Part 2: Object-Oriented World
Most of the examples in the previous part were about a single object that did not have dependencies on other objects (with an exception of some values – strings, integers, enums, etc.). This is not how most OO systems are built. In this part, we are finally going to look at scenarios where multiple objects work together as a system.
This brings about some issues that need to be discussed. One of them is the approach to object-oriented design and how it influences the tools we use to test-drive our code. You probably heard something about a tool called mock objects (at least from one of the introductory chapters of this book) or, in a broader sense, test doubles. If you open your web browser and type “mock objects break encapsulation”, you will find a lot of different opinions – some saying that mocks are great, others blaming them for all the evil in the world, and a lot of opinions that fall in between. The discussions are still heated, even though mocks were introduced more than ten years ago. My goal in this chapter is to outline the context and forces that lead to the adoption of mocks and how to use them for your benefit, not failure.
Steve Freeman, one of the godfathers of using mock objects with TDD, wrote: “mocks arise naturally from doing responsibility-driven OO. All these mock/not-mock arguments are completely missing the point. If you’re not writing that kind of code, people, please don’t give me a hard time”. I am going to introduce mocks in a way that will not give Steve a hard time, I hope.
To do this, I need to cover some topics of object-oriented design. In fact, I decided to dedicate the entire part 2 solely for that purpose. Thus, this chapter will be about object-oriented techniques, practices, and qualities you need to know to use TDD effectively in the object-oriented world. The key quality that we’ll focus on is objects’ composability.
After reading part 2, you will understand an opinionated approach to object-oriented design that is based on the idea of the object-oriented system being a web of nodes (objects) that pass messages to each other. This will give us a good starting point for introducing mock objects and mock-based TDD in part 3.
On Object Composability
In this chapter, I will try to outline briefly why object composability is a goal worth achieving and how it can be achieved. I am going to start with an example of an unmaintainable code and will gradually fix its flaws in the next chapters. For now, we are going to fix just one of the flaws, so the code we will end up will not be perfect by any means, still, it will be better by one quality.
In the coming chapters, we will learn more valuable lessons resulting from changing this little piece of code.
Another task for Johnny and Benjamin
Remember Johnny and Benjamin? Looks like they managed their previous task and are up to something else. Let’s listen to their conversation as they are working on another project…
Benjamin: So, what’s this assignment about?
Johnny: Actually, it’s nothing exciting – we’ll have to add two features to a legacy application that’s not prepared for the changes.
Benjamin: What is the code for?
Johnny: It is a C# class that implements company policies. As the company has just started using this automated system and it was started recently, there is only one policy implemented: yearly incentive plan. Many corporations have what they call incentive plans. These plans are used to promote good behaviors and exceeding expectations by employees of a company.
Benjamin: You mean, the project has just started and is already in a bad shape?
Johnny: Yep. The guys writing it wanted to “keep it simple”, whatever that means, and now it looks pretty bad.
Benjamin: I see…
Johnny: By the way, do you like riddles?
Benjamin: Always!
Johnny: So here’s one: how do you call a development phase when you ensure high code quality?
Benjamin: … … No clue… So what is it called?
Johnny: It’s called “now”.
Benjamin: Oh!
Johnny: Getting back to the topic, here’s the company incentive plan.
Every employee has a pay grade. An employee can be promoted to a higher pay grade, but the mechanics of how that works is something we will not need to deal with.
Normally, every year, everyone gets a raise of 10%. But to encourage behaviors that give an employee a higher pay grade, such an employee cannot get raises indefinitely on a given pay grade. Each grade has its associated maximum pay. If this amount of money is reached, an employee does not get a raise anymore until they reach a higher pay grade.
Additionally, every employee on their 5th anniversary of working for the company gets a special, one-time bonus which is twice their current payment.
Benjamin: Looks like the source code repository just finished synchronizing. Let’s take a bite at the code!
Johnny: Sure, here you go:
1 public class CompanyPolicies : IDisposable
2 {
3 readonly SqlRepository _repository
4 = new SqlRepository();
5
6 public void ApplyYearlyIncentivePlan()
7 {
8 var employees = _repository.CurrentEmployees();
9
10 foreach(var employee in employees)
11 {
12 var payGrade = employee.GetPayGrade();
13 //evaluate raise
14 if(employee.GetSalary() < payGrade.Maximum)
15 {
16 var newSalary
17 = employee.GetSalary()
18 + employee.GetSalary()
19 * 0.1;
20 employee.SetSalary(newSalary);
21 }
22
23 //evaluate one-time bonus
24 if(employee.GetYearsOfService() == 5)
25 {
26 var oneTimeBonus = employee.GetSalary() * 2;
27 employee.SetBonusForYear(2014, oneTimeBonus);
28 }
29
30 employee.Save();
31 }
32 }
33
34 public void Dispose()
35 {
36 _repository.Dispose();
37 }
38 }
Benjamin: Wow, there is a lot of literal constants all around and functional decomposition is barely done!
Johnny: Yeah. We won’t be fixing all of that today. Still, we will follow the boy scout rule and “leave the campground cleaner than we found it”.
Benjamin: What’s our assignment?
Johnny: First of all, we need to provide our users with a choice between an SQL database and a NoSQL one. To achieve our goal, we need to be somehow able to make the CompanyPolicies class database type-agnostic. For now, as you can see, the implementation is coupled to the specific SqlRepository, because it creates a specific instance itself:
1 public class CompanyPolicies : IDisposable
2 {
3 readonly SqlRepository _repository
4 = new SqlRepository();
Now, we need to evaluate the options we have to pick the best one. What options do you see, Benjamin?
Benjamin: Well, we could certainly extract an interface from SqlRepository and introduce an if statement to the constructor like this:
1 public class CompanyPolicies : IDisposable
2 {
3 readonly Repository _repository;
4
5 public CompanyPolicies()
6 {
7 if(...)
8 {
9 _repository = new SqlRepository();
10 }
11 else
12 {
13 _repository = new NoSqlRepository();
14 }
15 }
Johnny: True, but this option has few deficiencies. First of all, remember we’re trying to follow the boy scout rule and by using this option we introduce more complexity to the CommonPolicies class. Also, let’s say tomorrow someone writes another class for, say, reporting and this class will also need to access the repository – they will need to make the same decision on repositories in their code as we do in ours. This effectively means duplicating code. Thus, I’d rather evaluate further options and check if we can come up with something better. What’s our next option?
Benjamin: Another option would be to change the SqlRepository itself to be just a wrapper around the actual database access, like this:
1 public class SqlRepository : IDisposable
2 {
3 readonly Repository _repository;
4
5 public SqlRepository()
6 {
7 if(...)
8 {
9 _repository = new RealSqlRepository();
10 }
11 else
12 {
13 _repository = new RealNoSqlRepository();
14 }
15 }
16
17 IList<Employee> CurrentEmployees()
18 {
19 return _repository.CurrentEmployees();
20 }
Johnny: Sure, this is an approach that could work and would be worth considering for very serious legacy code, as it does not force us to change the CompanyPolicies class at all. However, there are some issues with it. First of all, the SqlRepository name would be misleading. Second, look at the CurrentEmployees() method – all it does is delegating a call to the implementation chosen in the constructor. With every new method required of the repository, we’ll need to add new delegating methods. In reality, it isn’t such a big deal, but maybe we can do better than that?
Benjamin: Let me think, let me think… I evaluated the option where CompanyPolicies class chooses between repositories. I also evaluated the option where we hack the SqlRepository to makes this choice. The last option I can think of is leaving this choice to another, “3rd party” code, that would choose the repository to use and pass it to the CompanyPolicies via its constructor, like this:
1 public class CompanyPolicies : IDisposable
2 {
3 private readonly Repository _repository;
4
5 public CompanyPolicies(Repository repository)
6 {
7 _repository = repository;
8 }
This way, the CompanyPolicies won’t know what exactly is passed to it via its constructor and we can pass whatever we like – either an SQL repository or a NoSQL one!
Johnny: Great! This is the option we’re looking for! For now, just believe me that this approach will lead us to many good things – you’ll see why later.
Benjamin: OK, so let me just pull the SqlRepository instance outside the CompanyPolicies class and make it an implementation of Repository interface, then create a constructor and pass the real instance through it…
Johnny: Sure, I’ll go get some coffee.
… 10 minutes later
Benjamin: Haha! Look at this! I am SUPREME!
1 public class CompanyPolicies : IDisposable
2 {
3 //_repository is now an interface
4 readonly Repository _repository;
5
6 // repository is passed from outside.
7 // We don't know what exact implementation it is.
8 public CompanyPolicies(Repository repository)
9 {
10 _repository = repository;
11 }
12
13 public void ApplyYearlyIncentivePlan()
14 {
15 //... body of the method. Unchanged.
16 }
17
18 public void Dispose()
19 {
20 _repository.Dispose();
21 }
22 }
Johnny: Hey, hey, hold your horses! There is one thing wrong with this code.
Benjamin: Huh? I thought this is what we were aiming at.
Johnny: Yes, except the Dispose() method. Look closely at the CompanyPolicies class. it is changed so that it is not responsible for creating a repository for itself, but it still disposes of it. This is could cause problems because CompanyPolicies instance does not have any right to assume it is the only object that is using the repository. If so, then it cannot determine the moment when the repository becomes unnecessary and can be safely disposed of.
Benjamin: Ok, I get the theory, but why is this bad in practice? Can you give me an example?
Johnny: Sure, let me sketch a quick example. As soon as you have two instances of CompanyPolicies class, both sharing the same instance of Repository, you’re cooked. This is because one instance of CompanyPolicies may dispose of the repository while the other one may still want to use it.
Benjamin: So who is going to dispose of the repository?
Johnny: The same part of the code that creates it, for example, the Main method. Let me show you an example of how this may look like:
1 public static void Main(string[] args)
2 {
3 using(var repo = new SqlRepository())
4 {
5 var policies = new CompanyPolicies(repo);
6
7 //use above created policies
8 //for anything you like
9 }
10 }
This way the repository is created at the start of the program and disposed of at the end. Thanks to this, the CompanyPolicies has no disposable fields and it does not have to be disposable itself – we can just delete the Dispose() method:
1 //not implementing IDisposable anymore:
2 public class CompanyPolicies
3 {
4 //_repository is now an interface
5 readonly Repository _repository;
6
7 //New constructor
8 public CompanyPolicies(Repository repository)
9 {
10 _repository = repository;
11 }
12
13 public void ApplyYearlyIncentivePlan()
14 {
15 //... body of the method. No changes
16 }
17
18 //no Dispose() method anymore
19 }
Benjamin: Cool. So, what now? Seems we have the CompanyPolicies class depending on a repository abstraction instead of an actual implementation, like SQL repository. I guess we will be able to make another class implementing the interface for NoSQL data access and just pass it through the constructor instead of the original one.
Johnny: Yes. For example, look at CompanyPolicies component. We can compose it with a repository like this:
1 var policies
2 = new CompanyPolicies(new SqlRepository());
or like this:
1 var policies
2 = new CompanyPolicies(new NoSqlRepository());
without changing the code of CompanyPolicies. This means that CompanyPolicies does not need to know what Repository exactly it is composed with, as long as this Repository follows the required interface and meets expectations of CompanyPolicies (e.g. does not throw exceptions when it is not supposed to do so). An implementation of Repository may be itself a very complex and composed of another set of classes, for example, something like this:
1 new SqlRepository(
2 new ConnectionString("..."),
3 new AccessPrivileges(
4 new Role("Admin"),
5 new Role("Auditor")
6 ),
7 new InMemoryCache()
8 );
but the CompanyPolicies neither knows or cares about this, as long as it can use our new Repository implementation just like other repositories.
Benjamin: I see… So, getting back to our task, shall we proceed with making a NoSQL implementation of the Repository interface?
Johnny: First, show me the interface that you extracted while I was looking for the coffee.
Benjamin: Here:
1 public interface Repository
2 {
3 IList<Employee> CurrentEmployees();
4 }
Johnny: Ok, so what we need is to create just another implementation and pass it through the constructor depending on what data source is chosen and we’re finished with this part of the task.
Benjamin: You mean there’s more?
Johnny: Yeah, but that’s something for tomorrow. I’m exhausted today.
A Quick Retrospective
In this chapter, Benjamin learned to appreciate composability of an object, i.e. the ability to replace its dependencies, providing different behaviors, without the need to change the code of the object class itself. Thus, an object, given replaced dependencies, starts using the new behaviors without noticing that any change occurred at all.
The code mentioned has some serious flaws. For now, Johnny and Benjamin did not encounter a desperate need to address them.
Also, after we part again with Johnny and Benjamin, we are going to reiterate the ideas they stumble upon in a more disciplined manner.
Telling, not asking
In this chapter, we’ll get back to Johnny and Benjamin as they introduce another change in the code they are working on. In the process, they discover the impact that return values and getters have on the composability of objects.
Contractors
Johnny: G’morning. Ready for another task?
Benjamin: Of course! What’s next?
Johnny: Remember the code we worked on yesterday? It contains a policy for regular employees of the company. But the company wants to start hiring contractors as well and needs to include a policy for them in the application.
Benjamin: So this is what we will be doing today?
Johnny: That’s right. The policy is going to be different for contractors. While, just as regular employees, they will be receiving raises and bonuses, the rules will be different. I made a small table to allow comparing what we have for regular employees and what we want to add for contractors:
| Employee Type | Raise | Bonus |
|---|---|---|
| Regular Employee | +10% of current salary if not reached a maximum on a given pay grade | +200% of current salary one time after five years |
| Contractor | +5% of average salary calculated for last 3 years of service (or all previous years of service if they have worked for less than 3 years | +10% of current salary when a contractor receives score more than 100 for the previous year |
So while the workflow is going to be the same for both a regular employee and a contractor:
- Load from repository
- Evaluate raise
- Evaluate bonus
- Save
the implementation of some of the steps will be different for each type of employee.
Benjamin: Correct me if I am wrong, but these “load” and “save” steps do not look like they belong with the remaining two – they describe something technical, while the other steps describe something strictly related to how the company operates…
Johnny: Good catch, however, this is something we’ll deal with later. Remember the boy scout rule – just don’t make it worse. Still, we’re going to fix some of the design flaws today.
Benjamin: Aww… I’d just fix all of it right away.
Johnny: Ha ha, patience, Luke. For now, let’s look at the code we have now before we plan further steps.
Benjamin: Let me just open my IDE… OK, here it is:
1 public class CompanyPolicies
2 {
3 readonly Repository _repository;
4
5 public CompanyPolicies(Repository repository)
6 {
7 _repository = repository;
8 }
9
10 public void ApplyYearlyIncentivePlan()
11 {
12 var employees = _repository.CurrentEmployees();
13
14 foreach(var employee in employees)
15 {
16 var payGrade = employee.GetPayGrade();
17
18 //evaluate raise
19 if(employee.GetSalary() < payGrade.Maximum)
20 {
21 var newSalary
22 = employee.GetSalary()
23 + employee.GetSalary()
24 * 0.1;
25 employee.SetSalary(newSalary);
26 }
27
28 //evaluate one-time bonus
29 if(employee.GetYearsOfService() == 5)
30 {
31 var oneTimeBonus = employee.GetSalary() * 2;
32 employee.SetBonusForYear(2014, oneTimeBonus);
33 }
34
35 employee.Save();
36 }
37 }
38 }
Benjamin: Look, Johnny, the class, in fact, contains all the four steps you mentioned, but they are not named explicitly – instead, their internal implementation for regular employees is just inserted in here. How are we supposed to add the variation of the employee type?
Johnny: Time to consider our options. We have a few of them. Well?
Benjamin: For now, I can see two. The first one would be to create another class similar to CompanyPolicies, called something like CompanyPoliciesForContractors and implement the new logic there. This would let us leave the original class as is, but we would have to change the places that use CompanyPolicies to use both classes and choose which one to use somehow. Also, we would have to add a separate method to the repository for retrieving the contractors.
Johnny: Also, we would miss our chance to communicate through the code that the sequence of steps is intentionally similar in both cases. Others who read this code in the future will see that the implementation for regular employees follows the steps: load, evaluate raise, evaluate bonus, save. When they look at the implementation for contractors, they will see the same order of steps, but they will be unable to tell whether the similarity is intentional, or a pure accident.
Benjamin: So our second option is to put an if statement into the differing steps inside the CompanyPolicies class, to distinguish between regular employees and contractors. The Employee class would have an isContractor() method and depending on what it would return, we would either execute the logic for regular employees or contractors. Assuming that the current structure of the code looks like this:
1 foreach(var employee in employees)
2 {
3 //evaluate raise
4 ...
5
6 //evaluate one-time bonus
7 ...
8
9 //save employee
10 }
the new structure would look like this:
1 foreach(var employee in employees)
2 {
3 if(employee.IsContractor())
4 {
5 //evaluate raise for contractor
6 ...
7 }
8 else
9 {
10 //evaluate raise for regular
11 ...
12 }
13
14 if(employee.IsContractor())
15 {
16 //evaluate one-time bonus for contractor
17 ...
18 }
19 else
20 {
21 //evaluate one-time bonus for regular
22 ...
23 }
24
25 //save employee
26 ...
27 }
this way we would show that the steps are the same, but the implementation is different. Also, this would mostly require us to add code and not move the existing code around.
Johnny: The downside is that we would make the class even uglier than it was when we started. So despite initial easiness, we’ll be doing a huge disservice to future maintainers. We have at least one another option. What would that be?
Benjamin: Let’s see… we could move all the details concerning the implementation of the steps from CompanyPolicies class into the Employee class itself, leaving only the names and the order of steps in CompanyPolicies:
1 foreach(var employee in employees)
2 {
3 employee.EvaluateRaise();
4 employee.EvaluateOneTimeBonus();
5 employee.Save();
6 }
Then, we could change the Employee into an interface, so that it could be either a RegularEmployee or ContractorEmployee – both classes would have different implementations of the steps, but the CompanyPolicies would not notice, since it would not be coupled to the implementation of the steps anymore – just the names and the order.
Johnny: This solution would have one downside – we would need to significantly change the current code, but you know what? I’m willing to do it, especially that I was told today that the logic is covered by some tests which we can run to see if a regression was introduced.
Benjamin: Cool, what do we start with?
Johnny: The first thing that is between us and our goal are these getters on the Employee class:
1 GetSalary();
2 GetGrade();
3 GetYearsOfService();
They just expose too much information specific to the regular employees. It would be impossible to use different implementations when these are around. These setters don’t help much:
1 SetSalary(newSalary);
2 SetBonusForYear(year, amount);
While these are not as bad, we’d better give ourselves more flexibility. Thus, let’s hide all of it behind more abstract methods that only reveal our intention.
First, take a look at this code:
1 //evaluate raise
2 if(employee.GetSalary() < payGrade.Maximum)
3 {
4 var newSalary
5 = employee.GetSalary()
6 + employee.GetSalary()
7 * 0.1;
8 employee.SetSalary(newSalary);
9 }
Each time you see a block of code separated from the rest with blank lines and starting with a comment, you see something screaming “I want to be a separate method that contains this code and has a name after the comment!”. Let’s grant this wish and make it a separate method on the Employee class.
Benjamin: Ok, wait a minute… here:
1 employee.EvaluateRaise();
Johnny: Great! Now, we’ve got another example of this species here:
1 //evaluate one-time bonus
2 if(employee.GetYearsOfService() == 5)
3 {
4 var oneTimeBonus = employee.GetSalary() * 2;
5 employee.SetBonusForYear(2014, oneTimeBonus);
6 }
Benjamin: This one should be even easier… Ok, take a look:
1 employee.EvaluateOneTimeBonus();
Johnny: Almost good. I’d only leave out the information that the bonus is one-time from the name.
Benjamin: Why? Don’t we want to include what happens in the method name?
Johnny: Actually, no. What we want to include is our intention. The bonus being one-time is something specific to the regular employees and we want to abstract away the details about this or that kind of employee, so that we can plug in different implementations without making the method name lie. The names should reflect that we want to evaluate a bonus, whatever that means for a particular type of employee. Thus, let’s make it:
1 employee.EvaluateBonus();
Benjamin: Ok, I get it. No problem.
Johnny: Now let’s take a look at the full code of the EvaluateIncentivePlan method to see whether it is still coupled to details specific to regular employees. Here’s the code:
1 public void ApplyYearlyIncentivePlan()
2 {
3 var employees = _repository.CurrentEmployees();
4
5 foreach(var employee in employees)
6 {
7 employee.EvaluateRaise();
8 employee.EvaluateBonus();
9 employee.Save();
10 }
11 }
Benjamin: It seems that there is no coupling to the details about regular employees anymore. Thus, we can safely make the repository return a combination of regulars and contractors without this code noticing anything. Now I think I understand what you were trying to achieve. If we make interactions between objects happen on a more abstract level, then we can put in different implementations with less effort.
Johnny: True. Can you see another thing related to the lack of return values on all of the Employee’s methods in the current implementation?
Benjamin: Not really. Does it matter?
Johnny: Well, if Employee methods had return values and this code depended on them, all subclasses of Employee would be forced to supply return values as well and these return values would need to match the expectations of the code that calls these methods, whatever these expectations were. This would make introducing other kinds of employees harder. But now that there are no return values, we can, for example:
- introduce a
TemporaryEmployeethat has no raises, by leaving itsEvaluateRaise()method empty, and the code that uses employees will not notice. - introduce a
ProbationEmployeethat has no bonus policy, by leaving itsEvaluateBonus()method empty, and the code that uses employees will not notice. - introduce an
InMemoryEmployeethat has an emptySave()method, and the code that uses employees will not notice.
As you see, by asking the objects less, and telling it more, we get greater flexibility to create alternative implementations and the composability, which we talked about yesterday, increases!
Benjamin: I see… So telling objects what to do instead of asking them for their data makes the interactions between objects more abstract, and so, more stable, increasing composability of interacting objects. This is a valuable lesson – it is the first time I hear this and it seems a pretty powerful concept.
A Quick Retrospective
In this chapter, Benjamin learned that the composability of an object (not to mention clarity) is reinforced when interactions between it and its peers are: abstract, logical and stable. Also, he discovered, with Johnny’s help, that it is further strengthened by following a design style where objects are told what to do instead of asked to give away information to somebody who then decides on their behalf. This is because if an API of an abstraction is built around answering specific questions, the clients of the abstraction tend to ask it a lot of questions and are coupled to both those questions and some aspects of the answers (i.e. what is in the return values). This makes creating another implementation of abstraction harder, because each new implementation of the abstraction needs to not only provide answers to all those questions, but the answers are constrained to what the client expects. When abstraction is merely told what its client wants it to achieve, the clients are decoupled from most of the details of how this happens. This makes introducing new implementations of abstraction easier – it often even lets us define implementations with all methods empty without the client noticing at all.
These are all important conclusions that will lead us towards TDD with mock objects.
Time to leave Johnny and Benjamin for now. In the next chapter, I’m going to reiterate their discoveries and put them in a broader context.
The need for mock objects
We already experienced mock objects in the chapter about tools, although at that point, I gave you an oversimplified and deceiving explanation of what a mock object is, promising that I will make up for it later. Now is the time.
Mock objects were made with a specific goal in mind. I hope that when you understand the real goal, you will probably understand the means to the goal far better.
In this chapter, we will explore the qualities of object-oriented design which make mock objects a viable tool.
Composability… again!
In the two previous chapters, we followed Johnny and Benjamin in discovering the benefits of and prerequisites for composability of objects. Composability is the number one quality of the design we’re after. After reading Johhny and Benjamin’s story, you might have some questions regarding composability. Hopefully, they are among the ones answered in the next few chapters. Ready?
Why do we need composability?
It might seem stupid to ask this question here – if you have managed to stay with me this long, then you’re probably motivated enough not to need a justification? Well, anyway, it’s still worth discussing it a little. Hopefully, you’ll learn as much reading this back-to-basics chapter as I did writing it.
Pre-object-oriented approaches
Back in the days of procedural programming1, when we wanted to execute different code based on some factor, it was usually achieved using an ‘if’ statement. For example, if our application was in need to be able to use different kinds of alarms, like a loud alarm (that plays a loud sound) and a silent alarm (that does not play any sound, but instead silently contacts the police) interchangeably, then usually, we could achieve this using a conditional like in the following function:
1 void triggerAlarm(Alarm* alarm)
2 {
3 if(alarm->kind == LOUD_ALARM)
4 {
5 playLoudSound(alarm);
6 }
7 else if(alarm->kind == SILENT_ALARM)
8 {
9 notifyPolice(alarm);
10 }
11 }
The code above makes a decision based on the alarm kind which is embedded in the alarm structure:
1 struct Alarm
2 {
3 int kind;
4 //other data
5 };
If the alarm kind is the loud one, it executes behavior associated with a loud alarm. If this is a silent alarm, the behavior for silent alarms is executed. This seems to work. Unfortunately, if we wanted to make a second decision based on the alarm kind (e.g. we needed to disable the alarm), we would need to query the alarm kind again. This would mean duplicating the conditional code, just with a different set of actions to perform, depending on what kind of alarm we were dealing with:
1 void disableAlarm(Alarm* alarm)
2 {
3 if(alarm->kind == LOUD_ALARM)
4 {
5 stopLoudSound(alarm);
6 }
7 else if(alarm->kind == SILENT_ALARM)
8 {
9 stopNotifyingPolice(alarm);
10 }
11 }
Do I have to say why this duplication is bad? Do I hear a “no”? My apologies then, but I’ll tell you anyway. The duplication means that every time a new kind of alarm is introduced, a developer has to remember to update both places that contain ‘if-else’ – the compiler will not force this. As you are probably aware, in the context of teams, where one developer picks up work that another left and where, from time to time, people leave to find another job, expecting someone to “remember” to update all the places where the logic is duplicated is asking for trouble.
So, we see that the duplication is bad, but can we do something about it? To answer this question, let’s take a look at the reason the duplication was introduced. And the reason is: We have two things we want to be able to do with our alarms: triggering and disabling. In other words, we have a set of questions we want to be able to ask an alarm. Each kind of alarm has a different way of answering these questions – resulting in having a set of “answers” specific to each alarm kind:
| Alarm Kind | Triggering | Disabling |
|---|---|---|
| Loud Alarm | playLoudSound() |
stopLoudSound() |
| Silent Alarm | notifyPolice() |
stopNotifyingPolice() |
So, at least conceptually, as soon as we know the alarm kind, we already know which set of behaviors (represented as a row in the above table) it needs. We could just decide the alarm kind once and associate the right set of behaviors with the data structure. Then, we would not have to query the alarm kind in several places as we did, but instead, we could say: “execute triggering behavior from the set of behaviors associated with this alarm, whatever it is”.
Unfortunately, procedural programming does not allow binding behavior with data easily. The whole paradigm of procedural programming is about separating behavior and data! Well, honestly, they had some answers to those concerns, but these answers were mostly awkward (for those of you that still remember C language: I’m talking about macros and function pointers). So, as data and behavior are separated, we need to query the data each time we want to pick a behavior based on it. That’s why we have duplication.
Object-oriented programming to the rescue!
On the other hand, object-oriented programming has for a long time made available two mechanisms that enable what we didn’t have in procedural languages:
- Classes – that allow binding behavior together with data.
- Polymorphism – allows executing behavior without knowing the exact class that holds them, but knowing only a set of behaviors that it supports. This knowledge is obtained by having an abstract type (interface or an abstract class) define this set of behaviors, with no real implementation. Then we can make other classes that provide their own implementation of the behaviors that are declared to be supported by the abstract type. Finally, we can use the instances of those classes where an instance of the abstract type is expected. In the case of statically-typed languages, this requires implementing an interface or inheriting from an abstract class.
