6. Typy danych ze Scalaz
Kto nie kocha porządnej struktury danych? Odpowiedź brzmi nikt, a struktury danych są super!
W tym rozdziale poznamy typy danych przypominające kolekcje oraz takie, które wzbogacają Scalę o dodatkowe możliwości i zwiększają bezpieczeństwo typów.
Podstawowym powodem, dla którego używamy wielu różnych typów kolekcji, jest wydajność. Wektor i lista mogą zrobić to samo, ale ich charakterystyki wydajnościowe są inne: wektor oferuje dostęp do losowego elementu w czasie stałym, podczas gdy lista musi zostać w czasie tej operacji przetrawersowana.
Wszystkie kolekcje, które tutaj zaprezentujemy, są trwałe (persistent): jeśli dodamy lub usuniemy element, nadal możemy używać poprzedniej, niezmienionej wersji. Współdzielenie strukturalne (structural sharing) jest kluczowe dla wydajności trwałych struktur danych, gdyż bez tego musiałyby one być tworzone od nowa przy każdej operacji.
W przeciwieństwie do kolekcji z bibliotek standardowych Javy i Scali, w Scalaz typy danych nie tworzą hierarchii, a przez to są dużo prostsze do zrozumienia. Polimorfizm jest zapewniany przez zoptymalizowane instancje typeklas, które poznaliśmy w poprzednim rozdziale. Sprawia to, że zmiana implementacji podyktowana zwiększeniem wydajności, lub dostarczenie własnej, jest dużo prostsze.
6.1 Wariancja typów
Wiele z typów danych zdefiniowanych w Scalaz jest inwariantna. Dla przykładu IList[A] nie jest podtypem
IList[B] nawet jeśli A <: B.
6.1.1 Kowariancja
Problem z kowariantnymi parametrami typu, takimi jak A w class List[+A], jest taki, że List[A] jest podtypem
(a więc dziedziczy po) List[Any] i bardzo łatwo jest przez przypadek zgubić informacje o typach.
Zauważ, że druga lista jest typu List[Char] i kompilator niezbyt pomocnie wyinferował Any jako
Najmniejszą Górną Granicę (Least Upper Bound, LUB). Porównajmy to z IList, która wymaga bezpośredniego wywołania
.widen[Any], aby pozwolić na ten haniebny uczynek:
Podobnie, gdy kompilator inferuje typ z dopiskiem with Product with Serializable to najprawdopodobniej
miało miejsce przypadkowe rozszerzenie typu spowodowane kowariancją.
Niestety, musimy uważać, nawet gdy konstruujemy typy inwariantne, ponieważ obliczenie LUB wykonywane jest również dla parametrów typu:
Podobny problem powodowany jest przez typ Nothing, który jest podtypem wszystkich innych typów, wliczając w to
ADT, klasy finalne, typy prymitywne oraz null.
Nie istnieją jednak wartości typu Nothing. Funkcje, które przyjmują Nothing jako parametr, nie mogą zostać uruchomione, a
funkcje, które zwracają ten typ, nigdy nie zwrócą rezultatu. Typ Nothing został wprowadzony, aby umożliwić używanie
kowariantnych parametrów typu, ale w konsekwencji umożliwił pisanie kodu, który nie może być uruchomiony, często przez przypadek.
W Scalaz uważamy, że kowariantne parametry typu wcale nie są potrzebne, ograniczając się tym samym do praktycznego
kodu, który może zostać uruchomiony.
6.1.2 Sprzeciwwariancja
Z drugiej strony, parametry kontrawariantne takie jak A w trait Thing[-A] mogą ujawnić niszczycielskie
błędy w kompilatorze. Spójrzmy na to, co Paul Phillips (były
członek zespołu pracującego nad scalac) nazywa contrarivariance:
Tak jak byśmy oczekiwali, kompilator odnalazł najdokładniejsze dopasowanie metod do argumentów. Sprawa komplikuje się jednak gdy użyjemy wartości niejawnych
Niejawne rozstrzyganie odwraca definicje “najbardziej dokładnego dopasowania” dla typów kontrawariantnych, czyniąc je tym samym kompletnie bezużytecznymi do reprezentacji typeklas i czegokolwiek co wymaga polimorficznych funkcjonalności. Zachowanie to zostało poprawione w Dottym.
6.1.3 Ograniczenia podtypów
scala.Option ma metodę .flatten, która konwertuje Option[Option[B]] na Option[B].
Niestety kompilator Scali nie pozwala nam na poprawne zapisanie sygnatury tej metody.
Rozważmy poniższą implementację, która pozornie wydaje się poprawna:
A wprowadzone w definicji .flatten przysłania A wprowadzone w definicji klasy. Tak więc jest to równoznaczne z
czyli nie do końca jest tym, czego chcieliśmy.
Jako obejście tego problemu wprowadzono klasy <:< i =:= wraz z niejawnymi metodami, które zawsze tworzą
instancje dla poprawnych typów.
=:= może być użyty do wymuszenia, aby dwa parametry typu były dokładnie takie same. <:< służy do wyrażenia
relacji podtypowania, pozwalając tym samym na implementację .flatten jako
Scalaz definiuje ulepszone wersje <:< i =:=: Liskov (z aliasem <=<) oraz Leibniz (===).
Poza dostarczeniem przydatnych metod i niejawnych konwersji, <=< i === są bardziej pryncypialne niż ich odpowiedniki
z biblioteki standardowej.
6.2 Ewaluacja
Java to język o ścisłej (strict) ewaluacji: wszystkie parametry przekazane do metody muszą zostać wyewaluowane do
wartości, zanim metoda zostanie uruchomiona. Scala wprowadza pojęcie parametrów przekazywanych przez nazwę (by-name)
za pomocą składni a: =>A. Takie parametry opakowywane są w zero-argumentową funkcję, która jest wywoływana za każdym razem, gdy odnosimy
się do a. Widzieliśmy tego typu parametry wielokrotnie, gdy omawialiśmy typeklasy.
Scala pozwala również na ewaluacje wartości na żądanie za pomocą słowa kluczowego lazy: obliczenia są wykonywane najwyżej raz
produkując wartość przy pierwszym użyciu. Niestety Scala nie wspiera ewaluacji na żądanie dla parametrów metod.
Scalaz formalizuje te trzy strategie ewaluacji za pomocą ADT
Najsłabszą formą ewaluacji jest Name, która nie daje żadnych gwarancji obliczeniowych. Następna jest Need gwarantująca
ewaluację najwyżej raz (at most once). Value jest obliczana przed utworzeniem, gwarantując tym samym ewaluację
dokładnie raz (exactly once).
Gdybyśmy chcieli być pedantyczni, moglibyśmy wrócić do wszystkich typeklas, które poznaliśmy do tej pory i zamienić przyjmowane
parametry w ich metodach na Name, Need i Value. Zamiast tego możemy też po prostu założyć, że normalne parametry
mogą być zawsze opakowane w Value, a te przekazywane przez nazwę w Name.
Gdy piszemy czyste programy, możemy śmiało zamienić dowolne Name na Need lub Value, i vice versa, bez zmieniania
poprawności programu. To jest właśnie esencja transparencji referencyjnej: zdolność do zamiany obliczeń na wartość wynikową
lub wartości na obliczenia potrzebne do jej uzyskania.
W programowaniu funkcyjnym prawie zawsze potrzebujemy Value lub Need (znane też jako parametry ścisłe i leniwe), ale nie mamy
zbyt wiele pożytku z Name. Ponieważ na poziomie języka nie mamy bezpośredniego wsparcia dla leniwych parametrów, metody często
przyjmują wartości przez nazwę, a następnie konwertują je do Need, zwiększając tym samym wydajność.
Name dostarcza instancje poniższych typeklas:
MonadComonadTraverse1Align-
Zip/Unzip/Cozip
6.3 Memoizacja
Scalaz potrafi memoizować funkcje za pomocą typu Memo, który nie daje żadnych gwarancji co do ewaluacji z powodu
dużej gamy różniących się implementacji:
Metoda memo pozwala nam na tworzenie własnych implementacji Memo. nilMemo nie memoizuje w ogóle, a więc funkcja wykonywana
jest za każdym wywołaniem. Pozostałe implementacje przechwytują wywołania funkcji i cache’ują wynik przy użyciu kolekcji z
biblioteki standardowej.
Aby wykorzystać Memo, wystarczy, że opakujemy naszą funkcję z użyciem wybranej implementacji, a następnie używać będziemy
zwróconej nam funkcji zamiast tej oryginalnej:
Jeśli funkcja przyjmuje więcej niż jeden argument, musimy wywołać na niej tupled, konwertując ją tym samym
do jednoargumentowej funkcji przyjmującej tuple.
Memo jest traktowany w specjalny sposób i typowe reguły czystości są nieco osłabione przy jego implementacji.
