - capacity, requests, etc. - if this person is not part of the team then they will have less information.
Now if such a person works so closely with the team that they have equivalent information then they are probably by default, a member of the team even if they are not a named a team member.
But when such decisions are made externally to the team they are often made with less information than the team have. That can lead to problems, work can be incorrectly assigned or teams overloaded with requests. When people feel unfairly treated their productivity may suffer.
And making such decisions externally to the team, with little team input, is likely to be demotivating for the team. Some of the responsibility and authority have been removed from the team. Team members may be less inclined to work beyond the letter of the request and their employment contract.
3.5 Value seeking teams
The team control the means of product. Prioritisation is within the team. The team is the unit of delivery, the work the comes out of the team should be valuable to the team’s customers, “the business”. Therefore teams need to be constantly seeking valuable work to do, and ideally the team are undertaking the most valuable work and not undertaking low value work.
In some domains “past performance does is not an indicator of future performance”. In software development recent past performance is a pretty good indicator of (near term) future performance.
When a team is value seeking - and has the capability to seek and deliver that value - then management and governance of the team should be based on the value actually delivered. Specifically the value that the team expects to deliver and the confidence that the team will deliver based on past performance.
In other words, governance of the team needs to look at:
- The value the team has delivered in the recent past: if a team has a poor record of recent deliveries than it is questionable whether the team should continue as is or be repurposed.
- The value the team propose to deliver in the near term, and some idea of where the team expect to find value in the longer term.
- Whether the recent track record of deliveries gives confidence that the forward looking suggestions are deliverable.
3.6 Discovery and delivery
In order to work effectively value seeking teams need to have skills of discovery and delivery. The teams needs to capability to look at the customer, potential customer, customer problems and the wider market or organisation; the team needs the skills to analyse these source and see where value could be added; the team also needs the skills to understand technology, and especially the newest technologies which allow new classes of customer problems and opportunities to be addressed. Finally, the team needs the skills to deliver on these opportunities. It should be obviously that the ability to think both tactically and strategically as appropriate is also needed.
A few individuals possess all these skills, but only a few. More likely a team would be staffed with multiple people who have more specialisation, while some individuals may undertake multiple roles and activities some will be specialists. For example, the team may include a product manager skilled in identifying market segments and understanding what potential customers want; the product manager may have coding experience, and maybe at crunch times might pair with programmers, but it is not the most effective use of their time to spend a lot of time coding.
Conversely, a programmer may well spend most of their time programming and while they could get on a plane and visit a customer occasionally it is not an effective use of their time to do so on a regular basis. Certainly it is good for programmers to meet customers from time to time but having them meet customers on a regular basis (particularly in product development endeavours) is not a productive use of their times or skills.
In order to seek and deliver value teams need both discovery and delivery skills. The mix of these skills will vary from team to team and place to place. However, whatever the mix there is one team, one team wins or looses together, the whole team crosses the finish line together.
3.7 Defining value, and benefit
Value seeking teams need to define what constitutes value. And they need to explain to their stakeholder(s), specifically those who govern the team, what this value is.
What constitutes value is an open question but one all value seeking teams need to address. For a start-up the simplest form of value is revenue, money paid by customers. Money allows the start-up to survive and perhaps grow but money is also information: the flow of purchases tells the team that customers consider their product valuable and that customers are prepared to trade their hard earned cash for the product. Information has value too although it may not be measured directly, or even soon, in terms of cash.
In a start-up company, the whole company is the team and by definition the team is value seeking. The start-up seeks to deliver value so that it may continue to play the game. If the team cannot deliver value - either because they cannot deliver or they deliver something with no value - then, through the power of market economics, the company will eventually fail and go out of business.
Outside of a start-up world questions of value become more complicated because there are other players, other considerations and multiple values. This is especially true in a corporate environment.
Consider for example a large international bank. Some of these banks employ tens of thousands of people inside the IT function alone. For a team buried inside the IT department of a bank determining value may be no simple question. The team may be many steps away from actual customers, instead they provide services to internal “stakeholders.” These stakeholders may have competing needs and varying levels of influence. Inside a large organization the tyranny of numbers means the difference a single team can make to the overall organization, and annual report, may be negligible.
In the corporate IT world it can be hard for a team to define value and more difficult still for teams to deliver enough value to have a discernible difference to the financial position of the company. (Conversely it is relatively easy for an IT endeavour to make a noticeable detrimental impact on a company’s position.)
Indeed while it is common to talk of value it is perhaps more correct to talk of benefit. Value implies cold hard, measurable, numbers, while benefit is a more inclusive description. The benefit a team may bring can be multiple sources:
- Increased revenue leading to higher profit
- Reduced cost leading to higher profit
- Increased understanding leading to reduced risk or new products
- Learning leading to better customer understanding which may make an immediate different to finances or may play out over years
- Learning which informs decisions which results in fewer mistakes, or bad decisions which in turn leads to improved financial results
- Better quality products which create happier customers, and which may after a delay lead to additional purchases and profits
In large organizations it can be incredibly difficult to see how the actions of one team make a difference. And since teams serve many different stakeholders it is possible that increased benefits to one stakeholder means reduced benefits elsewhere.
All this means it is essential that teams define what value and benefit mean to the team.
If the team can quantify this benefit with numbers good but quantification can cause its only problems. Consider the pursuit of shareholder value than lead to the Enron and Worldcom collapses at the start of the millennium. Or consider the financial engineering and “off balance sheet” stratagems that resulted in the collapse of Lehman Brothers, Royal Bank of Scotland and much of the financial sector during 2007-2009.
According to some authors (e.g. Admati and Hellwig 2014) the pursuit of ever for higher earnings per share which leads banks to dubious financial engineering which makes banks vulnerable to financial crisis. Pursuit of these numbers creates behaviours which impose risks on costs on entire societies. ing risk to entire economies.
Quantification can be useful but it can also lead in false directions. All quantification has to be tempered with qualification and understanding. Value seeking teams need to be able to modify the value they seek over time.
Finally, time needs to be consider.
Not only does value change over time, not only do short term value creation sometimes detract from long run value creation but it can be difficult to measure changes over short periods. Consider for example the billions invested globally in IT during the 1960s, 1970, 1980s and into the 1990s. When examined by economists it proved very difficult to see any added value during this time. (See Brynjolfsson and Saunders 2009 for a full discussion.)
3.8 References
Admati, A., and M. Hellwig. 2014. The Bankers New Clothes. Princeton University Press.
Brynjolfsson, E., and A. Saunders. 2009. Wired for Innovation. MIT Press.
Coplien, J. O., and N. B. Harrison. 2004. Organizational Patterns of Agile Software Development. Upper Saddle River, NJ: Pearson Prentice Hall.
- Thanks to László Szalai for this public domain image on Wikimedia.↩
4. Constraining Laws for Teams
Before delving too deep into team structures there are some principles, sometimes called laws, which teams need to be aware of. Readers already familiar with these laws may like to skim this chapter, however I ask that in doing so you consider the interplay of these laws when taken together.
For readers who are not familiar with these laws - and their consequences - they should be regarded as essential reading. These laws may not change a decision you are about to make today but they should inform your thinking. These are the deep principles upon which much of my Xanpan thinking is based. As such, understanding Xanpan as a whole requires understanding these laws.
4.1 Brook’s Law
No discussion of software teams can go very far before Brooks’ Law is mentioned. Indeed, chapter 1 has already mentioned the law:
“adding manpower to a late software project makes it later.” (Brooks 1975)
Brooks’ can be generalised as:
“adding people to software development slows it down”
Countless development teams have proved Brooks Law since he first wrote about it. Indeed, Brooks Law - together with Conway’s Law - form the bedrock on which much software team thinking need to be based.
When a new team member joins a software development effort they need to learn about what is going on, how the technologies are bring used, they system design and numerous other things. The team slows because existing members must take time to brief the new recruit and “bring them up to speed” - in other words, teach them how the team works and what they need to know, “knowledge transfer.” This process is sometimes called “on boarding.”
It is not just in the first week that new recruits need help. Some authors (e.g. Coplien and Harrison 2004) suggest it can take up to a year before new recruits are a net productivity gain. Personally I wouldn’t put the figure so high but it depends on many factors. It is reasonably safe to assume that few new employees do not require some assistance during their first three months.
In fact, the team slow down may well occurs long before a new recruit is added to the teams. New recruits don’t just appear. Managers must request more “resources” - perhaps they need to engage in lobbying of their own managers.
Once informal authorisation is given many companies will have a formal recruitment procedure to follow: job specifications must be written, checked, issued to human resources, sent to recruitment agents, the whole process must be managed and then….
Resumes and CVs arrive. These must be read, considered, rejections issued (one hopes), candidates called in for interview, and second interview, packages negotiated and job offers made.
All before someone gets to cut a line of code. Even if a personnel or human resources department manages much of the process team leaders and members will be distracted. The time they have for actual development work will be reduced.
Brooks’ Law does not imply that teams should not expand, that would be unrealistic and unsustainable. But it does mean that expanding a team is seldom a quick fix and if teams want to grow they must use some of their productivity capacity to grow their productive capacity.
Documentation
Plenty of teams have endeavoured to avoid these problems by writing documents to tell new recruits what they need to know. Unfortunately this doesn’t work well, there are a number of problems.
Firstly documentation tells people what the writer thinks the reader needs to know and not necessarily what the reader wants to know. This may mean it says more or less than is actually needed, it might express concepts in language the reader doesn’t follow and it may be silent on topics the reader is questioning.
Documentation is a form of explicit knowledge, those who study knowledge and learning have long recognised that much, if not most, of our knowledge is actually tacit, i.e. unspoken, things people don’t know they know, assumptions which are so obvious they aren’t recognised and more.
Added to that is the fact that reading is not the best form of knowledge sharing. Documentation can be very dry, it can be boring to read - especially when written in a very exact way favoured by lawyers and some computer people. As a result little that is read is retained for very long.
As if that weren’t bad enough documentation contains errors, Even if the documentation is rigorously checked unless it is actively maintained it will go out of date. Anyone who has ever joined a software development team and been confronted with a pile of documentation will also have experience of find documentation which differs from what it actually documents.
The net result is that documentation is a very ineffective form of communication. To make documentation effective it must be: extensive, effort must be taken to “mine” tacit knowledge, it must be rigorously checked and kept up to date. This all takes time, time which must be paid for and time which is taken away from development.
And making documentation effective can be expensive. According to Capers Jones “for large software projects, the cost of producing paper documents is more expensive than the code itself.” (Jones 2008). To that cost should be added the cost of reading the documentation.
Even if a team expends all this time, energy and money on documentation there is no guarantee it will ever be used. The team may never recruit another member, the project may be cancelled or the company go bankrupt. Documentation is an expensive hedge against Brooks’ Law which doesn’t work very well.
Perhaps the most important reason why documentation doesn’t help is because the new team member needs to be socialised into the team. People need to know who they other team members are, they need to feel part of the team, part of the social community. No documentation, no matter how good, can substitute for this.
Even if the documentation was perfect individuals would still need to learn about their new team members and that will take time. Reading documentation does not build trust and acceptance the way talking does.
Breaking Brooks’ Law?
“I’m pleased to report that Brooks’ Law can be broken.” (Sheridan 2013)
In Joy, Inc. Richard Sheridan makes a bold claim fortunately he is able to backup his claim.
“Our entire process is focused on breaking this law. Pairing, switching the pairs, automated unit testing, code stewardship, non-hero-based hiring, constant conversation, open work environment and visible artefacts all topple Brook’s assertion with each.”
Reading Sheridan’s description I believe he is right. Whether all these practices are this required I don’t know, maybe a team could get by without or another. However I suspect this list is actually shorter than it should be.
In the book Sheridan described a software development environment very different type from the one most developers and managers find themselves in. Menlo Inc, his company, goes to great lengths to build, share and strengthen their culture and community. Until more companies embrace this approach and there are more examples to examine it is difficult to say if Sheridan’s example can be copied, I hope so.
Right now I believe each of the practices Sheridan describes is worth adopting in its own right. Combined they are even better, and if they break Brook’s Law even better.
But I also know that just about every company I visit, and particularly large companies, can find a reason why they cannot adopt one or more of these practices. I guess that means that these companies will be constrained by Brooks’ Law.
4.2 Conway’s Law
“organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations” (Conway 1968)
Another interpretation ion of Conway’s Law would be:
“Ask four developers to build a graphical interface together and there will be four ways of performing any action: mouse, menu, keyboard short-cut and macro.”
The organization and structure of companies and teams plays a major role in determining the software architecture adopted by developers. In time the architecture comes to impose structure on the organization which maintains and uses the software.
