Semantic Search Using a Vector Database and Python and uv Interoperability
In this chapter we build a local semantic search engine using ChromaDB, a high-performance open-source vector database, accessed from Clojure via the libpython-clj2 Python interoperability bridge. The dependency management for the Python side is handled by uv, which provides a fast, reproducible virtual environment.
This chapter is closely related to the earlier libpython-clj2 chapter — the same bridge that let us call spaCy and Hugging Face models is used here to call ChromaDB’s Python client. If you have already worked through that chapter you will find the setup familiar; if not, you can still follow along since this project is self-contained.
The source code for this chapter is in the directory source-code/vectordb_semantic_search_python of the GitHub repository for this book: https://github.com/mark-watson/Clojure-AI-Book.
What Is a Vector Database?
A vector database stores documents not as plain text but as dense numerical vectors (also called embeddings). An embedding is a list of floating-point numbers — typically hundreds or thousands of dimensions long — that captures the meaning of a piece of text. Documents with similar meanings end up with embeddings that are geometrically close to each other.
When you perform a semantic search you supply a query string, convert it to an embedding using the same model that was used to embed the documents, and then find the stored embeddings that are closest to the query embedding. The result is a ranked list of documents that are semantically related to your query — not merely documents that contain the same keywords.
ChromaDB automates the embedding step: you supply raw text and ChromaDB calls the all-MiniLM-L6-v2 transformer model (via the ONNX runtime) to produce embeddings automatically. The model is downloaded on first use to ~/.cache/chroma/onnx_models/ and cached for subsequent runs.
Architecture Overview
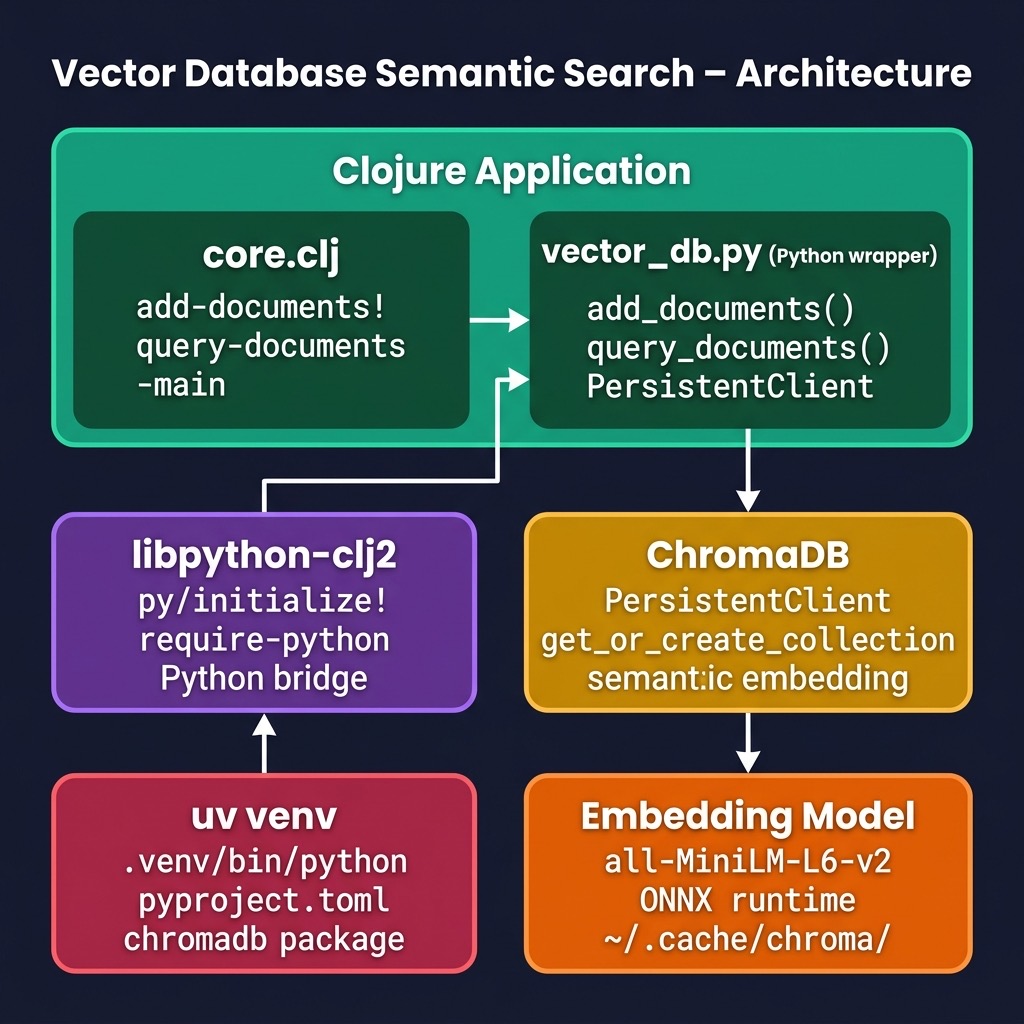
The application is structured in two layers:
-
Python layer —
vector_db.pywraps the ChromaDBPersistentClient. It exposes two plain functions,add_documentsandquery_documents, so that the Clojure code never has to deal with ChromaDB’s Python objects directly. -
Clojure layer —
core.cljinitialises the libpython-clj2 bridge pointing at the uv-managed virtual environment, importsvector_db.pyas a Python module, and exposes idiomatic Clojure functions that return plain Clojure maps.
Setting Up the Project with uv
The Python dependencies are declared in pyproject.toml:
1 [project]
2 name = "vectordb-semantic-search"
3 version = "0.1.0"
4 requires-python = ">=3.12,<3.14"
