In this reading, we look at a powerful idea, abstract data types, which enable us to separate how we use a data structure in a program from the particular form of the data structure itself.
Abstract data types address a particularly dangerous problem: clients making assumptions about the type’s internal representation. We’ll see why this is dangerous and how it can be avoided. We’ll also discuss the classification of operations, and some principles of good design for abstract data types.
What Abstraction Means
Abstract data types are an instance of a general principle in software engineering, which goes by many names with slightly different shades of meaning. Here are some of the names that are used for this idea:
Abstraction.
Omitting or hiding low-level details with a simpler, higher-level idea.
Modularity.
Dividing a system into components or modules, each of which can be designed, implemented, tested, reasoned about, and reused separately from the rest of the system.
Encapsulation.
Building walls around a module (a hard shell or capsule) so that the module is responsible for its own internal behavior, and bugs in other parts of the system can’t damage its integrity.
Information hiding.
Hiding details of a module’s implementation from the rest of the system, so that those details can be changed later without changing the rest of the system.
Separation of concerns.
Making a feature (or “concern”) the responsibility of a single module, rather than spreading it across multiple modules.
As a software engineer, you should know these terms, because you will run into them frequently. The fundamental purpose of all of these ideas is to help achieve the three important properties that we care about: safety from bugs, ease of understanding, and readiness for change.
User-Defined Types
In the early days of computing, a programming language came with built-in types (such as integers, booleans, strings, etc.) and built-in procedures, e.g., for input and output. Users could define their own procedures: that’s how large programs were built.
A major advance in software development was the idea of abstract types: that one could design a programming language to allow user-defined types, too. This idea came out of the work of many researchers, notably Dahl (the inventor of the Simula language), Hoare (who developed many of the techniques we now use to reason about abstract types), Parnas (who coined the term information hiding and first articulated the idea of organizing program modules around the secrets they encapsulated), Liskov and Guttag, who did seminal work in the specification of abstract types, and in programming language support for them.
The key idea of data abstraction is that a type is characterized by the operations you can perform on it. A number is something you can add and multiply; a string is something you can concatenate and take substrings of; a boolean is something you can negate, and so on.
In a sense, users could already define their own types in early programming languages: you could create a record type date, for example, with integer fields for day, month, and year. But what made abstract types new and different was the focus on operations: the user of the type would not need to worry about how its values were actually stored, in the same way that a programmer can ignore how the compiler actually stores integers. All that matters is the operations.
In Java, as in many modern programming languages, the separation between built-in types and user-defined types is a bit blurry. The classes in java.lang, such as Integer and Boolean are built-in; whether you regard all the collections of java.util as built-in is less clear (and not very important anyway). Java complicates the issue by having primitive types that are not objects. The set of these types, such as int and boolean, cannot be extended by the user.
Classifying Types and Operations
Types, whether built-in or user-defined, can be classified as mutable or immutable.
The objects of a mutable type can be changed: that is, they provide operations which when executed cause the results of other operations on the same object to give different results. So Date is mutable, because you can call setMonth( ) and observe the change with the getMonth( ) operation. But String is immutable, because its operations create new String objects rather than changing existing ones. Sometimes a type will be provided in two forms, a mutable and an immutable form. StringBuilder, for example, is a mutable version of String (although the two are certainly not the same Java type, and are not interchangeable).
The operations of an abstract type can be classified as follows:
Creators create new objects of the type.
A creator may take an object as an argument, but not an object of the type being constructed.
Producers create new objects from old objects of the type.
The concat() method of String , for example, is a producer: it takes two strings and produces a new one representing their concatenation.
Observers take objects of the abstract type and return objects of a different type.
The size() method of List, for example, returns an int.
Mutators change objects.
The add() method of List, for example, mutates a list by adding an element to the end.
We can summarize these distinctions schematically like this (explanation to follow):
creator: t* → T
producer: T+, t* → T
observer: T+, t* → t
mutator: T+, t* → void|t|T
These show informally the shape of the signatures of operations in the various classes.
Each T is the abstract type itself; each t is some other type.
The + marker indicates that the type may occur one or more times in that part of the signature, and the * marker indicates that it occurs zero or more times.
For example, a producer may take two values of the abstract type, like String.concat() does.
The occurrences of t on the left may also be omitted, since some observers take no non-abstract arguments, and some take several.
Mutators are often signalled by a void return type. A method that returns void must be called for some kind of side-effect, since otherwise it doesn’t return anything. But not all mutators return void. For example, Set.add() returns a boolean that indicates whether the set was actually changed. In Java’s graphical user interface toolkit, Component.add() returns the object itself, so that multiple add() calls can be chained together.
Abstract Data Type Examples
Here are some examples of abstract data types, along with some of their operations, grouped by kind.
int is Java’s primitive integer type. int is immutable, so it has no mutators.
creators: the numeric literals 0, 1, 2, …
producers: arithmetic operators +, -, ,
observers: comparison operators ==, !=, <, >
mutators: none (it’s immutable)
List is Java’s list interface. List is mutable. List is also an interface, which means that other classes provide the actual implementation of the data type. These classes include ArrayList and LinkedList.
creators: ArrayList and LinkedList constructors, Collections.singletonList
String is Java’s string type. String is immutable.
creators: String constructors
producers: concat, substring, toUpperCase
observers: length, charAt
mutators: none (it’s immutable)
This classification gives some useful terminology, but it’s not perfect.
In complicated data types, there may be an operation that is both a producer and a mutator, for example. Some people reserve the term producer only for operations that do no mutation.
Designing an Abstract Type
Designing an abstract type involves choosing good operations and determining how they should behave. Here are a few rules of thumb.
It’s better to have a few, simple operations that can be combined in powerful ways, rather than lots of complex operations.
Each operation should have a well-defined purpose, and should have a coherent behavior rather than a panoply of special cases. We probably shouldn’t add a sum operation to List, for example. It might help clients who work with lists of Integers, but what about lists of Strings? Or nested lists? All these special cases would make sum a hard operation to understand and use.
The set of operations should be adequate in the sense that there must be enough to do the kinds of computations clients are likely to want to do.
A good test is to check that every property of an object of the type can be extracted. For example, if there were no get operation, we would not be able to find out what the elements of a list are. Basic information should not be inordinately difficult to obtain. For example, the size method is not strictly necessary for List, because we could apply get on increasing indices until we get a failure, but this is inefficient and inconvenient.
The type may be generic: a list or a set, or a graph, for example. Or it may be domain-specific: a street map, an employee database, a phone book, etc.
But it should not mix generic and domain-specific features.
A Deck type intended to represent a sequence of playing cards shouldn’t have a generic add method that accepts arbitrary objects like ints or Strings. Conversely, it wouldn’t make sense to put a domain-specific method like dealCards into the generic type List.
Representation Independence
Critically, a good abstract data type should be representation independent.
This means that the use of an abstract type is independent of its representation (the actual data structure or data fields used to implement it), so that changes in representation have no effect on code outside the abstract type itself.
For example, the operations offered by List are independent of whether the list is represented as a linked list or as an array.
You won’t be able to change the representation of an ADT at all unless its operations are fully specified with preconditions and postconditions, so that clients know what to depend on, and you know what you can safely change.
Example: Different Representations for Strings
Let’s look at a simple abstract data type to see what representation independence means and why it’s useful. The MyString type below has far fewer operations than the real Java String, and their specs are a little different, but it’s still illustrative. Here are the specs for the ADT:
1 /** String represents an immutable sequence of characters. */ 2 publicclassMyString{ 3 4 //////////////////// Example of a creator operation /////////////// 5 /** @param b a boolean value 6 * @return string representation of b, either "true" or "false" */ 7 publicstaticMyStringvalueOf(booleanb){...} 8 9 //////////////////// Examples of observer operations ///////////////10 /** @return number of characters in this string */11 publicintlength(){...}12 13 /** @param i character position (requires 0 <= i < string length)14 * @return character at position i15 */16 publiccharcharAt(inti){...}17 18 //////////////////// Example of a producer operation /////////////// 19 /** Get the substring between start (inclusive) and end (exclusive).20 * @param start starting index21 * @param end ending index. Requires 0 <= start <= end <= string length.22 * @return string consisting of charAt(start)...charAt(end-1)23 */24 publicMyStringsubstring(intstart,intend){...}25 }
These public operations and their specifications are the only information that a client of this data type is allowed to know.
Following the test-first programming paradigm, in fact, the first client we should create is a test suite that exercises these operations according to their specs.
At the moment, however, writing test cases that use assertEquals directly on MyString objects wouldn’t work, because we don’t have an equality operation defined on these MyStrings. We’ll talk about how to implement equality carefully in subsequent discussions. For now, the only operations we can perform with MyStrings are the ones we’ve defined above: valueOf, length, charAt, and substring. Our tests have to limit themselves to those operations. For example, here’s one test for the valueOf operation:
We’ll come back to the question of testing ADTs in a later section of this reading.
For now, let’s look at a simple representation for MyString: just an array of characters, exactly the length of the string (no extra room at the end). Here’s how that internal representation would be declared, as an instance variable within the class:
1 privatechar[]a;
With that choice of representation, the operations would be implemented in a straightforward way:
Question to ponder: Why don’t charAt( ) and substring() have to check whether their parameters are within the valid range? What do you think will happen if the client calls these implementations with illegal inputs?
One problem with this implementation is that it’s passing up an opportunity for performance improvement. Because this data type is immutable, the substring() operation doesn’t really have to copy characters out into a fresh array. It could just point to the original MyString’s character array and keep track of the start and end that the new substring object represents. The String implementation in some versions of Java do this.
To implement this optimization, we could change the internal representation of this class to:
Because MyString’s existing clients depend only on the specs of its public methods, not on its private fields, we can make this change without having to inspect and change all that client code. That’s the power of representation independence.
Java’s interface is a useful language mechanism for expressing an abstract data type. An interface in Java is a list of method signatures, but no method bodies. A class implements an interface if it declares the interface in its implements clause, and provides method bodies for all of the interface’s methods. So one way to define an abstract data type in Java is as an interface, with its implementation as a class implementing that interface.
One advantage of this approach is that the interface specifies the contract for the client and nothing more. The interface is all a client programmer needs to read to understand the ADT. The client can’t create inadvertent dependencies on the ADT’s rep, because instance variables can’t be put in an interface at all. The implementation is kept well and truly separated, in a different class altogether.
Another advantage is that multiple different representations of the abstract data type can co-exist in the same program, as different classes implementing the interface. When an abstract data type is represented just as a single class, without an interface, it’s harder to have multiple representations. We saw that in the MyString example above, which was a single class. We couldn’t have both representations for MyString in the same program.
Java’s static type checking allows the compiler to catch many mistakes in implementing an ADT’s contract. For instance, it is a compile-time error to omit one of the required methods, or to give it the wrong return type. Unfortunately, the compiler doesn’t check for us that the code adheres to the specs of those methods that are written in documentation comments.
Example: Set
Java’s collection classes provide a good example of the idea of separating interface and implementation. Let’s consider as an example one of the ADTs from the Java collections library, Set. Set is the ADT of finite sets of elements of some other type E. Here is a simplified version of the Set interface:
1 publicinterfaceSet<E>{2 ...
We can match Java interfaces with our classification of ADT operations, starting with a creator:
1 // example of creator method2 /** Make an empty set.3 * @return a new set instance, initially empty4 */5 publicstaticSet<E>make(){...}
Unfortunately, Java interfaces are not allowed to have constructors, but (as of Java 8) they are allowed to contain static methods. So we can implement creator operations as static methods. This design pattern, using a static method as a creator instead of a constructor, is called a factory method. The MyString.valueOf( ) method we saw earlier is also a factory method.
