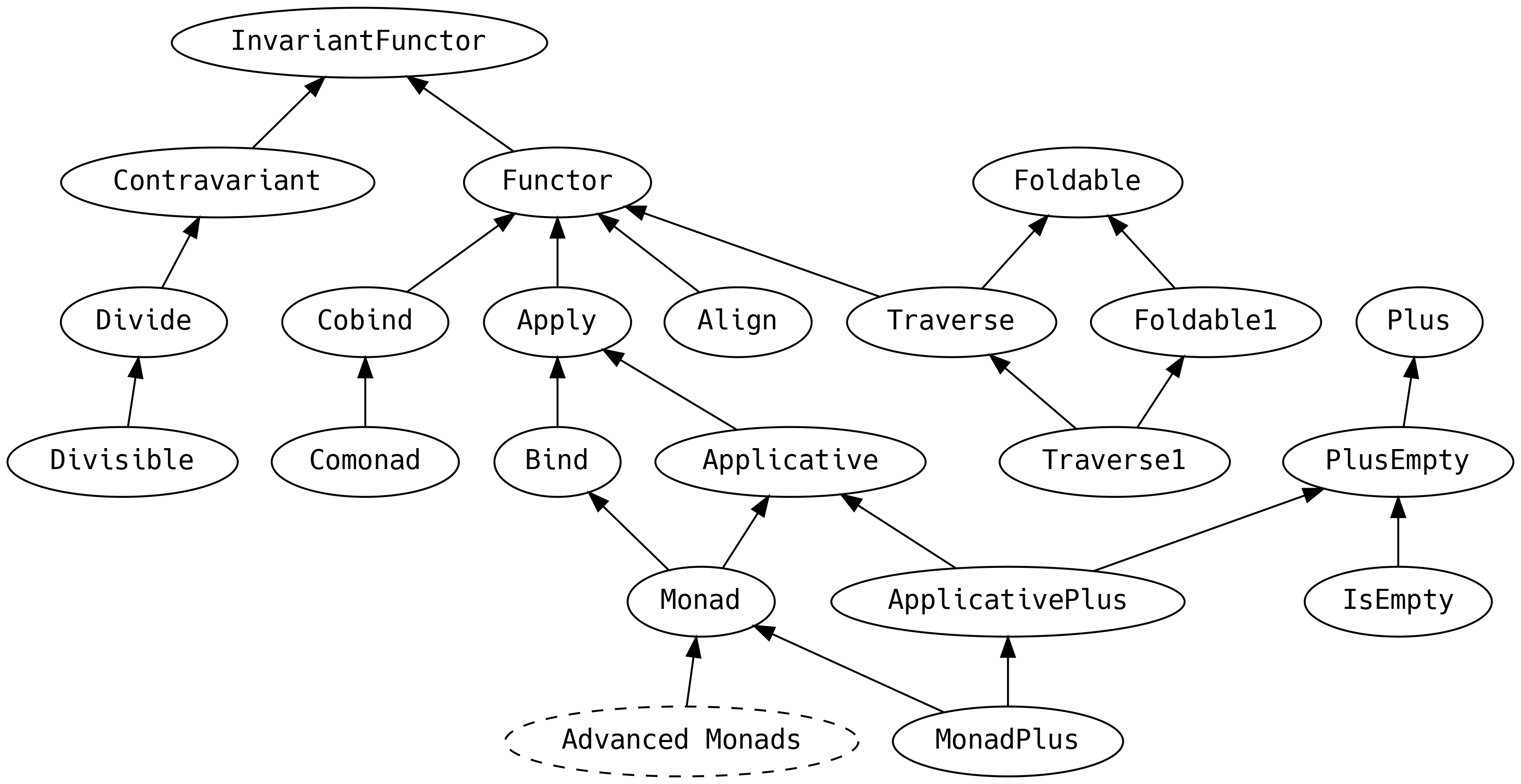
5. Typeklasy ze Scalaz
W tym rozdziale przejdziemy przez niemal wszystkie typeklasy zdefiniowane w scalaz-core. Nie wszystkie z nich
znajdują zastosowanie w drone-dynamic-agents, więc czasami będziemy używać samodzielnych przykładów.
Napotkać można krytykę w stosunku do konwencji nazewniczych stosowanych w Scalaz i programowaniu funkcyjnym w
ogólności. Większość nazw podąża za konwencjami wprowadzonymi w Haskellu, który bazował z kolei na dziale matematyki
zwanym Teorią kategorii. Możesz śmiało użyć aliasów typów, jeśli uważasz, że rzeczowniki pochodzące od
głównej funkcjonalności są łatwiejsze do zapamiętania (np. Mappable, Pureable, FlatMappable).
Zanim wprowadzimy hierarchię typeklas, popatrzmy na cztery metody, które są najistotniejsze z punktu widzenia kontroli przepływu. Metod tych używać będziemy w większości typowych aplikacji funkcyjnych:
| Typeklasa | Metoda | Z | Mając dane | Do |
|---|---|---|---|---|
Functor |
map |
F[A] |
A => B |
F[B] |
Applicative |
pure |
A |
F[A] |
|
Monad |
flatMap |
F[A] |
A => F[B] |
F[B] |
Traverse |
sequence |
F[G[A]] |
G[F[A]] |
Wiemy, że operacje zwracające F[_] mogą być wykonywane sekwencyjnie wewnątrz konstrukcji for przy użyciu
metody .flatMap, która zdefiniowana jest wewnątrz Monad[F]. Możemy myśleć o F[A] jak o kontenerze na
pewien efekt, którego rezultatem jest wartość typu A. .flatMap pozwala nam wygenerować nowe efekty F[B]
na podstawie rezultatów wykonania wcześniejszych efektów.
Oczywiście nie wszystkie konstruktory typu F[_] wiążą się z efektami ubocznymi, nawet jeśli mają instancję
Monad[F], często są to po prostu struktury danych. Używając najmniej konkretnej (czyli najbardziej ogólnej) abstrakcji
możemy w łatwy sposób współdzielić kod operujący na typach List, Either, Future i wielu innych.
Jeśli jedyne czego potrzebujemy to przetransformować wynik F[_], wystarczy, że użyjemy metody map, definiowanej w
typeklasie Functor. W rozdziale 3 uruchamialiśmy efekty równolegle, tworząc produkt i mapując go. W Programowaniu
Funkcyjnym obliczenia wykonywane równolegle są uznawane za słabsze niż te wykonywane sekwencyjnie.
Pomiędzy Monadą i Functorem leży Applicative, która definiuje metodę pure pozwalającą nam wynosić (lift)
wartości do postaci efektów lub tworzyć struktury danych z pojedynczych wartości.
.sequence jest użyteczna, gdy chcemy poprzestawiać konstruktory typów. Gdy mamy F[G[_]] a potrzebujemy G[F[_]],
np. zamiast List[Future[Int]] potrzebujemy Future[List[Int]], wtedy właśnie użyjemy .sequence.
5.1 Plan
Ten rozdział jest dłuższy niż zazwyczaj i wypełniony po brzegi informacjami. Przejście przez niego w wielu podejściach jest czymś zupełnie normalnym, a zapamiętanie wszystkiego wymagałoby supermocy. Potraktuj go raczej jako miejsce, do którego możesz wracać, gdy będziesz potrzebował więcej informacji.
Pominięte zostały typeklasy, które rozszerzają typ Monad, gdyż zasłużyły na swój własny rozdział.
Scalaz używa generacji kodu, ale nie za pomocą simulacrum. Niemniej, dla zwięzłości prezentujemy przykłady bazujące na
anotacji @typeclass. Równoznaczna składanie dostępna jest, gdy zaimportujemy scalaz._ i Scalaz._, a jej
implementacja znajduje się w pakiecie scalaz.syntax w kodzie źródłowym scalaz.
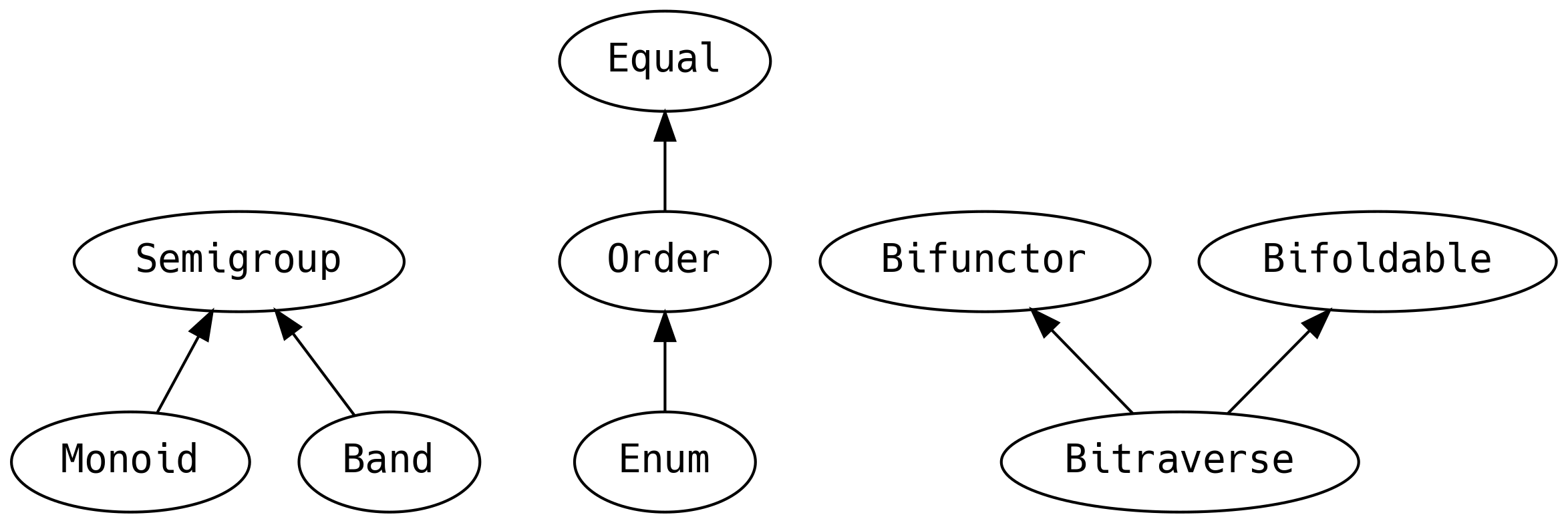

5.2 Rzeczy złączalne20
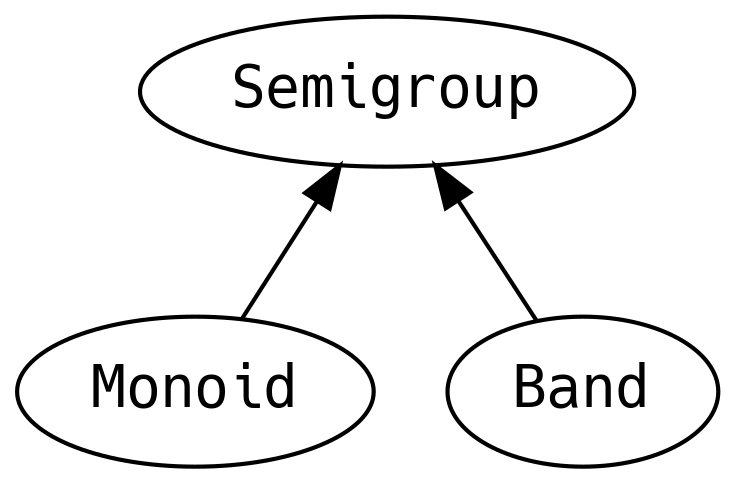
Semigroup (półgrupa) może być zdefiniowana dla danego typu, jeśli możemy połączyć ze sobą dwie jego wartości. Operacja ta
musi być łączna (associative), co oznacza, że kolejność zagnieżdżonych operacji nie powinna mieć znaczenia, np:
Monoid jest półgrupą z elementem zerowym (zero, zwanym również elementem pustym (empty), tożsamym (identity) lub neutralnym).
