Building a MicroGPT in Racket
In the next chapters we will use production-grade Large Language Models like GPT-5, Gemini, Claude, etc. Here we look at optional material: Karpathy’s MicroGPT re-implemented in Racket. Dear reader, this chapter has the practical value of introducing you to the low level ideas for implementing LLMs. Feel free to skip this chapter for now and proceed to the following LLM application-oriented chapters.
Introduction
In recent years, the artificial intelligence landscape has been completely transformed by large language models (LLMs) built upon the foundational Transformer architecture. Models like GPT-5, LLaMA, Gemma 3, and Claude contain tens of billions to trillions of parameters. Their capabilities are profound, ranging from generating sophisticated poetry to writing complex computer code. However, the sheer size and complexity of these production models can make them feel like impenetrable black boxes to developers and researchers trying to grasp their inner workings.
To understand how these massive systems operate, it can be beneficial to strip away the complexities of distributed training, massive datasets, and heavily optimized C++/CUDA backend libraries. One of the most famous educational projects in this domain is Andrej Karpathy’s MicroGPT written in Python (often associated with his broader nanoGPT and micrograd repositories). Karpathy’s work distills the essence of a Generative Pre-trained Transformer into a bare-bones, dependency-free implementation, allowing anyone to trace the mathematical operations from start to finish.
In this chapter, we will explore a complete, dependency-free port of MicroGPT written entirely in Racket. Racket is a general-purpose programming language in the Lisp-Scheme family, known for its powerful macro system and “language-oriented programming” philosophy. Its functional nature, expressive syntax, and excellent tool support make it a uniquely powerful tool for exploring complex algorithmic architectures. By stepping away from the heavy machinery of modern Python frameworks like PyTorch, TensorFlow, or JAX, we are forced to construct the foundational components from scratch. We will build an automatic differentiation engine (autograd), construct neural network layers, implement the multi-head self-attention mechanism, and design the training loop. This hands-on approach not only demystifies how modern AI systems learn but also beautifully demonstrates the expressive power and mathematical elegance of Racket.
Demystifying the Core Components
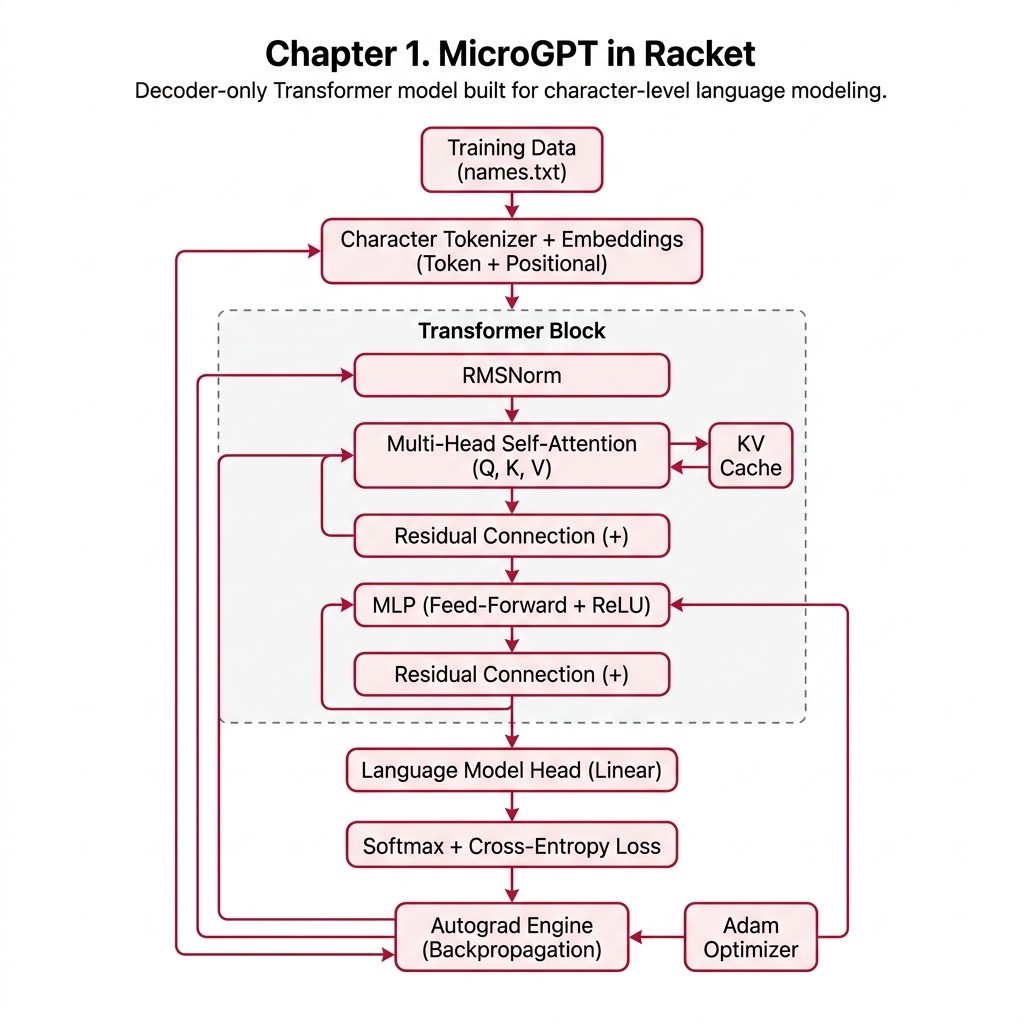
To build a functioning, end-to-end language model from scratch, we need to orchestrate several interacting systems. Our Racket implementation elegantly encapsulates these systems into a single, cohesive file. Let us break down the architecture into its primary constituents: the autograd engine, model parameter initialization, the Transformer architecture, the training loop, and the inference generator. Understanding each of these pieces is crucial for grasping the holistic behavior of a language model.