For example, suppose a Government decides to create a new social security system. “Obviously” this will be a major undertaking, it will require a database, some kind of interface and lots of “business logic” in-between. Obviously therefore it requires these database, interface and business logic developers, and since there are many of these folks testers and requirements specialists too.
Suddenly the roles, software and process architecture are visible. Any chance of developing a smaller system is lost. And since all these people are going to be expensive management must be added, requirements set and so on.
Come back in ten years time and the organisation maintaining the system will now impose the same architecture on the organisation. Reverse Conway’s Law can now be observed:
Organizations which maintain systems … are constrained to communication structures which which are copies of the system.
Now there must be database specialists, business logic specialists, etc. Moving away from such an organization structure is impossible.
Conway’s Law tell us that where there are organizational barriers there will be software interface barriers - layers, or APIs, or modules, or some such. This effect can be beneficial - it support modular software designs and application programming interfaces - and it can be detrimental, creating barriers which are obstacles rather than assets.
Conway’s Law must be considered when designing teams, organizations and systems. Attempting to break Conway’s Law - consciously or in ignorance - will generate forces that have the potential to destroy systems and organizations.
Like cutting wood along the grain it is better to consciously respect and work with Conway’s Law than attempt to break it or cut across the grain. This is the key part of Xanpan and informs much of this book.
4.3 Dunbar’s number: Natural breakpoints
“Extrapolating from the relationship for monkeys and apes gives a group size of about 150 - the limit on the number of social relationships that humans can have, a figured now graced with the title Dunbar’s Number.” (Dunbar 2010)
Much of this book is concerned with addressing the question “How big should a team be?” Before delving into this question too far it is worth considering the work of anthropologist Robin Dunbar and his eponymous number: 150.
Dunbar present a convincing case that 150 is the upper limit for organizational units of people. He also shows that this number reappears in military formations from Roman times onwards, in Neolithic villages, in Amish communities and in modern research groupings. Above 150 community is less cohesive, more behaviour control sets in and hierarchies are needed.
His research and analysis highlights several significant group sizings. Dunbar’s Number might be better called “Dunbar’s Numbers.” There appear to be different groups nested inside other groups, the smaller groups are tighter, and these groups seem to nest by a factor of three.
Thus, 3 to 5 people seems to be most people’s innermost group of friends, the next ring of friends is about 10 strong making taking the total to 13 to 15 people. Next 30 to 50, the typical military fighting platoon, and then 150 - the smallest independent unit in an military company, the point at which businesses start to create separate groupings.
Dunbar also suggests there is a grouping at 500 and 1,500, and that Plato suggested the ideal size for democracy was 5,300. Military unit sizes are an interesting parallel:
| Organizing unit | Size |
|---|---|
| Fireteam | Four or fewer soldiers |
| Section, Gruppe or Squad | eight to 12 soldiers - several fire teams |
| Platoon | 15 to 30 soldiers - two sections |
| Company | 80-250 soldiers - several platoons |
| Battalion | 300 to 800 soldiers |
(Source: Wikipedia, English edition.)
This list could continue, and of course there are variations between countries and even between different wings within one military. Broadly speaking these unit sizes follow Dunbar’s findings.
In the discussions which follow the fire team corresponds to an MVT (minimally viable team) while the section corresponds to a regular team.
4.4 Miller’s Magic seven
In Agile, especially Scrum, circles a team size of seven (plus or minus two) has become accepted wisdom. However this heuristic has is little more than that, a heuristic. I have seen little or no evidence to suggest five, six, seven, eight or nine is the best answer.
Those who state “Seven plus or minus two” are alluding to George Miller’s famous paper “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information” (Miller 1956). However I suspect that many, if not the vast majority, of those who cite this paper have never read it.
The the paper Miller considers the arguments for seven being a significant number in terms of brain processing capacity - the “chunks” of information the brain can work with. However in the end he concludes that while seven does reoccur again and again there is insufficient evidence to be conclusive.:
“For the present I propose to withhold judgment. Perhaps there is something deep and profound behind all these sevens, something just calling out for us to discover it. But I suspect that it is only a pernicious, Pythagorean coincidence.” (Miller 1956)
The paper might have been better titled: “The Magical Number Seven, Plus or Minus Two?”
In his closing words Miller also says “I feel that my story here must stop just as it begins to get really interesting.” Indeed, Miller’s paper is over 50 years old, psychologists and information theory have moved on.
Admittedly the five to nine person range should give the team a good chance of managing variability. At the lower end it would justify a tester and a requirements specialist and at the upper end could still work with only one of each. So based on my own arguments five to nine makes sense.
But I am prepared to accept larger teams, I believe there are circumstances where this is justified - which I will elaborate on later in this book.
Scrum Team sizing
So how did Miller’s paper on individual information processing come to get applied to software team size? The link seems to have be some Scrum texts: The Scrum Primer states “The team in Scrum is seven plus or minus two people” (Deemer et al. 2008). “While the 2011 Scrum Guide states: “more than nine members requires too much coordination. Large Development Teams generate too much complexity” (Sutherland and Schwaber 2013).
To complicate matters the Product Owner and Scrum Master may not be included in this count. The Scrum Guide says:
“The Product Owner and Scrum Master roles are not included in this count unless they are also executing the work of the Sprint Backlog.” (Sutherland and Schwaber 2013)
While the Scrum Primer implies that the Product Owner is outside the team. In short, different writers make different recommendations at different times so who are actually team members - and who “just involved” - is unclear.
It is a little unfair to point the finger at Scrum. As already noted, team in range of the four to eight people are seen elsewhere. Miller’s paper seems to have provided an easy rationale for enshrining team sizes of seven plus or minus two. Experience also shows there is a limit, however the limit might be a little larger than Scrum suggests.
4.5 Parkinson’s Law and Hofstadter’s Law
“work expands so as to fill the time available for its completion” Parkinson’s Law, Wikipedia
“It always takes longer than you expect, even when you take into account Hofstadter’s Law.” (Hofstadter 1980)
I am sure that if most readers cast their minds back a few years they will recall being at school, college or university. And I am sure most readers will have at some point been set “course work” or “project work.” That is work, an essay, a coding task, or some other assignment, which has to be completed by a certain date.
When I deliver training courses I usually ask the class: “Do you remember your college work? When did you do it?” I feel confident that like those on in my training classes most (honest) readers will admit to doing course work a few days before the deadline. And a few, very honest people, will admit to completing it the night before.
But very few people miss the deadline.
Once, during my masters degree, I began a piece of course work very early. I “completed” it very early, but I then used the remaining time to revisit the work, again, and again, and again. To edit it. To improve it.
Psychologists who study these things show that humans are very bad at estimating how long a task will take but very good at working to deadline (e.g. Buehler, Griffin, and Peetz 2010b). (Xanpan book one contains more discussion of this topic.)
During the late 1990s I worked at Reuters on a project to connect to the Liffe futures exchange. At first the deadline was very tight and it was hard to see how it could be met. But then it transpired that this deadline was to connect to “Equity Options” and this wasn’t particularly important. It was the second deadline, for “Financial Futures” which was the important one.
The second deadline was easy to make, so much so that far more software was developed to meet it. The system under development was allowed to expand to use all the time and resources available.
Software development is haunted by Parkinson’s and Hofstadter’s Laws. Asked to estimate how long something will take will inevitably results in too little time, but given plenty of time and work expands.
One research study (Buehler, Griffin, and Peetz 2010a) observed that optimism, about how long a task will take to perform, might cause someone to start a task earlier than someone who provided a pessimistic (longer) estimate. But the total time taken by the optimist to perform the task would actually be longer the time taken by the pessimist. Deadline may well be more important than estimates in determining completion times - (see Ariely and Wertenbroch 2002)
4.6 Gall’s Law - plus Parnas and Alexander
Less well known than the laws above but very important for software development is Gall’s Law:
“A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system.” (Gall 1986) via Wikipedia
Gall’s Law echoes the words of David Parnas:
“As a rule, software systems do not work well until they have been used, and have failed repeatedly, in real applications.”
Parnas and Gall are emphasising different aspects of the same thing. Something architect Christopher Alexander calls “organic growth.” The fact that all three have identified the same axiom in different settings can only lend weight to validity.
In software development a technique called “walking skeleton” advises teams to produce a simple, basic, working piece of code which just pushes all the right (high risk) parts of a system - a skeleton which just about walks. After creating this the team add the flesh - layer on functionality - onto something seen to work.
This principle can be applied to the teams as well as the software:
“A complex team that works is invariably found to have evolved from a simple team that worked. A team designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system”
Since a more complex team equates to a larger team this law starts to hint at how large teams can be created, and how Agile can be scaled, or rather, grown.
This obviously parallels Conway’s Law: if a team set out to build a walking skeleton then the skeleton needs to be build by a skeleton team. To build it with a bigger, more complex team, would be to build more than a minimal skeleton.
When teams start big Conway’s Law implies that the architecture will be big and complex, Gall’s Law tells implies that such a system will be unlikely to work and in time the team will need to start over with something smaller.
4.7 Kelly’s Laws
I would like to add my own two laws to this canon. Laws which I coined some years ago. Although scientifically untested I have found to be highly useful in navigating the issue of team size:
- Kelly’s First Law of software: Software scope will always increase in proportion to resources
- Kelly’s Second Law of software: Inside every large development effort there is a small one struggling to get out
The first of these laws follows from Parkinson’s Law while the second seems to be a consequence of interlay between Parkinson’s Law and Conway’s Law. Once a project gets big the work expands, there is still a small project in there somewhere!
If a software team is bigger than absolutely necessary it will come up with more work, bigger solutions, advanced architectures, that justify the team size. It is always easier to add someone to a team than to remove them unwillingly.
By keeping the team small, at least initially, create the opportunity to find a small solution. Starting with a big team will guarantee a big solution.
4.8 Conclusion
The list is not an exhaustive discussion of “laws” around teams, I’m sure behavioural psychologists could add some more - and perhaps find fault with some of my discuss.
Individually these laws provide heuristics for organizing and managing software teams. More importantly the interplay of these laws can be quite profound.
Given Dunbar’s number(s) there are limits on team size and effectiveness, considered with Conway’s Law there is a potential limit on system size. The only way around this is to decompose the a large system into multiple smaller systems. At first glance this run against Gall’s Law but this is not necessarily so provided those systems can be sufficiently separated.
But teams are not suddenly born fully formed and effective. Conway’s Law working with Gall’s Law again implies they must be grown. Brook’s Law implies that teams cannot be grown too fast and Parkinson’s Law means that over big teams will make their own work.
Kelly’s second law hints at the solution: avoid big, aim to stay small.
One may find these laws inconvenient, one may choose to attack the validity of these laws. Certainly these laws sit badly with the approach taken in many commercial environments. Rather than attack the laws and rather than seek to break the laws I find a better approach is to accept them and work with them. Finding a way to work with these laws can be commercially uncomfortable in the short run but in the longer term is usually more successful.
4.9 References
Ariely, D., and K. Wertenbroch. 2002. “Procrastination, Deadlines, and Performance: Self-Control by Precommitment.” Psychological Science 13 (3).
Brooks, F. 1975. The Mythical Man Month: Essays on Software Engineering. Addison-Wesley.
Buehler, R., D. Griffin, and J. Peetz. 2010a. “Finishing on Time: When Do Predictions Influence Completion Times?” Organizational Behavior and Human Decision Processes, no. 111.
———. 2010b. “The Planning Fallacy: Cognitive, Motivational, and Social Origins.” Advances in Experimental Social Psychology 43: 1–62.
Conway, M. E. 1968. “How Do Committees Invent?” Datamation, no. April 1968. http://www.melconway.com/research/committees.html.
Coplien, J. O., and N. B. Harrison. 2004. Organizational Patterns of Agile Software Development. Upper Saddle River, NJ: Pearson Prentice Hall.
Deemer, P., G. Benefield, C. Larman, and B. Vodde. 2008. “Scrum Primer.” http://www.scrumalliance.org/resources/339.
Dunbar, R. 2010. How Many Friends Does One Person Need? London: Faber and Faber.
Gall, J. 1986. Systemantics: The Underground Text of Systems Lore : How Systems Really Work and Especially How They Fail. 2nd ed. General Systemantics Press.
Hofstadter, Douglas R. 1980. Godel Escher Bach: An Eternal Golden Braid. Harmondsworth: Penguin Books.
Jones, C. 2008. Applied Software Measurement. McGraw Hill.
Miller, G. A. 1956. “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information.” The Psychological Review 63: 81–97. http://www.well.com/user/smalin/miller.html.
Sheridan, R. 2013. Joy, Inc. Penguin.
Sutherland, J., and K. Schwaber. 2013. “The Scrum Guide: The Definitive Guide to Scrum: The Rules of the Game.” Scrum.org. http://www.scrum.org/Scrum-Guides.