Aby nosić miano czystego wystarczy, aby wykonanie K => V było referencyjnie transparentne. Przy implementacji możemy
używać mutowalnych struktur danych lub wykonywać operacje I/O, np., aby uzyskać LRU lub rozproszony cache bez deklarowania efektów
w sygnaturze typu. Inne funkcyjne języki programowania udostępniają automatyczną memoizację zarządzaną przez środowisko
uruchomieniowe, Memo to nasz sposób na dodanie podobnej funkcjonalności do JVMa, niestety jedynie jako “opt-in”.
6.4 Tagowanie
W podrozdziale wprowadzającym Monoid stworzyliśmy Monoid[TradeTemplate] jednocześnie uświadamiając sobie, że
domyślna instancja Monoid[Option[A]] ze Scalaz nie robi tego, czego byśmy od niej oczekiwali. Nie jest to jednak przeoczenie
ze strony Scalaz: często będziemy napotykali sytuację, w której dany typ danych może mieć wiele poprawnych implementacji
danej typeklasy, a ta domyślna nie robi tego, czego byśmy chcieli lub w ogóle nie jest zdefiniowana.
Najprostszym przykładem jest Monoid[Boolean] (koniunkcja && vs alternatywa ||) lub Monoid[Int] (mnożenie vs dodawanie).
Aby zaimplementować Monoid[TradeTemplate] musieliśmy albo zaburzyć spójność typeklas, albo użyć innej typeklasy niż Monoid.
scalaz.Tag został zaprojektowany jako rozwiązanie tego problemu, ale bez sprowadzania ograniczeń, które napotkaliśmy.
Definicja jest dość pokrzywiona, ale składnia dostarczana użytkownikowi jest bardzo przejrzysta. Oto w jaki sposób możemy
oszukać kompilator i zdefiniować typ A @@ T, który zostanie uproszczony do A w czasie wykonania programu:
Kilka użytecznych tagów znajdziemy w obiekcie Tags:
First i Last służą do wyboru między instancjami Monoidu, które wybierają odpowiednio pierwszy lub ostatni
operand. Za pomocą Multiplication możemy zmienić zachowanie Monoidu dla typów liczbowych z dodawania na mnożenie.
Disjunction i Conjunction pozwalają wybrać między && i || dla typu Boolean.
W naszym przykładzie definiującym TradeTemplate, zamiast Option[Currency] mogliśmy użyć Option[Currency] @@ Tags.Last.
W rzeczywistości jest to przypadek tak częsty, że mogliśmy użyć wbudowanego aliasu LastOption
i tym samym sprawić, że implementacja Monoid[TradeTemplate] będzie znacznie czystsza.
Tworzymy wartości typu LastOption poprzez zaaplikowanie Tag na instancji Option. W tym wypadku wołamy
Tag(None).
W rozdziale o derywacji typeklas pójdziemy o jeden krok dalej i stworzymy monoid automatycznie.
Kuszącym może wydać się pomysł użycia Tagów do oznaczania danych na potrzeby walidacji (np. String @@ PersonName),
ale należy oprzeć się tym pokusom, gdyż za takim oznaczeniem nie stoją żadne weryfikacje wartości używanych w czasie wykonania.
Tag powinien być używany tylko do selekcji typeklas, a do ograniczania możliwych wartości dużo lepiej jest użyć
biblioteki Refined, którą poznaliśmy w Rozdziale 4.
6.5 Transformacje naturalne
Funkcja z jednego typu w drugi zapisywana jest w Scali jako A => B, ale jest to tylko syntax sugar dla
typu Function1[A, B]. Scalaz dostarcza podobny mechanizm w formie F ~> G dla funkcji z konstruktora typu
F[_] do G[_].
Intancje typu F ~> G nazywamy transformacjami naturalnymi (natural transformation) i mówimy, że są one
uniwersalnie kwantyfikowane, ponieważ nie ma dla nich znaczenia zawartość F[_].
Przykładem transformacji naturalnej jest funkcja, która konwertuje IList na List
Lub, bardziej zwięźle, korzystając ze składni udostępnianej przez kind-projector:
Jednak w codziennej pracy zdecydowanie częściej będziemy używać transformacji naturalnych do konwersji między
algebrami. Możemy, na przykład, chcieć zaimplementować naszą algebrę Machines, służącą do komunikacji z Google Container
Engine, za pomocą gotowej, zewnętrznej algebry BigMachines. Zamiast zmieniać naszą logikę biznesową i wszystkie testy,
tak aby używały nowej algebry, możemy spróbować napisać transformację naturalną BigMachines ~> Machines.
Powrócimy do tego pomysłu w rozdziale o Zaawansowanych Monadach.
6.6 Isomorphism
Czasami mamy do czynienia z dwoma typami, które tak naprawdę są dokładnie tym samym. Powoduje to problemy z kompatybilnością, ponieważ kompilator tego nie wie. Najczęściej takie sytuacje mają miejsce, gdy chcemy użyć zewnętrznych bibliotek, które definiują coś, co już mamy w naszym kodzie.
W takich właśnie okolicznościach z pomocą przychodzi Isomorphism, który definiuje relację równoznaczności
między dwoma typami. Ma on 3 warianty dla typów o różnym kształcie:
Aliasy typów IsoSet, IsoFunctor i IsoBiFunctor pokrywają najczęstsze przypadki: zwykłe funkcje,
transformacje naturalne i binaturalne. Funkcje pomocnicze pozwalają nam generować instancje Iso z gotowych
funkcji lub transformacji, ale często łatwiej jest użyć do tego klas Template. Na przykład:
Jeśli wprowadzimy izomorfizm, możemy wygenerować wiele standardowych typeklas. Dla przykładu
pozwala nam wyderywować Semigroup[F] dla typu F, jeśli mamy F <=> G oraz Semigroup[G].
Niemal wszystkie typeklasy w hierarchii mają wariant dla typów izomorficznych. Jeśli złapiemy się na
kopiowaniu implementacji danej typeklasy, warto rozważyć zdefiniowanie Isomorphismu.
6.7 Kontenery
6.7.1 Maybe
Widzieliśmy już Maybe, Scalazowe ulepszenie scala.Option. Jest to ulepszenie dzięki swojej inwariancji oraz braku
jakichkolwiek nieczystych metod, taki jak Option.get, które mogą rzucać wyjątki.
Zazwyczaj typ ten używany jest do reprezentacji rzeczy, które mogą być nieobecne, bez podawania żadnej przyczyny ani wyjaśnienia dla tej nieobecności.
.empty i .just są lepsze niż tworzenie Just i Maybe bezpośrednio, ponieważ zwracają Maybe, pomagając tym samym
w inferencji typów. Takie podejście często nazywane jest zwracaniem typu sumy (sum type), a więc mimo posiadania
wielu implementacji zapieczętowanego traita (sealed trait) nigdy nie używamy konkretnych podtypów w sygnaturach metod.
Pomocnicza klasa niejawna pozwala nam zawołać .just na dowolnej wartości i uzyskać Maybe.
Maybe posiada instancje wszystkich poniższych typeklas
AlignTraverse-
MonadPlus/IsEmpty Cobind-
Cozip/Zip/Unzip Optional
oraz deleguje implementację poniższych do instancji dla typu A
-
Monoid/Band -
Equal/Order/Show
Dodatkowo, Maybe oferuje funkcjonalności niedostępne w żadnej typeklasie
.cata to zwięźlejsza alternatywa dla .map(f).getOrElse(b) dostępna również pod postacią | jeśli f to identity
(co jest równoznaczne z .getOrElse).
.toLeft i .toRight oraz ich aliasy symbolicznie tworzą dysjunkcje (opisane w następnym podrozdziale), przyjmując
jako parametr wartość używaną w przypadku napotkania Empty.
.orZero używa instancji typeklasy Monoid do zdobycia wartości domyślnej.
.orEmpty używa ApplicativePlus, aby stworzyć jednoelementowy lub pusty kontener. Pamiętajmy, że podobną funkcjonalność
dla kolekcji udostępnia nam .to pochodzące z Foldable.
6.7.2 Either
Typ ulepszający scala.Either w Scalaz jest symbolem, ale przyjęło się nazywać go either lub Disjunction.
z odpowiednią składnią
pozwalającą na łatwe tworzenie wartości. Zauważ, że te metody przyjmują typ drugiej strony jako parametr. A więc
jeśli chcesz stworzyć String \/ Int mając Int, wołając .right, musisz przekazać String.
Symboliczna natura \/ sprawia, że dobrze się go czyta, gdy użyty jest jako infiks. Pamiętaj, że typy symboliczne w Scali
wiążą argumenty od lewej, a więc zagnieżdżone \/ muszą być ujęte w nawiasy.
\/ posiada prawostronne (co oznacza, że flatMap wykonywany jest na \/-) instancje typeklas:
-
Monad/MonadError -
Traverse/Bitraverse PlusOptionalCozip
oraz zależne od zawartości
-
Equal/Order -
Semigroup/Monoid/Band
Dodatkowo dostajemy kilka niestandardowych metod
.fold przypomina Maybe.cata i wymaga, aby obie strony zostały przemapowane do tego samego typu.
