7. Zaawansowane Monady
Znajomość Zaawansowanych Monad to element obowiązkowy, aby móc nazwać się doświadczonym programistą funkcyjnym.
Jednocześnie jesteśmy deweloperami, którzy nieustannie pragną prostego życia, a więc i nasza definicja “zaawansowania”
jest raczej skromna. Dla porównania: scala.concurrent.Future jest strukturą dużo bardziej skomplikowaną niż jakakolwiek
z prezentowanych w tym rozdziale Monad.
7.1 Always in motion is the Future22
Największym problemem z Future jest to, że rozpoczyna obliczenia w momencie stworzenia, tym samym łącząc definiowanie
programu z jego interpretacją (czyli np. uruchomieniem).
Future jest też nie najlepszym wyborem ze względów wydajnościowych: za każdym razem, gdy wywołujemy .flatMap,
domknięcie jest przekazywane do Executora, wywołując planowanie wątków i zmiany kontekstu. Nie jest niczym
nadzwyczajnym, aby 50% mocy obliczeniowej CPU wykorzystywane było na te właśnie operacje zamiast rzeczywistej pracy.
W efekcie program zrównoleglony za pomocą Future może okazać się wolniejszy od swojego sekwencyjnego odpowiednika.
Zachłanna ewaluacja w połączeniu z odwołaniami do executora sprawia, że niemożliwe jest określenie kiedy
zadanie się rozpoczęło, kiedy się zakończyło ani jakie pod-zadania zostały rozpoczęte. Zatem nie powinno nas dziwić,
że “rozwiązania” do monitorowania wydajności frameworków opartych o Future są solidnym źródłem utrzymania
dla nowoczesnych odpowiedników sprzedawców “cudownych remediów”.
Co więcej, Future.flatMap wymaga niejawnego przekazania parametru typu ExecutionContext, zmuszając
użytkownika do myślenia o logice biznesowej i semantyce uruchomienia w tym samym momencie.
7.2 Efekty i efekty uboczne
Jeśli nie możemy wywołać metod z efektami ubocznymi w naszej logice biznesowej ani w Future (ani w Id, Either,
Const itd.), to kiedy możemy je wywołać? Odpowiedź brzmi: wewnątrz Monady, która opóźnia wykonanie
do czasu interpretacji w punkcie wejścia do aplikacji. W takiej sytuacji możemy odnosić się do operacji I/O i mutacji
jako efektów, które widoczne są wprost w systemie typów, odwrotnie niż ukryte i nieoczywiste efekty uboczne.
Najprostszą implementacją takiej Monady jest jest IO
Metoda .interpret wywoływana jest tylko raz, na wejściu do naszej aplikacji:
Niemniej, taka prosta implementacja niesie ze sobą dwa duże problemy:
- może spowodować przepełnienie stosu
- nie umożliwia równoległego wykonywania obliczeń
Oba te problemy zostaną przez nas przezwyciężone w tym rozdziale. Jednocześnie musimy pamiętać,
że niezależnie jak skomplikowana jest wewnętrzna implementacja Monady, zasady tutaj opisane zachowują moc:
modularyzujemy definicję programu i jego wykonanie, tak aby móc wyrazić efekty w sygnaturach typów, sprawiając tym samym,
że rozumowanie o nich staje się możliwe, a reużycie kodu łatwiejsze.
7.3 Bezpieczeństwo stosu
Na JVMie każde wywołanie metody dodaje wpis do stosu wywołań aktualnego wątku (Thread), tak jakbyśmy
dopisywali element na początek Listy. Kiedy metoda kończy działanie, wierzchni wpis jest usuwany. Maksymalna długość
stosu wywołań determinowana jest przez flagę -Xss ustawianą przy uruchomieniu polecenia java. Wywołania
ogonowo-rekursywne są wykrywane przez kompilator Scali i nie dodają wpisów do stosu. Kiedy przekroczymy dozwolony
limit poprzez zawołanie zbyt wielu metod, napotkamy StackOverflowError.
Niestety, każde zagnieżdżone wywołanie na naszym IO, jak np. .flatMap, dodaje kolejne wywołania do stosu.
Najprostszym sposobem, aby zaobserwować to zjawisko, jest powtórzenie akcji w nieskończoność i sprawdzenie, czy
taki program przeżyje dłużej niż kilka sekund. Możemy użyć metody .forever pochodzącej z Apply (rodzica Monady):
Scalaz definiuje typeklasę BindRec, którą mogą implementować Monady niezagrażające przeładowywaniem stosu (stack safe).
Wymaga ona zachowywania stałego rozmiaru stosu przy rekurencyjnych wywołaniach bind:
Nie dla wszystkich programów potrzebujemy jej instancji, ale jest ona istotna dla Monad ogólnego przeznaczenia.
Aby osiągnąć wspomniane bezpieczeństwo, należy zamienić wywołania metod na referencje do ADT, czyli monadę Free:
ADT Free to naturalna reprezentacja metod z interfejsu Monad:
-
Returnreprezentuje.point -
Gosubreprezentuje.bind/.flatMap
Kiedy ADT odwzorowuje argumenty powiązanej funkcji, nazywamy to kodowaniem Churcha (Church encodnig).
Typ Free to skrót od FreeMonad i nazywa się tak, ponieważ pozwala uzyskać za darmo monadę dla dowolnego S[_]. Moglibyśmy
na przykład wskazać algebrę Drone lub Machines z rozdziału 3 i wygenerować struktury danych reprezentujące nasz program, które stałyby się naszym S[_].
Zastanowimy się jak może nam się to przydać pod koniec tego rozdziału.
7.3.1 Trampoline
Free jest typem bardziej ogólnym, niż tego w tym momencie potrzebujemy. Ustawiając algebrę S[_] na () => ?, czyli odroczone wykonanie
znane jako thunk, otrzymamy typ Trampoline, który pozwoli nam zaimplementować bezpieczną instancję Monady
.tailrecM pochodząca z BindRec uruchamia .bind tak długo, aż otrzymamy B. Mimo że technicznie rzecz biorąc,
nie jest to implementacja, którą spełnia wymagania anotacji @tailrec, to zachowuje stałą wielkość stosu, ponieważ
każde wywołanie zwraca obiekt ze sterty (heap), a rekurencja zostaje odroczona.
Dostępne są funkcje ułatwiające tworzenie Trampoline zarówno zachłannie (.done), jak i przez nazwę (.delay).
Możemy też stworzyć instancję Trampoline, przekazując inną jej instancję poprzez nazwę (.suspend):
Kiedy widzimy w naszym kodzie Trampoline[A] możemy w głowie podstawić w jej miejsce A, ponieważ
jej jedyną funkcją jest sprawienie, że nie przeładujemy stosu. Możemy uzyskać A, interpretując Free za pomocą .run.
7.3.2 Przykład: bezpieczna DLista
W poprzednim rozdziale przedstawiliśmy typ danych DList jako
Jednak w rzeczywistości jego implementacja przypomina bardziej:
Zamiast aplikować zagnieżdżone wywołanie f, używamy odraczającej Trampoline, którą interpretujemy za pomocą .run,
kiedy zajdzie taka potrzeba, np. w toIList. Zmiany są minimalne, ale w efekcie otrzymaliśmy bezpieczną wersję DList,
która nie przepełni stosu niezależnie od tego, jak duże będą przetwarzane listy.
7.3.3 Bezpieczne IO
Używając Trampoline, możemy w podobny sposób zabezpieczyć nasze IO:
Interpreter unsafePerformIO() specjalnie został nazwany w tak odstraszający sposób, aby zniechęcić
do używania go poza punktem wejścia naszej aplikacji.
Tym razem nie zobaczymy StackOverflowError:
Używanie Trampoline zazwyczaj wiąże się ze spadkiem wydajności w porównaniu do używania zwykłej referencji.
Okazuje się, że Free nie jest tak do końca za darmo.
7.4 Biblioteka Transformatorów Monad
Transformatory monad to struktury danych, które opakowują pewną wartość i dostarczają monadyczny efekt.
W Rozdziale 2 używaliśmy OptionT, aby móc użyć wartości typu F[Option[A]] w konstrukcji for, tak jakby była to
po prostu instancja F[A]. Uzyskaliśmy w ten sposób efekt opcjonalnej wartości. Aby osiągnąć ten sam rezultat,
moglibyśmy też użyć MonadPlus.
Poniższy zbiór typów danych często nazywany jest Biblioteką Transformatorów Monad (Monad Transformer Library, MTL). W tym podrozdziale opiszemy każdy z nich, zwracając uwagę na, to do czego mogą być przydatne i jak są zbudowane.
| E | Wnętrze | Transformator | Typeklasa |
|---|---|---|---|
| opcjonalność | F[Maybe[A]] |
MaybeT |
MonadPlus |
| błędy | F[E \/ A] |
EitherT |
MonadError |
| odczyt wartości w czasie wykonania | A => F[B] |
ReaderT |
MonadReader |
| dziennik/wielozadaniowość | F[(W, A)] |
WriterT |
MonadTell |
| zmieniający się stan | S => F[(S, A)] |
StateT |
MonadState |
| zachowaj spokój i idź dalej | F[E \&/ A] |
TheseT |
|
| kontrola przepływu | (A => F[B]) => F[B] |
ContT |
7.4.1 MonadTrans
Każdy transformator ma ogólny kształt T[F[_], A], dostarczając instancje co najmniej
Monady oraz Hoist(a więc i MonadTrans):
.liftM pozwala nam stworzyć instancję transformatora na podstawie F[A], na przykład, aby zbudować
OptionT[IO, String], wystarczy wywołać .liftM[OptionT] na IO[String].
.hoist wyraża tę samą koncepcję, ale dla transformacji naturalnych.
W ogólności istnieją trzy sposoby na uzyskanie transformatora:
- z instancji typu wewnętrznego, używając konstruktora
- z pojedynczej instancji
A, używają.purezMonady - z
F[A], używającliftMzMonadTrans
Z racji tego, jak działa inferencja typów w Scali, często oznacza to, że dość skomplikowana sygnatura typu musi być zapisania explicite. Transformatory dostarczają nam trochę wygodniejsze konstruktory w swoich obiektach towarzyszących jako obejście tego problemu.
