Specifications
Need for Specifications
Why Specifications?
Many of the nastiest bugs in programs arise because of misunderstandings about behaviour at the interface between two pieces of code. Although every programmer has specifications in mind, not all programmers write them down. As a result, different programmers on a team have different specifications in mind. When the program fails, it’s hard to determine where the error is. Precise specifications in the code let you apportion blame (to code fragments, not people!), and can spare you the agony of puzzling over where a fix should go.
Specifications are good for the client of a method because they spare the task of reading code. If you’re not convinced that reading a spec is easier than reading code, take a look at some of the standard Java specs and compare them to the source code that implements them. ArrayList, for example, in the package java.util, has a very simple spec but its code is not at all simple.
Specifications are good for the implementer of a method because they give the freedom to change the implementation without telling clients. Specifications can make code faster, too. Sometimes a weak specification makes it possible to do a much more efficient implementation. In particular, a precondition may rule out certain states in which a method might have been invoked that would have incurred an expensive check that is no longer necessary.
The contract acts as a firewall between client and implementor. It shields the client from the details of the workings of the unit — you don’t need to read the source code of the procedure if you have its specification. And it shields the implementor from the details of the usage of the unit; he doesn’t have to ask every client how she plans to use the unit. This firewall results in decoupling, allowing the code of the unit and the code of a client to be changed independently, so long as the changes respect the specification — each obeying its obligation.
Can we eliminate the need for specifications by allowing everyone access to all source code?
Source code is complicated and provides more details than needed. Understanding or even reading every line of code is an excessive burden.
- Suppose you had to read the source code of Java libraries in order to use them!
- The same applies to developers of different parts of the libraries.
A client cares only about what the code does, not how it does it.
Source code is ambiguous even though it may appear unambiguous and concrete.
- Which details of code’s behavior are essential, and which are incidental?
- Code invariably gets rewritten.
- Client needs to know what they can rely on.
- What properties will be maintained over time?
- What properties might be changed by future optimization, improved algorithms, or just bug fixes?
- Implementer needs to know what features the client depends on, and which can be changed.
The Role of a Specification
With a specification, + the client (the user of a method or a class) agrees to rely only on information in the description/specification of the method or class for their part, and + the implementer promises to support everything in the specification, and outside of the specification has perfect liberty to make implementation decisions.
Specifications facilitate change by reducing the Medusa effect: it is the specifications that should be turned to stone rather than the implementation.
Sadly, much code that is written lacks clear specifications. Clients have to work out what a method/class does by using it and observing the results, and this leads to bugs because programs have unclear dependencies (that reduce simplicity and flexibility).
Behavioural equivalence
Consider these two methods. Are they the same or different?
1 static int findA(int[] a, int val) {
2 for (int i = 0; i < a.length; i++) {
3 if (a[i] == val) return i;
4 }
5 return a.length;
6 }
7
8 static int findB(int[] a, int val) {
9 for (int i = a.length -1 ; i >= 0; i--) {
10 if (a[i] == val) return i;
11 }
12 return -1;
13 }
Of course the code is different, so in that sense they are different. Our question is whether we could substitute one implementation for the other. Not only do these methods have different code, they actually have different behaviour:
- when
valis missing,findAreturns the length ofaandfindBreturns -1; - when
valappears twice,findAreturns the lower index andfindBreturns the higher.
But when val occurs at exactly one index of the array, the two methods behave the same. It may be that clients never rely on the behaviour in the other cases. So the notion of equivalence is in the eye of the beholder, that is, the client. In order to make it possible to substitute one implementation for another, and to know when this is acceptable, we need a specification that states exactly what the client depends on.
In this case, our specification might be:
requires: val occurs in a
effects: returns index i such that a[i] = val
The Structure of a Specification
A specification of a method consists of several clauses:
- a precondition, indicated by the keyword requires
- a postcondition, indicated by the keyword effects
The precondition is an obligation on the client (i.e., the caller of the method). It’s a condition over the state in which the method is invoked. If the precondition does not hold, the implementation of the method is free to do anything (including not terminating, throwing an exception, returning arbitrary results, making arbitrary modifications, etc.).
The postcondition is an obligation on the implementer of the method. If the precondition holds for the invoking state, the method is obliged to obey the postcondition, by returning appropriate values, throwing specified exceptions, modifying or not modifying objects, and so on.
The overall structure is a logical implication: if the precondition holds when the method is called, then the postcondition must hold when the method completes.