So, in case of our alarms, we could make an interface with the following signature:
1 public interface Alarm
2 {
3 void Trigger();
4 void Disable();
5 }
and then make two classes: LoudAlarm and SilentAlarm, both implementing the Alarm interface. Example for LoudAlarm:
1 public class LoudAlarm : Alarm
2 {
3 public void Trigger()
4 {
5 //play very loud sound
6 }
7
8 public void Disable()
9 {
10 //stop playing the sound
11 }
12 }
Now, we can make parts of code use the alarm, but by knowing the interface only instead of the concrete classes. This makes the parts of the code that use alarm this way not having to check which alarm they are dealing with. Thus, what previously looked like this:
1 if(alarm->kind == LOUD_ALARM)
2 {
3 playLoudSound(alarm);
4 }
5 else if(alarm->kind == SILENT_ALARM)
6 {
7 notifyPolice(alarm);
8 }
becomes just:
1 alarm.Trigger();
where alarm is either LoudAlarm or SilentAlarm but seen polymorphically as Alarm, so there’s no need for ‘if-else’ anymore.
But hey, isn’t this cheating? Even provided I can execute the trigger behavior on an alarm without knowing the actual class of the alarm, I still have to decide which class it is in the place where I create the actual instance:
1 // we must know the exact type here:
2 alarm = new LoudAlarm();
so it looks like I am not eliminating the ‘else-if’ after all, just moving it somewhere else! This may be true (we will talk more about it in future chapters), but the good news is that I eliminated at least the duplication by making our dream of “picking the right set of behaviors to use with certain data once” come true.
Thanks to this, I create the alarm once, and then I can take it and pass it to ten, a hundred or a thousand different places where I will not have to determine the alarm kind anymore to use it correctly.
This allows writing a lot of classes that do not know about the real class of the alarm they are dealing with, yet they can use the alarm just fine only by knowing a common abstract type – Alarm. If we can do that, we arrive at a situation where we can add more alarms implementing Alarm and watch existing objects that are already using Alarm work with these new alarms without any change in their source code! There is one condition, however – the creation of the alarm instances must be moved out of the classes that use them. That’s because, as we already observed, to create an alarm using a new operator, we have to know the exact type of the alarm we are creating. So whoever creates an instance of LoudAlarm or SilentAlarm, loses its uniformity, since it is not able to depend solely on the Alarm interface.
The power of composition
Moving creation of alarm instances away from the classes that use those alarms brings up an interesting problem – if an object does not create the objects it uses, then who does it? A solution is to make some special places in the code that are only responsible for composing a system from context-independent objects2. We saw this already as Johnny was explaining composability to Benjamin. He used the following example:
1 new SqlRepository(
2 new ConnectionString("..."),
3 new AccessPrivileges(
4 new Role("Admin"),
5 new Role("Auditor")
6 ),
7 new InMemoryCache()
8 );
We can do the same with our alarms. Let’s say that we have a secure area that has three buildings with different alarm policies:
- Office building – the alarm should silently notify guards during the day (to keep office staff from panicking) and loud during the night, when guards are on patrol.
- Storage building – as it is quite far and the workers are few, we want to trigger loud and silent alarms at the same time.
- Guards building – as the guards are there, no need to notify them. However, a silent alarm should call the police for help instead, and a loud alarm is desired as well.
Note that besides just triggering a loud or silent alarm, we are required to support a combination (“loud and silent alarms at the same time”) and a conditional (“silent during the day and loud during the night”). we could just hardcode some fors and if-elses in our code, but instead, let’s factor out these two operations (combination and choice) into separate classes implementing the alarm interface.
Let’s call the class implementing the choice between two alarms DayNightSwitchedAlarm. Here is the source code:
1 public class DayNightSwitchedAlarm : Alarm
2 {
3 private readonly Alarm _dayAlarm;
4 private readonly Alarm _nightAlarm;
5
6 public DayNightSwitchedAlarm(
7 Alarm dayAlarm,
8 Alarm nightAlarm)
9 {
10 _dayAlarm = dayAlarm;
11 _nightAlarm = nightAlarm;
12 }
13
14 public void Trigger()
15 {
16 if(/* is day */)
17 {
18 _dayAlarm.Trigger();
19 }
20 else
21 {
22 _nightAlarm.Trigger();
23 }
24 }
25
26 public void Disable()
27 {
28 _dayAlarm.Disable();
29 _nightAlarm.Disable();
30 }
31 }
Studying the above code, it is apparent that this is not an alarm per se, e.g. it does not raise any sound or notification, but rather, it contains some rules on how to use other alarms. This is the same concept as power splitters in real life, which act as electric devices but do not do anything other than redirecting the electricity to other devices.
Next, let’s use the same approach and model the combination of two alarms as a class called HybridAlarm. Here is the source code:
1 public class HybridAlarm : Alarm
2 {
3 private readonly Alarm _alarm1;
4 private readonly Alarm _alarm2;
5
6 public HybridAlarm(
7 Alarm alarm1,
8 Alarm alarm2)
9 {
10 _alarm1 = alarm1;
11 _alarm2 = alarm2;
12 }
13
14 public void Trigger()
15 {
16 _alarm1.Trigger();
17 _alarm2.Trigger();
18 }
19
20 public void Disable()
21 {
22 _alarm1.Disable();
23 _alarm2.Disable();
24 }
25 }
Using these two classes along with already existing alarms, we can implement the requirements by composing instances of those classes like this:
1 new SecureArea(
2 new OfficeBuilding(
3 new DayNightSwitchedAlarm(
4 new SilentAlarm("222-333-444"),
5 new LoudAlarm()
6 )
7 ),
8 new StorageBuilding(
9 new HybridAlarm(
10 new SilentAlarm("222-333-444"),
11 new LoudAlarm()
12 )
13 ),
14 new GuardsBuilding(
15 new HybridAlarm(
16 new SilentAlarm("919"), //call police
17 new LoudAlarm()
18 )
19 )
20 );
Note that the fact that we implemented combination and choice of alarms as separate objects implementing the Alarm interface allows us to define new, interesting alarm behaviors using the parts we already have, but composing them together differently. For example, we might have, as in the above example:
1 new DayNightSwitchAlarm(
2 new SilentAlarm("222-333-444"),
3 new LoudAlarm());
which would mean triggering silent alarm during a day and loud one during the night. However, instead of this combination, we might use:
1 new DayNightSwitchAlarm(
2 new SilentAlarm("222-333-444"),
3 new HybridAlarm(
4 new SilentAlarm("919"),
5 new LoudAlarm()
6 )
7 )
Which would mean that we use a silent alarm to notify the guards during the day, but a combination of silent (notifying police) and loud during the night. Of course, we are not limited to combining a silent alarm with a loud one only. We can as well combine two silent ones:
1 new HybridAlarm(
2 new SilentAlarm("919"),
3 new SilentAlarm("222-333-444")
4 )
Additionally, if we suddenly decided that we do not want alarm at all during the day, we could use a special class called NoAlarm that would implement Alarm interface, but have both Trigger and Disable methods do nothing. The composition code would look like this:
1 new DayNightSwitchAlarm(
2 new NoAlarm(), // no alarm during the day
3 new HybridAlarm(
4 new SilentAlarm("919"),
5 new LoudAlarm()
6 )
7 )
And, last but not least, we could completely remove all alarms from the guards building using the following NoAlarm class (which is also an Alarm):
1 public class NoAlarm : Alarm
2 {
3 public void Trigger()
4 {
5 }
6
7 public void Disable()
8 {
9 }
10 }
and passing it as the alarm to guards building:
1 new GuardsBuilding(
2 new NoAlarm()
3 )
Noticed something funny about the last few examples? If not, here goes an explanation: in the last few examples, we have twisted the behaviors of our application in wacky ways, but all of this took place in the composition code! We did not have to modify any other existing classes! True, we had to write a new class called NoAlarm, but did not need to modify any code except the composition code to make objects of this new class work with objects of existing classes!
This ability to change the behavior of our application just by changing the way objects are composed together is extremely powerful (although you will always be able to achieve it only to certain extent), especially in evolutionary, incremental design, where we want to evolve some pieces of code with as little as possible other pieces of code having to realize that the evolution takes place. This ability can be achieved only if our system consists of composable objects, thus the need for composability – an answer to a question raised at the beginning of this chapter.
Summary – are you still with me?
We started with what seemed to be a repetition from a basic object-oriented programming course, using a basic example. It was necessary though to make a fluent transition to the benefits of composability we eventually introduced at the end. I hope you did not get overwhelmed and can understand now why I am putting so much stress on composability.
In the next chapter, we will take a closer look at composing objects itself.
Web, messages and protocols
In the previous chapter, we talked a little bit about why composability is valuable, now let’s flesh out a little bit of terminology to get more precise understanding.
So, again, what does it mean to compose objects?
Roughly, it means that an object has obtained a reference to another object and can invoke methods on it. By being composed together, two objects form a small system that can be expanded with more objects as needed. Thus, a bigger object-oriented system forms something similar to a web:
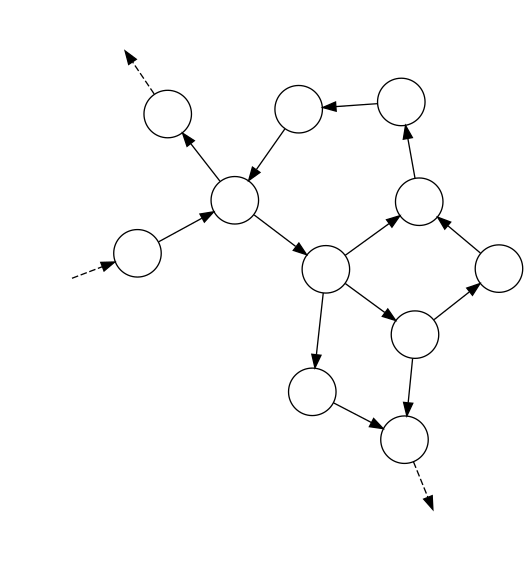
If we take the web metaphor a little bit further, we can note some similarities to e.g. a TCP/IP network:
- An object can send messages to other objects (i.e. call methods on them – arrows on the above diagram) via interfaces. Each message has a sender and at least one recipient.
- To send a message to a recipient, a sender has to acquire an address of the recipient, which, in the object-oriented world, we call a reference (and in languages such as C++, references are just that – addresses in memory).
- Communication between the sender and recipients has to follow a certain protocol. For example, the sender usually cannot invoke a method passing nulls as all arguments, or should expect an exception if it does so. Don’t worry if you don’t see the analogy now – I’ll follow up with more explanation of this topic later).
Alarms, again!
Let’s try to apply this terminology to an example. Imagine that we have an anti-fire alarm system in an office. When triggered, this alarm system makes all lifts go to the bottom floor, opens them and then disables each of them. Among others, the office contains automatic lifts, that contain their own remote control systems and mechanical lifts, that are controlled from the outside by a special custom-made mechanism.
Let’s try to model this behavior in code. As you might have guessed, we will have some objects like alarm, automatic lift, and mechanical lift. The alarm will control the lifts when triggered.
Firstly, we don’t want the alarm to have to distinguish between an automatic and a mechanical lift – this would only add complexity to the alarm system, especially that there are plans to add a third kind of lift – a more modern one – in the future. So, if we made the alarm aware of the different kinds of lifts, we would have to modify it each time a new kind of lift is introduced. Thus, we need a special interface (let’s call it Lift) to communicate with both AutoLift and MechanicalLift (and ModernLift in the future). Through this interface, an alarm will be able to send messages to both types of lifts without having to know the difference between them.
1 public interface Lift
2 {
3 ...
4 }
5
6 public class AutoLift : Lift
7 {
8 ...
9 }
10
11 public class MechanicalLift : Lift
12 {
13 ...
14 }
Next, to be able to communicate with specific lifts through the Lift interface, an alarm object has to acquire “addresses” of the lift objects (i.e. references to them). We can pass these references e.g. through a constructor:
1 public class Alarm
2 {
3 private readonly IEnumerable<Lift> _lifts;
4
5 //obtain "addresses" here
6 public Alarm(IEnumerable<Lift> lifts)
7 {
8 //store the "addresses" for later use
9 _lifts = lifts;
10 }
11 }
Then, the alarm can send three kinds of messages: GoToBottomFloor(), OpenDoor(), and DisablePower() to any of the lifts through the Lift interface:
1 public interface Lift
2 {
3 void GoToBottomFloor();
4 void OpenDoor();
5 void DisablePower();
6 }
and, as a matter of fact, it sends all these messages when triggered. The Trigger() method on the alarm looks like this:
1 public void Trigger()
2 {
3 foreach(var lift in _lifts)
4 {
5 lift.GoToBottomFloor();
6 lift.OpenDoor();
7 lift.DisablePower();
8 }
9 }
By the way, note that the order in which the messages are sent does matter. For example, if we disabled the power first, asking the powerless lift to go anywhere would be impossible. This is a first sign of a protocol existing between the Alarm and a Lift.
In this communication, Alarm is a sender – it knows what it sends (messages that control lifts), it knows why (because the alarm is triggered), but does not know what exactly are the recipients going to do when they receive the message – it only knows what it wants them to do, but does not know how they are going to achieve it. The rest is left to objects that implement Lift (namely, AutoLift and MechanicalLift). They are the recipients – they don’t know who they received the message from (unless they are told in the content of the message somehow – but even then they can be cheated), but they know how to react, based on who they are (AutoLift has its specific way of reacting and MechanicalLift has its own as well). They also know what kind of message they received (a lift does a different thing when asked to go to the bottom floor than when it is asked to open its door) and what’s the message content (i.e. method arguments – in this simplistic example there are none).
To illustrate that this separation between a sender and a recipient exists, I’ll say that we could even write an implementation of a Lift interface that would just ignore the messages it got from the Alarm (or fake that it did what it was asked for) and the Alarm will not even notice. We sometimes say that this is because deciding on a specific reaction is not the Alarm’s responsibility.

New requirements
It was decided that whenever any malfunction happens in the lift when it is executing the alarm emergency procedure, the lift object should report this by throwing an exception called LiftUnoperationalException. This affects both Alarm and implementations of the Lift interface:
- The
Liftimplementations need to know that when a malfunction happens, they should report it by throwing the exception. - The
Alarmmust be ready to handle the exception thrown from lifts and act accordingly (e.g. still try to secure other lifts).
This is another example of a protocol existing between Alarm and Lift that must be adhered to by both sides. Here is an exemplary code of Alarm keeping to its part of the protocol, i.e. handling the malfunction reports in its Trigger() method:
1 public void Trigger()
2 {
3 foreach(var lift in _lifts)
4 {
5 try
6 {
7 lift.GoToBottomFloor();
8 lift.OpenDoor();
9 lift.DisablePower();
10 }
11 catch(LiftUnoperationalException e)
12 {
13 report.ThatCannotSecure(lift);
14 }
15 }
16 }
Summary
Each of the objects in the web can receive messages and most of them send messages to other objects. Throughout the next chapters, I will refer to an object sending a message as sender and an object receiving a message as recipient.
For now, it may look unjustified to introduce this metaphor of webs, protocols, interfaces, etc. Still, I have two reasons for doing so:
- This is the way I interpret Alan Kay’s mental model of what object-oriented programming is about.
- I find it useful for some things want to explain in the next chapters: how to make connections between objects, how to design an object boundary and how to achieve strong composability.
By the way, the example from this chapter is a bit naive. For one, in real production code, the lifts would have to be notified in parallel, not sequentially. Also, I would probably use some kind of observer pattern to separate the instructions give to each lift from raising an event (I will demonstrate an example of using observers in this fashion in the next chapter). These two choices, in turn, would probably make me rethink error handling - there is a chance I wouldn’t be able to get away with just catching exceptions. Anyway, I hope the naive form helped explain the idea of protocols and messages without raising the bar in other topics.
Composing a web of objects
Three important questions
Now that we know that such thing as a web of objects exists, that there are connections, protocols and such, time to mention the one thing I left out: how does a web of objects come into existence?
This is, of course, a fundamental question, because if we are unable to build a web, we don’t have a web. Also, this is a question that is a little more tricky than it looks like at first glance. To answer it, we have to find the answer to three other questions:
- When are objects composed (i.e. when are the connections made)?
- How does an object obtain a reference to another one on the web (i.e. how are the connections made)?
- Where are objects composed (i.e. where are connections made)?
At first sight, finding the difference between these questions may be tedious, but the good news is that they are the topic of this chapter, so I hope we’ll have that cleared shortly.
A preview of all three answers
Before we take a deep dive, let’s try to answer these three questions for a naive example code of a console application:
1 public static void Main(string[] args)
2 {
3 var sender = new Sender(new Recipient());
4
5 sender.Work();
6 }
This is a piece of code that creates two objects and connects them, then it tells the sender object to work on something. For this code, the answers to the three questions I raised are:
- When are objects composed? Answer: during application startup (because
Main()method is called at console application startup). - How does an object (
Sender) obtain a reference to another one (Recipient)? Answer: the reference is obtained by receiving aRecipientas a constructor parameter. - Where are objects composed? Answer: at the application entry point (
Main()method)
Depending on circumstances, we may have different sets of answers. Also, to avoid rethinking this topic each time we create an application, I like to have a set of default answers to these questions. I’d like to demonstrate these answers by tackling each of the three questions in-depth, one by one, in the coming chapters.
When are objects composed?
The quick answer to this question is: as early as possible. Now, that wasn’t too helpful, was it? So here goes a clarification.
Many of the objects we use in our applications can be created and connected up-front when the application starts and can stay alive until the application finishes executing. Let’s call this part the static part of the web.
Apart from that, there’s something I’ll call dynamic part – the objects that are created, connected and destroyed many times during the application lifecycle. There are at least two reasons this dynamic part exists:
- Some objects represent requests or user actions that arrive during the application runtime, are processed and then discarded. These objects cannot be created up-front, but only as early as the events they represent occur. Also, these objects do not live until the application is terminated but are discarded as soon as the processing of a request is finished. Other objects represent e.g. items in cache that live for some time and then expire, so, again, we don’t have enough information to compose these objects up-front and they often don’t live as long as the application itself. Such objects come and go, making temporary connections.
- There are objects that have life spans as long as the application has, but the nature of their connections are temporary. Consider an example where we want to encrypt our data storage for export, but depending on circumstances, we sometimes want to export it using one algorithm and sometimes using another. If so, we may sometimes invoke the encryption method like this:
1 database.encryptUsing(encryption1);
and sometimes like this:
1 database.encryptUsing(encryption2);
In the first case, database and encryption1 are only connected temporarily, for the time it takes to perform the encryption. Still, nothing prevents these objects from being created during the application startup. The same applies to the connection of database and encryption2 - this connection is temporary as well.
Given these definitions, it is perfectly possible for an object to be part of both static and dynamic part – some of its connections may be made up-front, while others may be created later, e.g. when its reference is passed inside a message sent to another object (i.e. when it is passed as method parameter).
How does a sender obtain a reference to a recipient (i.e. how connections are made)?
There are several ways a sender can obtain a reference to a recipient, each of them being useful in certain circumstances. These ways are:
- Receive as a constructor parameter
- Receive inside a message (i.e. as a method parameter)
- Receive in response to a message (i.e. as a method return value)
- Receive as a registered observer
Let’s take a closer look at what each of them is about and which one to choose in what circumstances.
Receive as a constructor parameter
Two objects can be composed by passing one into a constructor of another:
1 sender = new Sender(recipient);
A sender that receives the recipient then saves a reference to it in a private field for later, like this:
1 private Recipient _recipient;
2
3 public Sender(Recipient recipient)
4 {
5 _recipient = recipient;
6 }
Starting from this point, the Sender may send messages to Recipient at will:
1 public void DoSomething()
2 {
3 //... other code
4
5 _recipient.DoSomethingElse();
6
7 //... other code
8 }
Advantage: “what you hide, you can change”
Composing using constructors has one significant advantage. Let’s look again at how Sender is created:
1 sender = new Sender(recipient);
and at how it’s used:
1 sender.DoSomething();
Note that only the code that creates a Sender needs to be aware of it having access to a Recipient. When it comes to invoking a method, this private reference is invisible from outside. Now, remember when I described the principle of separating object use from its construction? If we follow this principle here, we end up with the code that creates a Sender being in a totally different place than the code that uses it. Thus, every code that uses a Sender will not be aware of it sending messages to a Recipient at all. There is a maxim that says: “what you hide, you can change”3 – in this particular case, if we decide that the Sender does not need a Recipient to do its job, all we have to change is the composition code to remove the Recipient:
1 //no need to pass a reference to Recipient anymore
2 new Sender();
and the code that uses Sender doesn’t need to change at all – it still looks the same as before, since it never knew Recipient:
1 sender.DoSomething();
Communication of intent: required recipient
Another advantage of the constructor approach is that it allows stating explicitly what the required recipients are for a particular sender. For example, a Sender accepts a Recipient in its constructor:
1 public Sender(Recipient recipient)
2 {
3 //...
4 }
The signature of the constructor makes it explicit that a reference to Recipient is required for a Sender to work correctly – the compiler will not allow creating a Sender without passing something as a Recipient4.
Where to apply
Passing into a constructor is a great solution in cases we want to compose a sender with a recipient permanently (i.e. for the lifetime of a Sender). To be able to do this, a Recipient must, of course, exist before a Sender does. Another less obvious requirement for this composition is that a Recipient must be usable at least as long as a Sender is usable. A simple example of violating this requirement is this code:
1 sender = new Sender(recipient);
2
3 recipient.Dispose(); //but sender is unaware of it
4 //and may still use recipient later:
5 sender.DoSomething();
In this case, when we tell sender to DoSomething(), it uses a recipient that is already disposed of, which may lead to some nasty bugs.
Receive inside a message (i.e. as a method parameter)
Another common way of composing objects together is passing one object as a parameter of another object’s method call:
1 sender.DoSomethingWithHelpOf(recipient);
In such a case, the objects are most often composed temporarily, just for the time of execution of this single method:
1 public void DoSomethingWithHelpOf(Recipient recipient)
2 {
3 //... perform some logic
4
5 recipient.HelpMe();
6
7 //... perform some logic
8 }
Where to apply
Contrary to the constructor approach, where a Sender could hide from its user the fact that it needs a Recipient, in this case, the user of Sender is explicitly responsible for supplying a Recipient. In other words, there needs to be some kind of coupling between the code using Sender and a Recipient. It may look like this coupling is a disadvantage, but I know of some scenarios where it’s required for code using Sender to be able to provide its own Recipient – it allows us to use the same sender with different recipients at different times (most often from different parts of the code):
1 //in one place
2 sender.DoSomethingWithHelpOf(recipient);
3
4 //in another place:
5 sender.DoSomethingWithHelpOf(anotherRecipient);
6
7 //in yet another place:
8 sender.DoSomethingWithHelpOf(yetAnotherRecipient);
If this ability is not required, I strongly prefer the constructor approach as it removes the (then) unnecessary coupling between code using Sender and a Recipient, giving me more flexibility.
Receive in response to a message (i.e. as a method return value)
This method of composing objects relies on an intermediary object – often an implementation of a factory pattern – to supply recipients on request. To simplify things, I will use factories in examples presented in this section, although what I tell you is true for some other creational patterns as well (also, later in this chapter, I’ll cover some aspects of the factory pattern in depth).
To be able to ask a factory for recipients, the sender needs to obtain a reference to it first. Typically, a factory is composed with a sender through its constructor (an approach I already described). For example:
1 var sender = new Sender(recipientFactory);
The factory can then be used by the Sender at will to get a hold of new recipients:
1 public class Sender
2 {
3 //...
4
5 public void DoSomething()
6 {
7 //ask the factory for a recipient:
8 var recipient = _recipientFactory.CreateRecipient();
9
10 //use the recipient:
11 recipient.DoSomethingElse();
12 }
13 }
Where to apply
I find this kind of composition useful when a new recipient is needed each time DoSomething() is called. In this sense, it may look much like in case of the previously discussed approach of receiving a recipient inside a message. There is one difference, however. Contrary to passing a recipient inside a message, where the code using the Sender passed a Recipient “from outside” of the Sender, in this approach, we rely on a separate object that is used by a Sender “from the inside”.
To be more clear, let’s compare the two approaches. Passing recipient inside a message looks like this:
1 //Sender gets a Recipient from the "outside":
2 public void DoSomething(Recipient recipient)
3 {
4 recipient.DoSomethingElse();
5 }
and obtaining it from a factory:
1 //a factory is used "inside" Sender
2 //to obtain a recipient
3 public void DoSomething()
4 {
5 var recipient = _factory.CreateRecipient();
6 recipient.DoSomethingElse();
7 }
So in the first example, the decision on which Recipient is used is made by whoever calls DoSomething(). In the factory example, whoever calls DoSomething() does not know at all about the Recipient and cannot directly influence which Recipient is used. The factory makes this decision.
Factories with parameters
So far, all of the factories we considered had creation methods with empty parameter lists, but this is not a requirement of any sort - I just wanted to make the examples simple, so I left out everything that didn’t help make my point. As the factory remains the decision-maker on which Recipient is used, it can rely on some external parameters passed to the creation method to help it make the decision.
Not only factories
Throughout this section, we have used a factory as our role model, but the approach of obtaining a recipient in response to a message is wider than that. Other types of objects that fall into this category include, among others: repositories, caches, builders, collections5. While they are all important concepts (which you can look up on the web if you like), they are not required to progress through this chapter so I won’t go through them now.
Receive as a registered observer
This means passing a recipient to an already created sender (contrary to passing as constructor parameter where the recipient was passed during creation) as a parameter of a method that stores the reference for later use. Usually, I meet two kinds of registrations:
- a “setter” method, where someone registers an observer by calling something like
sender.SetRecipient(recipient)method. Honestly, even though it’s a setter, I don’t like naming it according to the convention “setWhatever()” – after Kent Beck6 I find this convention too much implementation-focused instead of purpose-focused. Thus, I pick different names based on what domain concept is modeled by the registration method or what is its purpose. Anyway, this approach allows only one observer and setting another overwrites the previous one. - an “addition” method - where someone registers an observer by calling something like
sender.addRecipient(recipient)- in this approach, a collection of observers needs to be maintained somewhere and the recipient registered as an observer is merely added to the collection.
Note that there is one similarity to the “passing inside a message” approach – in both, a recipient is passed inside a message. The difference is that this time, contrary to “pass inside a message” approach, the passed recipient is not used immediately (and then forgotten), but rather it’s remembered (registered) for later use.
I hope I can clear up the confusion with a quick example.
Example
Suppose we have a temperature sensor that can report its current and historically mean value to whoever subscribes to it. If no one subscribes, the sensor still does its job, because it still has to collect the data for calculating a history-based mean value in case anyone subscribes later.
We may model this behavior by using an observer pattern and allow observers to register in the sensor implementation. If no observer is registered, the values are not reported (in other words, a registered observer is not required for the object to function, but if there is one, it can take advantage of the reports). For this purpose, let’s make our sensor depend on an interface called TemperatureObserver that could be implemented by various concrete observer classes. The interface declaration looks like this:
1 public interface TemperatureObserver
2 {
3 void NotifyOn(
4 Temperature currentValue,
5 Temperature meanValue);
6 }
Now we’re ready to look at the implementation of the temperature sensor itself and how it uses this TemperatureObserver interface. Let’s say that the class representing the sensor is called TemperatureSensor. Part of its definition could look like this:
1 public class TemperatureSensor
2 {
3 private TemperatureObserver _observer
4 = new NullObserver(); //ignores reported values
5
6 private Temperature _meanValue
7 = Temperature.Celsius(0);
8
9 // + maybe more fields related to storing historical data
10
11 public void Run()
12 {
13 while(/* needs to run */)
14 {
15 var currentValue = /* get current value somehow */;
16 _meanValue = /* update mean value somehow */;
17
18 _observer.NotifyOn(currentValue, _meanValue);
19
20 WaitUntilTheNextMeasurementTime();
21 }
22 }
23 }
As you can see, by default, the sensor reports its values to nowhere (NullObserver), which is a safe default value (using a null for a default value instead would cause exceptions or force us to put a null check inside the Run() method). We have already seen such “null objects”7 a few times before (e.g. in the previous chapter, when we introduced the NoAlarm class) – NullObserver is just another incarnation of this pattern.