7.4.2 MaybeT
OptionT, MaybeT i LazyOptionT są zaimplementowane w podobny sposób, zapewniając opcjonalność
poprzez odpowiednio Option, Maybe i LazyOption. Skupimy się na MaybeT, aby uniknąć powtarzania się.
dostarcza MonadPlus
Powyższa implementacja może wydawać się skomplikowana, ale w rzeczywistości jedyne co tutaj się dzieje,
to delegacja operacji do Monad[F] i opakowywanie wyniku w MaybeT.
Sam klej i taśma.
Z tą monadą możemy pisać logikę obsługującą opcjonalność wewnątrz kontekstu F[_].
Alternatywnie musielibyśmy wszędzie umieszczać Option lub Maybe.
Wyobraźmy sobie, że odpytujemy portal społecznościowy, chcąc zliczyć liczbę gwiazdek danego użytkownika,
zaczynając od Stringa, który może, lub nie, wskazywać na konkretnego użytkownika. Oto nasza algebra:
Musimy wywołać getUser a wynik przekazać do getStars. Jeśli użyjemy typeklasy Monad,
będzie to dość skomplikowane, gdyż musimy obsłużyć przypadek Empty:
Jednak mając do dyspozycji MonadPlus, możemy wessać Maybe do F[_] za pomocą .orEmpty i skupić się na ważniejszych rzeczach:
Jednakże zwiększenie wymagań co do naszego kontekstu na typeklasę MonadPlus
może spowodować problemy na późniejszym etapie, jeśli nie będzie ona dostępna.
Rozwiązaniem jest zmiana kontekstu na MaybeT[F, ?] (co automatycznie daje nam
instancję MonadPlus dla dowolnej Monady), albo użyć MaybeT wprost w zwracanym typie,
za cenę nieco większej ilości kodu:
Każdy zespół musi sam wybrać między tymi opcjami, na bazie tego jakich interpreterów planują używać dla swoich programów.
7.4.3 EitherT
Wartość opcjonalna to tak naprawdę szczególny przypadek wartości, która może być błędem,
ale nic o tym błędzie nie wiemy. EitherT (i jego leniwy wariant LazyEitherT) pozwalają nam
użyć wartości dowolnego typu do wyrażenia błędu, który powie nam, co poszło nie tak w naszych
obliczeniach.
W praktyce EitherT to opakowana wartość typu F[A \/ B]
z instancją MonadError
.raiseError i .handleError są samoopisującymi się odpowiednikami throw i catch, które znamy
z pracy z wyjątkami.
MonadError dostarcza również dodatkową składnię do rozwiązywania popularnych problemów:
.attempt przenosi błędy z kontekstu do wartości.
.recover służy do zamiany błędów na wartości dla wszystkich przypadków, w przeciwieństwie do
.handleError, która pozwala nam zwrócić F[A], czyli tym samym częściowo obsłużyć błędy.
.emap, czyli either map, pozwala zaaplikować transformację, która sama w sobie może się nie udać.
MonadError dla EitherT wygląda następująco:
Nie powinno też dziwić, że możemy przepisać przykład z MonadPlus, używając MonadError i dostarczając informacje
o błędzie:
gdzie .orError to funkcja pomocnicza zdefiniowana na Maybe.
Wersja używająca EitherT bezpośrednio:
Najprostszą instancją MonadError jest \/, idealny typ do testowania logiki biznesowej wymagającej
tej typeklasy. Na przykład:
Nasz test dla .stars może pokryć takie warianty:
Po raz kolejny możemy skupić się na testowaniu logiki biznesowej bez zbędnych dystrakcji.
Możemy w końcu wrócić do naszego JsonClienta z Rozdziału 4.3
gdzie w API zawarliśmy jedynie szczęśliwą ścieżkę wykonania. Jeśli nasz interpreter dla tej algebry
działa jedynie dla F mających instancję MonadError musimy zdefiniować jakiego rodzaju błędy mogą się pojawić.
I faktycznie, jeśli zdecydujemy się interpretować EitherT[IO, JsonClient.Error, ?], to możemy mieć dwie warstwy błędów
które pokrywają odpowiednio problemy ze statusem odpowiedzi serwera oraz z naszym modelem dekodowanych obiektów.
7.4.3.1 Wybieranie typu błędu
Społeczność jest podzielona co do najlepszej strategii wyrażania błędów za pomocą E w MonadError.
Jedna szkoła mówi, że powinniśmy wybrać jakiś ogólny typ, np. String. Druga twierdzi, że każda aplikacja powinna mieć ADT
wyrażające błędy, aby każdy z nich mógł być raportowany i obsługiwany inaczej. Gang niepryncypialny woli używać Throwable dla maksymalnej
kompatybilności z JVMem.
Wprowadzenie wspomnianego ADT niesie za sobą dwa problemy:
- dodawanie nowych błędów jest niewygodne, a jeden z plików musi stać się monolitycznym repozytorium błędów, agregując ADT z pojedynczych podsystemów.
- niezależnie jak drobnoziarniste będą błędy, ich obsługa jest zazwyczaj taka sama: zaloguj i spróbuj ponownie albo przerwij przetwarzanie. Nie potrzebujemy do tego ADT.
ADT niesie ze sobą wartość, jeśli każdy wariant pozwala na inną strategię obsługi.
Kompromisem między ADT i Stringiem jest format pośredni, jak np. JSON, który jest rozumiany przez większość
bibliotek odpowiedzialnych za logowanie i monitoring.
Brak stacktrace’a może znacznie utrudnić zlokalizowanie fragmentu kodu odpowiedzialnego za zgłoszenie danego błędu.
Możemy rozwiązać ten problem, używając biblioteki sourcecode autorstwa Li Haoyi:
Mimo że Err jest referencyjnie transparentny, jego niejawna konstrukcja już nie.
Dwa wywołania Meta.gen wyprodukują różne wartości, ponieważ ich umieszczenie w kodzie
wpływa na zwracaną wartość:
Aby zrozumieć, czemu tak się dzieje, musimy zdać sobie sprawę, że metody sourcecode.* to tak
naprawdę makra, które generują dla nas kod. Jeśli napiszemy tę samą logikę wprost, to
wszystko stanie się jasne:
Zgadza się, zawarliśmy pakt z diabłem pod postacią makr, ale jeśli mielibyśmy tworzyć obiekty
Meta ręcznie to nasz kod zdezaktualizowywałby się szybciej niż nasza dokumentacja.
7.4.4 ReaderT
Monada ReaderT opakowuje A => F[B] pozwalając programowi F[B] zależeć od wartości A znanej dopiero w czasie wykonania.
Dla tych zaznajomionych ze wstrzykiwaniem zależności (dependency injection), jest to funkcyjny odpowiednik
anotacji @Inject znanej ze Springa lub Guice’a, tyle że bez dodatku XMLa czy refleksji.
ReaderT jest w rzeczywistości jedynie aliasem do bardziej ogólnego typu danych
nazwanego na cześć matematyka Henryka Kleisli.
Niejawna konwersja widoczna w obiekcie towarzyszącym pozwala nam używać Kleisli tam, gdzie spodziewamy się funkcji,
w efekcie czego możemy przekazywać instancje tego typu jako parametr do .bind lub >>=.
Najpopularniejszym zastosowaniem ReaderT jest dostarczanie informacji ze środowiska do naszego programu.
W drone-dynamic-agents potrzebujemy dostępu do tokenu odświeżającego OAuth 2.0 dla naszego użytkownika, aby
móc połączyć się z serwerem Google’a. Oczywistym wydaje się odczytanie RefreshTokens z dysku przy starcie aplikacji i
dodanie parametru RefreshToken do każdej metody. Okazuje się, że jest to problem na tyle częsty, że Martin Odersky
zaproponował nowy mechanizm funkcji niejawnych,
które mogłyby nam tutaj pomóc.
Lepszym rozwiązaniem jest zdefiniowanie algebry, która dostarczy potrzebnej nam konfiguracji, np:
Tym samym odkryliśmy typeklasę MonadReader, związaną z ReaderT, gdzie .ask jest tym samym
co nasza metoda .token, a S to RefreshToken:
wraz z implementacją
Prawa obowiązujące MonadReader zastrzegają, że S nie może zmieniać się między wywołaniami, a więc
ask >> ask === ask. W naszym przypadku oznacza to, że konfiguracja jest czytana raz. Jeśli
później zdecydujemy, że chcielibyśmy przeładowywać konfigurację za każdym razem, gdy jest potrzebna,
to możemy ponownie wprowadzić typ ConfigReader, który nie ma takich ograniczeń.
W naszej implementacji OAuth 2.0 możemy zacząć od przeniesienia parametru Monad do metod:
a następnie zamienić parametr refresh we fragment Monady
W ten sposób możemy przenieść dowolny parametr do MonadReader, co niesie największą wartość
dla wywołań, które tylko przekazują tę wartość z zewnątrz.
Drugą metodą w MonadReaderze jest .local
Możemy zmodyfikować S i uruchomić fa wewnątrz takiego kontekstu. Przykładowym zastosowaniem .local
może być generowanie “śladów stosu”, które mają sens dla naszej domeny, pozwalając nam tym samym
na zagnieżdżone logowanie! Polegając na typie Meta z poprzedniego rozdziału, możemy zdefiniować
poniższą funkcję:
i używać jej do opakowywania funkcji, które wymagają takiego kontekstu
automatycznie przekazując dalej wszystko, co nie jest oznaczone wprost. Plugin do kompilatora albo makro mogłoby działać odwrotnie, śledząc wszystko automatycznie.
Jeśli wywołamy .ask, zobaczymy dokładne ślady prowadzące do naszego wywołania, bez detali implementacyjnych
związanych z kodem bajtowym. Tym samym otrzymaliśmy referencyjnie transparenty ślad stosu!
Ostrożny programista mógłby chcieć w pewnym momencie przyciąć IList[Meta] aby uniknąć odpowiednika
przepełnienia stosu. Tym samym bardziej odpowiednią strukturą danych byłaby Dequeue.
