Natural Language Processing Using OpenNLP
I have worked in the field of Natural Language Processing (NLP) since the early 1980s. Many more people are interested in the field of NLP and the techniques have changed drastically. NLP has usually been considered part of the field of artificial intelligence (AI) and in the 1980s and 1990s there was more interest in symbolic AI, that is the manipulation of high level symbols that are meaningful to people because of our knowledge of the real world. As an example, the symbol car means something to us but to AI software this symbol in itself has no meaning except for possible semantic relationships to other symbols like driver and road.
There is still much work in NLP that deals with words as symbols: syntactic and semantic parsers being two examples. What has changed is a strong reliance on statistical and machine learning techniques. In this chapter we will use the open source (Apache 2 license) OpenNLP project that uses machine learning to create models of language. Currently, OpenNLP has support for Danish, German, English, Spanish, Portuguese, and Swedish. I include in the github repository some trained models for English that are used in the examples in this chapter. You can download models for other languages at the web page for OpenNLP 1.5 models (we are using version 1..6.0 of OpenNLP in this book which uses the version 1.5 models).
I use OpenNLP for some of the NLP projects that I do for my consulting customers. I have also written my own NLP toolkit KBSPortal.com that is a commercial product. For customers who can use the GPL license I sometimes use the Stanford NLP libraries that, like OpenNLP, are written in Java.
The following figure shows the project for this chapter in the Community Edition of IntelliJ:
We will use pre-trained models for tokenizing text, recognizing the names of organizations, people, locations, and parts of speech for words in input text. We will also train a new model (the file opennlp/models/en-newscat.bin in the github repository) for recognizing the category of input text. The section on training new maximum entropy classification models using your own training data is probably the material in this chapter that you will use the most in your own projects. We will train one model to recognize the categories of COMPUTERS, ECONOMY, HEALTH, and POLITICS. You should then have the knowledge for training your own models using your own training texts for the categories that you need for your applications. We will also use both some pre-trained models that are included with the OpenNLP distribution and the classification mode that we will soon create in the next chapter when we learn how to perform scalable machine learning algorithms using the Apache Spark platform where we look at techniques for processing very large collections of text to discover information.
After building a classification model we finish up this chapter with an interesting topic: statistically parsing sentences to discover the most probable linguistic structure of each sentence in input text. We will not use parsing in the rest of this book so you may skip the last section of this chapter if you are not currently interested in parsing sentences into linguistic components like noun and verp phrases, proper nouns, nouns, adjectives, etc.
Using OpenNLP Pre-Trained Models
Assuming that you have cloned the github repository for this book, you can fetch the maven dependencies, compile the code, and run the unit tests using the command:
1 mvn clean build test
The model files, including the categorization model you will learn to build later in this chapter, are found in the subdirectory models. The unit tests in src/test/java/com/markwatson/opennlp/NLPTest.java provide examples for using the code we develop in this chapter. The Java example code for tokenization (splitting text into individual words), splitting sentences, and recognizing organizations, locations, and people in text is all in the Java class NLP. You can look at the source code in the repository for this book. Here I will just show a few snippets of the code to make clear how to load and use pre-trained models.