Połączenie zero z dowolną inną wartością a powinno zwracać to samo niezmienione a.
Prawdopodobnie przywołaliśmy tym samym wspomnienie typu Numeric z Rozdziału 4. Istnieją implementacje typeklasy
Monoid dla wszystkich prymitywnych typów liczbowych, ale koncepcja rzeczy złączalnych jest użyteczna również
dla typów innych niż te liczbowe.
Band (pas) dodaje prawo, gwarantujące, że append wywołane na dwóch takich samych elementach jest
idempotentne, tzn. zwraca tę samą wartość. Przykładem są typy, które mają tylko jedną wartość, takie jak Unit,
kresy górne (least upper bound), lub zbiory (Set). Band nie wnosi żadnych dodatkowych metod, ale użytkownicy
mogą wykorzystać dodatkowe gwarancje do optymalizacji wydajności.
Jako realistyczny przykład dla Monoidu, rozważmy system transakcyjny, który posiada ogromną bazę reużywalnych
wzorów transakcji. Wypełnianie wartości domyślnych dla nowej transakcji wymaga wybrania i połączenia wielu
wzorów, z zasadą “ostatni wygrywa”, jeśli dwa wzory posiadają wartości dla tego samego pola. “Wybieranie” jest
wykonywane dla nas przez osobny system, a naszym zadaniem jest jedynie połączyć wzory według kolejności.
Stworzymy prosty schemat, aby zobrazować zasadę działania, pamiętając przy tym, że prawdziwy system oparty byłby na dużo bardziej skomplikowanym ADT.
Jeśli chcemy napisać metodę, która przyjmuje parametr templates: List[TradeTemplate], wystarczy, że zawołamy
i gotowe!
Jednak aby móc zawołać zero lub |+| musimy mieć dostęp do instancji Monoid[TradeTemplate]. Chociaż
w ostatnim rozdziale zobaczymy jak wyderywować taką instancję w sposób generyczny, na razie stworzymy ją ręcznie:
Jednak nie jest to do końca to, czego byśmy chcieli, gdyż Monoid[Option[A]] łączy ze sobą wartości wewnętrzne, np.
podczas gdy my chcielibyśmy zachowania “ostatni wygrywa”. Możemy więc nadpisać domyślną instancję Monoid[Option[A]]
naszą własną:
Wszystko kompiluje się poprawnie, więc wypróbujmy nasze dzieło…
Jedyne co musieliśmy zrobić to zdefiniować jeden mały kawałek logiki biznesowej, a całą resztę
zrobił za nas Monoid!
Zauważ, że listy płatności są ze sobą łączone. Dzieje się tak, ponieważ domyślny Monoid[List] zachowuje się ten właśnie sposób.
Gdyby wymagania biznesowe były inne, wystarczyłoby dostarczyć inną instancję Monoid[List[LocalDate]]. Przypomnij sobie
z Rozdziału 4, że dzięki polimorfizmowi czasu kompilacji możemy zmieniać zachowanie append dla List[E] w zależności
od E, a nie tylko od implementacji List.
5.3 Rzeczy obiektowe
W rozdziale o Danych i funkcjonalnościach powiedzieliśmy, że sposób, w jaki JVM rozumie równość nie działa dla wielu typów,
które możemy umieścić wewnątrz ADT. Problem ten wynika z faktu, że JVM był projektowany dla języka Java, a equals
zdefiniowane jest w klasie java.lang.Object, nie ma więc możliwości, aby equals usunąć ani zagwarantować, że jest
explicite zaimplementowany.
Niemniej, w FP wolimy używać typeklas do wyrażania polimorficznych zachowań i pojęcie równości również może zostać w ten sposób wyrażone.
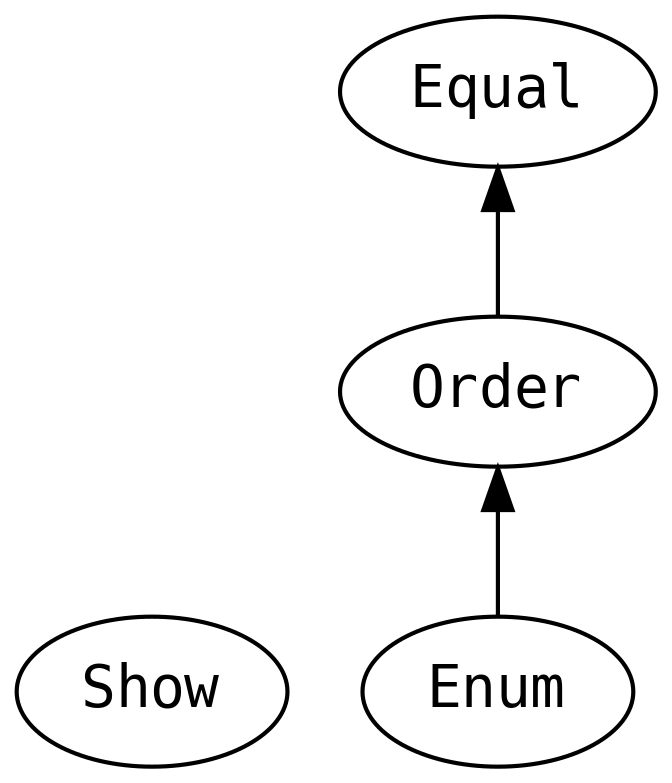
=== (potrójne równa się, triple equals) jest bezpieczniejszy względem typów (typesafe) niż == (podwójne równa się,
double equals), ponieważ użycie go wymaga, aby po obu stronach porównania znajdowały się instancje dokładnie tego samego typu.
W ten sposób możemy zapobiec wielu częstym błędom.
equal ma te same wymagania jak Object.equals
-
przemienność (commutative):
f1 === f2implikujef2 === f1 -
zwrotność (reflexive):
f === f -
przechodniość (transitive):
f1 === f2 && f2 === f3implikujef1 === f3
Poprzez odrzucenie uniwersalnego Object.equals, gdy konstruujemy ADT, nie bierzemy za pewnik, że wiemy jak
porównywać instancje danego typu. Jeśli instancja Equal nie będzie dostępna, nasz kod się nie skompiluje.
Kontynuując praktykę odrzucania zaszłości z Javy, zamiast mówić, że dane są instancją java.lang.Comparable,
powiemy, że mają instancję typeklasy Order:
Order implementuje .equal, wykorzystując nową metodę prostą .order. Kiedy typeklasa implementuje
kombinator prymitywny rodzica za pomocą kombinatora pochodnego, musimy dodać domniemane prawo podstawiania
(implied law of substitution). Jeśli instancja Order ma nadpisać .equal z powodów wydajnościowych, musi ona zachowywać
się dokładnie tak samo jak oryginał.
Rzeczy, które definiują porządek, mogą również być dyskretne, pozwalając nam na przechodzenie do poprzedników i następników:
EphemeralStream omówimy w następnym rozdziale, na razie wystarczy nam wiedzieć, że jest to potencjalnie nieskończona
struktura danych, która unika problemów z przetrzymywaniem pamięci obecnych w klasie Stream z biblioteki standardowej.
Podobnie do Object.equals, koncepcja metody .toString dostępnej w każdej klasie ma sens jedynie w Javie.
Chcielibyśmy wymusić możliwość konwersji do ciągu znaków w czasie kompilacji i dokładnie to robi typeklasa Show:
Lepiej poznamy klasę Cord w rozdziale poświęconym typom danych, teraz jedyne co musimy wiedzieć, to to że
Cord jest wydajną strukturą danych służącą do przechowywania i manipulowania instancjami typu String.
5.4 Rzeczy mapowalne
Skupmy się teraz na rzeczach, które możemy w jakiś sposób przemapowywać (map over) lub trawersować (traverse):
5.4.1 Funktor
Jedyną metodą abstrakcyjną jest map i musi się ona komponować (składać, compose), tzn. mapowanie za pomocą f, a następnie g
musi dawać ten sam wyniki jak mapowanie z użyciem złożenia tych funkcji (f ∘ g).
Metoda map nie może też wykonywać żadnych zmian, jeśli przekazana do niej funkcja to identity (czyli x => x)
Functor definiuje kilka pomocniczych metod wokół map, które mogą być zoptymalizowane przez konkretne instancje.