.local może być użyte również do śledzenie informacji kontekstowych, które są bezpośrednio związane
z aktualnie wykonywanym zadaniem, jak na przykład liczba spacji potrzebnych do wcięcia linii, gdy wyświetlamy
format przyjazny dla ludzi, zwiększając tę liczbę o dwa, gdy zwiększamy zagnieżdżenie.
W końcu, kiedy nie możemy zażądać instancji MonadReader, ponieważ nasza aplikacja nie umie takowej
dostarczyć, możemy zawsze zwrócić ReaderT
Jeśli wywołujący otrzyma ReaderT i ma pod ręką parametr token, to wystarczy, że wywoła
access.run(token), aby otrzymać F[BearerToken].
Faktycznie, biorąc pod uwagę fakt, że nie mamy zbyt wiele wywołujących, powinniśmy wrócić do tradycyjnych
parametrów funkcji. MonadReader ma na najwięcej zastosowań, gdy:
- możemy chcieć w przyszłości przerefactorować kod, aby konfiguracja była przeładowywana
- wartość nie jest używana przez metody pośredniczące (intermediate callers)
- chcemy lokalnie zmienić jakąś zmienną
Dotty może zatrzymać funkcje niejawne dla siebie, my już mamy wszystko, czego nam trzeba: ReaderT i MonadReader.
7.4.5 WriterT
Odwrotnością czytania jest pisanie, a transformator monad WriterT służy właśnie do tego.
Opakowywany typ to F[(W, A)], a nasz dziennik jest akumulowany wewnątrz W.
Mamy do dyspozycji nie jedną, a dwie powiązane monady: MonadTell i MonadListen!
MonadTell służy do spisywania dziennika a MonadListen do jego odtwarzania.
Ich implementacja dla WriterT wygląda następująco:
Oczywistym zastosowaniem MonadTell jest logowanie lub zbieranie danych audytowych. Raz jeszcze używając
Meta możemy wyobrazić sobie taki log
i użyć Dequeue[Log] jako naszego dziennika. Tym razem zmodyfikujemy metodę authenticate z części kodu
odpowiedzialnej za obsługę OAuth2.
Moglibyśmy nawet połączyć to podejście ze śledzeniem opartym o ReaderT, aby uzyskać ustrukturalizowany log zdarzeń.
Dziennik może zostać odzyskany za pomocą .written, a następnie dowolnie modyfikowany.
Jednak istnieje silny argument za tym, aby logowanie otrzymało swoją własną algebrę. Poziom logowania jest często potrzebny w momencie stworzenia wiadomości dla celów wydajnościowych, a ponadto logowanie często konfigurowane i zarządzane jest na poziomie całej aplikacji, a nie pojedynczych komponentów.
Parametr W w WriterT posiada Monoid, pozwalając nam tym samym na wszelkiego rodzaju monoidyczne operacje,
które będą działy się równolegle do naszego głównego programu. Możemy na przykład zliczać, ile razy coś się wydarzyło,
budować opis obliczeń lub tworzyć TradeTemplate dla nowej transakcji, gdy ją wyceniamy.
Popularną specjalizacją WriterT jest użycie go z monadą Id, sprawiając, że leżąca pod spodem wartość run to prosta tupla (W, A).
W taki sposób możemy nieść dodatkową monoidyczną kalkulację obok dowolnej wartości bez kontekstu F[_].
W skrócie WriterT i MonadTell to sposoby na multizadaniowość w stylu FP.
7.4.6 StateT
StateT pozwala nam włożyć (.put), wyciągnąć (.get) i zmodyfikować (.modify) wartość zarządzaną przez monadyczny kontekst.
Jest to czysto funkcyjny zamiennik dla var.
Jeśli mielibyśmy napisać nieczystą metodę korzystającą z mutowalnego stanu przechowywanego wewnątrz var, jej sygnatura
mogłaby przyjąć postać () => F[A], a ona sama zwracałaby inną wartość przy każdym wywołaniu, zaburzając w ten sposób transparentność
referencyjną. W czystym FP taka funkcja przyjmuje stan jako wejście i produkuje i zwraca zmodyfikowany stan jako wyjście.
Dlatego też StateT opakowuje S => F[(S,A)].
Powiązana monada to MonadState:
Struktura StateT jest zaimplementowana nieco inaczej niż transformatory, które widzieliśmy do tej pory,
nie jest case klasą, lecz ADT z dwoma wariantami:
które są wyspecjalizowaną formą Trampoline, dając nam bezpieczeństwo stosu, kiedy chcemy odwołać się
do leżącej pod spodem struktury za pomocą .run:
StateT ze swoim ADT w trywialny sposób implementuje MonadState
.pure otrzymał swoją kopię .stateT w obiekcie towarzyszącym:
a MonadTrans.liftM jak zawsze dostarcza nam konstruktor F[A] => StateT[F, S, A].
Popularną odmianą StateT jest F = Id. W takim wypadku opakowywany typ to S => (S, A).
Scalaz definiuje alias typu State i wygodne funkcje to interakcji z nim, które udają MonadState:
Wróćmy na chwilę do testów logiki biznesowej z drone-dynamic-agents. W Rozdziale 3 stworzyliśmy testowy interpreter Mutable,
który przechowywał liczbę wystartowanych i zatrzymanych węzłów w var.
Teraz wiemy już jak napisać dużo lepszy interpreter, używając State. Przy okazji skorzystamy z możliwości
zwiększenia dokładności naszej symulacji. Przypomnijmy nasz kluczowy obiekt przechowujący obraz świata:
Skoro piszemy symulację świata na potrzeby naszych testów, to możemy zdefiniować typ danych przechwytujący pełen jego obraz
Główną różnicą jest to, że mamy do dyspozycji zmienne started i stopped. Nasz interpreter może być budowany na bazie
State[World, a], pozwalając nam na weryfikacje tego, jak wygląda zarówno World, jak i WorldView po wykonaniu logiki biznesowej.
Interpretery udające zewnętrzne usługi Drone i Google będą wyglądać tak:
a my możemy przepisać nasze testy tak, aby zachowywały konwencję:
-
world1to stan świata przed uruchomieniem programu -
view1to widok świata z punktu widzenia aplikacji -
world2to stan świata po uruchomieniu programu -
view2to widok świata z punktu widzenia aplikacji po uruchomieniu programu
Przykład:
Moglibyśmy spojrzeć na naszą nieskończoną pętlę logiki biznesowej
i użyć w niej StateT do zarządzania stanem. Niestety, w ten sposób naruszylibyśmy Regułę Najmniejszej Mocy, wymagając
MonadState zamiast aktualnie wymaganego Applicative. Tak więc całkowicie rozsądne jest zarządzanie ręczne
i przekazywanie stanu do update i act.
7.4.7 IndexedStateT
Kod, który widzieliśmy do tej pory nie pochodzi ze Scalaz. Tak naprawdę StateT jest zaimplementowany tam
jako alias typu wskazujący na kolejny typ: IndexedStateT.
Implementacja IndexedStateT jest bardzo podobna do tej, którą widzieliśmy do tej pory, z dodatkiem
jednego parametru typu, który pozwala na to, by stan wejściowy S1 był inny niż stan wyjściowy S2:
IndexedStateT nie posiada instancji MonadState kiedy S1 != S2, więc w takiej sytuacji musi nas zadowolić
instancja samego Monad.
Poniższy przykład został zaadaptowany z prezentacji Vincentego Maqrqueza Index your State.
Wyobraź sobie, że musimy zaprojektować algebraiczny interfejs dla dostępu do wartości typu String
za pomocą klucza typu Int. Załóżmy, że jedna z implementacji będzie opierała się na komunikacji sieciowej,
a kolejność wywołań jest kluczowa. Nasze pierwsze podejście mogłoby wyglądać tak:
produkując błędy w czasie wykonania, jeśli .update lub .commit zostaną wywołane bez wcześniejszego użycia
.lock. Alternatywą mógłby być skomplikowany DSL, którego nikt nie umiałby użyć bez zaglądania do dokumentacji.
Zamiast tego użyjemy IndexedStateT, aby wymusić odpowiedni stan na wywołującym. Zacznijmy od możliwych stanów
wyrażonych jako ADT
i odświeżenia naszej algebry
co spowoduje, że próba wywołania .update bez wcześniejszego .lock spowoduje błąd kompilacji
pozwalając nam konstruować funkcje, które mogą być komponowane dzięki wyrażaniu swojego stanu explicite
7.4.8 IndexedReaderWriterStateT
Ci, którzy chcieli kombinacji ReaderT, WriterT i InedexedStateT nie będą zawiedzeni.
Transformator IndexedReaderWriterStateT opakowuje (R, S1) => F[(W, A, S2)] gdzie R
to Reader, W służy do monoidycznych zapisów, a S do indeksowanych aktualizacji stanu.
Do dyspozycji mamy skróty, bo trzeba przyznać, że te typy są tak długie, że wyglądają jak część API J2EE.
IRWST to bardziej wydajny odpowiednik ręcznie skonstruowanego stosu transformatorów
ReaderT[WriterT[IndexedStateT[F, ...], ...], ...].
7.4.9 TheseT
TheseT pozwala nam wybrać czy błędy mają zakończyć obliczenia, czy też mają być zakumulowane
w przypadku częściowego sukcesu. Stąd zachowaj spokój i idź dalej (keep calm and carry on).
Opakowywany typ danych to F[A \&/ B], gdzie A to typ błędów, z wymaganą instancją Semigroup,
jeśli chcemy je akumulować.
Nie istnieje żadna specjalna monada dla TheseT ponad Monad. Jeśli chcemy zakończyć
obliczenia, zwracamy This, ale akumulujemy błędy, zwracając wartość Both, która zawiera także
poprawnie obliczoną część wyniku.
