Rep Invariants and Abstraction Functions
In this reading, we study a more formal mathematical idea of what it means for a class to implement an ADT, via the notions of abstraction functions and rep invariants. These mathematical notions are eminently practical in software design. The abstraction function will give us a way to cleanly define the equality operation on an abstract data type, and the rep invariant will make it easier to catch bugs caused by a corrupted data structure.
Rep Invariant and Abstraction Function
We now take a deeper look at the theory underlying abstract data types. This theory is not only elegant and interesting in its own right; it also has immediate practical application to the design and implementation of abstract types. If you understand the theory deeply, you’ll be able to build better abstract types, and will be less likely to fall into subtle traps.
In thinking about an abstract type, it helps to consider the relationship between two spaces of values.
The space of representation values (or rep values for short) consists of the values of the actual implementation entities. In simple cases, an abstract type will be implemented as a single object, but more commonly a small network of objects is needed, so this value is actually often something rather complicated. For now, though, it will suffice to view it simply as a mathematical value.
The space of abstract values consists of the values that the type is designed to support. These are a figment of our imaginations. They’re platonic entities that don’t exist as described, but they are the way we want to view the elements of the abstract type, as clients of the type. For example, an abstract type for unbounded integers might have the mathematical integers as its abstract value space; the fact that it might be implemented as an array of primitive (bounded) integers, say, is not relevant to the user of the type.
Now of course the implementor of the abstract type must be interested in the representation values, since it is the implementor’s job to achieve the illusion of the abstract value space using the rep value space.
Suppose, for example, that we choose to use a string to represent a Set<Character> (a set of characters).
1 public class CharSet implements Set<Character> {
2 private String s;
3 ...
4 }
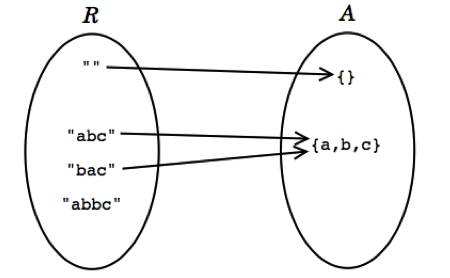
CharSetThen the rep space R contains Strings, and the abstract space A is mathematical sets of characters. We can show the two value spaces graphically, with an arc from a rep value to the abstract value it represents. There are several things to note about this picture:
- Every abstract value is mapped to by some rep value. The purpose of implementing the abstract type is to support operations on abstract values. Presumably, then, we will need to be able to create and manipulate all possible abstract values, and they must therefore be representable.
- Some abstract values are mapped to by more than one rep value. This happens because the representation is not a tight encoding. There’s more than one way to represent an unordered set of characters as a string.
-
Not all rep values are mapped. For example, the string “abbc” is not mapped. In this case, we have decided that the string should not contain duplicates. This will allow us to terminate the
remove()method when we hit the first instance of a particular character, since we know there can be at most one.
In practice, we can only illustrate a few elements of the two spaces and their relationships; the graph as a whole is infinite. So we describe it by giving two things:
1. An abstraction function that maps rep values to the abstract values they represent:
AF : R → A
The arcs in the diagram show the abstraction function. In the terminology of functions, the properties we discussed above can be expressed by saying that the function is surjective (also called onto), not necessarily bijective (also called one-to-one), and often partial.
2. A rep invariant that maps rep values to booleans:
RI : R → boolean
For a rep value r, RI(r) is true if and only if r is mapped by AF. In other words, RI tells us whether a given rep value is well-formed. Alternatively, you can think of RI as a set: it’s the subset of rep values on which AF is defined.
Both the rep invariant and the abstraction function should be documented in the code, right next to the declaration of the rep itself:
1 public class CharSet_NoRepeatsRep implements Set<Character> {
2 private String s;
3 // Rep invariant:
4 // s contains no repeated characters
5 // Abstraction Function:
6 // represents the set of characters found in s
7 ...
8 }
A common confusion about abstraction functions and rep invariants is that they are determined by the choice of rep and abstract value spaces, or even by the abstract value space alone. If this were the case, they would be of little use, since they would be saying something redundant that’s already available elsewhere.
The abstract value space alone doesn’t determine the AF or RI: there can be several representations for the same abstract type. A set of characters could equally be represented as a string, as above, or as a bit vector, with one bit for each possible character. Clearly we need two different abstraction functions to map these two different rep value spaces.