Dokumentacja została celowo pominięta, aby zachęcić do samodzielnego odgadnięcia co te metody robią, zanim spojrzymy na ich
implementację. Poświęć chwilę na przestudiowanie samych sygnatur, zanim ruszysz dalej:
-
voidprzyjmuje instancjęF[A]i zawsze zwracaF[Unit], a więc gubi wszelkie przechowywane wartości, ale zachowuje strukturę. -
fproductprzyjmuje takie same argumenty jakmap, ale zwracaF[(A, B)], a więc łączy wynik operacji z wcześniejszą zawartością. Operacja ta przydaje się, gdy chcemy zachować argumenty przekazane do funkcji. -
fpairpowiela elementAdo postaciF[(A, A)] -
strengthLłączy zawartośćF[B]ze stałą typuApo lewej stronie. -
strengthRłączy zawartośćF[A]ze stałą typuBpo prawej stronie. -
liftprzyjmuje funkcjęA => Bi zwracaF[A] => F[B]. Innymi słowy, przyjmuje funkcję, która operuje na zawartościF[A]i zwraca funkcję, która operuje naF[A]bezpośrednio. -
mapplyto łamigłówka. Powiedzmy, że mamyF[_]z funkcjąA => Bw środku oraz wartośćA, w rezultacie możemy otrzymaćF[B]. Sygnatura wygląda podobnie dopure, ale wymaga od wołającego dostarczeniaF[A => B].
fpair, strengthL i strengthR wyglądają całkiem bezużytecznie, ale przydają się, gdy chcemy zachować pewne informacje,
które w innym wypadku zostałyby utracone.
Functor ma też specjalną składnię:
.as i >| to metody pozwalające na zastąpienie wyniku przez przekazaną stałą.
W naszej przykładowej aplikacji wprowadziliśmy jeden brzydki hak, definiując metody start i stop tak,
aby zwracały swoje własne wejście:
Pozwala nam to opisywać logikę biznesową w bardzo zwięzły sposób, np.
albo
Ale hak ten wprowadza zbędną komplikację do implementacji. Lepiej będzie, gdy pozwolimy naszej algebrze zwracać
F[Unit] a następnie użyjemy as:
oraz
5.4.2 Foldable
Technicznie rzecz biorąc, Foldable przydaje się dla struktur danych, przez które możemy przejść
a na koniec wyprodukować wartość podsumowującą. Jednak stwierdzenie to nie oddaje pełnej natury tej
“jednotypeklasowej armii”, która jest w stanie dostarczyć większość tego, co spodziewalibyśmy
się znaleźć w Collections API.
Do omówienia mamy tyle metod, że musimy je sobie podzielić. Zacznijmy od metod abstrakcyjnych:
Instancja Foldable musi zaimplementować jedynie foldMap i foldRight, aby uzyskać pełną funkcjonalność
tej typeklasy, aczkolwiek poszczególne metody są często optymalizowane dla konkretnych struktur danych.
.foldMap ma alternatywną nazwę do celów marketingowych: MapReduce. Mając do dyspozycji F[A],
funkcję z A na B i sposób na łączenie B (dostarczony przez Monoid wraz z elementem zerowym),
możemy wyprodukować “podsumowującą” wartość typu B. Kolejność operacji nie jest narzucana, co pozwala
na wykonywanie ich równolegle.
.foldRight nie wymaga, aby jej parametry miały instancję Monoidu, co oznacza, że musimy podać
wartość zerową z oraz sposób łączenia elementów z wartością podsumowująca. Kierunek przechodzenia jest
zdefiniowany jako od prawej do lewej, co sprawia, że operacje nie mogą być zrównoleglone.
foldLeft trawersuje elementy od lewej do prawej. Metoda ta może być zaimplementowana za pomocą foldMap, ale
większość instancji woli dostarczyć osobną implementację dla tak podstawowej operacji. Ponieważ z reguły implementacje
tej metody są ogonowo rekursywne (tail recursive), nie ma tutaj parametrów przekazywanych przez nazwę.
Jedyny prawem obowiązującym Foldable jest to, że foldLeft i foldRight powinny być spójne z foldMap dla
operacji monoidalnych, np. dodawanie na koniec listy dla foldLeft i dodawanie na początek dla foldRight.
Niemniej foldLeft i foldRight nie muszą być zgodne ze sobą nawzajem: w rzeczywistości często produkują
odwrotne rezultaty.
Najprostszą rzeczą, którą możemy zrobić z foldMap to użyć funkcji identity i uzyskać tym samym fold
(naturalną sumę elementów monoidalnych), z dodatkowymi wariantami pozwalającymi dobrać odpowiednią metodę
zależnie od kryteriów wydajnościowych:
Gdy uczyliśmy się o Monoidzie, napisaliśmy:
Teraz wiemy już, że było to niemądre i powinniśmy zrobić tak:
.fold nie zadziała na klasie List z biblioteki standardowej, ponieważ ta definiuje już metodę o nazwie
fold, która robi coś podobnego na swój własny sposób.
Osobliwie nazywająca się metoda intercalate wstawia konkretną instancję typu A pomiędzy każde dwa elementy przed wykonaniem fold.
i jest tym samym uogólnioną wersją mkString:
foldLeft pozwala na dostęp do konkretnego elementu poprzez jego indeks oraz daje nam kilka innych, blisko związanych
metod:
Scalaz jest biblioteką czystą, składającą się wyłącznie z funkcji totalnych. Tam, gdzie List.apply wyrzuca wyjątek,
Foldable.index zwraca Option[A] oraz pozwala użyć wygodnego indexOr, który zwraca A, bazując na wartości domyślnej.
.element podobny jest do .contains z biblioteki standardowej, ale używa Equal zamiast niejasno zdefiniowanego
pojęcia równości pochodzącego z JVMa.
Metody te naprawdę wyglądają jak API kolekcji. No i oczywiście każdy obiekt mający instancje Foldable może być
przekonwertowany na listę:
Istnieją również konwersje do innych typów danych zarówno z biblioteki standardowej, jak i Scalaz, takie jak:
.toSet, .toVector, .toStream, .to[T <: TraversableLike], .toIList itd.
Dostępne są również przydatne metody do weryfikacji predykatów
filterLength zlicza elementy, które spełniają predykat, all i any zwracają true, jeśli wszystkie (lub jakikolwiek)
elementy spełniają predykat i mogą zakończyć działanie bez sprawdzania wszystkich elementów.
Możemy też podzielić F[A] na części bazując na kluczu B za pomocą metody splitBy
na przykład
Zwróć uwagę, że otrzymaliśmy dwa elementy zaindeksowane za pomocą 'b'.
splitByRelation pozwala uniknąć dostarczania instancji Equal, ale za to wymaga podania operatora porównującego.
splitWith dzieli elementy na grupy, które spełniają i nie spełniają predykatu. selectSplit wybiera grupy elementów,
które spełniają predykat, a pozostałe odrzuca. To jedna z tych rzadkich sytuacji gdzie dwie metody mają tę samą sygnaturę,
ale działają inaczej.
findLeft i findRight pozwalając znaleźć pierwszy element (od lewej lub prawej), który spełnia predykat.
Dalej korzystając z Equal i Order dostajemy metody distinct, które zwracają elementy unikalne.
distinct jest zaimplementowany w sposób bardziej wydajny niż distinctE, ponieważ może bazować na kolejności,
a dzięki niej odszukiwać elementy unikalne w sposób podobny do tego, w jaki działa algorytm quicksort. Dzięki temu
jest zdecydowanie szybszy niż List.distinct. Struktury danych (takie jak zbiory) mogą implementować distinct w
swoich Foldable bez dodatkowego wysiłku.
distinctBy pozwala na grupowanie, bazując na rezultacie wywołania podanej funkcji na każdym z oryginalnych elementów.
Przykładowe użycie: grupowanie imion ze względu na pierwszą literę słowa.
Możemy wykorzystać Order również do odszukiwania elementów minimalnych i maksymalnych (lub obu ekstremów), wliczając w to
warianty używające Of, lub By aby najpierw przemapować elementy do innego typu lub użyć innego typu do samego porównania.
Możemy na przykład zapytać o to, który element typu String jest maksimum ze względu (By) na swoją długość lub jaka jest maksymalna
długość elementów (Of).
Podsumowuje to kluczowe funkcjonalności Foldable. Cokolwiek spodziewalibyśmy się zobaczyć
w API kolekcji, jest już prawdopodobnie dostępna dzięki Foldable, a jeśli nie jest, to prawdopodobnie być powinno.
Na koniec spojrzymy na kilka wariacji metod, które widzieliśmy już wcześniej. Zacznijmy od tych, które przyjmują
instancję typu Semigroup zamiast Monoid:
zwracając tym samym Option, aby móc obsłużyć puste struktury danych (Semigroup nie definiuje elementu zerowego).
Typeklasa Foldable1 zawiera dużo więcej wariantów bazujących na Semigroupie (wszystkie z sufiksem 1)
i używanie jej ma sens dla struktur, które nigdy nie są puste, nie wymagając definiowania pełnego Monoidu dla elementów.
Co ważne, istnieją również warianty pracujące w oparciu o typy monadyczne. Używaliśmy już foldLeftM, kiedy po raz
pierwszy pisaliśmy logikę biznesową naszej aplikacji. Teraz wiemy, że pochodzi ona z Foldable:
5.4.3 Traverse
Traverse to skrzyżowanie Functora z Foldable.
Na początku rozdziału pokazaliśmy, jak ważne są metody traverse i sequence, gdy chcemy odwrócić kolejność konstruktorów typu
(np. z List[Future[_]] na Future[List[_]]).
W Foldable nie mogliśmy założyć, że reverse jest pojęciem uniwersalnym, ale sprawa wygląda zupełnie inaczej, gdy mamy do
dyspozycji Traverse.
Możemy też zipować ze sobą dwie rzeczy, które mają instancję Traverse, dostając None, gdy jedna ze stron
nie ma już więcej elementów. Specjalnym wariantem tej operacji jest dodanie indeksów do każdego elementu za pomocą
indexed.
zipWithL i zipWithR pozwalają połączyć elementy w nowy typ i od razu stworzyć F[C].
mapAccumL i mapAccumR to standardowe map połączone z akumulatorem. Jeśli nawyki z Javy każą nam sięgnąć po zmienna typu var
i używać jej wewnątrz map, to najprawdopodobniej powinniśmy użyć mapAccumL.
Powiedzmy, że mamy listę słów i chcielibyśmy ukryć te, które już wcześniej widzieliśmy. Chcemy, aby algorytm działał również dla nieskończonych strumieni danych, a więc kolekcja może być przetworzona jedynie raz.
Na koniec Traverse1, podobnie jak Foldable1, dostarcza warianty wspomnianych metod dla struktur danych, które nigdy nie są
puste, przyjmując słabszą Semigroupę zamiast Monoidu i Apply zamiast Applicative. Przypomnijmy, że
Semigroup nie musi dostarczać .empty, a Apply nie wymaga .point.