1 // examples of observer methods 2 3 /** Get size of the set. 4 * @return the number of elements in this set. */ 5 publicintsize(); 6 7 /** Test for membership. 8 * @param e an element 9 * @return true iff this set contains e. */10 publicbooleancontains(Ee);
Next we have two observer methods. Notice how the specs are in terms of our abstract notion of a set; it would be malformed to mention the details of any particular implementation of sets with particular private fields. These specs should apply to any valid implementation of the set ADT.
1 // examples of mutator methods 2 3 /** Modifies this set by adding e to the set. 4 * @param e element to add. */ 5 publicvoidadd(Ee); 6 7 /** Modifies this set by removing e, if found. 8 * If e is not found in the set, has no effect. 9 * @param e element to remove.*/10 publicvoidremove(Ee);
The story for these three mutator methods is basically the same as for the observers. We still write specs at the level of our abstract model of sets.
Interfaces are used pervasively in real Java code. Not every class is associated with an interface, but there are a few good reasons to bring an interface into the picture.
Documentation for both the compiler and for humans.
Not only does an interface help the compiler catch ADT implementation bugs, but it is also much more useful for a human to read than the code for a concrete implementation. Such an implementation intersperses ADT-level types and specs with implementation details.
Allowing performance trade-offs.
Different implementations of the ADT can provide methods with very different performance characteristics. Different applications may work better with different choices, but we would like to code these applications in a way that is representation-independent. From a correctness standpoint, it should be possible to drop in any new implementation of a key ADT with simple, localized code changes.
Flexibility in providing invariants.
Different implementations of an ADT can provide different invariants.
Optional methods. List from the Java standard library marks all mutator methods as optional. By building an implementation that does not support these methods, we can provide immutable lists. Some operations are hard to implement with good enough performance on immutable lists, so we want mutable implementations, too. Code that doesn’t call mutators can be written to work automatically with either kind of list.
Methods with intentionally underdetermined specifications.
An ADT for finite sets could leave unspecified the element order one gets when converting to a list. Some implementations might use slower method implementations that manage to keep the set representation in some sorted order, allowing quick conversion to a sorted list. Other implementations might make many methods faster by not bothering to support conversion to sorted lists.
Multiple views of one class.
A Java class may implement multiple methods. For instance, a user interface widget displaying a drop-down list is natural to view as both a widget and a list. The class for this widget could implement both interfaces. In other words, we don’t implement an ADT multiple times just because we are choosing different data structures; we may make multiple implementations because many different sorts of objects may also be seen as special cases of the ADT, among other useful perspectives.
More and less trustworthy implementations.
Another reason to implement an interface multiple times might be that it is easy to build a simple implementation that you believe is correct, while you can work harder to build a fancier version that is more likely to contain bugs. You can choose implementations for applications based on how bad it would be to get bitten by a bug.
Testing an Abstract Data Type
We build a test suite for an abstract data type by creating tests for each of its operations. These tests inevitably interact with each other, since the only way to test creators, producers, and mutators is by calling observers on the objects that result.
Here’s how we might partition the input spaces of the four operations in our MyString type:
1 // testing strategy for each operation of MyString: 2 // 3 // valueOf(): 4 // true, false 5 // length(): 6 // string len = 0, 1, n 7 // string = produced by valueOf(), produced by substring() 8 // charAt(): 9 // string len = 1, n10 // i = 0, middle, len-111 // string = produced by valueOf(), produced by substring()12 // substring():13 // string len = 0, 1, n14 // start = 0, middle, len15 // end = 0, middle, len16 // end-start = 0, n17 // string = produced by valueOf(), produced by substring()
Then a compact test suite that covers all these partitions might look like:
Notice that each test case typically calls a few operations that make or modify objects of the type (creators, producers, mutators) and some operations that inspect objects of the type (observers). As a result, each test case covers parts of several operations.
Invariants
Resuming our discussion of what makes a good abstract data type, the final, and perhaps most important, property of a good abstract data type is that it preserves its own invariants.
An invariant is a property of a program that is always true, for every possible runtime state of the program.
Immutability is one crucial invariant that we’ve already encountered: once created, an immutable object should always represent the same value, for its entire lifetime. Saying that the ADT preserves its own invariants means that the ADT is responsible for ensuring that its own invariants hold. It doesn’t depend on good behaviour from its clients.
When an ADT preserves its own invariants, reasoning about the code becomes much easier. If you can count on the fact that Strings never change, you can rule out that possibility when you’re debugging code that uses Strings – or when you’re trying to establish an invariant for another ADT that uses Strings.
Contrast that with a string type that guarantees that it will be immutable only if its clients promise not to change it. Then you’d have to check all the places in the code where the string might be used.
Immutability
We’ll see many interesting invariants. Let’s focus on immutability for now. Here’s a specific example:
1 /** 2 * This immutable data type represents a tweet from Twitter. 3 */ 4 publicclassTweet{ 5 6 publicStringauthor; 7 publicStringtext; 8 publicDatetimestamp; 9 10 /**11 * Make a Tweet.12 * @param author Twitter user who wrote the tweet.13 * @param text text of the tweet14 * @param timestamp date/time when the tweet was sent15 */16 publicTweet(Stringauthor,Stringtext,Datetimestamp){17 this.author=author;18 this.text=text;19 this.timestamp=timestamp;20 }21 }
How do we guarantee that these Tweet objects are immutable – that, once a tweet is created, its author, message, and date can never be changed?
The first threat to immutability comes from the fact that clients can — in fact must — directly access its fields. So nothing’s stopping us from writing code like this:
1 Tweett=newTweet("justinbieber",2 "Thanks to all those beliebers out there inspiring me every \3 day",4 newDate());5 t.author="GSatInRealTime";
This is a trivial example of representation exposure, meaning that code outside the class can modify the representation directly. Rep exposure like this threatens not only invariants, but also representation independence. We can’t change the implementation of Tweet without affecting all the clients who are directly accessing those fields.
Fortunately, Java gives us language mechanisms to deal with this kind of rep exposure:
1 publicclassTweet{ 2 3 privatefinalStringauthor; 4 privatefinalStringtext; 5 privatefinalDatetimestamp; 6 7 publicTweet(Stringauthor,Stringtext,Datetimestamp){ 8 this.author=author; 9 this.text=text;10 this.timestamp=timestamp;11 }12 13 /** @return Twitter user who wrote the tweet */14 publicStringgetAuthor(){15 returnauthor;16 }17 18 /** @return text of the tweet */19 publicStringgetText(){20 returntext;21 }22 23 /** @return date/time when the tweet was sent */24 publicDategetTimestamp(){25 returntimestamp;26 }27 28 }
The private and public keywords indicate which fields and methods are accessible only within the class and which can be accessed from outside the class.
The final keyword also helps by guaranteeing that the fields of this immutable type won’t be reassigned after the object is constructed.
But that’s not the end of the story: the rep is still exposed! Consider this perfectly reasonable client code that uses Tweet:
1 /** @return a tweet that retweets t, one hour later*/2 publicstaticTweetretweetLater(Tweett){3 Dated=t.getTimestamp();4 d.setHours(d.getHours()+1);5 returnnewTweet("GSatInRealTime",t.getText(),d);6 }
retweetLater takes a tweet and should return another tweet with the same message (called a retweet) but sent an hour later. The retweetLater method might be part of a system that automatically echoes funny things that Twitter celebrities say.
What’s the problem here? The getTimestamp call returns a reference to the same date object referenced by tweet t. t.timestamp and d are aliases to the same mutable object. So when that date object is mutated by d.setHours(), this affects the date in t as well, as shown in the snapshot diagram.
Tweet’s immutability invariant has been broken. The problem is that Tweet leaked out a reference to a mutable object that its immutability depended on. We exposed the rep, in such a way that Tweet can no longer guarantee that its objects are immutable. Perfectly reasonable client code created a subtle bug.
We can patch this kind of rep exposure by using defensive copying: making a copy of a mutable object to avoid leaking out references to the rep. Here’s the code:
Mutable types often have a copy constructor that allows you to make a new instance that duplicates the value of an existing instance.
In this case, Date’s copy constructor uses the timestamp value, measured in seconds since January 1, 1970. As another example, StringBuilder’s copy constructor takes a String. Another way to copy a mutable object is clone(), which is supported by some types but not all. There are unfortunate problems with the way clone() works in Java.
For more, see Josh Bloch, Effective Java, item 10.
So we’ve done some defensive copying in the return value of getTimestamp( ). But we’re not done yet! There’s still rep exposure. Consider this (again perfectly reasonable) client code:
1 /** @return a list of 24 inspiring tweets, one per hour today */ 2 publicstaticList<Tweet>tweetEveryHourToday(){ 3 List<Tweet>list=newArrayList<Tweet>(); 4 Datedate=newDate(); 5 for(inti=0;i<24;i++){ 6 date.setHours(i); 7 list.add(newTweet("GSatInRealTime","keep it up! you can do it",date)); 8 } 9 returnlist;10 }
This code intends to advance a single Date object through the 24 hours of a day, creating a tweet for every hour. But notice that the constructor of Tweet saves the reference that was passed in, so all 24 Tweet objects end up with the same time, as shown in this instance diagram.
Again, the immutability of Tweet has been violated. We can fix this problem too by using judicious defensive copying, this time in the constructor:
In general, you should carefully inspect the argument types and return types of all your ADT operations. If any of the types are mutable, make sure your implementation doesn’t return direct references to its representation. Doing that creates rep exposure.
You may object that this seems wasteful. Why make all these copies of dates? Why can’t we just solve this problem by a carefully written specification, like this?
1 /**2 * Make a Tweet.3 * @param author Twitter user who wrote the tweet.4 * @param text text of the tweet5 * @param timestamp date/time when the tweet was sent. Caller must never 6 * mutate this Date object again!7 */8 publicTweet(Stringauthor,Stringtext,Datetimestamp){
This approach is sometimes taken when there isn’t any other reasonable alternative – for example, when the mutable object is too large to copy efficiently. But the cost in your ability to reason about the program, and your ability to avoid bugs, is enormous. In the absence of compelling arguments to the contrary, it’s almost always worth it for an abstract data type to guarantee its own invariants, and preventing rep exposure is essential to that.
An even better solution is to prefer immutable types. If we had used an immutable date object, like java.time.ZonedDateTime, instead of the mutable java.util.Date, then we would have ended this section after talking about public and private. No further rep exposure would have been possible.
Immutable Wrappers Around Mutable Data Types
The Java collections classes offer an interesting compromise: immutable wrappers.
Collections.unmodifiableList() takes a (mutable) List and wraps it with an object that looks like a List, but whose mutators are disabled – set(), add(), remove() throw exceptions. So you can construct a list using mutators, then seal it up in an unmodifiable wrapper (and throw away your reference to the original mutable list), and get an immutable list.
The downside here is that you get immutability at runtime, but not at compile time. Java won’t warn you at compile time if you try to sort() this unmodifiable list. You’ll just get an exception at runtime. But that’s still better than nothing, so using unmodifiable lists, maps, and sets can be a very good way to reduce the risk of bugs.
How to Establish Invariants
An invariant is a property that is true for the entire program – which in the case of an invariant about an object, reduces to the entire lifetime of the object.
To make an invariant hold, we need to:
make the invariant true in the initial state of the object; and
ensure that all changes to the object keep the invariant true.
Translating this in terms of the types of ADT operations, this means:
creators and producers must establish the invariant for new object instances; and
mutators and observers must preserve the invariant.
The risk of rep exposure makes the situation more complicated. If the rep is exposed, then the object might be changed anywhere in the program, not just in the ADT’s operations, and we can’t guarantee that the invariant still holds after those arbitrary changes. So the full rule for proving invariants is:
then the invariant is true of all instances of the abstract data type.