Registering observers
Still, we want to be able to supply our own observer one day, when we start caring about the measured and calculated values (the fact that we “started caring” may be indicated to our application e.g. by a network packet or an event from the user interface). This means we need to have a method inside the TemperatureSensor class to overwrite this default “do-nothing” observer with a custom one after the TemperatureSensor instance is created. As I said, I don’t like the “SetXYZ()” convention, so I will name the registration method FromNowOnReportTo() and make the observer an argument. Here are the relevant parts of the TemperatureSensor class:
1 public class TemperatureSensor
2 {
3 private TemperatureObserver _observer
4 = new NullObserver(); //ignores reported values
5
6 //... ... ...
7
8 public void FromNowOnReportTo(TemperatureObserver observer)
9 {
10 _observer = observer;
11 }
12
13 //... ... ...
14 }
This allows us to overwrite the current observer with a new one should we ever need to do it. Note that, as I mentioned, this is the place where the registration approach differs from the “pass inside a message” approach, where we also received a recipient in a message, but for immediate use. Here, we don’t use the recipient (i.e. the observer) when we get it, but instead, we save it for later use.
Communication of intent: optional dependency
Allowing registering recipients after a sender is created is a way of saying: “the recipient is optional – if you provide one, fine, if not, I will do my work without it”. Please, don’t use this kind of mechanism for required recipients – these should all be passed through a constructor, making it harder to create invalid objects that are only partially ready to work.
Let’s examine an example of a class that:
- accepts a recipient in its constructor,
- allows registering a recipient as an observer,
- accepts a recipient for a single method invocation
This example is annotated with comments that sum up what these three approaches say:
1 public class Sender
2 {
3 //"I will not work without a Recipient1"
4 public Sender(Recipient1 recipient1) {...}
5
6 //"I will do fine without Recipient2 but you
7 //can overwrite the default here if you are
8 //interested in being notified about something
9 //or want to customize my default behavior"
10 public void Register(Recipient2 recipient2) {...}
11
12 //"I need a recipient3 only here and you get to choose
13 //what object to give me each time you invoke
14 //this method on me"
15 public void DoSomethingWith(Recipient3 recipient3) {...}
16 }
More than one observer
Now, the observer API we just skimmed over gives us the possibility to have a single observer at any given time. When we register a new observer, the reference to the old one is overwritten. This is not really useful in our context, is it? With real sensors, we often want them to report their measurements to multiple places (e.g. we want the measurements printed on the screen, saved to a database, and used as part of more complex calculations). This can be achieved in two ways.
The first way would be to just hold a collection of observers in our sensor, and add to this collection whenever a new observer is registered:
1 private IList<TemperatureObserver> _observers
2 = new List<TemperatureObserver>();
3
4 public void FromNowOnReportTo(TemperatureObserver observer)
5 {
6 _observers.Add(observer);
7 }
In such case, reporting would mean iterating over the list of observers:
1 ...
2 foreach(var observer in _observers)
3 {
4 observer.NotifyOn(currentValue, meanValue);
5 }
6 ...
The approach shown above places the policy for notifying observers inside the sensor. Many times this could be sufficient. Still, the sensor is coupled to the answers to at least the following questions:
- In what order do we notify the observers? In the example above, we notify them in order of registration.
- How do we handle errors (e.g. one of the observers throws an exception) - do we stop notifying further observers, or log an error and continue, or maybe do something else? In the example above, we stop on the first observer that throws an exception and rethrow the exception. Maybe it’s not the best approach for our case?
- Is our notification model synchronous or asynchronous? In the example above, we are using a synchronous
forloop.
We can gain a bit more flexibility by extracting the notification logic into a separate observer that would receive a notification and pass it to other observers. We can call it “a broadcasting observer”. The implementation of such an observer could look like this:
1 public class BroadcastingObserver
2 : TemperatureObserver,
3 TemperatureObservable //I'll explain it in a second
4 {
5 private IList<TemperatureObserver> _observers
6 = new List<TemperatureObserver>();
7
8 public void FromNowOnReportTo(TemperatureObserver observer)
9 {
10 _observers.Add(observer);
11 }
12
13 public void NotifyOn(
14 Temperature currentValue,
15 Temperature meanValue)
16 {
17 foreach(var observer in _observers)
18 {
19 observer.NotifyOn(currentValue, meanValue);
20 }
21 }
22 }
This BroadcastingObserver could be instantiated and registered like this:
1 //instantiation:
2 var broadcastingObserver
3 = new BroadcastingObserver();
4
5 ...
6 //somewhere else in the code...:
7 sensor.FromNowOnReportTo(broadcastingObserver);
8
9 ...
10 //somewhere else in the code...:
11 broadcastingObserver.FromNowOnReportTo(
12 new DisplayingObserver())
13 ...
14 //somewhere else in the code...:
15 broadcastingObserver.FromNowOnReportTo(
16 new StoringObserver());
17 ...
18 //somewhere else in the code...:
19 broadcastingObserver.FromNowOnReportTo(
20 new CalculatingObserver());
With this design, the other observers register with the broadcasting observer. However, they don’t really need to know who they are registering with - to hide it, I introduced a special interface called TemperatureObservable, which has the FromNowOnReportTo() method:
1 public interface TemperatureObservable
2 {
3 public void FromNowOnReportTo(TemperatureObserver observer);
4 }
This way, the code that registers an observer does not need to know what the concrete observable object is.
The additional benefit of modeling broadcasting as an observer is that it would allow us to change the broadcasting policy without touching either the sensor code or the other observers. For example, we might replace our for loop-based observer with something like ParallelBroadcastingObserver that would notify each of its observers asynchronously instead of sequentially. The only thing we would need to change is the observer object that’s registered with a sensor. So instead of:
1 //instantiation:
2 var broadcastingObserver
3 = new BroadcastingObserver();
4
5 ...
6 //somewhere else in the code...:
7 sensor.FromNowOnReportTo(broadcastingObserver);
We would have
1 //instantiation:
2 var broadcastingObserver
3 = new ParallelBroadcastingObserver();
4
5 ...
6 //somewhere else in the code...:
7 sensor.FromNowOnReportTo(broadcastingObserver);
and the rest of the code would remain unchanged. This is because the sensor implements:
-
TemperatureObserverinterface, which the sensor depends on, -
TemperatureObservableinterface which the code that registers the observers depends on.
Anyway, as I said, use registering instances very wisely and only if you specifically need it. Also, if you do use it, evaluate how allowing changing observers at runtime is affecting your multithreading scenarios. This is because a collection of observers might potentially be modified by two threads at the same time.
Where are objects composed?
Ok, we went through some ways of passing a recipient to a sender. We did it from the “internal” perspective of a sender that is given a recipient. What we left out, for the most part, is the “external” perspective, i.e. who should pass the recipient into the sender?
For almost all of the approaches described in the previous chapter, there is no limitation – you pass the recipient from where you need to pass it.
There is one approach, however, that is more limited, and this approach is passing as a constructor parameter.
Why is that? Because, we are trying to be true to the principle of “separating objects creation from use” and this, in turn, is a result of us striving for composability.
Anyway, if an object cannot both use and create another object, we have to make special objects just for creating other objects (there are some design patterns for how to design such objects, but the most popular and useful is a factory) or defer the creation up to the application entry point (there is also a pattern for this, called composition root).
So, we have two cases to consider. I’ll start with the second one – composition root.
Composition Root
let’s assume, just for fun, that we are creating a mobile game where a player has to defend a castle. This game has two levels. Each level has a castle to defend. When we manage to defend the castle long enough, the level is considered completed and we move to the next one. So, we can break down the domain logic into three classes: a Game that has two Levels and each of them that contains a Castle. Let’s also assume that the first two classes violate the principle of separating use from construction, i.e. that a Game creates its own levels and each Level creates its own castle.
A Game class is created in the Main() method of the application:
1 public static void Main(string[] args)
2 {
3 var game = new Game();
4
5 game.Play();
6 }
The Game creates its own Level objects of specific classes implementing the Level interface and stores them in an array:
1 public class Game
2 {
3 private Level[] _levels = new[] {
4 new Level1(), new Level2()
5 };
6
7 //some methods here that use the levels
8 }
And the Level implementations create their own castles and assign them to fields of interface type Castle:
1 public class Level1
2 {
3 private Castle _castle = new SmallCastle();
4
5 //some methods here that use the castle
6 }
7
8 public class Level2
9 {
10 private Castle _castle = new BigCastle();
11
12 //some methods here that use the castle
13 }
Now, I said (and I hope you see it in the code above) that the Game, Level1 and Level2 classes violate the principle of separating use from construction. We don’t like this, do we? Let’s try to make them more compliant with the principle.
Achieving separation of use from construction
First, let’s refactor the Level1 and Level2 according to the principle by moving the instantiation of their castles outside. As the existence of a castle is required for a level to make sense at all – we will say this in code by using the approach of passing a castle through a Level’s constructor:
1 public class Level1
2 {
3 private Castle _castle;
4
5 //now castle is received as
6 //constructor parameter
7 public Level1(Castle castle)
8 {
9 _castle = castle;
10 }
11
12 //some methods here that use the castle
13 }
14
15 public class Level2
16 {
17 private Castle _castle;
18
19 //now castle is received as
20 //constructor parameter
21 public Level2(Castle castle)
22 {
23 _castle = castle;
24 }
25
26 //some methods here that use the castle
27 }
This was easy, wasn’t it? However, it leaves us with an issue to resolve: if the instantiations of castles are not in Level1 and Level2 anymore, then they have to be passed by whoever creates the levels. In our case, this falls on the shoulders of Game class:
1 public class Game
2 {
3 private Level[] _levels = new[] {
4 //now castles are created here as well:
5 new Level1(new SmallCastle()),
6 new Level2(new BigCastle())
7 };
8
9 //some methods here that use the levels
10 }
But remember – this class suffers from the same violation of not separating objects use from construction as the levels did. Thus, to make this class compliant to the principle as well, we have to treat it the same as we did the level classes – move the creation of levels outside:
1 public class Game
2 {
3 private Level[] _levels;
4
5 //now levels are received as
6 //constructor parameter
7 public Game(Level[] levels)
8 {
9 _levels = levels;
10 }
11
12 //some methods here that use the levels
13 }
There, we did it, but again, the levels now must be supplied by whoever creates the Game. Where do we put them? In our case, the only choice left is the Main() method of our application, so this is exactly where we are going to create all the objects that we pass to a Game:
1 public static void Main(string[] args)
2 {
3 var game =
4 new Game(
5 new Level[] {
6 new Level1(new SmallCastle()),
7 new Level2(new BigCastle())
8 });
9
10 game.Play();
11 }
By the way, the Level1 and Level2 are differed only by the castle types and this difference is no more as we refactored it out, so we can make them a single class and call it e.g. TimeSurvivalLevel (because such level is considered completed when we manage to defend our castle for a specific period). After this move, now we have:
1 public static void Main(string[] args)
2 {
3 var game =
4 new Game(
5 new Level[] {
6 new TimeSurvivalLevel(new SmallCastle()),
7 new TimeSurvivalLevel(new BigCastle())
8 });
9
10 game.Play();
11 }
Looking at the code above, we might come to another funny conclusion – this violates the principle of separating use from construction as well! First, we create and connect the web of objects and then send the Play() message to the game object. Can we fix this as well?
I would say “no”, for two reasons:
- There is no further place we can defer the creation. Sure, we could move the creation of the
Gameobject and its dependencies into a separate object responsible only for the creation (e.g. a factory), but it would still leave us with the question: where do we create the factory? Of course, we could use a static method to call it in ourMain()like this:var app = ApplicationRoot.Create(), but that would be delegating the composition, not pulling it up. - The whole point of the principle we are trying to apply is decoupling, i.e. giving ourselves the ability to change one thing without having to change another. When we think of it, there is no point of decoupling the entry point of the application from the application itself, since this is the most application-specific and non-reusable part of the application we can imagine.
What I consider important is that we reached a place where the web of objects is created using the constructor approach and we have no place left to defer the creation of the web (in other words, it is as close as possible to application entry point). Such a place is called a composition root.
We say that composition root is “as close as possible” to the application entry point because there may be different frameworks in control of your application and you will not always have the Main() method at your service8.
Apart from the constructor invocations, the composition root may also contain, e.g., registrations of observers (see registration approach to passing recipients) if such observers are already known at this point. It is also responsible for disposing of all objects it created that require explicit disposal after the application finishes running. This is because it creates them and thus it is the only place in the code that can safely determine when they are not needed.
The composition root above looks quite small, but you can imagine it growing a lot in bigger applications. There are techniques of refactoring the composition root to make it more readable and cleaner – we will explore such techniques in a dedicated chapter.
Factories
Earlier, I described how it isn’t always possible to pass everything through the constructor. One of the approaches we discussed that we can use in such cases is a factory.
When we previously talked about factories, we focused on it being just a source of objects. This time we will have a much closer look at what factories are and what are their benefits.
But first, let’s look at an example of a factory emerging in code that was not using it, as a mere consequence of trying to follow the principle of separating objects use from construction.
Emerging factory – example
Consider the following code that receives a frame that came from the network (as raw data), then packs it into an object, validates and applies to the system:
1 public class MessageInbound
2 {
3 //...initialization code here...
4
5 public void Handle(Frame frame)
6 {
7 // determine the type of message
8 // and wrap it with an object
9 ChangeMessage change = null;
10 if(frame.Type == FrameTypes.Update)
11 {
12 change = new UpdateRequest(frame);
13 }
14 else if(frame.Type == FrameTypes.Insert)
15 {
16 change = new InsertRequest(frame);
17 }
18 else
19 {
20 throw
21 new InvalidRequestException(frame.Type);
22 }
23
24 change.ValidateUsing(_validationRules);
25 _system.Apply(change);
26 }
27 }
Note that this code violates the principle of separating use from construction. The change is first created, depending on the frame type, and then used (validated and applied) in the same method. On the other hand, if we wanted to separate the construction of change from its use, we have to note that it is impossible to pass an instance of the ChangeMessage through the MessageInbound constructor, because this would require us to create the ChangeMessage before we create the MessageInbound. Achieving this is impossible because we can create messages only as soon as we know the frame data which the MessageInbound receives.
Thus, our choice is to make a special object that we would move the creation of new messages into. It would produce new instances when requested, hence the name factory. The factory itself can be passed through a constructor since it does not require a frame to exist – it only needs one when it is asked to create a message.
Knowing this, we can refactor the above code to the following:
1 public class MessageInbound
2 {
3 private readonly
4 MessageFactory _messageFactory;
5 private readonly
6 ValidationRules _validationRules;
7 private readonly
8 ProcessingSystem _system;
9
10 public MessageInbound(
11 //this is the factory:
12 MessageFactory messageFactory,
13 ValidationRules validationRules,
14 ProcessingSystem system)
15 {
16 _messageFactory = messageFactory;
17 _validationRules = validationRules;
18 _system = system;
19 }
20
21 public void Handle(Frame frame)
22 {
23 var change = _messageFactory.CreateFrom(frame);
24 change.ValidateUsing(_validationRules);
25 _system.Apply(change);
26 }
27 }
This way we have separated message construction from its use.
By the way, note that we extracted not only a single constructor, but the whole object creation logic. It’s in the factory now:
1 public class InboundMessageFactory
2 : MessageFactory
3 {
4 ChangeMessage CreateFrom(Frame frame)
5 {
6 if(frame.Type == FrameTypes.Update)
7 {
8 return new UpdateRequest(frame);
9 }
10 else if(frame.Type == FrameTypes.Insert)
11 {
12 return new InsertRequest(frame);
13 }
14 else
15 {
16 throw
17 new InvalidRequestException(frame.Type);
18 }
19 }
20 }
And that’s it. We have a factory now and the way we got to this point was by trying to adhere to the principle of separating use from construction.
Now that we are through with the example, we’re ready for some more general explanation on factories.
Reasons to use factories
As demonstrated in the example, factories are objects responsible for creating other objects. They are used to achieve the separation of objects construction from their use. They are useful for creating objects that live shorter than the objects that use them. Such a shorter lifespan results from not all of the context necessary to create an object being known up-front (i.e. until a user enters credentials, we would not be able to create an object representing their account). We pass the part of the context we know up-front (a so-called global context) in the factory via its constructor and supply the rest that becomes available later (the so-called local context) in a form of factory method parameters when it becomes available:
1 var factory = new Factory(globalContextKnownUpFront);
2
3 //... some time later:
4 factory.CreateInstance(localContext);
Another case for using a factory is when we need to create a new object each time some kind of request is made (a message is received from the network or someone clicks a button):
1 var factory = new Factory(globalContext);
2
3 //...
4
5 //we need a fresh instance
6 factory.CreateInstance();
7
8 //...
9
10 //we need another fresh instance
11 factory.CreateInstance();
In the above example, two independent instances are created, even though both are created identically (there is no local context that would differentiate them).
Both these reasons were present in our example from the last chapter:
- We were unable to create a
ChangeMessagebefore knowing the actualFrame. - For each
Framereceived, we needed to create a newChangeMessageinstance.
Simplest factory
The simplest possible example of a factory object is something along the following lines:
1 public class MyMessageFactory
2 {
3 public MyMessage CreateMyMessage()
4 {
5 return new MyMessage();
6 }
7 }
Even in this primitive shape the factory already has some value (e.g. we can make MyMessage an abstract type and return instances of its subclasses from the factory, and the only place impacted by the change is the factory itself9). More often, however, when talking about simple factories, I think about something like this:
1 //Let's assume MessageFactory
2 //and Message are interfaces
3 public class XmlMessageFactory : MessageFactory
4 {
5 public Message CreateSessionInitialization()
6 {
7 return new XmlSessionInitialization();
8 }
9 }
Note the two things that the factory in the second example has that the one in the first example did not:
- it implements an interface (a level of indirection is introduced)
- its
CreateSessionInitialization()method declares a return type to be an interface (another level of indirection is introduced)
Thus, we introduced two additional levels of indirection. For you to be able to use factories effectively, I need you to understand why and how these levels of indirection are useful, especially when I talk with people, they often do not understand the benefits of using factories, “because we already have the new operator to create objects”. The point is, by hiding (encapsulating) certain information, we achieve more flexibility:
Factories allow creating objects polymorphically (encapsulation of type)
Each time we invoke a new operator, we have to put the name of a concrete type next to it:
1 new List<int>(); //OK!
2 new IList<int>(); //won't compile...
This means that whenever we change our mind and instead of using List<int>() we want to use an object of another class (e.g. SortedList<int>()), we have to either change the code to delete the old type name and put new type name or provide some kind of conditional (if-else). Both options have drawbacks:
- changing the name of the type requires a code change in the class that calls the constructor each time we change our mind, effectively tying us to a single implementation,
- conditionals require us to know all the possible subclasses up-front and our class lacks extensibility that we often require.
Factories allow dealing with these deficiencies. Because we get objects from a factory by invoking a method, not by saying explicitly which class we want to get instantiated, we can take advantage of polymorphism, i.e. our factory may have a method like this:
1 IList<int> CreateContainerForData() {...}
which returns any instance of a real class that implements IList<int> (say, List<int>):
1 public IList<int> /* return type is interface */
2 CreateContainerForData()
3 {
4 return new List<int>(); /* instance of concrete class */
5 }
Of course, it makes little sense for the return type of the factory to be a library class or interface like in the above example (rather, we use factories to create instances of our own classes), but you get the idea, right?
Anyway, it’s typical for a declared return type of a factory to be an interface or, at worst, an abstract class. This means that whoever uses the factory, it knows only that it receives an object of a class that is implementing an interface or is derived from an abstract class. But it doesn’t know exactly what concrete type it is. Thus, a factory may return objects of different types at different times, depending on some rules only it knows.
Time to look at a more realistic example of how to apply this. Let’s say we have a factory of messages like this:
1 public class Version1ProtocolMessageFactory
2 : MessageFactory
3 {
4 public Message NewInstanceFrom(MessageData rawData)
5 {
6 if(rawData.IsSessionInit())
7 {
8 return new SessionInit(rawData);
9 }
10 else if(rawData.IsSessionEnd())
11 {
12 return new SessionEnd(rawData);
13 }
14 else if(rawData.IsSessionPayload())
15 {
16 return new SessionPayload(rawData);
17 }
18 else
19 {
20 throw new UnknownMessageException(rawData);
21 }
22 }
23 }
The factory can create many different types of messages depending on what is inside the raw data, but from the perspective of the user of the factory, this is irrelevant. All that it knows is that it gets a Message, thus, it (and the rest of the code operating on messages in the whole application for that matter) can be written as general-purpose logic, containing no “special cases” dependent on the type of message:
1 var message = _messageFactory.NewInstanceFrom(rawData);
2 message.ValidateUsing(_primitiveValidations);
3 message.ApplyTo(_sessions);
Note that this code doesn’t need to change in case we want to add a new type of message that’s compatible with the existing flow of processing messages10. The only place we need to modify in such a case is the factory. For example, imagine we decided to add a session refresh message. The modified factory would look like this:
1 public class Version1ProtocolMessageFactory
2 : MessageFactory
3 {
4 public Message NewInstanceFrom(MessageData rawData)
5 {
6 if(rawData.IsSessionInit())
7 {
8 return new SessionInit(rawData);
9 }
10 else if(rawData.IsSessionEnd())
11 {
12 return new SessionEnd(rawData);
13 }
14 else if(rawData.IsSessionPayload())
15 {
16 return new SessionPayload(rawData);
17 }
18 else if(rawData.IsSessionRefresh())
19 {
20 //new message type!
21 return new SessionRefresh(rawData);
22 }
23 else
24 {
25 throw new UnknownMessageException(rawData);
26 }
27 }
28 }
and the rest of the code could remain untouched.
Using the factory to hide the real type of message returned makes maintaining the code easier, because there are fewer places in the code impacted by adding new types of messages to the system or removing existing ones (in our example – in case when we do not need to initiate a session anymore) 11 – the factory hides that and the rest of the application is coded against the general scenario.
The above example demonstrated how a factory can hide that many classes can play the same role (i.e. different messages could play the role of a Message), but we can as well use factories to hide that the same class plays many roles. An object of the same class can be returned from different factory method, each time as a different interface and clients cannot access the methods it implements from other interfaces.
Factories are themselves polymorphic (encapsulation of rule)
Another benefit of factories over inline constructor calls is that if a factory is received an object that can be passed as an interface, which allows us to use another factory that implements the same interface in its place via polymorphism. This allows replacing the rule used to create objects with another one, by replacing one factory implementation with another.
Let’s get back to the example from the previous section, where we had a Version1ProtocolMessageFactory that could create different kinds of messages based on some flags being set on raw data (e.g. IsSessionInit(), IsSessionEnd() etc.). Imagine we decided we don’t like this version anymore. The reason is that having so many separate boolean flags is too cumbersome, as with such a design, we risk receiving a message where two or more flags are set to true (e.g. someone might send a message that indicates that it’s both a session initialization and a session end). Supporting such cases (e.g. by validating and rejecting such messages) requires additional effort in the code. We want to make it better before more customers start using the protocol. Thus, a new version of the protocol is conceived – a version 2. This version, instead of using several flags, uses an enum (called MessageTypes) to specify the message type:
1 public enum MessageTypes
2 {
3 SessionInit,
4 SessionEnd,
5 SessionPayload,
6 SessionRefresh
7 }
thus, instead of querying different flags, version 2 allows querying a single value that defines the message type.
Unfortunately, to sustain backward compatibility with some clients, both versions of the protocol need to be supported, each version hosted on a separate endpoint. The idea is that when all clients migrate to the new version, the old one will be retired.
Before introducing version 2, the composition root had code that looked like this:
1 var controller = new MessagingApi(new Version1ProtocolMessageFactory());
2 //...
3 controller.HostApi(); //start listening to messages
where MessagingApi has a constructor accepting the MessageFactory interface:
1 public MessagingApi(MessageFactory messageFactory)
2 {
3 _messageFactory = messageFactory;
4 }
and some general message handling code:
1 var message = _messageFactory.NewInstanceFrom(rawData);
2 message.ValidateUsing(_primitiveValidations);
3 message.ApplyTo(_sessions);
This logic needs to remain the same in both versions of the protocol. How do we achieve this without duplicating this code for each version?
The solution is to create another message factory, i.e. another class implementing the MessageFactory interface. Let’s call it Version2ProtocolMessageFactory and implement it like this:
1 //note that now it is a version 2 protocol factory
2 public class Version2ProtocolMessageFactory
3 : MessageFactory
4 {
5 public Message NewInstanceFrom(MessageData rawData)
6 {
7 switch(rawData.GetMessageType())
8 {
9 case MessageTypes.SessionInit:
10 return new SessionInit(rawData);
11 case MessageTypes.SessionEnd:
12 return new SessionEnd(rawData);
13 case MessageTypes.SessionPayload:
14 return new SessionPayload(rawData);
15 case MessageTypes.SessionRefresh:
16 return new SessionRefresh(rawData);
17 default:
18 throw new UnknownMessageException(rawData);
19 }
20 }
21 }
Note that this factory can return objects of the same classes as version 1 factory, but it makes the decision using the value obtained from GetMessageType() method instead of relying on the flags.
Having this factory enables us to create a MessagingApi instance working with either the version 1 protocol:
1 new MessagingApi(new Version1ProtocolMessageFactory());
or the version 2 protocol:
1 new MessagingApi(new Version2ProtocolMessageFactory());
and, since for the time being we need to support both versions, our composition root will have this code somewhere12:
1 var v1Controller = new MessagingApi(new Version1ProtocolMessageFactory());
2 var v2Controller = new MessagingApi(new Version2ProtocolMessageFactory());
3 //...
4 v1Controller.HostApi(); //start listening to messages
5 v2Controller.HostApi(); //start listening to messages
Note that the MessagingApi class itself did not need to change. As it depends on the MessageFactory interface, all we had to do was supplying a different factory object that made its decision differently.
This example shows something I like calling “encapsulation of rule”. The logic inside the factory is a rule on how, when and which objects to create. Thus, if we make our factory implement an interface and have other objects depend on this interface only, we will be able to switch the rules of object creation by providing another factory without having to modify these objects (as in our case where we did not need to modify the MessagingApi class).
Factories can hide some of the created object dependencies (encapsulation of global context)
Let’s consider another toy example. We have an application that, again, can process messages. One of the things that are done with those messages is saving them in a database and another is validation. The processing of the message is, like in previous examples, handled by a MessageProcessing class, which, this time, does not use any factory, but creates the messages based on the frame data itself. Let’s look at this class:
1 public class MessageProcessing
2 {
3 private DataDestination _database;
4 private ValidationRules _validation;
5
6 public MessageProcessing(
7 DataDestination database,
8 ValidationRules validation)
9 {
10 _database = database;
11 _validation = validation;
12 }
13
14 public void ApplyTo(MessageData data)
15 {
16 //note this creation:
17 var message =
18 new Message(data, _database, _validation);
19
20 message.Validate();
21 message.Persist();
22
23 //... other actions
24 }
25 }
There is one noticeable thing about the MessageProcessing class. It depends on both DataDestination and ValidationRules interfaces but does not use them. The only thing it needs those interfaces for is to supply them as parameters to the constructor of a Message. As the number of Message constructor parameters grows, the MessageProcessing will have to change to take more parameters as well. Thus, the MessageProcessing class gets polluted by something that it does not directly need.