Możemy spojrzeć na TheseT z innej strony: A nie musi być wcale błędem. Podobnie jak w przypadku
WriterT, A może być nośnikiem dla innej wartości, którą obliczamy wraz z B. TheseT pozwala
zatrzymać się, gdy coś specyficznego dla A tego od nas wymaga. Jak wtedy, gdy Charlie Bucket
wyrzucił swoją czekoladę (B), jak tylko odnalazł Złoty Kupon (A).
7.4.10 ContT
Styl Przekazywania Kontynuacji (CPS, Continuation Passing Style) to styl programowania, w którym funkcje nigdy nie zwracają wartości, a zamiast tego kontynuują następne obliczenia. CPS jest popularny w JavaScripcie i Lispie, pozwalając na wykonywanie nieblokującego IO za pomocą callbacków, gdy dane stają się dostępne. Bezpośrednie przełożenie tego wzorca na nieczystą Scalę wygląda mniej więcej tak:
Możemy sprawić, że ten kod stanie się czysty, wprowadzając kontekst F[_]
i zwracając funkcję dla danego wejścia
ContT to opakowanie dla takiej właśnie sygnatury, z dodatkiem instancji typeklasy Monad
i wygodnej składni do tworzenia ContT z monadycznej wartości:
Jednak proste użycie callbacków nie wnosi nic do programowania czysto funkcyjnego, ponieważ
poznaliśmy już sposób na sekwencyjne łączenie nieblokujących, potencjalnie rozproszonych
obliczeń: Monadę. Aby zobaczyć dlaczego kontynuacje są użyteczne, musimy rozważyć
bardziej złożony przykład ze sztywnymi ograniczeniami projektowymi.
7.4.10.1 Kontrola przepływu
Załóżmy, że podzieliliśmy naszą aplikację na moduły, które mogą wykonywać operacje I/O, a każdy z nich rozwijany jest przez osobny zespół:
Naszym celem jest wyprodukować A0 na podstawie otrzymanego A1. Tam, gdzie JavaScript lub Lisp
sięgnęliby po kontynuacje (ponieważ IO może blokować), my możemy po prostu połączyć funkcje:
Możemy wynieść .simple do postaci kontynuacji, używając .cps i odrobiny boilerplate’u:
Co zyskaliśmy? Po pierwsze, warto zauważyć, że przepływ kontroli w tej aplikacji biegnie od lewej do prawej strony.

Co, gdy jako autorzy foo2 chcielibyśmy zmodyfikować wartość a0, którą otrzymujemy z prawej strony?
W praktyce oznacza to podzielenie foo2 na foo2a i foo2b

Dodajmy ograniczenie, że nie możemy zmodyfikować tego, jak zdefiniowane są metody flow i bar0.
Może na przykład pochodzą one z frameworka lub biblioteki, których używamy.
Nie jesteśmy w stanie przeprocesować a0 poprzez modyfikację żadnej z pozostałych metod barX,
jednak używając ContT, możemy zaimplementować metodę foo2 tak, aby mogła wykonać obliczenia
na podstawie wyniku kontynuacji next:
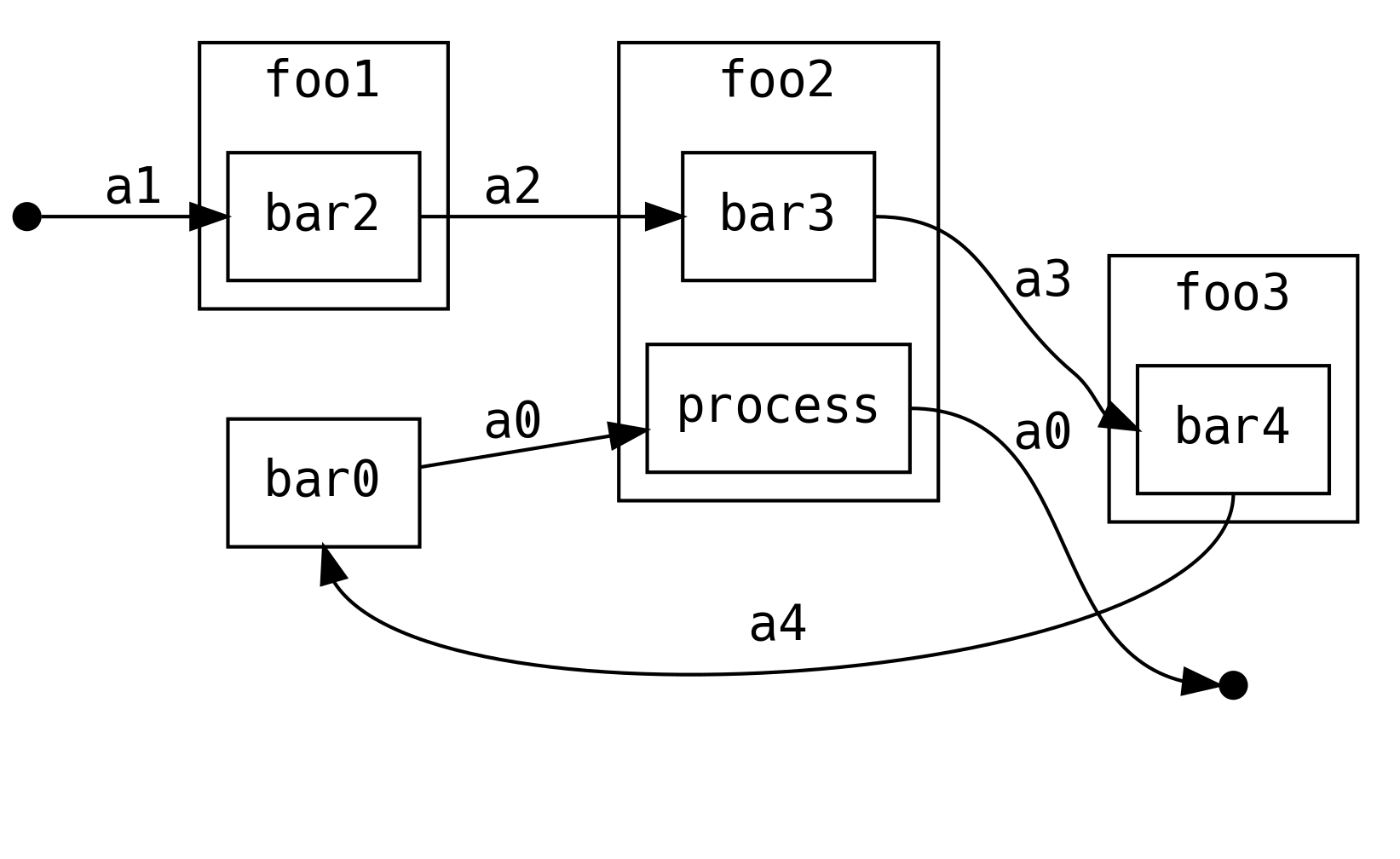
Na przykład w taki sposób:
Nie jesteśmy ograniczeni do .mapowania wartości. Możemy również wywołać .bind i zamienić
liniowy przepływ w pełnoprawny graf!
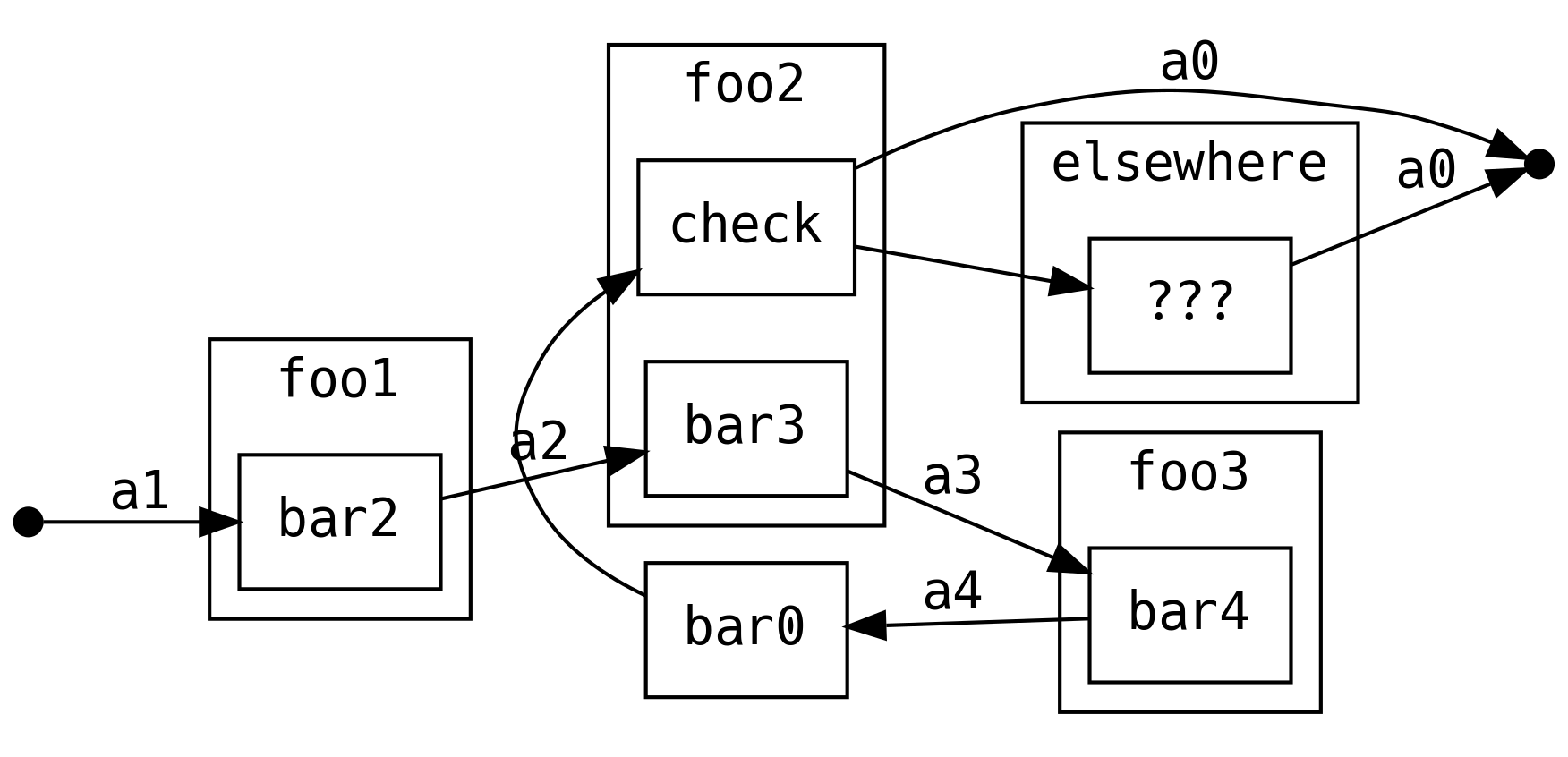
Możemy też zostać przy oryginalnym przepływie i ponowić wszystkie dalsze operacje.
