关于AI的关注和风险
 |
关于AI的关注是严肃的。风险是真实的。有时它们以歇斯底里的方式表达,但深入研究后,AI的影响有可能是非常破坏性的。 |
关于AI的问题和关注点很多,可以单独成书。这是我监测主题的词云。我肯定漏掉了一些。

关于这些主题有很多可用的信息,我鼓励你尽可能深入阅读。你可能会得出结论,认为风险大于收益,不希望在个人或组织中使用AI。这个决定带来了自身的风险;通常是被抛在后面。但这是个人选择。
如果你在Google上搜索“关于AI风险的书籍”,你会找到一些有价值的书籍选择。我最近听到的一个特别令人不寒而栗的播客是Ezra Klein与Dario Amodei的对话,Anthropic的联合创始人兼CEO(开发Claude.ai的公司)。你会了解到这些公司意识到风险。Amodei提到一个内部风险分类系统,称为A.S.L.,即“AI安全等级”(不是美国手语)。我们目前处于ASL 2,“具有早期危险能力的系统——例如能够提供如何制造生物武器的指示。”他将ASL 4描述为“使国家级行为者大大提高其能力……我们会担心朝鲜、中国或俄罗斯能够在各种军事领域大大增强其攻势能力,从而在地缘政治层面上获得重大优势。”令人毛骨悚然的东西。
在这个严峻的背景下,我将重点介绍对作家和出版商最相关的问题。
版权被侵犯了吗?
|
版权问题复杂而模糊。看起来某些仍在版权保护期内的书籍被包含在一些大型语言模型的训练中。但并不像一些作者担心的那样,他们的所有作品都被吸入了每一个大型语言模型中。 |
版权问题既是具体的也是广泛的。众所周知,所有的大型语言模型都是在开放网络上训练的——今天网络上的15亿个网站上的所有可抓取内容,无论是报纸文章、社交媒体帖子、网络博客,显然还有YouTube视频的转录内容。
有证据表明,至少有一个大型语言模型摄取了数千本非公共领域书籍的实际文本。
在没有向作者提供任何补偿的情况下,摄取所有这些文本来帮助建立价值数十亿美元的AI公司是否合法?AI公司围绕合理使用提出他们的论点;法院最终将做出决定。即使是合法的,这是否符合伦理或道德?伦理问题似乎比法律考虑要简单。你来决定。
显然,围绕版权的法律没有预见到AI带来的独特挑战,寻找法律解决方案将需要时间,可能是几年。(如果你想深入了解为什么法律不适合解决当前问题,阅读A. Feder Cooper和James Grimmelmann撰写的优秀论文《文件在电脑中:版权、记忆和生成式AI》)
作者的版权与AI
|
作者面临AI生成内容版权能力的额外问题。 |
美国版权局关于AI生成内容版权能力的立场声明AI本身不能持有版权,因为它缺乏作者的法律地位。这是有道理的。但这假设工作是100% AI生成的。如其他地方所讨论的,很少有作者会让AI生成整本书。更可能的是5%,或10% 或… 在这里,版权局显得犹豫(我也会这样)。
在最近的一次裁决中,版权局得出结论,一部由人类创作的文字与由AI服务Midjourney生成的图像相结合的图画小说构成了可受版权保护的作品,但单个图像本身不能受版权保护。天哪!
|
总之,作者和出版商需要对多方面不断发展的版权问题保持警觉。 |
长期影响是什么?