We can remove these dependencies from MessageProcessing by introducing a factory that would take care of creating the messages in its stead. This way, we only need to pass DataDestination and ValidationRules to the factory, because MessageProcessing never needed them for any reason other than creating messages. This factory may look like this:
1 public class MessageFactory
2 {
3 private DataDestination _database;
4 private ValidationRules _validation;
5
6 public MessageFactory(
7 DataDestination database,
8 ValidationRules validation)
9 {
10 _database = database;
11 _validation = validation;
12 }
13
14 //clients only need to pass data here:
15 public Message CreateFrom(MessageData data)
16 {
17 return
18 new Message(data, _database, _validation);
19 }
20 }
Now, note that the creation of messages was moved to the factory, along with the dependencies needed for this. The MessageProcessing does not need to take these dependencies anymore, and can stay more true to its real purpose:
1 public class MessageProcessing
2 {
3 private MessageFactory _factory;
4
5 //now we depend on the factory only:
6 public MessageProcessing(
7 MessageFactory factory)
8 {
9 _factory = factory;
10 }
11
12 public void ApplyTo(MessageData data)
13 {
14 //no need to pass database and validation
15 //since they already are inside the factory:
16 var message = _factory.CreateFrom(data);
17
18 message.Validate();
19 message.Persist();
20
21 //... other actions
22 }
23 }
So, instead of DataDestination and ValidationRules interfaces, the MessageProcessing depends only on the factory. This may not sound like a very attractive tradeoff (taking away two dependencies and introducing one), but note that whenever the MessageFactory needs another dependency that is like the existing two, the factory is all that will need to change. The MessageProcessing will remain untouched and still coupled only to the factory.
The last thing that I want to mention is that not all dependencies can be hidden inside a factory. Note that the factory still needs to receive the MessageData from whoever is asking for a Message, because the MessageData is not available when the factory is created. You may remember that I call such dependencies a local context (because it is specific to a single use of a factory and passed from where the factory creation method is called). On the other hand, what a factory accepts through its constructor can be called a global context (because it is the same throughout the factory lifetime). Using this terminology, the local context cannot be hidden from users of the factory, but the global context can. Thanks to this, the classes using the factory do not need to know about the global context and can stay cleaner, coupled to less things and more focused.
Factories can help increase readability and reveal intention (encapsulation of terminology)
Let’s assume we are writing an action-RPG game that consists of many game levels (not to be mistaken with experience levels). Players can start a new game or continue a saved game. When they choose to start a new game, they are immediately taken to the first level with an empty inventory and no skills. Otherwise, when they choose to continue an old game, they have to select a file with a saved state (then the game level, skills, and inventory are loaded from the file). Thus, we have two separate workflows in our game that end up with two different methods being invoked: OnNewGame() for a new game mode and OnContinue() for resuming a saved game:
1 public void OnNewGame()
2 {
3 //...
4 }
5
6 public void OnContinue(PathToFile savedGameFilePath)
7 {
8 //...
9 }
In each of these methods, we have to somehow assemble a Game class instance. The constructor of Game allows composing it with a starting level, character’s inventory and a set of skills the character can use:
1 public class FantasyGame : Game
2 {
3 public FantasyGame(
4 Level startingLevel,
5 Inventory inventory,
6 Skills skills)
7 {
8 }
9 }
There is no special class for “new game” or for “resumed game” in our code. A new game is just a game starting from the first level with an empty inventory and no skills:
1 var newGame = new FantasyGame(
2 new FirstLevel(),
3 new BackpackInventory(),
4 new KnightSkills());
In other words, the “new game” concept is expressed by a composition of objects rather than by a single class, called e.g. NewGame.
Likewise, when we want to create a game object representing a resumed game, we do it like this:
1 try
2 {
3 saveFile.Open();
4
5 var loadedGame = new FantasyGame(
6 saveFile.LoadLevel(),
7 saveFile.LoadInventory(),
8 saveFile.LoadSkills());
9 }
10 finally
11 {
12 saveFile.Close();
13 }
Again, the concept of “resumed game” is represented by a composition rather than a single class, just like in the case of “new game”. On the other hand, the concepts of “new game” and “resumed game” are part of the domain, so we must make them explicit somehow or we lose readability.
One of the ways to do this is to use a factory13. We can create such a factory and put inside two methods: one for creating a new game, another for creating a resumed game. The code of the factory could look like this:
1 public class FantasyGameFactory : GameFactory
2 {
3 public Game NewGame()
4 {
5 return new FantasyGame(
6 new FirstLevel(),
7 new BackpackInventory(),
8 new KnightSkills());
9 }
10
11 public Game GameSavedIn(PathToFile savedGameFilePath)
12 {
13 var saveFile = new SaveFile(savedGameFilePath);
14 try
15 {
16 saveFile.Open();
17
18 var loadedGame = new FantasyGame(
19 saveFile.LoadLevel(),
20 saveFile.LoadInventory(),
21 saveFile.LoadSkills());
22
23 return loadedGame;
24 }
25 finally
26 {
27 saveFile.Close();
28 }
29 }
30 }
Now we can use the factory in the place where we are notified of the user choice. Remember? This was the place:
1 public void OnNewGame()
2 {
3 //...
4 }
5
6 public void OnContinue(PathToFile savedGameFilePath)
7 {
8 //...
9 }
When we fill the method bodies with the factory usage, the code ends up like this:
1 public void OnNewGame()
2 {
3 var game = _gameFactory.NewGame();
4 game.Start();
5 }
6
7 public void OnContinue(PathToFile savedGameFilePath)
8 {
9 var game = _gameFactory.GameSavedIn(savedGameFilePath);
10 game.Start();
11 }
Note that using a factory helps in making the code more readable and intention-revealing. Instead of using a nameless set of connected objects, the two methods shown above ask using terminology from the domain (explicitly requesting either NewGame() or GameSavedIn(path)). Thus, the domain concepts of “new game” and “resumed game” become explicit. This justifies the first part of the name I gave this section (i.e. “Factories can help increase readability and reveal intention”).
There is, however, the second part of the section name: “encapsulating terminology” which I need to explain. Here’s an explanation: note that the factory is responsible for knowing what exactly the terms “new game” and “resumed game” mean. As the meaning of the terms is encapsulated in the factory, we can change this meaning throughout the application merely by changing the code inside the factory. For example, we can say that new game starts with inventory that is not empty, but contains a basic sword and a shield, by changing the NewGame() method of the factory to this:
1 public Game NewGame()
2 {
3 return new FantasyGame(
4 new FirstLevel(),
5 new BackpackInventory(
6 new BasicSword(),
7 new BasicShield()),
8 new KnightSkills());
9 }
Putting it all together, factories allow giving names to some specific object compositions to increase readability and they allow hiding the meaning of some of the domain terms for easier change in the future because we can modify the meaning of the encapsulated term by changing the code inside the factory methods.
Factories help eliminate redundancy
Redundancy in code means that at least two things need to change for the same reason in the same way14. Usually, it is understood as code duplication, but I consider “conceptual duplication” a better term. For example, the following two methods are not redundant, even though the code seems duplicated (by the way, the following is not an example of good code, just a simple illustration):
1 public int MetersToCentimeters(int value)
2 {
3 return value*100;
4 }
5
6 public int DollarsToCents(int value)
7 {
8 return value*100;
9 }
As I said, I don’t consider this to be redundancy, because the two methods represent different concepts that would change for different reasons. Even if I was to extract “common logic” from the two methods, the only sensible name I could come up with would be something like MultiplyBy100() which, in my opinion, wouldn’t add any value at all.
Note that so far, we considered four things factories encapsulate about creating objects:
- Type
- Rule
- Global context
- Terminology
Thus, if factories didn’t exist, all these concepts would leak to surrounding classes (we saw an example when we were talking about encapsulation of global context). Now, as soon as there is more than one class that needs to create instances, these things leak to all of these classes, creating redundancy. In such a case, any change to how instances are created probably means a change to all classes needing to create those instances.
Thankfully, by having a factory – an object that takes care of creating other objects and nothing else – we can reuse the ruleset, the global context and the type-related decisions across many classes without any unnecessary overhead. All we need to do is reference the factory and ask it for an object.
There are more benefits to factories, but I hope I managed to explain why I consider them a pretty darn beneficial concept for a reasonably low cost.
Summary
In the last chapter several chapters, I tried to show you a variety of ways of composing objects together. Don’t worry if you feel overwhelmed, for the most part, just remember to follow the principle of separating use from construction and you should be fine.
The rules outlined here apply to most of the objects in our application. Wait, did I say most of? Not all? So there are exceptions? Yes, there are and we’ll talk about them shortly when I introduce value objects, but first, we need to further examine the influence composability has on our object-oriented design approach.
Interfaces
Some objects are harder to compose with other objects, others are easier. Of course, we are striving for higher composability. Numerous factors influence this. I already discussed some of them indirectly, so time to sum things up and fill in the gaps. This chapter will deal with the role interfaces play in achieving high composability and the next one will deal with the concept of protocols.
Classes vs interfaces
As we said, a sender is composed with a recipient by obtaining a reference to it. Also, we said that we want our senders to be able to send messages to many different recipients. This is, of course, done using polymorphism.
So, one of the questions we have to ask ourselves in our quest for high composability is: on what should a sender depend on to be able to work with as many recipients as possible? Should it depend on classes or interfaces? In other words, when we plug in an object as a message recipient like this:
1 public Sender(Recipient recipient)
2 {
3 this._recipient = recipient;
4 }
Should the Recipient be a class or an interface?
If we assume that Recipient is a class, we can get the composability we want by deriving another class from it and implementing abstract methods or overriding virtual ones. However, depending on a class as a base type for a recipient has the following disadvantages:
- The recipient class may have some real dependencies. For example, if our
Recipientdepends on Windows Communication Foundation (WCF) stack, then all classes depending directly onRecipientwill indirectly depend on WCF, including ourSender. The more damaging version of this problem is where such aRecipientclass does something like opening a network connection in a constructor – the subclasses are unable to prevent it, no matter if they like it or not because a subclass has to call a superclass’ constructor. -
Recipient’s constructor must be invoked by any class deriving from it, which may be smaller or bigger trouble, depending on what kind of parameters the constructor accepts and what it does. - In languages that support single inheritance only, deriving from
Recipientclass uses up the only inheritance slot, constraining our design. - We must make sure to mark all the methods of
Recipientclass asvirtualto enable overriding them by subclasses. otherwise, we won’t have full composability. Subclasses will not be able to redefine all of theRecipientbehaviors, so they will be very constrained in what they can do.
As you see, there are some difficulties using classes as “slots for composability”, even if composition is technically possible this way. Interfaces are far better, just because they do not have the above disadvantages.
It is decided then that if a sender wants to be composable with different recipients, it has to accept a reference to a recipient in a form of interface reference. We can say that, by being lightweight and behaviorless, interfaces can be treated as “slots” or “sockets” for plugging in different objects.
As a matter of fact, on UML diagrams, one way to depict a class implementing an interface is by drawing it with a plug. Thus, it seems that the “interface as slot for pluggability” concept is not so unusual.
As you may have already guessed from the previous chapters, we are taking the idea of pluggability and composability to the extreme, making it one of the top priorities.
Events/callbacks vs interfaces – few words on roles
Did I just say that composability is “one of the top priorities” in our design approach? Wow, that’s quite a statement, isn’t it? Unfortunately for me, it also lets you raise the following argument: “Hey, interfaces are not the most extreme way of achieving composability! What about e.g. C# events feature? Or callbacks that are supported by some other languages? Wouldn’t it make the classes even more context-independent and composable, if we connected them through events or callbacks, not interfaces?”
Yes, it would, but it would also strip us from another very important aspect of our design approach that I did not mention explicitly until now. This aspect is: roles. When we use interfaces, we can say that each interface stands for a role for a real object to play. When these roles are explicit, they help design and describe the communication between objects.
Let’s look at an example of how not defining explicit roles can remove some clarity from the design. This is a sample method that sends some messages to two recipients held as interfaces:
1 //role players:
2 private readonly Role1 recipient1;
3 private readonly Role2 recipient2;
4
5 public void SendSomethingToRecipients()
6 {
7 recipient1.DoX();
8 recipient1.DoY();
9 recipient2.DoZ();
10 }
and we compare it with similar effect achieved using callback invocation:
1 //callbacks:
2 private readonly Action DoX;
3 private readonly Action DoY;
4 private readonly Action DoZ;
5
6 public void SendSomethingToRecipients()
7 {
8 DoX();
9 DoY();
10 DoZ();
11 }
We can see that in the second case we are losing the notion of which message belongs to which recipient – each callback is standalone from the sender’s point of view. This is unfortunate because, in our design approach, we want to highlight the roles each recipient plays in the communication, to make it readable and logical. Also, ironically, decoupling using events or callbacks can make composability harder. This is because roles tell us which sets of behaviors belong together and thus, need to change together. If each behavior is triggered using a separate event or callback, an overhead is placed on us to remember which behaviors should be changed together, and which ones can change independently.
This does not mean that events or callbacks are bad. It’s just that they are not fit for replacing interfaces – in reality, their purpose is a little bit different. We use events or callbacks not to tell somebody to do something, but to indicate what happened (that’s why we call them events, after all…). This fits well with the observer pattern we already talked about in the previous chapter. So, instead of using observer objects, we may consider using events or callbacks instead (as in everything, there are some tradeoffs for each of the solutions). In other words, events and callbacks have their use in composition, but they are fit for a case so specific, that they cannot be treated as a default choice. The advantage of interfaces is that they bind together messages that represent coherent abstractions and convey roles in the communication. This improves readability and clarity.
Small interfaces
Ok, so we said that the interfaces are “the way to go” for reaching the strong composability we’re striving for. Does merely using interfaces guarantee us that the composability will be strong? The answer is “no” – while using interfaces as “slots” is a necessary step in the right direction, it alone does not produce the best composability.
One of the other things we need to consider is the size of interfaces. Let’s state one thing that is obvious regarding this:
All other things equal, smaller interfaces (i.e. with fewer methods) are easier to implement than bigger interfaces.
The obvious conclusion from this is that if we want to have strong composability, our “slots”, i.e. interfaces, have to be as small as possible (but not smaller – see the previous section on interfaces vs events/callbacks). Of course, we cannot achieve this by blindly removing methods from interfaces, because this would break classes that use these methods e.g. when someone is using an interface implementation like this:
1 public void Process(Recipient recipient)
2 {
3 recipient.DoSomething();
4 recipient.DoSomethingElse();
5 }
It is impossible to remove either of the methods from the Recipient interface because it would cause a compile error saying that we are trying to use a method that does not exist.
So, what do we do then? We try to separate groups of methods used by different senders and move them to separate interfaces so that each sender has access only to the methods it needs. After all, a class can implement more than one interface, like this:
1 public class ImplementingObject
2 : InterfaceForSender1,
3 InterfaceForSender2,
4 InterfaceForSender3
5 { ... }
This notion of creating a separate interface per sender instead of a single big interface for all senders is known as the Interface Segregation Principle15.
A simple example: separation of reading from writing
Let’s assume we have a class in our application that represents enterprise organizational structure. This application exposes two APIs. The first one serves for notifications about changes of organizational structure by an administrator (so that our class can update its data). The second one is for client-side operations on the organizational data, like listing all employees. The interface for the organizational structure class may contain methods used by both these APIs:
1 public interface
2 OrganizationStructure
3 {
4 //////////////////////
5 //used by administrator:
6 //////////////////////
7
8 void Make(Change change);
9 //...other administrative methods
10
11 //////////////////////
12 //used by clients:
13 //////////////////////
14
15 void ListAllEmployees(
16 EmployeeDestination destination);
17 //...other client-side methods
18 }
However, the administrative API handling is done by a different code than the client-side API handling. Thus, the administrative part has no use of the knowledge about listing employees and vice-versa – the client-side one has no interest in making administrative changes. We can use this knowledge to split our interface into two:
1 public interface
2 OrganizationalStructureAdminCommands
3 {
4 void Make(Change change);
5 //... other administrative methods
6 }
7
8 public interface
9 OrganizationalStructureClientCommands
10 {
11 void ListAllEmployees(
12 EmployeeDestination destination);
13 //... other client-side methods
14 }
Note that this does not constrain the implementation of these interfaces – a real class can still implement both of them if this is desired:
1 public class InMemoryOrganizationalStructure
2 : OrganizationalStructureAdminCommands,
3 OrganizationalStructureClientCommands
4 {
5 //...
6 }
In this approach, we create more interfaces (which some of you may not like), but that shouldn’t bother us much because, in return, each interface is easier to implement (because the number of methods to implement is smaller than in case of one big interface). This means that composability is enhanced, which is what we want the most.
It pays off. For example, one day, we may get a requirement that all writes to the organizational structure (i.e. the admin-related operations) have to be traced. In such case, all we have to do is to create a proxy class implementing OrganizationalStructureAdminCommands interface, which wraps the original class’ methods with a notification to an observer (that can be either the trace that is required or anything else we like):
1 public class NotifyingAdminCommands : OrganizationalStructureAdminCommands
2 {
3 public NotifyingCommands(
4 OrganizationalStructureAdminCommands wrapped,
5 ChangeObserver observer)
6 {
7 _wrapped = wrapped;
8 _observer = observer;
9 }
10
11 void Make(Change change)
12 {
13 _wrapped.Make(change);
14 _observer.NotifyAbout(change);
15 }
16
17 //...other administrative methods
18 }
Note that when defining the above class, we only had to implement one interface: OrganizationalStructureAdminCommands, and could ignore the existence of OrganizationalStructureClientCommands. This is because of the interface split we did before. If we had not separated interfaces for admin and client access, our NotifyingAdminCommands class would have to implement the ListAllEmployees method (and others) and make it delegate to the original wrapped instance. This is not difficult, but it’s unnecessary effort. Splitting the interface into two smaller ones spared us this trouble.
Interfaces should model roles
In the above example, we split the one bigger interface into two smaller, in reality exposing that the InMemoryOrganizationalStructure class objects can play two roles.
Considering roles is another powerful way of separating interfaces. For example, in the organizational structure we mentioned above, we may have objects of class Employee, but that does not mean this class has to implement an interface called IEmployee or EmployeeIfc of anything like that. Honestly speaking, this is a situation that we may start of with, when we don’t have better ideas yet, but would like to get away from as soon as we can through refactoring. What we would like to do as soon as we can is to recognize valid roles. In our example, from the point of view of the structure, the employee might play a Node role. If it has a parent (e.g. an organization unit) it belongs to, from its perspective it might play a ChildUnit role. Likewise, if it has any children in the structure (e.g. employees he manages), he can be considered their Parent or DirectSupervisor. All of these roles should be modeled using interfaces which Employee class implements:
1 public class Employee : Node, ChildUnit, DirectSupervisor
2 {
3 //...
and each of those interfaces should be given only the methods that are needed from the point of view of objects interacting with a role modeled with this interface.
Interfaces should depend on abstractions, not implementation details
It is tempting to think that every interface is an abstraction by definition. I believe otherwise – while interfaces abstract away the concrete type of the class that implements it, they may still contain some other things not abstracted that are implementation details. Let’s look at the following interface:
1 public interface Basket
2 {
3 void WriteTo(SqlConnection sqlConnection);
4 bool IsAllowedToEditBy(SecurityPrincipal user);
5 }
See the arguments of those methods? SqlConnection is a library object for interfacing directly with an SQL Server database, so it is a very concrete dependency. SecurityPrincipal is one of the core classes of .NET’s authorization library that works with a user database on a local system or in Active Directory. So again, a very concrete dependency. With dependencies like that, it will be very hard to write other implementations of this interface, because we will be forced to drag around concrete dependencies and mostly will not be able to work around that if we want something different. Thus, we may say that these concrete types I mentioned are implementation details exposed in the interface. Thus, this interface is a failed abstraction. It is essential to abstract these implementation details away, e.g. like this:
1 public interface Basket
2 {
3 void WriteTo(ProductOutput output);
4 bool IsAllowedToEditBy(BasketOwner user);
5 }
This is better. For example, as ProductOutput is a higher-level abstraction (most probably an interface, as we discussed earlier) no implementation of the WriteTo method must be tied to any particular storage kind. This means that we have more freedom to develop different implementations of this method. Also, each implementation of the WriteTo method is more useful as it can be reused with different kinds of ProductOutputs.
Another example might be a data interface, i.e. an interface with getters and setters only. Looking at this example:
1 public interface Employee
2 {
3 HumanName Name { get; set; }
4 HumanAge Age { get; set; }
5 Address Address { get; set; }
6 Money Pay { get; set; }
7 EmploymentStatus EmploymentStatus { get; set; }
8 }
in how many different ways can we implement such an interface? Not many – the only question we can answer differently in different implementations of Employee is: “what is the data storage?”. Everything besides this question is exposed, making this a very poor abstraction. This is similar to what Johnny and Benjamin were battling in the payroll system when they wanted to introduce another kind of employee – a contractor employee. Thus, most probably, a better abstraction would be something like this:
1 public interface Employee
2 {
3 void Sign(Document document);
4 void Send(PayrollReport payrollReport);
5 void Fire();
6 void GiveRaiseBy(Percentage percentage);
7 }
So the general rule is: make interfaces real abstractions by abstracting away the implementation details from them. Only then are you free to create different implementations of the interface that are not constrained by dependencies they do not want or need.
Protocols
You already know that objects are connected (composed) together and communicate through interfaces, just as in IP network. There is one more similarity, that’s as important. It’s protocols. In this section, we will look at protocols between objects and their place on our design approach.
Protocols exist
I do not want to introduce any scientific definition, so let’s just establish an understanding that protocols are sets of rules about how objects communicate with each other.
Really? Are there any rules? Is it not enough the objects can be composed together through interfaces, as I explained in previous sections? Well, no, it’s not enough and let me give you a quick example.
Let’s imagine a class Sender that, in one of its methods, asks Recipient (let’s assume Recipient is an interface) to extract status code from some kind of response object and makes a decision based on that code whether or not to notify an observer about an error:
1 if(recipient.ExtractStatusCodeFrom(response) == -1)
2 {
3 observer.NotifyErrorOccured();
4 }
This design is a bit simplistic but nevermind. Its role is to make a certain point. Whoever the recipient is, it is expected to report an error by returning a value of -1. Otherwise, the Sender (which is explicitly checking for this value) will not be able to react to the error situation appropriately. Similarly, if there is no error, the recipient must not report this by returning -1, because if it does, the Sender will mistakenly recognize this as an error. So, for example, this implementation of Recipient, although implementing the interface required by Sender, is wrong, because it does not behave as Sender expects it to:
1 public class WrongRecipient : Recipient
2 {
3 public int ExtractStatusFrom(Response response)
4 {
5 if( /* success */ )
6 {
7 return -1; // but -1 is for errors!
8 }
9 else
10 {
11 return 1; // -1 should be used!
12 }
13 }
14 }
So as you see, we cannot just write anything in a class implementing an interface, because of a protocol that imposes certain constraints on both a sender and a recipient.
This protocol may not only determine the return values necessary for two objects to interact properly, but it can also determine types of exceptions thrown or the order of method calls. For example, anybody using some kind of connection object would imagine the following way of using the connection: first, open it, then do something with it and close it when finished, e.g.
1 connection.Open();
2 connection.Send(data);
3 connection.Close();
Assuming the above connection is an implementation of Connection interface, if we were to implement it like this:
1 public class WrongConnection : Connection
2 {
3 public void Open()
4 {
5 // imagine implementation
6 // for *closing* the connection is here!!
7 }
8
9 public void Close()
10 {
11 // imagine implementation for
12 // *opening* the connection is here!!
13 }
14 }
then it would compile just fine but fail badly when executed. This is because the behavior would be against the protocol set between Connection abstraction and its user. All implementations of Connection must follow this protocol.
So, again, there are rules that restrict the way two objects can communicate. Both a sender and a recipient of a message must adhere to the rules, or they will not be able to work together.
The good news is that most of the time, we are the ones who design these protocols, along with the interfaces, so we can design them to be either easier or harder to follow by different implementations of an interface. Of course, we are wholeheartedly for the “easier” part.
Protocol stability
Remember the last story about Johnny and Benjamin when they had to make a design change to add another kind of employees (contractors) to the application? To do that, they had to change existing interfaces and add new ones. This was a lot of work. We don’t want to do this much work every time we make a change, especially when we introduce a new variation of a concept that is already present in our design (e.g. Johnny and Benjamin already had the concept of “employee” and they were adding a new variation of it, called “contractor”).
To achieve this, we need the protocols to be more stable, i.e. less prone to change. By drawing some conclusions from experiences of Johnny and Benjamin, we can say that they had problems with protocols stability because the protocols were:
- complicated rather than simple
- concrete rather than abstract
- large rather than small
Based on the analysis of the factors that make the stability of the protocols bad, we can come up with some conditions under which these protocols could be more stable:
- protocols should be simple
- protocols should be abstract
- protocols should be logical
- protocols should be small
And some heuristics help us get closer to these qualities:
Craft messages to reflect the sender’s intention
The protocols are simpler if they are designed from the perspective of the object that sends the message, not the one that receives it. In other words, method signatures should reflect the intention of senders rather than the capabilities of recipients.
As an example, let’s look at a code for logging in that uses an instance of an AccessGuard class:
1 accessGuard.SetLogin(login);
2 accessGuard.SetPassword(password);
3 accessGuard.Login();
In this little snippet, the sender must send three messages to the accessGuard object: SetLogin(), SetPassword() and Login(), even though there is no real need to divide the logic into three steps – they are all executed in the same place anyway. The maker of the AccessGuard class might have thought that this division makes the class more “general purpose”, but it seems this is a “premature optimization” that only makes it harder for the sender to work with the accessGuard object. Thus, the protocol that is simpler from the perspective of a sender would be:
1 accessGuard.LoginWith(login, password);
Naming by intention
Another lesson learned from the above example is: setters (like SetLogin and SetPassword in our example) rarely reflect senders’ intentions – more often they are artificial “things” introduced to directly manage object state. This may also have been the reason why someone introduced three messages instead of one – maybe the AccessGuard class was implemented to hold two fields (login and password) inside, so the programmer might have thought someone would want to manipulate them separately from the login step… Anyway, setters should be either avoided or changed to something that reflects the intention better. For example, when dealing with the observer pattern, we don’t want to say: SetObserver(screen), but rather something like FromNowOnReportCurrentWeatherTo(screen).
The issue of naming can be summarized with the following statement: a name of an interface should be assigned after the role that its implementations play and methods should be named after the responsibilities we want the role to have. I love the example that Scott Bain gives in his Emergent Design book16: if I asked you to give me your driving license number, you might’ve reacted differently based on whether the driving license is in your pocket, or your wallet, or your bag, or in your house (in which case you would need to call someone to read it for you). The point is: I, as a sender of this “give me your driving license number” message, do not care how you get it. I say RetrieveDrivingLicenseNumber(), not OpenYourWalletAndReadTheNumber().
This is important because if the name represents the sender’s intention, the method will not have to be renamed when new classes are created that fulfill this intention in a different way.