I use static class initialization to load the model files:
1 static public Tokenizer tokenizer = null;
2 static public SentenceDetectorME sentenceSplitter = null;
3 static POSTaggerME tagger = null;
4 static NameFinderME organizationFinder = null;
5 static NameFinderME locationFinder = null;
6 static NameFinderME personNameFinder = null;
7
8 static {
9
10 try {
11 InputStream organizationInputStream =
12 new FileInputStream("models/en-ner-organization.bin");
13 TokenNameFinderModel model =
14 new TokenNameFinderModel(organizationInputStream);
15 organizationFinder = new NameFinderME(model);
16 organizationInputStream.close();
17
18 InputStream locationInputStream =
19 new FileInputStream("models/en-ner-location.bin");
20 model = new TokenNameFinderModel(locationInputStream);
21 locationFinder = new NameFinderME(model);
22 locationInputStream.close();
23
24 InputStream personNameInputStream =
25 new FileInputStream("models/en-ner-person.bin");
26 model = new TokenNameFinderModel(personNameInputStream);
27 personNameFinder = new NameFinderME(model);
28 personNameInputStream.close();
29
30 InputStream tokienizerInputStream =
31 new FileInputStream("models/en-token.bin");
32 TokenizerModel modelTokenizer = new TokenizerModel(tokienizerInputStream);
33 tokenizer = new TokenizerME(modelTokenizer);
34 tokienizerInputStream.close();
35
36 InputStream sentenceInputStream =
37 new FileInputStream("models/en-sent.bin");
38 SentenceModel sentenceTokenizer = new SentenceModel(sentenceInputStream);
39 sentenceSplitter = new SentenceDetectorME(sentenceTokenizer);
40 tokienizerInputStream.close();
41
42 organizationInputStream = new FileInputStream("models/en-pos-maxent.bin");
43 POSModel posModel = new POSModel(organizationInputStream);
44 tagger = new POSTaggerME(posModel);
45
46 } catch (IOException e) {
47 e.printStackTrace();
48 }
49 }
The first operation that you will usually start with for processing natural language text is breaking input text into individual words and sentences. Here is the code for using the tokenizing code that separates text stored as a Java String into individual words:
1 public static String[] tokenize(String s) {
2 return tokenizer.tokenize(s);
3 }
Here is the similar code for breaking text into individual sentences:
1 public static String[] sentenceSplitter(String s) {
2 return sentenceSplitter.sentDetect(s);
3 }
Here is some sample code to use sentenceSplitter:
1 String sentence =
2 "Apple Computer, Microsoft, and Google are in the " +
3 " tech sector. Each is very profitable.";
4 String [] sentences = NLP.sentenceSplitter(sentence);
5 System.out.println("Sentences found:\n" + Arrays.toString(sentences));
In line 4 the static method NLP.sentenceSplitter returns an array of strings. In line 5 I use a common Java idiom for printing arrays by using the static method Arrays.toString to convert the array of strings into a List<String> object. The trick is that the List class has a toString method that formats list nicely for printing.
Here is the output of this code snippet (edited for page width and clarity):
1 Sentences found:
2 ["Apple Computer, Microsoft, and Google are in the tech sector.",
3 "Each is very profitable."]
The code for finding organizations, locations, and people’s names is almost identical so I will only show the code in the next listing for recognizing locations. Please look at the methods companyNames and personNames in the class com.markwatson.opennlp.NLP to see the implementations for finding the names of companies and people.
1 public static Set<String> locationNames(String text) {
2 return locationNames(tokenizer.tokenize(text));
3 }
4
5 public static Set<String> locationNames(String tokens[]) {
6 Set<String> ret = new HashSet<String>();
7 Span[] nameSpans = locationFinder.find(tokens);
8 if (nameSpans.length == 0) return ret;
9 for (int i = 0; i < nameSpans.length; i++) {
10 Span span = nameSpans[i];
11 StringBuilder sb = new StringBuilder();
12 for (int j = span.getStart(); j < span.getEnd(); j++)
13 sb.append(tokens[j] + " ");
14 ret.add(sb.toString().trim().replaceAll(" ,", ","));
15 }
16 return ret;
17 }
The public methods in the class com.markwatson.opennlp.NLP are overriden to take either a single string value which gets tokenized inside of the method and also a method that takes as input text that has already been tokenized into a String tokens[] object. In the last example the method starting on line 1 accepts an input string and the overriden method starting on line 5 accepts an array of strings. Often you will want to tokenize text stored in a single input string into tokens and reuse the tokens for calling several of the public methods in com.markwatson.opennlp.NLP that can take input that is already tokenized. In line 2 we simply tokenize the input text and call the method that accepts tokenized input text.
In line 6 we create a HashSet<String> object that will hold the return value of a set of location names. The NameFinderME object locationFinder returns an array of Span objects. The SPan class is used to represnt a sequence of adjacent words. The **Span class has a public static attribute length and instance methods getstart and getEnd that return the indices of the beginning and ending (plus one) index of a span in the origianl input text.
Here is some sample code to use locationNames along with the output (edited for page width and clarity):
1 String sentence =
2 "Apple Computer is located in Cupertino, California and Microsoft " +
3 "is located in Seattle, Washington. He went to Oregon";
4 Set<String> names = NLP.locationNames(sentence);
5 System.out.println("Location names found: " + names);
6
7 Location names found: [Oregon, Cupertino, Seattle, California, Washington]
Note that the pre-trained model does not recognize when city and state names are associated.