Specifications in Java
Some languages (notably Eiffel) incorporate preconditions and postconditions as a fundamental part of the language, as expressions that the runtime system (or even the compiler) can automatically check to enforce the contracts between clients and implementers.
Java does not go quite so far, but its static type declarations are effectively part of the precondition and postcondition of a method, a part that is automatically checked and enforced by the compiler. The rest of the contract — the parts that we can’t write as types — must be described in a comment preceding the method, and generally depends on human beings to check it and guarantee it.
Java has a convention for documentation comments, in which parameters are described by @param clauses and results are described by @return and @throws clauses. You should put the preconditions into @param where possible, and postconditions into @return and @throws.
A specification like this:
static int find(int[] a, int val)
requires: val occurs exactly once in a
effects: returns index i such that a[i] = val
… might be rendered in Java like this:
1 /**
2 * Find value in an array.
3 * @param a array to search; requires that val occurs exactly once in a
4 * @param val value to search for
5 * @return index i such that a[i] = val
6 */
7 static int find(int[] a, int val)
The Java API documentation is produced from Javadoc comments in the Java standard library source code. Documenting your specifications in Javadoc allows Eclipse to show you (and clients of your code) useful information, and allows you to produce HTML documentation in the same format as the Java API docs.
Null references
In Java, references to objects and arrays can also take on the special value null, which means that the reference doesn’t point to an object. Null values are an unfortunate hole in Java’s type system.
You can assign null to any non-primitive variable:
1 String s = null;
2 int a[] = null;
and the compiler happily accepts this code at compile time. But you’ll get errors at runtime because you can’t call any methods or use any fields with one of these references:
1 s.length() // throws NullPointerException
2 a.length // throws NullPointerException
Note, in particular, that null is not the same as an empty string "" or an empty array.
On an empty string or empty array, you can call methods and access fields. The length of an empty array or an empty string is 0. The length of a string variable that points to null throws a NullPointerException.
Null values are troublesome and unsafe, so much so that you’re well advised to remove them from your design vocabulary. For good Java programming — null values are implicitly disallowed as parameters and return values. So every method implicitly has a precondition on its object and array parameters that they be non-null. Every method that returns an object or an array implicitly has a postcondition that its return value is non-null. If a method allows null values for a parameter, it should explicitly state it, or if it might return a null value as a result, it should explicitly state it. But these are in general not good ideas.
Avoid null.
There are extensions to Java that allow you to forbid null directly in the type declaration, e.g.:
1 static boolean addAll(@NonNull List<T> list1, @NonNull List<T> list2)
where it can be checked automatically at compile time or runtime.
What a Specification May Talk About
A specification of a method can talk about the parameters and return value of the method, but it should never talk about local variables of the method or private fields of the method’s class. You should consider the implementation invisible to the reader of the spec.
In Java, the source code of the method is often unavailable to the reader of your spec, because the Javadoc tool extracts the spec comments from your code and renders them as HTML.
Testing and Specifications
In testing, we talk about black box tests that are chosen with only the specification in mind, and glass box tests that are chosen with knowledge of the actual implementation. But it’s important to note that even glass box tests must follow the specification. Your implementation may provide stronger guarantees than the specification calls for, or it may have specific behaviour where the specification is undefined. But your test cases should not count on that behaviour. Test cases must obey the contract, just like every other client.
For example, suppose you are testing this specification of find:
1 static int find(int[] a, int val)
2 requires: val occurs in a
3 effects: returns index i such that a[i] = val
This spec has a strong precondition in the sense that val is required to be found; and it has a fairly weak postcondition in the sense that if val appears more than once in the array, this specification says nothing about which particular index of val is returned. Even if you implemented find so that it always returns the lowest index, your test case can’t assume that specific behaviour:
1 int[] array = new int[] { 7, 7, 7 };
2 assertEquals(0, find(array, 7)); // bad test case: violates the spec
3 assertEquals(7, array[find(array, 7)]); // correct
Similarly, even if you implemented find so that it (sensibly) throws an exception when val isn’t found, instead of returning some arbitrary misleading index, your test case can’t assume that behaviour, because it can’t call find() in a way that violates the precondition.
So what does glass box testing mean, if it can’t go beyond the spec? It means you are trying to find new test cases that exercise different parts of the implementation, but still checking those test cases in an implementation-independent way.