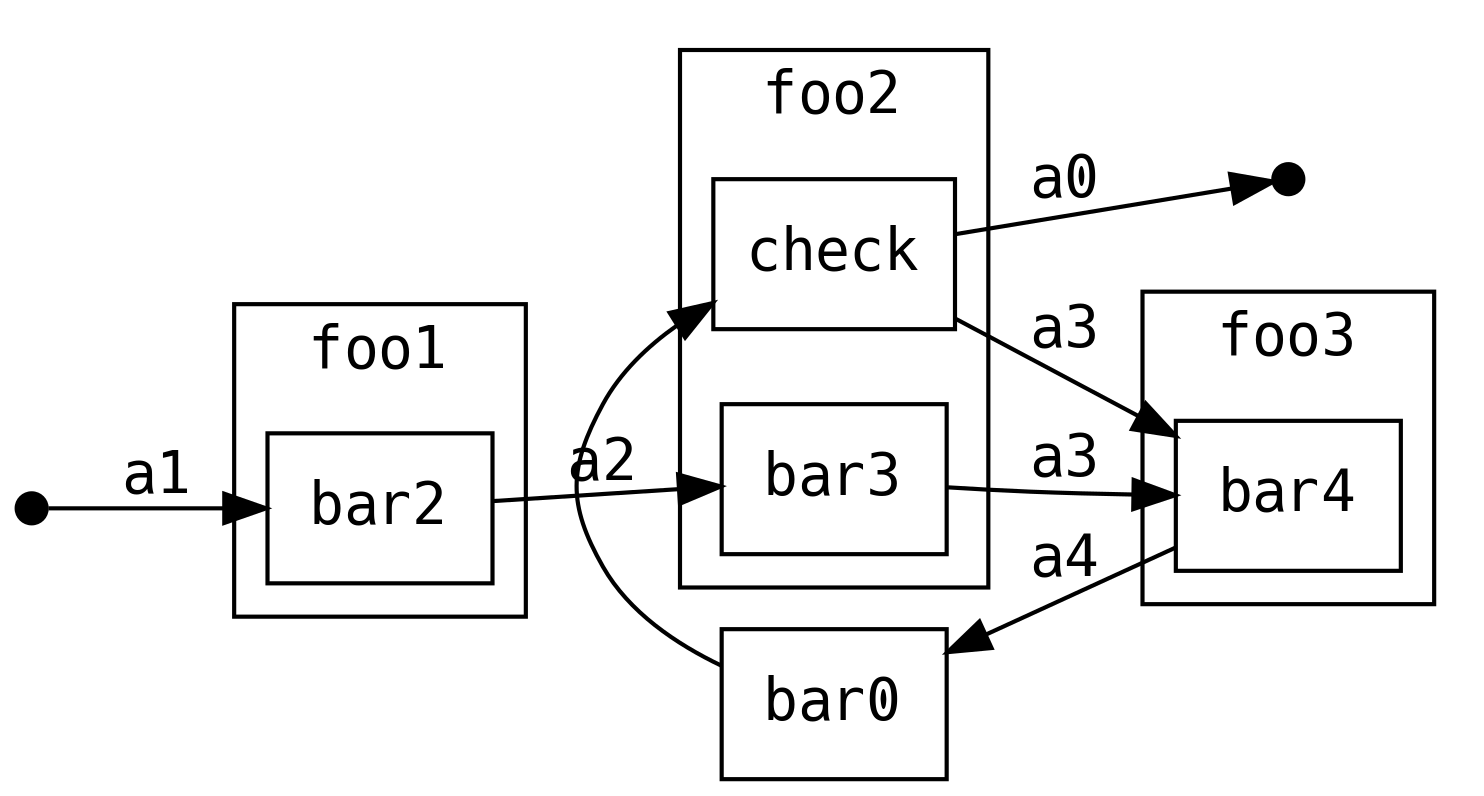
W tym wypadku ponawiamy operacje tylko raz, a nie w nieskończoność, np. upewniamy się, czy na pewno powinniśmy wykonać jakąś potencjalnie niebezpieczną operację.
W końcu możemy też wykonać akcje specyficzne dla kontekstu ContT, czyli w tym wypadku IO,
który pozwala nam na obsługę błędów i uprzątnięcie zasobów:
7.4.10.2 Kiedy zamówić spaghetti
Nie przez przypadek nasze diagramy wyglądają jak spaghetti. Tak właśnie dzieje się, kiedy
zaczynamy bawić się przepływem kontroli. Wszystkie mechanizmy, które omówiliśmy w tym podrozdziale,
można w łatwy sposób zaimplementować bezpośrednio, gdy możemy zmodyfikować flow, a więc
nie musimy używać ContT.
Jednak jeśli projektowalibyśmy framework, to system pluginów opartych na ConT i pozwalający użytkownikom
kontrolować przepływ byłby czymś wartym rozważenia. Czasem użytkownik po prostu chce spaghetti.
Gdyby kompilator Scali był napisany z użyciem CPS, to kolejne fazy kompilacji mogłyby komunikować się ze sobą w prosty i regularny sposób. Plugin kompilatora mógłby wykonywać akcje, bazując na wyinferowanym typie wyrażenia pochodzącym z późniejszej fazy kompilacji. Podobnie kontynuacje byłyby dobrym API dla narzędzie do budowania projektów (build tool) albo edytora tekstu.
Pułapką ConT jest fakt, że nie jest to struktura bezpieczna od przepełnienia stosu, a więc
nie nadaje się do tworzenia programów, które nigdy się nie kończą.
7.4.10.3 Great, kid. Don’t get ContT.
Bardziej złożony wariant ContT znany jako IndexedContT opakowuje (A => F[B] => F[C]).
Nowy parametr typu C definiuje typ zwracany przez cały program, który może być inny, niż
ten przekazywany między komponentami. Jednak jeśli B nie jest równe C to nie jesteśmy w stanie
zdefiniować Monady.
Korzystając z okazji do zgeneralizowania kodu tak, jak to tylko możliwe, zarówno typ IndexedContT, jak i ConT są
w praktyce zaimplementowane jako aliasy na jeszcze bardziej ogólną strukturę IndexedContsT (zwróć uwagę
na dodatkowe s przed T)
w której W[_] posiada instancję Comonad. Dla wspomnianych aliasów istnieją obiekty towarzyszące
z pomocnymi konstruktorami.
Wprawdzie pięć parametrów typów to raczej przesada, ale takie przegeneralizowanie pozostaje spójne ze specyfiką kontynuacji.
7.4.11 Stosy transformatorów i niejednoznaczne parametry niejawne
Czas podsumować naszą wycieczkę wśród transformatorów monad zdefiniowanych w Scalaz.
Kiedy wiele transformatorów jest składanych ze sobą, nazywamy to stosem transformatorów (transformer stack),
i mimo że jest to dość rozwlekłe, to można odczytać dostarczane w ten sposób funkcjonalności. Jeśli skonstruujemy
kontekst F[_] taki jak
wiemy, że dodajemy obsługę błędów typu E (istnieje MonadError[Ctx. E]) i stan S
(istnieje MonadState[Ctx, S]).
Niestety istnieją pewne praktyczne przeciwności co do stosowania takich stosów i towarzyszących im instancji typeklas:
- Wiele niejawnych instancji
Monadoznacza, że kompilator nie może odnaleźć odpowiedniej składni dla kontekstu - Monady nie komponują się w sposób ogólny, co oznacza, że kolejność zagnieżdżania ma znaczenie
- Wszystkie interpretery muszą obsługiwać ten wspólny kontekst. Dla przykładu: jeśli mamy implementację pewnej algebry,
która używa
IO, to i tak musimy opakować ją wStateTiEitherT, mimo że nie będą one używane w interpreterze. - Każda warstwa niesie ze sobą koszt wydajnościowy. Niektóre transformatory są gorsze niż inne, np.
StateTjest szczególnie kosztowny, ale nawetEitherTmoże sprawiać problemy z alokacją pamięci dla aplikacji o dużej przepustowości.
Porozmawiajmy o obejściach tych problemów.
7.4.11.1 Brak składni
Powiedzmy, że mamy algebrę
i typy danych
które chcielibyśmy użyć w naszej logice biznesowej:
Pierwszy problem: nasz kod się nie kompiluje.
Istnieją pewne taktyczne rozwiązania tego problemu. Najbardziej oczywistym jest przyjęcie parametrów wprost
i wymaganie jedynie Monady niejawnie poprzez ograniczenie kontekstu. Jednak oznacza to, że musimy ręcznie
przekazać MonadError i MonadState, kiedy wywołujemy foo1 oraz gdy wołamy inne metody, które wymagają
parametrów niejawnych.
Drugim rozwiązaniem jest pozostawienie parametrów jako implicit i użycie przesłaniania nazw tak by wszystkie
stały się jawne. Pozwala to innym wywoływać nas, używając niejawnego rozstrzygania, ale my nadal musimy
przekazywać parametry wprost, gdy są potrzebne.
Moglibyśmy też przesłonić tylko jedną z Monad, pozostawiając drugą tak, by mogła być użyta do dostarczenia
nam potrzebnej składni i gdy wywołujemy inne metody.
Trzecia opcja, która niesie ze sobą wyższy koszt początkowy, to stworzenie własnej typeklasy, która będzie przechowywać referencje do dwóch pozostałych, których potrzebujemy
i którą automatycznie wyderywujemy z dostępnych instancji MonadError i MonadState.
