Natural Language Processing
I have a Natural Language Processing (NLP) library that I wrote in Common Lisp. Here we will use code that I wrote in pure Scheme and converted to Racket.
The NLP library is still a work in progress so please check for future updates to this live eBook.
Since we will use the example code in this chapter as a library we start by defining a main.rkt file:
1 #lang racket/base
2
3 (require "fasttag.rkt")
4 (require "names.rkt")
5
6 (provide parts-of-speech)
7 (provide find-human-names)
8 (provide find-place-names)
There are two main source files for the NLP library: fasttag.rkt and names.rkt.
The following listing of fasttag.rkt is a conversion of original code I wrote in Java and later translated to Common Lisp. The provided Racket Scheme code is designed to perform part-of-speech tagging for a given list of words. The code begins by loading a hash table (lex-hash) from a data file (“data/tag.dat”), where each key-value pair maps a word to its possible part of speech. Then it defines several helper functions and transformation rules for categorizing words based on various syntactic and morphological criteria.
The core function, parts-of-speech, takes a vector of words and returns a vector of corresponding parts of speech. Inside this function, a number of rules are applied to each word in the list to refine its part of speech based on both its individual characteristics and its context within the list. For instance, Rule 1 changes the part of speech to “NN” (noun) if the previous word is “DT” (determiner) and the current word is categorized as a verb form (“VBD”, “VBP”, or “VB”). Rule 2 changes a word to a cardinal number (“CD”) if it contains a period, and so on. The function applies these rules in sequence, updating the part of speech for each word accordingly.
The parts-of-speech function iterates over each word in the input vector, checks it against lex-hash, and then applies the predefined rules. The result is a new vector of tags, one for each input word, where each tag represents the most likely part of speech for that word, based on the rules and the original lexicon.
#lang racket
(require srfi/13) ; the string SRFI
(require racket/runtime-path)
(provide parts-of-speech)
(define-runtime-path my-data-path "data")
;; FastTag.lisp
;;
;; Conversion of KnowledgeBooks.com Java FastTag to Scheme
;;
;; Copyright 2002 by Mark Watson. All rights reserved.
;;
(display "loading lex-hash...")
(log-info "loading lex-hash" "starting")
(define lex-hash
(let ((hash (make-hash)))
(with-input-from-file
(string-append (path->string my-data-path) "/tag.dat")
(lambda ()
(let loop ()
(let ((p (read)))
(if (list? p) (hash-set! hash (car p) (cadr p)) #f)
(if (eof-object? p) #f (loop))))))
hash))
(display "...done.")
(log-info "loading lex-hash" "ending")
(define (string-suffix? pattern str)
(let loop ((i (- (string-length pattern) 1)) (j (- (string-length str) 1)))
(cond
((negative? i) #t)
((negative? j) #f)
((char=? (string-ref pattern i) (string-ref str j))
(loop (- i 1) (- j 1)))
(else #f))))
;;
; parts-of-speech
;
; input: a vector of words (each a string)
; output: a vector of parts of speech
;;
(define (parts-of-speech words)
(display "\n+ tagging:") (display words)
(let ((ret '())
(r #f)
(lastRet #f)
(lastWord #f))
(for-each
(lambda (w)
(set! r (hash-ref lex-hash w #f))
;; if this word is not in the hash table, try making it ll lower case:
(if (not r)
(set! r '("NN"))
#f)
;;(if (list? r) (set! r (car r))))
;; apply transformation rules:
; rule 1: DT, {VBD, VBP, VB} --> DT, NN
(if (equal? lastRet "DT")
(if (or
(equal? r "VBD")
(equal? r "VBP")
(equal? r "VB"))
(set! r '("NN"))
#f)
#f)
; rule 2: convert a noun to a number if a "." appears in the word
(if (string-contains "." w) (set! r '("CD")) #f)
; rule 3: convert a noun to a past participle if word ends with "ed"
(if (equal? (member "N" r) 0)
(let* ((slen (string-length w)))
(if (and
(> slen 1)
(equal? (substring w (- slen 2)) "ed"))
(set! r "VBN") #f))
#f)
; rule 4: convert any type to an adverb if it ends with "ly"
(let ((i (string-suffix? "ly" w)))
(if (equal? i (- (string-length w) 2))
(set! r '("RB"))
#f))
; rule 5: convert a common noun (NN or NNS) to an adjective
; if it ends with "al"
(if (or
(member "NN" r)
(member "NNS" r))
(let ((i (string-suffix? "al" w)))
(if (equal? i (- (string-length w) 2))
(set! r '("RB"))
#f))
#f)
; rule 6: convert a noun to a verb if the receeding word is "would"
(if (equal? (member "NN" r) 0)
(if (equal? lastWord "would")
(set! r '("VB"))
#f)
#f)
; rule 7: if a word has been categorized as a common noun and it
; ends with "s", then set its type to a plural noun (NNS)
(if (member "NN" r)
(let ((i (string-suffix? "s" w)))
(if (equal? i (- (string-length w) 1))
(set! r '("NNS"))
#f))
#f)
; rule 8: convert a common noun to a present participle verb
; (i.e., a gerand)
(if (equal? (member "NN" r) 0)
(let ((i (string-suffix? "ing" w)))
(if (equal? i (- (string-length w) 3))
(set! r '("VBG"))
#f))
#f)
(set! lastRet ret)
(set! lastWord w)
(set! ret (cons (first r) ret)))
(vector->list words)) ;; not very efficient !!