Specifications for Mutating Methods
We will later discuss mutable vs. immutable objects, but here we will briefly mention the role of specification when dealing with mutability. Our specifications of find didn’t give us the opportunity to illustrate how to describe side-effects — changes to mutable data — in the postcondition.
Here’s a specification that describes a method that mutates an object:
1 static boolean addAll(List<T> list1, List<T> list2)
2 requires: list1 != list2
3 effects: modifies list1 by adding the elements of list2 to the end of it,
4 and returns true if list1 changed as a result of call
We’ve taken this, slightly simplified, from the Java List interface.
First, look at the postcondition. It gives two constraints: the first telling us how list1 is modified, and the second telling us how the return value is determined.
Second, look at the precondition. It tells us that the behaviour of the method if you attempt to add the elements of a list to itself is undefined. You can easily imagine why the implementor of the method would want to impose this constraint: it’s not likely to rule out any useful applications of the method, and it makes it easier to implement. The specification allows a simple implementation in which you take an element from list2 and add it to list1, then go on to the next element of list2 until you get to the end.
If list1 and list2 are the same list, this algorithm will not terminate — an outcome permitted by the specification.
Remember also our implicit precondition that list1 and list2 must be valid objects, rather than null. We’ll usually omit saying this because it’s virtually always required of object references.
Here is another example of a mutating method:
1 static void sort(List<String> lst)
2 requires: nothing
3 effects: puts lst in sorted order, i.e. lst[i] <= lst[j] for all 0 <= i < j \
4 < lst.size()
And an example of a method that does not mutate its argument:
1 static List<String> toLowerCase(List<String> lst)
2 requires: nothing
3 effects: returns a new list t where t[i] = lst[i].toLowerCase()
Just as we’ve said that null is implicitly disallowed unless stated otherwise, we will also use the convention that mutation is disallowed unless stated otherwise. The spec of toLowerCase could explicitly state as an effect that “lst is not modified”, but in the absence of a postcondition describing mutation, we demand no mutation of the inputs.
Exceptions
Now that we’re writing specifications and thinking about how clients will use our methods, let’s discuss how to handle exceptional cases in a way that is safe from bugs and easy to understand.
A method’s signature — its name, parameter types, return type — is a core part of its specification, and the signature may also include exceptions that the method may trigger.
Exceptions for Signalling Bugs
You’ve probably already seen some exceptions in your Java programming so far, such as ArrayIndexOutOfBoundsException (thrown when an array index foo[i] is outside the valid range for the array foo) or NullPointerException (thrown when trying to call a method on a null object reference). These exceptions generally indicate bugs in your code, and the information displayed by Java when the exception is thrown can help you find and fix the bug.
ArrayIndexOutOfBounds- and NullPointerException are probably the most common exceptions of this sort. Other examples include:
-
ArithmeticException, thrown for arithmetic errors like integer division by zero. -
NumberFormatException, thrown by methods likeInteger.parseIntif you pass in a string that cannot be parsed into an integer.
Exceptions for Special Results
Exceptions are not just for signalling bugs. They can be used to improve the structure of code that involves procedures with special results.
An unfortunately common way to handle special results is to return special values. Lookup operations in the Java library are often designed like this: you get an index of -1 when expecting a positive integer, or a null reference when expecting an object. This approach is OK if used sparingly, but it has two problems. First, it’s tedious to check the return value. Second, it’s easy to forget to do it. (We’ll see that by using exceptions you can get help from the compiler in this.)
Also, it’s not always easy to find a ‘special value’. Suppose we have a BirthdayBook class with a lookup method. Here’s one possible method signature:
java
class BirthdayBook {
LocalDate lookup(String name) { ... }
}
(LocalDate is part of the Java API.)
What should the method do if the birthday book doesn’t have an entry for the person whose name is given? Well, we could return some special date that is not going to be used as a real date. Bad programmers have been doing this for decades; they would return 9/9/99, for example, since it was obvious that no program written in 1960 would still be running at the end of the century. (They were wrong, by the way.)
Here’s a better approach. The method throws an exception:
java
LocalDate lookup(String name)
throws NotFoundException {
...
if ( ...not found... )
throw new NotFoundException();
...
}
and the caller handles the exception with a catch clause. For example:
java
BirthdayBook birthdays = ...
try {
LocalDate birthdate = birthdays.lookup("Alyssa");
} catch (NotFoundException nfe) {
...
}
Now there is no need for any special value, nor the checking associated with it.