Model interactions after the problem domain
Sometimes at work, I am asked to conduct a design workshop. The example I often give to my colleagues is to design a system for order reservations (customers place orders and shop deliverers can reserve who gets to deliver which order). The thing that struck me the first few times I did this workshop was that even though the application was all about orders and their reservation, nearly none of the attendees introduced any kind of Order interface or class with Reserve() method on it. Most of the attendees assume that Order is a data structure and handle reservation by adding it to a “collection of reserved items” which can be imagined as the following code fragment:
1 // order is just a data structure,
2 // added to a collection
3 reservedOrders.Add(order)
While this achieves the goal in technical terms (i.e. the application works), the code does not reflect the domain.
If roles, responsibilities, and collaborations between objects reflect the domain, then any change that is natural in the domain is natural in the code. If this is not the case, then changes that seem small from the perspective of the problem domain end up touching many classes and methods in highly unusual ways. In other words, the interactions between objects become less stable (which is exactly what we want to avoid).
On the other hand, let’s assume that we have modeled the design after the domain and have introduced a proper Order role. Then, the logic for reserving an order may look like this:
1 order.ReserveBy(deliverer);
Note that this line is as stable as the domain itself. It needs to change e.g. when orders are not reserved anymore, or someone other than deliverers starts reserving the orders. Thus, I’d say the stability of this tiny interaction is darn high.
Even in cases when the understanding of the domain evolves and changes rapidly, the stability of the domain, although not as high as usual, is still one of the highest the world around us has to offer.
Another example
Let’s assume that we have a code for handling alarms. When an alarm is triggered, all gates are closed, sirens are turned on and a message is sent to special forces with the highest priority to arrive and terminate the intruder. Any error in this procedure leads to shutting down power in the building. If this workflow is coded like this:
1 try
2 {
3 gates.CloseAll();
4 sirens.TurnOn();
5 specialForces.NotifyWith(Priority.High);
6 }
7 catch(SecurityFailure failure)
8 {
9 powerSystem.TurnOffBecauseOf(failure);
10 }
Then the risk of this code changing for other reasons than the change of how domain works (e.g. we do not close the gates anymore but activate laser guns instead) is small. Thus, interactions that use abstractions and methods that directly express domain rules are more stable.
So, to sum up – if a design reflects the domain, it is easier to predict how a change of domain rules will affect the design. This contributes to the maintainability and stability of the interactions and the design as a whole.
Message recipients should be told what to do, instead of being asked for information
Let’s say we are paying an annual income tax yearly and are too busy (i.e. have too many responsibilities) to do this ourselves. Thus, we hire a tax expert to calculate and pay the taxes for us. He is an expert on paying taxes, knows how to calculate everything, where to submit it, etc. but there is one thing he does not know – the context. In other words, he does not know which bank we are using or what we have earned this year that we need to pay the tax for. This is something we need to give him.
Here’s the deal between us and the tax expert summarized as a table:
| Who? | Needs | Can provide |
|---|---|---|
| Us | The tax paid | context (bank, income documents) |
| Tax Expert | context (bank, income documents) | The service of paying the tax |
It is us who hire the expert and us who initiate the deal, so we need to provide the context, as seen in the above table. If we were to model this deal as an interaction between two objects, it could e.g. look like this:
1 taxExpert.PayAnnualIncomeTax(
2 ourIncomeDocuments,
3 ourBank);
One day, our friend, Joan, tells us she needs a tax expert as well. We are happy with the one we hired, so we recommend him to Joan. She has her own income documents, but they are functionally similar to ours, just with different numbers here and there and maybe some different formatting. Also, Joan uses a different bank, but interacting with any bank these days is almost identical. Thus, our tax expert knows how to handle her request. If we model this as interaction between objects, it may look like this:
1 taxExpert.PayAnnualIncomeTax(
2 joansIncomeDocuments,
3 joansBank);
Thus, when interacting with Joan, the tax expert can still use his abilities to calculate and pay taxes the same way as in our case. This is because his skills are independent of the context.
Another day, we decide we are not happy anymore with our tax expert, so we decide to make a deal with a new one. Thankfully, we do not need to know how tax experts do their work – we just tell them to do it, so we can interact with the new one just as with the previous one:
1 //this is the new tax expert,
2 //but no change to the way we talk to him:
3
4 taxExpert.PayAnnualIncomeTax(
5 ourIncomeDocuments,
6 ourBank);
This small example should not be taken literally. Social interactions are far more complicated and complex than what objects usually do. But I hope I managed to illustrate with it an important aspect of the communication style that is preferred in object-oriented design: the Tell Don’t Ask heuristic.
Tell Don’t Ask means that each object, as an expert in its job, handles it well while delegating other responsibilities to other objects that are experts in their respective jobs and provide them with all the context they need to achieve the tasks it wants them to do as parameters of the messages it sends to them.
This can be illustrated with a generic code pattern:
1 recipient.DoSomethingForMe(allTheContextYouNeedToKnow);
This way, a double benefit is gained:
- Our recipient (e.g.
taxExpertfrom the example) can be used by other senders (e.g. pay tax for Joan) without needing to change. All it needs is a different context passed inside a constructor and messages. - We, as senders, can easily use different recipients (e.g. different tax experts that do the task they are assigned differently) without learning how to interact with each new one.
If you look at it, as much as bank and documents are a context for the tax expert, the tax expert is a context for us. Thus, we may say that a design that follows the Tell Don’t Ask principle creates classes that are context-independent.
This has a very profound influence on the stability of the protocols. As much as objects are context-independent, they (and their interactions) do not need to change when the context changes.
Again, quoting Scott Bain, “what you hide, you can change”. Thus, telling an object what to do requires less knowledge than asking for data and information. Again using the driver license metaphor: I may ask another person for a driving license number to make sure they have the license and that it is valid (by checking the number somewhere). I may also ask another person to provide me with directions to the place I want the first person to drive. But isn’t it easier to just tell “buy me some bread and butter”? Then, whoever I ask, has the freedom to either drive or walk (if they know a good store nearby) or ask yet another person to do it instead. I don’t care as long as tomorrow morning, I find the bread and butter in my fridge.
All of these benefits are, by the way, exactly what Johnny and Benjamin were aiming at when refactoring the payroll system. They went from this code, where they asked employee a lot of questions:
1 var newSalary
2 = employee.GetSalary()
3 + employee.GetSalary()
4 * 0.1;
5 employee.SetSalary(newSalary);
to this design that told employee do do its job:
1 employee.EvaluateRaise();
This way, they were able to make this code interact with both RegularEmployee and ContractorEmployee the same way.
This guideline should be treated very, very seriously and applied in almost an extreme way. There are, of course, few places where it does not apply and we’ll get back to them later.
Oh, I almost forgot one thing! The context that we are passing is not necessarily data. It is even more frequent to pass around behavior than to pass data. For example, in our interaction with the tax expert:
1 taxExpert.PayAnnualIncomeTax(
2 ourIncomeDocuments,
3 ourBank);
The Bank class is probably not a piece of data. Rather, I would imagine the Bank to implement an interface that looks like this:
1 public interface Bank
2 {
3 void TransferMoney(
4 Amount amount,
5 AccountId sourceAccount,
6 AccountId destinationAccount);
7 }
So as you can see, this Bank exposes behavior, not data, and it follows the Tell Don’t Ask style as well (it does something well and takes all the context it needs from outside).
Where Tell Don’t Ask does not apply
As I mentioned earlier, there are places where Tell Don’t Ask does not apply. Here are some examples off the top of my head:
- Factories – these are objects that produce other objects for us, so they are inherently “pull-based” – they are always asked to deliver objects.
- Collections – they are merely containers for objects, so all we want from them is adding objects and retrieving objects (by index, by a predicate, using a key, etc.). Note, however, that when we write a class that wraps a collection inside, we want this class to expose interface shaped in a Tell Don’t Ask manner.
- Data sources, like databases – again, these are storage for data, so it is more probable that we will need to ask for this data to get it.
- Some APIs accessed via network – while it is good to use as much Tell Don’t Ask as we can, web APIs have one limitation – it is hard or impossible to pass behaviors as polymorphic objects through them. Usually, we can only pass data.
- So-called “fluent APIs”, also called “internal domain-specific languages”17
Even in cases where we obtain other objects from a method call, we want to be able to apply Tell Don’t Ask to these other objects. For example, we want to avoid the following chain of calls:
1 Radio radio = radioRepository().GetRadio(12);
2 var userName = radio.GetUsers().First().GetName();
3 primaryUsersList.Add(userName);
This way we make the communication tied to the following assumptions:
- Radio has many users
- Radio must have at least one user
- Each user must have a name
- The name is not null
On the other hand, consider this implementation:
1 Radio radio = radioRepository().GetRadio(12);
2 radio.AddPrimaryUserNameTo(primaryUsersList);
It does not have any of the weaknesses of the previous example. Thus, it is more stable in the face of change.
Most of the getters should be removed, return values should be avoided
The above-stated guideline of “Tell Don’t Ask” has a practical implication of getting rid of (almost) all the getters. We did say that each object should stick to its work and tell other objects to do their work, passing context to them, didn’t we? If so, then why should we “get” anything from other objects?
For me, the idea of “no getters” was very extreme at first, but in a short time, I learned that this is in fact how I am supposed to write object-oriented code. I started learning to program using procedural languages such as C, where a program was divided into procedures or functions and data structures. Then I moved on to object-oriented languages that had far better mechanisms for abstraction, but my style of coding didn’t change much. I would still have procedures and functions, just divided into objects. I would still have data structures, but now more abstract, e.g. objects with setters, getters, and some query methods.
But what alternatives do we have? Well, I already introduced Tell Don’t Ask, so you should know the answer. Even though you should, I want to show you another example, this time specifically about getters and setters.
Let’s say that we have a piece of software that handles user sessions. A session is represented in code using a Session class. We want to be able to do three things with our sessions: display them on the GUI, send them through the network and persist them. In our application, we want each of these responsibilities handled by a separate class, because we think it is good if they are not tied together.
So, we need three classes dealing with data owned by the session. This means that each of these classes should somehow obtain access to the data. Otherwise, how can this data be e.g. persisted? It seems we have no choice and we have to expose it using getters.
Of course, we might re-think our choice of creating separate classes for sending, persistence, etc. and consider a choice where we put all this logic inside a Session class. If we did that, however, we would make a core domain concept (a session) dependent on a nasty set of third-party libraries (like a particular GUI library), which would mean that e.g. every time some GUI displaying concept changes, we will be forced to tinker in core domain code, which is pretty risky. Also, if we did that, the Session would be hard to reuse, because every place we would want to reuse this class, we would need to take all these heavy libraries it depends on with us. Plus, we would not be able to e.g. use Session with different GUI or persistence libraries. So, again, it seems like our (not so good, as we will see) only choice is to introduce getters for the information pieces stored inside a session, like this:
1 public interface Session
2 {
3 string GetOwner();
4 string GetTarget();
5 DateTime GetExpiryTime();
6 }
So yeah, in a way, we have decoupled Session from these third-party libraries and we may even say that we have achieved context-independence as far as Session itself is concerned – we can now pull all its data e.g. in a GUI code and display it as a table. The Session does not know anything about it. Let’s see:
1 // Display sessions as a table on GUI
2 foreach(var session in sessions)
3 {
4 var tableRow = TableRow.Create();
5 tableRow.SetCellContentFor("owner", session.GetOwner());
6 tableRow.SetCellContentFor("target", session.GetTarget());
7 tableRow.SetCellContentFor("expiryTime", session.GetExpiryTime());
8 table.Add(tableRow);
9 }
It seems we solved the problem by separating the data from the context it is used in and pulling data to a place that has the context, i.e. knows what to do with this data. Are we happy? We may be unless we look at how the other parts look like – remember that in addition to displaying sessions, we also want to send them and persist them. The sending logic looks like this:
1 //part of sending logic
2 foreach(var session in sessions)
3 {
4 var message = SessionMessage.Blank();
5 message.Owner = session.GetOwner();
6 message.Target = session.GetTarget();
7 message.ExpiryTime = session.GetExpiryTime();
8 connection.Send(message);
9 }
and the persistence logic like this:
1 //part of storing logic
2 foreach(var session in sessions)
3 {
4 var record = Record.Blank();
5 dataRecord.Owner = session.GetOwner();
6 dataRecord.Target = session.GetTarget();
7 dataRecord.ExpiryTime = session.GetExpiryTime();
8 database.Save(record);
9 }
See anything disturbing here? If no, then imagine what happens when we add another piece of information to the Session, say, a priority. We now have three places to update and we have to remember to update all of them every time. This is called “redundancy” or “asking for trouble”. Also, the composability of these three classes is pretty bad, because they will have to change a lot only because data in a session changes.
The reason for this is that we made the Session class effectively a data structure. It does not implement any domain-related behaviors, it just exposes data. There are two implications of this:
- This forces all users of this class to define session-related behaviors on behalf of the
Session, meaning these behaviors are scattered all over the place18. If one is to make a change to the session, they must find all related behaviors and correct them. - As a set of object behaviors is generally more stable than its internal data (e.g. a session might have more than one target one day, but we will always be starting and stopping sessions), this leads to brittle interfaces and protocols – certainly the opposite of what we are striving for.
Bummer, this solution is pretty bad, but we seem to be out of options. Should we just accept that there will be problems with this implementation and move on? Thankfully, we don’t have to. So far, we have found the following options to be troublesome:
- The
Sessionclass containing the display, store and send logic, i.e. all the context needed – too much coupling to heavy dependencies. - The
Sessionclass to expose its data via getters, so that we may pull it where we have enough context to know how to use it – communication is too brittle and redundancy creeps in (by the way, this design will also be bad for multithreading, but that’s something for another time).
Thankfully, we have a third alternative, which is better than the two we already mentioned. We can just pass the context into the Session class. “Isn’t this just another way to do what we outlined in point 1? If we pass the context in, isn’t Session still coupled to this context?”, you may ask. The answer is: not necessarily because we can make the Session class depend on interfaces only instead of the real thing to make it context-independent enough.
Let’s see how this plays out in practice. First, let’s remove those getters from the Session and introduce a new method called DumpInto() that will take a Destination interface implementation as a parameter:
1 public interface Session
2 {
3 void DumpInto(Destination destination);
4 }
The implementation of Session, e.g. a RealSession can pass all fields into this destination like so:
1 public class RealSession : Session
2 {
3 //...
4
5 public void DumpInto(Destination destination)
6 {
7 destination.AcceptOwner(this.owner);
8 destination.AcceptTarget(this.target);
9 destination.AcceptExpiryTime(this.expiryTime);
10 destination.Done();
11 }
12
13 //...
14 }
And the looping through sessions now looks like this:
1 foreach(var session : sessions)
2 {
3 session.DumpInto(destination);
4 }
In this design, RealSession itself decides which parameters to pass and in what order (if that matters) – no one is asking for its data. This DumpInto() method is fairly general, so we can use it to implement all three mentioned behaviors (displaying, persistence, sending), by creating an implementation for each type of destination, e.g. for GUI, it might look like this:
1 public class GuiDestination : Destination
2 {
3 private TableRow _row;
4 private Table _table;
5
6 public GuiDestination(Table table, TableRow row)
7 {
8 _table = table;
9 _row = row;
10 }
11
12 public void AcceptOwner(string owner)
13 {
14 _row.SetCellContentFor("owner", owner);
15 }
16
17 public void AcceptTarget(string target)
18 {
19 _row.SetCellContentFor("target", target);
20 }
21
22 public void AcceptExpiryTime(DateTime expiryTime)
23 {
24 _row.SetCellContentFor("expiryTime", expiryTime);
25 }
26
27 public void Done()
28 {
29 _table.Add(_row);
30 }
31 }
The protocol is now more stable as far as the consumers of session data are concerned. Previously, when we had the getters in the Session class:
1 public class Session
2 {
3 string GetOwner();
4 string GetTarget();
5 DateTime GetExpiryTime();
6 }
the getters had to return something. So what if we had sessions that could expire and decided we want to ignore them when they do (i.e. do not display, store, send or do anything else with them)? In case of the “getter approach” seen in the snippet above, we would have to add another getter, e.g. called IsExpired() to the session class and remember to update each consumer the same way – to check the expiry before consuming the data… you see where this is going, don’t you? On the other hand, with the current design of the Session interface, we can e.g. introduce a feature where the expired sessions are not processed at all in a single place:
1 public class TimedSession : Session
2 {
3 //...
4
5 public void DumpInto(Destination destination)
6 {
7 if(!IsExpired())
8 {
9 destination.AcceptOwner(this.owner);
10 destination.AcceptTarget(this.target);
11 destination.AcceptExpiryTime(this.expiryTime);
12 destination.Done();
13 }
14 }
15
16 //...
17 }
and there is no need to change any other code to get this working19.
Another advantage of designing/making Session to not return anything from its methods is that we have more flexibility in applying patterns such as proxy and decorator to the Session implementations. For example, we can use proxy pattern to implement hidden sessions that are not displayed/stored/sent at all, but at the same time behave like another session in all the other cases. Such a proxy forwards all messages it receives to the original, wrapped Session object, but discards the DumpInto() calls:
1 public class HiddenSession : Session
2 {
3 private Session _innerSession;
4
5 public HiddenSession(Session innerSession)
6 {
7 _innerSession = innerSession;
8 }
9
10 public void DoSomething()
11 {
12 // forward the message to wrapped instance:
13 _innerSession.DoSomething();
14 }
15
16 //...
17
18 public void DumpInto(Destination destination)
19 {
20 // discard the message - do nothing
21 }
22
23 //...
24 }
The clients of this code will not notice this change at all. When we are not forced to return anything, we are more free to do as we like. Again, “tell, don’t ask”.
Protocols should be small and abstract
I already said that interfaces should be small and abstract, so am I not just repeating myself here? The answer is: there is a difference between the size of protocols and the size of interfaces. As an extreme example, let’s take the following interface:
1 public interface Interpreter
2 {
3 public void Execute(string command);
4 }
Is the interface small? Of course! Is it abstract? Well, kind of, yes. Tell Don’t Ask? Sure! But let’s see how it’s used by one of its collaborators:
1 public void RunScript()
2 {
3 _interpreter.Execute("cd dir1");
4 _interpreter.Execute("copy *.cs ../../dir2/src");
5 _interpreter.Execute("copy *.xml ../../dir2/config");
6 _interpreter.Execute("cd ../../dir2/");
7 _interpreter.Execute("compile *.cs");
8 _interpreter.Execute("cd dir3");
9 _interpreter.Execute("copy *.cs ../../dir4/src");
10 _interpreter.Execute("copy *.xml ../../dir4/config");
11 _interpreter.Execute("cd ../../dir4/");
12 _interpreter.Execute("compile *.cs");
13 _interpreter.Execute("cd dir5");
14 _interpreter.Execute("copy *.cs ../../dir6/src");
15 _interpreter.Execute("copy *.xml ../../dir6/config");
16 _interpreter.Execute("cd ../../dir6/");
17 _interpreter.Execute("compile *.cs");
18 }
The point is: the protocol is neither abstract nor small. Thus, making implementations of an interface that is used as such can be pretty painful.
Summary
In this lengthy chapter, I tried to show you the often underrated value of designing communication protocols between objects. They are not a “nice thing to have”, but rather a fundamental part of the design approach that makes mock objects useful, as you will see when finally we get to them. But first, I need you to swallow a few more object-oriented design ideas. I promise it will pay off.
Classes
We already covered interfaces and protocols. In our quest for composability, We need to look at classes as well. Classes:
- implement interfaces (i.e. play roles)
- communicate through interfaces to other services
- follow protocols in this communication
So in a way, what is “inside” a class is a byproduct of how objects of this class acts on the “outside”. Still, it does not mean there is nothing to say about classes themselves that contributes to better composability.
Single Responsibility Principle
I already said that we want our system to be a web of composable objects. An object is a granule of composability – we cannot e.g. unplug a half of an object and plug in another half. Thus, a valid question to ask is: how big should an object be to make the composability comfortable – to let us unplug as much logic as we want, leaving the rest untouched and ready to work with the new recipients we plug in?
The answer comes with a Single Responsibility Principle (in short: SRP) for classes20, which says21:
There has been a lot written about the principle on the web, so I am not going to be wiser than your favorite web search engine (my recent search yielded over 74 thousand results). Still, I believe it is useful to explain this principle in terms of composability.
Usually, the hard part about this principle is how to understand “a reason to change”. Robert C. Martin explains22 that this is about a single source of entropy that generates changes to the class. Which leads us to another trouble of defining a “source of entropy”. So I think it’s better to just give you an example.
Separating responsibilities
Remember the code Johnny and Benjamin used to apply incentive plans to employees? In case you don’t, here it is (it’s just a single method, not a whole class, but it should be enough for our needs):
1 public void ApplyYearlyIncentivePlan()
2 {
3 var employees = _repository.CurrentEmployees();
4
5 foreach(var employee in employees)
6 {
7 employee.EvaluateRaise();
8 employee.EvaluateBonus();
9 employee.Save();
10 }
11 }
So… how many reasons to change does this piece of code have? If we weren’t talking about “reason to change” but simply a “change”, the answer would be “many”. For example, someone may decide that we are not giving raises anymore and the employee.EvaluateRaise() line would be gone. Likewise, a decision could be made that we are not giving bonuses, then the employee.EvaluateBonus() line would have to be removed. So, there are undoubtedly many ways this method could change. But would it be for different reasons? Actually, no. The reason in both cases would be (probably) that the CEO approved a new incentive plan. So, there is one “source of entropy” for these two changes, although there are many ways the code can change. Hence, the two changes are for the same reason.
Now the more interesting part of the discussion: what about saving the employees – is the reason for changing how we save employees the same as for the bonuses and pays? For example, we may decide that we are not saving each employee separately, because it would cause a huge performance load on our data store, but instead, we will save them together in a single batch after we finish processing the last one. This causes the code to change, e.g. like this:
1 public void ApplyYearlyIncentivePlan()
2 {
3 var employees = _repository.CurrentEmployees();
4
5 foreach(var employee in employees)
6 {
7 employee.EvaluateRaise();
8 employee.EvaluateBonus();
9 }
10
11 //now all employees saved once
12 _repository.SaveAll(employees);
13 }
So, as you might’ve already guessed, the reason for this change is different than one for changing the incentive plan, thus, it is a separate responsibility and the logic for reading and storing employees should be separated from this class. The method after the separation and extraction into a new class would look something like this:
1 public void ApplyYearlyIncentivePlanTo(IEnumerable<Employee> employees)
2 {
3 foreach(var employee in employees)
4 {
5 employee.EvaluateRaise();
6 employee.EvaluateBonus();
7 }
8 }
In the example above, we moved reading and writing employees out, so that it is handled by different code – thus, the responsibilities are separated. Do we now have a code that adheres to the Single Responsibility Principle? We may, but consider this situation: the evaluation of the raises and bonuses begins getting slow and, instead of doing this for all employees in a sequential for loop, we would rather parallelize it to process every employee at the same time in a separate thread. After applying this change, the code could look like this (This uses C#-specific API for parallel looping, but I hope you get the idea):
1 public void ApplyYearlyIncentivePlanTo(IEnumerable<Employee> employees)
2 {
3 Parallel.ForEach(employees, employee =>
4 {
5 employee.EvaluateRaise();
6 employee.EvaluateBonus();
7 });
8 }
Is this a new reason to change? Of course it is! Decisions on parallelizing processing come from different source than incentive plan modifications. So, we may say we encountered another responsibility and separate it. The code that remains in the ApplyYearlyIncentivePlanTo() method looks like this now:
1 public void ApplyYearlyIncentivePlanTo(Employee employee)
2 {
3 employee.EvaluateRaise();
4 employee.EvaluateBonus();
5 }
The looping, which is a separate responsibility, is now handled by a different class.
How far do we go?
The above example begs some questions:
- Can we reach a point where we have separated all responsibilities?
- If we can, how can we be sure we have reached it?
The answer to the first question is: probably no. While some reasons to change are common sense, and others can be drawn from our experience as developers or knowledge about the domain of the problem, there are always some that are unexpected and until they surface, we cannot foresee them. Thus, the answer for the second question is: “there is no way”. Which does not mean we should not try to separate the different reasons we see – quite the contrary. We just don’t get overzealous trying to predict every possible change.
I like the comparison of responsibilities to our usage of time in real life. The brewing time of black tea is usually around three to five minutes. This is what is usually printed on the package we buy: “3 — 5 minutes”. Nobody gives the time in seconds, because such granularity is not needed. If seconds made a noticeable difference in the process of brewing tea, we would probably be given time in seconds. But they don’t. When we estimate tasks in software engineering, we also use different time granularity depending on the need23 and the granularity becomes finer as we reach a point where the smaller differences matter more.
Likewise, a simplest software program that prints “hello world” on the screen may fit into a single “main” method and we will probably not see it as several responsibilities. But as soon as we get a requirement to write “hello world” in a native language of the currently running operating system, obtaining the text becomes a separate responsibility from putting it on the screen. It all depends on what granularity we need at the moment (which, as mentioned, may be spotted from code or, in some cases, known up-front from our experience as developers or domain knowledge).
The mutual relationship between the Single Responsibility Principle and composability
The reason I am writing all this is that responsibilities24 are the real granules of composability. The composability of objects that I have talked about a lot already is a means to achieve composability of responsibilities. So, this is what our real goal is. If we have two collaborating objects, each having a single responsibility, we can easily replace the way our application achieves one of these responsibilities without touching the other. Thus, objects conforming to SRP are the most comfortably composable and the right size.25.
A good example from another playground where single responsibility goes hand in hand with composability is UNIX. UNIX is famous for its collection of single-purpose command-line tools, like ls, grep, ps, sed etc. The single-purposeness of these utilities along with the ability of the UNIX command line to pass an output stream of one command to the input stream of another by using the | (pipe) operator. For example, we may combine three commands: ls (lists contents of a directory), sort (sorts passed input) and more (allows comfortably viewing on the screen input that takes more than one screen) into a pipeline:
1 ls | sort | more
Which displays sorted content of the current directory for a more comfortable view. This philosophy of composing a set of single-purpose tools into a more complex and more useful whole is what we are after, only that in object-oriented software development, we’re using objects instead of executables. We will talk more about it in the next chapter.
Static recipients
While static fields in a class body may sometimes seem like a good idea of “sharing” recipient references between its instances and a smart way to make the code more “memory-efficient”, they hurt composability more often than not. Let’s take a look at a simple example to get a feeling of how static fields constraint our design.
SMTP Server
Imagine we need to implement an e-mail server that receives and sends SMTP messages26. We have an OutboundSmtpMessage class which symbolizes SMTP messages we send to other parties. To send the message, we need to encode it. For now, we always use an encoding called Quoted-Printable, which is declared in a separate class called QuotedPrintableEncoding and the class OutboundSmtpMessage declares a private field of this type:
1 public class OutboundSmtpMessage
2 {
3 //... other code
4
5 private Encoding _encoding = new QuotedPrintableEncoding();
6
7 //... other code
8 }
Note that each message owns its encoding object, so when we have, say, 1000000 messages in memory, we also have the same amount of encoding objects.
Premature optimization
One day we notice that it is a waste for each message to define its encoding object since an encoding is a pure algorithm and each use of this encoding does not affect further uses in any way – so we can as well have a single instance and use it in all messages – it will not cause any conflicts. Also, it may save us some CPU cycles, since creating an encoding each time we create a new message has its cost in high throughput scenarios.
But how we make the encoding shared between all instances? Out first thought – static fields! A static field seems fit for the job since it gives us exactly what we want – a single object shared across many instances of its declaring class. Driven by our (supposedly) excellent idea, we modify our OutboundSmtpMessage message class to hold QuotedPrintableEncoding instance as a static field:
1 public class OutboundSmtpMessage
2 {
3 //... other code
4
5 private static Encoding _encoding = new QuotedPrintableEncoding();
6
7 //... other code
8 }
There, we fixed it! But didn’t our mommies tell us not to optimize prematurely? Oh well…
Welcome, change!
