Web Scraping
I often write software to automatically collect and use data from the web and other sources. As a practical matter, much of the data that many people use for machine learning comes from either the web or from internal data sources. This section provides some guidance and examples for getting text data from the web.
Before we start a technical discussion about web scraping I want to point out that much of the information on the web is copyright and the first thing that you should do is to read the terms of service for web sites to insure that your use of “scraped” or “spidered” data conforms with the wishes of the persons or organizations who own the content and pay to run scraped web sites.
Web Scraping Using the jsoup Library
We will use the MIT licensed Java library jsoup. One reason I selected jsoup for the examples in this chapter out of many fine libraries that provide similar functionality is the particularly nice documentation, especially The jsoup Cookbook which I urge you to bookmark as a general reference. In this chapter I will concentrate on just the most frequent web scraping use cases that I use in my own work: getting all plain text and links from a web site. It should be straightforward for you to take the following example and extend it with whatever else you may need from the jsoup Cookbook.
We need to require the jsoup dependency in the project file:
1 (defproject webscraping "0.1.0-SNAPSHOT"
2 :description "Demonstration of using Java Jsoup library"
3 :url "http://markwatson.com"
4 :license
5 {:name
6 "EPL-2.0 OR GPL-2+ WITH Classpath-exception-2.0"
7 :url "https://www.eclipse.org/legal/epl-2.0/"}
8 :dependencies [[org.clojure/clojure "1.10.1"]
9 [org.jsoup/jsoup "1.7.2"]]
10 :repl-options {:init-ns webscraping.core})
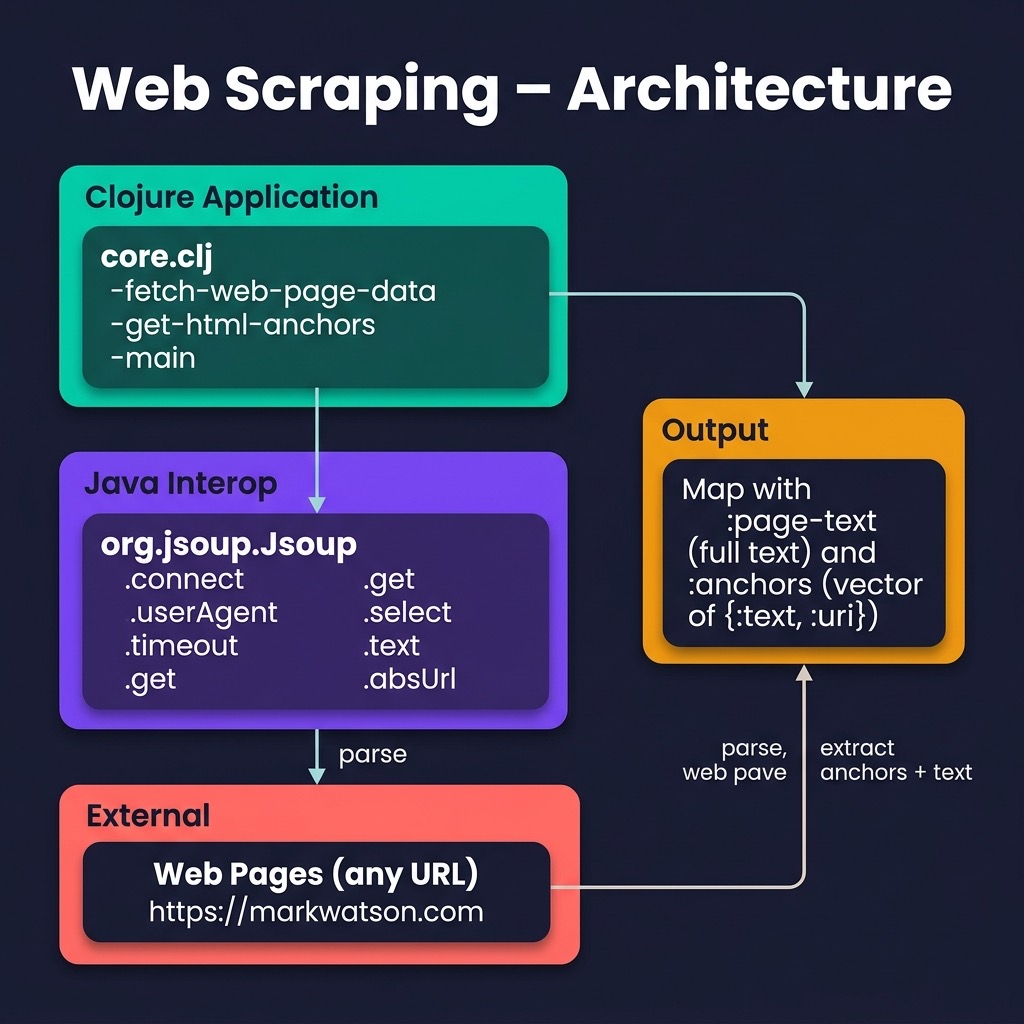
The example code for this chapter uses jsoup to get the complete plain text and also the anchor (<a href=…) data for a web page. In reading the following code let’s start at the end: lines 28-35 where we fetch data from a web site as a jsoup document object. Once we have this document object, we use the Java method text on to get plain text. On line 37 we use the utility function get-html-anchors that is defined in lines 6-23. On line 8 we search for all anchor patterns “a[href]”. For each anchor, we construct the full target URI. Lines 17-21 handle the corner case of URIs like:
1 https://example/com#faq
where we need to use a check to see if a URI starts with “http” in which case we just use the URI as is. Otherwise, treat the URI as a partial like “#faq” that is added to the base URI.