5. Team composition
The previous chapter outlined some heuristics for managing teams and discussed the team as a stable unit of production. This chapter will continue the elaboration of those heuristics by looking inside the team.
Next I want to look inside the team try to answer two questions:
- What roles should be found on the team?
- How many people should be on the team?
In order to answer these questions I first need to discuss team composition and put some preliminaries in place. Once these building blocks are in place discussion of teams can take place. If however you want to know the answers and aren’t interested to know how I reached those answer simply skip to the end of this chapter.
5.1 Who is on the team?
The answer is: Everyone required to deliver the product and generate value. The team exists to do the work, not to manage the work and not to make requests on others.
The teams should be staffed to deliver business benefit. The team needs all the skills to do the work they are responsible for - including identifying new work and measuring benefit delivered too. Dependencies on other teams should be minimised.
The closer the team is to being able to recognise business benefit without having to depend on other teams or individuals the greater the chance of success. A tight feedback loop is not only good for understanding customers/users and addressing business benefit directly. It is also motivating for individuals and teams. When people can see the difference their work makes they invest more of themselves in the work and feel greater achievement when they see the benefits of their work.
At a very minimum this means: all the technical team. Coders most certainly, tester (if test specialists are being used), requirements people (again if specialists are being used), and if necessary operations people, analysts, subject matter experts, and and and, the list could go on.
If specialists like software testers and requirements engineers (business analysts and/or product managers) are not employed then the people on the team need the skills, authority and time to undertake these roles as necessary.
The general rule is: minimise dependencies outside the team by putting the skills and authority inside the team.
Ideally - and there are a a few companies actually do this - the team is not just the technical people but the business too. Not just a Product Manager but the actual people in the business who will use the product, or the people who will market the product
I once saw a photo of a team at Redgate software in Cambridge. The photo showed a whole team in their office area. The team included programmer, testers, the product manager, the product marketeer, the website designer and some operations people too. All sat together and all fitted easily in a photo.
As said earlier: the team is the production unit, they are attempting to deliver benefit to the company. The team is a whole.
Another way of thinking about these teams is as Object Oriented Teams. They contain the data (knowledge) and functions (capabilities) to do the work needed. Rather than constitute teams along functional or hierarchical lines - akin to layers of procedural code - teams are objects. Each object, each team, delivers a service.
Managers can reason about teams, not individuals - a bigger unit of capacity. The internal workings of the team may be opaque, as long as the team delivers the service they may organise themselves as they feel fit.
Sooner or later this logic may find a limitation. Would it make sense for a team to include 50 call centre operators? I don’t know but I do know that if they are outside the team there needs to be regular and open communication. Of course there may be teams within teams in the same way that I can be both English and British (and even European) sub-teams may be nested as long the aims are common.
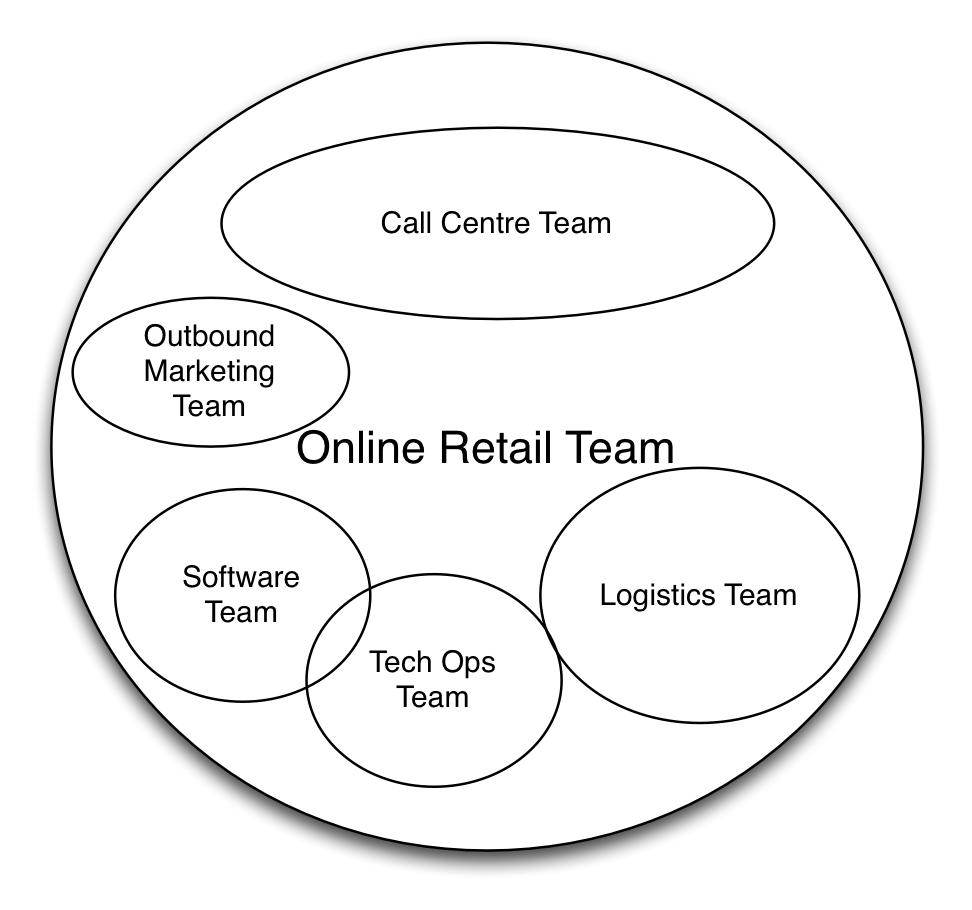
Consider hypothetical retailer team shown in the diagram. This hypothetical mail-order retailer is one team. This includes a large call centre team - taking orders and dealing with customers issues; an outbound marketing team (advertising, PR, etc.); a logistics team to manage the warehouse and get products to customers and of course technical teams to develop and operate the software customers and the other teams use.
In one sense this is one team with shared aims. But there are also sub-teams with their own aims which need to build to the overall aim. There needs to a shared understanding, a shared vision and a shared belonging. In a small retailer - an embryonic Amazon - all these people may sit in one room. The challenge, as teams and companies grow, is to maintain that which is shared.
Technical teams specifically need to be fully staffed with all the skills they need. When they share staff dependencies creep in and priority conflicts emerge.
And it makes sense to fully staff the team from as early as possible. If the team needs a professional software tester that person needs to be involved earlier rather than later.
Having said that, there is one occasion when this rule is broken: in the very beginning, when a truly new team is being formed. A full discussion of Minimally Viable Teams (MVT) must wait.
Finally, the more a team can be cross functional, the more it can contain all the skills it needs, and the less it needs to call out to other teams then the more effective work will flow through the team. Each time a team stalls because of a call out then it is a sign of where the team could be better.
Cross functional teams do not come into being by management edict. Few teams start off cross functional. Becoming a cross functional team has cost. In the long run those teams which consciously decide to become more cross functional will see benefits.
5.2 Developers are not the only fruit
There is a tendency among some managers to see programmers as the only people who matter on a team. This leads to unbalanced teams with many developers but no other specialists. However, there is some legitimacy in this point of view.
And there is a tendency among another group of managers to see programmers as a small part of the overall team. In these places multiple analysts and other requirements people and several layers of project and programme managers all conspire to ensure the few actual programmers are insulated from any actual users and kept well away from any decisions about what should be written. Such teams are also unbalanced and very expensive.
In an organization which develops software all roles except programmer are optional. Sometimes programmers are hidden - outsourced, off-shored, employed through opaque contracts - but if no code is written the organisation does not develop software.
One can object to the idea that all non-programming roles are option in principle but in practice programmer only teams do exist. Whether it is a good idea to staff a team with only programmers is another question. Some are very successful, some are utter disasters.
Larry Maccherone has collected data which shows that teams without can deliver the better quality than teams with testers and even teams with a high ratio of testers to coders (Maccherone 2014). However, teams without any testers are also shown to deliver the lowest quality. According to these studies teams without testers can also be highly responsive and productive.
This may sound confusing at first until one remembers these studies look statistically at many teams. The data shows a correction to a causation. One explanation is: average programmers teams without testers will perform badly, but elite developers may deliver better quality and service without testers.
I have seen without testers. Sometimes programmers can double up as testers. Sometimes they adopt practices to improve their quality and minimise the need for testing. And sometimes they just ship poor quality, buggy, software. I have seen all three models for teams without testers - and there are probably some more.
And I have seen teams without specialist requirements people - without product owners, product managers, business analysts and requirements engineers. Without a requirements specialists programmers might talk to the customers and stakeholders directly, they may work from a big document, they may invent what they think is needed, or they might create software which is unsuitable for the desired purpose.
I could continue by examining other roles which are often found in software development environments but the point is made. Without coders there is no software.
Having said that one needs to ask the question: how do these other roles help software programmers? How can other specialists help make for more productive teams?
This boils down to a question of scale.
On very small teams - micro-teams, less than two full time staff - it only makes sense to have a programmers. Hopefully talented programmers who can keep quality high, do a bit of testing and talk to customers directly. Having one business analysts for one programmer is not only expensive but likely to lead to too much emphasis on “what might be built” over “what can be built.”
Other management roles tend to fall into the same trap. There is an organisational smell when individuals are managed by more than one person and when organizations count fewer programmers than they do managers and analysts. As a general rule there should be more programmers than those who do not code or test.
Unfortunately it is not uncommon in corporate IT to see a small groups - hardly teams - of programmers and testers out numbered by non-producing roles. For example, at an American bank I observed an effort by two programmers in a remote location answering to a technical lead, with a tester in third location, answering to a test lead, they were managed by both a development manager and a project manager, in addition there a business analysts and architect were assigned to work part-time on the project. In other words: three active workers carried six non-coders. If this was not enough the bank added an Agile Coach to help “the team” improve their performance.
When this smell arises it is usually because the organization sees so little return from coding that they are fixated on “doing the right thing.” All these non-coders are there to ensure the limited resources are used to the greatest effect. Such organizations would undoubtedly be better of employing more coders and few non-coders, even accepting that some code would be “wrong” or “wasted” but with more coders there would be more right code.
Having a ratio of one tester for every programmer is a pretty damming endowment of the code quality. Organizations who find they need to get to this test to developer ratio - or even more testers than programmers - have a serious, and expensive, quality problem and would be well advised to invest in other mechanisms to improve quality. For example, training the programmers, instituting code reviews and introducing automated testing and unit and acceptance levels.
As a general rule one should expect the number of programmer on a team to be greater than any one other group; and on a health team the number of programmers may well be the greater than the sum of all the other roles on the team.
5.3 Ratios
Experience has taught me two ratios which I use as a rule-of-thumb when examining teams. Armed with these rations sizing team becomes for easier - a subject that will be examined in another chapter.
Requirements to programmers
1 Requirements specialist to between 3 and 7 programmers
Whether the requirements specialist is a business analyst, product manager, product owner, systems engineer, product specialist, requirements engineer or some other title there should be one of these for every three to seven programmers.
When a product is well established, the market is known and slow moving, and when the programmers know the domain - maybe even have direct customer contact, then, one requirements specialist may support seven programmers, hence 1:7.
Since the programmers are well versed in the product and the market - and therefore the needs of users - and change is slow, they will need less guidance and information from requirements specialist. Indeed the programmer may be minor experts in the domain themselves.
Still this ration may be higher than is commonly observed. I would justify 1:7 on the ground that building the wrong thing is very expensive. Therefore rather than employ an eighth, ninth or tenth programmer I would rather use extra requirements capacity to reduce demand and/or focus development on higher value work.
At the other end of the spectrum: when a product is new, when the market is fast moving, when customers are being added rapidly and when programmers are unfamiliar with what is needed - and the customers - then there is a greater need for requirements specialist. Therefore one specialist might work with just three developers.
In the extreme, in new teams or really rapidly changing environments this ratio may go lower, 1:2 maybe. However, once it gets so low the overhead in communication becomes difficult to justify.
If there are only two people working on a product it is probably better to have people with more varied skills and abilities and ask them to engage in requirements elicitation and implementation. When the team expands the third role may be only a programmer in preparation for when one of the first individuals becomes the specialist.
5.4 Tester to programmers
Use 1 Tester for between 3 and 7 programmers
The same ration applies, although for different reasons to the other side of the development pipelines.
When a team contains three full time programmers there is enough code produced to justify a dedicated tester. Since there are three individuals working the capacity for misunderstanding exists. The three individuals have probably divided the system into particular modules for each person and hence integration problems exist. So it makes sense the add professional testing of the overall product.
And if there is a user interface of any kind then there is always a need for for exploratory testing.
Therefore when a fourth person is added to a team of three that person should be a professional tester.