5.4.4 Align
Align służy do łączenia i wyrównywania wszystkiego, co ma instancję typu Functor. Zanim spojrzymy
na Align, poznajmy typ danych \&/ (wymawiany jako te, these lub hurray!),
A więc jest to wyrażenie alternatywy łącznej OR: A lub B, lub A i B jednocześnie.
alignWith przyjmuje funkcję z albo A, albo B (albo obu) na C i zwraca wyniesioną funkcję z tupli F[A] i F[B]
na F[C]. align konstruuje \&/ z dwóch F[_].
merge pozwala nam połączyć dwie instancje F[A] tak długo, jak jesteśmy w stanie dostarczyć instancję Semigroup[A].
Dla przykładu, Semigroup[Map[K,V]]] deleguje logikę do Semigroup[V], łącząc wartości dla tych samych kluczy, a w
konsekwencji sprawiając, że Map[K, List[A]] zachowuje się jak multimapa:
a Map[K, Int] po prostu sumuje wartości.
.pad i .padWith służą do częściowego łącznie struktur danych, które mogą nie mieć wymaganych wartości po jednej ze stron.
Dla przykładu, jeśli chcielibyśmy zagregować niezależne głosy i zachować informację skąd one pochodziły:
Istnieją też wygodne warianty align, które używają struktury \&/
i które powinny być jasne po przeczytaniu sygnatur. Przykłady:
Zauważ, że warianty A i B używają alternatywy łącznej, a This i That są wykluczające,
zwracając None, gdy wartość istnieje po obu stronach lub nie istnieje po wskazanej stronie.
5.5 Wariancja
Musimy wrócić na moment do Functora i omówić jego przodka, którego wcześniej zignorowaliśmy
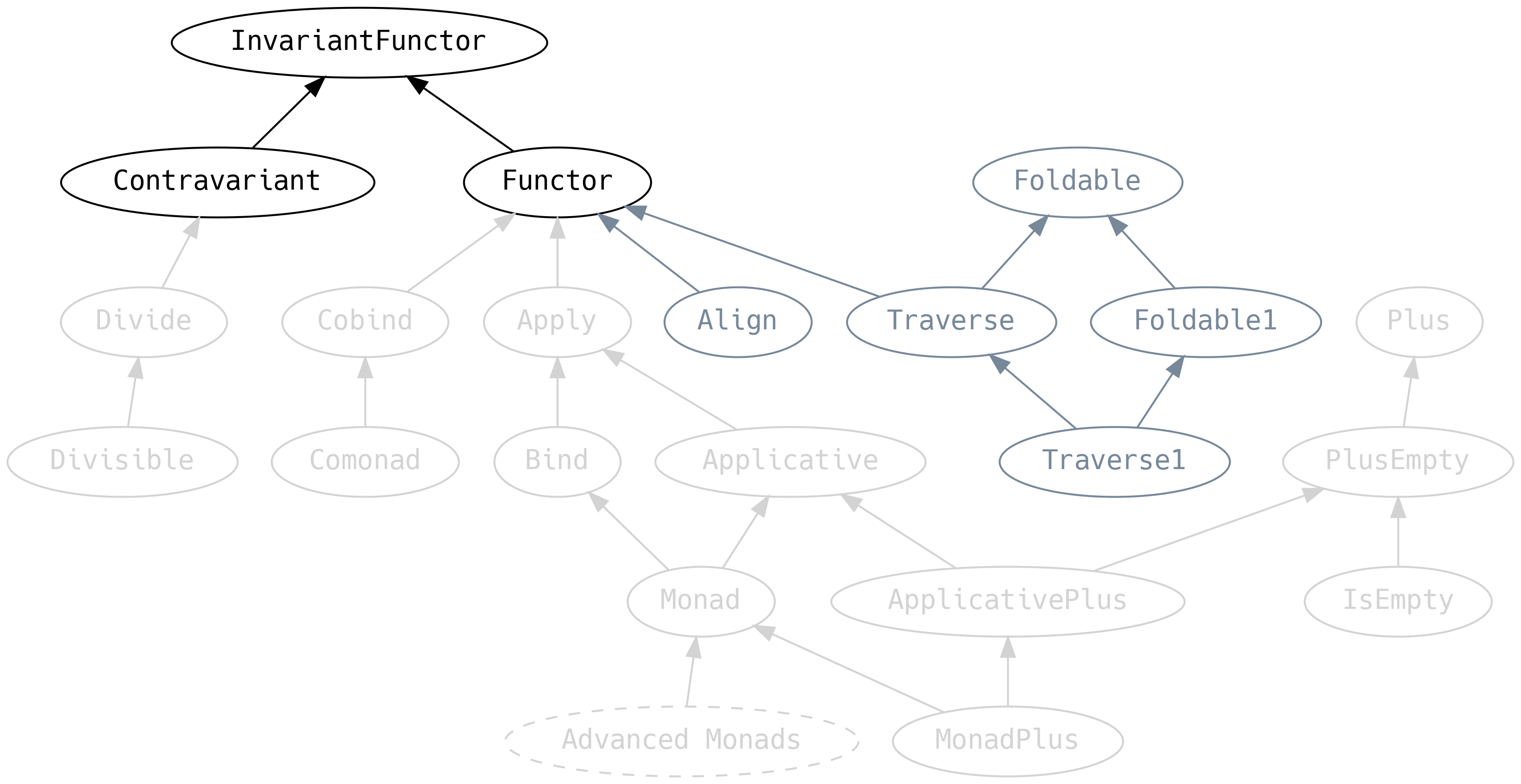
InvariantFunctor, znany również jako funktor wykładniczy, definiuje metodę xmap, która pozwala zamienić
F[A] w F[B] jeśli przekażemy do niej funkcje z A na B i z B na A.
Functor to skrócona nazwa na to, co powinno nazywać się funktorem kowariantnym.
Podobnie Contravariant to tak naprawdę funktor kontrawariantny.
Functor implementuje metodę xmap za pomocą map i ignoruje funkcję z B na A. Contravariant z kolei
implementuje ją z użyciem contramap i ignoruje funkcję z A na B:
Co istotne, określenia kowariantny, kontrawariantny i inwariantny, mimo że związane na poziomie
teoretycznym, nie przekładają się bezpośrednio na znaną ze Scali wariancję typów (czyli modyfikatory + i -
umieszczane przy parametrach typów). Inwariancja oznacza tutaj, że możliwym jest przetłumaczenie zawartości
F[A] do F[B]. Używając identity, możemy zobaczyć, że A może być w bezpieczny sposób zrzutowane (w górę lub w dół)
do B, zależnie od wariancji funktora.
.map może być rozumiana poprzez swój kontrakt: “jeśli dasz mi F dla A i sposób na zamianę A w B, wtedy dam ci F dla B”.
Podobnie, .contramap mówi, że: “jeśli dasz mi F dla A i sposób na zamianę B w A, wtedy dam ci F dla B”.
Rozważymy następujący przykład: w naszej aplikacji wprowadzamy typy domenowe Alpha, Beta i Gamma, aby zabezpieczyć się
przed pomieszaniem liczb w kalkulacjach finansowych:
ale sprawia to, że nie mamy żadnych instancji typeklas dla tych nowych typów. Jeśli chcielibyśmy użyć takich
wartości w JSONie, musielibyśmy dostarczyć JsEncoder i JsDecoder.
Jednakże, JsEncoder ma instancję typeklasy Contravariant a JsDecoder typeklasy Functor, a więc możemy
wyderywować potrzebne nam instancje, spełniając kontrakt:
- “jeśli dasz mi
JsDecoderdlaDoublei sposób na zamianęDoublewAlpha, wtedy dam ciJsDecoderdlaAlpha”. - “jeśli dasz mi
JsEncoderdlaDoublei sposób na zamianęAlphawDouble, wtedy dam ciJsEncoderdlaAlpha”.
Metody w klasie mogą ustawić swoje parametry typu w pozycji kontrawariantnej (parametry metody) lub
w pozycji kowariantnej (typ zwracany). Jeśli typeklasa łączy pozycje kowariantne i kontrawariantne może oznaczać to, że
ma instancję typeklasy InvariantFunctor, ale nie Functor ani Contrawariant.
5.6 Apply i Bind
Potraktuj tę część jako rozgrzewkę przed typami Applicative i Monad
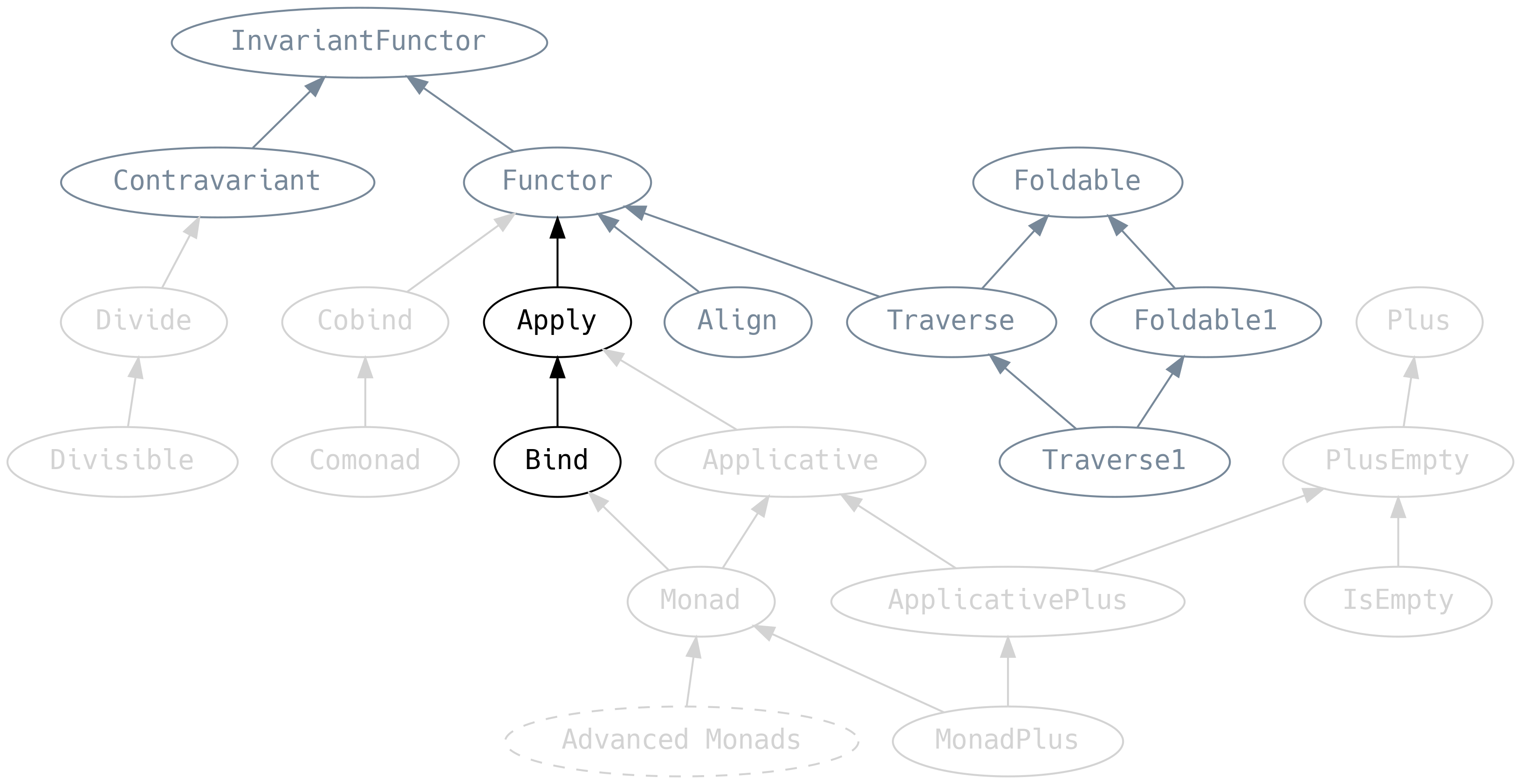
5.6.1 Apply
Apply rozszerza typeklasę Functor poprzez dodanie metody ap, która jest podobna do map w tym, że aplikuje otrzymaną funkcje na wartościach.