The Autograd Engine
At the heart of any modern neural network training process is the ability to automatically compute the gradients of the loss function with respect to the model’s millions (or in this case, hundreds) of parameters. This is achieved through a technique known as reverse-mode automatic differentiation.
In our Racket code, this mechanism is implemented using a simple struct called val. A val structure encapsulates a scalar piece of data, its current gradient, the child nodes from which it was computed, and the local gradients with respect to those children. This means that every time we perform a mathematical operation, we are not merely calculating a result; we are dynamically building a computational graph.
When operations like addition (u+), multiplication (u*), exponentiation (upow), or non-linearities like ReLU (urelu) are executed, they instantiate new val objects. These objects maintain pointers to their operands. For example, if c = (u+ a b), then c knows that it was created from a and b, and it stores the local derivatives of the addition operation.
Once a forward pass through the network is complete and a scalar loss value is computed (representing how wrong the network’s predictions were), the back function takes over. It performs a topological sort of the entire computational graph. Then, traversing this sorted list in reverse order, it applies the chain rule from calculus to propagate gradients backward from the loss down to every individual weight of the model. This dependency-free approach, heavily inspired by Karpathy’s micrograd, clearly illustrates that automatic differentiation is fundamentally just an automated, programmatic application of the chain rule over a directed acyclic graph.
Model Parameters and Initialization
A neural network is essentially an enormous collection of parameters—weights and biases—that are iteratively optimized over time. In our Racket implementation, these parameters are stored in a centralized hash table called *state-dict*.
The init-mod function defines the architectural shape of our MicroGPT. We initialize several distinct sets of matrices:
- wte: The token embedding matrix, which translates discrete character IDs into dense continuous vectors.
- wpe: The positional embedding matrix, which gives the model information about where a token is located in the sequence.
- lm_head: The final language modeling head, a linear layer that projects the internal representations back into the vocabulary space to predict the next character.
- Transformer Layers: For each layer, we initialize matrices for the attention mechanism (attn_wq, attn_wk, attn_wv, attn_wo) and the multi-layer perceptron (mlp_fc1, mlp_fc2).
