AIに関する懸念とリスク
 |
AIに関する懸念は深刻です。リスクは現実です。時にはヒステリックな形で表現されることもありますが、掘り下げてみると、AIの影響は非常に破壊的である可能性があります。 |
AIに関する問題と懸念は非常に多く、それだけで何冊もの本を埋め尽くします。以下は、私が監視しているトピックのワードクラウドです。いくつか見逃しているものもあるかもしれません。

これらのトピックに関する情報は豊富にあり、できるだけ深く読んでみることをお勧めします。リスクが利益を上回ると結論付け、個人的または組織内でAIの使用を追求しないことを選択するかもしれません。その決定には、通常の取り残されるリスクが伴います。しかし、それは個人の選択です。
「AIのリスクに関する本」をグーグルで検索すると、有益な書籍の選択肢が見つかります。最近特に衝撃的だったポッドキャストはEzra KleinがDario Amodeiと話したもので、彼はAnthropicの共同創設者兼CEO(Claude.aiを開発する会社)です。これらの企業がリスクを認識していることがわかります。Amodeiは「AI安全レベル」(A.S.L.、アメリカ手話ではありません)という内部リスク分類システムに言及しています。現在、ASL 2にあり、「生物兵器の作成方法を指示する能力を示し始めるシステム」を指すと説明しています。彼はASL 4を「国家レベルのアクターが能力を大幅に向上させることができる…北朝鮮や中国、ロシアが軍事分野でAIを利用して地政学的なレベルで大きな優位性を得ることを心配する状況」と述べています。恐ろしい話です。
この厳しい文脈の中で、著者や出版社に最も関連する問題を強調します。
著作権侵害?
|
著作権に関する問題は複雑で曖昧です。いくつかの本が著作権を保持している状態で、いくつかの大規模言語モデル(LLM)の訓練に含まれていたことは確かです。しかし、すべての著者の作品がすべての大規模言語モデルに取り込まれたわけではないということは確かです。 |
著作権に関する問題は、特定のものから広範なものまであります。すべてのLLMがオープンウェブ上で訓練されていることはよく知られています。今日のウェブ上の15億のサイトからスクレイピングできるすべてのもの、新聞記事、ソーシャルメディア投稿、ウェブブログ、そして、YouTubeビデオのトランスクリプトまでが含まれます。
証明されているように、少なくとも一つの大規模言語モデルは、パブリックドメインではない数千冊の本の実際のテキストを取り込んでいます。
これらのテキストを無償で取り込んで、億ドル規模のAI企業を構築することは合法だったのでしょうか?AI企業はフェアユースを主張していますが、最終的には裁判所が決定するでしょう。たとえ合法であっても、それは倫理的または道徳的だったのでしょうか?倫理の問題は法的な考慮よりも複雑ではないようです。皆さんが判断してください。
著作権に関する法律は、AIがもたらす独自の課題を予見していなかったことは明らかであり、法的解決策を見つけるには時間がかかるでしょう。おそらく数年かかるかもしれません。(この問題に特化した法律がなぜ不適切かについて詳しく知りたい場合は、A. Feder CooperとJames Grimmelmannによる優れた論文「The Files are in the Computer: Copyright, Memorization, and Generative AI」をお読みください。)
ここには最も著名な訴訟の13件のリストがあります。すべてが本に関するものではなく、画像や音楽も含まれています。そしてこちらのリストでは、すべての訴訟の進捗状況を更新しています。
著作権とAIに関する著者向け情報
|
著者はAI生成コンテンツの著作権に関して追加の問題に直面しています。 |
米国著作権局のAI生成コンテンツの著作権に関する見解は、AI単独では著作権を保持できないとしています。なぜなら、AIは著者としての法的地位を持っていないからです。それは理にかなっています。しかし、これは作品の100%がAI生成であることを前提としています。他の場所で議論されているように、少数の著者がAIに全体の本を生成させることはないでしょう。もっと現実的には5%、10%、あるいは…。ここで著作権局はつまずきます(私も同様ですが)。
最近の判決では、MidjourneyというAIサービスによって生成された画像と人間が執筆したテキストを組み合わせたグラフィックノベルは著作権を持つ作品と見なされましたが、個々の画像そのものは著作権で保護できないとされました。なんてことだ!
|
著者と出版社は、複数の方面から進化する著作権問題に注意を払うべきです。 |
長期的な影響は?