Teraz, gdy potrzebujemy S lub E mamy do nich dostęp poprzez F.S i F.E
I tak jak w drugim podejściu, możemy wybrać jedną z Monad jako niejawną w naszym bloku, importując ją
7.4.11.2 Komponowanie transformatorów
EitherT[StateT[...], ...] posiada instancję MonadError, ale nie MonadState, natomiast StateT[EitherT[...], ...]
daje nam obie.
Rozwiązaniem jest przestudiowanie reguł niejawnej derywacji transformatorów zawartych w obiektach towarzyszących, aby upewnić się, że najbardziej zewnętrzny z nich dostarcza wszystkie instancje, których potrzebujemy.
Zasada kciuka: im bardziej skomplikowany transformator, tym bliżej wierzchu stosu powinien być umieszczony. W tym rozdziale prezentowaliśmy je z rosnącym poziomem skomplikowania, co powinno ułatwić aplikację tej zasady.
7.4.11.3 Wynoszenie interpreterów
Kontynuując ten sam przykład, załóżmy, że nasza algebra Lookup ma interpreter oparty o IO
ale chcielibyśmy, aby nasz kontekst wyglądał tak
aby móc używać MonadError i MonadState. Oznacza to, że musimy opakować LookupRandom tak, aby mógł operować na Ctx.
Najpierw użyjemy metody .liftM z MonadTrans, która wynosi F[A] do postaci G[F, A]
Ważne jest, aby pamiętać, że parametr typu przekazywany do .liftM sam ma dwa parametry,
pierwszy o kształcie _[_] i drugi _. Jeśli stworzymy odpowiednie aliasy
to możemy abstrahować ponad MonadTrans, aby wynieść Lookup[F] do dowolnego Lookup[G[F, ?]]
tak długo jak G to transformator monad:
Możemy więc opakować algebrę kolejno dla EitherT i StateT
Innym sposobem osiągnięcia tego samego rezultatu w pojedynczym kroku jest użycie typeklasy MonadIO,
która pozwala nam wynieść IO do stosu transformatorów:
i posiada instancje dla wszystkich popularnych kombinacji transformatorów.
Boilerplate potrzebny, by wynieść interpreter oparty o IO do dowolnego kontekstu posiadającego
instancję MonadIO to dwie linie kodu (dla definicji interpretera), plus jedna linia dla każdego elementu algebry
i jedna linia wywołująca konwersję:
7.4.11.4 Wydajność
Największym problemem Transformatorów Monad jest ich narzut wydajnościowy. EitherT ma dość mały narzut,
gdzie każde wywołanie .flatMap generuje tylko garść obiektów, ale nawet to może wpłynąć na aplikacje
wymagające wysokiej przepustowości, gdzie każda alokacja ma znaczenie. Inne transformatory, takie jak
StateT, dodają trampolinę do każdego wywołania, a ContT przechowuje cały łańcuch wywołań w pamięci.
Jeśli wydajność staje się problemem, jedynym rozwiązaniem jest zrezygnować z Transformatorów Monad,
a przynajmniej ich struktur danych. Dużą zaletą typeklas opartych o Monad, takich jak np. MonadState,
jest fakt, że możemy stworzyć zoptymalizowany kontekst F[_], który będzie dostarczał wspomniane typeklasy.
Zobaczymy jak stworzyć optymalne F[_] w następnych dwóch rozdziałach, kiedy bliżej przyjrzymy się poznanym już
strukturom Free i IO.
7.5 Darmowy lunch
Nasza branża pragnie bezpiecznych, wysokopoziomowych języków, które pozwalają na zwiększenie wydajności deweloperów kosztem zmniejszonej wydajności kodu.
Kompilator Just In Time (JIT) na JVMie działa tak dobrze, że proste funkcje mogą działać porównywalnie szybko co ich odpowiedniki w C lub C++, ignorując koszt garbage collectora. Jednak JIT wykonuje jedynie optymalizacje niskopoziomowe: predykcję gałęzi (branch prediction), inlinowanie metod, rozwijanie pętli itd.
JIT nie zastosuje optymalizacji do naszej logiki biznesowej, jak na przykład łączenie wywołań sieciowych lub uruchamianie niezależnych zadań równolegle. Deweloper jest odpowiedzialny za tworzenie logiki biznesowej i jej optymalizacje, co efektywnie obniża czytelność i zwiększa koszt utrzymania kodu. Dobrze by było, gdyby wydajność i optymalizacja były problememami zupełnie niezależnymi.
Jeśli mielibyśmy do dyspozycji struktury danych, które opisują naszą logikę biznesową w kontekście wysokopoziomowych konceptów, a nie instrukcji maszynowych, moglibyśmy łatwo wykonać wysokopoziomowe optymalizacje. Takie struktury danych są zazwyczaj nazywane Darmowymi strukturami (Free structures) i mogą być generowane dla elementów naszych algebraicznych interfejsów dostarczając na za darmo instancje pewnych typeklas. Przykładowo, instancje Free Applicative mogą być wygenerowane i użyte do połączenia lub deduplikacji kosztownych operacji sieciowych.
W tym rozdziale zobaczymy jak tworzyć takie darmowe struktury i jak ich używać.
7.5.1 Free (Monad)
Zasadniczo, monada opisuje sekwencyjny program, gdzie każdy krok zależy od poprzedniego. Ograniczeni więc jesteśmy do modyfikacji, które wiedzą jedynie to, co już uruchomiliśmy i jaki krok uruchomimy jako następny.
Przypomnijmy, Free to struktura danych reprezentująca Monadę zdefiniowana jako trzy warianty:
-
Suspendreprezentuje program, który nie został jeszcze zinterpretowany -
Returnto.pure -
Gosubto.bind
Instancja Free[S, A] może być wygenerowana za darmo dla dowolnej algebry S. Aby zobaczyć to wprost,
rozważmy naszą algebrę Machines
Zdefiniujmy Free dla algebry Machines poprzez stworzenie ADT
odpowiadającego jej elementom. Każdy typ danych ma te same parametry wejściowe, jest sparametryzowany
typem zwracanym i ma taką samą nazwę:
Takie ADT jest Abstrakcyjnym drzewem składniowym (AST, Abstract Syntax Tree), ponieważ każdy element reprezentuje obliczenia w naszym programie.
Następnie zdefiniujmy .liftF, implementację Machines dla kontekstu Free[Ast, ?]. Każda metoda
deleguje implementację do Free.liftF tworząc Suspend:
Kiedy skonstruowaliśmy program sparametryzowany z użyciem Free, to aby go uruchomić, musimy przekazać
interpreter (transformację naturalną Ast ~> M) do metody .foldMap. Jeśli mielibyśmy interpreter,
który mapuje operacje do IO, moglibyśmy stworzyć program IO[Unit] z dostępnego AST
Dla kompletności zaimplementujmy interpreter, który deleguje operacje do ich bezpośredniej implementacji. Taki
interpreter może być użyteczny, jeśli reszta aplikacji również używa Free jako kontekstu, a my akurat mamy implementację
algebry bazującą na IO pod ręką.
Ale nasza logika biznesowa potrzebuje więcej niż tylko algebry Machines. Oprócz niej
potrzebna jest też algebra Drones, zdefiniowana jako:
Chcielibyśmy, aby nasze AST było kombinacją AST pochodzących z obu tych algebr. W Rozdziale
6 poznaliśmy Coproduct, dysjunkcję wyższego rodzaju:
Możemy więc użyć kontekstu Free[Coproduct[Machines.Ast, Drone.Ast, ?], ?].
Moglibyśmy tworzyć instancję koproduktu ręcznie, ale utonęlibyśmy w morzu boilerplate’u, a później musielibyśmy robić to raz jeszcze, jeśli chcielibyśmy dodać trzecią algebrę.
Z pomocą przychodzi typeklasa scalaz.Inject.
Niejawna derywacja wygeneruje instancję Inject, kiedy będziemy ich potrzebować, pozwalając nam
przepisać metodę liftF tak, aby działała dla dowolnej kombinacji AST:
W tym wypadku Ast :<: F mówi nam, że Ast jest częścią pełnego zbioru instrukcji F.
Łącząc ze sobą wszystkie elementy, załóżmy, że mamy program, który abstrahuje ponad konkretną Monadą
oraz gotowe implementacja algebr Machines i Drone, z użyciem których możemy stworzyć interpretery:
i połączyć je w większy zbiór instrukcji używając pomocniczych metod z obiektu towarzyszącego
NaturalTransformation
aby następnie użyć ich do wyprodukowania IO
Tym samym zatoczyliśmy koło! Mogliśmy przecież od razu użyć IO jako naszego kontekstu i uniknąć
Free. Po co więc zadaliśmy sobie cały ten trud? Poniżej znajdziemy kilka przykładów, gdy Free staje się użyteczne.
7.5.1.1 Testowanie: mocki i stuby
Może to zabrzmieć obłudnie, jeśli po napisaniu całego tego boilerplate’u powiemy, że Free może
służyć do zmniejszenia jego ilości. Istnieje jednak pewna granica, za którą Ast zaczyna
mieć sens: gdy mamy dużo testów, które wymagają stubowania implementacji.
Jeśli .Ast i .liftF zostały zdefiniowane dla danej algebry, możemy tworzyć interpretery częściowe:
które posłużą nam do testowania naszego programu.
Używając częściowych funkcji zamiast totalnych, narażamy się na błędy w czasie wykonania. Wiele zespołów godzi się na ten kompromis w swoich testach jednostkowych, bo popełniony błąd i tak zostanie wykryty, gdy testy te nie zakończą się sukcesem.
Moglibyśmy osiągnąć to samo zachowanie, implementując wszystkie metody z użyciem ??? i nadpisując
te, których aktualnie potrzebujemy.
7.5.1.2 Monitoring
Aplikacje serwerowe są często monitorowane przez agenty, które manipulują bajtkodem aplikacji, wstrzykując profilery i wydobywając różnego rodzaju informacje o działaniu naszego kodu i jego wydajności.