Summary
Abstract data types are characterized by their operations.
Operations can be classified into creators, producers, observers, and mutators.
An ADT’s specification is its set of operations and their specs.
A good ADT is simple, coherent, adequate, representation-independent, and preserves its own invariants.
An invariant is a property that is always true of an ADT object instance, for the lifetime of the object.
Invariants must be established by creators and producers, and preserved by observers and mutators.
Representation exposure threatens both representation independence and invariant preservation.
Java interfaces help us formalize the idea of an abstract data type as a set of operations that must be supported by a type.
These ideas connect to our three key properties of good software as follows:
Safe from bugs. A good ADT offers a well-defined contract for a data type, and preserves its own invariants, so that those invariants are less vulnerable to bugs in the ADT’s clients, and violations of the invariants can be more easily isolated within the implementation of the ADT itself.
Easy to understand. A good ADT hides its implementation behind a set of simple operations, so that programmers using the ADT only need to understand the operations, not the details of the implementation.
Ready for change. Representation independence allows the implementation of an abstract data type to change without requiring changes from its clients.
Rep Invariants and Abstraction Functions
In this reading, we study a more formal mathematical idea of what it means for a class to implement an ADT, via the notions of abstraction functions and rep invariants. These mathematical notions are eminently practical in software design. The abstraction function will give us a way to cleanly define the equality operation on an abstract data type, and the rep invariant will make it easier to catch bugs caused by a corrupted data structure.
Rep Invariant and Abstraction Function
We now take a deeper look at the theory underlying abstract data types. This theory is not only elegant and interesting in its own right; it also has immediate practical application to the design and implementation of abstract types. If you understand the theory deeply, you’ll be able to build better abstract types, and will be less likely to fall into subtle traps.
In thinking about an abstract type, it helps to consider the relationship between two spaces of values.
The space of representation values (or rep values for short) consists of the values of the actual implementation entities. In simple cases, an abstract type will be implemented as a single object, but more commonly a small network of objects is needed, so this value is actually often something rather complicated. For now, though, it will suffice to view it simply as a mathematical value.
The space of abstract values consists of the values that the type is designed to support. These are a figment of our imaginations. They’re platonic entities that don’t exist as described, but they are the way we want to view the elements of the abstract type, as clients of the type. For example, an abstract type for unbounded integers might have the mathematical integers as its abstract value space; the fact that it might be implemented as an array of primitive (bounded) integers, say, is not relevant to the user of the type.
Now of course the implementor of the abstract type must be interested in the representation values, since it is the implementor’s job to achieve the illusion of the abstract value space using the rep value space.
Suppose, for example, that we choose to use a string to represent a Set<Character> (a set of characters).
Then the rep space R contains Strings, and the abstract space A is mathematical sets of characters. We can show the two value spaces graphically, with an arc from a rep value to the abstract value it represents. There are several things to note about this picture:
Every abstract value is mapped to by some rep value. The purpose of implementing the abstract type is to support operations on abstract values. Presumably, then, we will need to be able to create and manipulate all possible abstract values, and they must therefore be representable.
Some abstract values are mapped to by more than one rep value. This happens because the representation is not a tight encoding. There’s more than one way to represent an unordered set of characters as a string.
Not all rep values are mapped. For example, the string “abbc” is not mapped. In this case, we have decided that the string should not contain duplicates. This will allow us to terminate the remove() method when we hit the first instance of a particular character, since we know there can be at most one.
In practice, we can only illustrate a few elements of the two spaces and their relationships; the graph as a whole is infinite. So we describe it by giving two things:
1. An abstraction function that maps rep values to the abstract values they represent:
AF : R → A
The arcs in the diagram show the abstraction function. In the terminology of functions, the properties we discussed above can be expressed by saying that the function is surjective (also called onto), not necessarily bijective (also called one-to-one), and often partial.
2. A rep invariant that maps rep values to booleans:
RI : R → boolean
For a rep value r, RI(r) is true if and only if r is mapped by AF. In other words, RI tells us whether a given rep value is well-formed. Alternatively, you can think of RI as a set: it’s the subset of rep values on which AF is defined.
Both the rep invariant and the abstraction function should be documented in the code, right next to the declaration of the rep itself:
1 publicclassCharSet_NoRepeatsRepimplementsSet<Character>{2 privateStrings;3 // Rep invariant:4 // s contains no repeated characters5 // Abstraction Function:6 // represents the set of characters found in s7 ...8 }
A common confusion about abstraction functions and rep invariants is that they are determined by the choice of rep and abstract value spaces, or even by the abstract value space alone. If this were the case, they would be of little use, since they would be saying something redundant that’s already available elsewhere.
The abstract value space alone doesn’t determine the AF or RI: there can be several representations for the same abstract type. A set of characters could equally be represented as a string, as above, or as a bit vector, with one bit for each possible character. Clearly we need two different abstraction functions to map these two different rep value spaces.
It is less obvious why the choice of both spaces does not determine AF and RI. The key point is that defining a type for the rep, and thus choosing the values for the space of rep values, does not determine which of the rep values will be deemed to be legal, and of those that are legal, how they will be interpreted. Rather than deciding, as we did above, that the strings have no duplicates, we could instead allow duplicates, but at the same time require that the characters be sorted, appearing in nondecreasing order. This would allow us to perform a binary search on the string and thus check membership in logarithmic rather than linear time. Same rep value space – different rep invariant:
1 publicclassCharSet_SortedRepimplementsSet<Character>{2 privateStrings;3 // Rep invariant:4 // s[0] < s[1] < ... < s[s.length()-1]5 // Abstraction Function:6 // represents the set of characters found in s7 ...8 }
Even with the same type for the rep value space and the same rep invariant RI, we might still interpret the rep differently, with different abstraction functions AF. Suppose RI admits any string of characters. Then we could define AF, as above, to interpret the array’s elements as the elements of the set. But there’s no a priori reason to let the rep decide the interpretation. Perhaps we’ll interpret consecutive pairs of characters as subranges, so that the string “acgg” represents the set {a,b,c,g}.
1 publicclassCharSet_SortedRangeRepimplementsSet<Character>{ 2 privateStrings; 3 // Rep invariant: 4 // s.length is even 5 // s[0] <= s[1] <= ... <= s[s.length()-1] 6 // Abstraction Function: 7 // represents the union of the ranges 8 // {s[i]...s[i+1]} for each adjacent pair of characters 9 // in s10 ...11 }
The essential point is that designing an abstract type means not only choosing the two spaces – the abstract value space for the specification and the rep value space for the implementation – but also deciding what rep values to use and how to interpret them.
It’s critically important to write down these assumptions in your code, as we’ve done above, so that future programmers (and your future self) are aware of what the representation actually means. Why? What happens if different implementers disagree about the meaning of the rep?
Example: Rational Numbers
Here’s an example of an abstract data type for rational numbers. Look closely at its rep invariant and abstraction function.
1 publicclassRatNum{ 2 privatefinalintnumer; 3 privatefinalintdenom; 4 5 // Rep invariant: 6 // denom > 0 7 // numer/denom is in reduced form 8 9 // Abstraction Function:10 // represents the rational number numer / denom11 12 /** Make a new Ratnum == n. */13 publicRatNum(intn){14 numer=n;15 denom=1;16 checkRep();17 }18 19 /**20 * Make a new RatNum == (n / d).21 * @param n numerator22 * @param d denominator23 * @throws ArithmeticException if d == 024 */25 publicRatNum(intn,intd)throwsArithmeticException{26 // reduce ratio to lowest terms27 intg=gcd(n,d);28 n=n/g;29 d=d/g;30 31 // make denominator positive32 if(d<0){33 numer=-n;34 denom=-d;35 }else{36 numer=n;37 denom=d;38 }39 checkRep();40 }41 }
The AF and RI for RatNum
Here is a picture of the abstraction function and rep invariant for this code. The RI requires that numerator/denominator pairs be in reduced form (i.e., lowest terms), so pairs like (2,4) and (18,12) above should be drawn as outside the RI.
It would be completely reasonable to design another implementation of this same ADT with a more permissive RI. With such a change, some operations might become more expensive to perform, and others cheaper.
Checking the Rep Invariant
The rep invariant is not just a neat mathematical idea. If your implementation asserts the rep invariant at run time, then you can catch bugs early. Here’s a method for RatNum that tests its rep invariant:
1 // Check that the rep invariant is true2 // *** Warning: this does nothing unless you turn on assertion checking3 // by passing -enableassertions to Java4 privatevoidcheckRep(){5 assertdenom>0;6 assertgcd(numer,denom)==1;7 }
You should certainly call checkRep() to assert the rep invariant at the end of every operation that creates or mutates the rep – in other words, creators, producers, and mutators. Look back at the RatNum code above, and you’ll see that it calls checkRep() at the end of both constructors.
Observer methods don’t normally need to call checkRep(), but it’s good defensive practice to do so anyway. Why? Calling checkRep() in every method, including observers, means you’ll be more likely to catch rep invariant violations caused by rep exposure.
Why is checkRep() private? Who should be responsible for checking and enforcing a rep invariant – clients, or the implementation itself?
No Null Values in the Rep
Recall from the reading on Specifications that null values are troublesome and unsafe, so much so that we try to remove them from our programming entirely.
We extend that prohibition to the reps of abstract data types. By default, in this course, the rep invariant implicitly includes x != null for every reference x in the rep that has object type (including references inside arrays or lists). So if your rep is:
1 classCharSet{2 Strings;3 }
then its rep invariant automatically includes s != null.
By stating that references cannot be null in the rep invariant you are adding to safety. You will often work with others who may have not had this approach as a dictum.
When it’s time to implement that rep invariant in a checkRep() method, however, you still must implement the s != null check, and make sure that your checkRep() correctly fails when s is null. Often that check comes for free from Java, because checking other parts of your rep invariant will throw an exception if s is null. For example, if your checkRep() looks like this:
then you don’t need assert s!= null, because the call to s.length() will fail just as effectively on a null reference. But if s is not otherwise checked by your rep invariant, then assert s != null explicitly.
Summary
The Abstraction Function maps a concrete representation to the abstract value it represents.
The Rep Invariant specifies legal values of the representation, and should be checked at runtime with checkRep().
For a slightly different – and compressed – view of RIs and AFs, consider the following summary.
We write specifications for methods because we wanted to state certain assumptions or describe some aspect of the method:
+ Preconditions, for example, indicate what are valid arguments and when one can call a method. We use preconditions because there are certain things that are impossible for a compiler to verify (there is only limited power in static analysis) and it would slow down our programs too much if we had to verify these conditions at runtime (e.g., make the JVM do a lot of checks).
+ Postconditions and effects tell us what we can expect after a method has finished, and this is important because not all changes in a language like Java involve what is returned by a method.
It is not always enough to reason about methods. When we define a datatype in Java we use the class abstraction that Java provides. We represent an abstract object (such as a git blob or a bicyclist in the Tour de France) using some other datatypes. The representations take the form of field declarations within the class.
Take the example of a line segment that may be represented by the two end points (x1, y1) and (x2, y2). We could easily declare a class called Segment with four floating point numbers x1, y1, x2, y2 as the internal fields (this is really a vector with 4 dimensions). We can then ask the question: Do all vectors in R<sup>4</sup> represent valid line segments? We might then conclude that a line segment cannot be of length 0 which would then eliminate those representations where x1 == x2 and y1 == y2. This type of constraint is something that is not communicated by the following definition:
java
public class Segment {
private double x1, x2, y1, y2;
...