現在の訴訟をGoogle Books訴訟と比較する人もいます。この訴訟は法的に解決するのに10年かかりました。これらの訴訟の控訴プロセスがどれだけ長引くかは誰にもわかりません。その間に、出版社はAI企業が敗訴するかのように行動することが賢明です。少なくとも理論上、Chat AIをライセンスしたり使用したりする人々に何らかの潜在的な責任を負わせることになります。
しかし、それが出版社にとって最も深刻な問題ではありません。それは認識です。多くの著者にとって、著名であろうと無名であろうと、井戸は毒されています。AIは執筆と出版のコミュニティ内で放射性物質と見なされているのです。AIの匂いがするものは何でも激しい批判を受けます。
多くの例があります。最近の事件では、イギリスの出版社Angry Robotは、大量の原稿提出を見込んでAIソフトウェアStorywiseを使用することを発表しました。わずか5時間で、その計画を撤回し、元の受信箱に戻ることになりました。
トレード出版社が内部でAIツールを使用する際の耐え難いジレンマ:著者に発覚すると、その後の嵐を乗り切るのは困難です。出版社は勇気を持ち、(少なくとも一部の)ツールを採用し、それらのツールがどのように訓練され、どのように利用されるかを明確に説明し、前進するしかありません。
イギリスでは、The Society of Authorsは厳格なアプローチを取っています:「出版社に対し、校正、編集(信頼性チェックや事実確認を含む)、索引作成、法的審査、デザインやレイアウトなど、あなたの作品に関連する目的でAIを大幅に使用しないことを確認するよう求めてください。オーディオブックのナレーション、翻訳、AIによるカバーアートのデザインを禁止することも検討してください。」
Authors Guildは「出版社が通常の業務の一環としてAIをツールとして使用することを探っている」と認めているようです。しかし、多くのGuildメンバーがそれほど理解を示しているとは思いません。
AI企業へのコンテンツライセンス
ほとんどの出版社、および多くの著者は、AI企業にコンテンツをライセンスする方法を模索しています。ライセンス条件やコンテンツの価値についてはそれぞれ異なる意見がありますが、少なくとも議論は進行中です。
いくつかのスタートアップが出版社(場合によっては個々の著者)と協力することを模索しています。Calliope NetworksやCreated by Humansはこの点で興味深い存在です。
7月中旬に、長年業界の著作権ライセンスの主力であったCopyright Clearance Centerが、「人工知能(AI)の再利用権を年次著作権ライセンス(ACL)に組み込んだ」と発表しました。「企業全体のコンテンツライセンスソリューションとして、数百万の作品からの権利を提供します。」
Publishers Weeklyは、CCCの社長兼CEOであるTracey Armstrongの「AIに賛成しながら著作権も尊重することが可能であり、AIとクリエーターへの敬意を結びつけることができる」という言葉を引用して発表を報じました。
すべてを包括するものではありませんが、これは出版業界が大規模言語モデルの開発者と協力する方向に一歩近づくための画期的な進展である可能性があります。
AIを避けるのは手遅れ
|
AIに汚染されることを好まない著者や出版社にとっては、悪いニュースです:あなたは今日もAIを使用しており、何年も前から使用しています。 |