有些人将当前的诉讼与谷歌图书诉讼相比,该诉讼花了10年时间才在法律上解决。谁知道这些案件的上诉程序会拖多久呢。在此期间,出版商明智的做法是假设AI公司会败诉,这至少在理论上使任何许可或甚至使用Chat AI的人暴露在某种潜在的责任下。
但这不是出版商最严重的问题。是观感。对许多作者来说,无论是知名的还是默默无闻的,水已经被污染了。AI在写作和出版界是有放射性的。任何与AI有关的东西都会引起强烈的批评。
有很多例子。在最近的一次事件中,英国出版商Angry Robot,一家“致力于现代成人科幻、奇幻和WTF最佳作品”的公司,宣布将使用名为Storywise的AI软件来处理预计的大量手稿提交。公司用了仅仅五个小时就取消了这一计划并回到了“旧收件箱“。
贸易出版商在内部使用AI工具时面临的难以承受的困境:如果你的作者发现了,你将很难应对随之而来的风暴。我相信出版商别无选择,只能勇敢面对,至少采用部分工具,清楚地解释这些工具是如何训练的以及如何使用的,然后继续前进。
在英国,作家协会采取强硬立场:“要求你的出版商确认在与你的作品有关的任何目的上不会大量使用AI,比如校对、编辑(包括真实性阅读和事实检查)、编索引、法律审查、设计和布局或其他任何未经你同意的用途。你可能希望禁止AI进行有声读物的朗读、翻译和封面设计。”
作家协会似乎接受“出版商开始探索在日常运营中使用AI作为工具,包括编辑和营销用途。”我认为协会的许多成员并不是那么理解。
向AI公司授权内容
大多数出版商和许多作者都在寻找向AI公司授权内容的方法。每个人对授权条款和内容价值的看法都不同,但至少讨论已经开始。
有几家初创公司希望与出版商(在某些情况下与个人作者)合作。Calliope Networks 和 Created by Humans 在这方面都很有趣。
七月中旬,长期以来在集体版权许可方面处于行业领先地位的版权清算中心宣布,推出其年度版权许可(ACL)中的“人工智能(AI)再使用权,这是一种企业范围的内容许可解决方案,为订阅的企业提供数百万作品的使用权。”
出版商周刊 报道了这一公告,引用了版权清算中心总裁兼首席执行官Tracey Armstrong的话:“可以同时支持AI和版权,并将AI与对创作者的尊重结合起来。”
尽管并不全面,但这很可能是将出版业与大型语言模型开发者合作向前推进的一次突破。
避免AI已经太晚了
|
对于那些不希望被AI污染的作者和出版商来说,消息不妙:你今天正在使用AI,而且多年来一直在使用它。 |
人工智能以不同形式已经集成到我们每天使用的大多数软件工具和服务中。人们依赖AI驱动的拼写和语法检查,例如在Microsoft Word或Gmail中。Microsoft Word和PowerPoint应用AI提供写作建议、设计和布局推荐等。虚拟助手如Siri和Alexa使用自然语言处理来理解语音命令并回答问题。电子邮件服务利用AI过滤消息、检测垃圾邮件和发送提醒。AI驱动客户服务聊天机器人并根据你的购买历史生成产品推荐。
其中大部分基于大型语言模型,如ChatGPT。
对于一个作者或编辑来说,说“我不希望我的手稿使用AI”基本上是不可能的,除非他们和他们的编辑都使用打字机和铅笔。
他们可以尝试说“我不希望使用生成式AI”在他们的书上。但这也很难分割处理。语法检查软件最初并不是基于生成式AI构建的。Grammarly已经将其作为产品的一个成分添加,其他所有拼写和语法检查器也将如此。生成式AI也是提供的营销软件的核心。
当作者使用AI时
作者使用AI的另一个方面与上面讨论的版权问题类似。在极端情况下,我们看到100% AI生成的内容在亚马逊上发布。大部分(全部?)质量都很差,但这并不妨碍它们被发布。(另见亚马逊部分。)对出版商来说,更令人担忧的是AI生成的稿件。是的,AI提高了数量,但大型出版商已经有一个数量过滤器。这个过滤器叫做代理。他们将不得不找到如何处理数量问题的解决方案,显然他们必须找到一个不使用AI的解决方案。
这有点像一个存在主义的问题——我想出版一本由‘机器’写的书吗?对于大多数出版商来说,这是一个明确的‘不’。轻而易举。那么,如果一本书有50%的内容是在有能力的作者监督下由LLM生成的呢?嗯,也试着说‘不’。那么25%,或者10%,或者5%呢?你在什么地方画线?