}
The restriction we want is therefore encoded as a rep invariant. The abstract function, in turn, tells us that if we have four double values that satisfy this rep invariant then they represent a particular line segment. (In a different situation, four doubles might just as well represent latitude, longitude, altitude and temperature of a location on the planet!)
We could therefore think of specs, rep invariants and abstraction functions as encoding assumptions we make when we write software. Separating the assumptions into different categories makes it easier to understand and maintain software, and to automate certain aspects of software verification.
The topics of today’s reading connect to our three properties of good software as follows:
Safe from bugs. Stating the rep invariant explicitly, and checking it at runtime with checkRep(), catches misunderstandings and bugs earlier, rather than continuing on with a corrupt data structure.
Easy to understand. Rep invariants and abstraction functions explicate the meaning of a data type’s representation, and how it relates to its abstraction.
Ready for change. Abstract data types separate the abstraction from the concrete representation, which makes it possible to change the representation without having to change client code.
Java’s interface is a useful language mechanism for expressing an abstract data type. An interface in Java is a list of method signatures, but no method bodies. A class implements an interface if it declares the interface in its implements clause, and provides method bodies for all of the interface’s methods. So one way to define an abstract data type in Java is as an interface, with its implementation as a class implementing that interface.
One advantage of this approach is that the interface specifies the contract for the client and nothing more. The interface is all a client programmer needs to read to understand the ADT. The client can’t create inadvertent dependencies on the ADT’s rep, because instance variables can’t be put in an interface at all. The implementation is kept well and truly separated, in a different class altogether.
Another advantage is that multiple different representations of the abstract data type can co-exist in the same program, as different classes implementing the interface. When an abstract data type is represented just as a single class, without an interface, it’s harder to have multiple representations. In the [MyString example from Abstract Data Types][1], MyString was a single class. We explored two different representations for MyString, but we couldn’t have both representations for the ADT in the same program.
Java’s static type checking allows the compiler to catch many mistakes in implementing an ADT’s contract. For instance, it is a compile-time error to omit one of the required methods, or to give a method the wrong return type. Unfortunately, the compiler doesn’t check for us that the code adheres to the specs of those methods that are written in documentation comments.
Example: MyString
Let’s revisit [MyString][1]. Using an interface instead of a class for the ADT, we can support multiple implementations:
```java
/** MyString represents an immutable sequence of characters. */
public interface MyString {
1 /** @return number of characters in this string */ 2 publicintlength(); 3 4 /** @param i character position (requires 0 <= i < string length) 5 * @return character at position i */ 6 publiccharcharAt(inti); 7 8 /** Get the substring between start (inclusive) and end (exclusive). 9 * @param start starting index10 * @param end ending index. Requires 0 <= start <= end <= string length.11 * @return string consisting of charAt(start)...charAt(end-1) */12 publicMyStringsubstring(intstart,intend);
}
```
We’ll skip the static valueOf method and come back to it in a minute. Instead, let’s go ahead using a different technique from our [toolbox of ADT concepts in Java][2]: constructors.
Here’s our first implementation:
```java
public class SimpleMyString implements MyString {
private char[] a;
private SimpleMyString() {}
1 /** Create a string representation of b, either "true" or "false". 2 * @param b a boolean value */ 3 publicSimpleMyString(booleanb){ 4 a=b?newchar[]{'t','r','u','e'} 5 :newchar[]{'f','a','l','s','e'}; 6 } 7 8 @Override 9 publicintlength(){returna.length;}10 11 @Override12 publiccharcharAt(inti){returna[i];}13 14 @Override15 publicMyStringsubstring(intstart,intend){16 SimpleMyStringthat=newSimpleMyString();17 that.a=newchar[end-start];18 System.arraycopy(this.a,start,that.a,0,end-start);19 returnthat;20 }
}
```
And here’s the optimized implementation:
1 publicclassFastMyStringimplementsMyString{ 2 3 privatechar[]a; 4 privateintstart; 5 privateintend; 6 7 privateFastMyString(){} 8 9 /** Create a string representation of b, either "true" or "false".10 * @param b a boolean value */11 publicFastMyString(booleanb){12 a=b?newchar[]{'t','r','u','e'}13 :newchar[]{'f','a','l','s','e'};14 start=0;15 end=a.length;16 }17 18 @Override19 publicintlength(){returnend-start;}20 21 @Override22 publiccharcharAt(inti){returna[start+i];}23 24 @Override25 publicMyStringsubstring(intstart,intend){26 FastMyStringthat=newFastMyString();27 that.a=this.a;28 that.start=this.start+start;29 that.end=this.start+end;30 returnthat;31 }32 }
Compare these classes to the [implementations of MyString in Abstract Data Types][1]. Notice how the code that previously appeared in static valueOf methods now appears in the constructors, slightly changed to refer to the rep of this.
Also notice the use of [@Override][3]. This annotation informs the compiler that the method must have the same signature as one of the methods in the interface we’re implementing. But since the compiler already checks that we’ve implemented all of the interface methods, the primary value of @Override here is for readers of the code: it tells us to look for the spec of that method in the interface. Repeating the spec wouldn’t be DRY, but saying nothing at all makes the code harder to understand.
And notice the private empty constructors we use to make new instances in substring(..) before we fill in their reps with data. We didn’t have to write these empty constructors before because Java provided them by default; adding the constructors that take boolean b means we have to declare the other constructors explicitly.
Now that we know good ADTs scrupulously [preserve their own invariants][4], these do-nothing constructors are a bad pattern: they don’t assign any values to the rep, and they certainly don’t establish any invariants. We should strongly consider revising the implementation. Since MyString is immutable, a starting point would be making all the fields final.
How will clients use this ADT? Here’s an example:
1 MyStrings=newFastMyString(true);2 System.out.println("The first character is: "+s.charAt(0));
This code looks very similar to the code we write to use the Java collections classes:
1 List<string>s=newArrayList<string>(); 2 ... 3 4 Unfortunately,thispattern**breakstheabstractionbarrier**we'veworkedsoh\ 5 ardtobuildbetweentheabstracttypeanditsconcreterepresentations.Clients\ 6 mustknowthenameoftheconcreterepresentationclass.Becauseinterfacesin\ 7 Javacannotcontainconstructors,theymustdirectlycalloneoftheconcretecl\ 8 ass'constructors.Thespecofthatconstructorwon'tappearanywhereintheint\ 9 erface,sothere'snostaticguaranteethatdifferentimplementationswilleven\10 providethesameconstructors.11 12 Fortunately,(asofJava8)interfaces_are_allowedtocontainstaticmethods,\13 sowecanimplementthecreatoroperation`valueOf`asastaticfactorymethodi\14 ntheinterface`MyString`:15 16 ```java17 publicinterfaceMyString{18 19 /** @param b a boolean value20 * @return string representation of b, either "true" or "false" */21 publicstaticMyStringvalueOf(booleanb){22 returnnewFastMyString(true);23 }
Now a client can use the ADT without breaking the abstraction barrier:
1 MyStrings=MyString.valueOf(true);2 System.out.println("The first character is: "+s.charAt(0));
Example: Set
Java’s collection classes provide a good example of the idea of separating interface and implementation.
Let’s consider as an example one of the ADTs from the Java collections library, Set. Set is the ADT of finite sets of elements of some other type E. Here is a simplified version of the Set interface:
1 /** A mutable set.2 * @param <e> type of elements in the set */3 publicinterfaceSet<e>{
Set is an example of a generic type: a type whose specification is in terms of a placeholder type to be filled in later. Instead of writing separate specifications and implementations for Set<string>, Set<integer>, and so on, we design and implement one Set<e>.
We can match Java interfaces with our classification of ADT operations, starting with a creator:
1 /** Make an empty set.2 * @param <e> type of elements in the set3 * @return a new set instance, initially empty */4 publicstatic<e>Set<e>make(){...}
The make operation is implemented as a static factory method. Clients will write code like Set<string> strings = Set.make(); and the compiler will understand that the new Set is a set of String objects.
1 /** Get size of the set.2 * @return the number of elements in this set */3 publicintsize();4 5 /** Test for membership.6 * @param e an element7 * @return true iff this set contains e */8 publicbooleancontains(Ee);
Next we have two observer methods. Notice how the specs are in terms of our abstract notion of a set; it would be malformed to mention the details of any particular implementation of sets with particular private fields. These specs should apply to any valid implementation of the set ADT.
1 /** Modifies this set by adding e to the set.2 * @param e element to add */3 publicvoidadd(Ee);4 5 /** Modifies this set by removing e, if found.6 * If e is not found in the set, has no effect.7 * @param e element to remove */8 publicvoidremove(Ee);
The story for these mutators is basically the same as for the observers. We still write specs at the level of our abstract model of sets.
<p style=”background:#eaeaea; padding:10px; margin-top:20px; text-align:right”>
In the Java Tutorials, read these pages:<br />
<a href=”http://docs.oracle.com/javase/tutorial/collections/interfaces/”> Lesson: Interfaces</a><br />
<a href=”http://docs.oracle.com/javase/tutorial/collections/interfaces/set.html”>The Set Interface</a><br />
<a href=”http://docs.oracle.com/javase/tutorial/collections/implementations/set.html”>Set Implementations</a><br />
<a href=”http://docs.oracle.com/javase/tutorial/collections/interfaces/list.html”>The List Interface</a><br />
<a href=”http://docs.oracle.com/javase/tutorial/collections/implementations/list.html”>List Implementations</a></p>
Why Interfaces?
Interfaces are used pervasively in real Java code. Not every class is associated with an interface, but there are a few good reasons to bring an interface into the picture.
Documentation for both the compiler and for humans.
Not only does an interface help the compiler catch ADT implementation bugs, but it is also much more useful for a human to read than the code for a concrete implementation. Such an implementation intersperses ADT-level types and specs with implementation details.
Allowing performance trade-offs.
Different implementations of the ADT can provide methods with very different performance characteristics. Different applications may work better with different choices, but we would like to code these applications in a way that is representation-independent. From a correctness standpoint, it should be possible to drop in any new implementation of a key ADT with simple, localized code changes.
Optional methods.
List from the Java standard library marks all mutator methods as optional. By building an implementation that does not support these methods, we can provide immutable lists. Some operations are hard to implement with good enough performance on immutable lists, so we want mutable implementations, too. Code that doesn’t call mutators can be written to work automatically with either kind of list.
Methods with intentionally underdetermined specifications.
An ADT for finite sets could leave unspecified the element order one gets when converting to a list. Some implementations might use slower method implementations that manage to keep the set representation in some sorted order, allowing quick conversion to a sorted list. Other implementations might make many methods faster by not bothering to support conversion to sorted lists.
Multiple views of one class.
A Java class may implement multiple methods. For instance, a user interface widget displaying a drop-down list is natural to view as both a widget and a list. The class for this widget could implement both interfaces. In other words, we don’t implement an ADT multiple times just because we are choosing different data structures; we may make multiple implementations because many different sorts of objects may also be seen as special cases of the ADT, among other useful perspectives.
More and less trustworthy implementations.
Another reason to implement an interface multiple times might be that it is easy to build a simple implementation that you believe is correct, while you can work harder to build a fancier version that is more likely to contain bugs. You can choose implementations for applications based on how bad it would be to get bitten by a bug.
Realizing ADT Concepts in Java
This table summarizes how some key ADT ideas can be implemented in Java.
ADT concept
How to implement in Java
Examples
Abstract data type
Single class
String
Interface + classes
List and ArrayList
Creator operation
Constructor
ArrayList()
Static (factory) method
Arrays.toList()
Constant
BigInteger.ZERO
Observer operation
Instance method
List.get()
Static method
Collections.max()
Producer operation
Instance method
String.trim()
Static method
Collections.unmodifiableList()
Mutator operation
Instance method
List.add()
Static method
Collections.copy( )
Representation
private fields
Summary
Java interfaces help us formalize the idea of an abstract data type as a set of operations that must be supported by a type.