Training a New Categorization Model for OpenNLP
The OpenNLP class DoccatTrainer can process specially formatted input text files and produce categorization models using maximum entropy which is a technique that handles data with many features. Features that are automatically extracted from text and used in a model are things like words in a document and word adjacency. Maximum entropy models can recognize multiple classes. In testing a model on new text data the probablilities of all possible classes add up to the value 1 (this is often refered to as “softmax”). For example we will be training a classifier on four categories and the probablilities of these categories for some test input text add up to the value of one:
The format of the input file for training a maximum entropy classifier is simple but has to be correct: each line starts with a category name, followed by sample text for each category which must be all on one line. Please note that I have already trained the model producing the model file models/en-newscat.bin so you don’t need to run the example in this section unless you want to regenerate this model file.
The file sample_category_training_text.txt contains four lines, defining four categories. Here are two lines from this file (I edited the following to look better on the printed page, but these are just two lines in the file):
Here is one training example each for the categories COMPUTERS and ECONOMY.
You must format the training file perfectly. As an example, if you have empty (or blank) lines in your input training file then you will get an error like:
The OpenNLP documentation has examples for writing custom Java code to build models but I usually just use the command line tool; for example:
The model is written to the relative file path models/en-newscat.bin. The training file I am using is tiny so the model is trained in a few seconds. For serious applications, the more training text the better! By default the DoccatTrainer tool uses the default text feature generator which uses word frequencies in documents but ignores word ordering. As I mention in the next section, I sometimes like to mix word frequency feature generation with 2gram (that is, frequencies of two adjacent words). In this case you cannot simply use the DoccatTrainer command line tool. You need to write a little Java code yourself that you can plug another feature generator into using the alternative API:
As I also mention in the next section, the last argument would look like:
For most purposes the default word frequency (or bag of words) feature generator is probably OK so using the command line tool is a good place to start. Here is the output from running the DoccatTrainer command line tool:
We will use our new trained model file en-newscat.bin in the next section.
Please note that in this simple example I used very little data, just a few hundred words for each training category. I have used the OpenNLP maximum entropy library on various projects, mostly to good effect, but I used many thousands of words for each category. The more data, the better.
Using Our New Trained Classification Model
The code that uses the model we trained in the last section is short enough to list in its entirety:
1 package com.markwatson.opennlp;
2
3 import opennlp.tools.doccat.DoccatModel;
4 import opennlp.tools.doccat.DocumentCategorizerME;
5
6 import java.io.*;
7 import java.util.*;
8
9 /**
10 * This program uses the maximum entropy model we trained
11 * using the instructions in the chapter on OpenNLP in the book.
12 */
13
14 public class NewsClassifier {
15
16 public static List<Pair<String,Double>> allRankedCategories(String text) {
17 DocumentCategorizerME aCategorizer = new DocumentCategorizerME(docCatModel);
18 double[] outcomes = aCategorizer.categorize(text);
19 List<Pair<String,Double>> results = new ArrayList<Pair<String, Double>>();
20 for (int i=0; i<outcomes.length; i++) {
21 results.add(new Pair<String, Double>(aCategorizer.getCategory(i), outcomes\
22 [i]));
23 }
24 return results;
25 }
26
27 public static String bestCategory(String text) {
28 DocumentCategorizerME aCategorizer = new DocumentCategorizerME(docCatModel);
29 double[] outcomes = aCategorizer.categorize(text);
30 return aCategorizer.getBestCategory(outcomes);
31 }
32
33 public static Pair<String,Float> classifyWithScore(String text) {
34 DocumentCategorizerME classifier = new DocumentCategorizerME(docCatModel);
35 double [] scores = classifier.categorize(text);
36 int num_categories = classifier.getNumberOfCategories();
37 if (num_categories > 0) {
38 String bestString = classifier.getBestCategory(scores);
39 for (int i=0; i<num_categories; i++) {
40 if (classifier.getCategory(i).equals(bestString)) {
41 return new Pair<String,Float>(bestString, (float)scores[i]);
42 }
43 }
44 }
45 return new Pair<String,Float>("<no category>", 0f);
46 }
47
48 static DoccatModel docCatModel = null;
49
50 static {
51
52 try {
53 InputStream modelIn = new FileInputStream("models/en-newscat.bin");
54 docCatModel = new DoccatModel(modelIn);
55 } catch (IOException e) {
56 e.printStackTrace();
57 }
58 }
59 }
In lines 33 through 42 we initialize the static data for an instance of the class DoccatModel that loads the model file created in the last section.