One day it turns out that in our messages, we need to support not only Quoted-Printable encoding but also another one, called Base64. With our current design, we cannot do that, because, as a result of using a static field, a single encoding is shared between all messages. Thus, if we change the encoding for a message that requires Base64 encoding, it will also change the encoding for the messages that require Quoted-Printable. This way, we constraint the composability with this premature optimization – we cannot compose each message with the encoding we want. All of the messages use either one encoding or another. A logical conclusion is that no instance of such class is context-independent – it cannot obtain its own context, but rather, context is forced on it.
So what about optimizations?
Are we doomed to return to the previous solution to have one encoding per message? What if this really becomes a performance or memory problem? Is our observation that we don’t need to create the same encoding many times useless?
Not at all. We can still use this observation and get a lot (albeit not all) of the benefits of a static field. How do we do it? How do we achieve the sharing of encodings without the constraints of a static field? Well, we already answered this question few chapters ago – give each message an encoding through its constructor. This way, we can pass the same encoding to many, many OutboundSmtpMessage instances, but if we want, we can always create a message that has another encoding passed. Using this idea, we will try to achieve the sharing of encodings by creating a single instance of each encoding in the composition root and have it passed it to a message through its constructor.
Let’s examine this solution. First, we need to create one of each encoding in the composition root, like this:
1 // We are in a composition root!
2
3 //...some initialization
4
5 var base64Encoding = new Base64Encoding();
6 var quotedPrintableEncoding = new QuotedPrintableEncoding();
7
8 //...some more initialization
Ok, encodings are created, but we still have to pass them to the messages. In our case, we need to create a new OutboundSmtpMessage object at the time we need to send a new message, i.e. on-demand, so we need a factory to produce the message objects. This factory can (and should) be created in the composition root. When we create the factory, we can pass both encodings to its constructor as a global context (remember that factories encapsulate global context?):
1 // We are in a composition root!
2
3 //...some initialization
4
5 var messageFactory
6 = new StmpMessageFactory(base64Encoding, quotedPrintableEncoding);
7
8 //...some more initialization
The factory itself can be used for the on-demand message creation that we talked about. As the factory receives both encodings via its constructor, it can store them as private fields and pass whichever one is appropriate to a message object it creates:
1 public class SmtpMessageFactory : MessageFactory
2 {
3 private Encoding _quotedPrintable;
4 private Encoding _base64;
5
6 public SmtpMessageFactory(
7 Encoding quotedPrintable,
8 Encoding base64)
9 {
10 _quotedPrintable = quotedPrintable;
11 _base64 = base64;
12 }
13
14 public Message CreateFrom(string content, MessageLanguage language)
15 {
16 if(language.IsLatinBased)
17 {
18 //each message gets the same instance of encoding:
19 return new StmpMessage(content, _quotedPrintable);
20 }
21 else
22 {
23 //each message gets the same instance of encoding:
24 return new StmpMessage(content, _base64);
25 }
26 }
27 }
The performance and memory saving is not exactly as big as when using a static field (e.g. each OutboundSmtpMessage instance must store a separate reference to the received encoding), but it is still a huge improvement over creating a separate encoding object per message.
Where statics work?
What I wrote does not mean that statics do not have their uses. They do, but these uses are very specific. I will show you one of such uses in the next chapters after I introduce value objects.
Summary
In this chapter, I tried to give you some advice on designing classes that do not come so naturally from the concept of composability and interactions as those described in previous chapters. Still, as I hope I was able to show, they enhance composability and are valuable to us.
Object Composition as a Language
While most of the earlier chapters talked a lot about viewing object composition as a web, this one will take a different view – one of a language. These two views are remarkably similar and complement each other in guiding design.
It might surprise you that I am comparing object composition to a language, but, as I hope you’ll see, there are many similarities. Don’t worry, we’ll get there step by step, the first step being taking a second look at the composition root.
More readable composition root
When describing object composition and composition root in particular, I promised to get back to the topic of making the composition code cleaner and more readable.
Before I do this, however, we need to get one important question answered…
Why bother?
By now you have to be sick and tired of how I stress the importance of composability. I do so, however, because I believe it is one of the most important aspects of well-designed classes. Also, I said that to reach high composability of a class, it has to be context-independent. To explain how to reach this independence, I introduced the principle of separating object use from construction, pushing the construction part away into specialized places in code. I also said that a lot can be contributed to this quality by making the interfaces and protocols abstract and having them expose as little implementation details as possible.
All of this has its cost, however. Striving for high context-independence takes away from us the ability to look at a single class and determine its context just by reading its code. Such class knows very little about the context it operates in. For example, a few chapters back we dealt with dumping sessions and I showed you that such dump method may be implemented like this:
1 public class RealSession : Session
2 {
3 //...
4
5 public void DumpInto(Destination destination)
6 {
7 destination.AcceptOwner(this.owner);
8 destination.AcceptTarget(this.target);
9 destination.AcceptExpiryTime(this.expiryTime);
10 destination.Done();
11 }
12
13 //...
14 }
Here, the session knows that whatever the destination is, Destination it accepts owner, target and expiry time and needs to be told when all information is passed to it. Still, reading this code, we cannot tell where the destination leads to, since Destination is an interface that abstracts away the details. It is a role that can be played by a file, a network connection, a console screen or a GUI widget. Context-independence enables composability.
On the other hand, as much as context-independent classes and interfaces are important, the behavior of the application as a whole is important as well. Didn’t I say that the goal of composability is to be able to change the behavior of application more easily? But how can we consciously decide about changing the application’s behavior when we do not understand it? And no further than the last paragraph we concluded that merely reading a class after class is not enough. We need to have a view of how these classes work together as a system. So, where is the overall context that defines the behavior of the application?
The context is in the composition code – the code that connects objects, passing real collaborators to each of them and showing how the connected parts make a whole.
Example
I assume you barely remember the alarms example I gave you in one of the first chapters of this part of the book to explain changing behavior by changing object composition. Anyway, just to remind you, we ended with a code that looked like this:
1 new SecureArea(
2 new OfficeBuilding(
3 new DayNightSwitchedAlarm(
4 new SilentAlarm("222-333-444"),
5 new LoudAlarm()
6 )
7 ),
8 new StorageBuilding(
9 new HybridAlarm(
10 new SilentAlarm("222-333-444"),
11 new LoudAlarm()
12 )
13 ),
14 new GuardsBuilding(
15 new HybridAlarm(
16 new SilentAlarm("919"), //call police
17 new LoudAlarm()
18 )
19 )
20 );
So we had three buildings all armed with alarms. The nice property of this code was that we could read the alarm setups from it, e.g. the following part of the composition:
1 new OfficeBuilding(
2 new DayNightSwitchedAlarm(
3 new SilentAlarm("222-333-444"),
4 new LoudAlarm()
5 )
6 ),
meant that we were arming an office building with an alarm that calls number 222-333-444 when triggered during the day, but plays loud sirens when activated during the night. We could read this straight from the composition code, provided we knew what each object added to the overall composite behavior. So, again, the composition of parts describes the behavior of the whole. There is, however, one more thing to note about this piece of code: it describes the behavior without explicitly stating its control flow (if, else, for, etc.). Such description is often called declarative – by composing objects, we write what we want to achieve without writing how to achieve it – the control flow itself is hidden inside the objects.
Let’s sum up these two conclusions with the following statement:
Wow, this is quite a statement, isn’t it? But, as we already noticed, it is true. There is, however, one problem with treating the composition code as an overall application description: readability. Even though the composition is the description of the system, it doesn’t read naturally. We want to see the description of behavior, but most of what we see is: new, new, new, new, new… There is a lot of syntactic noise involved, especially in real systems, where composition code is much longer than this tiny example. Can’t we do something about it?
Refactoring for readability
The declarativeness of composition code goes hand in hand with an approach of defining so-called fluent interfaces. A fluent interface is an API made with readability and flow-like reading in mind. It is usually declarative and targeted towards specific domain, thus another name: internal domain-specific languages, in short: DSL.
There are some simple patterns for creating such domain-specific languages. One of them that can be applied to our situation is called nested function27, which, in our context, means wrapping a call to new with a more descriptive method. Don’t worry if that confuses you, we’ll see how it plays out in practice in a second. We will do this step by step, so there will be a lot of repeated code, but hopefully, you will be able to closely watch the process of improving the readability of composition code.
Ok, Let’s see the code again before making any changes to it:
1 new SecureArea(
2 new OfficeBuilding(
3 new DayNightSwitchedAlarm(
4 new SilentAlarm("222-333-444"),
5 new LoudAlarm()
6 )
7 ),
8 new StorageBuilding(
9 new HybridAlarm(
10 new SilentAlarm("222-333-444"),
11 new LoudAlarm()
12 )
13 ),
14 new GuardsBuilding(
15 new HybridAlarm(
16 new SilentAlarm("919"), //call police
17 new LoudAlarm()
18 )
19 )
20 );
Note that we have several places where we create SilentAlarm. Let’s move the creation of these objects into a separate method:
1 public Alarm Calls(string number)
2 {
3 return new SilentAlarm(number);
4 }
This step may look silly, (after all, we are introducing a method wrapping a single line of code), but there is a lot of sense to it. First of all, it lets us reduce the syntax noise – when we need to create a silent alarm, we do not have to say new anymore. Another benefit is that we can describe the role a SilentAlarm instance plays in our composition (I will explain later why we are doing it using passive voice).
After replacing each invocation of SilentAlarm constructor with a call to this method, we get:
1 new SecureArea(
2 new OfficeBuilding(
3 new DayNightSwitchedAlarm(
4 Calls("222-333-444"),
5 new LoudAlarm()
6 )
7 ),
8 new StorageBuilding(
9 new HybridAlarm(
10 Calls("222-333-444"),
11 new LoudAlarm()
12 )
13 ),
14 new GuardsBuilding(
15 new HybridAlarm(
16 Calls("919"), //police number
17 new LoudAlarm()
18 )
19 )
20 );
Next, let’s do the same with LoudAlarm, wrapping its creation with a method:
1 public Alarm MakesLoudNoise()
2 {
3 return new LoudAlarm();
4 }
and the composition code after applying this method looks like this:
1 new SecureArea(
2 new OfficeBuilding(
3 new DayNightSwitchedAlarm(
4 Calls("222-333-444"),
5 MakesLoudNoise()
6 )
7 ),
8 new StorageBuilding(
9 new HybridAlarm(
10 Calls("222-333-444"),
11 MakesLoudNoise()
12 )
13 ),
14 new GuardsBuilding(
15 new HybridAlarm(
16 Calls("919"), //police number
17 MakesLoudNoise()
18 )
19 )
20 );
Note that we have removed some more news in favor of something more readable. This is exactly what I meant by “reducing syntax noise”.
Now let’s focus a bit on this part:
1 new GuardsBuilding(
2 new HybridAlarm(
3 Calls("919"), //police number
4 MakesLoudNoise()
5 )
6 )
and try to apply the same trick of introducing a factory method to HybridAlarm creation. You know, we are always told that class names should be nouns and that’s why HybridAlarm is named like this. But it does not act well as a description of what the system does. Its real function is to trigger both alarms when it is triggered. Thus, we need to come up with a better name. Should we name the method TriggersBothAlarms()? Naah, it’s too much noise – we already know it’s alarms that we are triggering, so we can leave the “alarms” part out. What about “triggers”? It says what the hybrid alarm does, which might seem good, but when we look at the composition, Calls() and MakesLoudNoise() already say what is being done. The HybridAlarm only says that both of those things happen simultaneously. We could leave Trigger if we changed the names of the other methods in the composition to look like this:
1 new GuardsBuilding(
2 TriggersBoth(
3 Calling("919"), //police number
4 LoudNoise()
5 )
6 )
But that would make the names Calling() and LoudNoise() out of place everywhere it is not being nested as TriggersBoth() arguments. For example, if we wanted to make another building that would only use a loud alarm, the composition would look like this:
1 new OtherBuilding(LoudNoise());
or if we wanted to use silent one:
1 new OtherBuilding(Calling("919"));
Instead, let’s try to name the method wrapping construction of HybridAlarm just Both() – it is simple and communicates well the role hybrid alarms play – after all, they are just a kind of combining operators, not real alarms. This way, our composition code is now:
1 new GuardsBuilding(
2 Both(
3 Calls("919"), //police number
4 MakesLoudNoise()
5 )
6 )
and, by the way, the Both() method is defined as:
1 public Alarm Both(Alarm alarm1, Alarm alarm2)
2 {
3 return new HybridAlarm(alarm1, alarm2);
4 }
Remember that HybridAlarm was also used in the StorageBuilding instance composition:
1 new StorageBuilding(
2 new HybridAlarm(
3 Calls("222-333-444"),
4 MakesLoudNoise()
5 )
6 ),
which now becomes:
1 new StorageBuilding(
2 Both(
3 Calls("222-333-444"),
4 MakesLoudNoise()
5 )
6 ),
Now the most difficult part – finding a way to make the following piece of code readable:
1 new OfficeBuilding(
2 new DayNightSwitchedAlarm(
3 Calls("222-333-444"),
4 MakesLoudNoise()
5 )
6 ),
The difficulty here is that DayNightSwitchedAlarm accepts two alarms that are used alternatively. We need to invent a term that:
- Says it’s an alternative.
- Says what kind of alternative it is (i.e. that one happens at day, and the other during the night).
- Says which alarm is attached to which condition (silent alarm is used during the day and loud alarm is used at night).
If we introduce a single name, e.g. FirstDuringDayAndSecondAtNight(), it will feel awkward and we will lose the flow. Just look:
1 new OfficeBuilding(
2 FirstDuringDayAndSecondAtNight(
3 Calls("222-333-444"),
4 MakesLoudNoise()
5 )
6 ),
It just doesn’t feel well… We need to find another approach to this situation. There are two approaches we may consider:
Approach 1: use named parameters
Named parameters are a feature of languages like Python or C#. In short, when we have a method like this:
1 public void DoSomething(int first, int second)
2 {
3 //...
4 }
we can call it with the names of its arguments stated explicitly, like this:
1 DoSomething(first: 12, second: 33);
We can use this technique to refactor the creation of DayNightSwitchedAlarm into the following method:
1 public Alarm DependingOnTimeOfDay(
2 Alarm duringDay, Alarm atNight)
3 {
4 return new DayNightSwitchedAlarm(duringDay, atNight);
5 }
This lets us write the composition code like this:
1 new OfficeBuilding(
2 DependingOnTimeOfDay(
3 duringDay: Calls("222-333-444"),
4 atNight: MakesLoudNoise()
5 )
6 ),
which is quite readable. Using named parameters has this small added benefit that it lets us pass the arguments in a different order they were declared, thanks to their names stated explicitly. This makes both following invocations valid:
1 //this is valid:
2 DependingOnTimeOfDay(
3 duringDay: Calls("222-333-444"),
4 atNight: MakesLoudNoise()
5 )
6
7 //arguments in different order,
8 //but this is valid as well:
9 DependingOnTimeOfDay(
10 atNight: MakesLoudNoise(),
11 duringDay: Calls("222-333-444")
12 )
Now, on to the second approach.
Approach 2: use method chaining
This approach is better translatable to different languages and can be used e.g. in Java and C++. This time, before I show you the implementation, let’s look at the final result we want to achieve:
1 new OfficeBuilding(
2 DependingOnTimeOfDay
3 .DuringDay(Calls("222-333-444"))
4 .AtNight(MakesLoudNoise())
5 )
6 ),
So as you see, this is very similar in reading, the main difference being that it’s more work. It might not be obvious from the start how this kind of parameter passing works:
1 DependingOnTimeOfDay
2 .DuringDay(...)
3 .AtNight(...)
so, let’s decipher it. First, DependingOnTimeOfDay. This is just a class:
1 public class DependingOnTimeOfDay
2 {
3 }
which has a static method called DuringDay():
1 //note: this method is static
2 public static
3 DependingOnTimeOfDay DuringDay(Alarm alarm)
4 {
5 return new DependingOnTimeOfDay(alarm);
6 }
7
8 //The constructor is private:
9 private DependingOnTimeOfDay(Alarm dayAlarm)
10 {
11 _dayAlarm = dayAlarm;
12 }
Now, this method seems strange, doesn’t it? It is a static method that returns an instance of its enclosing class (not an actual alarm!). Also, the private constructor stores the passed alarm inside for later… why?
The mystery resolves itself when we look at another method defined in the DependingOnTimeOfDay class:
1 //note: this method is NOT static
2 public Alarm AtNight(Alarm nightAlarm)
3 {
4 return new DayNightSwitchedAlarm(_dayAlarm, nightAlarm);
5 }
This method is not static and it returns the alarm that we were trying to create. To do so, it uses the first alarm passed through the constructor and the second one passed as its parameter. So if we were to take this construct:
1 DependingOnTimeOfDay //class
2 .DuringDay(dayAlarm) //static method
3 .AtNight(nightAlarm) //non-static method
and assign a result of each operation to a separate variable, it would look like this:
1 DependingOnTimeOfDay firstPart = DependingOnTimeOfDay.DuringDay(dayAlarm);
2 Alarm alarm = firstPart.AtNight(nightAlarm);
Now, we can just chain these calls and get the result we wanted to:
1 new OfficeBuilding(
2 DependingOnTimeOfDay
3 .DuringDay(Calls("222-333-444"))
4 .AtNight(MakesLoudNoise())
5 )
6 ),
The advantage of this solution is that it does not require your programming language of choice to support named parameters. The downside is that the order of the calls is strictly defined. The DuringDay returns an object on which AtNight is invoked, so it must come first.
Discussion continued
For now, I will assume we have chosen approach 1 because it is simpler.
Our composition code looks like this so far:
1 new SecureArea(
2 new OfficeBuilding(
3 DependingOnTimeOfDay(
4 duringDay: Calls("222-333-444"),
5 atNight: MakesLoudNoise()
6 )
7 ),
8 new StorageBuilding(
9 Both(
10 Calls("222-333-444"),
11 MakesLoudNoise()
12 )
13 ),
14 new GuardsBuilding(
15 Both(
16 Calls("919"), //police number
17 MakesLoudNoise()
18 )
19 )
20 );
There are a few more finishing touches we need to make. First of all, let’s try and extract these dial numbers like 222-333-444 into constants. When we do so, then, for example, this code:
1 Both(
2 Calls("919"), //police number
3 MakesLoudNoise()
4 )
becomes
1 Both(
2 Calls(Police),
3 MakesLoudNoise()
4 )
And the last thing is to hide the creation of the following classes: SecureArea, OfficeBuilding, StorageBuilding, GuardsBuilding and we have this:
1 SecureAreaContaining(
2 OfficeBuildingWithAlarmThat(
3 DependingOnTimeOfDay(
4 duringDay: Calls(Guards),
5 atNight: MakesLoudNoise()
6 )
7 ),
8 StorageBuildingWithAlarmThat(
9 Both(
10 Calls(Guards),
11 MakesLoudNoise()
12 )
13 ),
14 GuardsBuildingWithAlarmThat(
15 Both(
16 Calls(Police),
17 MakesLoudNoise()
18 )
19 )
20 );
And here it is – the real, declarative description of our application! The composition reads better than when we started, doesn’t it?
Composition as a language
Written this way, object composition has another important property – it is extensible and can be extended using the same terms that are already used (of course we can add new ones as well). For example, using the methods we invented to make the composition more readable, we may write something like this:
1 Both(
2 Calls(Police),
3 MakesLoudNoise()
4 )
but, using the same terms, we may as well write this:
1 Both(
2 Both(
3 Calls(Police),
4 Calls(Security)),
5 Both(
6 Calls(Boss),
7 MakesLoudNoise()))
8 )
to obtain different behavior. Note that we have invented something that has these properties:
- It defines some kind of vocabulary – in our case, the following “words” are form part of the vocabulary:
Both,Calls,MakesLoudNoise,DependingOnTimeOfDay,atNight,duringDay,SecureAreaContaining,GuardsBuildingWithAlarmThat,OfficeBuildingWithAlarmThat. - It allows combining the words from the vocabulary. These combinations have meaning, which is based solely on the meaning of used words and the way they are combined. For example:
Both(Calls(Police), Calls(Guards))has the meaning of “calls both police and guards when triggered” – thus, it allows us to combine words into sentences. - Although we are quite liberal in defining behaviors for alarms, there are some rules as to what can be composed with what (for example, we cannot compose guards building with an office, but each of them can only be composed with alarms). Thus, we can say that the sentences we write have to obey certain rules that look a lot like a grammar.
- The vocabulary is constrained to the domain of alarms. On the other hand, it is more powerful and expressive as a description of this domain than a combination of
ifstatements,forloops, variable assignments and other elements of a general-purpose language. It is tuned towards describing rules of a domain on a higher level of abstraction. - The sentences written define the behavior of the application – so by writing sentences like this, we still write software! Thus, what we do by combining words into sentences constrained by a grammar is still programming!
All of these points suggest that we have created a Domain-Specific Language28, which, by the way, is a higher-level language, meaning we describe our software on a higher level of abstraction.
The significance of a higher-level language
So… why do we need a higher-level language to describe the behavior of our application? After all, expressions, statements, loops and conditions (and objects and polymorphism) are our daily bread and butter. Why invent something that moves us away from this kind of programming into something “domain-specific”?
My main answer is: to deal with complexity more effectively.
What’s complexity? For our purpose, we can approximately define it as the number of different decisions our application needs to make. As we add new features and fix errors or implement missed requirements, the complexity of our software grows. What can we do when it grows larger than we can manage? We have the following choices:
- Remove some decisions – i.e. remove features from our application. This is very cool when we can do this, but there are times when this might be unacceptable from the business perspective.
- Optimize away redundant decisions – this is about making sure that each decision is made once in the code base – I already showed you some examples how polymorphism can help with that.
- Use 3rd party component or a library to handle some of the decisions for us – while this is quite easy for “infrastructure” code and utilities, it is very, very hard (impossible?) to find a library that will describe our “domain rules” for us. So if these rules are where the real complexity lies (and often they are), we are still left alone with our problem.
- Hide the decisions by programming on a higher level of abstraction – this is what we did in this chapter so far. The advantage is that it allows us to reduce the complexity of our domain, by creating bigger building blocks from which a behavior description can be created.
So, as you see, only the last of the above points really helps in reducing domain complexity. This is where the idea of domain-specific languages falls in. If we carefully craft our object composition into a set of domain-specific languages (one is often too little in all but simplest cases), one day we may find that we are adding new features by writing new sentences in these languages in a declarative way rather than adding new imperative code. Thus, if we have a good language and a firm understanding of its vocabulary and grammar, we can program on a higher level of abstraction which is more expressive and less complex.
This is very hard to achieve – it requires, among others:
- A huge discipline across a development team.
- A sense of direction of how to structure the composition and where to lead the language designs as they evolve.
- Merciless refactoring.
- Some minimal knowledge of language design and experience in doing so.
- Knowledge of some techniques (like the ones we used in our example) that make constructs written in general-purpose language look like another language.
Of course, not all parts of the composition make good material to being structured like a language. Despite these difficulties, I think it’s well worth the effort. Programming on a higher level of abstraction with declarative code rather than imperative is where I place my hope for writing maintainable and understandable systems.
Some advice
So, eager to try this approach? Let me give you a few pieces of advice first:
Evolve the language as you evolve code
At the beginning of this chapter, we achieved our higher-level language by refactoring already existing object composition. This does not at all mean that in real projects we need to wait for a lot of composition code to appear and then try to wrap all of it. I indeed did just that in the alarm example, but this was just an example and its purpose was mainly didactical.
In reality, the language is better off evolving along with the composition it describes. One reason for this is because there is a lot of feedback about the composability of the design gained by trying to put a language on top of it. As I said in the chapter on single responsibility, if objects are not comfortably composable, something is probably wrong with the distribution of responsibilities between them (for comparison of wrongly placed responsibilities, imagine a general-purpose language that would not have a separate if and for constructs but only a combination of them called forif :-)). Don’t miss out on this feedback!
The second reason is that even if you can safely refactor all the code because you have an executable Specification protecting you from making mistakes, it’s just too many decisions to handle at once (plus it takes a lot of time and your colleagues keep adding new code, don’t they?). Good language grows and matures organically rather than being created in a big bang effort. Some decisions take time and a lot of thought to be made.
Composition is not a single DSL, but a series of mini DSLs29
I already briefly noted this. While it may be tempting to invent a single DSL to describe the whole application, in practice it is hardly possible, because our applications have different subdomains that often use different sets of terms. Rather, it pays off to hunt for such subdomains and create smaller languages for them. The alarm example shown above would probably be just a small part of the real composition. Not all parts would lend themselves to shape this way, at least not instantly. What starts as a single class might become a subdomain with its own vocabulary at some point. We need to pay attention. Hence, we still want to apply some of the DSL techniques even to those parts of the composition that are not easily turned into DSLs and hunt for an occasion when we can do so.
As Nat Pryce puts it, it’s all about:
(…) clearly expressing the dependencies between objects in the code that composes them, so that the system structure can easily be refactored, and aggressively refactoring that compositional code to remove duplication and express intent, and thereby raising the abstraction level at which we can program (…). The end goal is to need less and less code to write more and more functionality as the system grows.
For example, a mini-DSL for setting up handling of an application configuration updates might look like this:
1 return ConfigurationUpdates(
2 Of(log),
3 Of(localSettings),
4 OfResource(Departments()),
5 OfResource(Projects()));
Reading this code should not be difficult, especially when we know what each term in the sentence means. This code returns an object handling configuration updates of four things: application log, local settings, and two resources (in this subdomain, resources mean things that can be added, deleted and modified). These two resources are: departments and projects (e.g. we can add a new project or delete an existing one).
Note that the constructs of this language make sense only in a context of creating configuration update handlers. Thus, they should be restricted to this part of composition. Other parts that have nothing to do with configuration updates, should not need to know these constructs.
Do not use an extensive amount of DSL tricks
In creating internal DSLs, one can use a lot of neat tricks, some of them being very “hacky” and twisting the general-purpose language in many ways to achieve “flluent” syntax. But remember that the composition code is to be maintained by your team. Unless each and every member of your team is an expert on creating such DSLs, do not show off with too many, too sophisticated tricks. Stick with a few of the proven ones that are simple to use and work, like the ones I have used in the alarm example.
Martin Fowler30 describes a lot of tricks for creating such DSLs and at the same time warns against using too many of them in the same language.
Factory method nesting is your best friend
One of the DSL techniques, the one I have used the most, is factory method nesting. Basically, it means wrapping a constructor (or constructors – no one said each factory method must wrap exactly one new) invocation with a method that has a name more fitting for a context it is used in (and which hides the obscurity of the new keyword). This technique is what makes this:
1 new HybridAlarm(
2 new SilentAlarm("222-333-444"),
3 new LoudAlarm()
4 )
look like this:
1 Both(
2 Calls("222-333-444"),
3 MakesLoudNoise()
4 )
As you probably remember, in this case, each method wraps a constructor, e.g. Calls() is defined as:
1 public Alarm Calls(string number)
2 {
3 return new SilentAlarm(number);
4 }
This technique is great for describing any kind of tree and graph-like structures as each method provides a natural scope for its arguments:
1 Method1( //beginning of scope
2 NestedMethod1(),
3 NestedMethod2()
4 ); //end of scope
Thus, it is a natural fit for object composition, which is a graph-like structure.
