Natural Language Processing Using OpenNLP
Here we use the Apache OpenNLP project written in Java. OpenNLP has pre-trained models for tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing, and coreference resolution. Here we use a subset of OpenNLP’s functionality. My Java AI book has a more complete treatment, including building custom classification models and performing chunk-parsing of sentence structure.
Currently, OpenNLP has support for Danish, German, English, Spanish, Portuguese, and Swedish. I include in the github repository pre-trained models for English in the directory models.
Using the Clojure and Java Wrappers for OpenNLP
I won’t list the simple Java wrapper code in the directory src-java here. You might want to open the files NLP.java and Pair.java for reference:
The project.clj file shows the setup for incorporating Java code into a Clojure project:
(defproject opennlp-clj "0.1.0-SNAPSHOT"
:description "Example using OpenNLP with Clojure"
:url "http://markwatson.com"
:license
{:name
"EPL-2.0 OR GPL-2+ WITH Classpath-exception-2.0"
:url "https://www.eclipse.org/legal/epl-2.0/"}
:source-paths ["src"]
:java-source-paths ["src-java"]
:javac-options ["-target" "1.8" "-source" "1.8"]
:dependencies [[org.clojure/clojure "1.10.1"]
;from my Java AI book:
;[com.markwatson/opennlp "1.0-SNAPSHOT"]
[opennlp/tools "1.5.0"]]
:repl-options {:init-ns opennlp-clj.core})
Note the use of :java-source-paths to specify where the Java codes are stored in the project. When you use lein run to try the example, both the Java and Clojure code are compiled. When I first wrote this example, I used the maven output target for the OpenNLP example in my Java AI book. I left the dependency in this project.clj file commented out and instead added the two Java source files to this project. Copying the code into this project should make it easier for you to run this example.
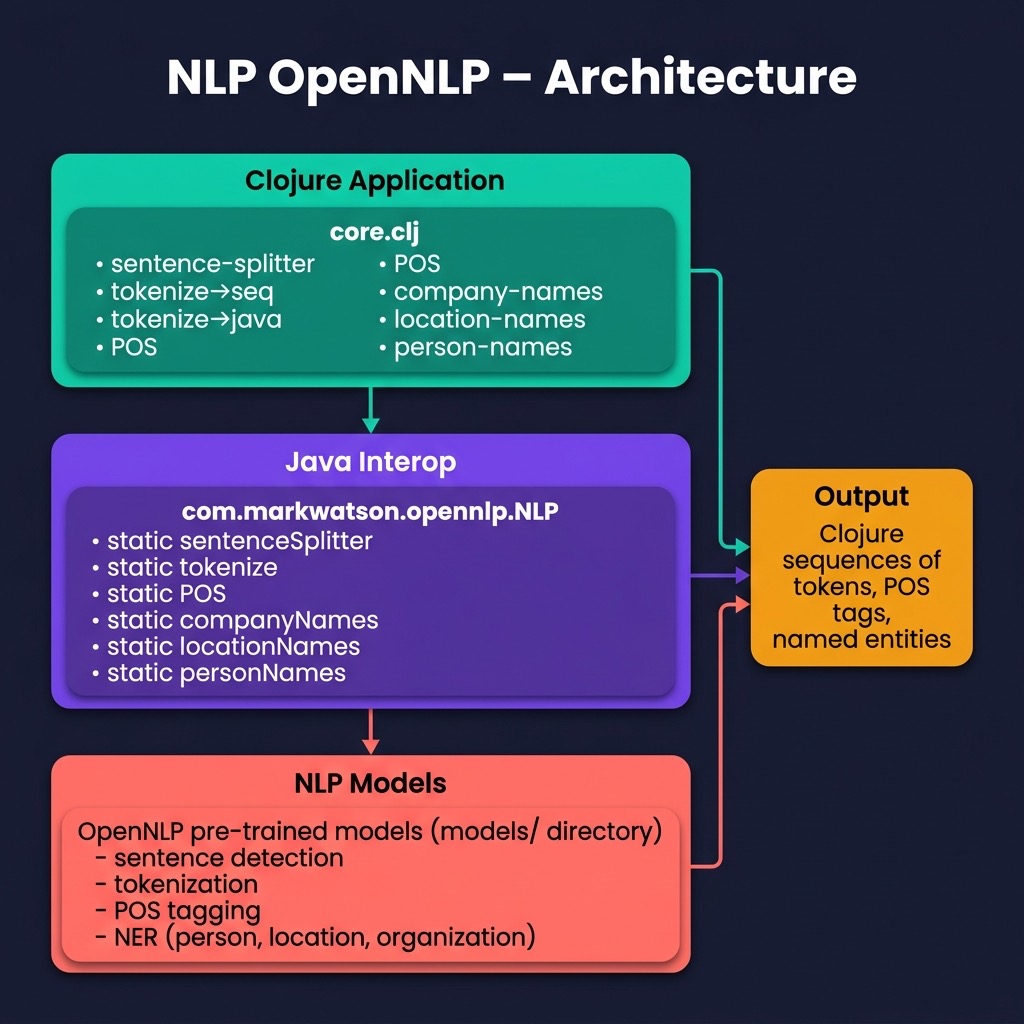
In the following listing, notice that I have two versions of tokenization functions:tokenize->java returns Java data structures andtokenize->seq returns a Clojure seq. The other example wrapper functions take a Java array of tokens as an argument.
1 (ns opennlp-clj.core
2 (:import (com.markwatson.opennlp NLP)))
3
4 (defn sentence-splitter
5 "tokenize entire sentences"
6 [string-input]
7 (seq (NLP/sentenceSplitter string-input)))
8
9 (defn tokenize->seq