Checked and Unchecked Exceptions
We’ve seen two different purposes for exceptions: special results and bug detection. As a general rule, you will want to use checked exceptions to signal special results and unchecked exceptions to signal bugs. In a later chapter, we will refine this a bit.
Some terminology: checked exceptions are called that because they are checked by the compiler:
- If a method might throw a checked exception, the possibility must be declared in its signature.
NotFoundExceptionwould be a checked exception, and that’s why the signature endsthrows NotFoundException. - If a method calls another method that may throw a checked exception, it must either handle it, or declare the exception itself, since if it isn’t caught locally it will be propagated up to callers.
So if you call BirthdayBook’s lookup method and forget to handle the NotFoundException, the compiler will reject your code. This is very useful, because it ensures that exceptions that are expected to occur will be handled.
Unchecked exceptions, in contrast, are used to signal bugs. These exceptions are not expected to be handled by the code except perhaps at the top level. We wouldn’t want every method up the call chain to have to declare that it (might) throw all the kinds of bug-related exceptions that can happen at lower call levels: index out of bounds, null pointers, illegal arguments, assertion failures, etc.
As a result, for an unchecked exception the compiler will not check for try-catch or a throws declaration. Java still allows you to write a throws clause for an unchecked exception as part of a method signature, but this has no effect, and is thus a bit funny, and we don’t recommend doing it.
All exceptions may have a message associated with them. If not provided in the constructor, the reference to the message string is null.
Throwable Hierarchy
To understand how Java decides whether an exception is checked or unchecked, let’s look at the class hierarchy for Java exceptions.
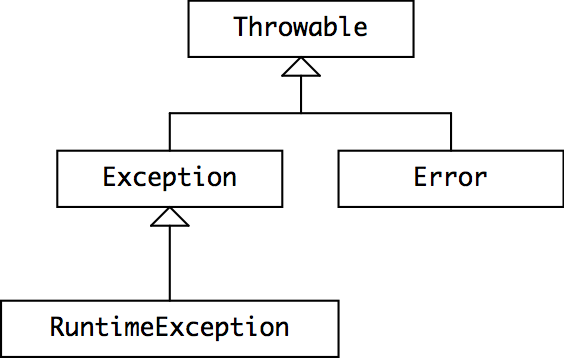
Throwable Class HierarchyThrowable is the class of objects that can be thrown or caught. Throwable’s implementation records a stack trace at the point where the exception was thrown, along with an optional string describing the exception. Any object used in a throw or catch statement, or declared in the throws clause of a method, must be a subclass of Throwable.
Error is a subclass of Throwable that is reserved for errors produced by the Java runtime system, such as StackOverflowError and OutOfMemoryError. For some reason AssertionError also extends Error, even though it indicates a bug in user code, not in the runtime. Errors should be considered unrecoverable, and are generally not caught.
Here’s how Java distinguishes between checked and unchecked exceptions:
-
RuntimeException,Error, and their subclasses are unchecked exceptions. The compiler doesn’t require them to be declared in thethrowsclause of a method that throws them, and doesn’t require them to be caught or declared by a caller of such a method. - All other throwables —
Throwable,Exception, and all of their subclasses except for those of theRuntimeExceptionandErrorlineage — are checked exceptions. The compiler requires these exceptions to be caught or declared when it’s possible for them to be thrown.
When you define your own exceptions, you should either subclass RuntimeException (to make it an unchecked exception) or Exception (to make it checked). Programmers generally don’t subclass Error or Throwable, because these are reserved by Java itself.
Exception Design Considerations
The rule we have given — use checked exceptions for special results (i.e., anticipated situations), and unchecked exceptions to signal bugs (unexpected failures) — makes sense, but it isn’t the end of the story. The snag is that exceptions in Java aren’t as lightweight as they might be.
Aside from the performance penalty, exceptions in Java incur another (more serious) cost: they’re a pain to use, in both method design and method use. If you design a method to have its own (new) exception, you have to create a new class for the exception. If you call a method that can throw a checked exception, you have to wrap it in a try-catch statement (even if you know the exception will never be thrown). This latter stipulation creates a dilemma. Suppose, for example, you’re designing a queue abstraction. Should popping the queue throw a checked exception when the queue is empty? Suppose you want to support a style of programming in the client in which the queue is popped (in a loop say) until the exception is thrown. So you choose a checked exception. Now some client wants to use the method in a context in which, immediately prior to popping, the client tests whether the queue is empty and only pops if it isn’t. Maddeningly, that client will still need to wrap the call in a try-catch statement.