Jednak w przypadku ap funkcja jest opakowana w ten sam kontekst co wartości, które są do niej przekazywane.
Warto poświęcić chwilę na zastanowienie się co to znaczy, że prosta struktura danych, taka jak Option[A], posiada
następującą implementację .ap
Aby zaimplementować .ap, musimy najpierw wydostać funkcję ff: A => B z f: Option[A => B], a następnie
możemy przemapować fa z jej użyciem. Ekstrakcja funkcji z kontekstu to ważna funkcjonalność, którą przynosi Apply.
Pozwala tym samym na łączenie wielu funkcji wewnątrz jednego kontekstu.
Wracając do Apply, znajdziemy tam rodzinę funkcji applyX, która pozwala nam łączyć równoległe obliczenia, a następnie
mapować ich połączone wyniki:
Potraktuj .apply2 jako obietnicę: “jeśli dasz mi F z A i F z B oraz sposób na połączenie A i B w C, wtedy
mogę dać ci F z C”. Istnieje wiele zastosowań dla tej obietnicy, a 2 najważniejsze to:
- tworzenie typeklas dla produktu
Cz jego składnikówAiB - wykonywanie efektów równolegle, jak w przypadku algebr dla drone i google, które stworzyliśmy w Rozdziale 3, a następnie łączenie ich wyników.
W rzeczy samej, Apply jest na tyle użyteczne, że ma swoją własną składnię:
której użyliśmy w Rozdziale 3:
Operatory <* i *> (prawy i lewy ptak) oferują wygodny sposób na zignorowanie wyniku jednego z dwóch równoległych
efektów.
Niestety, mimo wygody, którą daje operator |@\, jest z nim jeden problem: dla każdego kolejnego efektu alokowany jest
nowy obiekt typu ApplicativeBuilder. Gdy prędkość obliczeń ograniczona jest przez operacje I/O nie ma to znaczenia.
Jednak gdy wykonujesz obliczenia w całości na CPU, lepiej jest użyć krotnego wynoszenia (lifting with arity), które nie
produkuje żadnych obiektów pośrednich:
na przykład:
Możemy też zawołać applyX bezpośrednio:
Mimo tego, że Apply używany jest najczęściej z efektami, działa równie dobrze ze strukturami danych. Rozważ przepisanie
jako
Gdy chcemy jedynie połączyć wyniki w tuple, istnieją metody, które służą dokładnie do tego:
Dostępne są też uogólnione wersje ap dla więcej niż dwóch parametrów:
razem z wariantami .lift, które przyjmują zwykłe funkcje i wynoszą je do kontekstu F[_], uogólniając Functor.lift
oraz .apF, częściowo zaaplikowana wersja ap
A na koniec .forever
który powtarza efekt w nieskończoność bez zatrzymywania się. Przy jej użyciu instancja Apply musi być zabezpieczona prze
przepełnieniem stosu (stack-safe), w przeciwnym wypadku wywołanie spowoduje StackOverflowError.
5.6.2 Bind
Bind wprowadza metodę .bind, która jest synonimiczna do .flatMap i pozwala na mapowanie efektów/struktur danych
z użyciem funkcji zwracających nowy efekt/strukturę danych bez wprowadzania dodatkowych zagnieżdżeń.
Metoda .join może wydawać się znajoma tym, którzy używali .flatten z biblioteki standardowej. Przyjmuje ona
zagnieżdżone konteksty i łączy je w jeden.
Wprowadzone zostały kombinatory pochodne dla .ap i .apply2, aby zapewnić spójność z .bind. Zobaczymy później, że
to wymaganie niesie ze sobą konsekwencje dla potencjalnego zrównoleglania obliczeń.
mproduct przypomina Functor.fproduct i paruje wejście i wyjście funkcji wewnątrz F.
ifM to sposób na tworzenie warunkowych struktur danych lub efektów:
ifM i ap są zoptymalizowane do cachowania i reużywania gałezi kodu. Porównajmy je z dłuższą wersją
która produkuje nowe List(0) i List(1, 1) za każdym razem, gdy dana gałąź jest wywoływana.
Bind wprowadza też specjalne operatory:
Używając >> odrzucamy wejście do bind, a używając >>! odrzucamy wyjście`
5.7 Aplikatywy i monady
Z punkty widzenia oferowanych funkcjonalności, Applicative to Apply z dodaną metodą pure, a Monad
rozszerza Applicative, dodając Bind.
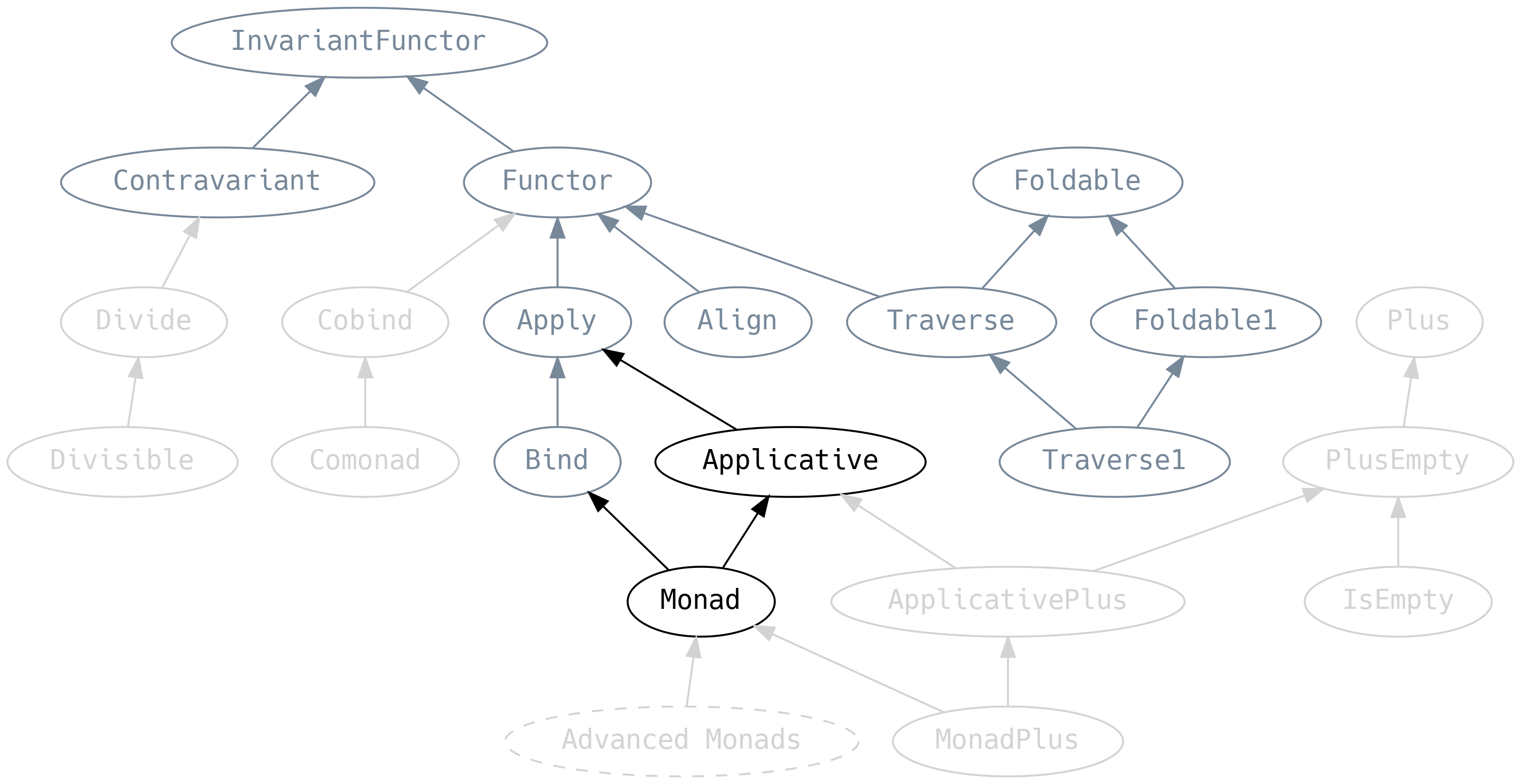
Pod wieloma względami Applicative i Monad są zwieńczeniem wszystkiego, co do tej pory widzieliśmy w tym rozdziale.
.pure (lub .point - alias powszechnie używany przy strukturach danych) pozwala nam na tworzenie efektów lub
struktur danych z pojedynczych wartości.