(list->vector (reverse ret))))
The following listing of file names.rkt identifies human and place names in text. The Racket Scheme code is a script for Named Entity Recognition (NER). It is specifically designed to recognize human names and place names in given text:
- It provides two main functions:
find-human-namesandfind-place-names. - Uses two kinds of data: human names and place names, loaded from text files.
- Employs Part-of-Speech tagging through an external
fasttag.rktmodule. - Uses hash tables and lists for efficient look-up.
- Handles names with various components (prefixes, first name, last name, etc.)
The function process-one-word-per-line reads each line of a file and applies a given function func on it.
Initial data preparation consists of defining the hash tables *last-name-hash*, *first-name-hash*, *place-name-hash* are populated with last names, first names, and place names, respectively, from specified data files.
We define two Named Entity Recognition (NER) functions:
-
find-human-names: Takes a word vector and an exclusion list.- Utilizes parts-of-speech tags.
- Checks for names that have 1 to 4 words.
- Adds names to
retlist if conditions are met, considering the exclusion list. - Returns processed names (
ret2).
-
find-place-names: Similar tofind-human-names, but specifically for place names.- Works on 1 to 3 word place names.
- Returns processed place names.
We define one helper functions not-in-list-find-names-helper to ensures that an identified name does not overlap with another name or entry in the exclusion list.
Overall, the code is fairly optimized for its purpose, utilizing hash tables for constant-time look-up and lists to store identified entities.
#lang racket
(require "fasttag.rkt")
(require racket/runtime-path)
(provide find-human-names)
(provide find-place-names)
(define-runtime-path my-data-path "data")
(define (process-one-word-per-line file-path func)
(with-input-from-file file-path
(lambda ()
(let loop ()
(let ([l (read-line)])
(if (equal? l #f) #f (func l))
(if (eof-object? l) #f (loop)))))))
(define *last-name-hash* (make-hash))
(process-one-word-per-line
(string-append
(path->string my-data-path)
"/human_names/names.last")
(lambda (x) (hash-set! *last-name-hash* x #t)))
(define *first-name-hash* (make-hash))
(process-one-word-per-line
(string-append
(path->string my-data-path)
"/human_names/names.male")
(lambda (x) (hash-set! *first-name-hash* x #t)))
(process-one-word-per-line
(string-append
(path->string my-data-path)
"/human_names/names.female")
(lambda (x) (hash-set! *first-name-hash* x #t)))
(define *place-name-hash* (make-hash))
(process-one-word-per-line
(string-append
(path->string my-data-path)
"/placenames.txt")
(lambda (x) (hash-set! *place-name-hash* x #t)))
(define *name-prefix-list*
'("Mr" "Mrs" "Ms" "Gen" "General" "Maj" "Major" "Doctor" "Vice" "President"
"Lt" "Premier" "Senator" "Congressman" "Prince" "King" "Representative"
"Sen" "St" "Dr"))
(define (not-in-list-find-names-helper a-list start end)
(let ((rval #t))
(do ((x a-list (cdr x)))
((or
(null? x)
(let ()
(if (or
(and
(>= start (caar x))
(<= start (cadar x)))
(and
(>= end (caar x))
(<= end (cadar x))))
(set! rval #f)
#f)
(not rval)))))
rval))
;; return a list of sublists, each sublist looks like:
;; (("John" "Smith") (11 12) 0.75) ; last number is an importance rating
(define (find-human-names word-vector exclusion-list)
(define (score result-list)
(- 1.0 (* 0.2 (- 4 (length result-list)))))
(let ((tags (parts-of-speech word-vector))
(ret '()) (ret2 '()) (x '())
(len (vector-length word-vector))
(word #f))
(display "\ntags: ") (display tags)