This suggests a more refined rule:
- You should use an unchecked exception only to signal an unexpected failure (i.e. a bug), or if you expect that clients will usually write code that ensures the exception will not happen, because there is a convenient and inexpensive way to avoid the exception;
- Otherwise you should use a checked exception.
Here are some examples of applying this rule to hypothetical methods:
-
Queue.pop()throws an uncheckedEmptyQueueExceptionwhen the queue is empty, because it’s reasonable to expect the caller to avoid this with a call likeQueue.size()orQueue.isEmpty(). -
Url.getWebPage()throws a checkedIOExceptionwhen it can’t retrieve the web page, because it’s not easy for the caller to prevent this. -
int integerSquareRoot(int x)throws a checkedNotPerfectSquareExceptionwhenxhas no integral square root, because testing whetherxis a perfect square is just as hard as finding the actual square root, so it’s not reasonable to expect the caller to prevent it.
The cost of using exceptions in Java is one reason that many Java API’s use the null reference as a special value. It’s not a terrible thing to do, so long as it’s done judiciously, and carefully specified.
Abuse of Exceptions
Here’s an example from Effective Java by Joshua Bloch (Item 57 in the 2nd edition).
java
try {
int i = 0;
while (true)
a[i++].f();
} catch (ArrayIndexOutOfBoundsException e) { }
What does this code do? It is not at all obvious from inspection, and that’s reason enough not to use it. … The infinite loop terminates by throwing, catching, and ignoring an
ArrayIndexOutOfBoundsExceptionwhen it attempts to access the first array element outside the bounds of the array.
It is supposed to be equivalent to:
java
for (int i = 0; i < a.length; i++) {
a[i].f();
}
Or (using appropriate type T) to:
java
for (T x : a) {
x.f();
}
The exception-based idiom, Bloch writes:
… is a misguided attempt to improve performance based on the faulty reasoning that, since the VM checks the bounds of array accesses, the normal loop termination test (
i < a.length) is redundant and should be avoided.
However, because exceptions in Java are designed for use only under exceptional circumstances, few, if any, JVM implementations attempt to optimize their performance. On a typical machine, the exception-based idiom runs 70 times slower than the standard one when looping from 0 to 99.
Much worse than that, the exception-based idiom is not even guaranteed to work! Suppose the computation of f() in the body of the loop contains a bug that results in an out-of-bounds access to some unrelated array. What happens?
If a reasonable loop idiom were used, the bug would generate an uncaught exception, resulting in immediate thread termination with a full stack trace. If the misguided exception-based loop were used, the bug-related exception would be caught and misinterpreted as a normal loop termination.
Test Yourself
Designing Specifications
Now, we will look at different specs for similar behaviours, and talk about the tradeoffs between them.
We will look at three dimensions for comparing specs:
- How deterministic it is: Does the spec define only a single possible output for a given input, or allow the implementor to choose from a set of legal outputs?
- How declarative it is: Does the spec just characterize what the output should be, or does it explicitly say how to compute the output?
- How strong it is: Does the spec have a small set of legal implementations, or a large set?
Deterministic vs. Underdetermined specs
Recall the two example implementations of find we began with in the previous part:
1 static int findA(int[] a, int val) {
2 for (int i = 0; i < a.length; i++) {
3 if (a[i] == val) return i;
4 }
5 return a.length;
6 }
7
8 static int findB(int[] a, int val) {
9 for (int i = a.length -1 ; i >= 0; i--) {
10 if (a[i] == val) return i;
11 }
12 return -1;
13 }
Here is one possible specification of find:
1 static int find(int[] a, int val)
2 requires: val occurs exactly once in a
3 effects: returns index i such that a[i] = val
This specification is deterministic: when presented with a state satisfying the precondition, the outcome is determined. Both findA and findB satisfy the specification, so if this is the specification on which the clients relied, the two implementations are equivalent and substitutable for one another. (Of course a procedure must have the name demanded by the specification; here we are using different names to allow us to talk about the two versions. To use either, you’d have to change its name to find.)
Here is a slightly different specification:
1 static int find(int[] a, int val)
2 requires: val occurs in a
3 effects: returns index i such that a[i] = val
This specification is not deterministic. Such a specification is often said to be non-deterministic, but this is a bit misleading. Non-deterministic code is code that you expect to sometimes behave one way and sometimes another. This can happen, for example, with concurrency: the scheduler chooses to run threads in different orders depending on conditions outside the program.