.swap zamienia strony miejscami, lewa na prawo, prawa na lewo.
Alias | na getOrElse jest podobny do tego w Maybe. Dostajemy też ||| jako alias na orElse.
+++ pozwala na łączenie dysjunkcji, priorytetyzując te, które wypełnione są po lewej stronie.
-
right(v1) +++ right(v2)givesright(v1 |+| v2) -
right(v1) +++ left (v2)givesleft (v2) -
left (v1) +++ right(v2)givesleft (v1) -
left (v1) +++ left (v2)givesleft (v1 |+| v2)
.toEither zapewnia kompatybilność z biblioteką standardową.
Połączenie :?>> i <<?: pozwala w wygodny sposób zignorować zawartość \/ wybierając jednocześnie nową wartość
zależnie od jego typu.
6.7.3 Validation
Na pierwszy rzut oka typ Validation (zaliasowany jako \?/ czyli szczęśliwy Elvis) wydaje się być klonem
Disjunction:
Z pomocną składnią
Jednak sama struktura danych to nie wszystko. Validation celowo nie posiada instancji Monad,
ograniczając się do:
Applicative-
Traverse/Bitraverse CozipPlusOptional
oraz zależnych od zawartości:
-
Equal/Order Show-
Semigroup/Monoid
Dużą zaletą ograniczenia się do Applicative jest to, że Validation używany jest wyraźnie w sytuacjach,
w których chcemy zebrać wszystkie napotkane problemy, natomiast Disjunction zatrzymuje się przy pierwszym i ignoruje
pozostałe. Aby wesprzeć akumulacje błędów, mamy do dyspozycji ValidationNel, czyli Validation z NonEmptyList[E]
po stronie błędów.
Rozważmy wykonanie walidacji danych pochodzących od użytkownika za pomocą Disjunction i flatMap:
Jeśli użyjemy |@|
nadal dostaniemy tylko pierwszy błąd. Wynika to z faktu, że Disjunction jest Monadą, a jego metody
.applyX muszą być spójne z .flatMap i nie mogą zakładać, że operacje mogą być wykonywane poza kolejnością.
Porównajmy to z:
Tym razem dostaliśmy z powrotem wszystkie napotkane błędy!
Validation ma wiele metod analogicznych do tych w Disjunction, takich jak .fold, .swap i +++, plus
kilka ekstra:
.append (z aliasem +|+) ma taką samą sygnaturę jak +++, ale preferuje wariant success
-
failure(v1) +|+ failure(v2)zwracafailure(v1 |+| v2) -
failure(v1) +|+ success(v2)zwracasuccess(v2) -
success(v1) +|+ failure(v2)zwracasuccess(v1) -
success(v1) +|+ success(v2)zwracasuccess(v1 |+| v2)
.disjunction konwertuje Validated[A, B] do A \/ B. Dysjunkcja ma lustrzane metody .validation i .validationNel,
pozwalając tym samym na łatwe przełączanie się między sekwencyjnym i równoległym zbieraniem błędów.
\/ i Validation są bardziej wydajnymi alternatywami dla wyjątków typu checked do walidacji wejścia, unikającymi
zbierania śladu stosu (stacktrace). Wymagają one też od użytkownika obsłużenia potencjalnych błędów, sprawiając tym samym,
że tworzone systemy są bardziej niezawodne.
6.7.4 These
Napotkaliśmy These, strukturę danych wyrażającą logiczne LUB, kiedy poznawaliśmy Align.
z metodami upraszczającymi konstrukcję
These ma instancje typeklas
MonadBitraverseTraverseCobind
oraz zależnie od zawartości
-
Semigroup/Monoid/Band -
Equal/Order Show
These (\&/) ma też wiele metod, których oczekiwalibyśmy od Disjunction (\/) i Validation (\?/)
.append ma 9 możliwych ułożeń i dane nigdy nie są tracone, ponieważ This i That mogą być zawsze
zamienione w Both.
.flatMap jest prawostronna (Both i That), przyjmując Semigroupy dla strony lewej (This), tak aby
móc połączyć zawartości, zamiast je porzucać. Metoda &&& jest pomocna, gdy chcemy połączyć dwie instancje
\&/, tworząc tuple z prawej strony i porzucając tę stronę zupełnie, jeśli nie jest wypełniona w obu instancjach.
Mimo że zwracanie typu \&/ z naszych funkcji jest kuszące, to jego nadużywanie to antywzorzec.
Głównym powodem dla używania \&/ jest łączenie i dzielenie potencjalnie nieskończonych strumieni danych w
skończonej pamięci. Dlatego też dostajemy do dyspozycji kilka przydatnych funkcji do operowania na EphemeralStream
(zaliasowanym tutaj, aby zmieścić się w jednej linii) lub czymkolwiek z instancją MonadPlus
6.7.5 Either wyższego rodzaju
Typ danych Coproduct (nie mylić z bardziej ogólnym pojęciem koproduktu w ADT) opakowuje Disjunction
dla konstruktorów typu:
Instancje typeklas po prostu delegują do instancji zdefiniowanych dla F[_] i G[_].
Najpopularniejszym przypadkiem, w którym zastosowanie znajduje Coproduct, to sytuacja, gdy chcemy
stworzyć anonimowy koprodukt wielu ADT.
6.7.6 Nie tak szybko
Wbudowane w Scalę tuple oraz podstawowe typy danych takie jak Maybe lub Disjunction są ewaluowane zachłannie
(eagerly-evaluated).
Dla wygody zdefiniowane zostały warianty leniwe, mające instancje oczekiwanych typeklas:
Wnikliwy czytelnik zauważy, że przedrostek Lazy jest nie do końca poprawny, a nazwy tych typów danych
prawdopodobnie powinny brzmieć: ByNameTupleX, ByNameOption i ByNameEither.
6.7.7 Const
Const, zawdzięczający nazwę angielskiemu constant, jest opakowaniem na wartość typu A, razem
z nieużywanym parametrem typu B.
Const dostarcza instancję Applicative[Const[A, ?]] jeśli tylko dostępny jest Monoid[A]:
Najważniejszą własnością tej instancji jest to, że ignoruje parametr B, łącząc wartości typu A, które napotka.
Wracając do naszej aplikacji drone-dynamic-agents, powinniśmy najpierw zrefaktorować plik logic.scala, tak aby używał
Applicative zamiast Monad. Poprzednią implementację stworzyliśmy, zanim jeszcze dowiedzieliśmy się, czym jest
Applicative. Teraz wiemy jak zrobić to lepiej:
Skoro nasza logika biznesowa wymaga teraz jedynie Applicative, możemy zaimplementować nasz mock F[a] jako
Const[String, a]. W każdym z przypadków zwracamy nazwę funkcji, która została wywołana:
Z taką interpretacją naszego programu możemy zweryfikować metody, które są używane:
Alternatywnie, moglibyśmy zliczyć ilość wywołań za pomocą Const[Int, ?] lub IMap[String, Int].
W tym teście zrobiliśmy krok dalej poza tradycyjne testowanie z użyciem Mocków. Const pozwolił nam
sprawdzić, co zostało wywołane bez dostarczania faktycznej implementacji. Podejście takie jest użyteczne,
kiedy specyfikacja wymaga od nas, abyśmy wykonali konkretne wywołania w odpowiedzi na dane wejście.
Dodatkowo, osiągnęliśmy to, zachowując pełną zgodność typów.
Idąc dalej tym tokiem myślenia, powiedzmy, że chcielibyśmy monitorować (w środowisku produkcyjnym) węzły,
które zatrzymywane są w metodzie act. Możemy stworzyć implementacje Drone i Machines używając Const i
zawołać je z naszej opakowanej wersji act
Możemy to zrobić, ponieważ monitor jest czysty i uruchomienie go nie produkuje żadnych efektów ubocznych.
Poniższy fragment uruchamia program z ConstImpl, ekstrahując wszystkie wywołania do Machines.stop i zwracając
wszystkie zatrzymane węzły razem WoldView.
Użyliśmy Const, aby zrobić coś, co przypomina niegdyś popularne w Javie Programowanie Aspektowe.
Na bazie naszej logiki biznesowej zaimplementowaliśmy monitoring, nie komplikując tej logiki w żaden sposób.
A będzie jeszcze lepiej. Moglibyśmy uruchomić ConstImpl w środowisku produkcyjnym, aby zebrać informacje
o tym, co ma zostać zatrzymane, a następnie dostarczyć zoptymalizowaną implementację korzystającą
ze specyficznych dla implementacji wywołań batchowych.
Cichym bohaterem tej opowieści jest Applicative, a Const pozwala nam pokazać, co jest dzięki niemu możliwe.
Jeśli musielibyśmy zmienić nasz program tak, aby wymagał Monady, nie moglibyśmy wtedy użyć Const, a zamiast tego zmuszeni
bylibyśmy do napisania pełnoprawnych mocków, aby zweryfikować jakie funkcje zostały wywołane dla danych argumentów.