Gdy naszym kontekstem jest Free, nie musimy uciekać się do manipulacji bajtkodem. Zamiast tego
możemy zaimplementować interpreter, który będzie monitorować wykonywane operacje i raportować je z użyciem efektów ubocznych.
Rozważmy użycie takiego “agenta” o typie Ast ~> Ast, który zapisuje inwokacje metod:
Moglibyśmy też wychwytywać wiadomości, które nas szczególnie interesują i logować, gdy się pojawią.
Możemy dołączyć Monitor do naszej produkcyjnej aplikacji opartej na Free za pomocą
lub połączyć transformacje naturalne wywołując pojedyncze
7.5.1.3 Monkey patching
Jako inżynierowie przywykliśmy już do próśb o dodanie dziwacznych zmian do kluczowej logiki aplikacji. Moglibyśmy chcieć wyrazić takie przypadki brzegowe jako wyjątki od reguły i obsługiwać je niezależnie od reszty aplikacji.
Wyobraźmy sobie, że otrzymaliśmy poniższą notatkę od działu księgowości
PILNE: Bob używa węzła
#c0ffeeprzy sprawozdaniu rocznym. NIE ZATRZYMUJCIE TEJ MASZYNY!1!
Nie ma możliwości, aby wytłumaczyć Bobowi, że nie powinien używać naszych maszyn dla jego super ważnych zadań, tak więc musimy zhakować naszą logikę biznesową i wypuścić zmianę na środowisko produkcyjne tak szybko, jak to możliwe.
Nasza łatka (monkey patch) może być przetłumaczona na strukturę Free, pozwalając nam zwrócić
wcześniej przygotowany wynik (Free.pure) zamiast wykonywania standardowych operacji. Implementacja
to specjalna transformacja naturalna:
I gotowe. Zerknąć czy działa, wypchnąć na produkcję i ustawić alarm na przyszły tydzień, żeby usunąć ten fragment i odebrać Bobowi dostęp do naszych serwerów.
W testach możemy użyć State, aby zapisywać wszystkie węzły, które zatrzymaliśmy:
Zaletą Free w tej sytuacji jest pewność, że obsłużyliśmy wszystkie użycia, nie musząc
szukać ich w logice biznesowej. Jeśli kontekstem naszej aplikacji jest IO, to moglibyśmy oczywiście
zaimplementować tę samą funkcjonalność w Machines[IO], ale używając Free, możemy taką
zamianę wyizolować i przetestować bez dotykania istniejącego kodu i bez wiązania się z IO.
7.5.2 FreeAp (Applicative)
Mimo tego, że ten rozdział nazywa się Zaawansowane Monady, to kluczowe jest, że
nie powinniśmy używać monad, dopóki naprawdę naprawdę nie musimy. W tym podrozdziale
zobaczymy, czemu FreeAp (free applicative) jest lepszy od monady Free.
FreeAp zdefiniowany jest jako struktura danych reprezentujące metody ap i pure z typeklasy Applicative:
Metody .hoist i .foldMap odpowiadają metodom .mapSuspension i .foldMap z Free.
Możemy też wygenerować Free[S, A] bezpośrednio z naszego FreeAp[S, A] używając .monadic,
co jest szczególnie przydatne, gdy chcemy włączyć małe programy oparte o FreeAp do całego systemu
opartego o Free.
Podobnie jak z Free, musimy stworzyć FreeAp dla naszego AST. Więcej boilerplate’u…
7.5.2.1 Grupowanie wywołań sieciowych
Rozpoczęliśmy ten rozdział wzniosłymi obietnicami dotyczącymi wydajności. Czas ich dotrzymać.
Aby zrozumieć, dlaczego powinniśmy zredukować ilość wywołań sieciowych, spójrzmy na ludzką wersję liczb latencji autorstwa Philipa Starka, bazującą na danych oryginalnie przygotowanych przez Petera Norviga.
| Komputer | Ludzka Skala Czasowa | Ludzka Analogia |
|---|---|---|
| Odwołanie do pamięci L1 | 0,5 sek. | Uderzenie serca |
| Mispredykcja gałęzi | 5 sek. | Ziewnięcie |
| Odwołanie do pamięci L2 | 7 sek. | Długie ziewnięcie |
| Zablokowanie/odblokowanie mutexa | 25 sek. | Przygotowanie herbaty |
| Odwołanie do pamięci głównej | 100 sek. | Umycie zębów |
| Skompresowanie 1 KB przez Zippy | 50 min. | Pipeline CI kompilatora Scali |
| Przesłanie 2 KB przez sieć 1Gbps | 5,5 godz. | Pociąg z Londynu do Edynburga |
| Losowy odczyt z dysku SSD | 1,7 dn. | Weekend |
| Sekwencyjny odczyt 1 MB z pamięci | 2,9 dn. | Długi weekend |
| Podróż po jednym datacenter | 5,8 dn. | Długie wakacje w USA |
| Sekwencyjny odczyt 1 MB z dysku SSD | 11,6 dn. | Krótkie wakacje w Europie |
| Przesunięcie głowicy dyskowej | 16,5 tyg. | Semestr akademicki |
| Sekwencyjny odczyt 1 MB z dysku | 7,8 mies. | Pełnopłatny urlop macierzyński w Norwegii |
| Wysłanie pakietu CA->Holandia->CA | 4,8 r. | Kadencja rządu |
Mimo że zarówno Free, jak i FreeAp niosą ze sobą narzut spowodowany alokacją pamięci (100 sekund na ludzkiej skali),
to za każdym razem, gdy uda nam się połączyć dwa żądania sieciowe w jedno zyskujemy prawie 5 lat.
Kiedy jesteśmy w kontekście Applicative, możemy bezpiecznie optymalizować naszą aplikację bez zaburzania oczekiwań
co do oryginalnego programu i bez komplikowania logiki biznesowej.
Przypomnijmy, że nasza główna logika biznesowa wymaga, na szczęście, jedynie instancji Applicative
Zacznijmy od stworzenia boilerplate’u lift dla nowej algebry Batch
oraz instancji DynAgentsModule używając FreeAp jako kontekstu
W Rozdziale 6 poznaliśmy typ danych Const, który pozwala nam analizować wykonanie programu. Nie powinno
więc dziwić, że FreeAp.analyze jest zaimplementowane z jego właśnie użyciem:
Używamy transformacji naturalnej i .analyze, aby zebrać wszystkie węzły, które powinny zostać wystartowane
Następnym krokiem jest rozszerzenie zbioru instrukcji z Orig do Extended, tak by zawierał
Batch.Ast, oraz napisanie programu z użyciem FreeAp, który wystartuje wszystkie zebrane wcześniej węzły
pojedynczym żądaniem.
Musimy również pozbyć się wszystkich wywołań Machines.Start, co możemy osiągnąć używając jeszcze jednej transformacji naturalnej
Mamy teraz dwa programy, które musimy połączyć. Przypomnijmy sobie operator *> z Apply
i złóżmy to wszystko razem jako jedną metodę
I tyle! Teraz wystarczy użyć .optimise razem z act w głównej pętli naszego programu.
7.5.3 Coyoneda (Functor)
To “darmowa” (free) struktura danych zawdzięczająca swoją nazwę matematykowi Nobuo Yoneda. Pozwala nam ona wygenerować “za darmo” instancję
typeklasy Functor dla dowolnej algebry S[_], tak długo, jak mamy w planie przetransformować ją do algebry, która taką instancję posiada.
Również w wersji kontrawariantnej:
API jest nieco prostsze niż Free i FreeAp, udostępniając transformację poprzez .trans
i możliwość pozbycia się struktury poprzez metodę .run (która przyjmuje faktyczną implementację
Functora lub ContravariantFunctora).
Coyo i cocoyo są przydatne, gdy chcemy wywołać .map lub .contramap na typie, który
takich metod nie posiada, ale wiemy, że w końcu i tak przekonwertujemy go do innego typu,
pozbawionego tych ograniczeń, a na razie nie chcemy się z nim wiązać. Przykładowo możemy
stworzyć Coyoneda[ISet, ?], pamiętając, że ISet nie posiada instancji typeklasy Functor, aby
wywołać metody jej wymagające, a później przekonwertować taki obiekt do typu IList.
Aby użyć coyo lub cocoyo do optymalizacji naszego programu, musimy dostarczyć oczekiwany boilerplate dla każdej algebry, której będziemy używać:
Optymalizacją, którą możemy zastosować to fuzja wywołań .map (map fusion), co pozwala nam przepisać
na
unikając pośrednich reprezentacji. Jeśli, na przykład, xs to Lista z tysiącem elementów,
to oszczędzamy dwa tysiące alokacji, wywołując .map tylko raz.
Jednak dużo prościej jest po prostu ręcznie zmienić oryginalną funkcję albo poczekać
na scalaz-plugin, który automatycznie wykona tego typu
optymalizacje.
7.5.4 Efekty rozszerzalne
Programy to tylko dane, a struktury typu free wyrażają to wprost, pozwalając nam na ich rearanżację i optymalizację.
Free jest bardziej niezwykła, niż nam się wydaje: pozwala sekwencyjnie łączyć arbitralne algebry i typeklasy.
Na przykład, istnieje Free dla MonadState. Ast i .liftF są nieco bardziej skomplikowane niż zwykle, bo
muszą uwzględniać parametr typu S oraz dziedziczenie po typie Monad:
Daje nam to okazje do użycia zoptymalizowanego interpretera, który może na przykład przechowywać stan w atomowym
polu, zamiast budować zagnieżdżone trampoliny StateT.
Możemy stworzyć Ast i .liftF dla niemal dowolnej algebry albo typeklasy. Jedyne ograniczenie jest takie, że
F[_] nie może pojawiać się jako parametr w żadnej instrukcji, a więc algebra musi móc mieć instancję typeklasy Functor.
Ograniczenie to wyklucza z użycia m.in. MonadError i Monoid.