;;(dotimes (i len)
(for/list ([i (in-range len)])
(set! word (vector-ref word-vector i))
(display "\nword: ") (display word)
;; process 4 word names: HUMAN NAMES
(if (< i (- len 3))
;; case #1: single element from '*name-prefix-list*'
(if (and
(not-in-list-find-names-helper ret i (+ i 4))
(not-in-list-find-names-helper exclusion-list i (+ i 4))
(member word *name-prefix-list*)
(equal? "." (vector-ref word-vector (+ i 1)))
(hash-ref *first-name-hash* (vector-ref word-vector (+ i 2)) #f)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 3)) #f))
(if (and
(string-prefix? (vector-ref tags (+ i 2)) "NN")
(string-prefix? (vector-ref tags (+ i 3)) "NN"))
(set! ret (cons (list i (+ i 4)) ret))
#f)
#f)
;; case #1: two elements from '*name-prefix-list*'
(if (and
(not-in-list-find-names-helper ret i (+ i 4))
(not-in-list-find-names-helper exclusion-list i (+ i 4))
(member word *name-prefix-list*)
(member (vector-ref word-vector (+ i 1)) *name-prefix-list*)
(hash-ref *first-name-hash* (vector-ref word-vector (+ i 2)) #f)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 3)) #f))
(if (and
(string-prefix? (vector-ref tags (+ i 2)) "NN")
(string-prefix? (vector-ref tags (+ i 3)) "NN"))
(set! ret (cons (list i (+ i 4)) ret))
#f)
#f))
;; process 3 word names: HUMAN NAMES
(if (< i (- len 2))
(if (and
(not-in-list-find-names-helper ret i (+ i 3))
(not-in-list-find-names-helper exclusion-list i (+ i 3)))
(if (or
(and
(member word *name-prefix-list*)
(hash-ref *first-name-hash* (vector-ref word-vector (+ i 1)) #f)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 2)) #f)
(string-prefix? (vector-ref tags (+ i 1)) "NN")
(string-prefix? (vector-ref tags (+ i 2)) "NN"))
(and
(member word *name-prefix-list*)
(member (vector-ref word-vector (+ i 1)) *name-prefix-list*)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 2)) #f)
(string-prefix? (vector-ref tags (+ i 1)) "NN")
(string-prefix? (vector-ref tags (+ i 2)) "NN"))
(and
(member word *name-prefix-list*)
(equal? "." (vector-ref word-vector (+ i 1)))
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 2)) #f)
(string-prefix? (vector-ref tags (+ i 2)) "NN"))
(and
(hash-ref *first-name-hash* word #f)
(hash-ref *first-name-hash* (vector-ref word-vector (+ i 1)) #f)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 2)) #f)
(string-prefix? (vector-ref tags i) "NN")
(string-prefix? (vector-ref tags (+ i 1)) "NN")
(string-prefix? (vector-ref tags (+ i 2)) "NN")))
(set! ret (cons (list i (+ i 3)) ret))
#f)
#f)
#f)
;; process 2 word names: HUMAN NAMES
(if (< i (- len 1))
(if (and
(not-in-list-find-names-helper ret i (+ i 2))
(not-in-list-find-names-helper exclusion-list i (+ i 2)))
(if (or
(and
(member word '("Mr" "Mrs" "Ms" "Doctor" "President" "Premier"))
(string-prefix? (vector-ref tags (+ i 1)) "NN")
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 1)) #f))
(and
(hash-ref *first-name-hash* word #f)
(hash-ref *last-name-hash* (vector-ref word-vector (+ i 1)) #f)
(string-prefix? (vector-ref tags i) "NN")
(string-prefix? (vector-ref tags (+ i 1)) "NN")))
(set! ret (cons (list i (+ i 2)) ret))
#f)
#f)
#f)
;; 1 word names: HUMAN NAMES
(if (hash-ref *last-name-hash* word #f)
(if (and
(string-prefix? (vector-ref tags i) "NN")
(not-in-list-find-names-helper ret i (+ i 1))
(not-in-list-find-names-helper exclusion-list i (+ i 1)))
(set! ret (cons (list i (+ i 1)) ret))
#f)
#f))
;; TBD: calculate importance rating based on number of occurences of name in tex\
t:
(set! ret2
(map (lambda (index-pair)
(string-replace
(string-join (vector->list (vector-copy word-vector (car index-pa\
ir) (cadr index-pair))))
" ." "."))