人工知能は、さまざまな形で、私たちが毎日使用しているほとんどのソフトウェアツールやサービスにすでに統合されています。人々は、Microsoft WordやGmailなどのプログラムでAIを活用したスペルチェックや文法チェックに依存しています。Microsoft WordやPowerPointは、執筆の提案を提供し、デザインやレイアウトの推奨を行うためにAIを活用しています。SiriやAlexaなどのバーチャルアシスタントは、音声コマンドを理解し質問に答えるために自然言語処理を使用しています。メールサービスは、AIを活用してメッセージをフィルタリングし、スパムを検出し、アラートを送信します。AIはカスタマーサービスのチャットボットを動かし、購入履歴に基づいた製品の推奨を生成します。
そして、これらの多くは、ChatGPTのような大規模言語モデルに基づいています。
著者や編集者が「私の原稿にAIを使用しないで」と言うのは、一般的に言ってもほぼ不可能です。彼らとその編集者がタイプライターや鉛筆を使っている場合を除いて。
彼らは「生成型AIを使わないで」と言おうとするかもしれません。しかし、これは難しい問題です。文法チェックソフトウェアは元々生成型AIに基づいて作られたものではありません。Grammarlyはそれを製品に組み込んでおり、他のスペルチェックや文法チェックツールも同様です。生成型AIはマーケティングソフトウェアのコアでもあります。
著者がAIを使用する時
著者とAIの使用に関するもう一つの側面は、上記で議論した著作権の問題と似ています。極端な例では、100%AIで生成されたコンテンツがAmazonで公開されています。そのほとんど(すべて?)はひどい品質ですが、それが公開されるのを妨げるものではありません。(Amazonのセクションも参照してください。)出版社にとってもっと懸念されるのは、AIで生成された投稿です。確かに、AIは量を増やしますが、大手出版社はすでに量をフィルタリングするシステムを持っています。そのフィルタはエージェントと呼ばれています。彼らが量の問題をどのように処理するかを見つける必要があり、どうやらAIを使用しない解決策を見つける必要があるようです。
それはある意味で存在的問題です—「私は『機械』によって書かれた本を出版したいのか?」多くの出版社にとって、それは明確な「いいえ」です。簡単なことです。では、50%のコンテンツが有能な著者の監督のもとでLLMによって生成された本はどうでしょうか?うーん、それも「いいえ」にしましょう。では、25%、10%、5%はどうでしょうか?どこで線を引くのでしょうか?
そして、線を引く仕事に取り掛かった今、スペルや文法ツールが少なくとも一部は生成AIに依存しているというジレンマをどう解決するのでしょうか?AI駆動の文字起こしツール、例えばOtter.aiやMicrosoft Wordに組み込まれた文字起こし機能はどうでしょうか?
特定の量のAI生成テキストを含む作品を公開しないと宣言した商業出版社は見つかりません。以下はAuthors Guildの見解です:
「原稿にかなりの量のAI生成のテキスト、キャラクター、またはプロットが組み込まれている場合、それを出版社に開示し、読者にも開示する必要があります。アイデアのブレインストーミング、アイデア生成、またはコピー編集のために単にツールとして使用される場合には、生成AIの使用を開示する必要はないと考えています。」
言うまでもなく、「かなりの」は定義されていません(オックスフォード辞書は「気づかれるほど大きい、または重要と考えられる」と定義しています)が、投稿は「de minimis AI生成テキスト」の包含がほとんどの出版契約に違反することを説明しています。法的には、de minimis は正確には指定されていませんが、一般的には「かなりの」とほぼ同じ意味です。
AIは文章中で検出できるか?