A new instance of the class DocumentCategorizerME is created in line 28 each time we want to classify input text. I called the one argument constructor for this class that uses the default feature detector. An alternative constructor is:
1 public DocumentCategorizerME(DoccatModel model,
2 FeatureGenerator... featureGenerators)
The default feature generator is BagOfWordsFeatureGenerator which just uses word frequencies for classification. This is reasonable for smaller training sets as we used in the last section but when I have a large amount of training data available I prefer to combine BagOfWordsFeatureGenerator with NGramFeatureGenerator. You would use the constructor call:
1 public DocumentCategorizerME(DoccatModel model,
2 new FeatureGenerator[]{new BagOfWordsFeatureGenerator(),
3 new NGramFeatureGenerator()});
The following listings show interspersed both example code snippets for for using the NewsClassifier class followed by the output printed by each code snippet:
String sentence = "Apple Computer, Microsoft, and Google are in the tech sec\
tor. Each is very profitable.";
System.out.println("\nNew test sentence:\n\n" + sentence + "\n");
String [] sentences = NLP.sentenceSplitter(sentence);
System.out.println("Sentences found: " + Arrays.toString(sentences));
New test sentence:
Apple Computer, Microsoft, and Google are in the tech sector.
Each is very profitable.
Sentences found: [Apple Computer, Microsoft, and Google are in the tech sector.,
Each is very profitable.]
sentence = "Apple Computer, Microsoft, and Google are in the tech sector.";
Set<String> names = NLP.companyNames(sentence);
System.out.println("Company names found: " + names);
Company names found: [Apple Computer, Microsoft]
sentence = "Apple Computer is located in Cupertino, California and Microsoft\
is located in Seattle, Washington. He went to Oregon";
System.out.println("\nNew test sentence:\n\n" + sentence + "\n");
Set<String> names1 = NLP.locationNames(sentence);
System.out.println("Location names found: " + names1);
New test sentence:
Apple Computer is located in Cupertino, California and Microsoft is located in S\
eattle, Washington. He went to Oregon
Location names found: [Oregon, Cupertino, Seattle, California, Washington]
sentence = "President Bill Clinton left office.";
System.out.println("\nNew test sentence:\n\n" + sentence + "\n");
Set<String> names2 = NLP.personNames(sentence);
System.out.println("Person names found: " + names2);
New test sentence:
President Bill Clinton left office.
Person names found: [Bill Clinton]
sentence = "The White House is often mentioned in the news about U.S. foreig\
n policy. Members of Congress and the President are worried about the next elect\
ion and may pander to voters by promising tax breaks. Diplomacy with Iran, Iraq,\
and North Korea is non existent in spite of a worry about nuclear weapons. A un\
i-polar world refers to the hegemony of one country, often a militaristic empire\
. War started with a single military strike. The voting public wants peace not w\
ar. Democrats and Republicans argue about policy.";
System.out.println("\nNew test sentence:\n\n" + sentence + "\n");
List<Pair<String, Double>> results = NewsClassifier.allRankedCategories(sent\
ence);
System.out.println("All ranked categories found: " + results);
New test sentence:
The White House is often mentioned in the news about U.S. foreign policy. Membe\
rs of Congress and the President are worried about the next election and may pan\
der to voters by promising tax breaks. Diplomacy with Iran, Iraq, and North Kore\
a is non existent in spite of a worry about nuclear weapons. A uni-polar world r\
efers to the hegemony of one country, often a militaristic empire. War started w\
ith a single military strike. The voting public wants peace not war. Democrats a\
nd Republicans argue about policy.