5 dependencies = [
6 "chromadb>=0.6.0",
7 ]
Install the virtual environment with a single command:
1 uv sync
To run the project, prefix Leiningen commands with uv run so that the virtual environment Python is on the path and libpython-clj2 can find it:
1 # Run the demo
2 uv run lein run
3
4 # Interactive REPL
5 uv run lein repl
The Python Wrapper: vector_db.py
Keeping the Python code in a thin wrapper module is a pattern recommended throughout this book. It makes the ChromaDB API easy to call from Clojure because all argument types are plain Python primitives (strings and lists):
1 import chromadb
2
3 # Initialize a local persistent database
4 client = chromadb.PersistentClient(path="./chroma_db")
5
6 def add_documents(collection_name, documents, metadatas, ids):
7 """
8 Add a collection of documents with metadata and unique IDs
9 to the vector database.
10 """
11 collection = client.get_or_create_collection(
12 name=collection_name)
13 # Ensure lists are passed as standard python lists
14 # (libpython-clj passes them as iterable collections)
15 collection.add(
16 documents=list(documents),
17 metadatas=list(metadatas),
18 ids=list(ids)
19 )
20 return True
21
22 def query_documents(collection_name, query_text, n_results=2):
23 """
24 Perform semantic search and return a list of maps
25 containing id, document, metadata, and distance.
26 """
27 collection = client.get_or_create_collection(
28 name=collection_name)
29 results = collection.query(
30 query_texts=[query_text],
31 n_results=int(n_results)
32 )
33
34 formatted = []
35 if results and 'documents' in results \
36 and results['documents']:
37 docs = results['documents'][0]
38 metas = results['metadatas'][0]
39 distances = results['distances'][0]
40 ids = results['ids'][0]
41
42 for i in range(len(docs)):
43 formatted.append({
44 "id": ids[i],
45 "document": docs[i],
46 "metadata": metas[i] if metas[i] else {},
47 "distance": float(distances[i])
48 })
49 return formatted
A few design decisions worth noting:
-
PersistentClientstores the ChromaDB data on disk under./chroma_db/. This means the collection survives across runs; you can add documents in one session and query them in another. -
get_or_create_collectionis idempotent — it creates the collection if it does not exist, and returns it if it does. - The
list()wrappers inadd_documentsare important because libpython-clj2 passes Clojure sequences as Java iterables, not Python lists. ChromaDB’scollection.addrequires genuine Python lists. - The returned
formattedlist contains Python dicts with string keys. libpython-clj2 converts these automatically to Clojure maps with keyword keys when they are received on the Clojure side.