But a ‘non-deterministic’ specification doesn’t call for such non-determinism in the code. The behaviour specified is not non-deterministic but under-determined. In this case, the specification doesn’t say which index is returned if val occurs more than once; it simply says that if you look up the entry at the index given by the returned value, you’ll find val.
This specification is again satisfied by both findA and findB, each ‘resolving’ the under-determinedness in its own way. A client of find can’t predict which index will be returned, but should not expect the behaviour to be truly non-deterministic. Of course, the specification is satisfied by a non-deterministic procedure too — for example, one that rather improbably tosses a coin to decide whether to start searching from the top or the bottom of the array. But in almost all cases we’ll encounter, non-determinism in specifications offers a choice that is made by the implementor at implementation time, and not at runtime.
So for this specification, too, the two versions of find are equivalent.
Finally, here’s a specification that distinguishes the two:
1 static int find(int[] a, int val)
2 // effects: returns largest index i such that
3 // a[i] = val, or -1 if no such i
Declarative vs. operational specs
Generally speaking, there are two kinds of specifications:
-
- Operational specifications give a series of steps that the method performs; pseudocode descriptions are operational.
- Declarative specifications don’t give details of intermediate steps. Instead, they just give properties of the final outcome, and how it’s related to the initial state.
Almost always, declarative specifications are preferable. They’re usually shorter, easier to understand, and most importantly, they don’t expose implementation details inadvertently that a client may rely on (and then find no longer hold when the implementation is changed). For example, if we want to allow either implementation of find, we would not want to say in the spec that the method “goes down the array until it finds val,” since aside from being rather vague, this spec suggests that the search proceeds from lower to higher indices and that the lowest will be returned, which perhaps the specifier did not intend.
One reason programmers sometimes lapse into operational specifications is because they’re using the spec comment to explain the implementation for a maintainer. Don’t. Do that using comments within the body of the method, not in the spec comment.
Stronger vs. Weaker Specifications
Suppose you want to substitute one method for another. How do you compare the specifications?
A specification A is stronger than or equal to a specification B if
- A’s precondition is weaker than or equal to B’s
- A’s postcondition is stronger than or equal to B’s, for the states that satisfy B’s precondition.
If this is the case, then an implementation that satisfies A can be used to satisfy B as well.
These two rules embody several ideas. They tell you that you can always weaken the precondition; placing fewer demands on a client will never upset them. And you can always strengthen the post-condition, which means making more promises.
For example, this spec for find:
1 static int find1(int[] a, int val)
2 requires: val occurs exactly once in a
3 effects: returns index i such that a[i] = val
can be replaced in any context by:
1 static int findStronger2(int[] a, int val)
2 requires: val occurs at least once in a
3 effects: returns index i such that a[i] = val
which has a weaker precondition.
This in turn can be replaced by:
1 static int findStronger3(int[] a, int val)
2 requires: val occurs at least once in a
3 effects: returns lowest index i such that a[i] = val
which has a stronger postcondition.
What about this specification:
1 static int find4(int[] a, int val)
2 requires: nothing
3 effects: returns index i such that a[i] = val,
4 or -1 if no such i
Diagramming Specifications
Imagine (very abstractly) the space of all possible Java methods.
Each point in this space represents a method implementation.
Here we’ll diagram findA and findB defined above.
A specification defines a region in the space of all possible implementations.
A given implementation either behaves according to the spec, satisfying the precondition-implies-postcondition contract (it is inside the region), or it does not (outside the region).
<img src=”https://dl.dropboxusercontent.com/u/567187/EECE%20210/Images/Designing%20Specifications/fig1.png”></img>
Both findA and findB satisfy findStronger2, so they are inside the region defined by that spec.
We can imagine clients looking in on this space: the specification acts as a firewall. Implementors have the freedom to move around inside the spec, changing their code without fear of upsetting a client. Clients don’t know which implementation they will get. They must respect the spec, but also have the freedom to change how they’re using the implementation without fear that it will suddenly break.
<img src=”https://dl.dropboxusercontent.com/u/567187/EECE%20210/Images/Designing%20Specifications/fig2.png”></img>
How will similar specifications relate to one another? Suppose we start with specification S1 and use it to create a new specification S2.
If S2 is stronger than S1, how will these specs appear in our diagram?
- Let’s start by strengthening the postcondition. If S2’s postcondition is now stronger than S1’s, S2 is the stronger specification.