This helps make our code…
Safe from bugs.
An ADT is defined by its operations, and interfaces do just that. When clients use an interface type, static checking ensures that they only use methods defined by the interface. If the implementation class exposes other methods — or worse, has visible representation — the client can’t accidentally see or depend on them. When we have multiple implementations of a data type, interfaces provide static checking of the method signatures.
Easy to understand.
Clients and maintainers know exactly where to look for the specification of the ADT. Since the interface doesn’t contain instance fields or implementations of instance methods, it’s easier to keep details of the implementation out of the specifications.
Ready for change.
We can easily add new implementations of a type by adding classes that implement interface. If we avoid constructors in favor of static factory methods, clients will only see the interface. That means we can switch which implementation class clients are using without changing their code at all.
Test Yourself
Java interfaces
Consider this Java interface and Java class, which are intended to implement an immutable set data type:
```java
/** Represents an immutable set of elements of type E. /
interface Set<e> {
/** make an empty set */
/A*/ public Set();
1 /** @return true if this set contains e as a member */
2 public boolean contains(E e);
3 4 /** @return a set which is the union of this and that */
/B/ public ArraySet union(Set<e> that);
}
/** Implementation of Set<e>. */
class ArraySet<e> implements Set<e> {
/** make an empty set */
public ArraySet() { … }
1 /** @return a set which is the union of this and that */2 publicArraySetunion(Set<e>that){...}3 4 /** add e to this set */5 publicvoidadd(Ee){...}
}
```
Which of the following statements are true about Set<e> and ArraySet<e>?
[ ] The line labeled A is a problem because Java interfaces can’t have constructors.
[ ] The line labeled B is a problem because Set mentions ArraySet, but ArraySet also mentions Set, which is circular.
[ ] The line labeled B is a problem because it isn’t representation-independent.
[ ] ArraySet doesn’t correctly implement Set because it’s missing the contains() method.
[ ] ArraySet doesn’t correctly implement Set because it includes a method that Set doesn’t have.
[ ] ArraySet doesn’t correctly implement Set because
[ ] ArraySet is mutable while Set is immutable.
Code review
Let’s review the code for FastMyString. Which of these are useful criticisms:
[ ] I wish the abstraction function was documented
[ ] I wish the representation invariant was documented
[ ] I wish the rep fields were final so they could not be reassigned
[ ] I wish the private constructor was public so clients could use it to construct empty strings
[ ] I wish the charAt specification did not expose that the rep contains individual characters
[ ] I wish the charAt implementation behaved more helpfully when i is greater than the length of the string
Collection interfaces & implementations
Assume the following lines of code are run in sequence, and that any lines of code that don’t compile are simply commented out so that the rest of the code can compile.
The code uses two methods from Collections, so you might need to consult their documentation.
Choose the most specific answer to each question.
java
Set<string> set = new HashSet<string>();
set now points to:
[ ] a HashSet object
[ ] an object that implements the Set interface
[ ] null
[ ] this line won’t compile
1 set=Collections.unmodifiableSet(set);
set now points to:
[ ] a HashSet object
[ ] a Collections object
[ ] an object that implements the Set interface
[ ] null
[ ] line 2 won’t compile
1 set=Collections.singleton("glorp");
set now points to:
[ ] a HashSet object
[ ] a Collections object
[ ] an object that implements the Set interface
[ ] null
[ ] line 3 won’t compile
1 set=newSet<string>();
set now points to:
- [ ] a HashSet object
- [ ] a Collections object
- [ ] an object that implements the Set interface
- [ ] null
- [ ] line 4 won’t compile
1 List<string>list=set;
set now points to:
- [ ] a HashSet object
- [ ] a Collections object
- [ ] an object that implements the Set interface
- [ ] null
- [ ] line 5 won’t compile
Recall that a type is a set of values — a (potentially unbounded) set of possible primitive values or objects. If we think about all possible List values, some are ArrayLists and others are LinkedLists. A subtype is simply a subset of the supertype.
“B is a subtype of A” means “every B object is also an A object.”
In terms of specifications, “every B object satisfies the specification for A.”
Substitution principle: Subtypes must be substitutable for their supertypes. In particular, a subtype must fulfill the same contract as its supertype, so that clients designed to work with the supertype can use the subtype objects safely.
An example of subtyping may occur in role-playing game. One might have a variety of characters so we could define a type Character. Characters may be be wizards, muggles, elves, droids, etc. If a Wizard has all the properties that a Character has and also supports the same operations then a Wizard may be a subtype of Character. A Wizard may have more properties than a generic character, and may be able to do more (example: cast a spell) but as long as a Wizard can pass off as a basic Character too, we would be able to establish a parent type and subtype relationship.
Subclassing, written with the extends keyword class B extends A, is one way to declare a subtyping relationship in Java. It is not the only way: other ways include implementing an interface (class B implements A) or one interface extending another (interface B extends A).
Subclassing
Some of you may want to watch this video on subclassing, in Java. This feature is also known as inheritance, in object-oriented languages.
Whenever we declare that B is a subtype of A, the Java type system allows us to use a B object whenever an A object is expected.
That is, when the declared type of a variable or method parameter is A, the actual runtime type can be B.
To understand the distinction between declared and runtime types, here is an example:
In the example, q has declared type Queue<Integer> but its runtime type is LinkedList<Integer>. Java permits this because LinkedList<Integer> is a subtype of Queue<Integer>.
In Effective Java by Joshua Bloch, Item 16: Favour composition over inheritance:
[Subclassing] is a powerful way to achieve code reuse, but it is not always the best tool for the job. Used inappropriately, it leads to fragile software.
Within one module, where the subclass and superclass implementations are under the control of the same programmer and maintained and evolved in tandem, subclassing may be appropriate. But subclassing in general is not safe, and here’s why:
Subclassing breaks encapsulation.
Bloch again:
In other words, a subclass depends on the implementation details of its superclass for its proper function.
The superclass’s implementation may change from release to release, and if it does, the subclass may break, even though its code has not been touched.
As a consequence, the subclass must evolve in tandem with its superclass, unless the superclass’s authors have designed and documented it specifically for the purpose of being extended.
Let’s look at several examples to see what can go wrong with careless subclassing.
Example from the Java library: java.util.Properties
1 publicclassPropertiesextendsHashtable{ 2 3 // Hashtable is an old library class that implements 4 // Map<Object,Object>, so Properties inherits methods like: 5 publicObjectget(Objectkey){...} 6 publicvoidput(Objectkey,Objectvalue){...} 7 8 // rep invariant of Properties: 9 // all keys and values are Strings10 // so provide new get/set methods to clients:11 publicStringgetProperty(Stringkey){12 return(String)this.get(key);13 }14 publicvoidsetProperty(Stringkey,Stringvalue){15 this.put(key,value);16 }17 }
The Properties class represents a collection of String key/value pairs. It’s a very old class in the Java library: it predates generics, which allow you to write Map<String,String> and have the compiler check that all keys and values in the Map are Strings. It even predates Map.
But at the time, the implementor of Properties did have access to Hashtable, which in modern terms is a Map<Object,Object>.
So Properties extends Hashtable, and provides the getProperty(String) and setProperty(String, String) methods shown above. What could go wrong?
Inherited superclass methods can break the subclass’s rep invariant.
Example: CountingList
This is a good point to learn about overriding from the Oracle/Sun Java tutorial. Pay attention to the use of the @Override annotation that helps us easily detect problems.
Let’s suppose we have a program that uses an ArrayList. To tune the performance of our program, we’d like to query the ArrayList as to how many elements have been added since it was created. This is not to be confused with its current size, which goes down when an element is removed.
To provide this functionality, we write an ArrayList variant called CountingList that keeps a count of the number of element insertions and provides an observer method for this count. The ArrayList class contains two methods capable of adding elements, add and addAll, so we override both of those methods:
1 publicclassCountingList<E>extendsArrayList<E>{ 2 3 // total number of elements ever added 4 privateintelementsAdded=0; 5 6 @Overridepublicbooleanadd(Eelt){ 7 elementsAdded++; 8 returnsuper.add(elt); 9 }10 11 @OverridepublicbooleanaddAll(Collectionc){12 elementsAdded+=c.size();13 returnsuper.addAll(c);14 }15 }
What if ArrayList.addAll works by calling addn times?
What if ArrayList.addAll sometimes calls addn times, and sometimes does it a different way, depending on the type of the input collection c?
When a subclass overrides superclass methods, it may depend on how the superclass uses its own methods.
Example: Photo Organizer
Here’s version 1.0 of a class to store photo albums:
Now version 2.0 of the photo organizer comes out, with a new feature for keeping track of the people in our photos. It has a new version of the Album class:
1 publicclassAlbum{2 protectedSet<Photo>photos;3 protectedMap<Person,Photo>photosContaining;4 // rep invariant: all Photos in the photosContaining map5 // are also in the photos set6 // ...7 }
The MyAlbum subclass breaks this new representation invariant.
When a class is subclassed, either it must freeze its implementation forever, or all its subclasses must evolve with its implementation.
Subtyping vs. Subclassing
Substitution principle
Subtypes must be substitutable for their supertypes.
The subtype must not surprise clients by failing to meet the guarantees made by the supertype specification (postconditions), and the subtype must not surprise clients by making stronger demands of them than the supertype does (preconditions).
B is only a subtype of A if B’s specification is at least as strong as A’s specification.
The Java compiler guarantees part of this requirement automatically: for example, it ensures that every method in A appears in B, with a compatible type signature.
Class B cannot implement interface A without implementing all of the methods in the interface.
And class B cannot extend class A and then override some method to return a different type or throw new checked exceptions.
But Java does not check every aspect of the specification: preconditions and postconditions we’ve written in the spec are not checked!
If you declare a subtype to Java — e.g. by declaring class B to extend class A — then you should make it substitutable.
Violating the substitution principle: mutability
Here’s an example of failing to provide substitutability:
By making it a subclass, we’ve declared to Java that MutableRational is a subtype of Rational… but is MutableRational truly a subtype of Rational?
Clients that depend on the immutability of Rational may fail when given MutableRational values. For example, an immutable expression tree that contains Rational objects — suddenly it’s mutable. A function that memoizes previously-computed values in a HashMap — suddenly those values are wrong.
Multithreaded code that uses the same Rational values in different threads, as we’ll see in a future class, is also in trouble.
MutableRational fails to meet guarantees made by Rational.
Specifically, the spec of Rational says that the value of objects will never change (immutability). The spec of MutableRational is not at least as strong as that of Rational.
In general, mutable counterparts of immutable classes should not be declared as subtypes. If you want a mutable rational class (perhaps for performance reasons), then it should not be a subtype of Rational.
String and StringBuilder (and StringBuffer, which is safe for multiple threads) offer an example of how to do it right. The mutable types are not subtypes. Instead, they provide operations to create a mutable StringBuilder/Buffer from an immutable String, mutate the text, and then retrieve a new String.
Violating the substitution principle: adding values
Another example, starting with a class for positive natural numbers:
1 /** Represents an immutable natural number ≥ 0. */2 publicclassBigNat{3 publicBigNatplus(BigNatthat){...}4 publicBigNatminus(BigNatthat){...}5 }
Now we need to write a program that deals with large integers, but both positive and negative:
1 /** Represents an immutable integer. */2 publicclassBigIntextendsBigNat{3 privatebooleanisNegative;4 }
BigInt just adds a sign big to BigNat. Makes sense, right? But is BigInt substitutable for BigNat?
Abstractly, it doesn’t make any sense.