1 (ns webscraping.core
2 (:require [clojure.string :as str]))
3
4 (import (org.jsoup Jsoup))
5
6 (defn get-html-anchors [jsoup-web-page-contents]
7 (let [anchors
8 (. jsoup-web-page-contents select "a[href]")]
9 (for [anchor anchors]
10 (let [anchor-text
11 (. (first (. anchor childNodes)) text)
12 anchor-uri-base
13 (. (first (. anchor childNodes)) baseUri)
14 href-attribute
15 (. (. anchor attributes) get "href")
16 anchor-uri
17 (if (str/starts-with? href-attribute "http")
18 href-attribute
19 (str/join ""
20 [anchor-uri-base
21 (. (. anchor attributes) get "href")]))
22 furi (first (. anchor childNodes))]
23 {:text (str/trim anchor-text) :uri anchor-uri}))))
24
25 (defn fetch-web-page-data
26 "Get the <a> anchor data and full text from a web URI"
27 [a-uri]
28 (let [doc
29 (->
30 (. Jsoup connect a-uri)
31 (.userAgent
32 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.0; rv:77.0) Gecko/20100101 Fi\
33 refox/77.0")
34 (.timeout 20000)
35 (.get))
36 all-page-text (. doc text)
37 anchors (get-html-anchors doc)]
38 {:page-text all-page-text :anchors anchors}))
On lines 32-33 I am setting the same user agent as my local web browser. In principle I would prefer making up a user agent name that contains my name and why I am spidering data, but in practice some web sites refuse requests from non-standard agents.
Let’s look at the test code for an example of fetching the text and links from my personal web site:
1 (ns webscraping.core-test
2 (:require [clojure.test :refer :all]
3 [clojure.pprint :as pp]
4 [webscraping.core :refer :all]))
5
6 (deftest a-test
7 (testing
8 "Fetch my website and check number of results"
9 (let [page-data
10 (fetch-web-page-data "https://markwatson.com")]
11 (pp/pprint page-data)
12 (is (= (count page-data) 2)))))
Output might look like (most of the output is not shown):
{:page-text
"Mark Watson: AI Practitioner and Lisp Hacker ...",
:anchors
({:text "Read my Blog",
:uri "https://mark-watson.blogspot.com"}
{:text "Fun stuff",
:uri "https://markwatson.com#fun"}
{:text "My Books",
:uri "https://markwatson.com#books"}
{:text "My Open Source Projects",
:uri "https://markwatson.com#opensource"}
...
{:text "leanpub",
:uri "https://leanpub.com/u/markwatson"}
{:text "GitHub",
:uri "https://github.com/mark-watson"}
{:text "LinkedIn",
:uri "https://www.linkedin.com/in/marklwatson/"}
{:text "Twitter",
:uri "https://twitter.com/mark_l_watson"}
... )}
For training data for machine learning it is useful to just grab all text on a web page and assume that common phrases dealing with web navigation, etc., will be dropped from learned models because they occur in many different training examples for different classifications.
I find the jsoup library to be robust for fetching and parsing HTML data from web pages. As we have seen, it is straightforward to use jsoup in Clojure projects.