Instancje Applicative muszę spełniać prawa gwarantujące spójność metod:
-
Tożsamość (Identity):
fa <*> pure(identity) == fa(gdziefatoF[A]) - zaaplikowaniepure(identity)nic nie zmienia -
Homomorfizm (Homomorphism):
pure(a) <*> pure(ab) === pure(ab(a)), (gdzieabto funkcjaA => B) - zaaplikowanie funkcji osadzonej w kontekścieFza pomocąpurena wartości potraktowanej w ten sam sposób jest równoznaczne z wywołaniem tej funkcji na wspomnianej wartości i wywołaniempurena rezultacie. -
Zamiana (Interchange):
pure(a) <*> fab === fab <*> pure(f => f(a)), (gdziefabtoF[A => B]) -purejest tożsama lewo- i prawostronnie -
Mappy:
map(fa)(f) === fa <*> pure(f)
Monad dodaje następujące prawa
-
Tożsamość lewostronna (Left Identity):
pure(a).bind(f) === f(a) -
Tożsamość prawostronna (Right Identity):
a.bind(pure(_)) === a -
Łączność (Associativity):
fa.bind(f).bind(g) === fa.bind(a => f(a).bind(g))gdziefatoF[A],ftoA => F[B], agtoB => F[C].
Łączność mówi nam, że połączone wywołania bind muszą być zgodne z wywołaniami zagnieżdżonymi. Jednakże,
nie oznacza to, że możemy zamieniać kolejność wywołań - to gwarantowałaby przemienność (commutativity).
Dla przykładu, pamiętając, że flatMap to alias na bind, nie możemy zamienić
na
start i stop są nieprzemienne, ponieważ uruchomienie, a następnie zatrzymanie węzła jest czymś innym
niż zatrzymanie i uruchomienie.
Nie mniej, zarówno start, jak i stop są przemienne same ze sobą samym, a więc możemy zamienić
na
Obie formy są równoznaczne w tym konkretnym przypadku, ale nie w ogólności. Robimy tutaj dużo założeń co do Google Container API, ale wydaje się to być rozsądnych wyjściem.
Okazuje się, że w konsekwencji powyższych praw Monada musi być przemienna, jeśli chcemy pozwolić na równoległe
działanie metod applyX. W Rozdziale 3 oszukaliśmy uruchamiając efekty w ten sposób
ponieważ wiedzieliśmy, że są one ze sobą przemienne. Kiedy w dalszych rozdziałach zajmiemy się interpretacją naszej aplikacji, dostarczymy dowód na przemienność operacji lub pozwolimy na uruchomienie ich sekwencyjnie.
Subtelności sposobów radzenia sobie z porządkowaniem efektów, i tym, czym te efekty tak naprawdę są, zasługują na osobny rozdział. Porozmawiamy o nich przy Zaawansowanych monadach.
5.8 Dziel i rządź
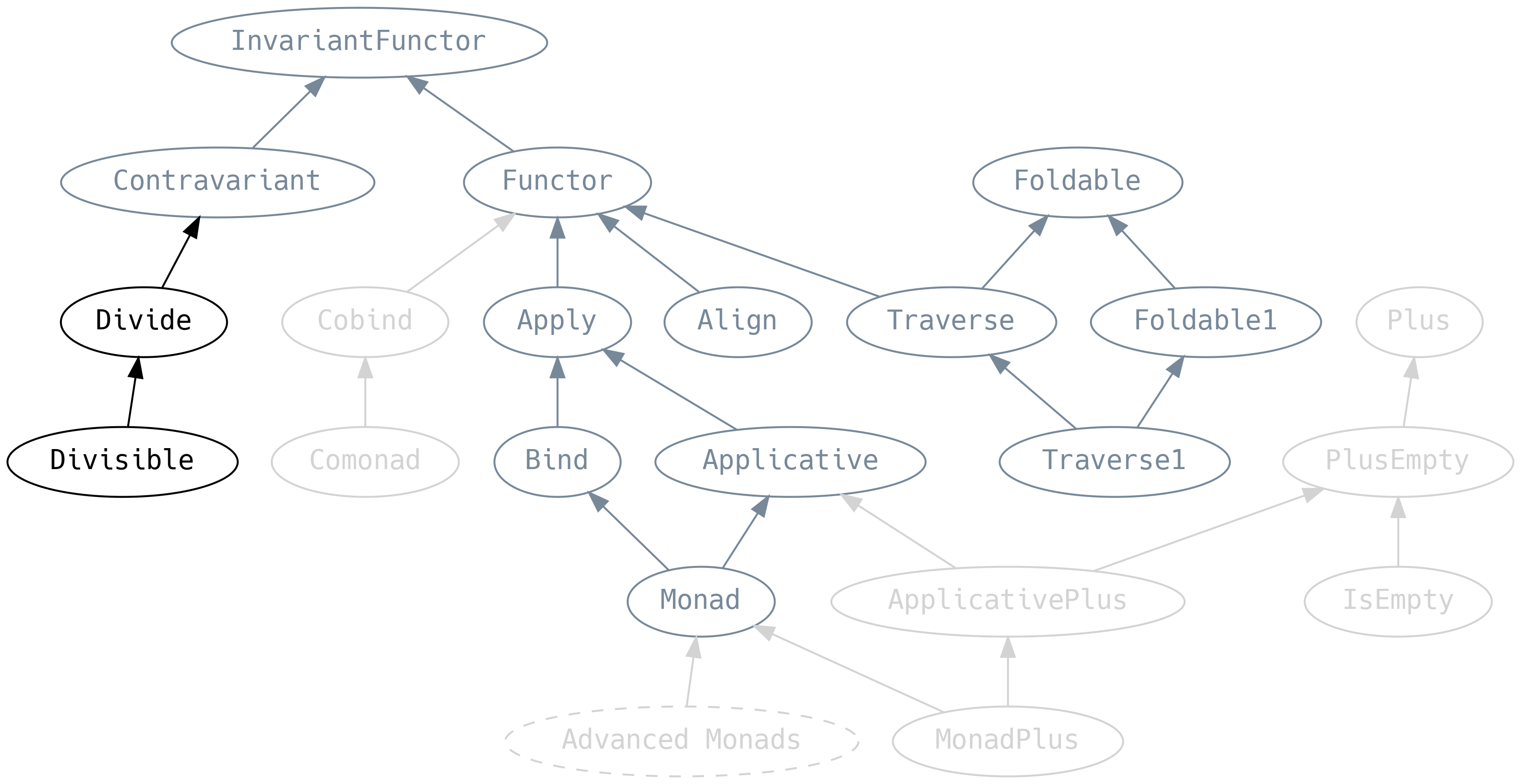
Divide to kontrawariantny odpowiednik Apply
divide mówi nam, że jeśli potrafimy podzielić C na A i B oraz mamy do dyspozycji F[A] i F[B]
to możemy stworzyć F[C]. Stąd też dziel i rządź.
Jest to świetny sposób na generowanie instancji kowariantnych typeklas dla typów będących produktami poprzez
podzielenie tychże produktów na części. Scalaz oferuje instancje Divide[Equal], spróbujmy więc stworzyć Equal
dla nowego typu Foo.
Podążając za Apply, Divide również dostarcza zwięzłą składnię dla tupli
Ogólnie rzecz biorąc, jeśli typeklasa, oprócz instancji Contravariant, jest w stanie dostarczyć również Divide,
to znaczy, że jesteśmy w stanie wyderywować jej instancje dla dowolnej case klasy. Sprawa wygląda analogicznie dla
typeklas kowariantnych z instancją Apply. Zgłębimy ten temat w rozdziale poświęconym Derywacji typeklas.
Divisible to odpowiednik Applicative dla rodziny Contravariant. Wprowadzana ona metodę .conquer, odpowiednik .pure:
.conquer pozwala na tworzenie trywialnych implementacji, w których parametr typu jest ignorowany. Takie instancje
nazywane są ogólnie kwantyfikowanymi (universally quantified). Na przykład, Divisible[Equal].conquer[INil[String]] tworzy
instancję Equal, która zawsze zwraca true.
5.9 Plus
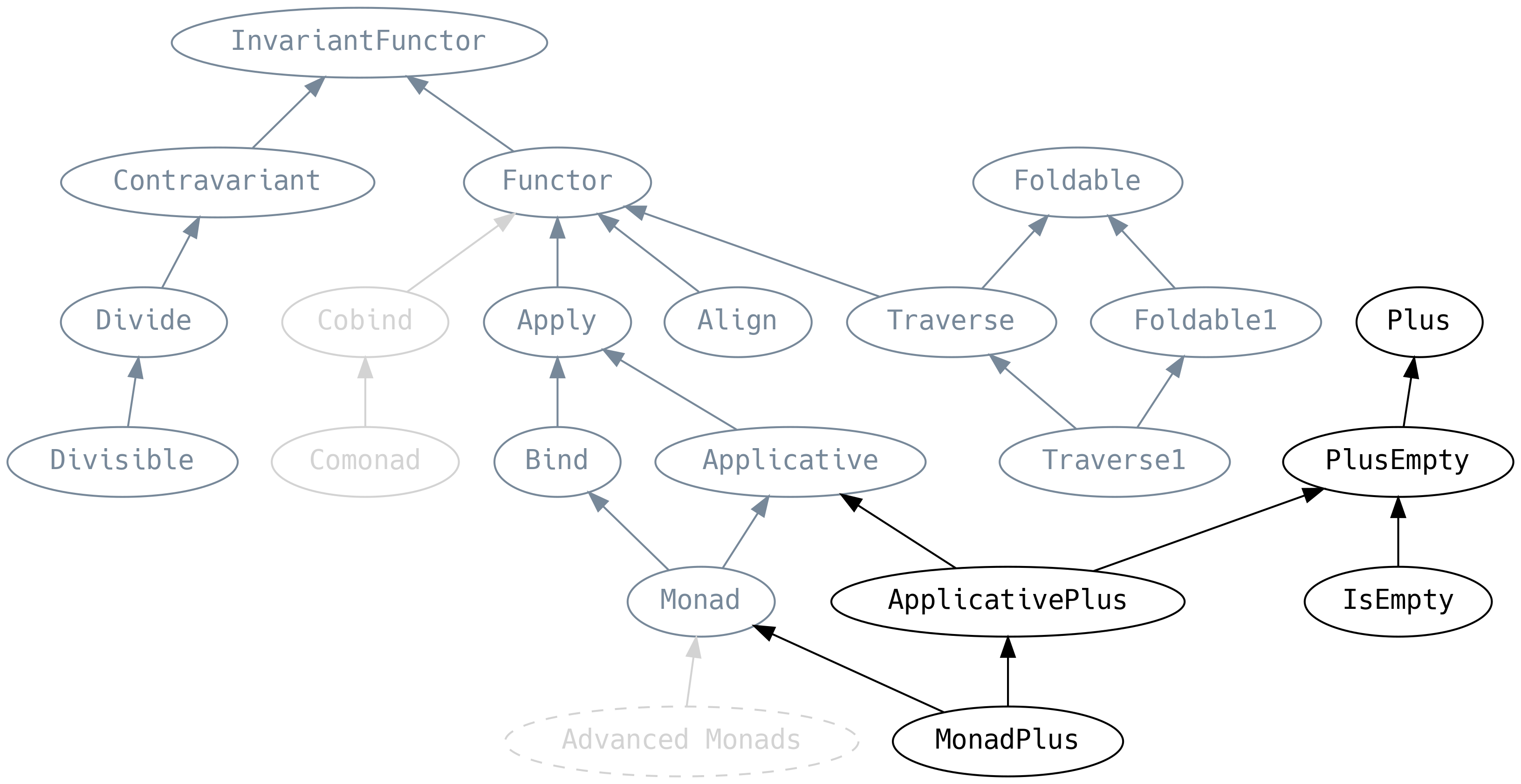
Plus to Semigroupa dla konstruktorów typu a PlusEmpty to odpowiednik Monoidu (obowiązują ich nawet te same prawa).