If further expansion is anticipated, or the work is expected to run for a long while, then delaying the addition of a tester will create problems later on because the first tester needs to catch-up with the work done already. This is particularly true when automation testing is to be used. Leaving it too long before starting to automate tests may make it impossible to adequately retro-fit the tests. (Fortunately programmers are more able to help with catch up here..)
When teams employ automated testing - especially if they use automated unit tests written in a test first fashion - then they may be able to maintain high quality even on large code bases. When team institute other quality control mechanisms - code review, automatic code analysis, regular builds and more - then it is possible that one tester may support seven programmers.
A teams of less than three which feels the need to add a dedicated tester one needs to examine the quality practices. How can two people create enough work to keep a third busy? Chances are if a two person team needs a tester they are producing very poor code.
5.5 Solo programmers
I read somewhere - although I can’t find the reference so I can’t cite it as fact - that over 50% of all development “projects” operate with a team of one. Fairly obviously this isn’t really a team, its an individual.
Whether this statistic is true or not it is certainly true that in my experience many organizations run many software development projects with one person “teams.” I might even go as far as to say staffing a project with one person is normal in many places.
For me teams start at three people. Anything less than two (full time) team members I consider to be “micro work” - or a “micro project” when the language of projects is used. On very small work efforts the dynamics of work are very different.
I’m sure there are some good reasons why one person projects are useful but normally I see them as bad smells. They are a means of looking busy without actually delivering much.
In particular one-person work efforts have their own, unique, dynamics because there is only one person. It is not so much a discussion of work flow or process as the working preferences of an individual. Having managers or other expert apply Xanpan, Scrum, Kanban or anything else to a “team” of 1-person - or even 2 people - is probably pointless. The individual may decide to adopt ideas from one of these approaches but working at such personal level there is little others can do.
Indeed, it is arguably whether it is worth investing management time in optimising the work of one person. Management time would probably be better spent in actually doing the work with the individual. (Unfortunately micro-projects are also fertile ground for those who practice micro-management to interfere.)
Micro-teams might be a way of hedging bets, they may be a way of reporting lots of “work in progress”, they may even be a way of satisfying many stakeholders in the short run (“Bill, Jane is working on your project as we speak”) but one, or even two person teams have a lot of negatives:
- Variability: when one person works on a development effort it will suffer from significant variability. If the one person get stuck on an issue, gets dragged off to consult on another project, falls ill or, heaven forbid, takes a holiday then the amount of work, and progress towards any given date, will be significantly effected.
- Schedule risk: obviously following on variability is risk, specifically schedule risk because of the influence of variability. It is very easy for a piece of work to be delayed, far harder to make up time or get ahead of the schedule.
- Knowledge risk: developers are normally quick to point out the “bus factor” when a piece of work is dependent on one person. In truth development efforts are surprisingly resilient to the loss of key individuals and bus accidents are rare. However I stopped laughing at “bus factor” claims the day I met a development manager who had lost a key member of staff in a bus accident. Resilience comes at a price: delay, lost schedules, lost targets and lost benefits. Very rarely is all capability lost but cost-effective capability is lost far more often than bus accidents.
- Quality and sounding boards: when an individual works alone they have nobody to consult about their work, no one to review their work, no one to bound ideas of, no one to keep honest when they decide to cut-a-corner and no one to share the pain when something goes wrong.
- Solo working efficiency: One might also consider the efficiency of one person working alone. Sure some programmers are solo individuals but on the whole people are social animals. They enjoy working and sharing with others. Everyone has days they are down and when you work alone there is nobody to help pick you up. When you work with others there are people to break your mood, even if you don’t want them to. And there are people to help cheer you up when accidents and problems hit.
Finally perhaps the most significant problem with micro-teams is simply:
Small teams reduce cash flow and return on investment
A later chapter will consider in more detail the financial implications of different teams sizes. Specifically it will examine the effects on cash-flow and return on investment of using multiple micro-teams against larger teams working on sequence projects. This analysis shows that:
Larger team which deliver products sooner improve cash-flow thus producing higher return on investment - calculated as net present value or internal rate of return.
In my view relying on one person micro-projects is a failure mode used by managers who cannot manage teams effectively. A far higher return on investment can be had from directing a larger team to a development effort, completing the work and recognising benefit and then advancing the team to the next effort.
5.6 Programmers
It may seem unfair to put programmers centre stage but as explained previously: programmers are the one constant in a development effort. Thus it makes sense to reason about team sizes based on the number of programmers in the team.
Once the number of programmers on the team is know then it is a lot easier to calculate how many testers and requirements specialists are needed by using the ratios already given.
Besides, most managers tend to reason about the number of programmers on a team first and only later, if at all, think about other roles. Which is a shame because I am not the only observer to have noticed that bottlenecks in development are more likely to be caused by a lack of testers, or even requirements specialists, than they are by a lack of programmers.
As already noted micro-teams exhibit a number of problems, therefore it makes sense to have more than one programmer on a development team. With two programmers the individuals can discuss solutions and approaches, they have a second pair of eyes to look at problems and, more importantly, there is now someone to review their code.
With two people on the “team” pair programming becomes an option. Although with just two the social dynamics will prove difficult as the two individuals will spend a large part of their working day in close conversation with each other.
With just two on the team it is questionable whether it is worth dedicating a requirements specialist or tester. Are they doing enough work to keep these people busy? If the tester and analyst roles cannot be kept busy then most organizations will seek to split their time with another piece or work. When this happens the individuals must engage in multi-tasking, so their performance falls, conflicting priorities will appear and delays will quickly develop.
Putting three developers on the team addresses these problems but it also means there is a step change. At two programmers analysts and testers will most likely not be dedicated, so the team size is probably two plus two halfs (one full time equivalent if your organization uses that terrible term.) But add a third and suddenly a dedicated tester and analysts make sense so the team jumps to five. Suddenly costs go up.
Even at 3+1+1 the additional roles may not be fully utilised and conflicting work may be added.
At three programmers there is more variety in discussions, more people to discuss design options and three possible pairing combinations to ease the social dynamics. Although pair programming become easier it still has problems. There is a not much variety in partners and at any time at least one person would be working.
In general the bigger the team the easier it is to justify dedicated specialist roles.
Four programmers looks like a much better position to be in. It is easier still to justify dedicated test and analysis people and there are now six pairing options, there is enough variety to make the social dynamics work.
It now become possible to think in terms of standard team sizes. As the number of programmers increases so to do the specialist roles - specifically testers and requirements specialists (analysts.) This graph shows the hypothetical model.
The next question is: how many programmers?
Before this question can be answered some more factors need to be considered so I must defer answering this question until a later chapter.
5.7 Pair testing? Pair analysis?
Having made the case for pair programming it is only fair to ask: if pairing is good for programmers wouldn’t it be good for testers and requirements specialists?
The short answer is: Yes. Pair testing and pair analysis make sense. There are even a few cases on record of these activities taking place.
Sometimes the pairing is heterogeneous. According to Dan North in the early days of Behaviour Driven Development a business analyst and programmer would pair. The BA would write a BDD style test, pass the keyboard to the programmer who would then write code to pass the test and push the keyboard back. All the time the pair would be talking and exchanging information.
There are also stories of testers pairing with programmers. Though given that organizations often use testers as a check on programmers such examples aren’t very common.
I’ve even heard of a triple: programmer, testers and business analyst. Although since BAs and testers overlap when it comes to validation this might have been overkill.
Still, pair programming is more talked about than practices and other forms of pairing are in their infancy. Certainly, given the ratios set out here it is only large teams that would have the staff to be able to support such pairings.
As with pair programming I encourage you to try pairing other roles. However my gut feeling is that heterogeneous pairing - pairing different roles - may prove more effective when it comes to testers and analysts.
Other roles and ratios
Having observed that all software producing organizations employ programmers it is also worth observing that there is very little consistency in the other roles used.
Software tester is the only role which even approaches programmer in ubiquity but how they undertake their role, what their relationship is with the programmer(s) and when they do there work are completely variable.
On the pre-programming side there isn’t even consensus on what the requirements specialist role is called! Inside corporations and consultancies one commonly find business analysts have largely replaced the out-dated system analyst role. Software product companies (what used to be called ISVs) tend to use product managers although these roles are more common in Europe than the USA. Requirements engineering serves as an umbrella term for analyst and product manager roles but many of these people filling these roles would not consider themselves requirements engineers.
There is very little consensus on whether teams have software architects - or what the software architect role is.
While the software designers - who may be called Designers, User Experience Designers (UXD), User Interface specialists, or some other title - have become more common in recent years they are still more often notable by their absence then presence. Such specialists are never found in internal, corporate, development.
Nor is there consensus on the use of project managers - some project managers are analysts while others understand little about software. Some are administrators while some are omni-present.
Unfortunately the Scrum method has muddied the waters further by introducing the role of Scrum Master. Some Scrum advocates accept the Scrum Master as a type of Project Manager (e.g. Schwaber 2004) while others reject the idea that Scrum Master maybe a project manager (e.g. Deemer et al. 2008). Certainly in practice many, usually large corporate, organizations view the Scrum Master as a project manager or project manager substitute. It is also true that many, usually small, organizations have rejected project managers in favour of a Scrum Master. And it is also true that many teams have neither roles.
While many Agile teams do have a dedicated role of Scrum Master, other Agile teams make do with a part-time Scrum Master (e.g. one who also works as a coder or one who works with multiple teams) while others make do without this role at all.
In my experience there is no clear advantage to having either of Project Managers or Scrum Master roles but the confusion over the roles does make conversation more complex! Indeed I am skeptical about the whole Scrum Master role. In the teams I observe I am more likely to see a need for Project Managers than Scrum Masters, and more likely still to see the opportunity to improve effectiveness by reducing the amount of project management undertaken.
Nor are the other non-manager leader and administrator roles - the roles I sometimes call Non-Commissioned Managers (NCMs) - consistent: team leads, technical leads, Scrum Masters, senior or lead developers and more are frequently absent.
Not only does one size not fit all but organizations don’t even agree on the standard sizes!
5.8 Finally
All the ratios and discussion above assumes each individual is dedicated to one team and one team only. Putting individuals on multiple teams leads to conflicts. It is better to avoid dividing individuals and forcing multi-tasking.
Companies must accept - if only as a matter of simple decency if not practicality - part time employees but it makes little sense to use full time employees as if they were two part-time employees.
As a general rule of thumb managers should favour short fat work endeavours rather than long thin ones. For example, it is better to use six staff work on project A and then move as a whole to a project B a few months later, than it is to have two staff troikas developer A and B in parallel over a longer period. This point will be discussed in more depth later.
5.9 References
Deemer, P., G. Benefield, C. Larman, and B. Vodde. 2008. “Scrum Primer.” http://www.scrumalliance.org/resources/339.
Maccherone, L. 2014. “The Impact of Agile Quantified.” In Lean Kanban UK. London.
Schwaber, K. 2004. Agile Project Management with Scrum. Microsoft Press.
6. Bug management strategies
Let me ask a philosophical question: When is a bug is a bug?
Consider the following scenarios:
- If a developer spots a flaw with their code before they hit compile is it a bug?
- If they hit compile and the compiler flags a syntax error is it a bug?
- If a fault is found during developer testing is it a bug? And if it is fixed is it still a bug?
- If it gets into the source code control system but is fixed before anyone else sees, specifically before a tester sees it, (e.g. the developer realises they made a mistake or another developer see it a fix is made) is it a bug?
- If it is found by a professional tester but never released to a customer is it a bug?
- If a customer reports it is it a bug?
One could probably come up with some more fine grained questions still, and the upper end of these questions could spin out indefinitely but this set will do. Most people would, I expect, answer No to the first few of those questions and Yes to the last. But those answers are by no means universal and there is a large grey area in the middle.
There are those who believe that almost any developer error constitutes a bug which should be logged and tracked. While this might have made sense in the days when processor cycles were expensive - and most likely programs were written on punch cards - in an age when processor cycles are almost too cheap to measure the most efficient way of finding many minor bugs is use the machine.
Few would argue that if a customer reports a bug it is a bug, a defect, something that might require rework. But many a customer report has been categorised as a change request or enhancement request rather than a bug. Which highlights another aspect of the philosophical debate: When is a bug a change request? To my mind this is another philosophical question but for many organizations it is actually a serious contractual question which could end in court.
Rather than continue this debate - which is also touched on in the Xanpan Volume 1 Quality Appendix - let me make two assumptions which I hope you can agree with:
- The term bug implies a defect of some sort, and whatever the type of defect rework is required to address the issue. Rework is disruptive and costly.
- The debate about what constitutes a bug tends to be more prevalent when quality levels are low and bug numbers are measured in the tens, hundreds or thousands. When numbers of bugs are counted in single figures, or even a few dozen it is easier to treat all request as work - whether it be bug, change request, enhancement or anything else.