All ranked categories found: [[COMPUTERS, 0.07257665117660535], [ECONOMY, 0.2355\
9821969425127], [HEALTH, 0.29907267186308945], [POLITICS, 0.39275245726605396]]
sentence = "The food affects colon cancer and ulcerative colitis. There is s\
ome evidence that sex helps keep us healthy. Eating antioxidant rich foods may p\
revent desease. Smoking may raise estrogen levels in men and lead to heart failu\
re.";
System.out.println("\nNew test sentence:\n\n" + sentence + "\n");
String results2 = NewsClassifier.bestCategory(sentence);
System.out.println("Best category found found (HEALTH): " + results2);
List<Pair<String, Double>> results3 = NewsClassifier.allRankedCategories(sen\
tence);
System.out.println("All ranked categories found (HEALTH): " + results3);
System.out.println("Best category with score: " + NewsClassifier.classifyWit\
hScore(sentence));
New test sentence:
The food affects colon cancer and ulcerative colitis. There is some evidence tha\
t sex helps keep us healthy. Eating antioxidant rich foods may prevent desease. \
Smoking may raise estrogen levels in men and lead to heart failure.
Best category found found (HEALTH): HEALTH
All ranked categories found (HEALTH): [[COMPUTERS, 0.1578880260493374], [ECONOMY\
, 0.2163099374638936], [HEALTH, 0.35546925520388845], [POLITICS, 0.2703327812828\
8035]]
Best category with score: [HEALTH, 0.35546926]
Using the OpenNLP Parsing Model
We will use the parsing model that is included in the OpenNLP distribution to parse English language input text. You are unlikely to use a statistical parsing model in your work but I think you will enjoy the material in the section. If you are more interested in practical techniques then skip to the next chapter that covers more machine learning techniques.
The following example code listing is long (68 lines) but I will explain the interesting parts after the listing:
1 package com.markwatson.opennlp;
2
3 import opennlp.tools.cmdline.parser.ParserTool;
4 import opennlp.tools.parser.Parse;
5 import opennlp.tools.parser.ParserModel;
6 import opennlp.tools.parser.chunking.Parser;
7
8 import java.io.FileInputStream;
9 import java.io.IOException;
10 import java.io.InputStream;
11
12 /**
13 * Experiments with the chunking parser model
14 */
15 public class ChunkingParserDemo {
16 public Parse[] parse(String text) {
17 Parser parser = new Parser(parserModel);
18 return ParserTool.parseLine(text, parser, 5);
19 }
20
21 public void prettyPrint(Parse p) {
22 StringBuffer sb = new StringBuffer();
23 p.show(sb);
24 String s = sb.toString() + " ";
25 int depth = 0;
26 for (int i = 0, size = s.length() - 1; i < size; i++) {
27 if (s.charAt(i) == ' ' && s.charAt(i + 1) == '(') {
28 System.out.print("\n");
29 for (int j = 0; j < depth; j++) System.out.print(" ");
30 } else if (s.charAt(i) == '(') System.out.print(s.charAt(i));
31 else if (s.charAt(i) != ')' || s.charAt(i + 1) == ')')