而且,现在你已经进入了画线的业务,你如何解决拼写和语法工具至少部分依赖于生成性AI的困境呢?像Otter.ai这样的AI驱动的转录工具,或者内置于Microsoft Word中的转录功能呢?
我找不到任何贸易出版商声明他们不会出版包含预定数量AI生成文字的作品。以下是作者协会对此话题的看法:
“如果您的稿件中包含大量AI生成的文本、角色或情节,您必须向出版商披露,并且也应该向读者披露。我们认为,作者仅在使用生成性AI作为头脑风暴、创意生成或校对工具时,无需披露。”
无需多说,‘大量’没有明确定义(牛津词典将其定义为“足以被注意到或被认为重要的”),但帖子继续解释说,包含超过“微不足道的AI生成文本”会违反大多数出版合同。法律术语中的微不足道没有精确规定,但一般来说,意思和大量差不多。
AI可以在写作中被检测到吗?
我在2024年5月主持了一场由BISG赞助的关于AI检测的网络研讨会。重播视频在YouTube上在线。简·弗里德曼在她的热点通讯中提供了网络研讨会的全面描述。
对于许多作者来说,AI的毒性意味着要将其远离他们的文字。出版商有特殊的负担——他们不创作文本,但一旦出版,他们就对文本承担重大责任。我们已经看到许多关于书籍的社会影响,或其他作家文字和创意的剽窃问题引发的激烈争议。现在有了AI,我们面临一整套新的伦理和法律问题,这些问题在出版学校里从未被提及。
其中一部分类似于人们对学生的担忧,认为使用AI在某种程度上是作弊,类似于从维基百科文章中抄袭,或者只是让朋友帮你写论文。
我们的一位网络研讨会讲者,教育家何塞·鲍恩,分享了他对学生的披露。这并不完全是作者使用的内容,但它展示了某种“AI使用的风险等级”。
学生模板披露协议
我独立完成了所有工作,没有朋友、工具、技术或AI的协助。
-
我完成了初稿,但随后请朋友/家人,AI改写/语法/抄袭软件阅读并提出建议。在这些帮助之后,我做了以下更改:
修正了拼写和语法
改变了结构或顺序
重写了整个句子/段落
我在遇到问题时使用了词典、字典,打电话给朋友,去了帮助中心,使用了Chegg或其他解决方案提供商。
我使用AI/朋友/导师帮助我生成创意。
我使用辅助工具/AI做了大纲/初稿,然后进行了编辑。(描述你的贡献性质。)
所以出版商可以为他们的作者起草类似的内容。假设作者披露了最高级别:我广泛使用了AI,然后编辑了结果。那么呢?你会自动拒绝稿件吗?如果会,为什么?
与此同时,如果你在关注,你会发现你刚刚阅读并喜欢的那本书,作者发誓没有用过Grammarly的拼写检查,实际上可能有90%是由AI生成的,由一位擅长隐藏其使用的作者生成。
然后你被迫重新思考这个问题。问题变成了:“为什么我如此坚定地想检测这个无法检测的东西?”
部分原因在于围绕AI生成文本的版权问题的危言耸听的担忧。版权局不会为100% AI生成的文本(或音乐、图像等)提供版权保护。那么50% AI生成的文本呢?嗯,我们只会覆盖作者生成的那50%。你怎么知道是哪一半?我们会再回复你的。
如果你能将每份手稿输入某个软件,它会告诉你是否使用了AI来创作文本,那不是很棒吗?
撇开唯一方法是使用AI工具这一问题,更重要的问题是,软件会(足够)准确吗?我能依赖它告诉我是否使用了AI来创作手稿吗?并且我能依赖它不会产生“误报”——即指示使用了AI,而实际上并没有吗?