This then is the state we wish to aim for. The rest of this chapter discusses management strategies for dealing with bugs - or to give them a more meaningful name: defects.
Some of these strategies are mutually exclusive but on the whole they may be used together.
But before discussing strategies it is necessary to take a small detour and consider the characteristics of bugs.
6.1 Characteristics of bugs
There are two characteristics of bugs which need to be considered when devising strategies for dealing with bugs.
The first characteristic is that, the effort to fix bugs is highly variable. By their nature the effort required to fix any bugs is more variable than new work, i.e. are less consistent in the amount of time they take to complete. Nor is it usually possible to break down a bug into pieces and fix each piece separately.
Second, compared to new code it is harder for individuals and teams to accurately estimate how long it will take to fix a bug in advance. Accurate estimation of new code can be hard enough, bugs are even more difficult to estimate. In part this is because as we have just discussed bug fixes are more variable.
Some bugs are hard to identify while easy to fix; others are easy to identify but hard to fix. And new tests must be put in place to ensure the fix works and the bug never returns. On occasions multiple bugs may interact further complicating matters. And it is even know for bugs to cancel each other out (see Two wrongs can make a right (Henney 2010)).
While many, perhaps most, bugs constitute a well defined piece of work which may be done in isolation some bugs are less easy to define. For example, in multi-threaded systems the interplay of almost parallel threads may make it very difficult to define what the problem is. I remember working with one senior developer in California who spent weeks tracking down a subtle multithread book in a Corba object broker. I can still see his drained face after all-night debugging sessions.
And once while working at Reuters I spent weeks tracking down a subtle bug which caused options prices to be incorrectly displayed. Even seeing the bug happen was hard: it only appeared in the afternoon, particularly Friday afternoons. At first the only way to see the problem was to place a Reuters terminal next to a Bloomberg terminal, and the only people who did that was Goldman Sachs. When I eventually found the bug it was not in the Reuters system at all but in the Liffe Connect trading system and only occurred when a trader went home early.
Combined these factors mean it might be impossible to estimate how long it will take to fix a bug, let alone estimate accurately!
The net result is that estimating the effort required to fix a bug is often of marginal value. However when bug fixing work is integrated with other, more predictable, less variable, work the net result is to reduce overall predictability of all work.
6.2 Strategy #1: Prevent at source
The first strategy for dealing with bugs is simply to not let them come into existence in the first place: prevention better than cure.
As discussed in the Xanpan volume 1 teams need to seek to minimise the amount of defects and rework required. This is why Xanpan explicitly includes technical practices to prevent errors, many of which originated in Extreme Programming (Beck 2000):
- Test Driven Development whether this be called TDD, Test First Driven Development, Design Driven Development, Automated Developer Unit Testing or another name the essential idea is to write code to test code.
- Acceptance Test Driven Development (ATDD): variations on ATDD may be found under names such as Behaviour Driven Development (BDD), Specification by Example, Automated System Testing and probably some other labels too. All forms represent a step up from TDD.
- Pair programming: two programmers working at one screen, one keyboard, talking and sharing as they co-develop the code.
- Mob or Posse programming: multiple developers working together, with one keyboard and a projector screen, possibly “peeling off” as the day goes on to work on specific sub-sections.
- Code review: formal (Code walkthroughs or Fagan inspections) or informal (asking for a review after a stand-up meeting, tapping a fellow developer on the shoulder and saying “can you please review this?”).
- Static analysis tools: frequently hooked into build systems and performing a form of code review.
- Continuous integration (to a source code control system) testing (i.e. regularly executing the tests mentioned above).
This list could go on and newer techniques continue to appear. In general unless I see evidence of teams engaging in some or all of these practices I am sceptical as to whether they are really “Agile.” Specifically teams who are not practising test driven development (or a related form of BDD) tend to be guilty until proven innocent in my mind, i.e. I consider they are not really agile although I am prepared to be proved wrong.
Maybe this is unfair of me. I know TDD is not applicable in every case and I know a team might find a better way of working in their technology and environment. But if TDD is not attempted, or dismissed too lightly, I am prone to cynicism.
6.3 Strategy #2: Fix close to origin
When a defect comes to light it should be kept within the team and within the current iteration if at all possible and dealt with immediately. The longer it is left to fester the more disruptive a fix will be - because some other code may have been built on top of it making the fix more difficult and increasing the possibly of new defect injection. And the longer it is left the less the original developer will remember about the circumstances in which it was created.
If a bug is found within an iteration it should be fixed in the same iteration if at all possible. Certainly the feature the bug is found in should not be considered done and should not be released. If it is found too late in the iteration to be fixed it should simply be carried to the next iteration and when fixed the whole feature may be considered done.
The aim should be to fix the bug as close to source as possible so as to limit the disruption it causes. This also means that if a separate bug fixing team (see below) is being used they should not be used to fix bugs created and found in the iteration. Only bugs which escape the iteration should be directed to the bug fixing team.
When a bug is fixed close to source - both in time and people - it reduces the possibility of the same mistake being made again. If it takes six weeks for a developer to fix a bug after creating it then there are six weeks when the same mistake may be made. If the issue is found and fixed in six hours there is far less possibility (and about 1,000 hours less) of the same mistake being repeated, and far less work that should be retested.
If the team are unable, or unwilling, to fix the bug then the whole feature should be deprioritised and removed from the code base. If the business representatives are prepared to ship the feature without a fix then the bug is not really a bug. It can be added to the backlog as another piece of work that will be prioritised on its own merits.
Key to adopting this approach is holding back functionality and features if faults are found. This in turn means the team must organise itself, and its tool chain (e.g. source code control and build systems) and design (e.g. feature toggles) so that features can be “pulled” from releases or never integrated in the first place.
How a team does this will depend on may factors, not least the tools they are using and their source code branching strategy. Some teams adhere to a “one true branch” or “develop on the trunk” strategy which can make pulling a feature difficult although not impossible.
Personally I am not a great believer in single branch development. Although I have suffered “merge hell” and cursed the need to merge branches I believe that branching and merging can be an effective strategy on occasions. To my mind small, focused, short lived (e.g. hours or days) branches - which some would call feature branches - are a very different proposition to long lived (e.g. weeks or months) branches with broad changes across a code base. I also believe that in modern code control systems (e.g. git and baazar) the very concept of a branch has changed.
In whatever way a team decide to organise their tools and design the key to this strategy is:
It must to be possible to sideline features which contain bugs written and found in the iteration so that other functionality can be released and used.
6.4 Strategy #3: Quick decision, quick fix
If for any reason the a bug escapes an iteration it needs to be fixed quickly. As mentioned before, the longer a bug lives the more difficult a fix becomes.
Saying “fix it quick” implies that a quick decision is made to fix the bug once it has escaped. This also means that the opposite decision is also open: no fix. It is entirely permissible for those in authority - product owner, manager or someone else - to decide a bug will not be fixed. As long as the organisation and team are prepared to live with this situation and the bug is marked “Closed - will not be fixed.”
(This of course reopens the philosophical question of “what is a bug?” but we will not reopen that discussion at this point.)
The aim of implementing this strategy is to limit the number of bugs a team must live with. The number of bugs which need to be administered and managed, when bugs are rampant it becomes very difficult to actually reason about bugs and what should be done. While bugs are open they tend to soak up time, energy and morale.
Yes: it is best to fix any bug shortly after it is identified. But there is little value is keeping a trivial bug open for months or years, long past the point when anyone expects it to be fixed. Such bugs get in the way of really being able to manage bugs and quality - they also detract from morale.
In order to make a quick decision the person, or persons, with the authority to make that decision need to be aviailable to make the decision. That probably means devolving authority to those closest to the work; and those with authority need to be available to make the decision. There is no point in putting this authority with a manager who can only spend a few hours a week with the team.
6.5 Strategy #4: Active bug management
In an organisation with many bugs there is much that can be done to manage bugs away. Normally the sheer number of bugs open makes it difficult to see which bugs are serious and which trivial, which need to be fixed and which should be simply closed “do not fix.” Not only this but masses of bugs are morale sapping and waste management time.
Of course managing bugs away does little in itself to improve the software quality but it does make managing a lot easier. When bug lists are short and under control work can be directed to where it is needed. When bug lists are long and out of control - all too common when an electronic tracking system is used - the sheer volume of bugs overwhelms effective management.
In a sense any bug list is just another backlog of work to do, a Bug Backlog. And for a team that backlog is just one source of work to do. The bug backlog can take its place alongside the Product Backlog (encompassing the Opportunity and Validated backlog where that model is used), the Technical Debt Backlog and any other backlog that is significant enough to get its own name.
Cumulatively these are all one backlog, they are all work to do for the team. Segmenting can be useful for analysis and reasoning but it does nothing to increase the resources available for fixing them.
The team have the capacity they have: there is no bug fixing fairy who will do it for them. They should work to increase the capacity but there will always be choices about whether to undertake rework on a defect or to do new work.
Managing bugs away demands that management devote time to bugs. I suggest this takes the form of a weekly meeting of a fixed duration, e.g. one or two hours. The meeting includes:
- A representative from the development team, usually a development manager, who has knowledge of the system (although not necessarily technical knowledge) and has the authority to have work done.
- One or more of the developers who will do the work: these will add a technical voice to the discussions.
- Representatives from customer services: speaking for real users and/or customer.
- Representatives from Testing/Quality assurance (if the organization has such group).
- Sometimes more senior managers will join the meeting if bugs have a high profile with customers.
Naturally a small meeting is better than a large meeting and the above list is dangerously close to being too long. The aim of listing so many roles is to ensure the meeting is properly able to reach a decision. There is no point in the meeting coming to a conclusion - say to fix a bug or change priority - only for, say, the Test Manager to turn around the next day and say “I don’t agree, change it back.”
The meeting occurs in the same time-slot each week - using the principle of rhythm outlined in Xanpan volume one. The meeting splits into two parts: the first part concerns itself with new issues and the highest priority bugs. This part repeats week after week looking at each weeks latest reports.
The second part of the meeting also repeats week after week but each time it starts where the previous meeting left off. It reviews every single bug logged and open.
The first item on the agenda is to review all bugs reported since the last seeking. Most likely test or customer services will have assigned a priority to the bug. If it was particularly serious, say effecting a live customer, work may already have been started, and even completed, on a fix. So the first action is to review all the new priority decision made in the last week and confirm the or change them.
Many, if not most, companies use a priority scoring system form 1 to 5 to rank bugs. Priority ones, P1s, are the highest priority while P5s are normally trivial.
The next meeting action is to review all the top priority bugs, normally those designated P1s. Having done this the absolute priority of these bugs needs to be decided. That is, which of the P1s should be fixed first? Which second? And so on all the way down to the last P1.
This might be a time consuming and painful exercise, especially the first time it is done, but it should be so. Bugs are painful and if people do not personally feel the pain the motivation for fixing them will be diminished. Besides: customers and users are feeling the pain so why shouldn’t some of those responsible for creating them feel some pain? Empathy has a role.
In reality after this has been done a couple of times, and once the development team have settled into a pattern and know approximately how many bugs they fix each week the exercise becomes less time consuming and less painful.
I have been known to write all P1s on red index cards (well pink cards to be exact) and have the meeting physically order the cards. This can be a very powerful technique for illuminating priorities and the pain customers have.
If there are too many P1s to make this process practical it is a clear sign that something is wrong. Either there are too many bugs classed as P1, and some should be moved to P2, or the company has a really serious quality problem and urgently needs to devote more time and energy to resolving the situation.
When the P1s have been dealt with the meeting moves to the other bugs. The remaining time is used to review all other bugs. This process is likely to take many meetings over several weeks, each meeting does as much review as it can in the remaining time. The second half of each meeting picks up where the last one left off.
Starting with the P2s the meeting should review each bug and decide:
- Is it still relevant? Maybe something has changed in the system and this problem is no longer seen.
- Does it has the correct priority, should it be higher or lower?
- Whether it is a duplicate of something else or can be closed for some other reason (e.g. the customer who reported it has gone bankrupt.)
When time runs out for the meeting someone records the position in the bug list. The meeting finishes until the following week. The next meeting follows the same agenda - review weekly decisions and prioritises P1s - before continuing to the bug review where it left off.
Once all P2s have been reviewed the meeting advances to P3s and so on. Once the whole list has been reviewed the oldest, lowest priority bugs, should, on mass, closed. Perhaps this means they must be marked as “Will not fix” or added to release knows as “Known issues” or some other administrative signal made.
For example, if after reviewing every bug over a six week period the company has ten P5 “trivial” bugs which have been open for more than one year they will be closed. Such bugs are unlikely to ever be fixed and have failed to demonstrate their importance.