2024年5月に、BISGがスポンサーとなったAI検出に関するウェビナーを主催しました。リプレイはYouTubeでオンラインで視聴できます。Jane Friedmanは自身のHot Sheetニュースレターでウェビナーの包括的な要約を提供しました。
多くの著者にとって、AIの毒性は言葉から遠ざけておくことを意味します。出版社は特別な負担を負います—テキストを作成するわけではありませんが、一度出版されると、テキストに対してかなりの義務を負います。社会的影響を含むコンテンツや他の作家の言葉やアイデアの盗用を巡って、爆発的な議論が巻き起こることを目にしてきました。今、AIによって新たな一連の倫理的および法的問題に直面していますが、これらの問題は出版学校で説明されていませんでした。
一部は学生が心配することと似ており、AIの使用はウィキペディアの記事をカンニングするのと同様に不正行為であると考える人もいます。または、友人にエッセイを書いてもらうことに似ているかもしれません。
私たちのウェビナーの講演者の一人である教育者のJosé Bowenは、学生向けの開示を共有しました。これは著者向けのものとは少し異なりますが、AIの使用リスクレベルの一種を示しています。
学生向けテンプレート開示契約
友人、ツール、技術、またはAIの助けを借りずに、すべて自分でこの作業を行いました。
-
最初の草稿は自分で書きましたが、その後、友人や家族、AIのパラフレーズ/文法/盗作ソフトウェアに読んでもらい、提案を受けました。この助けを受けて以下の変更を行いました:
スペルと文法の修正
構造や順序の変更
全文や段落の書き直し
問題に行き詰まり、シソーラスや辞書を使用したり、友人に電話したり、ヘルプセンターに行ったり、Cheggや他のソリューションプロバイダーを利用したりしました。
アイデアを生成するためにAI/友人/チューターを使用しました。
アウトライン/最初の草稿を作成するために支援/ツール/AIを使用し、その後編集しました。(あなたの貢献の性質を説明してください。)
そして出版社は、著者のためにこのようなものを作成することができます。たとえば、著者が上位レベルを開示するとしましょう:AIを広範に使用し、その結果を編集しました。それならどうしますか?自動的に原稿を拒否しますか?もしそうなら、なぜですか?
そして、その間に気づくことがあります。あなたが読んで気に入った原稿が、著者がGrammarlyでさえスペルチェックされていないと誓ったものが、実際にはAIによって90%生成されていたかもしれないこと。
その時、質問を再考せざるを得ません。それは、「なぜ私はこの見つけにくいものを見つけようとこんなにも決意しているのか?」ということになるのです。
部分的には、AI生成テキストの著作権性に関する警戒心から来ています。著作権事務所は100%AI生成テキスト(または音楽、画像など)には著作権保護を提供しません。しかし、50%AI生成テキストはどうでしょうか?私たちは著者が生成した50%のみをカバーします。そして、どの半分かをどうやって知るのでしょうか?それについてはまた後でお知らせします。
各原稿をソフトウェアに入力するだけで、テキストの作成にAIが使用されたかどうかを教えてくれるとしたら素晴らしいことではありませんか?
これを行う唯一の方法がAIツールを使用することであるという問題を脇に置いて、もっと重要な質問は、そのソフトウェアが(十分に)正確であるかどうかです。原稿の作成にAIが使用されたかどうかを教えてくれると信頼できるでしょうか?そして、実際には使用されていないのにAIが使用されたと示す「偽陽性」を生成しないと信頼できるでしょうか?
現在、市場にはこれらの課題に取り組む多数のソフトウェアがあります。これらのソフトウェアを評価する多くの学術研究は、その信頼性の低さを指摘しています。AI生成テキストがすり抜けます。さらに悪いことに、AIによって生成されていないテキストが汚染されたと誤ってラベル付けされます。
しかし、出版社は何らかの安全策を設けたいと思うでしょう。これらのツールは、せいぜい可能性のある懸念を警告することができるだけで、常に二重チェックが必要です。したがって、他のテキストよりも慎重に検査する必要があるテキストを警告することは効率でしょうか?