The Clojure Orchestration Layer: core.clj
The Leiningen project file declares a single external dependency — libpython-clj2 — plus several JVM options required to make the Python bridge work correctly on modern JVMs:
1 (defproject vectordb_semantic_search "0.1.0-SNAPSHOT"
2 :description
3 "Semantic search example using libpython-clj and ChromaDB"
4 :url
5 "https://github.com/mark-watson/Clojure-AI-Book"
6 :license {:name "EPL-2.0 OR GPL-2.0-or-later ..."
7 :url "https://www.eclipse.org/legal/epl-2.0/"}
8 :jvm-opts ["-Djdk.attach.allowAttachSelf"
9 "-XX:+UnlockDiagnosticVMOptions"
10 "-XX:+DebugNonSafepoints"
11 "-Dlibpython_clj.python_executable=.venv/bin/python"]
12 :dependencies [[org.clojure/clojure "1.11.1"]
13 [clj-python/libpython-clj "2.026"]]
14 :main ^:skip-aot
15 vectordb-semantic-search-python.core
16 :target-path "target/%s"
17 :profiles {:uberjar
18 {:aot :all
19 :jvm-opts
20 ["-Dclojure.compiler.direct-linking=true"]}})
The main source file src/vectordb_semantic_search_python/core.clj initialises Python, loads the wrapper, and provides idiomatic Clojure wrappers:
1 (ns vectordb-semantic-search-python.core
2 (:require [libpython-clj2.require :refer [require-python]]
3 [libpython-clj2.python :as py
4 :refer [py. py.-]]))
5
6 ;; Point libpython-clj2 at the uv-managed venv Python
7 (py/initialize!
8 :python-executable
9 (str (System/getProperty "user.dir")
10 "/.venv/bin/python"))
11
12 ;; Import the local Python wrapper
13 (require-python '[vector_db :as db])
14
15 (defn add-documents!
16 "Adds documents to a named ChromaDB collection.
17 documents, metadatas, and ids should be Clojure vectors."
18 [collection-name documents metadatas ids]
19 (db/add_documents collection-name
20 documents metadatas ids))
21
22 (defn query-documents
23 "Semantic search against a collection.
24 Returns a sequence of Clojure maps with keys
25 :id, :document, :metadata, and :distance."
26 [collection-name query-text n-results]
27 (db/query_documents collection-name
28 query-text n-results))
29
30 (defn -main
31 [& _]
32 (println "=== Starting Vector DB Semantic Search Demo ===")
33 (let [collection "clojure_ai_docs"
34 docs
35 ["Clojure is a modern Lisp dialect that targets
36 the JVM, CLR, and JavaScript. It features
37 functional programming and immutable data
38 structures."
39 "Python is an interpreted, high-level,
40 general-purpose programming language. It is
41 widely used in data science, AI, and machine
42 learning."
43 "French onion soup is a soup made from onions,
44 beef stock, and usually served with cheese and
45 bread."
46 "Generative adversarial networks (GANs) are a
47 class of machine learning frameworks where two
48 neural networks contest with each other in a
49 game."]
50 metadatas [{"type" "programming" "lang" "clojure"}
51 {"type" "programming" "lang" "python"}
52 {"type" "food" "cuisine" "french"}
53 {"type" "ai" "topic" "gan"}]
54 ids ["id_clojure" "id_python"
55 "id_soup" "id_gan"]]
56
57 (println "Inserting sample documents...")
58 (add-documents! collection docs metadatas ids)
59 (println "Documents inserted successfully.")