32 System.out.print(s.charAt(i));
33 else {
34 System.out.print(s.charAt(i));
35 for (int j = 0; j < depth; j++) System.out.print(" ");
36 }
37 if (s.charAt(i) == '(') depth++;
38 if (s.charAt(i) == ')') depth--;
39 }
40 System.out.println();
41 }
42
43 static ParserModel parserModel = null;
44
45 static {
46
47 try {
48 InputStream modelIn = new FileInputStream("models/en-parser-chunking.bin");
49 parserModel = new ParserModel(modelIn);
50 } catch (IOException e) {
51 e.printStackTrace();
52 }
53 }
54
55 public static void main(String[] args) {
56 ChunkingParserDemo cpd = new ChunkingParserDemo();
57 Parse[] possibleParses =
58 cpd.parse("John Smith went to the store on his way home from work ");
59 for (Parse p : possibleParses) {
60 System.out.println("parse:\n");
61 p.show();
62 //p.showCodeTree();
63 System.out.println("\npretty printed parse:\n");
64 cpd.prettyPrint(p);
65 System.out.println("\n");
66 }
67 }
68 }
The OpenNLP parsing model is read from a file in lines 45 through 53. The static variable parserModel (instance of class ParserModel) if created in line 49 and used in lines 17 and 18 to parse input text. It is instructive to look at the intermediate calculation results. The value for variable parser defined in line 17 has a value of:
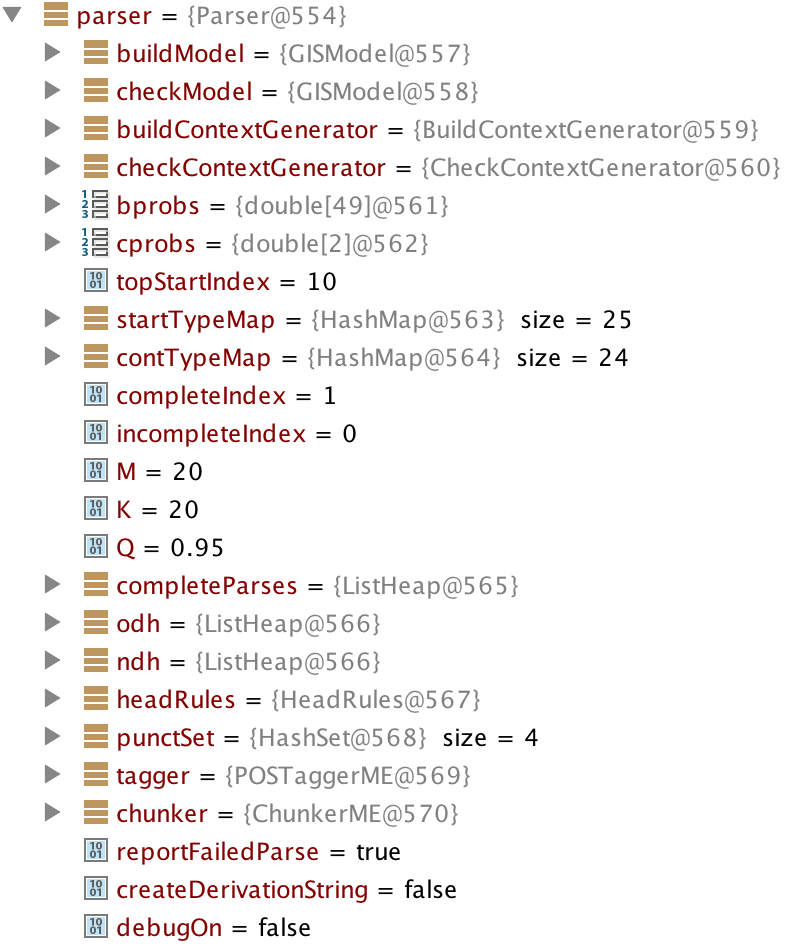
Note that the parser returned 5 results because we specified this number in line 18. For a long sentence the parser generates a very large number of possible parses for the sentence and returns, in order of probability of being correct, the number of resutls we requested.
The OpenNLP chunking parser code prints out results in a flat list, one result on a line. This is difficult to read which is why I wrote the method prettyPrint (lines 21 through 41) to print the parse results indented. Here is the output from the last code example (the first parse shown is all on one line but line wraps in the following listing):
1 parse:
2
3 (TOP (S (NP (NNP John) (NNP Smith)) (VP (VBD went) (PP (TO to) (NP (DT the) (NN \
4 store))) (PP (IN on) (NP (NP (NP (PRP$ his) (NN way)) (ADVP (NN home))) (PP (IN \
5 from) (NP (NN work))))))))
6
7 pretty printed parse:
8
9 (TOP
10 (S
11 (NP
12 (NNP John)
13 (NNP Smith))
14 (VP
15 (VBD went)
16 (PP
17 (TO to)
18 (NP
19 (DT the)
20 (NN store)))
21 (PP
22 (IN on)
23 (NP
24 (NP
25 (NP
26 (PRP$ his)
27 (NN way))
28 (ADVP
29 (NN home)))
30 (PP
31 (IN from)
32 (NP
33 (NN work))))))))
In the 1980s I spent much time on syntax level parsing. While the example in this section is a statistical parsing model I don’t find these models very relevant to my own work but I wanted to include a probalistic parsing example for completeness in this chapter.
OpenNLP is a great resource for Java programmers and its Apache 2 license is “business friendly.” If you can use software with a GPL license then please also look at the Stanford NLP libraries.