Nowością jest typeklasa IsEmpty, która pozwala na sprawdzenie czy F[A] jest puste:
Pozornie może się wydawać, że <+> zachowuje się tak samo, jak |+|:
Najlepiej jest przyjąć, że <+> operuje jedynie na F[_] nigdy nie patrząc na zawartość.
Przyjęła się konwencja, że Plus ignoruje porażki i wybiera “pierwszego zwycięzcę”. Dzięki temu
<+> może być używany jako mechanizm szybkiego wyjścia oraz obsługi porażek przez fallbacki.
Na przykład, jeśli chcielibyśmy pominąć obiekty None wewnątrz NonEmptyList[Option[Int]] i wybrać pierwszego
zwycięzcę (Some), możemy użyć <+> w połączeniu z Foldable1.foldRight1:
Teraz, gdy znamy już Plus, okazuje się, że wcale nie musieliśmy zaburzać koherencji typeklas w sekcji o Rzeczach złączalnych
(definiując lokalną instancję Monoid[Option[A]]). Naszym celem było “wybranie ostatniego zwycięzcy”,
co jest tożsame z wybranie pierwszego po odwróceniu kolejności elementów. Zwróć uwagę na użycie Interceptora TIE z
ccy i otc w odwróconej kolejności.
Applicative i Monad mają wyspecjalizowaną wersję PlusEmpty
.unite pozwala nam zwinąć strukturę danych, używając PlusEmpty[F].monoid zamiast Monoidu zdefiniowanego dla
typu wewnętrznego. Dla List[Either[String, Int]] oznacza to, że instancje Left[String] zamieniane są na .empty,
a następnie wszytko jest złączane. Jest to wygodny sposób na pozbycie się błędów:
withFilter pozwala nam na użycie konstrukcji for, którą opisywaliśmy w Rozdziale 2. Można nawet powiedzieć, że
Scala ma wbudowane wsparcie nie tylko dla Monad, ale i MonadPlus!
Wracając na moment do Foldable, możemy odkryć kilka metod, których wcześniej nie omawialiśmy:
msuml wykonuje fold, używając Monoidu z PlusEmpty[G], a collapse używa foldRight w kombinacji
z instancją PlusEmpty typu docelowego:
5.10 Samotne wilki
Niektóre z typeklas w Scalaz są w pełni samodzielne i nie należą do ogólnej hierarchii.

5.10.1 Zippy
Metoda kluczowa tutaj to zip. Jest to słabsza wersja Divide.tuple2. Jeśli dostępny jest Functor[F] to
.zipWith może zachowywać się jak Apply.apply2. Używając ap, możemy nawet stworzyć pełnoprawne Apply[F] z
instancji Zip[F] i Functor[F].
.apzip przyjmuje F[A] i wyniesioną funkcję F[A] => F[B] produkując F[(A, B)], podobnie do Functor.fproduct.
Bazą jest unzip dzielący F[(A,B)] na F[A] i F[B], a firsts i seconds pozwalają na wybranie
jednej z części. Co ważne, unzip jest odwrotnością zip.
Metody od unzip3 do unzip7 to aplikacje unzip pozwalające zmniejszyć ilość boilerplatu. Na przykład,
jeśli dostaniemy garść zagnieżdżonych tupli to Unzip[Id] jest wygodnym sposobem na ich wypłaszczenie:
W skrócie, Zip i Unzip są słabszymi wersjami Divide i Apply dostarczającymi użyteczne funkcjonalności
bez zobowiązywania F do składania zbyt wielu obietnic.
5.10.2 Optional
Optional to uogólnienie struktur danych, które mogą opcjonalnie zawierać jakąś wartość, np. Option lub Either.
Przypomnijmy, że \/ (dysjunkcja) ze Scalaz jest ulepszoną wersją scala.Either. Poznamy też Maybe - ulepszoną wersję
scala.Option.
Powyższe metody powinny wydawać się znajome, może z wyjątkiem pextract, która pozwala F[_] na zwrócenie
przechowywanej wartości lub specyficznego dla implementacji F[B]. Na przykład Optional[Option].pextract zwróci
nam Option[Nothing] \/ A, czyli None \/ A.
Scalaz daje nam operator trenarny dla wszystkich typów mających swoją instancję Optional.
Przykład:
5.11 Ko-rzeczy
Ko-rzecz zazwyczaj ma sygnaturę przeciwną do tego, co robi rzecz, ale nie musi koniecznie być jej odwrotnością. Aby podkreślić relacje między rzeczą i ko-rzeczą, wszędzie gdzie to możliwe zawrzemy obie sygnatury.
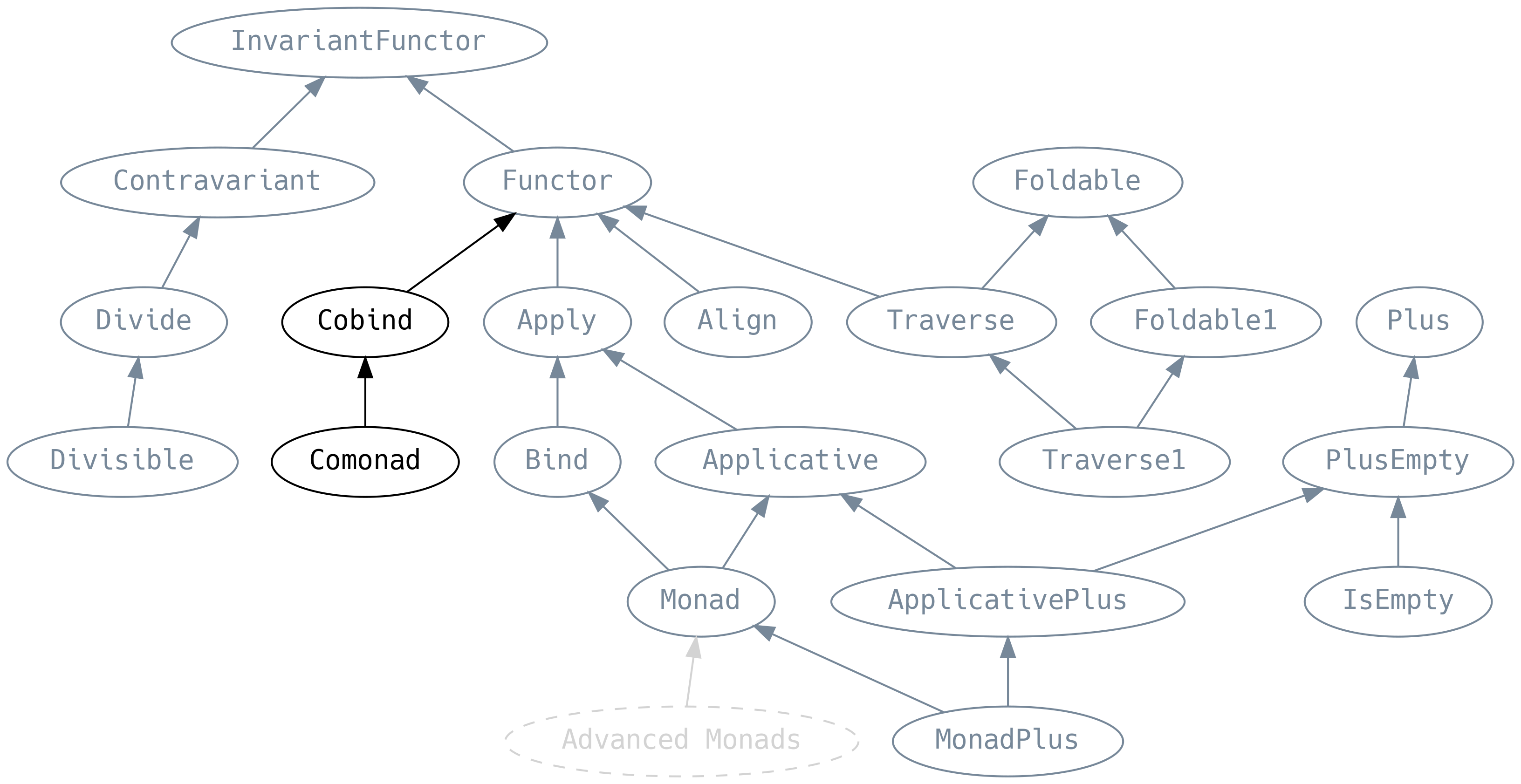

5.11.1 Cobind
cobind (znany również jako coflatmap) przyjmuje funkcję F[A] => B, która operuje na F[A], a nie jego elementach.
Ale nie zawsze będzie to pełne fa, często jest to substruktura stworzona przez metodę cojoin (znaną również jako
coflatten), która rozwija strukturę danych.