Next time the meeting convenes and after dealing with the P1s and new issues as usual the meeting will start afresh with the P2s. Again a series of meetings will traverse down the whole bug list. The aim is to remove all the duplicates, irrelevant, and other clutter bugs and ensure consistent and meaningful prioritisation. Getting prioritisation right on historic issues requires several passes as opinions will change over time.
At the end of the second pass the close criteria is tightened. For example, all P5 bugs which are more than six months old are marked as “Closed - will not fix.”
After several passes - in many meetings - the list will be shorter, the team will have a better idea of what bugs they really face and the meeting can cease the reviewing all the lower priority bugs. In time they may repeat the exercise but after several passes the true state of affairs will be a lot clearer.
6.6 Strategy #5: Bug fixing sub-team
This strategy starts from the decision to ring fence a proportion of the available capacity for bug fixing. This normally takes the form of designating one or more developers as the “Bug Fixing Team”. Their work is focused exclusively on fixing bugs.
By ring fencing one or more people as bug fixers the team devotes a proportion of their capacity to fixing bugs.
This approach also makes scheduling other work more predictable. As previously mentioned bug fixing is far more variable and difficult to estimate than other types of work. Thus overall predictability of a team suffers. When this variability is separated and managed as a separate stream of work the predictability of non-bug fixing work improves.
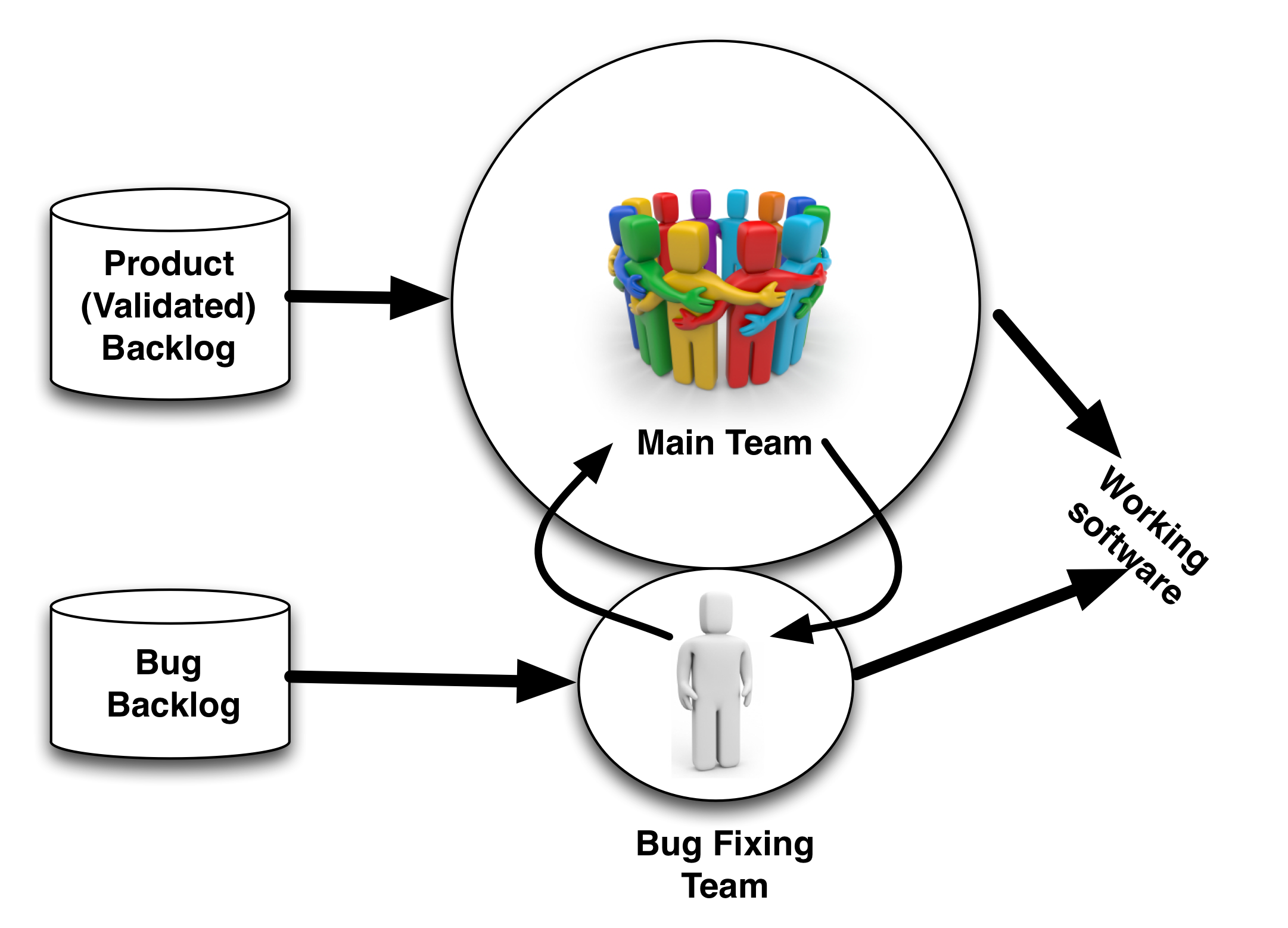
To be clear: bugs made recently - within the iteration or within the last few iterations - should most definitely be directed back to the main development team, as per strategy #2. Their work is not done if it contains bug.
There should be no incentives for doing a quick-and-dirty piece of work which someone else needs to tidy up. Not only does this result in poor quality code but it also obsfiscates any attempts to apportion costs correctly.
Developers should be rotated from the main team into the bug fix team on a regular schedule. For a team of four this might mean that every iteration one person fixes bugs, the next iteration they rotate back to the main team and someone else fixes bugs. Over the period of four iterations everyone will spend one iteration on fixing.
The rotation then repeats. So over a period of eight iterations everyone spends two iterations fixing bugs.
These two sub-teams sit together, indeed there is no need for anyone to move desks at all. People sit in their regular places and continue to share knowledge and assist one another. If this iterations fixer needs help from someone else they asks.
While the designated bug fixer will continue to attend iteration planning meetings, stand-ups and so on they bug fixing is effectively run as a separate iteration with its own schedule of work - driven from the bug prioritisation meeting described in strategy #4.
In fact since the time is ring fenced and the developer will work on one bug at a time - the highest priority bug first, then the next and so on - they may well abandon estimation altogether. In this context estimation adds little and since it is highly variable may actually cause confusion.
Can we also do small changes in the fixing team?
A question that comes up a lot. The short answer is: you can do anything you want, but does it make sense?
Having the bug fixing team do small changes might make sense when there are few bugs that need fixing but in that case it probably makes more sense to fold the sub-team back into the main team and do the work there. (Strategy #6.)
When there are a lot of bug then using the fix team to do small changes will impact their ability to do bug fixes and stay on top of bugs. Using them as such destroys the effectiveness as a bug fix team.
So while one can have the bug fix team work on non-bug work it defeats the purpose of having a dedicated fix team.
That said, if there are few bugs to fix, it might make sense to have a team addressing “small” pieces of work some of which happen to be bugs. When this happens the main team has effectively been divided into two teams which work on work with different characteristics.
6.7 Strategy #6: Fix within team
The alternative approach is to have one development team work on new work and bugs with no ring fencing.
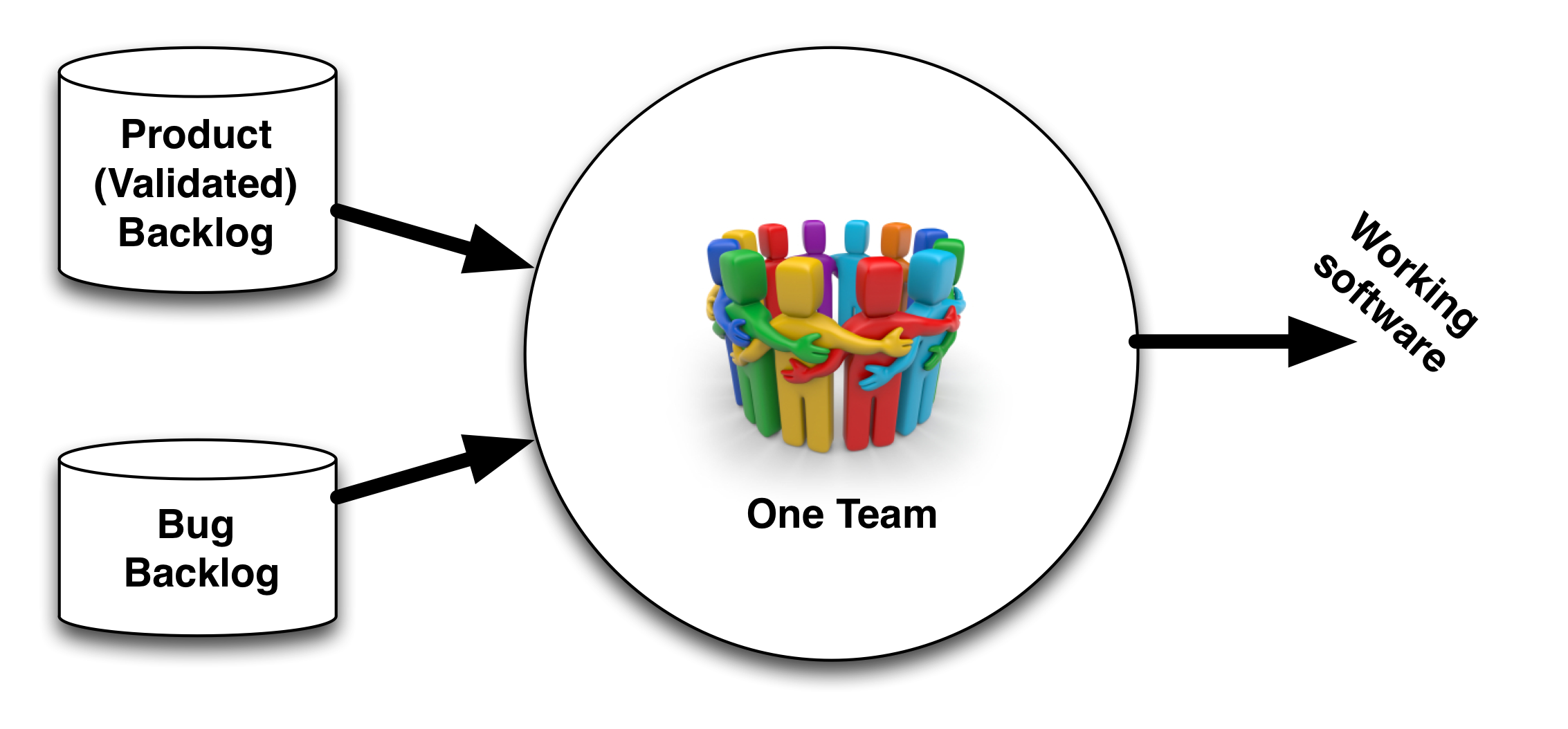
Having the main development team fix bugs as part of their regular work can be an effective strategy. The strategy tends to work best when few new bugs are being uncovered and few urgent fixes needed. When many bugs are being found and require fixes, and when urgent fixes are needed the knock on effect can be severe. Predictability and delivery of new work suffers.
Under this approach the bug list - or bug backlog - and backlog of work to do (product or validated backlog) is, as already described, effectively one long list of work to do. The Product Owner needs to consider both lists when choosing which work they would like done in the next iteration. Hence they must consider the value of a bug fix against the value of any other piece of development work on a case by case basis.
The team accept a bug fixes as they would any other piece of work to be done and endeavour to fix it. Given the greater variance in the nature of bug fixes any piece of work prioritised below the bug has a lower probability of being done than it would otherwise.
(It is worth noting that if there are a lot of bugs and the main team spend most of their time working on bugs then the main team is in effect a bug fixing team. So another strategy, seldom seen, is to have a large bug fixing team and a small new development team.)
There are several advantage to having the main team fix bugs. Firstly it removes any incentive for individuals to short-cut work by thinking that someone else will patch up the result.
Secondly it removes the need to designate anyone as “bug fixer” or to devise a rotation schedule.
Thirdly it increases chances that the most appropriate person to fix a bug will get to fix the bug.
However there are, besides reduced predictability, several disadvantages. More time will be spent in discussions about whether a bug should be fixed or not, and what the relative priority is vis-à-vis other pieces of work.
Experience shows bug fixes are less attractive to both sides - technical and business - then new work. Consequently new work is schedule more often and bugs less often, bug lists grow and become more difficult to manage. And customers never get fixes.
6.8 To estimate or not to estimate?
When a ring-fenced bug fixer or bug-fix team is being used it makes little sense to estimate the effort required to fix a bug. Bugs should be prioritised according to business need rather than development effort. The team has decided how much effort will be put into bug fixing, i.e. the effort of the ring fenced fixer(s).