We need to be able to say “every BigInt is a BigNat,” but not every integer is a positive natural! The abstract type of BigInt is not a subset of the abstract type of BigNat. It’s nonsense to declare BigInt a subtype of BigNat.
Practically, it’s risky.
A function declared to take a BigNat parameter has an implicit precondition that the parameter is ≥ 0, since that’s part of the spec of BigNat.
For example, we might declare
java
public double squareRoot(BigNat n);
but now it can be passed a BigInt that represents a negative number. What will happen? BigInt fails to make guarantees made by BigNat. Specifically, that the value is not negative. Its spec is not at least as strong.
One will need to be very comfortable with the distinction between overriding and overloading. Overloading is the act of creating multiple functions/methods with the same name. You should also read the Java tutorial regarding defining methods and overloading.
Violating the substitution principle: specifications
Here’s a subclass that is a proper subtype: immutable square is a subtype of immutable rectangle:
But what about mutable square and mutable rectangle? Perhaps MutableRectangle has a method to set the size:
1 publicclassMutableRectangle{2 // ...3 /** Sets this rectangle's dimensions to w x h. */4 publicvoidsetSize(intw,inth){...}5 }6 7 publicclassMutableSquareextendsMutableRectangle{8 // ...
Let’s consider our options for overriding setSize in MutableSquare:
1 /** Sets all edges to given size.2 * Requires w = h. */3 publicvoidsetSize(intw,inth){...}
No. This stronger precondition violates the contract defined by MutableRectangle in the spec of setSize.
1 /** Sets all edges to given size.2 * Throws BadSizeException if w != h. */3 voidsetSize(intw,inth)throwsBadSizeException{...}
No. This weaker postcondition also violates the contract.
1 /** Sets all edges to given size. */2 voidsetSize(intside);
No. This overloadssetSize, it doesn’t override it. Clients can still break the rep invariant by calling the inherited 2-argument setSize method.
Declared subtypes must truly be subtypes
Design advice: when you declare to Java that “B is a subtype of A,” ensure that B actually satisfies A’s contract.
B should guarantee all the properties that A does, such as immutability.
B’s methods should have the same or weaker preconditions and the same or stronger postconditions as those required by A.
This advice applies whether the declaration was made using subclassing (class B extends A) or interface implementation (class B implements A) or interface extension (interface B extends A).
Bloch’s advice in Item 16:
If you are tempted to have a class B extend a class A, ask yourself the question: “is every B really an A?” If you cannot answer yes to this question, B should not extend A. If the answer is no, it is often the case that B should contain a private instance of A and expose a smaller and simpler API: A is not an essential part of B, merely a detail of its implementation.
Even if the answer to this question is yes, you should carefully consider the use of extends, because — as we saw in the example of CountingList — the implementation of the subclass may not work due to unspecified behaviour of the superclass. In that example, the subclass’s methods broke because the superclass’s methods have an implicit dependence between them which is not in the superclass specification. Before using extends, you should be able to convince yourself that dependences amongst the superclass methods will not impact subclass behaviour.
Use composition rather than subclassing
Here’s Bloch’s recommendation from Item 16:
Instead of extending an existing class, give your new class a private field that references an instance of the existing class. This design is called composition because the existing class becomes a component of the new one.
Each instance method in the new class invokes the corresponding method on the contained instance of the existing class and returns the results. This is known as forwarding, [(or delegation)]. The resulting class will be rock solid, with no dependencies on the implementation details of the existing class.
The abstraction barrier between the two classes is preserved.
Favour composition over subclassing.
Let’s apply this approach to the Properties class:
1end-delete}
2public class Properties {
3 private final Hashtable table;
4 // ...
5}
6</code></pre>
7 8And to `CountingList`:
910```java
11 public class CountingList<E> implements List<E> {
12 private List<E> list;
13 public CountingList<E>(List<E> list) { this.list = list; }
14 // ...
15 }
16 '''
1718 `CountingList` is an instance of the **wrapper pattern**:
1920 + A wrapper modifies the behaviour of another class without subclassing.
21 + It also decouples the wrapper from the specific class it wraps --- `CountingLi\
22 st` could wrap an `ArrayList`, `LinkedList`, even another `CountingList`.
2324 A wrapper works by taking an existing instance of the type whose behaviour we wi\
25 sh to modify, then implementing the contract of that type by forwarding method c\
26 alls to the provided instance, delegating the work.
2728 So in `CountingList` we might see:
2930 ```java
31 public class CountingList<E> implements List<E> {
32 private List<E> list;
33 private int elementsAdded = 0;
3435 public CountingList<E>(List<E> list) { this.list = list; }
3637 public boolean add(E elt) {
38 elementsAdded++;
39 return list.add(elt);
40 }
41 public boolean addAll(Collection c) {
42 elementsAdded += c.size();
43 return list.addAll(c);
44 }
45 // ...
46 }
When subclassing is necessary, design for it.
Define a protected API for your subclasses, in the same way you define a public API for clients.
Document for subclass maintainers how you use your own methods (e.g. does addAll() call add()?).
Don’t expose your rep to your subclasses, or depend on subclass implementations to maintain your rep invariant.
Keep the rep private.
You can find more discussion of how to design for subclassing in Effective Java under Item 17: Design and document for inheritance or else prohibit it.
Interfaces and abstract classes
Java has two mechanisms for defining a type that can have multiple different implementations: interfaces and abstract classes.
An abstract class is a class that can only be subclassed, it cannot be instantiated.
There are two differences between the two mechanisms:
Abstract classes can provide implementations for some instance methods, while interfaces cannot.
New in Java 8 is a mechanism for providing “default” implementations of instance methods in interfaces.
To implement the type defined by abstract class A, class Bmust be a subclass of abstract class A (declared with extends). But any class that defines all of the required methods and follows the specification of interface I can be a subtype of I (declared with implements).
In Effective Java, Bloch discusses the advantages of interfaces in Item 17: Prefer interfaces to abstract classes:
Existing classes can be easily retrofitted to implement a new interface.
All you have to do is add the required methods if they don’t yet exist and add an implements clause to the class declaration.
Existing classes cannot, in general, be retrofitted to extend a new abstract class. If you want to have two classes extend the same abstract class, you have to place the abstract class high up in the type hierarchy where it subclasses an ancestor of both classes.
… but such a change can wreak havoc with the hierarchy.
With interfaces, we can build type structures that are not strictly hierarchical. Bloch provides an excellent example:
For example, suppose we have an interface representing a singer and another representing a songwriter:
In real life, some singers are also songwriters. Because we used interfaces rather than abstract classes to define these types, it is perfectly permissible for a single class to implement both Singer and Songwriter. In fact, we can define a third interface that extends both Singer and Songwriter and adds new methods that are appropriate to the combination:
A class Troubadour that implementsSingerSongwriter must provide implementations of sing, compose, and actSensitive, and Troubadour instances can be used anywhere that code requires a Singer or a Songwriter.
If we are favouring interfaces over abstract classes, what should we do if we are defining a type that others will implement, and we want to provide code they can reuse?
A good strategy is to define an abstract skeletal implementation that goes along with the interface. The type is still defined by the interface, but the skeletal implementation makes the type easier to implement. For example, the Java library includes a skeletal implementation for each of the major interfaces in the collections framework: AbstractList implements List, AbstractSet for Set, etc. If you are implementing a new kind of List or Set, you may be able to subclass the appropriate skeletal implementation, saving yourself work and relying on well-tested library code instead.
The skeletal implementation can also be combined with the wrapper class pattern described above. If a class cannot extend the skeleton itself (perhaps it already has a superclass), then it can implement the interface and delegate method calls to an instance of a helper class (which could be a private inner class) which does extend the skeletal implementation.
Writing a skeletal implementation requires you to break down the interface and decide which operations can serve as primitives in terms of which the other operations can be defined. These primitive operations will be left unimplemented in the skeleton (they will be abstract methods), because the author of the concrete implementation must provide them. The rest of the operations are implemented in the skeleton, written in terms of the primitives.
For example, the Java Map interface defines a number of different observers:
which returns a set of Map.Entry objects representing key/value pairs.
To make it easier to implement a new kind of Map, Java provides AbstractMap.
The documentation says:
> To implement an unmodifiable map, the programmer needs only to extend this class and provide an implementation for the entrySet method, which returns a set-view of the map’s mappings.
So:
1 publicclassMyMap<K,V>extendsAbstractMap<K,V>{2 publicSet<Map.Entry<K,V>>entrySet(){3 // my code here to return a set of key/value pairs in the map4 }5 // ...6 }
And the skeletal implementation, written for us by the authors of Map, implements the other methods in terms of entrySet:
1 publicclassAbstractMap<K,V>implementsMap<K,V>{ 2 publicbooleancontainsKey(Objectkey){ 3 // simplified version, actual code must handle null :( 4 for(Map.Entry<K,V>entry:this.entrySet()){ 5 if(entry.getKey().equals(key)){returntrue;} 6 } 7 returnfalse; 8 } 9 publicbooleancontainsValue(Objectvalue){10 // simplified version, actual code must handle null :(11 for(Map.Entry<K,V>entry:this.entrySet()){12 if(entry.getValue().equals(value)){returntrue;}13 }14 returnfalse;15 }16 publicSet<K>keySet(){17 // return a set of just the keys from this.entrySet()18 }19 publicCollection<V>values(){20 // return a collection of just the values from this.entrySet()21 }22 // ...23 }
Summary
In this reading we’ve seen some risks of subclassing: subclassing breaks encapsulation, and we must use subclassing only for true subtyping.
The substitution principle says that B is a true subtype of A if and only if B objects are substitutable for A objects anywhere that A is used. Equivalently, the specification of B must imply the specification of A. Preconditions of the subtype must be the same or weaker, and postconditions the same or stronger. Violating the substitution principle will yield code that doesn’t make semantic sense and contains lurking bugs.
Favour composition over inheritance from a superclass: the wrapper pattern is an alternative to subclassing that preserves encapsulation and avoids the problems we’ve seen in several examples. Since subclassing creates tightly-coupled code that lacks strong barriers of encapsulation to separate super- from subclasses, composition is useful for writing code that is safer from bugs, easier to understand, and more ready for change.
Test Yourself
Subclassing in Java
Question 1
Given the following classes, fill in the definition of the Cat class so that when greet() is called, the label “Cat” (instead of “Animal”) is printed to the screen. Assume that a Cat will make a “Meow!” noise, and that this is all caps for cats who are less than 5 years old.
```java
public class Animal {
protected String name, noise; protected int age;
public Animal(String name, int age) { this.name = name;
this.age = age;
this.noise = “Huh?”;
Assume that Animal and Cat are defined as above. What will be printed at each of the indicated lines?
```java
public class TestAnimals {
public static void main(String[] args) {
1 Animal a = new Animal("Scooby", 10);
2 Cat c = new Cat("Checkers", 6);
3 Dog d = new Dog("Beethoven", 4);
4 a.greet(); // Line A
5 c.greet(); // Line B
6 d.greet(); // Line C
7 a=c;
8 a.greet(); // Line D
9 ((Cat) a).greet(); // Line E
10 }
}
public class Dog extends Animal {
public Dog(String name, int age) {
super(name, age);
noise = “Bow wow!”;
}
In the example above, consider what would happen we added the following to the bottom of main:
java
a = new Dog("Ideefix", 10);
d = a;
Why would this code produce a compiler error? How could we fix this error?
Question 4
In the code segment below, which lines would cause compile-time errors and which ones would cause runtime errors? If you removed the lines that will result in errors, what would the output of main be?
Aside: The purpose of this question is to illustrate Java subclassing and its corner cases. It is not indicative of how one should use this feature of Java.