Przekonywające przykłady użycia Cobind są rzadkie, jednak kiedy spojrzymy na tabele permutacji metod typeklasy Functor,
ciężko jest uzasadnić, czemu niektóre metody miałyby być ważniejsze od innych.
| method | parameter |
|---|---|
map |
A => B |
contramap |
B => A |
xmap |
(A => B, B => A) |
ap |
F[A => B] |
bind |
A => F[B] |
cobind |
F[A] => B |
5.11.2 Comonad
.copoint (znany też jako .copure) wydostaje element z kontekstu. Efekty z reguły nie posiadają instancji
tej typeklasy, gdyż na przykład interpretacja IO[A] do A zaburza transparentność referencyjną.
Dla struktur danych jednakże może to być na przykład wygodny sposób na pokazanie wszystkich elementów wraz z ich sąsiadami.
Rozważmy strukturę sąsiedztwa (Hood), która zawiera pewien element (focus) oraz elementy na
lewo i prawo od niego (lefts i rights).
lefts i right powinny być uporządkowane od najbliższego do najdalszego elementu względem elementu środkowego focus,
tak abyśmy mogli przekonwertować taką strukturę do IList za pomocą poniższej implementacji
Możemy zaimplementować metody do poruszania się w lewo (previous) i w prawo (next)
Wprowadzając metodę more, jesteśmy w stanie obliczyć wszystkie możliwe do osiągnięcia pozycje (positions) w danym Hood.
Możemy teraz stworzyć Comonad[Hood]
cojoin daje nam Hood[Hood[IList]] zawierające wszystkie możliwe sąsiedztwa w naszej początkowej liście
Okazuje się, że cojoin to tak naprawdę positions! A więc możemy nadpisać ją, używając bezpośredniej
(a przez to wydajniejszej) implementacji
Comonad generalizuje koncepcję sąsiedztwa dla arbitralnych struktur danych. Hood jest przykładem zippera
(brak związku z Zip). Scalaz definiuje typ danych Zipper dla strumieni (jednowymiarowych nieskończonych struktur danych),
które omówimy w następnym rozdziale.
Jednym z zastosowanie zippera jest automat komórkowy (cellular automata), który wylicza wartość każdej komórki w następnej generacji na podstawie aktualnych wartości sąsiadów tej komórki.
5.11.3 Cozip
Mimo że nazwa tej typeklasy brzmi Cozip, lepiej jest spojrzeć na jej symetrię względem metody unzip.
Tam, gdzie unzip zamienia F[_] zawierające produkt (tuple) na produkt zawierający F[_], tam
cozip zamienia F[_] zawierające koprodukty (dysjunkcje) na koprodukt zawierający F[_].
5.12 Bi-rzeczy
Czasem mamy do czynienia z typami, które przyjmują dwa parametry typu i chcielibyśmy przemapować obie jego
strony. Możemy na przykład śledzić błędy po lewej stronie Either i chcieć przetransformować
wiadomości z tychże błędów.
Typeklasy Functor / Foldable / Traverse mają swoich krewnych, którzy pozwalają nam mapować obie strony wspieranych typów.
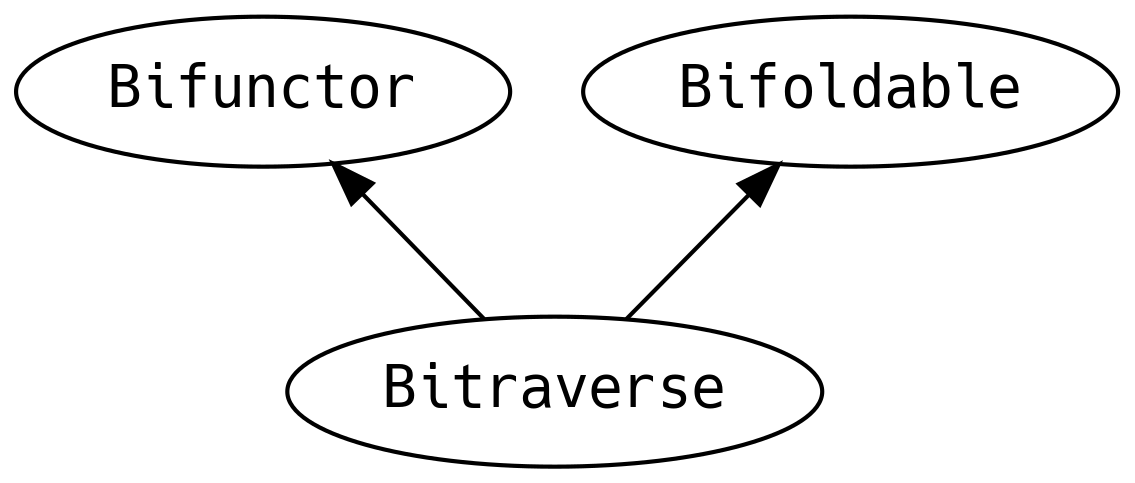
Mimo że sygnatury metod są dość rozwlekłe, to są to niemal dokładnie te same metody, które znamy
z typeklas Functor, Foldable i Traverse, z tą różnicą, że przyjmują dwie funkcje zamiast jednej.
Czasami funkcje te muszą zwracać ten sam typ, aby wyniki można było połączyć za pomocą Monoidu lub Semigroupy.
Dodatkowo możemy wrócić na chwile do MonadPlus (czyli Monady z metodami filterWith i unite), aby zobaczyć,
że potrafi ona rozdzielać (separate) zawartość Monady, jeśli tylko jej typ ma instancję Bifoldable.
Jest to bardzo przydatny mechanizm, kiedy mamy do czynienia z kolekcją bi-rzeczy i chcemy podzielić ją
na kolekcję A i kolekcję B.
5.13 Podsumowanie
Dużo tego! Właśnie odkryliśmy standardową bibliotekę polimorficznych funkcjonalności. Ale patrząc na to z innej perspektywy: w Collections API z biblioteki standardowej Scali jest więcej traitów niż typeklas w Scalaz.
To całkiem normalne, jeśli twoja czysto funkcyjna aplikacja korzysta jedynie z małej części omówionych typeklas, a większość funkcjonalności czerpie z typeklas i algebr domenowych. Nawet jeśli twoje domenowe typeklasy są tylko wyspecjalizowanymi odpowiednikami tych zdefiniowanych w Scalaz, to jest zupełnie ok, aby zrefaktorować je później.
Aby ułatwić nieco sprawę, dołączyliśmy cheat-sheet wszystkich typeklas i ich głównych metod w załączniku. Jest on zainspirowany przez Scalaz Cheatsheet Adama Rosiena.
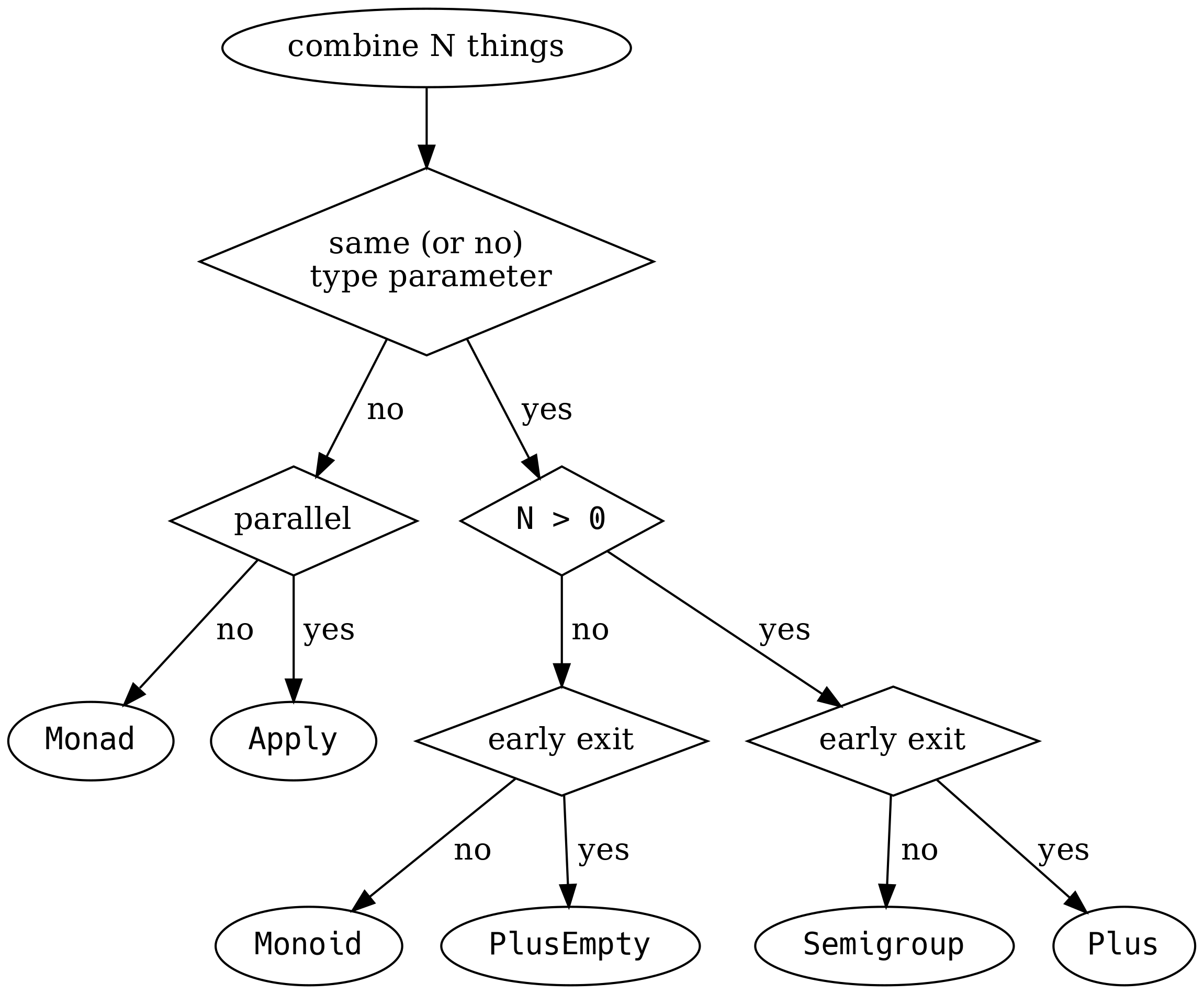
Aby pomóc jeszcze bardziej, Valentin Kasas pokazuję jak połączyć N rzeczy