Reguła Najmniejszej Mocy (Rule of Least Power) wymaga od nas, abyśmy używali Applicative zamiast Monad, kiedy tylko możemy.
6.8 Kolekcje
W przeciwieństwie do Collections API z biblioteki standardowej, Scalaz opisuje zachowanie kolekcji
za pomocą hierarchii typeklas, np. Foldable, Traverse, Monoid. Co pozostaje do przeanalizowania, to
konkretne struktury danych, ich charakterystyki wydajnościowe i wyspecjalizowane metody.
Ten podrozdział wnika w szczegóły implementacyjne każdego typu danych. Nie musimy zapamiętać wszystkiego, celem jest zrozumieć, jak działa każda ze struktur jedynie w ogólności.
Ponieważ wszystkie kolekcje dostarczają instancje mniej więcej tych samych typeklas, nie będziemy ich powtarzać. W większości przypadków jest to pewna wariacja poniższej listy.
Monoid-
Traverse/Foldable -
MonadPlus/IsEmpty -
Cobind/Comonad -
Zip/Unzip Align-
Equal/Order Show
Struktury danych, które nigdy nie są puste dostarczają również
-
Traverse1/Foldable1
oraz Semigroup zamiast Monoid i Plus zamiast IsEmpty.
6.8.1 Listy
Używaliśmy IList[A] i NonEmptyList[A] tyle razy, że powinny już być nam znajome.
Reprezentują on ideę klasycznej, jedno-połączeniowej listy:
Główną zaletą IList nad List jest brak niebezpiecznych metod, takich jak .head (jest ona niebezpieczna, gdyż wyrzuca wyjątek
w przypadku pustej kolekcji).
Dodatkowo, IList jest dużo prostsza, gdyż nie jest częścią hierarchii, oraz zużywa zdecydowanie mniej
pamięci. Ponadto, List z biblioteki standardowej ma przerażająca implementację, używającą var, aby obejść
problemy wydajnościowe:
Tworzenie instancji List wymaga ostrożnej i powolnej, synchronizacji wątków, aby zapewnić
bezpieczne publikowanie. IList nie ma żadnych tego typu wymagań, a więc może przegonić List pod względem wydajności.
6.8.2 EphemeralStream
Stream z biblioteki standardowej jest leniwą wersją Listy, ale obarczoną wyciekami pamięci i niebezpiecznymi
metodami. EphemeralStream nie przetrzymuje referencji do wyliczonych wartości, łagodząc problemy z przetrzymywaniem
pamięci. Jednocześnie pozbawiony jest niebezpiecznych metod, tak, jak Ilist.
.cons, .unfold i .iterate to mechanizmy do tworzenia strumieni. ##:: (a więc i cons) umieszcza nowy element na
początku EStreamu przekazanego przez nazwę. .unfold służy do tworzenia skończonych (lecz potencjalnie nieskończonych)
strumieni poprzez ciągłe wywoływanie funkcji f zwracającej następną wartość oraz wejście do swojego kolejnego wywołania.
.iterate tworzy nieskończony strumień za pomocą funkcji f wywoływanej na poprzednim jego elemencie.
EStream może pojawiać się w wyrażeniach pattern matchingu z użyciem symbolu ##::.
Mimo że EStream rozwiązuje problem przetrzymywania pamięci, nadal możemy ucierpieć z powodu
powolnych wycieków pamięci, jeśli żywa referencja wskazuje na czoło nieskończonego strumienia.
Problemy tej natury oraz potrzeba komponowania strumieni wywołujących efekty uboczne są powodem, dla którego
istnieje biblioteka fs2.
6.8.3 CorecursiveList
Korekursja (corecursion) ma miejsce, gdy zaczynamy ze stanu bazowego i deterministycznie produkujemy kolejne stany
przejściowe, tak jak miało to miejsce w metodzie EphemeralStream.unfold, którą niedawno omawialiśmy:
Jest to działanie odwrotne do rekursji, która rozbija dane do stanu bazowego i kończy działanie.
CorecursiveList to struktura danych wyrażająca EphemeralStream.unfold i będąca alternatywą dla EStream, która
może być wydajniejsza w niektórych przypadkach:
Korekursja jest przydatna, gdy implementujemy Comonad.cojoin, jak w naszym przykładzie z Hood.
CorecursiveList to dobry sposób na wyrażenie nieliniowych równań rekurencyjnych, jak te używane w
biologicznych modelach populacji, systemach kontroli, makroekonomii i modelach bankowości inwestycyjnej.
6.8.4 ImmutableArray
Czyli proste opakowanie na mutowalną tablicę (Array) z biblioteki standardowej, ze specjalizacją
dla typów prymitywnych:
Typ Array jest bezkonkurencyjny, jeśli chodzi prędkość odczytu oraz wielkość stosu. Jednak
nie występuje tutaj w ogóle współdzielenie strukturalne, więc niemutowalne tablice używane są zwykle tylko, gdy
ich zawartość nie ulega zmianie lub jako sposób na bezpieczne owinięcie danych pochodzących z zastanych
części systemu.
6.8.5 Dequeue
Dequeue (wymawiana jak talia kart - “deck”) to połączona lista, która pozwala na dodawanie i odczytywanie
elementów z przodu (cons) lub tyłu (snoc) w stałym czasie. Usuwania elementów z obu końców jest
stałe statystycznie.
Implementacja bazuje na dwóch listach, jednej dla danych początkowych, drugiej dla końcowych.
Rozważmy instancję przechowującą symbole a0, a1, a2, a3, a4, a5, a6
która może być zobrazowana jako
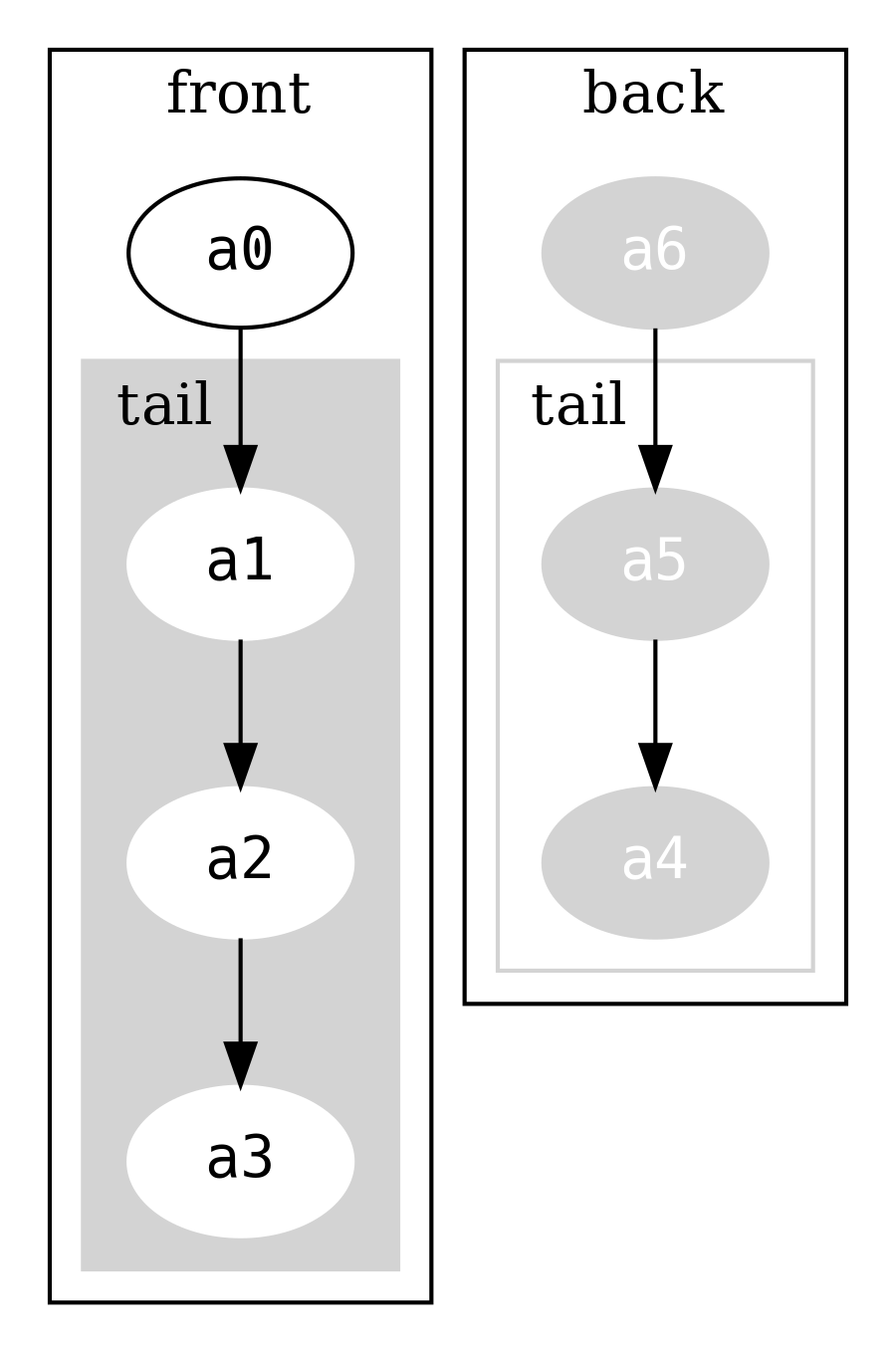
Zauważ, że lista przechowująca back jest w odwróconej kolejności.