It is less obvious why the choice of both spaces does not determine AF and RI. The key point is that defining a type for the rep, and thus choosing the values for the space of rep values, does not determine which of the rep values will be deemed to be legal, and of those that are legal, how they will be interpreted. Rather than deciding, as we did above, that the strings have no duplicates, we could instead allow duplicates, but at the same time require that the characters be sorted, appearing in nondecreasing order. This would allow us to perform a binary search on the string and thus check membership in logarithmic rather than linear time. Same rep value space – different rep invariant:
1 public class CharSet_SortedRep implements Set<Character> {
2 private String s;
3 // Rep invariant:
4 // s[0] < s[1] < ... < s[s.length()-1]
5 // Abstraction Function:
6 // represents the set of characters found in s
7 ...
8 }
Even with the same type for the rep value space and the same rep invariant RI, we might still interpret the rep differently, with different abstraction functions AF. Suppose RI admits any string of characters. Then we could define AF, as above, to interpret the array’s elements as the elements of the set. But there’s no a priori reason to let the rep decide the interpretation. Perhaps we’ll interpret consecutive pairs of characters as subranges, so that the string “acgg” represents the set {a,b,c,g}.
1 public class CharSet_SortedRangeRep implements Set<Character> {
2 private String s;
3 // Rep invariant:
4 // s.length is even
5 // s[0] <= s[1] <= ... <= s[s.length()-1]
6 // Abstraction Function:
7 // represents the union of the ranges
8 // {s[i]...s[i+1]} for each adjacent pair of characters
9 // in s
10 ...
11 }
The essential point is that designing an abstract type means not only choosing the two spaces – the abstract value space for the specification and the rep value space for the implementation – but also deciding what rep values to use and how to interpret them.
It’s critically important to write down these assumptions in your code, as we’ve done above, so that future programmers (and your future self) are aware of what the representation actually means. Why? What happens if different implementers disagree about the meaning of the rep?
Example: Rational Numbers
Here’s an example of an abstract data type for rational numbers. Look closely at its rep invariant and abstraction function.
1 public class RatNum {
2 private final int numer;
3 private final int denom;
4
5 // Rep invariant:
6 // denom > 0
7 // numer/denom is in reduced form
8
9 // Abstraction Function:
10 // represents the rational number numer / denom
11
12 /** Make a new Ratnum == n. */
13 public RatNum(int n) {
14 numer = n;
15 denom = 1;
16 checkRep();
17 }
18
19 /**
20 * Make a new RatNum == (n / d).
21 * @param n numerator
22 * @param d denominator
23 * @throws ArithmeticException if d == 0
24 */
25 public RatNum(int n, int d) throws ArithmeticException {
26 // reduce ratio to lowest terms
27 int g = gcd(n, d);
28 n = n / g;
29 d = d / g;
30
31 // make denominator positive
32 if (d < 0) {
33 numer = -n;
34 denom = -d;
35 } else {
36 numer = n;
37 denom = d;
38 }
39 checkRep();
40 }
41 }
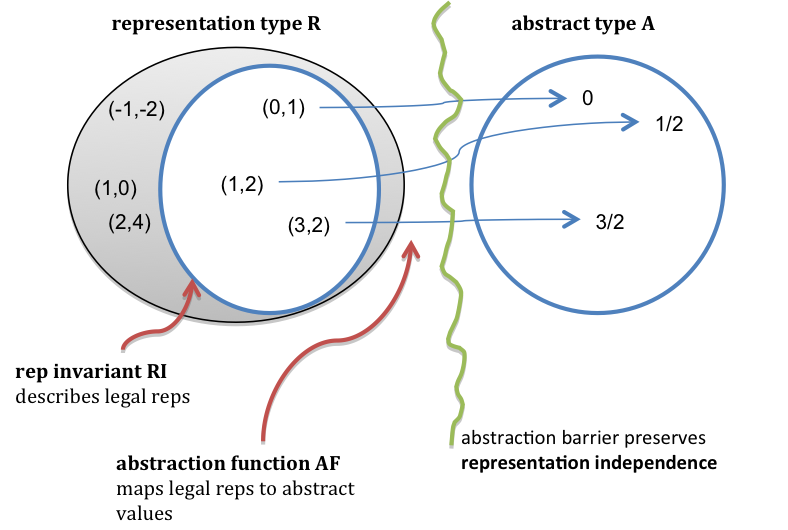
RatNumHere is a picture of the abstraction function and rep invariant for this code. The RI requires that numerator/denominator pairs be in reduced form (i.e., lowest terms), so pairs like (2,4) and (18,12) above should be drawn as outside the RI.
It would be completely reasonable to design another implementation of this same ADT with a more permissive RI. With such a change, some operations might become more expensive to perform, and others cheaper.