现在市场上有很多处理这些挑战的软件。 许多评估这些软件的学术研究指出它们的不可靠性。AI生成的文本会漏网。更糟的是,未由AI生成的文本会被错误地标记为被污染。
但图书出版商会希望有某种保障措施。看来,充其量这些工具可以提醒你可能的担忧,但你始终需要再次检查。所以或许它可以提醒你哪些文本需要比其他文本更仔细地检查?这是效率吗?
真正的效率在于超越对文本起源的担忧,而是保持我们现有的质量标准。
失业
“你不会被AI取代。你会被那些懂得使用AI的人取代。” —匿名
AI采用带来的失业可能会很严重。估计数值各不相同,但数据令人沮丧。有明显的例子:旧金山的无人驾驶出租车消除了……出租车和共享乘车司机。AI支持的诊断可能会减少对医疗技术人员的需求。
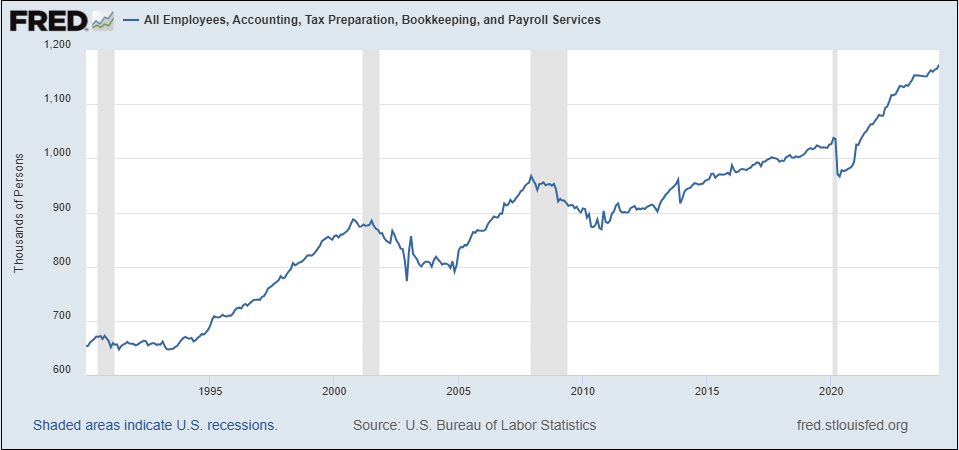
乐观的我指出一个例子,即电子表格的引入及其对就业的影响。如你在下图中所见,自1990年以来,“会计、税务准备、簿记和工资服务”领域的就业几乎翻了一番——这几乎不能算是对大部分自动化了这些任务的电子表格等技术的控诉。
Ethan Mollick与波士顿咨询公司(BCG)的研究 是一项旨在更好地理解AI对工作,特别是对复杂和知识密集型任务的影响的实验。该研究涉及758名BCG顾问,随机分配使用或不使用OpenAI的GPT-4进行两项任务:创意产品创新和商业问题解决。研究衡量了参与者的表现、行为和态度,以及AI输出的质量和特征。
研究发现之一是“AI作为技能的平衡器。我们在实验开始时评估得分最低的顾问在使用AI后,表现提升了43%,而顶级顾问也有所提升,但幅度较小。” 这篇完整的文章很有启发性,和Mollick的所有作品一样,既具挑衅性又易于理解。
教育
教育在关于AI的优劣辩论中一直处于中心位置。AI进入课堂的引入通常被视为一种诅咒,或者至少是一种挑战。其他教育者,如PW的主旨发言人Ethan Mollick,将AI视为教育者的一种了不起的新工具;Mollick坚持让他的学生使用ChatGPT。
关于这个话题最好的书是 Teaching with AI: A Practical Guide to a New Era of Human Learning 由José Antonio Bowen和C. Edward Watson所著。
我不会在这本书中深入探讨教育出版——这是一个庞大的话题,需另行撰写报告。可以说出版在教育中的兴趣正在减弱:AI工具是软件,而不是内容本身。
搜索的未来
|
搜索是AI中一个充满争议的话题。我鼓励你访问 perplexity.ai 和 You.com,了解事情的发展方向。下次你想进行Google搜索时,转到Perplexity看看。它不会显得大不相同——它类似于Google经常在搜索屏幕右侧或有时在搜索结果顶部弹出的知识图谱。不用点击链接,信息就在那里为你呈现。 |
Perplexity 更进一步地重新措辞从多个来源收集的信息,这样你真的不需要点击链接。它提供了来源的链接,但点击这些链接通常是不必要的——你已经得到了问题的答案。