Each parameter is initialized using a Gaussian distribution (random-gauss). This small amount of random noise provides the network with an asymmetrical starting state, breaking symmetry and allowing gradient descent to effectively navigate the loss landscape. Crucially, every weight generated is a val structure, ensuring that every calculation utilizing these weights is automatically tracked by the autograd engine.
The Transformer Architecture
The gp function serves as the central processing unit of the model. It implements the forward pass of a decoder-only Transformer. As data flows through this function, it undergoes a series of sophisticated transformations:
- Embeddings: Each discrete token (in our case, characters) and its position in the sequence are converted into dense vectors using our embedding matrices. These two vectors are added together to form the initial representation of the input sequence.
- Layer Normalization: We employ RMSNorm (Root Mean Square Normalization) to stabilize the neural activations. RMSNorm is computationally simpler than standard Layer Normalization because it does not require mean-centering, yet it is highly effective. It has become a standard technique in modern, highly optimized models like Meta’s LLaMA.
-
Multi-Head Self-Attention: This is the defining feature of the Transformer. The model linearly projects the input into three distinct representations: Queries (Q), Keys (K), and Values (V). For each attention head, the model computes the dot product of the Query and Key. This dot product determines how much “attention” the current token should pay to all past tokens. The attention scores are normalized using a
usoftmaxfunction and are then multiplied by the Value vector. To significantly speed up inference, we maintain a Key-Value (KV) cache. This cache stores past K and V computations, preventing the model from redundantly recalculating past context for every newly generated token. - Multi-Layer Perceptron (MLP): Following the attention mechanism, the data is passed through a simple feed-forward neural network equipped with a ReLU activation function. While the attention mechanism allows tokens to communicate with one another, the MLP allows each individual token to process and refine the information it has gathered.
-
Residual Connections: You will notice in the code that the outputs of the attention layer and the MLP layer are added back to their respective inputs (
set! x (map u+ x xr)). These residual connections create “shortcuts” for gradients to flow backward through the network, mitigating the vanishing gradient problem and enabling the training of deeper architectures. - Language Modeling Head: Finally, the refined representations are projected back into the vocabulary space. The output is a set of raw scores, or “logits,” representing the model’s prediction for what the next token in the sequence should be.
Training the Model: Learning from Data
The run-train function orchestrates the intricate dance of the learning process. The model trains by reading lines of text—in our specific example, from a file called names.txt—processing it character by character.
The training loop proceeds iteratively over many steps:
1. The Forward Pass: The model ingests a sequence of characters and attempts to predict the subsequent character for every position in the sequence simultaneously.
2. Loss Calculation: We utilize the cross-entropy loss function. By applying the softmax function to our raw logits, we convert them into a normalized probability distribution. The loss is calculated as the negative log-likelihood of the correct next character. If the model assigns a high probability to the correct character, the loss is low. If it assigns a low probability, the loss is high.
3. The Backward Pass: The back function is invoked on the final scalar loss value. This single function call ripples backward through the computational graph, computing the exact gradient for every parameter in the network.
4. Optimization: We update the parameters using the Adam optimization algorithm. Unlike simple stochastic gradient descent, Adam maintains running averages of both the gradients and the squared gradients. This allows it to adaptively tune the learning rate for each individual parameter, resulting in faster and more stable convergence.
By executing this loop over hundreds or thousands of steps, the model incrementally adjusts its internal weights. It slowly learns to assign higher probabilities to the correct sequences of characters, thereby absorbing the underlying statistical structure of the training data.
Inference: Hallucinating New Data
Once the model has completed its training phase and internalized the patterns of the dataset, we can use it to generate novel text via the run-inference function.
Starting with a special Beginning-Of-Sequence (BOS) token, we feed this initial context into the model to obtain the probabilities for the first character. We then sample from this probability distribution (using the random-choice function) to select a character. This newly generated character is appended to our context and fed back into the model to predict the next character. This autoregressive generation process continues in a loop until the model predicts the BOS token again, which we use to indicate the end of the sequence.