ret))
ret2))
(define (find-place-names word-vector exclusion-list) ;; PLACE
(define (score result-list)
(- 1.0 (* 0.2 (- 4 (length result-list)))))
(let ((tags (parts-of-speech word-vector))
(ret '()) (ret2 '()) (x '())
(len (vector-length word-vector))
(word #f))
(display "\ntags: ") (display tags)
;;(dotimes (i len)
(for/list ([i (in-range len)])
(set! word (vector-ref word-vector i))
(display "\nword: ") (display word) (display "\n")
;; process 3 word names: PLACE
(if (< i (- len 2))
(if (and
(not-in-list-find-names-helper ret i (+ i 3))
(not-in-list-find-names-helper exclusion-list i (+ i 3)))
(let ((p-name (string-append word " " (vector-ref word-vector (+ i 1))\
" " (vector-ref word-vector (+ i 2)))))
(if (hash-ref *place-name-hash* p-name #f)
(set! ret (cons (list i (+ i 3)) ret))
#f))
#f)
#f)
;; process 2 word names: PLACE
(if (< i (- len 1))
(if (and
(not-in-list-find-names-helper ret i (+ i 2))
(not-in-list-find-names-helper exclusion-list i (+ i 2)))
(let ((p-name (string-append word " " (vector-ref word-vector (+ i 1))\
)))
(if (hash-ref *place-name-hash* p-name #f)
(set! ret (cons (list i (+ i 2)) ret))
#f)
#f)
#f)
#f)
;; 1 word names: PLACE
(if (hash-ref *place-name-hash* word #f)
(if (and
(string-prefix? (vector-ref tags i) "NN")
(not-in-list-find-names-helper ret i (+ i 1))
(not-in-list-find-names-helper exclusion-list i (+ i 1)))
(set! ret (cons (list i (+ i 1)) ret))
#f)
#f))
;; TBD: calculate importance rating based on number of occurences of name in tex\
t: can use (count-substring..) defined in utils.rkt
(set! ret2
(map (lambda (index-pair)
(string-join (vector->list (vector-copy word-vector (car index-pai\
r) (cadr index-pair))) " "))
ret))
ret2))
#|