Odczyt snoc (element końcowy) to proste spojrzenie na back.head. Dodanie elementu na koniec Dequeue oznacza
dodanie go na początek back i stworzenie nowego FullDequeue (co zwiększy backSize o jeden). Prawie
cała oryginalna struktura jest współdzielona. Porównaj to z dodaniem nowego elementu na koniec IList, co wymaga
stworzenia na nowo całej struktury.
frontSize i backSize są używane do zbalansowywania front i back, tak, aby zawsze były podobnych rozmiarów.
Balansowanie oznacza, że niektóre operacje mogą być wolniejsze od innych (np. gdy cała struktura musi być przebudowana),
ale ponieważ dzieje się to okazjonalnie możemy ten koszt uśrednić i powiedzieć, że jest stały.
6.8.6 DList
Zwykłe listy mają kiepską wydajność, gdy duże listy są ze sobą łączone. Rozważmy koszt wykonania poniższej operacji:
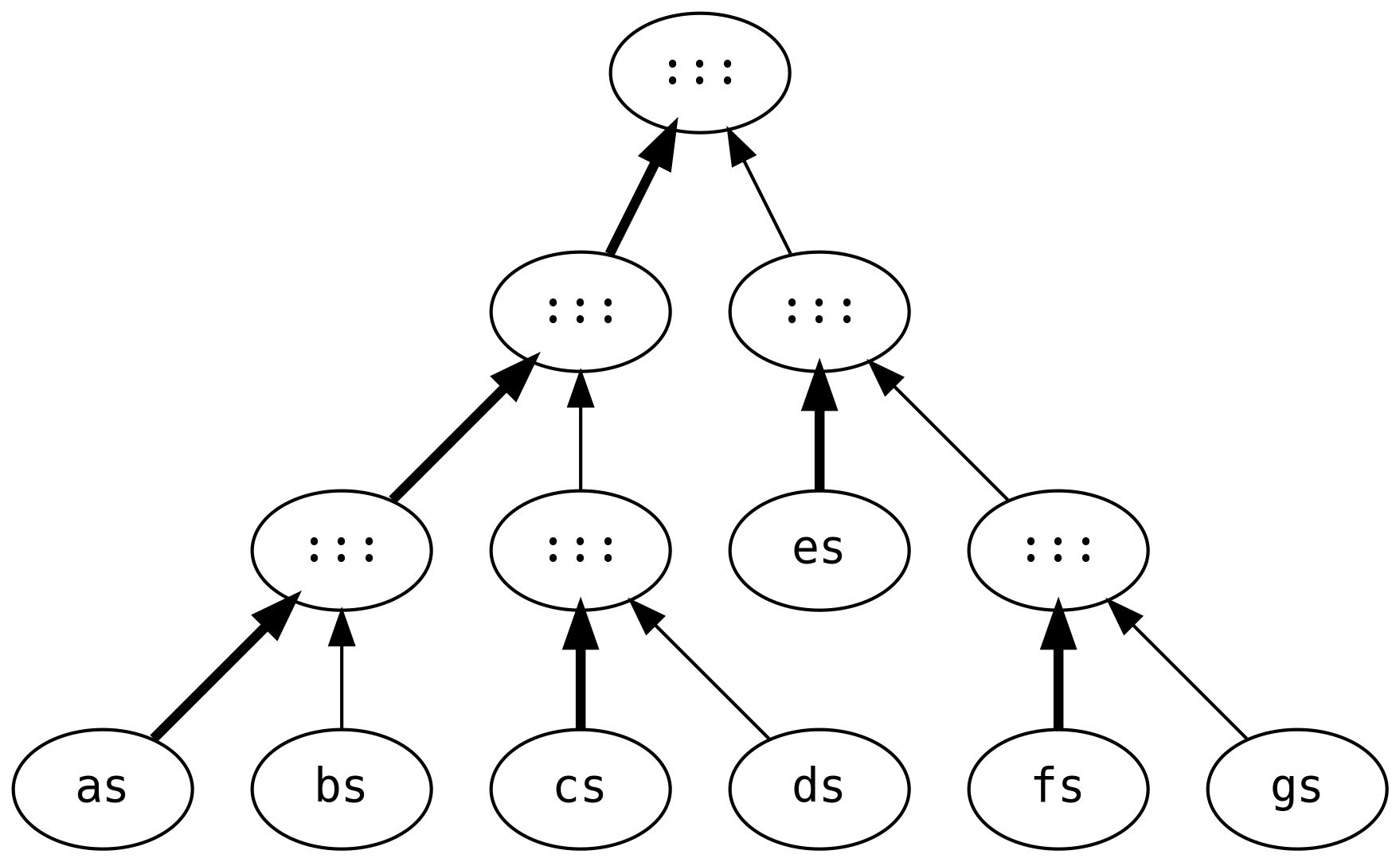
Tworzonych jest 6 list pośrednich, przechodząc i przebudowując każdą z list trzy krotnie (oprócz gs, która jest współdzielona
na wszystkich etapach).
DList (od difference list, listy różnic) jest bardziej wydajnym rozwiązaniem dla tego scenariusza. Zamiast
wykonywać obliczenia na każdym z etapów, wynik reprezentowany jest jako IList[A] => IList[A].
Odpowiednikiem naszych obliczeń jest (symbole muszą zostać stworzone za pomocą DList.fromIList)
gdzie praca podzielona jest na prawostronne (czyli szybkie) złączenia
wykorzystując szybki konstruktor na IList.
Jak zawsze, nie ma nic za darmo. Występuje tu narzut związany z alokacją pamięci, który może spowolnić nasz kod, jeśli ten i tak zakładał prawostronne złączenia. Największe przyspieszenie uzyskamy, gdy operacje są lewostronne, np.:
Lista różnic cierpi z powodu kiepskiego marketingu. Najprawdopodobniej znalazłaby się w bibliotece standardowej, gdyby
tylko nazywała się ListBuilderFactory.
6.8.7 ISet
Struktury drzewiaste są doskonałe do przechowywania uporządkowanych danych, tak aby każdy węzeł binarny przechowywał elementy od niego mniejsze w jednej gałęzi, a większe w drugiej. Jednak naiwna implementacja takiej struktury może w łatwy sposób stać się niesymetryczna, gdyż symetria zależeć będzie od kolejności dodawanie elementów. Utrzymywanie perfekcyjnie zbalansowanego drzewa jest możliwe, ale jednocześnie niewiarygodnie nieefektywne, ponieważ każde wstawienie elementu do drzewa powodowałoby jego pełne przebudowanie.
ISet to implementacja drzewa z ograniczoną równowagą (bounded balance), co oznacza, że jest ono zrównoważone
w przybliżeniu, używając size każdej gałęzi do równoważenia węzła.
ISet wymaga, aby A miało instancję typeklasy Order oraz musi ona pozostawać taka sama pomiędzy wywołaniami,
gdyż inaczej zaburzone zostaną wewnętrzne założenia, prowadząc tym samym do uszkodzenia danych. Innymi słowy,
zakładamy spójność typeklas, a więc dla dowolnego A istnieje tylko jedna instancja Order[A].
ADT ISetu niestety pozwala na wyrażenie niepoprawnych drzew. Staramy się pisać ADT tak, aby
w pełni opisywały to, co jest i nie jest możliwe poprzez restrykcję typów, ale nie zawsze jest to możliwe.
Zamiast tego Tip i Bin są prywatne, powstrzymując użytkowników przed przypadkowym niepoprawnych drzew.
.insert jest jedynym sposobem na konstrukcję drzew, definiując tym samym to, jak wygląda poprawna jego forma.
Wewnętrzne metody .balanceL i .balanceR są swoimi lustrzanymi odbiciami, a więc przestudiujemy jedynie
.balanceL, która jest wywoływana, gdy dodawana wartość jest mniejsza niż aktualny węzeł. Jest ona również
wołana przez metodę .delete.
Równoważenie wymaga, abyśmy sklasyfikowali scenariusze, które mogą się zdarzyć. Przejdziemy przez nie kolejno,
wizualizując (y, left, right) po lewej stronie i wersją zbalansowaną (znaną tez jako drzewo obrócone,
rotated tree) po prawej.