真の効率は、テキストの起源に関する懸念を超えて、既存の品質基準を維持することにあります。
失業
「あなたはAIに取って代わられるのではない。AIを使いこなせる人に取って代わられるのだ。」 —匿名
AIの採用による失業は深刻である可能性があります。推定値はさまざまですが、数字は厳しいです。明らかな例としては、サンフランシスコの自動運転タクシーがタクシーやライドシェアの運転手を排除することが挙げられます。AI支援の診断は、医療技術者の必要性を減らす可能性があります。
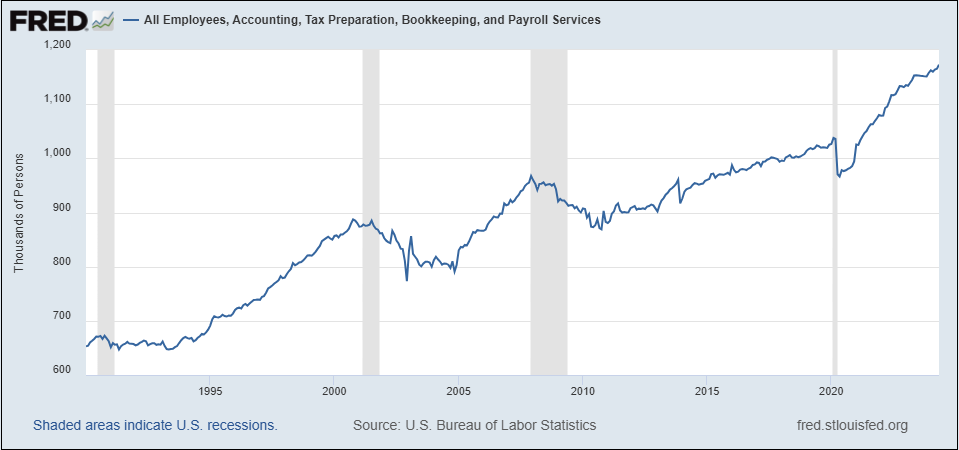
私の中の楽観主義者は、スプレッドシートの導入とその雇用への影響を一例として指摘します。下のグラフでわかるように、「会計、税務準備、簿記、給与サービス」における雇用は1990年以降ほぼ倍増しており、これらのタスクを大部分自動化したスプレッドシートやその他の技術に対する批判とは言えません。
Ethan Mollickのボストンコンサルティンググループ(BCG)と行った研究は、特に複雑で知識集約型のタスクにおけるAIの仕事への影響をよりよく理解するための実験でした。この研究には758人のBCGコンサルタントが参加し、ランダムにOpenAIのGPT-4を使うグループと使わないグループに割り当てられ、2つのタスク(創造的な製品イノベーションとビジネス問題解決)を行いました。研究は参加者のパフォーマンス、行動、態度、およびAIの出力の質と特性を評価しました。
発見の一つとして、「AIはスキルの平準化を行います。実験開始時に評価した結果が最も低かったコンサルタントは、AIを使用するとパフォーマンスが43%も向上しました。トップコンサルタントも向上しましたが、その幅は小さかったです。」 この記事全体は示唆に富んでおり、Mollickのすべての仕事と同様に、挑発的でありながらアクセスしやすい内容です。
教育
教育はAIに関する賛否両論の中心にあります。教室へのAIの導入は、大部分が呪いと見なされるか、少なくとも挑戦と見なされています。他の教育者、例えばPWの基調講演者であるEthan Mollickのように、AIを教育者のための注目すべき新しいツールとして受け入れています。Mollickは彼の学生にChatGPTを使うことを主張しています。
このトピックに関する最良の書籍は、José Antonio BowenとC. Edward Watsonによる*Teaching with AI: A Practical Guide to a New Era of Human Learning*です。
この本では教育出版には触れませんが、それは広大なトピックであり、別の報告書が必要です。おそらく、出版は教育内で二次的な関心事になりつつあります。AIツールはソフトウェアであり、コンテンツそのものではありません。
検索の未来
|
検索はAIにおいて困難なトピックです。perplexity.aiやYou.comを訪れて、今後の動向を垣間見ることをお勧めします。次回グーグル検索を始めようと思ったときには、代わりにPerplexityにアクセスしてみてください。劇的に異なるようには見えませんが、グーグルの検索画面の右側や検索結果リストの上部に表示される知識グラフに似ています。リンクをクリックする代わりに、情報がそこに直接表示されます。 |
パープレキシティはさらに一歩進んで、複数のソースから収集した情報を再構成して提示しますので、リンクをクリックする必要がほとんどありません。ソースへのリンクは提供されますが、すでに質問の答えが得られているため、クリックする必要はほとんどありません。
この一見控えめな変化は、検索エンジンを通じて発見されることに依存しているすべての企業や製品にとって、巨大な影響を及ぼします。検索者があなたのサイトに送られなくなった場合、どのようにして彼らと関わり、顧客に転換することができますか? 簡単な答えは、できないということです。
Joanna Pennは、新しい技術がライティングと出版に与える影響についての考察の最前線にいます。彼女は昨年12月に彼女のポッドキャストとブログでこの複雑なトピックに取り組みました。