10 "tokenize words to Clojure seq"
11 [string-input]
12 (seq (NLP/tokenize string-input)))
13
14 (defn tokenize->java
15 "tokenize words to Java array"
16 [string-input]
17 (NLP/tokenize string-input))
18
19 ;; Word analysis:
20
21 (defn POS
22 "part of speech"
23 [java-token-array]
24 (seq (NLP/POS java-token-array)))
25
26 ;; Entities:
27
28 (defn company-names
29 [java-token-array]
30 (seq (NLP/companyNames java-token-array)))
31
32 (defn location-names
33 [java-token-array]
34 (seq (NLP/locationNames java-token-array)))
35
36 (defn person-names
37 [java-token-array]
38 (seq (NLP/personNames java-token-array)))
Here I tokenize text into a Java array that is used to call the Java OpenNLP code (in the directory src-java). The first operation that you will usually start with for processing natural language text is breaking input text into individual words and sentences.
The test code for this project shows how to use these APIs:
1 (ns opennlp-clj.core-test
2 (:require [clojure.test :as test])
3 (:require [opennlp-clj.core :as onlp]))
4
5 (def
6 test-text
7 "The cat chased the mouse around the tree while Mary Smith (who works at IBM in Sa\
8 n Francisco) watched.")
9
10 (test/deftest pos-test
11 (test/testing "parts of speech"
12 (let [token-java-array (onlp/tokenize->java test-text)
13 token-clojure-seq (onlp/tokenize->seq test-text)
14 words-pos (onlp/POS token-java-array)
15 companies (onlp/company-names token-java-array)
16 places (onlp/location-names token-java-array)
17 people (onlp/person-names token-java-array)]
18 (println "Input text:\n" test-text)
19 (println "Tokens as Java array:\n" token-java-array)
20 (println "Tokens as Clojure seq:\n"
21 token-clojure-seq)
22 (println "Part of speech tokens:\n" words-pos)
23 (println "Companies:\n" companies)
24 (println "Places:\n" places)
25 (println "People:\n" people)
26 (test/is (= (first words-pos) "DT")))))
Here is the test output:
The part of speech tokens like DT (determiner), NN (noun), etc. are defined in the README file for this project.
Note: My Java AI book covers OpenNLP in more depth, including how to train your own classification models.
We take a different approach to NLP in the next chapter: using the libpython-clj library to call Python NLP libraries and pre-trained deep learning models. The Python models have more functionality but the OpenNLP library is much easier to setup and use with Clojure.