Think about what strengthening the postcondition means for implementors: it means they have less freedom, the requirements on their output are stronger. Perhaps they previously satisfied findStronger2 by returning any index i, but now the spec demands the lowest index i. So there are now implementations inside findStronger2 but outside findStronger3.
Could there be implementations inside findStronger3 but outside findStronger2? No. All of those implementations satisfy a stronger postcondition than what findStronger2 demands.
- Think through what happens if we weaken the precondition, which will again make S2 a stronger specification. Implementations will have to handle new inputs that were previously excluded by the spec. If they behaved badly on those inputs before, we wouldn’t have noticed, but now their bad behaviour is exposed.
<img src=”https://dl.dropboxusercontent.com/u/567187/EECE%20210/Images/Designing%20Specifications/fig3.png”></img>
We see that when S2 is stronger than S1, it defines a smaller region in this diagram; a weaker specification defines a larger region.
In our figure, since findB iterates from the end of the array a, it does not satisfy findStronger3 and is outside that region.
A specification S2 that is neither stronger nor weaker than S1 might overlap (such that there exist implementations that satisfy only S1, only S2, and both S1 and S2) or might be disjoint.
Designing Good Specifications
What makes a good method? Designing a method means primarily writing a specification.
About the form of the specification: it should be succinct, clear, and well-structured, so that it’s easy to read.
The content of the specification, however, is harder to prescribe. There are no infallible rules, but there are some useful guidelines.
The specification should be coherent: it shouldn’t have lots of different cases. Long argument lists, deeply nested if-statements, and boolean flags are a sign of trouble.
Consider this specification:
static int minFind(int[] a, int[] b, int val)
effects: returns smallest index in arrays a and b
at which val appears
Is this a well-designed procedure? Probably not: it’s incoherent, since it does two things (finding and minimizing) that are not really related. It would be better to use two separate procedures.
The results of a call should be informative. Consider the specification of a method that puts a value in a map:
1 static V put (Map<K,V> map, K key, V val)
2 requires: val may be null,
3 and map may contain null values
4 effects: inserts (key, val) into the mapping,
5 overriding any existing mapping for key,
6 and returns old value for key, unless none,
7 in which case it returns null
Note that the precondition does not rule out null values so the map can store nulls. But the postcondition uses null as a special return value for a missing key. This means that if null is returned, you can’t tell whether the key was not bound previously, or whether it was in fact bound to null. This is not a very good design, because the return value is useless unless you know for sure that you didn’t insert nulls.
The specification should be strong enough. There’s no point throwing a checked exception for a bad argument but allowing arbitrary mutations, because a client won’t be able to determine what mutations have actually been made. Here’s a specification illustrating this flaw (and also written in an inappropriately operational style):
1 static void addAll(List<T> list1, List<T> list2)
2 effects: adds the elements of list2 to list1,
3 unless it encounters a null element,
4 at which point it throws a NullPointerException
The specification should also be weak enough. Consider this specification for a method that opens a file:
1 static File open(String filename)
2 effects: opens a file named filename
This is a bad specification. It lacks important details: is the file opened for reading or writing? Does it already exist or is it created? And it’s too strong, since there’s no way it can guarantee to open a file. The process in which it runs may lack permission to open a file, or there might be some problem with the file system beyond the control of the program. Instead, the specification should say something much weaker: that it attempts to open a file, and if it succeeds, the file has certain properties.
The specification should use abstract types where possible, giving more freedom to both the client and the implementor. In Java, this often means using an interface type, like Map or Reader, instead of specific implementation types like HashMap or FileReader.
Consider this specification:
1 static ArrayList<T> reverse(ArrayList<T> list)
2 effects: returns a new list
3 which is the reversal of list, i.e.,
4 newList[i] == list[n-i-1] for all 0 <= i < n,
5 where n = list.size()
This forces the client to pass in an ArrayList, and forces the implementor to return an ArrayList, even if there might be alternative List implementations that they would rather use. Since the behaviour of the specification doesn’t depend on anything specific about ArrayList, it would be better to write this spec in terms of the more abstract List<T>.
Precondition or Postcondition?
Another design issue is whether to use a precondition, and if so, whether the method code should attempt to make sure the precondition has been met before proceeding. In fact, the most common use of preconditions is to demand a property precisely because it would be hard or expensive for the method to check it.