- wypełnione koła obrazują
Tip - trzy kolumny to
left | value | rightpochodzące zBin - diamenty wizualizują dowolny
ISet
Pierwszy scenariusz jest trywialny i zachodzi, gdy obie strony to Tipy. Nigdy nie napotkamy tego scenariusza, wykonując
.insert, ale może on wystąpić przy .delete
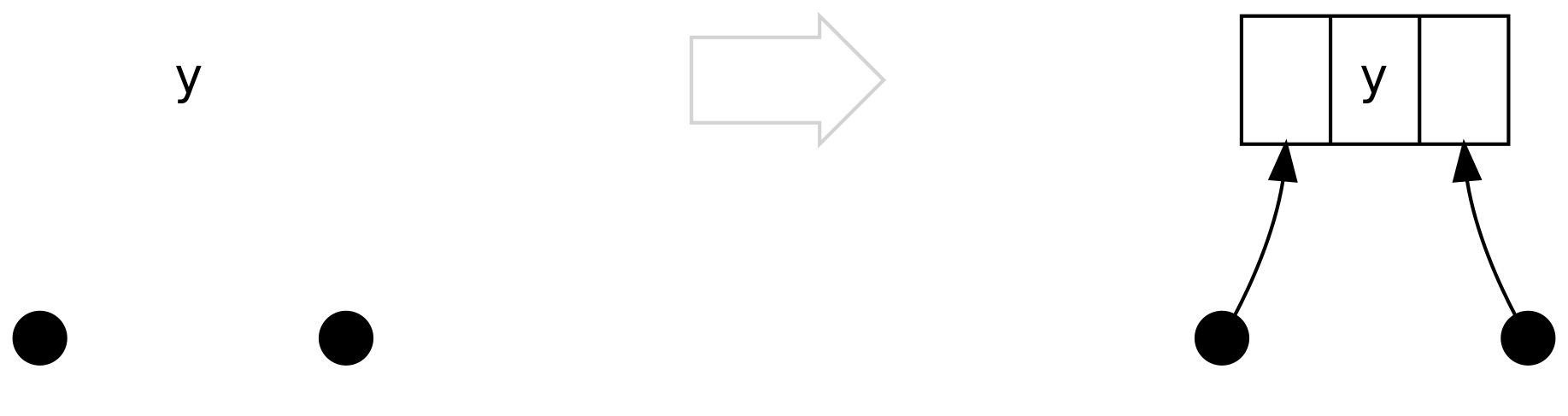
Drugi przypadek ma miejsce, kiedy lewa strona to Bin zawierający jedynie Tip. Nie musimy nic równoważyć, dodajemy
jedynie oczywiste połączenie:
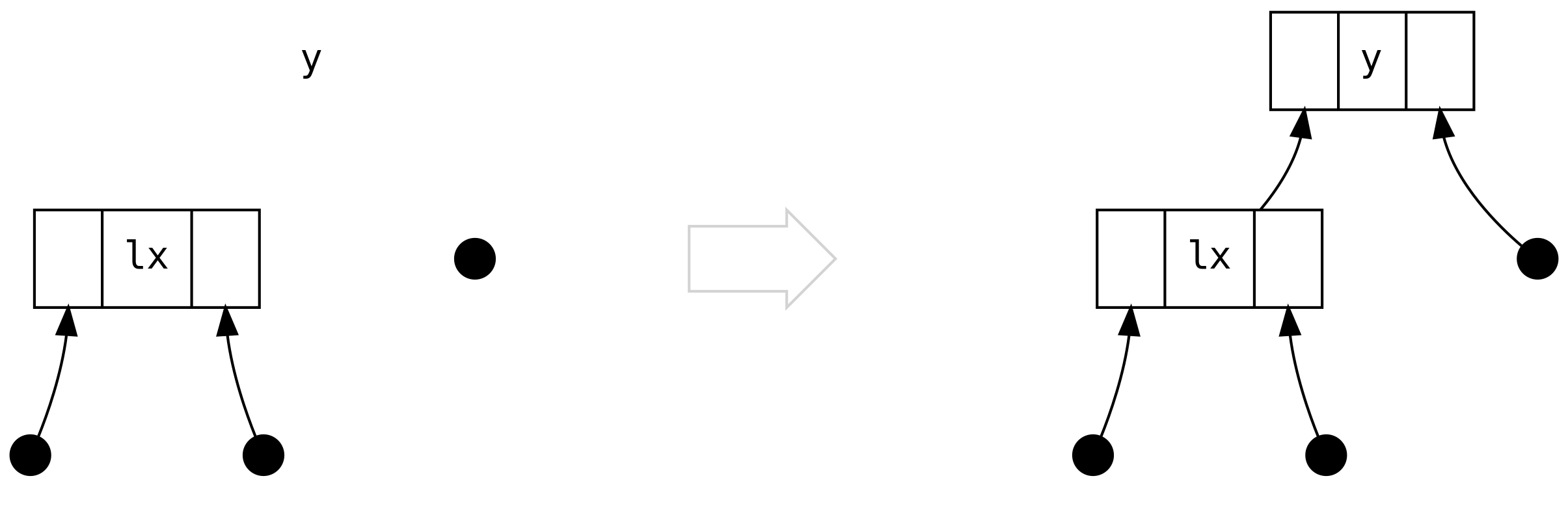
Przy trzecim scenariuszu zaczyna robić się interesująco: lewa strona to Bin zawierający
Bin po swojej prawej stronie.
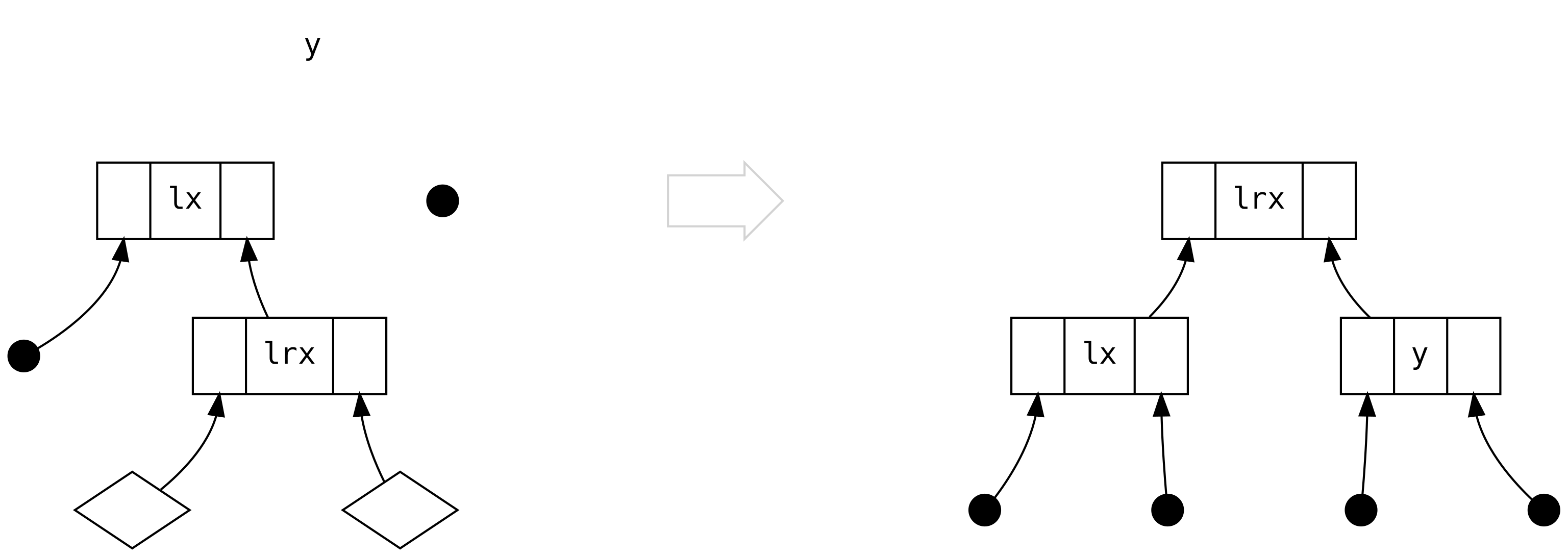
Ale co z dwoma diamentami poniżej lrx? Czy nie utraciliśmy właśnie informacji? Nie, nie utraciliśmy, ponieważ
możemy wnioskować (na podstawie równoważenia wielkości), że są one zawsze puste (Tip). Nie istnieje żadna reguła
w naszych scenariuszach, która pozwala na wyprodukowanie drzewa, w którym którykolwiek z tych węzłów to Bin.
Czwarty przypadek jest przeciwieństwem trzeciego.