In this scenario the time taken to estimate a bug is time that could have been spent trying to fix it. Since bugs fix estimate are unreliable the information content of such an estimate is very low so cost-benefit analysis is not going to be reliable.
When the main team is fixing bugs as part of their general work load it makes more sense to estimate the effort required to fix a bug so that work can be scheduled in the same fashion as other work. However given the higher variance in both bug estimates and time to fix this will result in a more variable velocity - as described below. Consequently future iterations will be less predictable because the velocity data will be more variable.
Variability?
Consider the example shown in the next graph. When bugs are estimated in the team and treated as any other work - shown by the combined line, the topmost (purple) line - the team averages 24.4 points per iteration with a standard deviation of almost 3.1. So one might reasonably expect the next iteration to result in a velocity between 21.3 and 27.5 points.
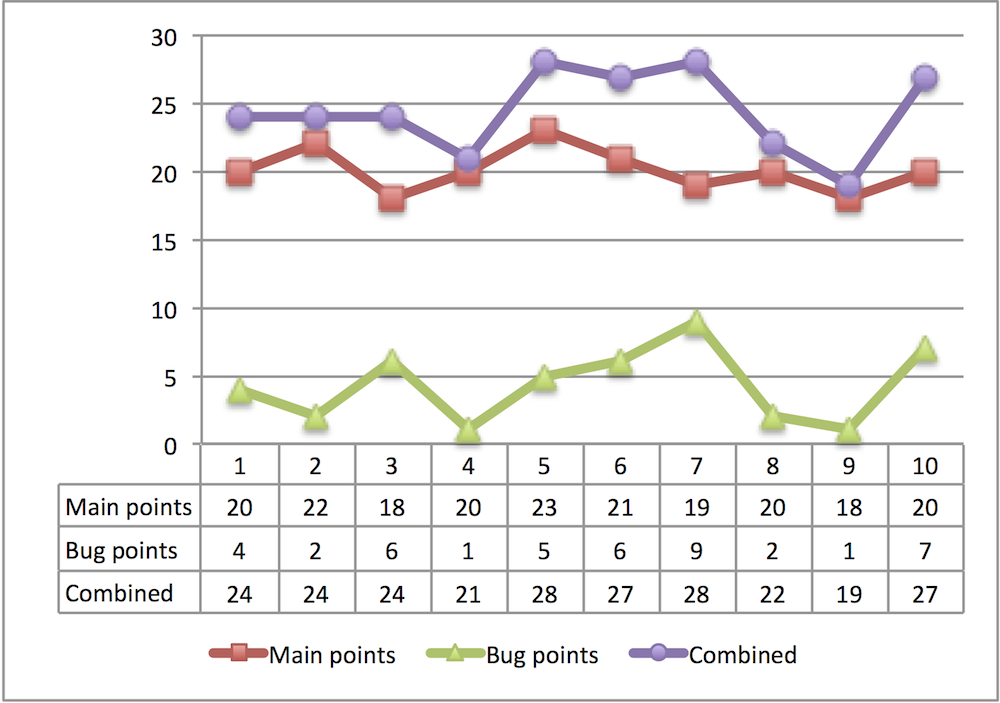
But if bugs are separated out - the bottom (green) line - the average score for bugs work alone is 4.2 with a standard deviation of 2.75. Meanwhile the non-bug fixing work - the middle (red) line averages 20.1 points and a standard divination of 1.6 implying a velocity in the next iteration of between 18.5 and 22.7.
Since future iterations will themselves contain a mix of bug fixes and new work they will themselves be more variable. The smaller the team the greater this effect because smaller teams find it more difficult to absorb variability.
When bugs are excluded from the teams velocity score the score is more stable and is a more reliable predictor of future capacity. Such an approach can only be recommended when fixes are undertake by a separated team as this limits the impact bug fixing has on velocity.
Teams which undertake bug fixing in the main team but do no estimating bugs will find velocity is not an accurate indicator of capacity. Since fixing bugs is still a highly variable activity it will still create variability in the measure of team capacity.
Bug fixing work is unpredictable therefore it will always have an impact when bundled together with a different type of work, e.g. new features. When bugs are estimated the variability of the estimates will introduce a second volatile variable to the calculations and the total variability becomes greater.
(This example has assumed a standard distribution for bug fix and other work effort. This is almost certainly not the case, you need to do your own analysis. The assumption is made here to illustrate how disruptive bundling two different types of work together can be.)
6.9 Choosing between strategies
Deciding between these strategies is not as difficult as it might seem. Four of the strategies are always valid:
- Strategy 1: Prevention
- Strategy 2: Keep close
- Strategy 3: Quick decision
- Strategy 4: Active bug management
When several passes of the bug backlog have been completed and strategies 1 and 2 are embedded than Active Bug Management may be reduced. Until then it is usually a good idea.
The real choice comes between the last two strategies:
- Strategy 5: Bug fixing sub-team
- Strategy 6: Fix within team
As a guide, fix bugs within the main team (#6) when:
- The number of bugs is low
- The need to fix bugs is limited
- Predictability is not of primary importance
When one or more of these conditions hold then it is best to fix bugs in the main team. In the longer term, a stable team working to improve quality and a track record of delivering will probably be best off adopting this strategy.
But bug fixing teams are preferable when one or both of these conditions hold:
- The number of bugs is high: definitely employ active management of bugs (strategy #4) and use a ring-fenced sub-team to address bugs.
- Predictability is very important
These heuristic are summarised in the diagram below.
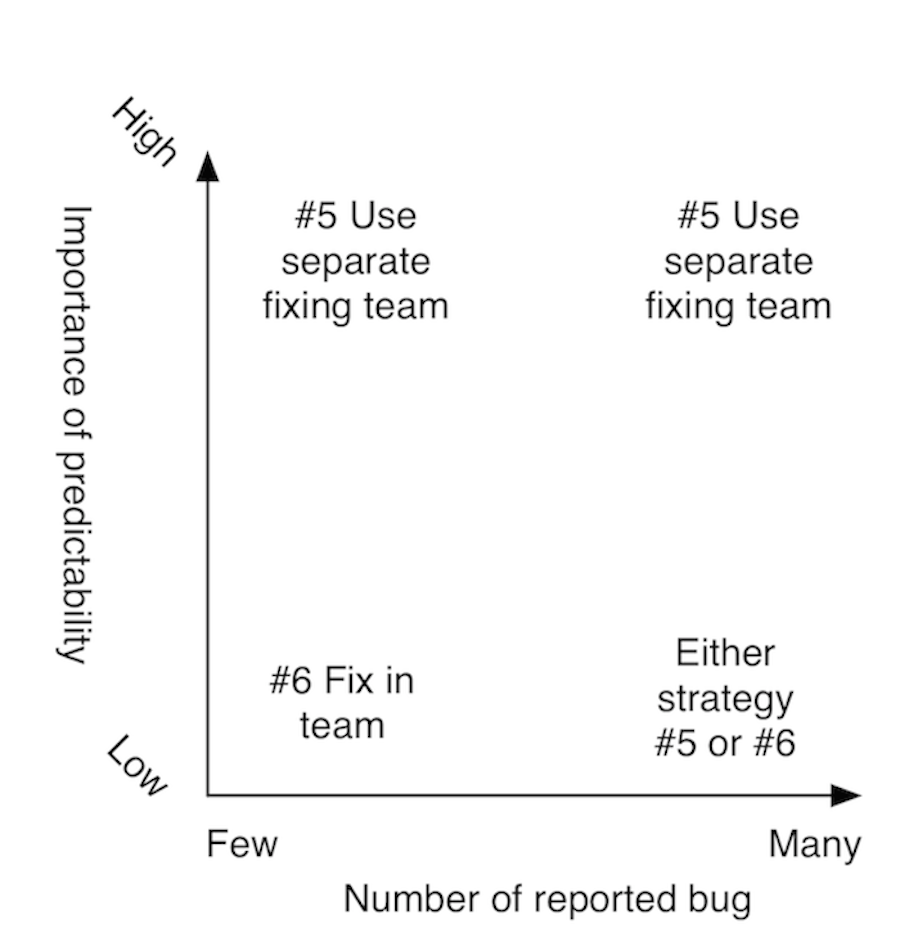
Under pressure to hasten deliveries, and improve predictability teams may be tempted to forego bug fixing altogether and drastically throttle fixes in the main team. This is almost certainly a mistake. Unfixed bugs represent a major risk to predictability and will complicate new work, which in turn will increase the time.
Given these heuristics the decision may seem easy but these are heuristics, there will always be other forces at work. Indeed these heuristics overlook another important force: team size.
Team size
Small development teams will always struggle to deliver new functionality when they must also handle large numbers of bugs. In these cases Active Bug Management becomes a vital tool.
The problem for a small team is that devoting any resource to bug fixing has a significant hit on delivering new functionality. For example a team of three developers which ring-fences one developer would devote 33% of their capacity to bug fixing while a team of six developers devoting one person to bug fixing still has over 83% of their capacity for new work. A team of 10 could put two people on bug fixing and still have 80% of their capacity for new work.
Thus it is more difficult for small teams to adopt strategy #5 (bug fixing sub-team) and will find pressure for them to follow #6 (fix in main team) but these are - because of the same maths - exactly the same teams which suffer the most schedule disruption from other sources. Small teams struggle to absorb variability whether from bug fixing or anywhere else.
When predicability is important, there are a lot of bugs which need addressing and the team is small something has to give. If nothing is done predictability and quality will suffer, the team may keep up the appearance of being on schedule but quality will be cut and this will eventually undermine the illusion of schedule.
I have seen, even been complicit in helping, teams hide such problems. If the organization can recognise the problem and steel itself to act there are two options:
- Option A is to simply accept the unpredictability and take no action to increase it. This might not the most politically acceptable cause of action if pursued openly. Yet it is possibly the most common even if is not explicitly stated or recorded.
- Option B is to take action. The question now is what action?
Bug fixing could be forgone but this too is risky, ignoring bugs may simply push the risk further down the line and increase the impact. The bugs that cannot be ignored will reduce predictability and slow the team down.
Giving the team more time to deliver might work but the longer the time to delivery the more the requirements will change. During the time the customers and sponsors of the work may become more frustrated, this may in turn cause them to push for premature release or discontinue funding.
Giving the team less time to deliver, throwing all efforts into bug control and fixing immediately and making a release very soon should at least establish a safe harbour. The initial product may not contain all the desired functionality but it would at least show truthfully where the team are at. Continuing to make small incremental additions and fixes with regular releases will allow the team to proceed safely if somewhat slowly. Overall they may take longer but at least they have a fighting chance.
Increasing the team size would address problems directly. Although due to Brooks Law (Brooks 1975) the team would still require more time.
A larger team could absorb variability better and open the option of ring fencing fixing capacity (strategy #5). Although it would take time for predictability to stabilise as new staff become familiar with the product and the code.
If increasing the team size is not possible, or would take too long to improve the situation the final option is to stop the work. When all viable options are precluded continuing the work as is - for a small team with lots of bugs and demands for predictability - very high risk. The team is unlikely to succeed so it probably makes sense to act early rather than let the story play out.
In such a situation it may be better to redirect all resources to a less challenged endeavour.
6.10 Other strategies
There are two other fix fixing strategies that are sometimes seen although neither are normally recommended. Both strategies are attempts to compromise between having a fixing team and working in the main team, as is often the case with compromises they less than optimal.
Stop and fix “bug blitz”
Team using this strategy stop all new development work and instead just fix bugs. In effect this is what many traditional teams do when they have finished the new development work. This may be disguised behind a euphemism such as “stabilising”, “hardening” or good old “maintenance”. The very existence of such a phase is a sign of poor and uncontrolled quality.
The first problem with this approach is knowing when to stop. Is the objective is to a set number of bugs? (What about new bugs which are found during this time?) Or perhaps just the P1s? (And what of P2s? And what if bugs are reprioritised?)
Why not fix all known bugs? If not, then how is the acceptable number of bugs to be set?
And once the team stop fixing bugs what when more are found? Do the team stop and blitz again?
The second and more significant problem with this approach happens when bug blitzing becomes standard practice. Repeated bugs blitzes detract from regular efforts to keep quality high and bugs under control. Why bother with strategies 1, 2, 3 and 4 if all the bugs are doing to be batched up till the end?
Team which regularly use bugs blitzes remind me of dieters who undertake repeated crash diets. The dieter stops eating until they obtain their desired weight whereupon they start to eat again as before. At some point they decide they weigh to much and crash diet again. Crash diets are not good for ones health and neither are repeated bug blitzes. In both case life style changes are required to fix the problem properly.