Because we sample from a probability distribution rather than greedily picking the single most likely token at every step, the model can generate diverse, creative, and sometimes surprising outputs. It effectively “hallucinates” new names or words that strongly resemble the stylistic patterns of the training data but were never explicitly contained within it.
Conclusion
This complete Racket implementation of MicroGPT vividly demonstrates that the core concepts underpinning modern large language models are not inscrutable magic. By methodically breaking down the architecture into its fundamental mathematical operations and constructing a rudimentary but fully functional autograd engine from scratch, we gain a profound, demystified understanding of how these powerful systems learn and operate.
Racket, with its unparalleled flexibility and expressive syntax, proves to be an exceptionally capable and elegant language for this endeavor. Its interactive nature makes it a joy to use for defining complex computational graphs and experimenting with novel neural network architectures.
In the following section, you will find the complete source code for our dependency-free MicroGPT. Reading carefully through this program listing will help solidify the theoretical concepts discussed in this chapter and provide you with a robust, transparent foundation for further experimentation and exploration in the fascinating world of language modeling.
Complete Source Code Listing for microgpt.rkt
1 #lang racket
2
3 ;;; microgpt.rkt — Karpathy's microGPT in dependency-free Racket
4
5 (require racket/math)
6
7 (provide run-microgpt)
8
9 ;; ============================================================
10 ;; UTILITIES
11 ;; ============================================================
12
13 (define (random-gauss mean std)
14 (+ mean (* std (sqrt (* -2 (log (max (random) 1e-15)))) (cos (* 2 pi (random))))))
15
16 (define (shuffle-list lst)
17 (sort lst (lambda (a b) (< (random) 0.5))))
18
19 (define (read-lines file-path)
20 (if (file-exists? file-path)
21 (with-input-from-file file-path
22 (lambda ()
23 (let loop ([lines '()])
24 (let ([line (read-line)])
25 (if (eof-object? line)
26 (reverse lines)
27 (let ([tr (string-trim line)])
28 (if (positive? (string-length tr))
29 (loop (cons tr lines))
30 (loop lines))))))))
31 '()))
32
33 (define *docs* '())
34 (define *uchars* "")
35 (define *bos* 0)
36 (define *vocab-size* 0)
37 (define *n-layer* 1)
38 (define *n-embd* 16)
39 (define *block-size* 16)
40 (define *n-head* 4)
41 (define *head-dim* 4)
42 (define *state-dict* (make-hash))
43 (define *params* '())
44
45 ;; ============================================================
46 ;; AUTOGRAD
47 ;; ============================================================
48
49 (struct val (data grad children local-grads) #:mutable #:transparent)
50
51 (define (make-val d [ch '()] [lg '()])
52 (val (if (val? d) (val-data d) (real->double-flonum d))
53 0.0 ch lg))
54
55 (define (ens v)
56 (if (val? v) v (make-val v)))
57
58 (define (u+ a b)
59 (let ([a (ens a)] [b (ens b)])
60 (make-val (+ (val-data a) (val-data b)) (list a b) '(1.0 1.0))))
61
62 (define (u* a b)
63 (let ([a (ens a)] [b (ens b)])
64 (make-val (* (val-data a) (val-data b)) (list a b) (list (val-data b) (val-data \
65 a)))))
66
67 (define (upow v p)
68 (let ([v (ens v)])