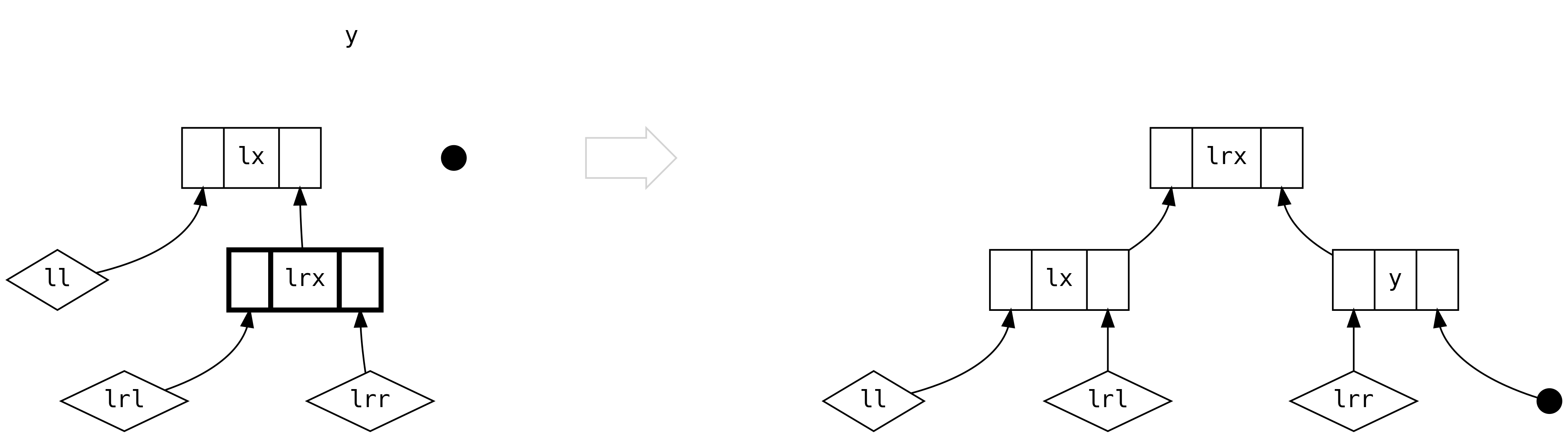
W scenariuszu piątym mamy do czynienia z pełnymi drzewami po obu stronach left i musimy oprzeć
decyzję o dalszych krokach na ich wielkości.
Dla pierwszej gałęzi, 2*ll.size > lr.size

a dla drugiej, 2*ll.size <= lr.size
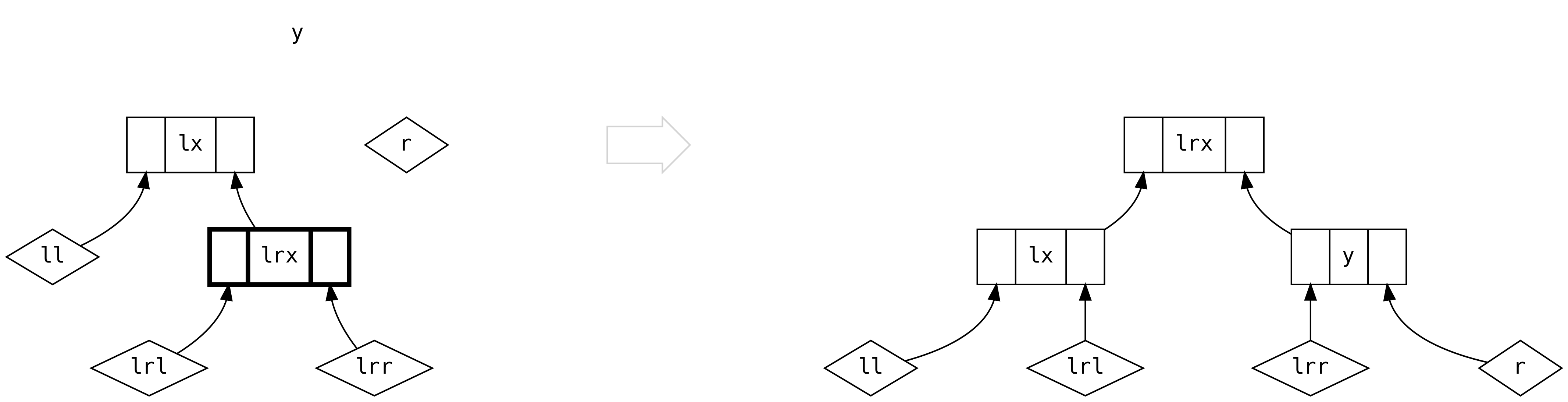
Szósty przypadek wprowadza drzewo po prawej stronie. Gdy left jest puste, tworzymy oczywiste połączenie.
Taka sytuacja nigdy nie pojawia się w wyniku .insert, ponieważ left jest zawsze pełne:

Ostatni scenariusz zachodzi, gdy mamy pełne drzewa po obu stronach. Jeśli left jest mniejszy niż
trzykrotność right, możemy po prostu stworzyć nowy Bin.

Jednak gdy ten warunek nie jest spełniony i left jest większy od right więcej niż trzykrotnie, musimy
zrównoważyć drzewa jak w przypadku piątym.

Tym samym doszliśmy do końca analizy metody .insert i tego, jak tworzony jest ISet. Nie powinno dziwić, że
Foldable jest zaimplementowany w oparciu o przeszukiwanie w-głąb. Metody takie jak .minimum i .maximum
są optymalne, gdyż struktura danych bazuje na uporządkowaniu elementów.
Warto zaznaczyć, że niektóre metody nie mogą być zaimplementowane tak wydajnie, jak byśmy chcieli. Rozważmy
sygnaturę Foldable.element
Oczywistą implementacją .element jest użyć przeszukiwania (prawie) binarnego ISet.contains.
Jednak nie jest to możliwe, gdyż .element dostarcza Equal, a .contains wymaga instancji Order.
Z tego samego powodu ISet nie jest w stanie dostarczyć instancji typeklasy Functor, co w praktyce okazuje się
sensownym ograniczeniem: wykonanie .map powodowałoby przebudowanie całej struktury. Rozsądnie jest przekonwertować
nasz zbiór do innego typu danych, na przykład IList, wykonać .map i przekonwertować wynik z powrotem. W konsekwencji
nie jesteśmy w stanie uzyskać Traverse[ISet] ani Applicative[ISet].
6.8.8 IMap
Wygląda znajomo? W rzeczy samej, IMap (alias na operator prędkości światła ==>>) to kolejne równoważone
drzewo, z tą różnicą, że każdy węzeł zawiera dodatkowe pole value: B, pozwalając na przechowywanie par klucz/wartość.
Instancja Order wymagana jest jedynie dla typu klucza A, a dodatkowo dostajemy zestaw przydatnych metod do aktualizowania
wpisów
6.8.9 StrictTree i Tree
Zarówno StrictTree, jak i Tree to implementacje Rose Tree, drzewiastej struktury danych z nieograniczoną
ilością gałęzi w każdym węźle. Niestety, z powodów historycznych, zbudowane na bazie kolekcji z biblioteki standardowej…
Tree to leniwa (by-need) wersja StrictTree z wygodnymi konstruktorami
Użytkownik Rose Tree powinien sam zadbać o balansowanie drzewa, co jest odpowiednie, gdy chcemy wyrazić hierarchiczną wiedzę domenową jako strukturę danych. Dla przykładu, w sztucznej inteligencji Rose Tree może być użyte w algorytmach klastrowania do organizacji danych w hierarchie coraz bardziej podobnych rzeczy. Możliwe jest również wyrażenie dokumentów XML jako Rose Tree.
Pracując z danymi hierarchicznymi, dobrze jest rozważyć tę strukturę danych, zanim stworzymy swoją własną.