1 classA{ 2 publicintx=5; 3 4 publicvoidm1(){ 5 System.out.println("Am1-> "+x); 6 } 7 8 publicvoidm2(){ 9 System.out.println("Am2-> "+this.x);10 }11 12 publicvoidupdate(){13 x=99;14 }15 }16 17 classBextendsA{18 publicintx=10;19 20 publicvoidm2(){21 System.out.println("Bm2-> "+x);22 }23 24 publicvoidm3(){25 System.out.println("Bm3-> "+super.x);26 }27 28 publicvoidm4(){29 System.out.print("Bm4-> ");30 super.m2();31 }32 }33 34 classCextendsB{35 publicinty=x+1;36 37 publicvoidm2(){38 System.out.println("Cm2-> "+super.x);39 }40 41 publicvoidm3(){42 System.out.println("Cm3-> "+super.super.x);43 }44 45 publicvoidm4(){46 System.out.println("Cm4-> "+y);47 }48 49 publicvoidm5(){50 System.out.println("Cm5-> "+super.y);51 }52 }53 54 classD{55 publicstaticvoidmain(String[]args){56 Ba0=newA();57 a0.m1();58 Ab0=newB();59 System.out.println(b0.x);60 b0.m1();// class B hides a field in class A. 61 b0.m2();// you should never hide fields.62 b0.m3();// as you’ll see, it’s confusing!63 Bb1=newB();64 b1.m3();65 b1.m4();66 Ac0=newC();67 c0.m1();68 Cc1=(A)newC();69 Aa1=(A)c0;70 Cc2=(C)a1;71 c2.m4();72 c2.m5();73 ((C)c0).m3();// very tricky!74 (C)c0.m3();75 b0.update();76 b0.m1();77 b0.m2();78 }79 }
Subtyping
Question 1
You’ve been hired to create a design the new Student Information System for UBC. The application needs a class to represent a student list containing the list of students registered in a course.
You’ve started to create a small class to do this and so far here’s what it looks like:
```java
public class StudentList {
private List<Student> students;
1 /** Create new empty student list */2 publicStudentList(){3 students=newArrayList<String>();4 }5 6 /** Add an item to the student list */7 publicvoidadd(Studentstudent1){8 students.add(student1);9 }
}
The co-op student from SFU, Todd Tweedledum, says that your code would be much better and shorter if you used subclassing instead of composition, and the whole job could be done with a single line of code:
java
public class StudentList extends ArrayList<Student> { }
```
Both versions “work” in the sense that they provide a way of storing a list of items. Is one of them better than the other? If so which one? Why?
Question 2
Does the following code snippet represent valid subtyping?
+ Why or why not?
+ Will the Java compiler detect any problems?
1 publicclassEmployee{ 2 ... 3 4 /** 5 * @param salary: the amount we want to set as base salary for the employee; 6 * salary should be greater than 100 7 */ 8 privatesetBaseSalary(intsalary){ 9 ...10 }11 ...12 }13 14 publicclassDeanextendsEmployee{15 ...16 17 /**18 * @param salary: the amount we want to set as base salary for the Dean;19 * salary should be greater than 100020 */21 @Overrides22 privatesetBaseSalary(intsalary){23 ...24 }25 ...26 27 }
Equality
Slides
Some slides related to this material may also provide a quick summary, but they are not intended to replace the reading.
Abstraction Function and Equality
In the previous readings we’ve developed a rigorous notion of data abstraction by creating types that are characterized by their operations, not by their representation. For an abstract data type, the abstraction function explains how to interpret a concrete representation value as a value of the abstract type, and we saw how the choice of abstraction function determines how to write the code implementing each of the ADT’s operations.
In this reading we turn to how we define the notion of equality of values in a data type: the abstraction function will give us a way to cleanly define the equality operation on an ADT.
In the physical world, every object is distinct – at some level, even two snowflakes are different, even if the distinction is just the position they occupy in space. (This isn’t strictly true of all subatomic particles, but true enough of large objects like snowflakes and baseballs and people.) So two physical objects are never truly “equal” to each other; they only have degrees of similarity.
In the world of human language, however, and in the world of mathematical concepts, you can have multiple names for the same thing. So it’s natural to ask when two expressions represent the same thing: are alternative expressions for the same ideal mathematical value.
Three Ways to Regard Equality
Formally, we can regard equality in several ways.
Using an abstraction function. Recall that an abstraction function f: R → A maps concrete instances of a data type to their corresponding abstract values. To use f as a definition for equality, we would say that equals if and only if .
Using a relation. An equivalence is a relation that is:
property
definition
reflexive
symmetric
transitive
To use as a definition for equality, we would say that equals if and only if .
These two notions are equivalent. An equivalence relation induces an abstraction function (the relation partitions T, so f maps each element to its partition class). The relation induced by an abstraction function is an equivalence relation (check for yourself that the three properties hold).
A third way we can talk about the equality between abstract values is in terms of what an outsider (a client) can observe about them:
Using observation. We can say that two objects are equal when they cannot be distinguished by observation – every operation we can apply produces the same result for both objects. Consider the set expressions {1,2} and {2,1}. Using the observer operations available for sets, cardinality |…| and membership ∈, these expressions are indistinguishable:
and
is true, and is true
is true, and is true
is false, and is false
… and so on
In terms of abstract data types, “observation” means calling operations on the objects. So two objects are equal if and only if they cannot be distinguished by calling any operations of the abstract data type.
Example: Duration
Here’s a simple example of an immutable ADT.
1 publicclassDuration{ 2 privatefinalintmins; 3 privatefinalintsecs; 4 // rep invariant: 5 // mins >= 0, secs >= 0 6 // abstraction function: 7 // represents a span of time of mins minutes and secs seconds 8 9 /** Make a duration lasting for m minutes and s seconds. */10 publicDuration(intm,ints){11 mins=m;secs=s;12 }13 14 /** @return length of this duration in seconds */15 publiclonggetLength(){16 returnmins*60+secs;17 }18 }
Now which of the following values should be considered equal?
1 Duration d1 = new Duration (1, 2);
2 Duration d2 = new Duration (1, 3);
3 Duration d3 = new Duration (0, 62);
4 Duration d4 = new Duration (1, 2);
Think in terms of both the abstraction-function definition of equality, and the observational equality definition.
Test Yourself
Any second now
Consider the code for Duration and the objects d1, d2, d3, d4 just created above.
Using the abstraction-function notion of equality, which of the following would be considered equal to d1?
- [ ] d1
- [ ] d2
- [ ] d3
- [ ] d4
Eye on the clock
Using the observational notion of equality, which of the following would be considered equal to d1?
- [ ] d1
- [ ] d2
- [ ] d3
- [ ] d4
== vs. equals()
Like many languages, Java has two different operations for testing equality, with different semantics.
The == operator compares references. More precisely, it tests referential equality. Two references are == if they point to the same storage in memory. In terms of the snapshot diagrams we’ve been drawing, two references are == if their arrows point to the same object bubble.
The equals() operation compares object contents – in other words, object equality, in the sense that we’ve been talking about in this reading. The equals operation has to be defined appropriately for every abstract data type.
For comparison, here are the equality operators in several languages:
language
referential equality
object equality
Java
==
equals()
Objective C
==
isEqual:
C#
==
Equals()
Python
is
==
Javascript
==
n/a
As programmers in any of these languages, we can’t change the meaning of the referential equality operator. In Java, == always means referential equality. But when we define a new data type, it’s our responsibility to decide what object equality means for values of the data type, and implement the equals() operation appropriately.
Equality of Immutable Types
The equals() method is defined by Object, and its default implementation looks like this:
In other words, the default meaning of equals() is the same as referential equality. For immutable data types, this is almost always wrong. So you have to override the equals() method, replacing it with your own implementation.
You can see this code in action. You’ll see that even though d2 and o2 end up referring to the very same object in memory, you still get different results for them from equals().
What’s going on? It turns out that Duration has overloaded the equals() method, because the method signature was not identical to Object’s. We actually have two equals() methods in Duration: an implicit equals(Object) inherited from Object, and the new equals(Duration).
1 publicclassDurationextendsObject{ 2 // explicit method that we declared: 3 publicbooleanequals(Durationthat){ 4 returnthis.getLength()==that.getLength(); 5 } 6 // implicit method inherited from Object: 7 publicbooleanequals(Objectthat){ 8 returnthis==that; 9 }10 }
We’ve seen overloading since the very beginning of the course in static checking. Recall from the Java Tutorials that the compiler selects between overloaded operations using the compile-time type of the parameters. For example, when you use the / operator, the compiler chooses either integer division or float division based on whether the arguments are ints or floats. The same compile-time selection happens here. If we pass an Object reference, as in d1.equals(o2), we end up calling the equals(Object) implementation. If we pass a Duration reference, as in d1.equals(d2), we end up calling the equals(Duration) version. This happens even though o2 and d2 both point to the same object at runtime! Equality has become inconsistent.
It’s easy to make a mistake in the method signature, and overload a method when you meant to override it. This is such a common error that Java has a language feature, the annotation @Override, which you should use whenever your intention is to override a method in your superclass. With this annotation, the Java compiler will check that a method with the same signature actually exists in the superclass, and give you a compiler error if you’ve made a mistake in the signature.
So here’s the right way to implement Duration’s equals() method:
The specification of the Object class is so important that it is often referred to as the Object Contract. The contract can be found in the method specifications for the Object class. Here we will focus on the contract for equals. When you override the equals method, you must adhere to its general contract. It states that:
equals must define an equivalence relation – that is, a relation that is reflexive, symmetric, and transitive;
equals must be consistent: repeated calls to the method must yield the same result provided no information used in equals comparisons on the object is modified;
for a non-null reference x, x.equals(null) should return false;
hashCode must produce the same result for two objects that are deemed equal by the equals method.
Breaking the Equivalence Relation
Let’s start with the equivalence relation. We have to make sure that the definition of equality implemented by equals() is actually an equivalence relation as defined earlier: reflexive, symmetric, and transitive. If it isn’t, then operations that depend on equality (like sets, searching) will behave erratically and unpredictably. You don’t want to program with a data type in which sometimes a equals b, but b doesn’t equal a. Subtle and painful bugs will result.
Here’s an example of how an innocent attempt to make equality more flexible can go wrong. Suppose we wanted to allow for a tolerance in comparing Duration objects, because different computers may have slightly unsynchronized clocks:
```java
private static final int CLOCK_SKEW = 5; // seconds
Which property of the equivalence relation is violated?
Test Yourself
Equals-ish
Consider the latest implementation of Duration that appeared earlier in the reading.
Suppose these Duration objects are created:
Duration d_0_60 = new Duration(0, 60);
Duration d_1_00 = new Duration(1, 0);
Duration d_0_57 = new Duration(0, 57);
Duration d_1_03 = new Duration(1, 3);
Which of the following expressions return true?
- [ ] d_0_60.equals(d_1_00)
- [ ] d_1_00.equals(d_0_60)
- [ ] d_1_00.equals(d_1_00)
- [ ] d_0_57.equals(d_1_00)
- [ ] d_0_57.equals(d_1_03)
- [ ] d_0_60.equals(d_1_03)
Skewed up
Which properties of an equivalence relation are violated by this equals() method?
- [ ] recursivity
- [ ] reflexivity
- [ ] sensitivity
- [ ] symmetry
- [ ] transitivity
Buggy equality
Suppose you want to show that an equality operation is buggy because it isn’t reflexive. How many objects do you need for a counterexample to reflexivity?
[ ] none
[ ] 1 object
[ ] 2 objects
[ ] 3 objects
[ ] all the objects in the type
Breaking Hash Tables
To understand the part of the contract relating to the hashCode method, you’ll need to have some idea of how hash tables work. Two very common collection implementations, HashSet and HashMap, use a hash table data structure, and depend on the hashCode method to be implemented correctly for the objects stored in the set and used as keys in the map.