60
61 (println "\n--- Query 1: 'neural network architectures' ---")
62 (let [results
63 (query-documents collection
64 "neural network architectures"
65 2)]
66 (doseq [res results]
67 (println "Match:" (:document res))
68 (println "Metadata:" (:metadata res))
69 (println "Distance:" (:distance res) "\n")))
70
71 (println "--- Query 2: 'functional programming language' ---")
72 (let [results
73 (query-documents collection
74 "functional programming language"
75 1)]
76 (doseq [res results]
77 (println "Match:" (:document res))
78 (println "Metadata:" (:metadata res))
79 (println "Distance:" (:distance res) "\n")))
80
81 (println "--- Query 3: 'cooking recipes and food' ---")
82 (let [results
83 (query-documents collection
84 "cooking recipes and food" 1)]
85 (doseq [res results]
86 (println "Match:" (:document res))
87 (println "Metadata:" (:metadata res))
88 (println "Distance:" (:distance res) "\n")))
89 (shutdown-agents)))
Several things are worth highlighting:
-
py/initialize!— called once at the top of the namespace, not inside a function. It starts the embedded Python interpreter and informs libpython-clj2 which Python binary to use. Pointing it at.venv/bin/pythonensures the ChromaDB package (and its ONNX dependencies) are visible. -
require-python— loadsvector_db.pyfrom the current working directory (where Leiningen is run) and binds it to the aliasdb. Calls todb/add_documentsanddb/query_documentstranslate directly to calls to the Python functions of the same names. -
shutdown-agents— called at the end of-mainto cleanly terminate Clojure’s thread pool. Without this call the JVM would hang for a noticeable period waiting for non-daemon threads to finish before exiting.
Running the Demo
1 $ uv run lein run
2 === Starting Vector DB Semantic Search Demo ===
3 Inserting sample documents...
4 Documents inserted successfully.
5
6 --- Query 1: 'neural network architectures' ---
7 Match: Generative adversarial networks (GANs) are a class
8 of machine learning frameworks where two neural
9 networks contest with each other in a game.
10 Metadata: {'type': 'ai', 'topic': 'gan'}
11 Distance: 1.322404384613037
12
13 Match: French onion soup is a soup made from onions, beef
14 stock, and usually served with cheese and bread.
15 Metadata: {'type': 'food', 'cuisine': 'french'}
16 Distance: 1.7437050342559814
17
18 --- Query 2: 'functional programming language' ---
19 Match: Clojure is a modern Lisp dialect that targets the
20 JVM, CLR, and JavaScript. It features functional
21 programming and immutable data structures.
22 Metadata: {'lang': 'clojure', 'type': 'programming'}
23 Distance: 0.9769030213356018
24
25 --- Query 3: 'cooking recipes and food' ---
26 Match: French onion soup is a soup made from onions, beef
27 stock, and usually served with cheese and bread.
28 Metadata: {'type': 'food', 'cuisine': 'french'}
29 Distance: 1.4435760974884033
The results demonstrate semantic matching. Query 1 asks about neural network architectures; the GAN document ranks first even though neither the word “architecture” nor “neural network” appears in that document verbatim — the model understands that GANs are a class of neural network architectures.
Similarly, Query 2 retrieves the Clojure document (not the Python one) because functional programming and immutable data are distinctly Clojure concepts. Query 3 correctly returns the French onion soup document for a query about cooking.
Note that the distance values are L2 (Euclidean) distances between embedding vectors, not similarity scores. Smaller values indicate a closer (more similar) match. ChromaDB uses the all-MiniLM-L6-v2 model, which generates 384-dimensional embeddings — a good balance between quality and speed for local use.
Note on the Model Cache
The first time you run the example, ChromaDB downloads the all-MiniLM-L6-v2 model weights in ONNX format to:
1 ~/.cache/chroma/onnx_models/
This directory can grow to several hundred megabytes. If you want to reclaim the disk space after experimenting, you can safely delete it; ChromaDB will re-download on the next run.
Wrap Up
In this chapter we demonstrated how to use a modern vector database — ChromaDB — from Clojure by leveraging the libpython-clj2 bridge and uv for Python dependency management. The key ideas are:
- Wrap the Python library in a thin Python module (
vector_db.py) that exposes simple functions taking and returning only primitive types. This makes the bridge straightforward and avoids dealing with opaque Python objects in Clojure. - Use
uv syncanduv runto manage the Python virtual environment reproducibly alongside the Leiningen project. - Call
shutdown-agentsat the end of-mainto avoid a slow JVM exit when using libpython-clj2.
This same pattern scales to any Python library: wrap it in a thin Python module, initialize the bridge pointing at your uv venv, and call in from idiomatic Clojure code.