When writing new code without fixing (and stock piling bug reports for later fixing) a team risks not having a releasable product. Each burst of new work needs a subsequent bug blitz. This in turn produces a culture of “do new work” and creates an incentive to postpone bug fixing further.
Business representatives are usually loathed to sanction a bug blitz because it implies new, valuable, work is not being done. This creates a reinforcing downward circle of poor quality is created. Occasionally business representatives will sanction a bug blitz but this is not something they do willingly.
There are a couple of exceptions when a bug blitz might be appropriate.
Teams sometimes use a blitz as a buffer between one project and another. This is not uncommon in corporate environments where teams are prevented from starting on new work until some ceremony has occurred, a formal sign-off or a financial start-of-year being the most common. Teams which are not allowed to work on CapEx Project work fix bugs while they wait.
One would not really call this state of affairs “Agile” but it can be a useful way to spend otherwise lost time.
The second occasion a bug blitz can make sense is as a one-off exercise to transition from the old way or working to the new. This has already been suggested earlier.
A team might decide to spend several weeks on bugs. During this time an intensive bug review (strategy #4) would be undertaken in parallel with a fix and test exercise. The aim is to bring the work to a releasable state now and then to resume new feature work while keeping the product release ready.
At the end of the period the team would push out a new release and switch to strategy #5 or #6 for future bugs.
Bug blizt is not technical tax/investment levy
Some teams practice a technique called “technical tax” or “technical investment levy” whereby the technical staff are allowed nominate an amount of work to improve the code base. For example, a 20% investment levy may allow the team to spent one iteration in five improving the architecture of the system.
This approach is not the same as a bug blizt because team nominate the work themselves, bugs should be dominated (via prioritization) by business representatives. A technical investment levy could be misused for bug blitzing but the motivation and rational of the two techniques are different.
Day a week
Strategy #5 described ring-fencing capacity by separating one or more programmers and having them work for the entire iteration on bugs. So over a two week period in a team of 5 developers would spend 10 days bug fixing and 40 on new work.
Another way of formulating this ratio would be to have everyone fix bugs on a Thursday. This would see 5 people devote two days to bug fixing (10 days again) with the other days used for new work.
This looks attractive because it shares the load and avoids one person being the fixer. However this is less clean cut than strategy #5 because it means everyone must, once week, switch their minds from new work to bugs and then back again. Partially done work is left hanging and then, perhaps, partially fixed bugs are left in hanging.
One might minimise this effect by making Friday (or Monday) the fixing day. However this might create other issues - if only an increased in long-weekends but development staff!
The two biggest arguments against this approach are firstly: what happens to a bug which isn’t fixed on the day? Does it interrupt routine work the next day or is it left until the next week?
Secondly in time the business representatives may well objective to seeing the entire team switch away from new - money earning - work to bug fixing each week.
Another problem arises if an urgent fix is requested on a day which is not the fixing day. If the team must act immediately it will disrupt their work. A dedicated fixer could switch to urgent work thereby limiting disruption.
Again this might be an effective strategy in the short term when combined with Active Bug Management and Quality improvements but in the longer term is likely to be difficult to implement effectively.
One team I met employed a soft version of this technique. At the end of an iteration programmers would pick up bugs rather than new features to work on if they did not have time to complete a new feature. This was itself a form of buffering with bugs. However it produced an incentive not to finish new features as quickly as possible and is therefore not recommended.
6.11 Why not?
Before leaving the subject of bugs it is worth considering why so few teams choose to actively pursue a bug strategies - or any other for managing bugs.
The answer to this question may be as simple as misplaced optimism. The desire for bug free, or near bug free, software, the desire for things “to be different this time” is so great we allow ourselves to be wish away the problem - or at least deny its existence.
However I believe there are several reasons more significant reasons why companies in general fail to devote appropriate resources to bugs and take steps to deal with the problem. The next subsections will name and explain what I believe are some of the more common reasons teams ignore bugs.
Quality is seen as negotiable
Firstly too many (managers) have come to believe quality is a negotiable property which can be traded-off against other properties. There is an assumption, possibly unspoken, that quality is a parameter in determining schedule: higher quality leads to a longer schedules while lower quality leads to shorter schedules and faster deliveries.
While it may be true that not fixing bugs is faster than fixing bugs this can result in an unusable product. There is good evidence that preventing defects shortens the overall development schedules.
It is as if there is a dial on the wall marketed Quality. Too many people believe that turning the dial down, to low quality, will increase the speed of the development team. Conversely turning the dial up, to higher quality, will slow the team down.
This might be true in some industries but it is not true in software development. The work of Capers Jones (C. Jones 2008) shows clearly that lower defect potentials and higher defect removal efficiency lead to shorter schedules. Jones is not alone in this, other authors have found the same result. Indeed IBM first published such a study in 1974. (See Jones again for details.)

This finding should not be surprising. Philip Crosby founded an entire quality movement on this premise with his book Quality is Free (Crosby 1980). Such findings have been found in silicon chip manufacturing, car production, rocket manufacturing and many others. High quality is the foundation of many Lean principles and practices (Womack, Jones, and Roos 1991).
While quality might be free in the long-term it is probably more correct to say, as Niels Malotaux suggests: “Quality is free but only if you invest in it.” In other words: retro-fitting quality (i.e. bug fixing) is expensive but expenditure to prevent and remove bugs at the earliest opportunity will pay back many times over.
Failure to appreciate the cost of a bug
At first sight a bug is cheap: “We can save a bit of money by taking a risk, we can accept a bit of shoddy code in the same way a window clearer skips the odd pane here and there to go faster. If anyone finds a problem it won’t take very long to fix it and issue a patch.”
One might get away with this thinking in an early stage start-up with few customers but as customers number increase the costs of finding a bug increases and the costs of fixing tend to increase massively. Lets stop and think of the costs associated with a bug:
- The cost of writing the code in the first place (Development cost).
- The cost of testing it (Test or development cost).
- The cost of false positive bug reports (Test cost). When bugs are common so too are false positives, people jump to assumptions about what doesn’t work more quickly.
- The costs of reporting the bug (Test cost).
- The cost of arranging a fix (Management time).
- The cost of fixing (Development time).
- Cost of fixing new bugs introduced by the fix: it has been suggested (C. Jones 2008) that 7% of bug fixes inject a new bug (Test and development time).
- The costs of support desk calls when a customer finds a bug (Support desk time).
- The costs of repeated support desk calls when multiple customers find a bug (Support desk time).
- Cost of administering duplicates bugs: entering, identifying, merging, etc. (Management and support desk).
- The costs of helping customers who are struggling to perform a task which is afflicted by a bug (Support desk time).
- The costs of issuing bug notification or “work around” notes to help effected customer (Support desk time).
- The potential lose of customer time, money and even business opportunities (Customer costs).
- Cost of shipping software late.
- Cost of poor predictability: costs incurred because deadlines are missed or other resources deployed at the wrong time.
- Cost of additional countermeasures to reduce risk.
- Cost other work not done.
Many of these costs occur for false positives - reported bugs which are later shown not to be bugs. And many of the costs occur each time a duplicate bug is raised.
This is a long list and we have yet to consider the cost of actually fixing the bug, retesting, issuing the fix, updating release notes, manuals, support desk databases and informing customers. Nor have we considered the cost of managing customer expectations and potentially lost sales.
Perhaps dwarfing even these costs is the potential loss of revenue to a company using the software which contains the bug. This might be direct (e.g. the bug stops the client performing some revenue generating action) or it might be indirect (e.g. loss of reputation.)
One of my clients produces a system used to position oil rigs correctly. I once asked how much it would cost to move an oil rig if it was incorrectly positioned, by say 1 meter or such: “of the top of my head, say $25 million” was the answer.
As discussed in the Quality Appendix to Xanpan volume 1 the need for high quality, few bugs, should not be taken as a reason to gold plate and over engineer software system. Such over engineering efforts create problems of their own. However there is an exceedingly good case for attempting to minimise the amount of rework, or work arising from work which we thought “done.”
Failure to value a bug
Just as it is wrong to look only at the cost of new development work it is wrong to only look at the cost - whether in money or time - of fixing a bug. In both cases it is important, probably more important, to consider the value the work will bring. In both cases assessing value can be difficult. In the case of bugs there are additional points that may need considering to assess the value of a fix.
In the case of bugs the financial business value of a fix may be very low but the reputation value an be very high. For example, a bug might not prevent the software being used for its primary purpose but the need on a regular basis for users to work around problems may do damage to the image of the product creators.
Sometimes the value of a bug fix might be necessary to fullfill contractual obligations. How much of the contract can be attributed to the bug might be debatable but if the bug prevent final acceptance and payment then it has a sever effect on cash-flow.
Then there are the technical benefits from fixing bugs. Bugs which regularly disrupt service or hinder programmers and testers from doing their development jobs might merit fixing even if the business customer seldom sees the issue. Similarly problems which lead to large number of support desk calls or interruptions to other work may be valued in terms of internal savings.
CapEx and OpEx demons
If you have never come across the terms CapEx and OpEx consider yourself lucky. They are accounting terms:
- CapEx is short for “Capital Expenditure”: Money spent under this heading appears on the balance sheet as an investment, so $100,000 of spend is balanced by the creation of a $100,000 asset.
- OpEx is short for “Operational Expenditure”: These monies do not return, they are gone. $100,000 spent on $100,000 is a $100,000 the company no longer has.
Some companies monitor and manage CapEx and OpEx more than others. The senior managers, their board members or even investors impose limits or set targets on each category.
Complicating things further some CapEx expenditures qualify for tax incentives so $100,000 CapEx invested on software development might entitle the company to a 10% tax deduction of $10,000.
New development work is often considered CapEx while bug fixing is considered OpEx. It is not only in software development that such accounting conventions cause problems. Exactly these conventions contributed to the failure of WorldCom in 2002: the company counted all network maintenance as CapEx rather than the more usual OpEx.
One can argue with these accounting conventions: a bug fixed as part new development on an existing product is CapEx but if fixed as an explicit bug fixing effort then it is OpEx. But these are the conventions that exist. While it is probably a sign that accounting has yet to catch up with the digital age there is little prospect of things changing soon.
These categories, and the management process associated with them can distort priorities and encourage bugs to be left unfixed. Rational engineering strategies, like ring fenced teams, for addressing bugs are sometimes denied.
When engineering options are constrained by accounting rules - rather than accounts reporting the engineering reality - it is a sign that the top level management do not understand the business they are running.
6.12 Finally
Having a few bugs, a total that can be counted on one hand, is a very different position from having hundreds or thousands of bugs. There existence of many bugs distorts thinking and action, they are likely the sign of deeper technical problems too.
Perhaps one of the reasons bugs present so many problems is simply that they should not exist. The mental pull of this view leads us to pay less attention to bugs than other work.
The good news is that teams who try can vastly reduce the number of bugs they have much to gain. The bad news is that few teams will eliminate them entirely.
Indeed as teams get better at avoiding simple coding bugs the energy put into finding these bugs will find new bugs, bugs relating to desired functionality, or usability, or some other category. Arguably preventing these bugs is harder but the value in fixing these bugs is also higher.
Many of the things we call “bugs” are temporary learning objects. They allow us to learn more about what is actually wanted. Without herculean efforts it would not be possible to foresee and prevent these. At this point the relationship between higher quality and shorter delivery schedules may break down. However this is a hypothesis and will only be clear in retrospect.
Until then teams should strive to prevent bugs as far as possible and efficiently remove those defects that do sneak through. To use the terminology of Capers Jones: Strive for low defect potential and high, and rapid, defect removal.
6.13 References
Beck, K. 2000. Extreme Programming Explained. Addison-Wesley.
Brooks, F. 1975. The Mythical Man Month: Essays on Software Engineering. Addison-Wesley.
Crosby, P. B. 1980. Quality Is Free: The Art of Marking Quality Certain. New American Library.
Henney, K. 2010. 97 Things Every Programmer Should Know, Henney. O’Reilly.
Jones, C. 2008. Applied Software Measurement. McGraw Hill.
Womack, J. P., D. T. Jones, and D. Roos. 1991. The Machine That Changed the World. New York: HaperCollins.
Version History
- Version 0.1 February 2015: First chapters previewed on LeanPub
- Version 0.2 March 2015: Added chapter 2: Constrains
- Version 0.3 March 2015: Added chapter 3: Team Composition
- Version 0.4: Added Bug management strategies
- Version 0.5 February 2016: Added Nature of the Team & rewrote Unfinished Book
- Version 0.6 March 2016: Book reorganisation, removed placeholder chapters and name change
- Version 0.7 March 2016: Final version (probably) - added “Requiem for an unfinished book”
In keeping with LeanPub practices this book will be updated, corrected and expanded over the months which follow. Sometimes these will be small increments, sometimes big ones.