69 (make-val (expt (val-data v) p) (list v)
70 (list (real->double-flonum (* p (expt (val-data v) (- p 1))))))))
71
72 (define (ulog v)
73 (let ([v (ens v)])
74 (make-val (log (val-data v)) (list v) (list (/ 1.0 (val-data v))))))
75
76 (define (uexp v)
77 (let ([v (ens v)])
78 (make-val (exp (val-data v)) (list v) (list (exp (val-data v))))))
79
80 (define (urelu v)
81 (let ([v (ens v)])
82 (make-val (max 0.0 (val-data v)) (list v) (list (if (positive? (val-data v)) 1.0\
83 0.0)))))
84
85 (define (uneg v) (u* v -1.0))
86 (define (u- a b) (u+ a (uneg b)))
87 (define (u/ a b) (u* a (upow b -1.0)))
88
89 (define (back v)
90 (define topo '())
91 (define seen (make-hasheq))
92 (define (build n)
93 (unless (hash-has-key? seen n)
94 (hash-set! seen n #t)
95 (for-each build (val-children n))
96 (set! topo (cons n topo))))
97 (build v)
98 (set-val-grad! v 1.0)
99 (for ([n topo])
100 (let ([grad (val-grad n)])
101 (for-each (lambda (c g)
102 (set-val-grad! c (+ (val-grad c) (* g grad))))
103 (val-children n)
104 (val-local-grads n)))))
105
106 ;; ============================================================
107 ;; MODEL PARAMETERS
108 ;; ============================================================
109
110 (define (make-matr nout nin [std 0.08])
111 (for/vector ([i (in-range nout)])
112 (for/vector ([j (in-range nin)])
113 (let ([v (make-val (random-gauss 0 std))])
114 (set! *params* (cons v *params*))
115 v))))
116
117 (define (init-mod)
118 (set! *state-dict* (make-hash))
119 (set! *params* '())
120 (define (mat k r c) (hash-set! *state-dict* k (make-matr r c)))
121 (mat "wte" *vocab-size* *n-embd*)
122 (mat "wpe" *block-size* *n-embd*)
123 (mat "lm_head" *vocab-size* *n-embd*)
124 (for ([i (in-range *n-layer*)])
125 (define (lmat s r c) (hash-set! *state-dict* (format "layer~a.~a" i s) (make-mat\
126 r r c)))
127 (lmat "attn_wq" *n-embd* *n-embd*)
128 (lmat "attn_wk" *n-embd* *n-embd*)
129 (lmat "attn_wv" *n-embd* *n-embd*)
130 (lmat "attn_wo" *n-embd* *n-embd*)
131 (lmat "mlp_fc1" (* 4 *n-embd*) *n-embd*)
132 (lmat "mlp_fc2" *n-embd* (* 4 *n-embd*)))
133 (set! *params* (reverse *params*)))
134
135 ;; ============================================================
136 ;; ARCHITECTURE
137 ;; ============================================================
138
139 (define (usum vs) (foldl u+ (make-val 0.0) vs))
140
141 (define (ulinear x w)
142 (for/list ([row (in-vector w)])
143 (foldl u+ (make-val 0.0) (map u* (vector->list row) x))))
144
145 (define (usoftmax logits)
146 (let* ([mx (apply max (map val-data logits))]
147 [exps (map (lambda (v) (uexp (u- v mx))) logits)]
148 [sum (usum exps)])
149 (map (lambda (e) (u/ e sum)) exps)))
150
151 (define (urmsnorm x)
152 (let* ([x2 (map (lambda (xi) (u* xi xi)) x)]
153 [mean-x2 (u/ (usum x2) (length x))]
154 [sc (upow (u+ mean-x2 1e-5) -0.5)])
155 (map (lambda (xi) (u* xi sc)) x)))
156
157 (define (gp tok-id pos-id keys-vec vals-vec)
158 (let* ([wte (hash-ref *state-dict* "wte")]
159 [wpe (hash-ref *state-dict* "wpe")]
160 [x (map u+ (vector->list (vector-ref wte tok-id))
161 (vector->list (vector-ref wpe pos-id)))]
162 [x (urmsnorm x)])
163 (for ([li (in-range *n-layer*)])
164 (let* ([xr x]
165 [x-norm (urmsnorm x)]
166 [wq (hash-ref *state-dict* (format "layer~a.attn_wq" li))]
167 [wk (hash-ref *state-dict* (format "layer~a.attn_wk" li))]
168 [wv (hash-ref *state-dict* (format "layer~a.attn_wv" li))]