6.8.10 FingerTree
Finger tree (drzewo palczaste) to uogólniona sekwencja z zamortyzowanym stałym czasem dostępu do elementów i logarytmicznym
złączaniem. A to typ elementów, a V na razie zignorujemy:
Przedstawmy FingerTree jako kropki, Finger jako prostokąty, a Node jako prostokąty wewnątrz prostokątów:
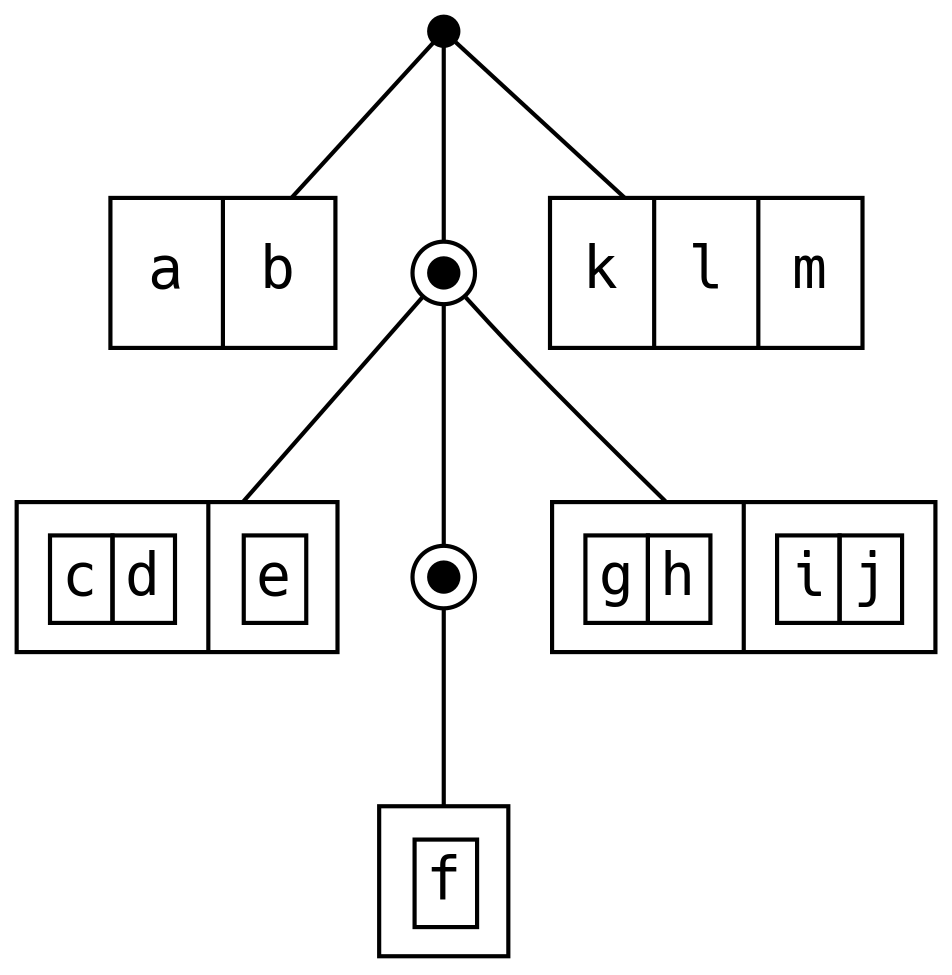
Dodanie elementy na początek FingerTree za pomocą +: jest wydajne, ponieważ Deep po prostu dodaje nowy element
do swojego lewego (left) palca. Jeśli palec to Four, to przebudowujemy spine, tak, aby przyjął 3 z tych
elementów jako Node3. Dodawanie na koniec (:+) odbywa się tak samo, ale w odwrotnej kolejności.
Złączanie za pomocą |+| lub <++> jest bardziej wydajne niż dodawanie po jednym elemencie, ponieważ instancje Deep
mogą zachować swoje zewnętrzne gałęzie, przebudowując jedynie spine.
Do tej pory ignorowaliśmy V. Ukryliśmy też niejawny parametr obecny we wszystkich wariantach tego ADT: implicit measurer: Reducer[A, V].
Reducer to rozszerzenie typeklasy Monoid pozwalające na dodanie pojedynczych elementów do M
Na przykład Reducer[A, IList[A]] może zapewnić wydajną implementację .cons
6.8.10.1 IndSeq
Jeśli jako V użyjemy Int, dostaniemy sekwencje zindeksowaną, gdzie miarą jest wielkość, pozwalając nam
na wyszukiwanie elementu po indeksie poprzez porównywanie indeksu z rozmiarem każdej gałezi w drzewie:
6.8.10.2 OrdSeq
Inną odmianą FingerTree jest sekwencja uporządkowana, gdzie miarą jest największa wartość w danej gałęzi:
OrdSeq nie posiada instancji żadnych typeklas, co sprawia, że przydatna jest tylko do stopniowego budowania
uporządkowanej sekwencji (zawierającej duplikaty). Jeśli zajdzie taka potrzeba, możemy zawsze skorzystać z bazowego FingerTree.
6.8.10.3 Cord
Najpopularniejszym użyciem FingerTree jest przechowanie tymczasowej reprezentacji Stringów w instancjach Show.
Budowanie pojedynczego Stringa może być tysiąckrotnie szybsze niż domyślna implementacja .toString dla case class,
która tworzy nowy ciąg znaków dla każdej warstwy w ADT.
Dla przykładu, instancja Cord[String] zwraca Three ze stringiem pośrodku i cudzysłowami po obu stronach
Sprawiając, że String wygląda tak jak w kodzie źródłowym
6.8.11 Kolejka Priorytetowa Heap
Kolejka priorytetowa to struktura danych, która pozwala na szybkie wstawianie uporządkowanych elementów (zezwalając na duplikaty) oraz szybki dostęp do najmniejszego elementu (czyli takiego z najwyższym priorytetem). Nie jest wymagane, aby elementy inne niż minimalny były przechowywane wg porządku. Naiwna implementacja mogłaby wyglądać tak:
Taki push jest bardzo szybki (O(1)), ale reorder, a zatem i pop bazują na metodzie IList.sorted, której
złożoność to O(n log n).
Scalaz implementuje kolejkę priorytetową za pomocą struktury drzewiastej, gdzie każdy węzeł ma wartość
mniejszą niż jego dzieci. Heap pozwala na szybkie wstawianie (insert), złączanie (union), sprawdzanie
wielkości (size), zdejmowanie (pop) i podglądanie (minimum0) najmniejszego elementu.
Heap zaimplementowany jest za pomocą Rose Tree z wartościami typu Ranked, gdzie rank to głębokość
subdrzewa, pozwalająca na balansowanie całej struktury. Samodzielnie zarządzamy drzewem, tak aby minimum
było zawsze na jego szczycie. Zaletą takiej reprezentacji jest to, że minimum0 jest darmowe:
Dodając nowy element, porównujemy go z aktualnym minimum i podmieniamy je jeśli nowa wartość jest mniejsza:
Dodawanie wartości, które nie są minimum, skutkuje nieuporządkowanymi gałęziami drzewa. Kiedy napotkamy dwa, lub więcej, poddrzewa tej samej rangi, optymistycznie dodajemy minimum na początek:
Uniknięcie pełnego uporządkowania drzewa sprawia, że insert jest bardzo szybki (O(1)), a więc
producenci wartości nie są karani. Jednak konsumenci muszą ponieść koszt tej decyzji, gdyż
złożoność uncons to O(log n), z racji tego, że musimy odszukać nowe minimum i przebudować drzewo.
Nadal jednak jest to implementacja szybsza od naiwnej.
union również odracza porządkowanie, pozwalając na wykonanie ze złożonością O(1).
Jeśli domyślna instancja Order[Foo] nie wyraża w poprawny sposób priorytetów, których potrzebujemy, możemy
użyć Tagu i dostarczyć własną instancję Order[Foo @@ Custom] dla Heap[Foo @@ Custom].
6.8.12 Diev - interwały dyskretne
Możemy wydajnie wyrazić zbiór liczb całkowitych 6, 9, 2, 13, 8, 14, 10, 7, 5 jako serię domkniętych przedziałów:
[2, 2], [5, 10], [13, 14]. Diev to wydajna implementacja tej metody dla dowolnego A, dla którego istnieje
Enum[A]. Tym wydajniejsza im gęstsza jego zawartość.
Kiedy aktualizujemy Diev, sąsiednie przedziały są łączone i porządkowane, tak, że dla każdego zbioru wartości
istnieje unikalna reprezentacja.
Świetnym zastosowaniem dla tej struktury są przedziały czasu. Na przykład w TradeTemplate z wcześniejszego rozdziału.
Jeśli okaże się, że lista payments jest bardzo gęsta, możemy zamienić ją na Diev dla zwiększenia wydajności,
nie wpływając jednocześnie na logikę biznesową, gdyż polega ona na typeklasie Monoid, a nie metodach specyficznych
dla Listy. Musimy tylko dostarczyć instancję Enum[LocalDate].
6.8.13 OneAnd
Przypomnij sobie Foldable, czyli odpowiednik API kolekcji ze Scalaz, oraz Foldable1, czyli jego wersję dla
niepustych kolekcji. Do tej pory widzieliśmy instancję Foldable1 jedynie dla NonEmptyList. Okazuje się, że
OneAnd to prosta struktura danych, która potrafi opakować dowolną kolekcję i zamienić ją w Foldable1:
Typ NonEmptyList[A] mógłby być aliasem na OneAnd[IList, A]. W podobny sposób możemy stworzyć niepuste
wersje Stream, DList i Tree. Jednak może to zaburzyć gwarancje co do uporządkowania i unikalności elementów:
OneAnd[ISet, A] to nie tyle niepusty ISet, a raczej ISet z zagwarantowanym pierwszym elementem, który może
również znajdować się w tym zbiorze.
6.9 Podsumowanie
W tym rozdziale przejrzeliśmy typy danych, jakie Scalaz ma do zaoferowania.
Nie musimy zapamiętać wszystkiego. Niech każda z sekcji zasadzi ziarno pewnej koncepcji, które może o sobie przypomnieć, gdy będziemy szukać rozwiązania dla konkretnego problemu.
Świat funkcyjnych struktur danych jest aktywnie badany i rozwijany. Publikacje naukowe na ten temat ukazują się regularnie, pokazując nowe podejścia do znanych problemów. Implementacja nowych struktur bazujących na literaturze to dobry sposób na swój własny wkład do ekosystemu Scalaz.