AIと検索の変革にとって、まだ初期段階です。
アマゾンのジャンク本
|
AI生成のジャンク本がアマゾンで問題になっていますが、その深刻さは感覚的なものかもしれません。一方で、これらの本は低品質で盗作されたコンテンツをオンライン書店にスパムのように送信し、時には実在する著者の名前を使って顧客を欺き、その評判を利用します。これらの本は読者にとって迷惑であるだけでなく、著者にとっても脅威となり、苦労して得た印税を奪う可能性があります。AI生成の本は、同じキーワード、カテゴリ、レビューを競うことで、アマゾンのサイト上で本物の本や著者のランキングや可視性にも影響を与えます。 |

Amazonは現在、著者に対し、AIを使用して本を作成した際の詳細を開示するよう要求しています。これが悪用される可能性があることは間違いありません。
アマゾンで「AI生成の本」を検索してみてください。たくさんあります。一部の結果は、AIを使って本を作成する方法についての本です。しかし、他の結果は、紛れもなくAI生成のものです。「面白くてかわいい猫の写真-世界でこのタイプの写真は見られない-PART-1」(原文のまま)はRajasekar Kasiにクレジットされています。著者ページには彼(?)のバイオについての詳細はありませんが、同じ名前で他に6冊のタイトルがクレジットされています。この本は2023年8月26日に出版され、レビューも売上ランキングもありません。電子書籍の文法的に誤ったタイトルは、印刷本の表紙の文法的に誤ったタイトルと一致しません。
しかし、他の著者は明らかにAIを広範に使用して本を作成しており、それを開示していません。前述のように、AIの使用を検出することは、熟練した「偽造者」にとってほぼ不可能です。塗り絵、ジャーナル、旅行本、料理本は、従来の出版に比べてごくわずかな時間と労力でAIツールを使って生成されています。
「korean vegan cookbook」を検索すると、Joanne Lee Molinaroによる1位のタイトルが最初に表示されます。しかし、そのすぐ後ろには明らかに模倣品である他のタイトルが続いています。「The Korean Vegan Cookbook: Simple and Delicious Traditional and Modern Recipes for Korean Cuisine Lovers」は2つのレビューがあり、そのうちの1つは「これはビーガン料理本ではありません。すべてのレシピに肉と卵が含まれています」と指摘しています。しかし、この本の売上ランキングは#5,869,771であり、オリジナルの本はリストで#2,852に位置しています。
被害の程度を判断するのは難しいです。これから良いことは何も起こりませんが、どれほど悪いのでしょうか?
アマゾンには「顧客にポジティブな体験を提供しない」本を削除することを許可するポリシーがあります。Kindleコンテンツガイドラインは、「顧客を誤解させる、または本の内容を正確に表していない説明的なコンテンツ」を禁じています。また、「顧客にとって通常は失望するコンテンツ」をブロックすることもできます。アマゾンの監視者を打ち負かすのは膨大な量でしょうか?それとも他に理由があるのでしょうか?
偏見
LLMは既にオンラインに公開されているものを学習して訓練されています。オンラインで公開されているものには偏見が多く含まれているため、LLMもその偏見を反映します。そしてもちろん、偏見だけでなく、憎悪もその学習に反映され、AI生成の言葉や画像における潜在的な出力となります。ポルノもAIの画像生成能力の驚異的な利便性の恩恵を受ける自然な分野であり、最近では若い女性が捏造されたヌード画像を発見し、男性のクラスメートがその容疑者として挙げられるという問題があります。The New York Timesは、子供の性的虐待のオンライン画像の増加について別途報じています。
著者や出版社は、AIツールを使用する際にこれらの内蔵された制限を認識する必要があります。