169 [wo (hash-ref *state-dict* (format "layer~a.attn_wo" li))]
170 [q (ulinear x-norm wq)]
171 [k (ulinear x-norm wk)]
172 [v (ulinear x-norm wv)])
173
174 (vector-set! keys-vec li (append (vector-ref keys-vec li) (list k)))
175 (vector-set! vals-vec li (append (vector-ref vals-vec li) (list v)))
176
177 (let* ([heads
178 (for/list ([h (in-range *n-head*)])
179 (let* ([hs (* h *head-dim*)]
180 [he (+ hs *head-dim*)]
181 [q-h (take (drop q hs) *head-dim*)]
182 [k-h (map (lambda (ki) (take (drop ki hs) *head-dim*)) (vec\
183 tor-ref keys-vec li))]
184 [v-h (map (lambda (vi) (take (drop vi hs) *head-dim*)) (vec\
185 tor-ref vals-vec li))]
186 [scores (for/list ([kt k-h])
187 (u/ (usum (map u* q-h kt)) (sqrt *head-dim*)))]
188 [aw (usoftmax scores)])
189 (for/list ([j (in-range *head-dim*)])
190 (usum (map (lambda (w vt) (u* w (list-ref vt j))) aw v-h)))))])
191 (set! x (ulinear (apply append heads) wo))
192 (set! x (map u+ x xr)))
193
194 (let ([xr x]
195 [x-norm (urmsnorm x)]
196 [fc1 (hash-ref *state-dict* (format "layer~a.mlp_fc1" li))]
197 [fc2 (hash-ref *state-dict* (format "layer~a.mlp_fc2" li))])
198 (set! x (map urelu (ulinear x-norm fc1)))
199 (set! x (ulinear x fc2))
200 (set! x (map u+ x xr)))))
201 (ulinear x (hash-ref *state-dict* "lm_head"))))
202
203 ;; ============================================================
204 ;; TRAINING
205 ;; ============================================================
206
207 (define (string-index str ch)
208 (for/first ([i (in-range (string-length str))]
209 #:when (char=? (string-ref str i) ch))
210 i))
211
212 (define (run-train)
213 (let* ([lr 0.01] [b1 0.85] [b2 0.99] [eps 1e-8] [steps 1000]
214 [np (length *params*)]
215 [m (make-vector np 0.0)]
216 [mv (make-vector np 0.0)])
217 (for ([step (in-range steps)])
218 (let* ([doc (list-ref *docs* (modulo step (length *docs*)))]
219 [tokens (append (list *bos*)
220 (for/list ([ch (in-string doc)])
221 (string-index *uchars* ch))
222 (list *bos*))]
223 [n (min *block-size* (- (length tokens) 1))]
224 [keys (for/vector ([i (in-range *n-layer*)]) '())]
225 [vals (for/vector ([i (in-range *n-layer*)]) '())]
226 [losses '()])
227
228 (for ([pos (in-range n)])
229 (let* ([logits (gp (list-ref tokens pos) pos keys vals)]
230 [probs (usoftmax logits)])
231 (set! losses (cons (uneg (ulog (list-ref probs (list-ref tokens (+ pos 1\
232 ))))) losses))))
233
234 (let* ([loss (u/ (usum losses) n)]
235 [t+1 (+ step 1)])
236 ;; Reset grads
237 (for ([p *params*]) (set-val-grad! p 0.0))
238 (back loss)
239
240 (for ([i (in-range np)]
241 [p *params*])
242 (let* ([grad (val-grad p)]
243 [m-val (+ (* b1 (vector-ref m i)) (* (- 1 b1) grad))]
244 [mv-val (+ (* b2 (vector-ref mv i)) (* (- 1 b2) (expt grad 2)))])
245 (vector-set! m i m-val)
246 (vector-set! mv i mv-val)
247 (let* ([mh (/ m-val (- 1 (expt b1 t+1)))]
248 [vh (/ mv-val (- 1 (expt b2 t+1)))])
249 (set-val-data! p (- (val-data p) (/ (* lr (- 1 (/ step steps)) mh) (\
250 + (sqrt vh) eps)))))))
251
252 (when (or (zero? (modulo t+1 10)) (= t+1 1))
253 (printf "step ~a/~a | loss ~a\n" t+1 steps (val-data loss))
254 (flush-output)))))))
255
256 ;; ============================================================
257 ;; INFERENCE
258 ;; ============================================================
259
260 (define (random-choice weights)
261 (let* ([total (apply + weights)]
262 [r (* (random) total)])