This approach looks great on paper but it’s not like everything just fits in all the time. There are two issues with factory methods that we need to address.
Where to put these methods?
In the usual case, we want to be able to invoke these methods without any qualifier before them, i.e. we want to call MakesLoudNoise() instead of alarmsFactory.MakesLoudNoise() or this.MakesLoudNoise() or anything.
If so, where do we put such methods?
There are two options31:
- Put the methods in the class that performs the composition.
- Put the methods in a superclass.
Apart from that, we can choose between:
- Making the factory methods static.
- Making the factory methods non-static.
First, let’s consider the dilemma of putting in composing class vs having a superclass to inherit from. This choice is mainly determined by reuse needs. The methods that we use in one composition only and do not want to reuse are mostly better off as private methods in the composing class. On the other hand, the methods that we want to reuse (e.g. in other applications or services belonging to the same system), are better put in a superclass that we can inherit from. Also, a combination of the two approaches is possible, where the superclass contains a more general method while the composing class wraps it with another method that adjusts the creation to the current context. By the way, remember that in many languages, we can inherit from a single class only – thus, putting methods for each language in a separate superclass forces us to distribute the composition code across several classes, each inheriting its own set of methods and returning an object or several objects. This is not bad at all – quite the contrary, this is something we’d like to have because it enables us to evolve a language and sentences written in this language in an isolated context.
The second choice between static and non-static is one of having access to instance fields – instance methods have this access, while static methods do not. Thus, if the following is an instance method of a class called AlarmComposition:
1 public class AlarmComposition
2 {
3 //...
4
5 public Alarm Calls(string number)
6 {
7 return new SilentAlarm(number);
8 }
9
10 //...
11 }
and I need to pass an additional dependency to SilentAlarm that I do not want to show in the main composition code, I am free to change the Calls method to:
1 public Alarm Calls(string number)
2 {
3 return new SilentAlarm(
4 number,
5 _hiddenDependency) //field
6 }
and this new dependency may be passed to the AlarmComposition via its constructor:
1 public AlarmComposition(
2 HiddenDependency hiddenDependency)
3 {
4 _hiddenDependency = hiddenDependency;
5 }
This way, I can hide it from the main composition code. This is the freedom I do not have with static methods.
Use implicit collections instead of explicit ones
Most object-oriented languages support passing variable argument lists (e.g. in C# this is achieved with the params keyword, while Java has ... operator). This is valuable in composition, because we often want to be able to pass an arbitrary number of objects to some places. Again, coming back to this composition:
1 return ConfigurationUpdates(
2 Of(log),
3 Of(localSettings),
4 OfResource(Departments()),
5 OfResource(Projects()));
the ConfigurationUpdates() method is using variable argument list:
1 public ConfigurationUpdates ConfigurationUpdates(
2 params ConfigurationUpdate[] updates)
3 {
4 return new MyAppConfigurationUpdates(updates);
5 }
Note that we could, of course, pass the array of ConfigurationUpdate instances using the explicit definition: new ConfigurationUpdate[] {...}, but that would greatly hinder readability and flow of this composition. See for yourself:
1 return ConfigurationUpdates(
2 new [] { //explicit definition brings noise
3 Of(log),
4 Of(localSettings),
5 OfResource(Departments()),
6 OfResource(Projects())
7 }
8 );
Not so pretty, huh? This is why we like the ability to pass variable argument lists as it enhances readability.
A single method can create more than one object
No one said each factory method must create one and only one object. For example, take a look again at this method creating configuration updates:
1 public ConfigurationUpdates ConfigurationUpdates(
2 params ConfigurationUpdate[] updates)
3 {
4 return new MyAppConfigurationUpdates(updates);
5 }
Now, let’s assume we need to trace each invocation on the instance of ConfigurationUpdates class and we want to achieve this by wrapping the MyAppConfigurationUpdates instance with a tracing proxy (a wrapping object that passes the calls along to a real object, but writes some trace messages before and after it does). For this purpose, we can reuse the method we already have, just adding the additional object creation there:
1 public ConfigurationUpdates ConfigurationUpdates(
2 params ConfigurationUpdate[] updates)
3 {
4 //now two objects created instead of one:
5 return new TracedConfigurationUpdates(
6 new MyAppConfigurationUpdates(updates)
7 );
8 }
Note that the TracedConfigurationUpdates is not important from the point of view of the composition – it is pure infrastructure code, not a new domain rule. Because of that, it may be a good idea to hide it inside the factory method.
Summary
In this chapter, I tried to convey to you a vision of object composition as a language, with its own vocabulary, its own grammar, keywords and arguments. We can compose the words from the vocabulary in different sentences to create new behaviors on a higher level of abstraction.
This area of object-oriented design is something I am still experimenting with, trying to catch up with what authorities on this topic share. Thus, I am not as fluent in it as in other topics covered in this book. Expect this chapter to grow (maybe into several chapters) or to be clarified in the future. For now, if you feel you need more information, please take a look at the video by Steve Freeman and Nat Pryce called “Building on SOLID foundations”.
Value Objects
I spent several chapters talking about composing objects in a web where real implementation was hidden and only interfaces were exposed. These objects exchanged messages and modeled roles in our domain.
However, this is just one part of the object-oriented design approach that I’m trying to explain. Another part of the object-oriented world, complementary to what we have been talking about are value objects. They have their own set of design constraints and ideas, so most of the concepts from the previous chapters do not apply to them, or apply differently.
What is a value object?
In short, values are usually seen as immutable quantities, measurements32 or other objects that are compared by their content, not their identity. There are some examples of values in the libraries of our programming languages. For example, String class in Java or C# is a value object because it is immutable and every two strings are considered equal when they contain the same data. Other examples are the primitive types that are built-in into most programming languages, like numbers or characters.
Most of the values that are shipped with general-purpose libraries are quite primitive or general. There are many times, however, when we want to model a domain abstraction as a value object. Some examples include date and time (which nowadays is usually a part of the standard library, because it is usable in so many domains), money, temperature, but also things such as file paths or resource identifiers.
As you may have already spotted when reading this book, I’m really bad at explaining things without examples, so here is one:
Example: money and names
Imagine we are developing a web store for a customer. There are different kinds of products sold and the customer wants to have the ability to add new products.
Each product has at least two important attributes: name and price (there are others like quantity, but let’s leave them alone for now).
Now, imagine how you would model these two things - would the name be modeled as a mere string and price be a double or a decimal type?
Let’s say that we have indeed decided to use a decimal to hold a price, and a string to hold a name. Note that both are generic library types, not connected to any domain. Is it a good choice to use “library types” for domain abstractions? We shall soon find out…
Time passes…
One day, it turns out that these values must be shared across several subdomains of the system. For example:
- The website needs to display them
- They are used in income calculations
- They are taken into account when defining and checking discount rules (e.g. “buy three, pay for two”)
- They must be supplied when printing invoices
etc.
The code grows larger and larger and, as the concepts of product name and price are among the main concepts of the application, they tend to land in many places.
Change request
Now, imagine that one of the following changes must make its way into the system:
- The product name must be compared as case insensitive since the names of the products are always printed in uppercase on the invoice. Thus, creating two products that differ only in a letter case (eg. “laptop” and “LAPTOP”) would confuse the customers as both these products look the same on the invoice. Also, the only way one would create two products that differ by letter case only is by mistake and we want to avoid that.
- The product name is not enough to differentiate a product. For example, PC manufacturers have the same models of notebooks in different configurations (e.g. different amount of RAM or different processor models inside). So each product will receive an additional identifier that will have to be taken into account during comparisons.
- To support customers from different countries, new currencies must be supported.
In the current situation, these changes are painful to make. Why? It’s because we used primitive types to represent the things that would need to change, which means we’re coupled in multiple places to a particular implementation of the product name (string) and a particular implementation of money (e.g. decimal). This wouldn’t be so bad, if not for the fact that we’re coupled to implementation we cannot change!
Are we sentenced to live with issues like that in our code and cannot do anything about it? Let’s find out by exploring the options we have.
From now on, let’s put the money concept aside and focus only on the product name, as both name and price are similar cases with similar solutions, so it’s sufficient for us to consider just one of them.
What options do we have to address product name changes?
To support new requirements, we have to find all places where we use the product name (by the way, an IDE will not help us much in this search, because we would be searching for all the occurrences of type string) and make the same change. Every time we need to do something like this (i.e. we have to make the same change in multiple places and there is a non-zero possibility we’ll miss at least one of those places), it means that we have introduced redundancy. Remember? We talked about redundancy when discussing factories and mentioned that redundancy is about conceptual duplication that forces us to make the same change (not literally, but conceptually) in several places.
Al Shalloway coined a humorous “law” regarding redundancy, called The Shalloway’s Law, which says:
Whenever the same change needs to be applied in N places and N > 1, Shalloway will find at most N-1 such places.
An example application of this law would be:
Whenever the same change needs to be applied in 4 places, Shalloway will find at most 3 such places.
While making fun of himself, Al described something that I see common of myself and some other programmers - that conceptual duplication makes us vulnerable and when dealing with it, we have no advanced tools to help us - just our memory and patience.
Thankfully, there are multiple ways to approach this redundancy. Some of them are better and some are worse33.
Option one - just modify the implementation in all places
This option is about leaving the redundancy where it is and just making the change in all places, hoping that this is the last time we change anything related to the product name.
So let’s say we want to add comparison with the letter case ignored. Using this option would lead us to find all the places where we do something like this:
1 if(productName == productName2)
2 {
3 ..
or
1 if(String.Equals(productName, productName2))
2 {
3 ..
And change them to a comparisong that ignores case, e.g.:
1 if(String.Equals(productName, productName2,
2 StringComparison.OrdinalIgnoreCase))
3 {
4 ..
This deals with the problem, at least for now, but in the long run, it can cause some trouble:
- It will be very hard to find all these places and chances are you’ll miss at least one. This is an easy way for a bug to creep in.
- Even if this time you’ll be able to find and correct all the places, every time the domain logic for product name comparisons changes (e.g. we’ll have to use
InvariantIgnoreCaseoption instead ofOrdinalIgnoreCasefor some reasons, or handle the case I mentioned earlier where comparison includes an identifier of a product), you’ll have to do it over. And Shalloway’s Law applies the same every time. In other words, you’re not making things better. - Everyone who adds new logic that needs to compare product names in the future will have to remember that character case is ignored in such comparisons. Thus, they will need to keep in mind that they should use
OrdinalIgnoreCaseoption whenever they add new comparisons somewhere in the code. If you want to know my opinion, accidental violation of this convention in a team that has either a fair size or more than minimal staff turnover rate is just a matter of time. - Also, there are other changes that will be tied to the concept of product name equality in a different way (for example, hash sets and hash tables use hash codes to help find the right objects) and you’ll need to find those places and make changes there as well.
So, as you can see, this approach does not make things any better. It is this approach that led us to the trouble we are trying to get away in the first place.
Option two - use a helper class
We can address the issues #1 and #2 of the above list (i.e. the necessity to change multiple places when the comparison logic of product names changes) by moving this comparison into a static helper method of a helper class, (let’s simply call it ProductNameComparison) and make this method a single place that knows how to compare product names. This would make each of the places in the code when comparison needs to be made look like this:
1 if(ProductNameComparison.AreEqual(productName, productName2))
2 {
3 ..
Note that the details of what it means to compare two product names are now hidden inside the newly created static AreEqual() method. This method has become the only place that knows these details and each time the comparison needs to be changed, we have to modify this method alone. The rest of the code just calls this method without knowing what it does, so it won’t need to change. This frees us from having to search and modify this code each time the comparison logic changes.
However, while it protects us from the change of comparison logic indeed, it’s still not enough. Why? Because the concept of a product name is still not encapsulated - a product name is still a string and it allows us to do everything with it that we can do with any other string, even when it does not make sense for product names. This is because, in the domain of the problem, product names are not sequences of characters (which stringss are), but an abstraction with a special set of rules applicable to it. By failing to model this abstraction appropriately, we can run into a situation where another developer who starts adding some new code may not even notice that product names need to be compared differently than other strings and just use the default comparison of a string type.
Other deficiencies of the previous approach apply as well (as mentioned, except for issues #1 and #2).
Option three - encapsulate the domain concept and create a “value object”
I think it’s more than clear now that a product name is a not “just a string”, but a domain concept and as such, it deserves its own class. Let us introduce such a class then, and call it ProductName. Instances of this class will have Equals() method overridden34 with the logic specific to product names. Given this, the comparison snippet is now:
1 // productName and productName2
2 // are both instances of ProductName
3 if(productName.Equals(productName2))
4 {
5 ..
How is it different from the previous approach where we had a helper class, called ProductNameComparison? Previously the data of a product name was publicly visible (as a string) and we used the helper class only to store a function operating on this data (and anybody could create their own functions somewhere else without noticing the ones we already added). This time, the data of the product name is hidden35 from the outside world. The only available way to operate on this data is through the ProductName’s public interface (which exposes only those methods that we think make sense for product names and no more). In other words, whereas before we were dealing with a general-purpose type we couldn’t change, now we have a domain-specific type that’s completely under our control. This means we can freely change the meaning of two names being equal and this change will not ripple throughout the code.
In the following chapters, I will further explore this example of product names to show you some properties of value objects.
Value object anatomy
In the previous chapter, we saw a value object - ProductName in action. In this chapter, we’ll study its anatomy - line by line, field by field, method after method. After doing this, you’ll hopefully have a better feel of some of the more general properties of value objects.
Let’s begin our examination by taking a look at the definition of the type ProductName from the previous chapter (the code I will show you is not legal C# - I omitted method bodies, putting a ; after each method declaration. I did this because it would be a lot of code to grasp otherwise and I don’t necessarily want to delve into the code of each method). Each section of the ProductName class definition is marked with a comment. These comments mark the topics we’ll be discussing throughout this chapter.
So here is the promised definition of ProductName:
1 //This is the class we created and used
2 //in the previous chapter
3
4 // class signature
5 public sealed class ProductName
6 : IEquatable<ProductName>
7 {
8 // Hidden data:
9 private string _value;
10
11 // Constructor - hidden as well:
12 private ProductName(string value);
13
14 // Static method for creating new instances:
15 public static ProductName For(string value);
16
17 // Overridden version of ToString()
18 // from Object class
19 public override string ToString();
20
21 // Non-standard version of ToString().
22 // I will explain its purpose later
23 public string ToString(Format format);
24
25 // For value types, we need to implement all the equality
26 // methods and operators, plus GetHashCode():
27 public override bool Equals(Object other);
28 public bool Equals(ProductName other);
29 public override int GetHashCode();
30 public static bool operator ==(ProductName a, ProductName b);
31 public static bool operator !=(ProductName a, ProductName b);
32 }
Using the comments, I divided the class into sections and will describe them in order.
Class signature
There are two things to note about the class signature. The first one is that the class is sealed (in Java that would be final), i.e. I disallow inheriting from it. This is because I want the objects of this class to be immutable. At first sight, sealing the class has nothing to do with immutability. I will explain it in the next chapter when I discuss the aspects of value object design.
The second thing to note is that the class implements an IEquatable interface that adds more strongly typed versions of the Equals(T object) method. This is not strictly required as in C#, every object has a default Equals(Object o) method, but is typically considered good practice since it allows e.g. more efficient use of value objects with C# collections such as Dictionary36.
Hidden data
The actual data is private:
1 private string _value;
Only the methods we publish can be used to operate on the state. This is useful for three things:
- To restrict allowed operations to what we think makes sense to do with a product name. Everything else (i.e. what we think does not make sense to do) is not allowed.
- To achieve immutability of
ProductNameinstances (more on why we want the type to be immutable later), which means that when we create an instance, we cannot modify it. If the_valuefield was public, everyone could modify the state ofProductNameinstance by writing something like:csharp productName.data = "something different"; - To protect against creating a product name with an invalid state. When creating a product name, we have to pass a string containing a name through a static
For()method that can perform the validation (more on this later). If there are no other ways we can set the name, we can rest assured that the validation will happen every time someone wants to create aProductName.
Hidden constructor
Note that the constructor is made private as well:
1 private ProductName(string value)
2 {
3 _value = value;
4 }
and you probably wonder why. I’d like to decompose the question further into two others:
- How should we create new instances then?
- Why private and not public?
Let’s answer them one by one.
How should we create new instances?
The ProductName class contains a special static factory method, called For(). It invokes the constructor and handles all input parameter validations37. An example implementation could be:
1 public static ProductName For(string value)
2 {
3 if(string.IsNullOrWhiteSpace(value))
4 {
5 //validation failed
6 throw new ArgumentException(
7 "Product names must be human readable!");
8 }
9 else
10 {
11 //here we call the constructor
12 return new ProductName(value);
13 }
14 }
There are several reasons for not exposing a constructor directly but use a static factory method instead. Below, I briefly describe some of them.
Explaining intention
Just like factories, static factory methods help explaining intention, because, unlike constructors, they can have names, while constructors have the constraint of being named after their class38. One can argue that the following:
1 ProductName.For("super laptop X112")
is not that more readable than:
1 new ProductName("super laptop X112");
but note that in our example, we have a single, simple factory method. The benefit would be more visible when we would need to support an additional way of creating a product name. Let’s assume that in above example of “super laptop X112”, the “super laptop” is a model and “X112” is a specific configuration (since the same laptop models are often sold in several different configurations, with more or less RAM, different operating systems, etc.) and we find it comfortable to pass these two pieces of information as separate arguments in some places (e.g. because we may obtain them from different sources) and let the ProductName combine them. If we used a constructor for that, we would write:
1 // assume model is "super laptop"
2 // and configuration is "X112"
3 new ProductName(model, configuration)
On the other hand, we can craft a factory method and say:
1 ProductName.CombinedOf(model, configuration)
which reads more fluently. Or, if we like to be super explicit:
1 ProductName.FromModelAndConfig(model, configuration)
which is not my favorite way of writing code, because I don’t like repeating the same information in method name and argument names. I wanted to show you that we can do this if we want though.
I met a lot of developers that find using factory methods somehow unfamiliar, but the good news is that factory methods for value objects are getting more and more mainstream. Just to give you two examples, TimeSpan type in C# uses them (e.g. we can write TimeSpan.FromSeconds(12) and Period type in Java (e.g. Period.ofNanos(2222)).
Ensuring consistent initialization of objects
In the case where we have different ways of initializing an object that all share a common part (i.e. whichever way we choose, part of the initialization must always be done the same), having several constructors that delegate to one common seems like a good idea. For example, we can have two constructors, one delegating to the other, that holds a common initialization logic:
1 // common initialization logic
2 public ProductName(string value)
3 {
4 _value = value;
5 }
6
7 //another constructor that uses the common initialization
8 public ProductName(string model, string configuration)
9 : this(model + " " + configuration) //delegation to "common" constructor
10 {
11 }
Thanks to this, the field _value is initialized in a single place and we have no duplication.
The issue with this approach is this binding between constructors is not enforced - we can use it if we want, otherwise, we can skip it. For example, we can as well use a separate set of fields in each constructor:
1 public ProductName(string value)
2 {
3 _value = value;
4 }
5
6 public ProductName(string model, string configuration)
7 //oops, no delegation to the other constructor
8 {
9 }
which leaves room for mistakes - we might forget to initialize all the fields all the time and allow creating objects with an invalid state.
I argue that using several static factory methods while leaving just a single constructor is safer in that it enforces every object creation to pass through this single constructor. This constructor can then ensure all fields of the object are properly initialized. There is no way in such case that we can bypass this constructor in any of the static factory methods, e.g.:
1 public ProductName CombinedOf(string model, string configuration)
2 {
3 // no way to bypass the constructor here,
4 // and to avoid initializing the _value field
5 return new ProductName(model + " " + configuration);
6 }
What I wrote above might seem an unnecessary complication as the example of product names is trivial and we are unlikely to make a mistake like the one I described above, however:
- There are more complex cases when we can indeed forget to initialize some fields in multiple constructors.
- It is always better to be protected by the compiler than not when the price for the protection is considerably low. At the very least, when something happens, we’ll have one place less to search for bugs.
Better place for input validation
Let’s look again at the For() factory method:
1 public static ProductName For(string value)
2 {
3 if(string.IsNullOrWhiteSpace(value))
4 {
5 //validation failed
6 throw new ArgumentException(
7 "Product names must be human readable!");
8 }
9 else
10 {
11 //here we call the constructor
12 return new ProductName(value);
13 }
14 }
and note that it contains some input validation, while the constructor did not. Is it a wise decision to move the validation to such a method and leave constructor only for assigning fields? The answer to this question depends on the answer to another one: are there cases where we do not want to validate constructor arguments? If no, then the validation should go to the constructor, as its purpose is to ensure an object is properly initialized.
Apparently, there are cases when we want to keep validations out of the constructor. Consider the following case: we want to create bundles of two product names as one. For this purpose, we introduce a new method on ProductName, called BundleWith(), which takes another product name:
1 public ProductName BundleWith(ProductName other)
2 {
3 return new ProductName(
4 "Bundle: " + _value + other._value);
5 }
Note that the BundleWith() method doesn’t contain any validations but instead just calls the constructor. It is safe to do so in this case because we know that:
- The string will be neither null nor empty since we are appending the values of both product names to the constant value of
"Bundle: ". The result of such an append operation will never give us an empty string or anull. - The
_valuefields of boththisand theotherproduct name components must be valid because if they were not, the two product names that contain those values would fail to be created in the first place.
This was a case where we didn’t need the validation because we were sure the input was valid. There may be another case - when it is more convenient for a static factory method to provide validation on its own. Such validation may be more detailed and helpful as it is in a factory method made for a specific case and knows more about what this case is. For example, let’s look at the method we already saw for combining the model and configuration into a product name. If we look at it again (it does not contain any validations yet):
1 public ProductName CombinedOf(string model, string configuration)
2 {
3 return ProductName.For(model + " " + configuration);
4 }
We may argue that this method would benefit from a specialized set of validations because probably both model and configuration need to be validated separately (by the way, it sometimes may be a good idea to create value objects for model and configuration as well - it depends on where we get them and how we use them). We could then go as far as to throw a different exception for each case, e.g.:
1 public ProductName CombinedOf(string model, string configuration)
2 {
3 if(!IsValidModel(model))
4 {
5 throw new InvalidModelException(model);
6 }
7
8 if(!IsValidConfiguration(configuration))
9 {
10 throw new InvalidConfigurationException(configuration);
11 }
12
13 return ProductName.For(model + " " + configuration);
14 }
What if we need the default validation in some cases? We can still put them in a common factory method and invoke it from other factory methods. This looks a bit like going back to the problem with multiple constructors, but I’d argue that this issue is not as serious - in my mind, the problem of validations is easier to spot than mistakenly missing a field assignment as in the case of constructors. You may have different preferences though.
Remember we asked two questions and I have answered just one of them. Thankfully, the other one - why the constructor is private, not public - is much easier to answer now.
Why private and not public?
My reasons for it are: validation and separating use from construction.
Validation
Looking at the constructor of ProductName - we already discussed that it does not validate its input. This is OK when the constructor is used internally inside ProductName (as I just demonstrated in the previous section), because it can only be called by the code we, as creators of ProductName class, can trust. On the other hand, there probably is a lot of code that will create instances of ProductName. Some of this code is not even written yet, most of it we don’t know, so we cannot trust it. For such code, we want to use only the “safe” methods that validate input and raise errors, not the constructor.
Separating use from construction39
I already mentioned that most of the time, we do not want to use polymorphism for values, as they do not play any roles that other objects can fill. Even though, I consider it wise to reserve some degree of flexibility to be able to change our decision more easily in the future, especially when the cost of the flexibility is very low.
Static factory methods provide more flexibility when compared to constructors. For example, when we have a static factory method like this:
1 public static ProductName For(string value)
2 {
3 //validations skipped for brevity
4 return new ProductName(value);
5 }
and all our code depends on it for creating product names rather than on the constructor, we are free to make the ProductName class abstract at some point and have the For() method return an instance of a subclass of ProductName. This change would impact just this static method, as the constructor is hidden and accessible only from inside the ProductName class. Again, this is something I don’t recommend doing by default, unless there is a very strong reason. But if there is, the capability to do so is here.
String conversion methods
The overridden version of ToString() usually returns the internally held value or its string representation. It can be used to interact with a third party APIs or other code that does not know about our ProductName type. For example, if we want to save the product name inside the database, the database API has no idea about ProductName, but rather accepts library types such as strings, numbers, etc. In such a case, we can use ToString() to make passing the product name possible:
1 // let's assume that we have a variable
2 // productName of type ProductName.
3
4 var dataRecord = new DataRecord();
5 dataRecord["Product Name"] = productName.ToString();
6
7 //...
8
9 database.Save(dataRecord);
Things get more complicated when a value object has multiple fields or when it wraps another type like DateTime or an int - we may have to implement other accessor methods to obtain this data. ToString() can then be used for diagnostic purposes to allow printing user-friendly data dump.
Apart from the overridden ToString(), our ProductName type has an overload with signature ToString(Format format). This version of ToString() is not inherited from any other class, so it’s a method we made to fit our goals. The ToString() name is used only out of convenience, as the name is good enough to describe what the method does and it feels familiar. Its purpose is to be able to format the product name differently for different outputs, e.g. reports and on-screen printing. True, we could introduce a special method for each of the cases (e.g. ToStringForScreen() and ToStringForReport()), but that could make the ProductName know too much about how it is used - we would have to extend the type with new methods every time we wanted to print it differently. Instead, the ToString() accepts a Format (which is an interface, by the way) which gives us a bit more flexibility.
When we need to print the product name on screen, we can say:
1 var name = productName.ToString(new ScreenFormat());
and for reports, we can say:
1 var name = productName.ToString(new ReportingFormat());
Nothing forces us to call this method ToString() - we can use another name if we want to.
Equality members
For values such as ProductName, we need to implement all equality operations plus GetHashCode(). The purpose of equality operations to give product names value semantics and allow the following expressions:
1 ProductName.For("a").Equals(ProductName.For("a"));
2 ProductName.For("a") == ProductName.For("a");
to return true, since the state of the compared objects is the same despite them being separate instances in terms of references. In Java, of course, we can only override equals() method - we are unable to override equality operators as their behavior is fixed to comparing references (except primitive types), but Java programmers are so used to this, that it’s rarely a problem.
One thing to note about the implementation of ProductName is that it implements IEquatable<ProductName> interface. In C#, overriding this interface when we want to have value semantics is considered a good practice. The IEquatable<T> interface is what forces us to create a strongly typed Equals() method:
1 public bool Equals(ProductName other);
while the one inherited from object accepts an object as a parameter. The use and existence of IEquatable<T> interface are mostly C#-specific, so I won’t go into the details here, but you can always look it up in the documentation.
When we override Equals(), the GetHashCode() method needs to be overridden as well. The rule is that all objects that are considered equal should return the same hash code and all objects considered not equal should return different hash codes. The reason is that hash codes are used to identify objects in hash tables or hash sets - these data structures won’t work properly with values if GetHashCode() is not properly implemented. That would be too bad because values are often used as keys in various hash-based dictionaries.
The return of investment
There are some more aspects of values that are not visible on the ProductName example, but before I explain them in the next chapter, I’d like to consider one more thing.
Looking into the ProductName anatomy, it may seem like it’s a lot of code just to wrap a single string. Is it worth it? Where is the return of investment?
To answer that, I’d like to get back to our original problem with product names and remind you that I introduced a value object to limit the impact of some changes that could occur to the codebase where product names are used. As it’s been a long time, here are the changes that we wanted to impact our code as little as possible:
- Changing the comparison of product names to case-insensitive
- Changing the comparison to take into account not only a product name but also a configuration in which a product is sold.