这种看似微小的变化对每个依赖搜索引擎被发现的公司和产品都有巨大的影响。如果搜索者不再被引导到你的网站,你如何吸引他们并将他们转化为客户呢?简单的答案是,你不能。
Joanna Penn 站在思考新技术对写作和出版影响的前沿。她在去年12月的播客和博客中讨论了这个复杂的话题。
对于AI和搜索的变革来说,现在还处于早期阶段。
亚马逊上的垃圾书籍
|
AI生成的垃圾书籍在亚马逊上是一个问题,尽管它们的严重程度可能比实际情况更令人感受深刻。一方面,这些书籍用低质量和抄袭的内容充斥着在线书店,有时还使用真实作者的名字来欺骗客户并利用他们的名声。这些书不仅对读者来说是个麻烦,对作者来说也是个威胁,可能会剥夺他们辛苦赚来的版税。AI生成的书籍还会影响真实书籍和作者在亚马逊网站上的排名和可见度,因为它们竞争相同的关键词、类别和评论。 |

亚马逊现在要求作者披露他们在创作书籍时使用AI的详细情况。毫无疑问,这可能会被滥用。
试着在亚马逊上搜索“AI生成的书籍”。有很多结果。其中一些是关于使用AI创作书籍的教程书。但其他的则是毫不掩饰地由AI生成的。《搞笑和可爱的猫咪图片-你在世界上看不到这些类型的照片-第一部分》(原文如此)被归功于Rajasekar Kasi。作者页面上没有他的(?)生平详情,但有另外六本书也以这个名字署名。这本书于2023年8月26日出版,没有评论,也没有销售排名。这本电子书的不合语法的标题与印刷书封面的不合语法的标题不匹配。
但其他作者显然在创作他们的书时大量使用了AI,却没有披露。如上所述,检测AI的使用对于熟练的‘伪造者’来说几乎是不可能的。涂色书、日记、旅游书和食谱书正以传统出版方式的一小部分时间和精力生成。
搜索“韩国素食食谱”,你会发现第一名是Joanne Lee Molinaro的书。但紧随其后的是其他显然是盗版的书籍。《韩国素食食谱:为韩国美食爱好者准备的简单美味的传统和现代食谱》有两个评论,其中一个指出“这不是一本素食食谱。所有的食谱都有肉和鸡蛋的成分。”但这本书的销售排名是#5,869,771,而原书的排名是#2,852。
很难确定造成的伤害程度。这对任何人都没有好处,但究竟有多糟糕呢?
亚马逊有相关政策,允许其移除任何未能“提供积极客户体验”的书籍。Kindle内容指南禁止“旨在误导客户或不准确描述书籍内容的描述性内容。”它们也可以屏蔽“通常让客户失望的内容。” 是数量太多让亚马逊的监管者难以应对?还是有其他原因?
偏见
LLM是基于已经发布在网上的内容进行训练的。已经发布在网上的内容充满了偏见,因此LLM也反映了这些偏见。当然不仅仅是偏见,还有仇恨,反映在它的学习中,现在可能会在AI生成的文字和图像中输出。色情是AI在图像处理上的另一自然受益者,最近有年轻女性发现被捏造的裸照,她们的男性同学可能是嫌疑人。《纽约时报》分别报道了网上儿童性虐待图片的增加。
作者和出版商在使用AI工具时需要意识到这些内在的限制。