As mentioned above, a non-trivial precondition inconveniences clients, because they have to ensure that they don’t call the method in a bad state (that violates the precondition); if they do, there is no predictable way to recover from the error. So users of methods don’t like preconditions. That’s why the Java API classes, for example, invariably specify (as a postcondition) that they throw unchecked exceptions when arguments are inappropriate. This approach makes it easier to find the bug or incorrect assumption in the caller code that led to passing bad arguments.
In general, it’s better to fail fast, as close as possible to the site of the bug, rather than let bad values propagate through a program far from their original cause.
Sometimes, it’s not feasible to check a condition without making a method unacceptably slow, and a precondition is often necessary in this case. If we wanted to implement the find() method using binary search, we would have to require that the array be sorted. Forcing the method to actually check that the array is sorted would defeat the entire purpose of the binary search: to obtain a result in logarithmic and not linear time.
The decision of whether to use a precondition is an engineering judgment. The key factors are the cost of the check (in writing and executing code), and the scope of the method. If it’s only called locally in a class, the precondition can be discharged by carefully checking all the sites that call the method. But if the method is public, and used by other developers, it would be less wise to use a precondition. Instead, like the Java API classes, you should throw an exception.
About access control
We have been using public for almost all of our methods, without really thinking about it. The decision to make a method public or private is actually a decision about the contract of the class.
<p style=”text-align: right; background: #eaeaea; padding: 15px;”> <strong>Additional Reading</strong><br /> <a href=”http://docs.oracle.com/javase/tutorial/java/package/index.html”>Packages</a> in the Java Tutorials.<br /> <a href=”http://docs.oracle.com/javase/tutorial/java/javaOO/accesscontrol.html”>Controlling Access</a> in the Java Tutorials. </p>
Public methods are freely accessible to other parts of the program. Making a method public advertises it as a service that your class is willing to provide. If you make all your methods public — including helper methods that are really meant only for local use within the class — then other parts of the program may come to depend on them, which will make it harder for you to change the internal implementation of the class in the future. Your code won’t be as ready for change.
Making internal helper methods public will also add clutter to the visible interface your class offers. Keeping internal things private makes your class’s public interface smaller and more coherent (meaning that it does one thing and does it well). Your code will be easier to understand.
We will see even stronger reasons to use private when we start to write classes with persistent internal state. Protecting this state will help keep the program safe from bugs.
About Static vs. Instance methods
<p style=”text-align: right; background: #eaeaea; padding: 15px;”> Read about the <a href=”http://www.codeguru.com/java/tij/tij0037.shtml#Heading79”><tt>static</tt> keyword on CodeGuru.</a> </p>
We have also been using static for almost all of our methods, again without much discussion. Static methods are not associated with any particular instance of a class, while instance methods (declared without the static keyword) must be called on a particular object.
Specifications for instance methods are written just the same way as specifications for static methods, but they will often refer to properties of the instance on which they were called.
For example, by now we’re very familiar with this specification:
1 static int find(int[] arr, int val)
2 // requires: val occurs in arr
3 // effects: returns index i such that arr[i] = val
Instead of using an int[], what if we had a class IntArray designed for storing arrays of integers? The IntArray class might provide an instance method with the specification:
1 int find(int val)
2 // requires: val occurs in *this array*
3 // effects: returns index i such that *the value at index i in this array* is v\
4 al
We will have much more to say about specifications for instance methods later.
Summary
A specification acts as a crucial firewall between implementor and client — both between people (or the same person at different times) and between code. Specifications make separate development possible: the client is free to write code that uses a module without seeing its source code, and the implementor is free to write the implementation code without knowing how it will be used.
Declarative specifications are the most useful in practice. Preconditions (which weaken the specification) make life harder for the client, but applied judiciously they are a vital tool in the software designer’s repertoire, allowing the implementor to make necessary assumptions.
As always, our goal is to design specifications that make our software:
- Safe from bugs. Without specifications, even the tiniest change to any part of our program could be the tipped domino that knocks the whole thing over. Well-structured, coherent specifications minimize misunderstandings and maximize our ability to write correct code with the help of static checking, careful reasoning, testing, and code review.
-
Easy to understand. A well-written declarative specification means the client doesn’t have to read or understand the code. You’ve probably never read the code for, say, Python
dict.update, and doing so isn’t nearly as useful to the Python programmer as reading the declarative spec. - Ready for change. An appropriately weak specification gives freedom to the implementor, and an appropriately strong specification gives freedom to the client. We can even change the specs themselves, without having to revisit every place they’re used, as long as we’re only strengthening them: weakening preconditions and strengthening postconditions.