Let’s find out whether introducing a value object would pay off in these cases.
First change - case-insensitivity
This one is easy to perform - we just have to modify the equality operators, Equals() and GetHashCode() operations, so that they treat names with the same content in different letter case equal. I won’t go over the code now as it’s not too interesting, I hope you imagine how that implementation would look like. We would need to change all comparisons between strings to use an option to ignore case, e.g. OrdinalIgnoreCase. This would need to happen only inside the ProductName class as it’s the only one that knows how what it means for two product names to be equal. This means that the encapsulation we’ve introduced without ProductName class has paid off.
Second change - additional identifier
This change is more complex, but having a value object in place makes it much easier anyway over the raw string approach. To make this change, we need to modify the creation of ProductName class to take an additional parameter, called config:
1 private ProductName(string value, string config)
2 {
3 _value = value;
4 _config = config;
5 }
Note that this is an example we mentioned earlier. There is one difference, however. While earlier we assumed that we don’t need to hold value and configuration separately inside a ProductName instance and concatenated them into a single string when creating an object, this time we assume that we will need this separation between name and configuration later.
After modifying the constructor, the next thing is to add additional validations to the factory method:
1 public static ProductName CombinedOf(string value, string config)
2 {
3 if(string.IsNullOrWhiteSpace(value))
4 {
5 throw new ArgumentException(
6 "Product names must be human readable!");
7 }
8 else if(string.IsNullOrWhiteSpace(config))
9 {
10 throw new ArgumentException(
11 "Configs must be human readable!");
12 }
13 else
14 {
15 return new ProductName(value, config);
16 }
17 }
Note that this modification requires changes all over the code base (because additional argument is needed to create an object), however, this is not the kind of change that we’re afraid of too much. That’s because changing the signature of the method will trigger compiler errors. Each of these errors will need to be fixed before the compilation can pass (we can say that the compiler creates a nice TODO list for us and makes sure we address each and every item on that list). This means that we don’t fall into the risk of forgetting to make one of the places where we need to make a change. This greatly reduces the risk of violating the Shalloway’s Law.
The last part of this change is to modify equality operators, Equals() and GetHashCode(), to compare instances not only by name, but also by configuration. And again, I will leave the code of those methods as an exercise to the reader. I’ll just briefly note that this modification won’t require any changes outside the ProductName class.
Summary
So far, we have talked about value objects using a specific example of product names. I hope you now have a feel of how such objects can be useful. The next chapter will complement the description of value objects by explaining some of their general properties.
Aspects of value objects design
In the last chapter, we examined the anatomy of a value object. Still, there are several more aspects of value objects design that I still need to mention to give you a full picture.
Immutability
I mentioned before that value objects are usually immutable. Some say immutability is the core part of something being a value (e.g. Kent Beck goes as far as to say that 1 is always 1 and will never become 2), while others don’t consider it as a hard constraint. One way or another, designing value objects as immutable has served me exceptionally well to the point that I don’t even consider writing value object classes that are mutable. Allow me to describe three of the reasons I consider immutability a key constraint for value objects.
Accidental change of hash code
Many times, values are used as keys in hash maps (.e.g .NET’s Dictionary<K,V> is essentially a hash map). Let’s imagine we have a dictionary indexed with instances of a type called KeyObject:
1 Dictionary<KeyObject, AnObject> _objects;
When we use a KeyObject to insert a value into a dictionary:
1 KeyObject key = ...
2 _objects[key] = anObject;
then its hash code is calculated and stored separately from the original key.
When we read from the dictionary using the same key:
1 AnObject anObject = _objects[key];
then its hash code is calculated again and only when the hash codes match are the key objects compared for equality.
Thus, to successfully retrieve an object from a dictionary with a key, this key object must meet the following conditions regarding the key we previously used to put the object in:
- The
GetHashCode()method of the key used to retrieve the object must return the same hash code as that of the key used to insert the object did during the insertion, - The
Equals()method must indicate that both the key used to insert the object and the key used to retrieve it are equal.
The bottom line is: if any of the two conditions is not met, we cannot expect to get the item we inserted.
I mentioned in the previous chapter that the hash code of a value object is calculated based on its state. A conclusion from this is that each time we change the state of a value object, its hash code changes as well. So, let’s assume our KeyObject allows changing its state, e.g. by using a method SetName(). Thus, we can do the following:
1 KeyObject key = KeyObject.With("name");
2 _objects[key] = new AnObject();
3
4 // we mutate the state:
5 key.SetName("name2");
6
7 //do we get the inserted object or not?
8 var objectIInsertedTwoLinesAgo = _objects[key];
This will throw a KeyNotFoundException (this is the dictionary’s behavior when it is indexed with a key it does not contain), as the hash code when retrieving the item is different than it was when inserting it. By changing the state of the key with the statement: key.SetName("name2");, I also changed its calculated hash code, so when I asked for the previously inserted object with _objects[val], I tried to access an entirely different place in the dictionary than the one where my object is stored.
As I find it a quite common situation that value objects end up as keys inside dictionaries, I’d rather leave them immutable to avoid nasty surprises.
Accidental modification by foreign code
I bet many who code or coded in Java know its Date class. Date behaves like a value (it has overloaded equality and hash code generation), but is mutable (with methods like setMonth(), setTime(), setHours() etc.).
Typically, value objects tend to be passed a lot throughout an application and used in calculations. Many Java programmers at least once exposed a Date value using a getter:
1 public class ObjectWithDate {
2
3 private final Date date = new Date();
4
5 //...
6
7 public Date getDate() {
8 //oops...
9 return this.date;
10 }
11 }
The getDate() method allows users of the ObjectWithDate class to access the date. But remember, a date object is mutable and a getter returns a reference! Everyone who calls the getter gains access to the internally stored instance of Date and can modify it like this:
1 ObjectWithDate o = new ObjectWithDate();
2
3 o.getDate().setTime(date.getTime() + 10000); //oops!
4
5 return date;
Of course, almost no one would probably do it in the same line like in the snippet above, but usually, this date would be accessed, assigned to a variable and then passed through several methods, one of which would do something like this:
1 public void doSomething(Date date) {
2 date.setTime(date.getTime() + 10000); //oops!
3 this.nextUpdateTime = date;
4 }
This led to unpredicted situations as the date objects were accidentally modified far, far away from the place they were retrieved40.
As most of the time it wasn’t the intention, the problem of date mutability forced us to manually create a copy each time their code returned a date:
1 public Date getDate() {
2 return (Date)this.date.clone();
3 }
which many of us tended to forget. This cloning approach, by the way, may have introduced a performance penalty because the objects were cloned every time, even when the code that was calling the getDate() had no intention of modifying the date41.
Even when we follow the suggestion of avoiding getters, the same applies when our class passes the date somewhere. Look at the body of a method, called dumpInto():
1 public void dumpInto(Destination destination) {
2 destination.write(this.date); //passing reference to mutable object
3 }
Here, the destination is allowed to modify the date it receives anyway it likes, which, again, is usually against developers’ intentions.
I saw many, many issues in production code caused by the mutability of Java Date type alone. That’s one of the reasons the new time library in Java 8 (java.time) contains immutable types for time and date. When a type is immutable, you can safely return its instance or pass it somewhere without having to worry that someone will overwrite your local state against your will.
Thread safety
When mutable values are shared between threads, there is a risk that they are changed by several threads at the same time or modified by one thread while being read by another. This can cause data corruption. As I mentioned, value objects tend to be created many times in many places and passed inside methods or returned as results a lot - this seems to be their nature. Thus, this risk of data corruption or inconsistency raises.
Imagine our code took hold of a value object of type Credentials, containing username and password. Also, let’s assume Credentials objects are mutable. If so, one thread may accidentally modify the object while it is used by another thread, leading to data inconsistency. So, provided we need to pass login and password separately to a third-party security mechanism, we may run into the following:
1 public void LogIn(Credentials credentials)
2 {
3 thirdPartySecuritySystem.LogIn(
4 credentials.GetLogin(),
5 //imagine password is modified before the next line
6 //from a different thread
7 credentials.GetPassword())
8 }
On the other hand, when an object is immutable, there are no multithreading concerns. If a piece of data is read-only, it can be safely read by as many threads as we like. After all, no one can modify the state of an object, so there is no possibility of inconsistency42.
If not mutability, then what?
For the reasons I described, I consider immutability a crucial aspect of value object design and in this book, when I talk about value objects, I assume they are immutable.
Still, there is one question that remains unanswered: what about a situation when I need to:
- replace all occurrences of letter ‘r’ in a string to letter ‘l’?
- move a date forward by five days?
- add a file name to an absolute directory path to form an absolute file path (e.g. “C:" + “myFile.txt” = “C:\myFile.txt”)?
If I am not allowed to modify an existing value, how can I achieve such goals?
The answer is simple - value objects have operations that, instead of modifying the existing object, return a new one, with the state we are expecting. The old value remains unmodified. This is the way e.g. strings behave in Java and C#.
Just to address the three examples I mentioned
- when I have an existing
stringand want to replace every occurence of letterrwith letterl:
1 string oldString = "rrrr";
2 string newString = oldString.Replace('r', 'l');
3 //oldString is still "rrrr", newString is "llll"
- When I want to move a date forward by five days:
1 DateTime oldDate = DateTime.Now;
2 DateTime newString = oldDate + TimeSpan.FromDays(5);
3 //oldDate is unchanged, newDate is later by 5 days
- When I want to add a file name to a directory path to form an absolute file path43:
1 AbsoluteDirectoryPath oldPath
2 = AbsoluteDirectoryPath.Value(@"C:\Directory");
3 AbsoluteFilePath newPath = oldPath + FileName.Value("file.txt");
4 //oldPath is "C:\Directory", newPath is "C:\Directory\file.txt"
So, again, anytime we want to have a value based on a previous value, instead of modifying the previous object, we create a new object with the desired state.
Immutability gotchas
Watch out for the constructor!
Going back to the Java’s Date example - you may think that it’s fairly easy to get used to cases such as that one and avoid them by just being more careful, but I find it difficult due to many gotchas associated with immutability in languages such as C# or Java. For example, another variant of the Date case from Java could be something like this: Let’s imagine we have a Money type, which is defined as:
1 public sealed class Money
2 {
3 private readonly int _amount;
4 private readonly Currencies _currency;
5 private readonly List<ExchangeRate> _exchangeRates;
6
7 public Money(
8 int amount,
9 Currencies currency,
10 List<ExchangeRate> exchangeRates)
11 {
12 _amount = amount;
13 _currency = currency;
14 _exchangeRates = exchangeRates;
15 }
16
17 //... other methods
18 }
Note that this class has a field of type List<>, which is itself mutable. But let’s also imagine that we have carefully reviewed all of the methods of this class so that this mutable data is not exposed. Does it mean we are safe?
The answer is: as long as our constructor stays as it is, no. Note that the constructor takes a mutable list and just assigns it to a private field. Thus, someone may do something like this:
1 List<ExchangeRate> rates = GetExchangeRates();
2
3 Money dollars = new Money(100, Currencies.USD, rates);
4
5 //modify the list that was passed to dollars object
6 rates.Add(GetAnotherExchangeRate());
In the example above, the dollars object was changed by modifying the list that was passed inside. To get the immutability, one would have to either use an immutable collection library or change the following line:
1 _exchangeRates = exchangeRates;
to:
1 _exchangeRates = new List<ExchangeRate>(exchangeRates);
Inheritable dependencies can surprise you!
Another gotcha has to do with objects of types that can be subclassed (i.e. are not sealed). Let’s take a look at the example of a class called DateWithZone, representing a date with a time zone. Let’s say that this class has a dependency on another class called ZoneId and is defined as such:
1 public sealed class DateWithZone : IEquatable<DateWithZone>
2 {
3 private readonly ZoneId _zoneId;
4
5 public DateWithZone(ZoneId zoneId)
6 {
7 _zoneId = zoneId;
8 }
9
10 //... some equality methods and operators...
11
12 public override int GetHashCode()
13 {
14 return (_zoneId != null ? _zoneId.GetHashCode() : 0);
15 }
16
17 }
Note that for simplicity, I made the DateWithZone type consist only of zone id, which of course in reality does not make any sense. I am doing this only because I want this example to be stripped to the bone. This is also why, for the sake of this example, ZoneId type is defined simply as:
1 public class ZoneId
2 {
3
4 }
There are two things to note about this class. First, it has an empty body, so no fields and methods defined. The second thing is that this type is not sealed (OK, the third thing is that this type does not have value semantics, since its equality operations are inherited as reference-based from the Object class, but, again for the sake of simplification, let’s ignore that).
I just said that the ZoneId does not have any fields and methods, didn’t I? Well, I lied. A class in C# inherits from Object, which means it implicitly inherits some fields and methods. One of these methods is GetHashCode(), which means that the following code compiles:
1 var zoneId = new ZoneId();
2 Console.WriteLine(zoneId.GetHashCode());
The last piece of information that we need to see the bigger picture is that methods like Equals() and GetHashCode() can be overridden. This, combined with the fact that our ZoneId is not sealed, means that somebody can do something like this:
1 public class EvilZoneId : ZoneId
2 {
3 private int _i = 0;
4
5 public override GetHashCode()
6 {
7 _i++;
8 return i;
9 }
10 }
When calling GetHashCode() on an instance of this class multiple times, it’s going to return 1,2,3,4,5,6,7… and so on. This is because the _i field is a piece of mutable state and it is modified every time we request a hash code. Now, I assume no sane person would write code like this, but on the other hand, the language does not restrict it. So assuming such an evil class would come to existence in a codebase that uses the DateWithZone, let’s see what could be the consequences.
First, let’s imagine someone doing the following:
1 var date = new DateWithZone(new EvilZoneId());
2
3 //...
4
5 DoSomething(date.GetHashCode());
6 DoSomething(date.GetHashCode());
7 DoSomething(date.GetHashCode());
Note that the user of the DateWithZone instance uses its hash code, but the GetHashCode() operation of this class is implemented as:
1 public override int GetHashCode()
2 {
3 return (_zoneId != null ? _zoneId.GetHashCode() : 0);
4 }
So it uses the hash code of the zone id, which, in our example, is of class EvilZoneId which is mutable. As a consequence, our instance of DateWithZone ends up being mutable as well.
This example shows a trivial and not too believable case of GetHashCode() because I wanted to show you that even empty classes have some methods that can be overridden to make the objects mutable. To make sure the class cannot be subclassed by a mutable class, we would have to either make all methods sealed (including those inherited from Object) or, better, make the class sealed. Another observation that can be made is that if our ZoneId was an abstract class with at least one abstract method, we would have no chance of ensuring immutability of its implementations, as abstract methods by definition exist to be implemented in subclasses, so we cannot make an abstract method or class sealed.
Another way of preventing mutability by subclasses is making the class constructor private. Classes with private constructors can still be subclassed, but only by nested classes, so there is a way for the author of the original class to control the whole hierarchy and make sure no operation mutates any state.
There are more gotchas (e.g. a similar one applied to generic types), but I’ll leave them for another time.
Handling of variability
As in ordinary objects, there can be some variability in the world of values. For example, money can be dollars, pounds, zlotys (Polish money), euros, etc. Another example of something that can be modeled as a value is path values (you know, C:\Directory\file.txt or /usr/bin/sh) – there can be absolute paths, relative paths, paths to files and paths pointing to directories, we can have Unix paths and Windows paths.
Contrary to ordinary objects, however, where we solved variability by using interfaces and different implementations (e.g. we had an Alarm interface with implementing classes such as LoudAlarm or SilentAlarm), in the world values we do it differently. Taking the alarms I just mentioned as an example, we can say that the different kinds of alarms varied in how they fulfilled the responsibility of signaling that they were turned on (we said they responded to the same message with – sometimes entirely – different behaviors). Variability in the world of values is typically not behavioral in the same way as in the case of objects. Let’s consider the following examples:
- Money can be dollars, pounds, zlotys, etc., and the different kinds of currencies differ in what exchange rates are applied to them (e.g. “how many dollars do I get from 10 Euros and how many from 10 Pounds?”), which is not a behavioral distinction. Thus, polymorphism does not fit this case.
- Paths can be absolute and relative, pointing to files and directories. They differ in what operations can be applied to them. E.g. we can imagine that for paths pointing to files, we can have an operation called
GetFileName(), which doesn’t make sense for a path pointing to a directory. While this is a behavioral distinction, we cannot say that “directory path” and a “file path” are variants of the same abstraction - rather, that are two different abstractions. Thus, polymorphism does not seem to be the answer here either. - Sometimes, we may want to have a behavioral distinction, like in the following example. We have a value class representing product names and we want to write in several different formats depending on the situation.
How do we model this variability? I usually consider three basic approaches, each applicable in different contexts:
- implicit - which would apply to the money example,
- explicit - which would fit the case of paths nicely,
- delegated - which would fit the case of product names.
Let me give you a longer description of each of these approaches.
Implicit variability
Let’s go back to the example of modeling money using value objects44. Money can have different currencies, but we don’t want to treat each currency in any special way. The only things that are impacted by currency are rates by which we exchange them for other currencies. We want the rest of our program to be unaware of which currency it’s dealing with at the moment (it may even work with several values, each of different currency, at the same time, during one calculation or another business operation).
This leads us to make the differences between currencies implicit, i.e. we will have a single type called Money, which will not expose its currency at all. We only have to tell what the currency is when we create an instance:
1 Money tenPounds = Money.Pounds(10);
2 Money tenBucks = Money.Dollars(10);
3 Money tenYens = Money.Yens(10);
and when we want to know the concrete amount in a given currency:
1 //doesn't matter which currency it is, we want dollars.
2 decimal amountOfDollarsOnMyAccount = mySavings.AmountOfDollars();
other than that, we are allowed to mix different currencies whenever and wherever we like45:
1 Money mySavings =
2 Money.Dollars(100) +
3 Money.Euros(200) +
4 Money.Zlotys(1000);
This approach works under the assumption that all of our logic is common for all kinds of money and we don’t have any special piece of logic just for Pounds or just for Euros that we don’t want to pass other currencies into by mistake46.
To sum up, we designed the Money type so that the variability of currency is implicit - most of the code is simply unaware of it and it is gracefully handled under the hood inside the Money class.
Explicit variability
There are times, however, when we want the variability to be explicit, i.e. modeled using different types. Filesystem paths are a good example.
For starters, let’s imagine we have the following method for creating backup archives that accepts a destination path (for now as a string - we’ll get to path objects later) as its input parameter:
1 void Backup(string destinationPath);
This method has one obvious drawback - its signature doesn’t tell anything about the characteristics of the destination path, which begs some questions:
- Should it be an absolute path, or a relative path. If relative, then relative to what?
- Should the path contain a file name for the backup file, or should it be just a directory path and a filename will be given according to some kind of pattern (e.g. a word “backup” + the current timestamp)?
- Or maybe the file name in the path is optional and if none is given, then a default name is used?
These questions suggest that the current design doesn’t convey the intention explicitly enough. We can try to work around it by changing the name of the parameter to hint the constraints, like this:
1 void Backup(string absoluteFilePath);
but the effectiveness of that is based solely on someone reading the argument name and besides, before a path (passed as a string) reaches this method, it is usually passed around several times and it’s very hard to keep track of what is inside this string, so it becomes easy to mess things up and pass e.g. a relative path where an absolute one is expected. The compiler does not enforce any constraints. More than that, one can pass an argument that’s not even a path, because a string can contain any arbitrary content.
It looks to me like a good situation to introduce a value object, but what kind of type or types should we introduce? Surely, we could create a single type called Path47 that would have methods like IsAbsolute(), IsRelative(), IsFilePath() and IsDirectoryPath() (i.e. it would handle the variability implicitly), which would solve (only - we’ll see that shortly) one part of the problem - the signature would be:
1 void Backup(Path absoluteFilePath);
and we would not be able to pass an arbitrary string, only an instance of a Path, which may expose a factory method that checks whether the string passed is in a proper format:
1 //the following could throw an exception
2 //because the argument is not in a proper format
3 Path path = Path.Value(@"C:\C:\C:\C:\//\/\/");
Such a factory method could throw an exception at the time of path object creation. This is important - previously, when we did not have the value object, we could assign garbage to a string, pass it between several objects and get an exception from the Backup() method. Now, that we modeled paths as value objects, there is a high probability that the Path type will be used as early as possible in the chain of calls. Thanks to this and the validation inside the factory method, we will get an exception much closer to the place where the mistake was made, not at the end of the call chain.
So yeah, introducing a general Path value object might solve some problems, but not all of them. Still, the signature of the Backup() method does not signal that the path expected must be an absolute path to a file, so one may pass a relative path or a path to a directory, even though only one kind of path is acceptable.
In this case, the varying properties of paths are not just an obstacle, a problem to solve, like in case of money. They are the key differentiating factor in choosing whether a behavior is appropriate for a value or not. In such a case, it makes a lot of sense to create several different value types, each representing a different set of path constraints.
Thus, we may decide to introduce types like48:
-
AbsoluteFilePath- representing an absolute path containing a file name, e.g.C:\Dir\file.txt -
RelativeFilePath- representing a relative path containing a file name, e.g.Dir\file.txt -
AbsoluteDirPath- representing an absolute path not containing a file name, e.g.C:\Dir\ -
RelativeDirPath- representing a relative path not containing a file name, e.g.Dir\
Having all these types, we can now change the signature of the Backup() method to:
1 void Backup(AbsoluteFilePath path);
Note that we don’t have to explain the constraints with the name of the argument - we can just call it path because the type already says what needs to be said. And by the way, no one will be able to pass e.g. a RelativeDirPath now by accident, not to mention an arbitrary string.
Making variability among values explicit by creating separate types usually leads us to introduce some conversion methods between these types where such conversion is legal. For example, when all we’ve got is an AbsoluteDirPath, but we still want to invoke the Backup() method, we need to convert our path to an AbsoluteFilePath by adding a file name, that can be represented by a value objects itself (let’s call its class FileName). In C#, we can use operator overloading for some of the conversions, e.g. the + operator would do nicely for appending a file name to a directory path. The code that does the conversion would then look like this:
1 AbsoluteDirPath dirPath = ...
2 ...
3 FileName fileName = ...
4 ...
5 //'+' operator is overloaded to handle the conversion:
6 AbsoluteFilePath filePath = dirPath + fileName;
Of course, we create conversion methods only where they make sense in the domain we are modeling. We wouldn’t put a conversion method inside AbsoluteDirectoryPath that would combine it with another AbsoluteDirectoryPath49.
Delegated variability
Finally, we can achieve variability by delegating the varying behavior to an interface and have the value object accept an implementation of the interface as a method parameter. An example of this would be the Product class from the previous chapter that had the following method declared:
1 public string ToString(Format format);
where Format was an interface and we passed different implementations of this interface to this method, e.g. ScreenFormat or ReportingFormat. Note that having the Format as a method parameter instead of e.g. a constructor parameter allows us to uphold the value semantics because Format is not part of the object but rather a “guest helper”. Thanks to this, we are free from dilemmas such as “is the name ‘laptop’ formatted for screen equal to ‘laptop’ formatted for a report?”
Summing up the implicit vs explicit vs delegated discussion
Note that while in the first example (the one with money), making the variability (in currency) among values implicit helped us achieve our design goals, in the path example it made more sense to do exactly the opposite - to make the variability (in both absolute/relative and to file/to directory axes) as explicit as to create a separate type for each combination of constraints.
If we choose the implicit approach, we can treat all variations the same, since they are all of the same type. If we decide on the explicit approach, we end up with several types that are usually incompatible and we allow conversions between them where such conversions make sense. This is useful when we want some pieces of our program to be explicitly compatible with only one of the variations.
I must say I find delegated variability a rare case (formatting the conversion to string is a typical example) and throughout my entire career, I had maybe one or two situations where I had to resort to it. However, some libraries use this approach and in your particular domain or type of application, such cases may be much more typical.
Special values
Some value types have values that are so specific that they have their own names. For example, a string value consisting of "" is called “an empty string”. 2,147,483,647 is called “a maximum 32 bit integer value”. These special values make their way into value objects design. For example, in C#, we have Int32.MaxValue and Int32.MinValue which are constants representing a maximum and minimum value of 32-bit integer and string.Empty representing an empty string. In Java, we have things like Duration.ZERO to represent a zero duration or DayOfWeek.MONDAY to represent a specific day of the week.
For such values, the common practice I’ve seen is making them globally accessible from the value object classes, as is done in all the above examples from C# and Java. This is because values are immutable, so the global accessibility doesn’t hurt. For example, we can imagine string.Empty implemented like this:
1 public sealed class String //... some interfaces here
2 {
3 //...
4 public const string Empty = "";
5 //...
6 }
The additional const modifier ensures no one will assign any new value to the Empty field. By the way, in C#, we can use const only for types that have literal values, like a string or an int. For our custom value objects, we will have to use a static readonly modifier (or static final in the case of Java). To demonstrate it, let’s go back to the money example from this chapter and imagine we want to have a special value called None to symbolize no money in any currency. As our Money type has no literals, we cannot use the const modifier, so instead, we have to do something like this:
1 public class Money
2 {
3 //...
4
5 public static readonly
6 Money None = new Money(0, Currencies.Whatever);
7
8 //...
9 }
This idiom is the only exception I know from the rule I gave you several chapters ago about not using static fields at all. Anyway, now that we have this None value, we can use it like this:
1 if(accountBalance == Money.None)
2 {
3 //...
4 }
Value types and Tell Don’t Ask
When talking about the “web of objects” metaphor, I stressed that objects should be told what to do, not asked for information. I also wrote that if a responsibility is too big for a single object to handle, it shouldn’t try to achieve it alone, but rather delegate the work further to other objects by sending messages to them. I mentioned that preferably we would like to have mostly void methods that accept their context as arguments.
What about values? Does that metaphor apply to them? And if so, then how? And what about Tell Don’t Ask?
First of all, values don’t appear explicitly in the web of objects metaphor, at least they’re not “nodes” in this web. Although in almost all object-oriented languages, values are implemented using the same mechanism as objects - classes50, I treat them as somewhat different kind of construct with their own set of rules and constraints. Values can be passed between objects in messages, but we don’t talk about values sending messages by themselves.
A conclusion from this may be that values should not be composed of objects (understood as nodes in the “web”). Values should be composed of other values (as our Path type had a string inside), which ensures their immutability. Also, they can occasionally accept objects as parameters of their methods (like the ProductName class from the previous chapter that had a method ToString() accepting a Format interface), but this is more of an exception than a rule. In rare cases, I need to use a collection inside a value object. Collections in Java and C# are not typically treated as values, so this is kind of an exception from the rule. Still, when I use collections inside value objects, I tend to use the immutable ones, like ImmutableList.
If the above statements about values are true, then it means values simply cannot be expected to conform to Tell Don’t Ask. Sure, we want them to encapsulate domain concepts, to provide higher-level interface, etc., so we struggle very hard for the value objects not to become plain data structures like the ones we know from C, but the nature of values is rather as “intelligent pieces of data” rather than “abstract sets of behaviors”.
As such, we expect values to contain query methods (although, as I said, we strive for something more abstract and more useful than mere “getter” methods most of the time). For example, you might like the idea of having a set of path-related classes (like AbsoluteFilePath), but in the end, you will have to somehow interact with a host of third-party APIs that don’t know anything about those classes. Then, a ToString() method that just returns internally held value will come in handy.
Summary
This concludes my writing on value objects. I never thought there would be so much to discuss as to how I believe they should be designed. For readers interested in seeing a state-of-the-art case study of value objects, I recommend looking at Noda Time (for C#) and Joda Time (for Java) libraries (or Java 8 new time and date API).