(define nn (find-human-names '#("President" "George" "Bush" "went" "to" "San" "Diego\
" "to" "meet" "Ms" "." "Jones" "and" "Gen" "." "Pervez" "Musharraf" ".") '()))
(display (find-place-names '#("George" "Bush" "went" "to" "San" "Diego" "and" "Londo\
n") '()))
|#
Let’s try some examples in a Racket REPL:
1 > Racket-AI-book/source-code/nlp $ racket 2 Welcome to Racket v8.10 [cs]. 3 > (require nlp) 4 loading lex-hash......done.#f 5 > (find-human-names '#("President" "George" "Bush" "went" "to" "San" "Diego" "to" "m\
6 eet" "Ms" "." "Jones
7 " "and" "Gen" "." "Pervez" "Musharraf" ".") '()) 8
9 + tagging:#(President George Bush went to San Diego to meet Ms . Jones and Gen . Per\10 vez Musharraf .)11 tags: #(NNP NNP NNP VBD TO NNP NNP TO VB NNP CD NNP CC NNP CD NN NN CD)12 word: President13 word: George14 word: Bush15 word: went16 word: to17 word: San18 word: Diego19 word: to20 word: meet21 word: Ms22 word: .23 word: Jones24 word: and25 word: Gen26 word: .27 word: Pervez28 word: Musharraf29 word: .'("Gen. Pervez Musharraf" "Ms. Jones" "San" "President George Bush")
30 > (find-place-names '#("George" "Bush" "went" "to" "San" "Diego" "and" "London") '())
31
32 + tagging:#(George Bush went to San Diego and London)
33 tags: #(NNP NNP VBD TO NNP NNP CC NNP)
34 word: George
35
36 word: Bush
37
38 word: went
39
40 word: to
41
42 word: San
43
44 word: Diego
45
46 word: and
47
48 word: London
49 '("London" "San Diego")50 >
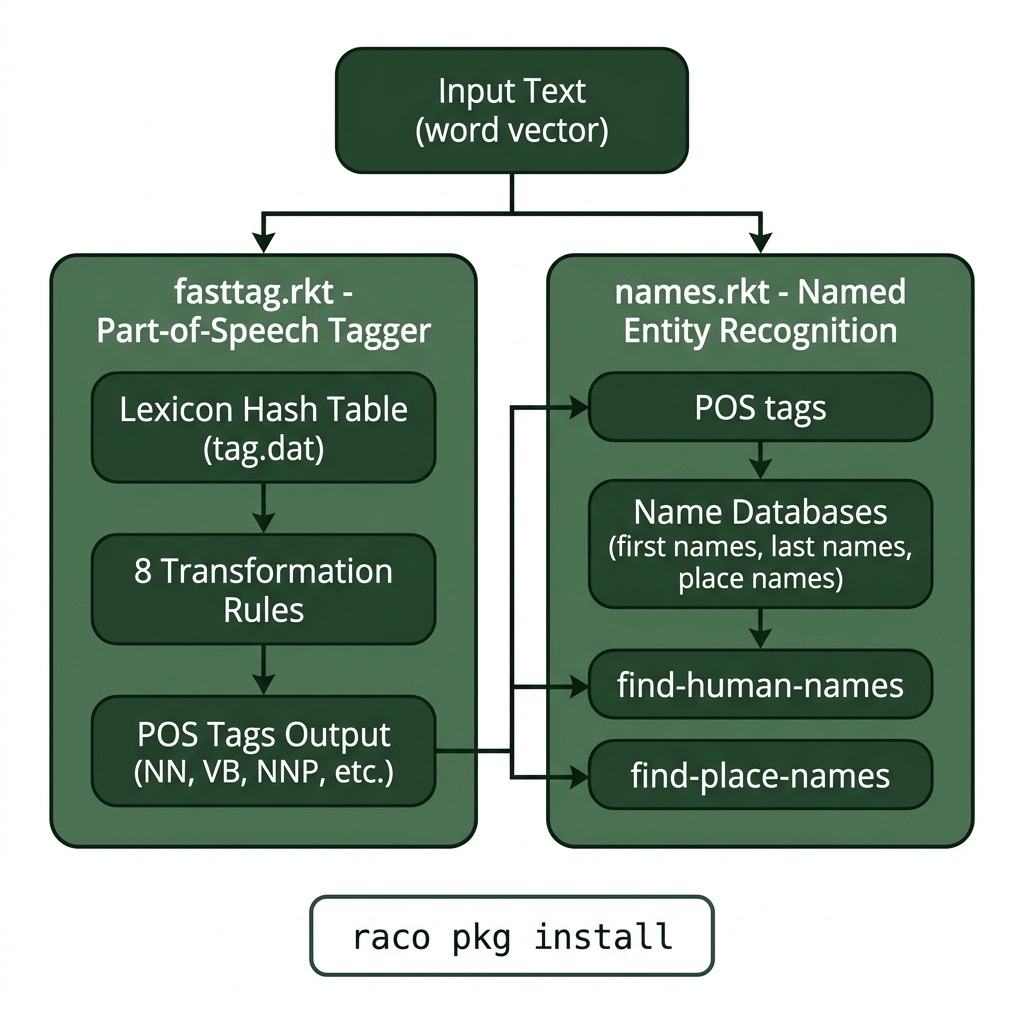
The following diagram shows the high-level architecture of the NLP library developed in this chapter:
NLP Wrap Up
The NLP library is still a work in progress so please check for updates to this live eBook and the GitHub repository for this book: