3. Projektowanie aplikacji
W tym rozdziale napiszemy logikę biznesową oraz testy dla czysto funkcyjnej aplikacji serwerowej.
Kod źródłowy tej aplikacji dostępny jest wraz ze źródłami tej książki w katalogu example.
Nie mniej lepiej nie zagłębiać się w niego, zanim nie dotrzemy do ostatniego rozdziału, gdyż
wraz z poznawaniem technik FP będziemy go istotnie zmieniać.
3.1 Specyfikacja
Nasza aplikacja będzie zarządzać farmą serwerów, tworzoną na bazie zapotrzebowania i operującą z możliwie niskim budżetem. Będzie ona nasłuchiwać wiadomości od serwera CI Drone i uruchamiać agenty (maszyny robocze) używając Google Container Engine (GKE), tak aby zaspokoić potrzeby kolejki zadań.
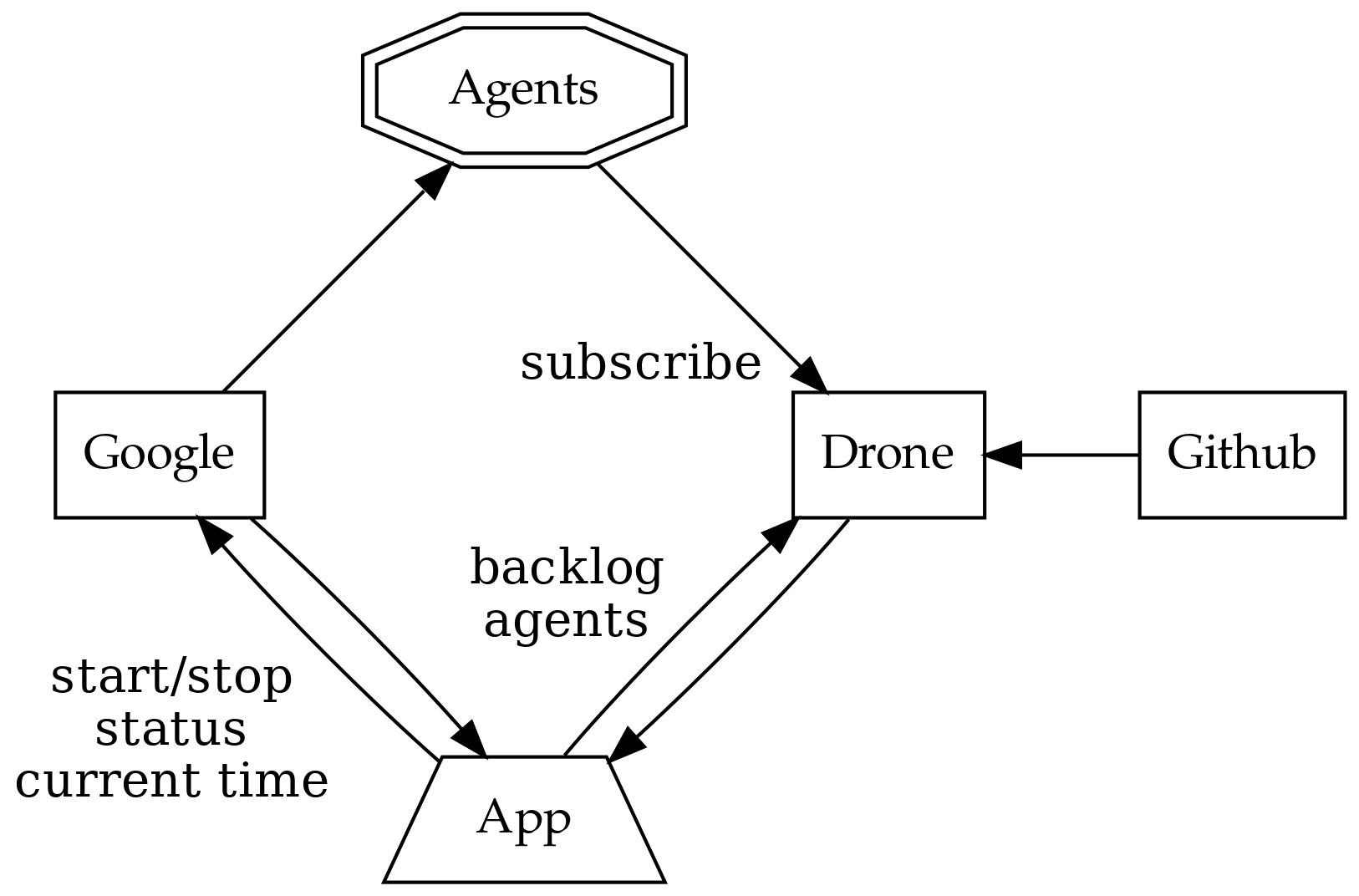
Drone otrzymuje pracę do wykonania kiedy kontrybutor zgłasza pull request w obsługiwanym projekcie na githubie. Drone przydziela pracę swoim agentom, gdzie każdy z nich przetwarza jedno zadanie w danym momencie.
Zadaniem naszej aplikacji jest zagwarantować, że zawsze jest dość agentów, aby wykonać potrzebną pracę, jednocześnie dbając, aby ich liczba nie przekroczyła określonej granicy i minimalizując całkowite koszta. Aby tego dokonać potrzebna będzie liczba elementów w kolejce i liczba dostępnych agentów.
Google potrafi tworzyć węzły (nodes), każdy z nich może być gospodarzem dla wielu agentów równocześnie. Agent podczas startu rejestruje się w serwerze, który od tej pory kontroluje jego cykl życia (wliczając cykliczne weryfikowanie czy agent jest nadal aktywny).
GKE pobiera opłatę za każdą minutę działania węzła, zaokrąglając czas do najbliższej godziny. Aby osiągnąć maksymalną efektywność, nie możemy po prostu tworzyć nowych węzłów dla każdego zadania. Zamiast tego powinniśmy reużywać wcześniej stworzone węzły i utrzymywać je do 58 minuty ich działania.
Nasza aplikacja musi być w stanie uruchamiać i zatrzymywać węzły, sprawdzać ich status (np. czas działania, aktywność) oraz wiedzieć, jaki jest aktualny czas wg GKE.
Dodatkowo, nie jest dostępne żadne API, które pozwoliłoby rozmawiać bezpośrednio z danym agentem, tak więc nie wiemy, czy aktualnie wykonuje on jakąś pracę dla serwera. Jeśli przypadkowo zatrzymamy agenta w czasie wykonywania pracy, jest to niewygodne, gdyż wymaga ludzkiej interakcji i ponownego rozpoczęcia zadania.
Kontrybutorzy mogą ręcznie dodawać agentów do farmy, tak więc liczba agentów i węzłów może być różna. Nie musimy dodawać węzłów, jeśli dostępni są wolni agenci.
W przypadku awarii powinniśmy zawsze wybierać najtańszą opcję.
Zarówno Drone, jak i GKE udostępniają JSONowe REST API zabezpieczone OAuth 2.0.
3.2 Interfejsy i algebry
Spróbujmy teraz skodyfikować diagram architektury z poprzedniego rozdziału. Po pierwsze powinniśmy zdefiniować prosty typ danych do przechowywania znacznika czasu z dokładnością do milisekund. Niestety typ taki nie jest dostępny ani w bibliotece standardowej Javy ani Scali.
W FP algebra zajmuje miejsce interfejsu z Javy lub zbioru poprawnych wiadomości obsługiwanych przez aktora z Akki. W tej właśnie warstwie definiujemy wszystkie operacje naszego systemu, które prowadzą do komunikacji ze światem zewnętrznym a tym samym do efektów ubocznych.
Istnieje ścisła więź między algebrami a logiką biznesową. Często przechodzić będziemy przez kolejne iteracje, w których próbujemy zamodelować nasz problem, następnie implementujemy rozwiązanie, tylko po to, aby przekonać się, że nasz model i zrozumienie problemu wcale nie było tak kompletne, jak nam się wydawało.
Użyliśmy typu NonEmptyList, który można łatwo utworzyć, wywołując metodę .toNel na standardowej liście, co zwraca nam
Option[NonEmptyList]. Poza tym wszystko powinno być jasne.
3.3 Logika biznesowa
Teraz przyszedł czas na napisanie logiki biznesowej, która definiuje zachowanie naszej aplikacji. Na razie rozpatrywać będziemy tylko szczęśliwy scenariusz (happy path).
Potrzebujemy klasy WorldView, która przechowywać będzie całość naszej wiedzy o świecie.
Gdybyśmy projektowali naszą aplikację przy użyciu Akki, WorldView najprawdopodobniej
zostałby zaimplementowany jako var wewnątrz stanowego aktora.
WorldView agreguje wartości zwracane przez wszystkie metody ze wcześniej zdefiniowanych algebr
oraz dodaje pole pending, aby umożliwić śledzenie nieobsłużonych jeszcze żądań.
Teraz prawie gotowi jesteśmy, aby zacząć pisać naszą logikę biznesową, ale musimy zadeklarować, że zależy ona
od algebr Drone in Machines.
Możemy zacząć od interfejsu dla naszej logiki
i zaimplementować go za pomocą modułu. Moduł zależy wyłącznie od innych modułów, algebr i czystych funkcji oraz
potrafi abstrahować nad F. Jeśli implementacja algebraicznego interfejsu zależy od konkretnego typu, np. IO,
nazywamy ją interpreterem.
Ograniczenie kontekstu (context bound) poprzez typ Monad oznacza, że F jest monadyczne, pozwalając nam tym samym na używanie
metod map, pure, i oczywiście, flatmap wewnątrz konstrukcji for.
Mamy dostęp do algebr Drone i Machines poprzez D i M. Używanie pojedynczych wielkich liter jest popularną konwencją
dla implementacji algebr i typeklas.
Nasza logika biznesowa działać będzie wewnątrz nieskończonej pętli, która może być zapisana jako pseudokod:
3.3.1 initial
Wewnątrz metody initial wywołujemy wszystkie zewnętrzne serwisy, a wyniki tych wywołań zapisujemy wewnątrz
instancji WorldView. Pole pending domyślnie pozostaje puste.
Przypomnij sobie, jak w Rozdziale 1 mówiliśmy, że flatMap (używany wraz z generatorem <-)
pozwala nam operować na wartościach dostępnych w czasie wykonania. Kiedy zwracamy F[_] to tak naprawdę
zwracamy kolejny program, który zostanie zinterpretowany w czasie wykonania. Na takim programie wywołujemy flatMap.
Tak właśnie możemy sekwencyjnie łączyć kod, który powoduje efekty uboczne, jednocześnie mogąc używać zupełnie czystej
(pozbawionej tychże efektów) implementacji w czasie testowania. FP może być przez to widziane jako Ekstremalne Mockowanie.
3.3.2 update
Metoda update powinna wywołać initial, aby odświeżyć nasz obraz świata, zachowując znane akcje, które oczekują na wywołanie (pole pending).
Jeśli węzeł zmienił swój stan, usuwamy go z listy oczekujących, a jeśli akcja trwa dłużej niż 10 minut, to zakładamy, że zakończyła się porażką i zapominamy, że ją zainicjowaliśmy.
Konkretne funkcje takie jak .symdiff nie wymagają testowych interpreterów, ponieważ mają bezpośrednio wyrażone zarówno
wejście, jak i wyjście. Możemy przenieść je do samodzielnego, bezstanowego obiektu, który można
testować w izolacji i testować jedynie publiczne metody modułu.
3.3.3 act
Metoda act jest nieco bardziej skomplikowana, więc dla zwiększenia czytelności podzielimy ją na dwie części:
wykrywanie akcji, które należy wykonać oraz wykonywanie tychże akcji. To uproszczenie sprawia, że możemy wykonać tylko
jedną akcję per wywołanie, ale jest to całkiem rozsądne, biorąc pod uwagę, że dzięki temu możemy lepiej kontrolować wykonywane akcje
oraz wywoływać act tak długo aż nie pozostanie żadna akcja do wykonania.
Wykrywanie konkretnych scenariuszy dzieje się poprzez ekstraktory bazujące na WorldView, co w praktyce jest
po prostu bardziej ekspresywną formą warunków if / else.
Musimy dodać agentów do farmy, jeśli praca gromadzi się w kolejce oraz nie ma żadnych agentów, aktywnych węzłów ani akcji oczekujących na wykonanie. Jako wynik zwracamy węzeł, który chcielibyśmy uruchomić.
Jeśli kolejka jest pusta, powinniśmy zatrzymać wszystkie nieaktywne (niewykonujące żadnych zadań) węzły. Pamiętając, że Google zawsze pobiera opłatę za pełne godziny, wyłączamy węzły jedynie w 58 minucie ich działania. Wynikiem jest lista węzłów do zatrzymania.
Jako zabezpieczenie finansowe zakładamy, że żaden węzeł nie może żyć dłużej niż 5 godzin.
Gdy już zdefiniowaliśmy scenariusze, które nas interesują, możemy przejść do implementacji metody act.
Gdy chcemy aby, węzeł został uruchomiony lub zatrzymany, dodajemy go do listy pending wraz z zapisem
czasu, w którym tę akcję zaplanowaliśmy.
Ponieważ NeedsAgent i Stale nie pokrywają wszystkich możliwych sytuacji, musimy również zdefiniować
zachowanie domyślne, które nie robi nic. Przypomnijmy z Rozdziału 2: .pure tworzy (monadyczny) kontekst używany
wewnątrz for z prostej wartości.
foldLeftM działa podobnie do foldLeft, z tą różnicą, że przyjmowana funkcja może zwracać wartość opakowaną w kontekst.
W naszym przypadku każda iteracja zwraca F[WorldView]. M w nazwie jest skrótem od Monadic. Niedługo dowiemy się
więcej o tego typu wyniesionych (lifted) funkcjach, które zachowują się tak, jak byśmy oczekiwali, ale przyjmują
funkcje zwracające wartości monadyczne zamiast zwykłych wartości.
3.4 Testy jednostkowe
Podejście funkcyjne do pisania aplikacji jest marzeniem projektanta: można skupić się na logice biznesowej,pozostawiając implementacji algebr pozostałym członkom zespołu.
Nasza aplikacja bardzo silnie zależy od upływu czasu oraz zewnętrznych webserwisów. Gdyby była to tradycyjna aplikacja napisania w duchu OOP, stworzylibyśmy mocki dla wszystkich wywołań lub testowych aktorów dla wysyłanych wiadomości. Mockowanie w FP jest równoznaczne z dostarczeniem alternatywnej implementacji algebr, od których zależymy. Algebry izolują części systemu, które muszą zostać zamockowane, czyli po prostu inaczej interpretowane w kontekście testów jednostkowych.
Zaczniemy od przygotowania danych testowych:
Implementujemy algebry poprzez rozszerzenie interfejsów Drone i Machines podając konkretny kontekst monadyczny,
który w najprostszym przypadku to po prostu Id.
Nasza “mockowa” implementacja zwyczajnie odtwarza wcześniej przygotowany WorldView.
Stan naszego systemu został wyizolowany, więc możemy użyć var do jego przechowywania:
Kiedy piszemy testy jednostkowe (używając FlatSpec z biblioteki Scalatest), tworzymy instancje Mutable
i importujemy wszystkie jej pola i metody.
Nasze drone i machines używają Id jako kontekstu wykonania, więc interpretacja naszego programu
zwraca Id[WoldView], na którym bez żadnych problemów możemy wykonywać asercje.