A hash table is a representation for a mapping: an abstract data type that maps keys to values. Hash tables offer constant time lookup, so they tend to perform better than trees or lists. Keys don’t have to be ordered, or have any particular property, except for offering equals and hashCode.
Here’s how a hash table works. It contains an array that is initialized to a size corresponding to the number of elements that we expect to be inserted. When a key and a value are presented for insertion, we compute the hashcode of the key, and convert it into an index in the array’s range (e.g., by a modulo division). The value is then inserted at that index.
The rep invariant of a hash table includes the fundamental constraint that keys are in the slots determined by their hash codes.
Hashcodes are designed so that the keys will be spread evenly over the indices. But occasionally a conflict occurs, and two keys are placed at the same index. So rather than holding a single value at an index, a hash table actually holds a list of key/value pairs, usually called a hash bucket. A key/value pair is implemented in Java simply as an object with two fields. On insertion, you add a pair to the list in the array slot determined by the hash code. For lookup, you hash the key, find the right slot, and then examine each of the pairs until one is found whose key matches the query key.
Now it should be clear why the Object contract requires equal objects to have the same hashcode. If two equal objects had distinct hashcodes, they might be placed in different slots. So if you attempt to lookup a value using a key equal to the one with which it was inserted, the lookup may fail.
Object’s default hashCode() implementation is consistent with its default equals():
1 publicclassObject{2 ...3 publicbooleanequals(Objectthat){returnthis==that;}4 publicinthashCode(){return/* the memory address of this */;}5 }
For references a and b, if a == b, then the address of a == the address of b. So the Object contract is satisfied.
But immutable objects need a different implementation of hashCode(). For Duration, since we haven’t overridden the default hashCode() yet, we’re currently breaking the Object contract:
d1 and d2 are equal(), but they have different hash codes. So we need to fix that.
A simple and drastic way to ensure that the contract is met is for hashCode to always return some constant value, so every object’s hash code is the same. This satisfies the Object contract, but it would have a disastrous performance effect, since every key will be stored in the same slot, and every lookup will degenerate to a linear search along a long list.
The standard way to construct a more reasonable hash code that still satisfies the contract is to compute a hash code for each component of the object that is used in the determination of equality (usually by calling the hashCode method of each component), and then combining these, throwing in a few arithmetic operations. For Duration, this is easy, because the abstract value of the class is already an integer value:
Josh Bloch’s book, Effective Java, explains this issue in more detail, and gives some strategies for writing decent hash code functions. The advice is summarized in a good StackOverflow post. Recent versions of Java now have a utility method Objects.hash() that makes it easier to implement a hash code involving multiple fields.
Note, however, that as long as you satisfy the requirement that equal objects have the same hash code value, then the particular hashing technique you use doesn’t make a difference to the correctness of your code. It may affect its performance, by creating unnecessary collisions between different objects, but even a poorly-performing hash function is better than one that breaks the contract.
Most crucially, note that if you don’t override hashCode at all, you’ll get the one from Object, which is based on the address of the object. If you have overridden equals, this will mean that you will have almost certainly violated the contract. So as a general rule:
Always override hashCode when you override equals. Also use @Override.
Test Yourself
Give me the code
Consider the following ADT class:
```java
class Person {
private String firstName;
private String lastName;
…
public boolean equals(Object obj) {
if (!(obj instanceof Person)) return false;
Person that = (Person) obj;
return this.lastName.toUpperCase().equals(that.lastName.toUpperCase());
}
1 public int hashCode() {
2 // TODO
3 }
}
```
Which of the following could be put in place of the line mrked TODO to make hashCode() consistent with equals()?
We’ve been focusing on equality of immutable objects so far in this reading. What about mutable objects?
Recall our definition: two objects are equal when they cannot be distinguished by observation. With mutable objects, there are two ways to interpret this:
when they cannot be distinguished by observation that doesn’t change the state of the objects, i.e., by calling only observer, producer, and creator methods. This is often strictly called observational equality, since it tests whether the two objects “look” the same, in the current state of the program.
when they cannot be distinguished by any observation, even state changes. This interpretation allows calling any methods on the two objects, including mutators. This is often called behavioral equality, since it tests whether the two objects will “behave” the same, in this and all future states.
For immutable objects, observational and behavioral equality are identical, because there aren’t any mutator methods.
For mutable objects, it’s tempting to implement strict observational equality. Java uses observational equality for most of its mutable data types, in fact. If two distinct List objects contain the same sequence of elements, then equals() reports that they are equal.
But using observational equality leads to subtle bugs, and in fact allows us to easily break the rep invariants of other collection data structures. Suppose we make a List, and then drop it into a Set:
If the set’s own iterator and its own contains() method disagree about whether an element is in the set, then the set clearly is broken. You can see this code in action on Online Python Tutor.
What’s going on? List<string> is a mutable object. In the standard Java implementation of collection classes like List, mutations affect the result of equals() and hashCode(). When the list is first put into the HashSet, it is stored in the hash bucket corresponding to its hashCode() result at that time. When the list is subsequently mutated, its hashCode() changes, but HashSet doesn’t realize it should be moved to a different bucket. So it can never be found again.
When equals() and hashCode() can be affected by mutation, we can break the rep invariant of a hash table that uses that object as a key.
Here’s a telling quote from the specification of java.util.Set:
Note: Great care must be exercised if mutable objects are used as set elements. The behavior of a set is not specified if the value of an object is changed in a manner that affects equals comparisons while the object is an element in the set.
The Java library is unfortunately inconsistent about its interpretation of equals() for mutable classes. Collections use observational equality, but other mutable classes (like StringBuilder) use behavioral equality.
The lesson we should draw from this example is that equals() should implement behavioral equality. In general, that means that two references should be equals() if and only if they are aliases for the same object. So mutable objects should just inherit equals() and hashCode() from Object. For clients that need a notion of observational equality (whether two mutable objects “look” the same in the current state), it’s better to define a new method, e.g., similar().
The Final Rule for equals and hashCode()
For immutable types:
equals() should compare abstract values. This is the same as saying equals() should provide behavioral equality.
hashCode() should map the abstract value to an integer.
So immutable types must override both equals() and hashCode().
For mutable types:
equals() should compare references, just like ==. Again, this is the same as saying equals() should provide behavioral equality.
hashCode should map the reference into an integer.
So mutable types should not override equals() and hashCode() at all, and should simply use the default implementations provided by Object. Java doesn’t follow this rule for its collections, unfortunately, leading to the pitfalls that we saw above.
Test Yourself
Bag
Suppose Bag<e> is a mutable ADT representing what is often called a multiset, an unordered collection of objects where an object can occur more than once. It has the following operations:
```java
/** make an empty bag */
public Bag<e>()
/** modify this bag by adding an occurence of e, and return this bag */
public Bag<e> add(E e)
/** modify this bag by removing an occurence of e (if any), and return this bag */
public Bag<e> remove(E e)
/** return number of times e occurs in this bag */
public int count(E e)
```
Which of the following expressions are true after all the the code has been run?
- [ ] b1.count("a") == 1
- [ ] b1.count("b") == 1
- [ ] b2.count("a") == 1
- [ ] b2.count("b") == 1
- [ ] b3.count("a") == 1
- [ ] b3.count("b") == 1
- [ ] b4.count("a") == 1
- [ ] b4.count("b") == 1
Bag behavior
If Bag is implemented with behavioral equality, which of the following expressions are true?
[ ] b1.equals(b2)
[ ] b1.equals(b3)
[ ] b1.equals(b4)
[ ] b2.equals(b3)
[ ] b2.equals(b4)
[ ] b3.equals(b1)
Bean bag
If Bag were part of the Java API, it would probably implement observational equality, counter to the recommendation in the reading.
If Bag implemented observational equality despite the dangers, which of the following expressions are true?
[ ] b1.equals(b2)
[ ] b1.equals(b3)
[ ] b1.equals(b4)
[ ] b2.equals(b3)
[ ] b2.equals(b4)
[ ] b3.equals(b1)
Autoboxing and Equality
One more instructive pitfall in Java. We’ve talked about primitive types and their object type equivalents – for example, int and Integer. The object type implements equals() in the correct way, so that if you create two Integer objects with the same value, they’ll be equals() to each other:
But there’s a subtle problem here; == is overloaded. For reference types like Integer, it implements referential equality:
1 x==y// returns false
But for primitive types like int, == implements behavioral equality:
1 (int)x==(int)y// returns true
So you can’t really use Integer interchangeably with int. The fact that Java automatically converts between int and Integer (this is called autoboxing and autounboxing) can lead to subtle bugs! You have to be aware what the compile-time types of your expressions are. Consider this:
1 Map<string,integer="">a=newHashMap(),b=newHashMap();2 a.put("c",130);// put ints into the map3 b.put("c",130);4 a.get("c")==b.get("c")→??// what do we get out of the map?
In some cases, we may want to not only test if two objects are equal but we may want to verify ordering of the objects.
In Java, a datatype that permits ordering of instances can be implemented using a a class that implements the interface Comparable. To implement the interface, one would need to implement a method [compareTo].
The signature for compareTo for type/class T is:
1 intcompareTo(To)
and the method returns a negative integer if this object is smaller than the object it is being compared to (o), it returns 0 if the two objects are equal, and a positive integer if this object is greater than the object it is being compared to.
compareTo should be consistent with equals: if equals(o) returns true then compareTo(o) should return 0.
Summary
Equality should be an equivalence relation (reflexive, symmetric, transitive).
Equality and hash code must be consistent with each other, so that data structures that use hash tables (like HashSet and HashMap) work properly.
The abstraction function is the basis for equality in immutable data types.
Reference equality is the basis for equality in mutable data types; this is the only way to ensure consistency over time and avoid breaking rep invariants of hash tables.
Equality is one part of implementing an abstract data type, and we’ve already seen how important ADTs are to achieving our three primary objectives. Let’s look at equality in particular:
Safe from bugs. Correct implementation of equality and hash codes is necessary for use with collection data types like sets and maps. It’s also highly desirable for writing tests. Since every object in Java inherits the Object implementations, immutable types must override them.
Easy to understand. Clients and other programmers who read our specs will expect our types to implement an appropriate equality operation, and will be surprised and confused if we do not.
Ready for change. Correctly-implemented equality for immutable types separates equality of reference from equality of abstract value, hiding from clients our decisions about whether values are shared. Choosing behavioral rather than observational equality for mutable types helps avoid unexpected aliasing bugs.
 ,
, 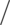
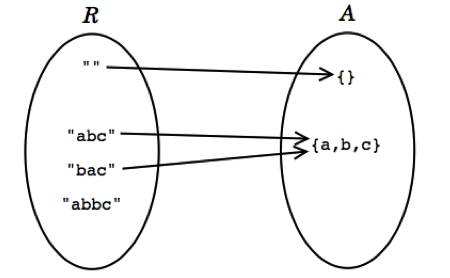
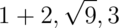 are alternative expressions for the same ideal mathematical value.
are alternative expressions for the same ideal mathematical value.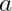 equals
equals 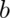 if and only if
if and only if 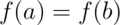 .
.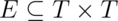 that is:
that is: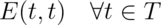

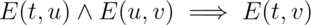
 as a definition for equality, we would say that
as a definition for equality, we would say that  equals
equals 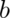 if and only if
if and only if 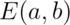 .
. and
and 
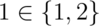 is true, and
is true, and 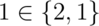 is true
is true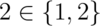 is true, and
is true, and 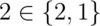 is true
is true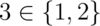 is false, and
is false, and 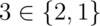 is false
is false