Checking the Rep Invariant
The rep invariant is not just a neat mathematical idea. If your implementation asserts the rep invariant at run time, then you can catch bugs early. Here’s a method for RatNum that tests its rep invariant:
1 // Check that the rep invariant is true
2 // *** Warning: this does nothing unless you turn on assertion checking
3 // by passing -enableassertions to Java
4 private void checkRep() {
5 assert denom > 0;
6 assert gcd(numer, denom) == 1;
7 }
You should certainly call checkRep() to assert the rep invariant at the end of every operation that creates or mutates the rep – in other words, creators, producers, and mutators. Look back at the RatNum code above, and you’ll see that it calls checkRep() at the end of both constructors.
Observer methods don’t normally need to call checkRep(), but it’s good defensive practice to do so anyway. Why? Calling checkRep() in every method, including observers, means you’ll be more likely to catch rep invariant violations caused by rep exposure.
Why is checkRep() private? Who should be responsible for checking and enforcing a rep invariant – clients, or the implementation itself?
No Null Values in the Rep
Recall from the reading on Specifications that null values are troublesome and unsafe, so much so that we try to remove them from our programming entirely.
We extend that prohibition to the reps of abstract data types. By default, in this course, the rep invariant implicitly includes x != null for every reference x in the rep that has object type (including references inside arrays or lists). So if your rep is:
1 class CharSet {
2 String s;
3 }
then its rep invariant automatically includes s != null.
By stating that references cannot be null in the rep invariant you are adding to safety. You will often work with others who may have not had this approach as a dictum.
When it’s time to implement that rep invariant in a checkRep() method, however, you still must implement the s != null check, and make sure that your checkRep() correctly fails when s is null. Often that check comes for free from Java, because checking other parts of your rep invariant will throw an exception if s is null. For example, if your checkRep() looks like this:
1 private void checkRep() {
2 assert s.length() % 2 == 0;
3 ...
4 }
then you don’t need assert s!= null, because the call to s.length() will fail just as effectively on a null reference. But if s is not otherwise checked by your rep invariant, then assert s != null explicitly.
Summary
The Abstraction Function maps a concrete representation to the abstract value it represents.
The Rep Invariant specifies legal values of the representation, and should be checked at runtime with checkRep().
For a slightly different – and compressed – view of RIs and AFs, consider the following summary.
We write specifications for methods because we wanted to state certain assumptions or describe some aspect of the method: + Preconditions, for example, indicate what are valid arguments and when one can call a method. We use preconditions because there are certain things that are impossible for a compiler to verify (there is only limited power in static analysis) and it would slow down our programs too much if we had to verify these conditions at runtime (e.g., make the JVM do a lot of checks). + Postconditions and effects tell us what we can expect after a method has finished, and this is important because not all changes in a language like Java involve what is returned by a method.
It is not always enough to reason about methods. When we define a datatype in Java we use the class abstraction that Java provides. We represent an abstract object (such as a git blob or a bicyclist in the Tour de France) using some other datatypes. The representations take the form of field declarations within the class.
Take the example of a line segment that may be represented by the two end points (x1, y1) and (x2, y2). We could easily declare a class called Segment with four floating point numbers x1, y1, x2, y2 as the internal fields (this is really a vector with 4 dimensions). We can then ask the question: Do all vectors in R<sup>4</sup> represent valid line segments? We might then conclude that a line segment cannot be of length 0 which would then eliminate those representations where x1 == x2 and y1 == y2. This type of constraint is something that is not communicated by the following definition:
java
public class Segment {
private double x1, x2, y1, y2;
...
}
The restriction we want is therefore encoded as a rep invariant. The abstract function, in turn, tells us that if we have four double values that satisfy this rep invariant then they represent a particular line segment. (In a different situation, four doubles might just as well represent latitude, longitude, altitude and temperature of a location on the planet!)
We could therefore think of specs, rep invariants and abstraction functions as encoding assumptions we make when we write software. Separating the assumptions into different categories makes it easier to understand and maintain software, and to automate certain aspects of software verification.
The topics of today’s reading connect to our three properties of good software as follows:
-
Safe from bugs. Stating the rep invariant explicitly, and checking it at runtime with
checkRep(), catches misunderstandings and bugs earlier, rather than continuing on with a corrupt data structure. - Easy to understand. Rep invariants and abstraction functions explicate the meaning of a data type’s representation, and how it relates to its abstraction.
- Ready for change. Abstract data types separate the abstraction from the concrete representation, which makes it possible to change the representation without having to change client code.