W tym trywialnym scenariuszu sprawdzamy, czy initial zwraca tę sama wartość, której użyliśmy
w naszej statycznej implementacji:
Możemy też stworzyć bardziej skomplikowane testy dla metod update i act,
które pomogą nam znaleźć błędy i dopracować wymagania:
Przejście przez pełen komplet testów byłby dość nudny, poniższe testy można łatwo zaimplementować,używając tego samego podejścia:
- nie proś o nowych agentów, gdy kolejka oczekujących jest niepusta
- nie wyłączaj agentów, jeśli węzły są zbyt młode
- wyłącz agenty, gdy backlog jest pusty a węzły wkrótce wygenerują nowe koszta
- nie wyłączaj agentów, gdy obecne są oczekujące akcje
- wyłącz agenty, gdy są zbyt stare, a backlog jest pusty
- wyłącz agenty, nawet jeśli wykonują prace, jeśli są zbyt starzy
- zignoruj nieodpowiadające oczekujące akcje podczas aktualizacji
Wszystkie te testy są synchroniczne i działają na wątku uruchamiającym testy oraz mogą być uruchamiane równolegle. Gdybyśmy zaprojektowali nasze testy z użyciem Akki, narażone byłyby na arbitralne timeouty, a błędy ukryte byłyby w logach.
Ciężko jest przecenić zwiększenie produktywności wynikające z prostych testów logiki biznesowej. Weź pod uwagę, że 90% czasu programisty podczas interakcji z klientem poświęcone jest na ulepszanie, aktualizowanie i poprawianie tych właśnie reguł. Wszystko inne to tylko szczegóły implementacyjne.
3.5 Przetwarzanie równoległe
Aplikacja, którą stworzyliśmy, uruchamia każdą z algebraicznych metod sekwencyjnie, mimo tego, że jest kilka oczywistych miejsc, w których praca może być wykonywana równolegle.
3.5.1 initial
W naszej definicji metody initial moglibyśmy zarządać wszystkich informacji równocześnie, zamiast wykonywać tylko jedno
zapytanie na raz.
W przeciwieństwie do metody flatMap, która działa sekwencyjnie, Scalaz dostarcza składnie Apply
przewidzianą do operacji równoległych:
możemy również użyć notacji infiksowej (infix notation):
Jeśli każda z operacji równoległych zwraca ten sam kontekst, możemy wywołać funkcję w momencie, gdy wszystkie zwrócą wynik.
Przepiszmy initial tak, aby skorzystać z tej możliwości:
3.5.2 act
W aktualnej implementacji act zatrzymujemy każdy z węzłów sekwencyjnie, czekając na wynik i kontynuując pracę,
dopiero gdy operacja się zakończy. Moglibyśmy jednak zatrzymać wszystkie węzły równolegle i na koniec zaktualizować
nasz obraz świata.
Wadą tego rozwiązania jest fakt, że błąd w którejkolwiek akcji spowoduje zwarcie, zanim zdążymy zaktualizować pole
pending. Wydaje się to być rozsądnym kompromisem, gdyż nasza metoda update poradzi sobie z sytuacją, w której
węzeł niespodziewanie się zatrzyma.
Potrzebujemy metody, która operuje na typie NonEmptyList i pozwoli nam przemapować każdy element na
F[MachineNode] i zwróci F[NonEmptyList[MachineNode]]. Metoda ta nazywa się traverse, a gdy na jej rezultacie
wywołamy flatMap, otrzymamy wartość typu NonEmptyList[MachineNode] z którą możemy sobie poradzić w prosty sposób:
Co więcej, wygląda na to, że wersja równoległa jest łatwiejsza do zrozumienia niż wersja sekwencyjna.
3.6 Podsumowanie
- Algebry definiują interfejsy między systemami
- Moduły implementują algebry, używając innych algebr
-
Interpretery to konkretne implementacje algebr dla określonego
F[_] - Interpretery testowe mogą zamienić części systemu wywołujące efekty uboczne, dając nam wysokie pokrycie testami.