Wraz z rozrostem AST programu obniża się wydajność interpretera, ponieważ instrukcja dopasowania (match)
ma złożoność liniową względem obsługiwanych wariantów. Alternatywą do scalaz.Coproduct jest biblioteka iotaz,
która używa zoptymalizowanej struktury danych, aby wykonać tę operację ze złożonością O(1) (używając liczb całkowitych
przydzielanych wariantom na etapie kompilacji).
Z przyczyn historycznych free AST dla algebry lub typeklasy jest nazywane Initial Encoding,
a bezpośrednia implementacja (np. z użyciem IO) to Finally Tagless. Mimo że omówiliśmy
interesujące koncepty używając Free, to ogólnie przyjęta jest opinia, że finally tagless
jest podejściem lepszym. Jednak aby użyć tego podejścia, musimy mieć do dyspozycji wydajny
typ efektu, który dostarczy nam wszystkie typeklasy, które omówiliśmy. Ponadto nadal
potrzebujemy sposobu na uruchomienie naszego kodu opartego o Applicative w sposób równoległy.
I dokładnie tym się teraz zajmiemy.
7.6 Parallel
Są dwie operacje wywołujące efekty, które prawie zawsze chcemy wykonywać równolegle:
-
.mapna kolekcji efektów, zwracając pojedynczy efekt. Można to osiągnąć za pomocą metody.traverse, która deleguje do.apply2danego efektu. - uruchomienie danej liczby efektów z użyciem operatora krzyku
|@|i połączenie ich wyników, również delegując do.apply2.
W praktyce jednak żadna z tych operacji nie jest domyślnie wykonywana równolegle. Przyczyna
jest prosta: jeśli nasze F[_] implementuje typeklasę Monad, wtedy muszą być zachowane
jej prawa co do apply2, tj.
Innymi słowy, Monadom wprost zabrania się wykonywania efektów równolegle.
Jednak, gdy mamy F[_], które nie jest monadyczne, wtedy może ono implementować
.apply2 w sposób równoległy. Możemy użyć mechanizmu @@ (tagów), aby stworzyć instancję typeklasy Applicative dla
F[_] @@ Parallel, która dorobiła się własnego aliasu Applicative.Par
Programy monadyczne mogą więc żądać niejawnego Par jako dodatku do ich Monad
Metody Traverse ze Scalaz wspierają równoległe wykonanie:
Jeśli w zakresie dostępna jest niejawna instancja Applictive.Par[IO], to możemy wybrać między
sekwencyjną i równoległa trawersacją:
Podobnie możemy wywołać .parApply lub .parTupled po tym, jak użyliśmy operatorów krzyku
Warto zaznaczyć, że kiedy mamy do czynienia z programami opartymi o Applicative, takimi jak
możemy używać F[A] @@ Parallel jako kontekstu, sprawiając, że .traverse i |@| wykonywane będą równolegle.
Konwersja między zwykłą i równoległą wersją F[_] musi być obsłużona ręcznie, co może być uciążliwe, więc
często łatwiej jest po prostu wymagać obu form Applicative.
7.6.1 Łamiąc Prawo
Możemy przyjąć bardziej śmiałe podejście do zrównoleglania: zrezygnować z prawa, które każe
.apply2 wykonywać operacje sekwencyjnie dla Monad. Jest to podejście mocno kontrowersyjne,
ale działa zadziwiająco dobrze dla większości rzeczywistych aplikacji. Musimy zacząć od prześledzenia kodu
w poszukiwaniu fragmentów, które mogłyby bazować na tym prawie, aby nie wprowadzić błędów. Później jest już tylko łatwiej.
Opakowujemy IO
i dostarczamy naszą własną implementację Monady, która uruchamia .apply2 równolegle, poprzez oddelegowanie
do instancji dla typu @@ Parallel
Od teraz możemy używać MyIO zamiast IO jako kontekstu naszej aplikacji i korzystać z automatycznego zrównoleglania.
Dla kompletności: naiwna i niewydajna implementacja Applicative.Par dla naszego IO mogłaby używać Future:
a z powodu błędu w kompilatorze Scali, który powoduje, że wszystkie instancje dla typów @@
traktowane są jako instancje osierocone, musimy explicite zaimportować tę niejawną wartość:
W ostatniej sekcji tego rozdziału zobaczymy, jak naprawdę zaimplementowany jest typ IO w Scalaz.
7.7 IO
IO ze Scalaz jest najszybszą strukturą danych pozwalającą na programowanie asynchroniczne, jaką możemy znaleźć w ekosystemie Scali,
nawet do 50 razy szybsza niż Future.23 Zaprojektowana została jako monada do obsługi efektów ogólnego przeznaczenia.
IO ma dwa parametry typu, a tym samym posiada instancję typeklasy Bifunctor, która pozwala
na zdefiniowanie błędów jako ADT specyficznego dla danej aplikacji. Niestety jesteśmy na JVMie oraz musimy
współpracować z istniejącymi bibliotekami, dlatego też zdefiniowany został pomocny alias, który używa
wyjątków jako typu błędów:
7.7.1 Tworzenie
Istnieje wiele sposobów na stworzenie IO z zarówno zachłannych i leniwych, jak i bezpiecznych i niebezpiecznych bloków kodu:
wraz z wygodnymi konstruktorami dla Taska:
Najczęściej używanym wariantem, szczególnie przy pracy z istniejącym kodem, jest Task.apply oraz Task.fromFuture:
Nie możemy przekazywać instancji Future bezpośrednio, ponieważ obliczenia wewnątrz niej rozpoczynają się zachłannie w momencie
stworzenia, dlatego też tworzenie to musi odbyć się wewnątrz bezpiecznego bloku.
Zauważmy, że ExecutionContext nie jest przekazywany niejawnie, odwrotnie niż przyjęta konwencja.
W Scalaz parametry niejawne zarezerwowane są dla typeklas, a ExecutionContext to parametr konfiguracyjny,
a więc powinien być przekazany wprost.
7.7.2 Uruchamianie
Interpreter IO nazywa się RTS, od runtime system, ale jego implementacja wybiega poza zakres tej książki.
W zamian omówimy funkcjonalności, które nam udostępnia.
IO to po prostu struktura danych, którą interpretujemy na końcu świata poprzez rozszerzenie SafeApp i zaimplementowanie
metody .run
Jeśli integrujemy się z istniejącym systemem i nie mamy kontroli nad punktem wejścia do naszej aplikacji, możemy
rozszerzyć RTS, zyskując dostęp do niebezpiecznych metod, których możemy użyć, aby wyewaluować IO
na wejściu do czysto funkcyjnej części kodu.
7.7.3 Funkcjonalności
IO dostarcza instancje dla Bifunctor, MonadError[E, ?], BindRec, Plus, MonadPlus (jeśli E formuje Monoid) oraz
Applicative[IO.Par[E, ?]].
W dodatku do funkcjonalności pochodzących z typeklas dostajemy implementację kilku specyficznych metod:
Instancja IO może być zakończona (terminated), co oznacza, że praca, która
była zaplanowana, zostanie odrzucona (nie jest to ani sukces, ani błąd). Narzędzia
do pracy z tym stanem to:
7.7.4 Fiber
IO może przywołać włókna (fibers), czyli lekką abstrakcję ponad wątkami udostępnianymi przez JVM.
Możemy rozgałęziać (.fork) IO i nadzorować (.supervise) niezakończone włókna, aby upewnić się, że
zostaną zakończone, kiedy IO się wykona:
Kiedy mamy do dyspozycji włókno możemy je włączyć z powrotem do IO (.join) lub przerwać
wykonywaną pracę (.interrupt).
Możemy używać włókien do osiągnięcia optymistycznej kontroli współbieżności. Wyobraźmy sobie, że mamy dane (data),
które chcemy przeanalizować oraz zwalidować. Możemy optymistycznie rozpocząć analizę i przerwać ją, gdy walidacja,
która uruchomiona jest równolegle, zakończy się niepowodzeniem.
Innym zastosowaniem włókien jest sytuacja, gdy chcemy rozpocząć akcję i o niej zapomnieć, jak na przykład niskopriorytetowe logowanie zdarzeń przez sieć.
7.7.5 Promise
Obietnica (Promise) reprezentuje asynchroniczną zmienną, która może być ustawiona dokładnie raz (poprzez .complete lub .error).
Następnie dowolna liczba odbiorców może odczytać taką zmienną, używając .get.
Promise nie jest zazwyczaj używany w kodzie aplikacyjnym. Jest to raczej element zaprojektowany do budowania
wyżejpoziomowych frameworków do obsługi współbieżności.
7.7.6 IORef
IORef to odpowiednik mutowalnej zmiennej w świecie IO.
Możemy odczytać jej wartość oraz dostajemy do dyspozycji szereg operacji do manipulacji nią.
IORef to kolejny typ danych, który może nam dostarczyć wysokowydajną instancję MonadState.
Spróbujmy stworzyć nowy typ wyspecjalizowany do obsługi Tasków
Możemy wykorzystać tak zoptymalizowaną implementację MonadState w SafeApp, gdy nasz .program
wymaga instancji tej typeklasy:
Bardziej realistyczna aplikacja wymagałaby zdecydowanie większej liczby różnych typeklas i algebr jako wejścia.
7.7.6.1 MonadIO
Typ MonadIO, który wcześniej widzieliśmy, został uproszczony poprzez ukrycie parametru E. Prawdziwa jego
forma wygląda tak:
wraz z drobną różnicą w boilerplacie kompaniującym naszej algebrze, uwzględniają dodatkowe E:
7.8 Podsumowanie
- Typ
Futurejest zepsuty, nie idź tą drogą. - Możemy zapanować nad bezpieczeństwem stosu za pomocą
Trampoline. - Biblioteka Transformatorów Monad (MTL) abstrahuje nad popularnymi efektami za pomocą typeklas.
- Transformatory Monad dostarczają domyślnych implementacji dla typeklas z MTL.
- Struktura
Freepozwala nam analizować, optymalizować i łatwo testować nasze programy. -
IOumożliwia implementowanie algebr jako efektów wykonywanych na świecie zewnętrznym. -
IOmoże wykonywać efekty równolegle i jest wysoce wydajnym fundamentem dla dowolnej aplikacji.