263 (let loop ([i 0] [acc 0.0])
264 (if (>= i (- (length weights) 1))
265 i
266 (let ([new-acc (+ acc (list-ref weights i))])
267 (if (< r new-acc)
268 i
269 (loop (+ i 1) new-acc)))))))
270
271 (define (run-inference)
272 (printf "\n--- inference (new, hallucinated names) ---\n")
273 (for ([i (in-range 20)])
274 (let ([keys (for/vector ([l (in-range *n-layer*)]) '())]
275 [vals (for/vector ([l (in-range *n-layer*)]) '())]
276 [tok *bos*]
277 [sample '()])
278 (let loop ([pos 0])
279 (when (< pos *block-size*)
280 (let* ([logits (gp tok pos keys vals)]
281 [lt (map (lambda (l) (/ (val-data l) 0.5)) logits)]
282 [mx (apply max lt)]
283 [exps (map (lambda (v) (exp (- v mx))) lt)]
284 [sum-exps (apply + exps)]
285 [probs (map (lambda (e) (/ e sum-exps)) exps)])
286 (set! tok (random-choice probs))
287 (unless (= tok *bos*)
288 (set! sample (cons (string-ref *uchars* tok) sample))
289 (loop (+ pos 1))))))
290 (printf "sample ~a: ~a\n" (+ i 1) (list->string (reverse sample))))))
291
292 ;; ============================================================
293 ;; MAIN
294 ;; ============================================================
295
296 (define (run-microgpt)
297 (set! *docs* (shuffle-list (read-lines "names.txt")))
298 (printf "num docs: ~a\n" (length *docs*))
299 (let ([chars '()])
300 (for ([doc *docs*])
301 (for ([ch (in-string doc)])
302 (unless (member ch chars)
303 (set! chars (cons ch chars)))))
304 (set! *uchars* (list->string (sort chars char<?)))
305 (set! *bos* (string-length *uchars*))
306 (set! *vocab-size* (+ *bos* 1)))
307 (printf "vocab size: ~a\n" *vocab-size*)
308 (init-mod)
309 (printf "num params: ~a\n" (length *params*))
310 (run-train)
311 (run-inference))
312
313 (module+ main
314 (run-microgpt))
Let’s run the code:
1 $ racket microgpt.rkt
2 num docs: 32033
3 vocab size: 27
4 num params: 4192
5 step 1/1000 | loss 3.3421
6 step 2/1000 | loss 3.5779
7 ...
8 step 997/1000 | loss 2.2916
9 step 998/1000 | loss 1.7724
10 step 999/1000 | loss 2.3279
11 step 1000/1000 | loss 2.3213
12
13 --- inference (new, hallucinated names) ---
14 sample 1: lereri
15 sample 2: nahand
16 sample 3: eleni
17 sample 4: amica
18 sample 5: calina
19 sample 6: alla
20 sample 7: marona
21 sample 8: chidynn
22 sample 9: kanan
23 sample 10: brann
24 sample 11: kalen
25 sample 12: jorena
The following diagram shows the high-level architecture of the MicroGPT Transformer model implemented in this chapter:
Wrap Up
This concludes our exploration of MicroGPT implemented from scratch in Racket. By studying the complete source code listing provided above, you have seen firsthand how the abstract mathematical concepts of reverse-mode automatic differentiation, self-attention, and autoregressive language modeling translate into concrete, functional code.
I highly encourage you to load microgpt.rkt into your own Racket REPL or DrRacket and run it. Try experimenting with the hyperparameters—adjust the *n-layer*, *n-embd*, or *n-head* variables and observe how they impact both the training time and the quality of the hallucinated outputs. You can also swap out the names.txt dataset for your own text files to see how the model adapts to entirely different linguistic patterns. By actively tinkering with this minimalistic implementation, you will cement your understanding of how modern generative AI truly works under the hood.